
Abstract
There is conflicting evidence about the relative benefit of slow- and fast-acting compression for speech intelligibility. It has been hypothesized that fast-acting compression improves audibility at low signal-to-noise ratios (SNRs) but may distort the speech envelope at higher SNRs. The present study investigated the effects of compression with a nearly instantaneous attack time but either fast (10 ms) or slow (500 ms) release times on consonant identification in hearing-impaired listeners. Consonant–vowel speech tokens were presented at a range of presentation levels in two conditions: in the presence of interrupted noise and in quiet (with the compressor “shadow-controlled” by the corresponding mixture of speech and noise). These conditions were chosen to disentangle the effects of consonant audibility and noise-induced forward masking on speech intelligibility. A small but systematic intelligibility benefit of fast-acting compression was found in both the quiet and the noisy conditions for the lower speech levels. No detrimental effects of fast-acting compression were observed when the speech level exceeded the level of the noise. These findings suggest that fast-acting compression provides an audibility benefit in fluctuating interferers when compared with slow-acting compression while not substantially affecting the perception of consonants at higher SNRs.
Introduction
It is widely accepted that due to the limited dynamic range of levels perceived by hearing-impaired (HI) listeners, level-dependent amplification is required to compensate for hearing loss. The majority of modern hearing aids apply dynamic-range compression (see Edwards, 2004; Souza, 2002 for reviews). In such systems, the gain is determined by one or more level-estimation circuits, which are characterized by attack and release time constants. The most commonly used attack times have values below 10 ms (Jenstad & Souza, 2005) to quickly reduce the gain in response to loud sounds. However, the optimal speed of gain recovery, that is, the release time, is still a subject of discussion. Shorter release times allow more gain to be applied to the low-intensity speech components (e.g., consonants) that follow other, high-intensity components (e.g., vowels) or noise bursts. This increased gain can potentially improve audibility and reduce the amount of forward masking, which in turn might lead to an improved speech recognition performance in HI listeners (Alexander & Rallapalli, 2017; Desloge, Reed, Braida, Perez, & D’Aquila, 2017; Desloge, Reed, Braida, Perez, & Delhorne, 2010; Edwards, 2002; Jenstad & Souza, 2005; Souza & Turner, 1998, 1999). On the other hand, with a very short release time, the gain follows the fast fluctuations of the signal, effectively reducing the temporal contrast and altering natural modulations in speech (Alexander & Rallapalli, 2017; Souza & Turner, 1996, 1998; Stone & Moore, 2003, 2004, 2007, 2008). The temporal characteristics of the speech signal provide important cues for speech intelligibility, especially for HI listeners (Rosen, 1992; Souza, Wright, Blackburn, Tatman, & Gallun, 2015). Temporal envelope distortion introduced by fast-acting amplification might therefore lead to a decrement in recognition performance (Jenstad & Souza, 2005, 2007; Walaszek, 2008). It is possible that optimal performance would be achieved if the time constants were adapted dynamically according to the current signal-to-noise ratio (SNR; Gatehouse, Naylor, & Elberling, 2003; Kates, 2010; Souza, Hoover, & Gallun, 2012; Yund & Buckles, 1995). For example, May, Kowalewski, Fereczkowski, and MacDonald (2017) evaluated different methods for blind estimation of the broadband SNR that could be applied in hearing aids. However, the relation between the optimal release time and SNR in connection to speech intelligibility is not yet known.
In the present study, it is hypothesized that potential negative effects of short release times will be more pronounced at higher SNRs, corresponding to higher speech input levels, where audibility and masking are less of a concern, and the compression is driven mostly by the speech signal. On the other hand, the additional gain applied by the fast-acting system is expected to provide an increasing benefit as the SNR decreases. To test these ideas, stimuli were designed to maximize the effects of compression release time. Consonant–vowel (CV) tokens were presented, and listeners were asked to report the consonant—a speech component that typically has a low intensity. The noise consisted of high-intensity bursts, separated by silent gaps and had very sharp onsets and offsets. The temporal onset of the CV token relative to the noise was controlled and chosen based on a previous study (Zaar, Kowalewski, & Dau, 2017). A wide range of SNRs and compression release times were tested to capture the potential interaction between the two factors. In addition, an analysis of the output level and audibility was performed for each experimental condition.
Methods
Listeners
Twelve young, normal-hearing (NH) listeners aged between 19 and 26 years (average age: 21.7 years) completed the task in the unaided condition. They all had pure-tone thresholds lower than 20 dB HL in the 250 to 8000 Hz range. The aided conditions were completed by nine older HI listeners aged between 66 and 77 years (average age: 71.4 years). Their hearing losses ranged from mild to moderately severe and were most prominent at high frequencies (see audiograms in Figure 1). All participants provided informed written consent, and all experiments were approved by the Science-Ethics Committee for the Capital Region of Denmark (reference H-16036391).
Pure-tone audiograms of the hearing-impaired listeners. Individual audiograms of Listeners 1 to 9 (from lowest to highest pure-tone average) are color coded according to the legend (color available online). The N2 standard audiogram (shown in black, Bisgaard et al., 2010) was used to derive the compression ratios, following the NAL-NL2 procedure (Keidser et al., 2011).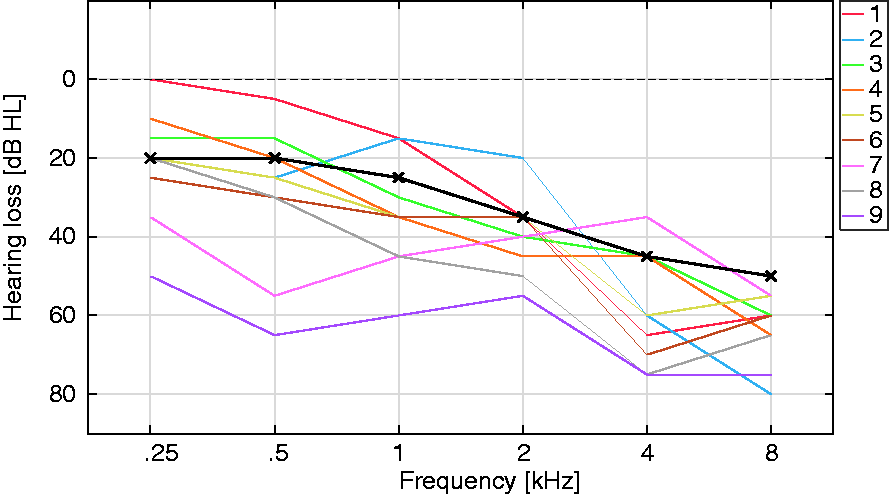
Stimuli
The target speech consisted of 15 consonant–vowel (CV) tokens: /bi, di, fi, gi, hi, ji, ki, li, mi, ni, pi, si, ʃi, ti, vi/ spoken by one male and one female talker (30 utterances in total), used previously by Zaar and Dau (2015). Four sound pressure levels (SPLs) were used: 45, 55, 65, and 75 dB. In the aided conditions, these were the levels at the input of the amplification system. Each utterance was presented to the listeners five times per test condition.
The noise was composed of five 100-ms bursts, separated by 100-ms silent gaps (corresponding to a 5-Hz repetition rate). Although rather artificial in nature, this noise envelope had the advantage that the sharp onsets and offsets and relatively long silent gaps emphasized the effects of compression time constants while ensuring that the consonant portion of speech would be affected by nonsimultaneous masking only (Desloge et al., 2017; Wilson et al., 2010). White noise (bandlimited between 0 and 22050 Hz) was chosen as a carrier to maximize masking of high-frequency consonants and to reduce potential spectral splatter due to noise onsets and offsets. The SPL was 65 dB, defined as the level of the noise bursts at the input to the hearing-aid simulator. The onset of the CV token was positioned 25 ms into the silent gap after the third noise burst, as shown schematically in Figure 2. The instantaneous SNR was therefore infinite. The broadband SNR values are still reported for consistency with previous literature. They are defined as the difference between the SPL of the token and the preceding noise burst.
A schematic representation of the stimulus temporal envelope. The noise (shown in gray) consisted of 100-ms long bursts of white noise, separated by 100-ms silent gaps. The speech token (shown in black) was positioned 25 ms after the offset of the third noise burst.
Thirty noise waveforms (one per utterance) were pregenerated and stored as WAV files. Each utterance was always presented with the same noise recording. This was done to limit the across-repetition variability due to the random fluctuations in the Gaussian noise carrier, while preventing noise-learning effects that could occur if only one noise waveform was used for all utterances (Rhebergen, Maalderink, & Dreschler, 2017; Zaar & Dau, 2015).
Amplification
Cutoff Frequencies, Compression Ratios, and Thresholds in Each of the Processing Channels.

Note. SPL = sound pressure level.
The compression thresholds (kneepoints) were frequency-dependent and calibrated so that compression in each channel was activated when the level of a broadband (white noise) input exceeded 50 dB SPL. The thresholds in each channel are provided in Table 1. Compression speed was dictated by the time constants of a one-pole-filter power-smoothing circuit (the so-called RC time constants; Kates, 1993). The attack time was always 5 ms. The release time was 10 ms in the fast compression condition and 500 ms in the slow condition. The third condition was linear, which used the same maximum gain values as used in the compression conditions, but a compression ratio (CR) of 1:1, that is, no compression. It thus simulated an “idealized” hearing aid that never applies compression and provides the maximum possible amplification. Such high gain is unrealistic for high-intensity inputs, as it would be excessively loud. Thus, this condition served as a baseline for the behavior of compression systems but only for lower intensity speech inputs—at 45 and 65 dB SPL in quiet (see “Experimental Conditions and Training” section later).
The CRs in each channel were based on the NAL-NL2 target for the N2 audiogram (Bisgaard, Vlaming, & Dahlquist, 2010) using the Slow setting, which yields higher CRs (cf. Keidser, Dillon, Flax, Ching, & Brewer, 2011). The N2 audiogram was chosen because it was most representative of the participants’ hearing losses. 1 Thus, CRs were the same for all listeners, ranging between 1.1:1 and 2.3:1 (see Table 1). To maximize audibility for each participant, individualized linear gain was applied after compression. It was based on the insertion gain prescribed by NAL-NL2 for a 50 dB SPL input for individual audiograms. The total gain (after compression and linear compensation) for each time frame was then interpolated from the channel frequencies to the DFT bins. A 512-point inverse DFT was then computed for each frame and a Tukey window with a length of 512 samples, including 128-sample tapered ends, was applied. The output signal was synthesized using the overlap-add procedure and presented monaurally over Sennheiser HD650 headphones.
In all conditions, the level-detection circuit of the compression and the resulting gain were driven by the mixture of speech and noise. Thus, the gain applied to the clean speech in the quiet condition was not controlled by the clean speech signal but rather shadow-controlled by the mixture, that is, the gain applied to the speech signal was identical in noisy and quiet conditions. This setup allowed the investigation of the effects of the gain fluctuations (resulting from the presence of the interrupted noise) on the CV token without actually presenting the interferer to the listeners’ ears.
Experimental Conditions and Training
Summary of Experimental Conditions: Presence of Noise, Input Level of Speech, and Type of Amplification Used.

Note. NH = normal-hearing; HI = hearing-impaired; SPL = sound pressure level.
Prior to the test runs, the listeners received training in each of the experimental conditions comprising of one presentation of each stimulus (each token spoken by each talker). This was done to familiarize the listeners with the speech material and the different processing types. Subsequently, the test was performed starting from the conditions assumed to be the easiest and progressively increasing the difficulty. Therefore, the quiet conditions were tested before the noisy conditions, and the highest input speech levels were tested first.
Results
For analyzing the quiet and noisy data sets, separate linear mixed-effects models were used with two fixed factors (speech level and amplification type) and one random factor (listener). Backwards elimination of nonsignificant effects was performed (Kuznetsova, Brockhoff, & Christensen, 2018), and the final model was used to establish significance between the results obtained with each amplification type at each speech level. To establish significance of differences between relevant levels of the interaction between amplification type and speech level (e.g., the difference in scores between amplification types at a given speech level or the differences across speech level for a given amplification type), the least-squares means approach was used with p values adjusted for multiple comparisons using the multivariate t adjustments (Lenth, 2017).
The distribution of the model residuals for the data obtained in the quiet conditions deviated from normal (it was “light-tailed”). Therefore, all recognition-rate data were transformed to rationalized arcsine units (RAU) prior to the statistical analysis. The transformation was not necessary for the data obtained in the noise-present conditions (the distribution of residuals was much closer to normal). Applying the transformation, however, did not affect the main conclusion of the analysis, and it was used in all cases for the sake of consistency. The recognition rates are nonetheless reported here in their nontransformed form for ease of interpretation.
Consonant Recognition in Quiet
The average consonant recognition rates for the stimuli presented in quiet are shown in Figure 3. It can be observed that the NH listeners (unaided) achieved recognition rates close to 100% at both speech input levels. The HI listeners (aided) performed much worse in all conditions and achieved maximum recognition rates of about 87% at 75 dB SPL. Significant differences were found between all amplification types for the lowest speech input level (45 dB SPL, p < .05 for linear vs. fast, p < .001 for linear vs. slow, p < .01 for fast vs. slow). The best recognition rate of 55% was achieved with linear amplification (that provided the highest gain), followed by fast (46%) and slow compression (34%).
Averaged consonant recognition rates for speech tokens in quiet, “shadow-controlled” by the mixture of speech and noise. Left: normal-hearing (NH) unaided and hearing-impaired (HI) aided with three types of amplification. Right: Only the HI data replotted. The error bars indicate ± one standard deviation. The significance levels are *.05, **.01, ***.001.
For the 65 dB SPL and 75 dB SPL speech input, no statistically significant differences between amplification types were observed. There is also no significant increase in performance between 65 and 75 dB SPL with either amplification type.
Consonant Recognition in Noise
The recognition rates in noise are shown in Figure 4. NH listeners achieved recognition rates of 95% for speech levels of 65 and 75 dB SPL (corresponding to SNRs of 0 and + 10 dB). The rate decreased to 73% at 45 dB SPL (−20 dB SNR). Aided HI listeners achieved the highest recognition rate of 77% at 75 dB SPL. For speech input levels of 55 and 65 dB SPL, the recognition rates observed with fast compression were 8% to 9% higher than with slow compression, with both differences being statistically significant (p < .05 and p < .001, respectively). At 45 and 75 dB SPL, there were no statistically significant differences in the recognition performance obtained with fast and slow compression.
The same as Figure 3 but presented in 5-Hz interrupted Gaussian noise (noise level: 65 dB SPL).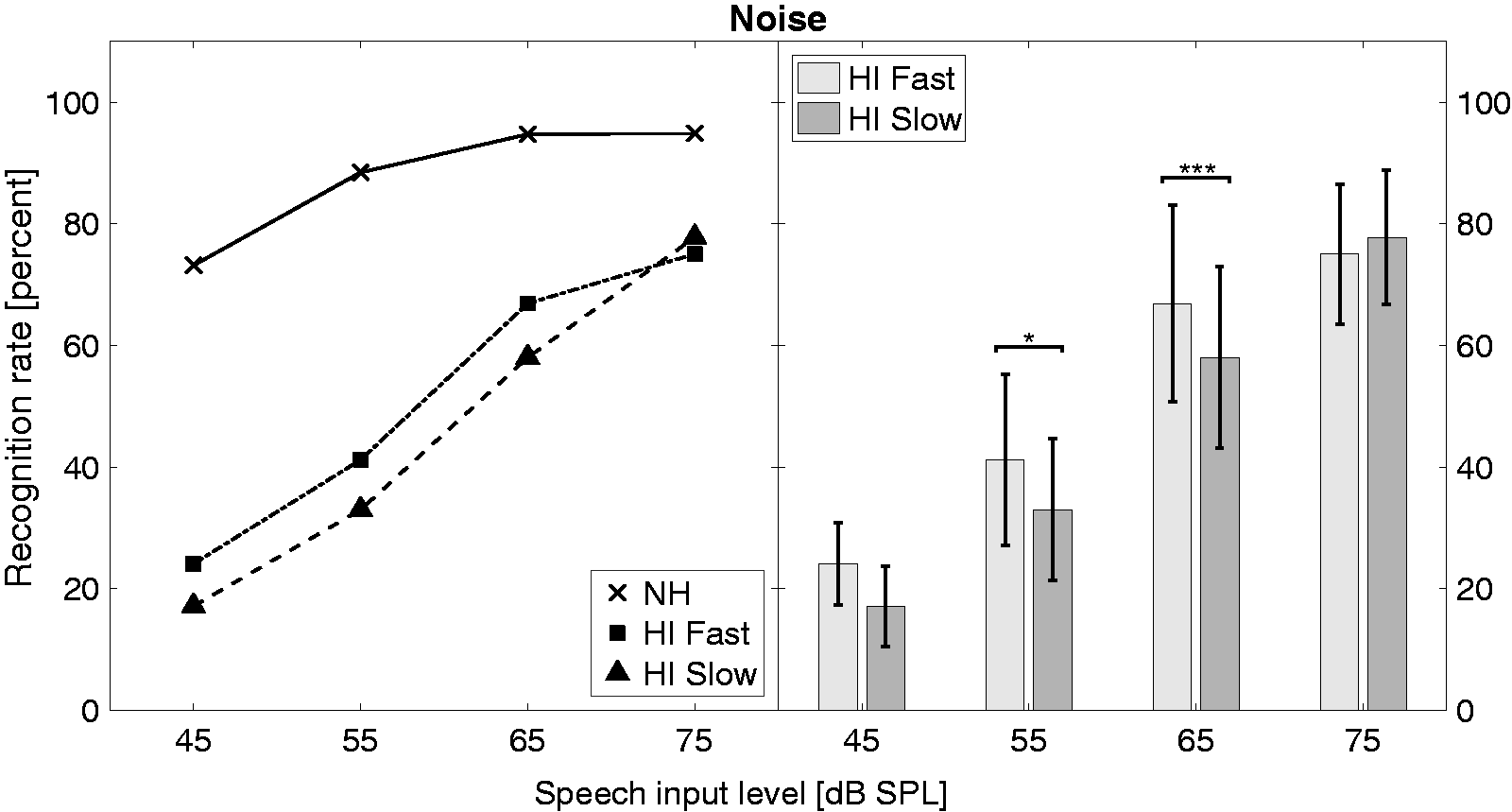
Consonant Output Level
Different amplification strategies provide different gains, which might influence the measured consonant recognition performance. Therefore, an analysis of the output speech levels was conducted. The root mean square (RMS) level of a CV is highly dependent on the vowel portion. To assess the amount of gain applied to the consonant, the output levels of the consonant portions were therefore measured for all possible combinations of speech tokens, listeners’ individual amplification settings, and input levels. The average values are shown in Figure 5. At each input level, the differences in output between the amplification conditions directly translate to the differences in the average gain they provide. The linear condition provided the highest gain and therefore the highest output level. At the lowest speech input level, fast- and slow-acting compression provide gain that is, respectively, 1.7 and 7.0 dB lower than linear. As the input level increases, the consonant at the output of both compressors receives progressively less overall gain. This decrease in gain is more pronounced for fast-acting compression. At the highest input levels, the outputs of the two compression systems converge, resulting in a difference of less than 2 dB at 75 dB SPL speech input level.
Averaged output level of the consonant portion of the stimulus for different amplification schemes, as a function of the overall speech input level.
Consonant Audibility and Performance
To further quantify the effect that the amount of audible information has on each listener’s performance, a metric of audibility was computed for each combination of consonant, talker, listener, input level, and processing condition. The consonant-only portion of the processed stimulus (at the output of the hearing-aid simulator) was considered. The digital signal level was measured in octave bands with center frequencies from 250 to 8000 Hz and converted to dB SPL. The individual listeners’ audiometric thresholds in dB SPL were subtracted from these values. A lower limit for the audiogram-corrected levels was assumed to be 0 dB (re. audiometric threshold). Subsequently, the audiogram-corrected levels were weighted using the band-importance functions for nonsense syllables from Pavlovic (1987) and summed across frequency yielding a measure of consonant audibility (in arbitrary units).
Each listener’s audibility metric values obtained in each experimental condition were averaged across stimuli (consonant and talker). Figure 6 shows a scatter plot of the resulting averaged audibility metric versus the corresponding RAU-transformed recognition scores. An overall trend of performance improvement with increasing audibility can be observed. The Spearman’s rank correlation coefficient (ρ) is 0.708 between the recognition score and the audibility index for the data in quiet and 0.797 for the data in noise. However, it is evident that the rate of performance growth changes when the audibility index reaches values of about 3 to 4. This is likely due to listeners reaching ceiling performance or, in some cases, due to a “roll-over effect.” Therefore, a two-section piecewise linear model was fitted to the data. The best-fitting models are shown in black in Figure 6. In quiet, the RMS error of the model fit is 22.3 RAU. In noise, the RMS error is equal to 17.7 RAU. Most of the variability may be attributed to different listeners showing different sensitivity to a similar increase in audibility. Nevertheless, individual fits were not performed, due to the risk of overfitting to a limited number of data points per listener.
RAU-transformed recognition scores for each HI listener and experimental condition, averaged across stimuli (consonant and talker), versus the corresponding values of the audibility metric for the consonant portion of the CV stimulus. Left panel: results in quiet; right panel: results in noise. Numbers indicate individual listeners, numbered from lowest to highest pure-tone average as in Figure 1. The best fit two-section linear model is shown in black. The Spearman’s rank correlation coefficient ρ for the data, the corresponding correlation p values, and the RMS error of the model fits are reported in each panel.
Discussion
Consonant recognition in noise was measured for HI listeners aided with a hearing-aid simulator and unaided NH listeners (used as a reference). Linear, fast- and slow-acting compression settings were considered. Interrupted noise was used as a masker, with sharp onsets and offsets and relatively long, silent gaps, during which the speech token was presented. This was designed to maximize the differences between fast- and slow-acting compression. In addition, a quiet condition was considered in which the noise was not presented to the listeners, but the gain applied to the speech stimulus was shadow-controlled by the corresponding noisy mixture. Thus, it is possible to disentangle the effects of forward masking and reduced gain due to compression.
In the quiet, shadow-controlled condition, the consonant recognition rates obtained by HI listeners at low speech input levels strongly depended on the amplification type. The best performance was obtained with linear amplification and fast compression, which provided higher gain and thus better audibility than slow compression. However, the effect was present only at the lowest speech input level. At the speech levels of 65 and 75 dB SPL, there was no statistically significant difference in the average performance between the two compression conditions. There was also no increase in performance between 65 and 75 dB SPL, which suggests a ceiling effect. Audibility seems to be important for recognition in quiet, as the proposed metric of audibility is strongly positively correlated with listener’s performance.
In contrast to the unaided NH listeners, HI listeners on average did not reach 100% performance, even when provided with a relatively high level of speech in quiet. However, there was a substantial spread in the recognition scores among the listeners, as shown in the right panel of Figure 3. As seen in Figure 6, some listeners do not benefit from the relatively high audibility that was provided to them. Their poor performance may be attributed to suprathreshold distortion that potentially occurs in the impaired auditory system. Amplification is unlikely to reduce the consequences of this distortion and might even be detrimental at high levels. The interaction of cognitive status and fast- versus slow-acting compression has been investigated in many studies (e.g., Gatehouse et al., 2003; Lunner & Sundewall-Thorén, 2007; Ohlenforst, Souza, & MacDonald, 2016). While no cognitive assessment of the participants was conducted in the present study, it should be noted that the stimuli in the present stimuli were nonsense CV tokens rather than intelligible speech. Thus, it was not possible for the HI listeners to make use of context or other top-down processing to improve performance. If the HI listeners in the present study are representative, one may surmise that near-normal speech intelligibility by HI listeners for contextual speech in quiet must require substantial top-down processing and listening effort.
Due to a large age difference between the NH and HI groups (nearly 50 years, on average), it is not possible to separate the effects of age and hearing loss on speech recognition. For example, Gordon-Salant, Yeni-Komshian, Fitzgibbons, and Barrett (2006) found that age had an effect on the listeners’ sensitivity to temporal cues used for consonant recognition.
In noise, fast-acting compression led to higher recognition rates for speech levels of 55 and 65 dB SPL, corresponding to a broadband SNR of −10 and 0 dB, respectively. Similar to the results in quiet, there was no statistically significant difference in performance at 75 dB SPL (+10 dB SNR) between the two compression conditions. Therefore, there was no statistically significant evidence for detrimental effects of fast-acting compression (e.g., due to temporal envelope distortion) on consonant recognition performance at higher speech input levels. However, possible ceiling effects in some of the HI listeners’ data may be a confounding factor here. The difference in the overall gain applied by fast- and slow-acting compression becomes relatively small at 75 dB SPL, as seen in Figure 5. The additional 2 dB of gain provided by the fast-acting system might be insufficient to provide a measurable benefit in terms of speech recognition. Moreover, the average benefit at 45 dB SPL in noise was 7% but with a p value of .076. Therefore, it is possible that the difficulty of the task at the lowest speech level contributed to the large uncertainty (relative to the difference between the average scores between the two compression conditions) and that significance would have been reached if a greater number of listeners had been considered.
As the compressor was shadow-controlled by the mixture of speech and noise when it was applied to speech in quiet, it behaved identically in both conditions. Therefore, a difference in performance between the two conditions can be attributed only to the presence of noise (i.e., forward masking). In quiet, the relative benefit of fast versus slow compression was 12% (p value < .01) at 45 dB SPL but not statistically significant at 65 dB SPL (−20 and 0 dB SNR, respectively). In noise, on the other hand, the benefit was statistically significant at 55 and 65 dB SPL but not at 45 dB SPL. This may be due to the higher gain provided to the speech token by fast-acting compression, which may improve the recovery from the noise-induced forward masking (at least at SNRs close to 0 dB, i.e., speech levels close to 65 dB SPL). Even though the speech target and the interrupted-noise masker do not overlap in time, they likely interact in the auditory system due to its limited temporal resolution. One could hypothesize that successful recognition is dependent on an “internal” or “neural” SNR as “seen” by the higher stages of the auditory system rather than the “external” or “acoustical” SNR measured at the eardrum. The metric of audibility seems to be strongly correlated with individual performance in noise, with Spearman’s ρ near 0.8. In this context, greater values of the audibility metric could be linked to an increased ability to overcome forward masking, improving the internal SNR across a range of auditory channels. The limitation of this approach is that, due to the flat power spectrum density of the masking noise, the power within an auditory channel increases with its center frequency. This could potentially lead to varying sensitivity to forward masking across frequency, which the proposed model does not take into account. However, in a yet unpublished study, the authors measured the recovery from forward masking using a wideband noise masker with a flat power spectrum density and tonal probes at 1 and 4 kHz. The results suggest that, at least in NH listeners, the recovery is less frequency-dependent than would be expected from the simple increase in power within the equivalent rectangular band between 1 and 4 kHz (the measured 2–3 dB increase in masked thresholds vs. the expected 5.4 dB). This could be explained, for example, by an internal compensation mechanism, such that at higher frequencies a lower SNR (a higher efficiency factor k, see Plack & Oxenham, 2002) is needed for the detection or, in the present case, for consonant identification.
Hearing-aid compression can also distort the envelope of the signal. Effects of CR and release time on envelope fidelity and speech recognition have been studied by Jenstad and Souza (2007), who quantified the amount of temporal envelope distortion using the envelope difference index (EDI; Fortune, Woodruff, & Preves, 1994). They found that the EDI (and hence the amount of distortion) increased with shorter release times and larger CRs. However, a detrimental effect on speech recognition was apparent only if the EDI values were above 0.25, which was attainable only with CRs of 4:1 and higher. Because the CRs used in the present study did not exceed 2.3:1, they were not high enough to substantially alter the signal envelopes. Specifically, the median values of the EDI (computed from the consonant portions of all the stimuli used here) were 0.058 and 0.022 for the fast- and slow-acting compression, respectively. Thus, even though a short release time led to a higher EDI, the values were well below the 0.25 threshold proposed by Jenstad and Souza (2007), and therefore, the temporal envelope distortion likely had little influence on speech perception. The spectral envelope of the stimulus can also be affected by multichannel fast-acting compression. This effect was presumably small, but it has not been quantified in any way which poses a potential confound. However, because fast-acting compression led to higher consonant recognition at low and medium speech levels (45 dB SPL in quiet and 55 to 65 dB SPL in noise), any potential detrimental effects of compression were presumably offset by superior audibility at these levels. At high speech input levels, the initial consonant of the CV stimulus elicits an attack response. Therefore, the release time becomes less critical to how the two compression systems “reshape” the temporal and spectral envelopes. Moreover, at the highest input levels, there were no systematic differences in consonant confusions between fast- and slow-acting compression, which again supports the conclusion that amplification-induced distortion did not play a role.
It is apparent that, at least in the conditions used in the present study, audibility of speech and the ability to overcome noise-induced forward masking are crucial for recognition. Using a short release time increases the energy of speech segments occurring in the dips of the interrupted noise by restoring gain more quickly. It is, however, unclear whether this would generalize to a broader range of interferers and speech stimuli. Recently, Desloge et al. (2017) proposed a system equalizing the short- and long-term energy of the signal, somewhat similar to instantaneous compression. This provided an increase in audibility of speech segments positioned in the gaps of interrupted and sinusoidally amplitude-modulated noise, which was reflected in a consonant recognition and sentence recognition improvement in HI listeners. Rhebergen et al. (2017) observed a similar benefit of fast-acting compression for sentence recognition when presented in 8-Hz interrupted noise at input SNRs from around −20 to −10 dB. However, for higher SNRs, compression was found to be detrimental, most likely due to reduction of speech peaks. In stationary noise, compression had no effect on recognition for SNRs up to −8 dB and was detrimental at higher SNRs. In all cases, the improvement and deterioration of speech recognition scores coincided, respectively, with an increase and a decrease in the long-term output SNR due to compression. The benefit of compression might also be less apparent in backgrounds that fluctuate but without marked temporal dips or with less coherent across-frequency comodulation (e.g., the “checkerboard noise” of Howard-Jones & Rosen, 1993). In their study of compression parameters, Alexander and Masterson (2015) used speech-shaped noise that was either unmodulated or had a temporal envelope derived from a two-talker mixture (in a manner similar to the International Collegium on Rehabilitative Audiology (ICRA) noise; Dreschler, Verschuure, Ludvigsen, & Westermann, 2001). In each condition, the sentences were mixed with noise at three different SNRs and processed in a compressor, using a 5-ms attack time and a release time of 40 ms (short) or 640 ms (long). With the shorter release time, the output level of speech increased. However, the fast-fluctuating gain amplified not only speech but also some segments of the background. As a result, the output long-term SNR decreased. This might have contributed to the lack of systematic benefit for intelligibility. It is possible that similar effects would have been observed in the present study if an additional masker had been added in the gaps.
Future research should focus on applying the shadow-control method together with the interrupted noise to study the complex interaction between compression, fluctuating noise and reverberation on speech recognition in HI listeners. Reverberation leads to “smearing” of noise and speech across time. This can potentially increase self-masking and noise-induced masking (Nábĕlek, Letowski, & Tucker, 1989) and introduce additional envelope distortion that may interact with the temporal alterations occurring due to compression (Shi & Doherty, 2008). Results from Reinhart, Souza, Srinivasan, and Gallun (2016) suggest that both fast-acting compression and reverberation have detrimental effects on speech recognition and that these effects are additive, at least in the absence of background noise. To date, however, very few studies on hearing-aid amplification have considered noise in addition to reverberation. The presence of noise does not only increase the amount of energetic masking but also affects the temporal envelope transfer in a different way than deterministic envelope manipulations (Noordhoek & Drullman, 1997). A combination of noise, reverberation, and compression might lead to complex interactions, affecting speech intelligibility in a way that is difficult to predict. In the context of this study’s experimental setup, with reverberation present, two effects might offset the advantage from increased audibility in the noise gaps. First, the noise energy would “spill over” into the silent gaps. This could have similar effects as an added masker—it would be amplified by the compressor, reducing the long-term output SNR. Second, the temporal smearing would smooth out the internal signal representation that the compressor uses to determine the gain (for details see, e.g., Giannoulis, Massberg, & Reiss, 2012). This could lead to a more sluggish response and obscure the effects of varying time constants, as shown by Reinhart, Zahorik and Souza (2017). Precise control of the acoustical conditions together with the shadow-control approach employed here could help disentangle the previously mentioned phenomena.
Conclusion
A small but systematic benefit of fast-acting compression for consonant recognition was found in both the quiet and the noisy conditions for speech levels below 65 dB SPL (0 dB SNR in noise). Despite potentially detrimental speech envelope distortions, no significant detrimental effects of fast-acting compression were observed for speech recognition when the speech level exceeded the level of the noise. These findings suggest that fast-acting compression provides an audibility benefit and, possibly, an improved recovery from forward masking in fluctuating interferers when compared with slow-acting compression while not substantially compromising the perception of short CV tokens at higher SNRs. It is not yet clear whether these effects persist in more realistic conditions, that is, with longer speech stimuli (multisyllable words, sentences) in fluctuating interferers with softer onsets/offsets. For example, if a voiced interferer was used (such as a competing talker), such short time constants might lead to detrimental intermodulation distortion offsetting the potential audibility advantage.
The findings from the present study and prospective future studies may inform SNR-dependent amplification strategies and individualized hearing-aid fitting strategies. The potential use of blind SNR estimation for hearing-aid applications has been investigated in May et al. (2017) and applied to dynamically manipulate compression parameters in real time (May, Kowalewski and Dau, 2018).
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by funding from Sonova AG (Stäfa, Switzerland) and the Technical University of Denmark.