
Abstract
This study examined music and speech perception in normal-hearing children with some or no musical training. Thirty children (mean age = 11.3 years), 15 with and 15 without formal music training participated in the study. Music perception was measured using a melodic contour identification (MCI) task; stimuli were a piano sample or sung speech with a fixed timbre (same word for each note) or a mixed timbre (different words for each note). Speech perception was measured in quiet and in steady noise using a matrix-styled sentence recognition task; stimuli were naturally intonated speech or sung speech with a fixed pitch (same note for each word) or a mixed pitch (different notes for each word). Significant musician advantages were observed for MCI and speech in noise but not for speech in quiet. MCI performance was significantly poorer with the mixed timbre stimuli. Speech performance in noise was significantly poorer with the fixed or mixed pitch stimuli than with spoken speech. Across all subjects, age at testing and MCI performance were significantly correlated with speech performance in noise. MCI and speech performance in quiet was significantly poorer for children than for adults from a related study using the same stimuli and tasks; speech performance in noise was significantly poorer for young than for older children. Long-term music training appeared to benefit melodic pitch perception and speech understanding in noise in these pediatric listeners.
Introduction
Pitch and timbre are important cues for both speech and music perception. For speech, pitch information can be used to segregate competing sound sources (Assmann & Summerfield, 1990; Brokx & Nooteboom, 1982; Darwin, 2008; Drullman & Bronkhorst, 2004), identify talkers (Carey, Parris, Lloyd-Thomas, & Bennett, 1996), perceive vocal emotion (Murray & Arnott, 1993), and understand lexical tones (Deutsch, Henthorn, & Dolson, 2004; Lin, 1988). Timbre information is especially important for perception of phonemes (Carlson, Granstrom, & Klatt, 1979; Goswami, Fosker, Huss, Mead, & Szűcs, 2011; Molis, 2005; Swanepoel, Oosthuizen, & Hanekom, 2012). For music, pitch is important for melody perception and segregation of multiple instruments. Timbre is important for instrument identification and for instrument segregation (Grey, 1977, 1978; McAdams, Winsberg, Donnadieu, De Soete, & Krimphoff, 1995). Pitch is generally associated with fundamental frequency (F0) and harmonic information, while timbre is associated with spectral and temporal envelope information. While pitch and timbre cues can be considered as independent (Marozeau, de Cheveigné, McAdams, & Winsberg, 2003; Marozeau & de Cheveigné, 2007), they are inexorably combined in many auditory objects. Distortions to pitch and timbre cues can interfere with auditory object perception (Crew, Galvin, & Fu, 2012, 2015; Fuller, Galvin, Maat, Free, & Başkent, 2014). Music training has been shown to provide advantages in both music and speech perception in adults (Kraus & Chandrasekaran, 2010; Parbery-Clark, Skoe, Lam, & Kraus, 2009; Schön, Magne, & Besson, 2004). Presumably, musicians are better able to perceive the cue of concern (pitch or timbre) in the presence of a possibly conflicting cue (Crew et al., 2015) or degraded listening conditions (Fuller, Galvin, Maat, et al., 2014; Fuller, Galvin, Free, & Başkent, 2014). In contrast, Allen and Oxenham (2014) found that musicians and nonmusicians may be similarly susceptible to interference between pitch and timbre cues. Other studies have shown only weak, inconsistent, or nonexistent musician effects for speech perception (Boebinger et al., 2015; Deroche, Limb, Chatterjee, & Gracco, 2017; Madsen, Whiteford, & Oxenham, 2017; Ruggles, Freyman, & Oxenham, 2014).
Most previous studies that have played pitch against timbre cues have focused on discrimination of F0 and spectral shape (Allen & Oxenham, 2014) or have used similarity ratings and multidimensional scaling to characterize the pitch and timbre space (Kong, Mullangi, Marozeau, & Epstein, 2011; Marozeau & de Cheveigné, 2007; Marozeau et al., 2003). Listeners in these studies were typically asked to compare short, simple stimuli (e.g., single notes), which may overestimate sensitivity to pitch or timbre cues relative to longer exemplars of running music or speech, as is encountered in everyday listening. In a melodic contour identification (MCI) task (Galvin, Fu, & Nogaki, 2007; Galvin, Qian-Jie, & Shannon, 2009), listeners must attend to changes in pitch direction over several notes, rather than focus on pitch differences only between two notes. In sentence recognition, listeners attend to the sequence of words strung together, rather than focusing only on differences in spectral and temporal envelopes associated with single phonemes. Thus, discrimination between relatively short stimuli may not predict listeners’ ability to use pitch or timbre cues over a longer period as occurs in everyday listening (e.g., a piece of music, running speech). As speech perception tasks become more difficult (e.g., under conditions of noise, spectral-temporal degradation), musicians may also exhibit some advantage over nonmusicians (Fuller, Galvin, Maat, et al., 2014; Fuller, Galvin, Free, & Başkent, 2014; Kraus & Chandrasekaran, 2010; Parbery-Clark et al., 2009; Schön et al., 2004).
Crew et al. (2015) introduced the Sung Speech Corpus as a tool with which to measure MCI and sentence recognition while manipulating the pitch and timbre cues within either task. For example, MCI can be measured using a single word (fixed timbre) or different words (mixed timbre). Similarly, sentence recognition can be measured using a single F0 across words (fixed pitch) or different F0s across words (mixed pitch). With adult normal-hearing (NH) listeners, Crew et al. (2015) found a musician advantage for MCI performance but not for sentence recognition. Different from musicians, MCI performance for nonmusicians was significantly poorer in the mixed timbre condition, suggesting greater difficulty in extracting pitch information from dynamically changing spectral envelopes.
All of the above-cited studies involved adult listeners. Depending on age, children may exhibit different sensitivity to pitch and timbre cues than observed with adults. Using pure-tone stimuli, developmental effects on frequency discrimination have been extensively studied (Cooper, 1994; Halliday, Taylor, Edmondson-Jones, & Moore, 2008; Jensen, 1993; Maxon & Hochberg, 1982; Thompson, Cranford, & Hoyer, 1999). Halliday et al. (2008) reported that pure-tone frequency discrimination for 11-year-olds was similar to adults, with poorer discrimination for younger children. In contrast, Stalinski, Schellenberg, and Trehub (2008) reported no significant difference between adults and children older than 8 years for F0 discrimination for three-note contours played by a piano sample, in which only the middle note was changed in frequency. Deroche, Zion, Schurman, and Chatterjee (2012) also found no signficant effect of age at testing in children between 6 and 16 years old for modulation frequency discrimination with noise or harmonic complex carriers. Different from frequency discrimination, pitch contour identification involves perception of the global pattern over the duration of the stimulus, requiring cortical network processes (Johnsrude, Penhune, & Zatorre, 2000; Lee, Janata, Frost, Hanke, & Granger, 2011; Tramo, Cariani, Koh, Makris, & Braida, 2005). Soderquist and Moore (1970) showed a training effect on frequency discrimination in 9-year-old children and suggested immature pitch contour identification at this age. Thus, while 8-year-olds may reach adult-like levels of pitch ranking or frequency discrimination (Stalinski et al., 2008), 8- to 9-year-olds may still exhibit immature pitch contour identification.
While children may lag behind adults in pitch contour identification, little is known about the effect of timbre on children’s pitch perception and vice-versa. When perceiving a melodic contour, do children rely more strongly on F0 or the spectral envelope (centroid or edge)? Do changes in pitch affect timbre perception (words in sentences)? Does early musical training affect interactions between pitch and timbre cues for music and speech perception? Does the interplay between pitch and timbre cues affect children differently from adults? To answer these questions, we measured music and speech perception in NH children aged between 8 and 16 years old using stimuli and methods similar to Crew et al. (2015). Music perception was measured using an MCI task; stimuli consisted of piano samples and sung speech with fixed timbre (same word across notes) or mixed timbre (different words across notes). Speech perception was measured using a closed-set matrix sentence recognition task; stimuli consisted of naturally spoken speech and sung speech with fixed pitch (same F0 across words) or mixed pitch (different F0 across words). Note that the speech perception task was intended to observe the effects of changes in F0 on perception of the dynamic spectral envelope cues in the five-word sentences. This is a simplification of the complexity associated with speech understanding in quiet and in noise, but the study was designed to measure the effects of pitch and timbre cues using the same stimuli, which could not be done by, for example, comparing familiar melody recognition to vocal emotion recognition.
Methods
Subjects
Thirty children (13 males and 17 females) aged between 8.1 and 16.9 years old (mean age at testing = 11.3 ± 2.6 years old) participated in this study. This age range was comparable to Deroche et al. (2012; 6–16 years old), who measured sensitivity to pitch cues in school-aged children. All participants had pure-tone hearing thresholds ≤15 dB HL at audiometric frequencies between 250 and 8,000 Hz and normal type A tympanometry (consistent with normal middle ear function). Subjects were paid for their participation in the study.
Demographic Information, Music Experience, and Responses to Questionnaire Items for the Pediatric Subjects.

Note. For subject, Music = musician, NM = nonmusician. F = female, M = male. For type of music experience (exp), C = compose music, P = play instrument, S = sing. For instrument, Vi = violin, Pi = piano, Ch = choir, Uk = ukelele, Tr = trombone, Fh = french horn, Sa = saxophone, Fl = flute.
Music Stimuli and Testing
Music perception was tested using an MCI task (Crew et al., 2015; Galvin et al., 2007, 2009). Melodic contours consisted of five-note sequences that represented nine changes in pitch: rising, rising-flat, rising-falling, flat, flat rising, flat falling, falling, falling-flat, and falling-rising. The spacing between consecutive notes (depending on the target contour) was 1, 2, or 3 semitones. The instrument playing the notes was a MIDI piano sample (Galvin, Fu, & Oba, 2008) or sung speech (Crew et al., 2015; Crew, Galvin, & Fu, 2016). For the piano sample, the lowest note in any contour was A3 (220 Hz), the highest note was A4 (440 Hz), the duration of each note was 250 ms, and the time between successive notes was 50 ms. For sung speech, each of the 50 words was produced by an adult male for each semitone between A2 (110 Hz) and A3 (220 Hz). For more details regarding the sung speech stimuli, see Crew et al. (2015, 2016). The lowest note in any contour was A2 (110 Hz), the highest note was A3 (220 Hz), and the duration of each note was 500 ms. Two sung speech conditions were tested: (a) fixed timbre, in which the same word Bob was used for each note (“Bob-Bob-Bob-Bob-Bob”) and (b) mixed timbre, in which words were randomly selected (for each trial) from within each category (name, verb, number, color, and clothing) and used for each note (e.g., “Bob-sells-three-blue-ties”). For piano and sung speech, all stimuli were normalized to have the same long-term RMS power (60 dB). For the mixed timbre condition, new words were selected for each trial. For each test block, there were 27 stimuli (9 contours × 3 semitone spacings).
Custom software (Angel Sound™; http://angelsound.emilyfufoundation.org) was used for testing. During each trial of a test, a contour was randomly selected (without replacement) from among the 27 stimuli and presented only once to the subject, who responded by clicking on one of the nine response boxes shown onscreen. No trial-by-trial feedback was provided, and stimuli were presented one time (no repeating of stimuli). The order of test conditions was randomized within and across subjects. Stimuli were presented at 60 dBA to the right channel of circumaural headphones (Sennheiser HDA 200) connected to a headphone amplifier (Tucker-Davis Technologies HB6).
Speech Stimuli and Testing
Sentence recognition was measured in quiet and in steady noise using a matrix-styled procedure (Crew et al., 2015, 2016; Hagerman, 1982; Kollmeier et al., 2015). Stimuli were the same as in Crew et al. (2015, 2016) and consisted of 50 words produced by an adult male for each semitone between A2 (110 Hz) and A3 (220 Hz), as well as spoken with a natural intonation. Three stimuli conditions were tested: (a) spoken speech, (b) sung speech with fixed pitch, in which each word of the sentence was sung at the same pitch (D#3, or 155 Hz), and (c) sung speech with mixed pitch, in which each sentence was paired with 1 of the 27 contours used for MCI testing. For each stimulus condition, there were 27 stimuli in each test (same as for the MCI task). For testing in noise, steady noise was matched to the spectrum of all words produced by the male talker; the signal-to-noise ratio (SNR) was 0 dB, calculated according to the long-term RMS of the sentence. The onset and offset of the noise were 500 ms before and after the sentence, respectively.
During testing, a sentence was randomly generated by selecting one word from each of the five categories (name, verb, number, color, and clothing). The subject responded by clicking on the words which they identified best matched what they heard in the sentence. Subjects were instructed to make a choice for each of the words in the sentence, and to guess if they were unsure. Once all five response words were selected, the subject pressed the Next button, and a new sentence was randomly generated. For more details about the speech testing, see Crew et al. (2015, 2016). The stimulus and noise conditions were randomized within and across subjects. Stimuli were presented at 60 dBA via the right channel of circumaural headphones (Sennheiser HDA 200) connected to a headphone amplifier (Tucker-Davis Technologies HB6). As with the MCI testing, no feedback was provided and stimuli were presented one time (no repeats).
Results
Music Perception
Figure 1 shows boxplots of overall MCI performance, as well as performance with 1, 2, and 3 semitone spacings for the piano, fixed timbre, and mixed timbre stimulus conditions, for the musician and nonmusician groups. The mean performance difference (across semitone spacings) between musicians and nonmusicians was 36.0, 24.7, and 30.9 percentage points for the piano, fixed timbre, and mixed timbre conditions, respectively. A split-plot repeated measures analysis of variance (RM ANOVA) with timbre (piano, fixed, and mixed) and semitone spacing (1, 2, and 3) as within-subject factors and group (musicians and nonmusicians) as the between-subject factor was performed on the MCI data; an arcsine transform (Studebaker, 1985) was performed on the data before analysis to reduce floor and ceiling effects. Results are shown in Table 2. There were significant effects for subject group (p < .001), semitone spacing (p = .010), and timbre (p < .001). Post hoc Bonferroni pairwise comparisons showed that performance was significantly better with three semitones than with one semitone (p = .010); there were no significant differences between the remaining spacing conditions (p > .05 in both cases). Post hoc Bonferroni pairwise comparisons showed that performance was significantly poorer with the mixed timbre than with the fixed timbre (p < .001) or piano conditions (p < .001). Although there was no significant interaction between timbre and group (p = .071), post hoc Bonferroni pairwise comparisons (two tailed) showed that musician performance was significantly poorer with the mixed timbre than with the fixed timbre (p < .001) or piano conditions (p = .012); there was no significant timbre effect for nonmusicians (p > .05 in all cases). Large effect sizes were observed for timbre, spacing, and group (η2 > 0.14 in all cases). Mann–Whitney rank sum tests also showed significantly higher musician self-ratings for musical confidence (p < .001) and pitch confidence (p = .004).
Boxplots for pediatric musician and nonmusician MCI scores with different stimulus types. The boxes show the 25th to 75th percentiles, the error bars show the 5th and 95th percentiles, the circles show outliers, the solid horizontal lines show median performance, and the dashed horizontal lines show mean performance. Clockwise from the top left, data are shown for overall MCI performance and MCI performance with 1-, 2-, or 3-semitone spacing. Note. MCI = melodic contour identification.

Speech Perception
Figure 2 shows boxplots of sentence recognition performance in quiet and noise with spoken speech and sung speech with fixed or mixed pitch. Note that because of time constraints, musician data were unavailable for one subject for speech in quiet and in noise, and nonmusician data were unavailable for five subjects for speech in quiet. In quiet, the mean performance difference between musicians and nonmusicians was −1.0, 9.8, and −2.5 percentage points for the spoken, fixed pitch, and mixed pitch conditions, respectively. In noise, the mean performance difference between musicians and nonmusicians was 10.9, 16.2, and 14.0 percentage points for the spoken, fixed pitch, and mixed pitch conditions, respectively.
Boxplots for pediatric musician and nonmusician sentence recognition scores in quiet (left panel) and in noise (right panel) with different stimulus types. The boxes show the 25th to 75th percentiles, the error bars show the 5th and 95th percentiles, the circles show outliers, the solid horizontal lines show median performance, and the dashed horizontal lines shows mean performance.
Split-plot RM ANOVAs with pitch (spoken, fixed, and mixed) and group (musicians and nonmusicians) as the between-subject factor was performed on the speech data in quiet and in noise; an arcsine transform (Studebaker, 1985) was performed on the data before analysis to reduce floor and ceiling effects. Results are shown in Table 2. There were significant pitch effects for speech in quiet (p = .008) and speech in noise (p < .001). There was a significant musician advantage for speech in noise (p = .026) but not for speech in quiet (p = .634). There was a significant interaction between pitch and group for speech in quiet (p = .015). For speech in quiet, post hoc Bonferroni pairwise comparisons (two tailed) showed that nonmusician performance was significantly poorer with the fixed pitch than with spoken speech (p = .012), with no significant differences among the remaining conditions (p > .05 in both cases); there was no significant pitch effect for musicians (p > .05 in all cases). For speech in noise, post hoc Bonferroni pairwise comparisons (two tailed) showed that performance was significantly better with spoken speech than with fixed (p < .001) or mixed pitch (p < .001). For speech in quiet and in noise, there was a large effect size for pitch (η2 > 0.14 in both cases). There was a small effect size of group for speech in quiet (η2 = 0.01), but a large effect size for speech in noise (η2 = 0.17).
Correlation Analyses
Results of Pearson Correlations.

Note. MCI = melodic contour identification.
MCI data were collapsed across the three timbre and three semitone spacing conditions. Speech data were collapsed across the three pitch conditions. Self-reported music and pitch discrimination data were collapsed into a single confidence variable due to covariance. For musicians, age at testing and musical experience were collapsed into the age or experience variable due to covariance. Unadjusted p values are shown for all correlations. The asterisks and italics represent significant correlations after Bonferroni adjustment for multiple pairwise comparisons.
After Bonferroni correction for multiple comparisons, across all subjects, significant correlations were observed between speech in noise and age at testing, between MCI and confidence, between MCI and speech in noise, and between speech in quiet and speech in noise. Among musicians, significant correlations were observed between speech in noise and age or experience, between speech in noise and age at training, between MCI and confidence, between MCI and speech in noise, and between speech in quiet and speech in noise. Among nonmusicians, significant correlations were observed only between speech in noise and age at testing.
While the Bonferroni-adjusted p values failed to meet significance level, medium and large effect sizes (r > 0.30) were observed between age and MCI and speech in quiet, between confidence and speech in noise, and between MCI versus speech in quiet, across all subjects. Among musicians, medium and large effect sizes were observed between MCI and age or experience, age at training, time spent training, and speech in quiet and between speech in quiet and age or experience, age at training, and time spent training. Among nonmusicians, medium and large effect sizes were observed between confidence and MCI, between MCI and speech in quiet, and between speech in noise and speech in quiet.
Age Effects
In this study, there was a broad range for age at testing which appeared to significantly contribute to speech performance. It is possible that speech and music performance may differ greatly between relatively young and old children. To further examine age effects, musicians and nonmusicians were grouped according to age range: 8 to 9 years (young) versus 10 to 16 years (older). Adult musician and nonmusician data from Crew et al. (2015) were added to the comparison (age range: 24–47 years old). The 10-year age cutoff was selected in consideration of data from Halliday et al. (2008) who reported that frequency discrimination was poorer for young children, but was comparable to adults by age 11 years. The 10-year age cutoff was also selected to establish comparable number of subjects for the nonmusicians where age effects might be better observed, as age at testing was significantly correlated with music training experience, creating a possible confound for observing age effects in musicians. Figure 3 shows overall MCI performance (averaged across semitone spacings; top row), speech in quiet (middle row), and speech in noise (bottom row) for young, older, and adult musicians (left column), nonmusicians (middle column), and all subjects (combined musician and nonmusician; right column). Note that there were no adult data for speech in noise.
Boxplots of overall MCI (top row), sentence recognition in quiet (middle row), and sentence recognition in noise scores (bottom row) for musicians (left column), nonmusicians (middle column), and all subjects (musicians and nonmusicians together; right column); the adult data are from Crew et al., 2015). Y (n) = young child subjects (8–9 years old); O (n) = older child subjects (10–16 years old); A (n) = adult subjects (24–47 years old). The boxes show the 25th to 75th percentiles, the error bars show the 5th and 95th percentiles, the circles show outliers, the solid horizontal lines show median performance, and the dashed horizontal lines show mean performance.
For musicians (left column in Figure 3), MCI performance generally worsened from piano to fixed timbre to mixed timbre for the young and older groups; adult performance was near-perfect across timbre conditions. MCI performance was generally better for adults than for young and older children and better for older than for young children. For speech in quiet, there were no strong differences among the three pitch conditions. Again, performance was generally better for adults than for young and older children and better for older than for younger children. For speech in noise, performance was generally better with spoken speech than with fixed or mixed pitch. Performance was generally better for older than for younger children.
For nonmusicians (middle column of Figure 3), MCI performance was markedly poorer with mixed timbre compared with the piano for young children and adults; for older children, performance was generally similar across timbre conditions. Performance was generally best for adults and better for older than for young children; in the mixed timbre condition, performance (although highly variable) was markedly better for adults and older children than for young children. Similar to musicians, nonmusician performance for speech in quiet was generally similar across pitch conditions. Performance was generally better for adults than for young and older children and better for older than for young children. For speech in noise, the fixed and mixed pitch conditions seemed to more strongly affect nonmusician than musician performance. Similar to musicians, nonmusician performance was generally better for older than for younger children.
Results of Split-Plot RM ANOVAs on Data Shown in Figure 3; Musician and Nonmusician Data Were Combined Within Each Age-Group. The Asterisks and Italics Indicate Significant Effects. For Post Hoc Pairwise Comparisons, Bonferroni Correction Was Applied.
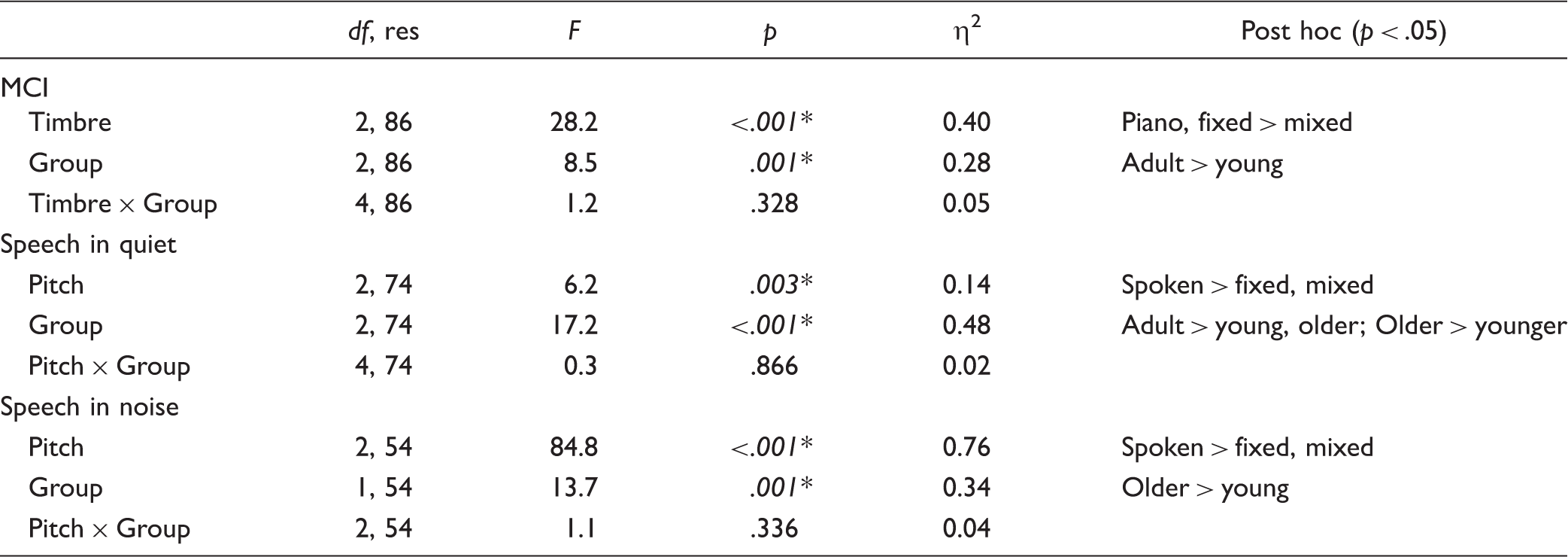
Note. MCI = melodic contour identification.
Discussion
Significant musician effects were observed for MCI and sentence recognition in noise but not for sentence recognition in quiet. MCI performance was significantly affected by timbre only in musicians. For musicians and nonmusicians, sentence recognition in noise was significantly poorer with sung speech (with fixed or mixed pitch) than with naturally produced spoken speech. Speech and music perception was generally poorer in children than in adults using the same listening tasks and stimuli. Later, we discuss the results in greater detail.
Music Perception
MCI performance was significantly better in musicians than nonmusicians. Musician performance was significantly better with the piano and fixed timbre than with the mixed timbre; nonmusician performance was not significantly affected by instrument timbre. Note that piano stimuli were shorter (250 ms/note) than the fixed or mixed timbre stimuli (500 ms/note). However, performance was similar between the piano and fixed timbre stimuli and better with the piano than with the mixed timbre stimuli, suggesting that 250 ms/note may have been sufficiently long to extract pitch for this listening task.
In general, MCI performance was poorer when the timbre cues varied across notes in the contour. Semantic complexity, due to the words changing across notes, may have also contributed to the poorer performance in the mixed timbre condition. For the piano or fixed timbre conditions, each note varied only in the dimension of pitch; the timbre (instrument or word) was unchanged within the contour. For the mixed timbre condition, both the timbre and the word changed. While sentence recognition in quiet was generally good, it was not near-perfect, as for the adults in Crew et al. (2015). This suggests that the present children may have had some difficulty with the speech materials or sentence constructs from the Sung Speech Corpus. Note that in Crew et al. (2015), MCI performance was poorer with the mixed timbre for nonmusician adults, who would presumably be less susceptible than children to changes in semantic information across notes. It would be interesting to observe whether MCI performance would be similarly affected by nonlinguistic stimuli with dynamic timbre (e.g., spectral bands, vowels, etc.). The mixed timbre sung speech used in this study and in Crew et al. (2015) is roughly analogous to sung lyrics, as are often encountered in everyday music listening. Sequential notes in musical melodies are not typically played by different instruments (e.g., except in gamelan music).
In this study, timbre cues significantly affected only musician MCI performance. Allen and Oxenham (2014) found no significant difference between musicians and nonmusicians in terms of the capacity of timbre cues to interfere with pitch perception. This discrepancy may be due to differences in stimuli and experimental design. In Allen and Oxenham (2014), F0 discrimination was measured using single 500 ms stimuli. In the present MCI task with the fixed or mixed timbre conditions, listeners were required to identify five-note melodic contours over a longer duration (500 ms × 5 note = 2500 ms total stimulus duration). Also, the MCI task required listeners to track changes in pitch direction, rather than the relatively simple discrimination in Allen and Oxenham (2014). It is unclear how such focused attention on differences between stimuli may relate to listeners’ ability to perceive changes in pitch with dynamic timbre cues over a longer duration, as occurs with music (especially vocal music). It is possible that when short-term memory demands are increased (as in the MCI task, relative to F0 discrimination), long-term music training may provide an advantage.
Mean MCI performance with the piano for the present children was approximately 20 percentage points poorer than observed for adults (Crew et al., 2015; Galvin et al., 2008). With the mixed timbre stimuli, MCI performance was significantly poorer than with the piano or fixed timbre stimuli, even with the relatively wide three-semitone spacing; similar patterns of results were observed in adults in Crew et al. (2015). When musician and nonmusician data were combined, MCI performance was significantly better with the piano and fixed timbre than with the mixed timbre, with no interaction between age-group (young, older, and adult) and timbre. Thus, while MCI performance was poorer in children than in adults, age did not seem to be a factor in terms of timbre effects when musicians and nonmusicians were combined in each age-group. Both adults and children seemed better able to extract melodic pitch information when the spectral envelope was relatively stable across notes. When only musicians were considered (top left panel of Figure 3), adults were not sensitive to timbre, but MCI performance progressively worsened from piano to fixed timbre to mixed timbre for the young and older children. The young musicians may have attended more strongly to spectral envelope cues than did older musicians, who may have been better able to extract pitch information according to F0. Previous studies have shown that cortical networks are required for processing of complex stimuli (Heffner & Whitfield, 1976; Tramo et al., 2005) and for pattern recognition (Johnsrude et al., 2000; Lee et al., 2011; Tramo et al., 2005). Moore and Linthicum (2007) reported that the auditory cortex does not mature until adolescence. When nonmusicians were considered, performance with the mixed timbre condition was markedly poorer than with the piano or fixed timbre for young and adult listeners (with no clear timbre effect for older children). Taken together, there is somewhat of a mixed result for age effects on MCI performance, with a clear advantage for adults, and a less-clear interaction with the present timbre conditions.
Across all subjects, MCI performance was not significantly correlated with age at testing. Note that before Bonferroni adjustment for multiple comparisons, there was a significant correlation between age at testing and MCI performance (r = 0.37, p = .042). The lack of correlation may be due to insufficient power (0.31 when α = 0.025) or to the fairly broad age range of children (8–16 years). If subjects 12 years or younger were considered (n = 20), there was a significant correlation between age at testing and MCI performance (r = 0.66, p = .002). There was no significant correlation for subjects older than 12 years (n = 10, r = 0.42, p = .225), suggesting that age effects that might have contributed to MCI performance may have been resolved by age 12 years. The data in Figure 3 show that performance was generally poorer for young (8–9 years old) than older (10–16 years old) children (especially for musicians), with adult performance much better than that of young or older children. While previous studies have shown that simple pitch discrimination performance in children becomes adultlike by age 10 years (Cooper, 1994; Maxon & Hochberg, 1982; Stalinski et al., 2008), the present data suggest that age may be a factor when listeners are required to use pitch information in a contour identification task, especially for children younger than 12 years old. Interestingly, while Deroche et al. (2012) found no significant age effects for F0 discrimination among children age 6 to 16 years old, Deroche, Kulkarni, Christensen, Limb, and Chatterjee (2016) found that perception of F0 sweeps was significantly poorer for children than for adults. The present correlation data are somewhat in agreement with Deroche et al. (2012), but a more detailed observation of the present age effects is in agreement with Deroche et al. (2016), where perception of changes in F0 sweeps may be more analogous to perception of melodic contours.
While long-term music training appeared to enhance MCI performance, there were no significant correlations between MCI performance and age or music experience, age that training was begun, or the amount of daily practice. It could be that the musicians had sufficient experience (all had more than 4 years of training) to perform well in the MCI task. Nonetheless, musicians were affected by stimulus type, with significantly poorer performance with the mixed timbre stimuli. It is possible that music training with a single instrument may have provided some advantage for the piano and fixed timbre stimuli; note that 11 of the 15 musicians took piano lessons. According to the questionnaire data, musicians reported significantly better confidence in pitch perception than did nonmusicians. While self-reported music or pitch discrimination confidence was not significantly correlated with MCI performance within musicians and nonmusicians, confidence was significantly correlated with MCI performance when musicians and nonmusicians were pooled together. This suggests some relationship between behavioral and subjective reports of musical pitch perception when musician status was not considered.
Interestingly, when data were collapsed across the timbre and pitch conditions, MCI performance was significantly correlated with speech perception in noise across all subjects (Table 3). This correlation appears to be highly driven by the musician data, as there was no significant correlation between MCI and speech in noise for nonmusicians. This correlation appeared to be driven by the fixed timbre or pitch (r = 0.50, p = .005) and mixed timbre or pitch conditions (r = 0.56, p = .002). Thus, relationships between speech and music perception may more strongly emerge with challenging stimuli and listening tasks.
Speech Perception
Across all subjects, mean performance in noise with spoken speech was 38 and 37 percentage points better than with sung speech with a fixed or mixed timbre, respectively. In quiet, mean performance with spoken speech was six points better than with fixed pitch and five points better than with mixed pitch. In quiet, there was a significant difference between the spoken and fixed speech conditions only for nonmusicians (p = .012). In noise, performance was significantly better with spoken speech than with the fixed or mixed pitch for musicians and nonmusicians (p < .05 in all cases). The 38-point deficit associated with the fixed pitch stimuli (relative to spoken speech) was much larger than reported in previous studies with adult listeners in which the natural pitch variation in running speech was flattened (Miller, Schlauch, & Watson, 2010) or distorted (Binns & Culling, 2007). Taken together, the production of sung speech in this study (and in Crew et al., 2015) appears to have had a greater effect on speech perception than F0 variations.
Speech performance in quiet was significantly poorer for young and older children than for the adults in Crew et al. (2015). Speech performance in quiet and in noise was significantly poorer for young than for older children. Thus, there appear to be general age effects for the present matrix-styled sentence test, similar to that observed with other sentence test materials (Myhrum, Tvete, Heldahl, Moen, & Soli, 2016; Ng, Meston, Scollie, & Seewald, 2011). Across all children, age at testing was significantly correlated with speech performance in quiet and in noise. This is consistent with findings that speech understanding in noise continues to improve until adolescence (Jamieson, Kranjc, Yu, & Hodgetts, 2004; Nelson & Soli, 2000; Neuman, Wroblewski, Hajicek, & Rubinstein, 2010).
There was a significant musician effect for speech performance in noise (but not in quiet). Among musicians, the amount of music training and the age that training was begun was significantly correlated with speech perception in noise. With NH adults, previous studies have reported significant musician effects in noise, but the musician advantage was often quite small (Parbery-Clark et al., 2009). Fuller, Galvin, Maat, et al. (2014) and Fuller, Galvin, Free, et al. (2014) observed musician effects only for pitch-mediated speech tasks such as vocal emotion and voice gender recognition, with no effect for sentence recognition in noise. Similarly, Ruggles et al. (2014) showed no musician effect for sentence recognition in noise when pitch cues were preserved or removed. A number of recent studies have suggested that musician advantages for speech perception may not be due to better perception of voice pitch cues (Baskent & Gaudrain, 2016; Deroche et al., 2017; Madsen et al., 2017). In this study, musicians may have been less susceptible to the atypical sung speech patterns, with or without variations in pitch.
Why Sung Speech in Children?
While many previous studies have examined various aspects of pitch and timbre perception, relatively few have explored interactions between pitch and timbre cues outside of simple discrimination or ranking tasks. The advantage of using sung speech is that listeners must extract useful pitch or timbre cues from longer stimuli, as may be encountered in everyday listening. However, the melodic contours and the matrix sentences in this study and in Crew et al. (2015, 2016) are quite different than would occur in everyday listening; duration and amplitude cues are held constant across notes or words, pitch information is quantized according to semitone steps, there are no natural transitions between subsequent notes or words, and so on. Still, the construction of the contours and sentences allows for direct manipulation of pitch and timbre information that is usually not possible with running speech or excerpts of music. This can provide important information about how pitch and timbre cues may contribute to speech and music perception, as well as how these cues may interfere with each other.
MCI and speech performance in quiet was significantly better in adults than in children, and there appeared to be broad age effects among children (see Figure 3). While both the MCI and speech tests used closed-set paradigms, there may have been a substantial cognitive load for these tasks, especially for the sentence recognition task where subjects had to select from 10 choices in each of five columns. For younger children, it may be preferable to include fewer stimuli in the MCI and sentence recognition tests. The poorer performance in children compared with adults may also have been partly associated with slight procedural differences between groups. In Crew et al. (2015), the adult subjects were allowed to repeat stimuli up to a maximum of three times; in the present study, stimuli were only presented one time, with no repeats. While allowing repetitions of stimuli may have improved performance in children, it would have also generated longer test blocks that may have adversely affected attentiveness, possibly reducing performance.
One issue that relates to musician advantages in children (as shown in this study) are covarying factors of which music training is only one of many influential variables. Parents who wish and can afford to invest in music lessons may provide a rich learning environment that can advantage their children in many ways. Corrigall, Schellenberg, and Misura (2013) showed significant correlations in children between the duration of music training and socioeconomic status (SES), duration of nonmusical extra-curricular activities, IQ, school performance, conscientiousness, and openness-to-experience. Swaminathan, Schellenberg, and Khalil (2017) also found a significant relationship between the amount of music training and SES, as well as with nonverbal intelligence, melody perception, and rhythm perception. The authors also found a significant relationship between music aptitude and intelligence after controlling for SES and music training and suggested that high-functioning children may be more likely to pursue music lessons because of fundamentally better music perception (apart from music training). In general, parents’ education, musical experience, and income would seem to be limiting factors in children’s participation in music training. In this study, 13 of the 15 musicians also had parents who were musicians, while only 6 of 15 nonmusicians had parents who were musicians. However, parents’ musicianship need not be a limiting factor in children’s musical training. Although it was less available now than in previous generations, music education was once a core activity in public and private schools, where there might be greater access to instruments and music lessons. A recent study by Ilari, Keller, Damasio, and Habibi (2016) investigated the benefits of 1 year of music training in school in underprivileged Latino children. Results showed better pitch perception and production in students who participated in the program and declining performance in those who did not. This suggests that music lessons in school (or otherwise funded) may benefit low SES children who may not otherwise have access to music training. The source of benefit of music training for speech perception in children remains unclear. Unfortunately, data related to families’ SES or to children’s cognitive function were not collected in this study but would be valuable for future music studies in children.
Conclusions
In this study, music and speech perception were measured in children; music perception was measured using an MCI task, and speech perception in quiet and in noise was measured using a matrix-styled sentence recognition task. Stimuli for MCI testing included a piano sample and sung speech with either fixed timbre or mixed timbre. Stimuli for speech testing included naturally spoken speech and sung speech with either fixed pitch or mixed pitch. Major findings included the following:
Significant musician advantages were observed for MCI and speech in noise but not for speech in quiet. The results with children were consistent with those from the related study with adults from Crew et al. (2015). MCI performance was significantly poorer with mixed timbre stimuli, suggesting possible interference between timbre and pitch cues for melodic pitch perception or possible influence of the semantic information contained within the mixed timbre stimuli. Sentence recognition in noise was significantly poorer with the fixed or mixed pitch stimuli than with spoken speech, suggesting susceptibility to the atypical speech patterns associated with sung speech. MCI and speech in quiet were significantly better for adults than for children. Among musicians, music and speech performance was generally better for older (10–16 years old) than for young musicians (8–9 years old); age effects were less clear among child nonmusicians. Age at testing was significantly correlated with speech performance in children, suggesting that development may have contributed to the pattern of speech results.
Supplemental Material
Appendix 1 -Supplemental material for Music and Speech Perception in Children Using Sung Speech
Supplemental material, Appendix 1 for Music and Speech Perception in Children Using Sung Speech by Yingjiu Nie, John J. Galvin III, Michael Morikawa, Victoria André, Harley Wheeler and Qian-Jie Fu in Trends in Hearing
Footnotes
Appendix A
Acknowledgments
The authors thank all the subjects for their participation in this study, as well as Taylor Arbogast, Diana Burke, Nikolas Mikus, Lindsey Seyfried, and Sarah Troy, for their assistance with data collection. The authors would also like to thank David Landsberger, Monita Chatterjee, Andrew Oxenham, and two anonymous reviewers for helpful comments.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.