
Abstract
This article presents a new, text-based measure of interdisciplinarity. The author compares the text of a scholar’s publications with text from multiple disciplines and measures the extent to which a scholar’s work integrates language from distal and proximate disciplines. The measure is tested on all faculty members employed at Stanford University between 1993 and 2008. Comparisons among text, citation, and coauthorship measures of interdisciplinarity; measures of disciplinarity; and other variables provide validity evidence for the measure. This text-based measure of interdisciplinarity offers new opportunities for data analysis, especially for unstructured text and within book-centric fields such as the humanities.
Keywords
Many scholars, research institutions, and funding agencies view interdisciplinary research as progressive and full of potential. Interdisciplinary approaches are thought to “advance fundamental understanding or . . . solve problems whose solutions are beyond the scope of a single discipline” (Committee on Facilitating Interdisciplinary Research 2005:2). These high hopes for interdisciplinarity have spurred universities and funding agencies in the United States to invest heavily in boundary-spanning research. Within universities, the numbers of interdisciplinary research centers, fellowships, and seed grants have grown exponentially and across academic fields over the past 30 years (Geiger 1990, 2011; Jacobs and Frickel 2009). At the national level, the National Science Foundation (2015), the Mellon Foundation (2015), and the National Institutes of Health (2014) provide grants and fellowships for interdisciplinary research and training. The National Institutes of Health (2014), in particular, was explicit about the goal “to change academic research culture such that interdisciplinary approaches and team science . . . are encouraged and rewarded.”
Despite the high interest and investment in interdisciplinarity, measures of this important scientific practice have been limited in their scope and application. Prior measures use labels chosen by editors (Porter et al. 2007; Uzzi et al. 2013; van Raan 2005; van Raan and van Leeuwen 2002), the characteristics of coauthors (Qin, Lancaster, and Allen 1997; Qiu 1992; Schummer 2004), or inclusion of the word interdisciplinary in article titles (Jacobs and Frickel 2009) to gauge the extent and occurrence of interdisciplinarity. A recent focus on citations in measures of interdisciplinarity (e.g., Porter et al. 2007; Rafols 2014) has led to the exclusion of the humanities and, often, the social sciences in quantitative analyses of interdisciplinarity. Although interdisciplinarity in these fields is common (Campbell et al. 2015), their citation data are poor in article repositories such as the Web of Science (WoS) and Scopus, which are the most common data source for measures of interdisciplinarity (Archambault and Larivière 2010). As a result, these important sites of interdisciplinarity are often excluded from analyses.
To date, text has played a very limited role in measures of interdisciplinarity, but it carries large potential. A text-based measure of interdisciplinarity makes new data sources accessible to study and may give researchers opportunities to better study fields such as the humanities and social sciences. In general, language is a key site at which interdisciplinarity can be assessed, because the use (or omission) of discipline-specific language situates scholarly work inside (or outside) particular epistemic communities (Knorr-Cetina 1999; Toulmin 1972, chaps. 2–4; Vilhena et al. 2014). For example, a publication focused on “prices,” “markets,” and “policy” is likely to draw on economics, while a publication describing “compounds,” “acids,” and “solutes” is likely drawing on chemistry. As a publication uses and blends the language of multiple disciplines, it demonstrates integration of the ideas, theories, or data from these disciplines. This kind of integration is the hallmark of interdisciplinarity (Committee on Facilitating Interdisciplinary Research 2005).
In this article, I describe a new, scalable, text-based measure of interdisciplinarity. To gauge interdisciplinary integration in text, I calculate the cosine similarity between a researcher’s published words and the words of disciplines to gauge whether and how a researcher is using language from multiple disciplines in his or her own work. By measuring the cosine similarities among pairs of disciplines, I gauge the distances among disciplinary sources. Discipline-to-discipline and scholar-to-discipline cosine similarity comparisons of text have often been used to map scientific fields (e.g., Boyack et al. 2011; Chuang et al. 2012; Moody and Light 2006; Skupin, Biberstine, and Börner 2013), but this article contributes a novel, additional step that allows these values to be combined into a single interdisciplinarity score (ID score) that describes the interdisciplinarity of a body of research. The ID score can then be compared and evaluated across scholars and disciplines.
To calculate a scholar’s ID score, I consider to which disciplines the scholar’s work is similar, how strongly similar it is, and how different the disciplines are from the scholar’s home discipline. From these characteristics, I create a weighted measure of interdisciplinarity. This text-based measure complements new data collection methods such as Web scraping and contains the potential to facilitate analysis of interdisciplinarity in the humanities and social sciences, which are rich in text, if poorly represented in the citation data of typical article repositories (Archambault and Larivière 2010).
In the analysis, I calculate the ID score using text data from WoS and a set of faculty members from Stanford University. I assess the validity of the text-based measure and make comparisons among this measure and other measures of interdisciplinarity. These comparisons suggest that a text-based measure of interdisciplinarity offers additional insights into interdisciplinarity above and beyond those offered by coauthorship or citation measures.
Measuring Interdisciplinarity: Prior Methods
Other researchers have provided extensive reviews of the efforts to define and measure interdisciplinarity (e.g., Porter et al. 2006; Rafols 2014; Rafols et al. 2012; Wagner et al. 2011). Here, I focus the review on one broadly used definition of interdisciplinarity and two of the most common methodological approaches to measuring it: coauthorship and citation analyses. I use the definition of interdisciplinarity to highlight its important components. I then describe the advantages and disadvantages of coauthorship, citation, and text measures of interdisciplinarity in how they conceptualize and measure these components, showing that a text-based measure offers new and extended opportunities for measuring and identifying interdisciplinarity.
A broadly used definition of interdisciplinarity is drawn from a National Academies report and describes it as the integration of theories, methods, ideas, or data from two or more specialized areas of research (Committee on Facilitating Interdisciplinary Research 2005). The key characteristics of this definition are integration of knowledge and diversity of sources (Porter et al. 2006, 2007). Previous measures of interdisciplinarity have focused on these characteristics (both explicitly and implicitly) but sought evidence of them in aspects of publications other than the published text itself.
Coauthorship Measures of Interdisciplinarity
Analyses of coauthorship (Qin et al. 1997; Qiu 1992; Schummer 2004) define interdisciplinary research using the attributes of its authors: the number of disciplines or departments represented among a study’s authors signal its diversity, and their collaborative production of a published work signals integration. In these measures, disciplinary boundaries are defined by the divisions between academic departments and appointments (e.g., Abbott 2001; Jacobs 2013; Turner 2000), and bridging these institutional boundaries is the defining characteristic of interdisciplinary research. In study sites such as industrial partnerships between universities and corporations or “big science” projects, the initiatives seek to foster collaboration and communication across these kinds of boundaries. Coauthored publications can be a key indication of success in these endeavors.
However, coauthorship measures of interdisciplinarity have limitations. These measures assume integration through the presence of coauthors from different disciplines but provide no means by which to gauge the extent of the integration in the research product itself. Notably, authors who do not collaborate can never be considered interdisciplinary. In the social sciences and humanities, single-authored research prevails, but interdisciplinary work proliferates in the digital humanities and programs such as area, gender, and feminist studies. Coauthorship measures are less likely to capture interdisciplinarity in these settings. Coauthorship measures also tend not to differentiate between cross-disciplinary collaborations that are proximal (e.g., business and economics) or distal (e.g., astronomy and music). Distal interdisciplinarity is typically evaluated as being more interdisciplinary (Yegros-Yegros, Rafols, and D’Este 2015), but conventional coauthorship measures are unable to capture this variation.
Citation Measures of Interdisciplinarity
Many of the limitations of coauthorship measures are not present in citation-based bibliometric measures of interdisciplinarity. Examining citations allows for individual interdisciplinarity and can account for the distances between disciplines (e.g., Porter et al. 2007). Citation analyses also allow researchers to examine both the impact and inputs of interdisciplinary research.
Van Raan (2005) and colleagues (van Raan and van Leeuwen 2002) examined how research is cited to gauge its impact and interdisciplinarity. These measures use the range of disciplines in which an institute or a person publishes and is cited to describe the diversity of the research (Rinia et al. 2001; van Raan and van Leeuwen 2002). These measures of how research is cited provide an excellent metric for gauging interdisciplinary potential: the diffusion of a single study into the discourse of diverse specialized research areas suggests future possibilities of working across those areas (van Raan 2005; van Raan and van Leeuwen 2002). A disadvantage of this measure is the difficulty of quantifying integration or diversity in the product itself: big discoveries in one field are often cited across disciplinary lines (Jacobs 2013:100–18), and having been cited across disciplinary boundaries does not necessarily indicate integration or diversity in the original publication.
Bibliometric analyses of articles’ reference lists are better suited to questions of integration and diversity within publications. As a result, an article’s citations have been the key data source for recent measures of interdisciplinarity (e.g., Larivière, Haustein, and Börner 2015; Leydesdorff and Goldstone 2014; Rafols 2014). These methods measure the interdisciplinarity of research by the co-occurrences of citations to diverse disciplines (Leydesdorff and Goldstone 2014; Porter et al. 2007; Rafols and Meyer 2010). Diversity is reflected in the number of disciplines represented and integration by their copresence in the article’s references. Porter et al. (2007) accounted for the distances between co-occurring disciplines and gave greater weight to combinations of distal disciplines. Clear intellectual communities arise in analyses of citation patterns (Moody and Light 2006; van Raan 2005), and citing work from a particular community reveals alignment with its ideas and topics (Moody and Light 2006; Stinchcombe 1982).
A disadvantage of the focus on citations in recent measures of interdisciplinarity has been the frequent exclusion of the social sciences and humanities in analyses of interdisciplinarity. Archambault and Larivière (2010) and Campbell et al. (2015) detailed the poor quality of citation data for these fields in article repositories such as WoS and Scopus. Hicks (2004) argued that the citation data are deprecated in part because of the greater importance of books in the social sciences and humanities, which are not catalogued and included in the citation data of the repositories. Campbell et al. (2015) found higher than expected rates of interdisciplinarity in these fields, which makes their exclusion from analyses of interdisciplinarity problematic. However, “citations are not the only ‘binding properties’ of a publication” (van Raan 1998:137) that connect an article into the larger landscape of academic discourse; we can turn to another data source to aid in the analysis of interdisciplinarity: text.
Using Text to Measure Interdisciplinarity
Text has been a rich data source for measures in the sociology of science. Börner et al. (2012) combined keywords with citation data to improve a global map of science, and Boyack et al. (2011) and Skupin et al. (2013) drew on keywords, abstracts, and titles to map the structure of the scientific fields represented in MEDLINE. Within a single discipline, Moody and Light (2006) used correlations among vectors of words to map the changing topography of sociological subfields and their relationships over time. In these studies, text has been a rich data source for identifying, outlining, and mapping disciplinary and subfield divisions in the academic landscape.
Text has helped locate the boundaries of academic communities but is mostly untapped as a data source for measuring the spanning of these boundaries by interdisciplinary scholars. To date, text has rarely been used as the primary, or even a complementary, data source in measures of interdisciplinarity: Rafols’s (2014) review of measures of interdisciplinarity shows the strong emphasis on citations in recent measures, especially at the author and article levels. There are a few examples of text used in measures of interdisciplinarity, but each has been limited in scope and application.
For example, Hellsten and Leydesdorff (forthcoming) analyzed semantic networks of word co-occurrences in editorial titles but only in the context of a single journal. Through these networks, they showed that editorial vision precedes and guides the development of interdisciplinarity in the journal’s articles. Moody and Light (2006:74–75) used text to gauge subfield spanning within sociology, again relying on text to create networks and using network diagrams to assess which papers span subfields and which lie within subfield clusters. Although each of these co-word, network-based approaches is appropriate for the research questions of the authors, scaling their qualitative analyses of network diagrams to a broader set of disciplines and journals would be challenging. The method used by Hellsten and Leydesdorff, especially, requires identifying and understanding particular terms to gauge the development of interdisciplinarity, set within the context of a particular field. It would be difficult to extend this method to a broad set of fields, in which disciplinary jargon (Vilhena et al. 2014) makes topics inaccessible to scholars trained outside the discipline.
Text is ripe with possibility as a data source for measuring interdisciplinarity. Published text is where science is communicated and debated (Latour 1987:31–62; Merton 1972:315–17) and the site where authors themselves choose the terms that best describe the contents and contribution of their studies. Through the use of discipline-specific language—jargon—authors align their work with distinct academic communities (Vilhena et al. 2014). An author’s use (or disuse) of particular disciplinary language makes his or her work more or less aligned with particular epistemic cultures (Knorr-Cetina 1999; Toulmin 1972, chaps. 2–4). When an author blends specialized, disciplinary vocabularies in an article, he or she integrates ideas, theories, and methods from different specialized research areas—the defining characteristics of interdisciplinarity. 1
The text-based method proposed here is a novel approach to measuring interdisciplinarity. It compares text using cosine similarity (as do the scholars who map academic landscapes) but takes an additional, new step in combining these values in a systematic way to gauge interdisciplinarity across scholars. Using text allows the inclusion of far more data points when assessing the interdisciplinarity of scholarly research: an article may have dozens of citations, but its abstract and title offer hundreds of words as data to help locate it in the academic landscape. Like citation-based measures, this text-based measure allows for single-author interdisciplinarity, which makes it more appropriate for use in the humanities and social sciences than coauthorship measures. A focus on text in measures of interdisciplinarity can allow researchers to skirt the disadvantages of citation-based measures when analyzing interdisciplinarity in the social sciences and humanities. Text for these fields is available in both article repositories and noncurated sources, such as the Web sites of academic presses, which may better represent work in book-based disciplines.
A key disadvantage of measuring interdisciplinarity with text is the time and computational power necessary for analysis. Measuring the linguistic similarity between a scholar’s work and the work of disciplines requires the collection of both scholars’ and disciplines’ texts, as I describe in the methods section below. Analyses using language are more computationally intense, as they involve hundreds of words per publication, compared with tens of citations or even smaller numbers of authors. However, opportunities afforded by a text-based measure of interdisciplinarity can offset these disadvantages, especially in potential extensions to the analysis of noncurated data sources. As I describe the method below, I note steps I took to minimize computational time.
Study Design
Although it could be used at the article, team, department, or center level, I use the measure in this article to describe interdisciplinarity at the level of the individual researcher. I measure interdisciplinarity at the person level for both theoretical and practical reasons. Theoretically, I focus on people because investments in interdisciplinarity are often made at the person level: grants, fellowships, and research center recruitment are focused on developing interdisciplinary people, more so than articles or departments. An accurate, widely applicable measure of interdisciplinarity at the person level is best suited to gauging where and through what interventions interdisciplinarity occurs.
Practically, measuring the interdisciplinarity of researchers allows me to compare my measure with prior measures of interdisciplinarity, which generally measure interdisciplinarity at the person level (e.g., Porter et al. 2007; Schummer 2004). My analysis features a correlation table comparing the text-based measure of interdisciplinarity with other measures. Using this table, I assess the validity of the text-based measure and contrast among the performances of different measures of interdisciplinarity. I suggest a theoretical framework for thinking about the conceptual differences among these measures and how each is best suited to measuring particular kinds of boundary-spanning in academic research. These comparisons suggest that text can offer complementary and new insights into interdisciplinarity alongside the conventional coauthorship and citation-based measures.
Data and Sample
I compare published text written by researchers with the published words of disciplines to measure the interdisciplinarity of researchers. As a sample of researchers, I use all tenure-track faculty members employed by Stanford University between 1993 and 2008 (n = 2,553). These data were collected as part of a larger and ongoing set of projects about interdisciplinarity (see also Biancani, McFarland, and Dahlander 2014; Dahlander and McFarland 2013). The faculty members span 99 academic departments and schools, and I apply the measure across academic fields including the humanities, social sciences, and medical specialties, rather than limiting my analysis to the natural sciences.
To collect the text of faculty publications (n = 111,311 articles), I use the results of a previous project, which matched each faculty member to his or her publications in Thompson Reuters WoS using an algorithm that drew on patterns of self-citation, e-mail addresses, reoccurring coauthors, and publication outlet (Levin et al. 2012). WoS contains the titles and abstracts of publications, which are the source of both the faculty and disciplinary corpora that I use in the measure. I use WoS subject codes (SCs) to collect publications representing each of the disciplines. SCs are category tags that are assigned to each journal in WoS. Each SC describes a particular area of inquiry, such as “Music” or “Applied Physics,” and journals are assigned one to six SCs on the basis of a combination of editor input and citation patterns among journals (Morillo, Bordons, and Gomez 2003).
Building the Text Corpora
The measure presented here compares a researcher’s published words with the words of disciplines. In the measure, I compare a corpus containing the titles and abstracts of a researcher’s publications (scholar corpus) with corpora containing titles and abstracts from articles in each of the disciplines (disciplinary corpora). To build a scholar’s corpus, I collected the titles and abstracts of all of a scholar’s publications in WoS between 1991 and 2008. I combined all of the text from these publications into a single list of words, following the bag-of-words approach.
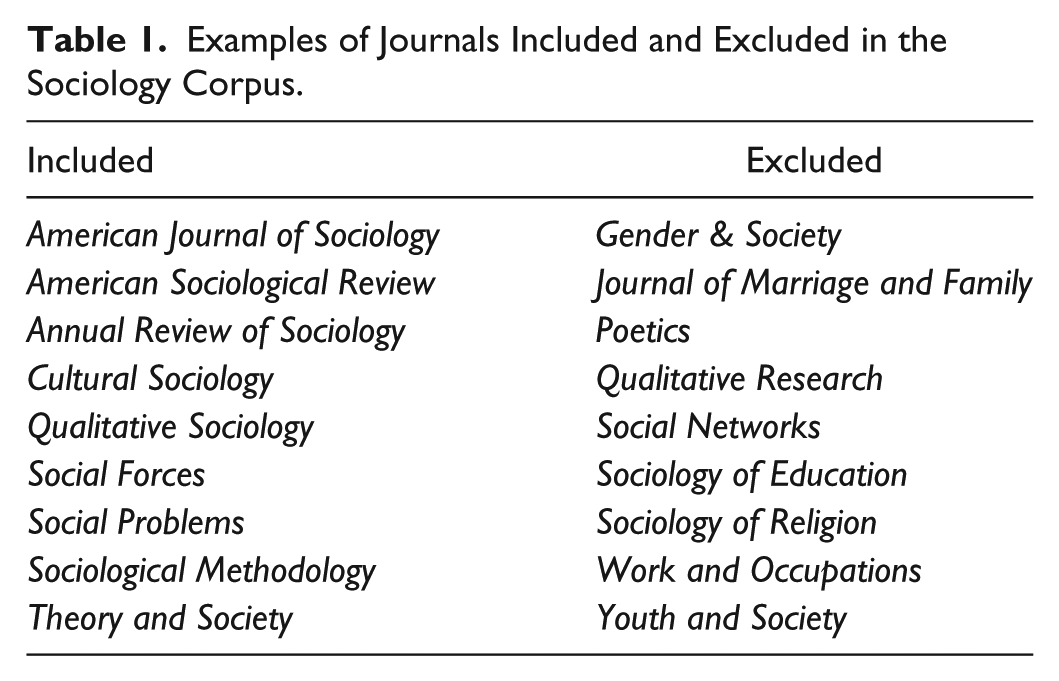
To create a corpus for each discipline, I collected a 10 percent random sample of all journals in WoS published between 1991 and 2008. I reduced the set of journals using two criteria. First, I eliminated journals tagged with more than one SC. This allowed me to best capture core disciplinary work, as I excluded interstitial journals that lie at the boundaries and overlapping areas of disciplines. Table 1 contains examples of sociology journals that are included and excluded in the sociology corpus as a result of this criterion. Core disciplinary journals such as the American Journal of Sociology and the Annual Review of Sociology are retained, whereas subfield-oriented journals, such as Sociology of Education and Social Networks are excluded.
Examples of Journals Included and Excluded in the Sociology Corpus.
To the single-tagged journals, I applied a second criterion and excluded journals tagged with any SC that could not be affiliated with a single discipline (e.g., “Social Sciences, Interdisciplinary”). Minerva and Social Science Research are examples of social science journals excluded in this step. By restricting the sample to only journals with discipline-based SC tags, I reduced ambiguity in the classification of journals according to SC: each journal is classified only by a single, discipline-based SC. Like prior researchers (Porter et al. 2007; Porter and Rafols 2009; Rafols and Meyer 2010), I extended the SC tag of a journal to each of the articles it contains and, for the analysis, consider the SCs at the article level rather than the journal level. In total, 1,318,581 articles are included in the disciplinary corpora.
Building Disciplines from SCs
The SCs in WoS vary widely in their level of specialization. For example, history is one SC, while physics is divided into eight SCs, differentiated by subfield. Other SCs, like “Thermodynamics” and “Demography,” are often considered subfields of broader disciplines, rather than disciplines in their own right. Representing each unique SC as a discipline misrepresents the way in which academic audiences tend to think about disciplines and the breadth of inquiry they can contain. It also misrepresents subfields as independent disciplines, distorting the classification system by which academics are typically sorted within institutions (Turner 2000).
As a result, I combined the SCs into 85 disciplinary clusters for use in the analysis. Appendix A contains a list showing the assignment of all 229 SCs to disciplinary clusters. I based the disciplinary clusters on the fields recognized and assessed by the National Research Council (NRC) in its 2011 analysis and ranking of graduate programs. The 2011 NRC rankings use data from the 2005–2006 academic year to compare and rank graduate departments from 5,000 higher education institutions in the United States (National Research Council 2011). The NRC rankings include 76 fields that range from established (psychology) to emerging (nanoscience). Like the SCs of WoS, the NRC fields also vary in their levels of specificity. For example, there are 7 fields representing various types of biology but only 1 for physics. As a result, I looked for alignment between the names of SCs used by WoS and the titles of NRC-ranked fields and used overlapping fields as the core disciplinary clusters. The NRC does not rank medical specialties or professional schools, so I also added a set of disciplinary clusters for established medical specialties and professional disciplines (i.e., law, education, oncology, etc.). All cluster names are listed in bold in Appendix A.
For the remaining WoS subject categories, I calculated pairwise cosine similarities among every pair of categories in three-year windows between 1991 and 2008. Using the mean of the three-year values for each pair of SCs, I placed each remaining SC into the disciplinary cluster containing its nearest discursive neighbor. When SCs were similarly close to multiple disciplinary clusters, I used descriptions of the SCs provided by WoS to determine the appropriate cluster assignment. The SCs assigned to disciplinary clusters using cosine similarity are denoted in plain text and indented below each cluster heading in Appendix A.
In the analysis, each disciplinary corpus is the combined abstracts and titles from the articles in each disciplinary cluster (n = 85). In the corpora for both scholars and disciplines, I removed generic stop words (is, and, or, we). In the disciplinary corpora, I removed corpus-specific stop words, which I defined as words that appear in all 85 disciplinary corpora and so offer no discriminatory power between the discourses of different disciplines. I stemmed the remaining words (Porter 1980), which removed endings like -ed and -ing (e.g., studies, studied, and studying are reduced to studi after being stemmed).
All text-based analyses in this paper rely on only unigrams (single words). Vilhena et al. (2014) argued that larger n-grams (i.e., multiword phrases) better capture more complex scientific concepts, but in a comparison between the unigram-based measure presented here and a measure using uni-, bi-, and trigrams, the two measures correlated very highly with each other (r = .98), and there were no significant differences between the two measures and their correlations with other key variables. By only using unigrams, the computation time of the key cosine similarity comparisons dropped from multiple days to a few hours.
Even when considering only single words, the corpora for the 85 clusters display concentrations in particular disciplinary language. As an example, Table 2 contains the 15 most frequent words in four of the disciplinary corpora. As theory leads us to expect, language differentiates among these different academic cultures (Knorr-Cetina 1999; Toulmin 1972; Vilhena et al. 2014). However, we can also observe some commonalities. For example, the letter C—most often representing carbon, Celsius, or a three-dimensional coordinate, [a, b, c]—is common in both of the sciences but does not appear in the most frequent words of the two social sciences. A text-based measure of interdisciplinarity leverages the linguistic differences and overlap among disciplines to gauge interdisciplinarity, as I describe in the following sections.
Fifteen Most Frequent Words in Four Disciplinary Corpora, with Counts and Percentage of Total Corpus.

Note: C often represents Celsius or carbon or is a three-dimensional coordinate (i.e., a, b, and c coordinates). In the vast majority of observed instances, N occurs as the chemical symbol for nitrogen. Numbers tend to occur in chemical formulas (e.g. “H2O” ) or as the value itself (e.g., “2 hours,” “2 species”).
Methodology
Comparing Scholars with Disciplines Using Cosine Similarity
The key components of the measure of interdisciplinarity are the calculated pairwise cosine similarity values between a scholar’s corpus and the corpora of disciplines. The greater the number of terms used in both corpora, the higher the similarity score. The base equation for cosine similarity using term frequency is

where s is the corpus for a scholar, d is the corpus for a discipline, and w is each unique term in the union of the two corpora; tfw,s is the frequency of term w in the corpus s, and
In my use of cosine similarity, I weight the measure with a term frequency–inverse document frequency (tf-idf) weighting scheme. Tf-idf weighting gives greater weight to overlapping words that are frequent in the two corpora being compared but also rare across the set of disciplinary corpora. Words that appear in fewer disciplinary corpora offer greater information about their disciplinary affiliations, so tf-idf weighting gives a higher weight to these words in the similarity calculation.
The tf-idf weighted cosine similarity measure is described by the following equation:

where idfw is the inverse document frequency for word w and is calculated as

where D is the total number of disciplines, and dw is the number of disciplinary corpora in which word w appears. The idfw values are calculated using all articles in the sample between 1991 and 2008 (n = 1,318,581). The fewer disciplinary corpora in which the words appears, the higher the idfw weight. One is added to each idfw value, so that no word receives a weight of zero, allowing every overlapping word to contribute to the cosine similarity calculation.
Typically, idf is calculated at the publication level, rather than the discipline level. In this case, the discipline level is more appropriate. Calculating idf at the publication level penalizes terms that are specific to large disciplines with many publications. For example, a word that is used commonly and only in biology (n articles = 29,534) is likely to appear in many more documents than a word that is used commonly and only in philosophy (n articles = 8,307), because there are so many more publications in biology than in philosophy. If idf were calculated at the publication level, the biology word would receive a lower idf weight than the philosophy word because it appears in more publications. In this case, I want these words—unique to each of their disciplines—to carry the same weight, because each is equally informative about a particular disciplinary affiliation. As a result, I calculate idf at the discipline level, where each disciplinary corpus is considered a document.
For each scholar, I calculate the tf-idf weighted cosine similarity scores between the scholar’s corpus and each of the disciplinary corpora using the TfidfVectorizer() method in python’s Scikit-learn package (Pedregosa et al. 2011). This creates a series of cosine similarity scores for a scholar, where each value is the similarity between the scholar’s corpus and the corpus of one discipline. A higher cosine similarity score indicates greater overlap between the language that a scholar uses and the language of a discipline. This overlap shows that a scholar is bringing ideas, knowledge, or theory from the discipline into his or her research. For more details, see Appendix B, which contains an example of the step-by-step calculation of cosine similarity.
Accounting for Distal and Proximal Integration of Language
As Porter et al. (2007) described, few measures of interdisciplinarity account for the relative distances between disciplines when measuring how research integrates ideas across them. Yet work is generally considered to be “more interdisciplinary” when the integrated fields are more distant from one another (Yegros-Yegros et al. 2015). To account for this in my measure, I created discipline-to-discipline similarity values between each pair of disciplinary corpora. I use these similarity scores as weights in my calculation of text-based interdisciplinarity.
The weights are tf-idf cosine similarity scores as described in the previous section (equation 2), but I substituted a disciplinary corpus (di) in place of the scholar’s corpus (s). I calculated the tf-idf cosine similarity between each disciplinary corpus (di) and each of the other disciplines’ corpora (dj), creating a matrix of discipline-to-discipline cosine similarity scores (
Cosine Similarity Values between Disciplinary Corpora.

Note: Cosine similarity values are from 2008, using text from 2006 to 2008.
Because idf weighting occurs at the discipline level, the cosine similarity values obtained are higher for the between-disciplines comparisons than those reported in other outlets (e.g., Porter et al. 2007). However, the relative magnitude and ordering of these values remains accurate. For each discipline in Table 3, its most similar fellow discipline follows conventional understandings of distal and proximate relationships between disciplines. For example, biology and ecology are the most proximate of all the pairings, while genetics and literature are the most distal.
Text-based maps of disciplines and science have generally found comparisons such as those described so far to be sufficient for describing the topography of an academic landscape. Disciplines are measured and mapped as distal or proximate to one another (Börner et al. 2012; Boyack et al. 2011; Skupin et al. 2013), and particular articles or authors are shown in relative positions to the clusters of work they draw upon (Chuang et al. 2012; Moody and Light 2006).
The measure in this article presents a novel second step that uses these comparisons as components and weights for a single ID score. This score is a metric of boundary spanning, weighted by distal and proximate spans. It allows the comparison of interdisciplinarity across scholars and disciplines. The next section describes the logic and method behind this second step and provides evidence for its design and execution.
ID Score: A Text-based Measure of Interdisciplinarity
The text-based measure of interdisciplinarity (ID score) is based on the discipline-to-discipline similarity values and the similarity values between scholars and disciplines. Logically, a measure of interdisciplinarity incorporating all 85 cosine similarity values between scholars and disciplines is likely to be noisy and imprecise. For example, knowing that one physicist’s work is slightly more similar to art history than her colleagues’ work is not a meaningful source of variation to include in the measure: almost certainly, all physics research is very different from art history, and capturing the small variation among physicists in that difference is not an accurate reflection of interdisciplinarity.
However, incorporating only one cosine similarity value is equally unlikely to accurately capture interdisciplinarity in scholarly work. By definition, interdisciplinarity is the integration of diverse disciplinary knowledge, and a measure that examines a scholar’s relationship with only a single discipline does not allow an assessment of diversity or integration. An accurate measure must lie between these two extremes: narrowing the range of disciplines to those that are meaningfully similar (or not) to a scholar’s work but retaining breadth in order to assess multiple relationships between the work of a scholar and that of disciplines.
Wide variation in the maximum cosine values between scholars and their closest disciplines (range = 0.002–0.65) suggested against using a cutoff value to narrow the range of person-discipline cosine similarity scores used in the ID score calculation (i.e., including only disciplines for which the person-discipline cosine similarity was greater than a particular value). Given the diversity, any one cutoff value would be too restrictive or too broad for many of the scholars in the sample. Instead, the ID score is calculated for each scholar using the same number of their closest disciplines, regardless of how close each scholar is to those particular disciplines.
I used both qualitative and quantitative analyses to determine how many of the closest disciplines to include in the ID score calculation. Qualitatively, I took a sample of 20 scholars from various disciplines and compared their vectors of cosine similarity values with their self-descriptions of their research interests on their curricula vitae. This analysis suggested that two to four disciplines fully capture a scholar’s self-described research agenda. To determine which of these values was best, I examined the distribution of similarity scores for the scholars.
At either end of the distribution, a scholar’s work is much more similar to or much more different from the work of a small number of disciplines. Figure 1 shows this trend, averaged across all the researchers in the sample. To generate Figure 1, I ordered the vector of cosine similarity scores for each scholar from most to least similar. I then took the mean cosine similarity value at each rank position across the sample and graphed these values against their rank numbers. The vertical line on the figure demarcates the closest four disciplines. The top four disciplines are contained in the portion of the graph in which the similarity scores are between scholars and disciplines are increasing most steeply from one rank to the next. As a result, I included four disciplines in the calculation of the ID score. In the “Results” section, I present further evidence for the decision to include four disciplines in the calculation of the ID score (see Figure 2).

Average cosine similarity value between scholars and disciplinary corpora, rank-ordered from most to least similar.

Change in correlation values between interdisciplinarity score and key comparison variables as number of disciplines used in interdisciplinarity score calculation varies.
The text-based measure of interdisciplinarity (ID score), then, is the sum of the scholar-discipline cosine similarity values for each scholar’s four closest disciplines, weighted by the discipline-to-discipline cosine similarities. Each scholar is assigned to a home discipline on the basis of his or her departmental affiliation and self-described research agenda, both of which are included in institutional data from Stanford. For scholars with joint appointments, I used the scholar’s own description of his or her research agenda to determine which discipline best represented his or her home discipline. In other research settings, these “home discipline” assignments can be drawn from affiliations with departments or research centers or inductively derived from outlets or other characteristics of scholars’ work.
I then created a weighted sum of the four highest person-to-discipline similarity values (

where s is a scholar, d is each discipline in the set of the scholar’s four most similar disciplines (Dmax4),
Table 4 shows the research area, closest disciplines, and ID scores for two hypothetical anthropologists. Scholar A is more disciplinary. Her research on native cultures is most similar to anthropology, her home discipline, and also similar to close disciplinary neighbors of anthropology. Scholar B is more interdisciplinary. His work uses the language of disciplines distal from anthropology, as he studies the genetic diversity of populations. We see these differences reflected in the ID scores for the two scholars: scholar B has an ID score nearly twice that of his disciplinary colleague. Appendix B contains the detailed, step-by-step construction of the ID scores for these two example anthropologists.
Closest Disciplines and Interdisciplinarity Scores for Two Example Anthropologists.

Assessing the Validity of the ID Score
The literature lacks comparisons among different measures of interdisciplinarity and infrequently provides validity evidence for existing measures. To address these issues here, I calculate different measures of interdisciplinarity, disciplinarity, and other key values for all Stanford faculty members employed between 1993 and 2008. I calculate the correlations among all variables and use these correlations to assess the validity evidence for the text-based ID score and contrast the ID score with other measures of interdisciplinarity.
In the following section, I describe the eight variables included in the analysis and then present the correlation table and validity evidence for the text-based ID score. I highlight patterns among the correlations and suggest ways of interpreting these data to gain insight into the dimensions and measures of interdisciplinarity.
Variables in the Analysis
My text-based measure of interdisciplinarity (ID score) is a normalized, weighted sum of the cosine similarity values between each researcher and his or her four closest disciplines. For comparison with the ID score, I replicated Porter et al.’s (2007) reference-based measure of interdisciplinarity, which measures interdisciplinarity as the citation of diverse disciplinary sources.
I also created a measure of coauthorship interdisciplinarity. The measure is the proportion of coauthored articles written with a Stanford colleague whose work is categorized under a different Classification of Instructional Programs code at the two-digit level (National Center for Education Statistics 2010). This measure (like all coauthorship measures) faces limitations in that it cannot be applied to solo authors. Additionally, the coauthorship data are limited to coauthorship among Stanford faculty members, not faculty members at other institutions. As a result, the coauthorship measure is calculated using a reduced set of scholars who coauthored publications with other Stanford faculty members (n = 1,757).
As rougher, affiliation-based measures of interdisciplinarity, I also include variables for whether a researcher has an affiliation with an interdisciplinary research center and whether the researcher has one or more courtesy appointments. For all variables, higher values indicate greater interdisciplinarity.
I also calculated two measures of disciplinarity to contrast with the measures of interdisciplinarity. The first is text based and is the cosine similarity between a scholar’s corpus and that of his or her home discipline. Higher cosine similarity indicates higher disciplinarity. A second measure of disciplinarity is based on the SCs of a scholar’s WoS publications. I measured the proportion of a scholar’s publications that are published in journals tagged with the SC of his or her home department (e.g., the proportion of “Computer Science” SCs for a faculty member in computer science). Higher values indicate higher disciplinarity, because scholars are publishing a greater proportion of their work in disciplinary journals.
I also include a variable for the cumulative count of publications for each scholar between 1991 and 2008 to show that my measure is not heavily influenced by a scholar’s productivity. The publication counts are log-transformed to correct for skew. In preliminary analyses, I included additional variables for word and citation counts. They were highly correlated with a scholar’s number of publications (r = .79 and r = .73, respectively) and showed the same pattern of relationships with the other measures. In the interest of brevity, I only present the publication count variable in the analysis below.
Results
Table 5 shows the correlations among and descriptive statistics for all eight variables. The relationships presented in Table 5 provide evidence for the validity of the text-based measure of interdisciplinarity. As convergent validity evidence, the measure correlates significantly and positively with the citation and coauthorship measures of interdisciplinarity (columns 2 and 3). The lack of significant relationships between ID score and both center memberships and courtesy appointments is likely related to the poor performance of these two variables as measures of interdisciplinarity. Both are also only weakly related to the coauthorship and citation measures of interdisciplinarity, and neither affiliation-based measure is strongly negatively related to the two measures of disciplinarity.
Correlation and Descriptive Statistics Table.

Note: P values were obtained using bootstrap resampling with 1,000 iterations for each pairwise correlation coefficient. CIP = Classification of Instructional Programs; ID = interdisciplinarity; SC = subject code.
Coauthorship correlations were calculated using only faculty members with at least one coauthored publication with another Stanford faculty member (n = 1,757); all other correlations calculated using n = 2,553.
p < .05. **p < .01. ***p < .001.
As discriminant validity evidence, the ID score also correlates significantly and negatively with the two measures of disciplinarity (columns 6 and 7). In column 8, ID score is weakly negatively correlated with a scholar’s number of publications. This weak association shows that although the method is text based, it is not strongly confounded by how much a scholar has written. Leahey (2007) found that performing subfield-spanning research is associated with lower productivity within sociology. The negative correlation here may reflect a similar suppression of productivity from spanning disciplinary boundaries.
Figure 2 shows how the strength of the correlations between ID score and the seven key comparison variables changes as the ID score is calculated with varying numbers of disciplines, ranging from 1 to 85 (x-axis). For ease of interpretation, the strength of correlation values (y-axis) are absolute values of the actual correlations, so that a downward slope always indicates decreasing strength of the relationship. All plots are presented on the same plotting scale in order to compare the magnitude and change of the correlations across variables. The vertical line on each plot indicates using four disciplines in the calculation of ID score.
Using four disciplines in the calculation of the ID score balances the relationships between the ID score and the other variables. For example, Figure 2e shows that using fewer or more disciplines in the calculation of ID score weakens the relationship between the measure and the cosine similarity between a scholar’s corpus and that of her home discipline. Increasing the number of disciplines slightly improves the correlations with the affiliation-based measures of interdisciplinarity (Figures 2c and 2d), but to a much greater extent, using more disciplines weakens the correlations with measures of disciplinarity (Figure 2e and 2f) and increases the correlation between ID score and a scholar’s number of publications (Figure 2g). Analysis of these figures suggests that four disciplines (5 percent) is a balanced sample to use in the calculation of the ID score.
Discussion
Although the text-based measure of interdisciplinarity is positively correlated with the other two main measures of interdisciplinarity in Table 5 (and they all correlate positively with one another), the strength of the relationships among the measures is lower than expected (r = .14–.21). In part, these weak to moderate correlations are likely a result of the complexity of interdisciplinarity: interdisciplinarity is a multifaceted concept that is difficult to measure (Porter et al. 2006; Rafols et al. 2012; Wagner et al. 2011), leading to measurement error and attenuated correlations. As a test to determine the influence of measurement error, I calculated split-half reliability estimates for the text-based ID score (r = .80) and Porter et al.’s (2007) citation-based measure (r = .95) and recalculated the correlation with correction for attenuation (Charles 2005; Spearman 1904). The correlation between the two measures is stronger after correcting for attenuation (r = .24) but remains moderate.
The low and moderate correlations among the measures of interdisciplinarity (even after correcting for attenuation) suggest qualitative, theoretical differences among these measures: though significantly related, the measures seem to capture complementary, not identical, dimensions of interdisciplinarity. Assessing the kinds of boundaries that each measure addresses may be a starting point for a theoretical framework to conceptualize their differences and best applications. Coauthorship measures attend to the crossing of social boundaries in academia (Lamont and Molnár 2002), which is related to, but also distinct from, the boundary spanning suggested by citing or using language across disciplinary boundaries. Citation-based measures of interdisciplinarity may better describe the bridging of symbolic and social boundaries in citation communities (Moody and Light 2006; Porter and Rafols 2009), whereas a text-based measure may best represent the bridging of discursive boundaries, such as those described by Toulmin (1972) and Vilhena et al. (2014). Further investigation of the similarities and differences among these measures may better establish a boundary-based theoretical framework for considering the distinct contributions of and best practices for each measure.
Other differences among these measures are highlighted in their associations with other variables in Table 5. For example, consider column 6, which shows the relationships between the measures of interdisciplinarity and a scholar’s cosine similarity with his or her home discipline. As expected (these two variables are intended to measure opposing concepts), ID score is strongly negatively related to the cosine similarity between the language of a scholar and her home discipline. However, Porter et al.’s (2007) measure is positively related to this measure of disciplinarity. This positive relationship suggests that when scholars cite outside of their disciplines, they are still likely to be using disciplinary language when they describe the research projects in their abstracts and titles.
Citation, as described by Latour (1987), is “do[ing] whatever you need to the former literature to render it as helpful as possible for the claims you are going to make” (p. 37). When citing, authors adopt and adapt ideas to strengthen their arguments. Citations to extradisciplinary sources represent the inclusion of cross-disciplinary literature and ideas in a scholarly work, but citations do not tell us how these ideas are integrated (if at all) into the text and discussion of that work. For research settings and questions that seek to gauge the bridging of both boundaries around citation communities and discursive communities, text measures of interdisciplinarity can complement citation-based measures to address both aspects of interdisciplinarity in research.
Conclusion
The contribution of this article is a new, text-based method of measuring interdisciplinarity. Its use of cosine similarity follows in the tradition of using text to map scientific fields (e.g., Börner et al. 2012; Boyack et al. 2011), but this measure adds a novel second step that allows these measurements to serve as the components and weights of a measure of interdisciplinarity rather than the distances between and coordinates of academic communities. By using text as data, I locate the measure in the language of publications, where interdisciplinarity is reflected in the integration of disciplinary jargon from multiple disciplinary sources (Vilhena et al. 2014). The measure attends to the dual aspects of interdisciplinarity, integration and diversity (Committee on Facilitating Interdisciplinary Research 2005), and also considers the disparity among the disciplines a scholar spans (Porter et al. 2007; Yegros-Yegros et al. 2015). I measure integration by gauging the presence and extent of different disciplinary vocabularies in scholarly work. I incorporate meaningful diversity in the measure by including data from the four disciplines most similar to a scholar’s work. And by weighting the measure with discipline-to-discipline similarity values, I take into account the disparity among the disciplines that a scholar’s work integrates.
By providing a validity assessment, this article enriches the literature on measuring interdisciplinarity. Previously, this literature has offered little in the way of comparative analysis or validity evidence. The results and discussion suggest differences and complements among the different measures of interdisciplinarity and posits a boundary-based theoretical framework that may help sociologists of science to better differentiate among these measures and their best applications.
Overall, the evidence presented here suggests that a text-based measure of interdisciplinarity is valid. Although I use the measure in this paper to measure the interdisciplinarity of a scholar and her research, the measure can be applied to any body of academic text. The research products of a research team, center, institute, or department are all potential data sources. Citation-based measures rely on the curation efforts of databases, but this text-based measure can be used on unstructured text. A curated collection such as WoS remains important for creating the disciplinary corpora, but the corpora of scholars, institutes, centers, and initiatives can be derived from any source, as long as researchers are able to assign them to a home discipline for the purposes of the discipline-to-discipline similarity weighting.
The ability to analyze noncurated text opens a clear path to better and broader examinations of interdisciplinarity in the social sciences and humanities. Future work can move beyond the curated contents of WoS and similar databases to analyze text collected from publishers’ Web sites or online products of the digital humanities. Further work can compare and validate the performance of a text-based measure of interdisciplinarity across academic fields and using a variety of data sources.
This method offers other options for expansion and development in the analysis of academic text. Abstracts and titles are like the advertisements of a publication: they seek to draw in the reader and give a succinct report of the article’s contents. However, testing the text-based measure of interdisciplinarity on larger sections of published articles, such as the methods or framing sections may reveal patterns behind how and in what ways integration occurs.
Identifying and describing different structural patterns of integration can motivate other interesting questions about interdisciplinarity and its impacts. Do different patterns of integration associate with different outcomes for the publication, in terms of citations and knowledge diffusion? Prior work (Uzzi et al. 2013) focused on the diversity of knowledge combinations on the basis of references but not on the structure and placement of ideas within the text.
Publications communicate the work and outcomes of research, but they are also the medium through which researchers establish their professional reputations and identities as disciplinary or interdisciplinary scholars. Future work could analyze interdisciplinarity at the paper level across the career arc of scholars. In this type of analysis, it would be possible to map interdisciplinarity across time within researchers and identify how interdisciplinarity occurs across the academic career course.
Footnotes
Appendix A: List of Disciplinary Clusters

| Assignment of Web of Science Subject Categories to Disciplinary Clusters. | |||
|---|---|---|---|
● Agriculture, Multidisciplinary ● Agronomy ● Architecture ● Art ● Biochemical Research Methods ● Biophysics ● Anatomy & Morphology ● Mathematical & Computational Bio. ● Mycology ● Ornithology ● Parasitiology ● Zoology ● Biodiversity Conservation ● Fisheries ● Limnology ● Marine & Freshwater Biology ● Ethics ● Sport Sciences ● Business, Finance ● Management ● Literature, Afr., Aust., Can. ● Literature, American ● Literature, British Isles ● Literature, Ger., Dutch, Scan. ● Literature, Romance ● Literature, Slavic ● Literary Theory & Criticism ● Literary Reviews ● Poetry ● Materials Science, Paper & Wood ● Materials Science, Ceramics ● Materials Science, Multidisciplinary ● Materials Science, Biomaterials ● Materials Science, Char., Testing ● Materials Science, Coat. & Films ● Materials Science, Composites ● Materials Science, Textiles ● Metallurgy & Metallurgical Eng. ● Oceanography ● Engineering, Marine ● Remote Sensing ● Engineering, Ocean |
● Chemistry, Applied ● Chemistry, Medicinal ● Chemistry, Multidisciplinary ● Chemistry, Analytical ● Chemistry, Inorganic & Nuclear ● Chemistry, Organic ● Chemistry, Physical ● Electrochemistry ● Spectroscopy ● Crystallography ● Polymer Science ● C.S., Artificial Intelligence ● C.S., Cybernetics ● C.S., Hardware & Arch. ● C.S., Information Systems ● C.S., Interdisciplinary App. ● C.S., Software Engineering ● C.S., Theory & Methods ● Cell Biology ● Cell and Tissue Engineering ● Reproductive Biology ● Andrology ● Peripheral Vascular Diseases ● Medical Ethics ● Allergy ● Integ. & Complementary Med. ● Medicine, Legal ● Medical Informatics ● Medicine, Research & Exp. ● Transplantation ● Tropical Medicine ● Toxicology |
● Evolutionary Biology ● Agricultural Economics & Policy ● Transportation ● Environmental Studies ● Industrial Relations & Labor ● Education, Scientific Disciplines ● Education, Special ● Engineering, Civil ● Transportation Science & Tech. ● Instruments & Instrumentation ● Robotics ● Telecommunications ● Engineering, Manufacturing ● Automation & Control Systems ● Operations Res. & Mgmt Science ● Energy & Fuels ● Engineering, Petroleum ● Mechanics ● Thermodynamics ● Horticulture ● Physics, Applied ● Physics, Fluids & Plasmas ● Physics, Atomic & Chem. ● Physics, Multidisciplinary ● Physics, Condensed Matter ● Physics, Nuclear ● Physics, Particles & Fields ● Physics, Mathematical ● Imaging Sci. & Photo Tech. ● Acoustics ● Microscopy ● Optics ● International Relations ● Planning & Development ● Public Administration ● Ergonomics ● Behavioral Sciences ● Substance Abuse ● Rehabilitation ● Health Care Sci. & Services ● Health Policy & Services |
● Agricultural Engineering ● Soil Science ● Water Resources ● Geography, Physical ● Geochemistry & Geophysics ● Engineering, Geological ● Geology ● Mineralogy ● Paleontology ● Mining & Mineral Processing ● Folklore ● History & Philosophy of Science ● History of Social Sciences ● Infectious Diseases ● Virology ● Language & Linguistics ● Psychology, Multidisciplinary ● Psychology, Psychoanalysis ● Psychology, Mathematical ● Psychology, Experimental ● Psychology, Social ● Psychology, Biological ● Psychology, Clinical ● Psychology, Educational ● Psychology, Development ● Psychology, Applied ● Neuroimaging ● Social Sciences, Biomedical ● Demography ● Social Work ● Social Sciences, Mathematical Methods ● Mathematics, ID Applications ● Dance |
Appendix B: Example Calculation of ID Score
To demonstrate the step-by-step calculation of the ID score, I use two hypothetical anthropologists (scholars A and B). Scholar A is disciplinary and studies native cultures. Scholar B is a biological anthropologist who is more interdisciplinary, collaborating with geneticists to study the genetic diversity of populations. For the sake of simplicity, each scholar’s corpus contains only three words. The corpus for scholar Ais “culture indigenous people.” The corpus for scholar B is “population genetic evolution.”
In the analysis presented in the article, I use the TfidfVectorizer() method in python’s Scikit-learn package (Pedregosa et al. 2011) to convert all scholar and discipline corpora to term frequency matrices, weighted by the inverse document frequency (idf) values. Here, I show how this process occurs, step by step.
Using the full set of scholar terms, I first create a term frequency matrix (Table B1). Each term frequency is a count of the number of times the term (row) appears in each corpus (column). To calculate the idf values, I count the number of disciplinary corpora in which each term appears, and use these counts in the idfw formula. For example, culture appears in 84 of the 85 disciplinary corpora, so the idf value for culture is
The idf values in Table B1 reveal some of the intuition of the tf-idf weighting used in the cosine calculations. All of the values are low, suggesting that all six words are used in many disciplines. Note, however, the difference in idf values between culture and indigenous. Culture occurs in 84 of the 85 disciplinary corpora, while indigenous appears in only 70 disciplinary corpora. The slightly rarer occurrence of indigenous makes it more informative in differentiating among disciplines, so it receives a higher idf weight (1.08) than that of culture alone (1.01). In Table B1, the idf values for each term are listed in the last column.
The values in Table B1 are used to calculate the tf-idf weighted cosine similarity between scholars A and B and the disciplines (equation 2 in the main text). Below is an example of the cosine similarity calculation comparing scholar A’s corpus with that of biology. The numerator contains three bracketed expressions, one for each of the overlapping terms between the two corpora. Within the brackets, I multiply three values: (1) the term’s frequency in scholar A’s corpus, (2) the term’s frequency in the biology corpus, and (3) the squared idf value. For example, the first bracketed expression is for the word culture, which appears 1 time in scholar A’s corpus and 3,137 times in the biology corpus and has an idf weight of 1.01. As a result, this expression is [1 × 3,137 × (1.01)2]. The numerator increases as (1) the frequency and proportion of overlapping terms increase and (2) the idf values increase. As a result, sharing more and rarer words is indicative of greater similarity between the two corpora.
The values in the denominator serve to length-normalize the cosine similarity value. In the denominator, the top line contains the term frequency for each term in the scholar corpus, multiplied by its idf value and squared. For example, the first term (1 × 1.01)2, is the frequency of the word culture (1) multiplied by its idf value (1.01) and squared. The idf-weighted corpus length is the square root of the sum of these values. All terms in scholar A’s corpus are included in the example below.
In the biology corpus, there are more than 130,000 words. In the interests of space, I show only the expressions for the three overlapping terms and one additional term here. The additional expression is (9,620 × 1.02)2. This expression is the squared product of the term frequency and idf value for the word population, drawn from Table B1. The full cosine similarity calculation would contain additional expressions for the other terms in Table B1 and the other tens of thousands of terms in the biology corpus that are not shown here.
In Table B2, I present the cosine similarity values between scholars A and B and the four disciplinary corpora to which they are most similar. Table 3 in the main text shows the pairwise discipline-to-discipline cosine similarity scores among the closest disciplines for each scholar. Higher values indicate disciplines that are more similar to one another in their language use. Because each scholar is an anthropologist, all
To calculate the ID score for each scholar (using equation 4 from the main text), I take the weighted, normalized sum of the cosine similarity values between each scholar and her four closest disciplines (Table B2). The weights are the discipline-to-discipline similarity values in Table 3. For scholar A, her nearest discipline is anthropology. The cosine similarity value between scholar A and anthropology is 0.196, and the similarity of anthropology to itself is 1.00, as the corpus is identical to itself. These two values are multiplied together in the numerator of the ID score calculation for scholar A: [0.196 × 1.00]. The next three expressions in the numerator perform the same operation, but for the other three disciplines. The denominator is the sum of the four cosine similarity values between the scholar and her four closest disciplines and serves to normalize the ID score. The following equations calculate the ID score for each scholar:
As expected, scholar B has a higher ID score than scholar A. Scholar B’s research, and corpus terms, draws on the ideas and vocabulary of scientific disciplines that are more distant from anthropology, as represented by the lower discipline-to-discipline cosine similarity values between anthropology and scholar B’s three closest disciplines (cosine values of 0.36, 0.41, 0.51, and 1.00, respectively). Scholar A is more disciplinary: her closest discipline is her own, and her corpus overlaps with disciplines that are proximal to anthropology. The discipline-to-discipline cosine values between anthropology and scholar A’s closest disciplines are much higher (cosine values of 1.00, 0.59, 0.66, and 0.43, respectively).
Acknowledgements
Special thanks to the anonymous reviewers, Charles Gomez, Erin Leahey, and Dan McFarland for their helpful feedback on this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This material is based on work supported by the National Science Foundation (NSF) Graduate Research Fellowship Program (No. DGE-114747). Any opinion, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the NSF. This work was also supported by the Stanford Graduate Fellowship Program. These data were collected by the Mimir Project conducted at Stanford University by Daniel McFarland, Dan Jurafsky, and Jure Leskovec. This project has been generously funded by the Brown Magic Grant, Dean of Research at Stanford University, and NSF Award No. 0835614. Access to these data was approved by the Mimir Project, and use followed institutional review board guidelines.