
Abstract
Evaluation of player value in sport can be measured in several ways. These measures, when captured over an entire career, provide insights concerning player contributions. Professional sports teams select young talent through a draft process with the goal of acquiring a player that will provide maximum value, but these expectations diminish as the pool of players grows smaller. In this paper, we develop valuation measures for draft picks in the National Hockey League (NHL) and analyze the value of each pick number with these measures. Specifically, we use different measures of player value to provide an expected value of that measure for each pick number in the draft. Our approach uses functional data analysis (FDA) to find a mean value curve from many observed functions in a nonparametric fashion. These functions are defined by each separate year of draft data. The resulting FDA model follows the assumption of monotonicity, ensuring that a smaller pick number always provides more expected value than any larger pick number. Based on a cross-validation approach, measuring value on annual salary provides the best predictive results. The proposed approach can be extended to sports in which an entry draft occurs and player career data are available.
Introduction
The National Hockey League (NHL) entry draft is an annual event held in the off-season to allow teams to acquire a prospect’s NHL rights. Draft-eligible prospects are typically ages 18 to 20 and come from Junior, College, or other pro leagues. The draft itself has been modified over the years, and consists of 224 picks over 7-rounds. With 32 teams in the NHL, this currently implies that each team receives 7 draft picks. The order of the draft is dependent on the standings from the previous season so the low-end teams get the earlier picks. More specifically, a draft lottery occurs prior to the draft, where the logistics of the lottery have changed over the years. In 2023, two draws were made to determine the top two draft positions from the 16 teams having the weakest records in the previous season. The remaining 14 draft positions were set according to team record. Under this lottery system, the worst finishing team from the previous season had a 25.5%, 18.8% and 55.7% chance of finishing first, second and third in the lottery, respectively. This is an attempt to promote parity in the NHL with an addition of randomness. The picks can also be traded amongst teams during, or in the years leading up to a specific draft.
The entry draft is a crucial moment on the NHL calendar as it is the opportunity to build for the future, with the goal of obtaining as much value through these picks as possible. As is the case with any sport, high draft picks (i.e. those chosen early in the draft) have a chance of becoming a “bust” or on the contrary, late draft picks have a chance of being a “steal”. Patrick Stefan was drafted 1st-overall in 1999 by the Atlanta Thrashers, which has been referred to as one of the worst draft picks in the history of the NHL (Bell, 2022). Stefan ended his career with 455 games-played and 188 points, an extremely disappointing career compared to most 1st-overall picks. By contrast, Pavel Datsyuk, who was drafted 171st-overall in 1998 by the Detroit Red Wings, finished his career with 953 games-played and 918 points, arguably one of the biggest steals in NHL draft history.
Chapter 12 of the book “Scorecasting” (Moskowitz and Wertheim, 2011) provides an engaging story involving the 1991 draft of the National Football League (NFL). In this draft, Mike McCoy of the Dallas Cowboys developed a chart that assigned perceived value to draft picks. The first draft pick was worth 3000 points, the second draft pick was worth 2600 points, and so on, in an exponentially decreasing order. With values assigned to draft picks, the Cowboys were able to trade picks to other teams, and accumulate value. Over the years, with better knowledge of the value of draft picks, the Cowboys had “fleeced” other teams, and set themselves up for a prolonged period of excellence that lasted for at least five years.
Since that time, many pick value charts have been created across professional sports. A sample of such contributions includes the National Basketball Association (Pelton, 2017), Major League Baseball (Cacchione, 2018), Major League Soccer (Swartz et al., 2013) and the National Football League (Massey and Thaler, 2013; Schuckers, 2011a).
In the NHL, there have been alternative constructions of pick value charts. Schuckers (2011b) used nonparametric regression on career games-played as a measure of player value. A review article on various issues associated with drafting in the National Hockey League was provided by Tingling (2017).
A major challenge in the construction of pick value charts is the determination of player value. Player value is an ambiguous term as it has different interpretations over the short term and the long term. Moreover, value is difficult to measure. For example, in hockey, goal scoring (a measure of excellence) is expected of forwards but not of defencemen. Teams may also hold different drafting objectives.
In this paper, functional data analysis (FDA) methods are used to construct pick value charts for the NHL. The rationale for FDA is that every draft season provides a range of player valuations, from the first draft pick to the last draft pick. Therefore, we argue that it is more sensible to regress the valuations on a yearly basis. That is, a year of valuations is considered a function, and FDA is concerned with the regression of functions rather than individual points. For an overview of applied FDA, see Ramsay and Silverman (2002). Another feature of the paper is that we assess pick value charts to give an indication of validity.
In Section DATA, we introduce the data where four metrics are proposed to assess player value. Importantly, we take into account the importance of considering performance metrics. The FDA model is described in Section Functional data analysis where its advantages are discussed with respect to pick value charts. The resultant FDA pick value charts are presented in Section Results where confidence intervals are provided. The inclusion of confidence intervals seems to be lacking from other contributions involving pick value charts. The quantification of uncertainty is important as teams need to make drafting decisions in light of uncertainty. We also validate the pick value charts via a cross-validation procedure which indicates that the metric based on salary percentile provides the best fit. We conclude with a short discussion in Section Discussion.
DATA
In this paper, we use three data sources. Sports Reference LLC (2022) data provides us with draft data from 1982-2016. This data are the full set of players that will be included in our analysis, even if players did not play in the NHL. The total number of players in this data is 8,613.
Vollman (2018) data provides us with player statistics from 1982–2006, including games-played (GP), goals (G), and assists (A), and advanced metrics such as point-share (PS). This data contains the players who played at least one game in the NHL. Of the drafted players from 1982–2006, we have player statistics for 2,803 players, including 72 players who were still active in the 2021–2022 season. Although more years of player statistics are available, we want to introduce player performance measures based on career contributions. Therefore, we truncate the draft data at 2006, allowing most players to complete their playing careers by 2022. We note that prior to the 1999–2000 season, there were only two points awarded for a single match. Subsequently, it was possible for three points to be awarded - if the match was tied at the end of regulation time, the loser received one point and the winner received two points. This rule change is incorporated in the PS statistic as calculated by Vollman (2018). Unfortunately, it means that point share is slightly higher after the rule change.
Lastly, Spotrac (2022) data provides contract information from 2001–2022 for players from the 2001–2016 drafts. This data includes the contract length, total value of the contract, and annual average value (AAV) of the contract. We calculate the percentile of each player’s AAV for all years under contract to normalize data in an effort to deal with inflation. In total, data was available for 1,144 players.
Data were cleaned as to match names across data sets. This included removing foreign letters, using full first names, and dealing with players with the same names to ensure consistency. A verification process was done to ensure all players were matched properly and no players were missed. We have ignored goaltenders from the data collection phase since various issues concerning goalies (e.g. performance, longevity) differ from positional players.
The NHL entry draft has evolved over the years as the number of teams in the league has increased. From 1982 to 1991 the draft consisted of 12-rounds, then fell to 9-rounds in 1995 and 7-rounds in 2005 which is now the present day amount. The current state of the NHL draft in 2022 involves 32 teams selecting for 7-rounds, for a total of 224 picks. There are rare cases of compensatory picks being awarded or picks being taken from teams due to violations of league rules, but those do not impact our analysis. To obtain a valuation of NHL draft picks, we truncate our data for past drafts to include only the first 224 picks. This applies to all drafts except 2006–2016 where less than 224 players were selected.
For our analysis, we only require a single explanatory variable, consistent with the proposed FDA framework. This variable will be the overall pick of the draft. Overall pick consists of the natural numbers
Measures of player value
This paper considers valuations of NHL draft picks using player statistics and salary information. A valuation will be obtained through four measures of player value. Measuring a player’s value is a difficult task as there are many ways to measure the quality of a career. A logical way is to use total games-played, as done in Schuckers (2011b), as this describes the longevity of a player.
Another way to view the problem is to use performance metrics as measures of player value. An advanced statistic, point-share, is what we will focus on. For this metric, a player’s value will be measured by both career average, and career total.
Although popular performance statistics (e.g. plus/minus) are measures of assessment, they are often confounded by other factors including the contribution of teammates. The use of salary data is another approach for player evaluation where we take the point of view that team executives (who determine salary) are knowledgeable about player value. This approach was utilized by Swartz et al. (2013) in the context of soccer.
Games-played (
)
The first measure of player value,
Using GP as a measure of player value does have drawbacks. One factor not taken into account is injuries. Injuries not only make players miss games but may also end players’ careers. For example, Mario Lemieux (drafted 1st overall in 1984), who is arguably one of the greatest players in NHL history only played 915 NHL games which ranks 492nd all-time. However, his points-per-game is second all-time only behind Wayne Gretzky, who played 1,487 games (24th all-time). Lemieux’s career was cut short by a variety of injuries, so using GP as a measure does not accurately represent the value that he provided during his career. Therefore, excellence over shorter durations is not captured by GP.
Another drawback is how teams and specifically general managers view the players they draft. There may be bias towards players drafted in the first round, especially in the top 5–10, because general managers do not want these picks to reflect poorly on their drafting ability. Also, these high-draft picks may be afforded more time to develop since they were seen to have great potential. Consequently, many high draft picks who become “busts” play more games than they would if they were a lower pick (Tingling, 2017).
Figure 1 provides histograms of
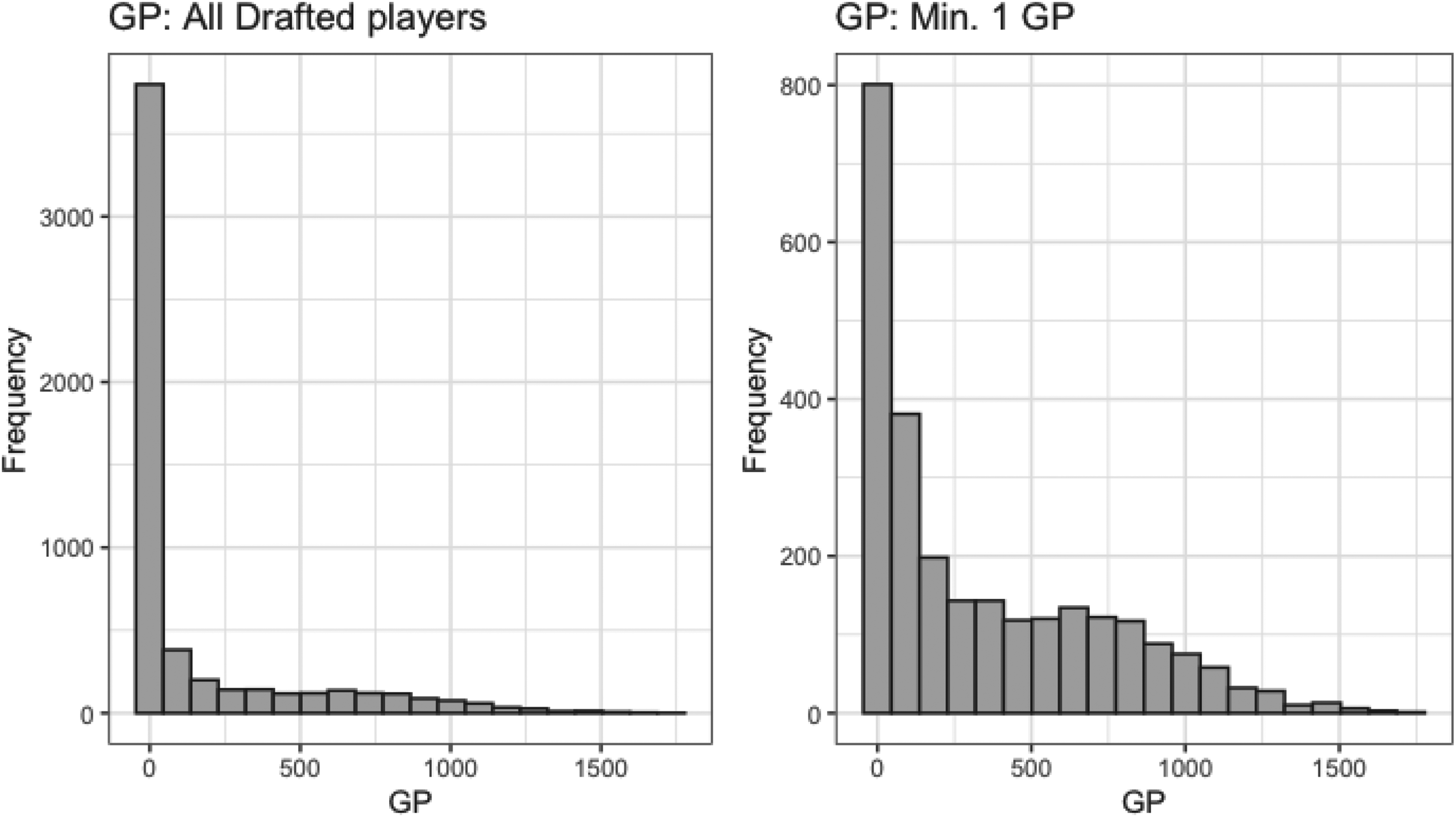
Histogram of games-played by all drafted players (left) and drafted players who played at least one NHL game (right).
Average point share (
)
The second measure of player value,
A feature of APS is that it uses both offensive and defensive contributions, something that most statistics do not consider. Offensive contributions that are considered in APS include goal production relative to the player’s time on ice and relative to an average team. Defensive contributions that are considered in APS include goal prevention relative to the player’s time on ice and relative to an average team. Prior to 1998–1999 season, time on ice was unavailable and the point share statistic was based on games played. Since the goal of the NHL is to win games, evaluating a player’s contribution to wins is a reasonable measure of player value. However, measuring player value through team success may not fully capture a player’s individual value. In some cases there are high level players on low level teams that are undervalued in this metric. For example, during the 2007–08 season Marian Hossa was traded from the Atlanta Thrashers to the Pittsburgh Penguins. Hossa, who had 66 points in 72 games that season, went from the 28th ranked team to the 4th ranked team, increasing his PS even though his contribution was similar for both teams.
In addition, APS measures a player’s excellence, without examining their longevity. This will increase the value of players who had their career cut short by injury or other factors.
Figure 2 provides histograms of
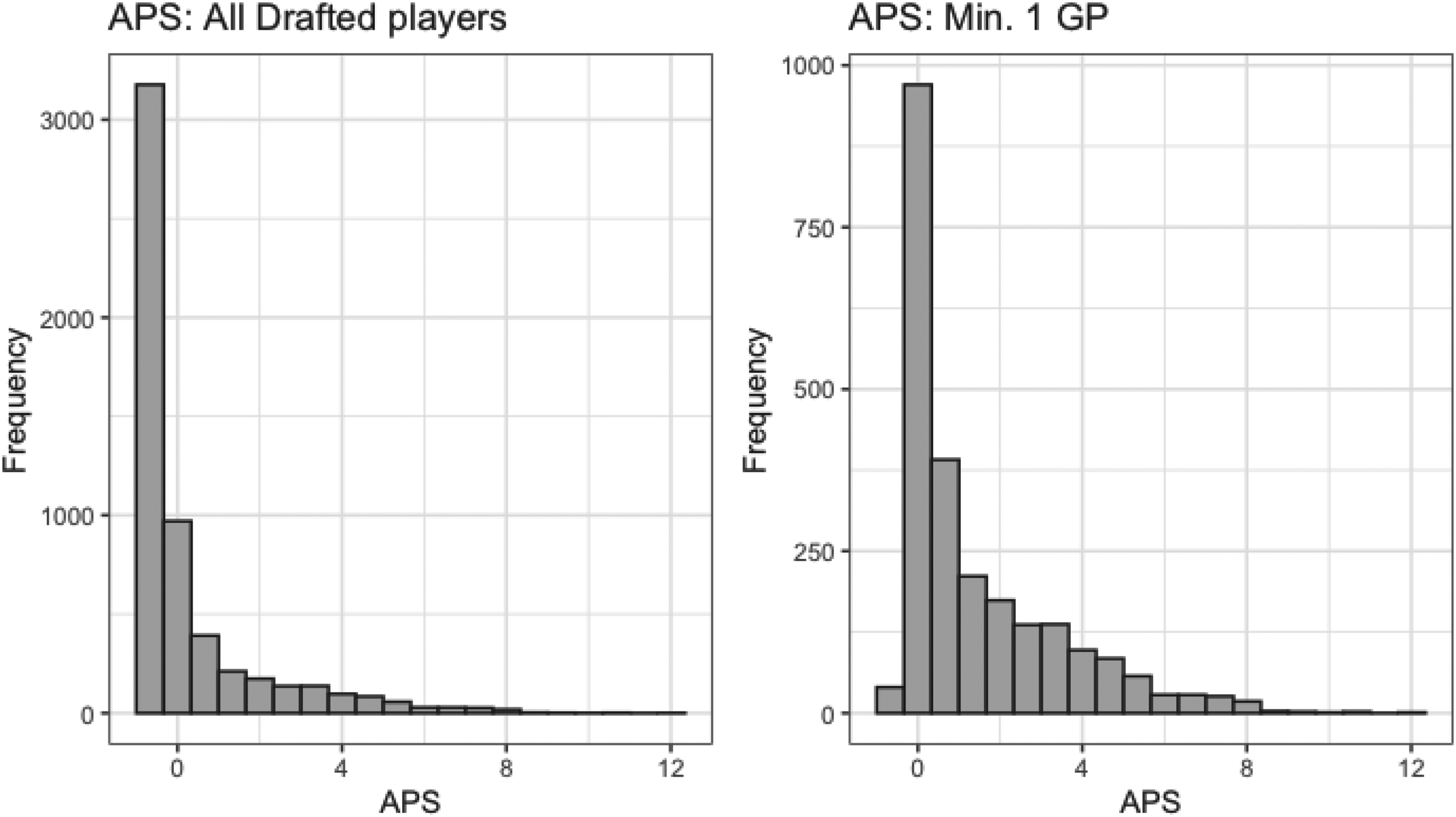
Histogram of average-point-share by all drafted players (left) and drafted players who played at least one NHL game (right).
Total point share (
)
The third measure of player value,
Figure 3 provides histograms of
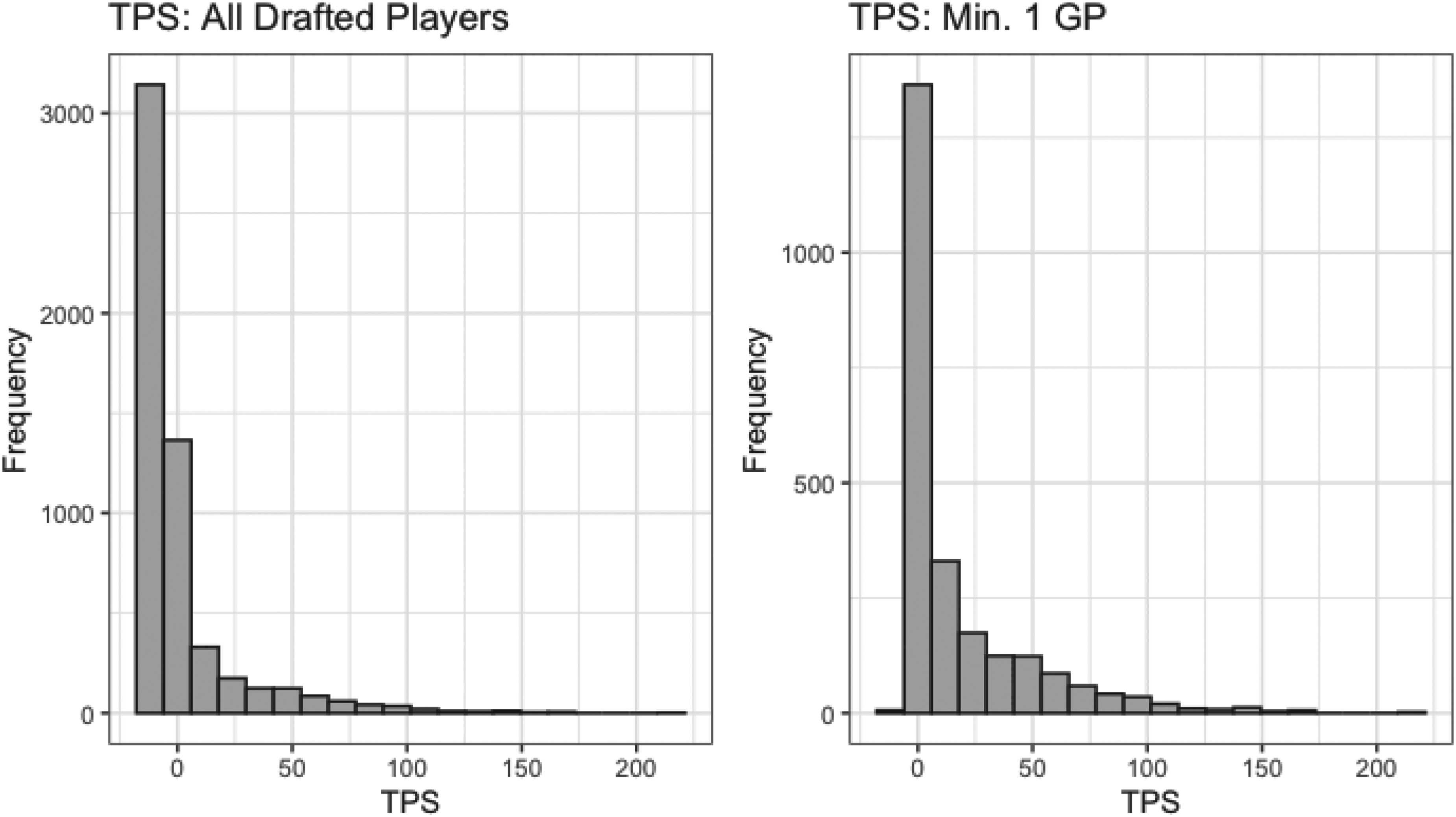
Histogram of total-point-share by all drafted players (left) and drafted players who played at least one NHL game (right).
Standardized salary ranking (
)
The fourth measure of player value,
This method of player value gives a different perspective than performance measures as salaries are determined by team executives. Performance measures surely play a role in how an executive views a players value, however, it is impossible to quantify everything that a team includes in defining player value. All of these underlying attributes will go into negotiating a player’s contract. This is the major benefit of using PAAV as a measure of player value. Another benefit is that PAAV captures brilliance over short-time spans versus measuring player value based on longevity.
A downside of using PAAV as a measure of player value is similar to the issue of games-played in Section Games-played (
Comparison of valuation metrics
Having introduced the four valuation metrics
Table 1 provides the top five performing players according to the four valuation metrics along with their draft pick number. We observe that the proposed excellence metrics correspond to widely recognized top players. We also suspect that it is more difficult to predict which players excel with respect to the longevity metrics
Top five performing players (and their pick number in parentheses) according to the four valuation metrics proposed in Section DATA.

Functional data analysis
Basic model
Functional data analysis is an emergent research area in which wide-ranging methods have already been developed (Ramsay and Silverman, 2005). In a sentence, FDA extends regression techniques involving points to regression involving functions in a nonparametric fashion.
FDA functions can be defined along various axes, although time is a common and logical axis. For this reason, FDA is particularly well suited to applications in sport since there are many sporting events of interest that occur longitudinally in time. For example, it is natural to consider sporting functions which correspond to players and teams across time horizons such as matches and seasons. However, to date, there have been very few applications of FDA to sporting problems. Two exceptions are Chen and Fan (2018) who investigated the score differential process in basketball, and Guan et al. (2022) who predicted in-game match outcomes in the National Rugby League.
In this investigation, we have a response variable 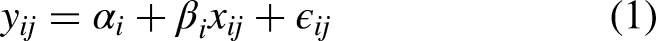
In this application, there are some immediate questions related to the assumptions of the linear regression model (1). First, the linearity assumption relating player value and draft position in equation (1) is highly questionable. In fact, all previous work has indicated that the value of draft picks has an exponential shape which tends to flatten towards the end of the draft. Second, the distributional assumptions associated with
Proposed model
Functional linear regression
The proposed FDA model addresses some of the shortcomings described in Section Basic model. We consider the model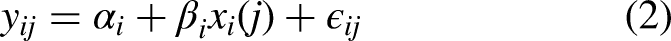
Introducing monotonicity in our model ensures we follow the assumption that on average, an earlier pick number is always more valuable than a later pick number. For example, we want to impose the condition that the 10th draft pick is more valuable than the 11th draft pick, on average. To restrict our functions to be monotonically decreasing in 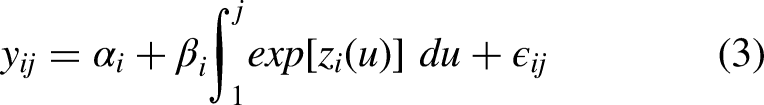
Basis functions
As stated in Section Basic model, the linearity assumption relating to player value is highly questionable. In our proposed model we address this issue and introduce nonlinearity through the use of basis-functions. Basis-functions, are denoted by 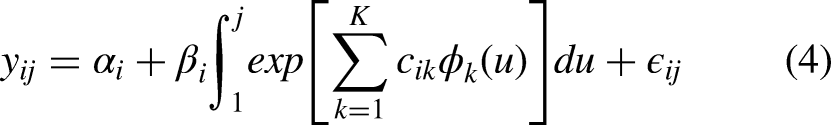
The number of knots specified determines the number of
Smoothing
Now that we have specified our model (4), we can define the smoothing technique. Our linear smoother is obtained by determining the coefficients of the basis-expansion,
Final model
Estimates for 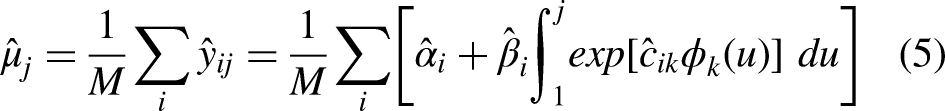
Model (4) is perhaps one of the most basic models that has been developed in FDA, but is of great practical importance.
Model (4) may be viewed as nonparametric (or perhaps more accurately, semiparametric) and therefore shares similarities with the approach taken by Schuckers (2011b) which uses a loess function for smoothing. One advantage that we see in the FDA approach is the simple implementation of monotonicity in the average pick value curve. Also, there is a difference in approach between regressing functions (e.g. the pick value curve for a year) as is done in FDA versus regressing points using loess (e.g. all pick values for a given year). In the latter, there is no consideration of the structure between adjacent picks in a given year. This may be important when some draft years are stronger than other draft years.
In our criticism of the basic linear regression model (1), we point out that there may be error skewness in the data which violates the assumption that
Results
We now explore the results of our proposed FDA model for the four measures of player value described in Section Games-played (
Pick value charts
We define each draft year,
Games-played (
)
Figure 4 provides the predicted curves,
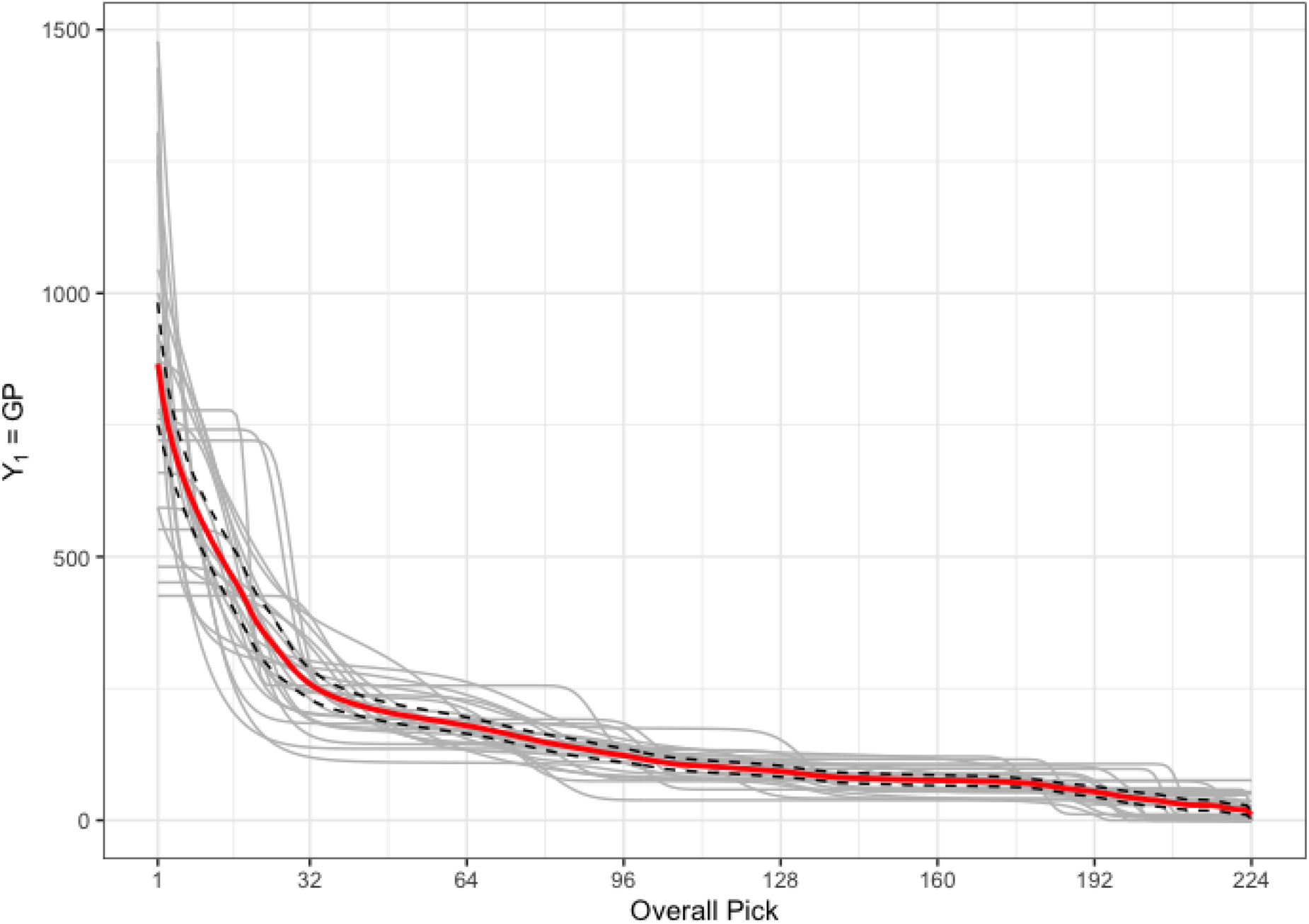
Plot of the measure of player value, GP. Shown are predicted curves,
Figure 4 also shows the 95% pointwise confidence interval for
Average point share (
)
Figure 5 provides the predicted curves,
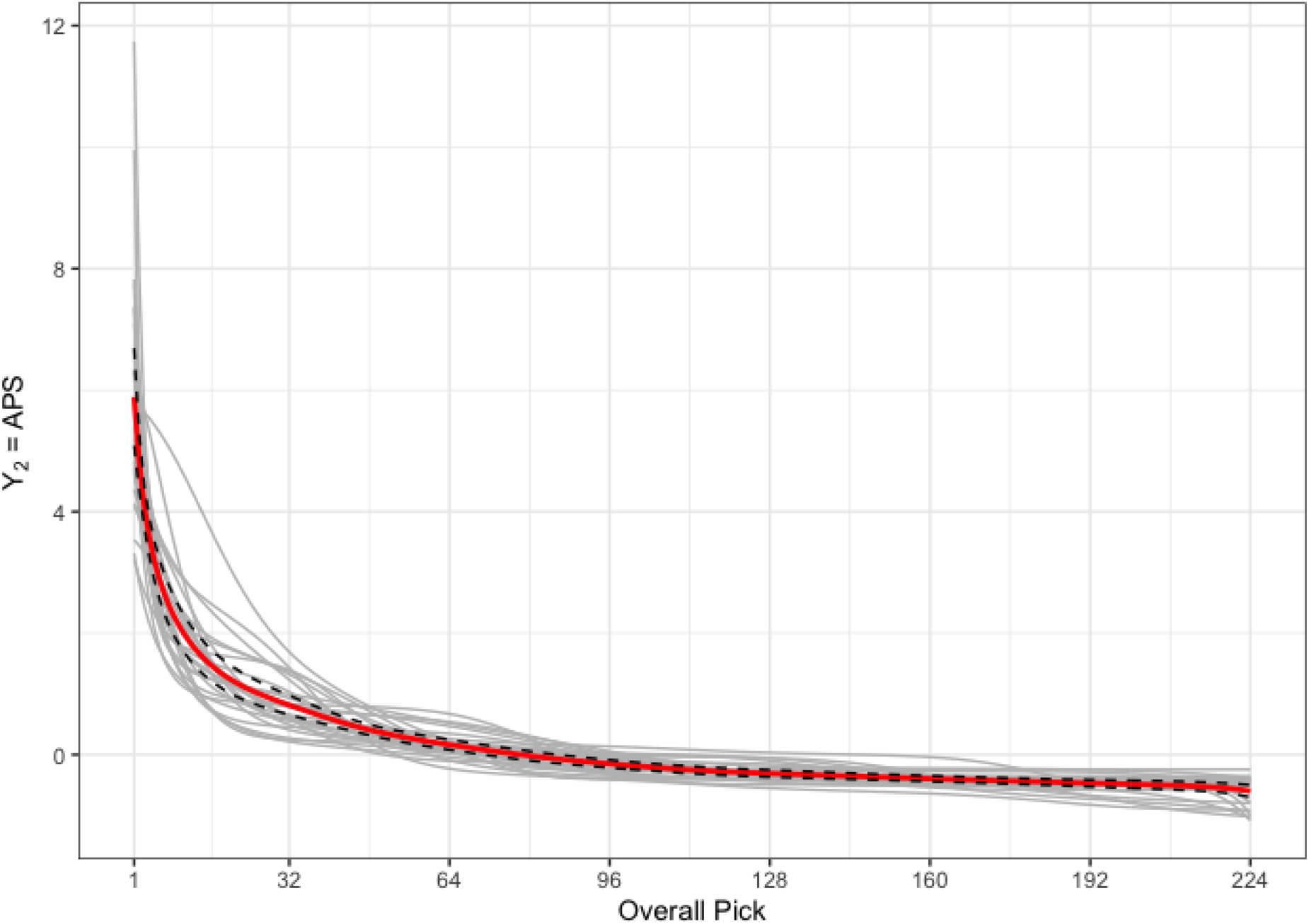
Plot of the measure of player value, APS. Shown are predicted curves,
Examining the 95% pointwise confidence interval in Figure 5 shows that players drafted early in the draft are predicted to provide value, but there is lots of variation in this prediction. We can also see that it is very likely that players drafted 50th or later are unlikely to provide much value over their careers. We observe less variation in APS than in GP.
Total point share (
)
Figure 6 provides the predicted curves,
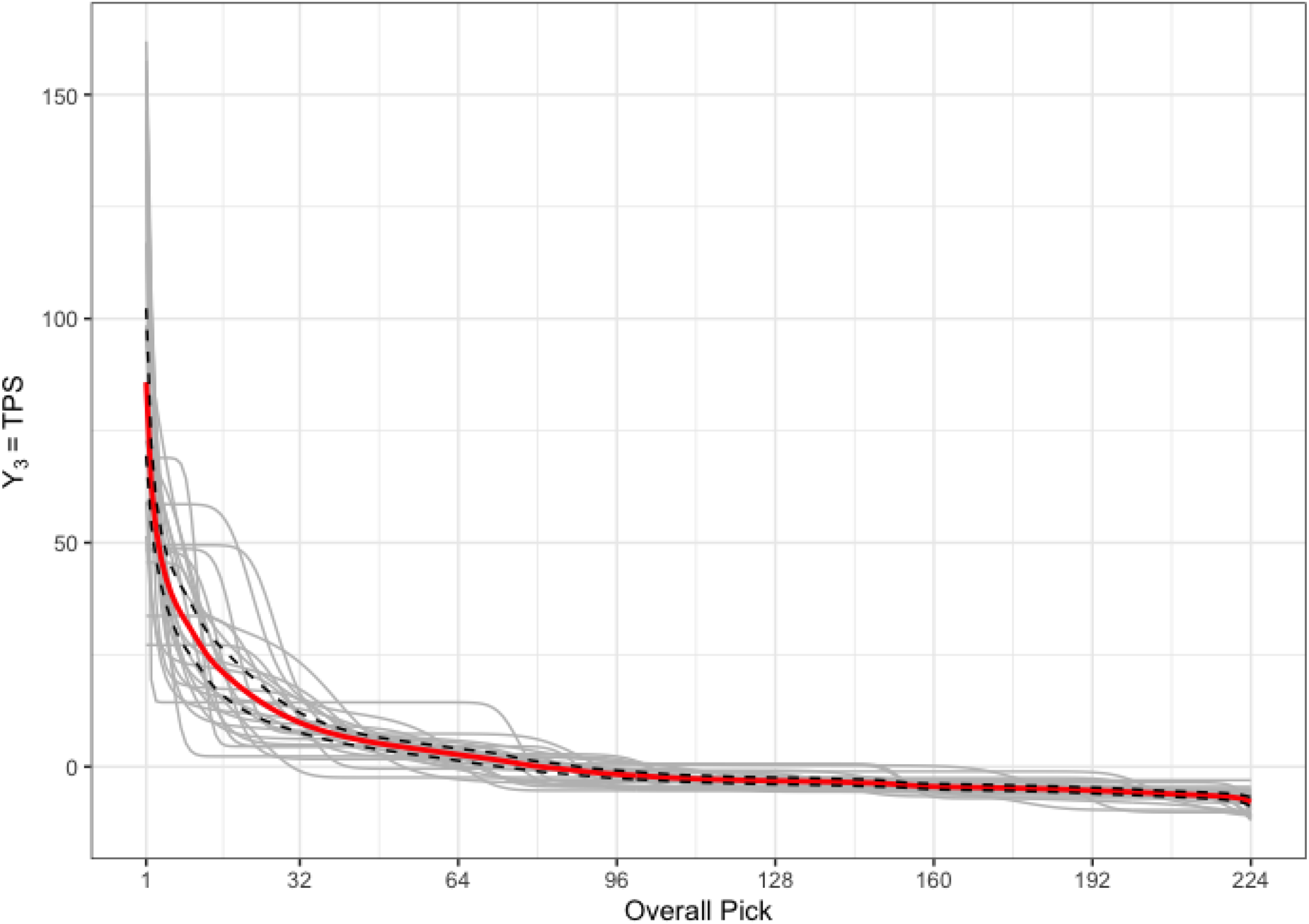
Plot of the measure of player value, TPS. Shown are predicted curves,
The 95% pointwise confidence interval in Figure 6 is similar to the confidence interval in Figure 5. However, the variation for early picks is larger for TPS than it is for APS. We can attribute this larger variation to the difference in career length across players. If two players have similar APS, the player who plays more games in the NHL will have a larger TPS than the player with fewer games.
Standardized salary ranking (
)
Figure 7 provides the predicted curves,
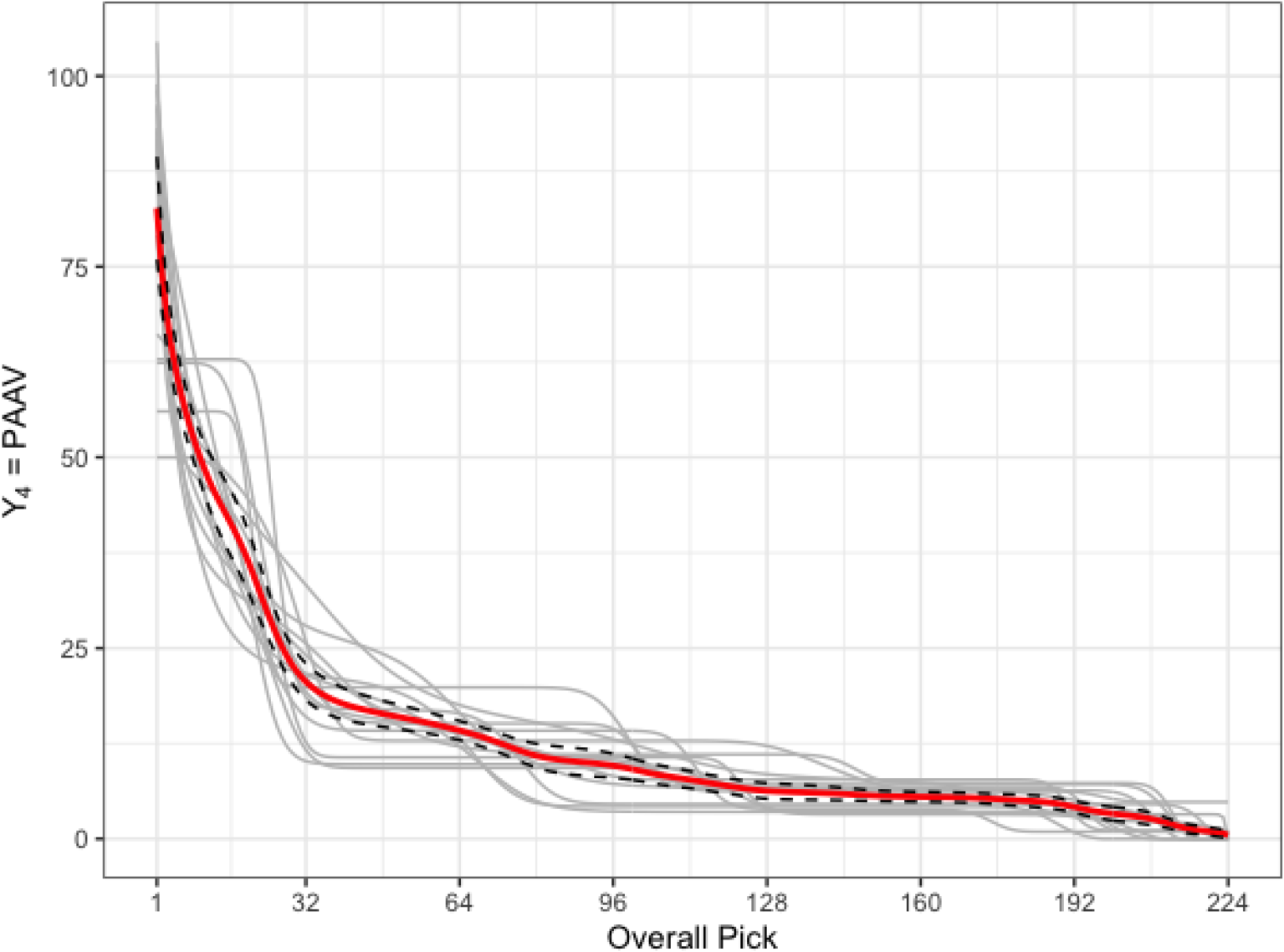
Plot of the measure of player value, PAAV. Shown are predicted curves,
The 95% pointwise confidence interval in Figure 7 shows relatively high variation up to pick 100, and very high variation for early picks.
Comparing value charts
To compare the four measures of player value, we can visualize the corresponding mean curves on one plot. Since all the measures of player value are in different scales, we first need to standardize them. To do this we set the value for
Figure 8 shows these standardized mean curves for the four measures of player value. The mean curves for APS and TPS are quite similar, with the small difference of APS being smoother. We also see that the mean curves for GP and PAAV are similar, and place a higher value overall compared to APS and TPS. This is likely due to GP and PAAV being non-performance based measures since there is a smaller gap between the top players and mid-tier players for these measures. Comparing the measures for longevity, GP and TPS, against the measures for excellence, APS and PAAV, there is not a substantial enough difference to make conclusions.
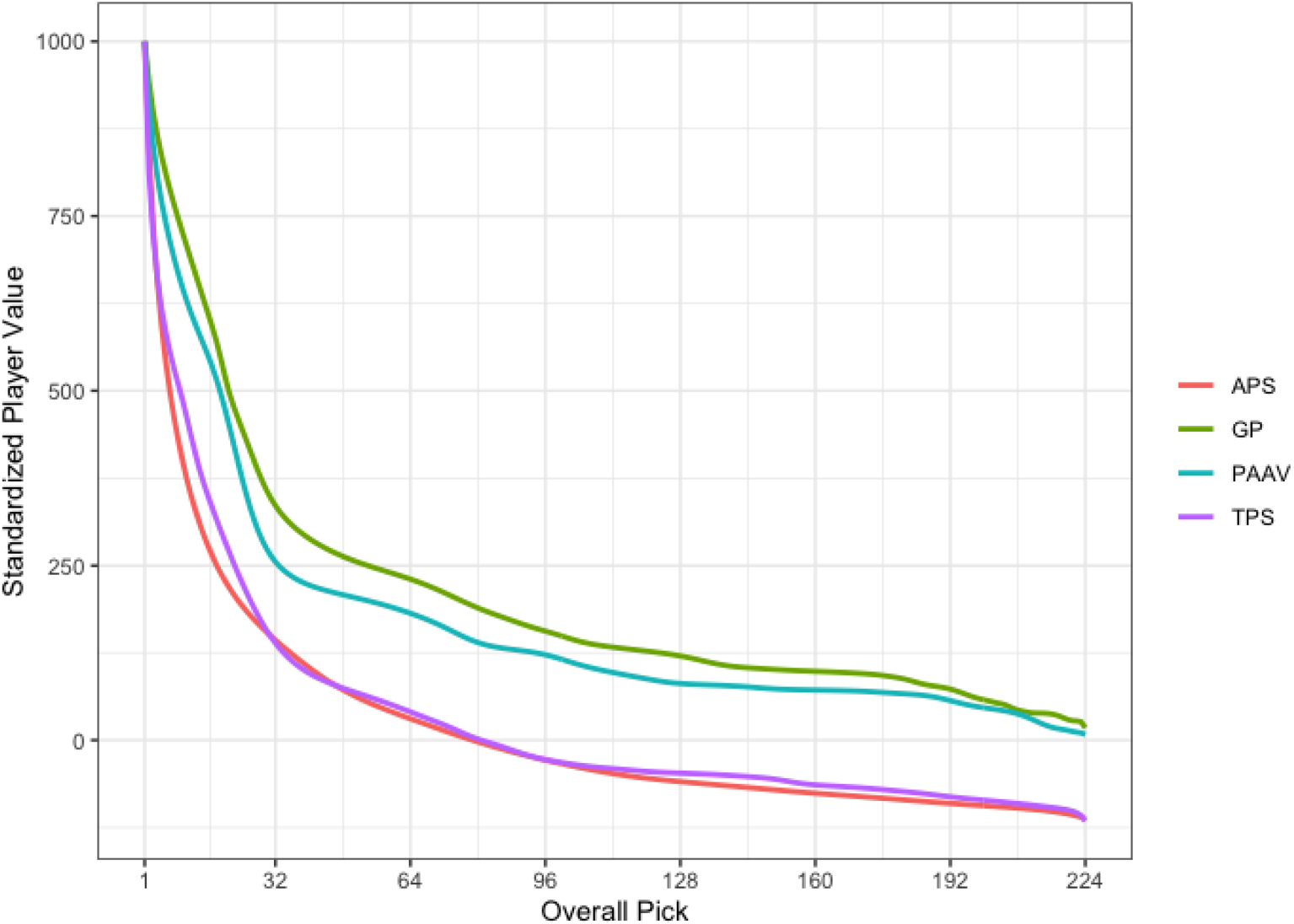
Plot of mean curves from all measures of player value,
Validation
We validate our model with a leave-one-out-cross-validation (LOOCV) for each measure of player value. This method involves taking one draft year out as a test year and completing the analysis, then repeating the process for all draft years in the dataset. We calculate the root-mean-square-error (RMSE) for each test year with the corresponding predicted values and take the average RMSE from all iterations. The RMSE for year
Root-mean-square-error (RMSE) results from the leave-one-out-cross-validation (LOOCV) performed on all measures of player value GP, APS, TPS, and PAAV.

We also investigate our model by comparing the most widely used measure of player value, GP, to the results from Schuckers (2011b), which includes predictions for the number of career GP we expect for draft picks from
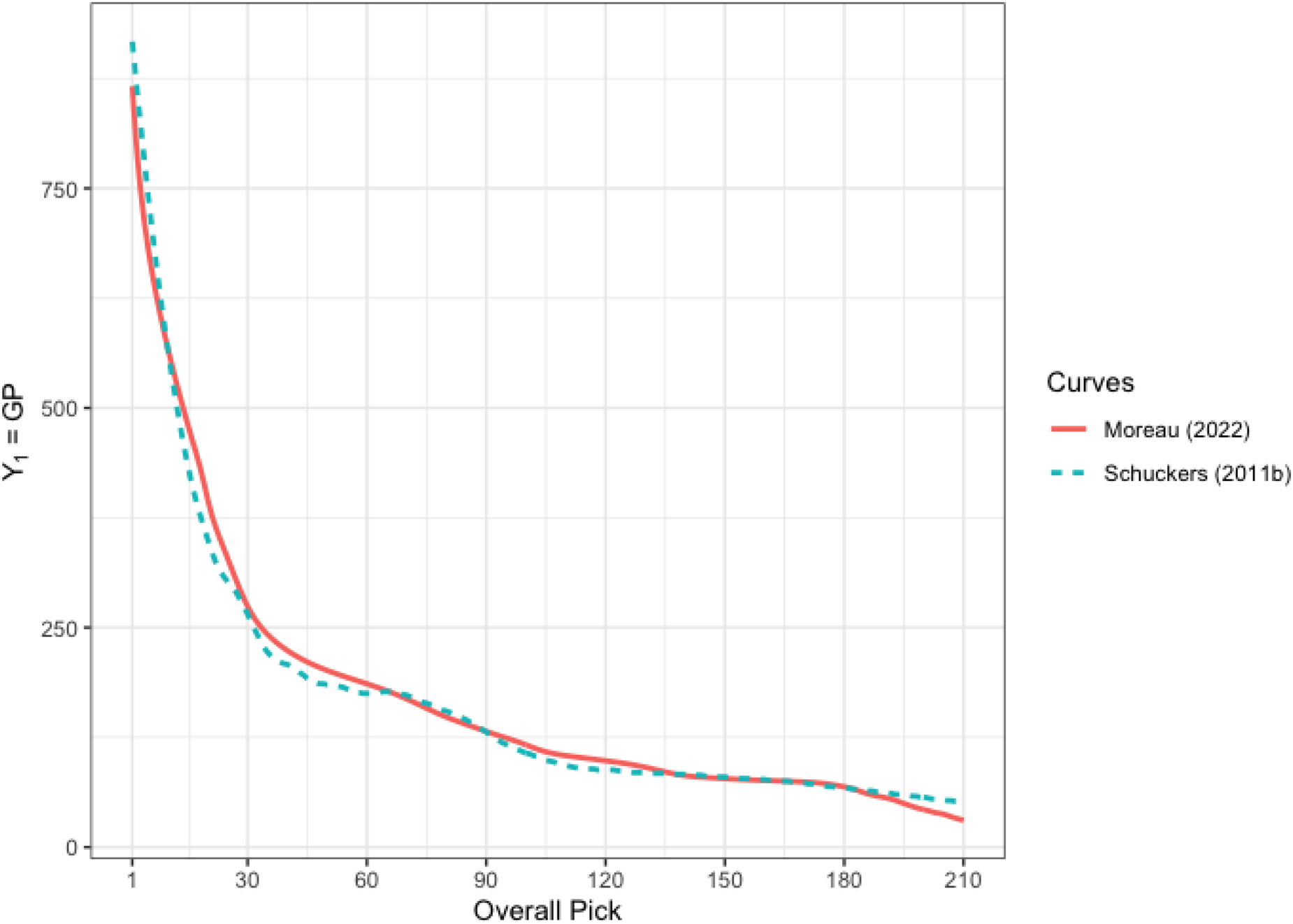
Comparison of predicted mean curves for GP from our derived model (5) and Schuckers (2011b) for draft picks 1–210.
We see the curve from Schuckers (2011b) is closely related to the one derived in this paper. Schuckers curve is not strictly monotonically decreasing, which was stressed as an important property of our proposed model. Besides that, it does not seem that FDA has provided much of a difference.
Having identified
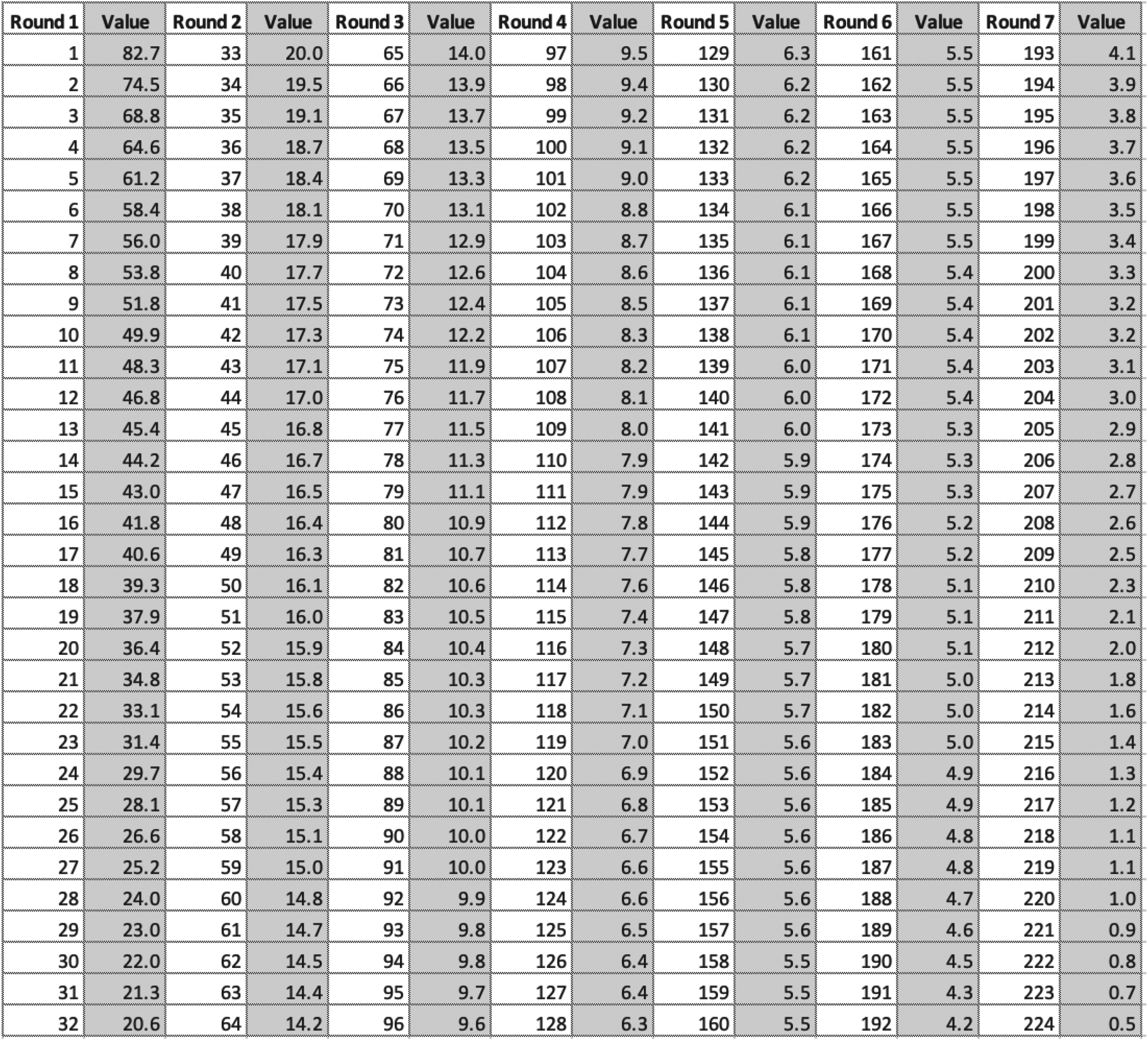
Numerical entries for the pick value chart based on the preferred metric
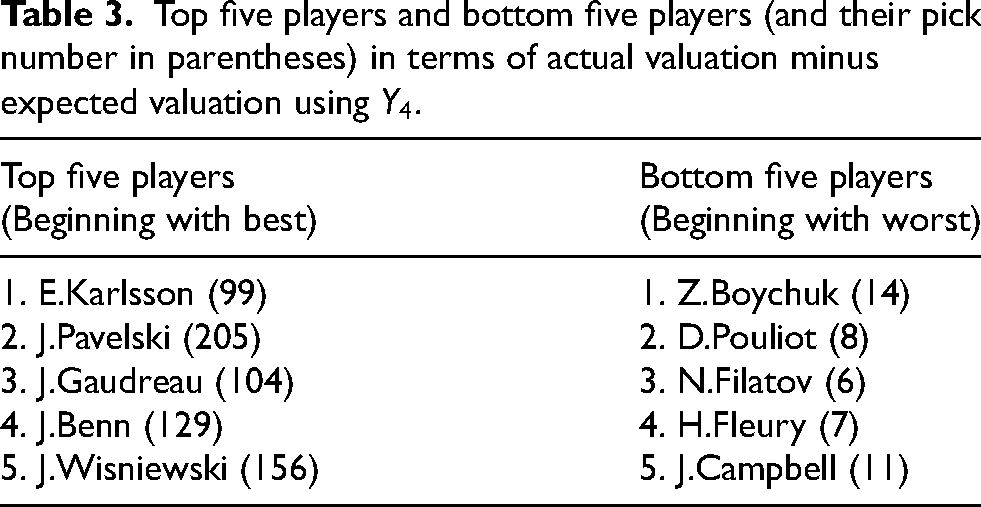
Top five players and bottom five players (and their pick number in parentheses) in terms of actual valuation minus expected valuation using
In the NHL pick value chart literature, there does not seem to be any studies of how value metrics have changed over time. Amongst the metrics
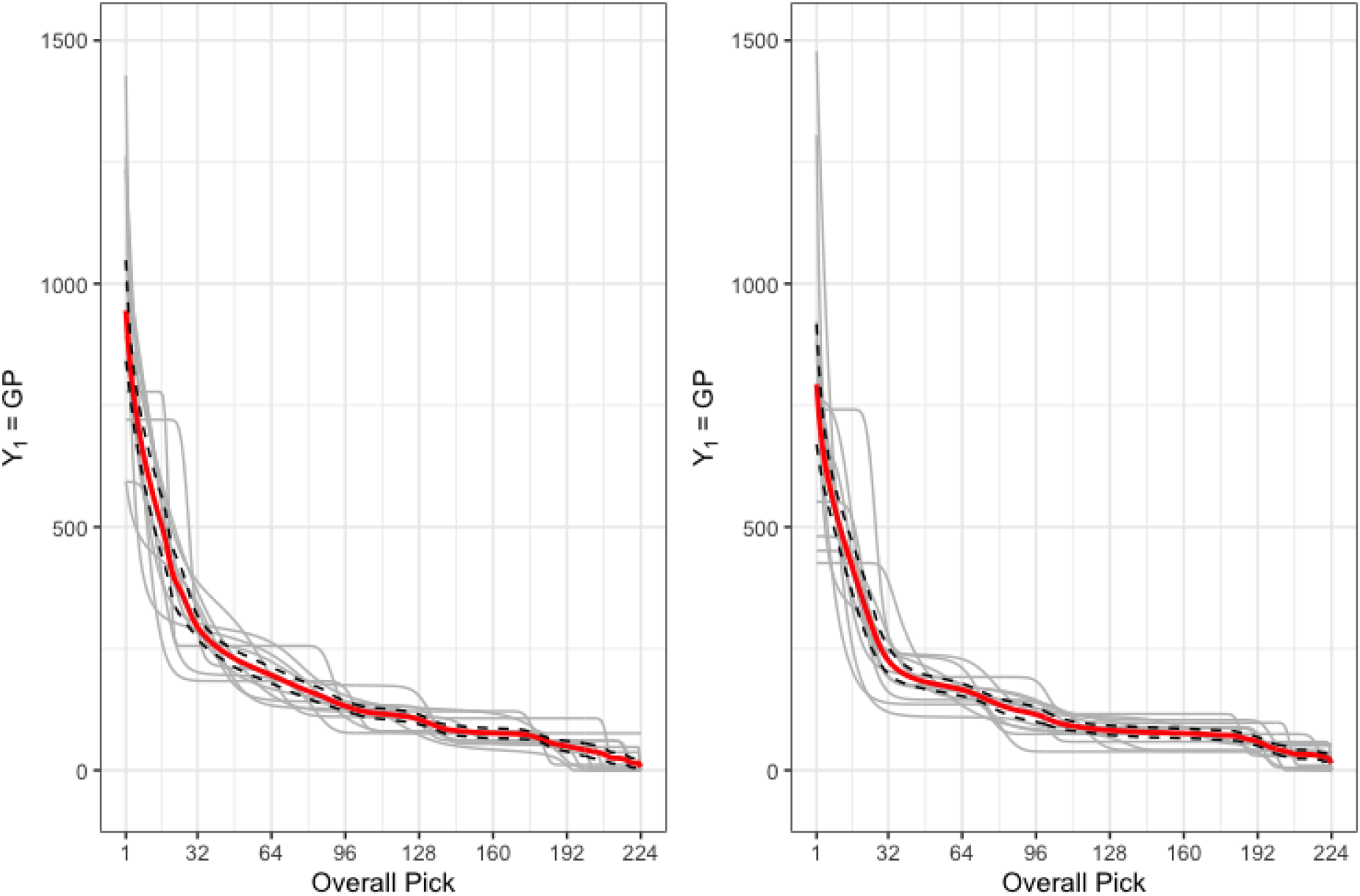
Pick value charts for the games played metric
Discussion
In this paper we develop valuation measures for draft picks in the NHL entry draft and analyze the value of each pick with these measures. We use FDA to find a mean value curve from many observed functions using a nonparametric approach. This approach allows us to use a functional linear regression framework that introduces nonlinearity to account for the differences of players across draft years. The four measures of player value used are games-played (GP), average-point-share (APS), total-point-share (TPS), and a standardized salary ranking (PAAV). The resulting mean value curve for each measure is the predicted value of a player drafted at a certain overall draft pick.
There are limitations to the proposed methods. Limitations of the measures of player value differ by measure, but include accounting for injuries, draft pick bias, and confounding variables such as teammates. Also, for GP, APS, and TPS, we are limited to using data only up until 2006. Surely the NHL has developed and changed over time, so not being able to use recent data may limit our accuracy when comparing our results to the present day. There is also a lack of reported salary data before 2001, and including more data may be beneficial to our results.
Although comparing many measures of player value is useful to determine differences, having a mean value curve from an all encompassing metric would be very useful. Developing one metric from a combination of many metrics and then using our proposed model would be an area of future work which we would like to explore.
Our draft value charts can be useful tools for NHL teams. They can be used as a trade tool, to determine a fair value when trading draft picks with another team. They can also be used as a salary-cap tool, to predict the contract value of a drafted player years in advance of signing.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: R. Moreau is an MSc graduate, H. Perera is Senior Lecturer and T. Swartz is Professor, Department of Statistics and Actuarial Science, Simon Fraser University, 8888 University Drive, Burnaby BC, Canada V5A1S6. Swartz (tswartz@sfu.ca) has been partially supported by the Natural Sciences and Engineering Research Council of Canada. The work has been carried out with support from the CANSSI (Canadian Statistical Sciences Institute) Collaborative Research Team (CRT) in Sports Analytics. The authors thank four anonymous Reviewers whose comments have improved the manuscript.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and publication of this article.