
Abstract

The previous editorial of the South Asian Journal of Business and Management Cases (Volume 13, Issue 1) focused on the ‘what’ and ‘why’ of hybrid review, emphasizing the structure of the manuscript with particular reference to contribution within each section. This editorial is an extension of the previous editorial, further delving into specifics of how to theoretically contribute through a hybrid review study. In doing so, we present a suggestive template that the authors can use when writing hybrid review studies for the South Asian Journal of Business and Management Cases. It is necessary to note that the template is only suggestive, and the authors can identify further creative but scientific ways of contributing to the field through hybrid studies.
Hybrid reviews are literature review studies that integrate multiple review methods. An example would be component integration, also called framework-based review (TCCM, ADO, AMO, etc.), or process integration (e.g., bibliometric and framework-based review) (Paul & Criado, 2020). The journal is currently focused on the latter.
It is noticed that most hybrid review manuscripts submitted to the journal fail to present bibliometric analysis meaningfully so as to contribute to the literature, which results in desk rejection. Hence, the remainder of the editorial focuses on two main aspects of bibliometric study: performance analysis and intellectual structure.
Meaningful Performance Analysis
Performance analysis, also called descriptive analysis, is the hallmark of a bibliometric study (Donthu et al., 2021). However, it remains a primary reason for manuscript rejection. The availability of various bibliometric tools (Bibiolshiny, VOS Viewer, BibExcel, CiteSpace, etc.) has made performance analysis an easy endeavour. However, the convenience has also resulted in poor presentation and description of the section. To elaborate further, there are two particular reasons for this.
The first is including multiple constituents of performance analysis without a rationale. These could include research productivity and evolution, prolific authors and documents, significant journals, significant countries, research collaboration between academic institutes. These are but a few types of performance analysis (see Donthu et al., 2021, for an exhaustive list). Since the bibliometric tools provide performance analysis output in an instant, novice authors tend to include all of them in the study. However, if you go through the bibliometric studies of the past few years in the management domain, you will notice a pattern change. There has been a reduction in the performance analysis section, reporting mostly four parameters: (i) research productivity, (ii) prolific documents, (iii) prolific journals and (iv) prolific authors. Instead, emphasis is given to the science mapping, which will be delved into in the latter part of the editorial. In SAJBMC, the author is expected to include these four. However, if the manuscript fails to adhere to the word limit, ‘prolific authors’ may be dropped.
The reasons for their inclusion are:
Research productivity signifies the relevance of the topic under study; hence, if more articles are published in the latter years of the study timespan, the area is relevant and growing. Presenting prolific documents based on high citations is necessary as it helps the scholars of the specific domain identify those documents that are a must-read to understand the literature. Presenting prolific journals is necessary as this information can be used to identify the relevant journals in the field for further search and publication. Presenting prolific authors enables scholars to find seminal and significant work done by the listed authors in the field. Apart from citing their work, scholars often follow and collaborate with prolific authors.
Researchers may include other parameters as well, but they should be relevant to the scope of the study. For instance, showing prolific countries may be relevant if the study is context specific (e.g., in the domain of international business). Simply put, too much focus on performance analysis is not required unless it adds value to the readers. Furthermore, it also results in taking up a significant word count, leaving little room for the rest of the study.
The second problem is that the researchers present the table as produced by the bibliometric tool without any insightful modification. They lose the chance to improvise and enhance the table/figure/graph and description, resulting in a lack of contribution. Hence, we present the following ways in which authors can add value to performance analysis parameters.
Research Productivity
The research productivity, which shows growth of the topic annually, is frequently presented as shown in Figure 1. However, Figure 2 provides an enhanced approach.
Traditional Way of Showing Research Productivity.
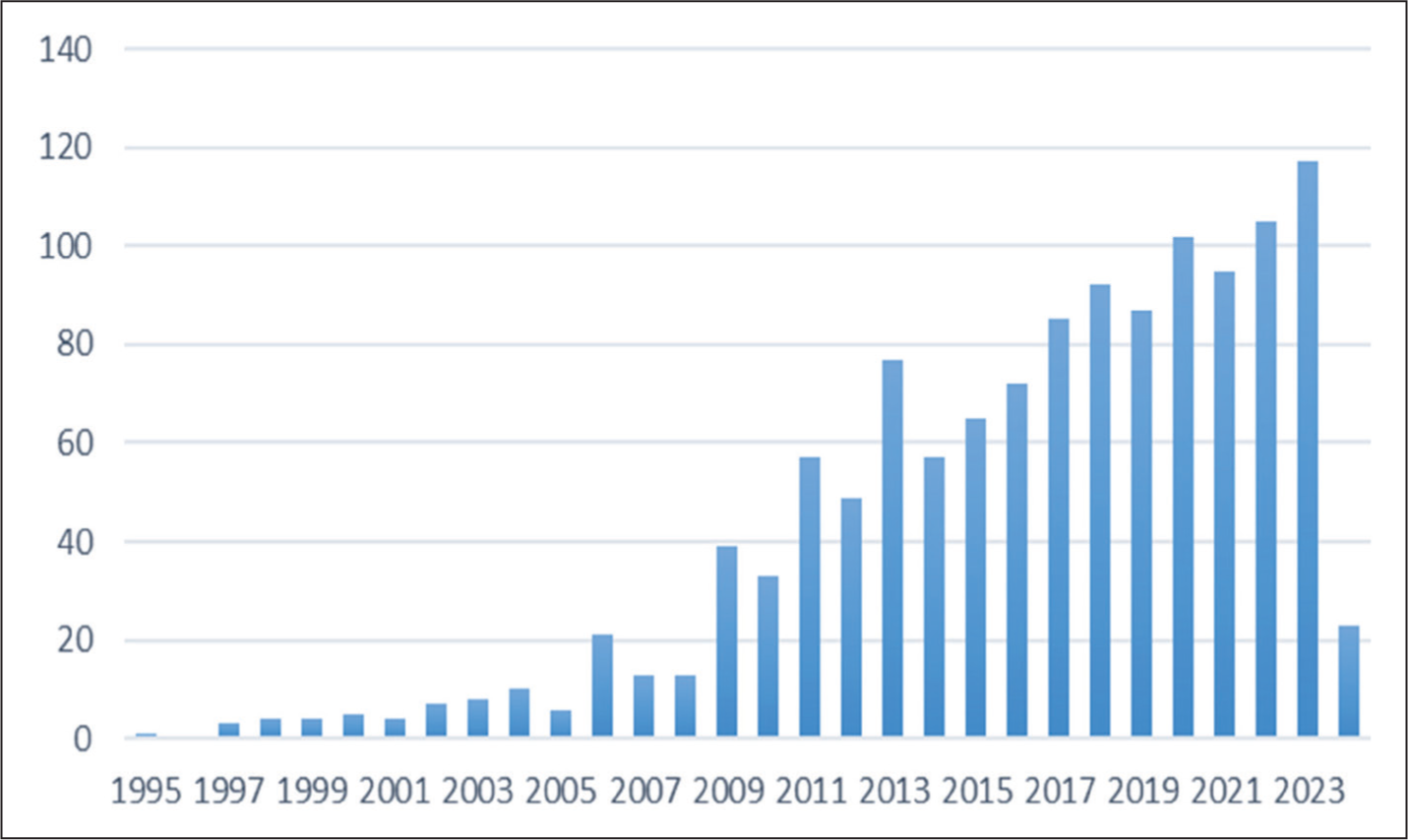
Drawing inspiration from previous studies (Det Udomsap & Hallinger, 2020; Donthu et al., 2021), we present Figure 2 as an enriched way of giving research productivity. Research productivity has significant potential to theoretically contribute to the study. While showing the publication growth is a must, authors may consider adding per-year citations for the articles. Annual citations per article indicate that the relevance of the articles published over the years is increasing. Based on these, authors can dig deeper into the reasons for higher citations in a particular year and discuss the relevance of previous articles. Such insight can help future researchers consider specific years when citations were high and build their arguments in an empirical research literature review section. Researchers can also highlight that for any unnatural increase in the number of publications in a year, such changes can be considered for further discussion. Mukherjee and colleagues (2022) note that such anomalies can be leveraged by the researcher for further examination.
Improvised Way of Showing Research Productivity to Enhance Value: Total Publication Per Year; Total Citation Per Year; Identifying Spikes in Publication; Identifying Phases; Labelling Phases.
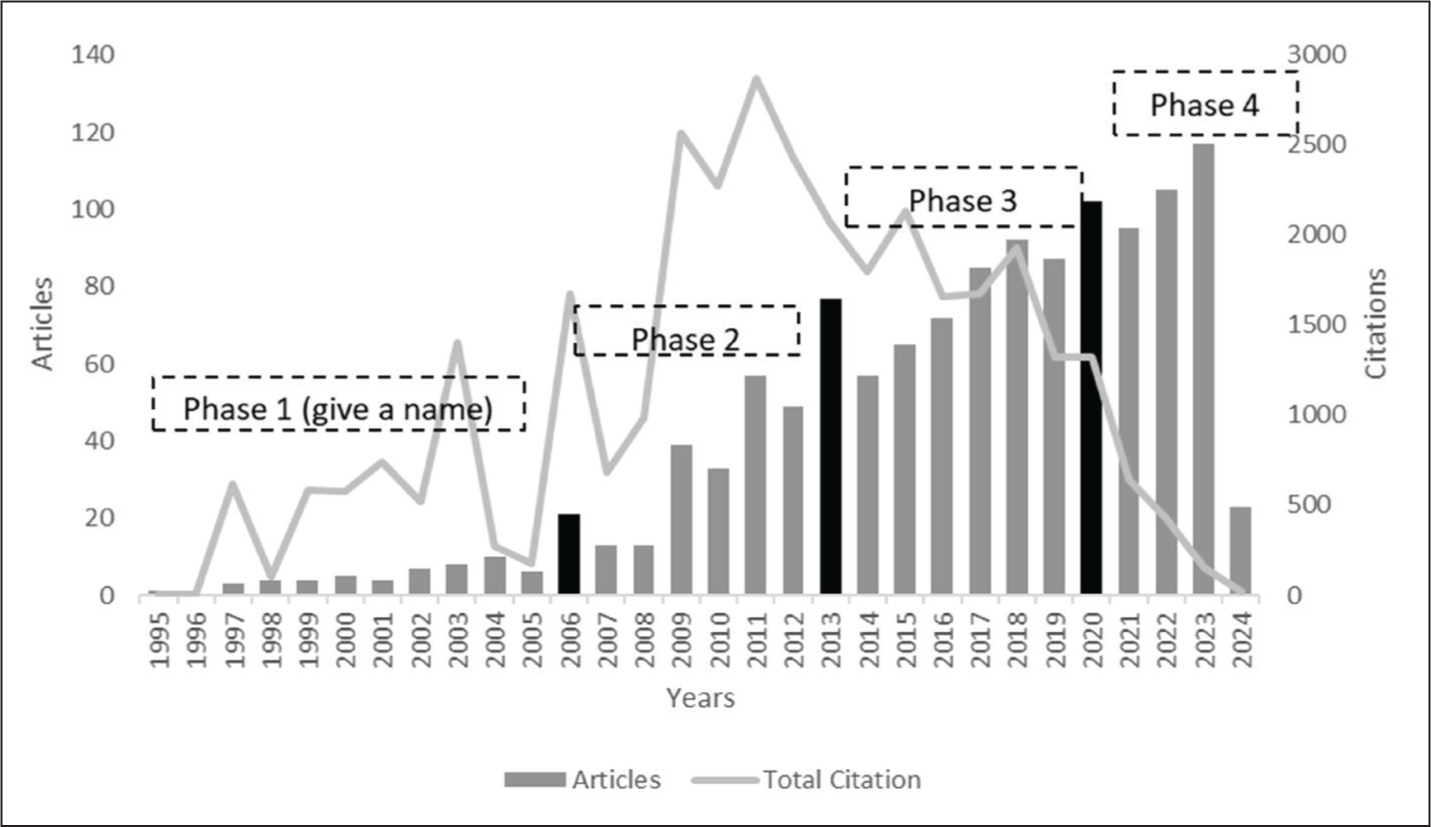
Similarly, a further contribution can be made by diving into the phases of literature, thus presenting how the topic has evolved. While bibliometric tools have the power to deliver the evolution of the literature, offering them along with annual production can provide a holistic picture of the research productivity. Additionally, labelling the phases of evolution can further enhance authors’ contribution to the field of knowledge. You may also present the research productivity in a tabular format with relevant information (refer Dontu et al., 2020, for tabular representation).
Prolific Documents
Prolific or highly cited documents from the literature corpus are significant sources of information. Scholars in the respective fields use it to identify the most relevant documents. Nonetheless, authors submitting bibliometric studies frequently fail to put enough effort to substantiate the relevance of the prolific documents. A common template used to present the prolific documents is shown in Table 1. Sometimes a few more columns are added, as shown in Table 2. However, sharing reasons why the documents are attracting higher citations provides a better explanation for the table. Thus, adding relevant columns may be a good idea (see Table 3). Providing additional information helps in two ways. First, in the description of the table, one can focus on fewer articles, like the top three or the top five.
Commonly Used Template for Prolific Articles.

Improvised Template for Prolific Documents.

Enhanced Template Showcasing Reasons for High Citation of Prolific Documents.

Second, the other prolific articles are not ignored; the table is enough to make sense of their contribution. Thus, scholars reading the article can use it for their research. Moreover, high global citation of particular documents also signifies that the study has an extensive scope, i.e., the study falls into several domains and therefore receives citations from the literature of several domains. High global citation and low local citation of a particular document also signify that it received less attraction within the corpus and, hence, acts as the authors’ contribution to highlight such documents by providing the most prolific articles list.
Prolific Authors
Like prolific documents, information on prolific authors is minimally presented, leaving readers with little information on how the authors have contributed to the field. The description, too, does not have enough information. Instead, the focus remains mostly on the author’s name and the number of citations the author has received. Table 4 can be used as a template to highlight the prolific authors’ contributions (the first four columns). Apart from the name and total citation of the author that are commonly presented in journals, a key area of discussion could be the highly cited articles by prolific authors in the field.
Enhanced Template for Prolific Authors and Journals.
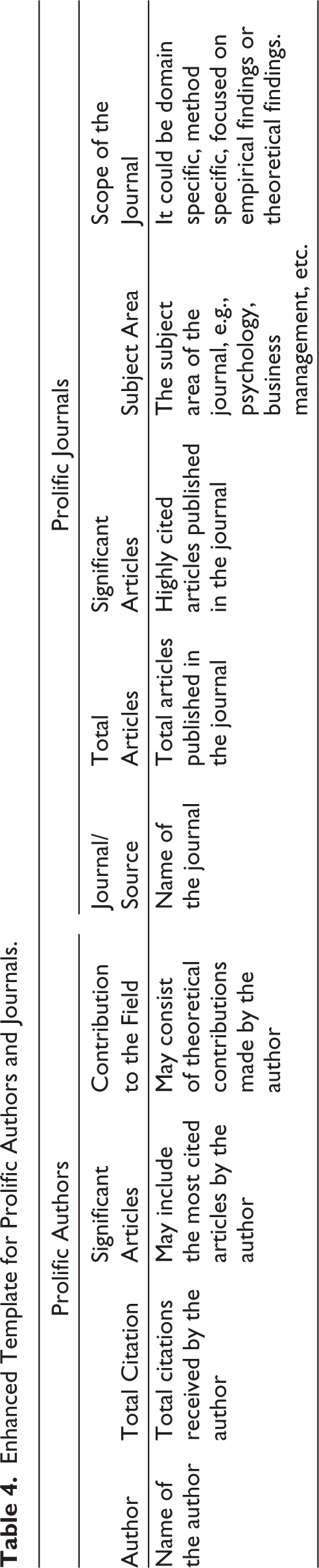
Additionally, key contributions can be included in the table for each article. It could be the development of a scale or framework or bringing a new perspective to the discourse of the topic being reviewed. Furthermore, discussion in the description can also be around the global citation delineating the reasons behind the same.
Prolific Journals
Table 4 also presents the most prolific journals and components that can be shown concerning the same. Providing information on the main articles from the journal can hold relevance since scholars can quickly identify which articles are of more importance to them. Secondly, sharing the journal’s scope will make it easier for authors in the domain to decide to publish their work in the said journal. Knowing the aims and scope of the journal is crucial for scholars to consider before submitting their manuscripts. If the journal is looking for papers with significant theoretical contributions, then the scholars should avoid intensively empirical papers, which is built on theory confirmation rather than contribution. Similarly, some journals are looking for policy-focused articles within the domain. Having such information in advance saves time for the authors planning to submit to one of the prolific journals.
Meaningful Intellectual Structure Presentations:
Intellectual structure, also known as science mapping, has several methods (Aria & Cuccurullo, 2017; Lim & Kumar, 2024). However, three methods are presented that are commonly found in bibliometric studies
1
:
Keyword co-occurrence: It provides the content of the corpus by building on the keywords of the documents. Co-citation: It presents the past of the domain by building on the cited documents. Bibliographic coupling: It provides emerging trends by building on the citing documents.
The output of each of the three results in cluster formations. These clusters present the relationship between the documents using different components, resulting in thematic structures from the corpus (Donthu et al., 2021).
It is necessary to understand that the clusters are provided by the tool, but the onus of interpreting and presenting the clusters meaningfully remains in the authors’ hands. We frequently receive manuscripts where the clusters are described in a few lines, which lack interpretations and insightful discussions. Moreover, the authors include all three without providing necessary reasoning as to why the three are needed. As Mukherjee (2022) noted, the bibliometric analysis has significant potential to make a theoretical contribution to the field. However, the authors fail to leverage the strength of the bibliometric analysis, making it about the tool rather than about the researcher (Lim & Kumar, 2024).
Mukherjee et al. (2022) and Lim and Kumar (2024) provide headways to authors for making theoretical contributions through bibliometric studies. Broadly, the authors should focus on presenting the ‘big picture’ in meaningful ways (Lim & Kumar, 2024). For this, they offer a sensemaking approach that can be adopted to make relevant and significant contributions through bibliometric analysis. The idea is that the authors should be able to derive insights from each cluster. It means that the authors need to ‘deep dive into the content associated with each cluster, allowing for a comprehensive interpretation of their thematic focus’ (Lim & Kumar, 2024, p. 20). Using previous literature, we present exemplars for each of the three science mapping methods that can explain how contributions can be made.
Keyword Co-occurrence
Keyword co-occurrence, also known as co-word analysis, creates clusters based on the words in the documents. The unit of analysis in this method is primarily the authors’ keywords. However, other sources are also utilized, including the article’s title and its abstracts and full texts (Donthu et al., 2021). We have noticed that many submitted manuscripts show a word cloud in the name of keyword co-occurrence. Note that word cloud only indicates the words’ frequency and cannot result in thematic cluster formation.
Hence, the focus should be on the associations between words in the literature which can be found through keyword co-occurrence. As stated by Callon et al. (1983):
Certain words and words-associations are stronger than granite, and the reader cannot muster enough dynamite to blow them apart…. We should rather describe words as forces, stocked and consolidated energy. A text then becomes a system made up of forces linked together, resting one upon another. (pp. 199–200)
Drawing from the above argument, keyword co-occurrence is established on the logic that the words occurring together have some relationship. Hence, there is a reason why they appear together (Aria & Cuccurullo, 2017). Thus, the scholar studying this relationship must delve further into the co-occurring words and derive the latent connections that are not clearly visible. These connections present the cognitive structure of the words (Aria & Cuccurullo, 2017).
An example would be Lages et al.’s (2023) review on the dark side of customer behaviour, in which the keyword co-occurrence resulted in three clusters. They clearly explain the meaning of the colours that each cluster is associated with and also highlight that in the dark side of customer behaviour, customer incivility is highly relevant due to the size of its node. Further, they deep dive into each cluster using content analysis and present a thematic picture of each cluster, thus illuminating the meaning from associations of the words. Similarly, Thomas and Gupta (2021) in their review on tacit knowledge discovered eight clusters using keyword co-analysis. They carefully analyse each cluster through content analysis and extracted antecedents, decisions and outcomes of tacit knowledge, thus presenting a meaningful understanding of the topic.
Chandra et al. (2022) performed keyword co-occurrence on personalized marketing, resulting in six clusters. Unlike previous examples, the authors gained insights from the clusters by focusing on the statistical attributes of the cluster (e.g., average publication year, citation, occurrence, degree of centrality, etc.). Using these parameters, the authors established the significance of keyword associations over others, thus identifying the essence of each cluster.
Hence, presenting which words are frequently occurring and which are occurring less in each cluster does not provide valuable knowledge. Instead, using such information and understanding the reasons behind the results of the keyword associations and their frequency will be of more value.
Co-citation Analysis
Co-citation analysis is based on the documents or publications that frequently appear together in the reference list of another document. It is assumed that the documents that are regularly cited together are thematically similar to each other. Thus plausibly, these cited documents are among the early publications. Moreover, these cited documents are not necessarily from the corpus. Hence, the output of citation analysis reveals the influential and seminal works while also discovering the foundational knowledge of the topic (Donthu et al., 2021). As stated by Small (1973):
‘In measuring co-citation strength, we measure the degree of relationship or association between papers as perceived by the population of citing authors. Furthermore, because of this dependence on the citing authors, these patterns can change over time, just as vocabulary co-occurrences can change as subject fields evolve. (p. 265)
Thus, co-citation analysis is used to identify the thematic evolution of the literature (Aria & Cuccurullo, 2017). In other words, the said method presents the past of the topic under investigation. Furthermore, apart from cited documents, co-citation analysis can be done using other units of analysis (Aria & Cuccurullo, 2017), including cited authors (White & Griffith, 1981) and cited journals (McCain, 1991). Nonetheless, each results in cluster formations from which the scholars need to draw inferences.
Bernatović et al.’s (2022) work is an excellent example of how to discuss co-citation analysis that adds value to the literature. In their study on knowledge-hiding behaviour, they present four clusters using co-citation analysis. Instead of just describing what the documents in the cluster talked about, they discussed the novel works in each cluster. Hence, they underlined the nuances of the clusters. Using prefixes such as ‘literature began with the acknowledgement’, ‘developed a measure’, introduced a new construct’, ‘went a step further to explain’, etc., the authors presented a chronological development of the literature on knowledge hiding, while citing the highly influential works.
To do this, they carefully identified the overarching theoretical domains in which the articles in the cluster fall. These theoretical backgrounds are identified in the thematic labels given to each cluster. For instance, the first cluster they named was ‘social exchange and knowledge hiding’, anchored in psychology, sociology and management. They further go on to present a co-citation table with the cluster labels, representative authors, content of the cluster and the core theoretical background.
Another relevant example of presenting co-citation analysis would be Okumus et al.’s (2021) article on food tourism. The four clusters or knowledge domains that emerged in their study were further split into sub-clusters. By extracting the sub-clusters, they showcase the latent themes within the main clusters and highlight the specific knowledge areas within the literature. For example, the first cluster termed ‘hospitality-focused perception and behaviour’ was divided into five sub-clusters: ‘quality’, ‘value’, ‘customer segmentation’, ‘menu design and content’, ‘satisfaction and loyalty’ and other ‘influential frameworks’.
However, it is necessary to remember that Okumus et al.’s (2021) work was primarily on co-citation analysis and did not include various other science-mapping techniques or framework-based reviews. Thus, presenting co-citation analysis in such a way should be undertaken in a hybrid study when the corpus is smaller.
Bibliographic Coupling
Unlike the co-citation network which evaluates the cited document, bibliographic coupling evaluates the citing documents (Aria & Cuccurullo, 2017). It is established on the premise that documents citing similar documents should also have a common connection in their content (Donthu et al., 2021). As postulated by Kessler (1963):
a number of scientific papers bear a meaningful relation to each other (they are coupled) when they have one or more references in common. (p. 49)
Another dissimilarity between bibliographic coupling and co-citation is that co-citation may have documents from out of the literature corpus collected by the author, while bibliographic coupling will only work on the corpus collected by the author.
Furthermore, since the method uses citing documents, it includes articles that are not as highly cited as well. Even the article that does not have a single citation is part of the bibliographic coupling, which is not the case in co-citation analysis. Given these fundamental analysis parameters, bibliographic coupling can identify research gaps as it recognizes the ‘recent and niche’ documents (Donthu et al., 2021). To perform bibliographic coupling, author, document and journal can be employed as the unit of analysis (Aria & Cuccurullo, 2017). Researchers have developed contemporary ways to present bibliographic coupling results to advance the knowledge of current literature rather than just describing the papers in the cluster.
Bartolacci et al.’s (2020) article on the financial performance and sustainability of small and medium enterprises identified three clusters through bibliographic coupling. An interesting point in their presentation is that, after discussing each cluster, the authors summarize the clusters in the form of propositions. It is a unique way to provide future directions through bibliographic coupling. In this article, the authors have included the propositions within each cluster itself, while other authors have used the knowledge derived from bibliographic coupling to provide detailed future research directions in a separate section.
For instance, in the study of Budler et al. (2021), bibliographic coupling was performed in three time frames. It resulted in clusters within each time frame. The last and the most recent time frame became the base for future research directions. This unconventional approach enabled the authors to draw gaps in the recent literature, resulting in an elaborate list of research questions on which scholars can build their future studies (also see Joshi et al., 2023).
Conclusion
Through this editorial, we hope to provide future journal contributors with some templates for presenting bibliographic analyses that expand knowledge in a given field. We would like to note that among the three intellectual structure techniques discussed above, the researcher need not include all of them. Rather, focusing on one is better, post which framework-based review can be undertaken. It is critical to remember that the methods to be included entirely depend on the research questions. These questions will be built on the research gaps identified by reviewing previous review studies in the domain under investigation.
Moreover, these are suggestions and not thumb rules to present bibliometric studies. Numerous review studies utilizing bibliometric analysis and published in high-quality journals have made methodical innovations that have resulted in robust and significant study conclusions.
Furthermore, following the suggestions may not necessarily result in acceptance of the article as multiple parameters are involved in the review process like the topic itself. Also, as the quality and methodology of review studies progress, the quality of the articles being submitted to SAJBMC is expected to increase. Hence, hybrid reviews should be experimented with to increase their contribution without compromising robustness.
Current Issue
The current issue includes six articles. The first three are review articles followed by three research case articles. The first review article by Varsha P S, Amrita Chakraborty and Arpan Kumar Kar is an invited article that discusses the process of undertaking a systematic literature review (SLR) study for early management scholars. The authors discuss different types of SLRs, their evolution in the management field and provide processual guidelines for conducting SLRs.
The second study by Diksha Sinha and Roopali Sharma used bibliographic coupling and thematically analysed seven clusters to discuss the evolution of floriculture literature. Further, future research direction is derived from content analysis resulting in four focus areas. They further suggest detailed future research directions in the floriculture domain.
In the third review article on international student mobility, Muhammad Sani Khamisu, Ratna Achuta Paluri and Vandana Sonwaney employed bibliometric and thematic analysis approaches. The authors identified six clusters using co-citation analysis, while keyword co-occurrence resulted in five clusters. Furthermore, the thematic analysis discovered five future research directions.
The fourth article, a research case, is a single narrative case study exploring career construction using the systems theory framework of career development. Written by Saima Zubair and Amani Moazzam, the case dives into the narrative story of a female medical professional in Pakistan, which resulted in various themes that represent the career construction experience of the participant.
The next research case, by Aditya Agrawal, Ashish Pandey and Payal Kumar, studies organizational healing. It investigates the effectiveness of a healing intervention implemented across a firm in India. The objective was to strengthen the weak connection between the newly appointed management and the current employees in a post-acquisition context.
The final research case of this issue is in the context of higher education institutes in Finland. In this study, Outi-Maaria Palo-oja and Pasi Juvonen conduct a micro-level analysis of how individuals inside merging organizations comprehend the strategy of the newly formed organization and the amount of cooperation necessary for its successful implementation.
Footnotes
Acknowledgements
We thank Sachin Tyagi, a Research Scholar at Birla Institute of Management Technology, for giving inputs with the editorial.