
Abstract
This paper reviews the hypothesis of harmonic cancellation according to which an interfering sound is suppressed or canceled on the basis of its harmonicity (or periodicity in the time domain) for the purpose of Auditory Scene Analysis. It defines the concept, discusses theoretical arguments in its favor, and reviews experimental results that support it, or not. If correct, the hypothesis may draw on time-domain processing of temporally accurate neural representations within the brainstem, as required also by the classic equalization-cancellation model of binaural unmasking. The hypothesis predicts that a target sound corrupted by interference will be easier to hear if the interference is harmonic than inharmonic, all else being equal. This prediction is borne out in a number of behavioral studies, but not all. The paper reviews those results, with the aim to understand the inconsistencies and come up with a reliable conclusion for, or against, the hypothesis of harmonic cancellation within the auditory system.
Introduction
Our environment is cluttered with sound sources, but to act effectively we must focus on one or a few and ignore the others. This is hard because the mixing process, by which sounds from the various sources add up before entering the ears, cannot be undone. We usually do not know the mixing matrix (i.e., the delays and gains applied to each source before adding) and, even if we did, that matrix is generally not invertible. Recovering individual sources is thus impossible except in very simple cases. Nonetheless, we sometimes feel that we can follow an individual source, for example, a voice within a conversation, or an instrument within an ensemble, as if it were alone. The ability to make sense of a complex acoustic scene in terms of individual sources is known as Auditory Scene Analysis (Bregman, 1990).
Auditory Scene Analysis is sometimes discussed as a process of “grouping” elements (e.g., partials) to form sources or objects (Bregman, 1990), for example, according to Gestalt principles. However, such “elements” are conceptual rather than operational. While sinusoids and clicks serve well as synthesis parameters, it may not be possible to extract them from the sound due to theoretical limits (e.g., time–frequency uncertainty tradeoff, Gábor, 1947) and physiological limits (e.g., temporal and frequency resolution of cochlear analysis, Moore & Glasberg, 1983; Plack & Moore, 1990). If they cannot be accessed, postulating that they can be grouped is perhaps misleading.
Fortunately, perfect isolation of each source is usually not necessary. According to the principle of unconscious inference (Helmholtz, 1867; Kersten et al., 2004), we need only to recover enough information to infer the presence or nature of a target. Regularities within the world, internalized as models within the perceptual system, allow us to fill in missing parts. This process, which manipulates incomplete information “under the hood,” provides us with the illusion of perceiving each object just as if true unmixing had taken place. Information about the source is partial but, thanks to inference, it appears to us that it is complete (al Haytham, 1030; Hatfield, 2002; Imbert, 2020).
For this to work, it is essential that the sensory representation be stripped of the influence of background objects. If not, a different background might lead to a different percept, defeating the goal of perceiving the target as if it were in isolation. In other words, the sensory representation should be made invariant to the presence of interfering sources. This is analogous to invariance with respect to intra-class variability in pattern classification (Duda et al., 2012).
Several aspects of auditory processing might contribute to this goal. If target and background differ by their spectral content, cochlear filtering can be used to split sensory input into channels dominated by the target, distinct from those that reflect the background. Discarding the latter then yields a representation that is invariant to the presence of the background—albeit incomplete because of the missing channels. Likewise, if target and background occur at different points in time, temporal resolution properties of the auditory system (Moore et al., 1988; Plack & Moore, 1990) can be used to discard time intervals contaminated by the background.
Putting both elements together, the target can be “glimpsed” within spectro-temporal gaps of the background (Cooke, 2006). The glimpsed “pixels” of the time-frequency representation are handed over to subsequent processing together with a mask to indicate their position. Discarded pixels are not merely set to zero: they are given zero weight (Cooke et al., 1997). Spectro-temporal glimpsing has been proposed in speech processing applications (Wang & Brown, 2006; Wang, 2008), and to account for human perceptual abilities and derive predictive measures of intelligibility (e.g., Best et al., 2019; Josupeit et al., 2020).
Binaural disparity is another potentially useful cue. In addition to head shadow effects that produce favorable target-to-masker ratios within certain frequency channels at either ear (Grange & Culling, 2016), perception benefits from binaural interaction, which is commonly understood to follow the well-known equalization cancellation (EC) model (Durlach, 1963), and its extensions (e.g. Culling & Summerfield, 1994; Breebaart et al., 2001; Akeroyd, 2004). Signals at each ear are differentially time-shifted and scaled (“equalization”), and then subtracted one from the other (“cancellation”) to suppress interaurally coherent sound from a competing source. The internal time shift and scale factor are tuned to match the interfering source. The EC model is assumed to involve temporally accurate neural patterns processed by specialized neural circuitry within the auditory brainstem (Tollin & Yin, 2005; Joris & van der Heijden, 2019).
To summarize this viewpoint, Auditory Scene Analysis entails canceling and/or ignoring irrelevant features of the sensory input, and matching the remainder to an internal model to produce a reliable percept. The process draws on spectro-temporal analysis within the cochlea, complemented by neural time-domain signal processing within the brain, to provide the brain with a rich—albeit incomplete—representation within which a target can be “glimpsed.” The glimpses are then interpreted according to a Helmholtzian inference process.
The remainder of this paper asks whether this process can be extended to include, as a cue, the harmonic (periodic) structure of interference such as a competing talker. So-called “double-vowel” experiments found that vowels mixed in pairs are easier to identify if their fundamental frequencies (F0s) differ (Brokx & Nooteboom, 1982; McKeown, 1992; Culling & Darwin, 1993; Assmann & Summerfield, 1994), suggesting that harmonic structure somehow assists segregation. Furthermore, it appears that this effect is driven mainly by the harmonicity of the background, for example, the competing vowel (Lea, 1992; Summerfield & Culling, 1992; de Cheveigné et al., 1997). This is the harmonic cancellation hypothesis.
To set the stage, I assume a “segregation module” that works hand in hand with a “pattern-matching” module (Figure 1). The segregated sensory pattern (dark red arrow) is accompanied by a “reliability mask” (gray arrow) to assist matching of a pattern that is incomplete or distorted by the segregation process. Sensory representations might consist of a spectral profile (e.g., place-rate representation), or a temporal, or place-time pattern. Examples of the latter are a matrix of autocorrelation functions (ACFs), one per channel (autocorrelogram), or the sum over channels of these ACFs (summary ACF, SACF) (Licklider, 1959; Lyon, 1984; Meddis & Hewitt, 1992). The flow of sensory information in this figure is purely bottom-up: the only top-down influence is attentional control (dotted arrow). Top-down transfer of a sensory-like pattern is also conceivable (“schema-driven” segregation), but not considered here.

Segregation and matching. Sensory input is stripped of correlates of interfering sources, and the selected pattern, possibly incomplete, is passed on for pattern-matching (or model-fitting), together with a mask that indicates which parts are missing or unreliable. Initial stages are under attentional control.
We want to know whether harmonic cancellation is instantiated in the auditory system, but it is often easier to reason in terms of the acoustic waveform, for clarity and to distinguish theoretical from implementation limits: if a principle fails in abstract terms, consideration of biological constraints is premature. That said, references to “cochlear filtering” or “neural processing” will sometimes creep into the discussion without warning. I beg your patience when this occurs.
Harmonic Cancellation—Possible Mechanisms
How might harmonic cancellation be implemented? This section investigates several hypotheses, including frequency-domain, time-domain, and hybrid models. A later section will ask which—if any—is used by the auditory system. The busy reader might want to read about frequency domain and time domain models, then skip to the Psychophysics section and come back for details as needed. There are also interesting things to be found in the Appendix.
Frequency Domain
Conceptually, harmonic cancellation is straightforward: just zero all spectral components at multiples of

Harmonic cancellation in the idealized frequency domain. Left: line spectra of a “target” sound (red) and a “background” (blue). Next to left: mixture. Next to right: harmonic mask with zeros at all harmonics of background. Right: recovered target.
A practical implementation, however, needs to deal with two issues: one is limited frequency resolution of the spectral representation, the other is the spectral widening expected when analyzing a time-limited or otherwise non-stationary signal. Figure 3(a) shows short-term amplitude spectra of two harmonic sounds, a 200 Hz “background” with a flat spectral envelope (blue), and a weaker 238 Hz “target” with a broad peak centered at 1 kHz (red).

Harmonic cancellation in the frequency domain using a short-term Fourier representation, or a filter bank. (a) 238 Hz target (red) and 200 Hz background (blue) analysed by a filter bank with 100 Hz resolution, (b) mixture, (c) harmonic mask, (d) target recovered from mixture (green), and same in the absence of the background (thin red), (e) same analysis but using a filter bank with non-uniform frequency resolution. Filter bandwidth depends on center frequency (CF) according to estimates of cochlear frequency resolution from Moore and Glasberg 1983 as implemented by Slaney (1993).
This spectral transform has limited frequency resolution (or, equivalently, infinite resolution but the signals are time-limited, in this case eight cycles of a 200 Hz fundamental, shaped with a Hanning window). When target and masker are mixed, here with a target-to-masker ratio (TMR) of
If we multiply the spectrum of the mix with a harmonic mask with zeros at the harmonics of the background (Figure 3(c)), we obtain a “recovered” spectral pattern (d, green) very different from the true target (a, red). Two terms contribute to this difference. One is multiplicative distortion from the masking procedure (compare d, red to a, red), the other is additive distortion due to the incompletely canceled background (compare d, green to d, red). The former can, in principle, be taken into account by a pattern-matching stage if it has access to the nature of that distortion, for example, via the gray arrow in Figure 1. The latter is more serious because it is unknown and cannot be compensated for, and because it implies that we miss our goal of invariance with respect to the background. The shape of the harmonic mask (Figure 3(c)) affects the balance between error terms but a different mask would not yield a radically different result. The contrast between Figure 2 (conceptual model) and Figure 3 (feasible implementation) is sobering.
Spectral resolution is critical. Cochlear filters are narrower, on a linear frequency scale, at low than at high CFs (Figure 3(e)). From this figure, it would seem that low-frequency target features might be recovered, but perhaps not high-frequency (compare green and thin red). This illustration used a bank of gammatone filters (Slaney, 1993) with equivalent rectangular bandwidths (ERBs) from psychophysical estimates (Moore & Glasberg, 1983). If cochlear filters were narrower (e.g., Shera et al., 2002; Sumner et al., 2018) a wider frequency range might be recoverable (not shown), but resolution would still be limited if the stimulus were short or non-stationary.
In summary, frequency-domain cancellation requires (a) a spectral representation with resolution sufficient to cancel background partials while retaining enough of the target to support pattern matching, (b) an estimate of the background period
Time Domain
Harmonic cancellation can also be implemented in the time domain by a simple filter with impulse response


Harmonic cancellation in the time domain. (a) Impulse response of the cancellation filter (left) and corresponding magnitude transfer function (right). (b) Input (left) and output (right) of the cancellation filter for the background 100 Hz vowel /a/ (top), target 132 Hz vowel /e/ (middle), and mixture at TMR=
Figure 4(b) shows a background vowel stimulus /a/ with fundamental 100 Hz (top), a weaker target vowel /i/ with fundamental 132 Hz (middle), and their mixture (bottom), before (left) and after (right) filtering with a cancellation filter with lag
In summary, time-domain cancellation requires (a) a time-domain signal representation such that Equation (1) can be implemented, (b) an estimate of the background period
Hybrid Models
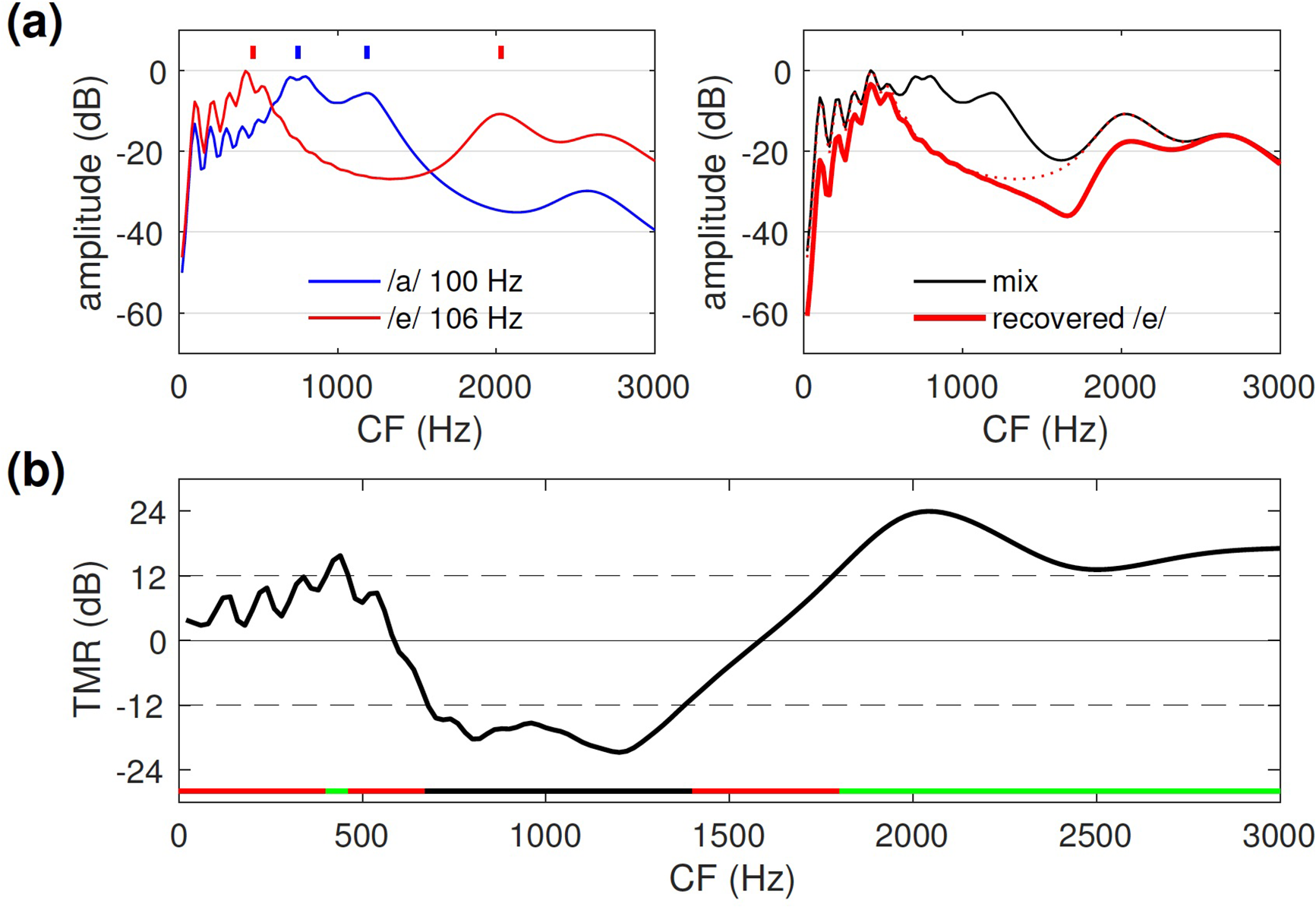
A hybrid model combines spectral and temporal processing, for example, cochlear filter bank analysis followed by time-domain harmonic cancellation within the brainstem. There is a rich literature based on this idea for the purpose of auditory modeling and sound processing applications (e.g., Lyon, 1983, 1988; Weintraub, 1985; Meddis & Hewitt, 1992; Assmann & Summerfield, 1990). A benefit of the filter bank is that TMR varies across channels, some favoring the target and others the background (Figure 5(a)), which may be useful if the dynamic range of temporal processing is limited.

(a) TMR within each channel of a model cochlear filter bank for an input consisting of a 124 Hz harmonic target mixed with a 100 Hz harmonic background with overall TMR=0 dB (black),
It is worth remembering that linear, time-invariant operators can be swapped: a time-domain cancellation filter applied to the acoustic waveform can instead be applied to each channel after filtering: the result is the same (Figure 5(b)). Cochlear filtering and transduction are both non-linear and non-stationary (e.g., adaptation), but the “equivalence” of Figure 5(b) may nonetheless be useful conceptually. I review briefly here a selection of hybrid schemes for harmonic cancellation, described in detail in the Appendix (Hybrid Models). In brief:
Hybrid Model 1: Cancellation-enhanced spectral patterns. A time-domain cancellation filter is applied to each channel of the cochlear filter bank, resulting in are cleaner spectral patterns for pattern matching. Hybrid Model 2: Channel rejection on the basis of periodicity. Channels dominated by the background periodicity are discarded, and the remaining channels are used to form a time-domain pattern for pattern matching, as in the concurrent vowel identification model of Meddis and Hewitt (1992). Hybrid Model 3: Cancellation filtering of selected channels. As in Hybrid Model 2, channels dominated by the background are discarded, and channels dominated by the target are left intact. In contrast to Hybrid Model 2, channels with intermediate TMR are processed by a cancellation filter. The result is used for time-domain pattern matching. Hybrid Model 4: Channel-specific cancellation filter. The parameter Hybrid Model 5: Synthetic delays. The “synthetic delay” mechanism of de Cheveigné and Pressnitzer (2006) is used to implement the relatively long delays Hybrid Model 6: Logan’s theorem. This is not a specific model but a processing principle. A narrowband signal can be reconstructed perfectly from its zero crossings (and hence also from its half-wave rectified version) (Logan, 1977). This implies that, despite the non-linearities, the temporal model can be implemented after transduction as if it were applied to the acoustic waveform (the theorem does not say how).
These examples illustrate how peripheral filtering and temporal processing might work hand-in-hand to enhance a spectral model (Hybrid Model 1) or a temporal model (Hybrid Models 2–6) of harmonic cancellation. To summarize, a wide variety of mechanisms can implement harmonic cancellation: spectral, temporal, and hybrid.
Alternatives to Harmonic Cancellation
It is important to consider alternatives: to the extent that they are viable, the case for harmonic cancellation is weaker. Other aspects of the spectral structure of the target or background might support segregation, even in situations that seem to implicate harmonic cancellation.
Harmonic Enhancement
According to this hypothesis, the harmonic structure of a target sound allows its extraction from a background. The idea is attractive: it fits with the Auditory Scene Analysis credo that components of a sound are “grouped” together, here on the basis of harmonicity, to form a coherent “object” that can be distinguished from other parts of the scene (Bregman, 1990). It is satisfying to hypothesize that voiced speech might be “engineered” for this purpose through evolution (e.g., Popham et al., 2018).
The mechanisms just reviewed can be re-purposed for enhancement. For example, the mask in Figure 2 can be made to select target harmonics rather than reject background harmonics. Likewise, replacing the minus by a plus in Equation (1), and setting

Incidentally, the term “harmonic enhancement” appears in other contexts with a different meaning: perceptual enhancement of one harmonic of a complex when it is turned on or off (e.g., Hartmann & Goupell, 2006). Hopefully no confusion will result from this overloading of the terminology.
Spectral Glimpsing
Between the lines of a harmonic spectrum are gaps where target components might be glimpsed (Deroche et al., 2013; Guest & Oxenham, 2019), and this might conceivably account for the benefit observed when a background is harmonic rather than inharmonic. Figure 5(a) shows how individual channels in the low-frequency region can preferentially reflect one source or the other, as long as partials are not too close. The spectral-glimpsing hypothesis glosses over the question of how target channels are distinguished from background channels. In that, it differs from Hybrid Model 2 above.
Waveform Interactions
The sinusoidal waveforms of two or more partials can interact within a channel of a filter bank to produce a complex “beat” pattern. This can occur between partials of the same sound (with a rate equal to the fundamental if the sound is harmonic) or partials of different sounds. The patterns that result are quite diverse (static summation, slow fluctuations, rapid beats, etc.), and they depend in a complex way on several parameters (frequencies, levels, filter shapes). The “waveform interactions” hypothesis is thus ill-defined unless further specified.
From slow to fast: phase-dependent summation of same-frequency partials constitutes a potential confound in experiments that include a “zero
Interaction of more than two harmonics produces a phase-dependent beat pattern that is more deeply sculpted for certain phase relations, such as cosine, or “Klatt” phase that approximates natural phonation with a glottal pulse within each period. Valleys between pulses might then allow a target to be glimpsed for a favorable alignment, as might occur if sounds of different F
Beat patterns might be exploited to group channels by correlation (Hall et al., 1984; Sinex et al., 2002; Sinex & Li, 2007; Fishman & Steinschneider, 2010; Shamma et al., 2011) or, alternatively, beat rates in the F
Beat amplitude depends non-monotonically on the amplitude of sources within the stimulus, and the shape of the beat pattern is phase-dependent (for three or more partials). Beat rate affects perceptual salience (e.g., roughness) non-monotonically, and the rate itself may depend non-monotonically on F
Modulation Filter Bank
An influential idea is that cochlear filtering and transduction are followed by analysis by a modulation filter bank within the auditory system (Kay & Matthews, 1972; Viemeister, 1979; Dau et al., 1997; Joris et al., 2004; Stein et al., 2005; Jepsen et al., 2008). Conceptually, this seems rather like reproducing internally an operation (spectral analysis) that is already carried out in the cochlea. A major difference, however, is that it occurs after demodulation of each output of the peripheral filter bank (non-linearity followed by smoothing), which makes it primarily sensitive to features of the waveform envelope, and less sensitive to carrier phase. The concept makes most sense when applied to slow fluctuations (e.g., below
Alternatively, the 2D pattern could be used to tag channels for the purpose of segregation (Ewert & Dau, 2000; Meyer et al., 1997). One might consider implementing this modulation filter bank using cancellation filters, which would result in a model similar to the hybrid models reviewed previously, a major difference being the demodulation step which renders the model sensitive to envelope periodicity rather than (or in addition to) waveform periodicity.
In Summary
Multiple models have been put forward to explain how the harmonic structure of sounds within an acoustic scene can be used to analyze the scene and attend to particular sources. Some fit the definition of harmonic cancellation, others do not. The next section reviews psychophysical evidence in favor—or against—this hypothesis and its alternatives.
Psychophysics
Detection Benefits from ΔF0
When presented with a mixture of two vowels, subjects more often report that they hear two vowels if the F0s differ (de Cheveigné et al., 1997; Arehart et al., 2005, 2011; McPherson et al., 2020). Likewise, when presented with a harmonic tone with one partial mistuned, they may detect the partial as “standing out” as a separate sound (Moore et al., 1985, 1986). Such a mistuned target tone can be detected at
Discrimination and Identification Benefit from
F
Mistuning one partial of a harmonic complex allows it to be matched to a pure tone (Hartmann et al., 1990), implying not only that this “second sound” is detectable, but also that its frequency can be accessed. Subjects are more likely to identify both vowels of a concurrent pair if their
Improved performance with
Background Harmonicity is Important
In “double vowel experiments,” listeners give two answers on each trial, but it has been noted that one constituent (the “dominant” vowel) is usually identified regardless of
With the
Gockel et al. (2002) found that the threshold for detecting noise in a harmonic masker was 11–14 dB lower than the converse, and Gockel et al. (2003) found a similar result for loudness. This suggests that a harmonic masker might be less potent than a noise masker, as expected from harmonic cancellation. As mentioned earlier, Micheyl et al. (2006) found that a harmonic complex tone (HCT) was easier to detect within a background consisting of another HCT than within noise, and Klinge et al. (2011) found a lower threshold for detection of a tone embedded in (but mistuned from) a harmonic rather than inharmonic or noise background (see also Oh & Lutfi, 2000).
All these results are consistent with harmonic cancellation. However, harmonic cancellation is not exclusive of other mechanisms, and one might expect the auditory system to use several or all if they are effective. The next section reviews evidence for harmonic enhancement.
Target Harmonicity is Less Important
The idea that harmonicity ensures that a sound does not “fall apart into a sea of individual harmonics” is seducing (Popham et al., 2018), but studies that tried to demonstrate an advantage of target harmonicity for segregation have met with mixed results. As noted earlier, in double-vowel experiments the benefit of a
For continuous speech, it has been hypothesized that target harmonicity (one aspect of “temporal fine structure,” TFS) could aid glimpsing within a spectro-temporally modulated noise, by tagging time–frequency regions that are voiced. However, a direct test of this hypothesis gave negative results (Shen & Pearson, 2019). There is however some evidence that continuity of target F
A difficulty in testing the enhancement hypothesis is that manipulation of the target might affect its intelligibility independently of any segregation effect. Whispered speech is reportedly less intelligible than voiced speech (Ruggles et al., 2014), and reverberation, which disrupts harmonicity of an intonated target, also degrades intelligibility (Deroche & Culling, 2011b). Manipulating F
An Intriguing Exception: Target Pitch
In contrast to results just reviewed, a target within a noise background is easier to detect if it is harmonic than inharmonic (McPherson et al., 2020). This inconsistency is resolved if we reflect that a harmonic target is likely detected in noise on the basis of its pitch (Scheffers, 1984; Hafter & Saberi, 2001; Gockel et al., 2006), which is probably more salient if the sound is harmonic. If frequency discrimination in noise relies on a pitch percept, it too should benefit from target harmonicity, as found by McPherson et al. (2020). Thus, we cannot with confidence attribute such benefits to enhanced segregation as opposed to an enhanced pitch percept.
It is also intriguing that the pitch of a target is easier to discriminate if mixed with a noise background rather than a harmonic background (Micheyl et al., 2006), opposite to what we expect of harmonic cancellation (indeed, in that study the same sounds were easier to detect within a harmonic background than a noise background). It would seem that background harmonicity interferes with target pitch, possibly in a way similar to the phenomenon of pitch discrimination interference (PDI) (Gockel et al., 2009; Micheyl et al., 2010). That interference is not absolute: the pitch of a mistuned partial may be heard within a harmonic background (Hartmann et al., 1990; Hartmann & Doty, 1996), and individual tones may be heard within a chord (Graves & Oxenham, 2019), consistent with skills found in competent musicians.
Is the Benefit Explained by Spectral Glimpsing?
Several results seem consistent with this hypothesis. The benefit of
However, Deroche et al. (2013, 2014a, 2014b) argued that the larger gaps that arise when a masker is made inharmonic should reduce masking, contrary to their results. A possible explanation is that cancellation and glimpsing are both involved (Deroche et al., 2014b), consistent with Hybrid Models 2 or 3.
Is the Benefit Explained by Waveform Interactions?
As pointed out earlier, waveform interaction comes in multiple forms, and it is not always clear which version of the hypothesis is implied when it is invoked. One difficulty, common to many versions, is that the non-monotonic dependency of beat amplitude on component amplitudes implies that the magnitude (and spectral locus) of beat-dependent cues should show non-monotonic variations with level, whereas identification usually varies monotonically with TMR. Another challenge is that F
Phase effects attributable to PPA were found at 50 Hz, but not at 100 Hz or higher (Summerfield & Assmann, 1991; de Cheveigné et al., 1997; Deroche et al., 2013, 2014; Green & Rosen, 2013, but see Summers & Leek 1998). Furthermore, reverberation should scramble the phase relations required by PPA, whereas it does not affect segregation unless F
Culling and Darwin (1994) attributed effects of small
The Special Case of Maskers With Frequency-Shifted or Odd-Order Harmonics
In experiments that require detecting (or matching the pitch of) a mistuned partial of rank
However, Roberts and Brunstrom (1998) found a similar result when the background series had been made inharmonic by shifting all partials by the same amount
An alternative is that harmonic cancellation is applied locally within peripheral channels, for example based on Hybrid Model 4 (analogous to what has been proposed for the binaural EC model, Culling & Summerfield, 1994; Akeroyd, 2004; Breebaart et al., 2001). Specifically: the shifted partials
This reasoning can be extended to the case of a background harmonic complex with only odd harmonics of F
In Summary
A body of evidence agrees with the hypothesis that harmonic cancellation assists auditory scene analysis, complementing the well-known benefits of peripheral frequency analysis. Dissenting results are sparse. The alternative hypothesis of harmonic enhancement, while attractive, garners little experimental support. Harmonic cancellation raises a number of issues that are discussed further in the Appendix. These include period estimation (necessary to apply cancellation), the relations between correlation and cancellation, analogies with the well-known EC model of Durlach, pattern matching with missing data, potential anatomical and physiological substrates, and the possible synergy between cochlear filtering and neural filtering.
Discussion
Periodicity (or harmonicity)—and its perceptual correlate, pitch—have long captured the attention and imagination of thinkers and scientists (Micheyl & Oxenham, 2010). A periodic sound within the right parameter range evokes a salient percept that is long-lasting in memory (McPherson et al., 2020), is robust to masking by noise (Hafter & Saberi, 2001; McPherson et al., 2020), and supports fine discrimination (e.g., Micheyl & Oxenham, 2010). However, the idea that a sound “falls apart” unless it is harmonic does not withstand a bit of reflection. A one-period tone pulse seems unitary without the aid of harmonicity, meaningless at that duration. A harmonic tone of longer duration may sound unitary, but so does noise which lacks harmonicity. An alternative proposition is that the percept evoked by a sound is unitary by default, and that “multiplicity” is inferred from the accumulation of evidence in favor of additional sources. A complex with a mistuned harmonic initially sounds like a single object but, given time and encouragement, a subject might detect something amiss and interpret it as an additional source. The process requires time (Moore et al., 1985; Hartmann et al., 1990; McKeown & Patterson, 1995), and is harder if the background is made inharmonic (Roberts & Brunstrom, 2003; Roberts & Holmes, 2006). Thus, one could argue, the harmonic nature of one part of the stimulus makes it easier to detect the presence of other parts. From this perspective, harmonicity of a source may contribute to a percept of multiplicity for mixtures in which it participates, rather than to its own unity.
That background harmonicity is crucial comes as a surprise, as it suggests that segregation must rely on an adventitious quality of the environment. Also surprising is that target harmonicity has only a minor role, as it goes against the attractive idea that communication sounds are “engineered” through evolution to be harmonic for resilience. It does make sense, however, when one realizes that cancellation works well (and enhancement poorly) at low TMR, which is when segregation is most needed. Infinite TMR improvement can be achieved, in principle, for very short stimuli for which enhancement offers more limited benefit. Cancellation meshes well with the concept that perception involves a quest for invariance to irrelevant dimensions.
Cancellation as a Model of Sound
The ability to cancel unwanted sounds is clearly useful for perception, but one might take a step further and argue that it is, in part, constitutive of perception. As a predictive model, a harmonic cancellation filter characterizes the part of input that it can cancel, just as an autoregressive model characterizes its spectral envelope, or a binaural EC model its spatial position. The residual, which by definition does not fit that model, informs us about “what else is out there.” It too can be characterized by recursively applying the same model or, alternatively, a compound model can be applied to the original sound to estimate parameters jointly (as in the multiple F
Like pattern classification (Duda et al., 2012), cancellation seeks invariance with respect to irrelevant dimensions of the input, specifically those that reflect the background. In contrast to classifiers that involve non-linear transforms, cancellation as described here is purely linear, which makes sense given that the acoustic mixing process itself is linear.
How Useful is it in Practice?
Auditory Scene Analysis benefits from multiple cues and regularities, of which harmonicity is but one. Harmonic cancellation is likely to be useful in situations where neither temporal separation, nor spectral separation, nor binaural disparities are effective to suppress interfering sources, and then only if the interference is harmonic. Thus, at best, it is one tool among many, beneficial in a restricted set of circumstances.
Measured in terms of TMR at threshold performance, the harmonicity benefit can reach
For vowel identification, the benefit is measurable for
Real speech maskers differ from ideal harmonic maskers in that periodic portions are sparsely distributed over time (Hu & Wang, 2008), the F
Learning?
Pattern-matching models of pitch perception (de Boer, 1976) postulate some form of harmonic template, or “sieve” (Schroeder, 1968; Duifhuis et al., 1982), and the same template is also required for a spectral domain model of segregation. This is non-trivial: the dictionary of templates must cover the full range of F0s, there must be some mechanism to align the templates accurately with the substrate of frequency analysis (e.g., cochlea), and each template itself is a complex affair involving multiple slots with accurate tuning. It has been proposed that templates are learned from exposure to harmonic sounds such as speech (Terhardt, 1974; Divenyi, 1979; Bowling & Purves, 2015; Saddler et al., 2020) possibly modulated by cultural preferences (McDermott & Hauser, 2004; McDermott et al., 2010, 2016; McPherson et al., 2020). The demonstration that templates can be learned from noise (Shamma & Klein, 2000; Shamma & Dutta, 2019) makes that argument more tenuous, and highlights the question of what, exactly, is being learned. Perhaps that algorithm discovers, rather than learns, the mathematical property that is exploited more directly by the cancellation filter.
The template-like properties of a time-domain cancellation filter (Equation (1), Figure 4) stem from mathematics, rather than learning. This is a big appeal: why jump through hoops when a simple solution is at hand? The organism may still need to discover that this regularity exists and is worth attending to, and the mechanism may need tuning, particularly if it involves combining frequency channels. This leaves ample room for learning, and possibly even cultural influences.
Is There Time?
In a classic chapter, de Boer (1976) likened auditory theory to a pendulum moving between “time” and “place” (spectrum). The pendulum is still swinging, and several recent papers have strengthened the case for spectral and place-rate accounts (e.g., Shera et al., 2002; Sumner et al., 2018; Verschooten et al., 2018; Whiteford et al., 2020; Su & Delgutte, 2020). Arguments for time remain (a) evidence for temporal mechanisms of binaural processing (see section Analogy with Binaural EC of the Appendix), (b) existence of specialized neural circuitry within the brain (see section Anatomy and Physiology of the Appendix), and (c) the simplicity, effectiveness and ease of implementation of a time-domain harmonic filter, in contrast to a harmonic template or sieve in the frequency domain.
Hybrid models offer the best of both worlds, but they may worry scholars who care about parsimony or falsifiability. As a case in point, if we admit that delay might arise by cross-channel interaction (de Cheveigné & Pressnitzer, 2006), it is hard to say anything for, or against, the hypothesis that processing involves neural delays. On the other hand, it would be unwise to let this blind us to the possibility that auditory system does rely on a combination of spectral and time-domain analysis.
My personal inclination is that auditory perception involves time-domain processing within the brain, but the effectiveness of that processing is enhanced by the peripheral bandpass filter bank that helps overcome the effects of non-linear transduction and noise (based on principles related to Logan’s theorem). High-resolution mechanical filtering serves to “pre-calculate” a set of useful basis functions upon which the brain then operates in the time-domain (see sections Transforms in Filter Space and Non-Linearity of the Appendix). In this perspective, cochlear mechanics are the “last chance” to process acoustical signals with good resolution, linearity, and low noise, before handing transduced patterns over to more flexible but less accurate neural processing.
Carving Sound at its Joints
Auditory Scene Analysis is often described as a process of assembling elements across the spectrum (simultaneous grouping) or across time (sequential grouping) (Bregman, 1990), mirroring the common process of additive or concatenative synthesis by which stimuli are created in the lab. It glosses over the issue of whether these ingredients are recoverable from the mix, upon which this assumption depends. Once the coins are thrown into the melting pot, can we pull them out intact? According to classic Auditory Scene Analysis, we can: spectral analysis reveals “natural kinds” (partials), between which are found the “joints” at which sounds may be carved (Campbell et al., 2011). Indeed, according to this view, a grouping mechanism is required for any complex sound to form a coherent whole, otherwise it might shatter into as many percepts as partials (although few of us would claim to ever have heard more than a couple of such percepts within a sound). The wisdom of invoking sinusoidal partials as “natural kinds” on which Auditory Scene Analysis processes operate is rarely questioned.
In contrast, harmonic cancellation requires no analysis-into-parts or grouping. Whereas a bandpass filter is defined by what it selects (a frequency band), a cancellation filter is defined by what it removes (periodic power at period
Conclusion
The harmonic cancellation hypothesis states that the harmonic (or periodic) structure of interfering sounds can be exploited to suppress or ignore them. A large body of experimental results are consistent with this hypothesis, whereas alternative hypotheses for F
Appendix: Deeper Issues
The harmonic cancellation hypothesis is straightforward and well supported experimentally, but it raises a number of interesting questions that are worth considering.
Hybrid models
The hybrid harmonic cancellation models enumerated in the main text are described here in greater detail.
Hybrid Model 1: Cancellation-enhanced spectral patterns. Each channel of a filter bank is convolved with a cancellation filter tuned to Hybrid Model 2: Channel rejection on the basis of periodicity. Filter bank channels are divided into two groups based on TMR (estimated based on residual power at the output of a cancellation filter tuned to Hybrid Model 3: Cancellation filtering of selected channels. Filter bank channels are divided into three groups based on TMR. Channels with large TMR are left untouched, channels with small TMR are discarded, and intermediate channels are processed by the cancellation filter. Keeping the first group intact reduces target distortion, and discarding the second group avoids contamination from noise if the cancellation filter is imperfect (as it might be due to non-linearity or noise). Cancellation filtering is reserved for channels with intermediate TMR, for which it can be effective. This model differs from Hybrid Model 2 by the presence of this third group. A similar suggestion was made by Guest and Oxenham (2019). Hybrid Model 3 is illustrated in Figure 6(b). The black line shows the TMR per channel at the output of a filter bank in response to the mix /a/+/e/ with overall TMR = 0 dB. Channels for which TMR exceeds some threshold (+12 dB in this example) are left intact (green), channels for which TMR is below a second threshold ( Hybrid Model 4: Channel-specific cancellation filter. In contrast to previous models, for which the parameter Hybrid Model 5: Synthetic delays. The cancellation filter of Equation (1) requires a delay equal to the background period (e.g., 20 ms for a 50 Hz fundamental). The existence of delays of this size in the auditory system has been questioned (e.g., Laudanski et al., 2014), and to address this issue it has been suggested that long delays might arise from cross-channel interaction (de Cheveigné & Pressnitzer, 2006). According to this model, the filter bank serves mainly that purpose: to help synthesize the delay Hybrid Model 6: Logan’s theorem. Rather than a specific model, this is a processing principle that addresses the issue of the non-linear transduction that follows cochlear filtering. Due to half-wave rectification, each transduced signal is “blind” to one-half of every cycle, and thus one might worry that some information was lost. Logan’s theorem states instead that a narrowband signal can be reconstructed perfectly from its zero crossings, and hence also from its half-wave rectified version (Logan, 1977; Shamma & Lorenzi, 2013). To the extent that it is applicable here, the benefit of cochlear filtering would be to linearize transduction, so that neural signal processing has, in effect, full access to the acoustic waveform (see the section “Non-Linearity” below). Two hybrid models of harmonic cancellation. (a) Hybrid Model 1. Left: power as a function of CF for synthetic vowels /a/, F
Period Estimation
Harmonic cancellation requires an estimate of the interferer period
From this perspective, cancellation is both an analysis tool (it cancels part of a signal to reveal the remainder), and an estimation tool (it estimates the period of the part it cancels). Applied recursively to a mixture of two sounds, it can reveal two periods: we first estimate the period of the dominant sound and cancel it, and then recurse on the remainder. These steps can be performed in parallel by searching the two-dimensional parameter space of a cascade of cancellation filters defined as
Associated with the period is an estimate of the degree to which the sound is, in fact, periodic. A straightforward measure is output power of a cancellation filter tuned to the period
The threshold beyond which a sound should be declared “aperiodic” depends on the application, and more specifically on the distributions of “periodic” and “aperiodic” sounds as defined by the application’s needs. It is worth noting that residual aperiodic power at the output of a narrowband filter (e.g., filter bank channel) takes on relatively low values even if the stimulus is aperiodic. The threshold needs adjusting accordingly.
Correlation and Cancellation
We can define the running autocorrelation function (ACF) at time


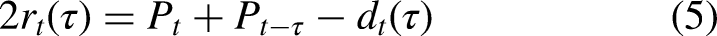



Equation (5) is useful to derive the ACF from the SDF or vice-versa. It can also be extended to more terms, for example to implement a cascade of cancellation filters in terms of correlation. This allows different modeling strands to be unified, and justifies some flexibility when speculating about hypothetical neural implementations (see below).
Analogy with Binaural EC
Durlach’s EC model has been successful in accounting for binaural unmasking (Durlach, 1963; Culling & Summerfield, 1994; Culling, 2007) and binaural pitch phenomena (Culling, Summerfield, & Marshall, 1998), and in predictive models of speech intelligibility (Beutelmann & Brand, 2006; Lavandier et al., 2012; Cosentino et al., 2014; Schoenmaker et al., 2016). Binaural interaction has also been couched in terms of inter-aural correlation rather than cancellation (Jeffress, 1948) but, as pointed out by Green (1992), an EC model can be implemented on the basis of inter-aural correlation, and vice versa, as the two are related:
An interesting suggestion is that EC might operate independently within frequency channels (Culling & Summerfield, 1994; Akeroyd, 2004; Breebaart et al., 2001), rather than with parameters common to all channels as in the original EC model (Durlach, 1963). It has been further suggested that EC parameters can be estimated and applied within short-time windows (Wan et al., 2014; Hauth & Brand, 2018), which paves the way for a spectro-temporal form of the EC model that supports “glimpsing” (Beutelmann et al., 2010).
A monaural version of the EC model has been invoked to explain comodulation masking release (CMR) (Piechowiak et al., 2007).
Anatomy and Physiology
Time-domain and hybrid models entail time-domain signal processing within the brain. Anatomical and physiological specializations to support such processing include transduction and coding of acoustic temporal structure in the auditory nerve (up to 4–5 kHz or possibly higher, Heinz et al., 2001; Hartmann et al., 2019; Carcagno et al., 2019; Verschooten et al., 2019), specialized synapses in the cochlear nucleus and subsequent relays, and fast excitatory and inhibitory interaction in the medial and lateral superior olives (MSO and LSO) (Grothe, 2000; Zheng & Escabí, 2013; Keine et al., 2016; Beiderbeck et al., 2018; Stasiak et al., 2018) and other nuclei (Albrecht et al., 2014; Caspari et al., 2015; Felix et al., 2017). Some of these circuits are interpreted as serving binaural interaction, but presumably could be borrowed for other needs (see Joris & van der Heijden, 2019; Kandler et al., 2020, for recent reviews).
The time-domain cancellation filter of Figure 4(c, left), Equation (1), can be approximated by the “neural cancellation filter” of Figure 4(c, right). Spikes arriving via the direct pathway are suppressed by the coincident arrival of spikes delayed by
Temporally accurate inhibitory transforms of sensory input are created in several nuclei, including cochlear nucleus (CN) (stellate-D cells), medial and lateral nuclei of trapezoid body (MNTB and LNTB), and ventral nucleus of the lateral lemniscus (VNLL) (Arnott et al., 2004; Caspari et al., 2015; Joris & Trussell, 2018). Fast interaction between direct and delayed neural patterns could in principle occur as early as the dendritic fields of cells in CN (Shore et al., 1991; Schofield, 1994; Davis & Voigt, 1997; Needham & Paolini, 2006; Xie & Manis, 2013), or as late as dendritic fields of the inferior colliculus (IC) (Caspari et al., 2015; Chen et al., 2019). A recent study reported evidence for an inhibitory “veto” mechanism at the axon initial segment of LSO principal neurons, with very narrow tuning to inter-aural time differences (Franken et al., 2021). Transmission failure at reputed “secure” synapses in CN and MNTB might conceivably reflect a similar veto mechanism (Mc Laughlin et al., 2008; Englitz et al., 2009; Stasiak et al., 2018).
The cancellation-correlation equivalence discussed earlier implies that fast interaction might also be excitatory-excitatory, the correlation pattern being later converted to a cancellation-like statistic by slower inhibitory interaction along the lines of Equations (5) and (8). Note, however, that finding a minimum of cancellation would then require subtraction of two large correlation values, which may be a problem if those values are coded by a representation (like rate of a Poisson-like process) for which the noise variance of the value increases with its mean. One might speculate that the cost of specialized fast inhibitory circuitry is recouped by the benefit of performing cancellation directly.
There is also evidence in favor of accurate rate-place spectral representations (Larsen et al., 2008; Fishman et al., 2013, 2014; Su & Delgutte, 2020) that might support a spectral version of the harmonic cancellation hypothesis, particularly as it has been argued that tuning might be narrower in humans than in most model animals (Shera et al., 2002; Verschooten et al., 2018; Sumner et al., 2018; Walker et al., 2019). Narrow tuning might also benefit a spectro-temporal mechanism, with the caveat that narrower filters are temporally more sluggish.
Sinex et al. (2002), Sinex and Li (2005), Sinex et al. (2007) report stronger responses in IC neurons for mistuned partials, consistent with the output of a cancellation filter, but they explain it by a different model based on cross-channel interaction of between-partial beat patterns, analogous to the waveform interaction models described earlier. Their model also accounts for the particular temporal structure of the response; whether that structure too could be explained by cancellation remains to be determined.
In summary, known neural circuitry might support both temporal and spectral mechanisms of harmonic cancellation, however I am not aware of evidence as strong as that reported in favor of the EC model. A rate-frequency response such as Figure 4(a) might evade notice if attention is devoted to peaks of activity rather than dips. It could also elude discovery if the output pattern follows a latency code rather than rate code (Chase & Young, 2007). The filter output in Figure 4(b) is evocative of ON–OFF patterns observed in the superior paraolivary nucleus (SPON) (Kandler et al., 2020) but this similarity could be fortuitous, indeed those patterns have been attributed to gap detection or duration encoding (Kadner & Berrebi, 2008).
Smart Pattern Matching
As discussed in the main text (Harmonic Cancellation—Possible Mechanisms), each recovered target pattern is affected by two error terms: imperfect cancellation of the background, and distortion undergone by the target. In the time-domain model, the first term can be reduced to zero over part of the pattern (red segment in Figure 4(b), right). This assumes the ability to locate and isolate reliable intervals, which is commonly granted for auditory perception (Viemeister & Wakefield, 1991; Moore et al., 1988).
There remains the second error term due to filter-induced target distortion. This can be mitigated if it is known to the pattern matching stage, for example, by applying the same distortion to each pattern in the dictionary. Distortion consists of an attenuation factor applied to each target component depending on how close it falls to the harmonic series of the background, as quantified by the filter transfer function (Figure 4(a), right). This produces a “moiré effect” that can be quantified (and thus taken into account) if F
Target patterns can be further refined if the background is stationary over more than two periods, as illustrated in Figure 7. Specifically, if the stimulus is long enough to define
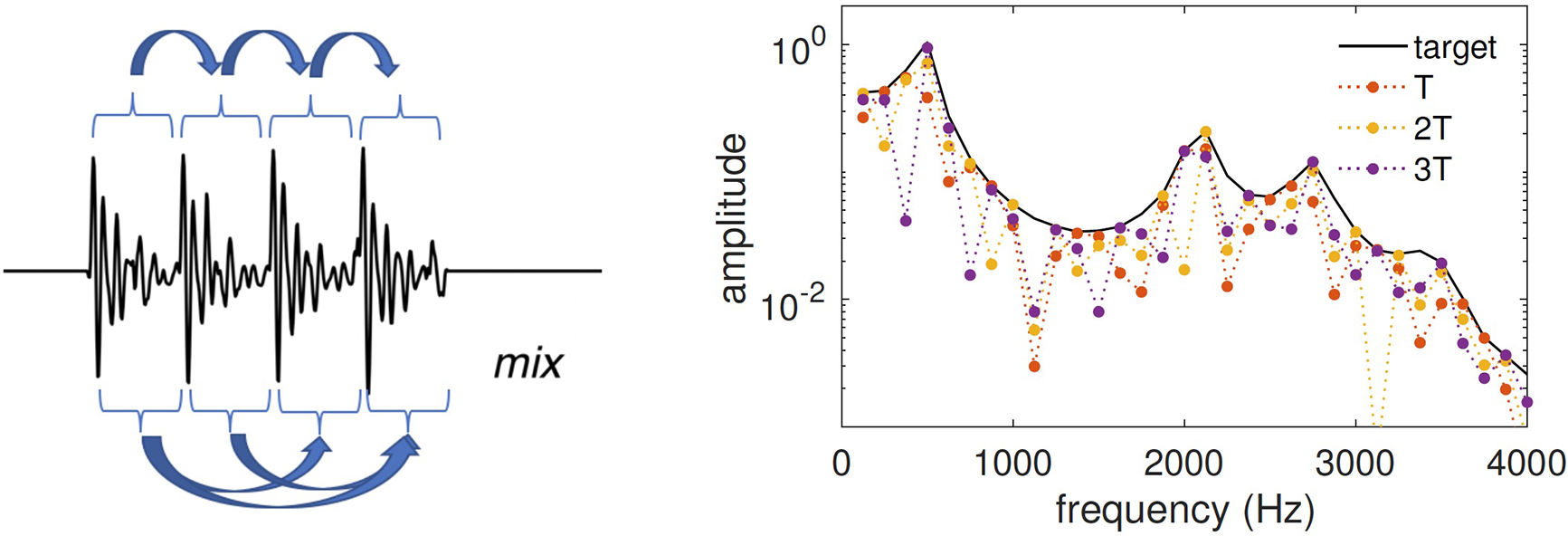
Left: waveform of the mix of target vowel /e/ (132 Hz) with background vowel /a/ (100 Hz) at TMR=
Transforms in Filter Space
The idea that cochlear filtering works hand in hand with neural filtering is intriguing. What are the possibilities, what are the limits? As an example, the bandwidth of cochlear filters is usually seen as a hard limit on spectral resolution, but it appears that with neural filtering that limit can be overcome, as exploited by past schemes such as the “second filter” (Huggins & Licklider, 1951), stereausis (Shamma et al., 1989), lateral inhibitory network (LIN) (Shamma, 1985), phase opponency (Carney et al., 2002), synthetic delays (de Cheveigné & Pressnitzer, 2006), EC (Durlach, 1963), selectivity focusing in inferior colliculus (IC) (Chen et al., 2019), and here harmonic cancellation.
This section attempts to make sense of this situation by casting both filtering stages into a common framework. Any filter can be approximated as a finite impulse response (FIR) filter of order
Extending to a
If the matrix
We can write

Why is this relevant here? It means that essentially any filter can be implemented (or its implementation can be complemented) by forming a weighted sum of cochlear filter outputs, as long as their impulse responses are long enough to reach the required order
A matrix of
There remains one difficult issue: given a periodic sound with period
The first is that, if principal component analysis (PCA) is applied to the matrix
The second point follows from the first: if PCA is applied to the matrix
The third point is that PCA is widely considered as a plausible neural operation (Oja, 1982; Qiu et al., 2012; Minden et al., 2018). Putting these pieces together, we can speculate that the hypothesis that Equation (1) is implemented in the brain as a weighted sum of filter bank outputs, rather than a simple delay
Again, such operations might seem implausibly complex for a biological implementation, but knowing that the option exists, in principle, and understanding how it works, can guide speculation that something similar is discoverable by a learning process.
Non-Linearity
Previous sections mostly glossed over the issue of non-linear transduction. The suggestion that linear operations can be swapped, as shown in Figure 5(b), or linear transforms inverted as in the previous paragraph, is moot if the systems are not linear. What can be salvaged from those simple ideas?
First, note that any time-invariant transform of a periodic signal is periodic with the same period (or submultiple of that period), so a canceation filter tuned to the period would produce zero output as in the linear case. Thus, for example, Hybrid Model 1 would work as advertized. Second, pattern distortions due to non-linearity may be compensated for in the pattern-matching stage. Thus, Hybrid Model 2 might also work. Third, more generally, we can invoke Logan’s theorem and assume that the deleterious effects of non-linearity, whatever they are, can be redressed by subsequent processing. The theorem doesn’t say how, but it is easy to imagine simple situations in which this might pan out. For example, sampling the steep phase characteristic of the cochlear filter bank at two points differing by
In summary, non-linearity does not prevent harmonic cancellation, although it does make it harder to understand the limits of what can be achieved, and how.
Footnotes
Acknowledgements
Mickael Deroche, John Culling and Josh McDermott made useful comments on a previous version, and Maria Chait and Israel Nelken offered useful advice. The manuscript also benefitted greatly from comments of two anonymous reviewers and the Editor, Chris Plack.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
This work was supported by grants ANR-10-LABX-0087 IEC, ANR-10-IDEX-0001-02 PSL, and ANR-17-EURE-0017.