
Abstract
The aim of this study was to assess whether a computer-based speech-in-noise auditory training (AT) program would lead to short- and long-term changes in trained and untrained measures of listening, cognition, and quality of life. A secondary aim was to assess whether directly training the underlying cognitive abilities required for speech perception in noise, using a computer-based visual training (VT) program without the auditory component, would elicit comparable outcomes as the AT program. A randomized crossover study with repeated measures was conducted with 26 adult cochlear implant users. Participants completed either 6 weeks of speech perception in noise training followed by 6 weeks of masked text recognition training, or vice versa. Outcome measures were administered twice before each training program, as well as twice after the completion of each program. The test battery was designed to evaluate whether training led to improvements in listening abilities, cognitive abilities, or quality of life. Mixed-effects models were conducted to analyze whether changes occurred on the trained tasks and on untrained outcome measures after training. Statistically significant improvements were shown for verbal recognition performance during both training programs, in particular for consonants in words, and during the first 2 weeks of training. This on-task learning, however, did not lead to clear improvements in outcomes measured beyond the training programs. This suggests that experienced cochlear implant users may not show transfer of on-task learning to untrained tasks after computer-based auditory and visual training programs such as the ones used in this study.
Difficulties understanding speech is one of the main consequences of hearing loss and commonly affects participation in social, leisure, and employment activities, particularly with more severe hearing loss (Boothroyd, 2007; Cunningham & Tucci, 2017). While cochlear implants (CIs) can improve access to speech for adults with severe hearing loss who obtain limited benefits from hearing aids, CIs do not fully overcome the listening difficulties imposed by the loss (see Boisvert et al., 2020 for a review). This is in part because of the effects of significant deafness on the neural integrity of the auditory pathways and because of the limitations of CI encoding strategies in replicating the speech signal (Wilson, 2015). As such, listening with a CI requires increased mental effort to recognize speech, which is exacerbated in complex listening situations, such as listening in noisy environments (Hughes et al., 2018; Winn, 2016). Audiological rehabilitation aims to support speech understanding and effective communication beyond hearing technologies, particularly when individuals experience residual difficulties after being optimally fitted with a device. This may include counseling on hearing loss and device management, monitoring of hearing, communication, and mental health outcomes related to hearing loss, as well as training of communication strategies, lipreading, and specific auditory training (AT; Boothroyd, 2007; Tye-Murray, 2019). AT per se aims to maximize individuals’ auditory skills through structured listening practices, to ultimately enhance communication, social participation and quality of life (Boothroyd, 2010). AT can be conducted face-to-face or via a computer. A recent cost-analysis study showed that computer-based auditory training (CBAT) programs incur the lowest costs for both clinicians and patients (Reis et al., 2019). Well-controlled studies assessing the efficacy of AT for individuals with hearing loss, however, are lacking, and the need to develop higher-level evidence has been highlighted in systematic reviews (Henshaw & Ferguson, 2013; Sweetow & Palmer, 2005). While an improvement in the quality of studies has recently been reported (Stropahl et al., 2020), that systematic review did not include studies which investigated the effects of AT on populations of CI users. Similarly, Pisoni et al. (2017) identified a lack of evidence available to confirm the benefits of CBAT beyond practice effects.
In addition to confirming the effectiveness of CBAT programs, better understanding the specific aspects of listening that are targeted by different AT approaches is necessary to improve the design and provision of future rehabilitation services. For example, it has been suggested that the improvement perceived with AT may be related to a greater extent to improved top-down abilities, such as attention, memory, or executive function, in comparison to improved sensory-specific (auditory) abilities (Tremblay, 2007). Because improving speech understanding is often the main goal of auditory rehabilitation, rehabilitation efficacy is commonly assessed by measuring posttraining changes in measures of speech perception (e.g., Fu et al., 2004; Miller et al., 2007; Oba et al., 2011; Schumann et al., 2015). Speech tokens (e.g., words or sentences) are the most commonly used stimuli for both the AT tasks and the measures of AT outcomes for adult CI users (Reis et al., 2019). This is despite the knowledge that speech perception testing provides limited information about everyday functioning (Alhanbali et al., 2018; Granberg et al., 2014; Vermiglio et al., 2018). Moreover, while some studies have found improvements in speech perception after AT, variation in outcomes exists (see Henshaw & Ferguson, 2013 for a review). A few studies report that some individuals do not benefit from training (Oba et al., 2013; Schumann et al., 2015; Tyler et al., 2010). Studies of AT effectiveness thus require, in addition to well-controlled study designs, the inclusion of assessments beyond trained speech perception measures and that are sensitive to individual characteristics. Individual characteristics such as age, onset and duration of hearing loss, or experience with the device are known to affect outcomes with a CI (Blamey et al., 2013; Krueger et al., 2008). As such, these characteristics may also impact AT outcome and should be controlled for when assessing AT benefit. Other relevant measures to assess changes in listening abilities with AT include measures of sensory sensitivity, spectral resolution, cognition, and self-reports. The addition of such measures can inform individual AT prognosis (predictor variable, when known before AT begins) or help identify the specific abilities that have been affected by the training (when used as outcome measures or covariate variables). For instance, spectral resolution, which is a nonlinguistic measure, may affect speech understanding in noise and, therefore, complements measures of speech perception. Measures of cognition are relevant because of the cognitive processes that are involved when listening to speech (see Arlinger et al., 2009; Pichora-Fuller et al., 2016; Rönnberg et al., 2013). In particular, working memory, phonological representations, and attention skills contribute to speech understanding (Pichora-Fuller et al., 2016; Rönnberg et al., 2008, 2013). Targeted AT may reduce the amount of cognitive resources required during listening (Tremblay & Backer, 2016), which could consequently make listening less effortful. For example, a faster response time in measures of cognition could indicate faster processing speed following training. Self-report measures of communication and quality of life can further inform how AT affects individuals’ management of communication in different situations, self-efficacy, activity, and social participation. This aligns with the World Health Organization’s International Classification of Functioning (https://www.who.int/classifications/icf/en/).
Although, to date, the effects of AT on cognitive abilities have not been investigated in adult CI users, research conducted with hard-of-hearing listeners offer insights into how these may interact. For example, Sweetow and Sabes (2006) found that hearing aid users showed improvements in inhibition control (visual Stroop test) and auditory working memory (listening span test) after auditory-cognitive training with the Listening and Communication Enhancement (LACE) program. Similarly, Ferguson et al. (2014) found that a group of unaided individuals with mild to moderate hearing loss showed improvement in divided attention (test of everyday attention), as well as in working memory (visual letter monitoring task) following 4 weeks of phoneme discrimination training. However, such improvements in cognitive abilities after a period of AT with the LACE program were not shown by Saunders et al. (2016) in neither new nor experienced hearing aid users. This may be due to different outcome measures used by the authors. Where possible, cognitive abilities in hard-of-hearing individuals should be measured with tasks that take their hearing loss into account, to ensure that it does not influence the results. When visual abilities are not compromised, using visual stimuli may be an appropriate adaptation (Dupuis et al., 2015; Füllgrabe, 2020).
A few studies have also evaluated the role of cognition from the opposite perspective, investigating whether training cognitive abilities could generalize to listening gains. Anderson et al. (2013) demonstrated that the speech reception threshold (SRT) of individuals with mild to moderate hearing loss improved 1.22 dB in the Quick Speech-in-Noise test (QuickSIN; Killion et al., 2004) following a cognitive training that focused on speed of auditory processing. Although these results were statistically significant, the authors indicated that this was just below the clinical significance of 1.9 dB for the QuickSIN. The findings of Anderson et al. (2013), however, were more encouraging than the results of Oba et al. (2013) who observed little to no benefit in CI users’ speech perception following a nonauditory cognitive training program using a visual digit span task. Similarly, in a study involving verbal and visuospatial working memory training with hearing aid users, no effects were seen for speech perception measures (Ferguson & Henshaw, 2015). While such findings could be indicative that cognitive training is not an effective intervention to improve speech perception in noise, multiple studies in perceptual learning indicate that transfer effects are only demonstrated when the untrained outcome measures are closely related to the tasks trained (see Ahissar et al., 2009 for a review). It is therefore possible that the findings of Oba et al. (2013) and Ferguson and Henshaw (2015) were due to a limited overlap between the trained cognitive tasks and the untrained speech perception tasks.
The text reception threshold (TRT) test is a visual analogue of the SRT and therefore requires abilities that overlap with those required for speech perception in noise (Zekveld et al., 2007). The TRT measures the ability of individuals to recognize text that is visually covered by adaptive vertical bar patterns. Up to 50.5% of shared variance exists between results on these two measures in normally hearing adults (Besser et al., 2012), indicating that the TRT test could assess nonauditory (cognitive) abilities relevant for speech perception in noise. The TRT has been suggested as a potential test that can be used to assess the cognitive processes involved in speech recognition, such as processing speed, attention, and working memory, and disentangle the underlying constructs of communication issues in individuals with a hearing loss (Kramer et al., 2009). Considering the overlap between the TRT and the SRT, such paradigm could also be useful to inform whether directly training cognitive abilities that are relevant to speech perception can elicit improvement in listening abilities and quality of life. The use of such paradigm should also enable for comparisons with AT programs that use speech-in-noise as training stimuli.
The present study integrated the aforementioned considerations in its design and aimed to assess whether a computer-based speech-in-noise AT program would lead to short- and long-term changes in trained and untrained measures of listening, cognition, and quality of life. A secondary aim was to assess whether directly training the underlying cognitive abilities required for speech perception in noise, using a computer-based visual training (VT) program without the auditory component, would elicit comparable outcomes to the AT program. To test this, adult CI users were enrolled in a crossover study and randomly allocated to one of two groups where both interventions were received, but in different order for each group. This allowed for comparisons between interventions and within subjects. Both the performance during the home-based training programs (on-task measures) and the outcomes on evaluations conducted in the lab (off-task measures) were assessed.
It was expected that both training programs would lead to learning effects larger than the procedural learning effects measured with the two baselines before the training began. Furthermore, it was expected that learning effect sizes on measures of listening, cognitive abilities, and quality of life would be larger after the AT compared to the VT due to the auditory component of the AT.
Methods
This study is reported in accordance with the Consolidated Standards of Reporting Trials extension for nonpharmacologic treatments (CONSORT-NPT Boutron et al., 2017). This study protocol was retrospectively registered with the ISRCTN trial registry (ISRCTN98523729) in September 2017, prior to the end of data collection. This study was approved by the Human Research Ethics Committees of Macquarie University and the Royal Victorian Eye and Ear Hospital. Data collection occurred between September 10, 2016 and March 1, 2018 at Macquarie University (MQU; Sydney), Fiona Stanley Hospital (FSH; Perth), and The HEARing Cooperative Research Centre (CRC; Melbourne).
Study Design
The study used a randomized crossover design as shown in Figure 1A. Participants completed a CBAT program and a computer-based VT program at different times, five times per week over a period of 6 weeks for each program. To control for procedural learning, outcome measures were assessed twice prior to participants starting each training program (i.e., T1 and T2). Participants attended testing sessions following the completion of each program to measure any immediate effects of training (T3). Retention of learning was assessed following a period of no training (T4). This occurred 3 months after training completion for participants at the MQU site and 1 month after training completion for participants at the FSH and the CRC sites. This period was shortened to meet data collection timing at the FSH and the CRC, which were included as study sites at a later stage to maximize recruitment of participants. Participants who completed both arms of the study attended a total of seven testing visits. Outcome measures collected at the fourth visit were used as both the retention assessment (T4) for the first training program and the first baseline (T1) for the second training program.

Randomized crossover study to assess the effectiveness of auditory training and visual training programs. A: Illustration of the crossover study design. No training interval was 3 months in one study site (MQU) and 1 month in the other two sites (FSH and CRC). B: Example of trial sequence used in the sentence module of the auditory and of the visual training programs. A consequent trial was presented if the correct alternative was selected. If an incorrect alternative was selected, the following screen contained feedback to participants.
Participants and Group Allocation
Adults with at least 1 year of CI experience, fluent in English, able to use a computer, who did not present significant cognitive impairment (assessed by the Mini-Cog test; Borson et al., 2003), or significant visual impairment (assessed with a visual letter monitoring test) were eligible to participate in the study. Participants were recruited by collaborating organizations including the SCIC Cochlear Implant Program, Royal Institute for the Deaf and Blind Children (RIDBC), the Australian Hearing Hub, Cochlear Limited Australia/New Zealand, FSH, and the Royal Victorian Eye and Ear Hospital, who advertised the study on their social media pages or directly contacted their research volunteers.
Speech understanding in noise assessed with Bamford-Kowal-Bench/Australia (BKB-A) sentences in four-talker babble at +10 dB signal-to-noise ratio (SNR; Bench & Doyle, 1979) was selected as the primary outcome measure. This was selected because difficulty understanding speech in noisy environments is one of the most common complaints of adults with hearing loss. This was also the measure most related to the training programs (i.e., masked verbal information) and, thus, for which most benefit was expected. A prospective sample size calculation, to show a clinically meaningful difference of 20-percentage points from T2 to T3 in the primary outcome measure, indicated a requirement to enroll 18 participants per intervention. This is consistent with publications, suggesting that a difference of at least 15-percentage points (Thornton & Raffin, 1978), or 20-percentage points (cf. Centers for Medicare and Medicaid Services, 2005), is clinically significant for open-set speech perception tests.
A total of 31 participants were initially enrolled in the study and randomized into the different study groups, and 26 completed the study (Figure 2). Data collectors allocated participants to either (a) the AT followed by VT (AT+VT) group or (b) the VT followed by the AT (VT+AT) group. Allocation was based on a randomization list pregenerated by the first author via a randomization software (http://www.randomization.com). Participants were informed about the group they were allocated to only at the end of the second study visit, to reduce the risk of a priori knowledge affecting their performance on outcome measures collected at T1 and T2. Author MR provided study protocol training to data collectors and oversight across the three study sites to ensure consistency. All participants signed the study consent form when enrolling in the study and received a compensation of AUD 40.00 at each testing visit they attended.

Study Flow Diagram, Following the CONSORT-NPT Reporting Guidance.
Outcome Measures
Outcome measures aimed to evaluate whether the training programs led to improvements in listening, cognitive abilities, or quality of life. All behavioral outcome measures were conducted in a sound-treated booth at the study sites. Auditory stimuli were presented at 65 dB SPL through a loudspeaker positioned at 0° azimuth and 1-meter distance of the participant. Bimodal CI users removed their hearing aid during the listening tests, to limit the risk of hearing fluctuations in the nonimplanted ear affecting the results (Hilly et al., 2016). Each testing visit lasted between 1 hr 30 min and 2 hr, and participants were given breaks in the middle of each session to minimize the risk of fatigue affecting their test performance. To further avoid fatigue-related bias, the order in which tests were administered for each participant was randomized for each testing visit they attended. Participants completed the self-report measures at home via an online platform (Qualtrics, 2018).
Listening Outcome Measures
Speech understanding in noise was assessed with BKB/A sentence lists (Bench & Doyle, 1979) in four-talker babble, each comprising of 16 sentences and scored based on the percentage of key words correctly repeated. Two SNR conditions were assessed. Three lists were administered at +10 dB SNR, and another three lists were presented at a second SNR. The second SNR was determined by participants’ performance in the +10 dB SNR condition at the first visit. For instance, if a score of ≥50% in the +10 dB SNR condition was obtained, three lists at 0 dB SNR were presented. However, if a score of <50% correct at +10 dB SNR was obtained, three lists were presented at +20 dB SNR. As such, once the conditions were determined at the first visit, each participant was tested at either +10 dB and 0 dB SNR, or at +20 dB and +10 dB SNR throughout the seven study visits. Such measures were adopted based on a pilot study which indicated that participants could reach ceiling effects when only the +10 dB SNR condition was presented, as well as when a +5 dB SNR condition was trialed. Some individuals, however, reached near to floor effects when the +10 dB SNR condition was assessed, and therefore, a +20 dB SNR condition was included.
Word recognition in quiet was assessed with Consonant-Nucleus-Consonant (CNC) word lists, based on the material developed by Peterson and Lehiste (1962). A list of 50 monosyllabic words was presented at each testing visit, and scoring was conducted based on the percentage of phonemes correctly repeated. Of the words used for testing, 559 (56.7%) differed from those used as training stimuli in the AT and the VT programs.
The spectral-temporally modulated ripple test (Aronoff & Landsberger, 2013) was used to assess whether training programs affected spectral resolution over time. This was a three-interval, forced-choice, adaptive task, where three sounds were presented, and participants selected the one that sounded different. Thresholds were scored based on the average of the last six reversals and described as ripples per octave.
Cognitive Outcome Measures
The Integrated Visual Auditory Continuous Performance Test assessed focused, sustained, divided, and alternating visual and auditory attention. Participants were instructed to click on the computer screen when a target number was seen or heard and not to click when nontarget numbers were presented. Performance was measured by the average reaction time and number of hits (i.e., accuracy) for target and nontarget items.
The Victoria Stroop Test (Spreen & Strauss, 1998) assessed inhibition control. Participants had to identify the printed colors of items in three categories, including dots, random words, and color-name words. Scoring was obtained by dividing the average reaction time on the color-name words category by the reaction time on the dots’ color-name category. Lower reaction times indicated better inhibition control.
The rhyme judgment test (Ausmeel, 1988) assessed the effects of training programs on phonological representations. Participants had to determine whether two words displayed simultaneously on the computer screen rhymed or not. Scoring was conducted based on the percentage of trials scored correctly and the average reaction time.
Verbal working memory was assessed with the reading span test (Baddeley et al., 1985). Participants were asked to identify whether sentences visually presented on a computer screen made sense or not. After a series of sentences was presented, participants were asked to recall either the first or the final words of each sentence. Scores were calculated by percentage of items correctly recalled throughout the test.
Self-Report Outcome Measures
Listening benefit was assessed with the Speech, Spatial and Qualities-12 questionnaire (SSQ-12; Noble et al., 2013), a 12-item questionnaire which measures auditory disability and handicap. Participants rated their abilities in a 0–10 visual analog scale, with the higher end of the scale reflecting better scores.
The Personal Report of Communication Apprehension (PRCA-24; McCroskey et al., 1985), a 24-item scale, assessed communication apprehension in four contexts: public, small groups, meetings, and interpersonal encounters. Scores range between 24 and 120, with scores from 24 to 55, 55 to 83, and 83 to 120 indicating low, moderate, and high level of communication apprehension, respectively.
Communication self-efficacy was assessed with the Self-efficacy for Situational Communication Management Questionnaire (Jennings et al., 2014). Participants rated their confidence to manage communication situations in simple and complex noisy environments in a 0–10 visual analog scale. Scores range from 0 to 200 with higher scores indicating greater self-efficacy.
Quality of life was assessed with the Quality of Life Scale (Burckhardt & Anderson, 2003), a 16-item questionnaire. Participants rated items through a 7-point satisfaction scale. Scores range from 16 to 112, with higher scores indicating greater quality of life. In addition, the SF-36 (Ware & Sherbourne, 1992) was used to assess health-related quality of life. It comprises questions related to activity limitations due to physical or emotional health problems. For this study, only five areas of the SF-36 were assessed: general health, vitality, social functioning, emotional role limitation, and mental health. Scores range from 1 to 100, with higher scores indicating greater health-related quality of life.
Training Protocol and Procedures
Both training programs used an individual, computer-based, home-delivered format. Participants were asked to use each program five times per week over a 6-week period. Bimodal listeners were asked to remove their hearing aid when completing the AT program. The layout of both training programs was identical, to ensure participants would be exposed to similar motivation levels. Training performance and adherence was monitored by investigators through the training platform.
AT Stimuli and Protocol
The AT target material consisted of Harvard/Institute of Electrical and Electronics Engineers (IEEE) sentences (Egan, 1948; IEEE, 1969) and Maryland CNC words (Causey et al., 1984), produced by two talkers (1 female, 1 male). This material was organized into three tasks that were delivered to participants in the following order: (a) initial consonant discrimination (i.e., /geek/, /seek/, /cheek/ for a total of 418 stimuli), (b) sentence recognition (for a total of 360 stimuli), and (c) final consonant discrimination (i.e., /dog/, /doll/, /dot/ for a total of 311 stimuli). The target stimuli were presented in four-talker babble, at levels ranging from +20 dB to –16 dB SNR in 2 dB steps. To avoid participants’ acclimatization to the background noise, 22 different four-talker babble segments available for each level were presented at random.
In each trial, participants were first prompted to listen to the stimulus (Figure 1B). The target stimulus was presented 1,000 ms after the four-talker babble started. The four-talker babble and the target stimulus presentation finished simultaneously. Following this, three alternatives appeared on the screen, and participants had to select the option they heard. Every time participants made an accurate choice, visual feedback was shown on the screen. However, if they chose an incorrect alternative, both the correct and the incorrectly selected alternatives were shown with replay buttons.
The first three trials of each task were delivered in quiet. The difficulty of training was modulated by adjusting the SNR in 2 dB steps, for every three consecutive trials correctly scored or every single trial incorrectly scored (3-up, 1-down). A training session ceased once participants completed 25 trials of each task. Following the end of each task, the total number of correct trials was shown to participants. On the following training session, participants commenced training at the level they finished each task on the previous session.
VT Stimuli and Protocol
The VT target material also consisted of Harvard/IEEE sentences (Egan 1948; IEEE, 1969), which differed from the ones used in the AT program, and CNC words (Causey et al., 1984), which overlapped with those used in the AT program. The VT program tasks were organized into (a) initial consonant identification (for a total of 320 stimuli), (b) sentence recognition (for a total of 358 stimuli, and (c) final consonant identification (for a total of 148 stimuli). Stimuli were grouped according to graphemes. Masking stimuli were based on the TRT (Zekveld et al., 2007), with levels ranging from 28% to 70% of stimulus unmasked, in 6-percentage point steps.
Stimuli presentation in the VT program followed the TRT500 procedures described in Besser et al. (2012). Each trial commenced with a series of vertical bars appearing on the screen (Figure 1B). The target stimulus was presented 1,500 ms after and remained on the screen for 500 ms. For the sentence recognition task, stimulus was presented in a word-by-word fashion, with an interval of 400 ms between each word. This reading speed was based on the between word interval used in the sentence task of the AT program. Following stimulus presentation, three alternatives appeared on the screen. As in the AT program, visual feedback was provided when a correct alternative was chosen. When an incorrect alternative was selected, both the correct and the incorrectly selected alternatives were shown for comparison.
For each task, the target stimuli were initially presented with no masking. As for the AT program, difficulty of training was modulated in a 3-up, 1-down protocol, where the width of the black vertical bars increased or decreased in 6-percentage point steps. Twenty-five trials of each task were completed within a training session. The total number of correct trials was shown to participants following the end of each task. On the following session, participants resumed training at the same difficulty level they finished each task on the previous session.
Data Analysis
Statistical analysis of training data (i.e., on-task learning) and outcome measures (i.e., off-task learning) was conducted by fitting linear mixed-effects models to the data using the lme4 package (Bates et al., 2015) in R (R Core Team, 2018). This modeling accounts for between and within individual variability while controlling for factors that may have influenced outcomes (Boisgontier & Cheval, 2016). Such an approach reduces error variance and increases the capacity of the model to detect any effects of training.
Differences between training allocation groups at T1 were tested with t tests for normally distributed data and with Kruskal–Wallis and Chi-squared tests for continuous nonnormally distributed and categorical data, respectively. Data from both allocation groups were then combined for analysis of training effects. The sequence in which training programs were completed was included as a factor in the analyses to control for possible order effects. Initially, exploratory models were created, which involved including demographic variables as factor as well as testing the interaction between some of these. Exploratory models were constructed by including age, CI experience, duration of hearing loss, onset of hearing loss, training order, amount of training sessions completed, timing of T4 (i.e., conducted 1 or 3 months after T3), working memory capacity (i.e., performance in the reading span test) as fixed factors, with a participant random effect. Different interactions between fixed factors were tested during this exploratory analysis. The model producing the lowest Akaike information criterion (AIC; Akaike, 1974) was used for analysis. The best-fitting model differed for the analysis of on-task training and off-task outcome measure data. Exploratory modeling indicated that the time of follow-up did not contribute to results at T4, and therefore, timing of follow-up was not included as a variable in the final models.
On-task improvement was assessed by comparing the last level of difficulty (i.e., SNR, TRT) at each training session, averaged across a block of five consecutive sessions (average SNR per week). Training order (AT or VT first) was included as a fixed factor, and each block of five training sessions was compared to the previous block of training sessions. To account for within group variance across sessions, a participant random effect was included. In the case where participants completed more than 30 training sessions, the additional sessions were excluded from the on-task learning analyses.
Short- and long-term off-task performance improvements were assessed by comparing outcome measures of listening, cognition, and quality of life at T3 and T4 in relation to T2, respectively. Independent variables included in the final model were age, onset of hearing loss, duration of severe to profound hearing loss (as reported by participants) in the ear with shorter time of auditory deprivation, CI experience (if bilateral, the duration of experience with the latest implanted ear was considered), training order (i.e., group allocation), as well as the interactions between timepoint and type of training (i.e., AT or VT), and amount of training sessions completed and timepoint (as a categorical variable). For speech perception measures, the interaction between timepoint and working memory capacity was also analyzed, as this has been previously suggested to support listening (cf. Rudner et al., 2011). Differences between estimated marginal means (EMM) were used to assess the effect of the different training programs. The significance threshold was set at .05. Tukey’s honestly significant difference method was used to adjust p values for multiple comparisons. More information can be found in the Supplemental Digital Content.
Results
Demographics
Demographics for the 26 participants who completed at least one arm of the study are described in Table 1. Participants were aged 42–84 years (mean = 63.23, SD = 10.76) and reported an average of 16.8 years (SD = 20.09) of severe-to-profound hearing loss in the ear with shorter duration of auditory deprivation. Participants reported a mean of 6.1 years (SD = 5.2) of CI experience. Demographics were balanced between study groups, except for the number of participants with prelingual hearing loss, which were randomly allocated to the same group (AT+VT). A significant difference between groups was found for word recognition in quiet scores (AT+VT: median = 24.0%; VT+AT: median = 58.0%, p = .045) and quality of life scores (AT+VT: median = 48.3; VT+AT: median = 37.9, p = .035) collected at T1.
Demographic Information of Study Participants Grouped by Allocation Order.
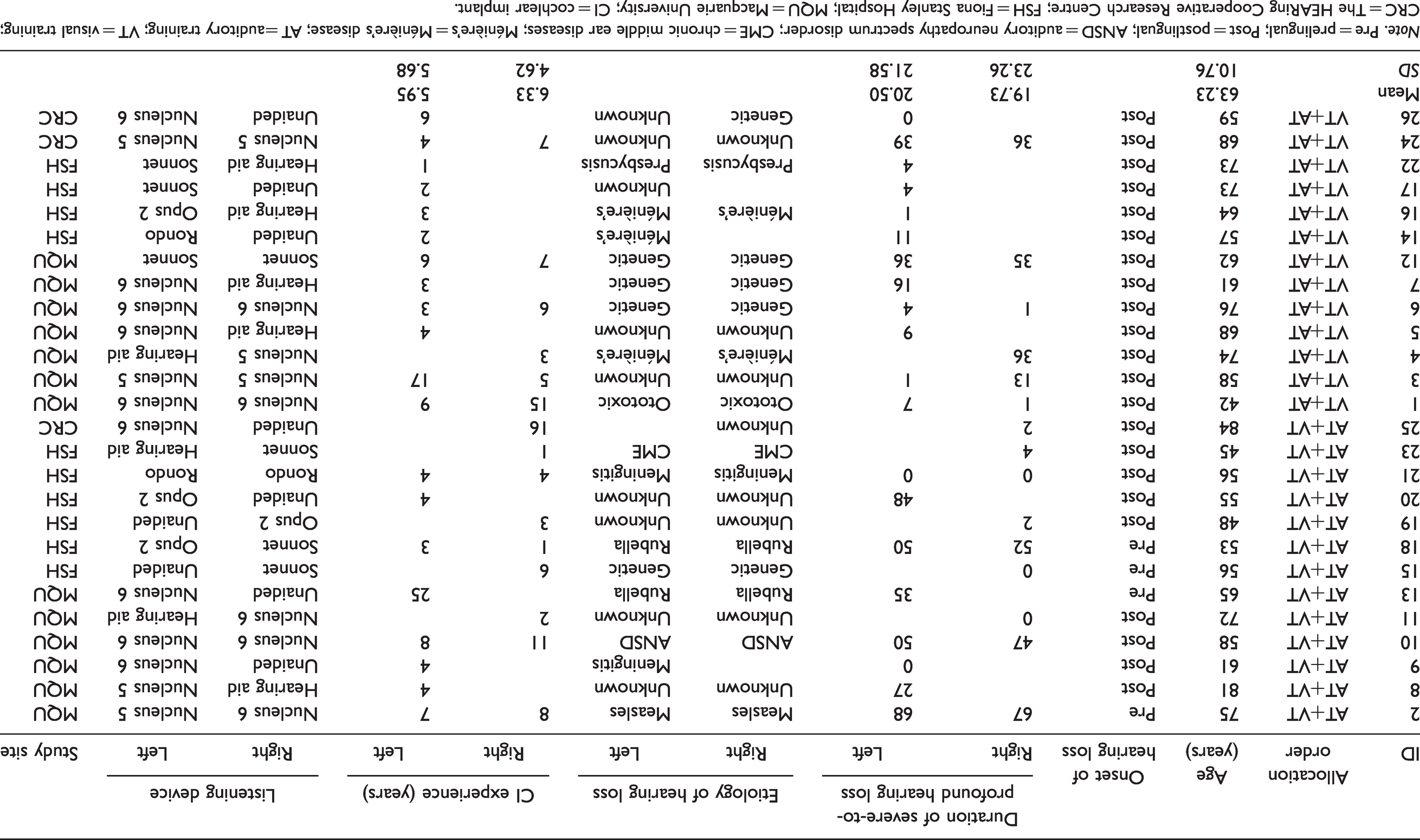
Note. Pre = prelingual; Post = postlingual; ANSD = auditory neuropathy spectrum disorder; CME = chronic middle ear diseases; Ménière’s = Ménière’s disease; AT = auditory training; VT = visual training; CRC = The HEARing Cooperative Research Centre; FSH = Fiona Stanley Hospital; MQU = Macquarie University; CI = cochlear implant.
Adherence and Time Taken on Training Programs
Of the 24 participants who completed the AT program, 17 (70.8%) completed 30 or more sessions, 6 (25%) completed between 26 and 29 sessions, and 1 (4.1%) completed 20 sessions. Four participants withdrew from the study after completing 0, 1, 7, and 13 AT sessions, respectively. Of the 24 participants who completed the VT, 14 (58.3%) completed 30 sessions or more, 8 (33%) completed between 26 and 29 sessions, and 2 (8.3%) completed between 20 and 25 sessions. The two participants who withdrew from the study did not complete any training sessions. The reasons for withdrawing from the study are outlined in Figure 2. Participants took on average 12.8 (SD = 3.1) min to complete individual AT sessions and 9.5 (SD = 2.5) min to complete individual VT sessions, which totaled 384 min of AT and 285 min of VT.
On-Task Performance
The decrease in SNR and TRT measured across blocks of training sessions suggests a positive effect of both the AT and VT programs (Figure 3). The largest successive improvements on the AT program tasks occurred between the first and second blocks of five training sessions (Table 2). Although some slight decreases in performance were registered during the AT program, an overall downward trend in the SNR presented to participants was shown across tasks. The EMM difference between the first and the last blocks of training was of 4.13 dB (95% CI: [2.66, 5.60]), 2.97 dB (95% CI: [1.17, 4.77]), and 1.26 dB (95% CI: [0.20, 2.31]) for the initial consonants, final consonants, and sentence modules, respectively.

Boxplots of On-Task Performance Over Time During the AT and the VT Programs for All Participants (n = 26). Each training block represents five consecutive training sessions. Lower values represent better performance. The median value is shown by the solid horizontal line with the lower and upper ends of the box showing the 25th and 75th percentiles, respectively, and the upper and lower ends of the whisker indicating the range of values within 1.5 times the interquartile range. The circles show individual scores.
Estimated Marginal Means for On-Task Performance Over the Six Blocks of Each Training Program.
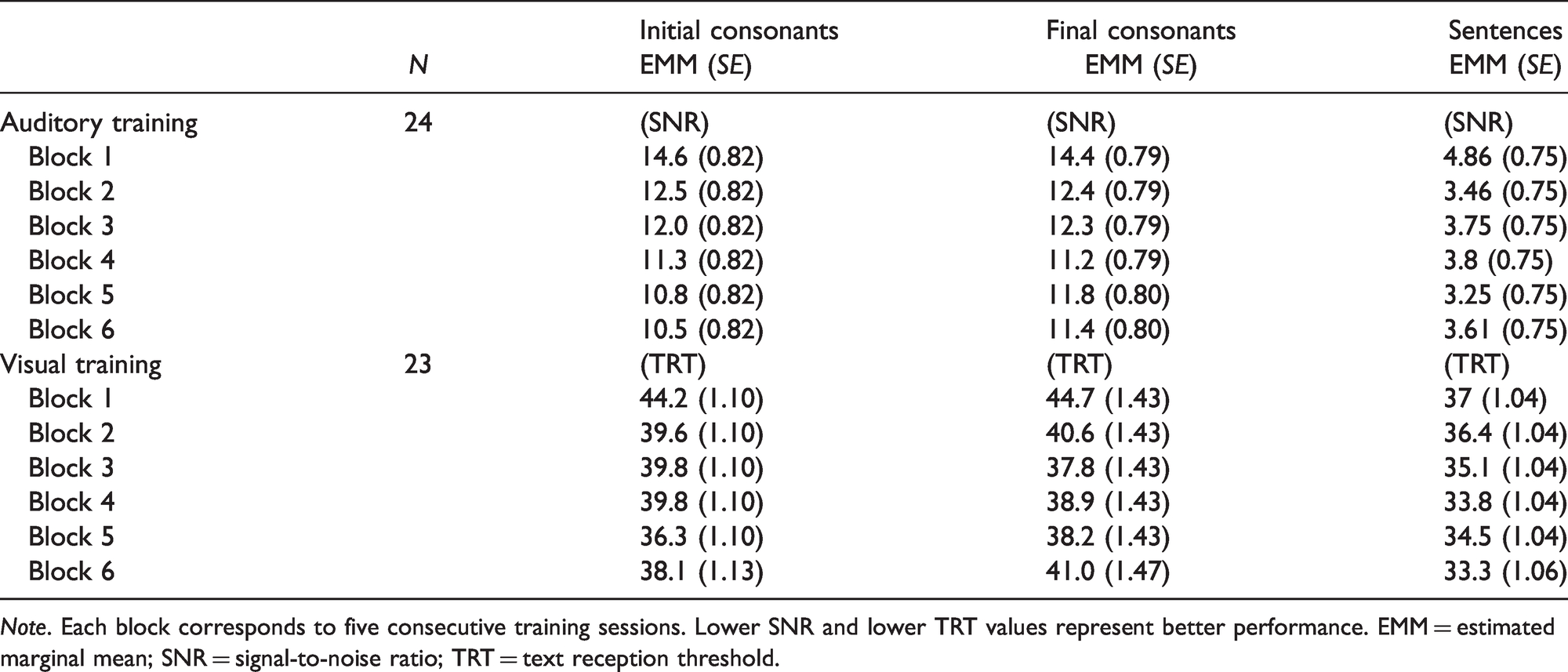
Note. Each block corresponds to five consecutive training sessions. Lower SNR and lower TRT values represent better performance. EMM = estimated marginal mean; SNR = signal-to-noise ratio; TRT = text reception threshold.
The largest successive improvements on the VT program occurred between the first and the second blocks of training for the initial consonants and final consonants tasks, and from the second to the third block of training for the sentence module. The EMM difference between the first and the last blocks of training was of 6.04% (95% CI: [3.22, 8.87]), 3.61% (95% CI: [3.61, 1.47]), and 3.70% (95% CI: [1.59, 5.81]) for the initial consonants, final consonants, and sentence modules, respectively. Improvements on performance were seen up to the fifth block of training for the initial consonant and final consonant tasks, and until the sixth block of training for the sentence module. It is not possible to conclude whether participants reached asymptote performance, because oscillations in performance were measured. Participants’ performance on training programs was not affected by the sequence in which these were completed.
Outcome Measures
Listening Outcome Measures
Figure 4 shows individual and group data for the AT and the VT programs on off-task listening outcome measures across testing sessions. The EMM for all listening outcome measures are presented in Table 3. No significant change was found in sentence understanding in noise at T3 or T4 in comparison to T2, for either of the training programs. A significant improvement (p = .04) was found for word recognition at T3 (EMM = 40.8%, SE = 6.48%) in relation to T1 (EMM = 32.6%, SE = 40.8%) for the AT program, but not in relation to T2. Performance at T4 (EMM = 36.4%, SE = 6.46%) was still higher than T1 and T2, although this difference was not significant. The VT program did not elicit such changes in word recognition. No significant difference was found across testing sessions for spectral resolution ability for either AT or VT programs.

Boxplots of Outcomes on Untrained Measures of Listening by Testing Session for All Participants (n = 26). The top row displays data for each individual signal-to-noise ratio (SNR) participants were tested on: 10 dB SNR (n = 26), 0 dB SNR (n = 12), 20 dB SNR (n = 14). For all tests, higher values represent better performance. The median value is shown by the solid horizontal line with the lower and upper ends of the box showing the 25th and 75th percentiles, respectively, and the upper and lower ends of the whisker indicating the range of values within 1.5 times the interquartile range. The circles show individual scores.
Estimated Marginal Means of Off-Task Listening Outcomes at Different Timepoints Before and After the Auditory and the Visual Training Programs.

Note. All participants completed the sentences in noise test at +10 dB SNR. Participants who scored ≥50% at +10 dB SNR at T1 were presented a second condition at 0 dB SNR at all testing sessions. Participants who scored <50% at +10 dB SNR at T1 were delivered a second condition at +20 dB SNR. For all tests, higher values represent better performance. EMM = estimated marginal mean; SNR = signal-to-noise ratio; T = test session.
Cognitive Outcome Measures
Individual and group data for the AT and the VT programs on measures of cognition across testing sessions are shown in Figure 5, whereas EMM are presented in Table 4. No significant difference was found for measures of visual or auditory attention or inhibition control following either training program. A significant decrease in reaction time was found at T3 for the phonological representation test following the AT and the VT programs in relation to T1, but not in relation to T2. Training programs did not significantly affect performance on the visual working memory task.

Boxplots of Outcomes on Untrained Measures of Cognitive Abilities by Testing Session for All Participants (n = 26). Faster reaction times (ms) represent better performance. The median value is shown by the solid horizontal line with the lower and upper ends of the box showing the 25th and 75th percentiles, respectively, and the upper and lower ends of the whisker indicating the range of values within 1.5 times the interquartile range. The circles show individual scores.
Estimated Marginal Means of Off-Task Cognitive Outcomes at Different Timepoints Before and After the Auditory and the Visual Training Programs.

Note. EMM = estimated marginal mean; T = test session; Phonological Rep = phonological representations.
aLower values represent faster reaction times in the first four columns of results.
Self-Report Outcome Measures
As shown in Table 5, no significant difference was found for self-report measures of listening, communication apprehension, and self-efficacy over time. For self-report measures of quality of life, participants showed high scores with both questionnaires used during the study, but lower scores were found in the general health and vitality sections of the SF-36 (Figure 6). A significant difference was found with the quality of life scale at T3 (EMM = 84.7, SE = 3.55) in relation to T2 (EMM = 79.9, SE = 3.55) for the AT program; however, this was not sustained at T4 (EMM = 81.4, SE = 3.57; Table 6). Unexpectedly, a significant negative difference was found for self-reported general health of the SF-36 with VT, both at T3 and at T4. When a secondary analysis was conducted, including age as an interaction with timepoint and training type, age was found to be a significant contributor to this result.
Estimated Marginal Means of Self-Reported Listening and Communication Abilities at Different Timepoints Before and After the Auditory and the Visual Training Programs.

Note. EMM = estimated marginal mean; T = test session.
aHigher values represent better scores.
bScores between 24 and 55, 55 and 83, and 83 and 120 indicate low, moderate, and high levels of communication apprehension, respectively.

Boxplots of Outcomes on Measures of Quality of Life by Testing Session for All Participants (n = 26). Higher values represent greater quality of life. The median value is shown by the solid horizontal line with the lower and upper ends of the box showing the 25th and 75th percentiles, respectively, and the upper and lower ends of the whisker indicating the range of values within 1.5 times the interquartile range. The circles show individual scores.
Estimated Marginal Means of Quality of Life Measures at Different Timepoints Before and After the Auditory and the Visual Training Programs.

Note. Higher values represent greater quality of life. Significant values are noted for differences in relation to the second baseline (T2). EMM = estimated marginal mean; T = test session.
*p< .05.
Discussion
The aim of the present study was to assess whether a computer-based speech-in-noise AT program would lead to short- and long-term changes in trained and untrained measures of listening, cognition, and quality of life. A secondary aim was to assess whether directly training the underlying cognitive abilities required for speech perception in noise, using a computer-based VT program without the auditory component, would elicit comparable outcomes as the AT program.
During training, on-task improvement occurred for trained tasks with both the AT and VT programs, and the majority of this improvement was found in the first weeks of training (first two blocks of five consecutive training sessions). Training order did not contribute to on-task learning for either of the training programs. This differs from the findings of the crossover study conducted by Bernstein et al. (2014), which indicated that CI users with a prelingual hearing loss showed greater improvement in an auditory-visual training (AV; i.e., auditory nonsense words combined with lipreading) if an auditory-only training was received first, and lower improvement in auditory-only performance if the AV was received first. The authors suggested that learning acquired in the first program contributed to enhanced performance in the second program. The visual stimuli used by Bernstein et al. (2014), however, were of a different nature (i.e., lipreading) than the visual stimuli used in this study (written text).
In the present study, despite on-task learning demonstrated for both the AT and VT programs, there was limited evidence for the transfer (generalization) of learning to untrained outcome measures, in particular when considering the baseline period with no training (procedural learning). For example, a statistically significant difference was shown for word recognition when comparing T3 to T1 (first baseline timepoint), but not when comparing T3 to T2 (second baseline timepoint). For quality of life, while a decrease in scores was shown for the SF-36 section of “general health” with VT, further analysis indicated that age may have contributed to this result, with participants ranging from 42 to 84 years old. Further analysis or interpretation of this result, however, would be speculative or require a follow-up study. The significant, although nonsustained, improvement between T2 and T3 in the Quality of Life Scale after AT is the only result in this study that could suggest some transfer of learning. Because this scale is focused on meaningful social interactions and participation, it seems logical that if there were benefits of AT, these benefits could be captured with that scale. It is counterintuitive, however, that quality of life outcomes would improve without measuring any improvements in specific listening or cognitive abilities. Replication of this result in further studies would increase confidence in the strength of the effect.
Considering the similarity between the speech materials that were trained and those that were included in the off-task outcome measures (untrained), transfer of learning was expected at least for the recognition of sentences in four-talker babble noise. However, this was not observed in the present study. Previous studies suggest that even when trained and untrained material are very similar in nature (i.e., speech perception), transfer of on-task improvement may be uncertain. For example, Miller et al. (2007) demonstrated that training with syllables did not transfer to improvement in recognition of sentences in noise, and Stacey et al. (2010) indicated that training with words did not transfer to improvement in recognition of words nor sentences. Other studies, however, which used monosyllabic words, digits, or nonsense words as training stimuli showed that CI users demonstrated improvement in recognition of sentences in noise (i.e., Fu et al., 2004; Oba et al., 2011; Schumann et al., 2015).
In this study, learning was shown to be specific to trained tasks. Adherence to the training programs was good, and the amount of training sessions completed by participants was included as a fixed effect in the analysis of outcome measures. Therefore, it is unlikely that this lack of generalization occurred because participants did not adhere to the training program. While it could be suggested that the duration of the training used in this study may have been insufficient, the training duration was comparable or longer to programs used in other training studies (cf. Molloy et al., 2012; Schumann et al., 2015). The training duration was also sufficient to induce on-task learning measurable in the two first weeks of training. One possible interpretation is that transfer did not occur because different procedures were used for training and testing. For instance, AT with both monosyllabic and sentence stimuli occurred in adaptive SNR, while testing occurred in quiet for words and fixed SNRs for sentences. The perceptual learning literature suggests that learning for low and high noise conditions rely on different mechanisms (see Dosher & Lu, 2007 for a review), and importantly these will place different demands on cognitive processes (Heinrich et al., 2015). Similarly, the task used for VT may not have been sufficiently cognitively demanding, as despite the on-task improvement shown, limited transfer to untrained measures occurred. While in this study the TRT500 was used as stimuli due to its relationship with the SRT, other versions of the TRT have been developed and are suggested to require higher investment of working memory and speed of processing (cf. Besser et al., 2013).
Two other aspects that could have contributed to the results of this study are the testing environment and CI optimization. Some participants have questioned whether their performance on outcome measures would have been better if they were in a familiar environment without being observed by a data collector. While this is possible, the test conditions remained constant across all testing timepoints. Second, CIs have to be programmed according to patients’ individual needs to be of benefit (Shapiro & Bradham, 2012). Currently, however, programming methods adopted by clinicians rely mostly on CI users’ subjective feedback—disregarding that many CI users have a poor sound referencing when clinicians program their devices’ electrical stimulation levels (Vaerenberg et al., 2014). It is possible that the CI users’ subjective response may not intersect with optimal fitting for speech perception performance, therefore impacting both the outcome measures and the potential to benefit from training. Távora-Vieira et al. (2018) demonstrated that in CI users with single-sided deafness, not all individuals had access to the speech spectrum with their CI, measured with Cortical Auditory Evoked Potentials (CAEPs) obtained with the speech tokens /m/, /g/, /t/, and /s/. The investigators were able to adjust the CIs’ programming so that CAEPs for all speech tokens were present. Although Távora-Vieira et al. (2018) did not investigate the correlation between the CAEP measure and speech understanding, the study raises a question regarding the CI programming optimization based on subjective input. As such, future AT studies might benefit from the use of physiological tests such as CAEPs before and after the training period. Remote care online tools which assess speech recognition and perceived listening as reported by Cullington et al. (2018), as well as self-adjustment of electrical stimulation levels (Vroegop et al., 2017), could further support future studies as well as adult CI users who choose to engage in home-based AT.
This study contributes to the discussion of effectiveness of AT in a scenario where findings have been mixed (Henshaw & Ferguson 2013), and where AT is seen as an important clinical component of rehabilitation for adult CI users (Reis et al., 2019). Importantly, the inclusion of a second baseline (T2) in the study design before the beginning of the training programs allowed to observe and control for some of the procedural learning that overestimate the benefit of AT (Pisoni et al., 2017). In addition, this study further demonstrates that training which focuses solely on speech perception may elicit on-task learning, but this may not generalize to nontrained tasks. Similarly, it demonstrates that training with a visual task that is associated with recognition of speech-in-noise also elicits on-task learning but is not sufficient to generalize to improvements on untrained measures. Nevertheless, programs that combine both auditory and cognitive training may have the potential to improve auditory and cognitive performance. For example, improvement in auditory and cognitive abilities has been shown in studies with unaided hard-of-hearing adults (Anderson et al., 2013) and hearing aid users (Sweetow & Sabes, 2006) following auditory-cognitive training. Further evidence is required, however, given that a recent study suggested that such improvement may not occur (i.e., Saunders et al., 2016). This is yet to be robustly examined in a population of adult CI users.
Limitations of the current study included the requirement to test participants at different SNR levels, based on their speech perception abilities in noise. This approach decreased the sample size included in the different analyses for the sentence recognition task. There was also an imbalanced distribution of prelingually deafened CI users, which were all randomly allocated to the same group, and thus led to the VT+AT group to have higher baseline performance for most tasks. While such distribution was not ideal, training order was not shown to be a factor that contributed to performance on training nor in outcome measures. In addition, when data were pooled for analysis, these disparities in distribution were no longer existent. Blinding of study personnel was also not possible with the resources which were available for this study.
The present study required a considerable amount of coordination within and across sites, resources, and time investment. Although measures were adopted to minimize the risks of bias in the study, several additional difficulties were encountered. For example, although recruitment was open for several months, an insufficient number of participants demonstrated interest in participating in the study before the data collection was scheduled to start. As time restrictions were imposed by the project’s timeframe, this meant that recruitment continued while data collection was ongoing. Due to this, it was not possible to conduct a stratified randomization of participants into groups, which led to an imbalance of participant demographics between groups. Two additional sites (CRC and FSH) were later included as a measure to maximize recruitment of participants; however, the time restrictions compromised the timing of the retention assessment (T4). While measures were taken in the statistical analyses to account for this population and design imbalance, these methodological limitations could have been avoided if recruitment of participants was finalized before data collection.
Conclusion
Although significant on-task improvements were shown for both AT and VT in this group of experienced CI users, neither resulted in improvements in outcome measures of listening and cognition that were not trained. Only one self-report measure of quality of life resulted in a significant improvement after AT, but this improvement was not sustained after the end of the training. These findings indicate that careful consideration should be made before adult CI users engage in AT that uses only speech-in-noise stimuli, as used in this study. Despite this, the current study did not indicate that training led to negative effects in these domains. Thus, these considerations should be made in conjunction to possible cost and time investment required for participation in AT programs.
Supplemental Material
sj-pdf-1-tia-10.1177_23312165211025938 - Supplemental material for Effectiveness of Computer-Based Auditory Training for Adult Cochlear Implant Users: A Randomized Crossover Study
Supplemental material, sj-pdf-1-tia-10.1177_23312165211025938 for Effectiveness of Computer-Based Auditory Training for Adult Cochlear Implant Users: A Randomized Crossover Study by Mariana Reis, Catherine M. McMahon, Dayse Távora-Vieira, Peter Humburg and Isabelle Boisvert in Trends in Hearing
Footnotes
Author Note
This work is part of the PhD thesis of MR (Reis, 2019). Parts of this work were presented at the Audiology Australia National Conference, Sydney, May 2018 and at the Cognitive Hearing Science for Communication Conference, Linköping, June 2019.
Acknowledgments
The authors thank research participants for their time and commitment dedicated to this study; the SCIC Cochlear Implant Program—an RIDBC service, Cochlear Ltd., the Royal Victorian Eye and Ear Hospital, and Fiona Stanley Hospital for assistance with recruitment of participants; Robert Cowan, Helen Goulios, Emma Scicluna, Kevin Logan, Steffanie Cohen, Vanessa Panak, Yolandi Joubert, Adrienne Paterson, Lisa Norden, Amanda Campbell, Kaixi Fu, and Sarah Lacey for facilitating study conduction and data collection in Perth and Melbourne; Dr. Rodrigo Reis for advice on statistical analyses; and Dr. Helen Henshaw for reviewing and commenting on earlier versions of this article.
Author Contribution
M. R., I. B., and C. M. M. conceived and designed the experiment. M. R. coordinated the study at Macquarie University, The HEARing Cooperative Research Centre, and across sites and collected the data at Macquarie University. D. T.-V. coordinated the study at Fiona Stanley Hospital, collected data, and supervised four data collectors at this site. M. R. analyzed the data and prepared the article with contributions from I. B., C. M. M., D. T.-V., and P.H. The research project was supervised by I.B. and C.M.M.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by the Macquarie University Research Enhancement Fund and also by the HEARing Cooperative Research Centre, established under the Australian Government’s Cooperate Research Centres Program. The HEARing CRC Program supports industry-led collaborations between industry, researchers and the community.
Supplemental material
Supplementary material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.