
Abstract
The perceived numerosity of simultaneous, spatially separated speech sources was used to evaluate the effectiveness of triple beamformer processing, compared to that of both a single-channel beamformer and natural listening. Participants made judgments of the total number of talkers present in a simulated sound field and the gender composition of the talker group. The perceived numerosity was always underestimated for groups of more than three talkers. Performance with the triple beamformer was roughly equivalent to that of natural listening, including a beneficial effect of spatial separation of the sources in azimuth. The gender mix of the talker group also affected the numerosity judgments although the perceived gender ratio was generally accurate even when the total group count was underestimated. Time-reversing the speech resulted in lower numerosity judgements (increased error) under both natural and triple beamformer listening, suggesting an influence of linguistic processing on source numerosity judgments. Overall, factors that enhanced source segregation and speech stream coherence decreased errors in numerosity judgments. A stimulus-derived metric—the composite of glimpsed energy retained for all talkers in the sound field—was found to be a reasonably accurate predictor of the subjective numerosity judgments.
Introduction
Although improving the recognition of speech from a single, “target” talker in a mixture of competing “masker” talkers is perhaps the most desirable outcome of a hearing aid algorithm, preserving the ability to decipher information about unattended sources of sound may also be quite important to the listener. This ability is key, for example, to determining when attention should be redirected from the current target source to another source or, more generally, simply informing the listener of the composition of events occurring in the sound field. In a room filled with voices, determining how many people are present, their locations and characteristics, may provide important context for social interactions and facilitate effective communication (e.g., Best et al., 2017a; Villard & Kidd, 2021; Yun et al., 2021).
A highly spatially-tuned (in azimuth) acoustic beamformer has been shown to provide an effective means for enhancing source segregation in multitalker “cocktail-party problem” listening situations (e.g., review in Kidd, 2017). The benefits of a sharply-tuned, single-channel beamformer focused on one talker (the target) in the midst of spatially distributed, competing talkers (maskers) may be substantial in some conditions (e.g., Best et al., 2017c). However, the gain in the selective amplification of the target source and the effective attenuation of competing sound sources has the drawback of reduced awareness and diminished perception of the characteristics/features of non-target sources in the sound field when they lie outside the “acoustic look direction” (ALD) of the beamformer.
In an attempt to mitigate these disadvantages of a single-channel beamformer, while retaining the benefit of enhancing the target-to-masker ratio (TMR), a 3-channel beamformer was developed, implemented in software, and tested in a variety of listening contexts (Jennings & Kidd, 2018; Kidd et al., 2020). This “triple-beam” composite beamformer is an experimental hearing aid processing algorithm which consists of three separate inputs to the listener derived from a 16-microphone array mounted on a headband across the top of the head (Kidd, 2017), thus the triple beamformer differs in some fundamental ways from a more traditional beamformer with a single-channel output. Although single-channel beamformers can improve the TMR for spatially separated sound sources (e.g., Doclo et al., 2008), source localization performance may be compromised (e.g., Kidd et al., 2020; Yun et al., 2021). However, it has been shown that the triple beamformer tested by Kidd et al. (2020) may provide the benefit of improved TMR while preserving some of the spatial cues necessary for accurate source localization outside of the ALD. This more complex beamforming approach is a result of routing one microphone output—the one aimed at the target—diotically to both ears, along with two additional channels directed to the left and right hemifields and routed only to their respective ipsilateral ears.
Using normal hearing (NH) participants, Kidd et al. (2020) investigated the effects that various triple beamformer configurations had on performance—using head-related transfer functions (HRTFs) and headphone-based presentation—for both a speech-on-speech (SOS) intelligibility task and a speech source localization task. The results were compared to performance with a single-channel beamformer in addition to natural listening (also simulated via HRTFs; see below). Kidd et al. found that the use of a triple beamformer could be beneficial for either task; however, different side-beam microphone angles produced different results: SOS intelligibility (with spatially separated maskers) was improved the most for smaller beam separations, similar to that of the single-channel beamformer, while larger side beam angles improved source localization performance the most, approximating that found in natural listening.
Yun et al. (2021) observed comparable triple beamformer results using similar experimental designs (side beam angles of ±40°) while testing both bilateral cochlear implant (CI) subjects and NH controls presented with vocoded stimuli. Even with the degraded signals that result from the CI/vocoded stimuli, the triple beamformer afforded some benefits to performance. For example, source localization with the triple-beam was comparable to that of natural listening, with response errors typically about 30° regardless of source angle. In contrast, errors for the single-channel beamformer were as much as 90°, and the sources often were reported at 0° azimuth even for the largest deviation from midline (i.e., 90°). Slightly smaller differences were found in speech intelligibility between the two beamformer conditions, with speech recognition thresholds (SRTs) for the triple-beam 6-dB higher (poorer) than for the single-beam (when the speech maskers were ±90° from the target speech), although the SRT for triple-beam was still 13 dB lower (better) than for natural listening.
In an attempt to roughly gauge the benefit of triple-beam for monitoring sources outside of the ALD of the center beam, Yun et al. also asked their subjects to count and report the number of distinct speech sources that were present in the sound field (assessing source “numerosity”); however, this was not the main purpose of the study and the empirical conditions tested were quite limited. For example, in addition to only a ±40° separation of the side beams, there were only two numbers of sources actually tested in the experiment—one or three—and the subjects were not informed of the possible number of sources during testing. Although triple-beam appeared to provide an advantage compared to single beam, large individual differences in performance occurred in all conditions and in some cases interpretation of the subjective judgments was difficult. Thus, although the triple-beam algorithm appeared to provide a benefit for tasks related to monitoring the off-axis sources in a complex sound field, the relevant empirical results from those tasks were limited and did not support strong conclusions.
More generally, obtaining a better understanding of the factors that influence the perception of the number and characteristics of the sources comprising a complex auditory scene has been of increasing interest over the past decade. (Refer to Kwak and Han (2020), for a recent review.) In terms of accuracy in judging source numerosity, Kawashima and Sato (2015) found that the maximum number of speech sources that reliably could be perceived was between 3 and 5, depending on the specific stimulus conditions, and that this limit occurred for both sound-field and headphone-based stimulus presentation. (Refer to Santala and Pulkki (2011), for similar sound-field work with different types of noise stimuli.) Numerosity judgments tended to be more accurate as speech duration increased and as the spatial separation between sources increased. When all talkers were of the same gender, numerosity judgment accuracy was poorer (i.e., underestimated for N > 3) than when the talker group was mixed gender with either an equal number of each gender or was only unequal in number by one. Because segregating talkers—as inferred from masking results (cf., Kidd et al., 2016)—is easier when perceived genders differ, this finding suggests that judging numerosity becomes more accurate as the strength of source segregation increases.
Later work by Zhong and Yost (2017), employed a source localization task in addition to numerosity judgements. Confirming the findings of Kawashima and Sato (2015), they reported that the average asymptote for perceived numerosity for speech sources was around four. Yost et al. (2019) found that discrimination of increments in talker group number did not greatly differ for a standard of more than four sources, and that judgments could be predicted by the overall level of the sources in the sound field. In addition, Yost et al. (2018) found that loudness judgments for multiple talkers were based on the levels of the individual sources for a standard of fewer than four sources; however, when the standard was four or more talkers, loudness judgments were based on overall level. These findings indicate that a potential confound may be present in controlled psychoacoustic experiments intended to assess numerosity per se and forms one of several stimulus-based cues that could be used to solve source counting tasks.
Higher asymptotes for the total perceived number of talkers, however, have been reported using different, potentially more complex, experimental designs. Weller et al. (2016) found that group mean numerosity values (for listeners with NH) approached six sources when tested with a reverberant room simulation in a sound field setting when the participants could freely move their heads during long (45-s) stimulus presentations (as opposed to stationary head position used during the aforementioned studies). In addition, Weller et al. found that, for participants with varying degrees of sensorineural hearing loss, numerosity judgment performance was poorer than NH and was negatively correlated with hearing loss. This finding raises the question of whether hearing aids could play a role in improving the accuracy of judgments of source numerosity.
In the Weller et al. study secondary judgments of talker gender were obtained, but only as an aid to scoring listener responses. However, because gender mix can affect numerosity judgments (Kawashima & Sato, 2015), it raises the question of how the perceived gender makeup influences the perceived total number of talkers in an auditory scene. As suggested above, the more distinct the sources sound, the more likely a listener is to perceptually segregate and/or discriminate sources. However, the improved segregablility of mixed gender sources in a group of talkers does not directly address whether the listener can estimate these mixtures. This leads to the question of whether listeners can accurately judge the gender composition of the group of talkers, that is, what is the proportion of male to female voices?
The primary aims of the present study were (a) to obtain a better understanding of the factors that underlie numerosity judgments of speech sources in complex auditory scenes and (b) to assess how well listeners could judge the gender composition within the groups of talkers. These factors include not only the gender distribution of the talkers in a group but also certain stimulus properties like overall level or broadband envelope characteristics that may, if not taken into account, afford cues to solving numerosity tasks in ways that could be antithetical to the intent of the study. Furthermore, we aimed to (c) evaluate the extent to which the triple beamformer algorithm affects/enhances these numerosity and gender judgments relative to a single-channel beamformer and to compare it with the performance obtained with natural binaural hearing. Finally, we (d) evaluate several stimulus-derived metrics for their accuracy in predicting observed human performance, as part of the goal of better understanding the basis for these perceptual judgments.
Methods
Participants
Eight NH individuals participated in the current study, including the first author; the other listeners were paid volunteers. The participants identified as being five females and three males, with an age range of 19–43 years (M = 27.1, standard deviation [SD] = 7.1). All listeners had NH based on pure-tone thresholds of 20 dB hearing level or better at octave frequencies from 250 to 8,000 Hz. In-lab audiograms were measured for all participants prior to online testing (see below) to screen for any hearing impairments. English was reported as the first and primary language for all participants. Experimental research procedures were approved by the institutional review board of Boston University, and all participants gave written informed consent prior to participating.
Stimuli and Procedure
The stimuli used in the present experiment were similar to that of Kidd et al. (2020) and were drawn from a speech corpus typically used for closed-set matrix-style speech identification tasks. All stimuli consisted of five-word sentences with the syntactic structure of: name, verb, number, adjective, and object (e.g., “Bob saw three red shoes.”) The speech corpus (refer to Kidd et al., 2008) was recorded from eleven male and eleven female talkers and included the natural production of eight exemplar words in each syntactic category. For each experimental trial, two to seven talkers were randomly selected from the corpus options. Talker gender was randomized in such a way that there was ultimately a balance between different gender mixes within a block. For instance, for a total of 4 sources, there were equal probabilities of having all four sources be of the same gender, two of each gender, or only one of the four being different (despite the probabilities of each being different with truly random selection). This quasi-random approach was used to equate the data set across the variables of interest. Sentences were constructed for each talker such that the words spoken were mutually exclusive. The beginning of the first word of all sentences was time-aligned across the talkers while the subsequent words were not time-aligned due to natural differences in word duration across talkers.
Each individual word was normalized in root-mean-square (RMS) prior to sentence construction. The level of each complete sentence (i.e., talker or auditory source) was then set to be between 50- and 55-dB sound pressure level (SPL), chosen randomly from a rectangular distribution, prior to processing based on microphone configuration (described below). Due to the use of remote testing—described in the next section—the accuracy of SPL values was not guaranteed; however, the relative levels between sources were known.
Each sentence was processed using the same types of microphone conditions used by both Kidd et al. (2020) and Yun et al. (2021). For “natural” listening, non-individualized HRTFs (obtained from Gardner & Martin, 1994) created from a Knowles Electronic Manikin for Auditory Research (KEMAR; G.R.A.S. Sound and Vibration, Holte, DK) were used to generate binaural channels for the stimuli. For both the single-channel beamforming condition (referred to as BEAM), and the triple-beam conditions (designated TRIPLE), the stimuli were convolved with impulse responses obtained from a microphone array mounted on a flexible circuit board spanning the top of the head of a KEMAR manikin (cf., Kidd, 2017; the impulse responses used for the beamformer conditions were obtained by the Sensimetrics Corporation (Malden, MA)). For the BEAM condition, the single-channel amplification was created by applying the beamforming algorithm to the stimuli with an acoustic look direction of 0° azimuth and creating diotic stimuli. For the TRIPLE conditions, three acoustic look directions were computed and applied to the stimuli with the result being three separate channels of amplification focused at three different azimuths. In addition to the beam focused at 0° azimuth and routed diotically to the listener, two additional (symmetric) beams of either ±30° or ±90° azimuth were created. The beam focused to the left side was routed only to the left ear of the listener while the beam focused to the right side was routed only to the right ear. These two conditions are referred to as TRIPLE 30 and TRIPLE 90 in the sections that follow. (For more details on the creation of the impulse responses used in these microphone configurations, as well as analyses of their output properties, refer to Sect. II.D of Kidd et al. (2020).) Upon selection of one of the four microphone conditions, the talkers for each experimental trial were set as any one of seven azimuth positions: 0°, ±30°, ±60°, ±90°. The source locations were chosen at random, with the only limitation being that there could be no more than two sources at the same location.
The participant was asked to indicate how many talkers were presented by selecting from the numbers 1–8 which were displayed on a graphical user interface (GUI). After this selection, a second query asked how many of a specified gender made up the group, with the numbers 0–8 as options. The gender for the secondary response was chosen randomly on each trial in order to discourage participants from focusing solely on only one gender when listening to each talker group. No correct answer feedback was given for either the primary or secondary responses.
Each microphone condition was tested separately with blocks of 24 trials. There were four samples for each possible number of total talkers presented, with the trial order being randomized. The complete experiment consisted of 20 blocks, with five blocks per microphone condition, with the block order also randomized. Participants ran the experiment self-paced, but typically over the course of two 1-h sessions.
Remote Testing Considerations
A remote testing platform, which had been previously validated (Byrne et al., 2022), was used to gather all of the present data. Listeners participated in the experiment from their own homes using personal computers and headphones. Each listener signed an online “Attestation of Low-Noise Distraction-Free Testing” agreement prior to beginning the experiment, agreeing to perform the tasks in a quiet and distraction-free environment.
The experiment was created in MATLAB (MathWorks, Natick, MA) and was compiled as a “Web App” to run on a Microsoft (Redmond, WA) Windows 2019 Virtual Machine (VM) using MATLAB Web App Server software. Participants accessed the experimental GUI over the Internet using whichever browser software that they preferred. On each trial, an uncompressed binaural WAV file with a 44100-Hz sampling rate was generated on the VM and was then presented to each participant through their own computer audio hardware. The different models of headphones used by each listener were: Apple (Cupertino, CA) AirPod Pro (used by two listeners) and EarPods, JLab (Carlsbad, CA) Studio Wireless, Sennheiser (Wedemark, Germany) HD 280 Pro, Sony (Tokyo, Japan) MDR-EX15LPW (used by two listeners) and MDR-V6. The specific hardware configurations of each participant (e.g., sound cards, audio enhancement settings, wireless compression protocols) were unknown.
In order to assess the quality of headphone spatialization, using the different remote setups and the non-individualized HRTFs of the KEMAR condition, a brief azimuth discrimination task was performed by each participant prior to data collection. For this test, only single words, randomly chosen from the speech corpus described above, were spatialized. All listeners were able to achieve greater than 95% accuracy (data not presented here) for discriminating 0° azimuth from ±5°, ±10°, and ±20°.
Overall level calibration for each new experimental session was set by the individual participants using presentation of sample speech. The audio samples were labelled: “loud voice (80 dB),” “normal conversation (60 dB),” and “quiet voice (40 dB).” Participants were instructed to adjust their computer volume until the samples of audio were subjectively matched to the descriptions. One must assume that participants were not able to adjust the “60 dB” speech to be truly 60 dB SPL; however, this method of calibration had been successfully used in Byrne et al. (2022) and allowed for the quietest stimuli to be clearly audible, while keeping the loudest stimuli within comfortable limits. The 40-dB range for the calibration stimuli was also considered more than adequate for testing the range of overall levels for speech which could occur in the present experimental task.
Results
Overall, the trends for judgments of numerosity in the present experiment were consistent with those from the previous research described above. As shown by the group mean data of Figure 1, the perceived number of talkers was less than the actual number once more than three talkers were present regardless of the microphone condition. Furthermore, the error due to underestimating the number of sources increased as more sources were present (i.e., diverges more from the dashed line in Figure 1). Among the different microphone conditions, the most accurate judgements of source numerosity were found for the KEMAR and TRIPLE 90 conditions—which past work (described in an earlier section) has found to provide more accurate localization performance—with the differences across conditions increasing as the number of sources increased. The errors in judging the number of talkers were greater for the TRIPLE 30 condition and, particularly, for the BEAM condition where sources typically do not sound spatialized. The ordering of the functions across conditions generally resembled the pattern of localization performance observed in Kidd et al. (2020), for similar listening conditions. This observation is consistent with the proposition that source counting is facilitated by spatialization of sources combined with high localization accuracy in multiple-source environments. However, even BEAM permitted the differentiation among numbers of talkers and yielded a pattern of results qualitatively similar to the conditions with binaural cues. As discussed in following sections, multiple acoustic cues are available for all microphone conditions, complicating the interpretation of numerosity judgments.
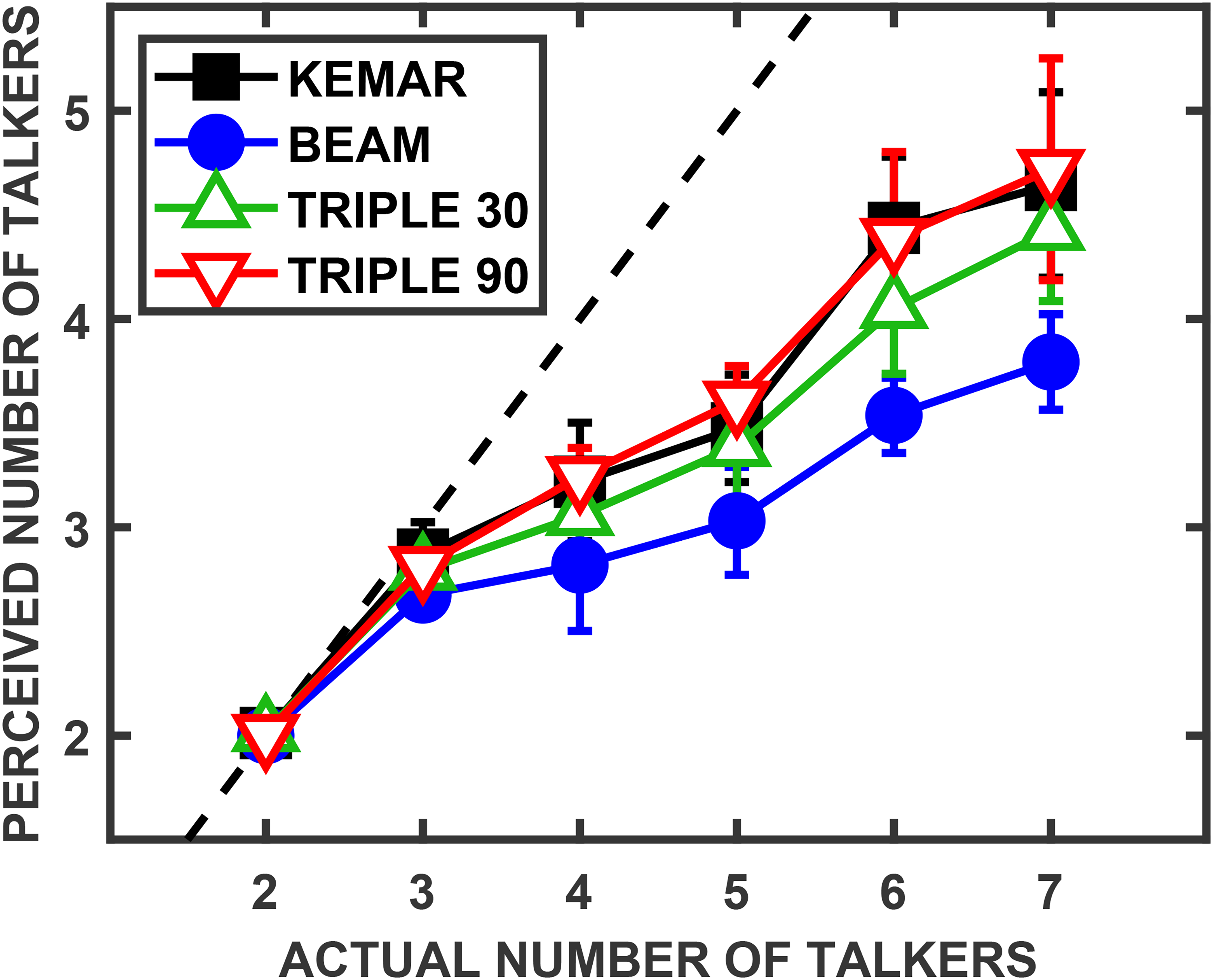
Group mean (N = 8) results for the perceived number of talkers plotted as a function of the actual number of talkers that were presented, with different functions/symbols for different microphone configurations. For this, and all subsequent figures, error bars represent the standard deviations (SD) of the means. (Note the difference in range of the X and Y axes, with the dashed line illustrating where the perceived judgments would match the actual number present.)
Given the procedure and number of blocks used, each participant had 20 numerosity judgments for each point shown in Figure 1, which were averaged within subject before computing the plotted group means and standard deviations. A 4-by-6 repeated-measures analysis of variance (ANOVA) confirmed that both the microphone configuration (KEMAR, BEAM, TRIPLE 30, and TRIPLE 90) [F(3,21) = 32.9, p < .001] and the number of talkers (2–7) [F(1.9,13.4) = 195.0, p < .001] were significant main effects affecting the perceived number of talkers, as was the interaction of the two factors [F(4.9,34.4) = 10.0, p < .001]. (For this and all subsequent ANOVAs, Mauchly's test of sphericity was performed. In cases where the assumption of sphericity were not met (p < .05), the Greenhouse–Geisser corrected ANOVA results are presented.)
There was also a clear effect of the gender mix, as evidenced by Figure 2. There was an increase in overall numerosity judgments (less error) as the gender mix was increased to be more evenly balanced, similar to that which was observed by Kawashima and Sato (2015). In the present study, though, there was a finer gradient of gender mixes tested than had been used previously. There were no clear differences between microphone conditions (not shown here), other than the overall shifts in judgments shown in Figure 1; therefore, for the purpose of Figure 2, the data from all four conditions were pooled. The effect of gender mix likely reflects better source segregation due to perceived differences in voice, i.e., the use of fundamental frequency or vocal tract resonance differences to strengthen source segregation.

(Top panel) The perceived number of talkers given different talker gender mixes (different functions/symbols), for all four microphone conditions pooled together. (Bottom panel) The proportions of talkers that were labelled as female by the listeners (black circles). As a reference, the gray square functions represent the actual gender ratios.
A 2-by-6 repeated-measures ANOVA revealed that two levels of the gender mix (same gender vs. 1 different) [F(1,7) = 36.3, p < .001] and the number of talkers (2 to 7) [F(2.2,15.2) = 146.4, p < .001] were significant main effects, as was the interaction of the two factors [F(5,35) = 7.74, p < .001]. For 7 total talkers only, post hoc t-tests found significant differences between the presence of 2 different gendered talkers compared to only 1 different [t(7) = 5.61, p < .001], as well as between 3 different compared to only 2 [t(7) = 4.11, p = .002], but there was not a significant difference between 1 different gendered talker and all talkers of the same gender [t(7) = 1.87, p = .052]. (The Bonferroni-corrected criterion for significance was α = .017 for this family of post hoc tests.)
Regarding a possible gender bias, there was a small tendency towards underreporting male talkers, as can be seen by the slightly upward skew of the gender ratio functions (black symbols) in the lower panel of Figure 2 relative to the underlying distributions (gray symbols); however, this trend was not consistent across subjects and was not significant. [A post hoc 4-by-6 repeated-measures ANOVA was performed for the number of missed talkers. Neither microphone configuration, F(3,21) = 1.74, p = .19, the number of talkers, F(5,35) = 2.26, p = .07, nor the interaction, F(15,105) = 0.11, p = .34, was significant.]
Although not perfectly aligned, the empirically observed gender ratio judgments were actually quite similar to the actual gender ratios present in the stimulus (Figure 2, lower panel). For instance, for a total of 7 talkers with 4 being female (i.e., 57.1% female), listeners responded on average that 55.7% (SD = 4.9%) were female, despite judging the total number of talkers as only 4.4 (on average) across all 4 microphone conditions. Therefore, the gender ratio was estimated accurately despite underestimating the total number of talkers.
Given that the different microphone configurations and the degree of source separation used in the present study previously had been shown to yield differences in performance for localization (Kidd et al., 2020) and numerosity judgments (Kawashima & Sato, 2015; Zhong & Yost, 2017), the present results were analyzed according to the distribution of the talkers over the range of possible azimuths. Figure 3 shows the perceived number of talkers as a function of the average separation in azimuth between talkers (referred to as the “mean talker spacing”). The three panels show results for three different numbers of talkers (reading top to bottom): 3, 4 and 5. The parameter of the graph in each panel is microphone conditions. Note that the range of average separations varies with the number of talkers and the constraints placed on colocation of sources (i.e., maximum of two talkers at any location). In most cases shown, except for KEMAR with four talkers, the microphone conditions providing binaural cues yielded significant positive correlations, i.e., the perceived number of sources increased as the sources were increasingly separated in azimuth. For the BEAM condition, none of the correlations between these two variables were significant, as might be expected given the lack of binaural cues for that condition. (The correlation statistics supporting these observations are presented in Table 1). For a total of 6 or 7 talkers (not shown here), the range of possible mean talker spacing was reduced even further and no significant correlations were found for any of the microphone conditions.

The perceived number of talkers as a function of the mean talker spacing in azimuth (i.e., spatial density) for different numbers of talkers (different panels show 3, 4, and 5 talkers, from top to bottom).
Correlation statistics for the functions shown in Figure 3 (perceived numerosity as a function of average source separation in azimuth).

Asterisks indicate significant (p < .013) findings after applying a Bonferroni correction.
Predictors of Numerosity Judgments
It is a reasonable assumption that the present numerosity judgments reflect the ability of a listener to segregate the various streams of speech and then explicitly count them or perhaps count the separate sources based on glimpses of the different voices. That is, when one voice is heard over the others even for a few brief moments and for only part of the speech stimulus, the listener may perceive and note the distinct voice and add it to the sum of sources heard. In such a case, presumably, the stronger the properties that distinguish the voices, the easier it would be to count them. Alternatively, it is possible that a general impression of numerosity based on past experience with the acoustic properties of various types of speech mixtures may yield accurate estimates without explicitly registering each individual source. However, in addition to these hypothetical numerosity strategies, the experimental controls typically put in place for psychoacoustic experiments also could create cues that may be used to solve the experimental task. A good example of a typical psychoacoustic control that could lead to accurate numerosity judgments is equating the different speech sources in level prior to mixing the stimuli. Such a control may potentially yield a viable cue to numerosity based on the perceived loudness of the speech mixture (cf., Yost et al., 2019). Another example is the change that occurs in the amplitude envelope as speech sources are combined; many voices mixed together tend to smooth the broadband envelope relative to a small number of talkers potentially providing a discernable acoustic cue that correlates with the number of talkers present. Although it is impractical to attempt to relate our data to all possible cues for numerosity, here we examine a few that seem plausible.
In an effort to predict the trends in perceived numerosity across conditions, three different metrics were calculated based on the stimuli that were presented in this experiment. The trial-by-trial stimuli were analyzed to determine: (a) the overall level of the stimuli; (b) the smoothness of the composite envelope; and (c) the amount of spectrotemporal energy for each talker that was not masked by competing talkers (i.e., “glimpses”; detail below) computed for each talker separately and then summed.
The first metric tested, overall level, was simply the RMS of the summed binaural channels on each trial and was motivated by the Yost et al. (2019) finding noted above that numerosity discrimination largely could be accounted for by level (when adding together equal-level sources). However, in the current experimental design, the stimulus level was affected both by the talker level rove (described in the methods section) and by the location in azimuth of each individual source. For the BEAM and TRIPLE conditions, talker level—when presented to the participants ear—depended on the azimuth relative to the placement of the directional microphones and could create a difference as large as 15-dB between different talkers. (For additional details, refer to the Appendix of Kidd et al., 2020.)
Numerosity judgments plotted as a function of the overall level of each trial (Figure 4, left panel) show nearly linear relationships within each microphone condition over a range of values; however, across conditions, there are differences in the ranges of overall level, in addition to differences in the slopes of the functions. (For the purpose of this plot and subsequent correlations, the overall RMS level was converted to dB and was grouped into bins of 1-dB width, an average numerosity value for each bin was computed for each individual subject, and then group mean trends were calculated across participants.) The correlations for these microphone condition functions were significant: KEMAR, r(46) = 0.80, p < .001; BEAM, r(88) = 0.48, p < .001; TRIPLE 30, r(87) = 0.65, p < .001; TRIPLE 90, r(65) = 0.77, p < .001. Thus, as the overall level increased the number of talkers reported by the listeners also increased; however, the slopes and ranges of the functions relating these two variables depended on the microphone condition.

(Left panel) The perceived number of talkers as a function of the overall level of the stimulus based on an analysis of all individual trials. (Right panel) Numerosity judgments as a function of the standard deviation of the composite stimulus envelope for each trial.
As noted above, another acoustic property that varies as the number of talkers increases is the smoothness of the broadband amplitude envelope; therefore, the composite envelope smoothness was evaluated as another possible predictor of perceived numerosity. Specifically, as the number of talkers increased the modulation of the broadband envelope decreased as competing talkers “filled in the gaps” between the words of the other talkers. The smoothness metric was derived from the waveform envelope (after a 3rd-order Butterworth filter, with a low-pass cutoff of 25 Hz) following the removal of the first 100 ms—eliminating the unwanted influence of the onset of voicing from quiet—as well the final 1 s of each channel which reduced artifacts due to any single voice extending beyond the others owing to a slower speaking rate. The resulting envelopes of both channels were then summed and the SD—normalized relative to the envelope mean (cf., Kidd et al., 1993; Richards, 1992)—was defined as the envelope smoothness of the trial, i.e., the smaller the value the smoother the envelope. While this metric would not account for envelope differences that occur across different auditory bands, it was deemed the most basic measure of smoothness for the purposes of predicting the overall results.
As may be seen from Figure 4 (right panel), the envelope smoothness functions appeared to have more consistency across microphone conditions than did the overall level metric (left panel), although the slopes still did vary somewhat between conditions. [The SD of the envelope was grouped into bins of 0.5 width for averaging. The correlations for envelope smoothness were significant: KEMAR, r(55) = 0.88, p < .001; BEAM, r(72) = −0.80, p < .001; TRIPLE 30, r(69) = −0.85, p < .001; TRIPLE 90, r(65) = −0.86, p < .001.] From these calculations, numerosity judgements also varied systematically with envelope smoothness with higher numbers of talkers reported for smoother envelopes.
The final predictor metric that was chosen was based on the amount of glimpsed energy that was retained for the stimuli. This was defined as the amount of “target” talker energy that remained after all spectrotemporal tiles for which “masker” talker energy is greater than that of the target were removed (Brungart et al., 2006; Wang, 2005). In order to compute this value for a group of talkers, each talker was considered as the “target” in turn and the other talkers considered “maskers” to obtained the glimpsed energy for that given talker.
Thus, for each talker on each trial, the binaural channels of only a single talker (temporarily designated as the target) were concatenated and analyzed using 128 logarithmically-spaced frequency channels, ranging from 80 Hz to 8 kHz, and 20-ms windows in the time domain, to create spectrotemporal tiles, with a 50% overlap between tiles (parameters used in previous research, e.g., Best et al., 2017b). The same process was repeated for the composite of the remaining talkers (temporarily designated as the maskers). Tiles for which the target energy was greater than the masker energy were retained, while those that were not were removed. The matrix of remaining spectrotemporal tiles was then resynthesized to create the glimpsed target, with the RMS compared to the original (non-glimpsed) target to derive the proportion of glimpsed target energy that was retained. This process was repeated for all of the talkers in the mix, separately designating each as the target.
As shown in the left-top panel of Figure 5, the average glimpsed energy retained for each individual talker decreased as the total number of talkers increased, as more energetic masking (cf., Kidd & Colburn, 2017) was present. It should be noted, however, that there was a difference between microphone conditions which became more pronounced as the number of total talkers increased. It was also observed that, when the energy retained for each individual talker instead was summed for a given trial (or by multiplying the average value by the number of talkers that were present), an ordering of functions emerged in the left-bottom panel of Figure 5 similar to that seen in the empirical results of Figure 1.

(Left, top panel) The average amount of glimpsed energy retained for an individual talker (see text) for each type of microphone condition as a function of the number of talkers. (Left, bottom panel) The summed amount of glimpsed energy retained after pooling the glimpsed energy of all talkers on a given trial. (Right panel) The perceived number of talkers as a function of the summed glimpsed energy retained based on an analysis of all individual trials.
When the perceived number of talkers was plotted as a function of the trial-by-trial summed glimpsed energy retained values (Figure 5, right panel), the numerosity judgments show orderly, linear relationships. Furthermore, the slopes of the straight-line fits were the most similar across microphone conditions of the predictor metrics examined. [The summed energy retained metric was grouped into bins of 0.25 width for averaging. The correlations for each of these functions were significant: KEMAR, r(104) = 0.90, p < .001; BEAM, r(82) = 0.86, p < .001; TRIPLE 30, r(101) = 0.88, p < .001; TRIPLE 90, r(120) = 0.91, p < .001.] Thus, the glimpsed energy metric also provided a robust predictor of perceived numerosity for the conditions tested here.
Because all three of these metrics were derived from the same stimuli, intercorrelations between the metrics were anticipated. So, in order to provide a better understanding of the relative strengths of these three predictors, a multiple-regression model was applied to the results. This analysis indicated that, as expected, the perceived number of talkers was accurately predicted from the combination of these three metrics: overall level, envelope smoothness, and summed glimpsed energy retained [F(3,3836) = 1528.2, p < .001, r2 = 0.54]. However, in terms of the variance accounted for by each metric, only summed glimpsed energy retained added significantly to the prediction (t = 51.7, p < .001), whereas overall stimulus level (t = 0.68, p = .50) and envelope smoothness (t = −0.09, p = .93) did not.
Although overall level was not expected to account for the results across all of the conditions tested here (and, in fact, the rove in level was intended to diminish the influence of this factor), it was somewhat unexpected that envelope smoothness did not contribute to the prediction, given the pattern of results in Figure 4. Upon further analysis, the lack of predictive value of both the overall level and envelope smoothness metrics may be understood by inspection of the underlying distributions of values of those metrics. In particular, there were overlapping distributions of those values for different total numbers of talkers that reduced the reliability of those metrics. For instance, when comparing 4 and 7 talkers, the difference between the distribution means for the summed glimpsed energy retained metric was 2.78σ (conservatively using the larger SD of the two distributions), i.e., the distributions of values for that metric were substantially separated and predictive. For both overall level and envelope smoothness, the distributions had considerable overlap and the means were separated by only 0.68σ and 0.53σ, respectively. Therefore, with all microphone conditions pooled together, the overall level and envelope properties vary too greatly to provide reliable cues for listeners to judge the number of speech sources.
Numerosity Judgments for Reversed Speech
The stimuli used in the current study differ in some important respects from natural conversational speech. The words were recorded individually with the talkers instructed to produce a consistent, moderate sound level with neutral intonation (described in Kidd et al., 2008). Sentence length materials, as used in this study, were created by concatenating the individual words drawn randomly from the eight exemplars in each syntactic category. While there are both advantages and disadvantages to this approach, one advantage is that it is straight-forward to time-reverse the speech on a word-by-word basis without affecting surrounding words to allow controlled comparisons of performance for intelligible vs. unintelligible speech. For example, time-reversing the individual words used in the current experiment causes only minor differences in many important acoustic properties of the stimuli, including the distributions of the three metrics discussed above. By comparing performance using the natural time-forward speech with that obtained after time-reversing the exact same speech on a word-by-word basis, it is possible to examine the hypothesis that certain linguistic factors (i.e., intelligibility and syntacticity) may influence perceived numerosity.
Past work has shown that voices can be discriminated and identified even with unintelligible time-reversed speech (e.g., Sheffert et al., 2002), although time-reversed speech maskers create much less informational masking in the identification of natural (time forward) speech (e.g., Kidd et al., 2016; Rennies et al., 2019). Thus, there is evidence of linguistic effects in multitalker scenarios that suggests the possibility of a role in numerosity and gender perception. Next, a follow-up experiment was conducted to determine whether the exact same speech presented naturally vs. time reversed influenced perceived numerosity.
Methods
Only KEMAR, BEAM, and TRIPLE 90 microphone processing were used, and the total number of sources could only be 3, 5, or 7 talkers. This subset of conditions was selected to reduce the time necessary to complete the task, as well as having the listeners run only 3 blocks per microphone condition (resulting in 12 trials per participant for each condition and number of sources).
Using this subset, a partial repetition of the first experiment was conducted with forward-speech blocks, while also being interleaved with reversed-speech blocks. For the reversed-speech trials, each individual word was time reversed (i.e., the syntactic order of the sentence remained the same), and all other stimulus variables were matched with a specific forward-speech trial. The number of talkers, individual talkers/genders, spatial positions, levels, and all words of the sentence were held constant across matched forward and reversed trials. The trial presentation order was randomized between matched blocks, and the block order was also randomized. With these exceptions, all other methodological details were identical to the previous experiment.
Seven of the subjects from the first experiment, not including the first author, participated in the reversed-speech experiment (five females, two males, 19–28 years of age). All listeners completed this version of the task after finishing the first experiment and used the same at-home experimental setup as they had previously. Participants ran the experiment self-paced, but typically over the course of a single 1-h session.
Results
To verify that the results from the first experiment were replicated using the reduced condition set (and one fewer participant), a 2-by-3-by-3 repeated-measures ANOVA was performed for only the forward speech conditions from both experiments. The ANOVA indicated no significant numerosity judgement differences between the first experiment and the forward-speech blocks that were obtained along with the reversed-speech blocks over the course of the second experiment. Specifically, there was not a main effect of experiment [F(1,6) = 3.14, p = .13], nor was there an interaction between experiment, microphone condition, and number of talkers [F(4,24) = 1.53, p = .22].
However, a difference was found between the forward and reversed-speech conditions with respect to perceived numerosity. A 3-by-3 repeated-measures ANOVA indicated that both the microphone configuration (KEMAR, BEAM, and TRIPLE 90) [F(2,12) = 18.0, p < .001] and the number of talkers (3, 5, and 7) [F(2,12) = 34.2, p < .001] were significant main effects influencing the difference in the perceived number of talkers between the forward and reversed conditions and the interaction of the two factors also was significant [F(4,24) = 12.59, p < .001]. As shown in the top panel of Figure 6, forward speech produced greater numerosity values (less error) than the reversed speech for both the KEMAR and TRIPLE 90 conditions (for the larger total number of talkers); however, there was no difference between forward and reversed speech for the BEAM conditions.
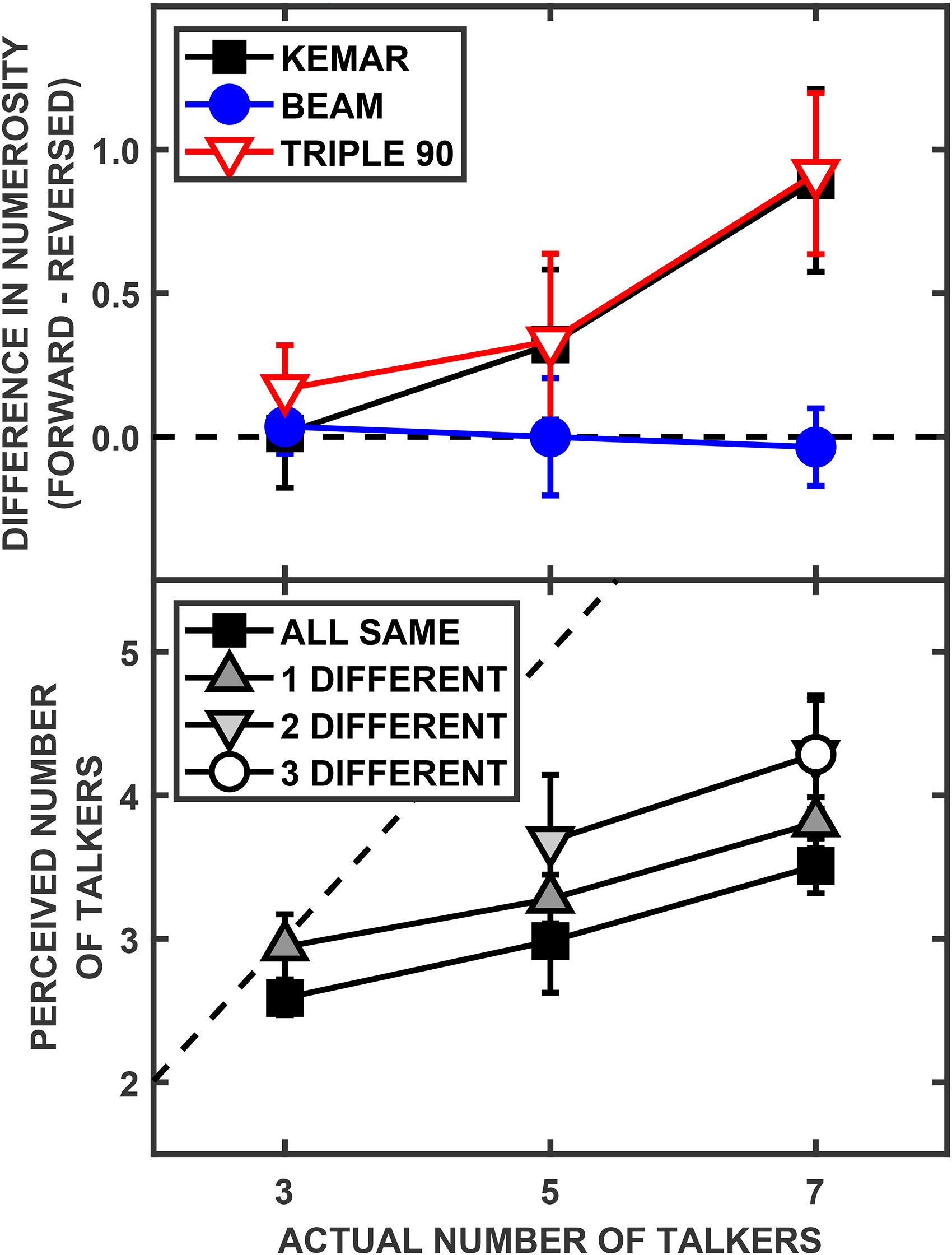
(Top panel) Group mean (N = 7) differences in the perceived number of talkers for forward-speech relative to reversed-speech for the three different microphone conditions tested, as a function of the actual number of talkers. (Bottom panel) Gender mix functions for reversed speech, in the same manner as shown in Figure 2 for forward speech.
As with forward speech, performance with reversed speech also showed a gender mix effect, despite the overall reduction in perceived numerosity (Figure 6, bottom panel). A 2-by-3 repeated-measures ANOVA revealed that two different levels of gender mix (same gender vs. 1 different) [F(1,6) = 7.78, p = .032] and the number of talkers (3, 5, and 7) [F(2,12) = 52.6, p < .001] were significant main effects, while the interaction of the two factors was not significant [F(2,12) = 0.26, p = .78]. For only 7 talkers, post hoc t-tests found significant differences between the presence of 1 different gendered talker compared to all the same gender [t(6) = 2.96, p = .013], as well as between 2 different compared to only 1 [t(6) = 4.54, p = .002], but there was not a significant difference between 3 different gendered talkers and only 2 different [t(6) = 0.0, p = .50]. (The Bonferroni-corrected criterion for significance was α = .017 for this family of post hoc tests.)
The effect of spatial density for reversed speech also paralleled the pattern of forward speech results from the first experiment (cf., Figure 3 and Table 1). For 3 talkers, both KEMAR and TRIPLE 90 had significant correlations between perceived numerosity and mean talker spacing [r(29) = 0.62, p < .001 and r(39) = 0.49, p = .001, respectively], while BEAM did not [r(29) = 0.23, p = .22]. For 5 talkers, only the correlation for TRIPLE 90 was significant [r(22) = 0.59, p = .003; KEMAR: r(22) = 0.26, p = .21; BEAM: r(22) = 0.05, p = .81].
The correlations between numerosity judgments and the summed glimpsed energy retained metric that was observed earlier for forward speech (Figure 5, right panel) were still present for reversed speech, as shown in Figure 7 (top panel). In addition, the slopes of all three microphone conditions were now more similar due to the overall reduction of KEMAR and TRIPLE 90 numerosity judgments. The correlations for each of those functions were significant: KEMAR, r(59) = 0.75, p < .001; BEAM, r(71) = 0.76, p < .001; TRIPLE 90, r(73) = 0.73, p < .001.

(Top panel) The perceived number of talkers for reversed speech as a function of the summed glimpsed energy retained (cf., Figure 5 for forward speech). (Bottom panel) The difference in the perceived number of talkers for forward speech relative to reversed speech for the same amount of summed glimpsed energy retained.
The time-reversing of the stimulus itself had only a minor impact on the range of summed energy retained values and thus cannot account for the reduction in perceived numerosity. Even when directly compared to the summed glimpsed energy retained values, the difference in the perceived number of talkers for forward and reversed speech (Figure 7, bottom panel) was significantly, and positively, correlated for both KEMAR and TRIPLE 90 conditions [r(55) = 0.51, p < .001, and r(66) = 0.48, p < .001, respectively], but was not significant for the BEAM condition [r(65) = −0.02, p = .87]. (There are slight differences in the abscissa values between the upper and lower plots, as only points for which all participants could contribute data for both forward and reversed versions were included.) This finding suggests that, in addition to the acoustic properties that correlate with numerosity judgments, word intelligibility aids in determining the number of speech sources present. (Given that summed glimpsed energy retained was the only previously tested metric which significantly added to the prediction of perceived numerosity for forward speech, analysis of the overall level and envelope smoothness metrics were not included for the time-reversed stimuli.)
Discussion
Overall Numerosity Judgments
To summarize the findings of this study: judgments of the number of talkers in a multitalker mixture were accurate, on average, only up to three separate talkers. When more talkers were present, numerosity judgments underestimated the true number of talkers. This result generally is consistent with past work on this topic reviewed in the Introduction. The size of the underestimates—the magnitude of the error—increased as the actual number of talkers increased although the functions relating the perceived number of talkers to the actual number of talkers continued to increase up to the largest number of talkers present (seven). This pattern resulted roughly in a 2-segment function, with a 1:1 relationship between actual and reported numerosity up to 3 talkers, then a segment with a slope less than 1 for greater than 3 talkers. The effects of the various factors tested in this study were evident primarily in the slopes of the second part of the function.
Although only eight participants were used, there was considerable agreement between the listeners, as indicated by the relatively small standard deviations across the group for many conditions. This may have resulted from the constraints on the stimuli and limited participant response options, though, and the small sample size included may limit the generalizability of the present results to more complex and variable auditory scenes.
Factors Which Improve Accuracy
The features/properties of the sources that tended to strengthen the extent to which they were segregated (i.e., perceived as separate or distinct), reduced the underestimates of numerosity resulting in more accurate judgments. This conclusion was based on the results from mixing male and female gender talkers (presumably segregation was enhanced by differences in vocal pitch and vocal tract resonances) and from increasing the average separation in physical location by azimuth (i.e., decreasing spatial density of sources). Physical separation of sources in azimuth created interaural time and level differences at the ears/microphones prior to any beamformer-specific processing. These interaural differences, which also furnish strong cues for source localization, were preserved in the TRIPLE beamformer conditions to different degrees depending on side beam angle but were absent in the single-channel BEAM case. However, even when all talkers were of the same gender and there were no interaural cues from differences in spatial location as in BEAM, the perceived number of sources was accurate up to three talkers and continued to increase across the range of talkers present. Thus, numerosity judgment accuracy improved with mixing talker genders and the strength of binaural cues (i.e., spatialization/lateralization) of sources especially for N > 3 talkers in the mixture.
Preservation of Gender Ratio of Talker Groups
The judgments of the ratio of genders present in the multitalker stimuli were quite accurate (Figure 2, lower panel) despite the overall trend of underestimating the number of talkers for more than three talkers. Even when the degree of underestimation was modulated by other factors (e.g., spatial or linguistic), this accuracy persisted. To our knowledge, this is the first time that gender composition ratios have been characterized in this manner and it is not clear exactly what factor(s) account for this finding. It is possible that the listeners may use a general impression of the ratio of genders present based on vocal pitch and simply scale the count of female/male talkers by that after making a judgment of the overall number of talkers. However, this finding bears further scrutiny.
A factor which could influence the perceived gender ratio, as well as account for the general benefit when the talker group was of mixed gender, could be the ability of a listener to perceive two separate gendered groups within the auditory scene. Yost et al. (2018) suggested that when less than four sources are present, listeners may adopt a focal attention strategy and perceive voices individually (i.e., count talkers), while global attention may be used for larger groups (e.g., use overall loudness to estimate the total number). Mixed-gender groups could facilitate focal attention for each gender rather than global attention of all talkers, thus, allowing for both a better estimation of total group size and the ratio between talkers of each gender.
In addition to gender groups potentially strengthening focal attention and enhancing the ability to count talkers, it is interesting to consider whether judgments about the properties of the distributions of talkers per se are the basis for decisions about gender ratios. Similar to the interaction between talker number and level seen by Yost et al. (2018), decisions about gender composition could also be based on some global property of the mixture. It is not entirely clear what such a global percept might be, but it could be related to how sparsely each gender distribution was sampled on a given trial (i.e., how many samples were drawn from distribution A vs. distribution B). There have been a few lines of research devoted to perceiving the properties of distributions per se (e.g., “sample discrimination”, Lutfi, 1989) but nothing we are aware of that is directly relevant to the gender ratio perception results found here.
Effects of Unintelligible Stimuli
Linguistic factors, as tested by time reversal of the words in the stimulus, played a role in numerosity judgments that was, at least superficially, similar to that of the two acoustic variables fostering source segregation discussed above. That is, using performance for the time-reversed word strings as a reference, the time-forward sentences yielded stronger perceptions of distinct, continuous and countable sources due to (we would argue) the intelligibility and syntactic structure of the speech. Because the words comprising the time-forward speech streams (even given the low semantic value of the randomized matrix-style sentences) were intelligible and syntactically correct, they were coherent over time to a degree the time-reversed word strings were not and thus could be segregated and counted more easily. Also, the connection between successive words according to identifiable talker characteristics is likely stronger for forward speech than for unfamiliar-sounding time-reversed speech. So, in that sense, the greater uncertainty about successive sounds due to time reversal may affect the ability of the listener to maintain the integrity of a specific speech stream. Different gender mixes and spatial separation of sources improved the accuracy of counting the number of speech sources for the time-reversed speech too, suggesting that those factors do not depend on linguistic structure to influence performance.
It is unclear if similar trends would have occurred had foreign language speech been used as the “unintelligible” speech instead of time-reversed speech. It is possible that the unnatural attack and decay patterns which occur for reversed speech could have made the discrimination of the vocal characteristics of different talkers more difficult. If a foreign language—which the participants had no verbal fluency in—was used, the more natural production of sounds may have served to differentiate talkers, and there may have been less of a detrimental effect of unintelligible stimuli compared to native language speech. However, research using familiar and unfamiliar languages has shown that performance for identifying voices was best when listeners were fluent in the language being spoken (e.g., Goggin et al., 1991; Thompson, 1987). Even when time-reversed, native language voices were rated as more dissimilar (i.e., more identifiable or discriminable) from one another than foreign language voices (Fleming et al., 2014).
Differences Between Microphone Conditions
In terms of the effects of the various listening conditions, the triple beamformer produced judgments of perceived numerosity comparable to natural presentation of speech sources, especially for the widest side beam angle. The spatial density of the talkers also influenced the TRIPLE conditions where binaural cues were present, compared to the single-channel beamformer condition where spatial density had no observed effect. The single-channel BEAM condition served as a reference for numerosity judgements without the benefit of source localization and therefore highlights the benefits that triple beamforming can provide. Using only colocated sources with KEMAR could have provided a similar reference with respect to lack of lateralization, but BEAM was preferable because it employed the same microphones and signal processing as the on-target beam of the TRIPLE conditions. (It is worth noting that the numerosity judgment for the smallest mean talker spacing for KEMAR in each panel of Figure 3 is roughly the same as the flat BEAM function.) Furthermore, the lack of any difference between the forward- and reversed-speech numerosity judgments for the BEAM condition (Figure 6, top panel) could be evidence of a floor for the perceived number of talkers in a group, as there was neither spatial cues nor natural speech (when reversed) to help distinguish the auditory sources.
Stimuli-Based Predictors
All three of the acoustic variables tested—overall level, broadband envelope smoothness, and glimpsed energy retained—individually were correlated with numerosity judgments. A multiple regression analysis indicated that the summed glimpsed energy retained metric accounted for a significant proportion of the variance across conditions. It should be noted, however, that the summed glimpsed energy retained metric does not predict some important aspects of the pattern of results. This is true for the significant beneficial effect of mixed gender talkers (Figure 2) and decreased spatial density (Figure. 3). The empirical results were also analyzed with respect to those factors and the summed glimpsed energy retained metric (not presented here), but no significant trends were observed. This suggests that the underlying benefit of those factors was due to perceptual segregation or subsequent cognitive processing and not directly related to the relatively simple acoustic metrics that were applied to the data.
Footnotes
Consent to Participate
All participants gave written informed consent prior to participating.
Consent for Publication
Not applicable.
Data Availability
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethical Considerations
The experimental research procedures were approved by the Institutional Review Board of Boston University, IRB Protocol Number: 3409E.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Institutes of Health, National Institute on Deafness and Other Communication Disorders (grant number R01-DC013286).