
Abstract
The loss of a job is the loss of a major social and economic role and is associated with long-term negative economic and psychological consequences for workers and families. Modeling the causal effects of a social process like layoff with observational data depends crucially on the degree to which the model accounts for the characteristics that predict loss. We report analyses predicting layoff in the Fragile Families data as part of the Fragile Families Challenge. Our model, grounded in empirical social science research on layoff, did not perform substantially worse than the best-performing model using data science techniques. This result is not fully unforeseen, given that layoff functions as a relatively exogenous shock. Future work using the results of the Challenge should attend to whether small improvements in prediction models, like those we observe across models of layoff, nevertheless significantly increase the validity of subsequent models for causal inference.
Introduction
Job loss is a disruptive event to individuals and families with far-reaching implications. Sociologists and economists have persuasively shown that displaced workers experience lengthy periods of unemployment, earnings losses, job quality declines, higher levels of depressive symptoms, social withdrawal, and poorer physical health (see Brand 2015 for a review of the literature). Studies have also documented a notable intergenerational effect; that is, parental job loss affects the well-being and attainment of children (Johnson, Kalil, and Dunifon 2012; Kalil and Ziol-Guest 2005, 2008; Peter 2016; Stevens and Schaller 2011). Brand and Simon Thomas (2014) show that children of single mothers, who may be particularly vulnerable to economic shocks, experience lower social-psychological well-being and educational attainment in young adulthood after a parental job loss.
With the Brand and Simon Thomas (2014) analysis as motivation, we joined the Fragile Families Challenge (hereafter referred to as the Challenge) to consider alternative models predicting layoff among disadvantaged primary caregivers and to ultimately improve causal estimates of the effects of parental layoff on children. The Challenge asked scholars from social and data science to develop models predicting six outcomes using the Fragile Families data: layoff of the child’s primary caregiver (the focus of this article), family material hardship, eviction, job training of the primary caregiver, academic achievement of the child, and grit of the child. Participants of the Challenge used information from the first five waves of the Fragile Families data (through age 9 of the child) to predict outcomes in the sixth wave (age 15). Participants developed models using training data, which accounted for one half of the total data in wave 6, and predictions were scored based on two sets of holdout data. The Challenge was designed to improve our knowledge of how techniques from social and data science can be used collectively to understand social processes and to inform policy to help mitigate some of the disadvantages facing low-income children. For more information about the details of the Challenge, see the Introduction to this special collection (Salganik et al. 2019).
In this article, we describe models that draw on social science research to predict layoff of the primary caregiver. We find that these simple models performed only moderately worse than the best-performing submissions that use more complex data science techniques. We emphasize that no model performed particularly well. As a relatively less self-selective social process among those considered in the Challenge, layoff presents some distinct lessons concerning our ability to generate predictive models. The article begins with a discussion of three key types of heterogeneity in social processes, focusing on that which is most relevant to the Challenge: pretreatment heterogeneity, that is, individual characteristics that vary systematically with the likelihood of experiencing a treatment. 1 We then describe our analytic approach and present our results from the leaderboard and the final holdout sample. We end with a discussion of our ability to predict an event like layoff and the generalizability and utility of models predicting layoff from the Challenge for future research.
Heterogeneity and Layoff
Three types of heterogeneity warrant discussion in considering a model of layoff and the degree to which we can infer causality in the effects of layoff on subsequent outcomes. First, and most relevant to the Challenge, is pretreatment heterogeneity. Modeling the causal effects of layoff with observational data, as opposed to randomized controlled trials, depends crucially on the degree to which the model accounts for these pretreatment characteristics. Research on layoff suggests that it functions as a relatively exogenous, or random, shock to individuals (Brand 2015). That is, while many social processes involve a high degree of self-selection (e.g., divorce or migration), layoff is typically the result of macroeconomic and business conditions beyond the control of individual workers. As a widespread event affecting workers with varied sociodemographic characteristics, attempts by social scientists to model layoff have produced generally weak predictions with low levels of variation explained (see Fallick 1996 for a review). It is thus unsurprising that different strategies for adjusting for pretreatment characteristics have produced substantively similar results (Brand 2006; Coelli 2011; Stevens and Schaller 2011). If layoff involved more self-selection, then strategies that differ in the degree to which they adjust for pretreatment characteristics used to predict layoff may yield more meaningfully different effect estimates. Outcomes in the Challenge like material hardship and academic achievement, by contrast, are social processes known to be strongly associated with a range of sociodemographic characteristics (Edin 2015; Reardon 2011; Sirin 2005).
Two other types of heterogeneity deserve mention: treatment heterogeneity and treatment effect heterogeneity. Treatment heterogeneity refers to variation in the key treatment in a causal process, in this case layoff. In prior research, respondents are typically asked open-ended questions pertaining to job separation, which then are categorized as layoff, downsizing, and plant closing. Researchers generally combine these categories to form an indicator of job loss. The Challenge focuses on self-reported layoff of the primary caregiver, which may differ from the combined measure of job loss characteristic of prior studies. Treatment effect heterogeneity indicates the degree to which the impact of layoff varies by population characteristics and contextual factors. For example, workers who are accustomed to socioeconomic stability and have few peers undergoing economic distress may be more psychologically harmed by a layoff event (Brand 2015). The submissions and results of the Challenge deal with modeling pretreatment heterogeneity, but these two additional types of heterogeneity have important implications for the generalizability of the Challenge and future work using its results. We return to the discussion of these implications in the Conclusion.
Modeling Approach
To construct a model predicting layoff, we draw on prior social science research that has demonstrated some association between job loss and sociodemographic, employment, family, psychosocial, and family background characteristics (Brand and Simon Thomas 2014). 2 To improve prediction of layoff, we use the most proximate information on the primary caregiver’s education and employment characteristics from the wave 5 interviews. Table 1 provides descriptive statistics of our selected variables. Sociodemographic and socioeconomic variables include race, sex, citizenship status, economic hardship, and education of the primary caregiver. Family variables include primary caregiver’s age, household size, and marriage/cohabitation status. We include family background of the primary caregiver using highest education of either parent (grandparent of the child in the Fragile Families data) and whether the caregiver reported having lived with both parents when she or he was age 15. We also include key employment variables. Workers in the manufacturing sector and other blue-collar industries are generally more likely to experience layoff (Brand 2015; Farber 2005). Other employment measures include employment status, self-employment status, full-time work, and union membership. Finally, models account for the possibility that individuals who exhibit poor mental health and delinquent behaviors are at higher risk of layoff (Brand and Simon Thomas 2014). We include variables indicating a major depressive episode, drinking, and impulsive or delinquent behavior. 3
Descriptive Statistics of Variables Used to Predict Layoff.
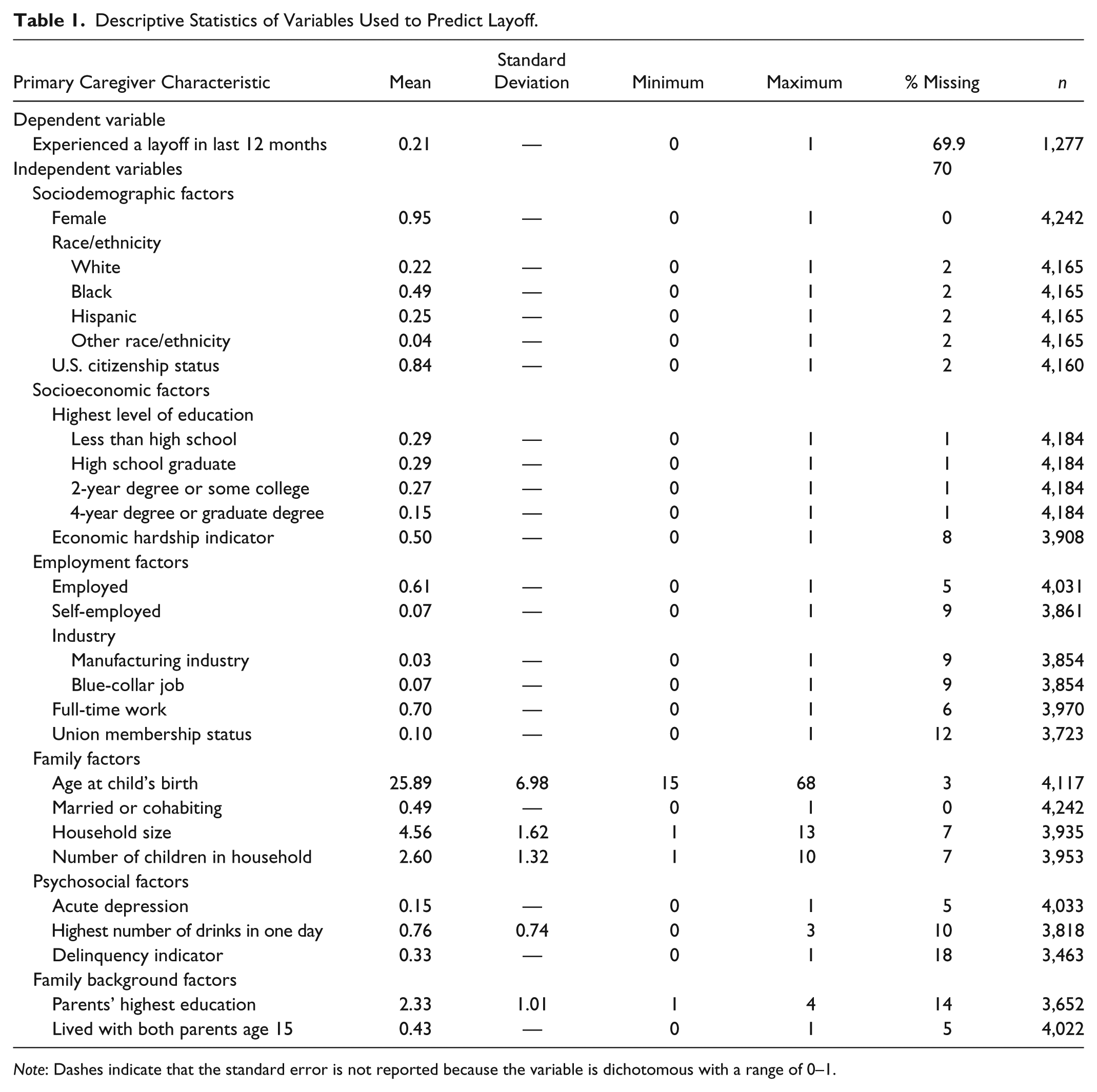
Note: Dashes indicate that the standard error is not reported because the variable is dichotomous with a range of 0–1.
We estimate logistic regression models to predict layoff of the primary caregiver; results are reported in odds ratios. Our submissions included a sequence of attempts to improve our predictions of layoff both by tailoring the models to the specific population in the Fragile Families data and by developing more parsimonious models to avoid overfitting. We present three of these specifications in Table 2. Model 1 was our first Challenge submission. It includes a set of covariates we hypothesized captured pretreatment heterogeneity in layoff based on prior literature. As 90 percent of the primary caregivers are mothers, a model used to predict job loss among single mothers in Brand and Simon Thomas (2014) guided our specification in model 2. Models 1 and 2 are quite similar, however, and include most of the same variables with slightly different specifications. We then specified a third, more parsimonious model. The motivation underlying this final model was to determine whether a more parsimonious model performed similarly on the leaderboard. Missing data presented an analytic challenge. We tested models that did and did not use imputation to handle missing data and tested various imputation strategies. The appendix provides more information about missing data and our imputation strategy. Below we discuss our interpretation of these models, their success on the leaderboard and in the final holdout samples, and how results changed with missing data imputation.
Logistic Regression Models 1 through 3 of Layoff Experienced in the Past 12 Months.
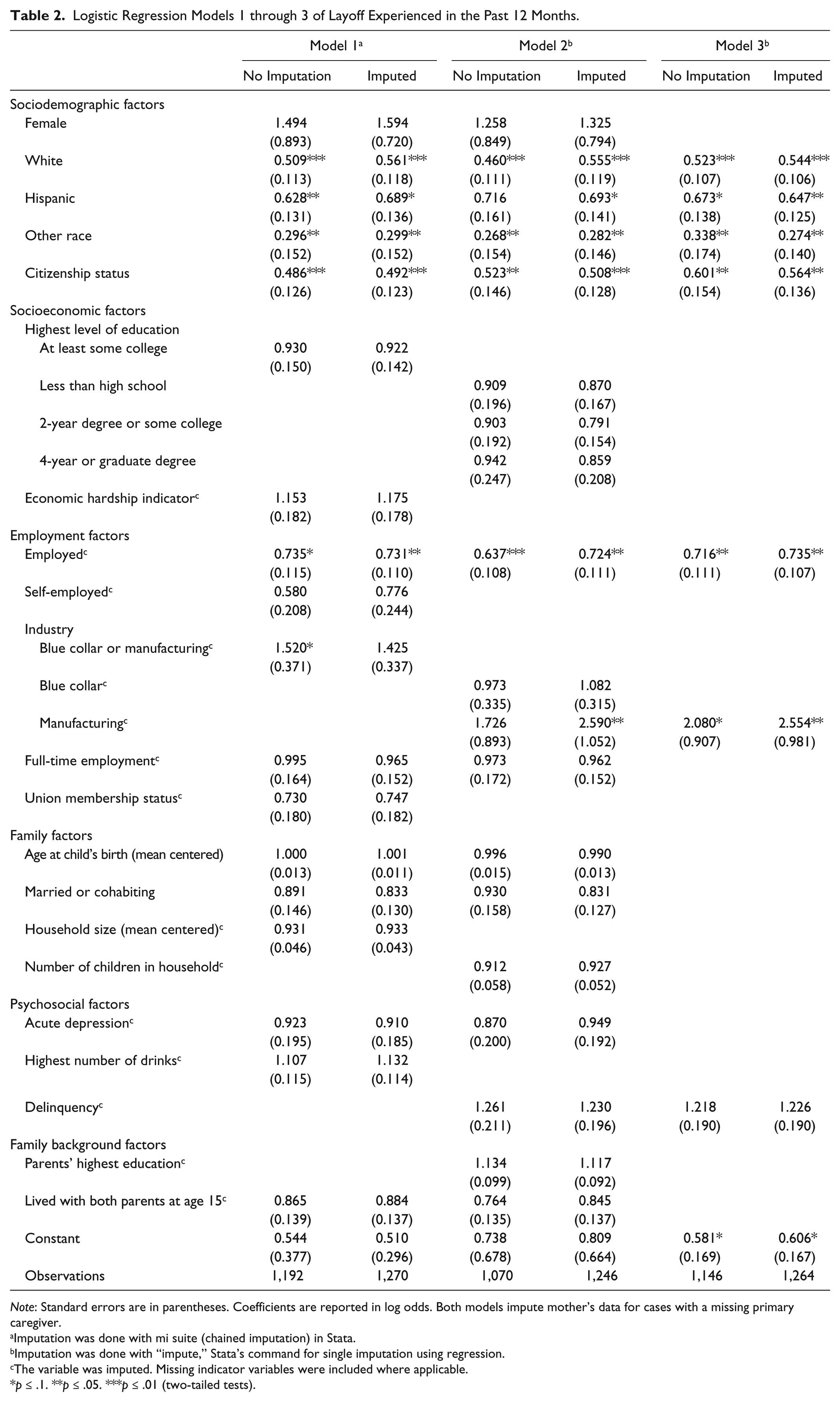
Note: Standard errors are in parentheses. Coefficients are reported in log odds. Both models impute mother’s data for cases with a missing primary caregiver.
Imputation was done with mi suite (chained imputation) in Stata.
Imputation was done with “impute,” Stata’s command for single imputation using regression.
The variable was imputed. Missing indicator variables were included where applicable.
p ≤ .1. **p ≤ .05. ***p ≤ .01 (two-tailed tests).
Results
Figure 1 presents our results from the leaderboard and final holdout samples. Success in the Challenge is indicated by mean-squared errors, which measure the accuracy of predicted probabilities of submitted models in the training and final holdout data. Despite our varying specifications and imputation approaches, we found minimal variation in success in predicting layoff in the Challenge. Our first model produced the best (lowest) scores in both the leaderboard and the final holdout samples. Using multiple imputation did not improve our score on the leaderboard and only slightly improved our score in the final holdout sample. Model 2 produced our worst results in the leaderboard and final holdout samples. Model 3 produced midrange leaderboard and final holdout scores.

Mean-squared error from leaderboard and holdout samples, models 1 through 3, with and without imputation, with best prediction and baseline.
We were surprised to find that our first model was most successful in the Challenge. Model 1, although grounded in prior work on job loss, less closely followed research on layoff among disadvantaged mothers. However, we emphasize that the margin of improved performance between this and our other specifications was quite small, as shown in Figure 1. Notably, there was little variation across our scores. Moreover, we observe little variation between our models and the best prediction. The mean-squared error of our best model (.164) is only about 1 percent worse than the mean-squared error produced by the winning model in the Challenge (.162). Likewise, the winning model scored only about 3 percent better than the baseline (.167), which predicted layoff in the leaderboard and final holdout samples using the mean of layoff in the training sample.
The difference between the scores from the best model and those from the baseline is smaller than for the other outcomes, as shown in Figure 2. While layoff has a difference of only about 3 percent between the baseline and the best model, material hardship has a difference of about 30 percent, and GPA has a difference of about 24 percent. The winning model predicting eviction, for which individual characteristics also have limited predictive power (Desmond 2016), performed 6 percent better than the baseline. Although the best submissions did improve the prediction of layoff, the relatively limited predictive power of even the top scores likely reflects the relatively exogenous process governing the risk of layoff. This result aligns with our theoretical prior.

Difference in predictive power between the baseline and the winning submissions for six outcomes in the Fragile Families Challenge.
We present our regression results for models 1 through 3 in Table 2. A few of our regression results are worth noting. As expected, conditional on all other covariates, respondents who are black, unemployed, and blue-collar or manufacturing workers were more likely to experience layoff six years later. Education is not associated with layoff in this sample after adjusting for other primary caregiver characteristics. We tested many measures of education and consistently found this result. This is not unexpected given the lower educational attainment, and thus less variation, among the disadvantaged Fragile Families sample. It is, however, a departure from prior findings (Brand and Simon Thomas 2014). In addition, citizenship was one of the most consistently statistically significant predictors of layoff across the models we tested, indicating the precarious position of noncitizen women in the urban labor market.
Conclusion
The Challenge offers insights into the utility of mass scientific collaboration for understanding social processes and ultimately improving social science research. We focus on a particular social process, parental layoff, that has been used to study the causal impact of socioeconomic mobility on a range of life outcomes. Our best-performing model of parental layoff, grounded in empirical social science research on job loss, did not produce substantially more error than the best-performing model using data science techniques. Indeed, we find notably small differences across the results of our own models and between ours and better-scoring submissions to the Challenge. Given prior work emphasizing the relatively less self-selective processes governing job loss, these findings are not unexpected. They also do not speak to the utility of data science techniques and collaborative models of more self-selective social processes.
We caution that results predicting layoff in the Challenge, and future work using these models to estimate the effects of layoff, pertain to a particular type of job loss and a particular population. First, the effects of job loss vary according to how we characterize loss (i.e., treatment heterogeneity). Researchers typically include layoff, downsizing, and plant closing in studies of job loss, while the Challenge used only a measure of whether the primary caregiver experienced a self-reported layoff. Plant closings are a more exogenous form of loss than (more individualized) layoffs and involve different economic and psychological consequences (Brand 2015). In addition, layoff in the Challenge pertains to disadvantaged primary caregivers, 90 percent of whom are mothers and almost half of whom are single parents. Results estimating effects of layoff on this group of individuals will likely differ from the results pertaining to the full population of workers experiencing a layoff (i.e., treatment effect heterogeneity). Brand and Simon Thomas (2014) show that children of the most disadvantaged single mothers experienced smaller reductions in social-psychological well-being and educational attainment. The effects of experiencing a layoff in this sample on subsequent outcomes will thus be influenced by both treatment and treatment effect heterogeneity and will not necessarily provide insight into the processes governing job loss among the majority of workers who experience loss.
Despite the limitations to drawing broader conclusions, future work on job loss will benefit from the knowledge advanced in this article and the Challenge more broadly. As data scientists develop increasingly powerful techniques, it will be important to marry those with social science knowledge about the particulars of social processes under consideration. Future research also should attend to whether small gains in predictive performance, like those we observe across models of layoff in the Challenge, significantly reduce selection bias and improve estimates of causal effects on subsequent outcomes.
Supplemental Material
clean_vars – Supplemental material for Predicting Layoff among Fragile Families
Supplemental material, clean_vars for Predicting Layoff among Fragile Families by Caitlin E. Ahearn and Jennie E. Brand in Socius
Supplemental Material
install – Supplemental material for Predicting Layoff among Fragile Families
Supplemental material, install for Predicting Layoff among Fragile Families by Caitlin E. Ahearn and Jennie E. Brand in Socius
Supplemental Material
keep_vars – Supplemental material for Predicting Layoff among Fragile Families
Supplemental material, keep_vars for Predicting Layoff among Fragile Families by Caitlin E. Ahearn and Jennie E. Brand in Socius
Supplemental Material
LICENSE_(1) – Supplemental material for Predicting Layoff among Fragile Families
Supplemental material, LICENSE_(1) for Predicting Layoff among Fragile Families by Caitlin E. Ahearn and Jennie E. Brand in Socius
Supplemental Material
README_(1) – Supplemental material for Predicting Layoff among Fragile Families
Supplemental material, README_(1) for Predicting Layoff among Fragile Families by Caitlin E. Ahearn and Jennie E. Brand in Socius
Supplemental Material
run_all – Supplemental material for Predicting Layoff among Fragile Families
Supplemental material, run_all for Predicting Layoff among Fragile Families by Caitlin E. Ahearn and Jennie E. Brand in Socius
Supplemental Material
SRD-17-0126 – Supplemental material for Predicting Layoff among Fragile Families
Supplemental material, SRD-17-0126 for Predicting Layoff among Fragile Families by Caitlin E. Ahearn and Jennie E. Brand in Socius
Supplemental Material
tables_(1) – Supplemental material for Predicting Layoff among Fragile Families
Supplemental material, tables_(1) for Predicting Layoff among Fragile Families by Caitlin E. Ahearn and Jennie E. Brand in Socius
Footnotes
Appendix: Missing Data
We imputed missing data for several variables from the Fragile Families data. First, layoff is measured at the level of primary caregiver, but our covariates predicting layoff come from individual surveys—either the biological mother, the biological father, or a nonparental primary caregiver. The primary caregiver’s status (mother, father, nonparent) was asked in wave 5, for which 14 percent of the sample is missing. For these cases, we could not match covariates with the appropriate survey response and could not impute from prior waves. More than 90 percent of the primary caregivers of known status are mothers. We took advantage of the high likelihood that primary caregivers are mothers and used mothers’ information for missing primary caregivers. In other words, we assumed that the missing primary caregivers were the biological mothers of the children and used the mother’s data to predict primary caregiver layoff in wave 6. We did this for all models reported in this article. We suspect this did not significantly affect our results because a case missing primary caregiver status in wave 5 was also likely to be missing in wave 6. Second, some data were missing in the manner that is typical of survey analysis. To handle these missing data, we used two different types of imputation: multiple imputation and single imputation. We first tested multiple imputation with model 1. Using Stata’s mi suite of commands, we used chained imputation with 10 imputations to impute variables that had 3 percent or more missing (see Table 1). We then tested whether results differed when we used a simpler, single imputation process. Results were virtually identical using both types of imputation, and the single imputation process is less computationally intensive. We therefore used the single imputation process in models 2 and 3. In sum, all models presented in Table 2 replace missing primary caregiver data with the biological mothers’ data. The imputation version of model 1 uses Stata’s mi suite of commands to conduct multiple imputation, and the imputation versions of models 2 and 3 use Stata’s single imputation command to impute missing data. Our imputed models nevertheless resulted in some missing predictions because we imputed only variables with at least 3 percent missing. After the submission window had closed for the Challenge, we reran these models using fully imputed predictors and found no substantive differences in our results. Finally, the Fragile Families Challenge required submissions to include predictions for all observations, and to comply with this requirement, we replaced remaining missing predicted probabilities with the mean of the layoff outcome variable in the training data (about 0.21).
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research made use of facilities and resources at the California Center for Population Research, UCLA, which receives core support from the National Institute of Child Health and Human Development, Grant R24HD041022. The ideas expressed herein are those of the authors. Funding for the Fragile Families and Child Wellbeing Study was provided by the Eunice Kennedy Shriver National Institute of Child Health and Human Development through grants R01HD36916, R01HD39135, and R01HD40421 and by a consortium of private foundations, including the Robert Wood Johnson Foundation. Funding for the Fragile Families Challenge was provided by the Russell Sage Foundation. The results in this article were created with Stata 14.2 (StataCorp 2015) for Macs using the following user-written commands and packages: fsum (Wolfe 2002) and estout (Jann 2005, ![]() ). Replication code for this article is available with the manuscript on the Socius website.
). Replication code for this article is available with the manuscript on the Socius website.
Supplemental Material
Supplemental material for this article is available with the manuscript on the Socius website.
1
We adopt the conventions of the potential outcome approach to causal inference and thus refer to layoff as a “treatment.” Layoff is of course not randomly assigned and is not analogous to a treatment in a randomized trial.
2
These variables have been theorized and shown empirically to have some impact on the likelihood of layoff. The decisions, however, governing the precise specification of models predicting layoff are seldom well articulated.
3
Our models do not include two potentially key predictors of job loss identified by prior research: tenure of current employment and mental ability. Tenure of employment is not available in the data set. Although Fragile Families administered a verbal aptitude test, almost 40 percent of the primary caregivers were missing information on this variable (i.e., more than any other variable for which we chose to impute missing data). We tested models that included this variable, but those models did not improve fit.
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.