
Abstract
Information extraction (IE) is a transformative process that converts unstructured text data into a structured format by employing entity and relation extraction (RE) methodologies. Identifying the relation between a pair of entities plays a crucial role within this framework. Despite the availability of various techniques for RE, their efficacy heavily depends on access to labeled data and substantial computational resources. To address these challenges, large language models (LLMs) have emerged as promising solutions; however, they are prone to generating hallucinated responses due to the limitations of their training data. To overcome these shortcomings, this work proposes a retrieval-augmented generation-based relation extraction (RAG4RE) approach to enhance RE performance. We evaluate the effectiveness of RAG4RE using various LLMs. By leveraging established benchmarks such as TACRED, TACREV, Re-TACRED and SemEval RE datasets, we aim to comprehensively assess the efficacy of our methodology. Specifically, we employ prominent LLMs, including Flan T5, Llama2, and Mistral, in our investigation. The results of our work demonstrate that RAG4RE outperforms traditional RE methods based solely on LLMs, with significant improvements observed in the TACRED dataset and its variations. Furthermore, our approach exhibits remarkable performance compared to previous RE methodologies across both TACRED and TACREV datasets, underscoring its efficacy and potential for advancing RE tasks in natural language processing.
Introduction
Information extraction (IE) is a process of converting unstructured text data into structured data by applying entity and relation extraction approaches. Identifying the relation between a pair of entities in a sentence, relation extraction (RE), is one of the most significant tasks in the IE pipeline (Grishman, 2015). RE plays a pivotal role in constructing domain-specific knowledge graphs (KGs) from text data and ensuring the completeness of KGs. An example of a relation type between entity pairs, such as per:cities_of_residence, is illustrated in Figure 1, where the head entity (Eugenio Vagni) is linked to the tail entity (Sulu). Various RE approaches have been developed, including supervised RE, distant supervision, unsupervised RE methods, rule-based and semi-supervised approaches (e.g., weakly supervised RE) (Agichtein & Gravano, 2000; Aydar et al., 2021; Efeoglu, 2022; Pawar et al., 2017). However, well-performing RE approaches, for example, supervised learning, require a large amount of labeled data and substantial computation time. Another effective method for identifying relation types between entities is fine-tuning language models (Chen et al., 2024; Cohen et al., 2022; Han et al., 2022; Li et al., 2023; Wang et al., 2022; Zhou & Chen, 2022). It is important to note, however, that both supervised learning approaches and fine-tuning language models demand significant GPU memory and computational time during their training phase.

Example of a Relation Between Head and Tail Entities in a Sentence.
General-purpose large language models (LLMs) exhibit remarkable inference capabilities when applied with zero-shot prompting techniques, allowing them to effectively handle key tasks in IE, such as entity recognition (ER) and RE. However, they are prone to generating hallucinated outputs when lacking prior knowledge, owing to the next-token prediction mechanism inherent in these autoregressive models. Additionally, LLM prompt-tuning approaches require both prompt template engineering and domain experts for domain-specific IE approaches (Chen et al., 2024). However, template engineering is time-consuming due to its manual nature. Retrieval-augmented generation (RAG) has been proposed to reduce hallucinations in LLMs when LLM-based conversational systems produce random responses to queries (Lewis et al., 2020). The RAG system functions akin to an open-book exam, integrating relevant information from the Embedding Database directly into the query (sentence) (Lewis et al., 2020). Although there have been attempts to apply the LLM approach in conjunction with zero-shot prompting techniques, such as multiple-choice questioning (Zhang et al., 2023) and rationale prompting (Xiong et al., 2023), these works underperform on RE benchmarks due to a high number of false predictions. Specifically, they do not incorporate relevant context or information into the query sentence within the prompt template. As a result, the RAG, using zero-shot settings, could improve and reduce false predictions of LLMs in identifying relation types between entity pairs in sentences.
Well-performing RE approaches, for example, supervised learning, require a large amount of labeled training data and significant computational time, as they learn RE patterns in a supervised manner. Another effective method-fine-tuning language models-requires considerable GPU memory and computational time, particularly when both the base model size and training data are large, as the base model weights and training data must be loaded into the GPU to facilitate efficient training (Han et al., 2022). In the era of LLMs, well-designed prompts (or the prompt engineering approaches) might help us identify the relations between entities in a sentence. It is clear that well-designed prompts yield highly accurate performance in other downstream tasks, for example, ontology-driven knowledge graph generation (Mihindukulasooriya et al., 2023), text-to-image generation (Ahmad et al., 2023) by including information about fictional characters in the prompt template as an example of zero-shot settings, and ontology matching (Hertling & Paulheim, 2023) by including information about the concept to be matched in the prompts. Building on previous works that utilize zero-shot prompting, enriching the context of the prompt could provide task-relevant information to the LLMs, improving their responses. This can be done while still preserving the zero-shot settings of the prompt within the context of RAG.
In this work, our goal is to explore the potential performance enhancement in relation extraction between entity pairs in a sentence through the use of a retrieval-augmented generation-based relation extraction (RAG4RE) approach,
1
which leverages zero-shot settings. Specifically, we propose a pipeline for RAG-based relation extraction that utilizes open-source language models. To evaluate our RAG4RE, we leverage RE benchmark datasets, such as TACRED (Zhang et al., 2017), TACREV (Alt et al., 2020), Re-TACRED (Stoica et al., 2021), and SemEval (Hendrickx et al., 2010) RE datasets. We utilize both encoder–decoder models, for example, Flan T5 (Thoppilan et al., 2022)—an instruction fine-tuned variant of the T5 model (Chung et al., 2024)—and decoder-only models like Llama2 (Touvron et al., 2023) and Mistral (Jiang et al., 2023), all of which are integrated into the approach outlined in Figure 2. Furthermore, we compare the performance of our RAG4RE approach with that of simple query (or vanilla) prompting to highlight how incorporating relevant contextual information into the prompt improves results and reduces false predictions. In this work, our findings are: The RAG-based RE (RAG4RE) approach has the potential to outperform both simple query (without relevant sentence), known as vanilla LLM prompting, and existing best-performing RE approaches from previous studies. While Decoder-only LLMs (Pan et al., 2024) still encounters hallucination issues on these datasets, our RAG4RE effectively mitigates this problem, especially when compared to the results obtained from the simple query.
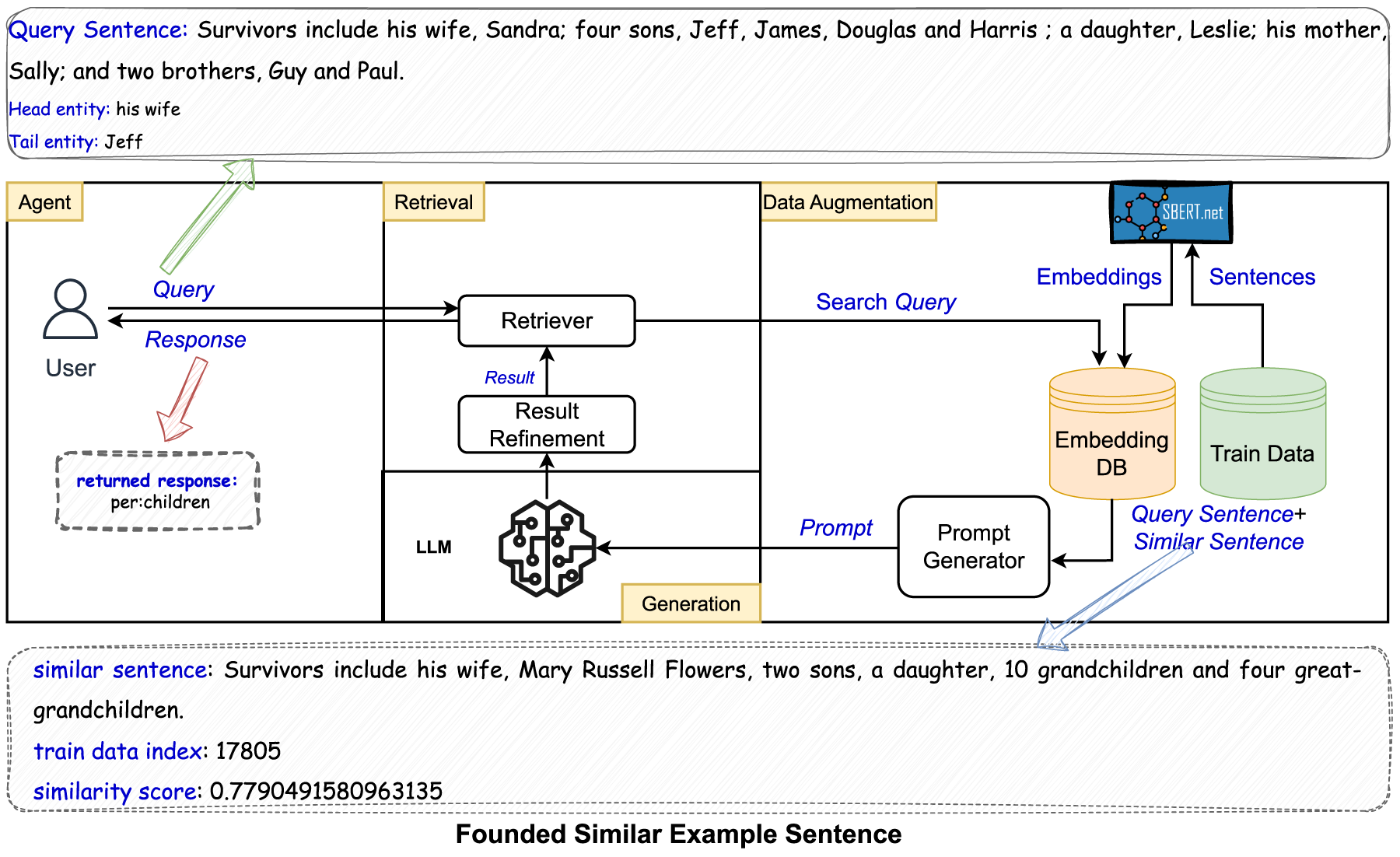
RAG-Based Relation Extraction (RAG4RE) Pipeline, Featuring a Sample Query Sentence and the Corresponding Similar Sentence Retrieved.
In the following section, we first summarize recent works in RE and RAG in Section 2, and then provide a detailed description of the proposed RAG4RE in Section 3. We evaluate our RAG4RE on RE benchmark datasets, integrating different types of LLMs in Section 4. Next, we conduct ablation studies, which yield promising results for SemEval and provide inspiration for applying RAG4RE to domain-specific datasets in Section 5. Subsequently, Section 6 discusses RAG4RE’s results in comparison to those of previous approaches. Finally, we summarize the outcomes of our RAG4RE approach in Section 7.
In this section, we summarize recent works into two categories: (i) relation extraction and (ii) retrieval-augmented generation.
Relation Extraction
RE is one of the main tasks of Information Extraction and plays a significant role among natural language processing tasks. RE aims to identify or classify the relations between entity pairs (head and tail entities).
RE can be carried out with various types of approaches: (i) supervised techniques including features-based and kernel-based methods, (ii) a special class of techniques which jointly extract entities and relations (semi-supervised), (iii) unsupervised, (iv) Open IE, and (v) distant supervision-based techniques (Pawar et al., 2017). Supervised techniques require a large annotated dataset, and its annotation process is time-consuming and costly (Pawar et al., 2017). Distant supervision is among one of the popular methods dealing with the problem of obtaining annotated data. The distant supervision, based on existing knowledge bases, brings its own drawbacks, and it faces the issue of wrongly labeled sentences troubling the training due to the excessive amount of noise (Aydar et al., 2021). Another popular approach is weakly supervised RE (Agichtein & Gravano, 2000). However, the weakly supervised approach is more error-prone because of semantic drift in a set of patterns per iteration of its incremental learning approach like a snowball algorithm (Agichtein & Gravano, 2000). In rule-based RE approaches, finding relations is mostly restricted by predefined rules (Pawar et al., 2017).
In terms of the best-performing RE approach, obtained by fine-tuning the language models, Cohen et al. (2022) proposed a span-prediction-based approach for relation classification instead of single embedding to represent the relations between entities. This approach has improved the state-of-the-art scores on the well-known datasets. DeepStruct (Wang et al., 2022) proposed an innovative approach aimed at enhancing the structural understanding capabilities of language models. This work introduced a pre-trained model comprising 10 billion parameters, facilitating the seamless transfer of language models to structure prediction tasks. Specifically, regarding the RE task, the output format entails a structured representation of (head entity, relation, tail entity), while the input format comprises the input text along with a pair of head and tail entities. Zhou and Chen (2022) concentrated on addressing two critical issues that affect the performance of existing sentence-level RE models: (i) Entity Representation and (ii) noisy or ill-defined labels. Their approach extends the pretraining objective of masked language modeling to entities and incorporates a sophisticated entity-aware self-attention mechanism, enabling more accurate and robust RE. Li et al. (2023) proposed a label graph to review candidate labels in the top-K prediction set and learn the connections between them. When predicting the correct label, they first compute that the top-K prediction set of a given sample contains useful information.
Zhang et al. (2023) generated multiple-choice question prompts from test sentences where choices consist of verbalization of entities and possible relation types. These choices are selected from the training sentence based on entities in a test sentence. However, it could not outperform the previously introduced rule and ML -based approaches. In the context of their works, Zhang et al. (2023) proved that enriching prompt context improves the prediction results on benchmark datasets such as TACRED and Re-TACRED. Melz (2023) focuses on auxiliary rationale memory for the RAG approach in the Relation Extraction task, and the proposed system learns from its successes without incurring high training costs. Chen et al. (2024) proposes a Generative Context-Aware Prompt-tuning method, which also tackles the problem of prompt template engineering. This work proposed a prompt generator that is used to find context-aware prompt tokens by extracting and generating words regarding entity pairs and evaluated on four benchmark datasets: TACRED, TACREV, Re-TACRED, and SemEval. Furthermore, Han et al. (2022) employed prompt-tuning approaches as a mask-filling task, utilizing various encoders such as BART, RoBERTa, and the encoder component of T5-large on datasets like TACRED, ReTACRED, TACREV, and Wiki80. Their approach achieved F1 scores of 75.3% on TACRED and 84.0% on TACREV. However, the primary limitation of this work lies in the time efficiency of these autoregressive models.
In this work, we introduce a retrieval-augmented generation-based relation extraction (RAG4RE) approach that operates in zero-shot settings to identify relations between entity pairs within a sentence. Previous approaches have been limited by their dependence on either labeled data during training (Chen et al., 2024; Cohen et al., 2022; Han et al., 2022; Li et al., 2023; Wang et al., 2022; Zhou & Chen, 2022) or by their use of prompt templates that lack sufficient contextual information (Zhang et al., 2023). In contrast, our RAG4RE method incorporates contextual information, reducing reliance on the potentially outdated internal knowledge of (vanilla) language models. A key advantage of our approach is that it eliminates the need for both a training process and a labeled dataset. We provide a detailed explanation of RAG in the next section.
Retrieval-Augmented Generation
RAG for large language models can be classified into two categories: (i) naive RAG and (ii) advanced RAG. Naive RAG follows basic steps: retrieval, augmentation, and generation. In contrast, the advanced version incorporates post-processing steps, such as selecting essential information, condensing the context to be processed, and emphasizing critical parts of the retrieval context before delivering the retrieved information to the user (Gao et al., 2023). The concept of RAG has been suggested as a way to minimize the undesired alterations in LLMs when conversational systems built on LLMs generate arbitrary responses to a query (Lewis et al., 2020). RAG is an example of open-book exams which are applied to the usage of LLMs. The retriever mechanism in RAG finds an example of the user query (prompt), and then the user query is regenerated along with the example by the data-augmentation module in RAG. Ovadia et al. (2024) evaluates the knowledge injection capacities of both fine-tuning and the RAG approach and found that LLMs dealt with performance problems through unsupervised fine-tuning while RAG outperformed the fine-tuning approach in unsupervised learning.
Methodology
In this work, we have developed an RAG4RE approach to identify the relation between a pair of entities in a sentence. Our proposed RAG4RE, illustrated in Figure 2, consists of three modules: (i) retrieval, (ii) data augmentation, and (iii) generation. Our proposed RAG4RE approach is a variant of an advanced RAG (Gao et al., 2023), as its retrieval module includes “Result Refinement” which applies post-processing after responses from the generation module. An example demonstrating the different responses returned to RAG4RE and a simple query is given in Table 11. The rest of the section explains the details of how each module of our proposed approach in Figure 2 works under specific subsections.
Retrieval
A user submits a sentence (query) along with a pair of entities (head and tail entities) that might have a relation to the Retrieval module as demonstrated in Figure 2. Then, the Retriever sends this query to the Data Augmentation module, which extends the original query with a semantically similar sentence from training dataset, as an example given in Figures 2 and 3. “Result Refinement” in this module applies post-processing techniques, if necessary, to the results returned by the Generation module. The “Result Refinement” consists of a couple of response processing steps, such as refining prefixes (e.g., changing “per:member_of” to “org:member_of” as illustrated in Table 1 and Figures 8(a) and 8(b)), and converting “no relation” answers into “no_relation” as defined in the predefined relation types. 2 Unfortunately, due to the nature of LLMs, which are based on next-token prediction, they might still generate undefined relation types, as analyzed in Section 4.3.

An Example of a Re-Generated Prompt from a Sample in the TACRED Dataset.
Prefix Refinement Samples From Flan T5 XL, Along With TACRED and Its Variants, Based on Predictions From the Evaluation Phase.

The data augmentation module includes an Embedding Database (DB) containing embeddings of the training data, which are computed using the Sentence BERT (SBERT) model (Reimers & Gurevych, 2019). In our approach, we use the “all-MiniLM-L6-v2” version of SBERT.
3
Within this module, the embedding of the query sentence is also computed by SBERT. The system then calculates similarity scores between embeddings of each training sentence in the Embedding DB and the query sentence embeddings using the cosine similarity metric, as described in equation 1. This formula measures the cosine similarity between two embedding vectors 
After computing the similarity scores between the query sentence embeddings and those in the embedding DB, the system selects the sentence with the highest similarity (top one) and incorporates it into the prompt template, as shown in Figure 4. For example, the cosine similarity score between the query sentence, “ Survivors include his wife, Sandra; four sons, Jeff, James, Douglas, and Harris; a daughter, Leslie; his mother, Sally; and two brothers, Guy and Paul.” and the top-ranked similar sentence, “ Survivors include his wife, Mary Russell Flowers, two sons, a daughter, 10 grandchildren, and four great-grandchildren.” is approximately

Illustration of the Re-Generated Prompt Template. The Blue-Colored Query Sentence, Head and Tail Entities, and Relation Types are Provided by the User.

Gives Number of Undefined Relation Predictions Across TACRED and Its Variants on Different LLMs Along with RAG4RE.These Relation Types are Not Defined in the Relation Types in Datasets (see Table 2).
The LLM generates a response for the prompts using zero-shot settings in the generation module. We integrate LLMs with different architectures, including encoder–decoder and decoder-only models (Pan et al., 2024), in our experiments so that we can evaluate the performance of our proposed RAG4RE approach with different LLMs and compare them within the RAG4RE framework. Subsequently, the response is sent to the “Result Refinement” in the Retrieval module. Result refinement might be necessary if the relation type includes a prefix, as the response might omit or incorrectly predict the prefix. For example, the response might return member_of or per:member_of instead of org:member_of as given in Table 1 4 (See Figures 8(a) and 8(b) for statistics about prefix refinement when Flan T5 has been integrated into our RAG4RE pipeline.). The Generation module concludes when the results are sent to the Retrieval module. Afterwards, the “Retriever” sends the results to the user. An example of the responses returned by the retriever is shown in Figure 2.
Evaluation
In this section, we examine the performance of our RAG4RE work. We first introduce the experimental settings in Section 4.1. Then, we present the results of our experiments in Section 4.2. Finally, false predictions are analyzed in Section 4.3.
Experimental Setup
In our work, we assess the effectiveness of our RAG4RE approach using well-established RE benchmarks, including the TACRED (Zhang et al., 2017), TACREV (Alt et al., 2020), Re-TACRED (Stoica et al., 2021), and SemEval (Hendrickx et al., 2010) RE datasets. These benchmarks consist of head and tail entities in the given sentences, along with the ground truth relation types between these entities. These widely recognized datasets serve as invaluable resources for evaluating the efficiency and performance of our approach. Further insights into the datasets can be found below and in Section 4.1.1. Additionally, we compare the performance of our RAG4RE approach, which incorporates a relevant (similar) sentence alongside a query sentence in its prompt template (see the prompt template in Figure 4), to that of a simple query prompt-referred to as the vanilla prompt-which excludes any relevant sentence related to the query sentence, as explored in previous works (Zhang et al., 2023). This comprehensive evaluation helps assess our approach’s performance across different LLMs.
Datasets
We utilize four benchmark datasets, as detailed below and in Table 2. Figure 6 and 7 provide statistics for the SemEval RE dataset, while Table 3 offers details about the ‘no_relation’ type in TACRED and its variants.
Overview of Benchmark Datasets. ‘-’ Indicates the Absence of a Validation Split.

Statistics of Relation Type ‘no_relation’ Across TACRED and Its Variants.

We evaluate our RAG4RE approach on the aforementioned benchmark datasets by integrating various LLMs, including Flan T5 (XL 9 and XXL 10 ), Llama-2-7b-chat-hf, 11 and Mistral-7B-Instruct-v0.2. 12 We use the instruction fine-tuned versions of Llama2 and Mistral, as Flan T5 (Thoppilan et al., 2022) is itself an instruction fine-tuned version of the T5 model (Chung et al., 2024).
Evaluation Metrics
We compare our RAG4RE approach with simple query, vanilla prompting, in terms of micro F1, Recall, and Precision scores, as given in equations 2, 3, 4. In these equations, True Positive, False Positive and False Negative are denoted as TP, FP and FN, respectively, where n in equations 2, 3, 4 points out total number of classes or categories, and i is an index representing a class or category in a multi-class classification problem, due to the imbalance in these benchmark datasets (see Table 3). To compute these metrics, we leverage the metrics library of sklearn.
13



In regard to hardware specifications, these language models have undergone evaluation utilizing a setup comprising 4 GPUs, with each GPU boasting a memory capacity of 12 GB in the NVIDIA system. Device details are NVIDIA GeForce GTX 1080 Ti (4GPUs X 12GB). Furthermore, the memory configuration reaches 300 GB.
Results
Our experiments are conducted using the four benchmark datasets mentioned in Section 4.1.1. Firstly, we assess the performance of our proposed RAG4RE and then compare it to that of a simple query (sentence), vanilla LLM prompting, in terms of micro F1 score. As mentioned earlier, our evaluation criteria take into account the micro F1 score, Recall, and Precision metrics due to the imbalanced labelling of the datasets (see Table 3). Furthermore, we explore how our approach enhances the performance of LLM responses. This is accomplished by incorporating the example sentence which is the most similar to the query sentence determined using the cosine similarity metric at equation 1 with SBERT embeddings into the prompt template alongside the query sentence in our proposed RAG4RE approach (see Data Augmentation in Figure 2). We compare the results of a simple query without any relevant sentence to our RAG4RE results at Table 4.
Experimental Results on Four Benchmark Datasets Using Different LLMs.

Experimental Results on Four Benchmark Datasets Using Different LLMs.
We utilize various LLMs, including Flan T5 XL and XXL, Mistral-7B-Instruct-v0.2, and Llama-2-7b-chat-hf, to conduct our experiments and evaluate the performance of our proposed RAG4RE framework. The results demonstrate that RAG4RE achieves remarkable performance compared to a simple query approach, as shown in Table 4 and Figure 9. Notably, RAG4RE consistently outperforms the simple query approach across the TACRED, TACREV, and Re-TACRED datasets, even when the underlying language model is varied. The highest F1 scores achieved, as detailed in Table 4, are 86.6%, 88.3%, and 73.3% for TACRED, TACREV, and Re-TACRED, respectively. These remarkable results are primarily accomplished by integrating the Flan T5 XL model into the Generation module. Nonetheless, RAG4RE does not achieve comparable performance on the SemEval dataset. This might be primarily due to either the predefined relations (target relation labels) in this dataset, which cannot be directly extracted from the sentence tokens, or the lack of knowledge about this dataset in the vanilla LLMs used in RAG4RE. Furthermore, the SemEval dataset includes manually annotated sentences for specific, defined semantic relation types (Hendrickx et al., 2010).
The remarkable improvement observed in RAG4RE’s results can be primarily attributed to the incorporation of relevant (or similar) example sentences, extracted from the training data of benchmark datasets, into the user query sentence. As highlighted in Lewis et al. (2020), RAG operates akin to an open-book exam, where adding a relevant (or similar) sentence to the query sentence facilitates the LLM’s understanding of the query sentence in the Generator module of our approach, as shown in Figure 2. The example sentence and query sentence might have similar or same entities, as illustrated in Figure 2, which helps the LLM make accurate inferences and reduce hallucinations. This interpretation is further supported by the results of the simple query and RAG4RE approaches, as outlined in Table 4.
Consequently, our RAG4RE has improved F1 scores on benchmark datasets, for example, TACRED, TACREV, and Re-TACRED, when compared its results to those of a simple query as demonstrated in Table 4. This performance improvement between simple query and RAG4RE can be explained by the spread of activation theory (Abramski et al., 2025). In terms of embeddings, similar sentences might contain the same or semantically similar (or closely related) entities as those in the query sentence. In this context, similar sentences serve as facilitators for comprehending the entities in the query sentence. This role can be explained by the spread of activation theory, which describes how a computational model activates one word (token) and spreads its influence to related words or concepts in the model (Abramski et al., 2025); for instance, “sky” reminds one of “blue” or “cloud” as explained by the spread of activation theory. In the next section, we closely analyze the prediction errors on TACRED, its variants, and SemEval for further insights about how RAG4RE works.
In this section, we analyze how RAG4RE improves the results of simple query (sentence) across three benchmarks, whereas it could not demonstrate this improvement on SemEval dataset. We mainly discuss false predictions and undefined relation types predicted by LLMs.
Decoder-only LLMs, for example, Mistral and Llama2, are prone to producing hallucinatory results when a simple prompt is sent to those models (Pan et al., 2024). In the responses of the experiments conducted with Mistral-7B-Instruct-v0.2 and Llama-2-7b-chat-hf, we observed such relation types that have not been defined in the relation types of the prompt template (See the example prompt in Figure 4). Therefore, we analyze these undefined relation types generated by LLMs in Figure 5 across TACRED and its variants. According to Figure 5, both decoder-only models used in our experiments generate more undefined relation types than encoder–decoder models, Flan T5 XL and XXL.
We also analyze the False Negative (FN) and False Positive (FP) relation predictions of three language models in Table 5. In terms of FN predictions, our RAG4RE has decreased its FN predictions on the Flan T5 XL model in Table 5. Likewise, our RAG4RE has reduced the number of FN predictions on Mistral-7B-Instruct-v0.2 and Llama-2-7b-chat-hf. Regarding dataset insights, the reason Flan T5 XL performs better on the TACREV and TACRED datasets but underperforms on ReTACRED is mainly due to the number of ‘no_relation’ labels in these datasets (see Table 6). ReTACRED is a reannotated version of TACRED created using a source code, while TACRED is noisier and less reliable. The relation type ‘no_relation’ in the ReTACRED dataset makes up 57.91% of the overall relation types in its test dataset, and Flan T5 XL generates 80.69% ‘no_relation’ predictions among all test relations. This means it generates ‘no_relation’ predictions as frequently as the proportion of ‘no_relation’ in the TACRED test dataset. This might be related to the data used in the training phase of Flan T5 models, as TACRED is a crawling dataset and the base model, T5, of Flan T5 was trained on a crawling dataset. 14 Additionally, the decrease in FNs is greater than the increase in FPs in most cases in Table 5.
Comparison of False Positives (FP) and False Negatives (FN) Between the Simple Query and RAG4RE Approaches Across Different LLMs.
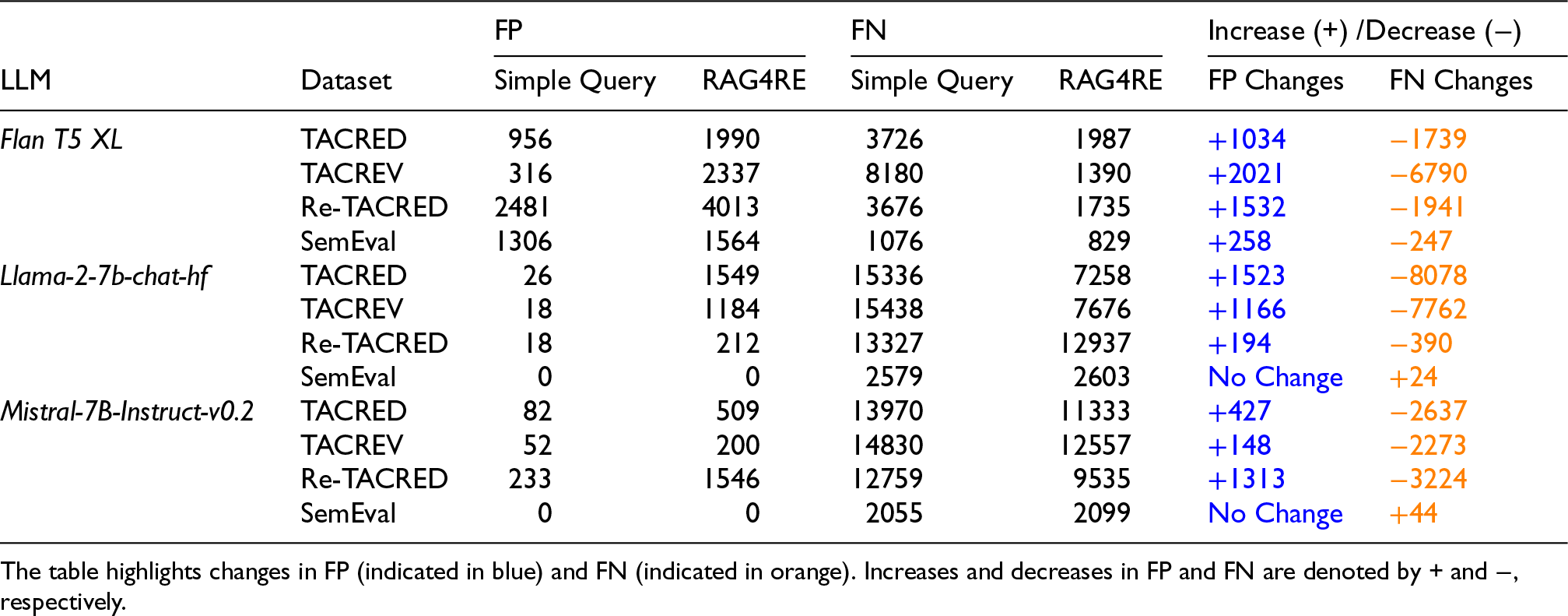
Comparison of False Positives (FP) and False Negatives (FN) Between the Simple Query and RAG4RE Approaches Across Different LLMs.
Statistics of no_relations Prediction Across TACRED and Its Variant Along With Flan T5 XL for RAG4RE.

With regards to the SemEval dataset, the increase in FPs is higher than the decrease in FNs when RAG4RE is used with Flan T5 XL, meaning the results are not improved. Similarly, the number of FNs has increased with decoder-only models when RAG4RE is used instead of a simple query, so the results are not improved. Additionally, the SemEval dataset is partially manually annotated and not a web crawling dataset; therefore, the vanilla LLMs might not have prior knowledge of this dataset.
Overall, when comparing the number of false predictions, both Llama-2-7b-chat-hf and Mistral-7B-Instruct-v0.2 produce higher numbers compared to Flan T5 XL. It is clear that RAG4RE mitigates hallucination problem of the simple query by reducing the number of false prediction on three language model types according to Table 5 on TACRED and its variants.
In this section, we conduct ablation studies: (i) prompt engineering approaches, (ii) comparing Llama variants and (iii) post-training approaches on SemEval. We evaluated these experimental approaches on original TACRED and SemEval datasets. 15
Prompt Engineering Approaches
This section evaluates two approaches: (i) one-shot prompting and (ii) another prompt template for RAG4RE. We first present the results of one-shot prompting in the following section, and then discuss the impact of varying prompt templates on the results.
One-Shot Prompting
In this section, we conducted an experiment using one-shot prompting as a prompt engineering approach with the original TACRED dataset and SemEval, alongside the previously used Flan T5 models (XL and XXL). This experiment departs from zero-shot settings and includes an example. We identified similar sentences and incorporated them into our prompt templates. For this section, we include head and tail entities, as well as their relation type, in the sample prompt template, as shown in Figures 4 and 10. The results in Table 7 show that the one-shot prompting approach cannot outperform RAG4RE when using the Flan T5 (XL and XXL) models on the TACRED and SemEval datasets, as indicated in Table 4. This one-shot approach also fails to achieve the performance of a simple query on TACRED (see Table 4). However, one-shot prompting with Flan T5 XL and XXL on SemEval improves micro F1 by 16.44% and 38.60%, respectively.
One-Shot Experiment on TACRED and SemEval.

One-Shot Experiment on TACRED and SemEval.
We also evaluate our RAG4RE system using a different prompt template that excludes the problem definition, as shown in Figure 4, on the TACRED and SemEval datasets. However, we do not evaluate this prompt template, shown in a sample in Figure 11, on TACREV or Re-TACRED, since they are variants of the TACRED dataset. Excluding the problem definition from the prompt template resulted in a decrease in the F1 score from 86.6% (see Table 4) to 82.89% for RAG4RE with Flan T5 XL, and a similar drop of 4.71% was observed for simple query results on TACRED in Table 8. In contrast, on the SemEval dataset, this prompt template resulted in an improvement, increasing the micro F1 score by 18.91% for simple queries and by 17.42% for RAG4RE with Flan T5 XL. These results indicate that the effectiveness of the prompt template is highly dependent on the dataset. While the choice of prompt template can significantly enhance or diminish RAG4RE performance, RAG4RE consistently outperformed simple queries on TACRED across both prompt templates, along with Flan T5. Similar to the previously used prompt template, no performance improvement was observed on SemEval with this prompt template when using the RAG4RE system.
Comparing Llama Variants
We evaluate a different instruction-tuned version of the Llama model: Llama-3.1-8B-Instruct. 16 This model has more parameters than the one used to produce the results shown in Table 4. Our goal is to examine whether the proposed approach behaves differently when using a model with a larger parameter count. As shown in Table 9, our RAG4RE approach outperforms the simple prompting baseline on the TACRED, TACREV, and Re-TACRED datasets when using Llama-3.1-8B-Instruct within our framework (illustrated in Figure 2), similar to the results obtained with Llama-2-7b-chat-hf. For the SemEval dataset, the simple query performs slightly better, though the results between the simple query and RAG4RE remain close, as seen in Table 9. Beyond internal comparisons, Llama-3.1-8B-Instruct with the simple query achieves higher performance than Llama-2-7b-chat-hf on four benchmark datasets (see Tables 4 and 9). However, when using the RAG4RE approach, Llama-3.1-8B-Instruct does not surpass Llama-2-7b-chat-hf on TACRED and TACREV.
Another Prompt Template Which Does Not Have Any Problem Definition.

Another Prompt Template Which Does Not Have Any Problem Definition.
The Experimental Results on Four Benchmark Datasets Along With Llama3.1-8B.

We propose that fine-tuning LLMs on a small subset of the SemEval dataset could enhance model performance and better adapt the LLMs to the domain of the dataset. Therefore, we fine-tune the Flan T5 Base (250M) model on two distinct versions of SemEval dataset: one based on the simple queries introduced in previous sections (see Table 11 for an example), and the original SemEval sentence dataset, where the input is a sentence and the output is a relation type. The subset is selected from the remaining data after identifying the sentences most similar to the test sentences in the training dataset. Fine-tuning is then performed on 5,283 samples (train and validation) from the SemEval training dataset using 5-fold cross-validation.
17
The hyperparameters are set to 5 epochs, a batch size of 16, and a learning rate of 0.001 along low-rank adaptation (LoRA) (Hu et al., 2021).
We first fine-tune the model on the original dataset 18 (see Table 12 for a sample from SemEval dataset) and evaluate its performance using simple queries and RAG4RE, as shown in Table 10. Afterwards, we also fine-tune the Flan T5 Base on the prompt datasets 19 and conduct the same evaluation approach along with simple query prompt and RAG4RE. According to the results in Table 10, our RAG4RE, utilizing these fine-tuned Flan T5 Base models, outperforms the simple query approach. As a result, these findings might provide inspiration for evaluating domain-specific datasets with RAG4RE.
Mean Metrics of the Fine-Tuned Flan T5 Base Models Across 5 Runs With 5-Fold Cross-Validation.

Mean Metrics of the Fine-Tuned Flan T5 Base Models Across 5 Runs With 5-Fold Cross-Validation.
In our experiments, we compared two methods: (i) RAG4RE and (ii) a simple query, vanilla LLM prompting, which lacks inclusion of the relevant example sentence described in Figure 4. Our findings indicate a notable enhancement in F1 scores when employing the RAG4RE approach over the simple query method on the TACRED dataset and its variations, as outlined in Table 4. This improvement stems from the integration of a relevant sentence into the prompt template, as illustrated in Figure 4. This inclusion of the relevant example sentence facilitates the predictions made by the LLM in the Generation module of our proposed architecture, as depicted in Figure 2.
The incorporation of this relevant sentence serves to mitigate hallucinations in the LLM’s responses, subsequently reducing the occurrence of false predictions, as demonstrated in Table 5. Additionally, while RAG4RE enhances the generation capabilities of LLM models, they might still produce hallucinated relation types. Figure 5 gives the count of undefined relations in predictions across datasets and LLMs. Mistral and Llama models generate a significant number of undefined relations-relations that do not exist in the predefined set of relation types in the given prompt. In contrast, the Flan T5 XL model produces the lowest undefined relations. Our assessment of the RAG4RE approach’s effectiveness is based on the integration of Flan T5 XL into the LLM within Figure 2, given that our approach, combined with Flan T5 XL, yields the highest F1 scores across benchmarks except for the SemEval (See Table 4). Although the prompt tuning approach using a mask filling template is applied with T5 Large (fine-tuning its encoder) and evaluated on TACRED (Han et al., 2022) (achieving an F1 score of 75.3%), its performance could not outperform that of Flan T5 XL with RAG4RE. This discrepancy in performance might be related to the size of the language models and the fact that only the encoder part of the T5 model is fine-tuned in Han et al. (2022).
The large margin between Re-TACRED and TACREV, or Re-TACRED and TACRED, is due to the percentage of sentences in their test datasets where the relation type between the given entities is ‘no_relation’ in RAG4RE approach. While TACRED and TACREV have high percentages of 78.56% and 79.86%, respectively, with Flan T5 XL predicting a high number of ‘no_relation’ sentences, Re-TACRED has only 57.91% of its test sentences labeled as ‘no_relation’, with Flan T5 XL predicting more than existing percent of no_relation (80.69%) (see Table 6). Furthermore, Re-TACRED evaluates 40 relation types, whereas TACREV and TACRED evaluate 42 relation types. Another important reason why Flan T5 XL does not perform better on ReTACRED might be related to that Flan T5 whose base model, T5, was trained on the C4 (Colossal Clean Crawled Corpus) dataset 20 which was constructed from free public data resource as TACRED dataset (Zhang et al., 2017) was constructed. Additionally, ReTACRED is reannotated with a codebase from TACRED and is not available on the web. Nevertheless, RAG4RE improves performance of the simple query approach on TACRED and its variant even if Flan T5 models might know dataset insight for TACRED. Likewise, fine-tuning Flan T5 with a small amount of the SemEval dataset could improve the performance of both RAG4RE and simple queries, as it would adapt the model to this specific dataset as shown in the ablation study in Section 5.3.
We present an analysis of the performance of our RAG4RE approach, comparing its F1 score with both LLM-based methods and state-of-the-art RE techniques reported in current literature. In terms of LLM-based RE approaches, our RAG4RE consistently outperforms other methods utilizing LLMs, as illustrated in Table 4, across all benchmark datasets except for SemEval. The reason for the superior performance of our RAG4RE, as presented in Table 4, is largely attributed to the absence of relevant sentence addition in the prompt templates of both LLMQA4RE (Zhang et al., 2023) whose prompt template is based on multiple-choice question and RationaleCL (Xiong et al., 2023) (with F1 of 80.8% on TACRED) based on conversational prompting based on rational strategy. Notably, neither competing method incorporated relevant sentences into their prompt templates. These results are further supported by Min et al. (2022), who compared the performance of multiple-choice tasks with classification tasks, demonstrating that language models perform better in classification tasks than in multiple-choice templates. Additionally, LMMQA4RE does not include the prefix of the relation in its TACRED and its variants’ prompt templates, so there is no need to address incorrect prefix predictions. In contrast, we incorporate the prefix in our RAG4RE architecture. The changes made to the prefix during the integration of Flan T5 (XL and XXL) can be observed in Figure 8. In addition to the performance comparison with LLM-based approaches, we also compare our results with the best-performing methods in the literature, as shown in Table 4. Our RAG4RE outperformed all state-of-the-art approaches, including recently proposed models, fine-tuned language models, and advanced techniques, on both TACREV and TACRED, achieving F1 scores of 86.8% and 88.3%, respectively. However, it did not achieve the same performance on ReTACRED, primarily due to the high number of ‘no_relation’ predictions, as detailed in Table 6. Similarly, due to the unique features of the SemEval dataset-such as directed relations and relations that cannot be predicted from sentence tokens, or was not used in the training of the vanilla LLMs used at Table 4-our RAG4RE did not yield promising results on this dataset. For example, the LLM-based approach, GAP (Chen et al., 2024), fine-tunes the RoBERTa large model (355M parameters) using a prompting strategy and achieves an F1 score of 90.3%. Likewise, our Flan T5 Base (250M) model fine-tuned on a subset of the SemEval train dataset improves the results of RAG4RE in Section 5.3.
With regard to ethical considerations, our proposed approach is evaluated on local hardware using open-source models. Therefore, no data is shared outside the local hardware. Furthermore, this study does not involve any human subject data, and thus does not have ethical concerns related to human data use. Nonetheless, the approach is designed to preserve privacy and can be applied to the evaluation of sensitive domain data, such as in the healthcare sector.
Overall, our RAG4RE demonstrates strong performance on the TACRED and TACREV datasets. However, its performance on SemEval does not achieve similar improvements, likely due to challenges posed by the predefined relation types (target relation labels) in this benchmark dataset or the limitations of vanilla LLMs’ prior knowledge (see results in Section 5.3). For example, directly extracting the “Cause-Effect (e2,e1)” relation type from the provided sentence tokens between entity 1 (e1) and entity 2 (e2) remains challenging for zero-shot LLM prompting, as this relation type often requires logical inference for accurate identification.
Conclusion and Future Work
In this work, we introduce a novel approach to RE called RAG4RE, which leverages zero-shot prompting settings. Our aim is to identify the relation types between head and tail entities in a sentence, utilizing an RAG-based LLM prompting approach.
We also claim that RAG4RE has outperformed the performance of the simple query (vanilla LLM prompting). To prove our claim, we conducted experiments using four different RE benchmark datasets: TACRED, TACREV, Re-TACRED, and SemEval, in conjunction with three distinct LLMs: Mistral-7B-Instruct-v0.2, Flan T5 (XL and XXL), and Llama-2-7b-chat-hf. Our RAG4RE yielded remarkable results compared to those of the simple query. Our RAG4RE exhibited notable results on the benchmarks compared to previous works. Unfortunately, our proposed methods, including vanilla LLMs, did not perform well on the SemEval dataset. This can be attributed either to the absence of logical inference in LLMs or to the lack of prior knowledge in vanilla LLMs regarding this dataset, as predefined or target relation types cannot be directly derived from the sentence tokens in the SemEval dataset. The ablation study conducted with SemEval in Section 5.3 yields promising results when the post-trained model is integrated into RAG4RE. These findings may also encourage the application of RAG4RE to domain-specific datasets. In addition to the results presented in Section 5.3, Llama-3.1-8B-Instruct outperforms Mistral-7B-Instruct-v0.2, Flan T5 (XL and XXL), and Llama-2-7b-chat-hf on the SemEval dataset. These findings suggest that larger models may serve as more effective domain experts compared to their smaller counterparts.
In future work, we aim to extend our approach to real-world dynamic learning scenarios, inspired by the ablation study on SemEval, and evaluate it on real-world datasets. Additionally, we intend to integrate fine-tuned LLMs on training datasets into our RAG4RE system to address the performance issues encountered when datasets require logical inference to identify relation types between entities in a sentence, and target relation types cannot be extracted from the sentence tokens as in SemEval.
Footnotes
Acknowledgements
Sefika Efeoglu is funded by the Turkish Ministry of National Education, Republic of Türkiye, under the Postgraduate Study Abroad Program.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Notes
Appendix A. Dataset Overview
Some Data from Benchmark Datasets.
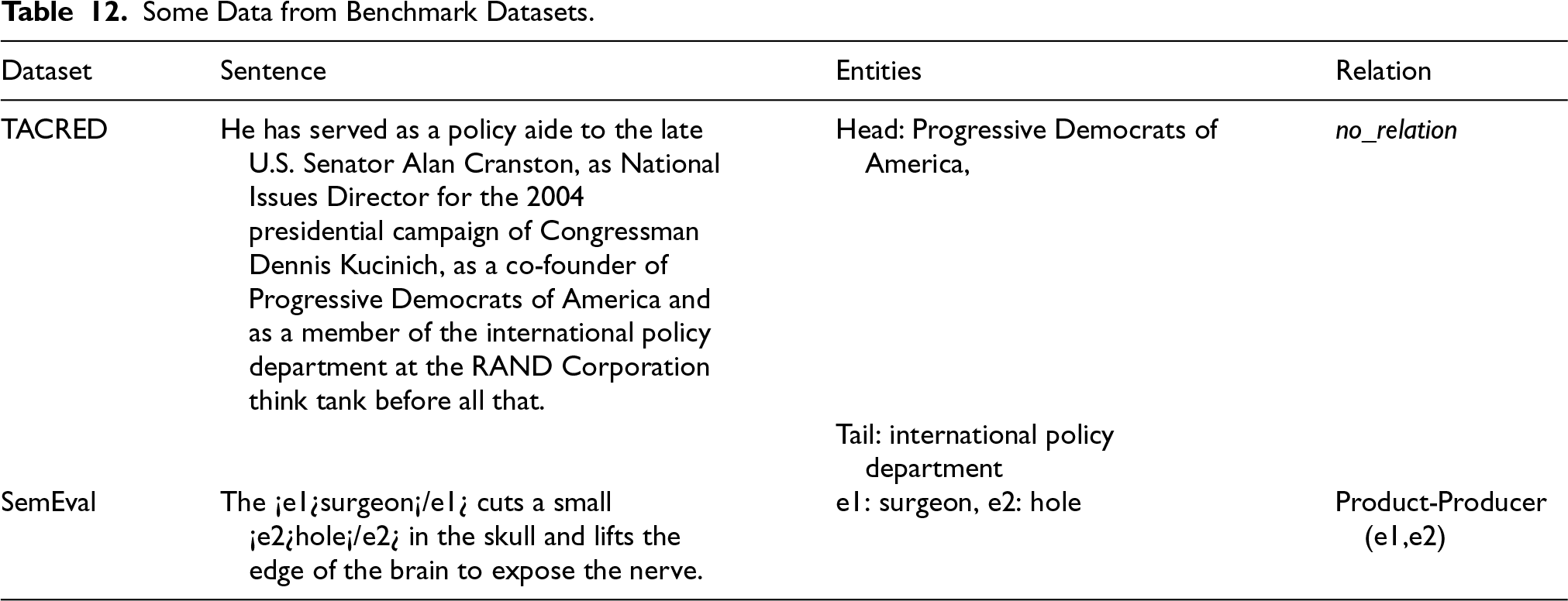
| Dataset | Sentence | Entities | Relation |
|---|---|---|---|
| TACRED | He has served as a policy aide to the late U.S. Senator Alan Cranston, as National Issues Director for the 2004 presidential campaign of Congressman Dennis Kucinich, as a co-founder of Progressive Democrats of America and as a member of the international policy department at the RAND Corporation think tank before all that. | Head: Progressive Democrats of America, | |
| Tail: international policy department | |||
| SemEval | The ¡e1¿surgeon¡/e1¿ cuts a small ¡e2¿hole¡/e2¿ in the skull and lifts the edge of the brain to expose the nerve. | e1: surgeon, e2: hole | Product-Producer (e1,e2) |