
Abstract

POSITIVE SAMPLE IDENTIFICATION IN THE PRE-ANALYTICAL PHASE
The pre-analytical phase starts from the sample collection and ends when the sample is escorted to be handled automatically. In the pre-analytics, the most important activity after the actual sampling is collecting the appropriate data for that specimen. Traditionally, the data collection is done either manually or there is no follow-up at all. Instead, one has trusted the memory and skill of the people who are handling the samples. It is worth emphasizing that the lack of the follow up information in the pre-analytic phase is one of the major problems encountered in the overall quality control. The reason for the poor data collection is the fact that the present systems do not support the data collection.
Efficient and functional data collection must be ubiquitous and capable of being automated. The data which is collected must be essential in terms of the total process and capable of being utilized in all phases. In addition, the data collection events must be registered automatically, so that its utilization does not create extra work for users of the system.
The use of the positive sample identification offers the possibility to create functional data collection systems. The follow-up data of the activities which has been done on that sample can be attached either automatically or manually to the sample identifier at every stage of the sample's existence. The automatically updated data can be specific codes, created by the program, e.g. identifying who took the sample and the time schedule for sample processing. The user has also the possibility to add manually extra text if he/she so wishes.
POSITIVE SAMPLE IDENTIFICATION IN THE MODULAR LABORATORY AUTOMATION
The main benefit of the positive sample identification can be achived with its use in conjunction with laboratory automation. It has qualities which support and complement traditional automation systems. The speed of handling the read/write data and adequate storage capacity for the data media are vital factors in every branch of the automation process. In the laboratory these factors are critical due to the unique characteristics of each analytical phase. It is essential that the sample can be identified at every stage, there is no leeway for error and there are many targets to be identified.
CHARACTERISTICS OF THE TRADITIONAL LABORATORY AUTOMATION
The basic way that present-day laboratory automation handles the object i.e. the sample tubes, is to place on it some kind of unambiguous identifier, normally a sample number. Generally, the sample number is coded in an electronically readable form, for example a bar code. The control software includes the arrays which are used to guide the movement of the sample in the automation. In practice, this means that at every point where the sample is handled, the sample identification number is read first and subsequently, the CPU's control software transmits information, on how to process that particular tube, to the handling unit.
In general, the functionality of current automation solutions contains some weak points. All the intelligence of the system is in the CPU and if this is not working, not a single part of the automation can be in operation. The construction of the system is complicated and complex.
Since all the functions are coordinated from a single point, during its construction one must have a clear and detailed plan from the very onset and a clear overall view which must include all the instruments to be connected to the automation. Any changes to the system configuration or expansion of the system will require alterations in the control software. Furthermore, these changes demand the input of expert personnel.
CHARACTERISTICS OF THE LABORATORY AUTOMATION BASED ON THE POSITIVE SAMPLE IDENTIFICATION
The positive sample identification brings two basic qualitites to automation solutions. The identifier which accompanies the tube can contain a remarkable amount of information. The information can be read quickly and accurately. These two qualities mean that the control of the automation can be decentralized to the function modules which are linked to the conveyor and the automation line. The decentralization usually begins with the identification memory so that the “itinerary” is written, this means that the memory circuit accompanying the sample contains information about all the function modules to which the sample must be routed.
The function modules themselves are sufficiently independent and versatile that they can observe the sample tube traffic in the conveyor around their own site. The modules will read the identification memories of all the passing tubes and if there is a note of this module, the sample will be removed from the main conveyor for handling in that function module.
In this kind of solution, the role of the control software differs considerably from the traditional pattern. The control software controls the loading level of the system's modules and it observes that the “traffic” flows smoothly. In addition, the control software can be used to transmit updated information of possible extra research requests about samples in the process. For example, if a request for supplemental activity is received, the location of the sample on the automation line is identified and the route information of the identification memory is updated to correspond to the altered situation. Similarly, it is possible to deliver further instructions to individual samples if required. The read/write speed of the positive sample identification makes it possible to read and write the sample data “at full speed” at the same time when the sample tube is still on the automation line. It is not necessary to stop the tube for data access or up-dating. Thanks to these features and the benefits of positive sample identification, the laboratory automation solutions which use it are 5 – 7 times faster than traditional techniques, e.g. those based on the use of a bar code.
THE USE OF THE POSITIVE SAMPLE IDENTIFICATION IN THE ANALYZERS
In most automatic analyzers the connection can be made in parallel with current bar code readers. This means that the identification antenna is installed for example under the bar code reader. The identification signals are linked to the programmable interface module from both the reader and the antenna. The signal will continue to the analyzer in the same form as if it had come directly from the bar code reader, a diagram of the connection is depicted in Figure 1.
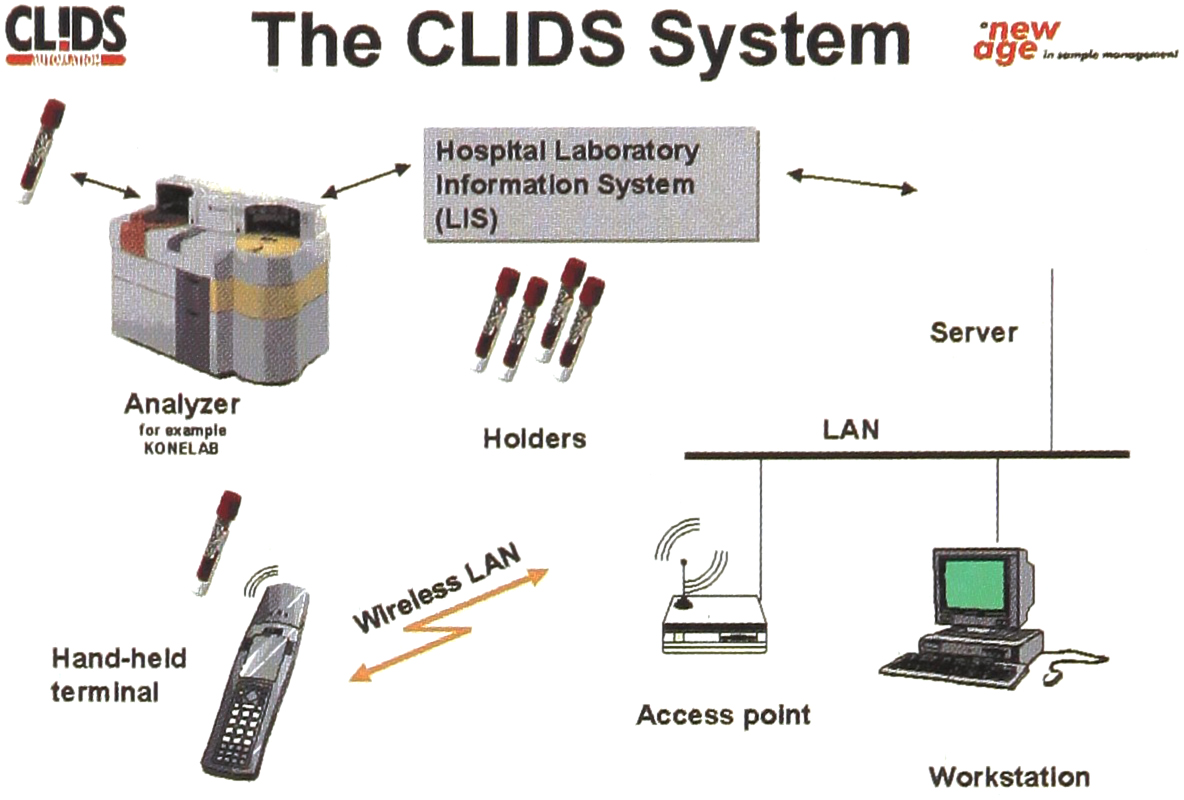
In most automatic analyzers the connection can be made in parallel with current bar code readers.
With this system the analyzer is able to handle both identification solutions without requiring that any modifications are made to the device. Equally, with this kind of solution, the interface constructed between the analyzer and the laboratory data system will not be altered in any way.
THE COMPARISON BETWEEN POSITIVE SAMPLE IDENTIFICATION AND BAR CODE
The capacity of the currently available electronic identification systems is 1 Kbit – 8 Kbit. In terms of characters this is equivalent to 256 – 2,048 characters. In the presently-used bar codes, the corresponding capacity is 38 – 128 characters. The time required to read the instructions with the positive identification system is 0.2 – 0.6 sec, whereas with bar codes it is a minimum of about 1 sec and frequently, if there is much to be read, even longer.
Any organization which uses the bar code for sample identification in the laboratory automation has to confirm that the used bar codes are also readable to the automation. This means that one must have access to high quality bar code printers. The stickers must also be of high-level quality and the individuals whose job is to stick the bar codes onto the sample tubes must ensure that they are placed in a position that the scanners can actually read them.
In contrast, with positive sample identification, the memory circuit in use is always readable, when it is brought within range of the readers. The memory circuit is not disposable but it can be erased and reused. The memory circuits can be re-used hundreds of thousands of times. A memory circuit which was sufficiently small to be suitable for use in positive sample identification was initially marketed in 1993.
In Finland, the construction of solutions which were based on this technology started in 1994. At the moment the first installations are in place and at the time of writing all the experience emphasizes that the theoretical advantages described in this article can be attained in practice. Future research will reveal not only the versatility of this system but also highlight other potential advantages. For more information contact: