
Abstract
Background:
Patient interest in orthobiologic injections continues to grow. While modern patients are increasingly reliant on artificial intelligence (AI) large language models (LLMs) for health information, it remains unclear whether AI-generated responses regarding orthobiologics are both accurate and written at a reading level suitable for patient education.
Purpose:
To assess the accuracy and readability of responses to common patient questions regarding orthobiologic injections from 3 popular AI LLMs (ChatGPT, Gemini, and Grok).
Study Design:
Cross-sectional Study.
Methods:
Responses to 20 common patient questions regarding orthobiologic injections were recorded from ChatGPT 4o, Gemini 2.5 Flash, and Grok 3 in July 2025. Four independent reviewers (2 fellowship-trained sports medicine orthopaedic surgeons and 2 fellowship-trained nonoperative sports medicine physicians) assessed AI responses for accuracy using the ChatGPT Response Rating System (CRRS) and the AI Response Metric (AIRM). Readability of responses was assessed using the Flesch-Kincaid Grade Level (FKGL).
Results:
Interrater reliability was strong for all accuracy ratings (ICCs >0.70; P < .05). While response accuracy was generally acceptable, 50% (10/20) of ChatGPT, 25% (5/20) of Gemini, and 30% (6/20) of Grok responses were deemed as requiring more than minimal clarification (CRRS >2). One-way matched analysis of variance (ANOVA) revealed a significant effect of AI model on both CRRS (P = .02) and AIRM scores (P = .02), with Gemini displaying improved accuracy compared with ChatGPT (CRRS, P = .04; AIRM, P = .03). Regarding readability, the mean FKGL of all 3 models was at a collegiate level or higher, and all responses exceeded the American Medical Association and National Institutes of Health-recommended 6th-grade reading level for patient education. One-way matched ANOVA revealed a significant effect of AI model on FKGL (P = .02), with Gemini displaying reduced readability compared with ChatGPT (P = .03).
Conclusion:
In this study, ChatGPT, Gemini, and Grok provided generally accurate information on orthobiologics but failed to produce responses at a patient-appropriate readability level. Gemini outperformed ChatGPT in accuracy, although all 3 models demonstrated significant limitations in clarity. Until these issues are resolved, AI-generated responses should serve only as supplemental resources, with final patient education directed by physicians.
Interest in regenerative medicine and orthobiologic injections for musculoskeletal conditions has grown rapidly in recent years. These treatments, such as platelet-rich plasma (PRP) and concentrated bone marrow aspirate (CBMA), use biologically derived substances to promote natural healing and regeneration, potentially delaying or eliminating the need for surgery.8,11 The efficacy of orthobiologic injections for reducing pain and enhancing healing has been investigated across a range of knee pathologies, including osteoarthritis, anterior cruciate ligament injuries, and meniscal injuries.2,3,6,11,14 However, substantial variability in study methodology and quality has limited the ability to make definitive recommendations regarding their indications and therapeutic benefits.17,19
Most orthobiologic injections 10 are not covered by insurance, and the out-of-pocket cost for a single treatment can exceed $2500. Compounding the issue, many of the most frequently accessed online resources about these treatments contain factual inaccuracies and are written at a reading level far exceeding what is recommended for patient education materials. 5 These factors can foster unrealistic expectations for patients, which may ultimately contribute to dissatisfaction and conflict with healthcare providers.
The public availability of artificial intelligence (AI) large language models (LLMs)—such as ChatGPT (OpenAI), Gemini (Google), and Grok (xAI)—has further transformed how patients access health information. These tools can provide instantaneous responses to a range of healthcare-related topics. However, these responses are not formally fact-checked and may at times include inaccuracies or misleading statements. As patients become increasingly reliant on AI for health-related information, it is critical to assess whether these platforms provide responses that are accurate and readable enough for patient education.
Fahy et al 4 previously assessed ChatGPT's responses to PRP-related questions and found that, although the responses were of moderate quality, they were written at a highly advanced reading level. To date, no studies have evaluated AI-generated responses to questions about orthobiologics more broadly, nor compared orthobiologic-related responses from independent LLMs. Given the growing popularity of these injections and the complexity surrounding their use, this study aimed to assess the accuracy and readability of responses generated by ChatGPT, Gemini, and Grok to 20 commonly asked patient questions regarding PRP, CBMA, and orthobiologics in general. We hypothesized that the LLMs would generate reasonably accurate answers to general questions. Still, answers to more nuanced questions would lack sufficient clinical detail, and responses would be written at a reading level exceeding recommendations for patient education materials.
Methods
Artificial Intelligence and Question Input
Two fellowship-trained sports medicine orthopaedic surgeons and 2 fellowship-trained nonoperative sports medicine physicians (K.H., R.D., D.H., P.J.) generated 20 questions regarding orthobiologic injections commonly asked by patients. The questions were developed collaboratively by the expert reviewer panel and intended to represent the most common questions about orthobiologic injections encountered in clinical practice. Several other peer-reviewed studies have used expert-chosen questions to assess the accuracy and readability of AI LLM responses.9,18 The full list of questions is presented in Table 1, and the full list of AI-generated responses is available in Supplementary Appendix S1. Question responses from 3 freely accessible online AI LLMs (ChatGPT-4o, Gemini 2.5 Flash, and Grok 3) were recorded in July 2025. Each response was then assessed for accuracy and readability.
Full Question List

Accuracy Analysis
Response accuracy was assessed by 4 independent raters using 2 separate evidence-based rating systems (K.H., R.D., D.H., P.J.). The 4 reviewers were the same individuals who generated the question list, comprising 2 fellowship-trained sports medicine orthopaedic surgeons and 2 fellowship-trained nonoperative sports medicine physicians. All reviewers attended different residency and fellowship programs. The reviewers range from early- to mid-career stage and all routinely counsel patients regarding orthobiologic injections. Additionally, the reviewers have previously published several academic works on both orthobiologic injections and AI as a patient education tool. Reviewers were blinded to the AI LLM of origin and each other's ratings while completing accuracy ratings. The mean of the 4 raters’ scores for each response was used for analysis. The first rating system used was the ChatGPT Response Rating System (CRRS). 15 CRRS grading is based on the necessity for clarification of the information presented in an AI response, and the CRRS grading scale is presented in Table 2.
ChatGPT Response Rating System

The second rating system used was the AI Response Metric (AIRM). 1 AIRM grading evaluates whether patients can adequately understand and use the information provided by AI and is based on the following 4 criteria: (1) surgeon comfort level with the patient reading the response; (2) response alignment with the current literature; (3) grammatical and syntax clarity; and (4) response completeness. The AIRM grading scale is presented in Table 3.
Artificial Intelligence Response Metric

Readability Analysis
Response readability was assessed using the publicly available online calculator WebFX (https://www.webfx.com/tools/read-able/). 18 The Flesch-Kincaid Grade Level (FKGL) was used to quantify readability for each response. The FKGL provides an estimate of the educational school level required to accurately comprehend written text (higher scores indicate that information is more difficult to read). 9 FKGL scores correspond to the United States educational grade level as follows: 0-3, early elementary (kindergarten to 3rd grade); 3-6, elementary school (3rd to 6th grade); 6-9, middle school (6th to 9th grade); 9-12, high school (9th to 12th grade); and 12+: college and beyond. The American Medical Association (AMA) and the National Institutes of Health (NIH) recommend that patient education materials be written at a 6th-grade level or lower to ensure patient comprehension. 7
Statistical Analysis
Statistical analysis was conducted using R software (R Core Team). Statistical significance was set at P < .05 for each test. Interrater reliability for the accuracy ratings between the 4 independent raters was assessed using 2-way random-effects intraclass correlation coefficients (ICCs). Differences between the mean CRRS and AIRM scores across the 3 models were evaluated using 1-way repeated measures analysis of variance (ANOVA). Assumptions of sphericity were tested using the Mauchly test, and Greenhouse-Geisser corrections were applied when sphericity was violated. Post hoc pairwise comparisons were performed using Tukey-adjusted estimated marginal means to identify differences between the specific models. Readability, assessed by FKGL scores, was compared between models using a 1-way repeated measures ANOVA, followed by Tukey-adjusted estimated marginal means for pairwise comparisons.
Results
Interrater reliability
The ICC for each model and rating system is presented in Table 4. Interrater reliability of accuracy ratings was strong, with all ICC values being considered substantial to almost perfect 12 (ICC >0.70).
Interrater Reliability a

Bold values indicate statistical significance (P < .05). AIRM, Artificial Intelligence Response Metric; CRRS, ChatGPT Response Rating System; ICC, intraclass correlation coefficient.
Accuracy
Table 5 presents the overall mean CRRS and AIRM scores for each model. While response accuracy was generally acceptable, 50% (10/20) of ChatGPT, 25% (5/20) of Gemini, and 30% (6/20) of Grok responses were deemed as requiring more than minimal clarification (CRRS >2). Notably, ChatGPT provided an answer to question 14 (How frequently can I have a platelet-rich plasma injection?) that was deemed by all 4 raters to be frankly inaccurate (CRRS = 4, AIRM = 4.5).
Mean AI Model Accuracy a

Data are presented as mean ± SD. AI, artificial intelligence; AIRMS, AI Response Metric Score; CRRS, ChatGPT Response Rating System.
One-way matched ANOVA testing revealed significant differences in CRRS scores across the 3 models (P = .02). Post hoc comparison of Tukey-adjusted estimated marginal means showed that Gemini scored significantly lower (greater accuracy) than ChatGPT (P = .04), with no significant differences between Grok and the other 2 models (Figure 1).
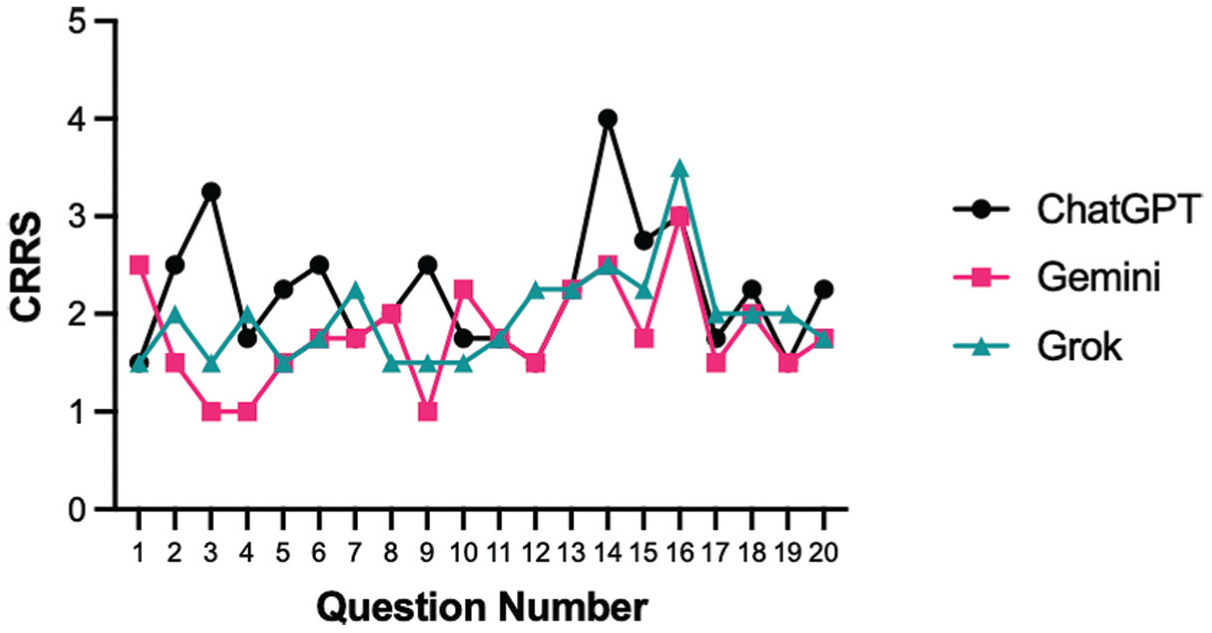
CRRS scores for each of the 20 questions across the 3 AI models. Each line represents 1 model (ChatGPT: black circles; Gemini: pink squares; Grok: green triangles), with points indicating the CRRS score for that question. AI, artificial intelligence; CRRS, ChatGPT Response Rating System.
Similarly, AIRM scores differed significantly between models (P = .02), with Gemini scoring significantly lower (higher accuracy) than ChatGPT (P = .03). There was no statistically significant difference in AIRM score between Grok and the other 2 models (Figure 2).
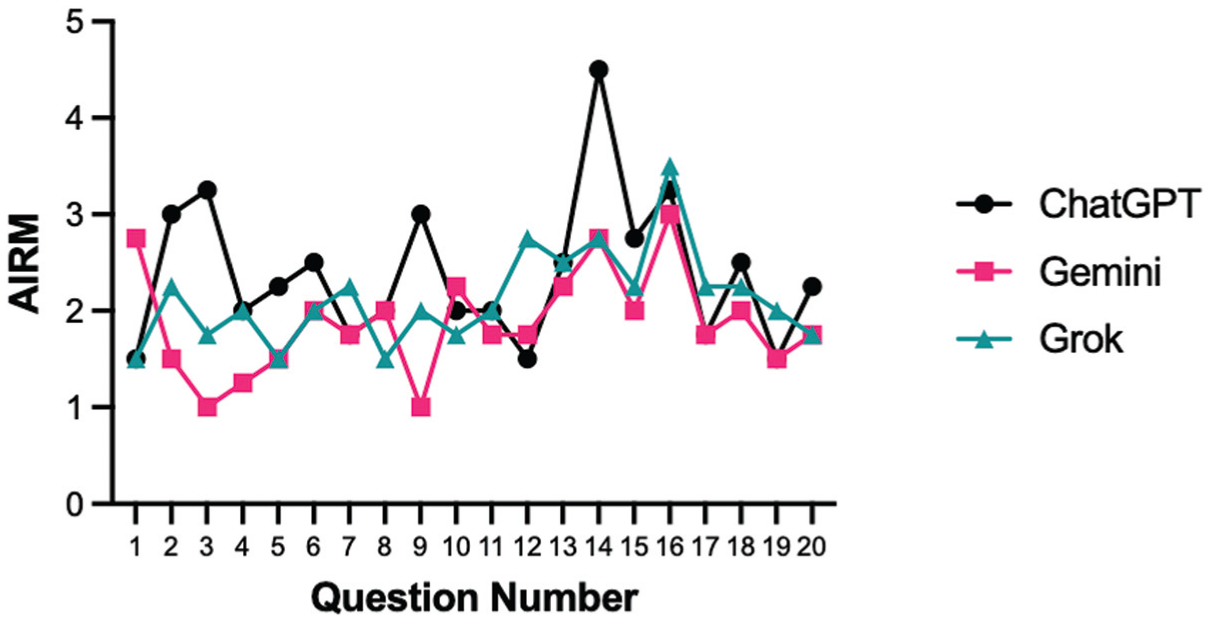
AIRM scores for each of the 20 questions across the 3 AI models. Each line represents one model (ChatGPT: black circles; Gemini: pink squares; Grok: green triangles), with points showing AIRM scores for that question. AI, artificial intelligence; AIRM, AI Response Metric.
Readability
All responses from all 3 AI models were above the AMA and NIH sixth-grade reading level threshold, and the mean FKGL for all 3 models was at a collegiate level or higher (ChatGPT = 15.2 ± 2.2, Gemini = 16.8 ± 2.8, Grok = 15.8 ± 2).
One-way matched ANOVA testing revealed a significant difference in FKGL across AI models (P = .02). Gemini FKGL scores were significantly higher (poorer readability) than ChatGPT (P = .03). There was not a statistically significant difference in FKGL scores between Grok and the other 2 models (Figure 3).

FKGL scores for each of the 20 questions across the 3 AI models. Each solid line represents 1 model (ChatGPT: black circles; Gemini: pink squares; Grok: green triangles), with points showing FKGL scores for that question. The dashed line represents the 6th-grade threshold recommended by the AMA and NIH for patient education materials. AI, artificial intelligence; AMA, American Medical Association; FKGL, Flesch-Kincaid Grade Level; NIH, National Institute of Health.
Discussion
The most important findings of this study are that, although AI LLM responses to common questions regarding orthobiologic injections were generally aligned with the current literature, there was substantial variability in accuracy across both questions and models. Equally importantly, all 3 AI models evaluated in this study produced responses requiring a collegiate reading level or higher, far exceeding the sixth-grade standard recommended by the AMA and the NIH for patient education materials. 7 Although Gemini responses were rated as more accurate than those from ChatGPT, with Grok performing comparably to both, intermodel differences in accuracy may be less meaningful in clinical practice given that all 3 models consistently required clarification and failed to meet basic health literacy standards. To our knowledge, this is the first study to compare the accuracy and readability of responses generated by 3 publicly accessible LLMs—Chat GPT-4o, Gemini 2.5 Flash, and Grok 3—when addressing common patient questions about PRP, CBMA, and orthobiologics in general.
These findings align with previous work showing that LLMs provide clinically reasonable yet imperfect patient information in musculoskeletal medicine. Fahy et al 4 reported that ChatGPT produced moderately accurate responses to PRP-related questions, but at an advanced reading level. This parallels our findings, in which AI-generated responses were aligned with current literature yet required substantial clarification and were inaccessible to the average patient.
Beyond PRP, studies in adjacent orthopaedic contexts reinforce these concerns. Ozduran et al 16 evaluated ChatGPT and Gemini in answering frequently asked questions about low back pain and found that, while both models provided factually acceptable responses, readability again exceeded recommended thresholds. Similarly, Liu et al 13 examined Claude, ChatGPT, and Gemini for perioperative education on superior capsular reconstruction and reported that Gemini and Claude produced more accurate and complete responses than ChatGPT, but none met health literacy standards. 13 Together with the current findings, these studies underscore 2 persistent themes: (1) accuracy varies across models, and Gemini often performs better than ChatGPT-based systems; and (2) readability remains the most consistent and significant limitation across clinical domains.
The present study adds uniquely to the literature by focusing on orthobiologics, which is an area of high patient demand, commonly significant out-of-pocket costs, and heterogeneous evidence. Unlike surgical or spine care contexts, where evidence standards are clearer, orthobiologics remain unsettled, amplifying the risks of inaccurate AI-generated guidance. The evolving nature of the orthobiologics literature may produce greater inconsistency in response accuracy relative to topics with a more settled evidence base, further highlighting the need for physician oversight and limiting the widespread adoption of AI LLMs as patient education tools for unsettled medical topics. Patients considering orthobiologic injections often have preconceived ideas about what the treatments may offer, and many rely on online tools for information. While previous work has centered mainly on surgical interventions or spine care, our analysis shows that the same dual limitations of LLMs also apply to regenerative treatments such as PRP and CBMA. This is particularly relevant as misinformation in this domain may amplify unrealistic expectations, contribute to patient dissatisfaction, and complicate shared decision-making with physicians.
The clinical relevance of these findings is 2-fold. First, inaccuracies in LLM responses— such as ChatGPT's erroneous recommendation on PRP injection frequency—illustrate how unvalidated AI content can directly misinform patients about dosing and safety. In a field already marked by variable evidence and limited insurance coverage, such misinformation could significantly impact patient choices and strain physician-patient relationships when patients’ expectations are not met. Second, the readability barrier remains a critical obstacle. With a mean FKGL in the collegiate range, patients with limited health literacy, representing nearly half of the United States population, are unlikely to benefit meaningfully from these AI-generated materials. Instead of bridging gaps in patient education, current LLM outputs risk widening disparities by privileging individuals with higher literacy and health knowledge.
The main strengths of this study include the use of 2 validated rating systems (CRRS and AIRM) to assess accuracy, the inclusion of 3 major publicly available LLMs, and independent evaluation by fellowship-trained physicians across operative and nonoperative sports medicine disciplines. These methodological features enhance reliability and provide a robust cross-model comparison.
However, this study has several limitations. First, responses were captured at a single time point, and given the rapid evolution of AI models, outputs from future versions of AI LLMs may differ substantially. Additionally, because the orthobiologic evidence base remains heterogeneous, accuracy assessments reflect the interpretation of a limited number of expert reviewers rather than comparison against settled scientific truth. This may limit the generalizability of the accuracy ratings. The expert raters were also the same individuals who generated the question list, which may have introduced bias in the accuracy ratings. Second, only 20 questions were analyzed, which, while representative of common clinical inquiries, cannot capture the entire spectrum of orthobiologic concerns. Furthermore, the 20 questions analyzed in this study were included based on their perceived clinical relevance by the expert reviewer panel. It is possible that these questions are not entirely representative of what patients are actually asking AI LLMs. Third, readability was assessed using a single validated tool (FKGL), which may not fully represent real-world comprehension. Finally, while physician raters ensured alignment with medical evidence, patient perspectives were not incorporated, which is particularly important given that physician ratings may underestimate readability barriers experienced by patients with lower health literacy. Future work should integrate patient reviewers to capture real-world usability.
Future research should prioritize methods to improve readability, including domain-specific fine-tuning of LLMs or post-processing algorithms that aim to simplify outputs without sacrificing accuracy. Promising strategies may include plain-language optimization algorithms, embedding health-literacy frameworks into training data, or leveraging patient-centered teach-back methods to validate AI-generated content. Partnerships among clinicians, patients, and developers will be essential to ensure patient-facing materials are both accurate and comprehensible, and this will require patient-centered studies to evaluate how individuals interpret and act upon AI-generated information in the context of orthobiologics. Finally, as LLM technology evolves, ongoing monitoring of model accuracy and readability will be essential to ensure safe and effective patient-facing use.
Conclusion
In this study, ChatGPT, Gemini, and Grok provide generally accurate information on orthobiologics but fail to produce responses at a patient-appropriate readability level. Gemini outperformed ChatGPT in accuracy, although all 3 models demonstrated significant limitations in clarity. Until these issues are resolved, AI-generated responses should serve only as supplemental resources, with final patient education directed by physicians.
Supplemental Material
sj-docx-1-ojs-10.1177_23259671251414852 – Supplemental material for Evaluating Artificial Intelligence-Generated Responses to Patient Questions Regarding Orthobiologic Injections
Supplemental material, sj-docx-1-ojs-10.1177_23259671251414852 for Evaluating Artificial Intelligence-Generated Responses to Patient Questions Regarding Orthobiologic Injections by Benjamin W. King, Jesse Seilern und Aspang, Kyle Hammond, Destin Hill, Prathap Jayaram, Jay Patel and Richard M. Danilkowicz in Orthopaedic Journal of Sports Medicine
Footnotes
Final revision submitted December 15, 2025; accepted December 22, 2025.
The authors have declared that there are no conflicts of interest in the authorship and publication of this contribution. AOSSM checks author disclosures against the Open Payments Database (OPD). AOSSM has not conducted an independent investigation on the OPD and disclaims any liability or responsibility relating thereto.
Ethical approval for this study was waived by Emory University (Non-human subjects research).
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.