
Abstract
Scholars have called for a merging of Universal Design for Learning and Culturally Sustaining Pedagogies to imagine a more complete vision of inclusion—one that sustains students’ distinct identities while centering variability. Doing so holds promise for creating equitable educational environments, especially for students multiply marginalized in schools. Assessing teachers’ self-efficacy to employ such equity-centered teaching (ECT) is one avenue for measuring their potential for implementation. However, while scales measuring self-efficacy for each distinct framework exist, none yet measure their cross-pollination. In this study, we operationalized this cross-pollination as ECT and utilized a six-stage approach to design a self-efficacy measure for ECT. We employed Item Response Theory (N = 225) to gather evidence of scale validity. Our construct concretizes a theoretical discussion into a tangible resource, and our scale extends measurement opportunities in the ECT literature by intersecting two important equity-oriented frameworks and synthesizing them into a single accessible tool.
Keywords
Since the inception of formal schooling in the United States, children have received inequitable opportunities to access relevant, responsive, and rigorous learning—by race, ethnicity, class, gender, and ability (Darling-Hammond, 2015; Tyack & Cuban, 1995). Although some progress has been made to ensure students from historically excluded groups physically learn within the same buildings and classrooms as historically privileged peers (Bahar, 2021; Malhotra, 2024), ample research supports that racist and ableist exclusion from meaningful learning persists in schools, for example, via differential learning experiences within classrooms (Bannister, 2016; Lambert, 2015) or persistent tracking practices within schools (Lofton, 2024; McClam et al., 2025; Umansky, 2016). Seeking to dismantle such exclusion, critical scholars have argued that physically including students with dis/abilities 1 via least restrictive environment mandates (Artiles & Kozleski, 2016; Cruz et al., 2024; Greenstein, 2016), and placing historically marginalized students in classrooms with privileged peers, but failing to position those students as “powerful producers of new social futures” (Calabrese Barton & Tan, 2019, p. 617), are insufficient for achieving educational justice. Rather, scholars have argued that greater attention must be allotted to the type and quality of instruction students receive once in the general education classroom—ultimately, to ensure that all children, no matter their background or the labels assigned to them, are meaningfully included in rich learning.
In 2016, Waitoller and Thorius put forth this vision: cross-pollinate the equity-oriented instructional frameworks of Universal Design for Learning (UDL) and Culturally Sustaining Pedagogies (CSP). UDL was originally created to support the design of grade-level instruction to be more accessible to students with dis/abilities (Rose & Meyer, 2002), whereas CSP was designed to sustain students’ cultural and linguistic backgrounds in the classroom (Paris & Alim, 2014). Drawing upon scholarship recognizing racism and ableism as interlocking forms of exclusion (Annamma et al., 2013; Sullivan & Thorius, 2010), Waitoller and Thorius (2016) argued that the cross-pollination of frameworks like UDL and CSP was necessary because, given their intertwined nature, “it is futile to dichotomize race and ability when addressing educational inequities” (p. 371). Other scholars have endorsed the need to actualize this theoretical call into practice to bring forth critical inclusion (Coppola et al., 2019; Cruz et al., 2024; Kulkarni et al., 2023; McClam et al., 2025; Pugach et al., 2019).
To achieve this goal of enacting a cross-pollinated inclusive pedagogy, Waitoller and Thorius’s (2016) theoretical framework must be operationalized and concretized into a pedagogical framework with related practices applicable in K–12 and postsecondary settings.
In other words, before the field can understand the impact of Waitoller and Thorius’s proposed framework on equitable learning outcomes, it must be defined in practical ways teachers can use. Then, measures must be created that allow district/school leaders and researchers to monitor teachers’ experiences with and use of the framework, ultimately so they can better support teachers in professional development efforts and relate results to students’ outcomes.
In the complex but needed pursuit of meaningful inclusion, teachers’ self-efficacy to enact the framework into practice requires early attention from district/school leaders and researchers—in both professional learning and evaluation efforts. Self-efficacy is a person’s belief in their ability to enact a practice (Bandura, 1986), and it is often considered a prerequisite to enactment (Comstock et al., 2023; Dixon, 2011). Self-efficacy measures are cost- and time-efficient for progress-monitoring of initiatives, such as professional learning (PL). Namely, PL leaders can use these measures to identify the pedagogical areas in which teachers believe they require further instruction and support and adjust subsequent PL design accordingly. Furthermore, self-efficacy measures can minimize several limitations inherent to other self-reported measures (see Cleary, 2009). Thus, in the scope of measurements needed to evaluate teachers’ cross-pollinated inclusive pedagogies and their role in student learning, it makes sense to first create a self-efficacy measure that can later be mapped onto an observation tool (which requires more resources to implement). Although some scales have been created to measure teacher self-efficacy, as well as other beliefs and practices, related to anti-racist teaching (e.g., Ludlow et al., 2008; Siwatu, 2007) or anti-ableist teaching (Cullen et al., 2010; Lombardi et al., 2015), we are not aware of any measure of teachers’ self-efficacy related to anti-racism and anti-ableism in one cross-pollinated, equity-oriented framework.
Therefore, in this study, we sought to first operationalize Waitoller and Thorius’s (2016) cross-pollinated theoretical framework into a cross-pollinated pedagogical framework, which we refer to as “equity-centered teaching” (ECT). We also sought to develop and evaluate a scale measuring teachers’ self-efficacy to enact this cross-pollinated framework, usable by researchers, PL leaders, instructional coaches, and others to identify the specific ECT practices in which teachers feel most and least capable of employing and responsively revise PL plans to align with teachers’ perceived needs. Ultimately, this scale can be used to guide PL design. We followed an iterative scale design process (Gehlbach & Brinkworth, 2011) to operationally define ECT with actionable scale items. Then, we collected evidence of the scale’s validity, reliability, and functioning using a series of correlational tests and item-response modeling (Wilson, 2023).
Theoretical Perspectives
Despite the landmark Supreme Court Brown v. Board of Education ruling, which legally ended racial segregation in U.S. public schools on the grounds that “separate educational facilities are inherently unequal” (Brown v. Board of Education, 1954, p. 11), much scholarship has documented the persistent inequitable educational experiences students of color frequently face in schools (Gutiérrez et al., 2024; Ispa-Landa, 2013; Ochoa, 2013; Tyson, 2011). Asset-based pedagogies have gained momentum over the past 2 decades as a vehicle to counter the deficit perspectives often underlying such inequitable experiences. Ladson-Billings (1995b) put forth perhaps one of the best-known asset-based pedagogical frameworks: Culturally Relevant Pedagogy (CRP). Building upon principles endorsed by U.S. civil rights advocates, foundational work from Freire (1973, 1974), and Ladson-Billings’ (1994) work that profiled successful teachers of African American children, Ladson-Billings proposed a set of pedagogical tenets—academic achievement, cultural competence, and sociopolitical/critical consciousness—that teachers should embody, ultimately to support students’ academic success, belonging, and ability to question existing power structures (Ladson-Billings, 1995b).
These tenets center around how teachers perceive themselves and their students, how they structure classroom community, and what they believe about the role of knowledge construction. Ladson-Billings (1995b) found, for example, that culturally relevant teachers promoted historically marginalized students’ academic development because they believed their students were academically capable and created opportunities for students to learn from one another; they planned lessons reflecting students’ backgrounds; and they situated themselves within their students’ communities to increase their own cultural competence. They believed that knowledge should be viewed from a critical lens, and therefore built students’ and their own critical consciousness.
CSP (Paris, 2012) builds upon CRP and offers a proposed shift from building educational experiences relevant to student backgrounds toward experiences that sustain those backgrounds. In other words, “CSP seeks to perpetuate and foster—to sustain—linguistic, literate, and cultural pluralism as part of the democratic project of schooling” (Paris & Alim, 2014, p. 88). In CSP, teachers are called on to ensure that students of color and emergent multilingual learners’ cultural and linguistic practices are cultivated and sustained through instruction, thus allowing students to receive opportunities to build upon their distinct identities in school, while still receiving access to develop dominant cultural competence. To Paris and Alim, CSP moves practitioners away from historical perspectives that seek to shape students from marginalized backgrounds to act more like middle class, white students and, instead, seeks to reshape schools as spaces where heterogeneous practices are sustained. Doing so requires centering community languages, valuing practices and knowledge students bring into the classroom, placing content and instruction in historical context, building students as agents of their own learning, and supporting them to contend with internalized oppressions stemming from decades of inequity (Paris & Alim, 2017).
Shortly after the passage of Brown v. Board of Education, in 1975 the United States Congress authorized what is known today as the Individuals With Disabilities Education Act. This Act mandated that students identified with dis/abilities and requiring special education services learn within the least restrictive environment “to the maximum extent appropriate” (IDEA Regulations, 2017. § 300.114). As a result, students with dis/abilities have increasingly gained physical inclusion in U.S. general education classrooms (Malhotra, 2024). Although the increase marks improvement towards the legislation’s equity goals, physical presence alone does not ensure meaningful inclusion into learning (Artiles & Kozleski, 2016; Cruz et al., 2024; Waitoller & Thorius, 2016). As an illustration, consider a mathematics classroom where students with dis/abilities are placed in fixed-ability groups within the general education space (Lambert, 2015). Although this classroom may physically include students with dis/abilities, such a learning environment does not create a meaningfully inclusive experience (Caroleo, 2024). Originally created to reduce instructional barriers for students with dis/abilities in general education classrooms, and thus enable meaningful inclusion, UDL (Rose & Meyer, 2002) was put forth as an instructional framework intended for teachers to design learning environments accessible for every learner (CAST, 2024).
Much like CRP, CSP, and other asset-based pedagogies do for students of color and emergent multilingual learners, UDL aims to provide an alternative to the traditional deficit perspectives applied to students with dis/abilities by proposing a framework that enables meaningful inclusion into learning for students across all abilities. To do so, UDL endorses offering multiple means of engagement, representation, and action and expression, so that all students have various access points to learn and acquire the content or skill of focus and ultimately build agency over their own learning (Gordon, 2024). Engagement refers to the affective network of the brain and considers ways students might develop interest in and persistence for their learning, because learning will be stifled without learner motivation and self-regulation strategies to reach a goal. Representation refers to how information is presented, such that all students can understand it, addressing the brain’s recognition network. Action and expression, then, deals with providing multiple ways for students to demonstrate what they have learned, which is related to the strategic network of the brain. The goal of learning should not change for individuals, as doing so risks lowering the bar of rigor for students; UDL instead proposes employing flexible teaching materials, instructional methods, assessments of learning, and classroom environments to “foster access and engagement” toward clear and relevant learning goals (Gordon, 2024, p. 67).
Cross-Pollinating Equitable Instructional Frameworks
While CSP and UDL have each gained momentum on their own as instructional tools to counteract exclusionary practices in schools based on race or dis/ability status, scholars have argued that school-situated mechanisms of exclusion based on these factors cannot be understood apart from one another, as they are entwined (Annamma et al., 2018). Furthermore, in the United States, the term “inclusion” has become primarily associated with students with dis/abilities physically learning within the general education classroom, lacking acknowledgement of other groups of learners historically excluded from rich learning in U.S. schools, such as students of color (Calabrese Barton & Tan, 2020), emergent multilingual learners (Cioè-Peña, 2017), and those at the intersections of multiple minoritized identities (e.g., multiply marginalized learners; Artiles & Kozleski, 2016; Kangas, 2021). From this perspective, Waitoller and Thorius (2016) proposed cross-pollinating UDL and CSP to maximize inclusion, not only by dis/ability or race, ethnicity, and language, respectively (as is often assumed within each separate framework), but rather by building lines of access to rich learning for students of all backgrounds.
Waitoller and Thorius (2016) proposed that elements of UDL and CSP be cross-pollinated to maximize meaningful inclusion for all students in general education classrooms. First, they suggested that CSP be extended in three ways—by explicitly attending to dis/ability as an essential component of a cultural identity, accounting for dis/ability cultural aspects in curricula (such as by recognizing ability pluralism, in addition to sociocultural forms of pluralism), and interrogating both racism and ableism. They proposed that UDL be extended in three ways as well: by nurturing students’ ability to interrogate multiple forms of oppression (similar to the proposed CSP extension), integrating critical reflexivity to adopt critical understandings of dis/ability and whiteness, and addressing how power and privilege stifle learning opportunities for those with intersectional racial and ability identities. Engaging in such a cross-pollination promotes critical inclusion, whereby the field may bridge the theoretical and practical gaps between CSP and UDL to promote meaningful inclusion for all students (Cruz et al., 2024). Other scholars have developed specific instructional units utilizing the cross-pollination (Coppola et al., 2019) and assessment approaches that reflect it (Hanesworth et al., 2018), providing a foundation of how the cross-pollination tangibly operates in practice.
Cross-Pollinating Across Instructional Contexts
Although UDL and CSP were originally employed in the K–12 setting, both frameworks have been applied to postsecondary contexts (Cole, 2017; Reardon et al., 2021), and work has been done to enumerate a UDL-CSP cross-pollinated vision in the postsecondary environment (Grier-Reed & Williams-Wengerd, 2018; Kulkarni et al., 2023). For example, Universal Design for Instruction (McGuire & Scott, 2006), a close relative of UDL, was explicitly created for undergraduate education and includes elements such as “perceptible information” and “flexibility in use,” which mirror UDL’s recognition dimension and underlying call for providing multiple means for students to access grade-level learning, respectively. The concept that educators must co-create classroom spaces where all students share an active role in the learning process is equally applicable to the university setting as it is to K–12 contexts (Grier-Reed & Williams-Wengerd, 2018). However, because teaching methods and pedagogical decisions may vary between K–12 and postsecondary educators, research must examine whether cross-pollinated elements of UDL and CSP are broadly applicable across contexts.
The Importance of Self-Efficacy for Research and Teacher Practice
Deriving from a social cognitive theory which posits that humans have personal agency in their development, the term self-efficacy refers to “people’s judgments of their capabilities to organize and execute courses of action required to attain designated types of performance” (Bandura, 1986, p. 391). Self-efficacy emerges and strengthens from explicit teaching of content, exposure to modeling, mastery experiences, feedback, and reinforcement (Bandura, 1977, 1997; Swackhamer et al., 2009). Bandura (1986) posited that self-efficacy beliefs are goal-directed and task- and domain-specific, meaning they are dynamic and in continual development (Wyatt, 2014). For example, a teacher may feel highly efficacious in building a classroom community but less efficacious in embedding rigor into math tasks; their self-efficacy levels for each task can also change over time based on various personal, occupational, and environmental factors (Cruz et al., 2020; Perrera et al., 2019), and exposure to professional learning (Burger, 2024; Comstock et al., 2023).
Self-efficacy has been linked to several desirable teacher outcomes (Zee & Koomen, 2016), such as the creation of supportive classroom communities (Burić & Kim, 2020), enactment of feedback-related practices (Dixon, 2011), inclusion of cognitive activation during instruction (Fauth et al., 2019), and reduction in stress levels and increase in job satisfaction (Skaalvik & Skaalvik, 2017). Related to ECT, specifically, research supports that teachers holding self-efficacy for equity-oriented pedagogies enact more of the practices aligned to those pedagogies (Comstock et al., 2023; Rusconi & Squillaci, 2023), which in turn brings about many academic and interpersonal benefits for learners (Cammarota & Romero, 2011; Dee & Penner, 2017; King-Sears et al., 2023).
For researchers or district/school/PL leaders seeking to monitor teacher practice over time, self-efficacy measures hold some advantages over other self-reported measures and observation measures (Cleary, 2009). Cleary pointed out that many self-report measures are often decontextualized in nature and do not establish specific conditions from which participants appraise their cognitive and motivational processes, meaning participants may provide responses that do not fully represent how they think or act within the moment. On the other hand, self-efficacy items typically provide more clear, contextual descriptions that situate the participant within their typical thinking and action within specific moments, thereby increasing the potential validity of the self-appraisals. Furthermore, as self-report measures that can be implemented rather quickly (as opposed to observation scales that require an additional person to watch and evaluate performance), self-efficacy scales are beneficial for capturing indicators of people’s practice without requiring additional human capital or time to implement.
Because of the impact of teacher self-efficacy on teacher practice and student outcomes—and the described advantages of self-efficacy measures for research and practice—several scholars have developed scales to measure teachers’ self-efficacy for equity-related teaching, such as culturally responsive teaching (Siwatu, 2007), multicultural education (Guyton & Wesche, 2005), and inclusive attitudes, practices, and strategies (Cullen et al., 2010; Lombardi et al., 2015; Sharma et al., 2012). These existing scales range from 13 items (Lombardi et al., 2015) to 40 items (Siwatu, 2007). Some scales established evidence of validity with data from only pre-service teachers (Sharma et al., 2012; Siwatu, 2007), leaving limitations with the validity of transference to practitioners.
Most importantly, for the purposes of this study, we are unaware of any previous scale measuring teachers’ self-efficacy for the UDL and CSP cross-pollination Waitoller and Thorius (2016) suggested (i.e., ECT), leaving a need for a scale that will accurately measure teachers’ confidence in enacting that pedagogy and establish a baseline of items that can be transferred to an enactment measure. If researchers or PL leaders wish to train educators in meaningful inclusion and monitor their efforts by measuring teachers’ self-efficacy for ECT over time, they risk having to merge two of the mentioned scales, which compromises survey scholars’ recommendation to keep surveys concise in length to prevent respondent satisficing behaviors (Dillman et al., 2014). Ultimately, developing a self-efficacy scale for ECT can help district/school leaders and researchers understand teachers’ perceptions of their abilities related to ECT and each associated ECT practice. Although self-efficacy is not a measure of actual ability, leaders can use this information over time to determine how PL initiatives do or do not address teachers’ beliefs about their ECT abilities and which ECT practices require further support. They may also identify teachers who feel confident in ECT and may serve as teacher-leaders in initiatives as well as those who require targeted individual support.
The Current Study
Since Waitoller and Thorius’s (2016) piece was published, designers of UDL have initiated some cross-pollination work by addressing “critical barriers rooted in biases and systems of exclusion for learners with and without disabilities” (CAST, 2024, Introducing UDL Guidelines 3.0 section, para. 2). These updated guidelines are an important step toward realizing Waitoller and Thorius’s (2016) vision, but most themes within the 3.0 revisions do not include building students’ critical consciousness as is needed to truly cross-pollinate UDL with CSP. To our knowledge, no scholars have yet proposed a concrete framework and accompanying self-efficacy scale that fully captures and operationalizes the cross-pollination of UDL and CSP. Therefore, building upon studies that have concretized the cross-pollination into subject-specific practices (Coppola et al., 2019) or higher education settings (Grier-Reed & Williams-Wengerd, 2018; Kulkarni et al., 2023), we aimed to achieve two research purposes: (1) operationalize the theoretical call to cross-pollinate UDL and CSP into a pedagogical framework we call ECT; and (2) develop and evaluate a scale that measures teachers’ self-efficacy to enact this cross-pollinated pedagogy, which might be applied to any subject and grade level. While these purposes are distinct, construct development (i.e., pedagogical framework creation) is embedded in the scale development process. As such, we describe these processes together in the method section.
Method
Construct and Scale Development Process
To achieve our research purposes, we employed an iterative survey design and revision process, following Gehlbach and Brinkworth’s (2011) six-stage process, which frontloads steps to enhance scale validity before conducting pilot testing and engaging in quantitative analysis. The steps include: (1) conducting a thorough literature review to define a construct; (2) gathering focus group and interview data about the draft construct; (3) synthesizing these data into a final construct; (4) developing survey items to measure the construct; (5) engaging in expert validation and revising the survey accordingly; and (6) conducting cognitive pretesting on the revised items and further revising based on cognitive pretesting results.
Initially Defining the Construct of Equity-Centered Teaching
We first set out to operationalize the cross-pollination of UDL and CSP through our development of ECT as a cross-pollinated pedagogical framework, using the first three steps from Gehlbach and Brinkworth (2011). We began by reviewing the foundational literature related to the original frameworks (CAST, 2024; Ladson-Billings, 1995a, ; Paris, 2012; Paris & Alim, 2014; Rose & Meyer, 2002) to understand their commonalities and differences. The first two authors underwent a series of iterative independent mapping of commonalities and differences between the two frameworks. For example, some shared commonalities were holding high expectations of students (by race/language or ability) and building access to content by providing intentional scaffolds rooted in students’ distinct cultural or ability backgrounds. Some differences were CSP’s emphasis on developing critical consciousness, whereas UDL emphasizes flexible demonstration of knowledge.
After this, the two authors defined initial dimensions and indicators shared between both frameworks and distinct to each to cross-pollinate the two into a single pedagogy. At first, they conceptualized the pedagogy as a set of merged and cross-pollinated practices that support and sustain culture and dis/ability across four teaching dimensions, which are all part of the instructional process: classroom community, planning for learning, teaching methods, and assessment. They created an initial conceptual map to convey the dimensions and the cross-pollinated indicators that mapped onto each dimension (see Figure 1). For example, as teachers plan for learning guided by the cross-pollinated pedagogy, they should (1) provide access through planned scaffolds connected to students’ backgrounds and learning needs, while maintaining the expectation that all students can reach the standards of focus; (2) leverage students’ needs, backgrounds, and interests in the instructional sequence—accounting for both culture/language and ability profiles; and (3) integrate critical consciousness development that considers the role and effects of systemic racism and ableism in schools and society. We envisioned such cross-pollination across all four dimensions, with a focus on contextually appropriate enactments of the dimensions across a variety of teaching settings.

Initial conceptual map to represent equity-centered teaching.
Developing Items to Measure ECTs
To fulfill our second research purpose of designing a scale to represent the overarching ECT construct, we engaged in the remainder of Gehlbach and Brinkworth’s (2011) iterative process. To develop our self-efficacy survey items (Step four), we used our conceptual map to adapt questions from existing scales (Curenton, 2020; Lombardi et al., 2015; Sharma et al., 2012; Siwatu, 2007) and develop original items to address identified gaps from these measures. We wanted at least one item to represent each indicator in the map. For example, we adapted an item from Curenton (2020) that represented the practice of encouraging children to question whether or not information was correct—which we identified as a teaching method that develops critical consciousness. Due to an absence in existing scales, we created an item about creating classroom structures where power is shared equally—which we identified as contributing to classroom community. In this process, we developed and finalized 31 items that represented practices that compose equity-centered teaching.
Next, we sought to structure the items into a valid self-efficacy measure. Surveys with item-specific questions, which are questions with answer choices unique to the question’s response dimension (as opposed to agree-disagree Likert responses), yield higher-quality data (Dykema et al., 2022). Furthermore, in studying psychometric properties of surveys, Simms et al. (2019) found little benefit to including greater than six response options. As such, we crafted our questions to be item-specific with five response options each, as illustrated in the following question: How confident are you in your ability to offer flexibility (i.e., choice) in how students demonstrate their understanding of content or skills? Not at all confident – slightly confident – moderately confident – quite confident – extremely confident. We established face and content validity for the scale by deploying a content validation survey with three equity-centered practices experts (step five) and conducting nine cognitive interviews with current and former educators (step six). Table 1 presents background information for our expert reviewers and cognitive interview participants.
Expert Reviewer and Cognitive Interviewee Sample Characteristics

One key theme that emerged from our expert review (Step five) was the need to better articulate the underlying indicators embedded within ECT (e.g., articulating the difference between integrating critical consciousness development versus expanding critical consciousness, originally found in separate dimensions). Expert reviewers suggested we refine our initial ECT construct conceptualization. They shared comments such as, “I’m not sure what [indicator] this would exactly map to,” “[this item] speaks to furthering learning, although I wonder if there is a way that it could function the other way [to be less equitable],” “I think this [restoring positive relationships item] is important, but is it about equitable teaching?” and “I think this [item] could be better tailored to speak to equity and to be clearer on what you mean.”
Finally, our cognitive interview process (Step six) yielded feedback that parallel questioning structure might result in respondent rushing, which is consistent with research about satisficing (i.e., survey respondents taking shortcuts) if bored (Krosnick, 1999). Although we initially intended to create a scale with aligned question stems to reduce cognitive load, we ultimately varied our questions to increase their item specificity even further and to reduce likelihood of straight line responding (Dillman et al., 2014) and other satisficing behaviors.
Revising the ECT Construct, Conceptual Map, and Scale Items
In response to the expert feedback, we developed an operational definition of ECT and revised our initial version of the conceptual map that articulated practices situated within each part of the instructional process to one that cross-pollinated UDL and CSP into five methods that cut across the entire instructional process. We revisited the literature, with particular attention to Waitoller and Thorius (2016), to consider how to best represent the needed cross-pollination into one construct via these five methods. This revision allowed us to ensure that all practices in the ECT construct fully captured the critical elements of UDL and CSP and centered equity. Both the operational definition and final conceptual map can be found in the results section.
We used the operational definition and final conceptual map to revise and reduce items in our scale to ensure each one fully captured the practices that compose the construct. For example, prior to the conceptual map revision, we had created an item that asked “How well can you use questioning strategies in response to student questions or misconceptions about systemic inequities?”; we originally conceptualized such questioning strategies as a teaching method that expanded critical consciousness. Through the conceptual map revisions and examining the listed practices—as well as considering the expert feedback about being more explicit in wording—we revised this question to ask, “How well can you use various strategies (e.g., metacognitive questioning, class reading, resource sharing, etc.) to guide your class to have courageous conversations about systemic inequities?” This change, with the provided examples and reference to a concrete practice (i.e., using strategies or having conversations), provided more specificity and more clearly represented the method of integrating critical consciousness. Conversely, we removed one item originally tied to the assessment dimension (“To what extent do you believe you can identify more than one way to assess a skill?”) since we determined that it was not necessarily cross-pollinated and rather just reflected UDL. Instead, we used questions that emphasized practices focused on building expertise for all (with “all” bolded and underlined) in ways that require the cross-pollination between UDL and CSP. Ultimately, we finalized a 29-item self-efficacy scale (see Appendix A), which we deployed during pilot testing.
Scale Evaluation Process
To gather evidence for the validity of our scale, entitled the Self-Efficacy for ECT Scale, we conducted pilot testing with current K–20 U.S. educators. We selected this grade level range, spanning early elementary to postsecondary, operating under the theoretical assumption that all educators, no matter their grade level, should be able to employ developmentally-appropriate ECT. We describe that process here.
Respondents
We surveyed a total of 225 educators with the scale. We utilized Prolific (2024), a survey recruitment platform, to recruit respondents. Once active, the survey was open to all registered Prolific users who met our inclusion criteria and remained open until we reached our target sample size—approximately 1.5 weeks later. To be included, respondents were required to: (1) live in the United States; (2) identify as a full-time or part-time educator; and (3) teach in either a K–12 or postsecondary setting. Prolific asks users to share demographic data during registration, so only eligible participants may respond to each advertised survey. We also included questions in our survey to ensure all participants completing the survey met the criteria for inclusion. Bots were screened out using an attention check question at the beginning of the survey and a set of open-ended questions in the middle of the survey. Most respondents in the sample taught in K–12 schools (72%). The sample was majority white (80%) and female (72%), which is consistent with the U.S. teaching population (National Center for Education Statistics, 2023). Teacher years of experience ranged from less than 1 full year to 39 years (M = 11.44, SD = 8.32). Teachers in our sample taught in 42 states, plus Washington, D.C. Table 2 shows descriptive data for the scale sample.
Pilot Testing Sample Characteristics

Note. Data is reported as a count (percentage). ELA = Reading/writing/English language arts. STEM = astronomy/biology/chemistry/computer science/environmental science/mathematics/ physics/neuroscience. Social sciences = anthropology/economics/geography/philosophy/political science/psychology/sociology.
Establishing Evidence of Reliability and Validity
We employed item response theory (IRT) to analyze how well each scale item measured ECT self-efficacy and establish evidence of the scale’s construct validity. IRT recognizes a latent trait as existing along a single, underlying continuum and allows for analysis of a scale’s performance at the person level, thereby offering more information about each item’s role in measuring the underlying latent trait (Zein & Akhtar, 2025). Items may vary by difficulty, or how hard they are to endorse; discrimination, or how well they differentiate between individuals at any given point along the continuum; and the extent to which individuals might guess the correct answer (Baker, 2005). Using these dimensions, IRT can be useful for determining how well individual items in a scale contribute to the overall scale performance and at what point on the latent trait continuum they provide information about individuals, independent of each of the other items in the scale. One of our goals during pilot testing was to reduce items to improve ease of scale use, which is an important application of IRT (Edelen & Reeve, 2007). As such, we chose to evaluate our scale using IRT, as opposed to classical test theory methods.
We conducted our analysis primarily in R (Version 4.2.2; R Core Team, 2022) using the mirt (Chalmers, 2012) and psych (Revelle, 2024) packages. We first calculated a weighted likelihood estimate reliability (WLE), expected a posteriori reliability (EAP), and Cronbach’s alpha (α) to determine our scale’s internal consistency. We then employed a two-parameter model, which calculated the difficulty and discrimination properties of each item. Because the items in our scale did not have an inherently correct or incorrect answer that respondents might guess, we did not include the third parameter. We utilized fixed effects graded response models to apply IRT to our ordinal items (Samejima, 2016; Zein & Akhtar, 2025), and we calculated the test information, item information, and characteristic curves to sum the item information and determine the range of self-efficacy values measured in the scale (Toland, 2013). We generated a Wright Map, constructed using WLEs, as well as infit and outfit statistics, using the Berkeley Assessment System Software (Berkeley Evaluation & Assessment Research Center, 2024). These statistics and map further supported the item reduction process.
To reduce items into a final scale, we used an iterative process, running different IRT models and comparing their goodness-of-fit with Akaike Information Criterion (AIC) and Bayesian Information Criterion (BIC), as well as the range of item information provided at each level of ECT self-efficacy. Finally, we referred to our concept map and ensured balanced item representation in the final scale for each method included in the map. After reducing our items into the final 15-item scale, we conducted additional tests to further understand the scale’s functioning. Specifically, we performed exploratory factor analysis (EFA) as a robustness check to examine the scale’s dimensionality.
Establishing Convergent Validity: Criterion Validation Measures
We included two measures in our survey that we hypothesized as related to, but not synonymous with, ECT. As the ECT construct includes elements of both anti-racist and anti-ableist teaching pedagogies, we sought to understand our scale’s relationship to other scales that assess beliefs about each of these pedagogies. We provide context on these measures below.
Teacher Attitudes Toward Inclusion
The Teacher Attitudes Toward Inclusion Scale (TATIS; Cullen et al., 2010) assesses the extent to which teachers hold positive attitudes toward three aspects of inclusive teaching. Specifically, the scale measures teachers’ beliefs about: (a) including students with dis/abilities in the general education setting, (b) educator roles and responsibilities related to inclusion, and (c) the efficacy of inclusion. Cullen et al. assessed construct validity for the scale using principal components analysis. Additionally, the authors assessed scale reliability using Cronbach’s alpha and reported a total scale reliability of α = .82. Although this scale does not measure self-efficacy and instead measures attitudes, we hypothesized that teacher attitudes toward inclusion would be related (although not identical) to their self-efficacy for ECT because our scale investigates the extent to which teachers believe they can successfully teach each student in their class, including dis/abled students.
Learning to Teach for Social Justice-Beliefs Scale
Since expressing asset-based thinking and integrating critical consciousness development are elements of social justice teaching and represent two methods in our concept map, we hypothesized a moderate positive correlation between a teacher’s self-efficacy for ECT and their beliefs about teaching for social justice. As such, we included the Learning to Teach for Social Justice-Beliefs (SJB) scale (Enterline et al., 2008), which measures teachers’ beliefs about the importance of education serving a social justice purpose. Again, though the SJB Scale is not a measure of self-efficacy, we anticipated a relationship between beliefs about social justice in education writ large and self-efficacy to enact ECT. Ludlow et al. (2008) assessed the scale using both classical test theory and Rasch IRT measurement principles. The authors reported scale reliability across two survey administrations: the first administration yielded α = .77 and the second administration yielded α = .71.
In using these two scales, one using a dis/ability justice lens and the other using a teaching for social justice lens—but both related to beliefs rather than self-efficacy—we aimed to generate evidence of convergent validity in line with an interpretive framework of our scale’s intended use (see Mari et al., 2023). Although beliefs and attitudes are a salient aspect of social cognitive theory, self-efficacy represents a distinct operationalization between belief and action (Bandura, 1986). Such self-reflection often begins with beliefs, but measuring self-efficacy represents a distinct, but related construct (see Pajares, 1996). Because we selected convergent validity scales that were theoretically correlated and not simply superficially similar (i.e., both are measures related to equity), we expected these scales to yield moderate correlation. A correlation higher than .90, for instance, might suggest redundancy rather than convergent validity (Mari et al., 2023).
Results
We first present our operational definition of ECT and final conceptual map, which comprises five methods that represent the ECT pedagogical framework. Then, we share the results of our scale validation analyses, where we describe our process for reducing the initial scale into a final, 15-item scale. The final scale retains adequate data fit while reducing redundancy and improving usability. Finally, we share the results of additional validity measure analyses: our robustness check confirmed scale unidimensionality, while our convergent validity checks confirmed construct validity.
Final ECT Conceptual Map
Our operational definition of ECT, finalized through our iterative scale development process, is as follows: ECT encompasses pedagogical methods teachers employ throughout the entire instructional process—during classroom community creation, while planning for learning, while teaching, and while assessing—that provides all students (especially those historically and multiply marginalized in schools by cultural or linguistic background and/or perceived ability) equitable engagement with rigorous, inclusive learning experiences. Our final conceptual map (see Figure 2) represents the five methods that drive this definition. These methods are: express asset-based thinking, create access and rigor, share power, cultivate expertise, and integrate critical consciousness.

Final equity-centered teaching conceptual map.
We created the conceptual map to ensure that we maintained the integral elements of each framework while synthesizing them into one framework. As such, the methods of expressing asset-based thinking and cultivating expertise represent core tenets of both UDL and CSP. Since access is key to UDL and rigor is essential to CSP, the method of creating access and rigor illustrates how both work in tandem for ECT; creating access without maintaining rigor can lower expectations for some students, and providing rigor without on-ramps to access it may exclude some learners. Next, the method of integrating critical consciousness is essential to CSP, and its inclusion addresses past critiques of UDL. Finally, the method of sharing power primarily derives from CSP, though it is also necessary to achieve UDL’s aim of building student autonomy and honoring varied forms of student engagement, representation, action, and expression. As a product, the map can be used to ensure that all essential elements of both UDL and CSP are embedded to support ECT.
Explanations of each method, with associated cross-pollinated practices and their guiding references used for cross-pollination, are shared in Table 3. Additionally, Appendix C shows how each item in the final scale maps on to the five ECT methods.
Equity-Centered Teaching Methods and Corresponding Practices and References

Scale Descriptive Analysis
All respondents completed all scale items. Descriptive statistics for items are displayed in Table 4. The mean responses (on a 1–5 scale) ranged from 3.29 to 4.13, skewing left. This is consistent with prior research suggesting survey respondents tend to display agreement bias on Likert-scale surveys (Toner, 1987) and overestimate their own abilities (Lawson et al., 2007). When running a model with all 29 original items, we found that all average inter-item correlations were positive. The test scale average inter-item correlation was .36, suggesting reasonable consistency and sufficiently unique item variance (Piedmont, 2014). Across multiple measures of scale reliability, we found that our 29-item scale had high internal consistency (WLE = 0.939, EAP = 0.944, α = 0.942). However, these high values also indicate possible item redundancy (Goforth, 2015). This confirmed that our goal of item reduction was reasonable for the scale in its 29-item form.
Descriptive Statistics of Scale Items

Note. Ectp = equity centered teaching practice. Each item identifies a specific practice that represents the ECT construct, so we named our items as such. Items in bold represent ones selected for final scale.
Scale Item Fit
We first ran our model with all 29 items to assess the scale’s overall performance. The test characteristic curve graph indicated that out of the possible 145 points (five possible points per item), a respondent with above-average self-efficacy was expected to score above 115 points, leaving a sufficient range to parse out latent trait levels, even among those with high self-efficacy (Toland, 2013). The estimated difficulty coefficients for every item contained both negative and positive coefficients—negative for the lowest levels of reported self-efficacy and increasingly more positive for higher levels—and the lowest and highest levels of coefficients varied across items. This suggested adequate item difficulty variation and that our items met standards for the range of difficulty that should appear in a scale (Wilson, 2023).
All discrimination coefficients were positive, suggesting respondents’ probability of answering a higher response option increased with their composite score, thus providing further evidence of validity (Columbia University, n.d.). Discrimination coefficients ranged from 1.020 to 2.084 and were all statistically significant at a 99% confidence level (see Table 5). All but one of the items (ectp27) fell within the ideal range of 0.75 to 1.33 on infit and outfit statistics. These statistics measure randomness in the data and assess for items that are either too predictable or may have extensive noise (see Appendix B for complete data on item properties). As a result of item 27’s slight underfit (outfit = 1.36), we dropped this item when creating the final scale.
Item Response Discriminations

Note. Ectp = equity centered teaching practice. Items ordered by response discrimination, from least to greatest.
p < .001.
Our Wright map, shown in Figure 3, allowed us to visually observe how well the items in the scale functioned and covered the range of person levels on the self-efficacy trait. The histogram on the left side of the Wright Map represents the distribution of person ability levels (i.e., teachers’ self-efficacy), whereas the thresholds on the right side indicate the relative difficulty levels of each item. A well-functioning scale demonstrates overlap between the range of person levels between these two distributions. Items with well-spaced category thresholds (represented by the shapes above each item on the right side of the Wright Map) are considered to be performing well, whereas items with clustered or overly spread thresholds perform less well. As shown in the Wright Map, the spacing and spread of the thresholds across each item indicated that the scale functioned well. The scale provided the most information about teachers with average and below-average self-efficacy, although specific items, such as ectp4 and etcp19, captured information for those with above-average self-efficacy. Conversely, some items demonstrated limited spread at the upper categories. For example, ectp12 and ectp16 did not include thresholds for Categories 3 and 4, suggesting they primarily captured variance among respondents with lower levels of self-efficacy. These patterns provided insights into item performance and guided decisions about item reduction and inclusion (see next section). Here, we removed items that demonstrated poor fit statistics or limited threshold information in order indicators to strengthen the scale’s functioning. Finally, taken together, the Wright Map and the item-level diagnostics suggested that the instrument sufficiently captured variability in respondents’ self-efficacy.

Wright Map by item.
Reducing Items into a Final Scale
When reducing the number of scale items, we sought to (1) maximize the information each item provided to the overall scale and balance AIC and BIC estimates of the model, (2) capture information about those with high levels of self-efficacy, and (3) fully represent our construct. We first retained the 10 items with the highest discriminatory values. Figure 3 displays information for two items as an example of the difference between an item we selected due to high discrimination and an item we eliminated due to low discrimination. As Figure 4 demonstrates, Item 3 (a retained item) provided approximately four times the amount of information as item 27 (a discarded item) across a wide range of the scale (−4 <

Item functionality comparison graph.
The test information functions between the full and reduced scales were almost identical, indicating that we covered the same range of self-efficacy levels in both scales (see Figure 5). Reliability estimates of the final scale still indicated high levels of internal consistency (WLE = .911, EAP = .905, α = .904), while also reducing item redundancy (Goforth, 2015; Wilson, 2023) and therefore resulting in a more usable scale.

Test information functions for full and final scales.
Fit statistics for the final scale indicated an adequate, but not excellent, fit to the data. The standardized root-mean-square residual (SRMSR) is the most important goodness-of-fit statistic for evaluating graded response models and is considered a good fit at SRMSR < .05 and an acceptable fit at .05 ≤ SRMSR ≤ .10 (Zein & Akhtar, 2025). Our model fell in the acceptable fit range (SRMSR = .067). Other fit statistics similarly fell in the acceptable fit range (RMSEA = .096, TLI = .941, CFI = .949), though M2, which is similar to a χ2 statistic, indicated that our model did not fit the data well: M2(90) = 276.091, p < .001). However, each item within the final scale fit the IRT model well (RMSEA ≤ .05 for all but one item; see Table 6). Given this individual item fit and overall adequate model fit, we proceeded with the selected 15 items. The final 15-item scale is shown in Appendix C.
Final Scale Item Fit Statistics

Note. Ectp = equity centered teaching practice.
Recognizing that K–12 and postsecondary settings are potentially distinct, we also conducted a post-hoc t-test to test for statistically significant differences in participant ECT sum scores by teaching setting. We found that there was a statistically significant difference between these groups, t(104.87) = 2.70, 95% CI [0.98, 6.35], p = .008, indicating a potential difference between K–12 and postsecondary educators’ self-efficacy for ECT.
Additional Validity Measures
Robustness Check
An important assumption of graded response models within an IRT framework is unidimensionality—that there is a single latent trait underlying the items in a measure (Zein & Akhtar, 2025). To test this assumption, we conducted EFA on the final 15-item scale. Factor loadings on a single factor EFA model ranged from 0.49 (Item 18) to 0.72 (Item 2), all of which exceeded the recommended cutoff for significant loadings given our sample size (Hair et al., 2010). The proportion of the variance explained by the single factor model was .39 (i.e., a single factor explained 39% of the variance). While a two-factor model had slightly more explained variance (cumulative variance = .44), the two factors were highly correlated (r = .7), indicating that a single factor may be more appropriate. A scree plot of eigenvalues confirmed that the unidimensionality assumption was reasonable for our scale (see Figure 6).

Scree plot for final scale.
Convergent Validity
To test for convergent validity, we computed a Pearson correlation coefficient between the Self-Efficacy for ECT Scale and both the TATIS and the SJB Scale. Correlation between our scale and TATIS was weak and statistically significant (r = .221, p < .001). Correlation between our scale and SJB was weak and non-significant (r = .104, p = .121). Because these scales measure similar but not identical constructs, we considered these correlations as evidence for both convergent and discriminant construct validity. That is, the measures should be moderately correlated (Lim, 2024), which is consistent with the notion that they capture theoretically overlapping yet conceptually separate dimensions. These findings confirm our hypothesis, reinforcing the specificity of our tool’s primary purpose as a measure of self-efficacy. Given the inherently interpretive nature of both convergent and divergent validity—where the strength of associations must be evaluated in light of theoretical expectations—these findings support our conceptualization of the construct (Mari et al., 2023). Our results also highlight the need for further research to clarify the boundaries and convergent properties of the construct. For instance, other robustness checks might examine the scale’s convergence with other measures of self-efficacy (e.g., Siwatu’s, 2007 CRTSE scale).
Discussion
In this study, we undertook two research purposes. First, we operationalized Waitoller and Thorius’s (2016) cross-pollinated theoretical framework into a pedagogical one. We then used that pedagogical framework to create a survey scale measuring teachers’ self-efficacy for enacting the framework, and, finally, we gathered evidence of validity for the scale. As Waitoller and Thorius argued in their piece, CSP might be extended with more explicit attention to dis/ability as an aspect of identity in need of sustaining, and UDL might be extended by adopting critical understandings of how ableism and racism are intertwined as mechanisms of exclusion in education. The need for this theoretical cross-pollination between CSP and UDL (Waitoller & Thorius, 2016) has gained momentum in recent years (e.g., Coppola et al., 2019; Cruz et al., 2024; Kulkarni et al., 2023; McClam et al., 2025; Pugach et al., 2019), but such a notion requires translation into practice and concrete measurement.
Our ECT pedagogical framework answers this call by intertwining elements present in both CSP and UDL—such as expressing asset-based thinking—with strengths of each individual framework—such as creating experiences of access found in UDL and integrating critical consciousness found in CSP. Furthermore, we extended Waitoller and Thorius’s (2016) work by enumerating a set of pedagogical methods, such as the ones just mentioned, that concretize ways such a cross-pollination might live out in practice. This concretization into five tangible methods that drive ECT—express asset-based thinking, create access and rigor, share power, cultivate expertise, and integrate critical consciousness—represents a novel conceptual contribution to the field.
We additionally built on this pedagogical concretization by creating the Self-Efficacy for ECT Scale, which measures teachers’ perceptions of their ability to enact practices encompassed within ECT. The scale extends currently available measures, such as Siwatu’s (2007) Culturally Responsive Teaching Self-Efficacy Scale, by cross-pollinating CSP, which centers students’ cultural identities, with UDL practices that treat student ability variability as an asset. Although enactment of ECT-aligned practices is of utmost importance for creating classrooms where all students can thrive, self-efficacy can influence the extent to which teachers take up specific practices (Dixon, 2011) and is initially less resource-intensive to use, making it a critical first construct to measure. Whether a teacher feels confident in their ability to provide varied resources to support students in meeting the lesson goal, for example, is a crucial element of whether they will be able to create experiences of both access and rigor in practice. Thus, our scale fills an important measurement need on the pathway from framework to enactment.
The final scale accomplishes the translation between theory and practice by capturing central ECT practices and integrating concepts from anti-racist and anti-ableist theories and operationalizing them as a tangible pedagogy. Questions such as, “How well can you position all students as having expertise to share during learning?” for example, synthesize CSP tenets of valuing students’ ways of being and knowing with UDL concepts of seeing student ability variability as an asset. Both the pedagogical framework and scale are concrete tools usable by a broad range of researchers and practitioners. At 15 items, the scale is succinct enough to be administered to teachers easily, yet comprehensive enough to grant sufficient attention to all methods and performance levels of the construct.
Across multiple measures, our analysis demonstrated evidence of reliability and validity for the 15-item Self-Efficacy for ECT Scale. Multiple measures of reliability demonstrated excellent internal consistency between the items on the scale. Although slightly lower for the finalized scale as compared to the initial one, each reliability measure still met thresholds that indicated strong consistency, which reinforced our choice to eliminate potentially redundant items from the original scale to save respondents time in scale completion. IRT analysis suggested that items on the scale performed well across a range of self-efficacy levels (Toland, 2013). The scale performed slightly less well at the higher levels of self-efficacy, so we intentionally selected items with higher difficulty for the final scale to adequately capture a wide span of abilities. Furthermore, EFA confirmed that our assumption of unidimensionality—essential for IRT (Zein & Akhtar, 2025)—held with our final scale.
Although measures of convergent validity demonstrated only a weak correlation between our scale and both the TATIS and the SJB Scale, each of the scales we included measured beliefs, which are related to but distinct from classroom practices (Buehl & Beck, 2014). A teacher’s beliefs may be either consistent or inconsistent with their practices, for example (Fang, 1996). Furthermore, given that our construct cross-pollinates two complex concepts, a high degree of correlation with either singular concept may not be detected. The statistically significant correlation between TATIS and the Self-Efficacy for ECT Scale, however, provides evidence for the relationship between our construct and other measures related to meaningful student inclusion. Taken together, the final 15-item Self-Efficacy for ECT Scale demonstrates evidence of both reliability and validity for use with in-service K–20 educators in the United States.
With this scale, we extend the measurement literature and provide a single accessible tool that assesses teachers’ self-efficacy for equitable inclusion. Without a synthesized scale, equity-oriented educational researchers seeking to measure teachers’ efficacy for adopting UDL and CSP practices have had to draw from multiple scales—potentially compromising the validity of each one and/or overloading study respondents with lengthy research questionnaires (Netemeyer et al., 2003). Researchers can use the present scale to measure the impacts of efforts to support teachers to grow their skills related to equitable pedagogy. Educational leaders seeking to support teachers in enacting ECT can also benefit from having readily accessible tools to bolster their development efforts.
We recommend that districts and researchers looking to support teacher growth in equity-centered practice develop educators in the ECT pedagogical framework and employ this scale to monitor growth in self-efficacy over time and determine which methods and practices require further development. Given that the scale provides the most information for individuals at low to moderate levels of self-efficacy, the scale may be best utilized with educators who are newer to the theories underpinning the scale and engaged in professional development efforts. That said, the scale does yield information for teachers at the higher range of the ECT self-efficacy trait, so it can be useful to help identify teachers with higher self-efficacy, as well. Furthermore, the pedagogical framework is applicable to all practitioners, regardless of their current levels of ECT expertise, as it provides concrete guidance for the methods equity-centered teachers employ. Schools and districts can use both tools to assess the current landscape of their teaching staff to determine where to best direct their efforts.
Cochran-Smith and Keefe (2022) write about the importance of moving past thin equity efforts in teacher education that rest on the notion of “good teaching” and instead seeking strong equity, which pursues redistribution, recognition, representation, and reframing to dismantle highly complex systems that perpetuate unequal access to opportunity to learn. The current pedagogical framework and scale, with their cross-pollinated notion of equity proposed by Waitoller and Thorius (2016), highlight methods and practices included in the conceptualization of strong equity, such as drawing on students’ cultural assets in designing classroom environments and learning experiences and recognizing systemic inequities embedded in teachers’ subjects. Therefore, both the framework and scale may be effective tools to support the shift away from equity as a “watchword . . . a catch-all term, connected, often rather vaguely, to an array of issues” (Cochran-Smith & Keefe, 2022, p. 10), and toward a meaningful conceptualization of equity for students who have long been marginalized and excluded from meaningful learning experiences in schools.
Limitations
This study holds a few notable limitations to consider while interpreting results. Although self-efficacy is related to teacher practice (Comstock et al., 2023; Dixon, 2011), the two constructs are not synonymous. Thus, a limitation of the scale, as with any self-reported scale, is that its results cannot fully reflect teacher practice. Therefore, we recommend researchers and practitioners use this scale in conjunction with measures that assess enactment of critically inclusive teaching. Similarly, we do not have data on the classroom makeup for individual teachers. The Self-Efficacy for ECT Scale seeks to measure teachers’ confidence in enacting practices that center groups historically excluded in education spaces, and an important element of understanding its functionality is testing for differences between teachers who teach in settings where such students are present versus where they are absent. As such, we recommend future work test for scale invariance in this way.
When examining self-efficacy scores by teaching setting with the final scale, we noted a statistically significant difference between K–12 and postsecondary educators’ mean self-efficacy scores. This denotes a potential difference in scale functioning between those groups, perhaps due to pedagogical differences between settings, differences in question interpretation across settings, or simply differing ECT self-efficacy levels between K–12 and postsecondary teachers. However, these results should be interpreted with caution, as our postsecondary educator sample was substantially smaller than our K–12 sample and the t-test confidence intervals were wide. In addition to conducting additional research on scale functionality with classroom makeup data included, we recommend further testing with larger samples of postsecondary educators to understand if there are, in fact, differences in scale functionality by setting. If so, future research might also include a qualitative analysis to understand how those differences arise in practice. Finally, EFA revealed that a single factor did not capture a majority of the variability in responses, meaning that the precision with which the items predicted a teacher’s ECT self-efficacy levels could be higher. Thus, this limitation further underscores the need for measures of enactment to obtain a more complete picture of teacher practice.
Future Research
We recommend several future directions for this work. First, future studies can gather additional evidence of scale validity and test for invariance across settings. Although we theorize that the tenets of ECT apply across settings, future studies should test this specifically. Next, we recommend employing this scale in equity-centered professional development efforts to measure changes in teachers’ self-efficacy for enacting ECT. Speaking to the importance of linking self-efficacy with practice, work can also be done to evaluate the relationship between self-efficacy results from this scale and measures of teacher practice, such as observations and various student outcomes (e.g., academic progress, sense of belonging, classroom climate). Developing a companion observation scale and guide for researchers, administrators, and coaches would be especially useful for ensuring alignment between what the pedagogical framework illuminates, what the scale measures, and what evaluators might look for in classroom practice. Conducting research on ECT enactment in classrooms could provide needed insight into the possibilities of increasing access to asset-based and inclusive practices (e.g., Abdulrahim & Orosco, 2020; Aronson & Laughter, 2016; Waitoller & Thorius, 2016).
Conclusion
The construct of ECT intersects two important equity-oriented frameworks and synthesizes them into a single pedagogical framework, thereby concretizing a theoretical discussion into a tangible resource educators might use. Our pedagogical framework shows promise for supporting student thriving in schools by increasing students’ skills, self-concept, and achievement (Aronson & Laughter, 2016; King-Sears et al., 2023). Furthermore, our scale notably extends the ECT literature by creating a single accessible tool that measures self-efficacy for the enactment of our intersected framework. Synthesizing frameworks that call for dismantling multiple forms of school-based exclusion present an avenue toward repair for students who have long been pushed to the margins. During a time in which educational equity is under attack (Ellis & Thorbecke, 2024; Fields, 2025; Grantam-Philips, 2025), now more than ever, schools need educators who are dedicated to creating learning environments where each student can thrive.
Footnotes
Appendix A: Distributed Scale
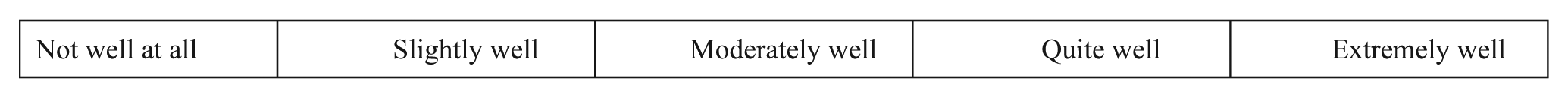
| Not well at all | Slightly well | Moderately well | Quite well | Extremely well |
Appendix B: Item Properties

| Item | Discrimination (SE) | Difficulty Level 1 | Difficulty Level 2 | Difficulty Level 3 | Difficulty Level 4 | Outfit MSQ | Infit MSQ |
|---|---|---|---|---|---|---|---|
| Ectp1 | 1.617* (0.207) | −3.594 | −2.178 | −0.907 | 1.017 | 0.99 | 0.97 |
| Ectp2 | 1.933* (0.226) | −2.165 | −1.454 | −0.074 | 1.412 | 0.91 | 0.93 |
| Ectp3 | 2.084* (0.241) | −3.099 | −1.583 | −0.095 | 1.519 | 0.81 | 0.81 |
| Ectp4 | 1.361* (0.177) | −3.373 | −1.793 | −0.179 | 1.602 | 1.05 | 1.06 |
| Ectp5 | 1.565* (0.199) | −4.139 | −2.146 | −0.74 | 0.895 | 0.96 | 0.96 |
| Ectp6 | 1.620* (0.202) | −4.042 | −1.98 | −0.509 | 1.091 | 0.97 | 1 |
| Ectp7 | 2.021* (0.239) | −3.587 | −1.889 | −0.588 | 1.051 | 0.84 | 0.85 |
| Ectp8 | 1.677* (0.208) | −3.569 | −2.103 | −0.487 | 1.288 | 0.92 | 0.94 |
| Ectp9 | 1.717* (0.208) | −3.482 | −1.815 | −0.317 | 1.275 | 0.95 | 0.95 |
| Ectp10 | 1.251* (0.182) | −3.75 | −1.16 | 0.562 | NA | 1.06 | 1.07 |
| Ectp11 | 1.817* (0.223) | −2.234 | −0.556 | 1.027 | NA | 0.84 | 0.85 |
| Ectp12 | 1.694* (0.216) | −2.704 | −1.037 | 0.433 | NA | 0.88 | 0.93 |
| Ectp13 | 1.114* (0.159) | −3.718 | −1.301 | 0.061 | 1.879 | 1.22 | 1.22 |
| Ectp14 | 1.908* (0.227) | −3.64 | −2.03 | −0.41 | 1.14 | 0.86 | 0.87 |
| Ectp15 | 1.296* (0.187) | −4.753 | −3.168 | −1.141 | 0.396 | 1.08 | 1.11 |
| Ectp16 | 1.591* (0.202) | −2.558 | −0.727 | 1.435 | NA | 0.93 | 0.93 |
| Ectp17 | 1.738* (0.208) | −3.925 | −1.564 | 0.026 | 1.72 | 0.9 | 0.91 |
| Ectp18 | 1.129* (0.167) | −5.303 | −1.988 | 0.333 | 1.899 | 1.22 | 1.19 |
| Ectp19 | 1.618* (0.203) | −4.05 | −2.167 | −0.287 | 1.351 | 0.95 | 0.94 |
| Ectp20 | 1.725* (0.209) | −3.533 | −1.846 | −0.162 | 1.743 | 0.94 | 0.92 |
| Ectp21 | 1.128* (0.163) | −3.841 | −1.388 | 0.203 | 2.133 | 1.24 | 1.21 |
| Ectp22 | 1.455* (0.189) | −2.307 | −0.554 | 1.328 | NA | 0.98 | 1 |
| Ectp23 | 1.233* (0.171) | −4.075 | −2.205 | −0.15 | 1.766 | 1.12 | 1.12 |
| Ectp24 | 1.910* (0.223) | −3.076 | −1.51 | −0.059 | 1.622 | 0.88 | 0.87 |
| Ectp25 | 1.488* (0.187) | −3.314 | −1.784 | −0.138 | 1.626 | 1.02 | 1.04 |
| Ectp26 | 1.375* (0.185) | −4.562 | −2.495 | −0.547 | 1.54 | 1.05 | 1.04 |
| Ectp27 | 1.020* (0.154) | −3.7 | −1.33 | 0.113 | 1.639 | 1.36 | 1.32 |
| Ectp28 | 1.377* (0.187) | −4.538 | −2.351 | −0.683 | 0.948 | 1.07 | 1.06 |
| Ectp29 | 1.237* (0.172) | −2.628 | −1.296 | 0.172 | 1.931 | 1.16 | 1.15 |
Note. Items in bold italics represent ones selected for final scale.
p < .001.
Appendix C: Final Scale (Organized by Dimension)
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the Maryland State Department of Education.
Notes
Authors
RACHEL S. MCCLAM is a doctoral candidate at the Johns Hopkins University School of Education. Her research examines the agentic (i.e., individual) and structural (i.e., systems) factors that support educators to build meaningfully inclusive classrooms; she especially situates her research in mathematics.
SARAH A. CAROLEO is a postdoctoral research associate at the Annenberg Institute at Brown University. In her research, she investigates how to leverage policy and mobilize teachers to increase meaningful inclusion in schools and instruction.
ALEXANDRA SHELTON is an assistant professor in the School of Education at Johns Hopkins University. Her research focuses on advancing equitable academic experiences for students of Color and multilingual learners with disabilities, with a particular emphasis on literacy.
REBECCA A. CRUZ is an assistant professor of education at Johns Hopkins University. Her research interests include examining disproportionality in special education and discipline and in redefining the concept of inclusion from a perspective that considers disability, not as an individual trait but as a product of political, social, and historical practices.
CORRINE M. ARAMBURO is an assistant professor in the College of Education and Human Services at the University of New Mexico. Her research interests are special education administration, continuous quality improvement and problem-solving, and education and teaching for students with extensive support needs.