
Abstract
Sharing datasets that change (through creates, updates, deletes) poses challenges to data consumers, including reconciling historical versioning and managing frequent changes. This is evident for Knowledge Graphs (KGs), materialized from such datasets, where synchronization happens through frequent regeneration. However, this is time-consuming, loses history, and wastes computing resources through redundant processing. We present a KG generation approach that efficiently handles evolving data sources with different change signaling strategies. We investigate change signaling strategies of real-world datasets, propose corresponding change detection algorithms, and introduce a declarative approach based on the RDF Mapping Language (RML) and Function Ontology to materialize changes for evolving KGs. Detected changes can be automatically published as a Linked Data Event Stream (LDES), using the Activity Streams 2.0 vocabulary to describe changes and communicate them over the Web. We implement our approach in the RMLMapper as Incremental RML and evaluate it both functionally, and quantitatively using a modified version of the GTFS Madrid Benchmark and several real-world data sources. Our approach reduces storage and computing requirements for generating and storing multiple KG versions (up to 315.83x less storage, 4.59x less CPU time, and 1.51x less memory) and reduces KG construction time up to 4.41x. Performance gains are more pronounced for larger datasets, while our approach's overhead partially offsets benefits for smaller ones. Overall, our approach lowers the cost of publishing and maintaining KGs and, via LDES, supports timely, Web-native dissemination of changes. We plan to optimize our change detection algorithms and use windowing to support streaming data.
Keywords
Introduction
Most real-world datasets are not static. Whether it be the inclusion of new data points, the rectification of errors, or the evolution of data collection methodologies, datasets are, by their very nature, subject to continuous change. The change frequency may vary, with some datasets undergoing rapid transformations while others experiencing a more gradual evolution. Regardless of the particular change frequency, data consumers find themselves impacted by these alterations. Consumers must take this continuous change flow into account when using the data (Valencio et al., 2013) and incorporate these changes to stay synchronized with the current state of the original dataset. This leads them to face challenges such as storing multiple versions to keep historic records, having enough capacity to handle any dataset’s size when processing changes, and keeping up with dataset’s change frequency. Moreover, data source changes impact data integration processes, such as Knowledge Graph (KG) generation, which are forced to fully repeat their computations every time one of the original data sources changes (Denny et al., 2017; Rojas et al., 2021). This approach could become unsustainable when dealing with large volumes of data. It could also affect applications depending on (near) real-time information: A generated KG supporting the application might be already outdated if the source data sources change faster than the (re-)generation process. In general, this may result into: (i) Wasted computing resources and time due to unnecessary reprocessing of all data, especially when large parts remain unchanged, (ii) loss of historic records given that commonly only the latest version remains available, and (iii) outdated KGs when the data integration process is not able to keep up with the change frequency of the original data sources.
Change Data Capture (CDC) techniques (Gupta & Giri, 2018; Hao et al., 2023) try to address this problem by capturing and characterizing data changes using, for example, database transaction logs, database triggers, comparing snapshots of data dumps, etc. Denny et al. (2017). However, current approaches for integrating heterogeneous data sources into KGs (Daga et al., 2021; Das et al., 2012; Dimou et al., 2014; Lefrançois et al., 2017; Vu et al., 2019) cannot use existing CDC techniques, as they mainly focus on a specific type of data source (e.g., relational database logs). In this paper, we introduce a declarative and incremental KG construction approach, capable of handling heterogeneous and changing data sources based upon a CDC-based technique. Our approach can cope with different data change signaling strategies, allowing to detect and incorporate these changes in an incremental and continuous fashion into an existing KG. We enumerate and discuss different data change signaling strategies (both explicit and implicit) observed in real-world datasets, that are used to communicate changes to data consumers. We also propose a set of algorithms to handle these change signaling strategies for and during KG construction. Our approach only regenerates the parts of a KG that were changed in the original data source(s) (created and updated), while deleted data entities are detected, labelled as such and made explicit.
We opt for a declarative approach to incrementally generate KGs given its engine-agnostic and extensible nature to handle different types of data sources (Van Assche et al., 2022a). We implement our approach using resource description framework mapping language (RML) as declarative mapping language to generate resource description framework (RDF), and function ontology (FnO) for describing data transformations and state management functions, which together constitute our approach called Incremental RML (IncRML). However, our approach is not dependent on these particular technologies and could be implemented with any other declarative mapping language and data transformation vocabulary. Furthermore, we allow to optionally and automatically publish these changes on the Web in the form of a Linked Data Event Stream (LDES) (Van Lancker et al., 2021). LDES allows publishing data changes as an append-only event log that consumers can read to synchronize their KG with the latest data available. We show how it is possible to produce an LDES from the detected data changes, materialized with our IncRML approach, which we choose to describe semantically with the W3C Activity Streams 2.0 vocabulary (Snell & Prodromou, 2017).
We extend our previous work (Van Assche et al., 2022b) on aligning LDES and RML, where we introduced a preliminary approach for continuously generating a KG by detecting and materializing changes in its data sources. Our previous work focussed only on handling data creations and updates. In this paper, we extend that work to also detect and communicate deletions. We also include extensive functional and performance evaluations using (i) different types of real-world datasets, (ii) an extended version of the GTFS Madrid Benchmark (Chaves-Fraga et al., 2020) that allows to control the type and amount of changes in a data source, and (iii) a set of test cases that guarantee the support for different change signaling strategies. To keep this paper self-contained, we include the discussions of our previous work along with its extensions. Concretely, our contributions are the following: An overview of different history and change signaling strategies observed in real-world data sources. A set of CDC-based algorithms to detect changes in any of these change signaling categories. The integration of these algorithms into a KG construction pipeline using RML, FnO, and (optionally) LDES. An extensive evaluation and benchmark on the impact and performance of incrementally generating and updating KGs.
Overall, our approach is more efficient in terms of execution time and computing resources for generating the RDF quads of a KG, in exchange for a small overhead when the KG is constructed the first time. We observe that by materializing only detected changes when generating KGs, our approach uses 3.24–315.83x less storage to store multiple versions of a KG while also consuming less computing resources (0.85–4.59x less CPU time, 0.72–1.51x less memory consumption) depending on the dataset. The RDF generation time is reduced by 0.97–4.41x depending on the data size. To guarantee a fair comparison with a traditional full KG re-materialization approach, we measured the total time that it takes to go from existing data to an updated triplestore using SPARQL
IncRML is usable for any kind of data source, as supported by the underlying declarative mapping language. While we use RML as mapping language in our implementation, the logical definitions and algorithms of IncRML may be implemented with other mapping languages since they rely on widely supported features such as IRI templates and data transformations (Van Assche et al., 2022a). IncRML also allows for semantically describing data changes using any ontology of choice (e.g., W3C Activity Streams 2.0) and then publishing such changes with a structured approach such as LDES or any other data publishing strategy. Thanks to our work, data source changes can be integrated faster and with less resources into live and replicated KGs while allowing to keep access to the historical records in the form of an LDES. Although we observed that further optimizations are needed for triplestores to effectively support larger data updates through standard SPARQL UPDATE queries.
The remainder of this paper is structured as follows: Section 2 discusses related works, Section 3 introduces the main technological concepts used in this work, namely RML, FnO, and LDES. Section 4 presents different identified change signaling strategies and describes the rationale of our approach. Section 5 shows how we implement our approach. In Section 6, we present our evaluation design. Section 7 discusses our results, and Section 8 concludes.
Related Work
In this section, we discuss related work on (i) mapping rules for declarative KG generation describing how a KG can be generated, (ii) CDC approaches for detecting changes in data sources, (iii) versioning strategies for KGs to store the history of data sources and its impact on storage for producers and consumers, (iv) versioned generation of KGs, and (v) incremental mapping rules execution for optimizing execution time and resource usage.
Mapping Rules for Declarative KG Generation
Declarative mapping rules for KG generation is an active research domain since the introduction of the R2RML W3C Recommendation (Das et al., 2012) for transforming relational databases into an RDF KG (Cyganiak et al., 2014). R2RML was extended as the RML (Dimou et al., 2014; Iglesias-Molina et al., 2023) to support heterogeneous data sources (e.g., JSON, XML, CSV) while keeping backwards compatibility with R2RML. Recently, a survey (Van Assche et al., 2022a) was performed of existing approaches and systems for declarative KG generation from heterogeneous data. RML is widely used for declarative KG generation and was extended to support exporting RDF to various targets such as files and SPARQL endpoints (Van Assche et al., 2021), RDF Collections and Containers (Debruyne et al., 2017; Michel et al., 2017), and access to Web APIs (Chortaras & Stamou, 2018; Van Assche et al., 2021).
Besides RML, other declarative mapping languages were proposed to transform heterogeneous data sources into RDF such as xR2RML (Michel et al., 2015, 2017), SPARQL-Generate (Lefrançois et al., 2017), SPARQL-Anything (Daga et al., 2021), ShExML (García-González et al., 2020), D-REPR (Vu et al., 2019), and OTTR (Skjæveland et al., 2018). xR2RML also extends R2RML with support for heterogeneous data sources and RDFS Collections and Containers (Brickley & Guha, 2014). SPARQL-Generate and SPARQL-Anything do not extend R2RML, but SPARQL instead to transform heterogeneous data sources into a KG. Therefore, they can reuse existing SPARQL engines and syntax. Similar to SPARQL-based approaches, ShExML uses Shape Expressions (ShEx) (Prud’hommeaux et al., 2014) as syntax, while D-REPR defines its own syntax.
Currently, the W3C Community Group on KG Construction 1 is working on standardizing RML as a W3C Recommendation (Iglesias-Molina et al., 2023) and is supported by multiple implementations such as the RMLMapper (Dimou et al., 2014), Morph-KGC (Arenas-Guerrero et al., 2022), or SDM-RDFizer (Iglesias et al., 2020). Therefore, we decided to implement our approach with RML as the declarative mapping language in this work, but any mapping language may be used.
Data transformation support is an important requirement when generating KGs from heterogeneous data sources (Van Assche et al., 2022a), using, for example, the FnO (De Meester et al., 2020), SPARQL Functions (Harris & Seaborne, 2013), or FunUL (Junior et al., 2017). FnO is a popular vocabulary for describing functions to perform data transformations, and it is integrated with RML through FNML 2 . This way, RML+FnO mapping rules can perform both the generation of a KG and data transformations without requiring ad hoc or use case specific scripts. We use FnO in this paper to integrate the implementation of our change detection algorithms with RML to incrementally generate a KG from heterogeneous data sources.
Change Data Capture
CDC (Gupta & Giri, 2018; Hao et al., 2023) refers to a technique, primarily used in databases, to identify and capture data changes so that those changes can be tracked, recorded, and propagated to other systems or applications. CDC’s primary purpose is identifying and capturing creations, updates, and deletions of data in a dataset to enable (near-)real-time synchronization of data across different systems. Most approaches focus on data sources which provide some sort of change signaling mechanism such as transaction logs, snapshots, triggers, or timestamps. Moreover, data sources may offer different granularity regarding change signaling, for example, change signaling on parts of the data source or the whole data source (Umbrich et al., 2010).
Log-based approaches (Hao et al., 2023; Ma & Yang, 2015) use database transaction logs to determine which changes were performed to the underlying data. As log systems are implementation-specific, these approaches are specific to each database. Snapshot-based approaches (Denny et al., 2017) compare the current version of a data source with previous versions to extract changes, requiring sufficient resources to store and compare these versions. Trigger-based approaches (Hu et al., 2019; MadeSukarsa et al., 2012; Valencio et al., 2013) hook into a data source to execute a trigger on each change, requiring support for triggers from the data source (e.g., stored procedures in relational databases). Timestamp-based approaches (Goyal & Dyreson, 2019) analyze a last-modified timestamp of a data source to detect and extract changes, requiring data sources to provide timestamp-annotated data.
Although these approaches clearly have their merit, many data sources do not signal their changes nor support triggers when a data record is changed (e.g., data streams, files, or Web APIs). Therefore, existing CDC approaches are insufficient to cover heterogeneous data sources which do not signal their changes to consumers. In this work, we combine and extend Timestamp-based and Snapshot-based approaches for detecting implicit and explicit changes.
Versioning of KGs
Several approaches for versioning of (RDF) KGs have been proposed (Papakonstantinou et al., 2016). Three main RDF archive storage strategies can be identified (Fernández et al., 2015): (i) Change-Based, (ii) Timestamp-Based, and (iii) Independent Copies. Change-Based only stores the changes; Timestamp-Based uses timestamps to define when a specific version is valid; and Independent Copies stores a copy of the data source each time it is updated.
Change-Based approaches include: R&Wbase (Vander Sande et al., 2013), based on Git 3 ; a Version Control Based RDF storage approach using patches, similar to Frommhold et al. (2016); Cassidy and Ballantine (2007), SemVersion Völkel et al. (2005), R43ples Graube et al. (2014), and Im et al. (2012). Timestamp-Based approaches for accessing different data source versions include: Memento (HTTP) (de Sompel et al., 2013) and x-RDF-3X (Neumann & Weikum, 2010) (SPARQL). OSTRICH (Taelman et al., 2018) and TailR (Meinhardt et al., 2015) are both hybrid approaches, combining all three strategies for efficient query operations. All approaches implementing the 3 strategies put the burden of resolving versions on the data producer.
LDES (Van Lancker et al., 2021) uses an Independent Copies approach on a entity level (aka. member in LDES terminology) for versioning. An LDES entity/member may be defined as a named node and its properties, as defined by its Concise-Bounded Description 4 , or as named graph and its contained triples. However, Independent Copies suffers from scalability problems as storage is not infinite (Fernández et al., 2015), LDES addresses this by dropping the oldest versions of entities in the event stream, according to a specific and configurable retention policy. Since LDES consumers are aware of the retention policy, they can decide to store the LDES members themselves if they need to for their particular use case. For example, if an LDES producer’s retention policy is 7 days and a consumer requires at least the last 30 days of data, the consumer must store a copy. If a consumer does not require history information longer than 7 days, it can solely rely on the LDES producer’s data. LDES allows consumers to synchronize their local copy of the member collection, similar to a Copy and Log approach (Salzberg & Tsotras, 1999). This way, versioning is resolved on the consumer side and several versioning strategies can be applied independent of the publisher. In this work, we allow our approach to use LDES as a publishing strategy for communicating KG changes on the Web.
Versioned Generation of KGs
Ontologies (Change Detection Ontology (Randles & O’Sullivan, 2022, 2023)) and benchmarks (EvoGen Benchmark Suite (Meimaris & Papastefanatos, 2016), BEAR benchmark (Fernández et al., 2015)) were proposed for versioned KGs. However, they are tied to a specific ontology or focus on querying the versions while we focus on the generation in this work. The EvoGen Benchmark Suite (Meimaris & Papastefanatos, 2016) allows generating synthetic versioned RDF data for benchmarking purposes. BEAR (Fernández et al., 2015) proposed a benchmark for Semantic Web archiving systems to evaluate full materialization of different versioned KGs, only materializing the changes, or annotating triples when they were created, updated, and deleted. However, both focus on materialized RDF for benchmarking query systems, while in this work, we focus on the generation of different KG versions from non-RDF heterogeneous data. The Change Detection Ontology (Randles & O’Sullivan, 2022, 2023) allows describing changes inside the original data sources as a changelog and is used in the MQ framework (Randles et al., 2022) to generate new KGs if changes are detected, using R2RML mappings from CSV, XML, and relational databases. However, this solution is tightly coupled with a specific ontology, while we aimed for a more generalized approach, that allowed to use any ontology to describe the detected changes.
Incremental Mapping Rules Execution
Execution planning of mapping rules has seen uptake in the KG community (Van Assche et al., 2022a) as seen in tools such as Morph-KGC (Arenas-Guerrero et al., 2022) and SDM-RDFizer (Iglesias et al., 2020). Both systems plan their execution and remove duplicates before they execute RML mapping rules to reduce the number of data records and improve performance. However, they consider that executing these mapping rules only happens once: If the datasets change, all the mapping rules must be fully executed again. Thus, incremental KG generation is not considered. Besides execution planning with Morph-KGC and SDM-RDFizer, existing work on incremental KG generation does not consider heterogeneous data as it focus on relational databases such as using log files to determine changes (Konstantinou et al., 2014), triggers to update virtualized views (Vidal et al., 2013), or indexing triples (Pu et al., 2014). There is no approach which supports heterogeneous data – besides relational databases – for example, JSON, XML, CSV. In this work, we present a novel approach to also detect changes in heterogeneous data and making them available to consumers, even if the data sources do not signal their changes. While our experiments focus on incremental KG generation from single data sources, multiple and heterogenous data source cases are also supported through the use of RML.
Background
In this section, we provide an introduction to the (i) RML, (ii) FnO, and (iii) LDES. These technologies came forward from Section 2 as prevalent methods to describe how a KG could be constructed from input datasets (RML), performing data transformations and generic functions during KG construction (FnO), and semantically describing and continuously publishing the KG changes (LDES) to allow for KG replication and synchronization.
RDF Mapping Language
RML (Dimou et al., 2014; Iglesias-Molina et al., 2023)
5
is an extension of W3C Recommendation R2RML (Das et al., 2012) to support heterogeneous data sources besides relational databases. RML mapping rules consist of Triples Maps (Listing 1: Lines 1–17) which define how the terms (subject, predicate, and object) of an RDF triple are generated. A named graph can also be specified using a Graph Map for generating RDF quads. Each Triples Map has one Logical Source (Listing 1: Lines 2–4), one Subject Map, and zero or more Predicate Object Maps. The Subject Map (Listing 1: Lines 6–9) defines how the subject IRIs are generated from the data source as defined by the Logical Source. This Subject Map also includes a Graph Map to specify the named graph of the RDF quad (Listing 1: Line 8). Predicate Object Maps (Listing 1: Lines 11–16) consist of Predicate Maps (Listing 1: Line 12) to specify the quad’s predicate and (Referencing) Object Maps (Listing 1: Lines 13–15) for the quad’s object. The Subject Map, Predicate Map, Object Map, and Graph Map are all Term Maps, generating an RDF term (an IRI, blank node, or literal). A Term Map may always generate the same RDF term with RML uses Triples Maps with a Logical Source, a Subject Map, Graph Map, and zero or more Predicate Object Maps to specify how RDF quads must be generated from the referenced data source.
The FnO (De Meester et al., 2020) semantically describes and declares implementation-independent functions and their relations to related concepts such as input parameters, outputs, mappings to concrete implementations, and executions. The alignment between RML and FnO (via FNML (De Meester et al., 2020)) specifies how a data transformation must be performed by specifying the function to execute (Listing 2: line 5) and its values (Listing 2: Lines 8–11). FnO is standalone which allows describing data transformations in a declarative way with or without RML. FnO is integrated in RML through an

FnO defines a data transformation by specifying the function and the function's values. FnO is aligned with RML through a fnml:FunctionMap which is an RML Term Map. The function toUppercase is executed on all referenced name data values of the data source.
LDES is an RDF data publishing approach fostered by the EU Semantic Interoperability Community
6
and officially adopted as a standard specification by the Flemish government through its Flemish Smart Data Space project
7
. LDES defines datasets in terms of a collection of immutable objects (a.k.a. members) such as versioned entities or observations (Listing 3), where every member must have its own unique IRI (Van Lancker et al., 2021). The main goal of a LDES is to enable efficient replication and synchronization of datasets over the Web. LDES allows data consumers to traverse the collection by relying on the TREE specification (Colpaert, 2022)
8
to semantically describe hypermedia relations among subsets or fragments of the data (Figure 1). These hypermedia relations can be defined in multiple ways, for example, by publishing fragments organized by time or by version, configuring tree-like data structures that can be efficiently traversed by clients. TREE also allows further describing the content of each member in an LDES collection through a SHACL shape ( Linked data event stream (LDES)’s structure allows to traverse the collection by clients with semantic descriptions of the collection’s relations. A data collection as an LDES with one member. The LDES member provides a sensor value at a given time and version.

In this section, we describe our incremental KG construction approach, which consists of the following high-level steps:
Petect changes in any heterogeneous dataset; construct RDF data from these changes; explicitly publish the changes with explicit semantics.
Section 4.1 introduces the overall approach. How to detect changes in any heterogeneous dataset requires us to first understand how a particular dataset may signal changes (step 1a), hence, Section 4.2 discusses the various change signaling strategies along 3 dimensions: History, change communication, and change types. Then, Section 4.3 describes the algorithms to detect both implicit and explicit changes in data collections (step 1b). Where Sections 4.1–4.3 focus on detecting and describing changes in existing datasets, Section 4.4 contextualizes this work as part of an entire processing pipeline, from original data to a published event stream of RDF data, integrated in a mature KG construction and publication pipeline (steps 2 and 3). The overall approach is shown in Figure 3, top (green) row.
Incremental RML
IncRML refers to the implementation of our proposed approach for incrementally generating a KG from heterogeneous data sources. It consists mainly of 2 high-level steps: (i) Detect changes in data sources, independent of whether they are signaled explicitly or implicitly, and (ii) enriching the original target ontology mapping to include additional metadata that makes explicit which quads are created, updated, and deleted. In general, our approach maximally relies on existing standards and specifications, both for the generation and the publishing of KGs. We aim at reducing execution time and resource consumption during the RDF generation process, as only the changes between consecutive data source versions are materialized. Through a CDC-based approach, we detect and extract changes during the KG generation process and (re-)generate the RDF triples/quads of all the entities (or members in LDES terminology) affected by such change. Each materialized member may include additional metadata specifying, for example, the type of change, the time of change, etc, as specified by LDES. Our approach does not limit the description of changes in data members to a specific ontology, thus it may be applied to any data collection modelled by an ontology with the semantics and expressivity to guarantee unique identification and describe member changes, or extensions thereof. This allows consumers to keep their local version of a KG in sync with the original producer across the Web, by interpreting the change semantics present in the materialized members and performing the corresponding create, update, and delete operations instead of fully re-fetching and re-ingesting a complete version of the KG every time there is an update.
Currently, RDF triplestores lack support for integrating LDES data directly, which poses the need for an additional intermediate step to interpret and execute the corresponding SPARQL
Change Signaling Strategies
We identified a set of change signaling strategies differing along three 3 dimensions: (i) availability of historical records, (ii) how changes are communicated to consumers, and (iii) type of change; by analyzing real-world datasets from various domains for example, bike-sharing data, public transport timetables, geographical data, traffic data, and meteorological data (Section 6.1.3).
History. We identified 3 different types of history availability: latest state: Latest state refers to datasets that publish only the latest version of all its members on every change. latest changes: Latest changes refers to datasets that publish only changed members (aka delta updates). Thus, consumers must have access to an initial complete version of the data upfront and reconcile updates over it. full history: Full history refers to datasets that are published including both historical and current versions of its members. The number of available versions is defined by the data publisher.
Change communication. We identified 2 change communication strategies: explicit: Dataset changes are explicitly communicated if metadata is also provided to point that a change has occurred (e.g., via uniquely identified members using timestamps, hashes, or logs). implicit: Dataset changes are implicitly communicated if members are changed without providing any kind of metadata indicating that a change happened, for example changes such as property updates, member deletions, or member creations, all happening silently across new versions of the data collection.
Change types. We identified 3 change types: create: A member is added to the dataset and it didn’t exist before. update: An existing member of the dataset is modified. New properties are added to the member or existing properties are modified. delete: An existing member of the dataset is deleted.
Moreover, change communication may differ depending on the type of change. For example: Created and updated members may have a unique identifier (explicit change), while deleted members are simply removed in newer versions of a data collection (implicit change). Table 1 shows a summary of the different change signaling strategy combinations with respect to history availability, change communication, and change types identified on the set of real-world datasets analyzed in this work.
Change Signaling Strategies According to Their History Availability and Change Communication.

Change communication can differ per type of change, even in the same dataset.
Datasets communicate their changes mainly in 2 ways, regardless of historical records availability: (i) Explicitly through uniquely identified members, logs, etc., and (ii) implicitly by silently changing dataset members. The latter imposes the need for consumers to detect these changes themselves. Our approach (Figure 2) combines Timestamp-based and Snapshot-based CDC approaches (Denny et al., 2017) to handle both explicit and implicit changes. In our approach, explicit changes are detected by relying on uniquely identified dataset members (e.g., via subject IRIs that depend on last modified timestamps). We detect implicit changes by comparing consecutive snapshots of dataset members, checking their subject IRIs, and (a subset of) their corresponding properties for changes.
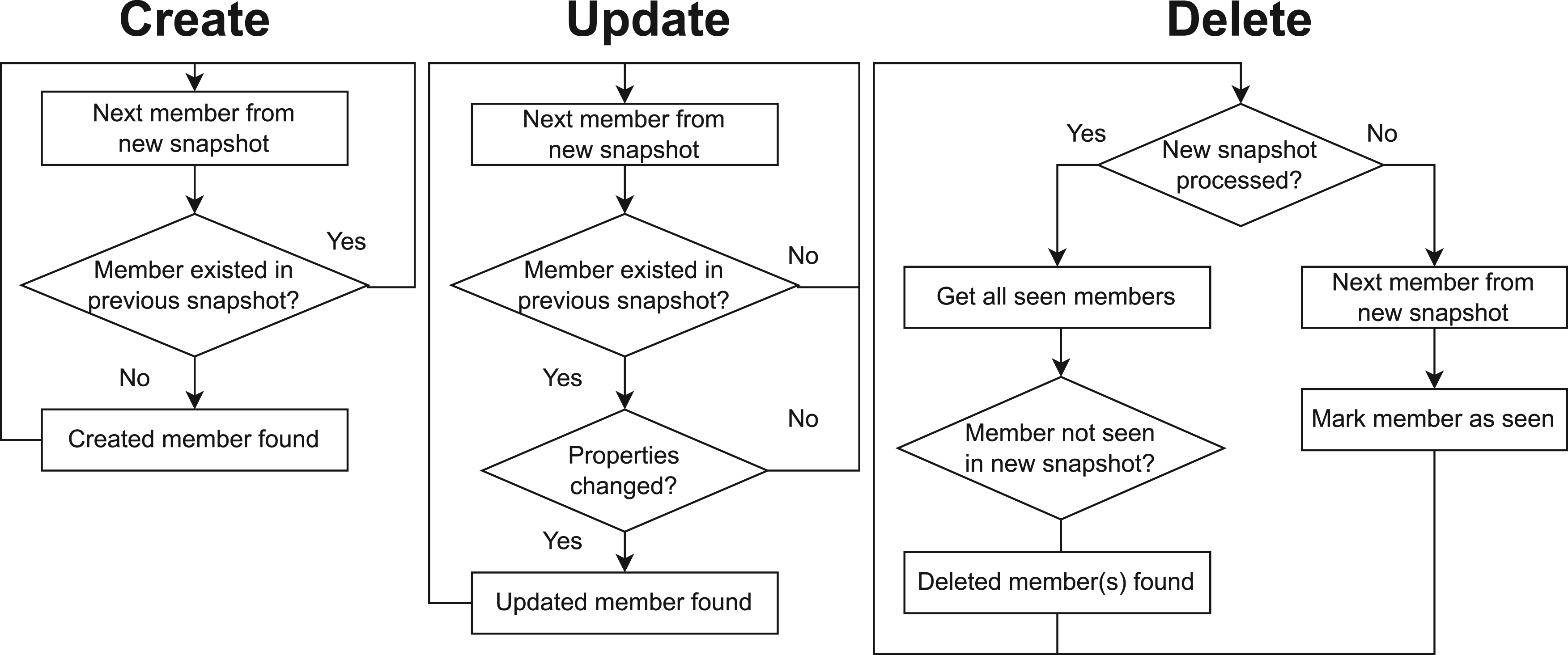
Implicit updates must be detected by a change data capture (CDC) algorithm. Creates and updates are detected by checking if the member already exists in a previous snapshot. Members in a dataset are identified through their generated IRI. If the IRI does not exist in a previous snapshot, we conclude that the member was created. If the IRI does exist and the properties of the member have changed, we conclude that the member was updated. Deletions are detected by checking if the member is no longer present compared to the previous snapshot of the dataset.

Our approach IncRML (top green row) for which we use RML+FnO (middle pink row). We use FnO described functions to perform CDC based on the characteristics of the dataset and RML for constructing RDF from the detected changes. Changed RDF quads may be published as an LDES via an LDES Event Stream Logical Target. The pipeline is continuously executed to extract changes from new versions of the datasets. Our approach can be used by any RML engine with support for FnO (orange squares). Example data (bottom blue row) shows how data creations (green), data updates (yellow), and data deletions (red) are detected through CDC FnO functions. It is assumed that the previous state contains info on data rows with IDs 0, 1, 2, and 3. The extracted changes are then incrementally transformed into RDF and published as LDES members. IncRML: incremental resource description framework mapping language; RML: resource description framework mapping language; FnO: function ontology; CDC: change data capture; LDES: linked data event stream.
It is important to note that implicit deletion communication is not possible when combined with full history or latest changes. Full history datasets must communicate deletions explicitly otherwise a data consumer cannot determine that a member was deleted implicitly, since it will encounter it as part of the historical records also present in the dataset. Even when a data consumer can tell apart historical records from new data, if a member stops occurring in a full history dataset, it could be ambiguously interpreted either as being deleted or as a non-updated member. Assuming that the member is to be deleted could result in both false-positive and false-negative deletion detection. Latest changes datasets are similar to full history regarding deletions. If such dataset do not explicitly communicate that a member is deleted, consumers cannot determine with full certainty if a member was deleted or simply remains unchanged.
Explicit changes can be directly detected and do not require additional processing effort during the KG generation process. Implicit changes, however, require a stateful processing approach, to keep track of members’ state across KG generation executions. Our approach introduces 3 algorithms to handle implicit changes, which scale in direct proportion to the number of members in the dataset. Each detection algorithm corresponds with a particular type of change: (i) create, detects when a new member is added to the dataset, (ii) update, detects when an existing member is modified in the dataset, and (iii) delete, detects when an existing member is deleted from the dataset. Next, we describe the logical flow of each algorithm in the case of implicit change communication.
Implicit Create. (Figure 2, left) For every dataset member being processed in the current version, the algorithm checks if the member was already present in a previous version of the dataset, based on its subject IRI. If not, a created member is found.
Implicit Update. (Figure 2, middle) Similar to create, the algorithm checks if the member was already present through its subject IRI and its properties. The algorithm does not necessarily check all properties of a member. It can simply check a predetermined subset which were labelled as watched properties. These properties can be used to, for example, compute a hash that allows to determine if a change has occurred. If the member’s subject IRI was present and its watched properties’ values were changed, a updated member is found.
Implicit Delete. (Figure 2, right) At KG generation time, the algorithm marks every generated member as seen. Once all members have been processed in the current version of the dataset, it identifies the members which were not seen in the current execution, with respect to the previous KG generation execution (if any). These are marked as the deleted members in the current version of the dataset.
Our approach effectively brings together (i) RML for declaratively defining generation rules for a KG; (ii) FnO for defining change detection functions across data source versions (Section 4.3); and (iii) LDES as an optional publishing strategy to publish semantically described changes as an event stream for consumers on the Web. Figure 3 presents a schematic view of a data processing pipeline using our approach to incrementally construct and publish a KG. If changes are detected, the corresponding RML mapping(s) is/are executed to generate and publish only the changed members to be later integrated into the KG. In practice, a member is generated by a RML Triples Map
9
(
Our CDC FnO functions monitor the Subject Maps and their correspondent Predicate Object Maps at execution time, to determine if there were any changes with respect to the previous execution. If so, the correspondent member is materialized and (optionally) published as a typed event in an LDES. As an example, we show how we can semantically annotate changed members using the W3C Activity Streams 2.0 vocabulary:
Implementation
In this section, we describe how we implement our proposed approach (Section 4) in the RMLMapper 12 based on a set of CDC FnO functions, RML mapping rules to construct a KG, and LDES for publishing an incrementally constructed KG as an event stream. Section 5.1 explains how we implement our CDC FnO functions, Section 5.2 discusses how we integrated RML with the CDC FnO functions, Section 5.3 explains how we implemented an LDES Logical Target for directly generating LDES annotated data, and Section 5.4 demonstrates how our implementation is applied on an example dataset.
CDC FnO Functions
Function Ontology (FnO) Functions for Explicitly and Implicitly Communicated Changes in Members.
Function Ontology (FnO) Functions for Explicitly and Implicitly Communicated Changes in Members.

Each type of change (creation, update, and deletion) has its own dedicated function.
The function persists the state of the properties per member in the location specified by
Each function requires an RML usage of a CDC FnO function for detecting implicit updates in a dataset.
We integrate our FnO functions with RML through FNML in a RML Triples Map (Listing 4). For each type of change we have an independent RML Triples Map with a conditional Subject Map referencing one of these FnO functions. When a function returns the IRI that it received as input, the Triples Map is executed completely, thus materializing the member and its properties. If no IRI is returned by the FnO function, the Triples Map is not executed, which means that the member did not change in the dataset. A separate Triples Map can be used (Listing 5) to generate additional metadata in the form of an event log to describe which type of changes took place in the dataset. A possible ontology to describe these change types is the W3C Recommendation Activity Streams 2.0 (Snell & Prodromou, 2017), but other ontologies can be used in the mappings as well, that is, Change Detection Ontology (Randles & O’Sullivan, 2023; Randles et al., 2022), or PROV-O 14 .
LDES Logical Target
We use LDES to publish a stream of dataset member changes events. LDES allows publishing only changed members as a stream which can be consumed by third-parties to replicate and synchronize with a dataset. We incrementally generate the detected changes (Section 5.2) and publish them as an LDES through an Event Stream Target in the RML mapping rules. An Event Stream Target is a subclass of an RML Logical Target with extra properties such as
Listing 5 provides an example of our alignment between LDES and RML with CDC FnO functions. In this example, we use RML mapping for generating an LDES from a CSV file as data source (data.csv). Each change type has a separate Triples Map with an FnO function as Subject Map. These functions return an IRI when changes are detected, thus triggering the full execution of the Triples Map. The generated RDF triples are written to the LDES Event Stream Target with the necessary LDES properties specified in the LDES Logical Target. W3C ActivityStreams 2.0 is used to indicate the type of change through an LDES-based event log. (Continued) Continued.

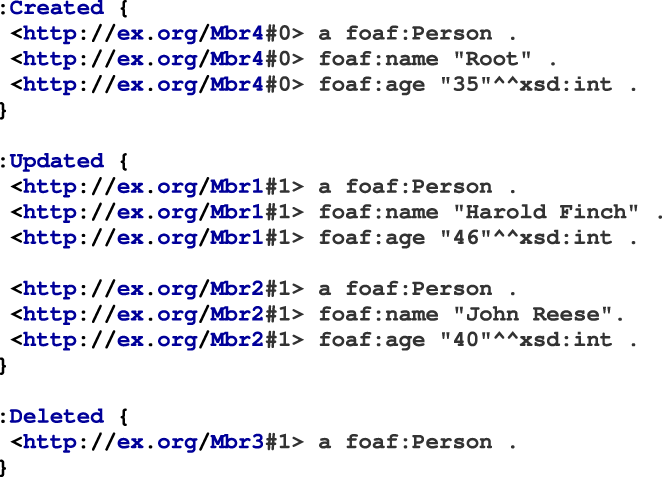
We demonstrate our approach through an example dataset (Figure 3) which consists of an initial version (Table 3(a)) and an implicitly updated version (Table 3(b)). Figure 3 also visualizes this example in the pipeline. The following changes (Table 3(c)) are extracted between the initial data (Table 3(a)) and the newer version (Table 3(b)) through CDC: Example Dataset with the Initial Dataset (Left), a Newer Version of the Dataset (Middle), and Extracted Changes by the Change Data Capture Functions Between the Initial Dataset and the Newer Version. The materialized KG in TriG of the initial dataset. All dataset members are materialized because this is the first time the dataset is processed. Thus, they are part of the Create named graph. The subject IRIs are versioned as required by LDES to publish versioned members. The materialized KG in TriG of the changed dataset. A member is deleted (ID 3), a member's age property is updated (ID 1 and 2), and a new member is created (ID 4). Unchanged members (ID 0) are not materialized. The subject IRIs are versioned as required by LDES to publish versioned members. The different named graphs are described using the W3C Activity Streams 2.0 ontology as as:Create, as:Update, and as:Delete.
The resulting RDF quads of the initial (Listing 6) and updated (Listing 7) datasets consist of 3 named graphs
16
:



In this section, we describe our methodology to evaluate our approach on several datasets using both synthetic and real-world data. First, we discuss our datasets and how they can be classified according to the different change signaling strategies identified in this work (Section 6.1). Then, we introduce our evaluation setup (Section 6.2).
Methodology
We apply our approach on (i) a set of artificial test cases (Section 6.1.1) to verify if our approach is able to handle all change signaling strategies listed in Section 4.2; (ii) an extended version of the GTFS Madrid Benchmark (Section 6.1.2) to measure the scalability, performance and resource consumption of our approach for incrementally generating KGs; and (iii) 5 different real-world datasets (Section 6.1.3) to investigate its performance and resource impact on different types of datasets (Section 4.2),
Functionality
Through a set of test cases (Table 4), we evaluate 3 change signaling strategy dimensions (history availability, change communication, and change type (Section 4.2)) to determine if our approach: (i) Can handle all dimensions, and (ii) is feasible to implement. We combined the 3 types of history availability (latest state, latest changes, and full history) with the 2 types of change signaling (explicit and implicit), and 3 change types (create, update, delete) resulting into 18 test-cases. We also included a test case where no change is applied to verify if an unchanged dataset is handled correctly by our approach, which yields additionally 6 more test-cases (24 in total). Since 2 combinations are not possible (Section 4: Implicit deletion signaling for full history and latest changes), we removed these from the test cases, bringing the number of test cases to 22.
22 Test Cases for Detecting Changes in Datasets.

22 Test Cases for Detecting Changes in Datasets.
Our approach is feasible to implement and covers detecting all possible change types and change signaling strategies.
We validate that all combinations of these dimensions are possible and use these test cases to verify that our implementation covers all possible scenarios. The test cases are publicly available on GitHub 18 .
We extended the GTFS Madrid Benchmark (Chaves-Fraga et al., 2020) data generator
19
to allow generating different versions of the benchmark data by supporting creations, updates, and deletions based on the GTFS data model. We implemented creations, updates, and deletions in the GTFS Madrid Benchmark similar to how real-world GTFS datasets are changed at the Belgian public transport agencies De Lijn and NMBS. This way, we keep the characteristics of GTFS Madrid Benchmark which aims at using real-world data from the metro in Madrid. Creations are applied by adding GTFS
We extend the GTFS Madrid Benchmark with 4 additional configuration parameters: seed: The random seed value used for configuring the random number generator. additions: The percentage defining how many creations must be added to the generated data. modifications: The percentage defining how many updates must be performed on the generated data. deletions: The percentage defining how many deletions must be applied on the generated data.
We aim on analyzing the impact of our approach on datasets of varying size and change characteristics, by measuring execution time and resource usage (storage, CPU time, and RAM usage) to detect and materialize changes into a KG (CHANGE) or materialize the complete KG (ALL). In particular, we analyze the overhead of our approach for detecting changes and the reduction in execution time and resource usage achieved by only materializing the changes instead of the complete KG. The reduction of our approach might be affected by the amount of changes, type of changes, and the dataset size. Therefore, we use data size scales (1, 10, and 100) with a fixed change percentage of 50%, equally divided among the different change types (16.67% creations, 16.67% updates, and 16.67% deletions), to obtain reference measurements of increasing dataset size scales. This way, we avoid that other dimensions for example, change percentage and change types impacts our analysis of results from the data size dimension. We divide the changes equally among change types and use scale 100 to analyze the change percentage dimension (0%, 25%, 50%, 75%, and 100%). We also experiment with the type of change by using a fixed change percentage of 50% and scale 100 for either creations, updates, or deletions to analyze the impact of each change type on execution time and resources. For each experiment we use 10 new versions of the GTFS dataset which we apply as updates over an initial base version. We select 50% as fixed change percentage to avoid outliers from 0% or 100% and scale 100 for analyzing the change type dimension.
We apply our approach on 5 types of real-world datasets: (i) BlueBike & JCDecaux bike-sharing data; (ii) timetables in GTFS format from the Belgian public transport agencies NMBS and De Lijn; (iii) OpenStreetMap (OSM) geographical data; (iv) dynamic message boards from the Flemish traffic controller centre Vlaams Verkeerscentrum (VVC); and (v) meteorological sensor data from the Belgian meteorological institute Koninklijk Meteorologisch Instituut van België (KMI). These datasets stand as representative examples for all the identified change signaling strategies (Table 5) regarding change communication, change types, and history availability. For each dataset, we collected released versions during 24 hours, with the exception of De Lijn and NMBS, since they only provide a new version per day. In this case, we collect new versions during a week. We use a timeframe instead of the number of versions to have different frequencies when new versions of the datasets are published, for example, VVC is changed more frequently (every 2–3 secs) compared to KMI (every 10 mins). Next we describe in detail each of the analyzed datasets, which are also summarized in Table 5.
Real-world Datasets Addressed in our Evaluation.

Real-world Datasets Addressed in our Evaluation.
Each dimension of dataset types is covered: Change signaling, change type and history availability. Some datasets only provide certain change types, inapplicable change types are marked as NA. OSM: OpenStreetMap; VVC: Vlaams Verkeerscentrum; KMI: Koninklijk Meteorologisch Instituut van België; NA: not applicable.
In practice, the outcome of a KG generation process is typically a set of RDF triples/quads that are subsequently ingested into an RDF triplestore, so that they can be queried and used in applications. In a traditional full re-materialization KG generation scenario (ALL), the ingestion process usually entails a complete deletion of the KG in the triplestore (if any), followed by an insertion of all the newly generated RDF quads. However, the materialized members generated by our approach after the CDC process (CHANGE), do not constitute on their own a complete and standalone version of the KG (except for the initial generation), and require an additional interpretation step to determine the proper operations to be performed over the triplestore that will bring the KG to its latest state. We implemented a proof-of-concept library 27 that performs this interpretation step (Figure 4) and produces the corresponding SPARQL UPDATE queries for each materialized member, based on their change semantics (i.e., type of change). By using a triplestore as the same system to make the standalone KG accessible for both the ALL and CHANGE strategy, we make sure we are not monitoring side-effects when using reconciliation systems that are different for the ALL and CHANGE strategy.

To guarantee a fair comparison of our approach (CHANGE) with a traditional approach (ALL), we initially observe the number of RDF quads generated by each approach. Our premise is that less RDF quads translate into faster ingestion and thus more efficiently updated KGs. To verify this, we also measured the time that takes to ingest via SPARQL
We evaluate our approach on the described datasets and a modified version of the GTFS Madrid Benchmark by measuring the following metrics: (i) Execution time to detect changes and materialize the complete or changed parts of a dataset into RDF; (ii) CPU usage to determine how CPU intensive is our generation approach; (iii) peak RAM memory usage to investigate the memory overhead of our approach; and (iv) storage usage of the generated KG on each new version to verify the impact of our approach for reducing storage of historical data. We execute this evaluation with and without our approach using the RMLMapper v6.3.0 29 to investigate how our approach impacts the measured metrics during RDF KG generation.
For each experiment, we materialize a KG from a given dataset and its corresponding updated versions as RDF quads. We manually verify if the output is complete and correct for each experiment. We compare 2 KG generation-and-version strategies:
In this work, we focus on measuring the generation step of both strategies to investigate the feasibility and impact of our approach over materializing the complete KG on each dataset version. Since our focus is the generation, we only perform a comparative experiment to have an indication of how our approach affects ingestion into triplestores using SPARQL
The experiments are executed on an Ubuntu 22.04.1 LTS machine (Linux 5.15.0-83-generic, x86_64) with an Intel(R) Xeon(R) CPU E5-2650 v2 @ 2.60Ghz, 48GB RAM memory and 2GB swap memory. Java JVM heap space is set to 90% of the available RAM memory. All experiments are executed 5 times, from which we report the median measurements of the execution. All resources and instructions to reproduce the experiments are available on Zenodo 30 .
In this section, we present the results obtained during the execution of our evaluation with and without our approach. We first perform a functional evaluation through a set of test cases (Section 7.1). Then, we evaluate the performance in terms of execution time and computing resources of our approach on an extended version of the GTFS Madrid Benchmark (Section 7.2), and real-world datasets (Section 7.3). We then reconcile the results of both the ALL and CHANGE scenario (i.e., make the latest version of a KG accessible after a set of changes) and report the results of our comparative experiment after triplestore ingestion (Section 7.4). In Section 7.5, we discuss the impact of our approach on the measured metrics.
Functionality
We integrated our set of 22 test cases (Table 4 of Section 6.1.1) as unit tests in the RMLMapper v6.3.0 31 to validate if all possible change types and change signaling strategies are covered by our approach and are feasible to implement. Through these test cases, we confirm the feasibility of our approach and its coverage of all possible dimensions regarding change signaling and history availability.
GTFS Madrid Benchmark
In this subsection, we discuss the results obtained for the 2 generation-and-version strategies (Section 6.2)
Initial Execution Results for All GTFS Madrid Benchmark for Strategies ALL (No Change Detection) and CHANGE (with Change Detection).

Initial Execution Results for All GTFS Madrid Benchmark for Strategies
We scale one dimension for each experiment to analyze its impact. GTFS
Execution Results for All GTFS Madrid Benchmark for Strategies

Only results of dataset updates are included, initial execution is not included. We scale one dimension for each experiment to analyze its impact. GTFS
Storage Usage for Initial and All Updates per Strategy of the GTFS Madrid Benchmark.

We scale one dimension for each experiment to analyze its impact. GTFS
The results show that our approach
Scaling data size. Our approach

GTFS Madrid Benchmark results for different data scales with a fixed amount of changes (50%). Only results of dataset updates are included, initial execution is not included.
Scaling amount of changes. We observe an

GTFS Madrid Benchmark results for different amount of changes with a fixed data size (scale 100). Only results of dataset updates are included, initial execution is not included.
Type of changes.

GTFS Madrid Benchmark results for different change types with a fixed data size (scale 100) and amount of changes (50%). Only results of dataset updates are included, initial execution is not included.
In this subsection, we discuss the results obtained from applying our approach over the set of real-world datasets described in Section 6.1.3, with respect to storage usage, execution time, CPU time, and memory usage. For each dataset, we measured these metrics following strategies
Initial Execution Results for All Real-world Use-cases for Strategies ALL (No Change Detection) and CHANGE (with Change Detection).

Initial Execution Results for All Real-world Use-cases for Strategies
Execution Results for All Real-life Datasets for Strategies

Only results of dataset updates are included, initial execution is not included.
Storage Usage for Initial and All Updates per Strategy of the Real-World Datasets.

Total storage usage is sum of the base dataset and the applied updates upon it.
We observe that our approach
Storage usage.

Our approach reduces the necessary resources to generate different versions of a knowledge graph (KG). Storage is reduced 3.24–315.83 times depending on dataset type. Execution time is reduced between 0.97–4.41 times depending on the dataset type. CPU time usage is reduced 0.85–4.59 times. Memory usage is mostly unaffected.
CPU time. Similar to execution time,
Memory usage. Results show that
Comparing the size of each update between ALL and CHANGE indicates that processing CHANGE updates requires less resources and time because they are smaller. To fully compare our approach with the ALL strategy (i.e., having access to the latest standalone version of a KG), we measure the total processing time of the ingestion step by ingesting the real-world datasets, via SPARQL
Table 12 presents the total time of processing all collected versions for each real-world dataset (as presented in Table 5), for each step of the pipeline: (i) KG generation time (as presented in Section 7.3), (ii) interpretation of the generated changes as SPARQL updates (using
Results for Generating, Interpreting, and Ingesting of the Different Real-World Datasets into a Triplestore (virtuoso).
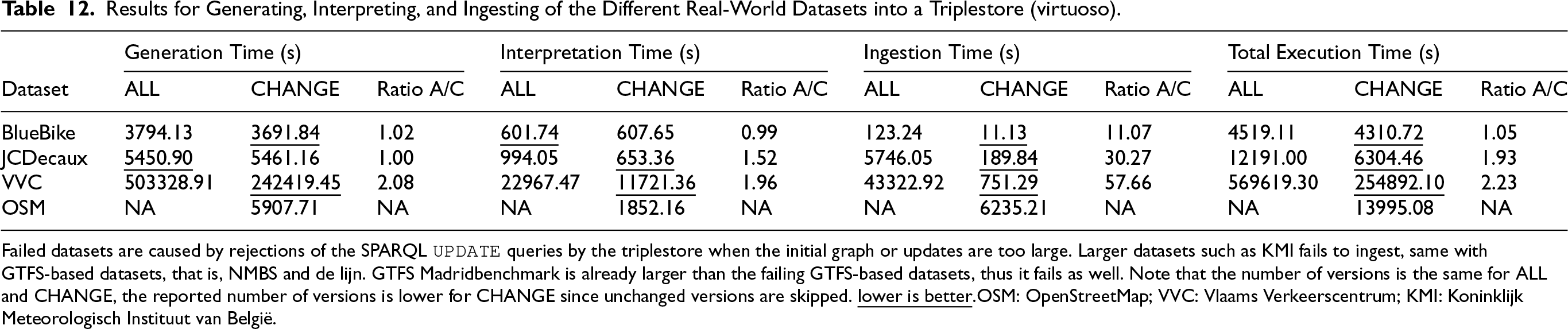
Results for Generating, Interpreting, and Ingesting of the Different Real-World Datasets into a Triplestore (virtuoso).
Failed datasets are caused by rejections of the SPARQL
Unfortunately, most of these SPARQL queries are immediately rejected if the number of the changes increases, due to reaching Virtuoso’s internal query length limits (10Mb). We overcame this problem by splitting up queries into multiple smaller ones, using the following pragmantic method: We started with 100 triples as upper limit and divided the queries in 2 parts each time a query failed, thus minimizing the number of queries needed. Depending on how the data is structured in RDF, Virtuoso was able to handle bigger queries or not, for example: Large string literals have a higher memory impact on Virtuoso. Therefore, only BlueBike, JCDecaux, and VVC were successfully ingested into Virtuoso. We further tried to optimize the queries by splitting them into smaller queries. This helped already for the JCDecaux dataset to ingest it, but not for bigger datasets with larger change sets such as NMBS, De Lijn, KMI, or GTFS Madrid Benchmark.
The results show a reduction on the overall ingestion time for the datasets that were successfully ingested, which includes also the time needed to interpret the change semantics and generate the corresponding SPARQL
In this subsection, we discuss the lessons learned (Table 13) from analyzing different real and synthetic datasets with varying change signaling strategies, change types, and history availability, for incremental KG generation.
Analysis Goals on Change Signaling Strategies, Change Types, and History Availability from Datasets Using Incremental Knowledge Graph (KG) Generation.

Analysis Goals on Change Signaling Strategies, Change Types, and History Availability from Datasets Using Incremental Knowledge Graph (KG) Generation.
Functionality. Our approach handles all possible dimensions and is feasible to implement. We implemented our approach by extending the RMLMapper v6.3.0 with
GTFS Madrid Benchmark. Our
Scaling the data size (1, 10, 100) has the most impact for GTFS
Scaling the amount of changes (0%, 25%, 50%, 75%, 100%) increases storage usage when more changes are present (11.70GB–12.93GB) since more new versions of dataset members are generated. CPU time usage and memory usage are unaffected because the number of dataset members remains unchanged, each dataset member is assessed to determine if it was changed or not.
Change types (create, update, delete) mostly affects the storage usage, for created members the storage usage (13.5GB) is higher compared to deleted (11.72GB) or updated members (11.71GB) because the new members that are added to the dataset need to be materialized. Deletions reduce the storage usage, but not significantly because deleting a GTFS Route only affects a subset of the dataset. Moreover, a tombstone comprising a few triples is still materialized to indicate thedeletion of the member for historical purposes.
Real-world datasets. Depending on the data size,
In general, this results show a clear advantage of our approach, in terms of required computational resources, with respect to the traditional way of generating RDF KGs. Even considering the additional step required to fully ingest and integrate the materialized member changes into a KG (Table 12), we observe a clear reduction on the total time execution (SPARQL generation + ingestion). The beneficial impact of our approach increases with the size of the original datasets and provided that the number of changes remain relatively low compared to the total size, which is usually the case in most practical scenarios. This positions our approach as a scalable solution with promising potential to be used in production.
Use cases benefiting from incremental KG generation. Our approach is the most beneficial for use cases where data changes frequently or requires historical data. For example: Real-time information for public transport, IoT sensor data for smart cities, or weather history for analyzing the impact of climate change (Section 7). Real-time data needs to be integrated quickly to provide up-to-date information and the time to regenerate a KG for each data change is longer and consumes more computing resources when dealing with large datasets, compared to incrementally generating KGs. If historical information is important, it is beneficial to use our approach as only changes throughout history are incorporated into the KG which saves storage. This way, consumers can access and store the complete history for analytical purposes. However, if the data is rather small, for example, BlueBike or JCDecaux bicycle data, our approach’s overhead to detect changes does not reduce the execution time or computing resources, but still provides an important reduction on storage requirements while providing access to historical information.
In this paper, we investigated how to detect and materialize only dataset updates towards establishing an incremental publishing approach for KGs. To achieve this, we designed an approach that combines established KG generation technologies and a novel KG publishing approach (IncRML), which we implemented by extending the RMLMapper, and evaluated on 5 types of heterogeneous datasets. We observed that in general, our IncRML achieves a reduction in execution time for RDF generation (up to 4.41x), CPU time (up to 4.59x), memory usage (up to 1.51x), and storage (up to 315.83x). In terms of ingesting and fully updating a KG hosted in a triplestore, we also observed faster ingestion in IncRML both overall for all updates (up to 57.66x) and on average for individual updates (up to 28.5x), although we were only able to measure this for smaller datasets in one triplestore (Virtuoso) due to internal query size limitations.
Through this work, we establish a trade-off for generating and publishing KGs, where following our approach can lead to significant time and computing resource savings to generate the raw RDF quads of a KG, at the cost of introducing an additional step for change reconciliation. On the other hand, a traditional KG generation is capable of producing an already updated and integrated KG, at the cost of additional computing resources and processing time. Nevertheless, our experiments indicate that despite the additional processing step required by IncRML, the overall processing time to update KGs is still lower (by a factor of 1.05–2.23) than with a fully re-materialization approach.
We evaluated our approach on a heterogeneous set of real-world datasets, including weather sensor data, public transport timetables, bike sharing data, live road traffic information and crowdsourced geospatial data. We show that our IncRML implementation is able to cover the different change communication strategies used by these set of real-world datasets (explicitly by the data source, or implicitly by silently changing the data), change types (creations, updates, and deletions), and history availability in the dataset (latest state, latest changes, or full history datasets).
Thanks to our approach, we provide the means to generate semantically annotated data and metadata from both implicitly and explicitly changed datasets. Therefore, we help to bring more transparency/provenance, in particular to implicitly signalled datasets. We integrate LDES as a Web native alternative to publish a semantically and structurally described stream of events that could enable data consumers to replicate and continuously synchronize with a KG, whether their changes are explicitly or implicitly signalled in the original data sources. Furthermore, our approach facilitates and reduces the cost of storing and publishing historic data, which is commonly an important requirement for for example, data analysis and machine learning applications. Existing LDES clients 32 can already take advantage of our incrementally generated KGs given that only changed members need to be processed, which is usually lower compared to the total size of a dataset. In general, IncRML show great potential to be further developed into production ready solutions that could lower the costs of creating and consuming KGs, with the goal of increasing adoption of Semantic Web technologies.
Further research includes expanding the pipeline to investigate the impact on end-to-end performance with different triplestores and increasing amount of consumers. On this direction, triplestores could be extended to allow direct native ingestion of incremental KGs (e.g., as an LDES) instead of performing full re-ingestion, thus benefiting from the usual lower amount of data that needs to be processed. On the other hand, we also highlight the need for more effective SPARQL
Investigating optimizations for the proposed change detection algorithms is also possible given that currently the implementation of our CDC algorithms as FnO functions uses in-memory lookup tables to detect changes. Avoid keeping the lookup tables in memory (e.g., using key-value stores) could reduce the memory footprint of IncRML even further. Also, exploring windowing techniques for streaming data, could allow to handle deletions on unbounded data streams. Our approach can perform change detection on streaming data, but requires a window definition for detecting deletions. Specifying a window is not supported yet in any declarative mapping language, but is considered by the W3C Community Group on KG Construction 33 . Another potential path for future work is querying of incremental KGs. Performing SPARQL queries on incrementally generated KGs requires further investigation to optimize query execution as we only tackled incremental generation. The study of approaches to handle schema-level (ontology and mappings) changes efficiently, is an important aspect to be consider (Conde-Herreros et al., 2024) since also the ontology and mappings can evolve besides the data itself. Lastly, performing a survey on dataset change signalling could be performed to validate our change signalling and communication strategies.
Footnotes
Funding
The described research activities were supported by the Special Research Fund (Ghent University grant BOF20/DOC/132) and SolidLab Vlaanderen (Flemish Government, EWI and RRF project VV023/10).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.