
Abstract
Introduction
Facial analysis is a fundamental component of any plastic, reconstructive, or maxillofacial consultation. Years of training and experience enable plastic surgeons to rapidly analyze an individual's face and quickly determine an impression of facial pathology, dysmorphism, and beauty. Much like the common proverb: “beauty is in the eye of the beholder,” individual plastic surgeons may have varying ideals when it comes to facial analysis—thus making this form of “gestalt” analysis truly subjective in nature.
The objective measurement of facial landmarks and proportions has become increasingly used to highlight areas of interest in preoperative assessments, detect post-operative changes in facial reanimation or cosmetic surgery, provide an objective measurement tool for researchers, or assist with the diagnosis of various cranial dysmorphologies.1,2 The ability to accurately extract facial landmarks and subsequently precisely calculate various proportions is integral to successful facial analysis. Multiple objective techniques for the measurement of soft tissue facial landmark measurements have been described and validated in prior literature.1,3,4 Direct surface measurements, popularized and standardized by Farkas, have yielded an extensive list of facial indices and population averages across ethnicities.1,5–7 Direct measurements, however, are operator dependent, time-consuming, subject to human error and require close, in-person contact with patients. Advances in photography and computer software have enabled highly accurate capture of human faces using precise markup tools, 3-dimensional reconstruction, and incorporation of computed tomography (CT) cephalometric imaging.4,8–11 Although powerful, these techniques are limited by their center-dependent availability, cost, and time.
Machine learning (ML)-derived facial recognition algorithms have increasingly been proven useful for automatic feature extraction, objective beauty measurements, and the diagnosis and management of craniofacial dysmorphology.12–14 Unfortunately, most ML tools rarely progress beyond initial prototype development and clinical translation to wide adoption and deployment are not typically seen. 15 Thus, there remains a need for a fast, cost-effective, scalable, and accurate tool for the detection and analysis of human facial landmarks in clinical settings to serve as a reliable foundation on which to build these valuable and powerful tools.
Facial recognition technology is becoming ever more prevalent and accessible on everyday devices. Recently, Google has published a collection of open-access computer vision models (ML Kit) for deployment in phone-based applications. 16 ML Kit offers a fast, powerful, easy-to-use pretrained face detection model that was developed by experts in the field of computer vision. This model is capable of real-time facial landmark recognition and provides 133 coordinate points representing the eyes, eyebrows, nose, cheeks, mouth, and facial outline. This open-source Application Programing Interface (API) offers novel opportunities for wider development and deployment of automated tools for facial analysis.
The purpose of this study is to build a proof-of-concept smartphone-based camera application leveraging the ML Kit facial landmark detector for basic facial analysis. We were also interested in the algorithm's ability to detect cranial dysmorphology. We developed an android based phone app, “Facekit,” available for download in the Google Play Store for compatible devices. The app first guides users to capture optimal frontal images of the face and then automatically extracts key facial landmarks and calculates a common set of facial proportions for automated facial analysis. Our goal was to assess the accuracy and utility of this pretrained ML model in measuring facial proportions compared to digital and direct surface measurements. Our app provides a platform for rapid scalability and incremental refinement of an easy-to-use clinical tool for facial analysis.
Methods
A smartphone camera app was developed for Android devices that leverage ML Kit for facial landmark extraction. It was optimized for clinical use by guiding image capture to a standardized frontal view of faces. Automated measurements of 4 horizontal proportions were calculated and compared to direct surface and digital measurements from 15 healthy volunteers.
App Development in Android Studio
For machine learning models to be easily deployable in clinical settings, they must be accessible through phone or computer-based applications that have access to patient data. The Android application, Facekit, was developed for this project using Android Studio in Kotlin programming language (JetBrains Inc) and deployed on a Google Pixel 5 (Google LLC) phone with a 12MP back-camera resolution. 17 Facekit is a camera-based application capable of detecting and analyzing landmarks of human faces for analysis. To control face image consistency, real-time face detection is activated in the camera preview that displays a bounding box around the face as well as head rotation and tilt information (Figure 1A). The app is programmed to only enable photo capture if head tilt and rotation are under 5°, ensuring consistent capture of frontal views. Prior to processing, users can choose to recapture the image or proceed with the analysis. Facial landmark detection is carried out by the Google ML Kit API (Figure 1C). By swiping up, users have access to basic precalculated facial proportions (Figure 1D).

Facekit App workflow. (A) Camera preview provides users with options of using front or back camera, real-time face detection to guide frontal view capture of a consistent image by displaying overhead rotation indicators, (B) Image review phase before analysis, (C) Graphic overlay of facial landmarks post machine learning (ML) processing, and (D) Facial proportion analysis output made visible with a sliding panel. Volunteer images were published with written consent.
Face Detection Model
ML Kit is a mobile SDK developed by Google engineers that provide best-in-class machine learning models for on-device deployment in both Android and iOS apps. This API allows researchers and clinicians to utilize premade computer vision models that would otherwise take too much time, compute power, or human resources to train. Input data processed by this API happens on-device and is not sent to any Google or cloud-based servers. The face detection module can detect human faces, identify key facial features, and get the contours of facial landmarks. The output is a list of Cartesian pixel coordinates representing several facial landmarks that are used in the calculation of facial proportions. Since true length calculations require a pixel to centimeter conversion for each image, the values compared in this study are ratios of lengths instead of the lengths themselves.
Data Collection
All procedures followed were in accordance with the Helsinki Declaration of 1975 as revised in 2008. We recruited 15 healthy participants (8 female; age range 22-30) with diverse ethnic backgrounds and skin tones, and with no identified facial deformities. Participants provided informed verbal consent to be included in this study. Additional written consent was obtained from one participant for whom identifying information is included in this article. In this study, we focused on 4 neoclassical canons of facial proportions which have shown consistency across ethnic backgrounds: orbital (∼1), orbitonasal (∼1), naso-oral (∼1.5), and naso-facial (∼0.25) (Figure 2). 6 These chosen proportions were considered easily measurable based on digital photographs and the algorithm's output. Direct surface measurements were taken by one author (ON). The landmarks measured were as follows: eye width (ex-en), intraocular distance (en-en), nose width (al-al), mouth width (ch-ch), and face width (zy-zy) (Figure 2). Subsequently, the subject's face was photographed using the Facekit app in frontal view. Subjects sat in a relaxed position with hair tied back and all had minimal or no makeup. Images were saved to the device prior to facial landmark analysis. Once processed, the output of the algorithm was recorded. Digital measurements of the same input image used for the algorithm were performed using Adobe Illustrator (Adobe Inc, 2018, USA) by calculating pixel distances between landmarks using the built-in ruler tool.
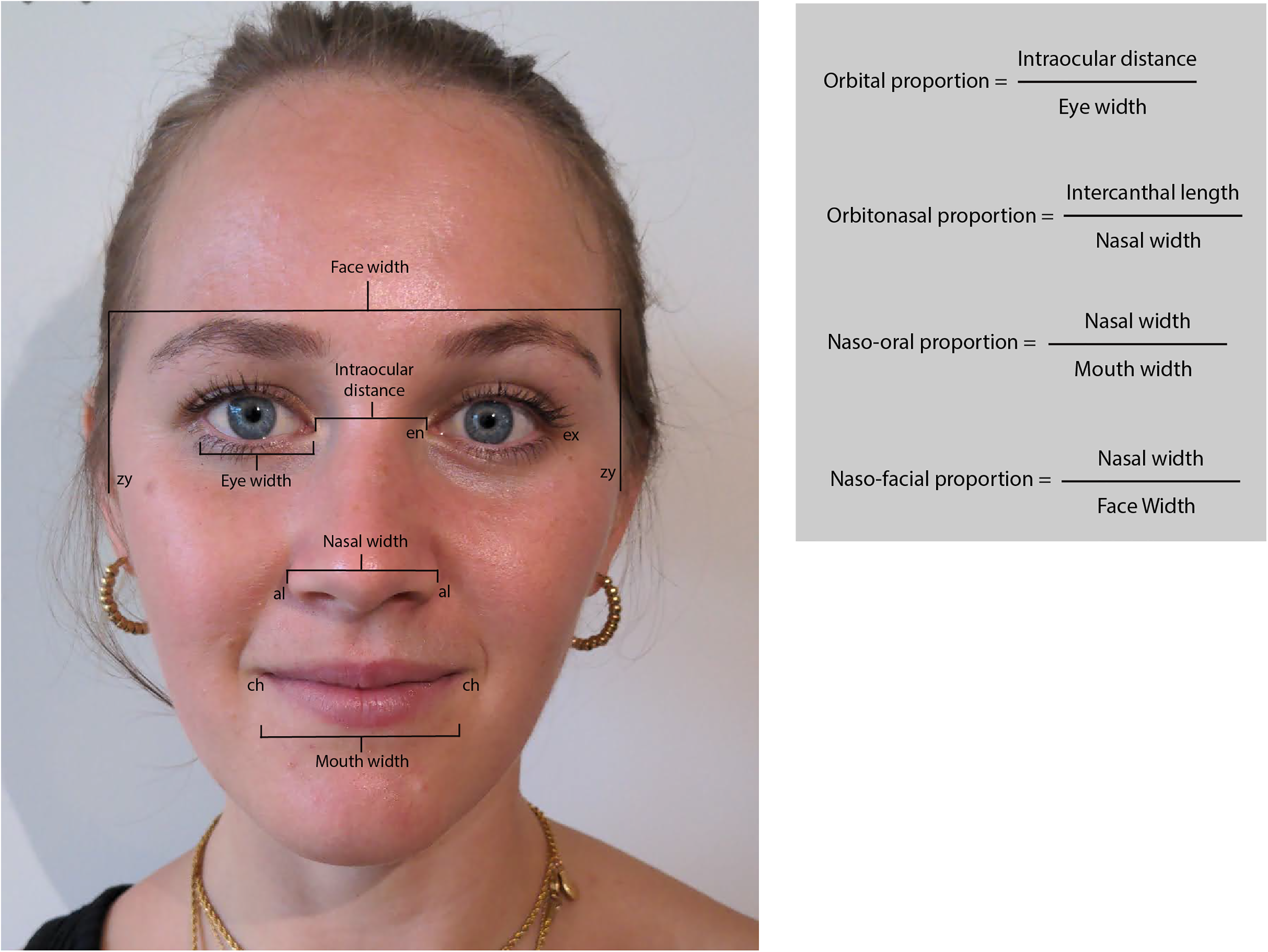
Facial measurements and proportions. Eye width is measured between the exocanthion (ex) and the endocanthion (en). Intercanthal distance is measured between the right and left endocanthions. Nasal width is measured between the 2 alar curvatures (al). Mouth width is measured between the 2 cheilions (ch). Face width is measured between the 2 zygions (zy). Image published with written consent.
Statistical Analysis
Statistical analysis was performed using Excel (Microsoft Inc) and the Real-Statistics resource pack software (Release 7.6, Zaiontz 2021). The mean and standard deviations of errors between measurements were calculated between direct-ML, digital-ML, and direct-digital methods. One factor repeated measures analysis of variance (ANOVA) (RMA) was used to assess significant differences between the measurement methods. The reliability of each of the ML measurements was assessed by computing the intraclass correlation (ICC) between ML and either direct surface or digital measurements. An ICC of 0.75 or above is considered excellent, between 0.4 and 0.5 is fair/moderate, and below 0.4 is poor. Pearson correlation coefficients were also calculated between each of the measurement techniques. By calculating limits of agreement using the mean and standard deviations, Bland-Altman plots provided a quantitative estimate of how closely measurements from 2 different methods lie and reveal any hidden systemic bias.
Results
The average measurement error between direct surface and digital methods compared to the ML method is shown in Table 1. Errors between direct and digital measurements were on average smaller than errors involving the ML method (Table 1, top). For methods that measure the same property, we expect their mean errors to not be significantly different. As calculated by repeated measures ANOVA (RMA), the mean errors for the 4 orbital proportions were significantly different in a 3-way comparison of our measurement methods (Table 1, bottom). Notably, the ML method poorly estimates the intraocular distance used in the calculation of orbital and orbitonasal proportion resulting in larger errors compared to other proportions.
Mean Error and Standard Deviation Between Direct Surface, Digital, and ML Measurements.
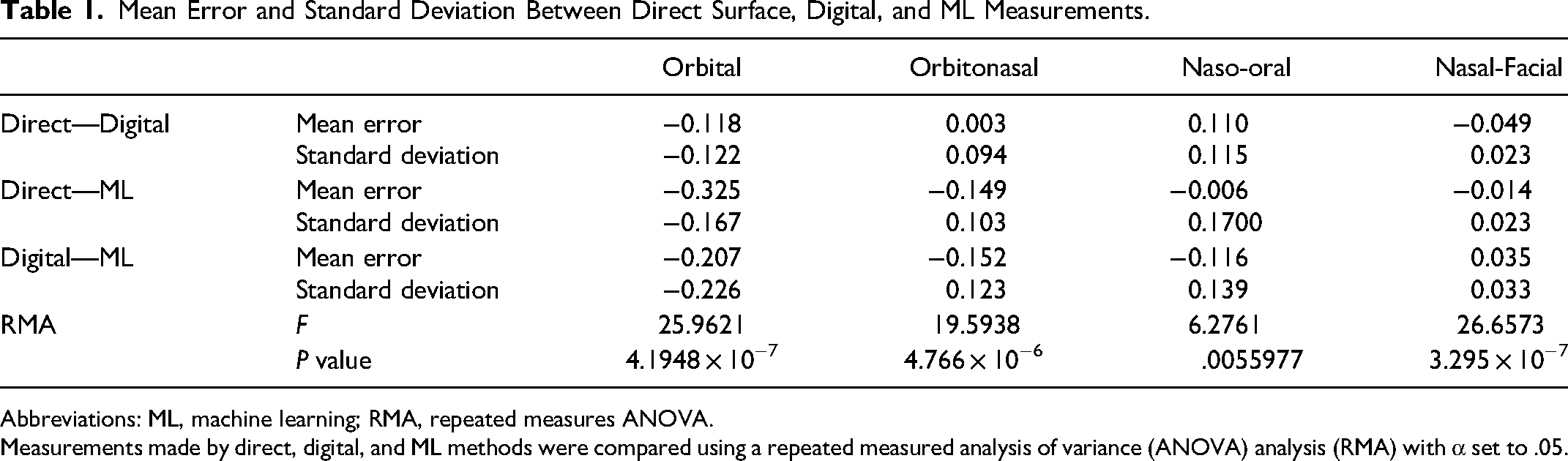
Abbreviations: ML, machine learning; RMA, repeated measures ANOVA.
Measurements made by direct, digital, and ML methods were compared using a repeated measured analysis of variance (ANOVA) analysis (RMA) with α set to .05.
The correlation coefficient (R), ICCs, and 95% confidence intervals for both moth methods against the novel ML methods are listed in Table 2. Comparisons between direct surface and digital measurements are not shown as they have been previously described in the literature. Correlation was high between direct surface and digital measurements for all 4 facial proportions measured (Figure 3, top). Correlation of measurements between the direct surface and ML method was weakest with orbital ratio (r = 0.225) and strongest in nasal-facial ratio (r = 0.535) as shown in Figure 3 bottom panel.
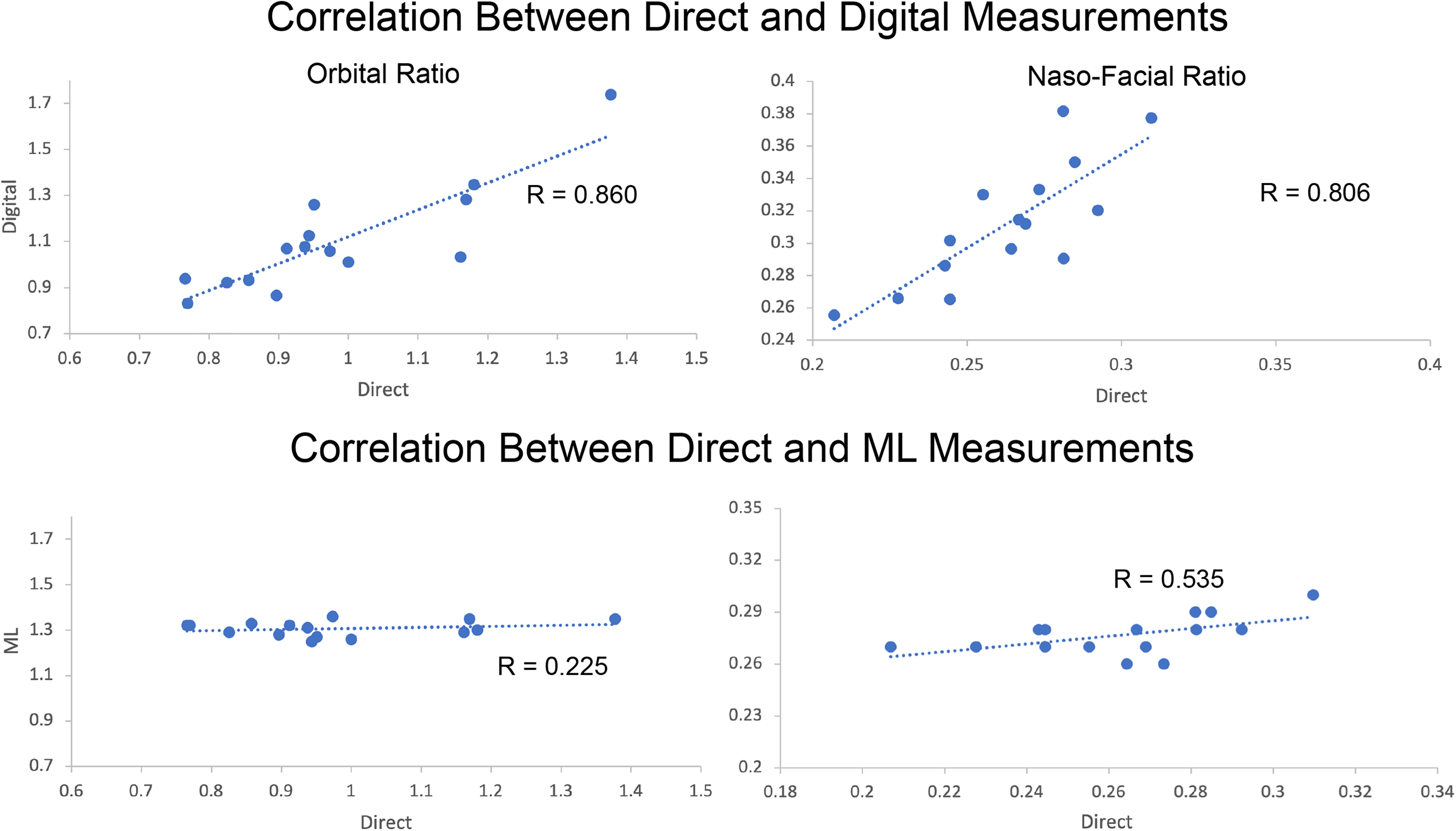
Top: Correlation of orbital ratio between direct surface and machine learning (ML) measurements. Each data point represents one subject. The axis represents the indicated facial proportion as measured by either direct surface or ML methods. Bottom: Correlation of naso-facial ratio between direct-ML measurements (Digital-ML comparisons exhibits a similar lack of correlation and are not shown).
Correlation (R) and Intraclass Correlation (ICC) Values of All Proportions for Direct Versus ML Measurements and Digital Versus ML Measurements.
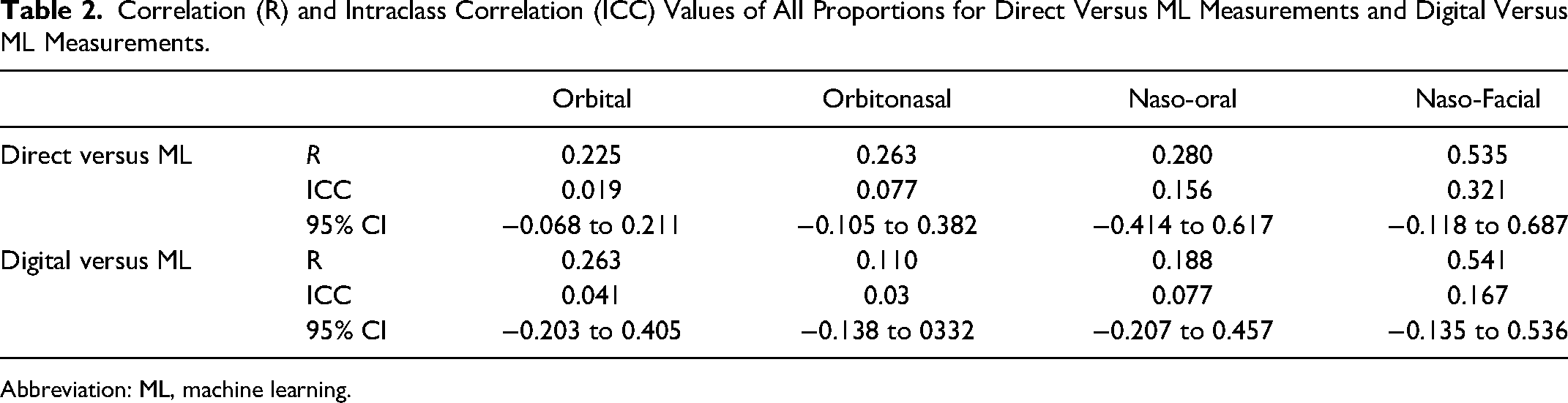
Abbreviation: ML, machine learning.
None of the facial proportions calculated by ML reached an ICC of 0.75. The naso-facial proportion ICC had the highest upper confidence interval of 0.687. Bland-Altman plots of agreement between digital and ML measurements with lower and upper limits of agreement lines are shown in Figure 4. Bland-Altman plots, or difference plots, evaluate the agreement between 2 methods that measure the same property, since correlation does not necessarily indicate agreement. Methods with high agreement cluster around the mean with minimal spread, while methods with bias or poor accuracy exhibit a larger spread away from the mean. As shown in Figure 4, the data do not cluster around the mean and are spread out across the limits of agreement.
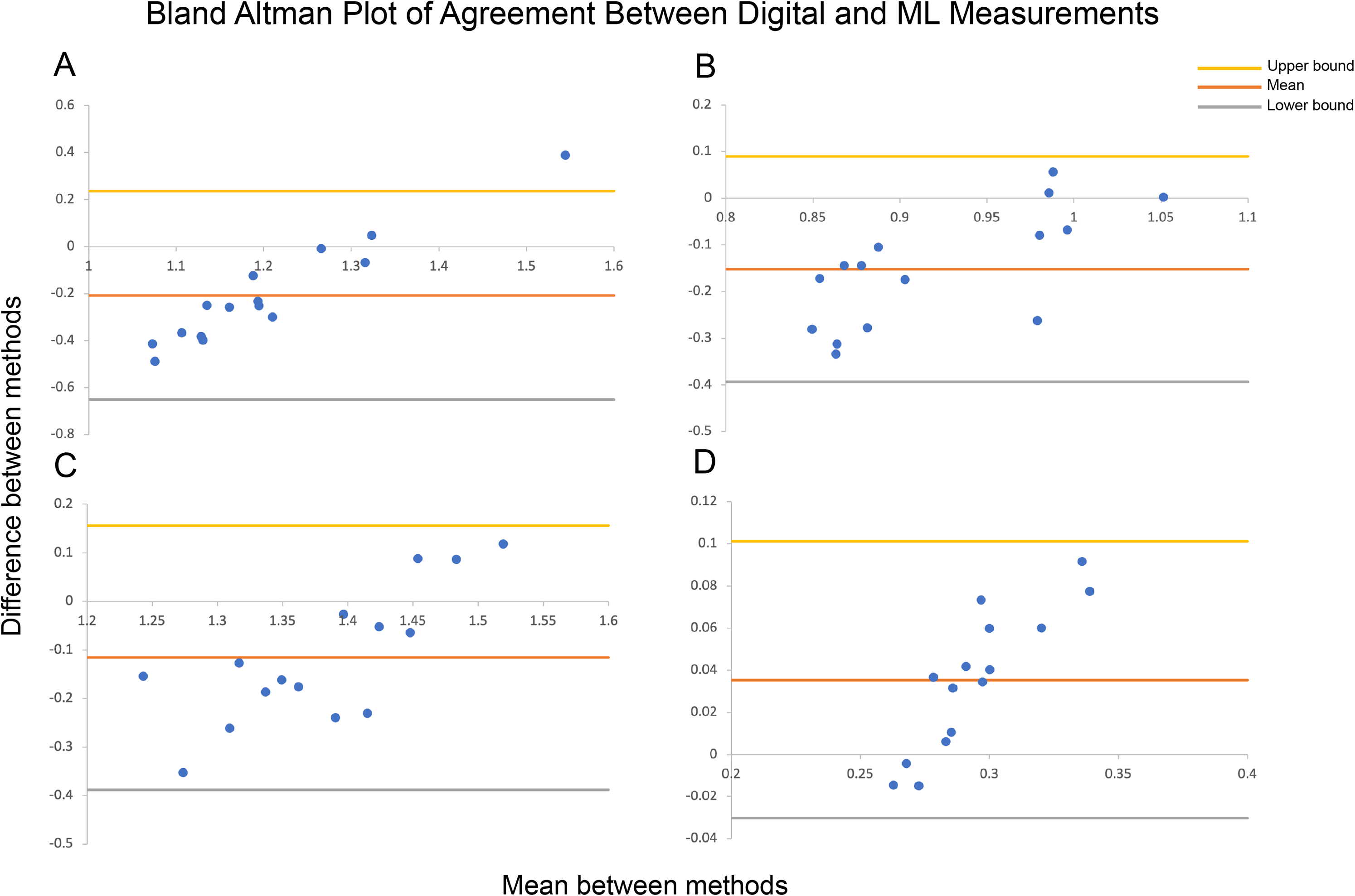
Bland-Altman plots of agreement between digital and machine learning (ML) measurements with lower and upper limits of agreement for (A) Orbital ratio, (B) Orbitonasal ratio, (C) Naso-oral ratio, and (D) Nasal-facial ratio (Direct-ML Bland-Altman plots not shown). Methods with high agreement cluster around the mean, while those with bias or high error will have a larger spread.
Lastly, the app was tested on publicly available images of craniofacial syndromes that characteristically exhibit hypertelorism: Frontonasal dysplasia, Apert's syndrome, and Crouzon syndrome. ML was unable to correctly identify asymmetrical or disproportionate orbital anatomy and produced orbital ratio measurements within similar ranges to healthy subjects. Facekit was also tested on publicly available images of patients with facial paralysis and was unable to identify the appropriate facial landmarks.
Discussion
We compared the agreement in measurements of 4 neoclassical facial ratios using direct surface, digital, and ML methods. The face detection algorithm used in this paper was developed and distributed for open-access use by Google's ML Kit project. We found that ML measurements performed poorly in facial proportions that rely on intraocular distance, while performing better in measurements relying on nose, mouth, and face widths. Overall, none of the measurements calculated by our app reached an acceptable level of agreement with either digital or direct surface methods, as indicated by ICC values. The poor performance could be attributed to several factors in the development of these algorithms. In the data preparation stage, manually labeled landmark positions may have not been accurate enough for use in facial analysis, creating ratios different than the ground truth. Bias may have been introduced either due to homogenous data or inadequate regularization during the training phase. Lastly, the algorithm appeared biased toward facial symmetry and contours that increase proportionally. This was evident in the analysis of faces with hypertelorism or facial droop where the app would artificially lengthen the eye width to match larger intercanthal distances or correct for the droop, respectively.
Machine learning algorithms have potential clinical and research applications within the field of plastic surgery by automating and streamlining data extraction and analysis of clinically important data.18,19 Convolutional neural networks (CNNs), a powerful deep learning network architecture used in computer vision applications, form the backbone of most modern approaches to facial recognition.12,20 CNNs are increasingly used in medical diagnostics where fast and repetitive pattern recognition is needed. 21 Barriers to the development of these algorithms go beyond knowledge expertise in the field of computer vision. To train a feature extraction model such as a CNN, researchers must first acquire a sizeable database (n>>1000) of images, manually label landmarks of interest, and have access to expensive and energy-intensive computing resources for training and validation of their models.22,23
Successful applications of ML in plastic surgery include accurate diagnosis and prognosis of burn patients, identification of congenital facial deformities, and various cosmetic surgery assessment applications. 24 Currently, however, the majority of published literature in facial recognition algorithms and plastic surgery has focused on how the performance of preexisting facial recognition algorithms is impacted by patients who have undergone plastic surgery procedures.12,14 For example, an ML algorithm designed to predict an individual's gender has been shown to be more likely to predict a feminine gender in a patient after facial feminization surgery and this has been qualified as an indicator of successful facial feminization surgery. 25 Although certainly interesting to experiment with, many research projects exploring ML in plastic surgery do not offer or discuss strategies for clinical translation. For clinicians to begin using ML solutions, barriers in the development process from model training to deployment and validation must be addressed. In this study, we examined the utility of a premade facial landmark detection algorithm for performing facial analysis using a smartphone camera application for a potential scalable pathway for clinical adoption.
Automatic facial feature analysis has been previously described in the literature. For facial paralysis assessments, Facegram, Facial Assessment by Computer Evaluation (FACE), and auto-eFACE are ML-based computer software tools capable of analyzing static or dynamic facial measurements with high accuracy.26–28 Although they require photography equipment and data transfer to a computer, they demonstrated high sensitivity and specificity in the assessment of facial paralysis before and after reanimation surgery. For cosmetic analysis, one study has demonstrated high accuracy for objective classification of female facial beauty using an algorithm based on decision trees. 29 This study primarily focused on vertical proportions, though values were not compared to digital or surface measurements and the authors did not discuss clinical translation. Aarabi et al proposed an automatic facial feature extraction procedure based on data from 12 judges and a k-nearest neighbor classification. 30 Their method, however, only provides coarse classification into 4 classes of beauty from which real-world applicability is difficult to appreciate. More recently, a deep learning algorithm (RhinoNet) was able to classify the rhinoplasty status of pre/post-operative patients and performed with effectively equivalent accuracy compared to plastic surgery residents. 31 Although the algorithm is limited in utility, the authors successfully deployed RhinoNet on a smartphone application for use in clinical settings. Knoops et al and Mendoza et al developed robust machine learning algorithms capable of diagnostics, risk stratification, and treatment simulation for orthognathic surgery.9,32 As these models rely on 3D scans from CT or magnetic resonance imaging, they are beneficial for a narrow range of patient populations. Geisler et al. created a labeled database of craniofacial syndrome images and developed a CNN to classify anomalies based on images only. 33 They were able to achieve a high level of sensitivity and specificity in classifying head shapes as metopic, sagittal, and unicoronal. To our knowledge, the tools mentioned above have not been widely deployed in clinical practice and there remains a need for a fast, versatile, and easily deployable automatic facial analysis tool.
The face detection model from ML Kit has several notable limitations. This study focused on facial proportions and not lengths as calibration of pixel to millimeter conversion requires fiduciary markers or complex depth calculation techniques. This model does not capture the forehead, therefore, it is not possible to calculate vertical proportions that include face height. A nasal analysis is particularly important for the rhinoplasty preoperative assessments. 34 In this model, the nose consists of only 5 landmarks, far from enough to analyze the complex anatomy of nasal features. Additionally, this model cannot recognize facial landmarks in profile angles, limiting its use in measuring ear and nose proportions. The authors are unaware of any algorithms reported in the literature capable of analyzing profile views of human faces. Lastly, ML models contain bias from their training data. Algorithms may be biased against categories of race, gender, culture, and age if the original training dataset did not adequately represent those categories. 35 As these data likely did not contain photos of cranial dysmorphology, the algorithm often attempts to infer symmetry where symmetry does not exist.
Although measurements calculated by the ML Kit algorithm did not reach a level of agreement with direct or digital methods, this study provides a paradigm for clinicians and researchers to assess the clinical utility and translation of open-access ML algorithms in plastic surgery. Additionally, Facekit is built with a modular design that supports the substitution of different algorithms with the potential for better performance on facial analysis tasks.
Future work will be required to improve the accuracy of open-access facial recognition software for its use in clinical practice. Specifically, these algorithms require more landmarks and an ability to function in both frontal and profile views. When investigators build high-performing algorithms, more effort should be made to making those accessible via smartphone or web-based interfaces for wider deployment and further validation. Our next step will be to assess the performance of a wider range of state-of-the art algorithms such as those built by Facebook, Microsoft, Amazon, and Apple to generate an index of clinical utility, as well as develop a novel algorithm based on up-to-date concepts in computer vision for specific use in plastic surgery assessments and provide wide deployment.
In conclusion, our study built and deployed a smartphone camera application for rapid facial feature extraction and analysis using a premade algorithm built by Google considered to be “best in class.” The performance of this algorithm was overall poor compared to direct surface and digital measurements. We conclude that pretrained facial recognition models are not sufficiently accurate to conduct a clinically useful facial analysis. Custom models trained with carefully labeled landmarks important to the plastic surgeon may offer a better solution to future automation of this task.
Footnotes
Authors’ Note
App development, primary data collection, statistical analysis, and manuscript writing: ON; Substantial contributions to the conception or design of the work, interpretation of data for the work: ON, TS, MH, CR, MM; Drafting the work or revising it critically for important intellectual content: ON, TS, MH, CR, MM; Final approval of the version to be published: ON, TS, MH, CR, MM; Agreement to be accountable for all aspects of the work in ensuring that questions related to the accuracy or integrity of any part of the work are appropriately investigated and resolved: ON, TS, MH, CR, MM. All procedures followed were in accordance with the Helsinki Declaration of 1975 as revised in 2008. As no patients or medical care were involved in this study, IRB approval was not needed. Participants provided informed verbal consent to be included in this study. Additional written consent was obtained from one participant for whom identifying information is included in this article.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article.