
Abstract
This survey focuses on the standard assumption in DSGE models: rational expectations (RE) with perfect information (PI) aka full information (FI)—hence FIRE. RE means model consistent expectations—agents be they households, firms, banks or policymakers know your model. PI (or FI) means agents observe or can infer the current and past state variables in your model. RE + PI (or FIRE) is a strong assumption. The purpose of this survey is to examine the literature that relaxes RE or PI or both. This is relevant for DSGE models in general, but particularly so for the efficacy of monetary policy in a New Keynesian environment when the expectation by agents of future policy is of crucial importance.
Introduction
There have been a number of recent assessments of the ‘state of macro’ and the contribution of dynamic stochastic general equilibrium (DSGE) models—a list that is by no means exhaustive would include: Blanchard (2009, 2016), Blanchard et al. (2010, 2013), Driffill (2011), Pesaran and Smith (2011), Blanchard and Summers (2017), Vines and Wils (2018), Christiano et al. (2018) and Levine (2020).
This survey has a more narrow focus on the standard assumption in DSGE models: rational expectations (RE) with perfect information (PI) aka full information (FI)—hence FIRE. RE means model-consistent expectations—agents be they households, firms, banks or policymakers know your model. PI (or FI) means agents observe or can infer the current and past state variables in your model. RE + PI (or FIRE) is a strong assumption. The purpose of this survey is to examine the literature that relaxes RE or PI or both. This is relevant for DSGE models in general, but particularly so for the efficacy of monetary policy in a New Keynesian (NK) environment when the expectation by agents of future policy is of crucial importance.
We begin with departures from RE and a recent behavioural macroeconomics literature. The ‘Behavioural Macro models’ section sets out the most common equilibrium concepts found in this literature. The third section sets out a standard NK model we use as an application in the rest of the paper. The fourth section moves on to models with heterogeneous agents consisting of both RE and non-RE agents and examines a class of equilibria when the latter can learn from the former through reinforcement learning. The fifth section then moves on to RE models where the PI assumption is relaxed in favour of imperfect information (II). The sixth section reviews important empirical results that assess, first, what we describe as the ‘wilderness’ of departures from RE and, second, the ability of the RE NK model with the II assumption to provide a better data fit than PI. The seventh section concludes the article.
Beyond RE: Equilibrium Concepts
In departures from RE, two sets of equilibrium concepts and related literature need distinguishing. The first is statistical learning, which poses the question: Can agents learn to be rational through econometrics and, in particular, recursive least-squares learning? The second are a class of equilibria which do not converge to RE which we term behavioural macro-models. We consider these in turn.
Statistical Learning
Applications to macroeconomics were pioneered by Evans and Honkapohja (2001). The main idea is to replace RE with statistical forecasts based on knowledge of the structure of the RE solution—perceived law of motion (PLM) found by recursive least squares. A statistical equilibrium is then one where in a stochastic steady state the PLM is equal to the actual law of motion (ALM). If the learning processes n converge in this sense and the PLM = ALM = the RE equilibrium, we have what the literature terms E-Stability . This idea has been described as the ‘principle of cognitive’ consistency: ‘economic agents should be as smart as (good) economists’ (see the survey by Evans & Honkapohja, 2009). Other more recent surveys on statistical learning that their seminal contribution subsequently produced include Milani (2012) and Eusepi and Preston (2018). It should be noted that these papers adopt different approaches to learning—Euler learning versus anticipated utility discussed later and see also section 4.4 of Eusepi and Preston (2016). But either approach assumes agents are good econometricians and use well-specified forecasts of the model RE equilibrium.
To formalize the concept, consider the state-space form of a log- linearized DSGE model:

where yt is the state vector of endogenous variables in deviation form about a steady state. Matrices are functions of parameters j. The model is driven by exogenous driving AR(1) processes wt.
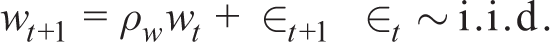
The minimal state variable (MSV) RE solution is
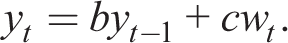
In the OLS learning equilibrium, agents know the form of the solution (2) and use recursive least squares to estimate
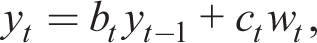
where [bt, ct] are time-varying parameters. E-stability has a large literature in itself, which includes McCallum (2007) and Ellison and Pearlman (2011).
Behavioural Macro-models
This class of models have one or more of the following features: (a) adaptive expectations in models of individual rationality (b) heterogeneous expectations and reinforcement learning (c) cognitive discounting and (d) agent inattention in otherwise rational models. We examine five concepts in turn.
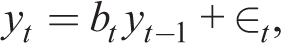
Let yi,t be the ith component of yt. Then assuming yt is observable (the data). Assume a perceived law of motion in the form of simple AR(1) learning rules
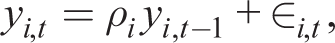
Solving for the actual law of motion, this leads to first-order autocorrelations in the stochastic steady state F (ρ, j), where ρ is the row vector of ρi and j are remaining parameters. Then given j, the stochastic consistent expectations equilibrium (SCEE) is the solution with the fixed point:
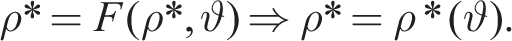
See Hommes and Zhu (2014) and Hommes et al. (2023). It should be stressed that the SCEE is not the RE equilibrium, unlike statistical learning with e-stability.
Gobbi and Grazzini (2015) perform OLS on a first-order VAR of the full state, including shock processes. Eusepi and Preston (2011) perform OLS on a finite approximation of an infinite VAR of a subset of the state space. Hommes and Zhu (2015) use a parsimonious first-order VAR to fit mean and persistence of each state variable to data. All these papers assume the solution of an RE model can be approximately expressed as a finite VAR, which in itself can be a strong assumption as shown by Fernandez-Villaverde et al. (2007). All these papers also use the SCEE concept (aka a Bayesian learning equilibrium). This contrasts with k-level thinking of Garcia-Schmidt and Woodford (2019) and Farhi and Werning (2019), where beliefs are updated iteratively with observed temporary and non-stochastic expectations equilibria over n stages.
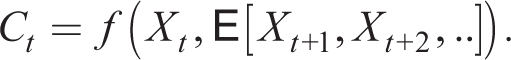
with perfect foresight E[Xt + i] = Xt + i, so beliefs coincide with outcomes. In a stochastic environment, they coincide on average. k-level with k = 1 thinking proposes a temporary equilibrium such that given a set of beliefs
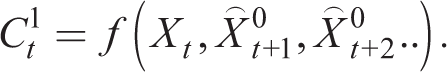
Similarly, for k = 2 thinking, we have
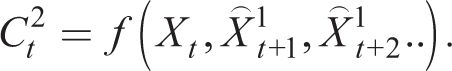
and so on. In the applications of this concept cited, as k → ∞, this iterative process converges with the RE equilibrium and has also been used to compute the solution of RE models.
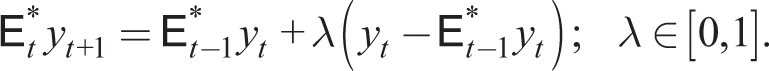
By iteration, this can be written as
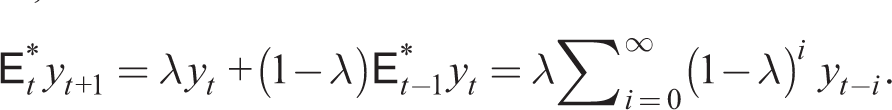
Thus, the expected value is a weighted average of past values of yt. Gelain et al. (2019) find that such a rule in an estimated NK model fits the data better than RE. It should be noted that, as for k-level thinking, AE is not an SCEE.
Anufriev et al. (2015) propose a more general adaptive expectations rule:
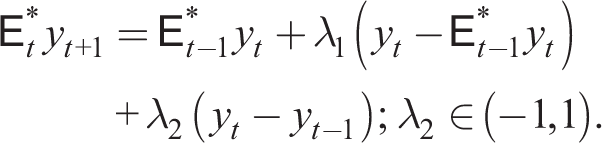
This conforms with lab experiments, a speciality of Hommes and colleagues.
Turning to AU, a closely related literature develops the concept of internal rationality (IR) (see Adam & Marcet, 2011). Under both IR and AU, agents maximize utility under uncertainty, given their constraints and a consistent set of probability beliefs about payoff-relevant variables that are beyond their control or external. Then with IR, beliefs take the form of a well-defined probability measure over a stochastic process (the ‘fully Bayesian’ plan). See Eusepi and Preston (2011) for an RBC BR model with AU, Preston (2005) and Woodford (2013), who adopt a similar NK framework, and Branch and McGough (2018) provide a discussion of EL versus AU. Cogley and Sargent (2008) compare the IR with AU and encouragingly find that AU can be seen as a good approximation to IR.
This subsection has reviewed a number of equilibrium concepts found in the literature that relax the RE assumption. In the rest of the paper, we will compare a standard NK that assumes RE with a number of behavioural counterparts. In the third and fourth sections, the behavioural model chosen is that with AU learning (concept IV). In the sixth section, the need for robust policy is demonstrated in its most clear fashion by comparing the RE model with EL (concept IV) and the inattention-myopia model (concept V). Finally, the section ‘Does Imperfect Information Improve Data Fit?’, reverts to AU in a comparison between RE with perfect and imperfect information.
RE and Bounded Rationality in the NK Model
Ultimately, our application will be conducted in terms of a linear NK RE model, under both perfect and imperfect information, and in a behavioural NK model. But first we step back to the underlying non-linear NK model and introduce the distinction between internal decisions and aggregate macro-variables. We start with the non-linear RE model and proceed from pure RE to pure BR in stages. The complete model set-up and its balanced growth steady state are summarized in Deák et al. (2023).
This subsection has reviewed a number of equilibrium concepts in the literature that go beyond RE.
Households
Household j chooses savings and between work and labour supply. Let Ct(j) be consumption and Ht(j) be the proportion of this available for work or leisure spent at the former. The single-period utility we choose, compatible with a balanced growth steady state, is
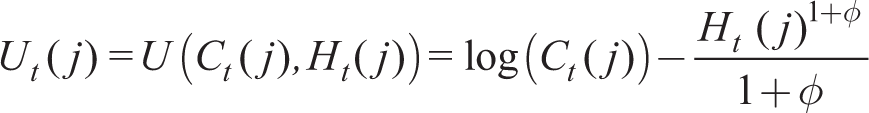
and the value function of the representative household at time t dependent on its assets B is

The household’s problem at time t is to choose paths for consumption {Ct(j)}, labour supply {Ht(j)} and holdings of financial savings to maximize Vt(j) given by (13) given its budget constraint in period t
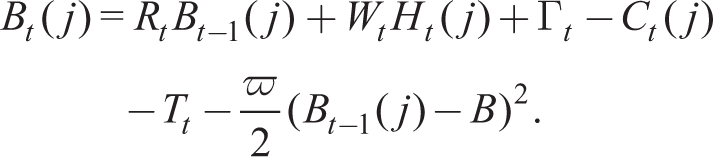
where Bt(j) is the given net stock of real financial assets at the end of period t, Wt is the wage rate, Tt are lump-sum taxes, Γ
t
are profits from wholesale and retail firms owned by households. In order to allow for a wealth distribution heterogeneous agents introduced later and to achieve a stationary path for bond holdings, we introduce a portfolio adjustment cost.
1
Rt is the real interest rate paid on assets held at the beginning of period t given by the Fischer equation
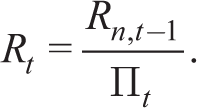
where Rn,t and Π
t
are the nominal interest and inflation rates, respectively. Wt, Rn,t, Π
t
and Γ
t
are all exogenous to household j. As usual, all real variables are expressed relative to the price of final output. The standard first-order conditions are
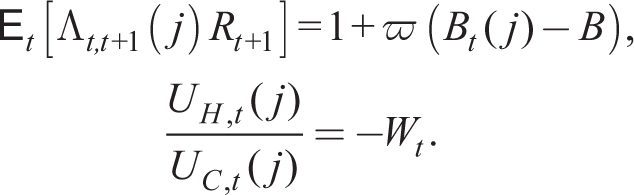
where Λt,t + 1 (j) ≡ ϐ
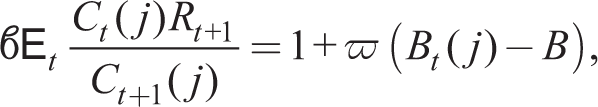
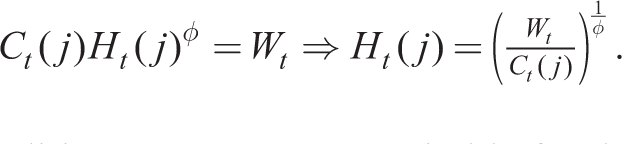
The first-order conditions up to now are suitable for the RE solution. We now express the solution in a form suitable for moving from a RE to a learning equilibrium. We consider the limit as ϖ → 0. Solving (14) forward in time and imposing the transversality condition on debt, we can write
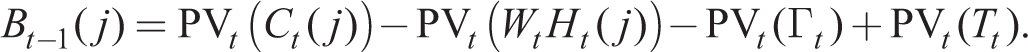
where the present (expected) value of a series
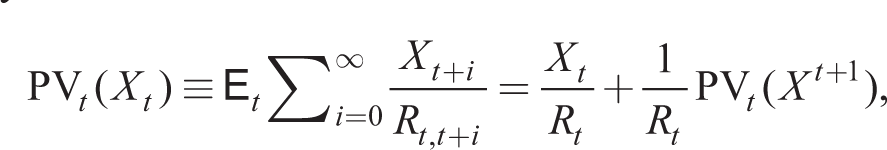
writing Rt,t+i = RtRt + 1Rt + 2 • • • Rt + i as the real interest rate over the interval [t − 1, t + i].
The forward-looking budget constraint (18) holds for the representative household. If we allow RE and BR agents to borrow from or lend to one another, we must allow for Bt−1 = 0. Then in a symmetric equilibrium with Ct(j) = Ct and Ht(j) = Ht, (18) and (17) become
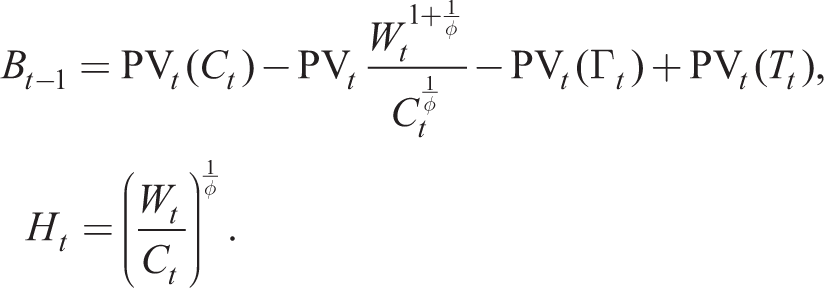
Solving (16) forward in time and using the law of iterated expectation, we have for i ≥ 1
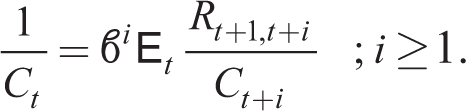
We now express the solution to the household optimization problem for Ct and Ht that are functions of point expectations
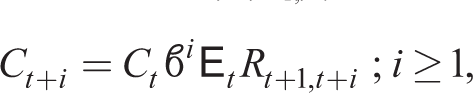
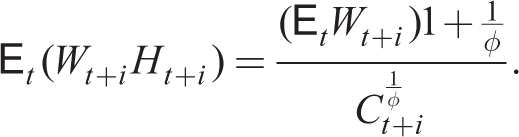
Substituting (21) and (22) into the forward-looking household budget constraint, using
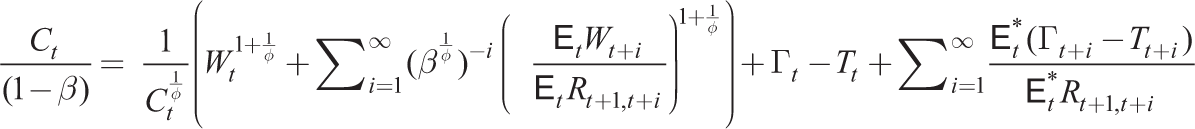
which can be written in recursive form as
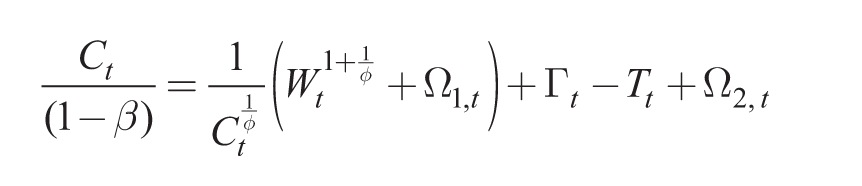
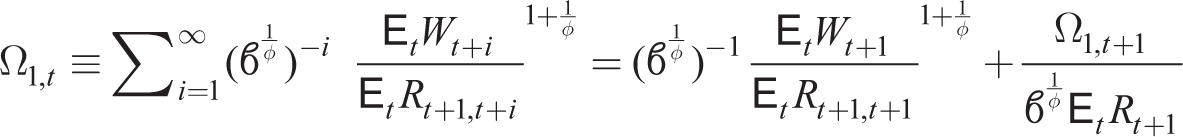
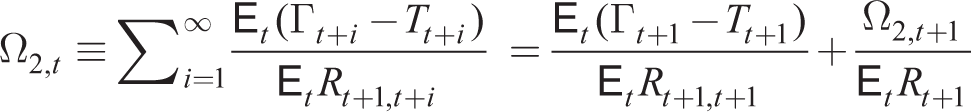
Consumption is then given by (23) assuming point expectations or by the symmetric form of the Euler equation (16) under full rationality (i.e., households know symmetric nature of equilibrium with Ct(j) = Ct). Ct is a function of rational point expectations
Firms, Government Expenditures and Monetary Policy
This section sets out the wholesalers and the retail sector which optimizes using Calvo-pricing contracts. We close the non-linear set-up with resource and balanced government budget constraints, a monetary policy rule and by specifying the structural shocks in the economy. Wholesale firms employ a Cobb–Douglas production function to produce a homogeneous output
where At is total factor productivity. Profit-maximizing demand for labour results in the first-order condition
The retail sector costlessly converts a homogeneous wholesale good into a basket of differentiated goods for aggregate consumption
where ζ is the elasticity of substitution. For each m, the consumer chooses Ct(m) at a price Pt(m) to maximize (25) given total expenditure
where
Following Calvo (1983), we assume that there is a probability of 1 − ξ at each period that the price of each retail good m is set optimally to PtO(m). If the price is not re-optimized, then it is held fixed. For each retail producer m, given its real marginal cost
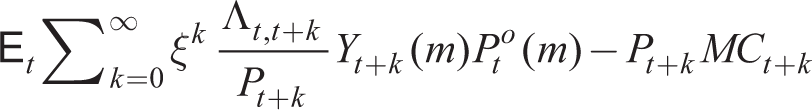
subject to (26), where
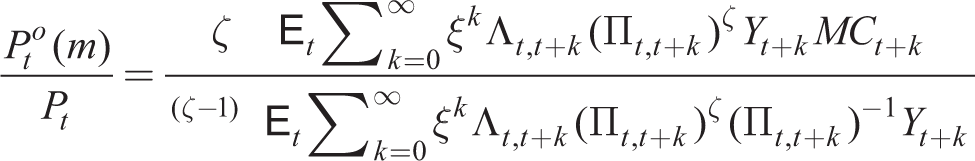
Denoting the numerator and denominator by Jt and JJt, respectively, and introducing a mark-up shock MSt to MCt, from Online Appendix D, we write in recursive form
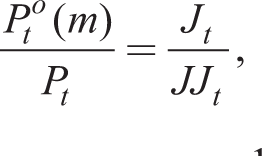
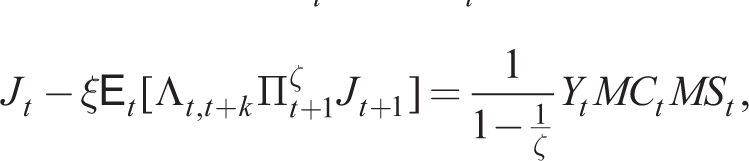
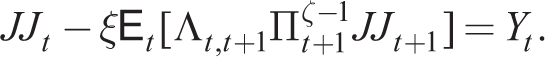
Using the fact that all resetting firms will choose the same price, by the law of large numbers, we can find the evolution of inflation given by
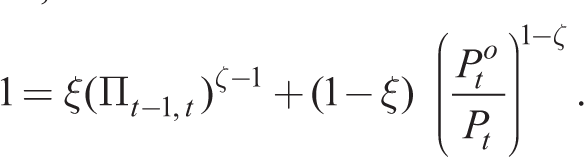
Price dispersion lowers aggregate output as follows. Market clearing in the labour market gives
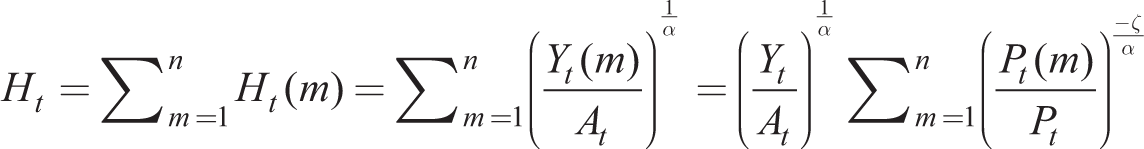
using (26). Hence equilibrium for good m gives
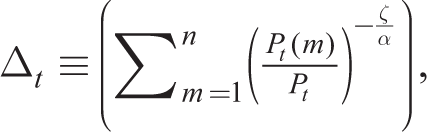
Assuming that the number of firms is large from Online Appendix E, we obtain the following dynamic relationship:
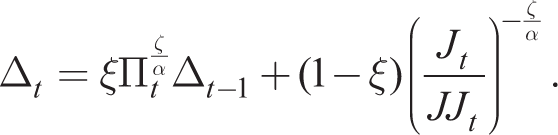
To close the model, we first require total profits from retail and wholesale firms, T
t
, are remitted to households. This is given in real terms by
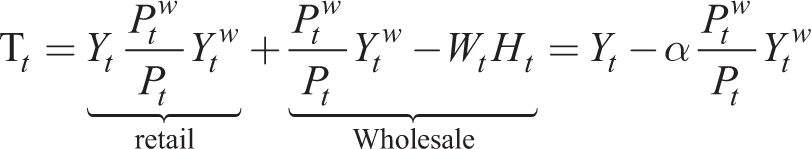
using the first-order condition (24). Then to complete closure, we have resource and balanced government budget constraints
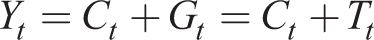
where Gt is an exogenous demand process, and a monetary policy rule for the nominal interest rate given by the following implementable Taylor-type rule
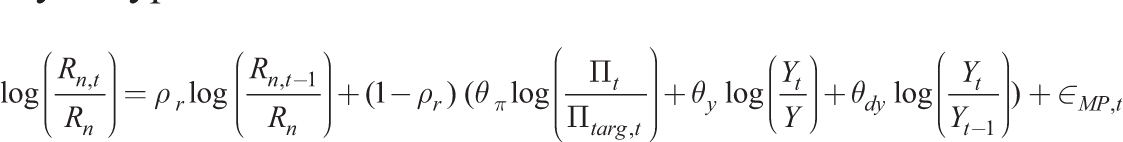
and εMP,t is an i.i.d. shock to monetary policy. Π targ,t is a time-varying inflation target and together with At, Gt and MSt follows an AR(1) process. This completes the model.
Recovering the NK Workhorse Model
We now show that the linearized form of the non-linear model about the steady state reduces to the standard workhorse model where rational expectations E
t
yt + 1 and E
t
πt + 1 or non-RE E*
t
yt + 1 and E*
t
πt + 1 can be treated as expectations by individual households and firms, respectively, of aggregate future output and inflation. We consider the linearized form of the above set-up about a zero inflation and growth deterministic steady state. We also ignore lending or borrowing between RE and BR agents. With RE, the household j’s first-order conditions take one of two forms. First, linearizing (23) we have
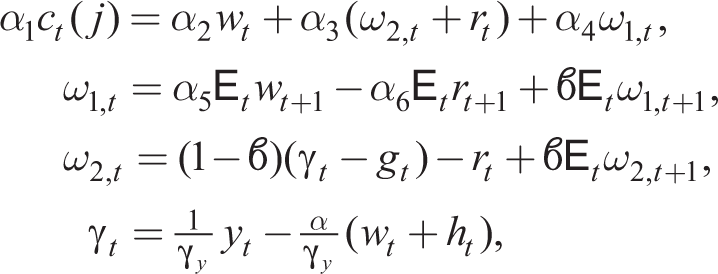
from (23) where lower case variables xt = log(Xt/X), where X is the steady state of
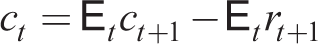
in a symmetric equilibrium. Under RE, (32) or (33) leads to the same equilibrium, but under BR, this is no longer the case.
Linearizing the household supply of hours decision, the resource constraint and the Fisher equation, we have
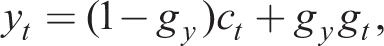
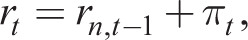
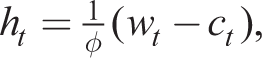
which completes the decisions of the household. Substituting out for ct from (34)
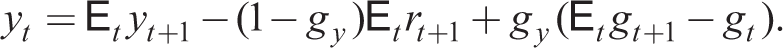
Turning to the supply side, for the wholesale sector
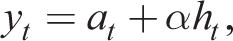
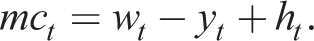
For retail firm m, linearizing the pricing dynamics (27)–(29) about a zero net equation steady state and solving forwards, we have
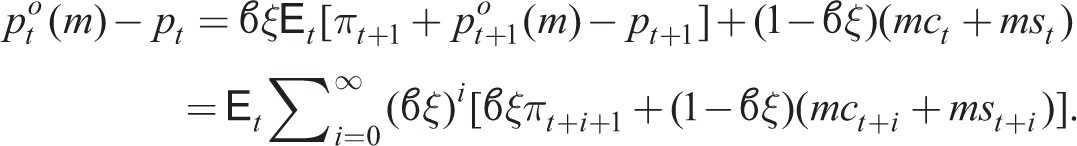
Then, in a symmetric equilibrium, we have
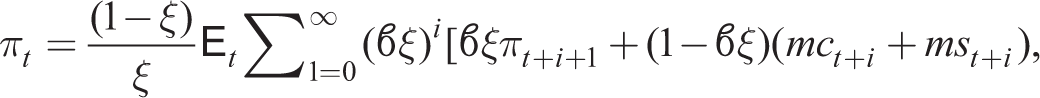
where E
t
[πt+i+1] and E
t
[mct + i + mst + i] are expectations of aggregate inflation and real marginal costs, both variables exogenous to individual price-setters. However, if price-setters know they are identical they know the aggregate price level over non-optimizing and optimizing firms
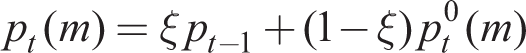
to obtain in a symmetric equilibrium
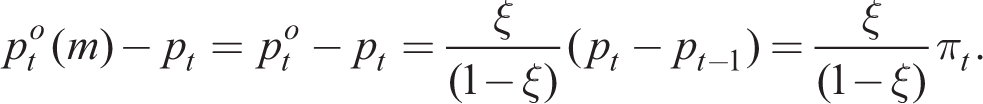
Then, substituting back into (40), we arrive at
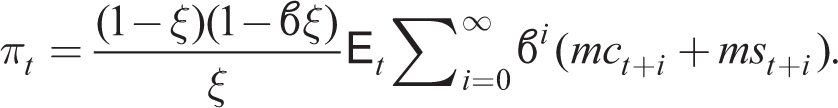
which omits learning about aggregate inflation. Under RE, (41) and (43) are equivalent. (43) is equivalent to
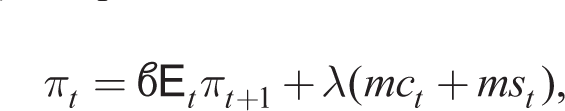
where
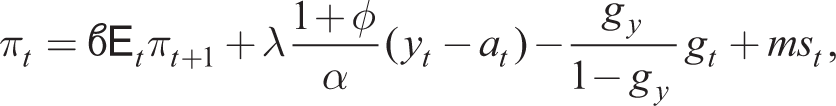
where we note that yt − at is the output gap. Equations (37), (45) and the Taylor rule (31) constitute the 3-equation NK RE model in output, inflation and the nominal interest rate given exogenous shock processes for gt, mst and the monetary shock. A simpler form omits government spending gt so gy = 0 and replaces the aggregate demand shock in (45) with an exogenous process that can be thought of as a risk premium shock to the Fischer equation (35).
The form of the Phillips curve (43) is often used in the behavioural NK literature (see, e.g., De Grauwe, 2012b), but as we have shown, this assumes that firms know they are identical. In our BR model with AU learning, we use (32) and (41), which do not make this assumption.
AU Learning and Market-consistent Information
With AU learning, our learning model is one where agents make fully optimal decisions given their individual specification of beliefs but have no macroeconomic model to form expectations of aggregate variables. We draw a clear distinction between aggregate and internal quantities so that identical agents in our model are not aware of this equilibrium property (nor any others).
To close the model, we need to specify the manner in which households and firms form their expectations. To do so, we assume that variables which are local to the agents, in a geographical sense, are observable within the period, whereas variables that are strictly macroeconomic are only observable with a lag. This categorization regarding information about the current state of the economy follows Nimark (2014). He distinguishes between the local information that agents acquire directly through their interactions in markets and statistics that are collected and summarized, usually by governments, and made available to the wider public.
3
The policy rate is announced by the central bank, so it is observed without a lag and it is common knowledge. Given this, we assume an adaptive expectations forecasting rule given below by (47) and (48) about variables external to agents’ decisions. Let xt = rt, rn,t, πt, wt, γt, gt, then household expectations are given by
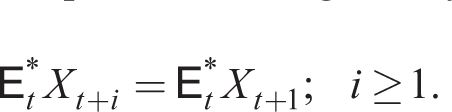
Expressing E
t
ω1,t + 1 and E
t
ω2,t + 1 in (32) as forward-looking summations and using (46), we arrive at the individual learning consumption equation
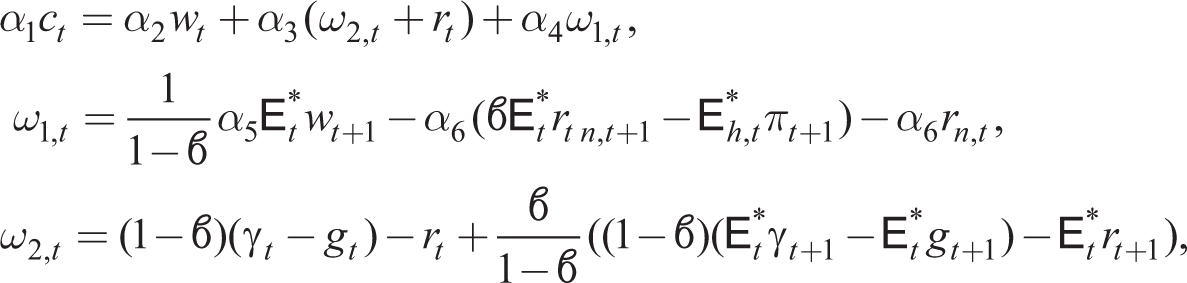
which is now expressed in terms of one-step-ahead forecasts by the standard adaptive expectations rule
4
:
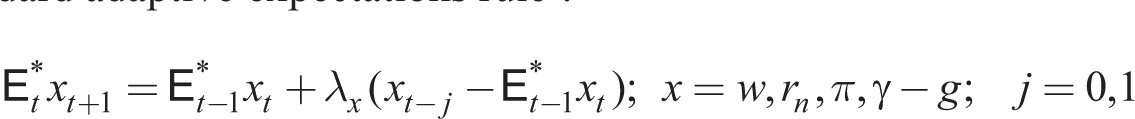
Households make inter-temporal decisions for their consumption and hours supplied given adaptive expectations of the wage rate, the nominal interest rate, inflation and profits. These macro-variables may in principle be observed with or without a one-period lag (j = 1, 0), but as stated earlier, we assume j = 0 for market-specific variables wt, γt − gt, and j = 1 for aggregate inflation πt. However, we assume the current nominal interest rate, rn,t, is announced and therefore also observed without a lag.
We distinguish household and firm expectations
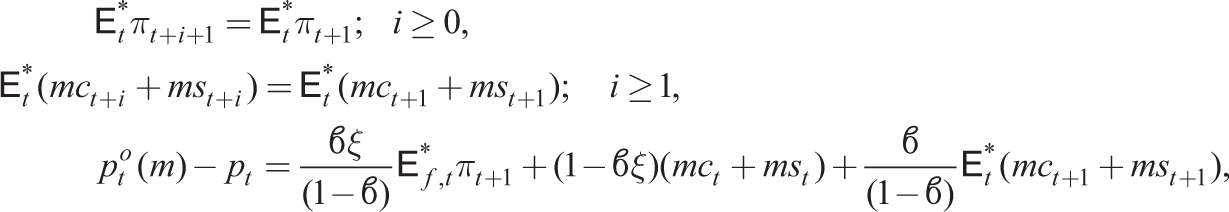
where again one-step-ahead forecasts are given by the adaptive expectations rule:
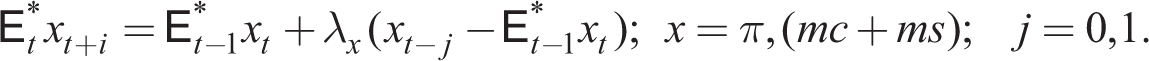
Retail firms make inter-temporal decisions for their price and output given adaptive expectations of the aggregate inflation rate and their post-shock real marginal shock wage rate. As before, these variables may be observed with or without a one-period lag (j = 1, 0), but for aggregate inflation, we assume j = 1 as for households, but j = 0 for the market-specific variable mct. Note that we can in principle distinguish between households’ and firms’ expectations of inflation.
Heterogeneous Expectations and Reinforcement Learning
There is a growing literature within behavioural macro-models based on the Brock and Hommes (1997) framework where agents learn from each other through reinforcement learning. More recently, DeGrauwe has used this framework based on the 3-equation linearized workhorse NK model.
RE expectations are then replaced with boundedly rational (BR) with simple fore casting rules; that is, replace E t (RE) with E* t (non-RE). This is the Euler equation learning (EL) approach. There are two types of agents with different forecasting rules. Both can use simple misspecified forecasting rules as in De Grauwe (2012b). One set can be rational as in Branch and McGough (2010) and Massaro (2013). See also Young (2004), Choi et al. (2009), De Grauwe (2011, 2012a) and Hommes et al. (2019). Jump and Levine (2019) provide a survey. All these papers feature misspecified equilibria which are not SCEE: the PLM is inconsistent with the ALM. There is a major modelling issue: Euler learning versus anticipated utility.
Heterogeneous Expectations with Fixed Proportions of RE and BR Agents
Now we turn to the heterogeneous expectations model with BR(AU) agents alongside RE agents with fixed proportions of each type. We assume all RE agents know the composite model. In addition, we impose informational inconsistency by assuming they have the same II set as the BR(AU) agents. The latter do not know the model, but do make individually optimal decisions given individual observations of the states and belief formations. The composite RE–BR model then has an equilibrium (in non-linear form)
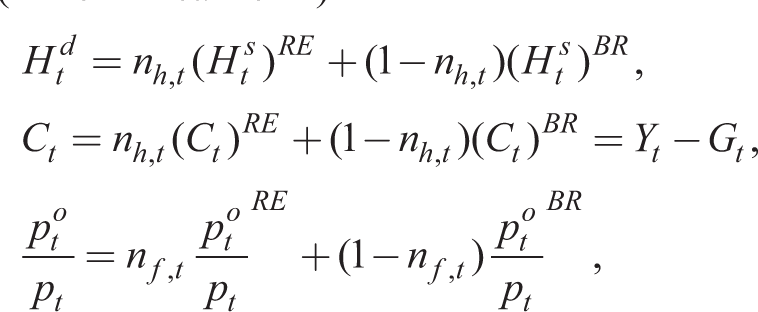
Zero net wealth in aggregate implies that
RE vs RE–BR Composite Expectations with nh = nf = 0.5, λx = 0.25, 1.0; Taylor rule with ρr = 0.7, υpi = 1.5 and υy = 0.3, υdy = 0; Monetary Policy Shock.
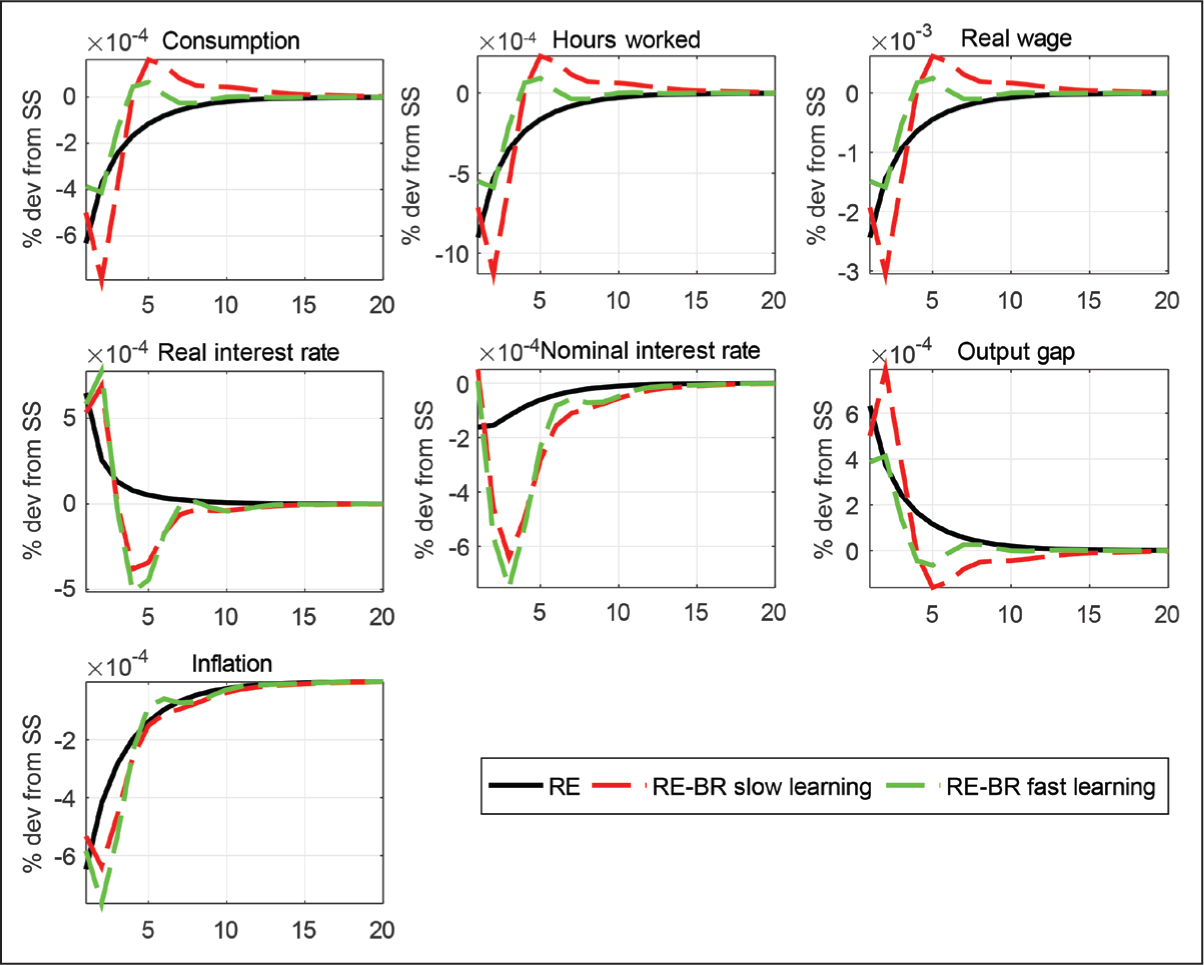
For our model of BR with AU, Figure 1 plots the impulse response functions (IRFs) with standard parameters for the rule for a shock to monetary policy under fast and slow learning. Not surprisingly, fast learning sees an IRF converge faster to the RE case, but in either case BR introduces more persistence compared with RE. This suggests that this feature should lead to a better fit of the data without relying on other persistence mechanisms (shocks, habit or price indexing). This we examine in the estimation of our model. 5
Endogenous Proportions of Rational and Non-rational Agents: Reinforcement Learning
Up to now we assume that the proportions of rational and non-rational agents ny,t and nπ,t are exogenous. As in Massaro (2013), in the estimation and main conclusions that follow, we retain this assumption, but in this sub section, we explore the extension that endogenizes these decisions by agents. Following Brock and Hommes (1997) and the reinforcement learning literature in general, these can be chosen as follows:
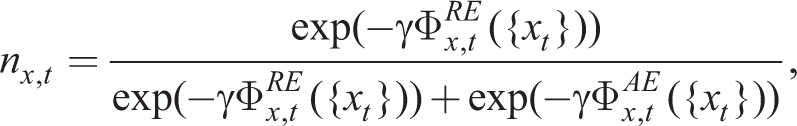
where
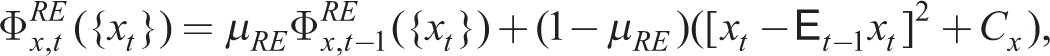
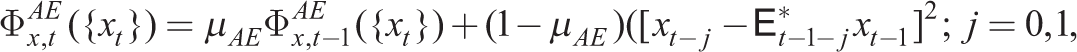
where ρRE and ρ
AE
capture the memory of the agents forming RE and AE (a measure of forgetfulness of past observations). Cx represents the relative costs of being rational in learning about variable xt. Thus, the proportion of rational agents in the steady state is given by
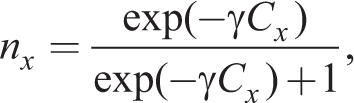
which is pinned down by the γCx.
A complete treatment of the model would require a departure from the linear Kalman filter solution for the II case for which we exploit the closed-form saddlepath solution that Pearlman et al. (1986) show both exists and is unique. We have also exploited the convenience of linear Bayesian estimation. In what follows we confine ourselves to the RE PI case and use the linear estimates obtained up to now.
Agents with reinforcement learning that now have proportions of rational households (nh,t) and firms (nf,t) are given by (49). Table 1 provides a third-order perturbation solution of the non-linear NK RE(PI)-BR model. We use the Bayesian estimation of the linear model in ‘the first, second, third section’ etc. where the model is linearized and the proportions nh,t and nf,t are fixed. Non-linear estimation would be required to pin down the parameters nh, nf in the steady state, and
Third-order Solution of the Estimated NK RE(PI)-BR Model;
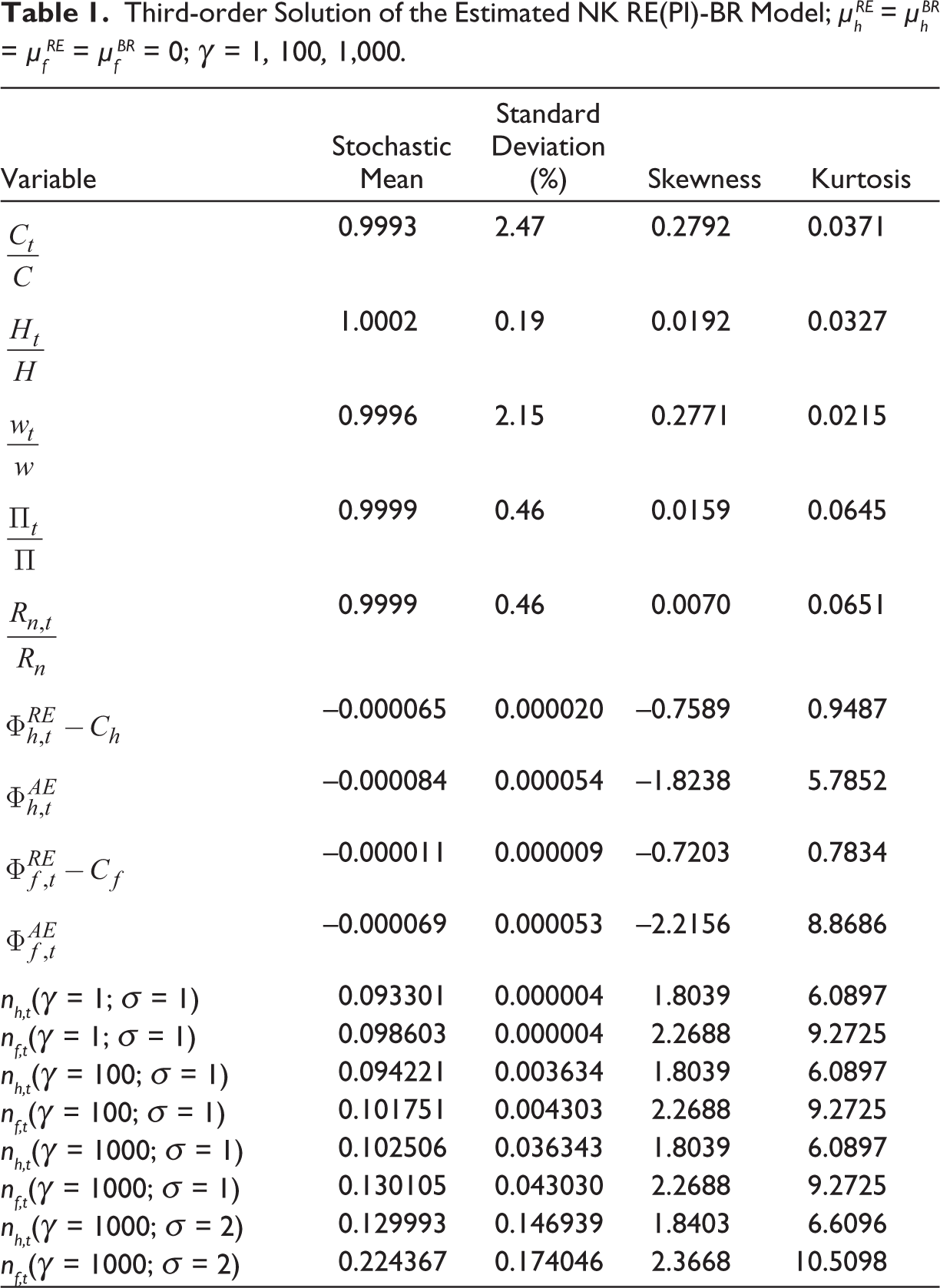
The main results from these simulations are as follows. First, reinforcement learning introduces high kurtosis and skewness 6 in macro variables. Second, reinforcement learning coupled with higher volatility of exogenous shocks results in the numbers of rational agents increasing from the estimated deterministic steady-state value of 0.093 and 0.099 to 0.13 and 0.22 for households and firms, respectively, in the stochastic steady state. Third, given that bounded rationality is a welfare-reducing friction in these models, it follows that volatility can actually be welfare-increasing in our homogeneous expectations setting.
Perfect Versus Imperfect Information
The seminal paper on the general solution of linear RE models assuming perfect (aka full) information (the standard assumption) is provided by Blanchard and Kahn (1980) showing existence and conditions for uniqueness.
Perfect information means that at time t, all agents have full information about all the state variables of the system. Conventional estimation is performed under the assumption that agents have perfect information (including shocks), but econometricians do not. Thus there is an inconsistency about information available to agents and econometricians. Here we adopt the informational consistency principle, which states that agents and econometricians have the same imperfect information set. Thus if econometricians do not have current data on technical progress, then it is assumed that agents also do not have this.
Angeletos and Lian (2016) provide an important survey paper on what they refer to as incomplete information literature. Here a comment on terminology is called for. Our use of perfect/imperfect information corresponds to the standard use in dynamic game theory when describing the information of the history of play driven by draws by nature from the distributions of exogenous shocks. Complete/incomplete information refers to agent’s beliefs regarding each other’s payoffs and information sets. In our set-up, the latter informational friction is absent.
Minford and Peel (1983) were the first to show the importance of information sets for the IRFs and second moments of RE models. Pearlman et al. (1986) generalized this for the general linear model. Pearlman (1992) extended this to optimal policy for fully optimal and time-consistent rules. Kalman filter ‘learning’ is central; see Hamilton (1994) and Adam and Billi (2006). Pearlman and Sargent (2005) and Levine et al. (2023) extend the representative agent II solution to a heterogeneous agent framework with diffuse information and show that a finite-space solution is available. The solution procedure of Pearlman et al. (1986) is applied in Collard and Dellas (2004, 2006, 2007), Levine et al. (2012a, 2012b) and Cantore et al. (2015). Following on from Pearlman (1992), Svensson and Woodford (2001, 2003) investigate the properties of the optimal solution under II. Ellison and Pearlman (2011) show e-stability (convergence to RE equilibrium under imperfect information). II is distinguished from the rational inattention literature, in which information assumptions are imposed, whereas in the latter, the acquisition of information was endogenous. See Sims (2005) and Mackowiak and Wiederholt (2009, 2011).
Why II? Some Empirical Motivation
Real Effects of Monetary Policy
II with the diverse information pricing model predicts highly persistent effects on real activity in contrast to the Phelps–Lucas model. This results in a hierarchy of expectations as seen in beauty contest models (forecasting the forecasts of others). To show this, we consider the following model from Woodford (2003).
In log-linear form, let qt be an exogenous process for nominal income and yt be output. Then the Lucas Philips curve is
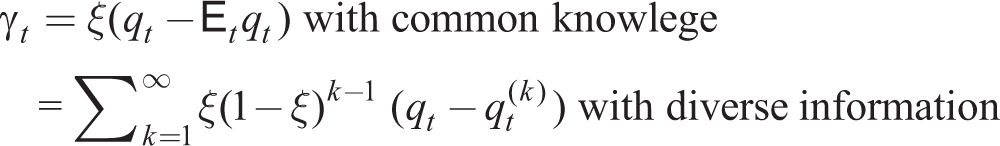
where qt(k) ≡ Ē t [qtk–1] is the k-order average expectation of the k–1 order average expectation. These higher-order expectations result in persistent effects of surprises without introducing other features such as Calvo or Rotemberg pricing.
Empirical Results
The Wilderness of Non-rationality
This section demonstrates the need for robust policy design using a special case of the four models for which in a balanced growth deterministic steady state both net inflation and growth is zero. Then about such a steady state, the linearized models take the form:
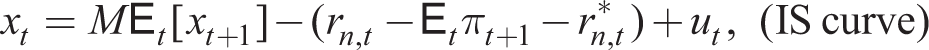
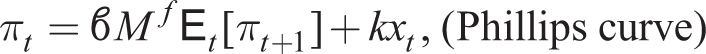
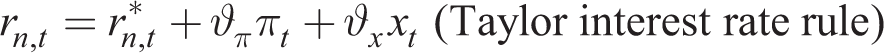
where xt is the output gap, πt is the gross inflation rate, rn,t is the nominal interest given by the original Taylor rule (ϑπ = 1.5, ϑx = 0.2), r*n,t is its natural rate, ut is a demand push shock, m = Mf = 1 for the RE case and M < 1, Mf < 1 for the myopia case.
To formulate possible heuristic rules that encompass those in these papers, we draw upon the general form of adaptive expectations from Anufriev et al. (2015) discussed in the ‘Behavioural Macro models’ section that takes the log-linear general form
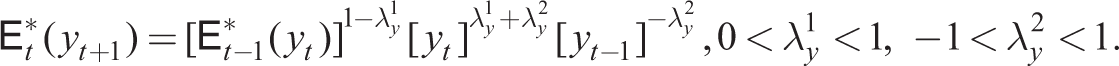
This encompasses simple adaptive expectations (
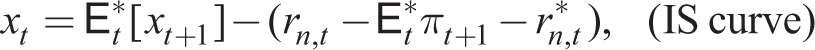
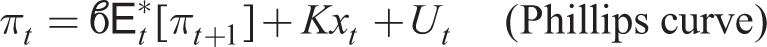
plus (54) as before where E
t
*(xt + 1) and E
t
*(πt + 1) are given by the general adaptive expectations rule (55) with y = x, π, which reduces to the simple adaptive expectations rule by putting
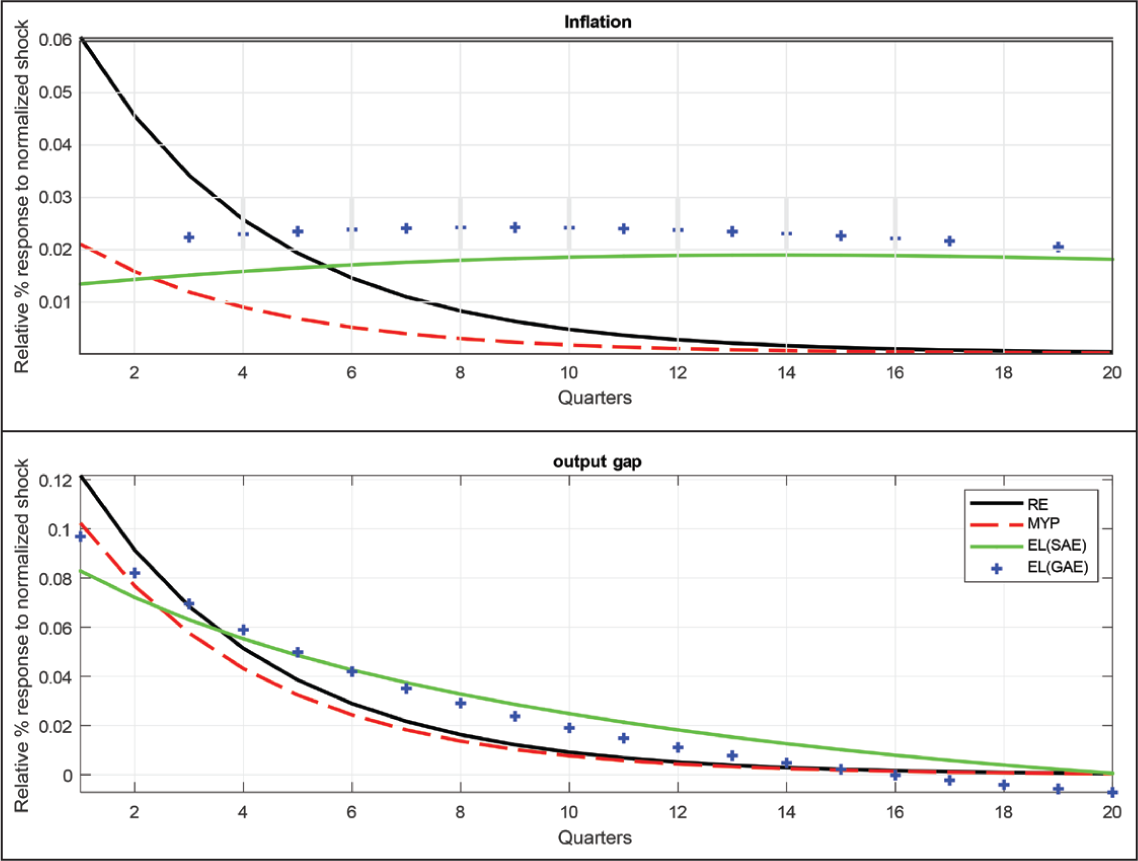
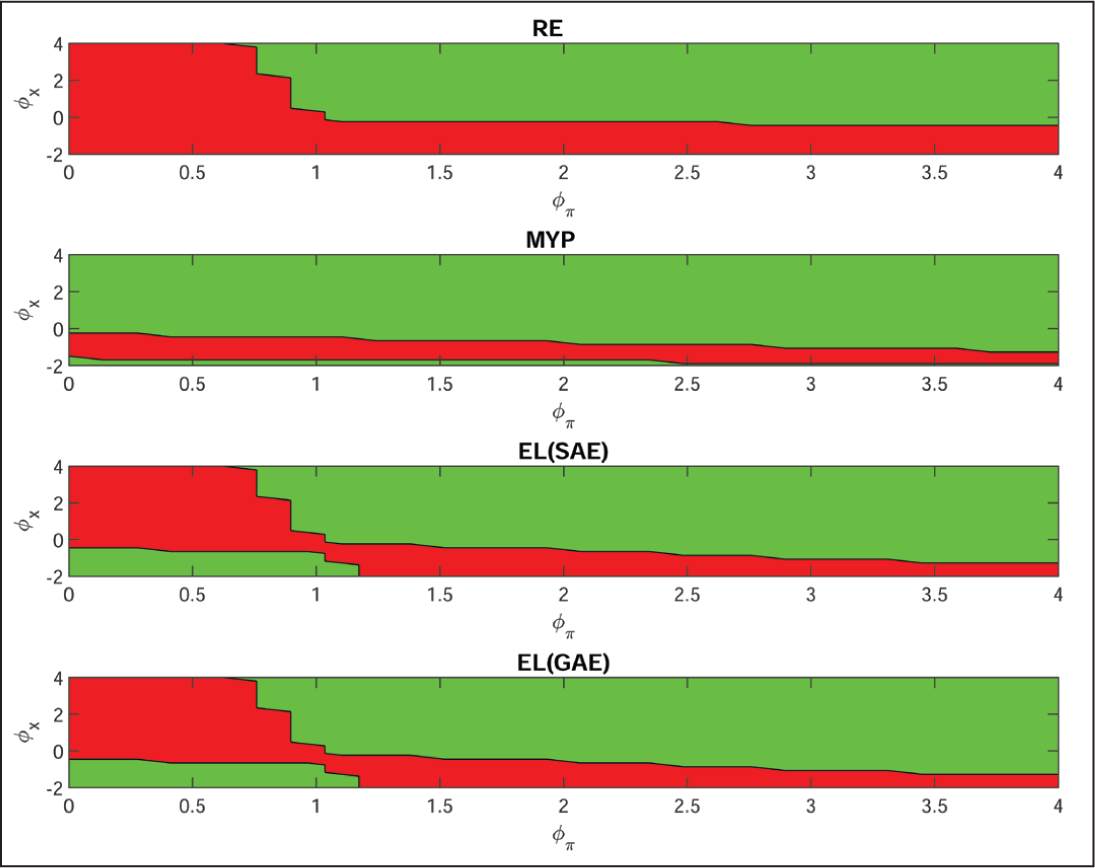
In Figures and 2 and 3, parameter values are set at their priors used later in the estimation. The demand shock follows an AR(1) process with persistence ρu = 0.75. These two graphs clearly illustrate the absence of robustness for the original Taylor rule, both in terms of the impulse responses to the demand shock in Figure 2 and the policy space that gives determinacy and stability in Figure 3. This clearly demonstrates the need for robust policy design across competing models (see Deák et al., 2023).
Does Imperfect Information Improve Data Fit?
We estimate five NK models with different assumptions regarding expectations and information summarized in Table 2. For the RE agents in either the ‘pure’ or composite RE–BR model, we compare the PI or II assumptions.
For each of these five models, Bayesian methods are employed to separately estimate the model parameters using Dynare adapted to handle II. 7 The sample period is 1984:1–2008:2, a subset of that used in Smets and Wouters (2007), which is also used extensively in the empirical and RBC literature. These observable variables are the log differences of the real GDP (GDPt) and the GDP deflator (DEFt), and the federal funds rate (FEDFUNDSt). All series are seasonally adjusted and taken from the FRED Database available through the Federal Reserve Bank of St. Louis and the US Bureau of Labor Statistics.
We first focus on Pure RE, Pure BR(AU) and Comp RE(PI)–BR(AU) when RE agents have a PI set. We employ the Bayes factor (BF) from the model marginal likelihoods to gauge the relative merits across the three models in Table 3.
Impulse Responses Comparison Between Four Log-linearized Models to a Demand Shock.
Summary of Estimated Models.

Log-likelihood Values and Posterior Model Odds: RE Agents with PI.

The BR models—Pure BR(AU) and Comp RE(PI)-BR(AU)—all substantially outperform, their RE counterpart, which is firmly rejected by the data. Formally, using the Bayesian statistical language of Kass and Raftery (1995), a BF, the quotient of the probabilities reported, greater than 100 (marginal log-likelihood difference over 4.61), offers ‘decisive evidence’. Thus, we have decisive support for the pure BR and some composite behaviour from the US data we observe. The BF difference between the non-RE models is also strong.
Next we assume a II set for the RE agents: It = [Ys−1, Πs−1, Rn,s], s ≤ t. An important point to stress is that this is the same information set we assume for BR agents when they come to update their heuristic rule. In this sense, we now have informational consistency across BR and RE agents, and also with the econometrician estimating the model. This feature, we believe, is new for the heterogeneous behavioural NK model literature. The results for the likelihood race are reported in Table 4.
Log-likelihood Values and Posterior Model Odds: RE Agents with II.

A very different picture now emerges when comparing the RE model with the behavioural alternatives. Two results are worth noting. First, RE with imperfect information (Pure RE(II)) wins the likelihood race against both Pure BR(AU) and Pure RE(PI). Again, in formal Bayesian language, the RE(II) model decisively dominates the pure BR-AU learning model and, not surprisingly, decisively dominates RE(PI), a finding that is consistent with that in Levine et al. (2012a). The second interesting result is that, when the composite heterogenous expectations model is estimated assuming the same II information set for everyone (Comp RE(II)–BR(AU)), it generates the highest log-likelihood value and outperforms all the competing models in fitting the data.
These results suggest that persistence can be injected into the NK model to improve data fit in two contrasting ways: bounded rationality with learning through heuristic rules or retaining RE but with II and Kalman-filtering learning.
Concluding Remarks
Our results for the workhorse NK model suggest a new perspective for the macro/NK/learning literature. Avenues for future work could embed the RE–BR composite model into a richer NK model along the lines of Smets and Wouters (2007), extend the linear Kalman filter to accommodate the non-linearity in reinforcement learning and use non-linear estimation methods to identify a number of parameters that cannot be identified using linear Bayesian estimation. The latter two non-linear extensions are major challenges. Future work could also examine optimal monetary policy and follow Geweke and Amisano (2012) and Deák et al. (2023) to address what has been called the ‘wilderness of non-RE’ to design a robust rule across all the BR model variants discussed in the article.
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The authors received no financial support for the research, authorship and/or publication of this article.