
Abstract
Automatic gain control (AGC) compresses the wide dynamic range of sounds to the narrow dynamic range of hearing-impaired listeners. Setting AGC parameters (time constants and knee points) is an important part of the fitting of hearing devices. These parameters do not only influence overall loudness elicited by the hearing devices but can also affect the recognition of speech in noise. We investigated whether matching knee points and time constants of the AGC between the cochlear implant and the hearing aid of bimodal listeners would improve speech recognition in noise. We recruited 18 bimodal listeners and provided them all with the same cochlear-implant processor and hearing aid. We compared the matched AGCs with the default device settings with mismatched AGCs. As a baseline, we also included a condition with the mismatched AGCs of the participants’ own devices. We tested speech recognition in quiet and in noise presented from different directions. The time constants affected outcomes in the monaural testing condition with the cochlear implant alone. There were no specific binaural performance differences between the two AGC settings. Therefore, the performance was mostly dependent on the monaural cochlear implant alone condition.
The combination of a cochlear implant (CI) with a contralateral hearing aid (HA) is known as bimodal stimulation. Globally, bimodal listeners currently account for more than one third of CI users (Devocht et al., 2015). It has been well established that the majority of bimodal listeners with moderate-to-severe hearing loss exhibit better speech recognition in quiet and in noise compared with CI-only use (Ching et al., 2007, Dorman et al., 2014a, Illg et al., 2014). Furthermore, the combination of an HA and a CI can also improve sound source localization performance (Ching et al., 2007), given that the two ears are stimulated compared with only one, in case of CI alone. The difference in performance between the bimodal combination and CI alone is known as the bimodal benefit.
A particular problem for bimodal listeners is that the loudness growth, the relation between the intensity of the sound and the induced loudness percept, from the two devices is different. Different loudness growth functions in the two ears decrease wearing comfort (Tyler et al., 2002) and may degrade binaural cue perception such as interaural level difference (Francart et al., 2008; Francart & McDermott, 2012b). While the discussion on loudness as a part of bimodal fitting is still ongoing (Vroegop et al., 2018), loudness balancing between the CI and the HA is often suggested as part of the fitting procedure (Ching et al., 2001; English et al., 2016; Veugen et al., 2016a).
An essential component of both the CI and HA is a compressor, also called automatic gain control (AGC). An AGC is needed to adapt the wide dynamic range of sounds to the limited dynamic range of hearing-impaired listeners. The AGC at the CI side is rarely changed (Vaerenberg et al., 2014). In contrast, the compression ratio of the HA depends on the fitting rule used and on possible fine tuning. Furthermore, on the HA side, the input–output function types also vary by manufacturer. Therefore, the loudness differences between devices depend on the fitting and the brand of hearing devices.
Matching the compressors of CI and HA could decrease the loudness differences between the two devices (Veugen et al., 2016a) and would be a relatively simple change to the devices, in contrast to some algorithms for precise loudness balancing (Francart & McDermott, 2012b). It has been suggested that speech recognition in quiet does not strongly depend on loudness differences between CI and HA (Dorman et al., 2014b), so matching compressors may yield benefits without influencing speech recognition in quiet.
Apart from loudness, AGC parameters could also influence speech recognition in a noisy environment. Previous research has shown that the majority of bimodal listeners can only understand speech at positive speech-to-noise ratios (SNRs; e.g., Francart & McDermott, 2012a; Morera et al., 2012). For a positive SNR at the HA input, compressive amplification results in a smaller (worse) long-term SNR at the HA output than at the input (Naylor & Johannesson, 2009; Souza et al., 2006), leading to decreased speech recognition. Therefore, slow time constants (attack and release time) result in a higher long-term SNR than fast (Naylor & Johannesson, 2009). In addition, slow time constants result in less temporal and spectral distortion than fast ones (Sanchez-Lopez et al., 2018). Behavioral tests have further demonstrated that slower attack times result in improved speech recognition in background noise (Stone & Moore, 2004). Also for bimodal listeners, it has been shown that an increase in SNR in the HA can improve speech recognition, even if the main contributor to speech understanding is the CI (Dieudonné & Francart, 2020). Therefore, we hypothesized that for the bimodal population, a combination of higher knee points and slow time constants of AGCs could improve the speech reception threshold (SRT), defined as the SNR at which 50% of the words will be recognized.
Veugen et al. (2016a) demonstrated a significantly larger bimodal benefit with matched AGCs and slow time constants in one very specific condition: The speech came from the front and the noise was on the HA side. There were no differences for noise coming from other directions and for speech in quiet. The Speech, Spatial, and Qualities of Hearing Scale (SSQ) questionnaire (Gatehouse & Noble, 2004) of the study of Veugen et al. revealed no differences between standard and matched AGCs. However, matched AGCs were rated better, based on a bimodal listening questionnaire, designed for this study.
It is unclear whether the effect found by Veugen et al. (2016a) was due to the loudness-matched compressors or to the effect of a better long-term SNR at the HA side caused by the slow time constants. If the effect is driven by the slow time constants, it should also be found in the monaural, CI-only, condition. Therefore, the CI-only condition should be tested with both fast and slow time constants. However, Veugen et al. only tested the CI-only with slow time constants. Therefore, the influence of time constants and loudness matching could not be disentangled.
Given that previous studies have not demonstrated any influence of loudness matching on speech recognition in quiet (Dorman et al., 2014b; Spirrov et al., 2018) or in noise (Spirrov et al., 2018), we hypothesized that the specific effect found by Veugen et al. (2016a) was mostly driven by the time constants alone and not by the particular matching of the AGCs. Given that the results were only specified as bimodal benefit (bimodal—CI-only speech recognition), we hypothesize that the effect was not bimodal but rather monaural. In principle, different time constants might improve binaural cue perception, which in turn might improve speech understanding in noise (i.e., binaural unmasking). However, given that the two ears are stimulated with different modalities (electrical vs. acoustical) and some bimodal listeners cannot even fuse these two modalities, there remains some doubt if binaural unmasking can really work across the two modalities. Recent experiments with speech in noise from different directions showed that the bimodal performance was largely determined by the performance with the best monoaural device (Williges et al., 2019). The bimodal group of this study did not demonstrate a binaural summation effect. Moreover, in a recent review on speech in noise from different directions for bimodal listeners, Dieudonné and Francart (2020) have also shown that there is probably no binaural unmasking at all in bimodal listeners. Using their framework to analyze binaural speech understanding, Dieudonné and Francart (2019) argue that any so-called squelch benefit that has been measured in the literature in bimodal listeners could be explained as the use of complementary information, that is, not because of binaural unmasking.
Finally, some confounding factors could hide the theoretically expected effect. For example, listeners’ short-term memory was suggested to play a role in the benefit of compression speed (Lunner & Sundewall-Thorén, 2007; Rudner et al., 2011; Souza & Sirow, 2014; Souza et al., 2015). Studies have shown that people with better short-term memory benefit more from fast compression and those with lower scores on short-term memory tests benefit from slow compression. The relation between compression speed and working memory is currently a topic of larger discussions in the HA community (Leijon, 2017; Ohlenforst et al. 2016). Short-term memory is suggested to reflect the processing speed of the brain. However, in the previous studies with HAs, the SNR was predominantly negative, which reverses the some of the effects of the compression. Therefore, the influence of short-term memory on compression speed in bimodal listeners is still unknown.
The aim of our study was (a) to investigate whether the very specific effect found by Veugen et al. (2016a) can be replicated; (b) to disentangle the effect of matching the knee points and the time constants, by systematically evaluating speech-in-noise performance in a monaural CI-only condition (fast or slow time constants) and bimodal use (matched slow or unmatched fast AGCs); and (c) to investigate the effect of cognition by also measuring short-term memory skills.
Methods
Conditions
We tested three conditions. In the first condition, we tested the participants’ own CI processor by Cochlear Ltd. and their own HA. In the other two conditions, we used a Nucleus 6 processor from Cochlear Ltd. plus an Enzo 3 D HA from GN Hearing, either in a standard configuration or matched slow configuration. The Nucleus 6 processor has a broadband AGC and the Enzo 3 D has an AGC with 17 separate bands. More information about the parameters of the AGCs for the other two conditions is given in Table 1.
Parameters of the AGCs for the Standard and Matched Slow Conditions.

Note. In the case of a CI, we used a dual loop AGC (AGC 1 and AGC 2 in the table), similar to Veugen et al. (2016a). Given the lower knee point of loop 2, the behavior of the AGC in the CI was mainly determined by this loop, which is similar to the abovementioned study. CR = compression ratio; AGC = automatic gain control; HA = hearing aid; CI = cochlear implant.
a125 ms at 250 Hz.
In the standard condition, the gains and the compression ratios of the HA were determined by the ˙ National acoustics laboratory, non-linear fitting rule, version 2 (NAL-NL2) fitting rule (Keidser et al., 2011). In the matched condition, we increased the gains for a level of 65 dB Sound Pressure Level (SPL) to be equal to those for a level of 50 dB SPL. This transforms the HA into a linear HA up to 65 dB. Further information is given in Figure 1.

Output Long-Term Speech-to-Noise Ratio (SNR) With and Without Compression. The dashed lines show the HA fitting for the matched AGC condition. When the speech level is above the noise level, as in the figure, the SNR is positive. SPL =Sound Pressure Level.
In general, the instantaneous speech level varies more than the noise level. Therefore, instantaneous SNRs are likely to remain positive even for negative long-term SNRs. However, if the attack time of an AGC is too fast, positive instantaneous SNRs can be reduced or even become negative.
For this study, the time constants were similar to those in the study of Veugen et al. (2016a). To further replicate this study, we had a double compressor on the CI side with a fast acting part containing the same parameters as those in Veugen et al. (knee at 71 dB, attack and release time of 3 and 80 ms).
Finally, to disentangle the influence of matching the knee points of the AGCs and the time constants, we tested both the bimodal configuration and the CI-only condition for speech in noise and in quiet. We hypothesized that if we observed an advantage of the slow AGC in the monaural, CI-only, condition, the effect would be due to the time constants and not to the matched knee points. In addition, for speech in quiet, we also tested the HA without the CI to investigate the influence of the compression in cases of severe to profound hearing loss.
Subjects
A total of 18 native German speakers participated in the experiment. The study was approved by the ethics committee of Medizinische Hochschule Hannover (7797 BO S 2018). We did not include subjects with profound hearing loss at low frequencies to ensure that they will benefit from their HA and will have true binaural hearing. Additional information is given in Table 2. The audiograms of the nonimplanted ear are shown in Figure 2. Five participants reported that they do not perceive balanced loudness with their own devices. Two participants reported that they do not perceive a fused sound image from their own HA and CI.
Information About the Tested Subjects: Age is Given in Years at the Time of Testing.
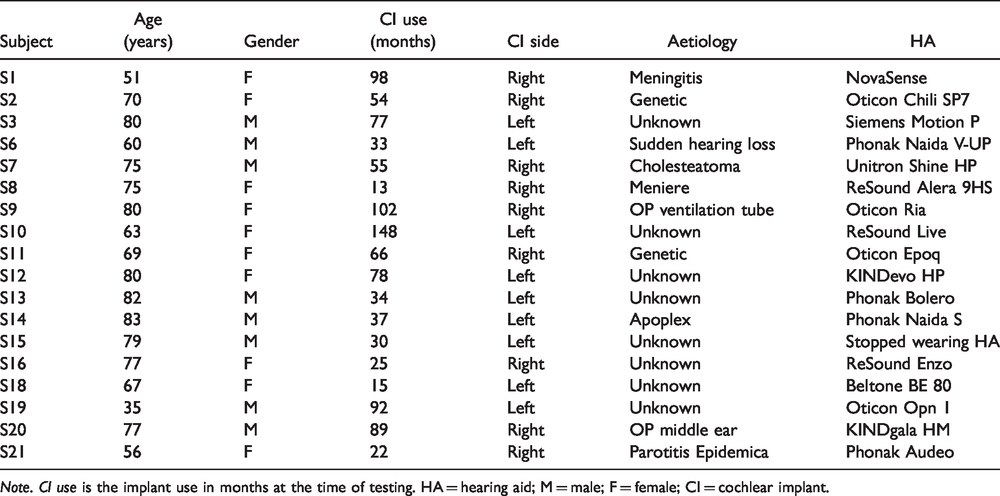
Note. CI use is the implant use in months at the time of testing. HA = hearing aid; M = male; F = female; CI = cochlear implant.

Pure-Tone Unaided Air Conduction Thresholds of the Nonimplanted Ear for the Tested Subjects (Dashed Lines), Together With the Average (Bold Black Line; Unmeasurable Thresholds Replaced by 130 dB HL). HL = Hearing Loss.
Stimuli and Tests
To measure speech in quiet, we used the Freiburg monosyllabic words uttered by a male speaker at 50 and 65 dBA (Hahlbrock, 1953). Given that each list consists of 20 words, each word has 5% weight in the final score. We tested bimodal, CI-only, and HA-only condition, with the order of testing selected at random for each participant.
For the speech-in-noise recognition test, we used the German matrix test sentences uttered by a male speaker (Wagener et al., 1999) at 65 dBA with a competing talker in Swedish. The competing talker was also a male speaker reading the story of the “North wind and the sun”. The level of the competing speaker was adapted using the procedure of Brand and Kollmeier (2002). We did not use the international female masker (Holube et al., 2010) used by Veugen et al. (2016a) because constantly changing languages distracts the listener, which has led to a high informational masking effect with this signal in earlier studies (Francart et al., 2010; Goossens et al., 2017).
We expanded the test protocol of Veugen et al. (2016a) by testing more spatial speech and noise combinations: speech and noise frontal (S0N0), speech frontal + noise from the HA side (90°, S0NHA), and speech frontal + noise from the CI side (90°, S0NCI). In addition, to disentangle the influence of the matched knee points from the influence of the time constants, we tested the bimodal configuration and added a CI-only condition.
Table 3 shows the conditions tested and the respective signal and noise directions.
Summary of Speech-In-Noise Tests.

Note. CI = cochlear implant; AGC = automatic gain control; HA = hearing aid.
Details From the Statistical Model on Speech in Quiet Results, Expressed in Rationalized Arcsine Units.
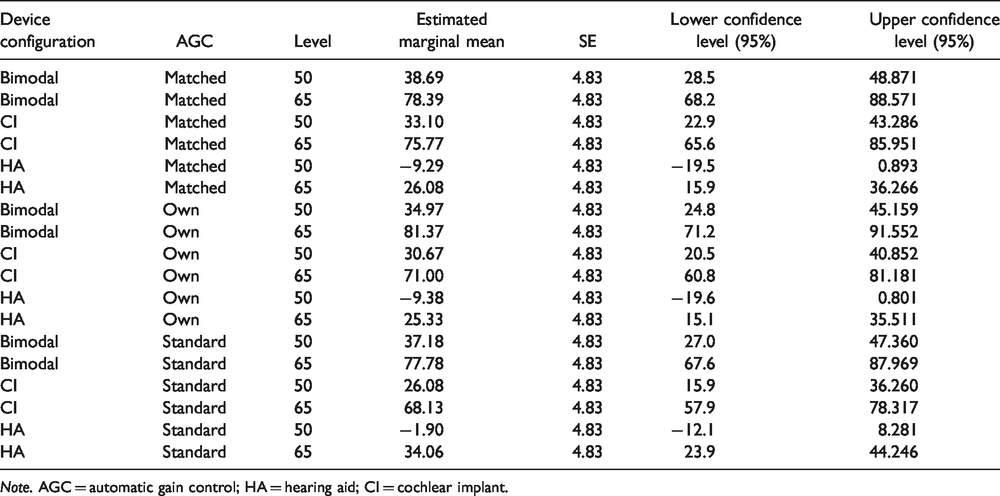
Note. AGC = automatic gain control; HA = hearing aid; CI = cochlear implant.
Details From the Statistical Model on Speech-in-Noise Results, Expressed in SRT.

Note. AGC = automatic gain control; HA = hearing aid; CI = cochlear implant; SRT = speech reception threshold.
Details From the Statistical Model on Bimodal Benefit, Expressed in dB.

Note. AGC = automatic gain control; HA = hearing aid; CI = cochlear implant.
The stimuli were presented in an audiometric booth with loudspeakers in 1 m distance, using the Oldenburg Measurement Applications (Version 1.3.6, HörTech GmbH, Oldenburg, Germany) on a regular personal computer (PC). The PC was connected to a RME Fireface 800 sound card (Audio AG, Haimhausen, Germany) driving Genelec (Genelec Iisalmi, Finland) loudspeakers.
We used two tests to measure short-term memory skills: a digit span test (Weschler, 1997) and a size comparison span test (Sörqvist et al., 2010). The former consists of sequences of numbers with increasing length (from 2 to 7 numbers). The numbers were presented via live voice. The participants were asked to repeat the sequences in a forward or backward order. In the size comparison span test, the participants compared the relative size of two objects (e.g., cat and cow) by clicking on a screen. Then a third word from the same category appeared on the screen (e.g., crocodile) that had to be remembered. Similar to the digit span test, the categories were presented in blocks with different lengths. This is a visual test and not influenced by possibly poor hearing.
We used the full SSQ questionnaire (Gatehouse & Noble, 2004) in order to be able to compare the results with those of Veugen et al. (2016a).
Protocol
We tested the participants’ own configuration first and then the standard and the matched slow condition in random order, balanced across participants. Each configuration was first fitted and then tested after a 4 weeks’ home trial. In the test session, we first assessed the SSQ. Then we tested speech in quiet and speech in noise. For speech in quiet, there was no familiarization with the material, given that the participants knew the test quite well from the clinical routine. For the speech-in-noise material, the participants were tested in quiet at 65 dB SPL to get familiar with the sentence structure and words. Then we started at 5 dB SNR. The first sentence was repeated and the SNR was changed until the participant recognized 50% of the sentence. At the end of the testing session, we fitted the second configuration and the procedure was repeated after 4 more weeks. Finally, digit and size comparison span tests were conducted during the last visit and a ranking of the different configurations was made by asking the participants how they would order different AGC configurations, in terms of preference. Since they did not know the test order, we asked whether they preferred their own or first or second configuration.
At the CI side, we used the participants’ clinical settings, namely, the T-levels, pulse width and gap, stimulation rate, and frequency allocation. Beamformer and adaptive dynamic range optimization (ADRO) were switched off. To ensure an optimal sound quality, the C-levels were adapted, if necessary.
To fit the HA, we first measured the unaided audiogram. Then, we fitted the HA using the NAL-NL2 rule. We measured the aided thresholds and changed the gains, if needed, to be as close as possible to the NAL-NL2 rule aided threshold. Finally, we adapted the gains based on participants’ feedback for speech quality. When changing the gains, we always preserved the prescribed compression ratios. At the end of the fitting, we loudness balanced the HA to the CI by using a simple broadband adjustment of the HA, based on the fitter’s voice. We did not use more elaborate loudness balancing procedures in order to remain close to general clinical practice. The reason for loudness balancing was to improve comfort and to ensure that the participants would accept the new hearing sensation. Previous studies did not find differences in speech recognition in quiet and in noise between broadband and three-band loudness balancing (Veugen et al., 2016b).
Statistical Analysis
Both, for speech in quiet and in noise, the test and retest results were averaged. The results from the speech in quiet experiment were transformed to rationalized arcsine units (Studebaker, 1985) to make them suitable for linear regression analysis.
Then, similar to Veugen et al. (2016a), we fitted a linear mixed model, treating subject as a random factor. The model to analyze speech in quiet contained three factors: AGC configuration (standard AGCs and matched AGCs with slow time constants), device configuration (bimodal, CI-only, and HA-only), and presentation level (50 and 65 dB). We excluded the condition with the own CI and HA from the linear mixed model, given that it was tested only for frontal noise direction. The speech-in-noise model also contained the factors AGC and device configuration, and in addition the factor noise direction (frontal, CI side, and HA side), also resulting in a three-factor model.
We did not apply factor analysis on SSQ results because aggregation across different factors (subject, response category, question number, and AGC configuration) resulted in different outcomes. Furthermore, previous work suggested different weights of each question in a given category (speech quality, spatial awareness, and speech recognition; Akeroyd et al., 2014). We report means across subjects per AGC configuration and response category. As a post hoc test, we used Wilcoxon-signed rank tests. For this test, we excluded subjects for which we had missing data. Furthermore, we used Holm correction for multiple comparison.
We provide more details from the statistical models in the Appendix.
Results
Speech Recognition in Quiet and in Noise
Group results for speech recognition in quiet and in noise are shown in Figure 3.
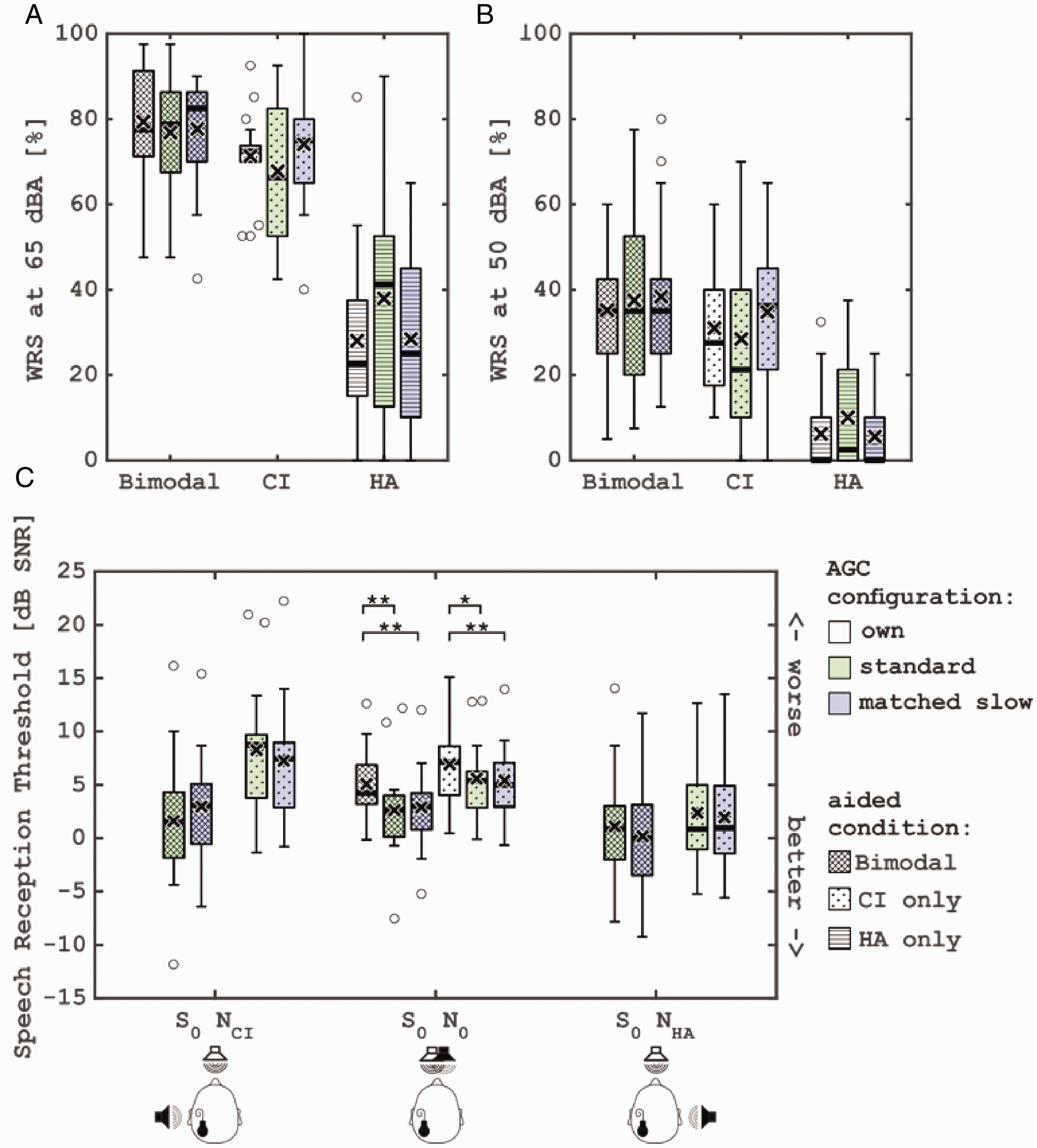
Group Results for Speech Recognition in Quiet and in Noise. Percentage of the word recognition score (WRS) in quiet as a function of the AGC configuration and stimulation level (panel A and B). Speech reception threshold in noise for the two aided conditions (bimodal cross hatched and CI-only dotted), three AGC configurations, and the three noise directions (panel C). Crosses present the mean, bars the median. The lower and the upper parts of the boxes present 25 and 75 percentile, respectively. Points present outliers. CI = cochlear implant; HA = hearing aid; SNR = speech-to-noise ratio; AGC = automatic gain control.
For speech in quiet, the linear mixed model showed a significant effect of level, F(1,289) = 542, p < .001, and device used, F(2,289) = 296, p < .001, but not of AGC configuration. There were no significant interactions between the factors. In two cases, there was a trend for an AGC condition effect.
Group results for speech recognition in noise are shown in Figure 3C.
We excluded the condition with the own CI and HA from the linear mixed model, given that it was tested only for frontal noise direction. The model showed no significant effect for factor AGC configuration (p = .66). Device configuration, F(1,187) = 87, p < .0001, and noise direction, F(2,187) = 39.7, p < .0001, on the other hand, were significant. Furthermore, there was a significant interaction between these two factors, F(2,187) = 11.8, p < .0001.
We conducted four additional pairwise comparisons on data that were not included in the model. In the frontal noise condition with the CI-only configuration, Wilcoxon pairwise comparisons with Holm corrections revealed that both matched AGCs (V = 142, df = 17, p = .006, conf.int = [0.68, 2.1]) and standard AGC (V = 131, df = 17, p = ,02, conf.int = [0.47, 2.12]) result in significantly better speech understanding than the own AGCs. Furthermore, in the bimodal configuration, both matched AGCs (V = 142, df = 17, p = .003, conf.int = [0.88, 3.1]) and standard AGCs (V = 146, df = 17, p = .001, conf.int = [0.85, 2.95]) were significantly better than the own AGCs.
We calculated the bimodal benefit by subtracting the results of the CI-only condition from the bimodal condition for each noise direction and device configuration. The bimodal benefit is shown in Figure 4. We reversed the sign in order to provide a more intuitive graph, that is, higher values reflect more benefit.

Bimodal Benefit. Result above the zero-line indicates that HA contributes to CI for speech recognition with competing talker. Crosses present the mean, bars the median. The lower and the upper parts of the boxes present 25 and 75 percentile, respectively. Points present outliers. AGC = automatic gain control.
We again excluded the own AGC configuration and fitted a linear mixed model on the data. Similarly, we found that noise direction was significant, F(2,85) = 42.5, p < .0001, while AGC configuration was only close to significance (p = .056). In addition, there was a significant interaction between these two factors, F(2,85) = 5.2, p = .007. Post hoc tests revealed that the matched AGC configuration resulted in significantly smaller benefit for noise direction at the CI side (S0NCI; V = 153, df = 17, p = .007, conf.int = [−3.73, −0.97]). The benefit was not significantly different for noise direction on the HA side S0NHA (p = .47).
Finally, similar to Veugen et al. (2016a), we calculated spatial release from masking by comparing the SRT in frontal noise with the SRT when noise is at the CI side or HA side. This was done separately for the bimodal and CI-only configuration. The results are shown in Figure 5.

Spatial Release From Masking. Results above zero-line indicate that SRT improves when noise moves from frontal direction. Crosses present the mean, bars the median. The lower and the upper parts of the boxes present 25 and 75 percentile, respectively. Points present outliers. AGC = automatic gain control; CI = cochlear implant.
We fitted two linear mixed models, one for each noise direction. The model showed that when noise is moved to the CI side, the AGC factor is not significant, while the device factor is significant, F(1,51) = 35.2, p < .0001. There was a significant interaction between the factors, F(1,51) = 4.4, p = .04. When moving noise to the HA side (S0NHA), only the device factor was significant, F(1,51) = 12.6, p = .0008.
Two Wilcoxon tests with Holm corrections on bimodal standard versus bimodal matched AGC configuration for noise the CI side (S0NCI) and on CI-only standard versus matched AGC for noise at HA side did not reveal significant differences.
Questionnaires
For illustrative purposes, we show the group results where we averaged the questions per category and per each subject in Figure 6.

Mean Responses Averaged Per Subject and Per Response Category of SSQ-Questionnaire. Crosses present the mean, bars the median. The lower and the upper parts of the boxes present 25 and 75 percentile, respectively. Points present outliers. AGC = automatic gain control; SSQ = Speech, Spatial, and Qualities of Hearing Scale.
Preferences and Cognition Tests
There was no clear preference trend for any AGC configuration. Seven people preferred standard AGC, six people the own AGC configuration, and five people the matched slow AGC. The preference could not be predicted from age or cognition.
The two cognition tests did not show significant correlations with either the SRT differences between the matched and the standard AGC, or with the SRT themselves.
Discussion
We investigated the effect of matching AGC parameters and did not find significant differences between the standard and the matched experimental AGC configurations for speech understanding in quiet or in noise. Interestingly, both bimodal AGC configurations, standard and matched, were better than the subjects’ own AGC configuration. Also, for the CI-only condition, slow matched AGCs were better than the subjects’ own AGCs. With respect to the bimodal benefit, we found that when the noise comes from the CI side, the standard AGC provided more benefit than the matched slow AGC. Finally, we did not find evidence that the bimodal AGC preferences or SRT differences (in terms of better performance with one of the AGC configurations) could be predicted from short-term memory tests.
One of our research questions was whether the effect found by Veugen et al. (2016a) could be replicated. This was not the case. Most of the observed differences seem to solely depend on the time constants and not on the bimodal matching as we found monaural (CI-only) effects. Our results underline the importance of the CI-only condition as a reference. Although not significant, in the CI-only condition with noise from the CI side, the standard AGC yielded slightly poorer SRTs than the matched AGC. In the bimodal condition with noise at the same side, the standard AGC yielded slightly better SRTs. This might explain why we did not find a significant combined effect (i.e., bimodal benefit), in contrast to Veugen et al., where the CI-only condition contained a slow AGC in both cases.
For speech in noise, the SRT is better than in the previous work of Veugen et al. (2016a). This can largely be explained by the better residual acoustic hearing found in our study group. Moreover, we also used a different type of noise in our test setup. As mentioned in the Methods section, the noise type used by Veugen et al. is likely more difficult due to informational masking. In addition, there was no frontal noise condition in the previous work of Veugen et al., but only noise at ±90°. It is interesting that although different algorithms were activated to improve speech understanding in the subjects’ own AGC configuration (e.g., SCAN, ADRO, and ASC), the matched and the standard AGC configurations yielded better SRTs. A possible explanation is that in five of the participants the devices were not loudness balanced for the subjects’ own AGC configuration. It is possible that restoring loudness balance could provide more reliable binaural cues and possibly help separating speech from noise.
It is known that CI-listeners perform worse in fluctuating noise than in steady noise (Veugen et al., 2016a; Zeng et al., 2008). It might be that faster changes in the CI create more confusion. In contrast, at the HA side, a faster AGC would be beneficial due to loudness recruitment. The slower AGC cannot react fast enough which would result in a sound that changes quickly from inaudible to too loud. It would be interesting in the future to test a combination of a slow AGC at CI side and a fast AGC at HA side. If speech recognition improves at the two ears due to the AGCs being better adapted to different modalities, binaural speech recognition can also improve.
The results from the SSQ are rather similar to those of the previous work. Results with the subjects’ own AGC configuration are a bit worse compared with the other configurations, which could be due to some bias of the participants knowing that these were their own settings and anticipating better settings with the study devices. By the study design, only standard and matched AGCs could be blinded to the user. However, there are still a number of unknown influencing factors such as lack of fusion between modalities or loudness balance which are not captured by current questionnaires. Therefore, a validated, specialized bimodal hearing questionnaire would be beneficial.
Footnotes
Appendix
Acknowledgments
Cochlear Ltd provided the necessary CI equipment. GN Hearing provided HAs. The authors would like to acknowledge the editor in chief Dr. Oxenham, the associate editor Dr. Baskent, and the two anonymous reviewers for their suggestions. Finally, the authors are grateful to the bimodal listeners who voluntarily participated in the experiments.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Dimitar Spirrov would like to acknowledge the support from Flanders Innovation (IWT Baekeland 140748). Eline Verschueren would like to acknowledge the support from Research Foundation Flanders (1S86118N). Cochlear Ltd also provided financial support.