
Abstract
Historical data is a valuable asset in sports science, offering insights into athlete development and performance trends. This study explores long-term patterns in competitive swimming by analyzing performance variability over the past 20 years. Instead of clustering similar data points, we grouped entire performance trajectories based on their overall shape, regardless of timing or duration. To model variability, we used a Markov Switching Regression (MSR) model to identify transitions between two volatility regimes: stable (low variance) and unstable (high variance). Only swimmers with at least 50 performances were included to ensure reliable estimates. We then applied the KmlShape clustering algorithm, using Fréchet distance, to group swimmers by the similarity of their volatility profiles and performance patterns. Results showed a link between age, volatility, and competitive outcomes. Swimmers who began earlier tended to have lower volatility and lower performance, while those starting later showed higher volatility and better performance, possibly due to more intense adaptation and pressure in competition. These findings highlight how historical data can inform athlete development. Coaches and analysts can use this approach to understand progression, refine training strategies, and manage performance variability. Future research should expand this framework across sports and demographics for broader applicability.
Introduction
In recent years, data analysis has become increasingly important in understanding and improving performance across various sports, including swimming. By leveraging advanced analytical techniques, coaches and athletes can gain insights into performance trends and identify areas for enhancement (Costa et al., 2021, Gao, 2006, Mooney et al., 2015, Xie at al., 2017, Woinoski et al., 2020 and Zhang et al., 2020). Longitudinal data, which encompasses repeated measurements of performance variables across multiple time points, allow for a deeper insight into how athletes evolve, adapt, and respond to training regimens, competitions, and recovery periods. These data are valuable not only for optimizing individual performance but also for identifying early indicators of potential injuries, fatigue, or declines in performance (Becerra-Muñoz et al., 2023, Busso et al., 1997, Busso, 2003, Imbach et al., 2022, Marchal et al., 2025 and Philippe et al., 2019).
To model longitudinal data, functional data analysis (FDA) provides a comprehensive framework for analyzing changes in athletic performance. It can be implemented in powerful tools to optimize training programs, improve decision-making processes, and support athletes in achieving peak performance in a sustainable and effective way. When dealing with functional data, FDA models athletes’ performance trajectories, capturing the continuous and uncertain nature of athletic performance, which may vary due to training, competition, and other factors. This approach provides a more nuanced understanding of how performance evolves, including periods of volatility where an athlete’s performance may fluctuate significantly (Forrester and Townend, 2015 Mallor et al., 2010, and Leroy at al., 2018).
One area of particular interest is the analysis of the swimming performance volatility, which refers to the variation in a swimmer’s results over time. To capture this volatility, the Markov Switching Regression model (MSR) is appropriate. Introduced by Goldfeldand and Quandt (1973) and later extended by Hamilton (1989) and Krolzig (1997), MSR has become one of the most popular statistical methods to identify regime shifts in economics and finance (Engel and Hamilton, 1990; Garcia and Perron, 1996; Hamilton, 1988, 1989; Kim and Yoo, 1995 and Kim and Nelson, 1998, among many others). The model is particularly useful when a system exhibits multiple distinct states, such as a swimmer’s performance fluctuating between high and low periods of athletic form. The MSR assumes there are different ”states” of performance (e.g., high, moderate, low) and the transition between these states is probabilistic. These states allow for a better understanding of the unpredictable nature of athletic performance and can assist in developing tailored training strategies. In sports, Sandri et al. (2020) used the Markov switching model to analyze individual basketball shooting performance according to two performance regimes that depend on interactions between players. They considered the effect of a teammate player
Swimming has been an area of interest for the statistical modeling of performance, where the outcome depends mostly on the swimmer’s own physical and mental abilities and, to a lesser extent, on the opponents (Bouvet et al., 2024; Leroy at al., 2018). Although external elements such as the presence of a coach or competition with other swimmers can play a role in psychological preparation or motivation, they can also introduce variability in a swimmer’s performance. For instance, Wilczyńska at al. (2022) suggest that a positive athlete-coach relationship can significantly impact the psychological state and performance of young athletes. Coaches not only provide technical guidance but also contribute to the mental and emotional readiness of athletes, which is crucial for competitive success. Another study presented by Jane (2015), using a national database of student athletes in Taiwan from 2008 to 2010, suggests that swimmers perform better when competing against faster peers. This indicates that the presence of strong competitors can serve as a motivational factor, pushing swimmers to enhance their performance. These psychological factors, therefore, contribute to the inherent volatility in a swimmer’s performance, as mental resilience and the ability to handle external pressures often determine the consistency of their results.
Swimming performances can vary greatly across different swimmers, age groups, and competition levels. On this basis, clustering methods offer powerful tools for analyzing training data, race results, and physiological measurements. For example, Morais et al. (2022) and Figueiredo et al. (2016) aimed to identify and classify the performance of young swimmers through cluster analysis based on a k-means algorithm. In a more recent study, Bouvet et al. (2024) introduced a novel approach involving double partition clustering of multivariate functional data. The authors used data from inertial measurement units to analyze technical skills, providing insights into biomechanical strategies for front-crawl sprint performance. Additionally, the clustering with Gaussian process models have gained significant attention for evaluating the ranking progression of different performance levels in swimming (Leroy et al., 2023; Veiga et al., 2024). These clustering methods are robust and efficient for many applications. However, studying longitudinal data with different trajectory shapes implies considering the asynchronicity between observations among individuals, the series’ time span, and the overall series shapes.
In this paper, we focus on grouping swimmers according to the similarity of their performance and volatility profiles, allowing for more personalized insights. A promising approach, ”KmlShape,” developed by Genolini et al. (2016), relies on time-series partitioning algorithms based on the shapes of trajectories rather than on classical distances. In this case, the Fréchet distance (Fréchet, 1906) allows for quantifying the similarity between two time series by the minimal distance required to ”transform” one series into another, and hence provides a more accurate comparison of the underlying trends (see, for example, Buchin et al., 2023, Reimering at al., 2018, and Driemel et al., 2015). Adapted to swimming data, KmlShape may capture subtle performance variations and their inherent volatility according to the time-series shape. Consequently, individual data spans, the age at which swimmers start and stop competing, performance trends, and short-term changes are considered for grouping swimmers. By applying such a method, coaches can gain a deeper understanding of how different swimmers’ performances progress over time, identifying distinct profiles within a group of swimmers and facilitating tailored training plans that target specific performance patterns and volatility characteristics.
The purpose of this paper is twofold: (i) to calculate the probabilities of variability in an athlete’s performance, and (ii) to cluster performance and volatility curves. After introducing the methods used to achieve these goals, we will discuss the results in light of the literature and practical considerations for swimming performance stakeholders.
Material & methods
Data description
We consider results from swimming competitions for thousands of athletes spanning from 1976 to 2024, including 163.146 females, 165.332 males, 18 different swimming styles, and publicly available from the French swimming federation (Extranat, 2025) . The dataset consists of multiple irregular, age-based performance time series, with each swimmer having a distinct set of data points at varying time intervals and for different swimming styles, as illustrated in Figure 1. For instance, 32% of female swimmers were tracked for only one year (33% for males), while 6% of females and 5.4% of males were followed for at least five years. The number of participants before 2002 is scarce, with only one swimmer recorded in 1987 and two in 1993. Additionally, the number of observations per swimmer is highly inconsistent. For example, while one swimmer may have only 10 recorded performances, another may have more than 100. To ensure the robustness of the analysis, we limited the dataset to the period from 2002 to 2024. The data were split by sex, and we selected swimmers with more than 50 observations per discipline. Swimmers’ points are calculated using a cubic function, according to WorldAquatics (2025).

Example of time series for five male swimmers in 100m freestyle competitions.
Formally, let

Since swimmers start and stop competing at different ages (e.g., starting between 10 and 40 years old, and retiring between 12 and 89 years old), we focused on swimmers who began competing between the ages of 10 and 20, and who retired between the ages of 25 and 40. This sampling strategy helps to avoid bias that could arise from early retirement at younger ages.
To ensure that each athlete’s performance time series was represented over a regular temporal grid—required for Markov Switching Regression (MSR)—we applied cubic spline interpolation. This method constructs a smooth curve that passes through all observed performance values, accommodating the irregular timing of the original measurements. Unlike piecewise linear interpolation, which produces sharp transitions between points, cubic splines yield smooth trajectories with continuous first and second derivatives. This was considered more appropriate for modeling athletic performance, which is expected to evolve gradually over time. We emphasize that this interpolation was used for resampling onto a regular grid, not for noise reduction, and that the interpolated data were subsequently analyzed using a model (MSR) that incorporates temporal dependencies. Spline interpolation was performed using cubic polynomials with knots at the observed data points and no smoothing penalty. (Schumaker, 2007 and Schumaker, 2015).
Markov switching models
Let

This setup defines a stationary autoregressive process with mean
In the MSR framework, the behavior of

The transition probabilities satisfy
In this model, we estimate the parameters
In Figure 2, we present the filtered probabilities for the performance regime of an athlete. These refer to estimates of the regime probability at time

(a) Fitted probabilities for regimes 0 and 1 for an athlete in 100m freestyle. The sum of the two probabilities at each time point equals 1. (b) The athlete’s performance with the dominant regime indicated at each time
Clustering time series
In this section, we cluster longitudinal performance series with respect to their shapes. Note that series were exploited in their original form, i.e. without time-normalization or resampling. The method is based on an extension of the k-means algorithm, in which we use a ”shape-conservative mean” (Genolini and Falissard, 2010; Hartigan and Wong, 1979; Khan and Ahmad, 2004; Redmond and Heneghan, 2007; Steinley and Brusco, 2007).
The aim of the k-means algorithm is to alternate between two steps. First, the initialization phase defines the mean trajectories of each cluster, calculates the distances between individual trajectories and cluster centroids, and assigns each individual to the nearest cluster. Second, the maximization step estimates the new mean trajectory for each cluster.
For shape-preserving partitioning, we use the clustering algorithm KmlShape (kmlShape library in R), which incorporates several shape-respecting distance metrics. This distance takes a small value when individuals exhibit similarly shaped trajectories, and a large value otherwise. As proposed by Genolini et al. (2016), we use the Fréchet distance to compute the distances between individuals and cluster centers, and the Fréchet mean to construct cluster centroids that reflect the shape-respecting average. The algorithm stops when cluster memberships remain unchanged between iterations
We applied this algorithm twice: once to cluster the performance curves of each athlete, and again to cluster the individual stability profiles throughout their swimming careers.
Formally, let
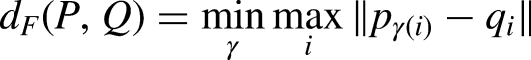
Given a set of trajectories


Statistical analysis
Differences between clusters were evaluated using exploratory one-way Analysis of Variance (ANOVA), followed by post hoc comparisons with Tukey’s p-value adjustment. Marginal mean differences (
Results
This section presents the results of the analysis conducted on a sample of 282 male swimmers competing in the 100m freestyle event.
Markov switching models
By applying the MSR model to each swimmer’s time series (see Section ”Markov Switching Models”), we estimated the probability at each time point
Clustering stability profiles
Clustering the regime 0 probabilities using the KmlShape algorithm with a hierarchical method yielded three distinct groups: 54% of athletes were assigned to Cluster 1 (red), 28% to Cluster 2 (green), and 18% to Cluster 3 (blue), as shown in Figure 3.
An analysis of group-level stability showed that Cluster 1 exhibited 44% stability, while Clusters 2 and 3 demonstrated 46% and 40% stability, respectively. These results indicate that swimmers in Cluster 3 displayed the most volatile performance patterns. The average stability levels significantly differed between clusters (

Transformed (cluster-specific) performance volatility for each cluster generated by the kmlShape algorithm using the discrete Fréchet distance. Each curve represents the aligned shape-based prototype series capturing the characteristic temporal pattern of that cluster. A value below 0.5 indicates a more probable assignment to the stable regime.
We further examined differences in age-related variables across clusters. Specifically, the ages at which athletes began (minimum age) and stopped (maximum age) competing differed significantly between stability groups (see Appendix, Table A1).
Clustering performances curves
We next applied the same KmlShape algorithm to raw performance trajectories (i.e., points as a function of age in days). This yielded three clusters, illustrated in Figure 4. The first cluster (red, ”low performance”), representing the largest portion of the sample (52% of athletes), had a mean score of 480 points, with interquartile range [420, 548]. The second cluster (green, ”moderate performance”), with a mean of 600 points and interquartile range [547, 652], included athletes with mid-level scores and broader variability. The third cluster (blue, ”high performance”) included swimmers with the highest average scores (mean
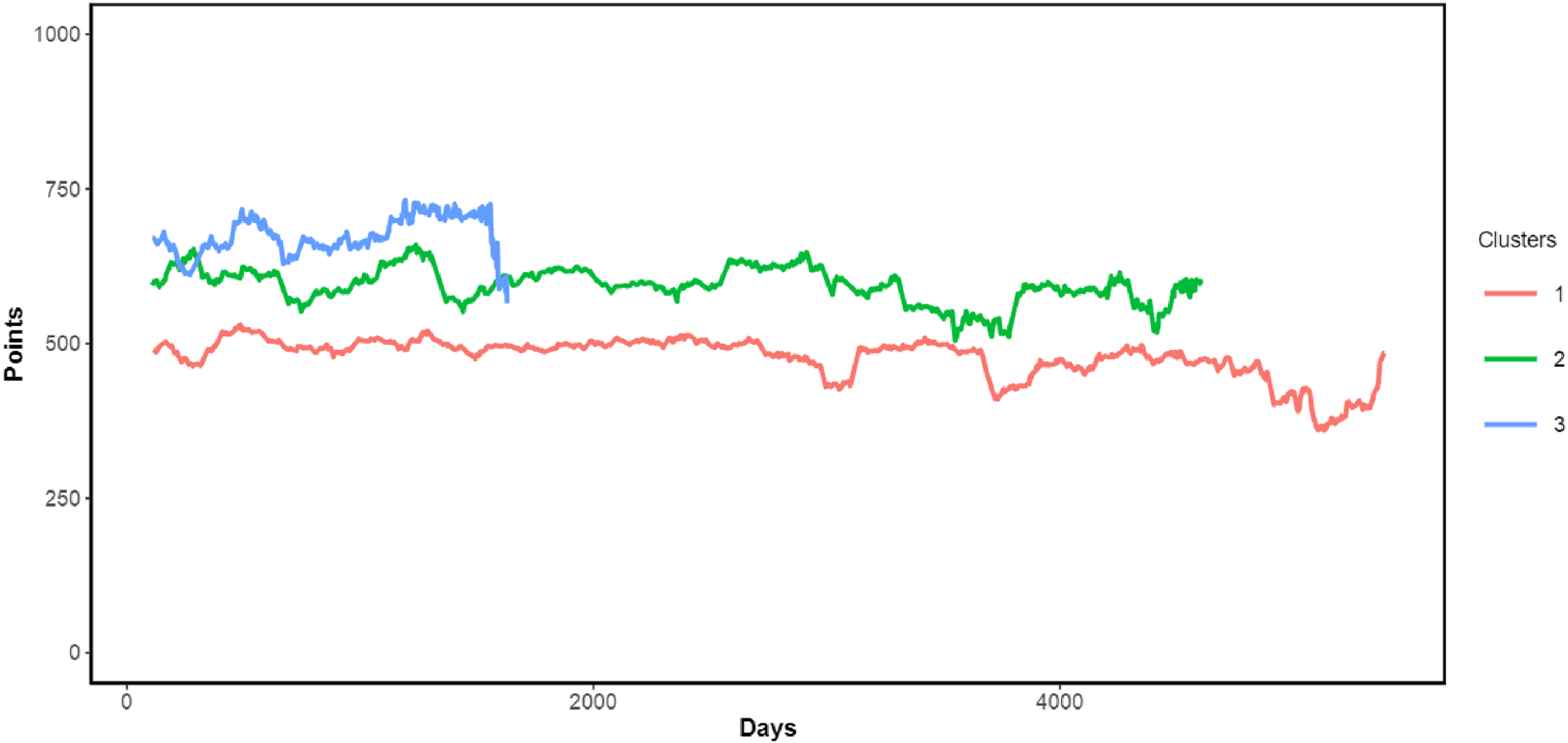
Transformed (cluster-specific) performance curves for each cluster generated by the kmlShape algorithm using the discrete Fréchet distance.

Distribution of time series in each performance’s category by stable state (regime 0). The scatter colors represent the probability values of regime 0. (a) Low performance, (b) Moderate performance and (c) High performance
We also compared the age of competition onset and cessation across performance clusters. The mean starting ages were 13, 15, and 16 years for Clusters 1, 2, and 3, respectively (see Appendix, Figure A1). Corresponding stopping ages were 27, 29, and 32 years. These age-related differences were statistically significant (see Appendix, Table A2), underscoring the relevance of age in performance differentiation.
Relationship between stability and performance
Finally, we examined the distribution of athletes within the intersection of these clusters (see Figure 6). We found that 78% of swimmers in the low-performance cluster also belonged to cluster 1 of the stable regime group (regime 0), and 89% of swimmers in the high-performance cluster belonged to cluster 3, the most volatile cluster of the stable regime group. These findings suggest an association between later starting age, greater performance volatility, and higher performance levels. To formally assess this relationship, we fitted a linear mixed model with performance as the dependent variable. Predictors included age (in days), probability of belonging to the stable regime, and competition starting age as fixed effects, and competitors as random effects. All predictors showed significant effects, with the age for a given competition exhibiting the greatest effect over the performance (

Effective of athletes by the stability clustering in each category of performance.
Validation on female sample
To validate our findings, we repeated the full analysis on an independent dataset consisting of 140 female swimmers competing in the 100m freestyle. The results closely mirrored those of the male sample, with three clearly distinguishable clusters for both performance and stability. Age, performance volatility, and competition onset age remained significant predictors. Full results are reported in Appendix, Tables A4-A7 and Figures A2-A3.
Discussion
This study aimed to examine swimmer behavior through two models: the first utilized a Markov Switching Regression (MSR) model to capture performance volatility, assessing fluctuations in individual swimmers’ performance over time. The second model applied a hierarchical clustering algorithm, KmlShape, to group athletes based on the similarity of their performance trajectories, even when these trajectories varied in terms of timing or length, by utilizing the Fréchet distance.
The choice of the number of clusters is critical. In our study, we selected three clusters based on visual inspection of trajectory shapes. We carefully examined the resulting mean trajectories for different values of k (ranging from 2 to 5). The three-cluster solution provided the best compromise between interpretability and distinctiveness. The shapes of the trajectories within each cluster were well-separated, with minimal overlap and high intra-cluster coherence. The hierarchical pre-clustering using the Fréchet distance yielded a clear separation into three main branches. This natural split supported the choice of k = 3 as a meaningful representation of the data’s underlying structure.
It should be noted that clustering was performed on trajectories with their original temporal extents (i.e., not resampled or time-normalized), meaning that differences in duration may have indirectly influenced the Fréchet distance and the resulting cluster structure. In studies where clustering itself is the primary objective, additional preprocessing steps such as time-normalization or resampling would be advisable to minimize the impact of differing temporal extents on the clustering outcome.
After clustering, we may have a key limitation associated with performing statistical tests: when groups are defined using the same data on which the tests are conducted, classical inference procedures such as ANOVA can suffer from inflated Type I error rates due to selection bias. This issue has been formally demonstrated in recent work by Gao et al. (2022), who show that this inflation persists even when clustering and testing are conducted on independent subsets of the data. More recent developments by González-Delgado et al. (2023) offer promising post-clustering inference frameworks that account for the clustering process by conditioning on the selection event, enabling statistically valid p-values and confidence intervals. Although such methods are not yet directly compatible with all forms of clustering—such as those based on trajectory shapes (e.g., KmlShape)—they represent a valuable direction for future research. Incorporating these methods could strengthen the statistical rigor of cluster-based comparisons, especially in applications where cluster separation informs decision-making or hypothesis generation.
Markov Switching models have been widely recognized for their ability to model performance variability in sports, as seen in studies on basketball (Sandri et al., 2020), by positing the existence of multiple regimes or states between which athletes or teams may switch. This approach allows for a nuanced understanding of performance dynamics, accounting for significant variations due to factors like physical condition, mental state, or external circumstances. Our findings align with the broader literature, highlighting the importance of regime-switching in capturing performance volatility.
However, the specification of the number of regimes and the structure of transition probabilities remain a critical aspect of MSR model application. Incorrect choices in this regard can significantly influence the model’s performance and lead to misleading or unstable results (Song and Woźniak, 2020). In our analysis, testing with more than two regimes resulted in inconsistent and sometimes implausible probability estimates, such as constant probabilities of zero, suggesting that a higher number of regimes introduced instability in probability distributions rather than improving the model in capturing performance dynamics. This underlines the importance of considering the number of regimes carefully in relation to the specific aims of the study. For our purpose of examining volatility, a two-regime model —representing stable (i.e. low variance) and unstable (i.e. high variance) performance states– proved to be sufficient.
Additionally, the robustness of the MSR model relies on having a sufficient number of observations. Therefore, we restricted our analysis to swimmers with at least 50 data points to ensure the reliability of the model and the robustness of our findings.
After estimating the probability of being in the stable regime (regime 0) for each swimmer, we proceeded to group athletes based on their volatility profiles using the KmlShape clustering algorithm. Using a hierarchical approach paired with the Fréchet distance, it resulted in three distinct clusters based on performance volatility, which were associated with the athletes’ competition start and end ages. Clusters 1 and 2 represented athletes with relatively stable performance, with athletes in these groups beginning their careers at ages younger than 14. This period of early development is characterized by significant physical and psychological changes that can lead to fluctuations in performance. As swimmers grow and adapt to new training regimes, these fluctuations may occur as they develop new skills, adjust to physical changes, and encounter the pressures of competitive environments (Bergeron et al., 2015; Malina, 2011). In contrast, Cluster 3 represented athletes with higher volatility, typically associated with later onset and more significant fluctuations as athletes adapt to the physical demands of the sport.
When we applied the same clustering approach to performance points (as a function of age), we identified three clusters, each corresponding to distinct performance levels. The majority of athletes fell into the first cluster, indicating lower performance levels. Notably, the average age at which athletes in this cluster began competing was below 13, coinciding with the period of puberty and the adolescent growth spurt (Malina, 2011). During this time, athletes are undergoing significant physical changes, which may initially hinder their performance. However, as athletes mature physically and mentally, their performance typically improves with the right training regimen.
While young male and female athletes exhibit similar performance levels before puberty, clear differences emerge during and after puberty. These differences are primarily attributed to hormonal changes, relative ages (Difernand et al., 2025), and the resulting physical developments (Handelsman, 2017; Handelsman et al., 2018). The impact of these physiological changes on athletic performance underscores the importance of considering gender-specific developmental trajectories in training and performance analysis.
Our analysis revealed several interesting trends. Younger athletes tended to exhibit more stable performance but also performed at lower levels compared to older athletes. Early starters often remain in the developmental phase of their careers, leading to greater consistency but lower overall performance. In contrast, athletes who start later may experience greater physiological changes as they adapt to the demands of swimming, resulting in more volatile performance patterns. This is further illustrated by the data in Figure 5 and Appendix, Table 2.
The adaptation process of late-starting athletes, coupled with the intense pressure of competing against more experienced peers, can contribute to psychological stress. This stress, in turn, can lead to performance volatility, as athletes struggle to maintain focus and composure during competitions (Özdemir, 2019). These findings highlight the complex interplay between physical development, training, and psychological factors in determining athlete performance.
To generalize the findings of this study, future research should consider expanding the scope to include other sports disciplines and to incorporate both male and female athletes in the sample. Access to a larger, more diverse dataset could provide valuable insights into the factors driving the observed trends, including the role of training methods, physiological factors, or external influences such as coaching style and peer dynamics. Exploring these aspects could provide a more comprehensive understanding of the determinants of performance volatility and strategies for improving athletic outcomes. In addition, incorporating more data into the analysis enhances the potential for predictive modeling (Saavedra et al., 2010; Silva et al., 2007). By training models on broader and more varied performance histories, we can better anticipate future outcomes, identify early signs of performance shifts, and support data-driven decision-making in training and competition planning using functional data.
Conclusion
This study offers key insights into swimmer performance volatility and stability. Our results suggest that younger swimmers tend to exhibit lower volatility but also lower performance, with age playing a critical role in both the stability of performance and the development of competitive abilities. These findings underscore the importance of considering age-related factors when evaluating athlete performance.
From a practical standpoint, these results emphasize the value of historical performance data for coaches. By understanding not only an athlete’s performance but also their volatility, coaches can better tailor training programs to meet individual needs, thereby improving performance and reducing volatility. This approach could significantly enhance the efficiency of training regimens and support athletes in reaching their full potential.
Supplemental Material
sj-pdf-1-san-10.1177_22150218261419295 - Supplemental material for Analyzing swimming performances based on series dynamics and volatility
Supplemental material, sj-pdf-1-san-10.1177_22150218261419295 for Analyzing swimming performances based on series dynamics and volatility by Chayma Daayeb, Arij Amiri, Robin Pla and Frank Imbach in Journal of Sports Analytics
Footnotes
Author contributions
Conceptualisation, C.D., F.I.; methodology and investigation, C.D., A.A., F.I.; data curation, R.P., F.I.;recruitment, R.P.; resource development, C.D., F.I.; formal analysis, C.D., A.A., F.I.; writing original draft preparation, C.D., F.I.; writing-review and editing, C.D., F.I.; supervision, F.I.; project administration, F.I. All authors have read and agreed to the published version of the manuscript.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and publication of this article.
Data availability statement
Correspondence and requests for materials should be addressed to F.I.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.