
Abstract
Decoding speech envelopes from electroencephalogram (EEG) signals holds potential as a research tool for objectively assessing auditory processing, which could contribute to future developments in hearing loss diagnosis. However, current methods struggle to meet both high accuracy and interpretability. We propose a deep learning model called the auditory decoding transformer (ADT) network for speech envelope reconstruction from EEG signals to address these issues. The ADT network uses spatio-temporal convolution for feature extraction, followed by a transformer decoder to decode the speech envelopes. Through anticausal masking, the ADT considers only the current and future EEG features to match the natural relationship of speech and EEG. Performance evaluation shows that the ADT network achieves average reconstruction scores of 0.168 and 0.167 on the SparrKULee and DTU datasets, respectively, rivaling those of other nonlinear models. Furthermore, by visualizing the weights of the spatio-temporal convolution layer as time-domain filters and brain topographies, combined with an ablation study of the temporal convolution kernels, we analyze the behavioral patterns of the ADT network in decoding speech envelopes. The results indicate that low- (0.5–8 Hz) and high-frequency (14–32 Hz) EEG signals are more critical for envelope reconstruction and that the active brain regions are primarily distributed bilaterally in the auditory cortex, consistent with previous research. Visualization of attention scores further validated previous research. In summary, the ADT network balances high performance and interpretability, making it a promising tool for studying neural speech envelope tracking.
Introduction
The reconstruction of speech information from electroencephalogram (EEG) signals encompasses a diverse array of speech features, including Mel spectra (Ramirez-Aristizabal & Kello, 2022; Zhou et al., 2022), speech envelopes (Accou et al., 2023), fundamental frequency (Van Canneyt et al., 2021), semantic differences (Broderick et al., 2018), and word surprises (Brodbeck et al., 2018). Such methods hold profound implications for the objective diagnosis of hearing loss (Bidelman et al., 2020), the prediction of speech intelligibility (Accou et al., 2021), and the exploration of cerebral mechanisms underlying speech processing (Gonzalez et al., 2024; Van Canneyt et al., 2021). These stem from the EEG's ability to reflect the brain's auditory responses, which vary across different hearing states. Employing EEG-based reconstruction of speech information in a clinical setting to evaluate hearing loss necessitates a method capable of accurately capturing speech features from EEG, which is very challenging (Accou et al., 2023).
In previous studies, linear models have been prevalently employed for the reconstruction of speech features, utilizing methods such as the multivariate temporal response function (mTRF) (Bialas et al., 2023; Crosse et al., 2016; Ding & Simon, 2012b, 2012a; O'Sullivan et al., 2015), mutual information (De Clercq et al., 2023), and canonical correlation analysis (De Cheveigné et al., 2018). These approaches conceptualize the brain's processing of speech through linear frameworks. Notably, mTRF has emerged as a critical instrument in EEG audiology research due to its robust interpretability. However, when tasked with reconstructing speech envelopes from EEG signals, these linear methodologies frequently yield suboptimal results (Thornton et al., 2022). Typically, linear techniques achieve reconstruction scores (Pearson correlation coefficient) ranging merely from 0 to 0.1. Furthermore, they often necessitate the formulation of distinct linear models for each individual, a practice that is impractical in clinical environments.
In contrast to linear methods, nonlinear methods based on neural networks have shown excellent performance in EEG-based speech tasks. In speech recognition tasks, long short-term memory and generative adversarial networks have been able to decode the speech spectrum contained therein and provide preliminary results for further speech synthesis (Krishna et al., 2020). For stereo EEG (Petrosyan et al., 2021) and electrocorticography (Wang et al., 2020) based speech decoding tasks, a number of nonlinear methods combining both lightness and interpretability have also been proposed. In addition, some researchers have also used neural network models to decode music directly from EEG and functional magnetic resonance imaging (fMRI) (Daly, 2023). The advantages of nonlinear neural networks are also evident in the task of speech envelope reconstruction. Early attempts to use deep learning methods for reconstructing speech from EEG signals can be traced back to Ciccarelli et al. (2019), who compared nonlinear neural networks with linear methods for two-talker attention decoding. Building upon this work, Thornton et al. (2022) further explored the application of deep learning in speech envelope reconstruction from EEG signals. They compared fully connected neural network (FCNN) and convolutional neural network (CNN) to the linear methods, demonstrating that nonlinear methods can robustly reconstruct speech envelopes from EEG signals. Despite leveraging insights from previous EEG signal processing methodologies, the performance of these approaches in accurately restoring speech envelopes is hampered by the oversimplified structures of the models. Accou et al. (2023) introduced a more sophisticated decoding network called the very large augmented auditory inference (VLAAI) network, designed specifically for reconstructing speech envelopes from EEG signals. Nevertheless, the complexity of the VLAAI network hinders its interpretability, potentially limiting its applicability in clinical settings.
In this study, we propose a novel architecture dubbed the auditory decoding transformer (ADT) network, which leverages a transformer decoder-based structure for reconstructing natural speech envelopes from EEG signals. The efficacy of the ADT network in speech envelope reconstruction was evaluated across two distinct datasets. Our methodology incorporates spatio-temporal convolution for EEG feature extraction, followed by reconstruction of the speech envelope utilizing an anticausal masked transformer decoder. The contributions of our ADT network to the field are multifaceted:
Utilizing a spatio-temporal convolution for feature extraction, the ADT network achieves efficient feature extraction and enables the elucidation of the feature extractor's behavior through visualized weights. This renders the ADT network a less opaque entity. The ADT network is designed to disregard EEG signals preceding speech onset by implementing anticausal masking within the transformer decoder layers. This constraint enhances realism and fortifies the robustness of speech envelope reconstruction. The ADT network's capability in envelope reconstruction was rigorously tested using the SparrKULee and DTU datasets. Comparative analyses indicate that the ADT network's performance in studying neural envelope tracking is comparable to other nonlinear methods, demonstrating improved reconstruction performance.
Materials and Methods
Datasets and Preprocessing
To evaluate the ADT network, we engaged the publicly accessible SparrKULee dataset furnished by Katholieke Universiteit Leuven in Belgium (Bollens et al., 2023). In addition, to further scrutinize the ADT network's capacity for generalization, we employed a subset of the DTU dataset, which is also publicly accessible (Fuglsang et al., 2018). The SparrKULee dataset comprises data from 85 participants, all of whom have normal hearing and are aged between 18 and 30 years. Before participating in the study, individuals were mandated to complete a questionnaire verifying the absence of any neurological or auditory conditions. The study's eligibility was contingent upon hearing thresholds below 25 dBHL, ascertained through a pure tone audiogram. During experiments, EEG recordings were obtained as participants engaged with 2–8 (average 6) individual stories, which were presented in a randomized sequence. These stories, narrated in Flemish (Belgian Dutch) by a native speaker, varied across participants to ensure that a broad spectrum of unique speech content was covered. Breaks were interspersed throughout the recording sessions to maintain participant comfort. This dataset features approximately 157 h of EEG data. For all subjects, the intensity of the auditory stimuli was uniformly maintained at 62 dBA for each ear. Recordings were conducted in an environment that was both soundproof and electromagnetically shielded.
The DTU dataset consists of EEG recordings from 18 Danish participants exposed to natural Danish speech articulated by one or two speakers under different reverberation conditions. This dataset has been previously utilized in studies conducted by Fuglsang et al. (2018) and Wong et al. (2018). For our research, we focused exclusively on the trials involving a single speaker. Each trial spanned roughly 50 s, providing each participant with a total of 500 s of auditory data. It is important to note that this data was utilized strictly for evaluation purposes and did not contribute to the training dataset.
The extraction of the speech envelopes involved using a gammatone filter bank composed of 28 filters. These filters were evenly distributed across equivalent rectangular bandwidths, with their center frequencies spanning from 50 Hz to 5 kHz. The envelope of the filtered signal was then determined using the Hilbert transform, further refined by applying a power of 0.6 to accentuate its features. Aggregating the outputs from all filters provided the final speech stimulus envelope. The EEG signal was processed through meticulous steps, beginning with high-pass filtering. A first-order Butterworth filter was applied with a cutoff frequency set at 0.5 Hz. To preserve the phase information, zero-phase filtering was conducted in both forward and reverse directions, eliminating phase distortion. The MWF Toolbox (https://github.com/exporl/mwf-artifact-removal) was employed to address artifacts within the EEG signal, effectively enhancing signal clarity. After artifact removal, both EEG and speech envelope were downsampled to 64 Hz. The partitioning of each EEG record into training, validation, and test sets followed, comprising 80%, 10%, and 10% of the data, respectively. To mitigate potential artifacts prevalent at the beginning and end of the recordings, the validation and test sets were meticulously extracted from the central portion of each record. Normalization processes were then applied to both the EEG and speech envelope data within the training set, calculating the mean and variance for each channel. This normalization, involving the subtraction of the mean and division by the variance, was extended to the training, validation, and test sets to ensure consistency across data. Given the DTU dataset's exclusive use for evaluation, each trial therein was individually normalized, thereby serving as a distinct test set.
Auditory Decoding Transformer Network
Figure 1 illustrates the architecture of the ADT network, which adopts a decoder-only design derived from the transformer model. A unique feature of this configuration is the integration of a spatio-temporal convolutional layer strategically positioned to capture the spatio-temporal characteristics embedded within EEG signals. This preprocessing step ensures that the EEG signals are optimally conditioned before their progression through the successive layers of the transformer, facilitating a more nuanced and effective decoding of auditory information.
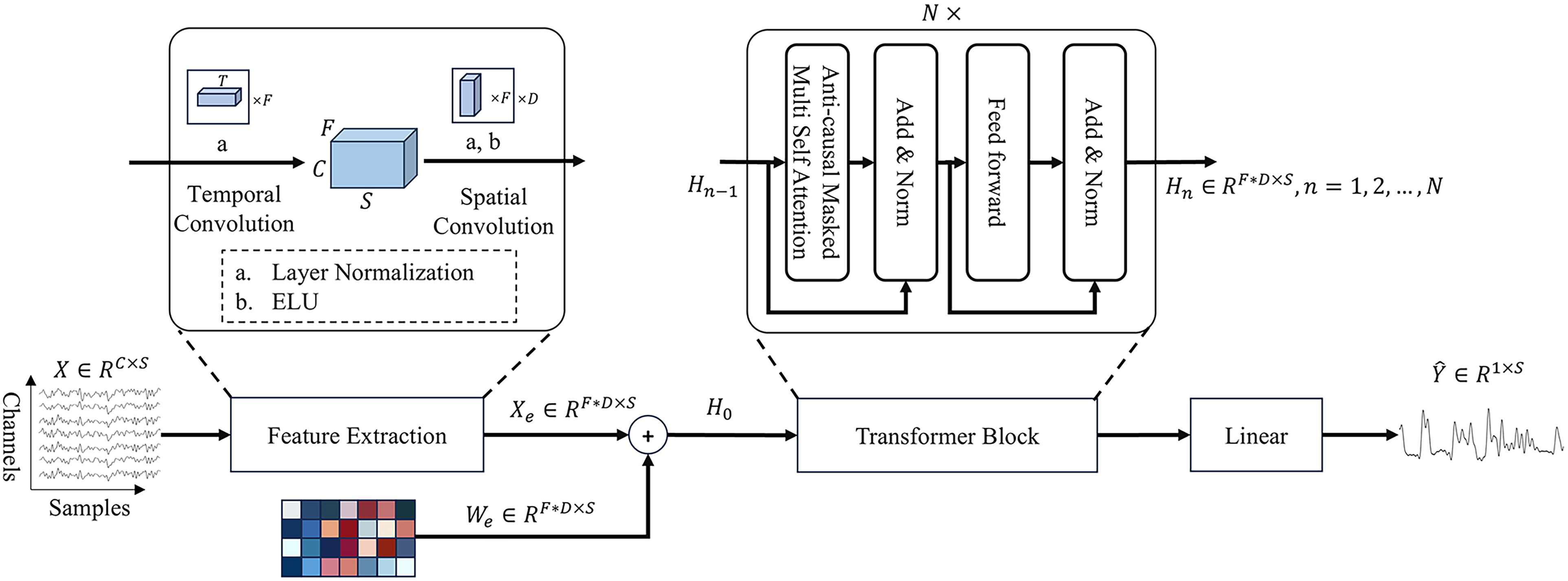
The structure of the auditory decoding transformer (ADT) network consists of three parts: feature extraction layer, transformer block, and linear layer.
The processing of an EEG signal segment

Subsequent to the feature extraction, the features undergo further processing via a multilayer transformer decoder, a specialized variant of the original transformer architecture proposed by Vaswani et al. (2017). This phase includes the execution of the anticausal masked self-attention mechanism on the input features, followed by the decoding of the speech envelope's high-dimensional features through a forward network layer, culminating in the envelope's derivation through a linear transformation:





The core of



The other component of the
The network is optimized using a loss function defined as the negative Pearson correlation coefficient:


Three different mechanisms of self-attention. (Left) Anticausal masked self-attention means that reconstructing the speech envelope at the current time depends only on the current and subsequent electroencephalogram (EEG) signal, while causal masked self-attention (right) is the opposite. Normal self-attention (middle) receives information within the entire time samples.
Models for Comparison
Experimental Setups
In this study, we implemented the ADT network utilizing TensorFlow 2.8.0 alongside the recreation of all the comparative models previously discussed. The training process for all models was standardized, using the negative Pearson correlation coefficient as the loss function and the Adam optimizer. The optimizer settings included a learning rate of 10–3, with a decay factor of 0.5 applied after a patience interval after 5 epochs without improvement and an early stopping mechanism activated after 10 epochs without improvement. This rigorous training process was conducted on an NVIDIA RTX A6000 GPU.
For evaluating the models’ performance on the SparrKULee and DTU datasets, we employed the Wilcoxon signed-rank test from the scipy package with Benjamini–Hochberg correction from the statsmodels package. This statistical method was chosen to provide a robust comparison of the models’ output. This analytical approach ensures a thorough and scientifically sound assessment of each model's capability to decode speech envelopes from EEG signals, grounding our findings in statistical significance.
Results
Experiment 1: Self Evaluation
This section focuses on optimizing the hyperparameters for the ADT, specifically the embedding dimension. The initial configuration set the embedding dimension to 64, and the ADT network was trained comprehensively. Upon completion of the training phase, an examination of the linear layer's parameters reveals a significant finding: 40 weights register nearly negligible (absolute value less than 0.05), suggesting a more efficient embedding dimension could be 32. To corroborate this inference, a subsequent visualization of the ADT network, now with the embedding dimension set to 32, was conducted. This adjustment resulted in a more concentrated distribution of parameters within the linear layer, confirming the suitability of a 32-dimensional embedding. Figure 3 illustrates the comparative densities of the linear layer's weights across both ADT networks’ configurations, providing a clear visual endorsement of the 32-dimensional embedding as the more optimal choice.

Visualization of the weights of the linear layer in auditory decoding transformer (ADT) networks with embed dimensions of 64 (up) and 32 (down). The horizontal coordinate indicates the serial number and the vertical coordinate indicates the value of the weights. Points in blue indicate that the absolute value of the weights is less than 0.05.
Following the selection of the embedding dimension, our next step involved identifying the optimal count of transformer blocks for the ADT network. Figure 4 (left) displays a comparative analysis of the ADT network's performance across a range of transformer block quantities, specifically 1, 2, 4, and 8, on the SparrKULee dataset. Based on this evaluation, we concluded that setting the number of transformer blocks to four strikes the best balance between complexity and performance.

(Left) Auditory decoding transformer (ADT) network's performance with different transformer blocks; (right) ADT network's training process on SparrKULee dataset.
The configuration of the remaining hyperparameters was informed by insights gained from previous experiments: temporal kernels
Experiment 2: Performance Evaluation
This section presents the performance of ADT on the SparrKULee dataset and the DTU dataset. Figure 5 displays the reconstruction scores of six models in the SparrKULee data. The data points in the figure represent the average reconstruction scores of each subject on the test set. The ADT network has an average reconstruction score of 0.168, which is higher than the average reconstruction scores of 0.159 for Happyquokka (p < .01), 0.130 for VLAAI (p < .001), 0.147 for CNN (p < .001), 0.094 for FCNN (p < .001), and 0.093 for linear model (p < .001). As a complement, we trained the ADT network without masking and using the causal mask with the same conditions. The average reconstruction score of the ADT network without masking is 0.161, which is lower than that of the ADT network with anticausal masking (p < .001) and close to Happyquokka (p > .5). The average reconstruction score for the ADT network with causal masking was 0.146, lower than the ADT network with anticausal masking (p < .001), the ADT network without masking (p < .001), Happyquokka (p < .001), and CNN (p > .05). Theoretically, the ADT network with the causal mask is more suitable as a baseline for envelope reconstruction for nonlinear methods.

(Left) Comparison of the performance of the auditory decoding transformer (ADT) network and other models on the test set of the SparrKULee dataset. (Right) Comparison of the performance of the ADT network without masking and with causal masking on the test set of the SparrKULee dataset. Each point in the box-and-line plot is a subject's average reconstruction score over all stimuli (n.s.:
Figure 6 displays the reconstruction scores of the six models on the DTU dataset, which was completely invisible to the models during training. The data points in the figure represent the average reconstruction scores for each subject. The average reconstruction score for the ADT network is 0.167, slightly higher than 0.152 for Happyquokka and 0.151 for CNN, but not significantly different. However, it is higher than 0.107 for VLAAI (p < .05), 0.097 for FCNN (p < .01), and 0.090 for linear model (p < .001).
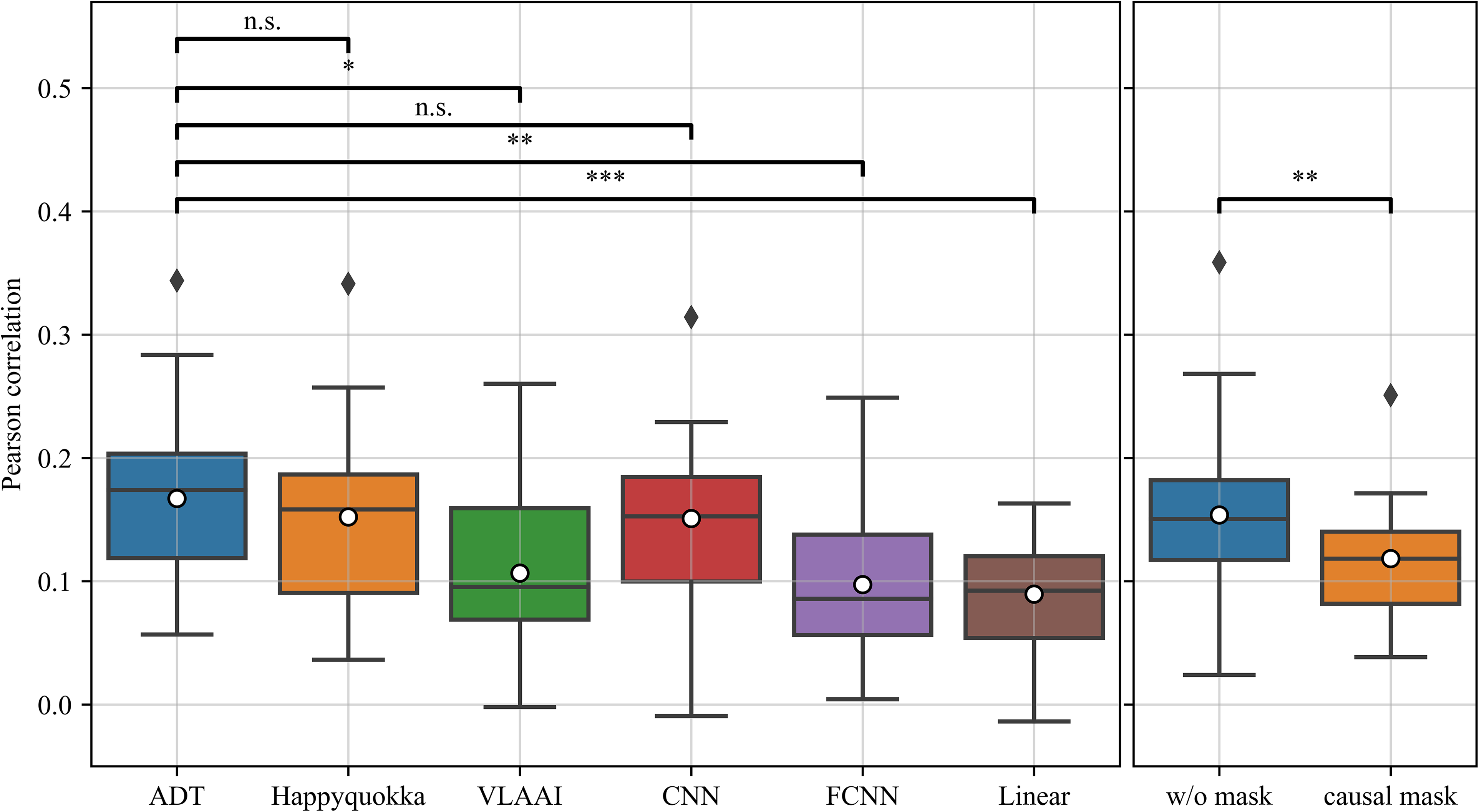
(Left) Comparison of the performance of the auditory decoding transformer (ADT) network and other models on the DTU dataset. (Right) Comparison of the performance of the ADT network without masking and with causal masking on the DTU dataset. Each point in the box-and-line plot is a subject's average reconstruction score over all stimuli (n.s.:
The average reconstruction score of the ADT network without masking is 0.154, which is slightly lower than that of the ADT network with anticausal masking (p > .05) and close to Happyquokka (p > .5). The average reconstruction score for the ADT network with causal masking was 0.118, lower than the ADT network with anticausal masking (p < .05), the ADT network without masking (p < .01), Happyquokka (p < .05), and CNN (p < .05). Performance evaluation on both datasets demonstrates that the ADT network's ability to reconstruct speech envelopes is comparable to existing state-of-the-art models.
Experiment 3: Interpretability Analysis
In this section, we delve into the interpretability of the ADT network by visualizing its feature extraction layer. This is the advantage of ADT network over other deep learning models. Drawing inspiration from analogous research, our objective is to shed light on the internal mechanics of the ADT network, particularly the construction of the feature representation. Figure 7 showcases the visualization of parameters within the spatio-temporal convolution network layer of the ADT network. This analysis treats the temporal convolution kernels as filters that capture temporal dynamics, while the spatial convolution kernels are projected onto a brain topography. This projection enables visual discernment of the specific contributions of different frequency bands and brain regions to the task of speech envelope reconstruction. This visualization enhances understanding of the ADT network's functionality and facilitates comparison between artificial neural networks and human knowledge.

Visualization of feature extraction layer’s weights. Each of the eight columns shows the learned temporal kernel and its corresponding frequency domain representation for the 0.25-s window and the four associated spatial kernels. 24 electrodes associated with the temporal lobe were labeled in the brain topography, including 10 temporal lobe electrodes: “F7,” “F8,” “T7,” “T8,” “P7,” “P8,” “FT7,” “FT8,” “TP7,” “TP8,” and 14 electrodes adjacent to the temporal lobe: “F5,” “F6,” “C5,” “C6,” “P5,” “P6,” “AF7,” “AF8,” “FC5,” “FC6,” “CP5,” “CP6,” “PO7,” and “PO8.”
Figure 7 offers a compelling visual distinction among the temporal kernels within the frequency domain. Notably, kernels 4 and 7 demonstrate a pronounced concentration of power within the beta frequency band, signifying their specialized role in extracting information pertinent to this segment of the EEG signal. Moreover, the spatial kernels reveal a pronounced intensity within the temporal lobe region (e.g., spat. kernel 1, temp. kernel 1; spat. kernel 1, temp. kernel 2; spat. kernel 1, temp. kernel 7), a critical area known for processing auditory stimuli and encompassing the auditory cortex. The visualization underscores a darker hue in this region, which aligns seamlessly with clinical insights regarding the auditory cortex's pivotal role in sound perception (Hickok & Poeppel, 2007). Furthermore, some of the spatial kernels display an apparent left–right symmetric distribution (e.g., spat. kernel 2, temp. kernel 6; spat. kernel 3, temp. kernel 8), a pattern that closely mirrors findings from previous studies on reconstructing speech features from EEG signals (Gillis et al., 2022; Van Canneyt et al., 2021; Weissbart et al., 2020). This symmetry reinforces the ADT network's processing fidelity in relation to established neuroscientific observations and highlights its ability to accurately capture and utilize bilateral auditory processing pathways in the brain.
Some spatial kernels show strong activity in the prefrontal lobes (e.g., spat. kernel 2, temp. kernel 3; spat. kernel 3, temp. kernel 2). When combined with the energy distributions in their corresponding temporal kernels, these brain topographies resemble those used to extract eye movements. This is because when independent component analysis (ICA) is used to remove artifacts, similar components to the eye components are usually removed. Previous studies have similarly considered the ability of deep learning models to actively remove noise (Bertoni et al., 2021; Liu et al., 2024).
Following the visualization and analysis phase, we embarked on a further investigation by selectively removing the eight temporal kernels to discern their individual and collective impact on the model's overall performance. To facilitate this, we categorized the temporal kernels into three groups based on their predominant frequency domain characteristics, aiming to unveil the distinct contributions of each frequency band to the speech envelope reconstruction process. These categorizations are as follows: temporal kernels 1, 3, and 6 are associated with low-frequency bands (0.5–8 Hz), serving as indicators of slower neural oscillations; temporal kernels 2, 5, and 8 correspond to mid-frequency bands (8–14 Hz), capturing intermediate neural dynamics; and finally, temporal kernels 4 and 7 are linked to high-frequency bands (14−32 Hz), reflective of rapid neural activities.
To quantitatively assess the influence of these categorically differentiated kernels, we conducted combinatorial ablation studies. In this experimental setup, each kernel or group of kernels was systematically nullified within the model to observe the resultant effect on reconstruction scores. Table 1 presents the outcomes of these ablation studies, showcasing the reconstruction scores on the SparrKULee test set following the strategic zeroing out of specific temporal kernels.
Reconstruction Scores When Temporal Kernel(s) Was/Were Removed in the Test Set of the SparrKULee Dataset.
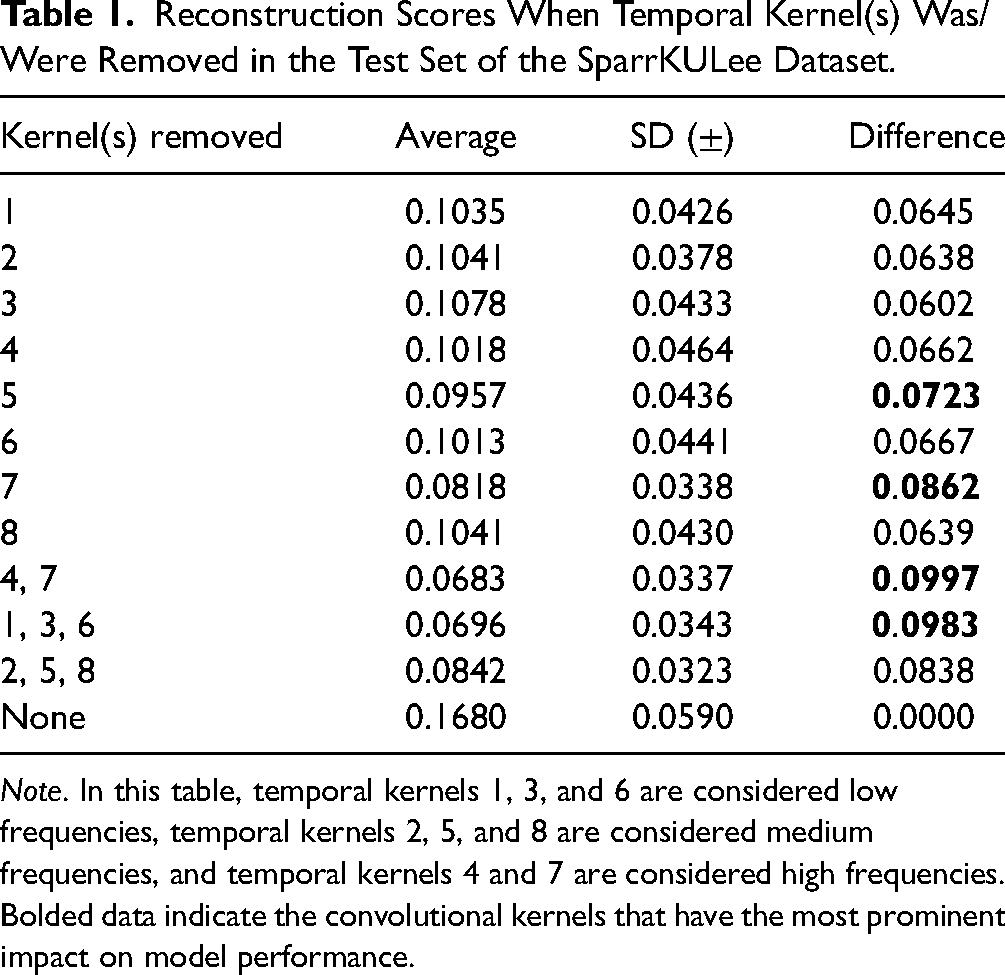
Note. In this table, temporal kernels 1, 3, and 6 are considered low frequencies, temporal kernels 2, 5, and 8 are considered medium frequencies, and temporal kernels 4 and 7 are considered high frequencies.
Bolded data indicate the convolutional kernels that have the most prominent impact on model performance.
In the ablation study, we noted a pronounced impact on the ADT network's performance, particularly when temporal kernels 5 and 7 were subjected to ablation, more so than with the other temporal kernels. Moreover, the removal of temporal kernels associated with high-frequency bands (4 and 7) markedly influenced the ADT's functionality. This observation brings an interesting perspective to the discourse initiated by Thornton et al. (2022) regarding the presumed negligible impact of high-frequency bands on speech envelope reconstruction. Our designation of high-frequency bands within the temporal kernels is predicated on the prominence of their peak frequencies within the frequency domain. Nonetheless, this classification does not imply an exclusive concentration of their energy within the high-frequency spectrum. Notably, temporal kernel 4 retains a portion of its energy within the mid and low-frequency bands, suggesting a potential role in providing auxiliary energy for the reconstruction process.
Finally, we performed a detailed visual analysis of the attention scores. Figure 8 shows the average attention scores in the test set of the SparrKULee dataset. Particularly in the first layer, head 1 and head 4 demonstrate a diagonal pattern, revealing how the ADT network relies on EEG signals within 0–0.5 s to accurately reconstruct the current speech envelope. The discovery of this diagonal pattern not only demonstrates the network's efficiency in time-series analysis but also echoes similar patterns found in previous studies, where time-aligned features are crucial for decoding speech signals.
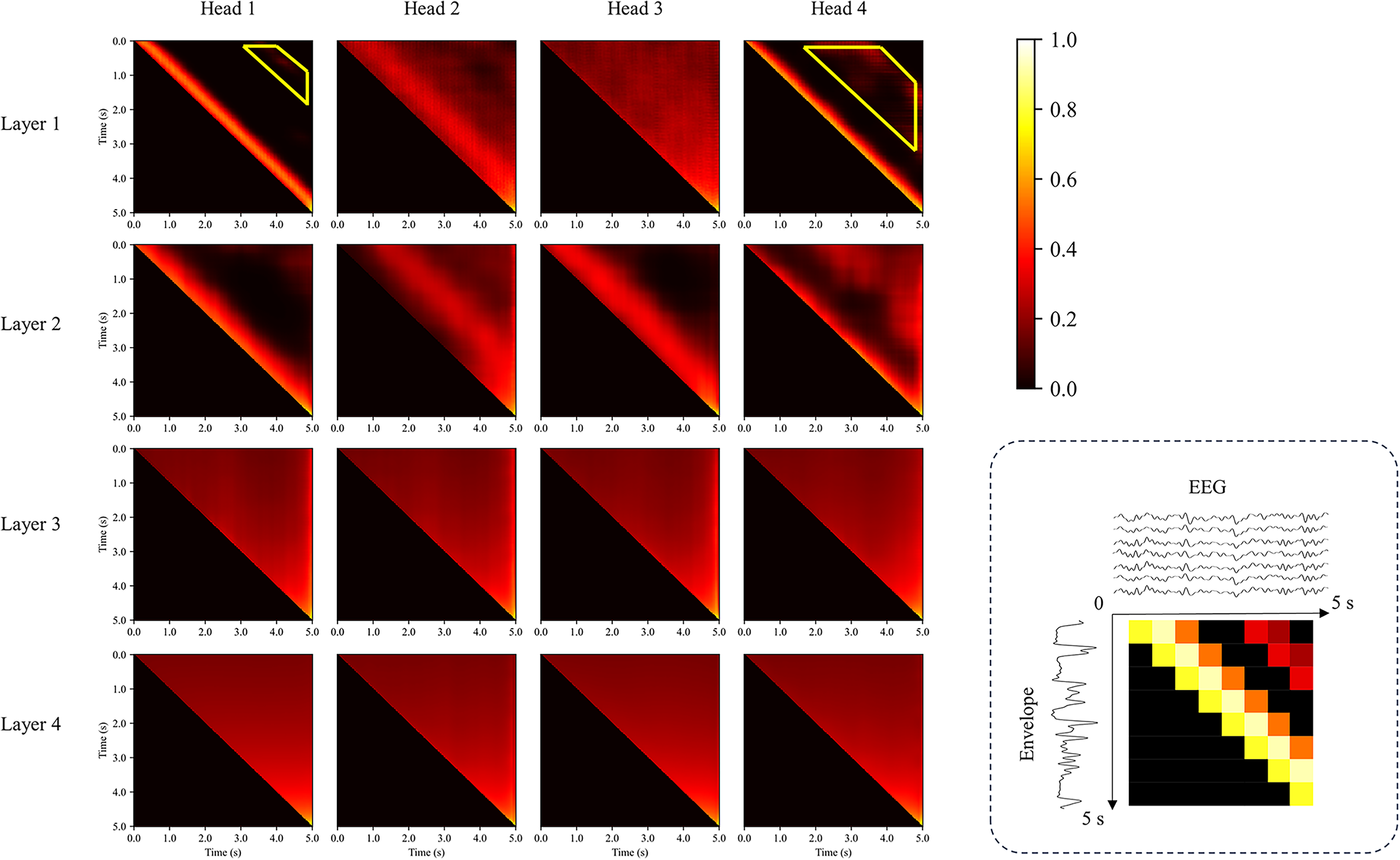
Visualization of attention scores. To enhance image contrast, attention scores are nonlinearly transformed. Attention scores are averaged over a sample of the test set, and they explain the correlation between the envelope and the EEG at different times. The subfigure in the lower right corner is a simple example. Both the horizontal and vertical axes are time axes and are 5 s in length.
Discussion
In this study, we visualized the linear layers within the output layer of the ADT network to determine the embedding dimensions of the model. We also tested the number of transformer blocks to identify the optimal configuration. This parameter adjustment method significantly reduced our workload. Although we did not conduct an exhaustive search of all parameters, the reconstruction performance of the ADT network was comparable to many existing methods used for reconstructing speech envelopes. The ADT network demonstrated impressive performance on the SparrKULee dataset, showcasing its reconstruction capabilities, and also showed generalization capability on the DTU dataset involving cross-linguistic data.
ADT network employs spatio-temporal convolution to extract features from EEG signals, which not only makes the feature extraction process interpretable but also yields compact and informative features. In addition, ADT network introduces the structure of the transformer based on inverse causal masking. Transformer has achieved great success in various time-series tasks by its powerful attention mechanism and parallel processing capability (Wen et al., 2023). By applying transformer to EEG signal decoding, ADT network can better model the long-range dependency between EEG signals and speech envelopes and extract richer and finer speech features.
More importantly, the design of anticausal masking is consistent with the causal relationship of speech signal processing: the brain's response to speech always occurs after the speech signal, but not before it. By using anticausal masking, ADT network can only access the EEG signals of the current and future moments when reconstructing the speech envelope of each moment, but not the past EEG information. This information limitation forces the model to learn more accurate and reliable speech–brain mapping relationships. Experimental results show that anticausal masking significantly improves the envelope reconstruction performance of ADT network compared to variants with no masking or causal masking, confirming the effectiveness of anticausal masking in modeling speech-evoked brain responses. In contrast, other nonlinear models, such as Happyquokka, tend to overlook the speech–brain mapping relationship, which may lead to suboptimal or less stable reconstruction performance. This is evidenced by the observation that Happyquokka's performance is comparable to that of ADT network without masking.
In the medical field, deep learning models often face skepticism due to their lack of interpretability, despite their accuracy and efficiency (Ribeiro et al., 2016). The same challenge exists in deep learning-based speech envelope reconstruction, where the “black box” nature of these networks limits their applicability. Although neural networks like VLAAI have been able to stably reconstruct speech envelopes from EEG signals, mTRF remains the most widely used method (Gonzalez et al., 2024).
To improve the interpretability of the model, we visualized the spatio-temporal convolutional layer parameters and attention scores, revealing the inner workings of the ADT network. This approach aligns with previous research and provides insights that are difficult to obtain in nonlinear models. However, our interpretations of the ADT network, particularly those involving spatial kernels, remain somewhat subjective. Fully quantifying the interpretability of the ADT network and comparing it with traditional linear methods remain a challenge.
We also encountered some issues in interpreting the ADT network. For instance, the yellow trapezoidal region marked in Figure 8 indicates that EEG signals 2–4 s after an event still respond to the current speech, which is significantly more noticeable than in adjacent regions. The reason for this phenomenon remains unclear. This might suggest that nonlinear methods have a potential advantage in capturing long-distance information, which linear methods typically cannot.
Future research should focus on several areas: first, more comprehensive optimization of the model's parameters to further enhance its performance; second, the development of better visualization and interpretation tools to improve model interpretability; and third, validating the model on larger and more diverse datasets to ensure its generalization capability and practical applicability. With these efforts, we believe that the application prospects of the ADT network in the field of speech envelope reconstruction will be further broadened.
Conclusion
This study introduces the ADT network, which utilizes anticausal masking to effectively reconstruct speech envelopes from EEG signals. The ADT network generates embedded features through spatiotemporal convolutions and decodes the speech envelope using stacked anticausal masking transformers. The ADT network achieves performance comparable to state-of-the-art methods while offering interpretability through the visualization of spatiotemporal convolutional layer parameters. It provides new insights into how EEG models can better capture and explain features in recorded EEG responses. The code for the ADT network is made public to maximize its usefulness. The code for this study can be found at https://github.com/ruix6/ADT_Network.
Supplemental Material
sj-docx-1-tia-10.1177_23312165241282872 - Supplemental material for ADT Network: A Novel Nonlinear Method for Decoding Speech Envelopes From EEG Signals
Supplemental material, sj-docx-1-tia-10.1177_23312165241282872 for ADT Network: A Novel Nonlinear Method for Decoding Speech Envelopes From EEG Signals by Ruixiang Liu, Chang Liu, Dan Cui, Huan Zhang, Xinmeng Xu, Yuxin Duan, Yihu Chao, Xianzheng Sha, Limin Sun, Xiulan Ma, Shuo Li and Shijie Chang in Trends in Hearing
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Key Research and Development Program of China, Natural Science Foundation of Liaoning Province, General Research Program of Liaoning Provincial Department of Education (Grant Nos. 2022YFF1202800, 2021-YGJC14, and JYTMS20230133).
Supplemental Material
Supplemental material for this paper is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.