
Abstract
The sources and consequences of a sensorineural hearing loss are diverse. While several approaches have aimed at disentangling the physiological and perceptual consequences of different etiologies, hearing deficit characterization and rehabilitation have been dominated by the results from pure-tone audiometry. Here, we present a novel approach based on data-driven profiling of perceptual auditory deficits that attempts to represent auditory phenomena that are usually hidden by, or entangled with, audibility loss. We hypothesize that the hearing deficits of a given listener, both at hearing threshold and at suprathreshold sound levels, result from two independent types of “auditory distortions.” In this two-dimensional space, four distinct “auditory profiles” can be identified. To test this hypothesis, we gathered a data set consisting of a heterogeneous group of listeners that were evaluated using measures of speech intelligibility, loudness perception, binaural processing abilities, and spectrotemporal resolution. The subsequent analysis revealed that distortion type-I was associated with elevated hearing thresholds at high frequencies and reduced temporal masking release and was significantly correlated with elevated speech reception thresholds in noise. Distortion type-II was associated with low-frequency hearing loss and abnormally steep loudness functions. The auditory profiles represent four robust subpopulations of hearing-impaired listeners that exhibit different degrees of perceptual distortions. The four auditory profiles may provide a valuable basis for improved hearing rehabilitation, for example, through profile-based hearing-aid fitting.
Currently, “profiling” has gained broad attention as a tool for typifying groups of observations (e.g., users, recordings, or patients) that follow similar patterns. Data-driven profiling can uncover complex structures that are “hidden” in the data. It has been used as a diagnostic tool in various fields (Shah et al., 2019) such as functional imaging (Krohne et al., 2019), genetics (Li et al., 2004), psychology (Gerlach et al., 2018), or logopedics (Sharma et al., 2019). The idea of using computational data analysis that applies principles of the knowledge discovery from databases (KDD; Frawley et al., 1992) has recently gained attention in the field of audiology in connection with hearing-aid features (Lansbergen & Dreschler, in press; Mellor et al., 2018). As in stratified medicine (Trusheim et al., 2007), which pursues the identification of subgroups of patients (phenotypes) for the purpose of implementing more targeted treatments, it is of interest to identify subgroups of hearing-impaired (HI) listeners who might benefit from targeted hearing-aid fittings. As such, data-driven auditory profiling could help identify groups of listeners that are characterized by specific hearing disabilities and support precision audiology.
Hearing devices are the usual treatment for a hearing loss (Cunningham & Tucci, 2017). Hearing-aid fitting mainly consists of the adjustment of amplification parameters to compensate for audibility loss and impaired loudness perception. Advanced hearing-aid signal processing features, such as adaptive compression speed, beamforming, and noise reduction, are typically not individually adjusted in this process, even though they could, in principle, be considered in the compensation of suprathreshold hearing deficits (Kiessling, 2001; Neher et al., 2016). However, the characterization of individual suprathreshold hearing deficits can be complex and requires more testing than standard audiometry. The definition of suprathreshold auditory deficits is commonly based on Plomp’s (1978) model, where hearing deficits affecting speech intelligibility are comprised of an “attenuation” and a “distortion” component. Although the attenuation component is assumed to affect speech intelligibility only in quiet, the distortion component is assumed to do so also in noise, yielding elevated speech reception thresholds (SRTs) in both cases. Kollmeier and Kiessling (2018) extended Plomp’s approach and suggested a model that includes an attenuation component (affecting pure-tone sensitivity), a distortion component (affecting speech intelligibility in noise), and a neural component (affecting binaural processing abilities [BIN]). Their model assumes that a sensorineural hearing loss is characterized by several factors: an “audibility loss,” a “compression loss,” a “central loss,” and a “binaural loss.” In general, these modelling approaches (Kollmeier & Kiessling, 2018; Plomp, 1978) are rather conceptual and do not pinpoint specific underlying impairment factors nor specific measures to quantify these types of losses.
There have been some attempts to stratify HI listeners based on the shapes of their audiograms. Several classification schemes have been proposed in earlier studies, some of which were based on data-driven approaches (Bisgaard et al., 2010; Chang et al., 2019; Parthasarathy et al., 2020), where computational methods for data analysis were used for identifying the most common audiometric profiles. Based on results from human temporal bone studies, Schuknecht and Gacek (1993) proposed four different types of age-related hearing loss: sensory presbycusis, neural presbycusis, metabolic presbycusis, and mechanical presbycusis. Sensory presbycusis was related to alterations in the organ of Corti and typically associated with basilar membrane compression loss, reduced frequency selectivity, and elevated audiometric thresholds. This type of age-related hearing loss was considered to reflect the loss of outer hair cells (OHCs; Ahroon et al., 1993) and/or inner hair cells (IHCs; Lobarinas et al., 2013) and was characterized by sloping audiograms. Neural presbycusis was related to a substantial loss of nerve fibers in the spiral ganglion. This type of presbyacusis was characterized by a progressive loss of speech discrimination performance, even though the audiometric thresholds remained unchanged over the same time period. Metabolic presbycusis was related to the atrophy of the stria vascularis that affects the OHC function and the transduction in the sensory cells because of a decreased endocochlear potential (EP). This type of impairment was associated with flat audiograms and did not affect speech discrimination (Pauler et al., 1986). Finally, conductive presbycusis corresponded to a gently sloping hearing loss at high frequencies, not reflecting morphological alterations in the sensory cells or stria vascularis but yielding elevated thresholds. This type of presbyacusis might reflect an atypical organization in the organ of Corti that affects its mechanical properties (Motallebzadeh et al., 2018; Raufer et al., 2019). However, recent results obtained with new techniques developed for histopathological analysis suggested that OHC dysfunction might have been underestimated in age-related hearing loss (Wu et al., 2020).
Animal studies, where selective damage to the sensory cells or a change of the EP was induced, have allowed a consistent definition of the metabolic and sensory types of impairments in terms of audibility loss (Ahroon et al., 1993; Lobarinas et al., 2013; Mills et al., 2006). Dubno et al. (2013) proposed a classification into sensory and metabolic audiometric phenotypes based on an approach that combined findings from animal models, expert medical advice, and data-driven techniques. The main goal of their study was to analyze a large database of audiograms of HI individuals and to identify connections between the findings from the animal studies with induced hearing losses and those based on human data. Although Schuknecht and Gacek (1993) characterized the metabolic and sensory types of presbyacusis in terms of physiological impairments observed in humans, Dubno et al. (2013) proposed a phenotypical classification of the audiograms of HI listeners. Dubno et al.’s classification was thus solely based on the shape of the pure-tone audiogram. While this may help predict the possible origin of a listener’s audibility loss, suprathreshold auditory processing deficits cannot be inferred from their phenotypes. The perceptual consequences of sensory or metabolic presbyacusis beyond audibility loss have not yet been studied.
We hypothesize that a listener’s hearing deficit can be characterized by two independent types of “auditory distortions,” type-I (ADI) and type-II (ADII), as illustrated in Figure 1. In this two-dimensional space, a normal-hearing (NH) listener would be placed at the origin, whereas other listeners, with auditory deficits that differ in the degree of the two types of distortions, would be placed at different positions along the two dimensions. Each type of distortion would then be defined by specific deficits observed in behavioral tasks that covary together and define a given auditory profile. While Profile C represents a high degree of both types of distortion, Profiles B and D reflect hearing deficits dominated by one of the two distortions. Profile A, the group with a low degree of distortions, represents only mild hearing deficits.

Sketch of the Hypothesis. The hearing deficits of a given listener can be described as a combination of two independent perceptual distortions. In a two-dimensional space, there would be four subgroups of listeners (Profiles A–D), which exhibit different degrees of the two distortion types.
Recently, Sanchez-Lopez et al. (2018) proposed a data-driven method for auditory profiling that was tested and verified by analyzing two data sets from previous experimental studies (Johannesen et al., 2016; Thorup et al., 2016). Thorup et al. (2016)’s data set was collected in a clinical setup using listeners with either near-normal audiometric thresholds (26 listeners), obscure dysfunction (4 listeners), or mild-to-moderate high-frequency hearing loss (29 listeners). The age of the listeners ranged from 41 to 70 years in the near-normal hearing group and from 52 to 80 years in the HI group. The data set contained 27 variables consisting of audiometric thresholds, loudness perception, speech perception in quiet and in noise, BIN, and the reading span test. Johannesen et al. (2016)’s data set was obtained in a research setting using 67 HI listeners with moderate-to-severe hearing losses. The age of the listeners ranged from 25 to 82 years. The data set contained 11 variables consisting of audiometric thresholds, aided speech recognition thresholds, frequency modulation detection, and basilar membrane compression estimates.
The method was tailored to the hypothesis of the four auditory profiles. In their study, it was hypothesized that distortion type-I covaries with a loss of audibility, whereas distortion type-II was assumed to be unrelated to audibility. However, the results of the analysis of two different data sets did not support this hypothesis. In fact, the analysis of the two data sets showed that distortion type-I was connected to high-frequency hearing loss and reduced speech intelligibility. Regarding distortion type-II, the analysis of one of the data sets (Thorup et al., 2016) provided a link to reduced BIN, whereas the analysis of the other data set (Johannesen et al., 2016) was linked to low-frequency hearing loss. These mixed results were attributed to differences between the two data sets in terms of the selection of the listeners and chosen behavioral tests. The authors concluded that a new data set that included a larger variability of impairment factors across listeners was needed to better characterize the listeners’ ADs and, thus, the auditory profiles. Furthermore, they suggested that the chosen tests should investigate several aspects of auditory processing while at the same time being clinically feasible (i.e., time-efficient, reliable, and reasonably accomplishable for patients with diverse abilities).
The current study focused on the scientific basis of the auditory profiling and not on its application in audiological practice. A new data set was therefore generated with the aim of overcoming the limitations discussed in Sanchez-Lopez et al. (2018). Seventy-five older listeners with different hearing abilities were tested with a test battery for characterizing hearing deficits. The behavioral tasks included measures of audibility, loudness perception, BIN, speech perception, spectrotemporal modulation (STM) sensitivity, and spectrotemporal resolution (Sanchez-Lopez et al., 2020). These outcomes include several measures that can be connected to previous approaches, such as the attenuation-distortion model (regarding speech perception measures) and the neural component (regarding BIN). Therefore, it was of interest to further investigate the connections between outcome measures and the two distortion types in a data-driven approach. The analysis of the new data set was performed with a refined version of the data-driven method provided in Sanchez-Lopez et al. (2018). Importantly, the current study did not aim to disentangle the effects of audibility and suprathreshold deficits but to identify four robust listener subpopulations based on the data-driven analysis of the new data set. The outcomes of the analysis were discussed in relation to previous classification approaches as well as in terms of implications toward profile-based rehabilitation strategies. Moreover, a decision tree consisting of the auditory measures that best classified the listeners into the four profiles was generated.
Method
The data-driven method was proposed as an alternative to the “expert-driven” method used by Dubno et al. (2013). Although experts in hearing science and audiology can classify listeners based on different criteria, the present approach adopted a hypothesis-driven approach to the data-driven analysis method. Therefore, the development of the data-driven method for auditory profiling was based on two premises: (a) the identification of relevant outcome measures that tap into two independent sources of variation and (b) the identification of extreme exemplars that can serve as “prototypes” of different subgroups of listeners.
Description of the Data Set
Seventy-five listeners participated in the study. Seventy of the listeners presented various degrees and shapes of symmetrical, sensorineural hearing losses, while five showed normal audiometric thresholds (25 dB HL in the frequency range between 0.25 and 4 kHz). The participants were aged between 59 and 82 years (median: 71 years). Thirty-eight of them were female. In addition, one young NH listener with experience with the tests (Participant 0) was included for the analysis as suggested in Sanchez-Lopez et al. (2018). This participant reflected an “optimal performer” and was used as a reference in the profiling method. Besides the profiling method, the optimal performer was also included in the correlation and regression analyses. The listeners were recruited from the clinical databases at Odense University Hospital (OUH), Odense, Denmark and Bispebjerg Hospital (BBH), Copenhagen, Denmark and the Hearing System Section of the Technical University of Denmark (DTU), Kgs Lyngby, Denmark. All listeners completed the “BEAR test battery” (Sanchez-Lopez et al., 2020). This test battery consists of a total of 10 psychoacoustic tests. The tests are divided into six aspects of auditory processing: audibility, speech perception, loudness perception, BIN, STM sensitivity, and spectrotemporal resolution.
The tests were carried out in a double-walled booth (at BBH and DTU) or in a small anechoic chamber (at OUH). The stimuli were presented via headphones (Sennheiser HDA200). The stimuli were presented monaurally, except for those used for testing BIN. The stimulus level was adjusted to be audible (i.e., above the audiometric threshold). For example, the test of interaural phase differences (IPDs) was presented at 35 dB sensation level, whereas the tone-in-noise (TiN) detection task was performed using a noise level of 70 dB HL. Only one listener presented a pure-tone audiometric threshold above 70 dB HL at 2 kHz (listener 20).
The data set (Sanchez-Lopez et al., 2019) consisted of 26 outcome variables corresponding to 75 listeners with different hearing abilities. Table 1 summarizes the outcome variables used in the analysis.
Description of the Tests, Dimensions, and Outcome Measures Contained in the BEAR3 Data Set(Sanchez-Lopez et al., 2019).

Note. For each test, a reference is included. The tests are divided by categories, and the outcome variables are presented in the right column. LF = lower frequencies; HF = high frequencies; FLFT = fixed-level frequency threshold; HTL = hearing threshold levels; MCL = most comfortable level; DynRLF = dynamic range for low frequency; DynRHF = dynamic range for high frequency; SRTQ = speech reception threshold in quiet; SRTN = speech reception threshold in noise; SScore4dB = sentence recognition score at +4 dB SNR; IPD = interaural phase difference; BMR = binaural masking release; TiN = tone-in-noise; SMR = spectral masking release; TMR = temporal masking release.
There were six outcomes related to audibility (AUD) and loudness perception (LOUD) represented in a total of 11 variables: (a) pure-tone average at low frequencies (AUDLF; f 1 kHz) and at higher frequencies (AUDHF; f > 1kHz); (b) fixed-level frequency threshold measured at 80 dB sound pressure level; (c) hearing threshold levels (HTL) estimated from the loudness function, averaged for low (HTLLF) and high (HTLHF) frequencies; (d) most comfortable level (MCL) estimated from the loudness function, averaged for low (MCLLF) and high (MCLHF) frequencies; (e) dynamic range (DynR) estimated as the difference between the uncomfortable level and HTL, estimated from the loudness function for low (DynRLF) and high (DynRHF) frequencies; and (f) slope of the loudness function at low (SlopeLF) and high (SlopeHF) frequencies. For the outcome measures estimated from the loudness function, the low-frequency average corresponded to the center frequencies 0.25, 0.5, and 1 kHz and the high-frequency average corresponded to the center frequencies 2, 4, and 6 kHz. There were four variables related to speech perception. Two of them related to speech-in-quiet: (a) SRT in quiet (SRTQ) and (b) maximum word recognition score (maxDS); and two of them related to speech-in-noise (SiN): (c) SRT in noise (SRTN) and (d) sentence recognition score at +4 dB signal-to-noise ratio (SScore4dB). There were three variables related to BIN: maximum frequency for detecting an IPD of 180 (IPDfmax); binaural pitch detection performance, estimated as the percent correct after 20 dichotic presentations (BP20); and binaural masking release (BMR). BMR was estimated as the difference between the threshold in the diotic TiN detection condition (N0S0) and the threshold in the dichotic TiN detection condition where the tone was out of phase between the ears (N0S). The frequency of the tone presented in the two conditions was 0.5 kHz. The STM and spectrotemporal processing variables included (a) short-STM test, which assesses STM sensitivity at +3 dB modulation depth (sSTM8) and (b) the fast STM detection threshold (fSTM8). In both tests, the stimulus was a three-octave wide noise centered at 0.8 kHz which was spectrotemporally modulated (Bernstein et al., 2016); the TiN detection threshold at 500 Hz (TiNLF) and at 2 kHz (TiNHF). The spectrotemporal processing abilities (STR) were assessed by two derived measures: (a) spectral masking release (SMR) estimated as the difference between the TiN detection threshold and the corresponding threshold with the noise shifted toward higher frequencies (center frequency of the noise, fc;noise = 1:1ftone); and (b) temporal masking release (TMR) estimated as the difference between the TiN masked threshold and the corresponding threshold with the tone presented in temporally modulated noise (modulation frequency, fm = 4 Hz).
Preprocessing of the Data
For each of the tests, the outcome measures of interest were extracted from the raw results. For example, the SRT in quiet was estimated from the word discrimination scores obtained at different speech levels. When the tests contained frequency-specific measures, the results were grouped into low-frequency (1 kHz) and high-frequency (>1 kHz) averages. This decision was motivated by previous studies (Bernstein et al., 2016; Sanchez-Lopez et al., 2018; Wu et al., 2019) where a similar division of the averaged audiometric thresholds was undertaken. In the case of monaural measures, the mean values across ears were used. The data were cleaned following the principles of KDD, to remove outliers or unreliable data before the analysis. For example, some of the listeners performed the SiN test at lower levels than the level recommended for the hearing-in-noise measurements (Nielsen & Dau, 2011). Because SiN perception is of great interest in the present analysis, unreliable measurements of SRTs in noise (SRTN) and sentence recognition scores (SScore4dB) were considered as missing data. In the next step, the data were normalized between the 25th and 75th percentiles, such that the 25th percentile corresponded to a value of –0.5 and the 75th to a value of 0.5. In total, 26 variables were selected from the outcome measures, as shown in Table 1. The resulting data set (BEAR3) is publicly available (Zenodo; doi: 10.5281/zenodo.3459579; Sanchez-Lopez et al., 2019).
Stages of the Data-Driven Method
As in Sanchez-Lopez et al. (2018), the data-driven analysis used here was based on unsupervised learning and was divided into three main steps illustrated in the top panel of Figure 2:

Sketch of the Refined Data-Driven Method for Auditory Profiling. Top panel: The unsupervised learning stages of Sanchez-Lopez et al. (2018): (I) dimensionality reduction; (II) archetypal analysis; (III) profile identification. Bottom panel: In each iteration, a subset of the data set was processed using dimensionality reduction, archetypal analysis, and profile identification. The profile identification stage was twofold: (1) In each of the iterations, the profiles were identified based on the archetypal analysis. (2) After 1,000 iterations, the probability was calculated based on the prevalence of each observation and the number of identifications as each of the profiles. Listeners with higher probabilities of belonging to an auditory profile were placed close to the corners in the square representations, and the ones with lower probability (p < .5) were located inside the gray square.
I Dimensionality reduction: Based on principal component analysis, a subset of variables that were highly correlated with the first two principal components, PC1 and PC2, was kept for the following Steps (2 and 3). The subset could consist of 3, 4, or 5 variables per PC. Hence, up to 10 variables could be kept for the next step. The to-be-kept variables were chosen in an iterative process using a leave-one-out cross-validation. In each iteration, one variable was removed according to the variance explained by the remaining variables, that is, the subset of variables that explained the largest amount of variance was kept, and the left-out variable was discarded. In addition, because the use of several intercorrelated variables in principal component analysis can bias the results, highly correlated variables were removed. If two variables resulting from Step 1 were highly correlated (Pearson’s correlation coefficient, r > .85), one of them was dropped, and this step was repeated.
II Archetypal analysis: This unsupervised learning technique is similar to cluster analysis. However, the results are archetypal patterns across the multivariate data rather than clusters or groups of observations. The data were decomposed into two matrices—the test matrix, which contained the extreme patterns of the data (archetypes), and the subject matrix, which contained the weights for each archetype. A given subject was then represented as a convex combination of the archetypes (Cutler & Breiman, 1994). The specific method used here was similar to the one proposed in Mørup and Hansen (2012). The analysis was limited to four archetypes to improve the interpretability of the results on the scope of the hypothesis (see Figure 1).
III Profile identification: The subject matrix was used to estimate the distance between observations and the four archetypes. Each listener (subject) was then assigned to an auditory profile group based on their weights in the subject matrix. The sum of weights for each listener was always 1. Listeners with a weight above 0.51 for one of the four archetypes were identified as belonging to that auditory profile (Ragozini et al., 2017). Otherwise, they were left “unidentified” (“U”). The specific labels (A–D) were assigned as follows. The Archetype A reflected the average best performance (i.e., a better performance for the majority of the outcome variables compared with the other archetypes), and the Archetype C reflected the poorest performance. For the distinction between the two remaining groups, B was assumed to have a higher degree of high-frequency hearing loss than D, based on Sanchez-Lopez et al. (2018). Therefore, the criterion applied for B and C was based on the variables AUDHF and HTLHF rather than the resulting archetypes.
Iterative Data-Driven Profiling
The robust data-driven auditory profiling method aimed to improve the previous method proposed in Sanchez-Lopez et al. (2018) by reducing the influence of the data on the definition of the auditory profiles. In any data-driven analysis, and especially in unsupervised learning, individual data points can clearly influence the results and lead to misinterpretations. Resampling techniques, such as bagging or Monte Carlo estimation, have been demonstrated to reduce the influences of individual data points on the statistical analysis. Moreover, bagging can improve cluster analysis, making the results less sensitive to the type and number of variables (Dudoit & Fridlyand, 2003). The three unsupervised learning steps were repeated 1,000 times, as illustrated in the bottom panel of Figure 2. Before each repetition, the full data set was decimated randomly in terms of subjects and tests in each iteration. The analysis was performed with only 83% of the data (69 out of 75 listeners and 24 out of 26 variables) in each repetition. In the case of missing data, an algorithm based on spring metaphor was used to predict those data points. Furthermore, in Step 1 (dimensionality reduction), the number of selected variables (6, 8, or 10) was also randomly selected in each iteration to further randomize the procedure. Steps 2 (archetypal analysis) and 3 (profile identification) yielded a preclassification of the subjects contained in the subset of the data corresponding to each iteration. The probability of each listener of being identified as a given auditory profile depended on the number of times a given listener was “out-of-bag” in individual repetitions and the profile identification result from Step 3. In each iteration, the profile probabilities [P(A), P(B), P(C), or P(D)] and the probability of being unidentified [P(U)] were updated. This iterative process was chosen to avoid that few individual listeners bias the derived profiles.
After 1,000 repetitions, the listeners were divided into four subgroups based on the computed probabilities. If a given listener showed a probability above .5 of belonging to any of the auditory profiles, the listener was assigned to that profile. However, if the highest probability was below .5, but P(U) was also below .5, the listener was considered “in-between” two profiles. The criterion for the “in-between” listeners to be included in one of the four clusters was that the difference between the two highest probabilities had to be above .1 to be considered significant. The remaining of the “in-between” listeners was considered inconclusive and not assigned to any profile. The projection of the probabilities on a two-dimensional space was done by considering four vectors, one for each profile probability, pointing toward each of the corners in a squared representation, as depicted in the right-bottom panel of Figure 2. Graphically, the listeners belonging to an auditory profile were then placed close to the corners.
Distortion Estimation From the Square Representation
The final output of the refined data-driven method was the probability, P, of being identified as belonging to an auditory profile (A–D). Regarding the square representation or convex hull, which resembled the hypothesis shown in Figure 1, the probabilities of belonging to an auditory profile were depicted as vectors with the origin at the center of the square and oriented toward each of the four corners (Figure 2). Assuming that P(B) and P(C) are proportional to ADI and that assuming that P(C) and P(D) are proportional to ADII, this yields:


Decision Trees
A decision tree was fitted to the entire data set following the splitting criterion of weighted impurity (Breiman et al., 2017). Because it was of interest to obtain a decision tree with outcome measures beyond audiometry, the variables from the pure-tone audiometry were excluded from this analysis (i.e., AUDLF and AUDHF). The resulting decision tree was pruned to only have three levels and a maximum of seven binary splits. Because of the missing data, the decision tree was surrogated, that is, it ignored the missing data to facilitate its interpretability.
Results
Summary Statistics of the Data Set
The percentiles of the outcome variables corresponding to the 75 participants and excluding the optimal performer are shown in Table 2.
Results of the test battery (BEAR3 dataset) presented as the 5th, 25th, 50th and 75th and 95th percentiles.

Note. AUDLF = pure-tone average at low frequencies; AUDHF = pure-tone average at high frequencies; FLFT = fixed-level frequency threshold; HTLLF = hearing threshold levels averaged for low frequency; HTLHF = hearing threshold levels averaged for high frequency; MCLLF =most comfortable level averaged for low frequency; MCLHF = most comfortable level averaged for high frequency; DynRLF = dynamic range for low frequency; DynRHF = dynamic range for high frequency; maxDS = maximum word recognition score; SRTN = speech reception threshold in noise; IPD = interaural phase difference; BMR = binaural masking release; STM = spectrotemporal modulation; TiN = tone-in-noise; TMR = temporal masking release; SMR = spectral masking release.
Data-Driven Auditory Profiling
The BEAR3 data set was analyzed with an iterative data-driven auditory profiling method. The main results can be summarized by the probabilities of the listeners of belonging to a given auditory profile (A–D) and the expected performance of the listeners identified in each of the four groups (prototypes).
Figure 3 shows the results of the analysis where each listener is located in the two-dimensional space according to their degree of type-I and type-II distortion. The degree of distortion was calculated based on the probability of belonging to any of the four auditory profiles (expressions 1 and 2). Listeners located close to a corner exhibited a high probability of belonging to a corresponding profile. Uncategorizable listeners can be found inside the gray area representing a low probability of being classified as belonging to one of the four auditory profiles. After 1,000 iterations, the probability of being uncategorizable P(U) was also calculated. If this probability was greater than the probability of belonging to any of the four profiles, the listener was considered “uncategorizable.” Profile A (n = 24) and Profile C (n = 22) represented the most populated groups. The five NH listeners were placed at the bottom-left corner in Profile A. Profile B (n = 13) and Profile D (n = 9) represented smaller subgroups. Four listeners showed a high probability of being uncategorizable (labeled between asterisks in Figure 3), and four other listeners were “inconclusive” as reflected in similar probabilities of belonging to two profiles. The average results of the five listeners showing the highest probabilities of belonging to each one of the auditory profiles (excluding the NH listeners) were considered to represent the prototypes shown in Figure 4.
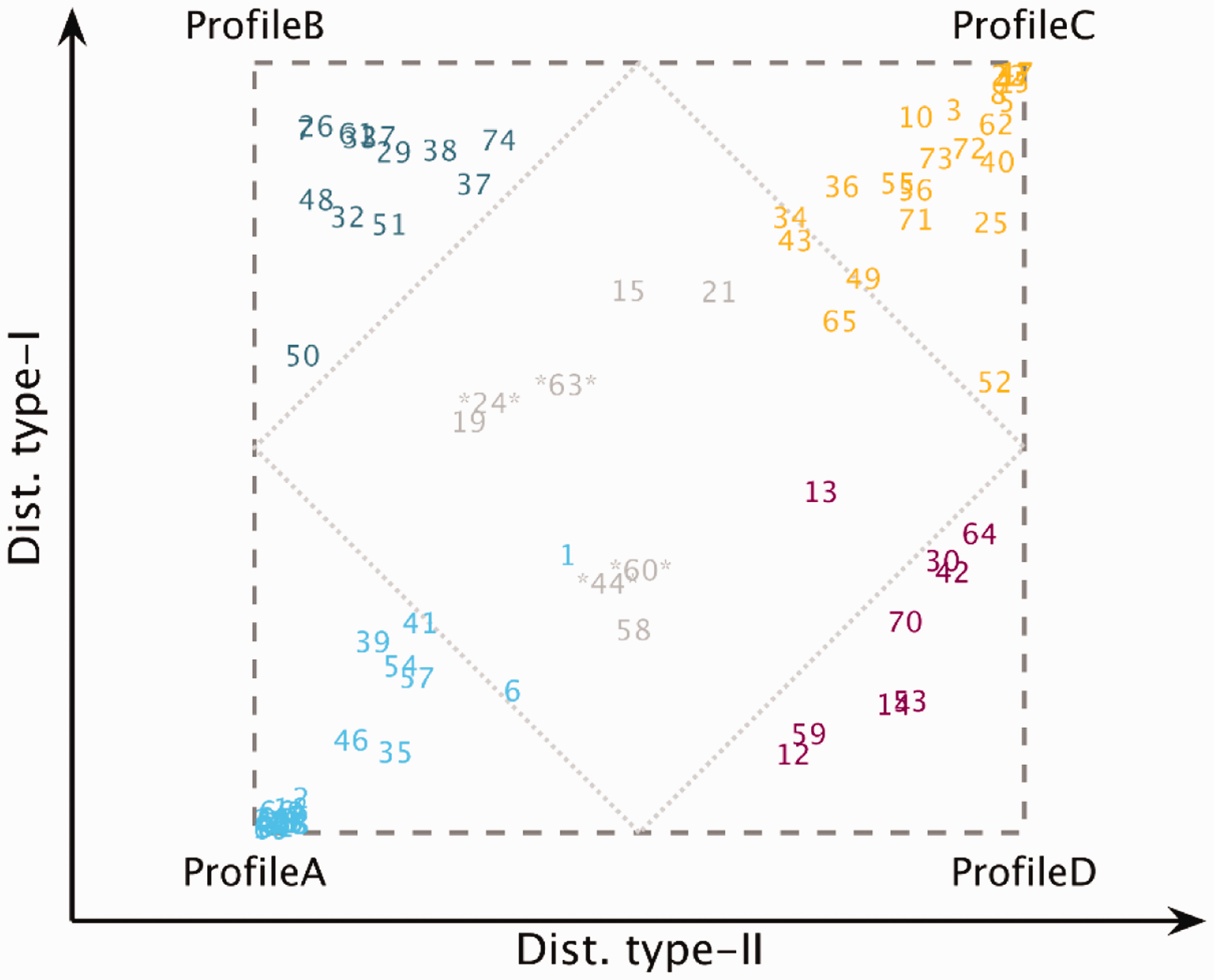
Square Representation of the Auditory Profiles. The listeners are placed in the square representation based on their probability of belonging to one of the subgroups. The inner rhombus delimits the area of inconclusive profile membership, that is, listeners showing a probability <.5 of belonging to any subgroup. The listeners marked with two asterisks were considered uncategorizable and showed P(U) >0.5.

Prototypes (Ptype): Percentile Rank Across Variables Corresponding to the Extreme Exemplars of the Different Patterns Found in the Data. The 26 outcomes corresponding to the different aspects of auditory processing are divided into the following subdimensions: AUD: Audibility; LOUD: Loudness; SiN: speech-in-noise perception; SiQ: speech-in-quiet; BIN: binaural processing abilities. STM: spectrotemporal modulation sensitivity; STR: spectrotemporal processing abilities, divided into temporal and spectral masking release as well as tone-in-noise detection. Subgroups of measures with frequency-specific outcomes were divided into low (LF) and high (HF) frequencies.
The prototypes show archetypal patterns in the data associated with the performance obtained by the four different groups. A higher percentile rank corresponds to a higher percentile of the overall data distribution and thus to a “good” performance. Each point in Figure 4 corresponds to the mean of the listeners forming the corresponding prototype. Likewise, a low percentile rank corresponds to a “poorer” performance. Prototype A (blue circles in Figure 4) showed a good performance in most of the outcome measures. However, the outcomes sSTM8 and TiNLF were below the 50th percentile. Prototype C (yellow squares) showed the poorest performance for most outcome measures, with only MCLLF and IPDfmax above the 30th percentile. Prototype B (dark-green upward-pointing triangles), with a high degree of distortion type-I and a low degree of distortion type-II, showed a good performance for the outcome measures obtained at lower frequencies and for BP20, whereas performance was poor for the outcomes obtained at higher frequencies, IPDfmax and for the SiN perception tests. In contrast, Prototype D (magenta left-pointing triangles), with a high degree of distortion type-II and a low degree of distortion type-I, showed a poor performance for outcome measures obtained at low frequencies, especially in terms of loudness, TMRLF and SMRLF, whereas the performance was good (above the 60th percentile) for most outcomes measures obtained at higher frequencies, SiN perception, and IPDfmax. Overall, the prototypes showed opposite results for the profiles located in opposite corners of Figure 3 (A vs. C and B vs. D) for the majority of the variables.
Relations Between AD Types and Outcome Measures
The relations between the two types of distortions and outcome measures were studied using stepwise regression analysis (Table 3). Distortion type-I was found to be associated with elevated hearing thresholds at higher frequencies, a reduced TMR, and increased TiN detection thresholds at low frequencies. Furthermore, distortion type-I was significantly correlated with SRTN (r = .76, p < .0001), even when the effects of audibility were partialled out (r = .33, p < .01). In contrast, the correlations found between distortion type-I and speech recognition in quiet (r = .71, p < .0001) were not significant when partialling out audibility (r = .15, p > .1). Distortion type-II was only associated with hearing thresholds at low frequencies. The restrictive criterion (increase of R2 > .01) did not include other variables in the model. However, distortion type-II was significantly correlated with the slope of the loudness function (r = .82, p < .0001) and with the amount of SMR at low frequencies (r = .64, p > .0001). In addition, distortion type-II was correlated with SRTQ (r = .86, p < .0001) but not with SRTN (r = .23, p > .05). However, the correlation between SRTQ and distortion type-II was weaker when controlling for the effects of audibility (r = .28, p < .05). Moreover, the majority of the auditory outcomes were not significantly correlated with distortion type-II when hearing thresholds were partialled out, except for TMRHF (r = .35, p < .01).
Stepwise Regression Analysis of Auditory Distortion (AD) Type-I and Type-II.

Note. The priority was established based on the accumulated adjusted R2 > .01. Columns show the predictor name, the estimate, standard deviation (SE), t value, and probability of a significant contribution (p). HTLHF = hearing threshold levels for high frequency; HTLLF = hearing threshold levels averaged for low frequency; TMR = temporal masking release; TiNLF = tone-in-noise detection threshold at 500 Hz.
The outcome measures related to BIN (Figure 4) gave unexpected results. Indeed, the Prototypes B and C showed opposite trends for IPDfmax and BP20, which suggests that they reflect different ADs. Distortion type-I was significantly correlated with both IPDfmax and BP20, but only BP20 remained significant after controlling for audibility (r = .34, p < .01). In contrast, distortion type-II was only correlated with BP20 before partialling out the effects of audibility (r = .58, p < .0001) but not after (r = .14, p = .3). Besides, IPDfmax was neither correlated with any of the two distortion types when controlling for audibility nor with any of the other BIN outcome measures (r ≪ .1, p > .15). Instead, IPDfmax was highly correlated with the TiN detection threshold at low frequencies (r = .53, p < .0001)—one of the main predictors of distortion type-I—even when audibility was partialled out (r =.56, p < .0001).
Decision Tree for the Identified Auditory Profiles
Figure 5 shows the decision tree fitted to the BEAR3 data set using the identified auditory profiles as well as the uncategorizable listeners. The decision tree has three levels. The first level corresponds to high-frequency hearing loss as estimated using ACALOS, which splits the listeners into two branches: Profiles A and D (HTLHF < 49 dB HL) are separated from Profiles B and C (HTLHF > 49 dB HL), together with one listener from Profile D. Thus, this first level makes a classification based on the degree of distortion type-I. The second level corresponds to outcomes measured at low frequencies and estimated using the loudness functions, which divide the listeners according to their degree of distortion type-II. Profile D (HTLLF > 28 dB HL) and Profile C (SlopeLF > 0.4 CU/dB and maxDS < 100%). i.e. The third level makes use of outcomes related to loudness, STM, and SMR for classifying the uncategorizable listeners.

Decision Tree Fitted to the Data Set Using the Auditory Profiles as the Output. For each binary split, the right branch corresponds to a “poor” result and the left branch to a “good” result. In each binary split, the number of listeners assigned to each branch is shown together with the most likely outputs. The classes (A–D) are together with the number of listeners belonging to that class and the number of identified listeners for a given profile.
Discussion
The data-driven method for auditory profiling presented here provides new knowledge about hearing loss characterization. Regarding previous data-driven auditory profiling (Sanchez-Lopez et al., 2018), the present results are in good agreement with the analysis performed on the data of Johannesen et al. (2016) data set. This suggests that the use of data from a representative sample of different degrees of hearing loss (e.g., in Johannesen et al., 2016) and a NH reference (e.g., in Thorup et al., 2016) is crucial for robust profile-based hearing-loss characterization.
Two Types of Distortion to Characterize Individual Hearing Loss
The term distortion in hearing science has typically been associated with elevated SRTN, as reflected in Plomp’s (1978) SRT model. Here, we introduced the term auditory distortions to describe the perceptual consequences of sensory hearing impairment, including (but not limited to) loss of sensitivity. The two types of perceptual distortions considered here should thus be considered as consequences, and not sources of sensory impairments. An interesting aspect of our data-driven profiling method is that the ADs reflect two fairly independent dimensions of perceptual deficits associated with sensorineural hearing impairments. To reiterate, distortion type-I was associated with elevated hearing thresholds at higher frequencies and was significantly correlated with elevated SRTN. Furthermore, for this distortion type, TMRHF and TiNLF were poorer even when the effect of the audiometric thresholds was controlled for. Distortion type-II was associated with low-frequency hearing loss and steep loudness functions. However, listeners with a high degree of distortion type-II and a low degree of distortion type-I (Profile D) did not exhibit exclusive audibility loss, as they also exhibited an abnormal loudness growth and a reduced SMR.
Although Plomp’s attenuation and distortion components are often assumed to be independent, some impairment mechanisms may, in fact, affect both SiN perception and audiometric thresholds, especially at high frequencies (Moore, 2016), which is consistent with distortion type-I. Schädler et al. (2020) attempted to model suprathreshold auditory deficits that are independent of audibility loss. Their results suggested that reduced speech intelligibility represents an auditory perceptual deficit that may be associated with reduced TiN detection which is in agreement with the results from the current study. However, as demonstrated here, SiN perception can also be affected by deficits that covary with audiometric thresholds (distortion type-I), which should not be underestimated, especially when the high-frequency hearing loss exceeds 50 dB HL (Profiles B and C), as depicted in Figure 6.

Audiometric Thresholds of the Four Auditory Profiles and Speech Intelligibility in Noise. Left panel: The average audiometric thresholds of each profile are shown together with the audiograms of the individual ears. Right panel: Speech reception thresholds in noise (SRTN), with boxplots of the HI and NH data (left) and the four auditory profiles (right). The multicomparison analysis revealed significant differences between the groups (***p < .0001, **p < .001).
Regarding the “neural component” or binaural loss associated with reduced BIN (Kollmeier & Kiessling, 2018), the BIN measures considered in the present study provided contradictory results in connection to the proposed auditory profiles. Even though IPDfmax represents a test that has been proposed to reveal binaural disabilities related to the disruption of temporal fine structure (TFS) coding (Füllgrabe & Moore, 2017), recent studies have linked the detection of IPDs to outcomes from cognitive tests (Füllgrabe et al., 2015; Strelcyk et al., 2019). This suggests that IPDfmax might not reflect a purely auditory process but might also depend on top-down processes such as processing speed or selective attention. Because IPDfmax and TiNLF were strongly correlated, the two tasks might be affected by either cognitive or auditory processes, which should be investigated further.
The two types of ADs shown here were consistent with Plomp’s (1978) approach. The profiles with a low degree of distortion type-I (Profiles A and D) exhibited a loss of sensitivity, but their speech-reception thresholds in noise were comparable to the ones of NH listeners. In contrast, the profiles with a high degree of distortion type-I (Profiles B and C) exhibited elevated SRTN (see the right panel of Figure 6). Distortion type-I may then be considered as a “speech intelligibility-related distortion” and distortion type-II as a “loudness perception-related distortion.” However, the two AD types presented here are, in fact, the result of a data-driven analysis of a large multidimensional data set rather than the conceptual interpretation of speech intelligibility deficits. Moreover, the listeners with higher degrees of the two types of distortions showed perceptual deficits with respect to spectrotemporal processing and BIN, thus reflecting deficits that are beyond a simple combination of loudness and speech intelligibility deficits.
Auditory Profiles and Audiometric Phenotypes
Figure 6 shows the average audiometric thresholds corresponding to the listeners belonging to the four robust auditory profiles. Profile A corresponds to a mild, gently sloping high-frequency hearing loss; Profile B corresponds to a steeply sloping high-frequency hearing loss; Profile C corresponds to a hearing loss between 30 and 50 dB HL at low-frequencies and above 50 dB HL at high frequencies; and Profile D corresponds to a fairly flat hearing loss with audiometric thresholds between 30 and 50 dB HL. Interestingly, these four audiometric configurations look similar to the audiometric phenotypes (Dubno et al., 2013), which are based on Schuknecht’s metabolic and sensory types of presbyacusis (Schuknecht & Gacek, 1993). The main difference between the two approaches is that the audiometric threshold functions shown here correspond to four subgroups of HI listeners, which are the result of a data-driven analysis involving various auditory measures (and not only audiometric thresholds). Based on audiometric thresholds only, the listeners in Profile A and Profile B would be classified into the same phenotypical category (i.e., sensory hearing loss [SHL] according to Dubno et al.), even if they present substantial differences in suprathreshold auditory hearing abilities such as speech intelligibility.
Figure 6 shows the audiometric thresholds corresponding to the four robust auditory profiles. Profile A corresponds to a mild, gently sloping high-frequency hearing loss; Profile B corresponds to a steeply sloping high-frequency hearing loss; Profile C corresponds to a low-frequency hearing loss between 30 and 50 dB HL and above 50 dB HL at high frequencies; and Profile D corresponds to a fairly flat hearing loss with audiometric thresholds between 30 and 50 dB HL. Interestingly, these four audiometric configurations look similar to the audiometric phenotypes of Dubno et al. (2013), which are based on Schuknecht’s metabolic and sensory types of presbyacusis (Schuknecht & Gacek, 1993). The main difference between the two approaches is that the audiometric thresholds shown here correspond to four subgroups of HI listeners, which are the result of a data-driven analysis involving several auditory measures and not only the audiometric thresholds.
In previous studies, metabolic hearing loss (MHL) yielded flat elevated audiometric thresholds but did not affect speech intelligibility in noise (Pauler et al., 1986), which is consistent with the results of the present study for Profile D listeners. In MHL, the atrophy of the stria vascularis produces a reduction of the EP in the scala media (Schmiedt et al., 2002). The EP loss mainly affects the electromotility properties of the OHC (i.e., the cochlear amplifier). Therefore, MHL can be considered as a cochlear gain loss that impairs OHC function across the entire cochlea. This, in turn, affects the hearing thresholds and is associated with a reduced frequency selectivity (Henry et al., 2019). In the present study, Profile D was characterized by an abnormal loudness function, particularly at low frequencies, and a significantly reduced SMR, although SiN intelligibility and binaural TFS sensitivity were near-normal. However, one needs to bear in mind that the results observed for the listeners in Profile D might also be compatible with other types of impairments. SHL is typically associated with OHC dysfunction, which yields elevated thresholds at more specific frequency regions, a loss of cochlear compression, and reduced frequency selectivity (Ahroon et al., 1993). However, audiometric thresholds above about 50 dB HL at high frequencies cannot be attributed only to OHC due to the limited amount of gain induced by the OHC motion, which implies additional IHC loss or a loss of nerve fibers (Hamernik et al., 1989; Stebbins et al., 1979; Wolak et al., 2019). Therefore, listeners classified as Profile B or Profile C (i.e., with a higher degree of distortion type-I and a high-frequency hearing loss) may exhibit a certain amount of IHC dysfunction that might produce substantial suprathreshold deficits. Animal studies have shown that audiometric thresholds seem to be insensitive to IHC losses of up to about 80% (Lobarinas et al., 2013). This suggests that hearing thresholds >50 dB HL might indicate the presence of a substantial loss IHC and might be associated with hearing deficits that distort the internal representation, not only in terms of frequency tuning but also in terms of a disruption of temporal coding due to the lack of sensory cells (Moore, 2001; Stebbins et al., 1979).
Profile B’s audiometric thresholds are characterized by a sloping hearing loss with normal values below 1 kHz. However, Profile B exhibited the poorest performance in the IPDfmax test, which cannot be explained by an audibility loss. Neural presbyacusis is characterized by a loss of nerve fibers in the spiral ganglion that is not reflected in the audiogram. Furthermore, primary neural neurodegeneration, recently termed cochlear synaptopathy (Kujawa & Liberman, 2009; Wu et al., 2019) or deafferentation (Lopez-Poveda, 2014), might be reflected in the results of some of the suprathreshold auditory tasks used here. However, the perceptual consequences of primary neural degeneration are still unclear due to the difficulty of assessing auditory nerve fibers loss in living humans (Bramhall et al., 2019). This makes it difficult to link the effects of deafferentation to the reduced BIN observed in listeners in Profile B and Profile C.
As suggested in Dubno et al. (2013), the audiometric phenotype characterized by a severe hearing loss (similar to the one corresponding to Profile C) might be ascribed to a combination of MHL and SHL. In the present study, Profile C listeners performed similarly to Profile B listeners in suprathresholds tasks related to distortion type-I (e.g., SRTN and TMRHF) and also similarly to Profile D listeners in tasks related to distortion type-II (e.g., loudness perception). In contrast, Profile C listeners also showed poorer performance in tests such as binaural pitch detection, TiN detection, and STM sensitivity, which is not consistent with the idea of a simple superposition of the other profiles. As mentioned earlier, these deficits observed in Profile C listeners might be a consequence of auditory impairments that are unrelated to the loss of sensitivity, such as deafferentation, which can be aggravated by the presence of MHL and SHL. However, it has been found that STM sensitivity could be a good predictor of aided speech perception only in the cases of a moderate high-frequency hearing loss (Bernstein et al., 2016). They suggested that cognitive factors might be involved in the decreased speech intelligibility performance when the high-frequency hearing loss is >50 dB HL. Therefore, Profile C listeners might be affected by both auditory and nonauditory factors that worsen their performance in some demanding tasks.
Stratification in Hearing Research and Hearing Rehabilitation
In the present study, the two principal components of the data set seemed to be dominated by the listeners’ low- and high-frequency hearing thresholds. This suggests that suprathreshold deficits might be associated with different forms of audibility loss. However, other suprathreshold hearing deficits, which do not covary with a loss of sensitivity, might be hidden in the four auditory profiles and could explain the individual differences across listeners belonging to the same profile. To explore these additional deficits not covered by the present approach, stratification of the listeners might be necessary. Papakonstantinou et al. (2011) studied the correlation of different perceptual and physiological measures with speech intelligibility in stationary noise. In their study, all listeners had a steeply sloping high-frequency hearing loss consistent with Profile B. Their results showed a highly significant correlation between pure-tone frequency discrimination and speech intelligibility in stationary noise. However, Lőcsei et al. (2016) did not find this association between frequency discrimination and speech intelligibility in a sample with listeners with mild-to-moderate hearing losses. This suggests that the investigation of certain phenomena in separated auditory profiles might reveal new knowledge about hearing impairments that cannot be generalized to the entire population of HI listeners.
Other approaches have attempted to identify why listeners with similar audiograms present substantial differences in suprathreshold performance. Recently, Souza et al. (2020) showed how older HI listeners vary in terms of their use of specific cues (either spectral or temporal cues). The so-called profile cue characterizes the listener’s predominant strategy for speech discrimination. The “profile cue” resulted from a syllable identification task, which was independent of the audiometric thresholds. Some listeners used temporal envelope cues and showed good temporal discrimination abilities, whereas other listeners relied on spectral cues and were able to discriminate spectral modifications in a speech signal. Even though a spectral discrimination task using a speech-like signal was promising for predicting the “profile cue,” this test seemed to be influenced by the audiometric thresholds. Because their participants presented audiograms similar to the ones observed for Profiles B, C, and D (Figure 6), it is possible that the categorization of the listeners based on auditory profiling, together with the spectral discrimination task (not included in the present study), could enable an efficient prediction of the “profile cues” and clarify its connection to suprathreshold auditory deficits.
Overall, the participants of the present study would be candidates for hearing aids. Hearing-aid users often show a large variability in terms of benefit and preference to specific forms of hearing-aid processing (Neher et al., 2016; Picou et al., 2015; Souza et al., 2019). In some studies, the HI listeners were stratified based on their audiograms (Gatehouse et al., 2006; Keidser et al., 1995; Keidser & Grant, 2001; Larson et al., 2002). However, the existing hearing-aid fitting rules do not make use of suprathreshold auditory measures that might help tune the large parameter space of modern hearing technology. In fact, the HA parameters are still adjusted based on the audiogram and empirical findings that provide some fine-tuning according to the HA user experience or the gender of the patient (Keidser et al., 2012). Furthermore, candidacy for specific hearing-aid processing (e.g., beamforming) could be driven by specific suprathreshold auditory deficits (e.g., Füllgrabe et al., 2018; Neher et al., 2017) or nonauditory aspects (e.g., Neher et al., 2016; Souza et al., 2019). The four auditory profiles presented here showed significant differences in suprathreshold measures related to two independent dimensions, a speech intelligibility-related distortion and a loudness perception-related distortion. Therefore, the present data-driven profiling method allows stratifying the listeners beyond what can be achieved with an audiogram. This may help optimize hearing-aid fitting parameters for a given patient. Recently, it has been suggested that different advanced signal processing strategies should be considered to compensate for different cochlear pathologies (Henry et al., 2019). Because the four auditory profiles showed interesting similarities to the sensory and metabolic phenotypes proposed by Dubno et al. (2013), new forms of signal processing aimed at overcoming the hearing deficits associated with the two identified dimensions may be developed and evaluated. Furthermore, the current approach may inspire different forms of model-based hearing loss compensation (Bondy et al., 2004) to restore auditory function based on biologically inspired technology. This can lay the foundations for precision medicine (Jameson & Longo, 2015) applied to the perceptual rehabilitation of the hearing deficits. The implementation of a clinically feasible classification procedure depends on different factors, such as time efficiency and the availability of the necessary auditory tests and hearing-aid algorithms.
Limitations of the Data-Driven Auditory Profiling Approach
A clear limitation of the data-driven method proposed here is its constraint to two dimensions of independent auditory deficits and four subgroups. The advantage of the proposed method is that it can provide results that can be easily interpreted even when using advanced computational methods for data analysis. Usually, advanced data-driven methods provide meaningful results, but they are not necessarily linked to an initial hypothesis (Figure 1). In our approach, the imposed link between method and hypothesis leads to a constraint in terms of dimensions and subgroups. However, it would be interesting to extend the current data-driven method to allow for a third (or even higher) dimension which might partly explain additional variance in the data in future research.
The definition of the auditory profiles reflected the main sources of hearing deficits in a relatively large and heterogeneous population of HI listeners. However, this group only contained older adults (>60 years) with symmetric sensorineural hearing losses. An extension of the auditory profiling method proposed here might be based on an even more heterogeneous group of participants, which might require different data-analysis techniques for proper analysis and interpretation (Hinrich et al., 2016). The insights from the current method could then be applied mainly to a population of mild-to-severe age-related hearing losses and to some extent to other types of nonsyndromic hearing losses, for example, noise-induced hearing loss, but cannot be generalized to the whole variability of existing auditory pathologies.
The presented data-driven approach for hearing loss characterization was intentionally limited to the use of psychoacoustical measures and the use of auditory tests with potential for clinical implementation. Physiological measures, such as otoacoustic emissions and auditory evoked potentials, were not considered in the current approach. This was a decision in the interest of the characterization of the perceptual consequences derived of the hearing deficits rather than the “sources” of the hearing loss. Cognitive factors are also important for characterizing the overall “listening profile” of individuals with hearing loss, as suggested in several studies (e.g., Humes, 2007; Rönnberg et al., 2016). In the present study, cognitive factors were considered as a confound rather than a missing part of the auditory profiling approach. A better understanding of the sensory dysfunction is needed to provide an efficient compensation of the hearing deficits rather than a compensation for the audibility loss. However, it would be of great interest to explore the cognitive factors from a bidirectional point of view. Cognition can affect the perception of the auditory stimuli presented in the test battery, and the listener’s cognitive resources can also be affected by the distortions reflected by the auditory profiles and lead to an effortful listening experience (Füllgrabe, 2020; Peelle, 2018; Pichora-Fuller et al., 2016).
Besides the potential for clinical implementation, the tests that were language independent were prioritized. However, a test battery representing speech intelligibility deficits would be of great relevance. Such a test battery could be tested on a population of people with different hearing abilities and analyzed using a similar data-driven profiling method as the one presented here. This test battery might involve speech intelligibility tests in the presence of different interferers and spatial configurations (e.g., Lőcsei et al., 2016). Besides, it might contain tests where speech intelligibility is affected by reverberation, audible distortions, or the use of amplification. In such a study, phenomena such as masking release or binaural unmasking could be further investigated using a data-driven approach.
The current study focused on the basis of auditory profiling and not on their clinical application. For the latter, other considerations such as the reliability, time efficiency, and ease of administration of the tests must be taken into account. In its present form, the BEAR test battery may be unfeasible to be administered in the clinic, but some individual tests have the potential to be implemented in the clinical practice and to guide the characterization of individual hearing deficits. The evaluation and optimization of the auditory profiling approach should be undertaken carefully, bearing in mind that the purpose of the classification is a better intervention. First, it needs to be demonstrated that the stratification applied to hearing rehabilitation is beneficial for the patient, and second, the identification of a set of measures to better characterize the auditory deficits needs to be optimized to find a balance between the time spent in the additional tests and the benefit obtained with this approach.
Conclusion
Using a data-driven approach, four auditory profiles (A–B–C–D) were identified that showed distinct differences in terms of suprathreshold auditory processing capabilities. The listeners’ hearing deficits could be characterized by two independent types of AD, a “speech intelligibility-related distortion” affecting listeners with audiometric thresholds >50 dB HL at high frequencies, and a loudness perception-related distortion affecting listeners with audiometric thresholds >30 dB HL at low frequencies. The four profiles showed similarities to the audiometric phenotypes proposed by Dubno et al. (2013), suggesting that Profile B may be resulting from a sensory loss and Profile D may be resulting from a metabolic loss. Profile C may reflect a combination of a sensory and metabolic loss, or a different type of hearing loss that results in substantially poorer suprathreshold auditory processing performance. The success of this approach provides new methods to identify homogeneous subpopulations to better investigate the perceptual consequences of different etiologies. The current results enable precision audiology and provide new avenues for developing auditory-profile-based compensation strategies for hearing rehabilitation. Furthermore, auditory profiling showed potential for hearing diagnostic that can help disentangle the effects of different types of impairments. This might be particularly useful for the development of therapeutics for hearing loss (Kujawa & Liberman, 2019) supporting precision medicine.
Supplemental Material
sj-pdf-1-tia-10.1177_2331216520973539 - Supplemental material for Robust Data-Driven Auditory Profiling Towards Precision Audiology
Supplemental material, sj-pdf-1-tia-10.1177_2331216520973539 for Robust Data-Driven Auditory Profiling Towards Precision Audiology by Raul Sanchez-Lopez, Michal Fereczkowski, Tobias Neher, Sébastien Santurette and Torsten Dau in Trends in Hearing
Supplemental Material
sj-xlsx-2-tia-10.1177_2331216520973539 - Supplemental material for Robust Data-Driven Auditory Profiling Towards Precision Audiology
Supplemental material, sj-xlsx-2-tia-10.1177_2331216520973539 for Robust Data-Driven Auditory Profiling Towards Precision Audiology by Raul Sanchez-Lopez, Michal Fereczkowski, Tobias Neher, Sébastien Santurette and Torsten Dau in Trends in Hearing
Footnotes
Acknowledgments
We thank F. Bianchi, S. G. Nielsen, M. El-haj-Ali, O. M. Cañete, and M. Wu for their contribution to the design of the BEAR test battery and work in the data collection. Also, we appreciate the valuable input from J. B. Nielsen, J. Harte, W. Whitmer, G. Naylor, and O. Strelcyk among others. We would also like to thank G. Encina-Llamas, A. A. Kressner, and E. N. MacDonald who suggested some improvements in an earlier version of this article. This work was part of the Better hEAring Rehabilitation project; the funding and collaboration of all partners are sincerely acknowledged.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Innovation Foundation Denmark Grand Solutions 5164-00011B (Better hEAring Rehabilitation project) Oticon, GN Hearing, WSAudiology, and other partners (Aalborg University, University of Southern Denmark, the Technical University of Denmark, Force, Aalborg, Odense, and Copenhagen University Hospitals).
Supplemental Material
Additional figures illustrating the performance of the auditory profiles in each individual tests are provided as supplemental files. The figures are presented in boxplots as the right panel of ![]() . The correlations and partial correlations of each of the variables with the estimate of auditory distortions type-I and type-II are also provided as additional files.
. The correlations and partial correlations of each of the variables with the estimate of auditory distortions type-I and type-II are also provided as additional files.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.