
Abstract
Noise reduction systems have been implemented in hearing aids to improve signal-to-noise ratio and listening comfort. The aim of this study was to evaluate the efficacy of hearing aid noise reduction for Mandarin speakers. The results showed a significant improvement in acceptable noise levels and speech reception thresholds with noise reduction turned on. Sound quality ratings also suggested that most listeners preferred having noise reduction turned on for listening effort, listening comfort, speech clarity, and overall sound quality. These results suggest that the noise reduction system used in this study might improve sentence perception in steady-state noise, noise tolerance, and sound quality, although not all listeners preferred aggressive noise reduction. However, due to large interindividual variation, clinical application of the results should be on an individual basis.
Keywords
Introduction
Difficulty listening in noise is one of the main complaints from hearing aid users. Noise reduction (NR) algorithms are therefore implemented to reduce annoyance caused by noise and to improve speech intelligibility and hearing comfort in noise (Brons, Houben, & Dreschler, 2013). In mainland China, residents in metropolises are routinely exposed to noisy environments. For example, Zheng, Cai, Song, and Chen (1996) found that the average noise exposure level for residents in Beijing, including personal living as well as work environments, was higher than 70 dBA over a 24-hour period. The highest noise levels are experienced during work hours and can average up to 80 dBA on average, although the overnight average noise levels of 40 dBA are noted during sleeping hours. Given the noise levels that typical hearing aid users in mainland China have to tolerate, it is important to examine the efficacy of NR, a common feature of modern hearing aids.
Benefits of NR
NR algorithms in hearing aids continuously estimate the signal-to-noise ratio (S/N) within specific bands and reduce the gain in the frequency regions dominated by noise (Brons et al., 2013), resulting in increased S/N. Based on the physical improvement of S/N, improved speech intelligibility could be expected. However, there are mixed findings regarding the efficacy of these NR functions. Most studies have not shown such functions to cause a significant improvement in speech perception in noise (Alcántara, Moore, Kühnel, & Launer, 2009; Bentler, Wu, Kettel, & Hurtig, 2008; Brons et al., 2013; Brons, Houben, & Dreschler, 2014; Brons, Houben, & Dreschler, 2015; Loizou & Kim, 2011; Nordrum, Erler, Garstecki, & Dhar, 2006), although hearing aid users often prefer to have NR turned on rather than off (Boymans & Dreschler, 2000; Brons et al., 2014; Ricketts & Hornsby, 2005). Improved listening comfort and sound quality have been reported (Brons et al., 2013; Brons et al., 2015; Loizou & Kim, 2011; Nordrum et al., 2006). Thus, increased noise tolerance does not necessarily result in better speech intelligibility (Brons et al., 2015), and self-reported sound quality measures could inform preferences that may not be demonstrated via speech reception measures (Ricketts & Hornsby, 2005).
In addition to speech perception and self-reported sound quality measures, an acceptable noise level (ANL) test has been used to evaluate the efficacy of NR functions (Olsen & Brannstrom, 2014; Peeters, Kuk, Lau, & Keenan, 2009). The ANL is defined as the lowest S/N an individual is willing to accept while listening to speech (Nabelek, Tampas, & Burchfield, 2004). The ANL is calculated by subtracting the maximum acceptable background noise level (BNL) from the most comfortable level (MCL). The BNL is the maximum BNL that an individual finds acceptable (Ho et al., 2013).
Mueller, Weber, and Hornsby (2006); Wu and Stangl (2013); and Lowery and Plyler (2013) found significantly improved ANLs with NR turned on. The variable of ANL has been shown to predict the degree of real-world hearing aid usage with relatively high accuracy. Nabelek, Freyaldenhoven, Tampas, Burchfiel, and Muenchen (2006) showed that unaided ANLs had an 85% accuracy rate at predicting successful hearing aid use in individuals who had worn hearing aids for 3 months to 3 years. Wu, Ho, Hsiao, Brummet, and Chipara (2016) measured ANL in 132 adults before hearing aid fitting and reported 55% to 68% accuracy at predicting real-word hearing aid outcomes as evaluated by the International Outcome Inventory for Hearing Aids (IOI-HA; Cox & Alexander, 2002). These studies hypothesized that, if NR algorithms could increase noise tolerance, they would turn individuals with high ANLs into more successful hearing device users. Overall, these studies suggested increased noise tolerance with NR functions, which may facilitate listening in noise and result in successful hearing aid use.
Mandarin Speech Perception
Mandarin Chinese is a tonal language in which lexical tones contribute to the understanding of words and sentences. There are four Mandarin tones, and each has its own unique fundamental frequency (F0) height and contour (Chen, Wong, Chen, & Xi, 2014). Lexical tones and the F0 contour contribute to Mandarin sentence recognition in noise (Chen et al., 2014; Zhu, Wong, & Chen, 2014). Although there are more English consonants than vowels, there are more Mandarin vowels than consonants (Adunka, Buss, Clark, Pillsbury, & Buchman, 2008). Chen, Wong, and Wong (2013) found that vowels contribute more than consonants to Mandarin sentence perception, resulting in a 3:1 advantage for vowel-only sentences over consonant-only sentences. By contrast, a 2:1 advantage has been reported in English (Cole, Yan, Mak, Fanty, & Bailey, 1996). Lexical tone information is carried by the vowel segments (Chen et al., 2013). Together, these factors contribute to low-frequency information being more important for speech understanding in Mandarin than in English (Chen et al., 2013; Kuo, 2013).
Ho et al. (2013) suggested that measured ANLs in Mandarin and English were comparable in listeners with normal hearing. In fact, NR functions are expected to benefit hearing aid users no matter which language they speak. However, it remains unclear whether the effects of NR on ANL will be comparable between Mandarin and other languages, given the strong reliance on low-frequency cues in Mandarin. Performance also varies with the type of NR function (Brons et al., 2015). Thus, this study aimed to evaluate the efficacy for Mandarin speakers of the NR function implemented in a commercial hearing aid, using speech reception, ANL, and self-report sound quality measures.
Methods
Subjects
The sample size was predetermined using G*Power 3.1.9.2 for Windows (Kiel University, Kiel, Germany) for an effect size (partial ŋ2) of 0.29, α set at .05 for a two-tailed test, power (1 − β) set at 0.99, and nonsphericity correction ɛ set at 0.5. The estimated effect size was based on previous research evaluating the effects of NR on ANL (Wu & Stangl, 2013). The resulting sample size requirement was 32.
There were four inclusion criteria: First, participants should have symmetrical moderate to severe hearing loss. Symmetry in hearing thresholds was defined as an interaural difference of no more than 10 dB across the octave frequencies from 250 to 8000 Hz in audiometric thresholds. Although it would be desirable to include individuals with diverse degrees of hearing impairment, it is uncommon for adults with mild hearing impairment in mainland China to acquire hearing aids, whereas individuals with profound hearing loss may respond differently to NR and were therefore not included in the study. Second, participants should be native standard Mandarin speakers living in Beijing and should not speak other Chinese dialects. Third, they should exhibit normal cognitive ability as measured by the Montreal Cognitive Assessment (Chinese version; Yu, Li, & Huang, 2012). Finally, all participants should have worn hearing aids for at least the past 3 months and for at least five hours per day. These criteria are somewhat arbitrary, but according to Humes and Krull (2012), benefits are expected to stabilize by 4 to 6 weeks after hearing aid fitting. Clinical experience in mainland China also suggests that those who make good use of hearing aids for daily listening use them for approximately 4 to 5 hours per day.
Forty-three potential participants meeting the aforementioned criteria were initially contacted by audiologists at the Shengkang Hearing Center, Beijing, China, by phone. Thirty-four participants agreed to participate. However, 2 of them dropped out later because of their busy schedules, resulting in a total of 32 participants who completed all testing. The mean audiometric results are shown in Figure 1. The participants (9 women and 32 men) ranged in age from 23 to 81 years (mean = 55, standard deviation [SD] = 17) and had been diagnosed with sensorineural hearing loss. Twenty-eight of them were bilaterally fitted with hearing aids, while the rest (n = 4) were unilaterally fitted. Thirty participants were fitted with behind-the-ear hearing aids, while the rest were wearing in-the-ear units. The mean duration of prior hearing aid use was 1.59 years (SD = 0.01, range = 1.58–1.61), the mean duration of hearing aid use per day was 12.04 hours (SD = 3.34, range = 5.00–18.00), and the mean level of education received was 9.36 years (SD = 1.70, range = 6–15). Each participant received RMB 200 (or about USD 25) as a transportation allowance for his or her participation. Ethical approval was obtained from the University of Hong Kong. Written informed consent was obtained prior to the study.
Mean pure-tone thresholds with SDs as error bars.
Hearing Aid Fitting
A new pair of Phonak Q50 hearing aids with 12 channels was used during testing. If bilaterally fitted (n = 29) previously, the participant tried a new pair of Phonak Q50 hearing aids during the testing, while a single Phonak Q50 hearing aid was used by those with previous unilaterally fitting (n = 3). Participants wore the hearing aids only under the experimental conditions of the research study. Testing was conducted using participants’ custom earmolds.
Pure-tone audiometry was conducted to determine air- and bone-conduction thresholds. Hearing aids were fitted based on these audiometric thresholds. Insertion gain values based on the average real-ear-to-coupler difference were prescribed using the ‘Adaptive Phonak Digital Tonal (APDT)’ algorithm. This algorithm is a proprietary one designed to cater to tonal language speakers and is the default fitting formula for Phonak hearing aids fitted in China since 2016. This algorithm is based on Phonak’s proprietary Adaptive Phonak Digital fitting algorithm (Latzel, 2013). The main modifications are more gain for low-level low-frequency inputs to accommodate the special features of tonal languages and dual compression instead of syllabic compression was adopted. The attack and release times for dual compression are several seconds in order to preserve the spectrum more effectively than syllabic compression, which may reduce the spectral and temporal contrast of the output signal. In comparison to the National Acoustic Laboratories-Non-linear 2 (NAL-NL2), the APDT algorithm uses a dual compression algorithm, leading to more linear processing for speech-like signals to better maintain the dynamic properties of speech.
Then, the real-ear test was performed using the “Real ear and feedback measurement” tool in Phonak Target fitting software (Version 4.1). This tool measured the feedback path with the hearing aids worn on the ear to determine the individual vent effect so that appropriate compensation could be applied to the initial fitting. No further target matching was conducted. All adaptive parameters other than the NR function (or NoiseBlock) were turned off, and the microphone was set to omnidirectional mode. The SoundRecover function, which provides nonlinear frequency compression, was also turned off.
For individualized fine-tuning and adjustment, the “North Wind and Sun” passage (Holube, Fredelake, Vlaming, & Kollmeier, 2010) was presented at 65 dBA in quiet via a computer to ensure listening comfort and, for those with bilateral fittings, loudness balance between ears. If the amplified speech was rated as too loud on one side, the broadband gain for 65 dB input (or G65) for the corresponding side was reduced in 1 dB steps until the speech signals became comfortable and balanced. If the passage was rated as too soft on one side, the broadband G65 setting for the corresponding side was increased in 1 dB increments for comfort. Then, a short, lively orchestral piece featuring a carillon and wind instruments was played at 70 dBA so that users could adjust the gain of the hearing aids to ensure good music quality. If the music was rated as too tinny, the high G50, G65, and G80 settings were reduced. If the music was rated as too boomy, the low G50, G65, and G80 settings were increased.
The NR Function
The NR function (NoiseBlock) used in this study employs a Wiener filter—type algorithm working in all hearing aid channels. A signal estimator and a noise floor estimator were used to determine a short-term S/N estimate in each channel. When the S/N is worse than 15 dB in each channel, NR is activated with an attack time of several seconds and a release time of several milliseconds. There are four default settings in the Target software with progressively greater NR, namely, (a) noise reduction off (NRoff), (b) noise reduction 8 (NR8), (c) noise reduction 14 (NR14), and (d) noise reduction 20 (NR20). NR8, NR14, and NR20 refer to certain levels of the Phonak NoiseBlock feature that correspond to a weak, a moderate, and a strong suppression setting for noise cancellation, respectively (see Figure 2). Depending on the S/N, different amounts of signal attenuation would be expected (see Figure 3). Spectral values are attenuated more at lower S/N, particularly below 300 Hz or above 2000 Hz, for a given NR setting. In addition, a stronger NR setting leads to higher attenuation in each channel.
A color-coded representation of the spectral energy (spectrogram) of the phrase “boat trip to Canada” as a function of time over a 5-s interval with a sampling rate of 44.1 kHz and a fast Fourier transform size of 4,096 points for NRoff (upper), NR8 (middle), and NR14 (lower). The phrase was recorded from the hearing aid output in a 2-cc coupler using a female voice played at 65 dB sound pressure level (SPL). The masker was a spectrally matched noise played at 0 dB S/N. The duration of the recorded test signal was 30 s overall. The initial 25 s was discarded to allow for adaptation of the NR algorithm. The color bar ranges from −70 to −40 dB relative to full scale (dBFS), a unit of measurement for amplitude levels below the maximum possible digital level (0 dBFS). High SPL levels are color coded dark red, while low levels are presented in dark blue. Gain reduction at each frequency at various S/Ns for NR8 (upper) and NR14 (lower). S = International Speech Test Signal (ISTS), N = unmodulated noise spectrally matched to the ISTS. SNR = signal-to-noise ratio.
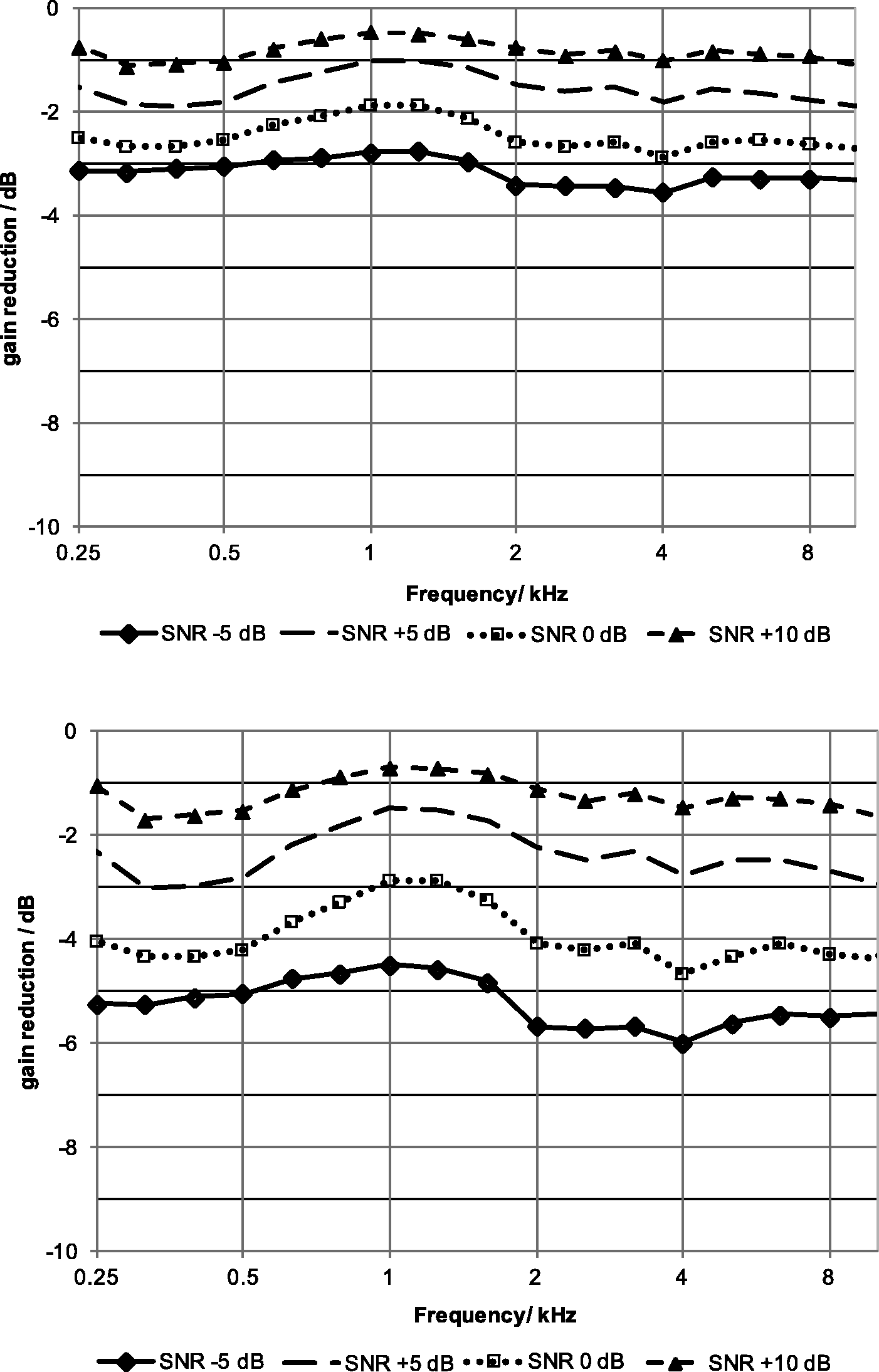
Three measurements (i.e., speech reception, ANL, and self-reported sound quality measures) were used for the evaluation of efficacy of NR. NRoff, NR8, NR14, and NR20 were the current default values in Target; consequently, they were used for the measurement of sound quality. However, four test conditions would be time-consuming, and the parameter space of NR strength may be too small to yield significant results for ANL measurement and the Mandarin Hearing in Noise Test (MHINT; Wong, Soli, Liu, Han, & Huang, 2007), according to a pilot study. Three test conditions (i.e., NRoff, NR10, and NR20), therefore, were used for the measurement of speech perception and the ANL.
The ANL Test
The ANL test was administered using custom software on a MATLAB platform (Version 4.1). The same software was used by Fredelake, Holube, Schlueter, and Hansen (2012) to measure ANL. Although continuous discourse and multitalker babble are often used as the background noise in the ANL test (Mueller et al., 2006), sentences and background noise from the MHINT were chosen for the ANL test conducted in this study. Fredelake et al. (2012), Mueller et al. (2006), and Peeters et al. (2009) demonstrated the reliability of the ANL test using nonmodulated speech-shaped noise as the competing stimuli. Mueller et al. (2006) also used the HINT sentences to obtain the ANL because the time gaps between sentences provided a listening situation that is probably more typical of real-world listening than continuous discourse.
Thirty sentences from three randomly selected lists of the MHINT were selected for ANL measurements, and nonmodulated speech-shaped noise from the MHINT was used as the masker. The noise was modified so that the masker was continuously on to engage the NR function. The Chinese translation of the ANL test instructions was reported in Ho et al. (2013). As instructions, listeners’ interpretation of test instructions, examiner attitude, and culture could affect ANL measurement (Brannstrom, Holm, Kastberg, & Olsen, 2014; Ho et al., 2013), these factors were carefully controlled in this study. Thus, the version reported in Ho et al. (2013) was adapted for use among the Mandarin-speaking population in mainland China by changing some words (e.g., “音响/ yin1xiaŋ1/” were used instead of “喇叭/la3pa1/” to refer to loudspeaker) in order to account for differences in vocabulary and culture between Taiwan and mainland China. Care was taken to ensure that the written instructions were consistent in meaning with those reported in Ho et al. (2013) and with the original ANL (Nabelek et al., 2004) and at the same time were clear and could be easily understood by the participants. The instructions used in this study can be found in Appendix A.
Prior to ANL testing, both oral and written instructions were given. The third author verbally confirmed with participants that they understood the instructions well. Participants were given opportunities to ask questions before and after the practice run, prior to actual data collection. Reinstruction and clarifications were provided when requested. Participants repeated MCL and BNL practice trials until they understood the instructions correctly. For MCL evaluation, participants were asked to select the level most comfortable for listening, somewhere between “too loud to bear” and “too soft to understand.” They were instructed to give a “thumbs-up” hand signal if they wanted the signals to be higher and to give a “thumbs-down” signal if they wanted the signal level reduced. The third author would adjust the sound levels in 1 dB steps by pressing an “up and down” arrow on the screen, while referring to participants’ hand signals indicating their preferences. The BNL was measured with the tester adjusting the BNL using the ANL tool while participants listened to MHINT sentences presented at the MCL. Participants chose the maximum level at which they were willing to accept the noise while listening to the speech for a long time, with the maximum level restricted to 100 dB HL (Ho et al., 2013). ANL was calculated by subtracting the BNL from the MCL (i.e., ANL = MCL – BNL). Thus, a lower ANL indicates greater tolerance of noise. The order of NR settings was randomized to reduce the effects of fatigue on the ANL of any NR condition (Brannstrom et al., 2014). The NR setting was adjusted after each ANL measurement. Three trials were performed for each NR setting for each participant. The ANL score for each NR setting was the mean of these three trials.
Speech Perception
Speech reception thresholds (SRTs) were obtained using the MHINT. The SRT is defined as the presentation level at which a listener is able to correctly repeat 50% of the sentences within a list. The MHINT sentence lists were randomly selected from the remaining nine lists. SRT was measured in the Noise Front condition using an adaptive procedure, with noise fixed at 65 dBA and speech level varied adaptively according to the correctness of responses (Wong et al., 2007). As mentioned earlier, the noise used for MHINT testing was a steady-state speech-spectrum-shaped noise.
Both oral and written instructions (see Appendix B) were given before SRT measurements. Reinstruction and clarifications were provided when requested. Several practice lists were administered before the actual SRT measurements to ensure that participants fully understood the instructions. Participants were asked to make guesses even if they were not able to hear the sentences clearly. Only one list of the MHINT was used to obtain SRTs, and only aided SRTs were obtained. The order of NR settings was randomized within and across participants.
Sound Quality Measurement
Paired comparisons of sound quality were obtained using a continuous discourse passage, “Holiday in Hangzhou,” taken from the Chinese Phonak Target Media Database. This passage was spoken by a female native standard Mandarin speaker in a natural conversational manner and presented in cafeteria noise. The noise level was fixed at 65 dBA, and the passage was presented at 5 dB S/N. A paired comparison method was used to evaluate self-reported preferences in listening comfort, listening effort, speech clarity, and general sound quality in the four NR conditions. Test instructions for the sound quality comparisons were listed in Appendix C.
Participants were instructed to compare two randomly selected NR settings, without knowing what they were. The four NR settings were combined into six pairs (NRoff/NR8, NRoff/NR14, NRoff/NR20, NR8/NR14, NR14/NR20, and NR8/NR20). Although paired comparison results of each pair were from only one trial, participants were allowed to listen to “Holiday in Hangzhou” under each NR setting for as long as they wanted and were allowed to go back and forth as many times as they needed before they made their final decisions. Participants were encouraged to choose between the two contrastive conditions if they could, although a “no preference” response was still accepted. Both the contrastive sound quality rating conditions (i.e., NRoff, NR8, NR14, and NR20) and the listening conditions (i.e., listening comfort, listening effort, speech clarity, and general sound quality) were counterbalanced during testing.
Statistical Analysis
A repeated-measures analysis of variance (ANOVA) was used to examine the effects of NR settings (i.e., NRoff, NR10, and NR20) on ANL scores and SRTs. Pearson product–moment correlation coefficients were computed to assess the relationship between the ANLs and the SRTs. The binomial test was used to determine whether more aggressive NR was significantly preferred over less aggressive NR. All statistical analyses were performed using IBM SPSS Statistics for Windows, Version 22.0.
Results
The ANL Test
The mean ANLs in the NRoff, NR10, and NR20 conditions were 6.0 dB, 4.3 dB, and 2.6 dB, respectively. Great variability in results was observed, with SDs of 4.7 dB (95% confidence interval: 4.3–7.7 dB), 3.9 dB (2.9–5.7 dB), and 4.3 dB (1.1–4.1 dB), respectively, noted in these conditions. Figure 4 shows the results.
ANLs in the three NR conditions. The mean is represented by the plus sign. The median is indicated by the vertical line in the center of the box. The interquartile range (i.e., the third quartile minus the first quartile) is represented by the width of the box. Lines extending from the upper and lower edge of the box correspond to the highest and lowest values that are within 1.5 times the interquartile range. *indicates a significant difference in results between the two NR conditions.
A repeated-measures ANOVA was used to examine the effects of NR settings. The dependent variable was ANL score, while the independent variables were the three test conditions (i.e., NRoff, NR10, and NR20). ANL scores in each test condition were normally distributed as verified by the Shapiro–Wilk test. For the ANL, Mauchly’s test indicated that all the assumptions of repeated-measures ANOVA were met, except that the assumption of sphericity was violated, χ2(2) = 12.23, p < .01. Therefore, the degrees of freedom were corrected using Greenhouse-Geisser estimates of sphericity (ɛ = .75). The results indicated a significant effect of NR setting, F(1.5, 46.45) = 29, p < .001, ω2 = .48. Post hoc pairwise comparisons with Bonferroni corrections (adjusted p = .017) revealed that ANL scores were significantly higher in the NRoff condition than when hearing aids were set to NR10 (mean difference = 1.7, p < .001) or NR20 (mean difference = 3.4, p < .001) and were significantly higher in the NR10 condition than when hearing aids were set to NR20 (mean difference = 1.7, p < .001). In other words, more aggressive NR settings resulted in significant reductions in ANL and thus greater tolerance of noise.
Speech Perception
Figure 5 shows mean SRTs of 7.7 dB, 6.7 dB, and 6.1 dB, obtained in the three NR conditions, respectively. Great variability in results was again observed, with SDs of 3.9 dB (95% confidence interval: 6.3–9.1 dB), 3.1 dB (5.6–7.8 dB), and 3.7 dB (4.7–7.4 dB), respectively, in the three NR conditions. SRTs in each test condition were normally distributed as verified by the Shapiro–Wilk test. A repeated-measures ANOVA indicated a significant NR setting effect, F(2, 62) = 10.37, p < .001, ω2 = .25. Mauchly’s test indicated that the assumption of sphericity was not violated, χ2(2) = .99, p > .05. Therefore, no correction for degrees of freedom was needed. Post hoc pairwise comparisons with Bonferroni corrections (adjusted p = .017) showed that SRTs were significantly higher in the NRoff condition than when hearing aids were set to NR10 (mean difference = 1, p < .05) or NR20 (mean difference = 1.60, p < .01), while SRTs obtained in the NR10 and NR20 conditions were not significantly different.
Mean SRTs in the three NR conditions. The mean is represented by the plus sign. The median is indicated by the vertical line in the center of the box. The interquartile range (i.e., the third quartile minus the first quartile) is represented by the width of the box. Lines extending from the upper and lower edge of the box corresponds to the highest and lowest values that are within 1.5 times the interquartile range. *indicates a significant difference in results between the two NR conditions.
The Relationship Between the ANL and Speech Perception
Pearson product–moment correlation coefficients were computed to assess the relationship between the ANLs and SRTs. There was no significant correlation between the two variables obtained in any of the three NR settings (r = −.02, p > .05 with NRoff; r = −.14, p > .05 with the NR10 setting; and r = −.26, p > .05 with the NR20 setting).
Sound Quality
Self-Reported Preferences for Sound Quality as the Percentage of Participants in the Six Paired Comparison Conditions.

Note. The contrastive condition that resulted in significantly more participants preferred over the other are bolded. NR = noise reduction.
p < .05. **p < .01.
Specifically, for listening effort, binomial tests indicated that the proportion of participants (72%) who preferred NR8 was significantly higher than the proportion of participants (25%) who preferred NRoff, p < .01, when the two settings were compared. The proportion of participants (59%) preferring NR14 or NR20 was significantly higher than the proportion of participants (41%) preferring NRoff, p < .05, when NR14 or NR20 were compared to NRoff. However, the proportion of participants (34%) preferring NR20 was significantly lower than the proportion of participants (63%) preferring NR14, p < .05, when the two settings were compared. In addition, the proportions of listeners preferring one setting to another were statistically nonsignificant when NR8 was compared to NR14 and when NR8 and NR20 were compared.
For listening comfort, binomial tests indicated that the proportion of participants (69%) who preferred NR8 was significantly higher than the proportion of participants (25%) who preferred NRoff, p < .01, when the two settings were compared. The proportion of participants (69%) preferring NR14 was significantly higher than the proportion of participants (31%) preferring NRoff or NR8, p < .01, when NR20 was compared to NRoff or NR8. In addition, the proportion of participants (69%) preferring NR20 was significantly higher than the proportion of participants (31%) preferring NR8, p < .01, when the two settings were compared. However, the proportions of listeners preferring one setting to another were statistically nonsignificant when NRoff was compared to NR14 and when NR14 and NR20 were compared.
For speech clarity, binomial tests indicated that the proportion of participants (66%) who preferred NR8 was significantly higher than the proportion of participants (25%) who preferred NRoff, p < .01, when the two settings were compared. The proportion of participants (63%) preferring NR14 or NR20 was significantly higher than the proportion of participants (38%) preferring NRoff, p < .01, when NRoff was compared to NR14 or NR20. The proportion of participants (53%) preferring NR14 was significantly higher than the proportion of participants (34%) preferring NR8, p < .05, when the two settings were compared. The proportion of participants (59%) preferring NR20 was significantly higher than the proportion of participants (41%) preferring NR8, p < .05, when the two settings were compared. However, the proportion of participants (28%) preferring NR20 was significantly lower than the proportion of participants (69%) preferring NR14, p < .01, when the two settings were compared.
For overall quality, binomial tests indicated that the proportion of participants (65%) who preferred NR8 was significantly higher than the proportion of participants (22%) who preferred NRoff, p < .01, when the two settings were compared. The proportion of participants (63%) preferring NR20 was significantly higher than the proportion of participants (38%) preferring NRoff, p < .01, when the two settings were compared. However, the proportion of participants (28%) preferring NR20 was significantly lower than the proportion of participants (69%) preferring NR14, p < .01, when the two settings were compared. In addition, the proportions of listeners preferring one setting to another were statistically nonsignificant when NR8 was compared to NR14 and NR20 and when NR14 was compared to NRoff.
In summary, although preferences varied across participants and settings, the general trends were as follows: (a) the most aggressive NR setting of the NR14/NR20 contrastive pair was less preferred, while the NR8 setting of the contrastive pair NRoff/NR8 attracted the highest percentage of participants preferring it; and (b) very few participants reported no preference between the two contrastive settings in the paired comparisons, and the only ones in which even a small percentage of participants had difficulties defining a preference were those that exhibited small differences in NR (e.g., comparing NR8 and NR14). Overall, most listeners preferred some NR to no NR. However, the NR20 setting seemed to be less preferred than the other NR conditions.
Discussion
Noise Tolerance and Preference for NR Settings
Significant differences in ANLs were noted across the NR settings. These results are congruent with findings in the sound quality paired comparison measurements. Overall, the NR function used in this study resulted in increased tolerance of noise, and the relationship was progressive, that is, more aggressive NR settings resulted in higher tolerance.
In addition to better ANLs, most participants also preferred more aggressive NR settings (except when NR20 was compared to NR14) for comfort, reduced listening effort, speech clarity, and improved overall sound quality. Furthermore, the majority of participants (approximately 70%) preferred some form of NR over no NR, suggesting that NR was helpful in enhancing the four types of sound quality measured. Interestingly, approximately 71% of participants in Ricketts and Hornsby (2005) also strongly preferred having an NR function turned on, although the algorithm used in that study was different from the one used in this study. Similarly, Brons et al. (2015) reported reduced noise annoyance, more natural speech, and a general preference toward NR functions, while Bentler et al. (2008) and Desjardins and Doherty (2014) reported reduction in listening effort with NR turned on. Boymans and Dreschler (2000) also reported preference for NR.
Nevertheless, we must note that not all NR algorithms have yielded significant improvement in ANLs (e.g., Brons et al., 2015; Mueller et al., 2006). The lack of significant findings could be due to measurement methods not being sensitive to changes and could also be due to differences in the NR algorithms used across studies (Brons et al., 2015). In this study, sound quality was compared at positive S/N, which is probably best at revealing effects of NR function when speech intelligibility is already at a maximum (Boymans & Dreschler, 2000; Brons et al., 2015; Neher, Grimm, Hohmann, & Kollmeier, 2014; Neher & Wagener, 2016). At low S/N, NR may not work as effectively in reducing noise annoyance (Brons et al., 2013). That is, when speech is submerged in noise, the task of NR processing in separating speech from noise becomes more difficult, resulting in classification errors and thus greater speech distortion and poorer intelligibility (Brons et al., 2014). Perceptually, listeners may also have greater difficulty in detecting the effects of NR at poor S/N. Neher et al. (2014) also found that stronger NR is preferred at higher S/N (+4 dB S/N) than when S/N was at 0 or −4 dB. Whether the NR algorithm works as well at low S/N has not been evaluated in this study and should be noted when counseling hearing aid users.
Based on the criteria recommended by Nabelek et al. (2006), listeners with ANLs of less than 7 dB have an increased probability of becoming successful users (i.e., full-time users as determined by a use pattern questionnaire from Nabalek’s study), while the outcomes of those with ANLs between 7 and 14 dB could not be easily predicted. However, some other studies have found that ANLs cannot be used to predict successful hearing aid use as measured by certain other questionnaires and inventories. For example, Freyaldenhoven, Nabelek, and Tampas (2008) found that ANL results did not correlate with any of the four scales of the Profile of Hearing Aid Benefit (Cox & Alexander, 1995), and Olsen and Brannstrom (2014) reported no relationship between ANL and IOI-HA findings. Among those reporting a significant relationship (e.g., Ho et al., 2013; Taylor, 2008), ANL accounted for no more than 68% of the variance of other outcome measures. In other words, listeners did not base their judgment of hearing aid benefit on noise tolerance only.
As in previous studies reporting ANLs with SDs ranging from 1.8 to 7 dB (e.g., Brons et al., 2015; Freyaldenhoven et al., 2008; Mueller et al., 2006; Nabelek et al., 2006; Nabelek et al., 2004; Nabelek, Tucker, & Letowski, 1991; Peeters et al., 2009), large variability in ANLs (SDs ranged from 2.6 to 6.0 dB) was also found in this study. Several studies have suggested that a change of ANLs on the order of 3 to 4 dB is required to yield the minimal clinically important difference (MCID; Freyaldenhoven, Thelin, Plyler, Nabelek, & Burchfield, 2005; Kim & Bryan, 2011; Mueller et al., 2006; Olsen, Lantz, Nielsen, & Brannstrom, 2012). In this study, although statistically significant differences were observed between ANLs obtained in the three NR conditions, only the difference between NRoff and NR20 reached this MCID. In other words, ANL differences exceeding this MCID across NR settings may not be observed in clinical situations unless the settings are quite different. In addition, Franklin, Johnson, White, Franklin, and Smith-Olinde (2013) reported that participants with high levels of the personality trait openness accepted more noise and performed better in ANL testing than those with high levels of the trait conscientiousness. The traits “openness” and “conscientiousness” refer to personality dimensions from the Big Five Inventory. Individuals who score high on the openness dimension tend to be open to new experiences and are especially tolerant, imaginative, artistic, and cultured, while those with conscientious personalities are likely to be thorough, meticulous, organized, and responsible (Barrick & Mount, 1991; Franklin et al., 2013). Research participants, including those in this study, are probably more open to new experiences (e.g., clinical trials) than those who were invited but were unwilling to take part; this trait of openness might have made them more accepting of noise readily. Thus, although this study showed a clear general trend in which more aggressive NR reduces ANL, significant improvement in ANL may not be observed clinically, especially in those who are more conscientious than open. Clinicians must also note that not all individuals prefer more aggressive NR.
Nonetheless, similar to the participants in Brons et al. (2014) and Brons et al. (2015), listeners with hearing impairment in this study were able to distinguish among the four NR settings evaluated, despite the small magnitudes of the differences between then. Although systematic comparisons were not made, it has been noted that the evaluation of listening quality in specific situations has often resulted in preference for NR (e.g., Boymans & Dreschler, 2000; Brons et al., 2014; Ricketts & Hornsby, 2005), while measures that summarize ratings in a scale have not (e.g., Alcántara, Moore, Kühnel, & Launer, 2009; Boymans & Dreschler, 2000). In other words, while clinicians should have confidence in their clients’ ability in judging sound quality differences in specific situations, they should not expect a significant change in aggregate ratings. This observation requires further verification.
Speech Reception
With NR turned on, listeners demonstrated improved speech reception and reported reduced noise annoyance and improved speech clarity, as stated earlier. Reduced noise annoyance is expected to release cognitive resources for better listening, leading to improved speech perception in noise. However, as mentioned earlier, not all studies reported improved speech intelligibility with NR algorithms (e.g., Alcántara et al., 2009; Boymans & Dreschler, 2000; Brons, Houben, & Dreschler, 2012; Loizou & Kim, 2011; Mueller et al., 2006; Nordrum et al., 2006; Ricketts & Hornsby, 2005). Differences in research methodologies and NR algorithms could have caused variations in performance (Alcántara et al., 2009; Ricketts & Hornsby, 2005). On the other hand, language differences may also contribute to variations in results. More specifically, differences in acoustic and linguistic characteristics lead to variations in the contributions of different frequency bands to speech intelligibility across languages (Wong, Sultana, & Chen, 2017). Frequencies below 708 Hz contribute more to speech intelligibility in Mandarin than in English (Kuo, 2013). As shown in Figure 3, NR gives less gain reduction in this frequency region than for frequencies above 2 kHz, which may better preserve the spectral content that is important for perceiving Mandarin sentences. This finding could have implications for the effects of NR algorithms on the perception of other tonal languages such as Cantonese, in which low frequencies are especially important for speech intelligibility, as they are in Mandarin (Wong & Soli, 2005).
Although NR functions improved speech reception, the aggressive NR setting of NR20 did not improve speech reception compared to NR10. Brons et al. (2014) also argue that NR algorithms may exhibit similar effects on both speech and noise within a frequency channel; thus, reduced gain in a channel may not result in improved S/N. At the NR20 setting, many listeners also commented that the sentence intensity seemed to reduce and that some words were too soft to be understood. The question is whether additional gain to compensate for the reduced sound intensity would allow users take greater advantage of more aggressive NR settings.
However, it is worth noting that only one list of the MHINT was used, although the lists and the order of NR settings had been randomized. This limitation may have increased the variability of the MHINT results. Controlling this variability in future studies may help to better reveal the true differences across NR settings. At this point, the NR settings yielded mean SRTs that differed by less than 1 dB, which may not result in noticeable differences in clinical situations.
The Relationship Between Speech Perception and ANL
Although NR function improved both ANL and SRT, these results were not correlated. The lack of correlation is not surprising, as Mueller et al. (2006) and Nabelek et al. (2004) reported the same results. Although the SRT is a measure of benefit from amplification, the ANL is a measure of tolerance of background noise and appears to predict which patients are likely to become good users of hearing aids. These two measures contribute to the assessment of different aspects of hearing aid outcomes and benefits at moderate levels of noise (Nabelek et al., 2004). Although Peeters et al. (2009) reported a significant relationship between ANL and SRT, a careful analysis revealed that their ANL instructions were altered to increase the emphasis on speech intelligibility; thus, it is not surprising that the relationship was significant.
Brons et al. (2015) suggested that there is a tradeoff between listening comfort and speech intelligibility. In fact, a small number of participants preferred no NR because sentences sounded louder and seemed easier to follow. They preferred speech clarity even if it came with additional noise. All participants in this study were experienced hearing aid users, and thus they had probably adapted to listening in noise (Nabelek et al., 2004), such that aggressive NR algorithms might not have improved their speech understanding further. Some others preferred listening comfort; they were more willing to bear the speech distortion and reduced listening levels associated with aggressive NR settings. There might be greater tolerance of noise without improved intelligibility. Again, findings from self-report measures would help us understand the effects of NR algorithms from users’ perspectives.
Conclusion
Increased noise tolerance and improved speech reception were demonstrated with NR turned on. Although increased NR resulted in improved noise tolerance and sound quality, the most aggressive NR did not result in better outcomes than the level below it and was not preferred. We must also note that improved noise tolerance might not result in better speech reception ability. Although the efficacy of NR as used in this study was established, its clinical significance and, in particular, its ability to predict real-life benefits should be examined in future studies. The findings from this study may not be directly applicable to hearing aids employing different NR characteristics (Brons et al., 2015; Peeters et al., 2009) or in listening environments not evaluated in this study. The effectiveness of NR when combined with other adaptive features such as compression should also be examined.
Footnotes
Appendix A. Instructions for the ANL Test
Acknowledgments
The authors would like to acknowledge the participants for their contribution to this research. The authors are also grateful to Solveig Christina Voss and Jinyu Qian from Phonak, who assisted with the setup of the study and provided technical information about hearing aid settings. The authors also want to thank the staff of the Shengkang Hearing Center (Beijing) for their support in participant recruitment.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The work described in this article was partially supported by the Research Support Scheme 2017/2018 of the Department of Special Education and Counselling at the Education University of Hong Kong and by Phonak China.