
Abstract
Tire degradation plays a critical role in Formula One race strategy, influencing both lap times and optimal pit-stop decisions. This paper introduces a Bayesian state-space modeling framework for estimating latent degradation dynamics of Formula One tires using publicly available timing data from the FastF1 Python API. Lap times are modeled as a function of fuel mass and latent tire pace, with pit stops represented as structural state resets. Several model extensions are explored, including compound-specific degradation rates, time-varying degradation dynamics, and a skewed-t observation model to account for asymmetric driver errors. While Lewis Hamilton’s performance in a single Grand Prix serves as an illustrative case study, predictive robustness is evaluated across 19 race sessions from the 2025 season using rolling-origin cross-validation. The proposed state-space model is compared to a structurally comparable AR(1) benchmark with stint resets and demonstrates superior performance in the majority of races in terms of both RMSPE and CRPS. Although compound-specific differences are not always statistically distinct, the results show that the state-space approach provides interpretable, probabilistic, and computationally efficient estimates of tire degradation, offering a principled foundation for real-time strategy modeling and performance prediction in Formula One racing.
Keywords
Introduction
One of the most important factors contributing to race strategy in a Formula 1 Grand Prix is tire degradation. As tires degrade throughout the course of a race, drivers are forced to go slower. As such, it can be beneficial to enter the pit lane for a new set of tires. However, drivers lose time relative to their competitors while they are waiting for new tires to be put on. In this way, deciding to make a pit stop is a delicate balance, and can easily affect a competitor’s results. A dramatic example of this occurred during the 2024 Italian Grand Prix, in which Charles Leclerc of Ferrari beat Oscar Piastri of McLaren (Giles, 2024). Leclerc only stopped once for new tires, while Piastri–who was leading the race and on track to win–made a second pit stop later in the race that cost him victory. By stopping early for a set of “hard” tires and continuing till the end of the race, Ferrari was able to beat their opponent even though their car was generally slower than the McLaren throughout that weekend.
In each Formula 1 Grand Prix, there are three different dry tire compounds for teams to choose from, along with an intermediate tire and a full wet tire for rainy conditions. The dry tires–referred to as “hard”, “medium”, and “soft”–are designed by tire manufacturer Pirelli to degrade at different rates (Pirelli, n.d.). Tire degradation itself is a phenomenon which occurs as a result of the extreme forces put through the tires during a Grand Prix. These forces cause shearing of the rubber from the surface of the tire and thermal degradation of the tire carcass due to friction (Farroni et al., 2016). Softer tires provide more grip initially and allow for faster lap times. However, they degrade faster than harder tires, which leads to slower lap times and a need to pit sooner. On the other hand, harder tires are not as quick, but degrade more slowly. Therefore, a driver can typically do more laps at a reasonable pace on a harder tire.
As tires wear, lap times tend to increase throughout a stint (a set of laps completed on a single set of tires). Because replacing degraded tires can yield faster overall race times, strategists must balance tire longevity against short-term performance. Predictive models of degradation can help answer questions such as “How rapidly do lap times deteriorate?” or “When does degradation become performance-limiting?” In live racing, models must also be interpretable and computationally efficient enough to inform real-time decisions. To address this, we propose a Bayesian state-space model that represents tire degradation as a latent process observed indirectly through lap times.
To the best of our knowledge, there are no examples in the literature that apply state-space models to the phenomenon of tire degradation in Formula 1. While prior research (e.g., Todd et al., 2025) has explored deep learning approaches for tire energy prediction, those methods often lack interpretability and explicit uncertainty quantification—features that are crucial in operational race environments. Because of this, we believe that state space models could be an asset to F1 teams looking to gain an edge in predictive modeling.
Unlike deterministic tire degradation models that impose a fixed functional form for wear over a stint, the proposed state-space framework treats degradation as a latent stochastic process that evolves over laps and is inferred from observed lap times. This allows the model to capture within-race variability and quantify uncertainty rather than assuming a single pre-specified curve. In contrast to black-box machine learning approaches such as deep neural networks, our method is deliberately structurally interpretable: latent states correspond to physically meaningful quantities (e.g., underlying degradation rates and stint resets), and parameters retain clear performance-related interpretations. Finally, while classical autoregressive models can describe autocorrelation in lap times, they lack an explicit representation of pit-stop resets and do not separate degradation dynamics from observation noise. The proposed state-space formulation integrates these elements in a probabilistic and computationally efficient framework suitable for real-time race applications.
Beyond predictive performance alone, the primary contribution of this work is a probabilistic and interpretable framework for modeling tire degradation in race conditions. The state-space formulation provides full uncertainty quantification for both latent degradation states and future lap-time predictions, which is essential for risk-aware strategic decision-making. At the same time, the latent states and parameters retain clear physical and performance-related interpretations, allowing the model outputs to be understood and communicated in operational settings. Finally, the model is designed to remain computationally efficient, making real-time or near–real-time deployment feasible during race events where rapid updating is required.
Using publicly available data from the FastF1 Python API v3.6.0 (Oehrly, 2025), we illustrate the modeling framework using Lewis Hamilton’s 2025 Austrian Grand Prix as a representative example. Model selection and structural assessment are conducted using this session to provide a detailed illustration of the methodology. To address questions of robustness and generalizability, predictive performance is then evaluated across 19 race sessions from the 2025 season using rolling-origin cross-validation. Each race session is modeled independently, preserving the within-race information structure while allowing cross-session assessment of predictive stability. The selected state-space specification is compared to a structurally comparable AR(1) benchmark with explicit stint resets.
Across sessions, the state-space model demonstrates stable predictive performance and achieves lower root mean squared predictive error and continuous ranked probability score in the majority of races relative to the AR(1) benchmark. We find limited evidence of statistically distinct degradation rates between the hard and medium compounds in this case study–likely due to a lack of data and modern tire management practices, where drivers target consistent lap times to control wear. However, the framework provides coherent probabilistic estimates of degradation dynamics and uncertainty across heterogeneous race contexts.
The remainder of this paper is organized as follows. The Data Section describes the data and preprocessing steps used to construct the lap-time series. The Section entitled “Bayesian state-space model” provides background on state-space models and details the proposed specifications. The Results Section presents model selection results for the Austrian Grand Prix and cross-session validation results across the 2025 season. The final section concludes with discussion and potential extensions to multi-driver or hierarchical modeling frameworks.
The main contributions of this work are:
A probabilistic state-space model for tire degradation that represents wear as a latent stochastic process with explicit pit-stop reset dynamics. Empirical validation across 19 race sessions demonstrating robustness relative to a structurally comparable AR(1) benchmark. Full uncertainty quantification for latent degradation states and lap-time forecasts, enabling risk-aware strategic analysis. An interpretable modeling framework in which parameters and states correspond to meaningful performance and degradation mechanisms rather than black-box representations. A computationally efficient inference procedure that supports near–real-time updating and practical use in race-engineering contexts.
Data
The FastF1 Python API v3.6.0 (Oehrly, 2025) provides access to detailed timing and telemetry data for each Formula 1 Grand Prix weekend. For the purposes of this study, we extract official race-session data for the 2025 season, restricted to completed Grand Prix race sessions and excluding practice, qualifying, and sprint events. For each race, we obtain lap times, tire compound information, and pit-stop indicators for Lewis Hamilton. These variables are sufficient to construct the lap-level time series required for modeling tire degradation.
The Austrian Grand Prix serves as a representative example for model selection and structural assessment. This race was chosen because it features typical dry conditions and limited external interruptions, making it suitable for illustrating degradation dynamics without atypical track characteristics. Figure 1 displays Hamilton’s lap times by lap number, colored by stint.

Tire Degradation for Lewis Hamilton during the Austrian Grand Prix. We can see a subtle but noticeable increase in lap times throughout the course of each stint. In the second stint on the hard tires, we can also see a warm-up period from laps 28 to 38.
To evaluate predictive robustness, cross-validation is conducted across 19 race sessions from the 2025 season. Five races were excluded for the following reasons: the Australian and British Grands Prix were conducted under wet or mixed conditions, which introduce fundamentally different degradation regimes; the Belgian and Miami Grands Prix contained incomplete timing data; and the Dutch Grand Prix was excluded because the driver did not finish the race. The final dataset therefore consists of 19 dry race sessions comprising 998 laps and 51 stints. A summary of the dataset is provided in Table 1.
Summary of race sessions included in the analysis.

.
Data cleaning
Preprocessing was intentionally minimal to preserve the natural degradation signal. Laps in which the driver entered or exited the pit lane were removed, as these laps reflect pit-lane speed limits rather than competitive race pace. Laps completed under safety car or virtual safety car conditions were also excluded, since substantially reduced speeds during these periods result in negligible degradation and would distort the underlying process. Lastly, we excluded the final four laps of the Singapore Grand Prix because extreme heat during this race led to a brake failure for Lewis Hamilton, which caused a drastic and sustained increase in lap times that was unrelated to tire degradation. No additional smoothing or filtering was applied.
Distributional characteristics
Although lap times form a structured time series, deviations from local degradation trends are evident. Figure 2 displays the distribution of within-stint linear residuals for the Austrian Grand Prix. While most residuals are concentrated near zero, occasional large positive deviations are visible, reflecting transient driver errors, traffic effects, or other race interruptions. This asymmetric tail behavior motivates consideration of heavy-tailed and skewed observation models rather than strictly Gaussian errors.
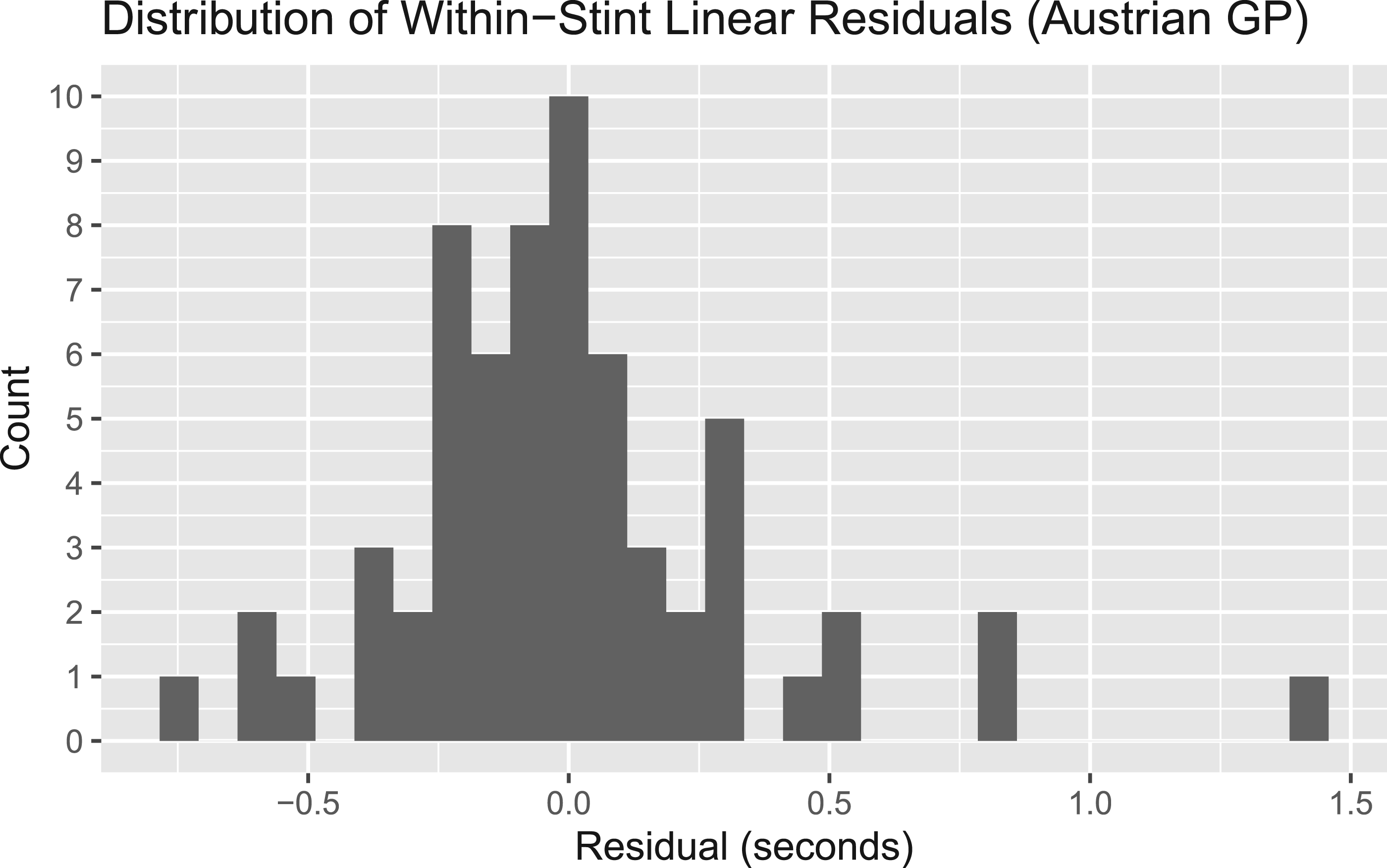
Histogram of residual lap times from within-stint linear trend models for the Austrian Grand Prix. Occasional large positive deviations are visible, motivating the consideration of heavy-tailed observation models.
Fuel mass covariate
Fuel load is included as a lap-level covariate to account for the well-known relationship between vehicle mass and lap time. Because direct fuel mass measurements are not available in the FastF1 API, fuel load is assumed to start at 110 kilograms on lap 1—the regulatory maximum—and decrease linearly to one by the final lap. Although teams may start with slightly less than the maximum, it is operationally reasonable to assume near-zero fuel at race completion due to optimization of starting load.
An alternative assumption would be exponential fuel decay, reflecting the possibility that heavier cars at the beginning of a stint consume fuel at a slightly higher rate. Relative to a linear specification, exponential decay would imply somewhat larger early-stint fuel adjustments and faster convergence later in the stint. In practice, such differences would primarily affect the magnitude of the fuel coefficient
Code availability
For the interested reader, a Github repository with scripts for pulling data, performing cross validation, and generating the paper itself is available at:
Bayesian state-space model
In this section we’ll first briefly review state space models, then describe in detail the process used to model latent degradation rates through the observable lap time process. All models were fitted using the software package Stan (Stan Development Team, 2020).
Background
State-space models (SSMs) are a popular modeling framework for time-series data due to their flexibility. They have found applications in a wide range of areas, from ecological time series (Auger-Méthé et al., 2021), to financial data (Zeng and Wu, 2013), to sports analytics.
State-space models (SSMs) have been widely used in sports analytics to model latent, time-varying performance components and to generate sequential forecasts as new observations become available. For example, Glickman and Stern (2005) develop a state-space framework for modeling evolving team strength in the National Football League, treating underlying ability as a stochastic process inferred from game outcomes. Similarly, Koopman and Lit (2019) propose time-varying strength models for forecasting football match results, while Ötting et al. (2020) apply latent-state models to capture dynamic performance effects in competitive settings. More recently, Michels et al. (2023) and Winkelmann and Michels (2026) employ state-space formulations to model within-match performance dynamics and betting markets, emphasizing interpretable latent processes and probabilistic forecasting. In contrast to much of this literature—where latent states typically represent evolving team or player strength across matches—the present study focuses on intra-race tire degradation in Formula One, where performance evolves within stints and is subject to structural resets induced by pit stops. This domain-specific reset structure, together with fuel effects and degradation dynamics, motivates a tailored state-space specification designed for interpretable and computationally efficient real-time application.
The defining feature of SSMs is their ability to model both a latent unobserved time series via a state equation
A variety of methods exist for estimation and inference, including the Kalman filter for linear-Gaussian models (Kalman, 1960), Sequential Monte Carlo methods for nonlinear or non-Gaussian systems, and particle MCMC for joint inference on states and parameters (Andrieu et al., 2010). This paper uses Stan and MCMC for model fitting and posterior sampling due to its flexibility and ease of implementation.
Base model specification and parameter interpretation
We start with the observation equation for a driver’s lap times:

Here
Now we present the process equation:



As mentioned earlier, the latent states
The assumption of linear degradation within a stint serves as a first-order approximation to lap-time evolution over relatively short race segments, which typically span 15–25 laps. In modern race conditions, drivers often target consistent lap times to manage tire wear, resulting in approximately linear trends in observed performance within a stint. While higher-order or nonlinear specifications could be considered, preliminary analysis indicated limited improvement in predictive performance relative to the added complexity. The linear formulation therefore provides an interpretable baseline for modeling degradation dynamics.
Extensions of the basic model
We will propose three extensions to this basic model. The first is to estimate different degradation rates for each tire compound, and the second is to allow the degradation rate
Extension 1 - compound specific degradation
As mentioned earlier, Formula 1 tires are designed to degrade at different rates by Pirelli (n.d.). Therefore, a natural first extension to make to the base model is to estimate different degradation rates for each compound. With this in mind, our process equation becomes: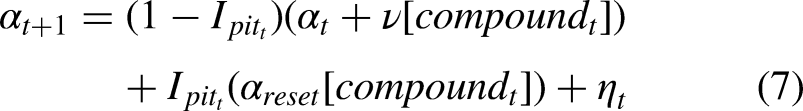


As mentioned above, the main thrust of this extension is to estimate different degradation rates and reset points for each tire compound used by the driver.
Extension 2 - time-varying degradation
When tires degrade, there is a loss of mechanical grip as rubber is torn from the surface of the tire. One might well expect that this loss of grip could lead to increased sliding and therefore a compounding of degradation over time. With this in mind, we propose for the second extension a model in which the degradation rate itself increases over time. Under this extension, our process equations become:


The most important difference here is that the degradation rate
Extension 3 - skewed T distribution
Our final extension to the base model is to use a skewed t distribution (Hansen, 1994) for the observation error. Since drivers are given target lap times by their engineers throughout the race, we expect to observe extreme values predominately in the positive direction. For instance, a driver might make a mistake that could lead to an increase of several tenths of a second in lap time, but then return to the target times given by the team. A positively skewed t distribution would capture the possibility of extreme values in the positive direction. The base model would have the same process equation, but the observation equation becomes:

Because of the skewed t distribution’s heavy tails (with lower degrees of freedom), this model should be more robust to outliers than than those using normally distributed errors.
Discussion of priors
In general, we lean on moderately strong priors since we are relatively data poor and have ample information to inform priors. Further, informative priors improve convergence stability and speed, making the model more practical in race conditions.
It should also be noted that lap times often differ by mere tenths of a second. Therefore, priors which at first glance appear very strong, are only moderately so. Given lap times vary by ˜0.5s per stint, priors with SD = 0.1 represent plausible but informative uncertainty levels.
Base model
The priors for our base model are:



We use a relatively strong prior on the observation standard errors
We also use a half-normal prior on the degradation rate to restrict it to be positive, as a negative overall degradation rate would be nonsensical (if the degradation rate is not allowed to change with time as in extension 3). We centered the prior at
Lastly, the prior on the
Extension 1 - compound specific degradation
The error standard deviation priors for the compound specific degradation model remain the same as before. However, the degradation rate and state resets change since we have to estimate parameters for each tire compound. We have the following extra priors in place of the 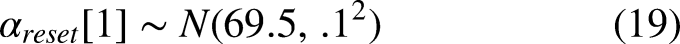

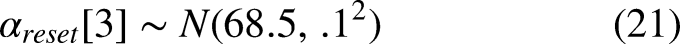
Here
As mentioned in the previous section, there is data from the second free practice session of that race weekend which suggested that the race pace of the medium tires would be 69-69.5 seconds per lap. We use the lower end of this spectrum to account for greater incentive to do faster lap times during the actual race. Then, we make the hard tire reset value a half second slower–and the soft tire a half second faster relative to the medium tires–to reflect our beliefs that the soft tires will start out faster and the hard tires will start out slower.
Extension 2 - time-varying degradation
Here, the error standard deviation priors are the same as the base model, and the reset parameters are the same as for the compound specific degradation model. The main difference is that we include a prior for the degradation state reset 
Extension 3 - skewed T distribution
For the final extension, we have only updated the observation equation. We let 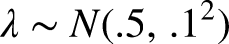
Finally, we do not use a prior on the degrees of freedom because we know that outliers can occur due to driver mistakes or getting stuck behind a slower car, and therefore there is a need for heavy tails. Furthermore, we want the model to fit quickly enough that it can provide strategic information during a race. Adding a prior on the degrees of freedom would make the model take longer to run with little added benefit.
Results
In this section we will discuss the results of fitting the various models. In particular, we will discuss estimates of degradation rates across tire compound and prediction of lap times.
Model selection
Forecasting in this study is performed in a one-step-ahead framework within each race session. For each session, models are estimated using data available up to a given lap and evaluated on subsequent laps using rolling-origin cross-validation. Importantly, race sessions are modeled independently rather than pooled across events, so predictive assessment reflects within-race updating and cross-session robustness rather than multi-race joint training.
We used rolling-origin-recalibration cross validation to perform model selection (Tashman, 2000). We describe the cross validation scheme below. Let
Fold 1 - Train:
Fold 2 - Train:
…
Fold
…
Fold 1 - Train:
Fold 2 - Train:
…
Fold
In this way we perform cross validation on each stint of the driver’s race, and calculate the root mean squared predictive error for each stint so that we can analyze model performance at the stint-level. Letting 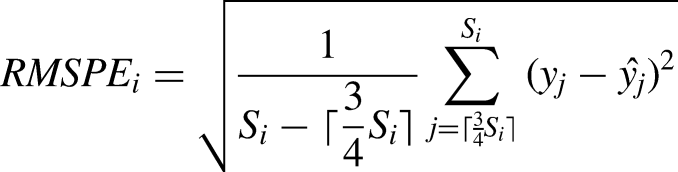
Cross validation results - RMSPE.

.
Since we obtained samples from the one step ahead predictive distributions using Stan, we also use the Continuous Rank Probability Score (Matheson and Winkler, 1976) with the same cross validation scheme as above to evaluate our probabilistic forecasts. Let 
Continuous rank probability score.

.
The SSM with skewed t errors is shown to be the best in terms of RMSPE, beating the base model by nearly a tenth. Given the scale of the data, this indicates that the skewed t model performs best on out-of-sample data. Interestingly, this model performs much better than the others in the second stint where there is an extreme outlier in the positive direction. Since performance of the state space models is close among those with normal errors we will still examine them all in the remaining sections, but for out-of-sample prediction we deem the SSM with skewed t errors to perform best.
We see a similar pattern in the Continuous Rank Probability Scores (CRPS) for each of the models (Table 3). The skewed t model beats the other models in all stints, but again performs particularly well in stint 2. The CRPS takes into account the full forecast distribution, so forecasts for the skewed t model are likely able to capture extreme values that the normally distributed models are unable to.
Cross-session predictive validation (2025 Season)
While the Austrian Grand Prix serves as a representative session for model selection and structural comparison, we assess robustness by applying the selected skewed t state-space model and the AR(1) benchmark to 19 race sessions from the 2025 season. Each session is modeled independently using the same rolling-origin cross-validation scheme described in Section 5.1, and race-level predictive metrics are obtained by averaging stint-level scores within each race.
Across the 19 sessions, the state-space model achieves lower RMSPE than the AR(1) benchmark in 15 of 19 races (Table 4). The advantage is slightly more pronounced with CRPS, where the state-space model outperforms the AR(1) specification in 16 sessions. This provides further evidence that the skewed t observation model is more appropriate for uncertainty quantification than Gaussian-based alternatives. On average across races, the skewed t state-space model yields lower predictive error and improved probabilistic calibration, indicating stable performance across heterogeneous circuits and race conditions.
These results suggest that the predictive improvements observed in the Austrian Grand Prix are not isolated to a single session, but reflect a consistent advantage of the state-space formulation relative to a structurally comparable autoregressive benchmark.
Model assessment
For our initial model selection on the Austrian Grand Prix, we obtained posterior samples for the state-space models via Hamiltonian Monte Carlo sampling with 4 chains of 15000 samples each after 15000 burn-in iterations.
For the 19-race cross-validation study, we reduced computation by using two chains with 5,000 post-warmup draws per chain following 5,000 warmup iterations. For certain sessions, additional iterations (15,000–25,000 total) were required to achieve satisfactory
It can be seen from Figure 3 that the models all fit the data reasonably well, and are fairly similar. Notably however, the skewed t distribution is not nearly as affected by outliers in the first and second stints, leading to a better fit.

Fit of the various models with 90% credible intervals. The smoothed predictions are based on the entire time series, as opposed to one-step-ahead predictions which are based solely on observations that occur before the prediction. The smoothed predictions are a basic check that show the model fits the data well. Interestingly, we can see that the skewed t model is not nearly as affected by the outlier on lap 43.
Fitting the first and second extensions of the base model
In the previous section we saw that the skewed t model performed best. While we did expect this model to perform better than the base model, it is surprising that the compound-specific and time-varying degradation models were outperformed by the base model, especially considering that the entire purpose of having different tire compounds in F1 is so that certain compounds will degrade more quickly.
Table 5 shows the estimated values of
Cross-race CV results. Overall means do not include the Singapore grand prix.

.
Estimated degradation rates with 95% credible intervals.
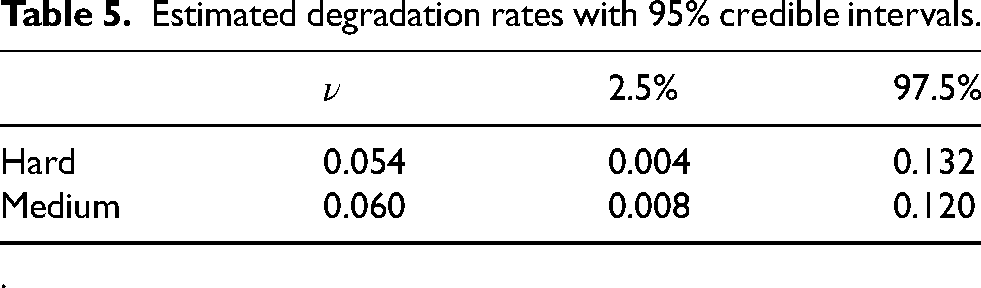
.
While we do estimate a slightly higher degradation rate for the medium compound tires, the credible intervals have a large degree of overlap, indicating that the data provides little evidence that there is a difference in degradation rate between the compounds.
From Table 6 it can be seen that the estimated
Estimated

.
Interestingly, the degradation rate

Degradation rates for each lap as estimated by the time-varying degradation model. Interestingly, the degradation rate begins below zero in each stint, indicating the model is capable of capturing a warm-up period for the tires before they begin degrading.
Of course, in both model extensions we see that our degradation estimates do not meaningfully change across the tire compounds used. This is likely why the base model performs better in terms of prediction than our extensions. Another important consideration is that drivers strive to achieve target lap times set by their engineers during a race. Thus, they are not driving at the absolute limit and are actively trying to manage their degradation rates. This partly explains why we tend to see a linear decay. That being said, each stint only has around 20 laps, so we don’t have much data to differentiate what would likely be a small effect size.
Prediction of lap times with uncertainty
One benefit of these models is the ability to quickly assimilate new data points and get predictions for the next lap time with uncertainty intervals. For example, if we run the base model on laps 1-43 to predict lap 44, we get the results seen in Figure 4.
Figures 5 and 6 also support our claim that the models do a good job at forecasting the next lap time. It takes between 15 and 30 seconds to run the base and extension 1 models, giving plenty of time to use the results for decision making in the rest of a lap. In addition, if the fully extended model with increasing degradation rate

One-step-ahead prediction of lap 44, given laps 1 to 43. Our point estimate is clearly robust to the outlier on the previous lap. We can also see evidence of the skewed t observation errors in the credible intervals. While the 90% interval appears fairly symmetric, we see that increasing the probability extends the interval farther in the positive direction than in the negative direction (relative to the point estimate).

One step ahead predictions with 90% credible intervals for the skew t model. Generally speaking, the models do a good job of predicting the next lap time. The uncertainty intervals almost always contain the observation.
Limitations and considerations
Firstly, the Austrian Grand Prix did not have a safety car. Safety cars come onto the track when there has been a serious crash, and all drivers are forced behind the safety car to limit their speeds. As such, driving under safety car conditions drastically reduces degradation since the drivers are limited to much slower speeds. Such a situation could be easily accounted for by extending our model to suspend the degradation process for laps done under safety car conditions.
Secondly, Lewis Hamilton’s drive at the Austrian Grand Prix was fairly uneventful and so he was minimally impeded by the drivers ahead. If a driver gets stuck behind a slower car, this can cause an artificial increase in lap times that isn’t due to tire degradation. The easiest way to address this if necessary is to add a covariate to the observation equation for the distance to the driver ahead. Future work, however, will likely look into more sophisticated ways to address this, such as a multivariate time series with all drivers and dependent errors based on the distance to the driver ahead.
Conclusion
This paper introduced a Bayesian state-space framework for modeling tire degradation in Formula 1 racing, demonstrating that such models can capture the latent deterioration of tire performance while providing interpretable and probabilistic predictions of lap times. Using Lewis Hamilton’s 2025 Austrian Grand Prix as a case study, the proposed approach showed superior predictive performance relative to an AR(1) baseline, particularly when observation errors were modeled with a skewed t distribution to account for asymmetric driver mistakes.
Although degradation rates between tire compounds were not found to differ greatly, teams that have access to more telemetry data could likely discern meaningful differences between tire compounds. The state-space framework’s ability to assimilate new data in real time and output predictive uncertainty makes it a strong candidate for integration into race strategy tools.
Future work should extend the model across multiple drivers to better quantify compound-specific degradation patterns, refine priors using telemetry or surface-temperature data, and explore hierarchical structures for team or track-level effects. Overall, the Bayesian state-space approach provides a statistically principled and computationally efficient foundation for studying tire behavior and optimizing strategy in Formula 1.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and publication of this article.