
Abstract
This study investigated the effect of temporal misalignment between acoustic and simulated electric signals on the ability to process fast speech in normal-hearing listeners. The within-ear integration of acoustic and electric hearing was simulated, mimicking the electric-acoustic stimulation (EAS) condition, where cochlear implant users receive acoustic input at low frequencies and electric stimulation at high frequencies in the same ear. Time-compression thresholds (TCTs), defined as the 50% correct performance for time-compressed sentences, were adaptively measured in quiet and in speech-spectrum noise (SSN) as well as amplitude-modulated noise (AMN) at 4 dB and 10 dB signal-to-noise ratio (SNR). Temporal misalignment was introduced by delaying the acoustic or the simulated electric signals, which were generated using a low-pass filter (cutoff frequency: 600 Hz) and a five-channel noise vocoder, respectively. Listeners showed significant benefits from the addition of low-frequency acoustic signals in terms of TCTs, regardless of temporal misalignment. Within the range from 0 ms to ±30 ms, temporal misalignment decreased listeners’ TCTs, and its effect interacted with SNR such that the adverse impact of misalignment was more pronounced at higher SNR levels. When misalignment was limited to within ±7 ms, which is closer to the clinically relevant range, its effect disappeared. In conclusion, while temporal misalignment negatively affects the ability of listeners with simulated EAS hearing to process fast sentences in Mandarin, its effect is negligible when it is close to a clinically relevant range. Future research should validate these findings in real EAS users.
Keywords
Introduction
Speech is inherently dynamic in real-world listening scenarios. Speech rate varies depending on individual talkers, speaking styles, emotions, and other factors (Miller et al., 1984; Shen et al., 2023; Yuan et al., 2006). However, existing speech tests typically use materials with fixed rates, which may not fully capture how listeners perform in dynamic listening environments. Compared to slow speech, fast speech impairs comprehension and increases listening effort (Winn & Teece, 2021). This deterioration is exacerbated by aging, background noise, and hearing loss (Adams et al., 2012; Jafari et al., 2013). Previous studies have shown that listeners with unilateral cochlear implants (CIs) experience a greater decline in speech recognition performance as speech rate increases, compared to those with normal hearing (NH) (Fu et al., 2001; Ji et al., 2013; Li et al., 2011; Su et al., 2016).
Electric-acoustic stimulation (EAS) is a beneficial option for patients with severe-to-profound hearing loss in the mid-to-high frequencies who still have preserved low-frequency (LF) residual hearing. This technology combines an ipsilateral hearing aid (HA) with a CI. By providing crucial LF information and temporal fine structure via the acoustic signal, EAS significantly enhances listeners’ speech recognition performance in both quiet and noisy environments compared to using a CI alone (Chen & Loizou, 2010; Fu et al., 2017; Gifford et al., 2017; Yoon et al., 2021). However, the effect of this additional acoustic input on processing fast speech remains unclear. Temporal misalignment between HA and CI signals arises due to differences in signal processing techniques and auditory pathways (Francart & McDermott, 2013; Pieper et al., 2022). Consequently, speech recognition may not be fully optimized (Wu et al., 2020). Therefore, it remains unknown whether this temporal misalignment compromises listeners’ ability to process fast speech effectively.
CI listeners exhibit certain deficits in processing speech at high speech rates, showing a greater decline in performance and increased individual variability compared to NH listeners (Fu et al., 2001; Ji et al., 2013; Li et al., 2011; Su et al., 2016). This may be partly attributed to the reduced frequency and temporal resolution caused by hearing loss and signal processing, which hinder the extraction of critical auditory cues. These studies on fast speech processing typically presented speech materials at fixed rates, specifically slow, normal, and fast, and corresponding speech recognition scores were measured as outcomes. While this provides valuable data, it means the full extent of listeners’ capacity to process fast speech remains unmeasured, as ceiling and floor effects may occur, limiting the accurate assessment of their performance at extreme rates. Some studies circumvented this limitation by employing an adaptive procedure to determine the speech rate at which listeners achieve a 50% correct speech recognition score, known as the time-compression threshold (TCT, Kociński & Niemiec, 2016; Meng et al., 2019; Schlueter et al., 2014; Versfeld & Dreschler, 2002), which is analogous to the speech reception threshold (SRT, Plomp & Mimpen, 1979). Meng et al. (2019) reported that the mean TCT of CI listeners in quiet was 6.6 syllables per second (syl/s) when using the Mandarin Speech Perception corpus, and 6.9 syl/s when using the Mandarin Hearing in Noise Test corpus as test materials.
TCTs in quiet have been found to significantly correlate with sentence recognition scores in quiet as well as SRTs in speech-spectrum noise (SSN) and babble noise (Meng et al., 2019). This suggests that CI listeners with better speech recognition may tolerate higher speech rates. Building on this relationship, we hypothesize that the TCT of EAS listeners may be higher than that when listening to CI signals alone. However, their TCT in the EAS condition may be reduced by the temporal misalignment between acoustic and electric signals.
Temporal misalignment between acoustic and electric signals refers to the difference in latency with which sound information reaches the auditory nerve via the HA's acoustic pathway versus the CI's electric pathway. In the presence of temporal misalignment, either the acoustic or electric signal is delayed relative to the other in terms of neural stimulation timing. In studies investigating temporal misalignment, it has been manipulated by delaying CI signals in patients who used a HA contralaterally (Angermeier et al., 2021, 2023; Richter et al., 2024) or by using simulation to temporally shift signals interaurally (Wess et al., 2017) and monaurally (Wu et al., 2020) in NH listeners. In simulation studies, the maximum temporal misalignment varied, with values set at ±15 milliseconds (ms), or even ±100 ms. Currently, no published studies have measured the extent of temporal misalignment in the EAS population. However, studies on bimodal patients using an HA and a CI contralaterally have reported temporal misalignment of approximately 7 ms across frequencies (Zirn et al., 2015) and approximately 3.5 ms (Engler et al., 2020). The extent of temporal misalignment is influenced by the processing time of the HA and CI, as well as the time required for signals to travel through the respective auditory pathways. Thus, the actual extent of temporal misalignment may vary among individuals depending on the specific devices used.
Wu et al. (2020) demonstrated that in NH listeners with simulated EAS hearing, speech recognition under SSN and 2-talker babble noise deteriorated in the presence of temporal misalignment. This deterioration likely occurs because a delay between the acoustic and electric signals can blur acoustic cues in the temporal, spectral, and intensity domains, impairing listeners’ ability to extract meaningful information from speech signals. For example, the temporal envelope, an essential component of speech, is widely recognized as crucial for speech intelligibility (Qi et al., 2017; Swaminathan et al., 2016). When the acoustic and electric signals are combined with a delay, the temporal envelope of the resulting signal may become flattened, reducing speech recognition. The fundamental frequency (F0) and first formant (F1) in the acoustic signal may become misaligned with higher-frequency formants conveyed by the electric signal, potentially distorting syllable boundaries and impairing word segmentation. In addition, most Mandarin syllables are formed by the structure of /initial consonant - final vowel/ (Třísková, 2011). Given that vowels are more intense than consonants, delays between signals may create an across-frequency temporal overlap between vowel and consonant segments, potentially leading to an upward spread of masking.
More importantly, as speech rate increases, the delay between signals may span more phonemic units due to the reduced duration of each phoneme. Consequently, the aforementioned disruptions may become more pronounced. Therefore, we speculate that increased speech rate exacerbates the negative impact of the delay between acoustic and electric signals on speech recognition. In other words, delays between the two signal types may lower listeners’ TCT.
Previous studies have primarily examined the effect of fast speech on speech recognition in quiet, leaving the impact of noise unclear. Signal-to-noise ratio (SNR) may influence the effect of temporal misalignment on EAS listeners’ TCTs. As the SNR increases, speech content is less masked by background noise, reducing task difficulty. This may allow listeners to exhibit greater tolerance to fast speech, leading to higher TCTs. As previously speculated, the impact of temporal misalignment may be more pronounced at higher speech rates. Thus, we hypothesize that the benefit of increasing SNR on TCT might be diminished by the presence of temporal misalignment. More precisely, temporal misalignment would lead to a greater reduction in TCT as SNR increases, indicating an interaction between these two factors.
Additionally, the type of noise may influence speech perception. Research by Grose et al. (2015) in NH listeners, using time-compression ratios of 0%, 33%, and 50% revealed that time-compressed sentences led to worsened SRTs in both steady and modulated noise, with greater deterioration observed in modulated noise. This suggests that the benefit of glimpsing in temporal dips diminishes as speech rate increases. Gransier et al. (2022) further confirmed this finding, reporting a 5.3 dB reduction in glimpsing benefit as speech rate increased from 2.7 to 6.6 syl/s. Given that CI users have an impaired ability to glimpse in dips (Baumann et al., 2009), their processing of fast speech, particularly in modulated noise, is likely to differ from that of NH listeners. This potential vulnerability suggests that noise type could influence EAS listeners’ tolerance to fast speech. Therefore, this study also examined the effect of noise type on listeners’ TCT.
In summary, this study investigated three main factors on fast speech processing ability, as measured by TCTs, within the context of simulated EAS: (a) the effect of combining acoustic and electric signals ipsilaterally, by comparing the electric-only (E-only) and EAS conditions; (b) the effect of different extent of temporal misalignment between the acoustic and simulated electric signals; and (c) the effect of different listening backgrounds on the aforementioned factors. To ensure precise experimental control over specific acoustic and electric signal parameters and to isolate the independent effect of temporal misalignment, EAS hearing was simulated by presenting NH listeners with processed signals. This approach was chosen for several key reasons, including the inability to manipulate HA or CI signal delays in existing EAS devices and the need to circumvent the challenges in recruiting a sufficiently large and homogeneous cohort of EAS patients, which often present with considerable etiological variability. Temporal misalignment was introduced by delaying either the acoustic or simulated electric signal relative to the other. This study comprised two experiments. Experiment 1 systematically examined the impact of temporal misalignment on TCTs across different listening backgrounds. Based on the findings of Experiment 1, Experiment 2 reduced the temporal misalignment to clinically relevant levels to assess its effects. The findings of this study will bridge existing gaps in the literature and provide researchers and clinicians with a better understanding of how EAS listeners may process fast speech.
Method
Participants
Sixty participants (mean age = 20.50 years, 15 females) were recruited for Experiment 1, and 16 participants (mean age = 20.19 years, 6 females) were recruited for Experiment 2 from the university campus. All participants had pure-tone thresholds equal to or better than 20 dB HL in the range of 250–8,000 Hz. Participants were native Mandarin speakers with no speech, language, neurological, or cognitive impairments. Ethics approval was obtained from the Human Research Ethics Committee (HREC) at the University of Hong Kong.
Test Materials
The Mandarin Hearing in Noise Test (MHINT) corpus was used as the test material (Wong et al., 2007). Each list consists of 20 phonemically balanced sentences, each containing 10 monosyllabic words. Two types of noise were used in noisy environments: SSN and amplitude-modulated noise (AMN). The SSN had the same long-term speech spectrum as the average spectrum of all sentences, while the AMN was generated by sinusoidally modulating the SSN at an 8 Hz rate with full modulation depth. To ensure that listeners achieved a speech recognition score of over 50% on the first sentence in all listening conditions, positive SNR values of 4 dB and 10 dB were selected based on pilot data.
Since the speech rate of the MHINT sentences was not controlled during their development, slight deviations in speech rate among sentences were observed. To eliminate such deviations, the speech rate of each sentence was adjusted to the average rate (4.97 syl/s) of all sentences as a preprocessing step. The speech rate of a sentence was calculated by dividing the number of syllables by its duration, which was detected using a voice activity detection algorithm (Segbroeck et al., 2013). Speech rate adjustment was realized by a synchronized overlap-add, fixed synthesis (SOLAFS) algorithm (Hejna & Musicus, 1991), as described in Meng et al. (2019). The MATLAB code used for this algorithm was obtained from the following website: https://www.ee.columbia.edu/~dpwe/resources/matlab/solafs-matlab.html. This algorithm uniformly stretched or compressed speech signals without changing the pitch. Although there are variations in pause and phoneme duration in naturally fast speech (Kuwabara, 1997), the uniform algorithm was selected over a non-uniform one because it better preserves the original speech's long-term and modulation spectra while achieving the targeted compression ratio (Schlueter et al., 2014). The speech rate of each sentence was adjusted before noise was added at the fixed SNR.
Signal Processing
The signal processing methods were consistent across both experiments. Experiment 1 simulated both the E-only and EAS conditions, whereas Experiment 2 was limited to the EAS condition. A zero-phase digital filtering scheme was used throughout the signal processing to compensate for filter delays.
The E-only condition simulates listening to electric signals only, using a five-channel noise vocoder, derived from a broader eight-channel system (Wu et al., 2020). The input signal was either clean speech in the quiet condition or a speech-in-noise mixture at a defined SNR in the noise conditions. The input signals were pre-emphasized with a first-order high-pass filter that had a cutoff frequency (
The EAS conditions involve listeners hearing acoustic and simulated electric signals ipsilaterally. Given that most listeners with EAS configurations have residual hearing in a limited frequency range, low-pass filtering was employed to generate band-limited signals to represent acoustic signals (Fu et al., 2017; Wu et al., 2020). Low-pass filtering was achieved using a linear-phase finite impulse response (FIR) filter, implemented through the resample function in MATLAB, limiting the spectral region to below 600 Hz. The internally designed anti-aliasing filter has a very high order (approximately 1.6 million taps, Kaiser window with β = 5), resulting in a sharp spectral cutoff (−6 dB at ∼600 Hz), a narrow transition bandwidth (<0.2 Hz), and high stopband attenuation (>45 dB). The simulated acoustic signal was combined with the electric signal processed by the same method as in the E-only condition. Different delay values were introduced to create conditions with and without temporal misalignment. For conditions with delays, a relative time shift (±15 and ±30 ms in Experiment 1 and ±3.5 and ±7 ms in Experiment 2) was applied between the acoustic and simulated electric signals. Positive values indicated that the simulated electric signal was temporally shifted earlier relative to the acoustic signal while the negative values indicated the opposite. For conditions with a 0 ms delay, there was no temporal misalignment between signals. All processing was realized by customized scripts in MATLAB 2021b.
Test Conditions
Test conditions for the two experiments are shown in Table 1. In Experiment 1, participants were randomly divided into five groups, each corresponding to a different listening background, defined as the acoustic environment in which the speech stimuli were presented, including Quiet, SSN at 4 dB SNR (SSN_4 dB), SSN at 10 dB SNR (SSN_10 dB), AMN at 4 dB (AMN_4 dB), and AMN at 10 dB SNR (AMN_10 dB). Each group consisted of 12 participants. Within each group, participants completed trials in E-only conditions and EAS conditions with five values of delay (0, ±15, and ±30 ms).
Test Conditions of Experiments 1 and 2.

Abbreviations: E-only: simulated electric signal only; EAS: electric-acoustic stimulation; SSN: speech-spectrum noise; AMN: amplitude-modulated noise; dB: decibel.
In Experiment 2, participants were randomly divided into two groups of eight participants. Based on findings from Experiment 1, all participants were presented exclusively with EAS stimuli, under only two listening backgrounds (quiet and SSN at 10 dB SNR). Temporal misalignment was introduced as delays of 0, 3.5, and 7 ms, with a positive delay applied to one group and a negative delay to another. Given the absence of published data on temporal misalignment specifically in EAS patients, these values were informed by studies measuring similar effects in bimodal listeners (contralateral CI + HA) (Engler et al., 2020; Zirn et al., 2015). The delay range was purposefully constrained to be smaller than that used in Experiment 1, aiming to more accurately reflect the temporal misalignment typically observed in clinical populations.
Figure 1 illustrates the spectrograms of an MHINT sentence under different EAS conditions, highlighting the effects of speech rate and delay. The top row shows the sentence at the original speech rate (4.97 syl/s) at 0 ms and +15 ms delay conditions. In contrast, the bottom row displays the time-compressed EAS speech. The speech rate for the 0 ms delay condition was 15.41 syl/s, while the +15 ms delay condition had a rate of 13.48 syl/s. These rates were determined based on the average TCTs of the participants in the corresponding condition. Notably, the spectrograms reveal that a higher speech rate amplifies the effect of delay, resulting in a more noticeable temporal misalignment that spans more portions of phonetic units.

Spectrograms of an MHINT Sentence Under Different EAS Conditions in Quiet. The Content is 他讲话时吞吞吐吐(/tā Jiǎng huà shí tūn tūn tǔ tǔ/, Meaning “He Slurred as He Spoke”). The Top Row Shows the EAS Speech at the Original Speech Rate (4.97 syl/s), While the Bottom Row Shows the Time-Compressed EAS Speech (15.41 syl/s and 13.48 syl/s). The Left Column Represents a 0 ms Delay Between the Acoustic and Electric Portions, and the Right Column Represents a +15 ms Delay.
Test Procedure
After an introduction by the researcher, participants signed an informed consent form. A screening pure-tone audiometry test was conducted using an Amplivox 260 audiometer to assess participants’ hearing status. Participants who passed the screening at 20 dB HL for frequencies from 250 Hz to 8,000 Hz were included.
The experiment consisted of a practice block and a formal block. During the practice block, which lasted approximately 10 min, participants familiarized themselves with the test procedures and the speech recognition task. They listened to signals presented through supra-aural headphones (Sennheiser HDA300) from a laptop and were instructed to repeat all words they heard. In Experiment 1, one list in E-only and one in the EAS condition at a delay of 0 ms were administered in the practice block. In Experiment 2, the test conditions of two practice lists were EAS in quiet and in SSN_10 dB at a delay of 0 ms. Feedback on the correctness of responses was provided. Audio signals across conditions had the same RMS and were presented at a fixed level. Participants confirmed that this level was comfortable, and actual sound pressure levels (dB SPL) were not measured.
In the formal block, participants completed 12 lists in total. In each list, 20 sentences were presented randomly in order. The initial speech rate was set as the average speech rate of all original MHINT sentences (4.97 syl/s). The speech rate of each sentence was adjusted by a one-down/one-up adaptive procedure based on listeners’ responses to the last sentence. The speech rate of the next sentence was increased by R times the initial rate if the recognition score exceeded 50%, decreased by R times the initial rate if the score was below 50%, and maintained if the score was equal to 50%. R was set to 0.25 until the second reversal, reduced to 0.15 between the second and fifth reversal, and to 0.1 thereafter until the end of the list. Speech rate adjustment was realized by the algorithm introduced in the section of test materials. The TCT of a trial was computed as the average speech rate of the last eight sentences presented. The minimum speech rate was set as half of the original rate due to distortions in extremely slow sentences. The trial ceased if participants obtained a speech recognition score of less than 50% for four consecutive presentations. In this case, the TCT was denoted as not measurable. Each condition was repeated twice. The final TCT was the average of two trials. The sequence of conditions was randomized for each participant. Breaks were provided as needed. The entire experiment took approximately 1–1.5 hr.
Data Analysis
The Shapiro–Wilk test was used to assess data distribution, and Levene's test was used to check for the assumption of equal variances. Data from one participant in the negative group in Experiment 2 were excluded because the TCT in one condition deviated from the mean by three standard deviations. All analyses of variance (ANOVA) were conducted in SPSS (IBM, version 25). Box plots are used to represent the distribution of data. In each plot (Figure 2–6), the central line represents the median, the box edges represent the 25th and 75th percentiles, and the whiskers extend to the minimum and maximum values. Individual data points for each condition are also plotted.
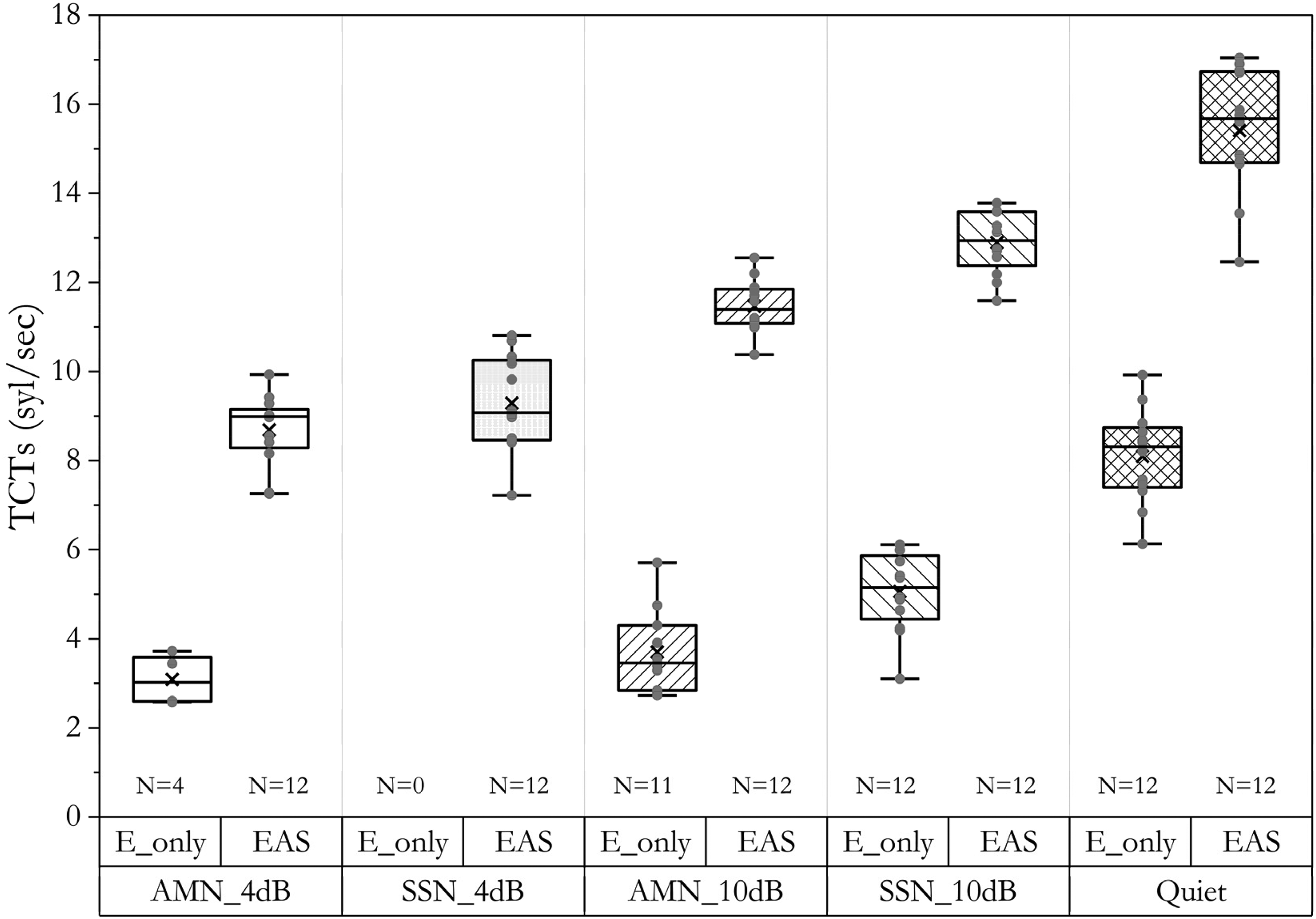
The TCTs (Syllables per Second) for the E-Only and the EAS Conditions in the Absence of Temporal Misalignment, Measured Across Different Listening Backgrounds (AMN_4 dB, SSN_4 dB, AMN_10 dB, SSN_10 dB, Quiet). The Number of Participants (N) With Measurable Data Is Indicated.

The TCTs (Syllables per Second) at Different Values of Delays in Quiet. All Participants (N = 12) Had Measurable Data.

The TCTs (Syllables per Second) at Different Values of Delays in Two Types of Noise (AMN, SSN) at Two Levels of SNR (4 dB, 10 dB). All Participants (N = 48) Had Measurable Data.
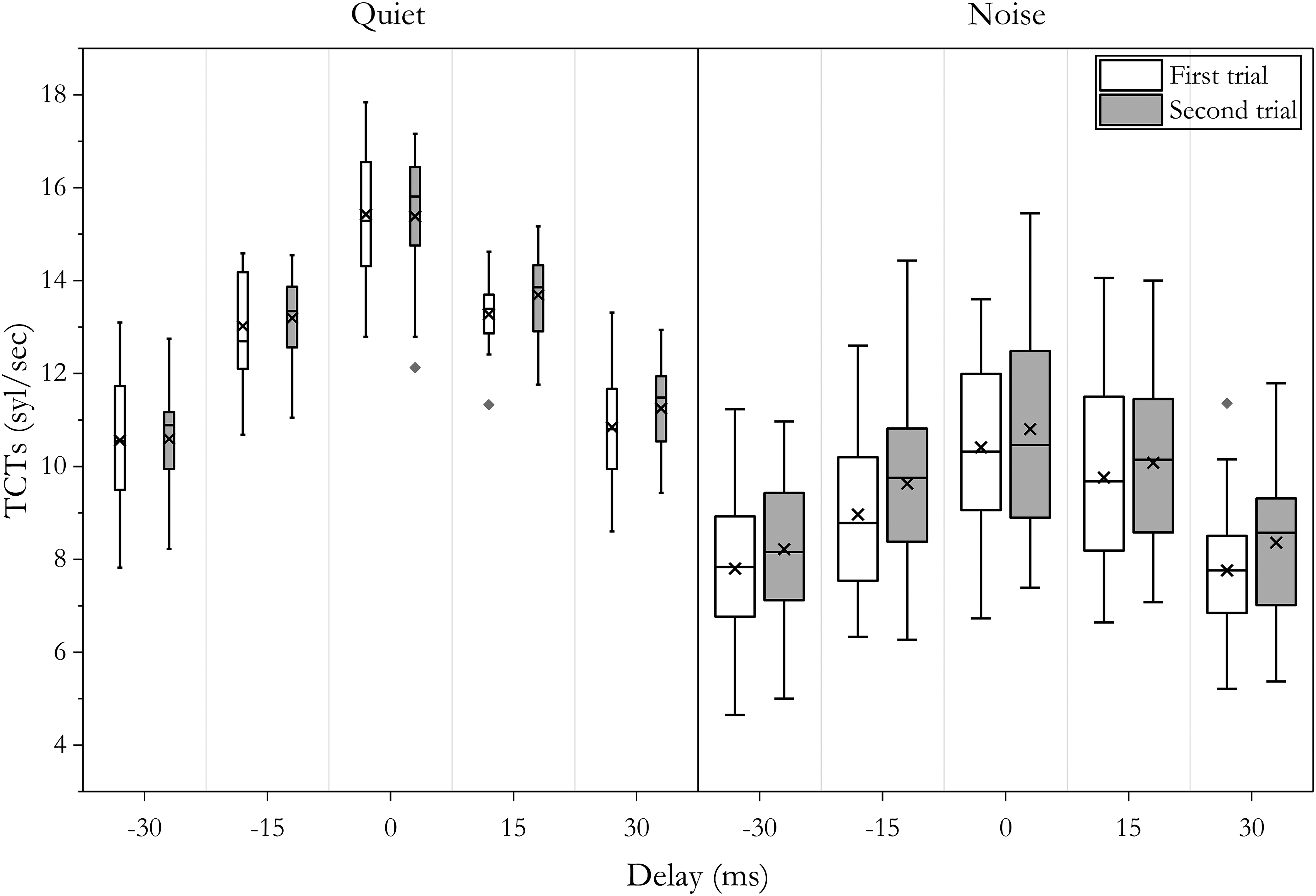
The TCTs (Syllables per Second) at Different Values of Delays Measured at the First and Second Trial in Quiet (Left, N = 12) and Noise (Right, N = 48), With Noise Type and SNR Collapsed. The Width of the Box Represents the Sample Size (N). All Participants Had Measurable Data.

The TCTs (Syllables per Second) at Different Values of Delay in Quiet and SSN in the Positive (N = 8) and Negative Groups (N = 7). All Participants Had Measurable Data.
For Experiment 1, to examine the effect of combining acoustic and electric signals, we first performed a two-way mixed ANOVA (2 listening modes * 3 listening backgrounds) on TCTs under E-only and EAS conditions with no temporal misalignment. For data with temporal misalignment, separate analyses were conducted for the quiet and noise conditions. A one-way repeated-measures ANOVA (5 delays) was performed on the data in quiet, while a three-way mixed ANOVA (5 delays * 2 noise types * 2 SNRs) was conducted for the data in noise. We also performed paired T-tests to examine the benefits of adding acoustic signals in the presence of temporal misalignment. For Experiment 2, a three-way mixed ANOVA (2 listening backgrounds * 3 delays * 2 groups) was conducted. Additional analyses were performed to assess the effects of repeated measurements and test order on the TCTs. Throughout the analysis, post hoc and pairwise comparisons were performed where applicable, with significance adjusted using the Bonferroni correction.
Results
Experiment 1
The Effect of Adding Acoustic Signals
The TCTs in the E-only conditions and the EAS conditions in the absence of temporal misalignment are shown in Figure 2. In AMN_4 dB, only four out of 12 participants had measurable TCTs in the E-only condition during the first or second trial, with an average TCT of 3.09 ± 0.5 syl/s. In contrast, the TCT in AMN_10 dB for the E-only condition was not measurable for just one participant, while the remaining participants had an average TCT of 3.7 ± 0.91 syl/s. In SSN, the average TCT in the E-only condition was 5.03 ± 0.95 syl/s at 10 dB SNR but was not measurable at 4 dB SNR. These results suggest that, regardless of the noise type (stationary or modulated), listeners’ ability to process speech at a faster rate improved at higher SNRs, where the test difficulty was reduced. This was also demonstrated by all participants completing the TCT measurement in the E-only condition in quiet and in the EAS condition across all listening backgrounds.
Due to insufficient valid data in the E-only condition under AMN_4 dB and SSN_4 dB, where many participants were unable to perform the task, statistical comparisons between listening modes (E-only vs. EAS) could not be conducted. Therefore, a two-way mixed ANOVA was conducted, including only the remaining conditions (E-only and EAS at AMN_10 dB, SSN_10 dB, and Quiet), to examine the effects of listening mode and listening background on TCTs. Data in each condition followed a normal distribution (p > .05) and had equal variance (p >.05). The two-way mixed ANOVA revealed significant main effects of the listening mode (within-subjects, F[1,32] = 1,349.779, p < .001) and listening background (between-subjects, F[2,32] = 88.866, p < .001), but the interaction was not significant (F[2,32] = 0.612, p = .549). The significant main effect of listening mode indicated that listeners had significantly higher TCTs with EAS hearing at a delay of 0 ms compared to the E-only condition, suggesting that the addition of acoustic signals significantly enhanced listeners’ ability to process fast speech. Post-hoc analysis of the listening background showed significant differences among the three conditions (p < .001).
The Effect of Delay, Listening Background, and SNR on TCT
The one-way repeated-measures ANOVA for TCT in quiet (Figure 3) showed a significant main effect of delay (F[4,55] = 38.320, p < .001). Post hoc analysis indicated that TCTs without temporal misalignment were significantly higher than those in all other conditions with temporal misalignment. Except for the pairs of −15 ms vs +15 ms and −30 ms vs +30 ms, all other pairs showed significant differences (p < .001).
For the three-way mixed ANOVA (2 noise types * 2 SNRs * 5 delays) on TCT in noise (Figure 4), Mauchly's Test of Sphericity indicated that the assumption of sphericity was met for the within-subjects factor delay (p = .260) and its interaction with other factors (p > .05). The main effects of noise type, SNR, and delay were all significant (p < .001). Delay significantly interacted with SNR (p = .003), while all other interactions were non-significant (p > .05). The significant main effect of noise type (F[1,44] = 18.783, p < .001) showed that listeners had significantly higher TCTs in SSN than in AMN. The main effect of SNR (F[1,44] = 196.616, p < .001) indicated that TCTs at 10 dB SNR were significantly higher than those at 4 dB SNR. The main effect of delay (F[4,176] = 181.362, p < .001) showed that TCT significantly decreased as delay increased. Post hoc analysis showed that except for the pair of −30 ms vs +30 ms (p = 1.000), all other pairs had significant differences (p < .05).
The two-way interaction between SNR and delay (F[4,176] = 8.416, p < .001) was significant, suggesting the effect of delay varied depending on SNR levels, and vice versa. At both SNR levels, listeners’ TCT decreased as the delay value increased. However, the pairwise comparison showed that the negative impact of delay on TCT was greater at the higher SNR. At 4 dB SNR, TCT at 0 ms was significantly higher than that at −30 ms by 2.06 syl/s (p < .001) and +30 ms by 1.94 syl/s (p < .001). In contrast, at 10 dB SNR, the TCT at 0 ms exhibited greater differences compared to the ± 30 ms delays, being higher by 3.05 syl/s at −30 ms (p < .001), and 3.13 syl/s at +30 ms (p < .001), respectively. The TCT at 10 dB SNR was significantly higher than at 4 dB SNR (p < .001) at all delay values, while the difference in TCTs between the two SNR levels was greater at smaller delays. At 0 ms, the TCT at 10 dB SNR was 3.19 syl/s higher than that at 4 dB SNR, whereas at +30 ms and −30 ms, the difference was reduced to 2.00 syl/s and 2.19 syl/s, respectively. Therefore, as SNR increased, the negative impact of delay became more pronounced, suggesting that at better SNRs, listeners are more affected by temporal misalignment when recognizing fast speech.
In addition, paired T-tests were conducted to examine whether listeners still perceive significant benefits from the addition of acoustic signals in the presence of temporal misalignment. Since TCTs in SSN_4 dB and AMN_10 dB were not measurable in some participants, paired T-tests were performed on TCTs in quiet, SSN_10 dB, and AMN_10 dB only. Results showed that TCTs in the EAS condition at all values of delays were significantly higher than those in the E-only condition in all three listening backgrounds (p < .05). This suggests that even though there is temporal misalignment between the acoustic and simulated electric signals, listeners still perceive significant benefits from the addition of acoustic signals in processing fast speech.
The Effect of Repeated Measurements
Figure 5 shows the TCTs measured at the first and second trials in quiet and noise. To examine potential effects of repeated measurements, a two-way repeated-measures ANOVA (2 trials * 5 delays) on TCT for the quiet condition revealed that the main effect of repeated measurements was non-significant (F[1,11] = 1.187, p = .299). Its interaction with delay was also non-significant (F[4,44] = 0.315, p = .866). A separate one-way repeated-measures ANOVA on the effect of test order (12 levels) on TCT also showed a non-significant main effect (F[11,121] = 0.148, p = .707).
For the noise condition, a four-way mixed ANOVA (2 trials * 5 delays * 2 noise types * 2 SNRs) on TCT showed a significant main effect of repeated measurements (F[1,176] = 47.11, p < .001). The TCT at the second trial improved by 0.48 syl/s (SE = 0.07, 95% CI [0.338, 0.618]) relative to the first trial. However, this effect was not reflected in any significant interactions (p > .05). Considering that most TCT data for the 4 dB SNR condition in the E-only condition were not measurable, a two-way mixed ANOVA (12 test orders * 2 noise types) was conducted on the TCT data at 10 dB SNR. With the assumption of sphericity met (p = .660), the main effect of test order was nonsignificant (F[11,209] = 1.424, p = .164), and it did not significantly interact with noise type (F[11,209] = 0.926, p = .516). This supports the validity of test condition randomization.
Experiment 2
Experiment 2 aimed to more accurately reflect the temporal misalignment typically observed in clinical populations. Figure 6 illustrates the results obtained under three temporal misalignment conditions (0, 3.5, and 7 ms) in quiet and SSN from two groups. A three-way mixed ANOVA (2 listening backgrounds * 3 delays * 2 groups) was conducted. Mauchly's Test of Sphericity indicated that the assumption of sphericity was met for the within-subjects factor delay (p = .848) and its interaction with listening background (p = .182). The main effect of the listening background was significant (F[1,13] = 402.780, p < .001) while the main effect of delay (F[2,26] = 1.140, p = .265) was nonsignificant. Although the main effect of group was significant (F[1,13] = 5.359, p = .038), it did not significantly interact with the other two factors (p > .05). This suggests that the differences between the TCTs in the two groups may arise from participant variability.
A four-way mixed ANOVA (2 trials * 3 delays * 2 listening background * 2 groups) was conducted to examine the effect of repeated measurements on TCT and its interaction with other factors. With the assumption of sphericity being met for within-subject factors and their interactions (p > .05), the main effect of repeated measurements was non-significant (F[1,26] = 0.289, p = .600) and its interaction with all other factors was non-significant (p > .05). A two-way mixed ANOVA (12 test orders * 2 groups) was conducted. With the assumption of sphericity being met for test order (p = .147), the main effect of test order was not significant (F[11,143] = 1.548, p = .121), and its interaction with group was also nonsignificant (F[11,143] = 1.433, p = .164).
Discussion
Our study investigated the impact of temporal misalignment between the acoustic and simulated electric signals on the TCT of listeners with normal hearing in different listening backgrounds. TCT is defined as the speech rate at which listeners correctly recognize 50% of the presented sentences, reflecting their ability to process fast speech. Two experiments were conducted: Experiment 1 examined a wide range of temporal misalignment to explore its effects in quiet and noisy environments at varying SNRs, while Experiment 2 focused on a clinically relevant range of misalignment to investigate its potential clinical implications.
Overall, Experiment 1 revealed three key findings: (a) listeners experienced significant improvements in TCTs from the addition of the acoustic signal across quiet, stationary, and modulated noise conditions, regardless of temporal misalignment; (b) temporal misalignment had a significantly negative impact on TCTs with simulated EAS hearing; and (c) temporal misalignment significantly interacted with SNR, leading to a greater negative impact on TCTs at higher SNRs and reducing the benefits of increasing SNR. However, when temporal misalignment was limited to within ±7 ms, Experiment 2 found no significant effect on listeners’ TCTs in quiet and stationary noise.
The Benefits of Adding LF Acoustic Signal
In quiet, the average TCT in the E-only condition was 8.10 syl/s, increasing to 15.41 syl/s when the LF acoustic signal was added without temporal misalignment. A similar substantial improvement was observed in both stationary and modulated noise at 4 dB and 10 dB SNR. This significant enhancement highlights the benefits of adding an acoustic signal for processing fast speech compared to listening to a simulated electric signal alone, in both quiet and noisy environments. In our study, the E-only signal contained speech envelope information from just five channels with center frequencies ranging from 941 Hz to 5,025 Hz, while the acoustic signal supplemented low-frequency information up to 600 Hz. The addition of the acoustic signal provided listeners with temporal fine structure and crucial acoustic cues, such as the F0 and the F1 of some vowels, which are known to enhance speech recognition (Chen et al., 2014; Moore, 2021; Swanepoel et al., 2012). In particular, studies have shown that the F0 and amplitude envelope of the target speech are critical for this benefit, with their combined effect providing significant improvement in intelligibility, especially in noisy backgrounds (Brown & Bacon, 2009a, 2009b).
Existing studies have shown that EAS listeners achieve significantly higher speech recognition scores than when using their CI alone across various listening environments (Gifford et al., 2013, 2017). However, these studies used sentence materials presented at a normal and fixed speech rate. In reality, speech rate varies dynamically depending on individual talkers, emotions, and speaking styles (Miller et al., 1984; Shen et al., 2023; Yuan et al., 2006). When speech rate increases, our results indicate that, compared to listening to E-only signals, listeners can utilize additional cues provided by the acoustic signal in the EAS condition, allowing for greater tolerance to faster speech. It is worth noting that EAS listeners perceive acoustic signals that are amplified by HAs based on their specific hearing loss configurations. Even if some patients may achieve aided thresholds close to or within the normal hearing range (≤ 20 dB HL), their ability to utilize LF acoustic cues may not be as effective as that of NH participants in this study, who listened to purely low-pass filtered signals. As a result, the benefits of LF acoustic hearing for processing fast speech in actual EAS listeners may be smaller than those observed in the present study.
The Negative Impact of Temporal Misalignment: Experiment 1
Experiment 1 demonstrated that temporal misalignment, within a range of ±30 ms, significantly affected listeners’ TCTs in both quiet and noise, consistent with our hypothesis. As the delay between the acoustic and simulated electric signals increased, listeners’ TCTs decreased significantly. Post hoc analysis revealed that TCTs at a delay of ±15 ms were significantly lower than those at 0 ms in both quiet and noisy conditions. The finding that temporal misalignment significantly reduces listeners’ TCTs is consistent with previous research demonstrating a clear link between speech processing abilities across different speaking rates.
Speech recognition abilities at a normal speech rate are correlated with the ability to perceive faster speech (Gransier et al., 2022; Meng et al., 2019). Meng et al. (2019) showed that unilateral CI listeners’ TCTs in quiet were significantly positively correlated with their normal-rate speech recognition scores in both quiet and noise. Gransier et al. (2022) similarly showed that SRTs for time-compressed speech in quiet at multiple fixed speech rates were significantly correlated with those for normal-rate speech in noise. These findings suggest that similar underlying auditory processing limitations affect a listener's capacity for both normal-rate and faster speech recognition. In order words, listeners who perform well at a normal speech rate tend to have a better ability to perceive faster speech, and vice versa.
Using sentences from MHINT at their original rate, Wu et al. (2020) have shown that temporal misalignment at ±15 ms can negatively impact speech recognition scores in SSN and 2-talker babble noise among listeners with simulated EAS hearing. Following the logic that similar auditory processing limitations underpin speech processing ability at different rates, it is logical that temporal misalignment, a factor known to degrade normal-rate speech perception, also significantly impairs listeners’ tolerance for time-compressed speech. This may be attributed to the smearing of crucial auditory cues and the distortion of across-frequency timing cues, which are essential for robust speech processing at all rates.
Experiment 1 also revealed a significant interaction between temporal misalignment and SNR. At higher SNR levels, the negative impact of temporal misalignment on listeners’ TCTs was significantly greater in both stationary and modulated noise. The reduction in TCT due to increasing delay was more pronounced in quiet than in noise. As the quiet condition represents an infinite SNR, the greater negative impact of temporal misalignment at higher SNRs is consistently demonstrated across our data.
One possible explanation is that temporal misalignment introduces greater distortion at higher speech rates. At higher SNRs, where task difficulty is lower, listeners can extract more useful speech information, allowing them to tolerate faster speech. This is supported by higher TCT at 10 dB SNR compared to 4 dB SNR in the absence of temporal misalignment. However, for the same amount of delay, the temporal misalignment spans more phonetic units as the speech rate increases. As shown in Figure 1, spectrograms of EAS-simulated sentences with a 15 ms delay demonstrate that temporal misalignment between low and mid-to-high frequency components affects a larger portion of phonemes when the sentence is time-compressed. This suggests that listeners may require greater effort to resolve across-frequency timing distortions, which could explain the significantly greater impact of temporal misalignment at higher SNRs.
The Negative Impact of Temporal Misalignment: Experiment 2
When temporal misalignment was limited to ±7 ms in Experiment 2, no significant main effect on listeners’ TCTs was observed in quiet and in SSN at 10 dB SNR. Given the findings from Experiment 1, where the effect of delay was more pronounced at higher SNRs, it is likely that temporal misalignment would also remain insignificant in more challenging noisy environments, such as at an SNR of 4 dB.
It is worth noting that our study measured TCT, which corresponds to the speech rate at which listeners recognize only half of a sentence. In real-life communication, where listeners must understand a larger portion of speech for fluent conversations, the effective speech rate is lower. Participants in this study achieved TCTs more than twice or even three times the speech rate of MHINT sentences (4.97 syl/s), whereas everyday speech is generally slower. Given these factors, it is reasonable to suggest that the impact of a small temporal misalignment (e.g., within ±7 ms) on speech recognition may be minimal in daily listening scenarios. This speculation aligns with previous findings obtained from real EAS users, which indicated that the timing differences between acoustic and electric stimulation within one ear in the typical ranges (up to 6 ms) for commercial devices have no significant influence on speech perception (Geißler et al., 2015). Nevertheless, as our findings were derived from a simulated EAS condition rather than data from real EAS users, the apparent agreement should be interpreted cautiously.
The Effect of Noise Type on TCTs
Experiment 1 showed that noise type had a significant effect on listeners’ TCT. The TCT in AMN was significantly lower than in SSN. This suggests that the potential benefit of glimpsing speech in the temporal dips of AMN is diminished at higher speech rates. Although this appears to run counter to the common assumption that glimpsing generally improves speech recognition in fluctuating noise (Cooke, 2006), our findings are consistent with specific previous research.
For example, Grose et al. (2009, 2015) found that when sentences were time-compressed to 33% of their original duration, listeners’ SRT deteriorated significantly more in modulated noise than in steady-state noise. This suggests that an increased speech rate imposes greater constraints on speech recognition in modulated noise than in stationary noise. Even though our study employed a fixed SNR and an adaptive speech rate procedure, while Grose et al. (2009, 2015) used fixed speech rates and an adaptive SNR procedure, we found consistent results showing that listeners are less tolerant of faster speech rates in modulated noise.
This result is likely due to the reduced intelligibility of glimpsed speech content at higher speech rates. In our study, speech rate modification occurred before the addition of noise. While a higher speech rate provides more opportunities to glimpse speech content within the unchanged duration of temporal gaps, the intelligibility of these glimpsed segments is concurrently reduced. Our data, therefore, suggest that the negative effect of a higher speech rate on glimpsed speech intelligibility outweighs the benefits of glimpsing more speech content, leading to lower TCTs in AMN compared to SSN.
The Effect of Repeated Measurements on TCTs
In this study, TCT was measured twice for each condition. Experiment 1 showed that the TCT in noise measured in the second trial was significantly higher than that in the first trial, suggesting a short-term improvement in performance, possibly reflecting rapid adaptation or procedural learning effects. Similar short-term improvements have also been reported in previous research (e.g., Schlueter et al., 2016), where both young NH adults and listeners with hearing loss demonstrated the largest SRT improvement on time-compressed sentences within the first measurement.
Repeated measurements did not show a significant interaction with delay, but visual inspection of the data suggested that improvements were more pronounced in delayed conditions (Figure 5). However, our experimental design was not specifically structured to investigate the effects of training, making it unclear if the observed adaptation truly mitigated the negative effects of temporal misalignment. This ambiguity arises from two potential factors.
On one hand, the greater improvement observed in the delayed conditions relative to that in the aligned condition could be due to the practice trial design. The practice trial at 0 ms condition, which was conducted before the formal block, may have been sufficient to familiarize listeners with the task and thus exhausted the potential for further improvement in that condition. As a result, the improvements in the delayed conditions appear more pronounced by comparison.
On the other hand, the improvement seen in the delayed conditions might not reflect the maximum possible gain from the learning effect. Listeners were exposed to materials with varying delays between trials of the same condition, meaning the observed improvement likely comes from a combination of specific adaptation and generalized learning. Given that generalization effects are often smaller than direct learning effects (Banai & Lavner, 2014), it is plausible that dedicated training for a specific delay condition could have yielded a much greater improvement. Furthermore, long-term training over multiple sessions might offer additional benefits beyond brief exposure. Therefore, future research could explore whether specific and long-term training can effectively reduce the negative impact of temporal delay on speech recognition.
Limitations
There are several limitations to this study. First, our study utilized an algorithm that uniformly compressed speech without altering its pitch. In contrast to this uniform manipulation, natural fast speech production involves talker variations and changes in acoustic characteristics, such as pause, vowel, and consonant duration (Kuwabara, 1997). Consequently, listeners’ performance with the time-compressed speech used here may not be directly comparable to their performance with naturally produced fast speech. Second, due to a significant number of test conditions and the limited availability of test materials, we were unable to include all critical factors as within-subjects variables. As a result, key parameters, such as noise type and SNRs in Experiment 1 and the simulated electric signal leading or lagging in Experiment 2, were designated as between-subjects variables. Thus, the observed effects of these factors might have been influenced by individual differences among the subject groups. Third, our findings were obtained under specific conditions using SSN and AMN at 8 Hz with full modulation depth. Given the complex, dynamic, and variable nature of noise in everyday listening environments, caution should be exercised when generalizing these noise-related findings. For example, the opportunities for listeners to take advantage of glimpsing in single- or multi-talker babble would differ from those in the present study, which may alter the observed effects of temporal misalignment compared to SSN. Future research should consider more representative noise conditions to better understand real-world listening challenges.
Additionally, this study simulated EAS hearing in NH listeners by using a low-pass filter and a noise vocoder. While this approach has been used in previous studies (Chen & Loizou, 2010; Fu et al., 2017; Yoon et al., 2021) to avoid uncontrolled variables related to the etiology of EAS patients, it is important to acknowledge the potential differences between our simulated scenario and the real patient population. Specifically, our simulation did not account for several critical factors. First, we were unable to incorporate patient-specific auditory characteristics such as varying degrees of residual hearing and neural survival on the cochlear side. Second, our model also fell short of fully replicating the complexities of both HA and CI signal processing. For example, it did not factor in the non-linear amplification and the potential venting effect of HAs that restrict access to very low-frequency sounds. Furthermore, the simulation of electric signals only represented a single parameter setting, which cannot fully capture the variety of electrode designs, frequency allocations, dynamic ranges, or potential frequency mismatches present in real world. Therefore, caution is needed when generalizing these findings to the patient population.
Conclusion
This study investigated the effect of temporal misalignment between acoustic and simulated electric signals on TCTs in two experiments with normal-hearing participants. Experiment 1 demonstrated that listeners benefited from the addition of low-frequency acoustic signals, showing improved TCTs compared to listening to simulated electric signals alone, regardless of temporal misalignment between the signals. Within the range from 0 ms to ±30 ms, temporal misalignment decreased listeners’ TCTs, and its effect interacted with SNR such that the adverse impact of misalignment was more pronounced at higher SNR levels. When temporal misalignment was reduced to within ±7 ms, closer to a clinically relevant range, its effect on TCTs disappeared. In conclusion, temporal misalignment impairs the ability of listeners with simulated EAS hearing to process fast sentences in Mandarin, but this impact becomes negligible when misalignment is close to a clinically relevant range. Future research should validate these findings among real EAS listeners.
Footnotes
Acknowledgments
The authors would like to thank all the participants who participated in this study. We also thank the editor and anonymous reviewers for their constructive feedback and insightful comments, which have significantly enhanced the clarity and rigor of this manuscript. This work is part of the first author's PhD project.
Ethical Considerations
This study was approved by the Human Research Ethics Committee (HREC) at the University of Hong Kong (approval no. EA230257) on July 10, 2023.
Consent to Participate
All participants provided written informed consent prior to participating.
Informed Consent Statements
All participants provided written informed consent prior to participating.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Key Research and Development Program of China (2023YFF1203502), and the National Natural Science Foundation of China (62371217).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The data that support the findings of this study are available from the corresponding author upon reasonable request.