
Abstract
Cochlear implant (CI) users, even with substantial speech comprehension, generally have poor sensitivity to pitch information (or fundamental frequency, F0). This insensitivity is often attributed to limited spectral and temporal resolution in the CI signals. However, the pitch sensitivity markedly varies among individuals, and some users exhibit fairly good sensitivity. This indicates that the CI signal contains sufficient information about F0, and users’ sensitivity is predominantly limited by other physiological conditions such as neuroplasticity or neural health. We estimated the upper limit of F0 information that a CI signal can convey by decoding F0 from simulated CI signals (multi-channel pulsatile signals) with a deep neural network model (referred to as the CI model). We varied the number of electrode channels and the pulse rate, which should respectively affect spectral and temporal resolutions of stimulus representations. The F0-estimation performance generally improved with increasing number of channels and pulse rate. For the sounds presented under quiet conditions, the model performance was at best comparable to that of a control waveform model, which received raw-waveform inputs. Under conditions in which background noise was imposed, the performance of the CI model generally degraded by a greater degree than that of the waveform model. The pulse rate had a particularly large effect on predicted performance. These observations indicate that the CI signal contains some information for predicting F0, which is particularly sufficient for targets under quiet conditions. The temporal resolution (represented as pulse rate) plays a critical role in pitch representation under noisy conditions.
Introduction
Cochlear implants (CIs) have been promising choices to restore or improve the hearing ability of people with severe to profound hearing loss. A typical CI device extracts amplitude envelopes of multiple sub-bands and delivers electrical pulses amplitude modulated with the envelopes through a multi-channel electrode placed along the cochlear duct to directly stimulate auditory nerves (Loizou, 1999). A scoping review by Boisvert et al. (2020), for example, reported that the implantation resulted in an improved mean score for monosyllabic words and sentence perception under a quiet condition. Furthermore, many sophisticated CI devices and speech-processing strategies have been proposed to improve speech perception (Carlyon & Goehring, 2021; Clark, 2015; Peterson et al., 2010; Wilson & Dorman, 2008; Zeng et al., 2008). Nevertheless, even modern CI devices cannot compensate for aspects of hearing functions that are important in daily life, such as speech perception under noisy conditions (Boisvert et al., 2020; Friesen et al., 2001), music appraisal (Drennan & Rubinstein, 2008; Limb & Roy, 2014; McDermott, 2004), and sound localization (Dorman et al., 2016; Verschuur et al., 2005).
The present study is concerned with the difficulty of pitch perception by CI users (Geurts & Wouters, 2001; Gfeller et al., 2002; Nimmons et al., 2008; Sucher & McDermott, 2007; Vandali et al., 2005). Pitch is a fundamental aspect of auditory sensation and plays important roles in a variety of perceptions such as music, paralinguistics, tonal languages (e.g., Mandarin), and auditory grouping and selective listening (McDermott & Oxenham, 2008; Oxenham, 2008, 2012).
CI users generally exhibit difficulty in pitch perception across major speech coding strategies (Vandali et al., 2005) and among stimuli or tasks (Kang et al., 2009; McDermott, 2004; Nimmons et al., 2008; Swanson et al., 2019; Zeng et al., 2014). Sucher and McDermott (2007), for example, reported that the pitch ranking by CI users was significantly worse than those by a normal hearing group, assessed using vowels with a fundamental frequency (F0). This insensitivity to pitch negatively impacts the quality of life of CI users (Prevoteau et al., 2018).
The difficulty in perceiving pitch could be attributed to device-oriented, patient-oriented, and surgical-oriented factors. The device-oriented factor includes the constraints of the acoustic information conveyed by the CI signal (Limb & Roy, 2014). The temporal pitch constraint of the CI signal is introduced by coarse-envelope representation by discrete pulse trains at a fixed pulse rate (in pulses per second, pps). The majority of CI users exhibited challenges in discriminating rate pitch above approximately 300 Hz (Carlyon et al., 2010; Moore & Carlyon, 2005; Vandali et al., 2013; Venter & Hanekom, 2014; Zeng, 2002; Zhou et al., 2019). The place-pitch information is constrained by the number of electrode channels (12–24), which inherently lacks the ability to transmit finely graded spectral information typically conveyed by inner hair cells in a healthy cochlea (around 3,500). Under current technical constraints, the best combination of those temporal and spectral specifications has been sought to maximize the efficiency for speech comprehension, and pitch perception has not been the primary interest. Thus, it is arguable that the current CI configurations are not generally optimal for pitch perception across CI users.
We should note, however, that there is a large variety of pitch sensitivity across CI users (Bissmeyer et al., 2020; Goldsworthy & Shannon, 2014; Kenway et al., 2015; Kong & Carlyon, 2010; Looi et al., 2004; Ping et al., 2012; Townshend et al., 1987) and those with high sensitivity can discriminate as small as a one-semitone difference (Nimmons et al., 2008). This indicates the possibility that the CI signal contains sufficient information necessary for F0 estimation, particularly in quiet conditions, and patient/surgical-oriented factors are the main bottlenecks for pitch perception. To argue the relative contributions of the limiting factors for pitch perception by individuals or populations of CI users, it is important to identify the upper limit of pitch-related information contained in the CI signals with various combinations of the pulse rate and number of channels.
One approach to estimating the information content is to measure the pitch sensitivity of normal-hearing listeners presented with vocoded stimuli simulating CI signals. Earlier studies used this approach to examine how much spectral resolution or number of channels is needed to achieve sufficient pitch perception (Crew & Galvin, 2012; Kong et al., 2004; Mehta & Oxenham, 2017). The results suggested that as many as 16–32 channels would be required for the listener to identify a melody sufficiently. It should be noted that the acoustical signals were synthesized with noise- or sinewave-vocoders. The noise or sinewaves in the signal may interfere with pitch perception, possibly leading to an overestimation of the required spectral resolution for adequate pitch perception. It is important to note also that this approach is applicable only to listeners with normal auditory development, thus cannot capture the contribution of neuroplasticity in the auditory system. When we consider that CI is generally effective for prelingually deaf children with early implantation (Kral & Sharma, 2012; Nagels et al., 2024; Naik et al., 2021; Nicholas & Geers, 2007; Nikolopoulos et al., 1999; Niparko et al., 2010), the upper limit of F0 estimation, with appropriate neural plasticity, may be higher than that estimated for normal-hearing listeners with vocoded-signals.
Another approach for finding the upper limit is to evaluate pitch discrimination by using a computational model. Erfanian Saeedi et al. (2014, 2017) examined the place and temporal features extracted from simulated CI signals and reported that a 4-semitone difference or more in F0 is required to discriminate between two stimuli using the criterion of accuracy. One concern with those studies is that they focused on pre-extracted input features, namely place and temporal cues, which were chosen on the basis of the researchers’ assumptions. Useful but non-obvious cues for pitch estimation may have been overlooked, which may lead to underestimating the actual amount of information contained in the CI signal. We also point out that those previous studies (Erfanian Saeedi et al., 2014, 2017) examined only artificial speech sounds, not naturalistic musical sounds.
We aimed to estimate the upper bound of F0 information more directly from the CI signal. We constructed a computational model that receives (simulated) CI pulse signals as inputs (CI model) rather than pre-extracted features. We also examined a computational model with raw waveform input (waveform model), which is an upper-bound model where all information of a sound is available. The models are deep neural networks (DNNs), data-driven estimators of F0 information, modified from a DNN model that can track the F0 of acoustic signals with very high accuracy (Kim et al., 2018). To evaluate the effect of spectral and temporal resolution on F0 estimation, the simulated CI signals were generated by varying the numbers of channels and pulse rates. The CI pulse input was obtained from a monophonic signal consisting of instrumental or singing sounds that would be encountered in daily life. To explore the adverse effect of noise on the accuracy of F0 estimation, we also included stimulus conditions in which inputs to the CI simulator (or the raw waveform for the waveform model) were superimposed on real-recorded stationary noise. The stimulus conditions with and without noise are referred to as noisy and quiet conditions, respectively. We trained the models with a dataset consisting of a mixture of quiet and noisy conditions and evaluated the models separately for the two stimulus conditions. Training and evaluation were conducted using entirely separate samples (i.e., a held-out evaluation set) to prevent data leakage. As the CI models were trained with systematically varying numbers of channels and pulse rates, we analyzed the relative contributions of place-of-excitation and timing-of-stimulation cues in CI stimulation patterns for F0 estimation. To provide a deeper analysis of the interaction between the fidelity of temporal cues and the F0 range to be estimated, we also varied the temporal-envelope cues by adjusting the cut-off frequency of the low-pass filter used for envelope extraction.
For the reader's convenience, the abbreviations used in this paper are summarized in Table 1.
Summary of Abbreviations

Materials and Methods
F0-Estimation Model
To estimate the F0 information in the CI signal, we constructed the waveform and CI models on the basis of Convolutional Representation for Pitch Estimation (CREPE) (Kim et al., 2018). 1 The procedures for F0 training and evaluation are summarized in Figure 1. The waveform model is trained using raw waveform signals and produces each probability corresponding to discrete F0 values in cents. Note that a cent is a unit of measurement for musical intervals, with one cent being one-hundredth of a semitone. A semitone corresponds to a frequency difference of approximately 5.95%. During optimization, the model uses binary cross-entropy loss with F0 labels applied with Gaussian smoothing to soften penalties for nearly correct predictions (Bittner et al., 2017). The CI model serves as the counterpart to the waveform model, taking simulated CI pulse signals as input instead of raw waveform signals. In the prediction phase, the model's estimation is a weighted average over a specified range (e.g., ±3 in Figure 1) centered on a node with the highest probability. Further details are provided below, and the details of the DNN model and training configuration are elaborated in Supplemental Material A.
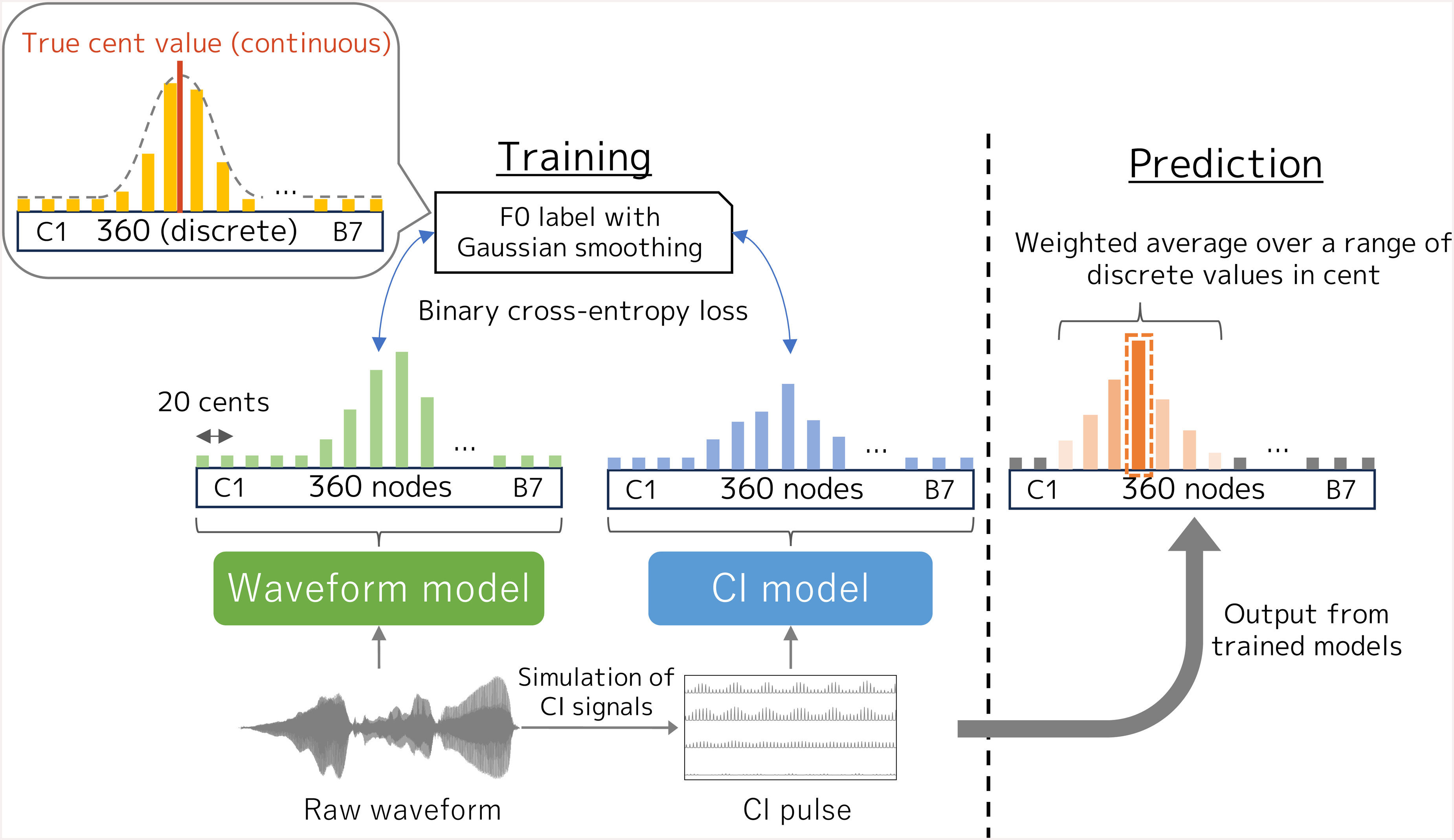
Overview of training and prediction schemes for waveform and CI models. Left and right panels illustrate training and prediction processes, respectively.
The models’ training and estimation target was the discrete values 
To train the models, the binary cross-entropy loss 


Training and Test Datasets
Datasets for Model Training
To train and evaluate the waveform and CI models, we conducted the experiment with three open-access datasets: MDB-stem-synth (Salamon et al., 2017), bach10 (Duan et al., 2010), and nsynth (Engel et al., 2017). The datasets contain singing and instrumental sounds consisting of a single musical note or melody to simulate situations that could be listened to in daily life. The sounds were represented with a sampling frequency of 16 kHz and 16-bit quantization. MDB-stem-synth and nsynth contain only monophonic sounds, and bach10 contains monophonic and polyphonic sounds, but only the monophonic part was used in this study. All datasets contain clear F0 annotations and corresponding time information; hence, the sound portion for training was extracted with 1,024 points centered on that time point. The nsynth dataset (Engel et al., 2017) had been initially partitioned into training, development, and evaluation sets, but MDB-stem-synth (Salamon et al., 2017) and bach10 (Duan et al., 2010) were not. Since each file for those two datasets was composed for each piece of music, the files were divided per piece of music to ensure that similar timbres and F0s were not included in the training and evaluation set (i.e., preventing data leakage). Specifically, the number of files was split into a 3:1:1 ratio for the training:development:test sets in each dataset. Therefore, the amount of combined data after partitioning was 121.8, 22.2, and 80.1 hours for training, development, and test, respectively.
In addition to the above datasets consisting of the target sounds in isolation (quiet condition), we generated noisy-conditioned datasets in which the above data were superimposed with samples from the noise dataset JEIDA-NOISE (Itahashi, 1990). This was done to simulate daily situations in which signals of interest are mixed with background noise. JEIDA-NOISE consists of 17 types of real-recorded sources featuring mostly stationary environmental noise. Specifically, it includes two types of in-car noise, two types of exhibition hall noise, station noise, telephone-booth noise, two types of factory noise, highway noise, crowd noise, two types of train noise, two types of computer-room noise, two types of air-conditioner noise, and elevator lobby noise. The total duration of this noise dataset is 66.7 hours. Since very few recordings in this dataset had a clear F0 or explicit harmonic structures, there was no need to relabel the F0 values in the training data when simulating natural noisy conditions. The noise data in JEIDA-NOISE has power concentrated in a low-frequency band similar to pink noise. During superimposing, 1,024 segments were randomly selected from among all sound sources, and the signal-to-noise ratio (SNR) was randomly selected from 0 to 15 dB. This SNR range is based on common everyday listening situations (Smeds et al., 2015). We evaluated the waveform and CI models trained with mixed data of quiet and noisy conditions.
Datasets for Model Evaluation
The evaluation process was conducted on two realistic test sets simulating sounds that could be encountered in daily life. The evaluation data simulated quiet and noisy conditions as described in Section “Datasets for Model Training”. The analyses of the evaluation results (described later) were conducted separately for quiet and noisy conditions. Note that the F0 range for the evaluation set was from 32.7 to 1,975.5 Hz.
Evaluation Measures
A percentage of correct answers (percent correct) was used as the performance measure representing the overall F0-estimation accuracy of the model (Kim et al., 2018; Salamon et al., 2014). The estimation was regarded as “correct” when the estimated F0 fell within 50 cents (half a semitone) around the ground-truth value. Furthermore, to analyze values near the ceiling, we also presented the performance using rationalized arcsine units (RAU) (Studebaker, 1985).
Simulation of Cochlear-Implant Signals
Among the several signal-processing strategies for CI (Loizou, 1999; Vandali et al., 2000; Wilson et al., 1991; Zeng et al., 2008), we focused on the classic continuous-interleaved sampling (CIS) strategy (Wilson et al., 1991), which has been available for major CI manufacturers. 2 Figure 2 shows the generation procedure for 4 channels (Loizou, 1998; Loizou, 1999: Loizou, 2006; Wilson et al., 1991; Zeng et al., 2008).

Basic CIS strategy. PEF, BPF, and HWR denote pre-emphasis filter, band-pass filter, and half-wave rectifier, respectively.
A waveform signal 
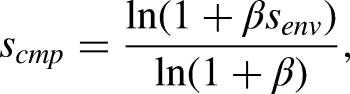
In accordance with the user configurability of a CI device, we investigated various pulse rates of the interleaved Gaussian pulse and various numbers of channels. Specifically, five pulse rates of 400, 600, 800, 1,200, and 2,000 pps and 1, 4, 8, 12, 16, and 20 channels were used. Although the condition at 400 pps could be affected by aliasing due to the 300-Hz cut-off frequency for extracting the amplitude envelope (i.e., it is desirable to sample above 600 pps according to the sampling theorem), we included this experimental condition for reference (for the analysis of the aliasing effect caused by pulse rate, see the supplemental material). Note that we define the pulse rate as the value for each channel; hence, if the simulation ran with 10 channels at 1,200 pps, the total pulse rate of the input signal would be 12,000 pps. The cut-off frequency of the BPF for each channel was determined on a logarithmic scale between 0 and 8,000 Hz starting at 250 Hz. For example, for 4 channels, the bands were 0–250, 250–793.7, 793.7–2,519.8, and 2,519.8–8,000 Hz, and for 6 channels, 0–250, 250–500, 500–1,000, 1,000–2,000, 2,000–4,000, and 4,000–8,000 Hz. Figure 3 illustrates examples of output CI signals for two musical tones at two different F0 values (98.0 and 493.9 Hz). The left panel shows clear periodicity corresponding to F0, highlighting strong temporal cues. The right panel, representing a relatively higher F0, illustrates poor temporal envelope cues but clear place cues, which show higher values in the channels related to F0.

Example of input waveform and output CI signals. Each column visualizes outcomes from waveforms at different F0: (a) 98.0 Hz (G2) and (b) 493.9 Hz (B4). CI signal is generated by interleaved Gaussian pulse with 1 or 20 channels and 1,200 pps. Electrode number with highest value corresponds to electrode position being at apical place. Bandwidths of electrodes 1 to 20 are, respectively, 6,666.1–8,000.0, 5,554.6–6,666.1, 4,628.4–5,554.6, 3,856.7–4,628.4, 3,213.6–3,856.7, 2,677.8–3,213.6, 2,231.3–2,677.8, 1,859.3–2,231.3, 1,549.3–1,859.3, 1,290.9–1,549.3, 1,075.7–1,290.9, 896.3–1,075.7, 746.9–896.3, 622.3–746.9, 518.6.5–622.3, 423.1–518.6, 360.1–432.1, 300.0–360.1, 250.0–300.0, and 0.0–250.0 Hz. Red line indicates extracted envelope after amplitude compression.
Results
Examples of F0 Tracking
An example of F0-estimation time series for an excerpt of jazz music is shown in Figure 4. From Figure 4(a), the waveform model (raw waveform inputs as a performance upper bound) achieved a near-perfect tracking result (the orange lines, indicating the model estimates, overlap with the black-dashed lines, indicating ground truth). The estimates from the CI model with 20 channels also followed the general patterns of the ground truth (Figure 4(b)). However, in the case of the 1-channel CI model (Figure 4(c)), there were notable failures in certain instances, particularly at higher F0 values (≥500 Hz). We can interpret the difference between the performances of the waveform and CI models as reflecting the loss of pitch-related information by the CI encoding.

Example tracking results of F0 estimated from (a) waveform model, (b) CI model with 20 channels and (c) CI model with 1 channel. Each panel shows time series of F0 estimations as orange (blue) solid line for waveform model (CI model) and ground-truth values as black-dashed line for first 20 seconds from evaluation example, specifically “MusicDelta_ModalJazz_STEM_04.RESYN.wav” in MDB-stem-synth. Pulse rate of CI models (i.e., panels (b) and (c)) is 2,000 pps.
Overall Accuracy of F0 Estimation
Figure 5 summarizes the accuracy of F0 estimation. The percent correct (the percentage of instances in which the model estimates fall in a certain range around the ground truth; see Section “Evaluation Measures”) is plotted as a function of the number of electrode channels for various pulse rates (indicated with different symbols). The transformed proportion correct in RAU is also shown in the bottom panels. The dashed lines indicate the performance of the waveform model (serving as an upper bound model where all information on the waveform is available). The red line with open triangles is the condition when the input was a continuous amplitude envelope (Env model).

Performance of F0 estimation models under (a) quiet condition and (b) noisy condition. Panels show percent correct (top) and rationalized arcsine units (RAU) (bottom) as function of number of channels of CI signal. Each line indicates differences in pulse rate and other temporal constraints. Black-dashed line indicates percent correct or RAU of waveform model. Each value shows mean of five networks initializing parameters with different random seeds, and shaded region shows 95% bootstrap confidence intervals of mean.
Under the quiet condition (Figure 5(a)), the percent correct from the CI model generally increased with increasing pulse rate and number of channels, approaching that from the waveform model. When the number of channels was 8 or more, CI models had no marked difference with any pulse rates.
Under the noisy condition (Figure 5(b)), the percent correct was generally lower than under the quiet condition for both the waveform and CI models. There was also a tendency for percent correct improvement with increasing pulse rate and number of channels. However, in contrast to the quiet condition, when the pulse rate was 400 pps, even with 8 channels, the percent correct falls short compared with the other four CI model versions with higher pulse rates (see the vertical differences between the lines in the figure). To achieve a certain level of performance (e.g., percent correct of ∼75%), as few as 4 channels were sufficient when the pulse rate was 600 pps, while a large number of channels (12) were required when the pulse rate was 400 pps. We also confirmed a similar pattern for the 400 pps condition in the RAU-transformed percent correct (shown in the bottom panels of Figure 5), suggesting that ceiling effects had only a minor impact on the performance differences.
We can assume that the pulse rate determines the temporal resolution of the envelope representation of the original input signal because the CI signal was generated by superimposing an amplitude envelope with a pulse sequence, which can be considered as the pulse-vocoded signal (cf., noise-vocoded speech signal; Shannon et al., 1995). Thus, the above results indicate the importance of the temporal resolution of the envelope signal, especially for fewer channels (<8 channels). When we trained and tested for one of the CI model versions with an input of intact envelop signal (i.e., with maximum temporal resolution; red triangles in Figure 5), the percent correct of the Env model was superior or similar to the CI model in most cases, as expected. When the number of channels was 8 or higher, the performance of the CI models was comparable to that of the Env model regardless of the pulse rate.
Comparison of Ground-Truth and Estimation
We explored the nature of F0-estimation errors. Figure 6 shows confusion matrices comparing ground-truth and estimated F0s. The left and right panels represent quiet and noisy conditions, respectively. The top panels are for the waveform model, while the middle and bottom panels are for the CI models with 1 and 20 channels, respectively, both operating at a pulse rate of 2,000 pps. Each cluster in the figure represents the proportion of stimuli by color for a particular pair of a ground-truth (horizontal axis) and estimated value (vertical axis). A high number of estimations around the diagonal of the figure suggest that a model was able to estimate F0 with high accuracy. The percent correct described in the previous section reflects the total number of estimations on the diagonal line. As expected by the relatively high percent correct values shown in Figure 5(a), there is a high number of estimations on the diagonal lines in Figure 6(a) (quiet condition). Under the noisy condition (Figure 6(b)), the clusters far from the diagonal were more apparent, confirming that F0 estimation was more difficult than that under the quiet condition. There were discrete lines that paralleled the diagonal. The lines separated from the diagonal by about one octave, indicating the octave error. Comparing the CI models with different numbers of channels, we also note that F0 estimation was challenging at higher frequencies under the 1-channel condition, which has weak place cues. Nevertheless, even in the 20-channel condition, octave errors were still present at the highest F0s tested, suggesting that this type of confusion could, in principle, be conveyed by place cues (with relatively weaker temporal cues) in the CI output.
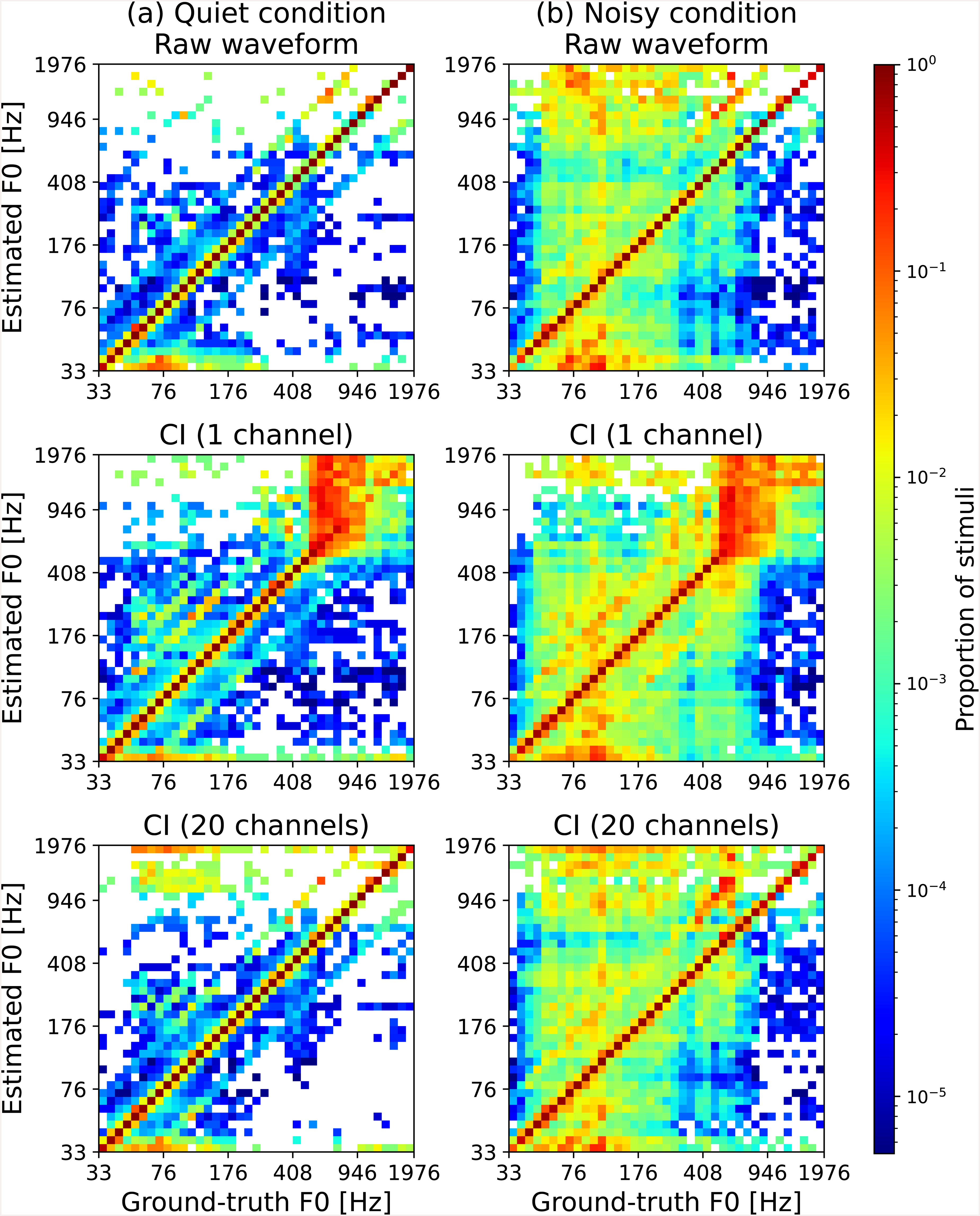
Confusion matrices between ground-truth F0 and estimated F0. Each column shows results under (a) quiet condition and (b) noisy condition. Top panels represent results for waveform model, while middle and bottom panels show matrices for CI model with 1 and 20 channels (both with pulse rate of 2,000 pps). Axes of all panels are on log scale. For easier identification of clusters with relatively lower counts, count represented as proportion is on log scale, and number of samples in each column was normalized to sum to one. Empty clusters indicate that count is zero. Note that this figure plots results of one of trained models with different random seeds.
Figure 7 summarizes the estimation errors (i.e., the difference from the ground truth), representing the mean absolute error (MAE) of F0. The analysis results were consistent with those on the percent correct described earlier: for all the configurations of the CI model, the degree of error under the quiet condition (Figure 7(a)) was smaller than that under the noisy condition (Figure 7(b)), confirming the distractive effect of background noise in general. The effect of the pulse rate was apparent, particularly under the noisy condition (i.e., smaller pulse rate resulting in larger MAE).
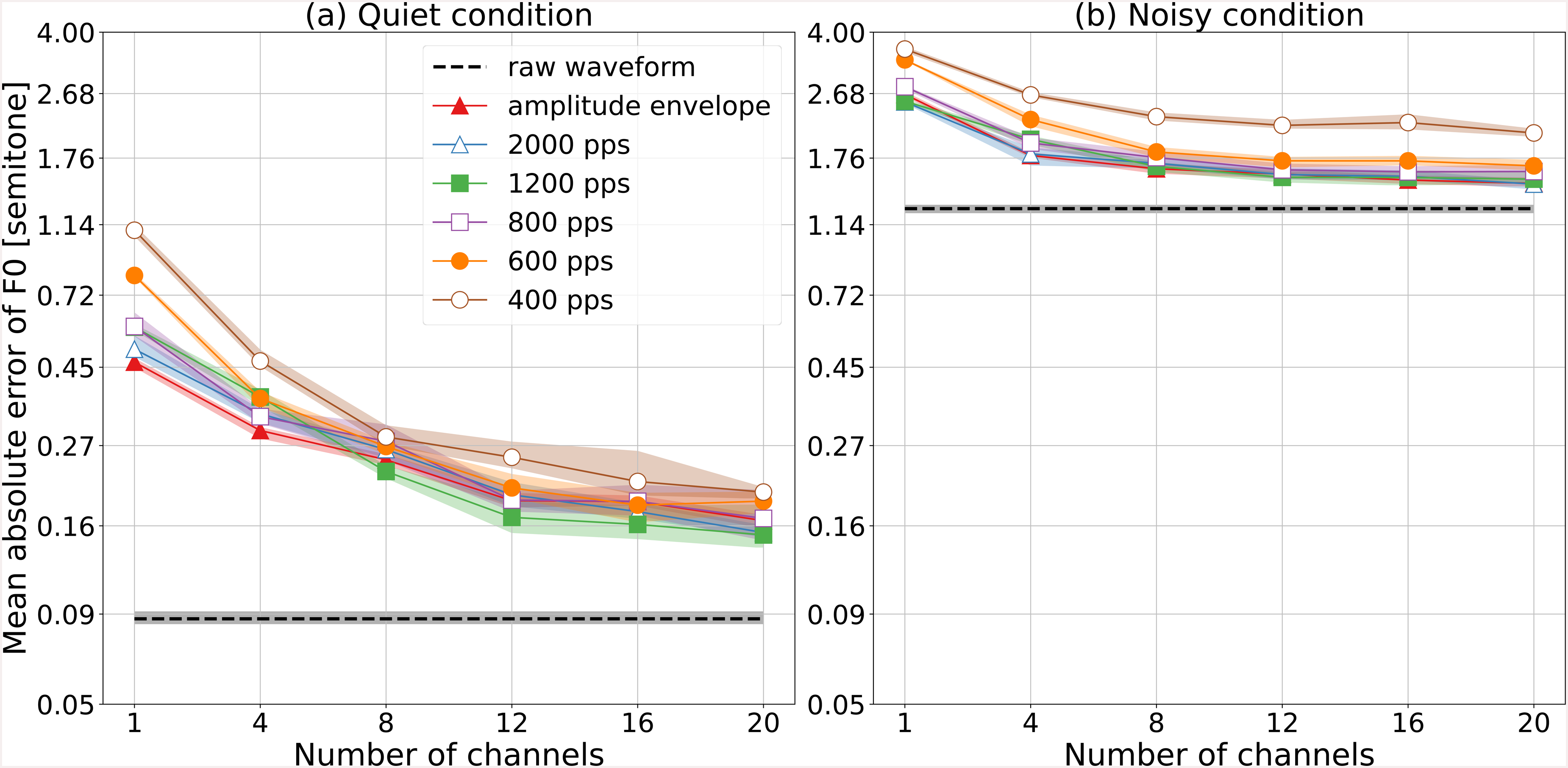
Mean absolute error (MAE) of F0 between predicted and ground-truth values in semitones on log scale under (a) quiet condition and (b) under noisy condition. Panels show MAE as function of number of channels of CI signal. Each line indicates differences in pulse rate, specifically 2,000, 1,200, 800, and 400 pps. Black-dashed line indicates MAE of waveform model. MAE shows mean of five networks initializing parameters with different random seeds, and shaded region shows 95% bootstrap confidence intervals of mean.
Relationship Between Performance and Signal-to-Noise Ratio
Section “Overall Accuracy of F0 Estimation” indicated that model performance was generally worse under noisy conditions than under quiet conditions, and this was true for both the waveform and CI models. We further explored the noise effect and examined how the SNR affected performance. To calculate the percent correct for each SNR condition, we randomly extracted 5,000 samples from the original clean test set and added noise samples, randomly extracted from JEIDA-NOISE, to them at levels ranging from 0 to 15 dB in 3-dB increments. In this process, the noise differed between samples but was the same across different dB conditions. We focused on the CI model configured with 2,000 pps and 20 or 1 channels. Figure 8 plots the percent correct as a function of SNR. To assess the effect of SNR on the performance of F0 estimation, we applied a linear mixed model (LMM) with SNR as a fixed effect and the F0-estimation model as a random effect. For each F0-estimation model, five networks were trained with initial parameters generated by different random seeds. The percent correct values were RAU-transformed and served as the response variables in the LMM. The LMM revealed a significant positive effect of SNR on the RAU-transformed percent correct (coefficient = 1.717, standard error = 0.030, P < .001), indicating that the performance varied significantly across SNR levels, with higher accuracy observed in high SNR conditions compared to low SNR conditions.

Effect of noise intensity on model performance. This panel plots percent correct as function of SNR from 0 to 15 dB in increments of 3 dB. Red circles, blue triangles, and green squares indicate waveform model, CI model (2,000 pps, 20 channels), and CI model (2,000 pps, 1 channel), respectively. Percent correct shows mean of five networks initializing parameters with different random seeds, and shaded region shows 95% bootstrap confidence intervals of mean.
The three functions (i.e., the red, blue, and green lines) were generally parallel. To achieve a given percent correct (e.g., 90%), the CI model with 20 channels required about a 6-dB higher SNR than the waveform model. While the differences in the number of channels (place cues) affected the overall performance, there was no significant difference in the performance with respect to SNR (slope of each line).
Relationship Between F0 and Accuracy
The “Comparison of Ground-Truth and Estimation” section suggests that place cues, determined by the number of channels, play an important role in accurately estimating higher F0. We elaborated this by plotting percent correct as a function of ground-truth F0 for conditions with different numbers of channels (Figure 9). The line color represents each pulse rate. For each frequency range, we randomly sampled 2,000 instances per range to ensure an equal number of instances falling in each ground-truth F0 range for deriving the percent correct. For both quiet (Figure 9(a)) and noisy conditions (Figure 9(b)), poor place cues (i.e., conditions of using around 1 to 8 channels) degraded accuracy in the higher F0 range. However, accuracy in the lower F0 range, below approximately 300 Hz, was high, as it would provide sufficient temporal cues below the cut-off frequency of the low-pass filter.

Performance of F0 estimation models (a) under quiet condition and (b) noisy condition. Panels show percent correct as function of ground-truth F0 range. Each line indicates differences in pulse rate, while each row represents channel. Percent correct shows mean of five networks initializing parameters with different random seeds, and shaded region shows 95% bootstrap confidence intervals of mean.
Impact of the Upper-Cut-Off Frequency of the Temporal Envelope Cues
We further investigated the effect of temporal envelope cues by investigating different cut-off frequencies of the low-pass filter used for envelope extraction, that is, 50, 100, 200, 300, and 600 Hz. The panels in Figures 10 and 11 are analogous to those in Figures 5 and 9, respectively, but controlling cut-off frequency instead of pulse rate. In this analysis, the pulse rate for all CI models was 2,000 pps. The overall performance illustrated in Figure 10 suggests that finer temporal cues provide better accuracy. At 600 Hz, which was higher than the commonly used 300 Hz, performance was comparable to those with raw waveforms. The greater the number of channels, the smaller the accuracy differences between the CI models with different cut-off frequencies. However, the poorest temporal-cue condition (50 Hz) showed significantly poorer performance, even in the finest place-cue condition (20 channels), compared with other models. The details of this accuracy are illustrated for each F0 range in Figure 11. From the results under the 1-channel condition in a quiet environment (Figure 11(a)), the accuracy was high when the F0 range was below the cut-off frequency, indicating that the cut-off frequency dictates the temporal cues necessary to accurately estimate F0. With a larger number of channels, accuracy improved, especially in the higher F0 range, as also shown in Figure 9. However, the performance of the CI model with a 50-Hz cut-off frequency (i.e., the temporal envelope cues are presented minimally) could not be fully compensated even with finer place cues (20 channels) within the 60- to 180-Hz ground-truth F0 range. Under noisy conditions (Figure 11(b)), the CI model with the lowest cut-off frequency demonstrated poor accuracy across all channels, even when the true F0 range was below 60 Hz.

Performance of F0 estimation models (a) under quiet condition and (b) noisy condition. Panels show percent correct (top) and rationalized arcsine units (RAU) (bottom) as function of number of channels of CI signal. Each line indicates differences in cut-off frequency of low-pass filter. Pulse rate for all CI models is 2,000 pps. Black-dashed line indicates percent correct or RAU of waveform model. Each value shows mean of five networks initializing parameters with different random seeds, and shaded region shows 95% bootstrap confidence intervals of mean.
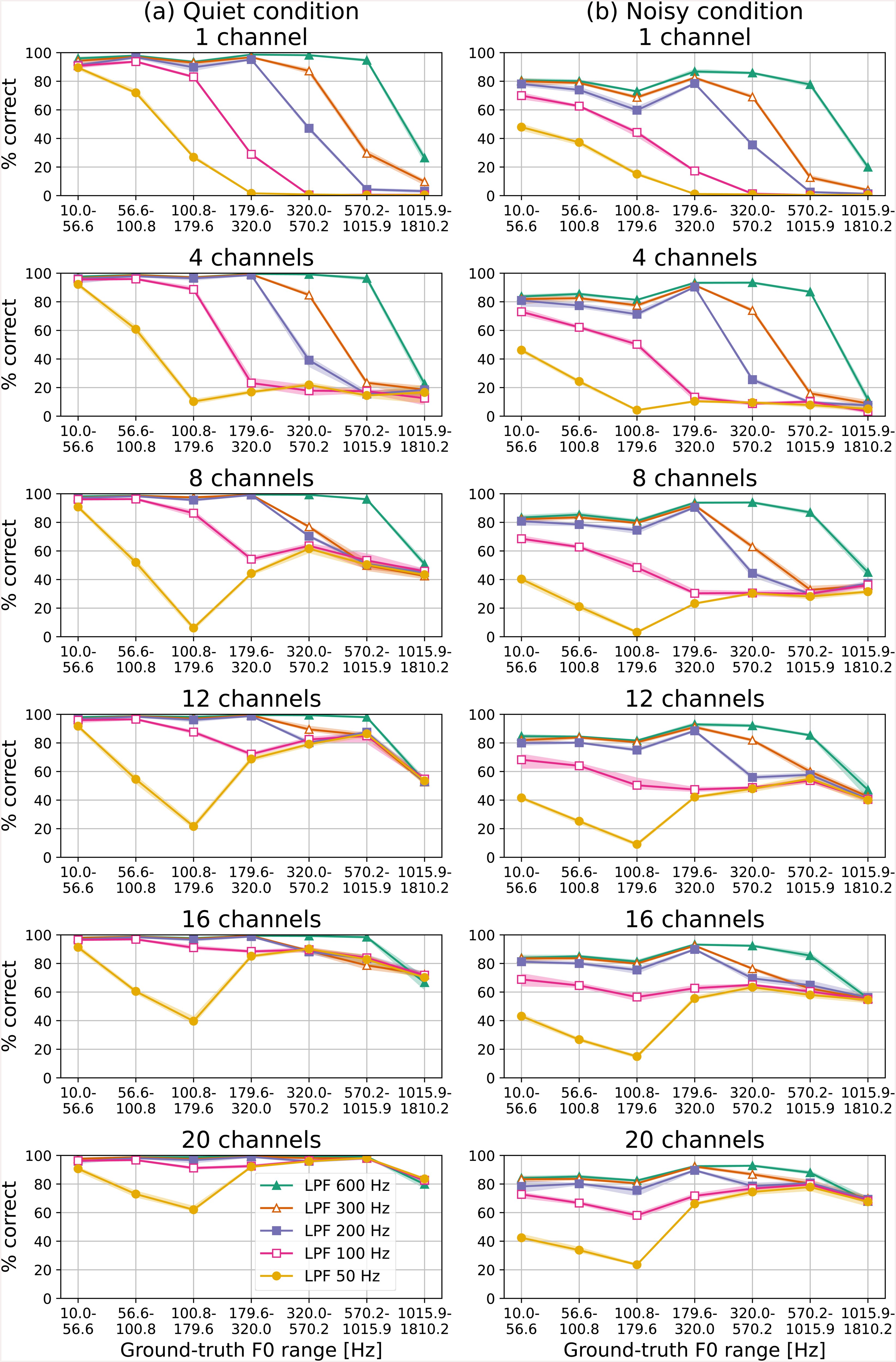
Performance of F0 estimation models (a) under quiet condition and (b) noisy condition. Panels show percent correct as function of ground-truth F0 range. Each line indicates differences in cut-off frequency of low-pass filter, while each row represents channel. Percent correct shows mean of five networks initializing parameters with different random seeds, and shaded region shows 95% bootstrap confidence intervals of mean.
Discussion
Previous studies have shown that a CI group was less accurate than a normal hearing group in a pitch-discrimination task, but some CI users were able to discriminate with high accuracy despite the degradation in the CI signal. This study was mainly motivated by those findings, and we systematically investigated the upper limit of the amount of F0 information contained in the CI signal, along with the effect of the number of channels and pulse rate. The results under the quiet condition indicate that the CI signal had sufficient information for estimating the F0 with a certain number of channels. In contrast, under the noisy condition, it was difficult to estimate F0 from the CI signal, and the performance gap between the CI and waveform models was greater than that under the quiet condition. As expected, there was a clear correlation between the SNR and F0-estimation performance.
In the quiet condition, the CI signal contained substantial F0 information under conditions where the pulse signals were generated with almost 8 channels regardless of the pulse rate (Figure 5(a)). Thanks to the introduction of multi-channel CI devices, around 8 channels are practical for any manufacturer (Zeng et al., 2008). Moreover, our results indicate that increasing the number of channels to 8 or more further improves F0 estimation. This is comparable to recent studies (Berg et al., 2019; Croghan et al., 2017), which demonstrated that speech intelligibility improved with more than 7 to 10 channels. On the other hand, some studies have shown that increasing the number of electrodes beyond 7 to 10 channels does not necessarily improve speech performance under both quiet and noisy conditions (Fishman et al., 1997; Friesen et al., 2001). These discrepancies highlight the need for further investigation to better understand the relationship between the number of channels and auditory outcomes. The CI models were also able to estimate F0 with an MAE within a fraction of a semitone under quiet conditions (Figure 7(a)). From the above findings, current CI users may in principle exhibit higher pitch perception, no matter what device they use. In fact, a previous study (Nimmons et al., 2008) has shown that some CI users could identify one-semitone difference in a pitch-discrimination task. Therefore, the results under the quiet condition suggest that the main reason for the deterioration in the pitch sensitivity of CI users is due to neuroplasticity of relevant brain areas induced by auditory experience or implantation age, along with other patient-oriented and/or surgical-oriented factors such as neural survival, and insertion depth of electrode array, rather than device-oriented factors.
Contrary to the results under the quiet condition, the difficulty of F0 estimation was demonstrated under noisy conditions (Figure 5(b)). This was consistent with previous studies showing that CI listeners had not fully recovered their hearing ability under noisy conditions compared with normal-hearing listeners. For example, a scoping review (Boisvert et al., 2020) summarized an almost 30% performance gap in a sentence-recognition task under a noisy condition compared with under a quiet condition. The main reasons for this negative impact were the vulnerability of the temporal envelope against interference sounds and the absence of a temporal fine structure (TFS) in the CI signal, which was impaired in the process of deriving the envelope from the raw waveform (Moore, 2019). The TFS cue has played a critical role in perceiving speech in the presence of competing sounds through experiments on normal-hearing listeners by using a vocoded signal in English (Hopkins & Moore, 2010) and in Mandarin (Kong & Zeng, 2006). In fact, the Env model (i.e., received an amplitude envelope as input) performed significantly poorer than the waveform model (Figures 5(b) and 7(b)). Nevertheless, there is no compelling evidence that adding TFS cues helps CI users’ perception, and this topic remains a subject of ongoing debate (Carlyon & Goehring, 2021; Wouters et al., 2015).
The performance differences within CI model versions were relatively slight for 8 or more channels compared with fewer channels, regardless of pulse rate under the quiet condition or over 600 pps under the noisy condition. It seems that with a limited number of channels (<8 channels), the place cue became unreliable, prompting reliance on the temporal cue. Similarly, with a low pulse rate (<600 or 800 pps), the temporal cue was unreliable, leading to reduced accuracy. The tendency led to the importance of combining the place cues and rate of stimulation (or temporal cues), as shown in previous CI studies (Bissmeyer & Goldsworthy, 2022; Erfanian Saeedi et al., 2017; Luo et al., 2012). We can interpret the present data as indicating that the contemporary CI configuration, with over 600 or 800 pps and more than 8 channels, is near optimal for the purpose of extracting F0 information from the envelope.
To determine model performance with actual listeners in a realistic noise environment, we should examine a wide range of environmental sounds as the background noise. The current study involved using one class of environmental sounds, that is, real-recorded sounds, which had essentially no harmonic structure, hence, no F0 information. Future studies may include other types of noise with a certain amount of F0 information, which would compete with the target F0.
We also recognize that the simulations of CI signals used in the present study did not sufficiently cover the properties of modern CI devices currently available. Factors that can affect the performance include the bandwidth or filter-shape configurations of the band-pass filter, characteristics of the microphone, automatic gain control, and other signal processing functions. We also simulated a CIS strategy, but did not test, for example, the fine structure processing strategy (Wilson & Dorman, 2008; Wilson et al., 2005; Wouters et al., 2015), which was proposed for better music appreciation (Müller et al., 2012). Nevertheless, the contribution of the present paper is demonstrating the significance of directly extracting F0 information using DNNs from the basic pulsatile CI signal. Future studies may take advantage of this approach as a tool for evaluating the benefits of various parameters and strategies including n-of-m strategies such as used in the Cochlear make of CI.
Another concern is that our approach did not explicitly incorporate auditory neural representations of CI users into the model. For example, a previous study (Saddler et al., 2021) used simulated auditory nerve representations as the input to DNN models to develop a model of pitch perception. Another DNN study (Brochier et al., 2022) used neural excitation patterns converted from CI device outputs to predict speech perception of CI. For this study, the pulsatile signal derived from CI processors was applied to DNN models to determine whether the primary cause of the deterioration in CI users’ pitch sensitivity is the CI signal, rather than biological, patient-specific, or surgical factors. Future studies may include the simulation of auditory nerve responses to acoustic stimuli to investigate the effects of channel interaction, neural survival, and electrode-array insertion depth.
The analyses under noisy conditions (400 pps of the pulse rate in Figure 5(b)) further revealed the importance of the resolution of the temporal envelope information determined from the pulse rate of CI signals. The effect of varying the pulse rate has been explored in several studies (Arora, 2012; Arora et al., 2009; Fu & Shannon, 2000; Loizou et al., 2000; Shannon et al., 2011). The study by Arora (2012), for example, has shown that CI users improved their speech recognition, especially under noisy condition, as the pulse rate increased to about 500 pps per channel. Our analyses indicate that under the quiet condition (Figure 5(a)), the signal with 400 pps and 8 channels would be sufficient for the CI model to achieve the same performance as that of an Env model (regarded as the condition of no information loss by temporal sampling). Under the noisy condition (Figure 5(b)), however, the same input was not sufficient to reach the Env model's performance, even though the signal with 800 pps and the 8 channels would be sufficient. While our results indicate that increasing the pulse rate generally led to performance improvements, the speech perception of CI users does not consistently improve with higher pulse rates and can sometimes even worsen (Brochier et al., 2017). Therefore, future work may include considering factors such as between-channel interactions induced by high pulse rates (Boulet et al., 2016).
It is important to point out that actual CI listeners do not always take advantage of high pulse rates in pitch discrimination on the basis of temporal information, which has been demonstrated in several earlier studies. For example, when the stimuli were simple pulse trains, in which a higher pulse rate is expected to evoke a higher pitch percept, most CI users exhibited difficulty in discriminating the pulse rate with a baseline pulse rate above approximately 300 pps, which is much smaller than a normal hearing listener (Carlyon et al., 2010; Moore & Carlyon, 2005; Vandali et al., 2013; Venter & Hanekom, 2014; Zeng, 2002; Zhou et al., 2019). We should note that it is difficult to determine the “true” upper-bound pulse rate: The task performance varied considerably among CI users (some are able to detect rate changes around 700 or 1,000 pps; Kong & Carlyon, 2010; Townshend et al., 1987). Furthermore, the upper limit of pulse rate discrimination may also change due to improvements brought by perceptual learning (Bissmeyer et al., 2020; Goldsworthy & Shannon, 2014), although these improvements may stem from procedural or task-specific factors, such as an increased understanding of the task requirements or perhaps picking up on extraneous cues specific to the experiment, limiting their generalizability to real-life situations. Another form of temporal information that could be associated with pitch perception is the amplitude envelope as a modulator of the pulse train. Studies that assessed the detection or discrimination of the amplitude envelope with various pulse rates (Fraser & McKay, 2012; Galvin & Fu, 2005; Green et al., 2012; Pfingst et al., 2007) indicate that increased pulse rates of the pulse train could induce no effect or even degraded performance under conditions such as exceptionally high carrier rate (e.g., 4,000 pps) or reduction in the level of carrier.
As shown in Figures 9, 10, and 11, we examined the interplay between the fidelity of place-of-excitation and temporal cues with the F0 range by varying the number of channels and pulse rate or cut-off frequency for envelope extraction. The results indicate that accurate estimation of low F0 was possible even in the absence of place cues (i.e., with just one channel) and that the cut-off frequency affected the estimable low F0 range, highlighting the importance of temporal-envelope-cue fidelity. Conversely, estimating higher F0 required a certain number of channels, indicating the contribution of place cues. This aligns with previous studies, which demonstrated that the number of channels affects the accuracy of melody perception at high F0 ranges (from 414 to 1,046 Hz; primarily place cues) (Singh et al., 2009). As shown in Figure 3, these tendencies are somewhat natural, as a CI signal can provide strong temporal cues for low F0 and strong place cues but no timing cues for high F0. We also observed a similar trend in the F0 tracking results shown in Figure 4. Even when temporal cues had very limited fidelity (e.g., the LPF 50-Hz condition in Figure 11, where LPF denotes low-pass filter), performance at high F0 was well compensated by increasing the number of channels. Several studies of CI users explored the contributions of place and temporal pitch for melody recognition using different F0 ranges comprised of pure or harmonic tones (Singh et al., 2009; Swanson et al., 2019). While different studies reported varying performances between F0 ranges, possibly due to differences in stimulus composition (e.g., harmonic composition), our CI model with sufficient temporal and place cues demonstrated almost no differences and achieved nearly perfect performance under quiet conditions.
It is interesting that the CI models with more than a certain number of channels and pulse rates achieved almost perfect accuracy in estimating the F0 under quiet condition, while a previous study (Erfanian Saeedi et al., 2017) demonstrated only slight, better-than-chance performance, also under quiet condition. One possible reason for the marked difference between the studies is the difference in the model structure. The model in the previous study had a single feed-forward layer with pre-extracted features, while the CI model is capable of acquiring more complex expressions in “raw” signals. We trained models with a much larger amount of data than previous studies, as typical for DNN models. Another factor could be differences in the input signals to the model. The previous study used the across-time average of the cochleogram as a place cue and inter-spike-interval histogram as a temporal cue, while we used the two-dimensional pulsatile CI signal for the model input. The CI model could have acquired latent features other than the above two cues. For example, when the temporal cues had been extracted, all spikes were integrated between channels to calculate input features, presumably leading to the loss of temporal cues per channel. However, a previous biologically-motivated modeling study (Shamma & Dutta, 2019) has shown that the processing procedure of an unresolved pitch would differ from a resolved pitch in the temporal axis. The CI model may have implicitly enabled such different processing between channels. We hope that future studies exploring the detailed internal representations of a DNN model (Adadi & Berrada, 2018; Arrieta et al., 2020) will reveal specific cues and processing strategies to take advantage of the latent features in CI signals.
Supplemental Material
sj-docx-1-tia-10.1177_23312165241298606 - Supplemental material for Estimating Pitch Information From Simulated Cochlear Implant Signals With Deep Neural Networks
Supplemental material, sj-docx-1-tia-10.1177_23312165241298606 for Estimating Pitch Information From Simulated Cochlear Implant Signals With Deep Neural Networks by Takanori Ashihara, Shigeto Furukawa and Makio Kashino in Trends in Hearing
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Japan Society for the Promotion of Science (grant number JP23H01063).
Supplemental Material
Supplemental material for this paper is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.