
Abstract
Evolving an ontology involves re-learning, re-enriching and re-validating knowledge in the face of changes to the domain, and techniques applied for them can be adapted to ontology evolution. The possibilistic approach to axiom scoring has been applied over complete and large datasets in ontology learning. This paper presents an adaptation of the possibilistic approach to axiom scoring to the context of Resource Description Framework data streams for ontology evolution, a scenario which forcefully deals with incomplete and time-dependent data. Possibilistic axiom scoring is used in two distinct scenarios: (1) With previously known property axioms, allowing for the exploration of the effectiveness of the approach in a scenario in which no incorrect data was present; and (2) in an evolving knowledge scenario, in which neither the properties nor the axioms were known and the dataset was obtained from publicly available sources, possibly both incomplete and with errors. Results show the effectiveness of the approach in accepting/rejecting axioms for the ontology's properties. The different approaches to possibility and necessity proposed in literature are recontextualized in terms of their bias towards selective confirmations or counterexamples – showing that some axioms benefit from a more lenient approach, while others present a lower risk of introducing inconsistencies by having harsher acceptance conditions.
Introduction
Ontology Evolution – especially when performed automatically or semi-automatically – cannot be detached from other subfields of ontology studies in computer science, such as ontology learning, enrichment, and validation (Khadir et al., 2021; Polleres et al., 2023). Many steps and techniques are transversal to these fields; consider, for example, how evolutionary processes occur: New knowledge needs to be learned so it can be formalized into the ontology, and data can be used to further enrich the evolving schema into a more expressive and precise result. Ontology evolution is, in a way, the process of re-learning, re-enriching and re-validating an ontology in the face of changes to the domain, particularly when these are triggered by the data itself.
While many ontology learning approaches imply the acquisition of data through text, more recently there has been a shift towards using continuous streams of (structured and semi-structured) data (Khadir et al., 2021; Polleres et al., 2023; Su et al., 2016). Data streams carry, implicitly or explicitly, a time dimension that can and must be taken into consideration if it is meant to guide evolutionary processes (Esling & Agon, 2012; Hamilton, 1994; Polleres et al., 2023; Su et al., 2016). This means the ontology is not learned once, but that learning and evolving the ontology are inextricably linked and the data used to trigger those processes is both limited and transient.
Ontology learning and evolution solutions tend to focus on the identification and materialization of changes in concepts and roles and the hierarchies between them, but the same attention has not been given to the axiomatization of said structures (Canito et al., 2022) – particularly when dealing with the inherent incompleteness that comes with data obtained via streams.
The Time Constrained instance-guided Ontology Evolution (TICO) (Canito et al., 2023) tool is an ontology evolution framework that analyses new ontology individuals to understand if the concepts defined on the ontology have changed over time. The framework implements a set of operators that compare definitions present in an ontology to the structure of individuals incoming through a Resource Description Framework (RDF) stream. The result of the application of these operators is a set of evolutionary actions that can be triggered to produce changes in the ontology – generating new versions of specific concepts and properties to suit the patterns found in the individuals. If sufficient difference between the individuals of the concepts being analyzed and the version of them asserted in the ontology is identified, TICO uses a 4-D Fluents (Burek et al., 2019) approach to reify new, disjoint definitions of the concept for each time period – or Time Slice – in a strictly positive monotonic fashion; the tool aims to iteratively evolve an ontology as a result of the analysis of small numbers of individuals. The architecture of TICO has been described in Canito et al. (2023) and allows for the analysis of streams of RDF individuals to extract potential evolutionary actions that add temporally-bound axioms to the ontology. In this paper, the authors use the architecture of TICO as a base for stream-guided ontology evolution with a focus on the identification of ontology property constructors. This is done by analysing extensional evidence for and against each of the ontology roles’ constructors and ascertain if the data shows enough support for their inclusion in newer versions of the ontology.
The work presented in this paper aims to assess the degree to which it is possible to identify changes in OWL property axioms through the analysis of incomplete, unbounded and changing RDF data provided by streams, and to establish which metrics and assumptions/constraints are more suitable for this task. To do so, axiom testing analysis from both statistical and possibilistic perspectives will be executed. Additionally, when applying the solution to an ontology evolution scenario, this work aims to assess if and how the knowledge already present in the ontology should affect the decision to include/exclude suggested axioms.
The main contributions of this work are therefore: Adaptation of the possibilistic approach to axiom testing as described in the works of Tettamanzi et al. (2017) to the context of streams of RDF individuals/instances, followed by an extensive, in-depth analysis of the robustness of the proposed metrics. This includes the analysis of the effects of the number and variety of the individuals that can be analysed simultaneously when searching for potential axioms in RDF data streams. Combining acceptance/rejection index (ARI) with other metrics in order to accommodate for the potential existence of errors in data: The percentage of selective confirmations w.r.t the support and an evolving form of the ARI which is informed by the knowledge present in previous versions of the ontology. For this purpose, the approaches will be tested against an ontology generated from publicly available data, for which no a priori information about property characteristics is known.
The rest of the paper is organized as follows: Section 2, Background, which contextualizes the work in the field of ontology learning/evolution and describes existing works on axiom scoring; Section 3, Property Axiom Scoring, which describes the solution and details the definitions of the axioms pertaining to each of the property characteristics in OWL and how to evaluate their presence in an RDF data stream. Section 4, Effects of Sliding Window size and suitability of ARI for axiom scoring, establishes the suitability of the possibilistic approach and the ARI to axiom scoring in RDF streams and compares its performance with that of traditional information-retrieval metrics; Section 5, titled Accommodating for errors in data and the effects of previous knowledge in axiom-inclusion decisions, compares a combination of ARI and selective confirmations with an evolving form of ARI to assess how they deal with potentially incomplete and noisy data obtained from public datasets. Finally, Section 6 presents the Conclusions.
Changes to domain knowledge must first be identified and quantified, so that they can be materialized into executable actions that will modify an ontology into a new version of itself – i.e., evolutionary actions (Kondylakis & Papadakis, 2018; Peixoto et al., 2015). To identify if there is a need for a change at the ontology level – if and which evolutionary actions should be considered – it is often necessary to analyze data that is external to the ontology (Benomrane et al., 2016b; Cardoso et al., 2018). Examples of this include identifying changes in the way end users apply the concepts in the ontology to the data, (Kondylakis & Papadakis, 2018) evaluating corpora regarding the domain to extract new concepts and compare them to existing ones, (Benomrane et al., 2016a; Cano-Basave et al., 2016; Cardoso et al., 2018) frequently through the application of Natural Language Processing algorithms, and the analysis of datasets of structured data (Kondylakis & Papadakis, 2018; Peixoto et al., 2015) (such as RDF datasets). It is possible to conceive ontology evolution as ontology learning with extra steps: New concepts and roles must be derived from existing data, but they also must be compared and made consistent with previously established ones, or otherwise have to update their definitions.
The identification and execution of evolutionary actions when they concern the addition of classes and properties – and the hierarchies between them – are relatively well documented in literature (Canito et al., 2022; Ghidalia et al., 2024; Kondylakis & Papadakis, 2018). The identification of the axioms that could enrich them (e.g., class expression restrictions and property axioms), however, is not as popular – potentially stemming from the fact that many ontologies are often used as taxonomies and lack axiomatic complexity (Ghidalia et al., 2024). This axiomatic complexity, however, is particularly relevant for lower-level ontologies, which need to describe the intricacies of their domains with varying degrees of detail and can be used to determine the consistency of data they describe, and to derive implicit information using reasoners (Nguyen, 2021). For that, it is necessary not only to identify changes in concepts and roles and their relative novelty, but also to enrich them with axioms: Ontology evolution is the more useful the more it applies the precepts of ontology learning. Furthermore, (Canito et al., 2022; Ghidalia et al., 2024) detail the relative popularity of different types of evolutionary actions as they are described in literature, noting that while identifying new properties and property hierarchies is often considered, identifying and changing their property axioms in particular is still a relatively understudied field.
Ontology learning can be defined as the processes and techniques applied to design ontologies either automatically or semi-automatically (Khadir et al., 2021). According to Al-Aswadi et al. (2020) said techniques can be classified into two main categories: (1) Linguistic-based approaches and (2) machine learning-based approaches, which can be further divided into statistics or logic-based.
Linguistic-based approaches focus on the analysis of large corpora of text to identify potential concepts and the relationships between them (Al-Aswadi et al., 2020; Belhoucine & Mourchid, 2018; Venu et al., 2017). To do so, they seek for patterns and syntactic information in the text – making them particularly language-dependent. Machine learning-based approaches, on the other hand, can use different types of input data for their training: Both structured and unstructured. Statistics-based approaches are usually applied to identify the co-occurrence of terms, association rules and hierarchies (Al-Aswadi et al., 2020; Ghidalia et al., 2024). Logic-based approaches, on which the work described in this paper is grounded, use logical inference or inductive logic programming to derive rules from positive and negative examples found in structured datasets. This approach is particularly suited for learning rules and formalizing axioms. On the Ontology Learning Layer Cake (Buitelaar et al., 2005), which is used to describe the layers of the learning process and, by extension, the possible tasks it encompasses, rule and axiom extraction is depicted as the final sub-task in the process and the least explored in literature (Al-Aswadi et al., 2020).
In OWL, an axiom is a statement that expresses what is true in the domain described through the ontology. The number and type of axioms directly affect the expressivity of the ontology by adding more information to the description of classes, properties, and assertions, among others, and the relationships between them. For example, an ontology that can specify if a certain property is a mandatory element of a class, or how many times that role can be applied to an individual, is more expressive (and potentially more complete) than one in which those assertions are not established (Khadir et al., 2021).
Axiom testing is the process of evaluating the credibility of a given hypothesis concerning the relationships in a domain – the property axiom – by assessing whether the individuals of said domain (e.g., facts of an RDF dataset) confirm or deny a hypothesis (Tettamanzi et al., 2017) – i.e., whether they are confirmations or counterexamples of the axiom. The selective confirmation (Scheffler & Goodman, 1972) principle can be put into effect as well: A fact selectively confirms a hypothesis when not only it favours that hypothesis but also fails to confirm its negation. Not all facts are equally relevant for axiom testing, and, as such, the number of examples needs to be considered not in the context of all analysed instances, but only of those that do entail the relationships under scrutiny (Tettamanzi et al., 2017).
Property characteristics, from a perspective of axiom suggestion for ontology enrichment purposes, have been described in Bühmann & Lehmann (2012). This work describes enrichment methods that have been implemented as part of the DL-Learner framework. The approach involves using different queries to look specifically for axiom support in a triple store, considering both the count of examples and the average of the 95% confidence interval when suggesting axioms to the user. However, while the approach tackles the discovery and materialization of ontology axioms, including property axioms, it depends on (large) knowledge bases containing a complete collection of samples that can be analysed as a whole – and by analysing only these samples to generate possibilities it is, in a way, working under a closed world assumption. Similarly Sais et al. (2017) describe how to identify and materialize changes in property axioms but requires large and self-contained datasets to do so, falling under the same assumption.
The possibilistic approach has been applied in the works of Tettamanzi et al. (Malchiodi & Tettamanzi, 2018; Nguyen & Tettamanzi, 2019; Tettamanzi et al., 2014, 2015, 2017) for axiom testing against RDF facts in ontology learning and validation/evaluation scenarios. As the name indicates, the possibilistic approach deals with the degree of possibility of an event, such as an axiom – which falls in a range between impossible and possible [0,1]. Possible, unlike probable (from probability distributions), does not mean that the axiom must be true: Only that it is compatible with the known state of the world. While probability theory is suited for the representation of random and observed phenomena, the possibilistic theory better reflects how to deal with incomplete knowledge. In Tettamanzi et al. (2014) (and, by extension Tettamanzi et al., 2017), the authors detail how using such an approach is more suitable for candidate axiom scoring than statistical/frequentist approaches, claiming that the nature of the inductions necessary for ontology learning and evolution makes it such that statistical analysis ends up with largely arbitrary and unobjective results. Through the analysis of the results obtained in Section 4, the authors of this paper reached the same conclusion, and the possibilistic approach will be used to complement the statistical analysis. Being an unsupervised approach, the possibilistic approach is particularly suited for application to RDF streams and can accommodate for the incomplete nature of the data they provide. However, to the best of our knowledge, the possibilistic approach has only been applied for ontology validation, and its applicability to suggest new axioms from data analysis is either understudied or non-existent.
Property Axiom Scoring
Problem Definition
The application scenario of the TICO framework involves the existence of several streams of sensor data arriving in near real-time which are subject to transformations by data scientists, introducing new and unpredicted changes that are not in the original ontology. While the original application scenario was in the field of Predictive Maintenance, TICO is agnostic and can suggest changes to any ontology following changes in the individuals of the streams under analysis. TICO receives as input an ontology and a stream of individuals and outputs a set of evolutionary actions that can be executed over the original ontology to generate a new, evolved version of it. Consider, for example, a stream

Familial relationships between individuals in a stream.
The individuals are separated into three consequent groups, which correspond to different periods of analysis, at the end of which the ontology that represents these individuals may be updated. When analyzing the first group, one can conclude, for example, that the properties hasMother and hasFather should de functional, and the property hasBrother is both symmetrical and transitive. However, upon analyzing the second group of individuals, this assessment must be revised: The property hasBrother is still symmetrical, but no longer transitive, i.e., the brother of my brother is not necessarily my brother as well.
Now consider that, as society grows more open to different familial structures, individuals in the stream may now in fact have two legal parents of the same gender (represented by the third group in Figure 1); in order to accurately reflect reality, the application of the property hasMother must now accommodate for this necessity, and this change in how the property is used means its functionality is obsolete and should be reconsidered: The ontology should evolve to accommodate for the change in how the property is effectively used. This paper focuses on the changes introduced to TICO that go beyond the detection of new properties and into recognizing the property axioms that should be added with them. Unlike other logic-based approaches, TICO does so by analyzing positive and negative evidence regarding a set of known and predetermined rules – the property axioms – to ascertain if they should be added to the ontology. To better understand the property axiom testing process on which this paper focuses, consider Figure 2 and the descriptions that follow.

Data structures concerning the property axiom testing process.
The analysis is triggered by the arrival of a new individual on the stream. The visualization provided by Figure 2 shows: The timeframe The named individual i, which is composed by a set of RDF triples with the same Subject The use of i and its properties to instantiate query patterns for specific property axiom The query results being used to classify i as selective confirmation or counterexample for each
TICO receives as input a stream of individuals
(RDF Stream): An RDF stream is a (possibly infinite) sequence of triples < Subject, Predicate, Object>, in which: Subject is an IRI or blank node; Predicate is an IRI, and Object is a IRI, blank node or literal.
(Timeframe): An RDF stream can be divided into subsequences (
The consideration noted in Definition 2 stems from TICO's original application scenario – real-time sensor data – in which each individual encapsulates a sensor reading that took place at a particular moment, and no new data is added to previous readings. The remaining elements present in Figure 2 are described next. Each individual is only analysed once per timeframe, and no records about the individuals or the statistics they informed are maintained between timeframes. 1
FunctionalObjectProperty ( InverseFunctionalObjectProperty ( TransitiveObjectProperty ( SymmetricObjectProperty ( AsymmetricObjectProperty ( IrreflexiveObjectProperty (
and therefore:

All property axioms for a given property P can be expressed as first-order logic implications in the form:

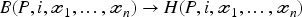
For a named individual If there's at least one substitution for B and the negation of H under the Unique Name Assumption (UNA): The named individual There is a substitution for both B and H, and no substitution for the negation of There is a substitution for B, but no substitution for If there is no substitution for B,
This distinction between confirmation and selective confirmation follows from the selective confirmation principle (Scheffler & Goodman, 1972): A selective confirmation is a confirmation in which
Considering both UNA and the fact that only individuals in the domain of the property are counted, functionality, inverse functionality, irreflexivity and asymmetry cannot generate weak counterexamples – the imposed constraints guarantee that an individual is always classified as either a selective confirmation or counterexample – there are always substitutions for either H or
On the other hand, the openness of the world and unknown facts about individuals in the range of the properties greatly affect the classification process for the transitivity and symmetry axioms – consider, for instance, that the individuals in the range of the properties may not be present in the sliding window when the query is executed, and therefore it is not possible to assess if that individual is also in the domain of the property (necessary for both axioms). Selective confirmations are indisputable, as their mere existence implies that the data was, in fact, complete. Counterexamples, on the other hand, imply proving a negative, making them particularly harder to identify under the constraints and assumptions of the methodology employed. As such, any substitutions that do not selectively confirm these axioms are treated as weak counterexamples.

When the query is executed over
The analysis of real-time data can unravel patterns regarding a property's usage that may hint at its formal definition. Each property axiom, per virtue of its definition, corresponds to a different pattern in the data (cf. Table 2). Consider the generic task

Consider a
Example Individuals in a
and Respective Properties.
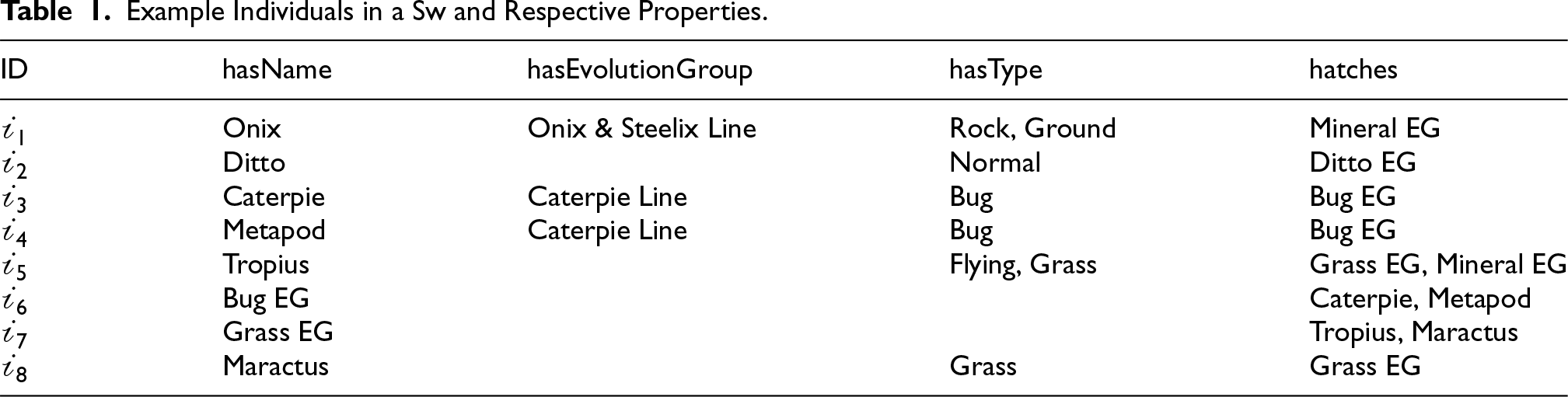
Example Individuals in a
Considering the potential Inverse Functionality of the hasEvolutionGroup property, i.e., Samples: Selective confirmations: Strong counterexamples:
Individuals
Consider the potential symmetry of the Samples: Selective confirmations: Weak counterexamples:
The details of how each property axiom is defined and the formula to search for in the data are described in Table 2.
The work described in Tettamanzi et al. (2017) also introduces the concept of an ARI and its application to axiom scoring: Positive values suggesting acceptance, negative suggesting rejection and values close to zero indicating ignorance. For any 
If counterexamples are strong, a single counterexample is sufficient to quash N, regardless of how many selective confirmations are found. Ergo, counterexamples have more weight in the decision-making process than selective confirmations – when strong counterexamples are available, the strong form of N and 

In the cases in which counterexamples are not sufficient to exclude a hypothesis – being weak counterexamples – the possibility of an axiom being true is directly related to the existence of selective confirmations. N and 
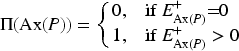
This second set of formulas ensures the decision is influenced more by the selective confirmations – with
Table 3 summarizes which forms of N and
Definitions, Formula, Selective Confirmation and Counterexamples for Each Property Axiom.

Definitions, Formula, Selective Confirmation and Counterexamples for Each Property Axiom.
Acceptance/Rejection Index (ARI) Form to Apply for Each Property Axiom.

Returning to the example in Table 1, not all individuals in the domain or range of the hatches property are equally available to be analysed – e.g., there is mention of an individual “Mineral EG” that is not among the individuals currently in
Axiom Scoring for the hatches Property Using the Strong Forms of N and

By not having information about individuals such as Mineral EG and Ditto EG, it is not possible to have all the data needed for the remaining individuals to count as selective confirmations. In the cases of T and S, incomplete data may lead to false negatives, and selective confirmations are much harder to find as they require more individuals to be on the same sliding window. When using the weaker forms to compute ARI for T and S, the results reflect the potential for those axioms to be present (see Table 5).
Axiom Scoring for the hatches Property Using the Weak Forms of N and

While ARI can be updated with each new individual on the stream, it only influences the ontology evolution process at the end of

Considering the ontology evolution application scenario, in which a potential new version (or at least for of some of its axioms) is created at the end of each ARI calculated during 
A
Both ARI and 

As F and T axioms are incompatible, and F is computed on stricter terms (using the stronger-form), F is considered to take precedence over T in case of both being flagged for inclusion. As such, whenever the algorithm concludes that the same property could be both F and T, it will only classify it as F. Similarly, an axiom cannot be simultaneously T, S and IR. In these cases, precedence is given to T and S.
The following sections will illustrate the application the possibilistic approach to axiom scoring in two different scenarios:
To establish the strength of the devised solution, experiments were first conducted against a dataset in which some property constructors were previously known. With the ontologies known and the datasets curated, there is no expectation of counterexamples to be found for the assertions present in the ontology.
For a better understanding and discussion of the results, they have been separated according to the following questions: What should be the size of the sliding window in order to effectively learn property axioms and how does the number of samples (i.e., individuals that use the property under scrutiny) in the stream influence it? Furthermore, the following subquestion will be investigated: How does ARI compare with precision, recall and f-measure? How does it compare to the application of selective axiom confirmations exclusively? How well do the weak forms of N and
The experiments described below were carried out using the set of ontologies in Table 6, which were selected for their property axioms and population sizes.
Properties and Their Respective Axioms by Class.

Each populated ontology was split into samples of 3000 random individuals, which are then sequentially subjected to the analysing queries. To simulate an RDF stream scenario, the individuals of the ontology are queued (and dequeued when necessary) into the sliding window one at a time. Queries are executed over the sliding window, guaranteeing they never have access to all existing individuals in the ontology simultaneously and therefore operate under the original restrictions of the TICO solution. Because it is not possible for one property to employ all property axioms simultaneously, we can restrict the analysis to only individuals that make use of the properties shown in Table 6 for performance reasons – and individuals that work as confirmations for those properties can work as counterexamples for others.
For the purposes of this work, a modified version of the queries described in Bühmann & Lehmann (2012) are used as confirmation queries (CQs), in which the differences account for the streaming nature of the use case and the granularity of the search (here at the individual level and not at the triple level). Two different types of queries can be used for each property axiom: The CQs, which ascertain if a property axiom could be present, and the negation queries (NQ), which ascertain the opposite. Each class of query (CQ or NQ) provides its own confusion matrix, and the meaning of their solutions varies depending on whether the true class corresponds to the existence or non-existence of the axiom. This reasoning is illustrated in Table 7.
Confusion Matrix and Respective Query Results.

CQ: confirmation query; NQ: negation query.
The CQ looks for positive cases of functionality: If a given individual is compatible with the axiom, either by having only one use of the property or the object being a duplicate. An individual that can be selected with this query is a selective confirmation of the functionality axiom. If the property is indeed functional – i.e., if the true class in Table 7 is AXIOM – then this result is a true positive. On the other hand, if the axiom was present but the query does not yield any results, it is a false negative. If the true class is ¬AXIOM – i.e., it is known that the functionality axiom is not present – and the query returns a result, it is a false positive. Following the same reasoning, an empty set here is the correct result for the individual and therefore a true negative.
The NQ, on the other hand, looks for explicit counterexamples: For an individual to result in a non-empty set when queried, it must definitively have at least two uses of the property, and their objects be distinct. If the true class in Table 7 is AXIOM and the NQ returns a non-empty set of solutions, it must forcefully be a false positive – there should not have been any solutions for the query, as functionality is present. If it returns an empty set, it is a correct identification and a true negative. In the same vein, the true class is ¬AXIOM – and the query has results, it is doing so correctly and, therefore, a true positive. If it returns none – claiming the axiom is present when it should not be – it accounts for a false negative.
Code snippet 2 and Code snippet 3 show one possible difference between confirmation and NQs, using the functionality axiom as an example. Each query is executed for each individual being tested and generates a result set with a size of either 0 or 1 query solutions.


Traditional information retrieval statistics, e.g., precision, recall and f-measure are computed as follows:
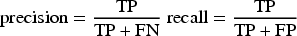

To ascertain how ‘quickly’ and effectively the queries can identify the possibility/probability of an axiom being present for a given individual, three different sliding windows sizes are analysed: 10, 50 and 100 individuals (corresponding, roughly, to 0.2%, 2.3% and 4.7% of all individuals in the sample, respectively). Theoretically, the more individuals in the sliding window that can be used to answer a query, the more precise the classification of each individual as a selective confirmation or counterexample should be. However, for performance reasons, it is interesting to see if reliable conclusions can be made from as little data as possible.
While all properties used by each class were studied, for the sake of brevity, we will focus on presenting the results for a property from a class with a high variance in the usage of its properties – i.e., not all individuals of the same type will use the same properties – and those for a class with lower variance, in which all individuals always use the same properties.
This section analyses the effects of both the window size and the influence of support in the sample. As previously explained, for an individual to constitute support, it must be the domain of the property being investigated. However, even if a stream is comprised only by individuals of the same type, there is no guarantee that all of them will employ the same properties. For the following experiments, two classes from the CMT ontology were selected – Paper and Person – as the first always employs all its properties and the second has more variety to it, with some properties being used in a very low fraction of its individuals. To ascertain the influence of the window size (
Considering that the dataset is clean, and no counterexamples can be found, the results in favour of an axiom are fairly evident regardless of the window size applied (perfect precision combined with necessity, possibility, and ARI of 1). However, it is important to investigate the more interesting cases in which counterexamples are indeed possible, by analysing the evolution of the metrics in the cases where an axiom is known not to be present.
The values presented in Table 8 are applied on the following experiments, assessing how the relevance of each individual for support affects the evolution of the metrics and the potential results. The following graphs show the evolution of specific measure in function of the number of individuals analysed.
Number of Individuals on the Stream to Analyse, Window Sizes, and Percentage of Support in Each Sample for Each of the Studied Properties.

Number of Individuals on the Stream to Analyse, Window Sizes, and Percentage of Support in Each Sample for Each of the Studied Properties.
The readByMetaReviewer property does not feature any of the explored property axioms, but it is present in all individuals of the Paper class. The study of the evidence for and against the IF axiom for this property shows how the proper identification of each individual as a selective confirmation or a counterexample is affected by the changes in window size – that as more individuals are analysed, it becomes apparent that the same property is used by more individuals with the same value – and the number of counterexamples starts to increase. Most of the changes occur when analysing the first 60 individuals out of the sample, as shown in Figure 3, with most individuals (around 94%) being incorrectly categorized as selective confirmations due to lack of information to the contrary. However, by increasing

Evolution of the selective confirmations of IF for the readByMetaReviewer property with

Evolution of the Precision of IF for the readByMetaReviewer Property with
ARI is always steadily negative, with the improvements in the classification of individuals changing how negative it skews, improving from −0.36 to −0.71, as shown in Figure 5 (featuring only the first 60 individuals, after which the metrics stabilize). The metrics evolve differently when not all individuals in the stream are considered support.
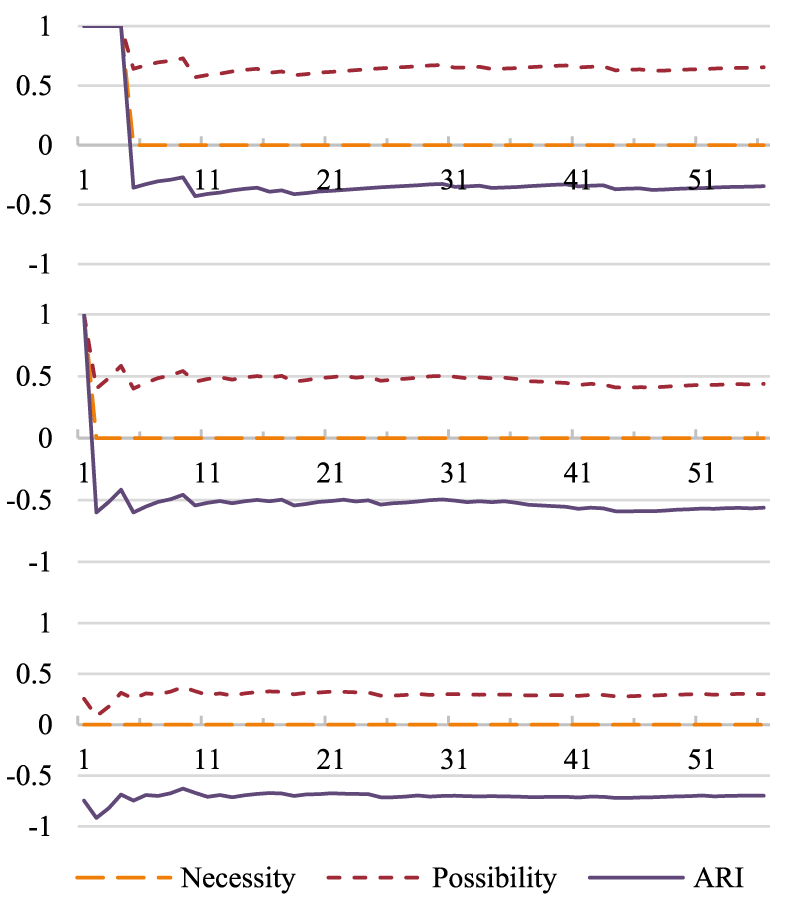
Evolution of N,
Consider the results in Figure 6, which were obtained when searching for inverse functionality of the rejectedBy property, which is used by 1279 individuals of the Paper class (≈50%).

Evolution of selective confirmations of IF for the rejectedBy property with
Selective confirmations for the IF axiom start high (at 100%), as a single individual with a single use of the property cannot be flagged as a counterexample. After analysing 60 individuals, counterexamples account for more than 70% of the samples; 80% after 120, and their number finally stabilizes around 85% as the analysis progresses. With a sliding window of 50, there should be more available evidence for each query to ascertain if the axiom is present. This seems indeed to be the case: While the 70% threshold obtained with a
Precision, recall and f-measure show similar evolution patterns as those of support, as seen in the first graph of Figure 7. All metrics start low, with a quick but unsteady increase until around 50 individuals have been analysed, and equally stabilizing as the analysis progresses.

Evolution of precision, recall and f-measure of IF for the rejectedBy property with
Precision peaks at around 85%, as expected from the results presented in Figure 6. Recall stabilizes around 45% and f-measure at 60%. With a similar evolution to that of the support for the same window size, as illustrated in the second graph of Figure 7, similar levels of precision, recall and f-measure are obtained but with their values stabilizing higher and later (f-measure reaching 60% after circa 40 samples and 65% after 100). This effectively shows that by having a bigger sliding window – i.e., by having more individuals available for each query to search in – it is possible to track more nuances in the data and better classify each individual as a selective confirmation or counterexample. In further increasing
If one were to trust these metrics by themselves, it could be concluded that the approach can identify if the property is not IF with a certainty of 65%. Here, necessity, possibility and ARI can provide a faster and more complete idea of the classification that must be done when giving the proper weight to the counterexamples. The following Figures illustrate the evolution of ARI using the same three window sizes as before.
Figure 8 shows necessity starting at 1, as only one individual has been analysed, and it is not a counterexample. However, as the second individual provides a counterexample, it immediately drops and stays at 0. Possibility, as determined by the number of selective confirmations, suffers a gradual loss as less and less selective confirmations are found in the data, and stabilizes very close to 0 (but with a positive value, as individuals that do not explicitly contradict the axiom can still be found) after around 50 individuals.
Evolution of N,
ARI, as a function of the other two metrics, shows a similar evolution from 50 individuals onwards, stabilizing very close to −1, which strongly advocates for axiom rejection, as seen in Figure 9.

Evolution of N,
There are no discernible changes in the evolution of necessity, possibility and ARI when the window size is increased, as the number of selective confirmations and counterexamples is not as relevant for these metrics as the mere presence of counterexamples is. The metrics support the reasoning that a bigger window provides a better classification of each sample as either a selective confirmation or a counterexample, but only to a certain extent.
Similar to support and information retrieval metrics, Figure 10 displays how ARI evolves slightly faster but is not significantly improved. Unlike the Paper class previously explored, Person has even more variance in the application of its properties – e.g., the property addedBy is used by 734 of the 3000 individuals studied (≈25%), while rejectPaper is used only by 4 of them (≈0.1%) – although it is relevant to note that rejectPaper is the inverse property of rejectedBy, which is more widely used. While this change in frequency affects the evolution of the metrics being studied, the results follow the same trends as before: By allowing the queries to access more individuals, metrics are improved, but only until a certain point. The speed at which they improve, however, is indeed affected by the variety in the data, as shown in Figure 11.

Evolution of N,

Evolution of confirmations of IF for the property addedBy with
The results show that if potential variations in use of the properties can be expected, increasing

Evolution of precision, recall and f-measure of IF for the property addedBy with
Furthermore, it is important to note that for the smaller values of
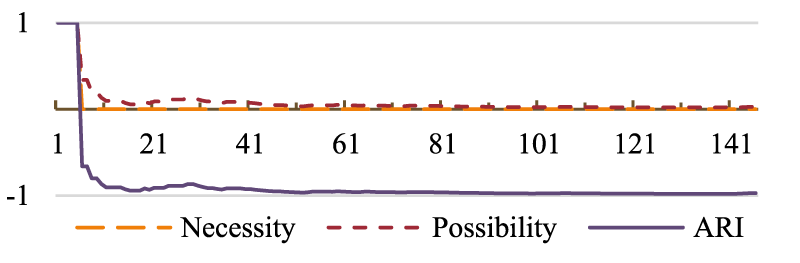
Finally, the changes in the evolution of necessity, possibility and ARI follow the information retrieval ones, by showing how a small window size for a type with high property variety takes longer to stabilize, as seen in Figure 13.

Evolution of N,
However, while there are significant improvements when

Evolution of N,
In conclusion, in the cases where there is a very limited number of counterexamples, ARI may never reach its lower threshold; but remains reliably negative, even when f-measure is at its lowest – showing that the possibilistic approach is indeed robust and applicable when scoring axioms in streams and with limited data, and more so than a strictly probability-based one. It nonetheless benefits from increased number of counterexamples, implying that a
Depending on the completion of the data, the incompleteness of the ontology, or simply because no such cases have ever been documented – the same sample can easily selectively confirm multiple property axioms. Consider, for example, that falsifying both F and IF axioms rely on the existence of more than one sample, or at least that the one sample uses the same property more than once. This is an unreasonable expectation to have about the data, and any decision to include the axioms needs to consider the fact that absence of evidence is not evidence of absence.
Since a bigger window size allows for better categorization of samples, it is possible to see the effect in evolution of IF's ARI for the functional property hasAuthor. Consider the difference between the graphs in Figure 15.
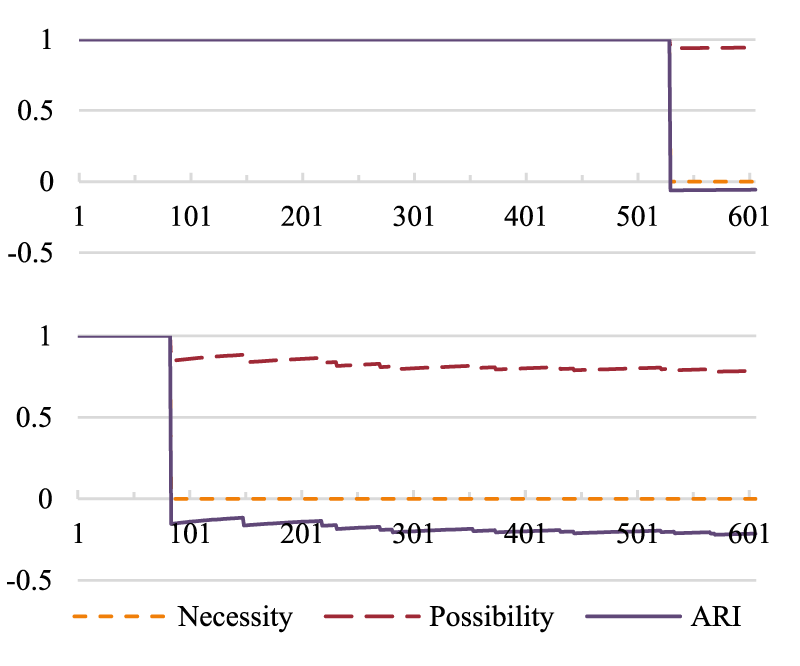
Evolution of N,
Not only is the number of counterexamples very low, but they also take some time to occur in the stream. This means that while there are counterexamples, since there are so many sequential selective confirmations – and they continue even after a few counterexamples are encountered – N may drop to 0, and
Again, it is important to reiterate that this is a fortunate case: While the counterexamples may have taken longer to arrive and be few, they were still identifiable. When such is not the case, it has to be considered that just because a property is only used once per sample, it does not necessarily mean that it must certainly be both functional and inverse functional (although it is possible to be both at once) – even if their
Transitivity was studied using the Wine and Plant ontologies, with similar results. Since the Wine ontology had more available individuals with transitive properties (a total of 82), the following results reflect those exclusively.
Figure 16 shows how the lack of explicit confirmations affects the support for an axiom. It was necessary to analyse at least 30 individuals until a confirmation could be found, with the number increasing steadily until it reaches around 15%. Information retrieval metrics, as seen in Figure 17, also illustrate the clear lack of selective confirmations, which informed the decision to apply the weak forms of

Evolution of confirmations and counterexamples of T for the property locatedIn with

Evolution of information retrieval metrics of T for the property locatedIn with
By giving more weight to the very hard to find selective confirmations than to the very easily incorrectly identified counterexamples, Figure 18 shows it is possible to obtain a positive, albeit conservative, ARI.

Evolution of the weak forms of
Should the strong form of possibility and necessity been applied instead, ARI would tend towards extremely negative (circa −1), even if the possibility was seen increasing (very) slowly.
Of the three options in window size studied – of 10, 50 and 100 individuals – the results show that there is a significant improvement between going from 10 to 50, but hardly any from 50 to 100. We find 50 individuals to be a good middle ground for these datasets; while the results can be improved by employing bigger sliding windows, they also validate our assumption that it is possible to efficiently learn property axioms from a relatively small number of samples.
The observation of the previous results show that the computation of ARI contains more information than that just the percentage of selective confirmations and could potentially be used in its place. Additionally, ARI shows better performance than traditional information retrieval metrics, achieving sharper results and considerably earlier. However, since the existence of a single counterexample immediately skews ARI towards negative,
For axioms that are relatively easy to falsify, but not so easy to prove, like F and IF, a higher threshold for ARI should allow for some errors in the data while still strongly advocating for the inclusion of said axioms. On a window size of 50 individuals, we argue that ARI should be of 1 for an axiom to be considered for inclusion, but have a proportion of
There is a second part to the discussion of the existence of counterexamples: Axioms that are the opposite of one another. While a property can be both functional and inverse functional at the same time, it cannot be both symmetrical and asymmetrical. Furthermore, while a selective confirmation of S is a counterexample of AS, a selective confirmation of either does not necessarily mean that the property axiom must to be present; any decision-making processes need to take this in consideration. This is especially evident in the case of property hasDecision of the CMT ontology, which is functional, but shows N,
Experiment II: Accommodating for Errors in Data and the Effects of Previous Knowledge in Axiom-Inclusion Decisions
The following experiment pertains to shows the applicability of the solution for the purpose of ontology enrichment/evolution. This is done by analysing a stream of individuals in which not only new properties are added over time, but the known properties are also applied in different ways to describe the data. As such, a suitable dataset needs to support the following: (1) Have several properties that connect the individuals in diverse ways, such that all different property axioms being studied could be tentatively discovered, (2) the application of said properties should change over time, as the domain naturally evolves, (3) the property axioms are not previously known.
The goal of this experiment is to answer the following questions: When combining ARI and Support, are any inconsistencies introduced? To which extent? Are the inconsistencies the result of incorrect data or valid, but marginal uses of the properties? If previous knowledge is considered in the decision to include/exclude a property axiom, does it prevent or increase the amount of inconsistencies introduced?
The ontologies in use pertain to the Pokémon domain as it is described in Wikidata (Wikidata, n.d). Pokémon is a series of games about cataloguing fictional wild creatures of the same name. Over the years, several games have been released, and each generation of games – a total of nine, at the time of writing, – introduces (and refines) mechanics, regions and creatures. Much of this information is publicly available on Wikidata. New subproperties of those present in Wikidata were created (but not characterized) that pertain to specific relationships in the Pokémon domain – Wikidata's properties, by design, are high level and lack the nuance necessary to describe specific domains beyond very simple connections between its individuals (e.g., part of, instance of).
The experiments detailed below show how axiom scoring can be used to determine which axioms could be associated with each property, and how their usage changes with each new generation of games. Table 9 shows the values and thresholds employed, and the application of both ARI and the percentage of selective confirmations (
Values and Thresholds Employed in the Experiments.

Values and Thresholds Employed in the Experiments.
Generation I
Generation I (Gen I) features games with relatively simple mechanics. It introduces one region, one Pokédex (the Pokémon encyclopaedia) and 151 Pokémon. Using the data available on Wikidata, enough information was extracted to ascertain the properties described below. Table 10 shows the names, percentage of selective confirmations, proposed property axioms and ARIs for each.
Gen I Properties.

Gen I Properties.
ARI: acceptance/rejection index; Gen I: Generation I.
bordersWith, a property that establishes a connection between two locations (e.g., cities or roads) that share a border, seems a target candidate for S, but the results do not support it (selective confirmations amounted to 1%). Interestingly, the results show there is sufficient positive evidence for T, and adding this axiom to the ontology does not make it inconsistent – although including it would allow for entailing incorrect conclusions about the data. Counterexamples were found for AS and IR. locatedIn is another property related to the geography of the region. However, since only one region has been introduced as of Gen I, it is classified as F, with no contradictions on the data.
With each Pokémon belonging to a single evolution group (described by the hasEvolutionGroup property) but each group having more than one creature, the expected axiom for this property would be F, which the results support.
Of the datatype properties, three of them were classified as F even though counterexamples were found – since the percentage of selective confirmations was considered sufficient, and the deviations should pertain to possible errors in the data. In this case, we can verify if this was the cause, by using the reasoners provided by Protégé (in this case, HermiT 2 ) and adding said axioms to the ontology and analysing the explanations provided in case inconsistencies are found.
Figure 19 shows the inconsistency explanations for the hasWeight property, in which it is possible to see there are 6 individuals with more than one entry, and the duplicates’ values seem to correspond to the same value under different representation systems (metric vs imperial), which suggest that using the same property to represent both may not be adequate.

Reasoner's explanation for inconsistency for property hasWeight.
Figure 20 shows how there is one single individual that contradicts the functionality of the hasHeight property, with the same apparent justification as the hasWeight.

Reasoner's explanation for inconsistency in property hasHeight.
Figure 21, on the other hand, shows there are 2 individuals with more than one colour, both belonging to the same evolutionary group. This may be an oversight in the data acquisition from Wikidata, which often mixes the information of all generations.

Reasoner's explanation for inconsistency in property hasColor.
Generation II (Gen II) improves on Gen I by introducing a new region (adjacent to the first one), while still allowing the player to visit the one introduced in Gen I. The Pokédex is expanded to accommodate for the new region: The player now effectively can access not one, but two Pokédexes, one at the national level (with all creatures) and a regional one (with the creatures inhabiting the new region exclusively, which may or may not be new). Therefore, the same creature may now be associated with more than one Pokédex entry, but each entry will be associated to its own numbering system (and potentially, description). Information about the creature's shape is also added, and the number of Pokémon grows from 151 to 251. Additionally, some new game mechanics are included: Creatures can now have one of three genders (female, male, and unknown), and can reproduce within a given group (not necessarily only with members of the same species).
Information about the properties present in Gen II is displayed in Table 11. For the sake of brevity, only changes in axioms are shown. If an axiom is removed, it is preceded by a – symbol, and by a + otherwise.
Gen II Properties.

Gen II Properties.
ARI: acceptance/rejection index; Gen II: Generation II.
hasPokedexEntry, which relates a Pokémon to its corresponding Pokédex information, loses the F axiom – as the new region introduced a new Pokédex, and therefore a Pokémon may have more than one entry. However, it retains the IF axiom, as each entry relates to a single creature. presentIn, a property which describes in which generation a given entity or mechanic is featured, can now point to more than one option and, therefore, is no longer F. Of the new properties, alternateDexEntry connects any two entries in different Pokédexes that describe the same creature and therefore should be classified at least as S. The results show not only this happens, but it also does not contradict the T, F and IF property axioms.
With the introduction of genders, each species displays one of several possible gender ratios (via the hasGenderRatio property), and as such has been classified as F. As no evidence was found against it, it is also classified as AS and IR. hatches, which relates a creature with its reproductive group, and each reproductive group with the Pokémon in it, has sufficient ARI to be classified as T, but not S. Finally, the only datatype property added in Gen II, hasShape, does not meet the criteria for any of the property axioms.
When adding the proposed axioms to the object properties in the ontology of Gen II, no inconsistencies are generated. However, the same cannot be said for the datatype properties. According to Figure 22, there are some inconsistencies regarding the use of the hasName property, namely when describing the evolutionary groups. Because new Pokémon were introduced in between generations and added to existing evolutionary groups, some of their names to have undergone changes that have not been corrected.

Inconsistencies with the use of the hasName property.
As seen in Figure 23, in addition and similar to the inconsistencies present in Gen I, there are a few (six) entities with two or more uses of the property hasColor.

Inconsistencies with the use of the hasColor property.
Generation III (Gen III) introduces two more regions, and no longer features those of Gens I and II. It also introduces two new mechanics: Abilities and contests. Each Pokémon can now have one or two of the 77 possible abilities – some of which are considered ‘signature abilities’, as they are only shown for specific Pokémon or specific evolutionary groups. Furthermore, 135 new Pokémon are added (to a total of 386). The changes and additions to the properties and their axioms are shown in Table 12.
Gen III Properties.

Gen III Properties.
ARI: acceptance/rejection index; Gen III: Generation III.
With the introduction of contests, moves now have no longer only a type in battle, but a type that shows in contest (the two are not related). As such, the property hasMoveType is no longer compatible with functionality. Once again, with the introduction of a new region and a new Pokédex, the same Pokémon can have multiple entries – and although these are still alternatives to each other, and therefore symmetrical, there is now more than one possible alternative and the property can no longer be classified as either F or IF.
Finally, hatches maintains its T. Evidence against IR was below the minimum threshold (selective confirmations amounting to 95% of the data) – but as it was already classified as such, the axiom is not added. Following the definition of a signature ability discussed above, the property is properly classified as F (each Pokémon/evolutionary group has only one signature ability) and IF (each signature ability is used by only one Pokémon/evolutionary group). Since no counterexamples for IR and AS are found, these axioms are also added to the property. As the percentage of counterexamples found for F in hasWeight has once again lowered below the minimum threshold, the property axiom is reinstated.
As with Gen II, when the axioms discovered are added to object properties in the ontology for Gen III, they do not produce inconsistencies. However, with support for hasColor at 98% and hasHeight as 99%, counterexamples are rare but produce some inconsistencies.
Generation IV (Gen IV) introduces once again a new region and, with it, comes a new catalogue and new Pokémon (totalling 493). There is also the introduction of 47 new abilities and 113 new moves. Several evolutionary groups from Gen I were expanded with new elements, and moves are now classified not only according to their previously known contest and type categories, but with an additional damage category that is fully independent from its type. It is also in this generation that the games make use of alternate forms of the same Pokémon (including, but not limited to, differences by gender). Generation V (Gen V) raises the total number of Pokémon to 649, and once again introduces a new region while limiting access to the previous ones, but does not introduce any new properties.
Changes and additions to the properties of the ontology for Gen IV are displayed in Table 13:
Gen IV Properties.

Gen IV Properties.
ARI: acceptance/rejection index; Gen IV: Generation IV.
The inclusion of these axioms in both Gen IV and Gen V ontologies does not cause inconsistencies beyond those already discovered in previous generations.
Generation VI (Gen VI) introduces 72 new Pokémon (to a total of 721), 58 new moves and 24 new abilities (to a total of 617 and 188, respectively). It also adds a new battle mechanic, the Mega Evolution, which is a type of alternative form that can be (temporarily) triggered in battle. Like previous generations, Gen VI introduces a new region and a new Pokédex, while also revisiting the region first introduced in Gen III. Table 14 shows the changes in the property axioms in Gen VI, while Table 15 does so for Gen VII:
Gen VI Properties.

Gen VI Properties.
ARI: acceptance/rejection index; Gen VI: Generation VI.
Gen VII Properties.

ARI: acceptance/rejection index; Gen VII: Generation VII.
hasMegaEvolution, a relationship between a Pokémon and its Mega Evolution alternate form, is both F and IF (theoretically meaning that a Pokémon can only have one mega evolution and that evolution belongs to only one Pokémon). The mechanic is triggered by the usage (with the uses property) of different battle items, and each of them causes a specific evolution to occur.
When the axioms are added to the Gen VI ontology, they do not produce inconsistencies – contrary to what would be expected when the percentage of confirmations is below 100%. However, upon closer analysis, it is possible to see that there are indeed few, but valid, cases in which a Pokémon can have more than one mega evolution, caused by the application of more than one item. In the dataset for Gen VI, there are two such occurrences, shown in Figure 24. The reasoner fails to flag these as inconsistencies unless the individuals are explicitly stated as being different (which would always be the case under the UNA).

Rare, but valid individuals which do not support F for the hasMegaEvolution and uses properties.
Generation VII (Gen VII) sees the introduction of regional forms, as the same creature adapts to different habitats: Effectively another specific type of alternate form. It also increases the number of Pokémon to 802 and introduces a new region and its respective Pokédex. It revisits the region introduced in Gen I, adding new alternate forms to some previously known Pokémon.
With the introduction of new abilities, Gen VII alters how signature abilities work, and a few Pokémon can now have more than one signature ability – as such, hasSignatureAbility can no longer be F, and isSignatureAbilityOf can no longer be IF. Thankfully, in this case, the number of counterexamples is above the threshold and the axioms are correctly removed. If the axioms are added to the ontology, by UNA they generate some inconsistencies. Figure 25 shows one such case, in which a valid selective confirmation of a creature has more than one known regional variant.

Rare, but valid individuals which do not support the F and IF for the hasRegionalForm property.
Generation VIII (Gen VIII) introduces two new regions, each with its individual Pokédex. The national one, which catalogues all creatures, now goes up to 890, with 19 new regional forms. The mega evolution mechanic is removed from the games. Generation IX (Gen IX) introduces another region and its respective catalogue, and 103 new creatures (raising the total to 1008). While it introduces the concept of convergent evolution – creatures that fill the same ecological niches also sharing physical similarities – information about this was not present in Wikidata at this time. Finally, this generation introduces a few more regional forms and a new type of alternative form that is not well described in Wikidata.
Because of alterations on how signature abilities are assigned to evolutionary groups between games, Table 16 shows the changes in the associated properties.
Gen VIII and Gen IX Properties.

Gen VIII and Gen IX Properties.
ARI: acceptance/rejection index; Gen VIII: Generation VIII; Gen IX: Generation IX.
Once again, this is a case in which the inconsistencies refer to valid uses of the property, meaning the application of the axioms is in the wrong, as shown in Figure 26:

Evolutionary line with more than one signature ability, a counterexample to the F of hasSignatureAbility.
Experiments show that allowing for some leeway in terms of inconsistency can result in the discovery of errors in the data, such as duplicates, or potential mistakes in modelling that do not account for the possible alternatives. It also shows that not all inconsistencies are caused by said incorrections, and some valid, but outlier information can get flagged as inconsistent.
Evolving ARI depends not on a minimum threshold on the percentage of selective confirmations,
The following experiments are divided in two different sections, namely: Applicability and robustness of ARI for axiom scoring. Considering the dataset was obtained from Wikidata, which is often incomplete and sometimes offers incorrect or even contradictory information, we consider the percentage of selective confirmations does not need to equal 100% for the axiom to be accepted. Furthermore, in this case, the analysis is done from a point of complete ignorance, in which no previous versions of any axiom are considered. This should allow for a more informed decision about which thresholds to consider for axiom inclusion in the following experiments. Analysis of
First, we must consider how conservative the approach will be by defining the relative weight of previous knowledge,
To avoid this,
Make Table 17 shows the thresholds employed for the following experiments – maintaining the acceptance thresholds for the strong and weak forms of ARI (
Values and Thresholds Employed in the Experiments.

First of all, it is interesting to see the effects of the different weights affect the evolution of
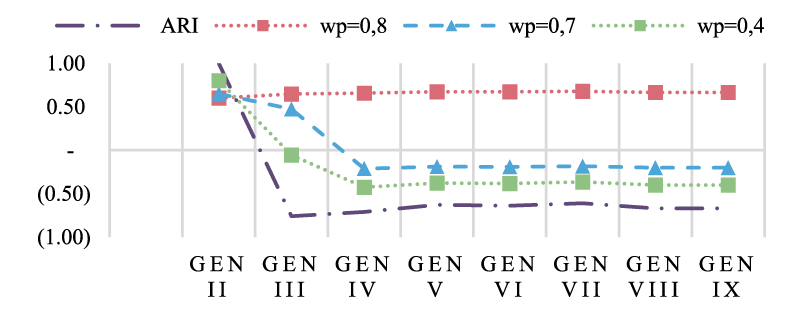
Evolution of
Starting with the datatype properties, which were the ones creating the most inconsistencies since early generations, we can see that without taking

Comparison of the decisions made using
Differences in the decisions reached ARI, ARI+

Decisions regarding the T of the hatches property.
With the more conservative approach to change provided by
In some generations, isSignatureAbilityOf and hasSignatureAbility were shown to have valid counterexamples that were not considered because of the chosen value for
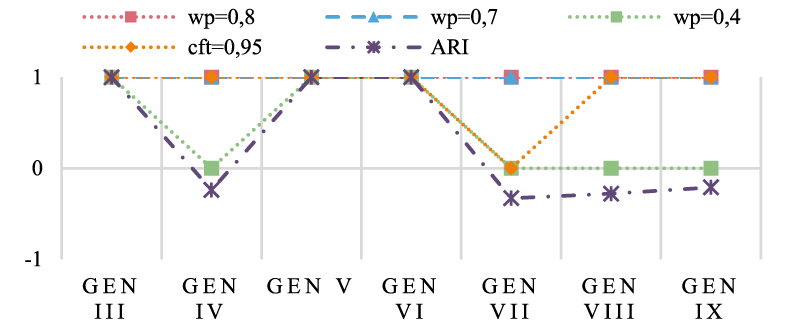
Comparison of the decisions to include/exclude the F axiom for the hasSignatureAbility property.

Comparison of the decisions to include/exclude the IF axiom for the isSignatureAbilityOf property.
hasRegionalForm, which was considered F, IF and S, is now instead classified as T and S for all generations in which it is featured. This happens because

Comparison of the decisions to include/exclude the F axiom for the hasRegionalForm property.
Since F is no longer associated with the property, it can assume the T axiom, for which it did have sufficient ARI and

Comparison of the decisions to include/exclude the T axiom for the hasRegionalForm property.
The inclusion of the T and S axioms to the ontologies of Gens VIII and IX does not produce inconsistencies.
Using ARI by itself does not allow for inconsistencies to arise, which in turn means that in spite of its utility for axiom scoring, it does not allow for the very likely possibility of errors and inconsistencies in the data – which is especially relevant when developing an ontology from publicly-available information from sources such as Wikidata. By combining ARI and
The results show that is still possible to counter some errors in data when using
Conclusions
This paper presented an adaptation of the possibilistic approach to axiom scoring to the context of RDF data streams for ontology evolution. The different approaches to possibility and necessity proposed in literature were recontextualized in terms of their bias towards selective confirmations or counterexamples, and the assumptions regarding the openness of the world under which they operate, and proved effective. Some axioms, namely transitivity and symmetry, benefit from a more lenient approach, relying more on selective confirmations than on counterexamples – while the others benefit from stricter acceptance conditions to prevent the proliferation of inconsistencies.
To test the applicability of the solution, it was applied in two distinct scenarios: (1) A first one, in which the property axioms were previously known, and which allowed for the exploration of the effectiveness of the approach for their discovery in a scenario where no incorrect data was present; and (2) a second one, in which the neither the properties nor their axioms were known, and the dataset was obtained from publicly available sources, possibly both incomplete and with errors.
Regarding Experiment I, results show that possibilistic approach is well suited to suggest potential axioms for ontology properties in an instance-guided ontology evolution scenario, achieving conclusions about inclusion/exclusion of axioms from a relatively small sample of individuals (roughly 2.3%), and substantially faster than using traditional information retrieval metrics – making it particularly suitable for quickly learning new axioms from streams of RDF data. This, however, is not achieved without some caveats: The approach is not sufficiently robust to cases in which there are inconsistences or errors in data, with the strong approach being particularly unable to recover from counterexamples that may reflect said errors. No approach can effectively deal with all potential negative side effects of dealing with an open world and with incomplete knowledge; if ARI is used independently of support, it cannot account for missing or incorrect information.
Additionally, this experiment shows that the size and variety of the individuals in the dataset affect the speed and accuracy of the identification of axioms, suggesting that some finetuning of parameters may be necessary to achieve the best results depending on the application scenario.
Experiment II aimed to overcome the issue with ARI identified in Experiment I in two ways: (1) By combining it with a minimum percentage of selective confirmations and (2) by attributing weight to previous knowledge between timeframes. Axioms that are not 100% supported by ARI may therefore be accepted: This allows for the identification of potential errors in data but may also erroneously suggest discarding valid information. Acknowledging the information provided by previous versions of the ontology when deciding for or against an axiom is helpful in identifying and maintaining property axioms for which positive evidence is inherently harder to find – however, it also allows for the continued integration of incorrect axioms. Here, the combination of support and ARI seems to achieve the better results when it comes to introducing the least amount of inconsistencies over time; the downside being that it may erroneously consider valid, but marginal uses of properties as irrelevant, and therefore the results still need to be analysed on a case-by-case basis. Ultimately, the experimental results show that ARI can be made more resistant to errors in data, benefiting from being combined with other metrics – but more work is needed in this regard to further explore which metrics – and in which way – can be combined in a more systematic fashion that is less dependent of empiric analysis of specific use-cases.
Finally, and although it was out of the scope of the experiments performed for this work, it is also important to consider the possibility of over-characterization of the properties in an ontology. The results show that the current solution will almost always propose one or more axioms for each property – which may or may not make sense, depending on the application context and purpose of the ontology; upper-level ontologies, by definition and application, benefit from excluding superfluous axioms. Even for lower-level ontologies, there is always an argument to be done in favour of simplicity of design, which should not be more complex than necessary to achieve its goals. In the future, the suitability of the suggested axioms should not rely solely on the fact that their addition to the ontology does not introduce inconsistencies, but be motived too by their capacity to allow for richer inference processes to happen in order to unlock the data's true potential.
Footnotes
Funding
The authors received the following financial support for the research, authorship, and/or publication of this article: This work has been supported by the European Union under the Next Generation EU, through a grant of the Portuguese Republic's Recovery and Resilience Plan Partnership Agreement under the project PRODUTECH R3. It has received Portuguese National Funds through Portuguese Foundation for Science and Technology under the project UIDP/00760/2020 and the Ph.D scholarship with reference SFRH/BD/147386/2019. Additionally, this work benefited from the informed and pertinent insights by INRIA's mOeX team and the efforts made by Wikidata's Project Pokémon (![]() ).
).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.