
Abstract
In addition to providing a set of techniques to analyze educational data, I claim that data science as a field can provide broader insights to education research. In particular, I show how the bias-variance tradeoff from machine learning can be formally generalized to be applicable to several prominent educational debates, including debates around learning theories (cognitivist vs. situativist and constructivist theories) and pedagogy (direct instruction vs. discovery learning). I then look to see how various data science techniques that have been proposed to navigate the bias-variance tradeoff can yield insights for productively navigating these educational debates going forward.
Keywords
Introduction
In recent years, data science and machine learning have been used to make sense of various forms of educational data. Educational data science can enhance our understanding of learning and teaching; give insights to teachers, students, and administrators about learning happening in the classroom; and lead to the creation of data-driven adaptive learning systems. However, I claim that machine learning and data science have more to offer than a set of techniques that can be applied to educational data. Theoretical concepts and principles in machine learning can provide broader insights to education research. In particular, in this article, I show that the bias-variance tradeoff from machine learning can provide a new lens with which to view prominent educational debates.
The field of education is filled with seemingly perennial debates that have important implications on the nature of education research and practice. These debates span epistemology (e.g., positivism vs. constructivism), ontology (e.g., cognitive vs. situative theories of learning), methodology (e.g., quantitative vs. qualitative), and pedagogy (e.g., direct instruction vs. discovery learning). Interestingly, many researchers have contended that these debates are often premised on false dichotomies and admit that a moderate position is more warranted (Alfieri et al., 2011; A. L. Brown & Campione, 1994; Cobb, 2007; Doroudi et al., 2020; Greeno, 2015; Johnson & Onwuegbuzie, 2004; Kersh & Wittrock, 1962; Shaffer, 2017; Shaffer & Serlin, 2004; Tobias & Duffy, 2009), yet these debates persist and many researchers still seem to favor one side over the other, resulting in somewhat isolated research communities that speak past each other (if they speak to each other at all; Jacobson et al., 2016).
In this article, I show that the bias-variance tradeoff can be formally generalized to help explain the nature of these debates in the education literature. I first introduce the bias-variance tradeoff and how it is used in statistics and machine learning. I then describe a formal generalization of the bias-variance decomposition and map this generalized version to debates around theories of learning, methodology, and pedagogy, while also showing how these tradeoffs are rooted in similar debates in the history of artificial intelligence (AI). While the first two sections that introduce and formalize the bias-variance tradeoff are somewhat technical, later sections of the article primarily make descriptive claims and use representative quotations from prominent researchers in these debates. As such, the article aims to be accessible to and of interest to both quantitative and qualitative education researchers. We will then look towards how data scientists and machine learning researchers have productively navigated the bias-variance tradeoff, in order to find several insights on how to navigate the corresponding educational debates. I finally discuss how the bias-variance tradeoff can help us understand overarching themes across these debates, including how debates around epistemology in education research could explain why these debates are ongoing, despite pragmatic attempts to overcome them.
By mapping the bias-variance tradeoff to these educational debates, I hope to accomplish several goals. First, it can help us understand the relationships between various educational debates (e.g., on learning theories, methodology, pedagogy, and epistemology) as well as debates in other fields (e.g., machine learning, AI, and linguistics). Second, it provides a novel way to formally rationalize the comparative advantages of both sides in each debate, rather than using strawman arguments. Third, it can help us understand surprising connections between different approaches that may seem unrelated at first glance. For example, it can help us explain the connection between situativist and constructivist theories, as well as the connection between these theories and neural networks. On a more meta level, this articel shows how a quantitative technique (the bias-variance tradeoff) can give insights on qualitative methods. Finally, related to the previous point, it can help us see connections between pragmatic techniques for navigating the bias-variance tradeoff in data science and analogous techniques for productively navigating these educational debates. In short, the purpose of this article is not to resolve these perennial debates in education but rather to provide a framework with which we can better understand them and hopefully carry more meaningful conversations going forward.
The Bias-Variance Tradeoff
The bias-variance tradeoff was first formally introduced by Geman et al. (1992). It refers to the fact that when trying to make a statistical prediction (e.g., estimating a parameter of a distribution or fitting a function), there is a tradeoff between the accuracy of the prediction and its precision, or equivalently between its bias (opposite of accuracy) and variance (opposite of precision). Many education researchers may be familiar with the concepts of bias and variance in terms of validity and reliability in measurement. In this section, I will first informally explain the notion of bias and variance using targets, and then explain the notion more precisely as it has been used in the machine learning literature. This section and the one that follows provide the necessary technical background in a way that is meant to be accessible to education researchers but not explicitly tied to concerns in education research. However, these sections make way for a more informed discussion of how these ideas extend to education.
Suppose a process randomly generates points on a target (e.g., an archer shooting arrows at the target) as shown in Figure 1a. The bias of the process is how far the points are from the center of the target on average, as depicted by the blue solid line, and the variance of the process is a measure of how far the points are to the centroid of the points on average, as depicted by the black dotted lines. Precisely, the variance can be estimated by taking the mean of the squared distances from each point to the centroid of the points (the dotted lines shown in Figure 1a). Figure 2 shows examples of low bias and low variance, high bias and low variance, low bias and high variance, and both high bias and high variance. Now suppose an archer has only one shot at the target and wants to be as close to the center as possible. One way to measure how far the archer’s shot will likely be from the center is the mean squared error, which is the average distance from a point to the center of the target, which can be estimated as the mean of the squared distances between all the points and the center of the target as shown in Figure 1b. The mean squared error increases as the bias or variance increases. In fact, a well-known result is that the mean squared error decomposes into a bias and variance term:

In the context of machine learning, the goal is to estimate a function that minimizes the mean squared error distance between the estimated function and the true function. To fit a function, an algorithm searches for a best fitting function (or estimator) in a function class. A function class is a set of functions that usually have the same underlying form but must be instantiated with particular parameters. For example, the class of linear estimators using a particular set of features (fit via linear regression) is one function class. The bias of a function class represents how different the best fitting model in the function class is from the target function. For example, if we wanted to predict
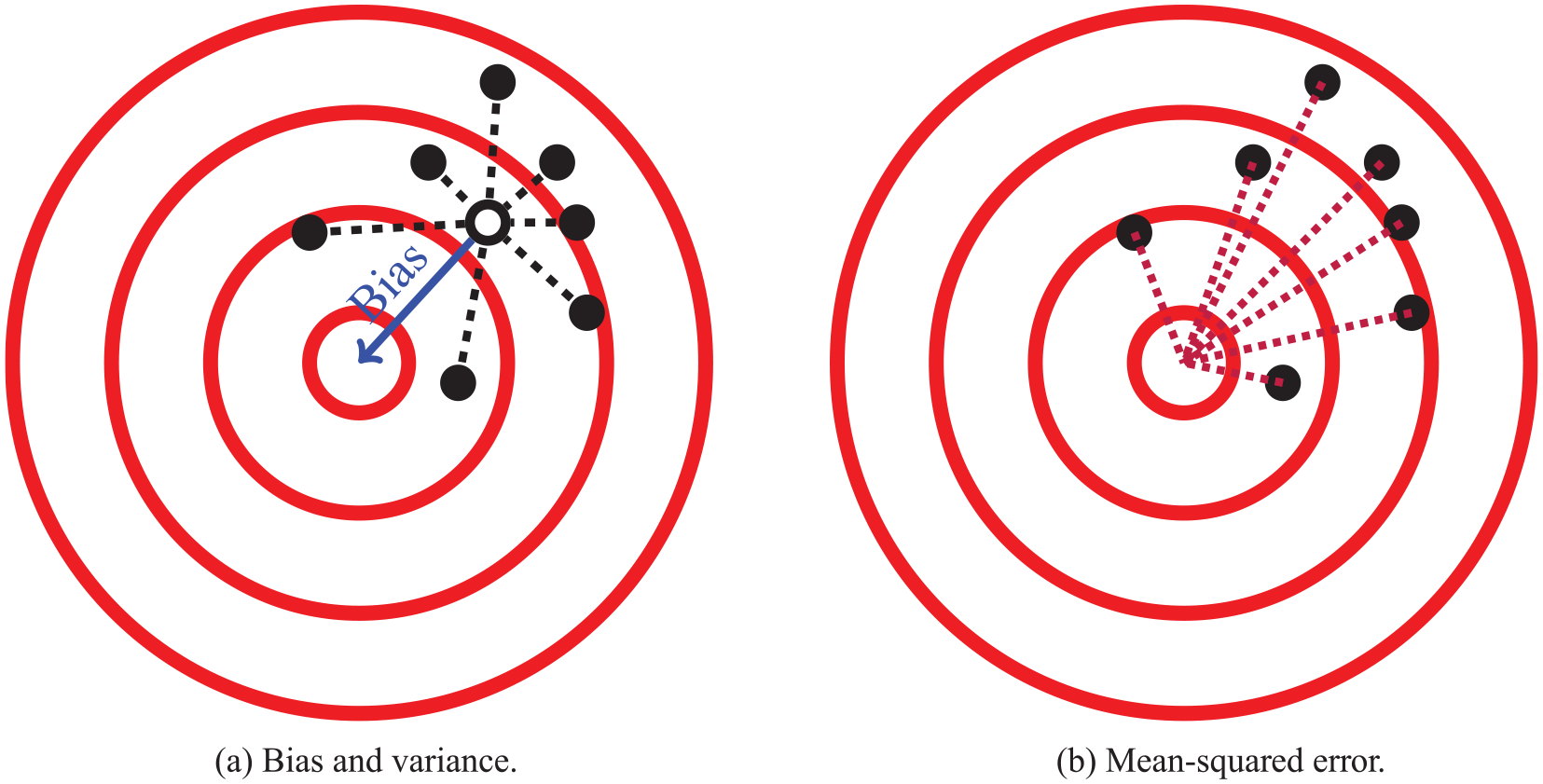
A depiction of the bias-variance tradeoff using targets. If these points are thought of as arrows, then the goal would be for the points to be near the center of the target. (a) To the extent which the points are far from the center, they suffer from bias (solid blue line) and/or variance (dashed black lines). (b) The bias and variance combine to form mean squared error (dotted purple lines).

A depiction of varying combinations of bias and variance: (a) low bias and low variance, (b) high bias and low variance, (c) low bias and high variance, and (d) high bias and high variance.
Thus, to effectively use machine learning one tries to use a function class that balances the bias-variance tradeoff. Ideally, we would use the smallest function class that can capture the target function. However, given that we do not know the form of the target function ahead of time, this is not always possible. 1
We will now formally express the notion of bias and variance. Suppose we are trying to predict some target function

The variance of the predictor’s function class (for a given

A standard measure for the error in a prediction is the mean squared error,
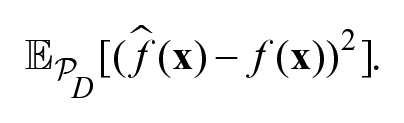
We can now formally express the bias-variance decomposition of the mean squared error 2 :
Theorem 1 (Bias-Variance Decomposition). Under the setting described above, the mean squared error decomposes into a bias term and variance term as follows:

The bias-variance decomposition gives us a sense of why there is a bias-variance tradeoff. For two function classes that have the same prediction error, if one function class is more biased than the other, then we know the other must have higher variance. Naturally, many good machine learning techniques tend to be more susceptible to either bias or variance. Figure 3 shows how bias, variance, and mean squared error tend to change as a a function of model complexity. 3 Increasing model complexity could correspond to increasing the number of features in a linear regression, increasing the highest degree in a polynomial regression, or increasing the number of layers in a neural network. As the complexity increases, the bias tends to decrease but the variance tends to increase. There is typically a degree of complexity where the mean squared error is minimized by effectively balancing bias and variance. Many techniques have been proposed to navigate this bias-variance tradeoff. We will discuss some of these techniques at the end of this article, in the context of navigating tradeoffs that exist in education.

A depiction of how bias, variance, and mean squared error change as a function of model complexity. While a bias-variance tradeoff is present, there is usually an optimal point of model complexity that minimizes mean squared error by effectively balancing bias and variance. Note that the plots shown here are completely hypothetical and do not correspond to any real data or algorithms.
The Generalized Bias-Variance Decomposition
Notice that in the target diagrams, the source of bias and variance is due to the random mechanism by which the points were generated. This randomness could be due to random fluctuations in a (novice) archer’s aim. In the case of machine learning, this randomness comes from the data used to estimate the function. Notice that in the archer’s case there are no data present. While in the machine learning literature, the bias-variance tradeoff is often represented as being about overfitting or underfitting to data, a key insight of this article is that the bias-variance tradeoff is not really about data but rather a property of any random mechanism that tries to approximate some target. This can be shown more precisely by noting that the proof of the bias-variance decomposition is agnostic to the source of randomness; the decomposition holds regardless of the probability distribution the expectations are taken over. In the case of machine learning, this may be due to a data set used to fit a function, but in other cases, like that of an archer or that of a teacher (as discussed in the next section), the randomness could be due to an archer’s aim or the chaotic stochasticity of a typical classroom environment, respectively. This leads us to a generalization of the bias-variance decomposition:
Theorem 2 (Generalized Bias-Variance Decomposition). Suppose our goal is to approximate some target:
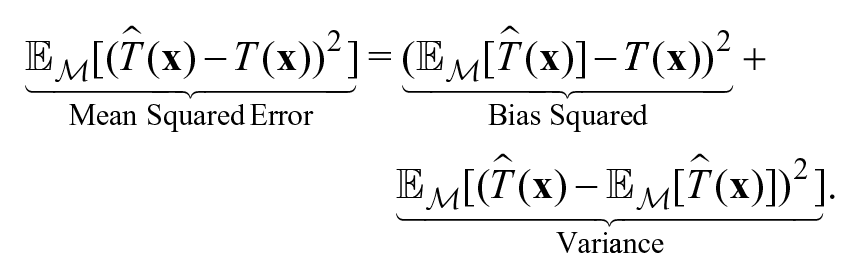
A proof of the theorem is given in Appendix A. The only real difference between Theorem 1 and Theorem 2 is that the stochasticity of the mechanism
Generalized Bias-Variance Decomposition Applied to Machine Learning

The Bias-Variance Tradeoff in Education
We can now analyze how the bias-variance tradeoff applies to many educational debates. In what follows, we will discuss several prominent educational debates, focusing primarily on debates around learning theory and pedagogy (but also bringing up connections to other related debates). In each section, I first give a summary of the debates and then examine how the generalized bias-variance decomposition can help characterize the different positions in the debates. I rely heavily on historical examples from the history of AI and the learning sciences and give illustrative quotes from researchers on either side of the debates. In doing so, I establish historical precedence for these bias-variance tradeoffs, even though I am the first, to my knowledge, to explicitly connect the tradeoff to these debates.
I note that a lot of nuance can be lost when these debates are dichotomized. Just as machine learning approaches have varying levels of bias and variance, positions on these debates are not always on one extreme in a dichotomy. However, by treating approaches as being relatively “high bias” and “high variance” (as is often done in machine learning), I hope to show how the bias-variance tradeoff can bring insights to these debates. Table 2 shows a set of dichotomies that arise in the ensuing discussion and that exhibit such tradeoffs.
Dichotomies Discussed or Mentioned in This Article That Exhibit a Sort of Bias-Variance Tradeoff

Note. Many of these phenomena are related/overlapping, but they are not synonymous.
Theories of Learning: Cognitivism Versus Situativism/Constructivism
Over the past few decades, there have been several debates around the nature of learning. One prominent debate has been between cognitivists and situativists, as epitomized by the discourse between Anderson et al. (1996, 1997) and Greeno (1997). Cognitivists, or information-processing psychologists, posit that learning happens in the individual’s mind and that we can develop precise theories of cognition and learning, including computational architectures and simulatable models. Situative theorists, on the other hand, claim that cognition happens in a particular sociocultural context and is thus context-dependent (J. S. Brown et al., 1989; Lave & Wenger, 1991). As such, situative theories typically do not employ precise computational models to predict learning; rather they rely extensively on qualitative techniques such as ethnography and ethnomethodology (Greeno, 1997).
Another related debate on the nature of learning is between cognitivists and (radical) constructivists. Radical constructivism is rooted in Piaget’s genetic epistemology, and claims that every individual necessarily constructs their own reality as they learn, and there is no way of knowing if that reality corresponds to an external reality (von Glasersfeld, 1991). Constructivism and situativism may seem unrelated at first glance, but the same information-processing psychologists found themselves engaging in similar debates with both groups. Indeed, according to Anderson et al. (1998), The alliance between situated learning and radical constructivism is somewhat peculiar, as situated learning emphasizes that knowledge is maintained in the external, social world; constructivism argues that knowledge resides in an individual’s internal state, perhaps unknowable to anyone else. However, both schools share the general philosophical position that knowledge cannot be decomposed or decontextualized for purposes of either research or instruction. (p. 235)
Sometimes, the debate between cognitive and situative theories is recast as being about unit of analysis—cognitivists focusing on the individual and situativists focusing on social groups and communities of individuals. In this sense, constructivism, which also focuses on individual cognition, can be recast as a flavor of cognitivism (Derry, 1996). However, this can obscure the nature of these debates. The bias-variance tradeoff can help demonstrate why situativists and constructivists (even if they differ in their unit of analysis) often find themselves agreeing, and on the opposite side of cognitivists.
Table 3 shows how the generalized bias-variance decomposition can be mapped to these debates around learning. The target is the “true” scientific theory of learning, and our goal, as learning scientists, is to find a theory of learning that can approximate the true theory. (Some learning scientists may deny that there is such a “true” theory of learning or whether our goal is really to approximate such a theory. Indeed, these epistemological differences play an important role in the educational debates we are discussing here, and we will revisit them later in the Discussion section later.) The development of a theory requires collecting data from human subjects and, through various kinds of data analysis, creating models of how people learn. Cognitivists develop precise computational models that can be simulated and fit to data—much like machine learning models. Situativists and constructivists, on the other hand, tend to rely on qualitative methods and case studies to construct qualitative models and theories about how people learn.
Generalized Bias-Variance Decomposition Applied to the Debate on Educational Learning Theories

Situative theories developed in reaction to the cognitive tradition, with many early situative researchers originally being cognitivists. These researchers were disheartened with cognitive theories, because they could not describe the rich kinds of learning that happen in authentic environments (outside of labs and even formal schooling environments). In other words, they found cognitive theories to be biased. On the other hand, cognitive theorists found the situative perspective to be too imprecise, informal, and not generalizable, or in other words, high variance. Indeed, according to Anderson et al. (1997), We have sometimes declined to use situated language (what Patel, 1992, called “situa-babel”) because we do not find it a precise vehicle for what we want to say. In reading the literature of situated learning, we often experience difficulty in finding consistent and objective definitions of key terms. (pp. 18–19)
Moreover, in a critique of information-processing psychology from a constructivist perspective, Cobb (1990) noted the presence of a bias-variance tradeoff
5
: It can be argued that there is a trade-off between accounting for the subjective experience of doing mathematics and the precision inherent in expressing models in the syntax of computer formalisms . . . [constructivism] gives greater weight to mathematical experience and [cognitivism] greater weight to precision. (p. 68)
If learning really is context-dependent, then how can the result of an ethnographic study in a very specific context generalize? Any specific study might “overfit” to a particular situation, but perhaps on average, situative theories are more accurate (less biased) because they describe learning in more complete terms. For example, situativist accounts are more likely to account for the social aspects of learning or nuances that appear only when the rich classroom context or authentic informal learning context is taken into account. On the other hand, information-processing theories are often developed by studying adults in lab settings, where the nuances that appear in authentic learning settings are minimized. Appendix B gives quotations to illustrate why constructivists and qualitative researchers view the high-variance nature of their theories essential.
To make the application of the bias-variance tradeoff here more concrete, suppose for the sake of argument that we are trying to learn a function f to predict some learning event

and in many cases,
The bias-variance tradeoff described here can also explain debates in methodology that appear in education research, and the social sciences more generally (i.e., quantitative vs. qualitative, reductionistic vs. holistic, and controlled experiments vs. design experiments); the connection to these debates is briefly described in Appendix D.
Analogues to Bias-Variance Tradeoffs in Artificial Intelligence
The bias-variance tradeoff in learning theories can be better understood by noticing that it actually has historical roots in similar tradeoffs that have appeared in the history of AI. The cognitive perspective is rooted in the tradition of symbolic and rule-based approaches that were popular in the early days of AI research. Rule-based AI is often seen as being biased because it is theory-driven, in contrast to more data-driven approaches to AI, such as machine learning, especially connectionist neural networks. 6 On the other hand, neural networks and other black box machine learning algorithms have higher variance because they are more susceptible to overfitting to particular data. While connectionism seemingly has little to do with educational theories of learning, parallels have been drawn between connectionism, situativism, and constructivism (Quartz, 1999; Vera & Simon, 1993; Winograd, 2006); indeed, neural networks could help do away with the factoring assumption mentioned earlier. For example, diSessa (1993) proposed an influential constructivist theory of how students develop intuitive conceptions in fields such as physics through the activation of networks of p-prims (“phenomenological primitives”). While this model was developed by diSessa and utilized by later researchers using deep qualitative interviews of students, diSessa (1993) also initially sketched a connectionist architecture for how p-prims might form networks that could result in conceptual change (though such a connectionist architecture was never implemented to my knowledge). In this sense, the bias-variance tradeoff between educational theories of learning is not so far removed from the associated tradeoff between theory-driven and data-driven approaches in AI and machine learning. 7
However, in the history of AI, another distinction of approaches was made by Schank (1983) that is more useful for our purposes: the distinction between “neats” and “scruffies.” According to Kolodner (2002), “Neats” . . . were taking a careful, experimental, and (to us “scruffies”) slow route toward getting small results that would hopefully add up to a coherent big picture. “Scruffies,” on the other hand, were taking a more intuitive and holistic and (to the “neats”) far messier approach, using modeling and observational methods to get at the big picture, hoping that it will provide guidance on which smaller details to focus on. While neats focused on the way isolated components of cognition worked, scruffies hoped to uncover the interactions between those components. (p. 139)
It should be clear where the bias-variance tradeoff lies in these approaches. Kolodner (2002) pointed out that Herbert Simon, Allen Newell, and John Anderson were prototypical neats, while Seymour Papert, Marvin Minsky, and Roger Schank were prototypical scruffies. Many of these names should be recognizable. Interestingly, all of these researchers not only were AI and cognitive science researchers but also played an important role in defining theories that would affect education research. Simon, Newell, and Anderson were three of the pioneers of information-processing psychology. Papert was a student of Piaget (one of the founders of constructivism), and he and Minsky developed an approach to AI and education research that drew heavily on constructivist ideas. Papert later founded constructionism, a learning theory that built on Piaget’s constructivism (Papert, 1988). Schank, who coined the term learning sciences and effectively founded the field (Schank, 2016), took a similar approach to Papert and Minsky in his AI research (Brockman, 1996) and education research. Similar tradeoffs can be seen in other areas of cognitive science. For example, in linguistics, Noam Chomsky can be regarded as a neat whose Universal Grammar is acknowledged as being a high-bias (low-variance) theory (Lappin & Shieber, 2007; Norvig, 2017). Indeed, Chomsky engaged in debates with both Piaget and Schank, and more recently, researchers have used higher variance machine learning models and computational learning theory to challenge his theory (Lappin & Shieber, 2007). Thus, the existence of a bias-variance tradeoff in learning theories is not a coincidence but rather an offshoot of similar tradeoffs in AI, which gave rise to the field of machine learning, where the tradeoff was later formalized.
Pedagogy: Direct Instruction Versus Discovery Learning
The debate around direct instruction versus discovery learning has surfaced in various ways throughout the history of education (Bruner, 1961; Ray, 1961; Winch, 1913), and is still a topic of controversy in education research (Kirschner et al., 2006; Munter et al., 2015; Tobias & Duffy, 2009). Direct instruction refers to directly and explicitly teaching students what you want them to learn. Discovery learning suggests that students should be left to discover and construct knowledge for themselves with limited intervention from teachers. In many ways, direct instruction is rooted in cognitive theories and discovery learning is rooted in constructivist theories of learning (Kirschner et al., 2006), and as such, this debate parallels the debate around learning theories; the bias-variance tradeoff can help us see this relationship from another angle.
Table 4 shows a mapping of the generalized bias-variance decomposition to this debate on pedagogy. Here the goal is to come up with the best educational experience for each student (i.e., a function that maps educational experiences to students). The instructor must choose an instructional intervention, and that intervention will in turn determine the precise educational experience that each student receives. Notice that the process by which the intervention results in an educational experience for each student is assumed to be stochastic because it depends on how the intervention actually pans out, how receptive the student is to the intervention, various unrelated distractions that might come up in the classroom, and so on. 8 For example, the teacher may start with some lesson plan, but if a student appears to be struggling, the teacher may change the lesson or instructional technique as needed. On the other hand, the teacher may decide to give students time to research an open-ended project, therefore giving the students much control over their educational experiences, resulting in varied experiences depending on each student’s level of motivation, prior knowledge, metacognitive skills, and so on. Notice that the source of randomness here is very different from randomness in the data used to create a theory or fit a machine learning model. That is, here the instructor is not using randomly generated data to construct an instructional strategy. Rather, the instructor can predetermine their instructional strategy ahead of time, but the result of that strategy is not completely in the instructor’s hands.
Generalized Bias-Variance Decomposition Applied to the Pedagogical Debate on Direct Instruction Versus Discovery Learning

The bias in an instructional strategy is the average degree to which the educational experience that a student receives is suboptimal. The variance in an instructional strategy is the variance in educational experiences that a student might receive as a result of that strategy. Direct instruction falls on the bias side of the spectrum because students are directly taught what the instructor or other experts believe the students need to know, which may not actually be what each student would benefit from most. For example, Spiro et al. (1988) explicitly pointed out several “reductive biases” that could result from direct instruction in ill-structured domains, whereby students oversimplify the complexities and nuances of the domain.
On the other hand, discovery learning lies on the variance side of the spectrum, as (in its most extreme form) it suggests leaving students to discover the best educational experience for themselves. As such, there is a lot of variation in the possible educational experiences that students end up receiving. Proponents of direct instruction would cite this as a limitation of discovery learning; students might end up reaching a dead end in their discovery process or construct misconceptions. Proponents of discovery learning find direct instruction to be overly focused on direct knowledge acquisition and performance-based metrics in well-defined domains but insufficient to account for richer notions of learning such as learning in ill-defined domains (Spiro et al., 1988), preparing for future learning (Schwartz et al., 2009), or becoming a participant in a community of practice (Lave & Wenger, 1991). These other forms of learning naturally require varied educational experiences to support the variety of situations in which students might have to use (or reconstruct) their knowledge in the future.
Papert (1987b) explicitly discussed how high variance is necessary in order to allow for different students to receive the right educational experience for them (in the context of children learning mathematics through the Logo programming language): Whenever children are exposed to this sort of thing, a certain number of children seem to get caught by discovering zero. Others get excited about other things. The fact that not every child discovers zero this way reflects an essential property of the learning process. No two people follow the same path of learnings, discoveries, and revelations. You learn in the deepest way when something happens that makes you fall in love with a particular piece of knowledge. (p. 82)
Navigating the Bias-Variance Tradeoff
While the bias-variance tradeoff seems to imply that by reducing bias one has to increase variance or vice versa, such a tradeoff is not necessarily an equal exchange of bias and variance, meaning there could be ways to find an “optimal” amount of bias and variance, as depicted by the minimum of the mean squared error plot in Figure 3. In the machine learning literature, there are many proposed techniques for effectively navigating the bias-variance tradeoff in order to minimize mean squared error. Indeed, throughout the history of AI, researchers have advocated for combining symbolic or logical AI approaches with (high variance) statistical AI (Bach et al., 2017; Domingos et al., 2006; Hu et al., 2016; Minsky, 1991). For example, in an article called “Logical Versus Analogical or Symbolic Versus Connectionist or Neat Versus Scruffy,” Minsky (1991) argued that neither purely connectionist nor purely symbolic systems seem to be able to support the sorts of intellectual performances we take for granted even in young children. . . . I’ll argue that the solution lies somewhere between these two extremes, and our problem will be to find out how to build a suitable bridge. (p. 37)
We now turn to some concrete techniques for effectively navigating the bias-variance tradeoff to minimize mean squared error in the educational debates we have discussed.
Increasing the Amount of “Data”
As mentioned before, as the amount of data increases, the variance of a machine learning function class decreases. Thus, as the amount of data increases, higher variance techniques become more effective. As the amount of data goes to infinity, then the best function class is one that has zero bias, no matter what the variance is (since it will diminish). This can also be seen in terms of reliability and validity in social sciences research. It is okay to have a high-validity, low-reliability survey if the number of survey respondents is very large. One consequence of this is that one should pick a method with the right amount of variance for the amount of data one has. Another implication is that if one wants to use a high-variance method (e.g., because it has less bias than other methods), one should collect more data to minimize overfitting. Of course, collecting more data is not always easy; for example, conducting ethnographic studies of many learning situations can be quite costly, which can limit one’s ability to create a generalizable theory of situated learning (if that is one’s goal).
But how does “more data mean less variance” give us insights into debates around pedagogy, where data are not present? We can think of data as a limited resource that regulates the degree of stochasticity in machine learning algorithms. An analogous resource in the case of debates around pedagogy is instructional time. Much of the argument against discovery learning is around efficiency. While it would be great if students could rederive all scientific laws, who has the time to do that? It took centuries the first time around! Direct instruction is efficient, and if time is limited, it can lead to more quickly disseminating knowledge to students. But if one has more instructional time available, then perhaps some of that time could be spent on discovery activities where students can develop more robust understandings. Indeed, in Mehta and Fine’s (2019) detailed study of potentially promising American high schools, the authors found that most schools and teachers were not able to provide deeper learning opportunities to their students due to the need to cover a lot of instructional material, which is done more efficiently via lecture; however, one progressive project-based learning school was able to effectively engage students in sustained deeper learning by largely avoiding the demands of traditional standards.
Raw instructional time is not the only resource of interest; sometimes a more relevant variable is the number of instructional activities of interest. Spiro et al. (1991) argued that for ill-structured domains where there is “case-to-case irregularity” students need to see a variety of cases in order to have robust knowledge of that domain. Not only does direct instruction not suffice due to its proneness to “oversimplification” and other “reductive biases,” but the more examples students see, the more likely they are to generalize better. For example, medical students would need to encounter several cases of different patients with similar conditions due to the nuances that appear across cases; simply reading books about medical conditions is not enough. But if instructional time is limited, teaching generic principles via direct instruction might be more effective than having students work with one or two cases, as they might “overfit” their understanding to those particular cases. Therefore, discovery learning is useful in this case only if a student can see sufficiently many cases in order to obtain a generalizable understanding of the ill-structured domain.
Regularization
In machine learning, regularization is one of the most common techniques to mitigate variance (at the expense of adding some bias). Rather than simply trying to only minimize mean squared error, one adds a regularization parameter that constrains the complexity of the function class. In particular, the objective of a machine learning algorithm might be as follows:

The term on the left is the empirical mean squared error on the data set. If one just minimizes that quantity, one risks overfitting (especially with a high-variance function class) to the particular data set. The left-hand term is some measure of the complexity of
Analogously, in teaching, discovery learning can be made more effective by adding in a small amount of guidance, which may prevent the student from getting lost in their discovery process at the expense of biasing the student towards the teacher’s “right answer.” This guidance could bias students away from their optimal educational experience but may typically lead to a more productive experience than letting students figure everything out on their own. Indeed, researchers on both sides of the direct instruction versus discovery learning debate have realized that the optimal form of instruction is somewhere in the middle, often referred to as guided discovery learning (A. L. Brown & Campione, 1994; Gagné & Brown, 1961; Kersh & Wittrock, 1962; Tobias & Duffy, 2009). Like a regularization parameter, a “guidance parameter” can regulate how much a student should struggle before receiving guidance. A small amount of struggle and failure could be productive, but letting students drown in the deep end of discovery is not. The question then becomes how much guidance is optimal. In machine learning, to find the optimal regularization parameter, one can use a technique known as cross-validation; there is no clear analogue to cross-validation in the instructional setting, but a similar procedure would simply be to try different amounts of guidance to learn over time how much guidance seems to be optimal. Of course, the optimal amount of guidance might vary from student to student and from one instructional situation to another. Perhaps, in some cases it is best for a good teacher to rely on their intuition (which is not altogether uncommon in setting regularization parameters either).
Model Ensembles
Model ensemble learning techniques, such as bagging, boosting, and stacking, combine multiple models to reduce the bias and/or variance of the individual models when making predictions. For example, stacking or stacked generalization can take multiple models as input and then use a meta-algorithm (e.g., linear regression) to assign a weight to each subalgorithm to make a final prediction that could correct for biases in the input models (Breiman, 1996; Wolpert, 1992).
The main takeaway for our purposes is that by combining multiple models/theories, we can perhaps mitigate the biases or variance in the individual models. For example, by looking to various studies of situated learning or learning in constructivist classrooms, we can look for overarching trends and patterns that appear across the studies. Such trends are likely to not overfit to particular situations but rather could give us insights that might generalize well across situations. At the same time, these insights might avoid biases in cognitive models that disregard richness and social dynamics of authentic learning environments.
To see how model ensembles can help mitigate bias, we can take inspiration from Papert and Minsky’s approach to AI. In an early report on their state of AI research, Minsky and Papert (1971) discussed their use of microworlds in contrast to rigid symbolic approaches to AI (like that of Simon, Newell, and Anderson): We are dependent on having simple but highly developed models of many phenomena. Each model—or “micro-world” as we shall call it—is very schematic . . . we talk about a fairyland in which things are so simplified that almost every statement about them would be literally false if asserted about the real world. Nevertheless, we feel they are so important that we plan to assign a large portion of our effort to developing a collection of these micro-worlds and finding how to embed their suggestive and predictive powers in larger systems without being misled by their incompatibility with literal truth.
In other words, they were comfortable with using a collection of models that were admittedly very biased, because perhaps by integrating these biased models together they could create less biased systems (possibly at the expense of being higher variance). Papert (1980, 1987a) extended this AI notion of microworlds to “slices of reality” that children can interact with (e.g., on a computer) when learning. Each of these microworlds allow students to discover and explore but with bounds that constrain the space of discovery, bounds that bias the world potentially into being very incomplete and inaccurate conceptions of reality. But to Papert this did not matter; it is by discovering reality through multiple (biased) microworlds, that a learner could develop robust understanding of the macroworld (see Appendix B for a brief exposition of microworlds in Papert’s educational theory).
This is similar to Spiro et al.’s (1988) suggestion of needing multiple cases to learn about an ill-structured domain. In fact, (Spiro et al., 1991) advocated for the need to be able “to construct from those different conceptual and case representations a knowledge ensemble tailored to the needs of the understanding or problem-solving situation at hand” (p. 24). While each case is biased and not wholly representative of the domain at large, by examining many different cases, a learner can develop more robust knowledge about the domain. While these ideas suggest high-level parallels between ensemble learning and approaches to discovery learning, perhaps more formal connections can be made to existing ensemble learning techniques.
Discussion
Here we discuss two other important differences that cut across the various bias-variance tradeoffs that we have previously discussed. Namely, we look at (1) the distinction between predictive (or descriptive) power and prescriptive power and (2) how these bias-variance tradeoffs relate to debates around epistemology, which can help explain why these debates linger to this day.
Predictive Power Versus Prescriptive Power
Another difference that can arise between techniques that tend to have more bias versus techniques that tend to have more variance is that the former are often more conservative (often relying on existing theories), which in turn is better at predicting things as they are. On the other hand, higher variance approaches tend to explore a broader space of potential solutions, which while prone to overfitting could lead to prescribing new solutions.
This point was made clear by Papert (1980) when contrasting Minsky’s and his approach to AI and education research with that of other AI researchers like Newell and Simon. He saw a key difference in their approach being “seeing ideas from computer science not only as instruments of explanation of how learning and thinking in fact do work, but also as instruments of change that might alter, and possibly improve, the way people learn and think” (pp. 208–209).
To contextualize this claim, let us first examine Simon and Newell’s (1971) approach to AI. Their interest was in developing AI programs for problem-solving that that were aligned with how humans solve problems, which in turn would also lead to their cognitivist theory of information-processing psychology. In fact, their approach was to develop programs intentionally limited by human capabilities (see Appendix B). This is in stark contrast to modern machine learning approaches that are primarily data-driven and allow for computational techniques that humans very likely do not use (at least not consciously) when solving problems. This allows for developing programs that can detect patterns in high-dimensional data that people can simply not do. More recently, deep learning has demonstrated the ability to create AI that can exhibit superhuman performance. Recent deep learning agents such as DeepMind’s AlphaGo (an agent that can beat experts at the ancient game of Go; Silver et al., 2016) and AlphaStar (an agent that has beaten experts at the popular computer game StarCraft II; Vinyals et al., 2019) not only beat humans but also do so by exhibiting new strategies to playing these games that humans can study and possibly learn from (Chan, 2017).
Similarly, Papert and Minsky were interested in finding ways to change how people learn altogether. That is, while Simon, Newell, and other cognitivist researchers were interested in more efficiently teaching students by understanding how the mind works; Papert and Minsky were interested in finding ways to fundamentally alter and improve how people learn by understanding how the mind could work.
For example, while a firm student and proponent of Piaget, Papert saw his mentor’s theory of developmental stages as being a predictive theory, but not a prescriptive theory. According to Papert (1987b), “One might say that the formal stage arrived so late precisely because there were no computers” (p. 93). Taking a more discovery-oriented approach, Papert (1980, 1987b) believed that by using microworlds, children could reach the formal operational stage before researchers like Piaget had ever observed previously. Thus high-variance approaches do not find themselves confined by existing theories, and hence can find solutions outside of the scope of such theories, which may have a biased way of looking at things as they are. However, it is important to note that Papert’s starting point was Piagetian theory; it is merely by tweaking the theory that he was able to escape it. This points again to the need for techniques that can combine the best worlds, for example, by taking the predictive power of existing theories as a starting point to establish powerful prescriptive theories and instructional techniques.
Epistemology Debates
If the solution is to combine aspects from both sides of a debate (e.g., cognitivist and situativist theories, or discovery and direct instruction), and researchers realize that moderate positions are better than the extremes, then why do these debates persist? It may seem as though pragmatic considerations should determine the optimal mix of different positions (and the optimal amount of bias and variance), but I claim that these debates linger on, at least in part, due to different philosophical worldviews and epistemologies.
Advocates of cognitive theories, quantitative methodologies, and direct instruction tend to have realist and positivist (or postpositivist) beliefs about the nature of knowledge, learning, and the world. That is, they believe there is a “true” theory out there and empirical observations can help us approximate, or even discover, that truth. On the other hand, advocates for situative theories, qualitative methods, and discovery learning tend to hold constructivist 9 and interpretivist epistemologies, positing that each person’s understanding of the world is a mental construction and does not necessarily correspond to an external reality (which does not mean they necessarily deny the existence of such a reality; von Glasersfeld, 1991).
A positivist researcher is likely to believe their theory is correct or at least an approximation of reality, and thus may not readily admit that it is biased. For similar reasons, realists are also more likely to be fond of teaching an “essential” standardized curriculum to all students, not viewing their curriculum as biased by their understandings of reality. Constructivist researchers, on the other hand, are comfortable admitting that they and their colleagues will each have different theories of learning based on their experiences, none of which are correct but all of which might give insights onto reality; constructivists accept that their theories are naturally high variance. Moreover, constructivist teachers believe that their students will construct different understandings, and thus higher variance instructional strategies are necessary to suit individual differences; thus, constructivist educators will yield some of their authority in the classroom to students as they construct the subject matter for themselves (Munter et al., 2015; von Glasersfeld, 1991).
Speaking in terms of the target diagrams, an epistemologically constructivist researcher or educator may think that (1) there is no target (objective reality) to begin with or (2) it is a movable target that will vary from researcher to researcher, from context to context, or from student to student. The goal may not be to pinpoint one true universal theory of learning or to adopt one universally applicable teaching practice, but to find the approach that best fits the problem here and now. When viewed in the context of generalization however; this results in high variance.
Many social scientists have argued that these epistemological differences can amount to an incommensurability in different research paradigms (Lincoln et al., 2017), adopting the concept from Thomas Kuhn’s (1962) depiction paradigms in the natural sciences. However, some have argued that incommensurable (even as initially intended by Kuhn) does not imply that different paradigms cannot be meaningfully compared in order to arrive at a richer understanding of the various perspectives (Bernstein, 1983; Cobb, 2007; Donmoyer, 2006). Indeed, a recent trend appears to be that many education researchers are explicitly choosing to adopt pragmatism (in the tradition of John Dewey, Charles Sanders Peirce, and William James) as their epistemological stance to move away from age-old epistemological debates that might hinder the progress of doing good education research (Cobb, 2007; Doroudi et al., 2020; Taber, 2010). Perhaps because constructivists are accepting of the limitations to their approach (i.e., that it is high variance), they tend to be more pragmatic and are willing to draw from competing approaches to navigate the bias-variance tradeoff (Cobb, 2007; Danish & Gresalfi, 2018; Derry, 1996; Greeno, 1998; Sfard, 1998; Shaffer, 2017). On the other hand, if a realist/positivist researcher or teacher denies that their approach is biased, then they may not see the need to draw from researchers who adopt alternative epistemologies (Anderson et al., 1997).
It is important to note that these different epistemologies are not necessary aspects of the bias-variance tradeoffs. For example, in machine learning, many researchers will tend to adopt a positivist or empiricist approach when choosing to find the model that best fits the data, regardless of where the approach lies on the bias-variance tradeoff. This could also explain why the use of neural networks (in a traditional machine learning fashion) does not have a closer historical correspondence to the research approach of constructivists or situativists; they do not align epistemologically.
Conclusion
I have shown how the bias-variance tradeoff in machine learning can be formally generalized to provide insights into age-old educational debates. While this framework does not resolve these debates, it can justify why the different positions are all trying to do something meaningful (in terms of “minimizing mean squared error”). It can also help explain relationships between concepts that may seem unrelated at first glance. For example, while situativist and constructivist theories sometimes have different units of analysis, they are aligned by their position on the bias-variance tradeoff. Similarly, due to their high-variance nature, neural networks can be seen as being related to situativist and constructivist theories, although that connection is limited due to epistemological differences.
Moreover, by looking toward concrete data science and machine learning techniques to navigate the bias-variance tradeoff, we can discover analogous ways of tackling similar tradeoffs in education. Many of these ways of navigating the tradeoffs have been proposed throughout the history of AI and the learning sciences, but sometimes only in passing in isolated articles, rather than being presented systematically. By situating these debates onto the bias-variance tradeoff, we can systematically identify solutions that have been proposed in the past as well as offer new solutions by looking to the machine learning literature. This article simply begins to illustrate how certain concepts such as the bias-variance tradeoff, overfitting, regularization, and model ensembles relate to approaches in education research, with the hopes of inspiring researchers to find ways to concretely and productively apply these concepts to educational problems. Perhaps by working together, machine learning researchers and education researchers can find new ways to utilize the science of data to productively advance the science of teaching and learning in ways that move past seemingly never-ending paradigmatic differences.
Footnotes
Appendix A
Appendix B
Appendix C
Appendix D
Acknowledgements
Winograd (2006) identified a division of AI and HCI researchers into two camps that cut across both fields, which effectively align with the bias-variance tradeoffs we see in education research as well (see Appendix D). While he did not refer to the bias-variance tradeoff explicitly, reading this work led me to the recognition of the role that the tradeoff plays in educational debates. I would also like to thank Alexander Ihler for the suggestion of thinking of instructional time as a resource that is analogous to “data” in the context of debates around pedagogy.
Notes
Author
SHAYAN DOROUDI is an assistant professor at the University of California, Irvine School of Education and (by courtesy) Department of Informatics. He works at the intersection of educational data science, educational technology, and the learning sciences, and his work draws inspiration from the histories of these fields.