
Abstract
Knowledge graphs provide machine-interpretable data that allow automatic data understanding and deduction of new facts. However, machines are not the only consumers of such semantic data. Human users could also benefit from graph-structured data by browsing and exploring it to detect interesting associations and draw conclusions. To achieve that, methods that allow for search over knowledge graphs are highly sought after. Keyword search is an intuitive and common way to retrieve relevant data (e.g., documents) and can also be leveraged to search over knowledge graphs. In this survey paper, we derive the typical architecture of a system for keyword search over graph-shaped data, we formally define the problem, we highlight related challenges, and we compare with existing relevant surveys to identify the gaps. We conduct a comprehensive review of studies dealing with the topic of keyword search over graph-shaped data (e.g., knowledge graphs) following a systematic method. Based on that, we derive and define different aspects for classifying existing works. We also give an overview of how those systems are evaluated and highlight possible future research directions.
Introduction
Knowledge graphs (KGs) have shown their importance in many application areas (e.g., search, question answering, or recommendations). Thus, the data represented as KGs is continuously increasing—a fact also evidenced by the continuous growth of KGs such as Wikidata (Cantallops et al., 2019). While their semantic data representation can be directly leveraged by machines to accomplish a specific task (e.g., inference), end users and domain experts should also be able to access and explore the KGs. This is a first step in allowing us to go beyond simple information lookup and enable the discovery of new facts and correlations given by the graph structure. We can distinguish between two scenarios: (1) KG querying and search includes the usage of structured queries, interactive query builders, keyword search, or question answering. (2) KG exploration comprises visualization and browsing, faceted search, graph analytics, and summarization.
While structured queries allow the formulation of the information need in a precise way, the most familiar and intuitive method to search over data collections is keyword search (Agarwal et al., 2010). This reduces the time to learn new technologies and does not require an intricate knowledge of the underlying domain and the data schema. Therefore, keyword search is also used and adapted to work over KGs.
The typical generic components of a system for keyword search over graph-shaped data are depicted in Figure 1: Graph preprocessing: refers to the operations applied to prepare and index the data graph for efficient query processing (e.g., keyword-node index) and answer retrieval (e.g., shortest paths index or summary graph). Keyword mapping: this step consists of mapping words or a group of words in the query to a graph’s nodes and edges. Answer retrieval: this step consists of finding results relevant to the query (e.g., using graph traversal). The retrieval unit varies depending on the used technique (e.g., tree or entity). Answer ranking: this step ranks results in the order of relevance and is also dependent on the specific results nature. Answer presentation: refers to the way the results are provided to the user and the different features that are provided to support the search experience.

Typical Generic Components of a System for Keyword Search Over Graph-Shaped Data.
Implementing these common system components poses the following main challenges: Finding accurate mappings between keyword terms and graph elements: this includes a correct interpretation and disambiguation of the query keywords. This is a crucial step since it directly affects the efficiency and effectiveness of the subsequent answer retrieval phase. Scaling to large graphs: this includes the development of techniques to accelerate the retrieval of answers (e.g., suitable indexing solutions or greedy algorithms). Ranking retrieved answers: this includes the development of ranking functions that leverage different aspects depending on the type of the answer.
Those challenges lead to increasing research efforts in this area. To the best of our knowledge, there are four surveys that give an overview of the state of research on keyword search over graph-shaped data, focusing on different aspects. However, they show some shortcomings (e.g., outdated), which are discussed in Section 2. Therefore, we close this gap by performing a systematic review with the following contributions: We perform a We propose a We provide a comprehensive review of We identify remaining research gaps and propose potential
With this survey, we aim at enabling academic researchers who deal with the same topic to understand the state-of-the-art and use it to identify research gaps, providing a comprehensive introduction and summary for newcomers, and helping tool developers and engineers by selecting systems that are suitable for integration into their applications.
The remainder of this survey is organized as follows: In Section 2, we position our work with respect to existing surveys. In Section 3, we define the task of keyword search over graph-shaped data as used within this survey. In Section 4, we describe the methodology for the systematic literature review, and in Section 5, we outline the different aspects used for the classification of relevant works. In Section 6, we present the different methods used to evaluate relevant systems, and in Section 7, we give a summary overview of them. In Section 8, we cluster relevant works and provide a detailed description for each one. Section 9 concludes the review and discusses future research directions.
We identified four surveys focusing on keyword search over graph-shaped data, as shown in Table 1. However, two of them (Wang & Aggarwal, 2010; Yu et al., 2010) are quite outdated (2010), and one (Ghanbarpour & Naderi, 2019), dating from 2019, reports only on one aspect (answer ranking). One survey (Yu et al., 2010) considers only relational databases. However, this is still relevant as well since relational databases can also be modeled as graphs by considering the tuples as nodes and foreign key relations as edges (Feddoul, 2020). The most recent survey (Yang et al., 2021) classifies existing works based on the type of returned answer as already proposed in an earlier survey (Yu et al., 2010). While the latter also includes an overview of methods depending on the schema of relational databases, (Yang et al., 2021) concentrates on schema-free approaches. Both works use a classification that mixes two aspects in one concept, namely the answer type and the way of scoring the final answer. In Wang and Aggarwal (2010), works are classified in a rather generic manner based on the underlying data type, namely Keyword Search on XML Data and Keyword Search over Relational Databases, which are both considered schema-dependent, whereas Keyword Search on Graphs refers to schema-free approaches. In Ghanbarpour and Naderi (2019), the authors concentrate on the answer ranking aspect. The proposed factors for the answer ranking slightly overlap with the ones proposed in Section 5, but we adjust and add other ranking types while preserving the distinction between the important aspects. Similar to Yang et al. (2021), they also mix the two factors of answer scoring and ranking. In addition, we also notice the inconsistent use of category names (e.g., “centralized ranking function” to refer to the distinct-root semantics as in Yang et al., 2021).
Summary Table Comparing Existing Surveys With This One.

Summary Table Comparing Existing Surveys With This One.
In addition to the previously mentioned shortcomings, none of the existing surveys report on methodologies used for evaluating the systems, including, for example, the used ground truth, datasets, common benchmarks, and metrics. Furthermore, only one work considered the ranking (Ghanbarpour & Naderi, 2019). Overall, for a certain consistency and simplicity of definitions, it is beneficial to consider each classification aspect separately, as suggested and extended in our proposed categorization (cf. Section 5). In addition, our literature review demonstrates that this area of research is constantly evolving, resulting in new publications that were not included in previous surveys and more works considering KGs.
We consider the task of using keywords to search over graph-shaped data where, given a graph
Figure 2 shows an example graph 1 with nodes and edges on both schema and instance levels. For the sake of brevity, we illustrate only the relations between concepts/classes and link them to their instances. This implies that each relation on the schema level has also its counterpart on the instance level (e.g., H1 place of birth Ci1). All nodes and edges have labels. The graph is directed, and the distance between a pair of nodes is given by the number of edges on the path between them (e.g., distance between H1 and Ci1 is one). The considered keyword query consists of two terms german and city. Each term has its corresponding keyword node either on the schema (city) or instance level (german). Three example answers that connect the keywords are provided. For the sake of simplicity, we omit the instance-class relations in the answer representation (e.g., Ci1-City). In the example, Ci1, Ci2, and Ci3 are considered valid answer entities for the given query.
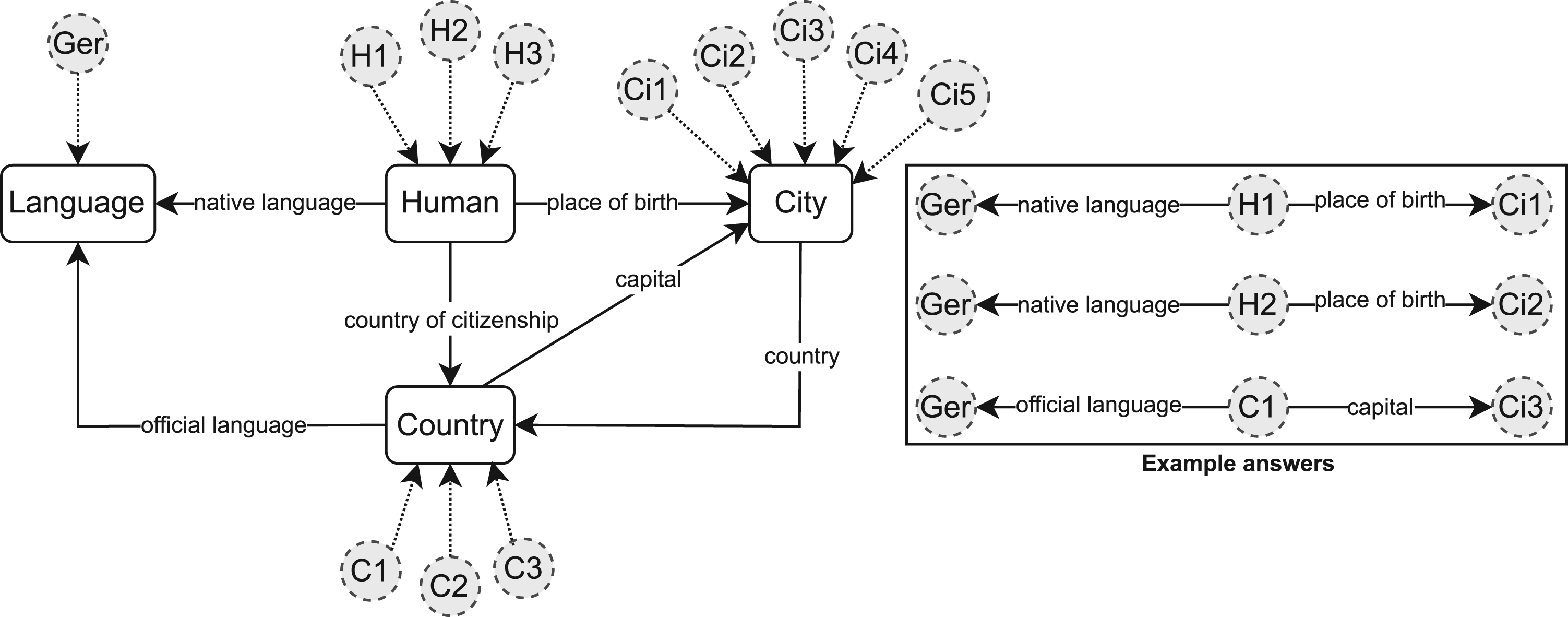
Example KG With Some Possible Answers to the Query Q={german, city}. Boxes Represent the Concepts/Classes on the Schema Level, Dotted Circles are Individuals (Instance Level), and Dotted Arrows State That an Individual is an Instance of a Class. Ger is the Abbreviation of the Label German. Note. KG = knowledge graph.
To collect relevant works in the area of keyword search over graph-shaped data, we performed a systematic literature review inspired by the guidelines provided by Brereton et al. (2007) and Kitchenham and Charters (2007). This allowed us to summarize and classify existing related work as well as determine remaining research gaps. The general process consists of three phases: Plan review: includes the identification of the need for the review and the development of the review protocol, which describes the steps that will be followed while conducting the review. Conduct review: includes the concrete steps of performing the review, starting from the identification of relevant publications. Document review: includes writing a report about the review and publishing it.
The identification of the need for the review was already addressed in Section 2 and the review protocol will be clarified while describing the second phase. Furthermore, the last phase is addressed by this survey. For those reasons, we only describe the conduct review phase in more detail in the following:
Inclusion criteria.
Publication year starting from 2013 (last 10 years). Open/institutional access. English language. Paper type: conference, journal, or workshop paper. Content fits to the topic of keyword search over graph-shaped data
5
.
Exclusion criteria.
Paper type: PhD symposium, Demo/poster, or extended abstract. Not peer reviewed (e.g., only published on an open access archive). Newer paper of the same approach or system exists (keep the newest).
At the end, we selected and classified 35 works.
We also included a subset of works that were published before 2013. This includes popular first works dealing with the keyword search problem over relational data (Bhalotia et al., 2002; He et al., 2007; Kacholia et al., 2005), in addition to one of the very first works operating over KGs (Tran et al., 2009), and three other papers (Dalvi et al., 2008; Golenberg et al., 2008; Kimelfeld & Sagiv, 2008) that also seemed relevant and cited one of the pioneer works in this field (Bhalotia et al., 2002).
The literature review allowed us to derive four important aspects for categorizing related works as shown in Figure 3, namely the search space, answer type, answer ranking, and answer scoring.
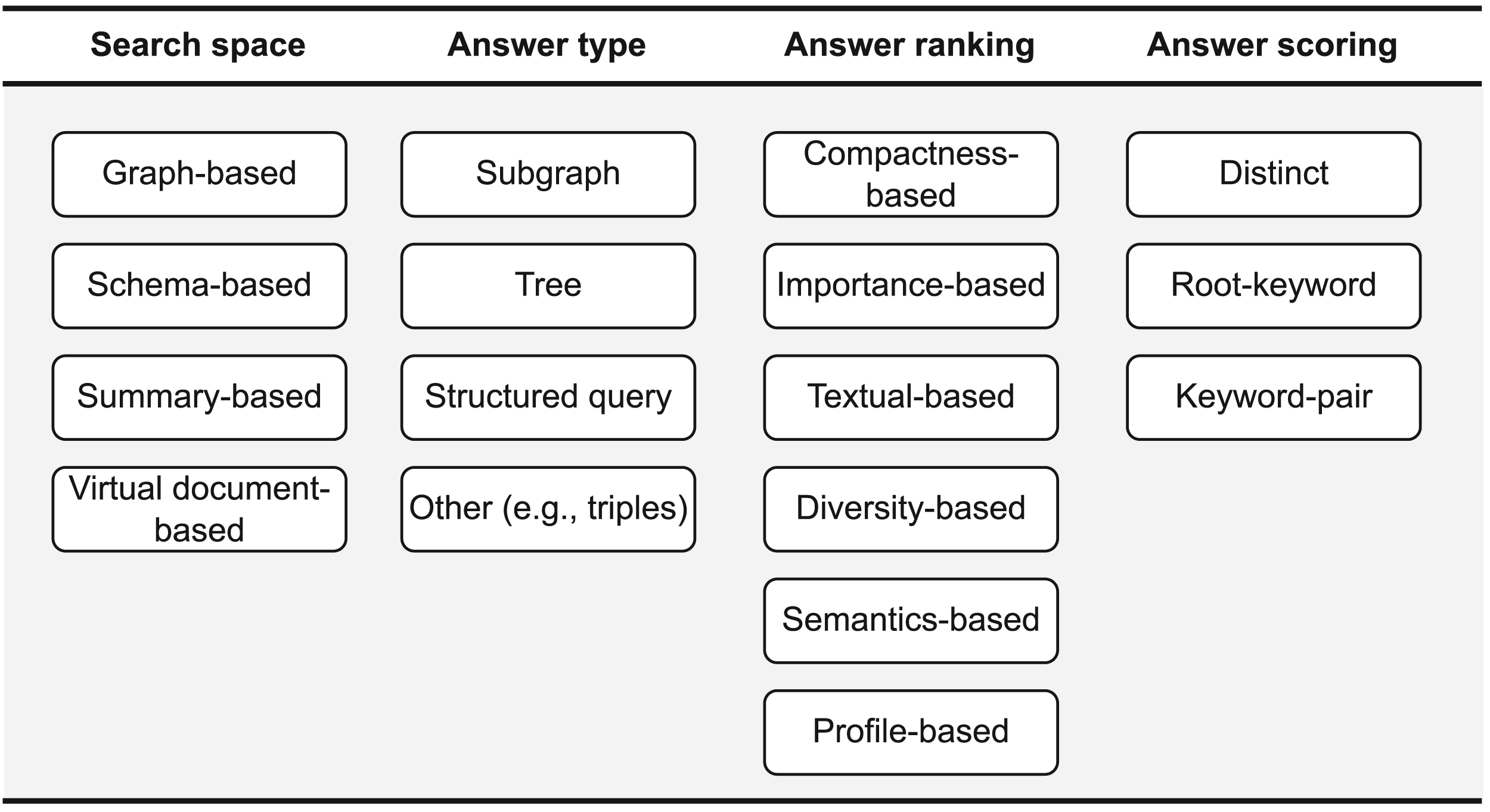
Dimensions for Classifying Approaches for Keyword Search Over Graph-Shaped Data.
Graph-based. Search for answers over the whole graph. Schema-based. Operate on a provided data schema to find answers. Summary-based. Operate on a summarized version (e.g., replace a collection of instances with their corresponding class) of the data graph without relying on a predefined schema. Virtual document-based. Build documents from the textual content of the graph elements and retrieve relevant ones using information retrieval techniques.
Subgraph. The answer is a set of connected keyword nodes. A special case is the r-clique, where the answer is a subgraph connecting keywords and the shortest distance between any pair of keyword nodes is equal to or lower than Tree. The answer is a graph that has no cycles (tree) and that connects all keyword nodes (Valiente, 2021). A tree can be either directed or undirected and further characterized using the following properties: Rooted directed: a rooted directed tree is a tree in which a specific node is distinguished and called root, and there exist directed paths (pointing away from the root) from the root to each keyword node (Bhalotia et al., 2002). Distinct rooted: a distinct rooted tree is a tree with a distinct root with respect to a collection of top- Minimal: the minimality is defined here with respect to the keywords and states that all the leaves of the tree are keyword nodes (in other words, there are no leaf nodes not containing keywords (Lu et al., 2019), or the answer has no other subtree containing the keywords). Structured query. The answer is a query equivalent to a previously found intermediate answer (subgraph or tree). When executed, the query returns relevant concrete results (e.g., triples or entities in case of RDF graphs). Other types. There are also specific cases, where relevant answers are triples or entities of an RDF graph. Those are directly retrieved without having an intermediate step where a subgraph/tree/query is formed. This is usually the case when a graph’s textual content is indexed (e.g., triple index), and the answers are retrieved using traditional ranking functions as used in document retrieval. Another specific answer type, introduced by just a single work, is the Key-core (Zhang et al., 2022), which represents a subgraph that is formed by connecting two minimal rooted directed trees containing all keywords. Furthermore, for each tree, the distance between each keyword node and the root, and the sum of keyword-node distances are smaller than two specific thresholds.
Figure 4 depicts some example answers of the query Q={german, city} over the KG of Figure 2. The first three answers are distinct rooted trees with respect to the five examples. Moreover, all four first answers are rooted directed trees that are also minimal. The last answer contains a cycle and thus is not a tree but a subgraph. The provided SPARQL query is also a possible answer type, which is equivalent to the tree Language—Human—City on the schema level. It returns the entities Ci1 and Ci2 that represent the cities where the German native speaker humans H1 and H2 were born.

Different Example Answers of the Query Q={german, city} Over the KG of Figure 2 Together With Their Types. ns: Is an Example Namespace. Note. KG = knowledge graph.
Compactness-based. Use the size (e.g., tree height or number of nodes) of the retrieved structure as a quality criterion. Importance-based. Use specific criteria (e.g., node in-degree) that may reflect the popularity and importance of the answer elements. Textual-based. Use matches between query keywords and the textual content of the answer as a ranking factor (e.g., TF/IDF; Leskovec et al., 2020). Diversity-based. Include criteria that aim at penalizing results showing a certain aspect of redundancy. Semantics-based. Use semantic characteristics of KGs to rank answers (e.g., semantic distance). Profile-based. Use user profiles
7
to provide answers closer to the user intent.
Distinct scoring. The total weight is calculated as the sum of individual weights: Root-keyword scoring. The total weight is calculated as follows: Keyword-pair scoring. The total weight of an answer is calculated as follows
In the same final score, two different scoring schemes can be combined, one for edges and the other for nodes. Furthermore, some of the works have restricted the nodes incorporated while calculating the edge weight and consider only specific ones (e.g., roots and leaves containing keywords).
During the literature review, we also came across several specific groups of works that deal with the following aspects: parallel processing (Guan et al., 2018; Hao et al., 2015; Liu et al., 2016; Virgilio & Maccioni, 2014; Yang et al., 2019), probabilistic/uncertain RDF graphs (Lian et al., 2015), temporal graphs (Gkirtzou et al., 2015; Liu et al., 2018b), distributed graphs (Yuan et al., 2017), incomplete graphs (Hao et al., 2021), or search results diversification 9 (Bikakis et al., 2013; Park, 2018; Wang et al., 2017b; Zhong et al., 2018). We considered them as special use cases, and thus decided to only shortly report them here without further analysis and refrain from including them in the overview tables (cf. Section 7).
In general, two aspects are evaluated: effectiveness and efficiency. While the latter deals with the execution time and memory usage, effectiveness judges the ability of the system to retrieve results that are relevant to the query and requires an underlying dataset that is searched through using keywords, a set of user queries, and corresponding results together with their relevance judgments. We also notice that some systems have used approach-specific aspects and metrics for the evaluation: #nodes explored/touched (Kacholia et al., 2005), index performance (He et al., 2007; Tran et al., 2009), cache misses (Dalvi et al., 2008), repetition rate (Zhang et al., 2014), answer compactness (diameter) (Kargar & An, 2015), or #intermediate results (Lu et al., 2019).
Table 2 gives an overview of the data 10 and metrics used for evaluating the effectiveness of the surveyed systems (sorted in ascending chronological order). All the systems evaluate efficiency (e.g., execution time), except for Kharrat et al. (2016) and Sitthisarn (2014) that only assess effectiveness.
Overview of the Data and Metrics Used for Evaluating the Effectiveness of Surveyed Systems.

Overview of the Data and Metrics Used for Evaluating the Effectiveness of Surveyed Systems.
Note. ? = not mentioned in the paper; * = no evaluation; - = does not apply; M = manual; R = random; G = generated. Dataset refers to the underlying data queried using keywords.
Furthermore, for one system (Kimelfeld & Sagiv, 2008), no evaluation was conducted, and the other works with no entries did not evaluate effectiveness.
Queries and datasets. We observe that the number of queries used for evaluation varies between 5 and 467. The number of queries is larger when they are randomly generated or an existing benchmark is used, while we notice only dozens of queries by manual creation, since it is a time and personnel-consuming task. Furthermore, the most used datasets are: DBLP, IMDb, 11 and DBpedia (Lehmann et al., 2015).
Ground truth. For each query, a list of potentially relevant results is needed. This is either manually created by result rating from users or by manually creating a corresponding structured query, or automatically generated (other system, structured query, or a tool for benchmark construction). In general, we observe that only 10 systems evaluated their approaches using existing test collections (Coffman Coffman & Weaver, 2014), DBpedia-Entity v1/v2 (Balog & Neumayer, 2013; Hasibi et al., 2017), and QALD 12 that provide both queries and relevant results.
Metrics. Most of the metrics used to measure the effectiveness are: precision, recall, F1-measure, precision at k (P@k), discounted cumulative gain (DCG) and its variants, average precision (AP), mean AP (MAP), and mean reciprocal rank (MRR). However, we notice that some single systems used other metrics that are shortly mentioned while summarizing the works in Section 8 (e.g., rank difference, the fraction of queries with results, Kendall-Tau, or the mean of the user scores). In the following, we briefly define the most popular metrics:

Recall is defined as the ratio between the number of retrieved elements that are relevant and the total number of all existing relevant elements (Cleverdon, 1967):

These definitions may be slightly adapted by some works depending on the nature of the retrieved answer. For example, Dosso and Silvello (2020) define a triple-based variant of precision and recall to compare a generated and a ground truth subgraph, by defining recall as the ratio between the relevant triples and the total number of triples in the ground truth. Another adaptation is given by Navarro et al. (2021), where precision and recall are calculated for each generated SPARQL answer. Here, recall is a function of the intersection between the generated and ground truth query.
The F1-measure is calculated by combining both precision and recall as follows (Zhang & Zhang, 2009):

The previous metrics are set-based measures. Next, we define rank-based metrics that also consider the order in which the documents are retrieved.




However, the DCG is not normalized, which makes it difficult to compare different queries with varying result sizes. To deal with this, the normalized DCG (nDCG) is introduced. The normalization (
One work (Sinha et al., 2018) used an improved variant of the DCG, called Rank-DCG (Katerenchuk & Rosenberg, 2016). Dosso and Silvello (2020) propose a triple-based DCG (tp-DCG) based on a new notion of relevance (graph-based) that is calculated as the fraction of relevant triples in a subgraph-shaped answer.

Tables 3 and 4 provide an overview of all systems described in detail in Section 8 sorted in ascending chronological order. In addition to the aspects introduced in Section 5, the following criteria are also reported: the underlying data, the goal in terms of returned results, the availability of an index, the search algorithm used, the type of the intermediate result, and the specific ranking. Most of the approaches either work over any graph-structured data or over KGs (RDF). Furthermore, some of the works also require the existence of a data schema (ontology) to answer the query, and only one work operates on attributed graphs. The majority of works are graph-based (22), followed by summary-based (5), schema-based (4), and virtual document-based (4) approaches. Overall, the aim is to retrieve the top-
Overview of Surveyed Methods for Keyword Search over Graph-Shaped Data.

Overview of Surveyed Methods for Keyword Search over Graph-Shaped Data.
Note.
Overview of Surveyed Methods for Keyword Search Over Graph-Shaped Data (Indexing and Ranking).

Note.
Even if we notice an inconsistency in the naming of the search algorithms used, works that aim at extracting tree or subgraph-shaped results usually rely on graph traversal algorithms (e.g., backward, breadth-first, depth-first, or random walk). The latter are either adapted to work with a specific index structure (Dalvi et al., 2008; Kacholia et al., 2005; Zhong & Liu, 2009), or a specific result (Ghanbarpour et al., 2020; Lu et al., 2019; Zhang et al., 2022), or data graph shape (Han et al., 2017; Zheng et al., 2016). Some works also exploit approximation algorithms that aim at computing the top-
Most of the works use a compactness-based ranking (18), followed by importance-based (15) and textual-based (12) ones. However, semantics-based (3), diversity-based (1), and profile-based (1) rankings are only rarely used. Almost half (16) of the works combine at least two ranking methods. The distinct answer scoring is mostly used (7), followed by the root-keyword (6) and the keyword-pair (4) scoring. Here also, we notice that two scoring types may be combined when, for each graph element, a different scoring is used. In addition, the specific answer scoring type may be applied only for either nodes or edges. Furthermore, for each system, we also document the type of index used and the specific rankings (cf. Table 4). An index is usually used to support keyword to graph element matching, or to accelerate the graph traversal by storing a specific set of shortest paths between two nodes. Almost half of the works (14) use a keyword to graph element index (keyword-element).
In general, we observe that most works have focused on traversing the whole graph to find tree-shaped answers for now. This shows that the overall trend is to enhance efficiency. However, answer ranking is not sufficiently investigated, which is demonstrated by the fact that in most cases, the most intuitive ranking type is used (e.g., compactness-based).
In the following, we give detailed descriptions of the collected relevant works. We structure them into subsections based on the search space aspect, since it appeared to best cluster relevant works into distinct groups. Other aspects will be clearly mentioned for each work in the short summary, together with the method of evaluation used. In total, we report on 22 graph-based, four schema-based, five summary-based, and four virtual document-based methods.
Graph-based Methods
Graph-based methods do not aim at reducing the size of the graph but directly search for answers over it. Since most of the works are graph-based, we further categorize them with respect to the answer type to improve readability. We also notice that all the answer types are covered in this case.
Tree
Bhalotia et al. (2002) presented Browsing ANd Keyword Searching (BANKS), a system enabling keyword search over relational databases.
Method. The database is modeled as a directed graph by considering the tuples as nodes and the foreign key relations as edges. The query answer is defined as a rooted directed tree. BANKS models each relation between two nodes using two types of edges: forward (initial edges pointing from foreign key to primary key) and backward (additional edges in the opposite direction). This ensures finding a rooted tree directed away from the root. BANKS aims at finding an approximate set of top-
Ranking. An importance-based ranking was used where each node is assigned a weight based on its importance (node prestige). The node weight is calculated as the fraction of the number of incoming edges and the maximum node weight, giving a higher score to nodes with more incoming edges. For the edges, a weighting based on the edges’ importance (proximity) is proposed. Each forward edge is given a weight of 1, whereas a backward link
Evaluation. Evaluation of performance, effectiveness, together with parameters effect were conducted using a part of the DBLP dataset (paper titles, their authors, and citations) and a dataset about the master/PhD dissertations in the IIT Bombay. The authors used an internally created gold standard with seven queries and their corresponding relevant answers. The rank difference between the ground truth answers and the actual answers was used as an evaluation metric.
Kacholia et al. (2005) state that the backward search in BANKS may not efficiently perform in the cases where: (1) a query keyword has many matching nodes in the graph, or (2) some of the visited nodes have a large in-degree, since it prevents exploring other directions until all incoming edges are visited.
Method. To overcome the previous shortcoming, this work proposes a bidirectional search paradigm to retrieve rooted directed trees which does not traverse the graph only backwards but also forwards, starting from potential answer roots in the direction of keyword nodes. For this purpose, the authors propose a node prioritization heuristic (spreading activation) that regulates the traversal. Keyword nodes are assigned an initial score given by
Ranking. Since the focus was on the search algorithm, and not on the ranking of answers, the same importance-based scoring as proposed by BANKS was used with the multiplication-based relevance score. The only difference is the used final answer scoring for edges, which is root-keyword based, in contrast to BANKS.
Evaluation. The evaluation focuses on the efficiency aspect and compares the bidirectional search with BANKS and the Sparse algorithm (Hristidis et al., 2003) using the following metrics and five manually created queries: number of nodes explored and the nodes touched, as well as the time taken. Results show that the bidirectional search is faster than both baseline algorithms. A very small effectiveness analysis (precision and recall (cf. Section 6)) was conducted using the same queries and their corresponding results generated using an SQL query. Both backward and bidirectional performed equally with respect to effectiveness.
He et al. (2007) propose Bi-Level INdexing for Keyword Search (BLINKS) and aim at exploiting indexes to precompute and store possible shortest paths. This is to deal with the fact that both backward and bidirectional search algorithms’ performance relies more or less on the graph structure and the position of the different keywords in the graph, which makes the performance unpredictable.
Method. The index is filled using backward search and consists of two kinds of lists: (1) a keyword-node list that stores for each keyword the list of nodes that can reach it ordered by distance, and (2) a node-keyword map which stores the shortest distance between nodes and keywords, to optimize forward expansions.
BLINKS does not aim at indexing all possible paths (single-level index) since it will result in very large indexes for large-scale graphs. However, it proposes a bi-level index by dividing the whole graph into blocks (subgraphs): the top-level block index maps keyword/nodes to blocks, and the intra-block index stores detailed information within each block (e.g., intra-block keyword-node lists). The backward search strategy is also enhanced using equi-distance and cost-balanced expansions. BLINKS answers are distinct rooted directed trees to avoid answers that deliver only a few additional information compared to the rest, and technically allow more effective indexing.
Ranking. Again, the focus was not on the ranking, but on the query processing and indexing strategy. The authors propose a scoring function for the answer that combines three aspects (compactness-based, importance-based, and textual-based): sum of the shortest path distances from the root for each keyword node, sum of the matching score for each keyword with its corresponding node (e.g., TF/IDF), and the score of the answer root (e.g., PageRank; Page et al., 1999). However, for convenience, only the sum of the shortest path distances from the root for each keyword node is considered. The same aggregation is used for edge weights (root-keyword scoring).
Evaluation. Only efficiency experiments (comparison with the bidirectional algorithm Kacholia et al., 2005) were conducted, including execution time with different parameters (e.g., graph partitioning method) and index performance using 10 queries over the DBLP XML 14 and IMDb 15 datasets. Results reveal that BLINKS is overall faster than the baseline.
Kimelfeld and Sagiv (2008) use a different family of algorithms to efficiently retrieve all answers.
Method. The authors use threaded enumerators, which enable one enumeration algorithm to directly use elements produced by another one (or itself) instead of waiting until the latter finishes. The desired answers are minimal trees, which means that there exists no other subtree in the answer that connects the respective keyword nodes. Three types of answers are considered: directed, undirected, and strong (undirected with all keywords as leaves). The work focuses on the efficiency aspect and aims at proposing answer enumeration algorithms that solve the problem with polynomial delay between two output answers, except for the first answer, where the delay is exponential. For that, algorithms for each answer type are investigated, with the following different purposes with respect to how the answers are presented: sorted, heuristically sorted, and unsorted. The authors consider the sorted variant as the most wanted one and propose an algorithm with polynomial delay given an acyclic data graph and a directed answer. Algorithms for the unsorted scenario for all types of answers with polynomial delay are also proposed. Furthermore, a proposition is given about how the latter can be enhanced to output the answers in a heuristic order. Answer ranking was not addressed, and there is no practical evaluation of the proposed approaches; instead, theoretical proofs are elaborated.
Golenberg et al. (2008) combine the methods proposed by Bhalotia et al. (2002); Kacholia et al. (2005) by using shortest-path iterators to find the first answer, and includes the work done in Kimelfeld and Sagiv (2008) to generate the rest of the nonredundant answers using a more practical and faster approach.
Method. Kimelfeld and Sagiv (2008) retrieve answers (minimal rooted directed trees) with a polynomial delay (ranking them by order of increasing weights) and is based on heuristics for generating Steiner trees. To simplify the problem, Golenberg et al. (2008) propose the usage of two rankings, a simple one while exploring the graph, and another one after generating candidate answers. A condition for this to work is that the primary ranking should be highly correlated with the final one. The problem is further simplified to increase efficiency and restricted to the enumeration of answers in a two-approximate order (“if one answer precedes another, then the first is worse than the second by at most a factor of 2”).
Ranking. In general, the authors combine compactness-based, importance-based, and diversity-based rankings. The primary ranking weight used during the exploration is the height of a subtree (“maximum length of any path from the root to a leaf”). The final ranking of generated answers is calculated as a combination of: an absolute relevance score based on the in-degree/out-degree of the nodes belonging to an edge, and the redundancy penalty which aims at producing diversified answers by “penalizing answers based on their degree of similarity to the ones that have already been given a final rank.” The total score of an answer is inversely proportional to its total weight using a distinct scoring for nodes and edges.
Evaluation. The efficiency of the algorithm was evaluated with an increasing number of query keywords. The correlation between the primary and final ranking, together with the effect of the redundancy penalty on ranking quality, isalso evaluated. No information was provided on the used evaluation dataset/queries.
Kargar and An (2015) aim to find a practical algorithm to solve the hard problem of retrieving top-
Method. First, needed indexes are prepared, which include a keyword-node index and a shortest path index between each pair of nodes within a certain distance. After finding keyword nodes in the graph, top-
Ranking. The edge weight used during the evaluation is based on the in-degree of the two edge nodes. The final answer score is calculated using a keyword-pair scoring considering the edge weight as pairwise node weight.
Evaluation. The efficiency evaluation is done using 15 queries over three datasets (DBLP XML, IMDb (MovieLens
16
), and Mondial
17
), where two approach versions (original and another one starting from nodes containing rarest keywords) were compared with BANKS, Dynamic (Ding et al., 2007), and an algorithm that produces communities as answers (Qin et al., 2009). In addition to the runtime also answer compactness was reported. Both proposed versions are faster than the other systems. The effectiveness was evaluated by first calculating the percentage of produced ground truth (generated using a naive algorithm that produces all r-cliques) answers using their approximate approach. In addition, a small user study was conducted with four manually created user queries over DBLP, and eight users were asked to rate the answers. The proposed system, BANKS, and dynamic achieve better precision than the community algorithm over all queries using the P@k with
Park and Lim (2015) propose an index-based approach for answering keyword queries over graphs that can be modified to also accept answers that have more than one node corresponding to a specific keyword.
Method. Similar to Wang et al. (2015), the approach starts by constructing an inverted index that stores for each keyword in the graph corresponding nodes (containing the keyword or connected to other nodes containing the keyword) together with their relevance score to the keyword. This index is used to find top-
Ranking. Each node is assigned a textual-based and compactness-based score that is calculated as the multiplication between two elements: a matching score calculated based on the number of occurrences of the keyword in the node, and a distance score calculated as the shortest path between the considered node and the one containing the keyword. The total relevance score of an answer tree is the sum of the relevance scores between the root and the keyword nodes (root-keyword scoring).
Evaluation. The system was compared (shortest distance set to 4) with BLINKS using 30 queries manually constructed over three datasets (Mondial, IMDb, and DBLP XML). The answer trees of the different approaches were rated by five adjudicators, and the P@10 and P@20 were calculated. The proposed approach outperforms BLINKS for 73% of the queries, but the latter is still faster.
Lu et al. (2019) address the efficiency issue by ignoring some redundant intermediate results during graph expansion.
Method. The authors consider directed graphs and define a query answer as a minimal rooted undirected tree with a fixed size (number of nodes). The rationale behind their algorithm (canonical form-based search) is to consider only intermediate result trees that have a canonical form Zaki (2005) while searching the graph. Answer ranking was not addressed.
Evaluation. Experiments are run to evaluate the efficiency of the algorithm using the TPC-H benchmark 18 (decision support database) and the IMDb 19 database and 10 randomly generated queries. The work is compared with the other two systems that generate all answers without redundancy checking (Hristidis & Papakonstantinou, 2002; Kargar et al., 2015). Results reveal that the proposed approach is faster than the baseline for retrieving trees of size six. Furthermore, their algorithm always produces less number of intermediate results compared to the baselines.
Cheng et al. (2020) tackle the case where subtrees connecting all the keywords may not exist, or they exist, but they are far away from each other, resulting in a noncompact answer. While previous works retrieve top-
Method. A method is proposed that still ensures the compactness of the answers by not requiring that all keywords should be connected (relaxed answer). The authors formulate an optimization problem that aims at finding an optimal answer with a tradeoff between compactness (the smallest answer diameter) and the degree of relaxation (covering more keywords). For traversing the graph, a best-first strategy (CORE) is used, where the best search direction that may yield a better answer (minimal relaxed) compared to the current one is followed. The exploration terminates if the remaining possible answers cannot be better than the current best answer. The algorithm requires determining a specific desired answer diameter. Answer ranking was not addressed.
Evaluation. The evaluation was conducted over the RDF versions of Mondial (40 queries from Coffman’s benchmark; Coffman & Weaver, 2014), LinkedMDB 20 (200 random natural language questions transformed to keywords), and DBpedia (438 queries from DBpedia-Entity v2; Hasibi et al., 2017). The baselines used are: a previous algorithm version of the same authors (CertQR+), and another algorithm for calculating Group Steiner Trees (GST) (Li et al., 2016) with edge weights assigned with one. By calculating the compactness of GST answers, it is shown that it fails to find answers in a lot of cases and also finds noncompact answers. In a second step, it is shown that their relaxed method finds complete answers in the case of a number of keywords lower than 10 and 100. The runtime of their approach outperforms CertQR+. Since CORE only computes the top-1 optimal answer, P@1 was used for calculating effectiveness over the DBpedia benchmark (“P@1 = 1 if a computed answer contained a gold-standard answer entity, otherwise P@1 = 0”) and compare CORE with CertQR+ and the GST algorithm. Results show that both CORE and CertQR+ have comparable results, and the GST-based approach slightly outperforms both approaches with respect to the mean P@1.
Shi et al. (2021) aim at improving the performance of algorithms that calculate semantically cohesive minimal trees. The latter should consist of entities with minimal pairwise semantic distance. Similar to (Cheng et al., 2020), the top-1 answer is retrieved.
Method. The authors state that using the semantic distance as an additional factor increases the difficulty of the Steiner tree problem and thus propose two approximation algorithms: quality-oriented and efficiency-oriented. The answer is defined as a minimal tree following the same definitions by some of the previous works, and the aim is to find the single best answer. Each vertex is assigned a weight and each pair of vertices is assigned a semantic distance function. The problem of computing an optimum answer is approximated by first computing a set of relevant paths that lead to each keyword from a specific root node. After that, the candidate paths are transformed into an answer by merging the paths and removing unnecessary edges and vertices to make it a minimal tree. This tree is not necessarily optimal, but it is shown that it has a guaranteed approximation ratio. The quality-oriented algorithm finds a minimum cost path for each root, whereas the efficiency-oriented algorithm relaxes this definition by computing the path only for roots that are keywords.
Ranking. The total cost of an answer is calculated using a weighted additive function that aggregates the total PageRank-based vertices weights (importance-based) with the total pairwise semantic distance (semantics-based) of vertices following a distinct scoring. A concrete implementation of the semantic distance is out of scope, but it should be independent of the graph structure.
Evaluation. An evaluation was conducted using three synthetic KGs generated by the LUBM benchmark and three DBpedia subgraphs, including the whole graph. For each LUBM dataset, 250 queries were generated by varying two parameters: the number of keywords and the average number of vertices matched with each keyword. For DBpedia, queries from DBpedia-Entity v2 were filtered by removing keywords without matches. For the evaluation, existing metrics were reused: (1) a PageRank-based vertex scoring and (2) a semantic distance function calculated as the Jaccard distance between the sets of types of entities (Cheng et al., 2017). The latter requires entities having multiple types, which is not available for LUBM. For that, the angular distance between entity embedding vectors using RDF2Vec (Ristoski et al., 2019) is calculated (structural semantics). The metrics used are: the runtime compared to BANKS-II (Kacholia et al., 2005) and DPBF (Ding et al., 2007), the ratio between the cost of the approximate and optimum answers (only on small graphs, using an exact version from their algorithm) and the cohesiveness ratio between a baseline answer (BANKS-II and DPBF) and their answer, where cohesiveness is defined as the sum of the pairwise semantic distance. The runtime of the efficiency-oriented algorithm was comparable to BANKS-II. The quality-oriented algorithm showed poor performance by reaching timeouts (200 s) most of the time. The effectiveness was evaluated by conducting a user study using 14–20 queries from the DBpedia-Entity v2 dataset with 16 participants (281 queries). Each participant was presented with the query and corresponding answers retrieved by different methods (DPBF, efficiency-oriented approach) and was asked to rate each answer on a scale (1–4).
Subgraph
Zhang et al. (2014) aim at retrieving r-cliques that are ranked based on the combination of various aspects.
Method. The first step is the weights’ assignment to nodes and edges in the graph. After that, the search space is narrowed down by selecting only the top-
Ranking. The node weights are calculated as a function of the keyword frequency and PageRank, and the edge weights are calculated as a function of the degree of their respective nodes. The total score of an answer is a linear combination of the sum of the node weights and edge weights (distinct scoring), multiplied by other factors (answer size, keywords count in the query). The ranking is a combination of compactness-based, textual-based, and importance-based factors.
Evaluation. The evaluation was performed using five randomly generated queries from each of the DBLP and IMDb datasets. Relevance judgments were carried out by five users that were asked to score the nodes in the results based on the relevance to the query. Results show that the proposed approach is faster and more effective compared to the Dup-Free algorithm (Kargar et al., 2013).
Zheng et al. (2016) propose a method that transforms the RDF graph to a bipartite graph.
Method. The method aims at optimizing the efficiency of the keyword search task by taking advantage of the nature of the adjacency matrix of a bipartite graph. First, the RDF graph is transformed to a bipartite graph that consists of two sets represented as nodes with labels: one set with entities/classes and another one with properties. First, the keyword query is expanded using synonyms from WordNet. The result is then matched to graph elements and a connecting subgraph is extracted.
Ranking. The list of possible subgraphs is ranked using a textual-based score based on the number of keywords contained in a specific subgraph.
Evaluation The evaluation is performed by comparing with three other systems (KREAG: Li & Qu, 2011; BLINKS and EASE: Li et al., 2008) using DBLP with 10 manually created queries. Both the execution time and effectiveness are reported using P@5, AP at 5 (AP@5), and the MRR as metrics (cf. Section 6). Results show that the proposed approach is faster and more accurate.
Ouksili et al. (2017) focus on the problem where keywords cannot be mapped to the underlying graph elements because of missing information (e.g., relation). In contrast to Zheng et al. (2016), the existence of a data schema (ontology) is required.
Method. The main idea is to leverage external knowledge defined in the form of patterns, which will add new missing triples. The pattern defines an equivalence between a property and a property path (e.g., two authors are collaborators if they have written the same paper). Those patterns are manually defined and are either domain-specific or generic by using standard properties (e.g., owl:sameAs). The approach starts with a fragment extraction step that extracts matching graph elements, and next, the set of elements is expanded using a pattern store. Possible fragment combinations are constructed by applying a Cartesian product. For each possible combination, the smallest minimal subgraph is retrieved.
Ranking. The used ranking is both textual-based using a term-frequency based matching score, and compactness-based using the size of the subgraph (sum of nodes and edges). Patterns are considered when computing the size of a subgraph by reducing the size by 1 if the subgraph contains a path from a pattern.
Evaluation. Two datasets were used: AIFB
21
and a dataset about conferences. The actual approach using patterns was compared with two other configurations without external knowledge. The effectiveness is evaluated with P@k and the normalized DCG at k (NDCG@k) with
Rihany et al. (2018) have the same motivation as Ouksili et al. (2017) and focus on enhancing the keyword to graph element matching by using WordNet as an external knowledge base.
Method. The approach starts with keyword matching, where the first graph elements with exact matching labels are retrieved. If this step fails, related terms are retrieved from WordNet using different relations (e.g., synonyms). Since for each keyword a list of matching elements is retrieved, possible combinations are derived using the Cartesian product. For each possible combination, the smallest minimal subgraph is retrieved using the Dijkstra algorithm (Dijkstra, 1959).
Ranking. The result subgraphs are ranked based on a function that depends on the number of matching elements and the number of connecting nodes. This function favors small answers with more exact matching nodes (textual-based and compactness-based).
Evaluation. The evaluation was done using 10 queries from each of AIFB and a subset of DBpedia about movies. It is shown that the approach without external knowledge usage is faster and evaluates effectiveness using a subset of 10 queries and three users. Results reveal that P@10 and P@5 are always above 0.92 for both datasets.
Bryson et al. (2020) are motivated by the fact that shortest path-based methods will assign the same score to connecting subgraphs having the same length.
Method. The authors propose a function for assigning scores to nodes based on a random walk with restart. Different from previously mentioned works, they define attributed graphs as underlying data and aim at finding a top-1 or top-
Ranking. The used ranking is importance-based and assigns scores to nodes relative to others by taking the whole graph into consideration. In contrast to PageRank, the proposed approach is query-dependent. The total answer score is calculated using the keyword-pair scoring considering node weights.
Evaluation. The method is evaluated using DBLP XML and IntAct PPI 22 (molecular interaction data) datasets and compared with six systems (shortest-path-based, embedding-based, and PageRank-based). The quality of the answers is evaluated using different dataset-dependent metrics and the runtime of their distributed version. For IntAct PPI, the expression level of each protein is calculated, where “a cost value is assigned to each protein; the lower the cost, the higher the expression level” using 100 randomly generated queries with 2 to 6 genes. For the DBLP dataset, the h-index is used as a metric of quality with 100 randomly generated skill sets (2 to 6 skills). For the discovered subgraph, the average h-index of the members is calculated. Their approach results in answers with a higher expression level and a higher average h-index compared to the others.
Ghanbarpour et al. (2020) aim at retrieving minimal r-cliques called minimal covered r-clique. The motivation behind that is to overcome the limitations of finding Steiner trees, distinct root trees (losing results having the same root, considering the distance to the root not between each two keyword nodes), r-cliques, and r-radius Steiner graphs (Kargar & An, 2015; Kargar et al., 2014; Li et al., 2008) (not minimal) based on previous definitions.
Method. The work uses adapted versions (BKS and its improvement called BKSR) of the Bron-Kerbosch (Bron & Kerbosch, 1973) and Tomita (Tomita et al., 2006) algorithms that originally aimed at finding maximal cliques (with the largest possible number of vertices). The algorithms are also improved to return nonduplicate minimal covered r-cliques. Furthermore, the authors propose algorithm versions (BKSM and BKSRM) that are dedicated to also work on parallel configurations. This is possible since the answers are constructed independently of each other. An approximate version to generate top-
Ranking. The authors use an importance-based edge weight that is a function of the in-degree of its nodes as defined by Kacholia et al. (2005). Tests are performed using a uniform compactness-based scoring, by assigning one to all edges. The final answer score is calculated using a keyword-pair scoring considering the edge weight as pairwise node weight.
Evaluation. The different approximate versions of the proposed approach are evaluated against the r-clique and r-clique-rare algorithms (Kargar & An, 2015) over IMDb (MovieLens) and DBLP XML data using the same fove queries for each dataset. Results show that BKS and BKSR are faster than r-clique and close to r-clique-rare, but still do not outperform it for both datasets. However, the parallel setting outperforms all the other algorithms. The other evaluated aspect is the compactness using the average percentage of cliques with the maximum
Structured Query
Wang et al. (2015) propose an index-based approach that decreases memory consumption while performing keyword search over graphs.
Method. First, the RDF graph is transformed to an attributed graph that consists of interlinked subject nodes with text information (predicate, class, and predicate linking to another entity). The approach starts with an offline phase where the index is constructed. The index stores for each keyword in the data graph the corresponding list of pairs of nodes (node1 containing the keyword, node2 reachable from node1), and the shortest distance between the pair of nodes over 2 hops. The index is leveraged in an online phase to extract the top-
Ranking. The ranking is compactness-based using the tree diameter, which is calculated as the maximum distance among the shortest distances of all pairs of nodes.
Evaluation. The evaluation mainly concentrated on the efficiency aspect, comparing the indexing time, memory usage, and the runtime with two other index-based approaches (Rclique Kargar & An, 2011, Gdensity Li et al., 2012). Results show that the proposed system is faster and requires less memory usage over the two datasets DBLP XML and DBLP2
23
. The effectiveness was manually checked and compared with Rclique. The keyword queries were manually created by first randomly selecting 20 subgraphs with diameter four over DBpedia, constructing corresponding SPARQL queries, and formulating keyword queries by selecting one or two keywords from each node. Afterwards, it is manually checked if any of the top-
Kharrat et al. (2016) propose a SPARQL query generation method specific to DBpedia. In contrast to Wang et al. (2015), it aims at retrieving only the top-1 answer and requires the existence of a data schema (ontology).
Method. The first step is query preprocessing using WordNet, followed by the keyword matching of query terms to DBpedia concepts/properties/instances. The next step is a query expansion with semantically related concepts using some properties (e.g., rdfs:seeAlso or owl:sameAs). Afterwards, ambiguous terms are filtered by calculating the pairwise relatedness between keywords. The latter is based on the intersection between the set of matching terms (DBpedia IRIs, text in this case) for each keyword. Then, all possible combinations are generated from the matching elements, candidate subgraphs for each combination are constructed using predefined graph patterns, ranked, and the top-1 result is translated to a SPARQL query.
Ranking. The subgraphs are ranked based on a compactness-based measure, which is calculated as the sum of the shortest paths between each pair of matching elements (keyword-pair scoring).
Evaluation. The effectiveness of the system is evaluated using 50 queries, and the following metrics: The fuzzy precision, which is calculated as the sum of the average correctness rate for each query divided by the queries returning results. The correctness rate of an answer is calculated as the set of correct terms that match the user’s intention (subject, predicate, and object) divided by the set of all terms. The other used metrics are recall (queries returning results divided by the total number of queries) and the F1-measure (cf. Section 6) as a combination of the fuzzy precision and recall. No information was provided about the origin of the queries, the used ground truth, and the dataset. The reached results are as follows: 0.52 (F1), 0.43 (recall), and 0.5 (fuzzy precision).
Han et al. (2017) propose an efficient and accurate keyword search system over RDF data by leveraging bipartite graphs together with translation-based graph embeddings. Similar to Kharrat et al. (2016), the goal is to find just the top-1 result.
Method. The method starts with a segmentation and annotation phase where the user query is first tokenized, annotated using types (entity, class, and relation), and then matched to a specific graph element. The result is a ranked list of possible query annotations. The second step is the query graph assembly, where the detected graph elements need to be linked with each other. For that, the found possible matches are modeled as a bipartite graph where each pair of entities/classes and each set of possible matching relations is represented as a node, and there is a crossing weighted edge between the set of entities/classes and the set of edges. The algorithm tries to find the optimal connection (subset of crossing edges) called assembly query graph with the minimum cost and transforms it to a SPARQL query. The constraint here is that the query should ideally contain classes, entities, and as many needed relations, which are not always present given the nature of keyword queries, and in this case, the graph elements cannot be connected. The authors point to this issue and shortly state that, in this case, the missing relation should be first determined using a suitable algorithm for minimum spanning tree finding.
Ranking. Since the goal is to find just one best answer, the algorithm does not output a list of top-
Evaluation. The system is compared in terms of efficiency and effectiveness with two approaches: PBF (Ding et al., 2007), a graph-based approach, and SUMG (Tran et al., 2009), a summary graph-based approach. Two datasets were used: 6th Open Challenge on Question Answering over Linked Data (QALD-6; Unger et al., 2016) with 100 queries, and Free917 (Cai & Yates, 2013) with 80 selected queries converted to keywords. Their approach using graph embeddings is also compared with two traditional link prediction methods. The system performed better than both other approaches and ranked the third place in QALD-6, competing with question answering systems. The most time-consuming part was the keyword-graph element mapping, but on average, the system was faster than the two baselines.
Izquierdo et al. (2021) propose a different method that does not rely on traversing the graph.
Method. The very first preprocessing step is to calculate offline the so-called K-minimum value (KMV)-synopses over the whole graph, where “A KMV-synopsis of a set defines a random sample of size
Ranking. The used ranking is both textual-based using keyword matching scores and importance-based using InfoRank.
Evaluation. The evaluation compares the approach with: (1) a schema-based RDF keyword search tool (García et al., 2017; previous work of some of the same authors), and (2) a virtual document-based approach (Dosso & Silvello, 2020). For (1), an adapted version of Coffman’s benchmark using Mondial and IMDb databases with a total of 64 queries is used. The ground-truth answers were generated using a tool for automatic benchmark construction for keyword search (Neves et al., 2021). The effectiveness is measured using the following metrics: MAP (cf. Section 6), Top-1, and the MRR. The reached scores are as follows for Mondial and IMDb, respectively: MAP of 0.96 and 0.76, Top-1 of 0.96 and 0.76, and an MRR of 0.79 and 0.72, and thus also outperforms the baseline. The average execution time was 11.4 s and 0.60 s for IMDb and Mondial, with no big differences compared to the baseline. For (2), the same benchmark was used as in the virtual document-based baseline, including the following datasets: LUBM, 25 BSBM, 26 IMDb, 27 and DBpedia 28 and also using the same metrics. The proposed approach outperforms the baseline for all metrics.
Other
Bae et al. (2014) propose a system that exploits indexing and semantic similarity scores to find the triples relevant to a specific keyword (not query).
Method. The first step is the offline preparation of five indexes: predicates, subject/object, incoming/outgoing vertices, literals, and similarity scores between two literals. The approach starts by finding the literal vertex corresponding to a certain keyword, filters candidate nodes without a common predicate with the input keyword node, traverses the graph in a depth-first manner, and considers only nodes (literals) with a semantic score greater than a specific threshold. The list of relevant triples is presented to the user.
Ranking. The ranking of target nodes (or triples) is performed based on the similarity score, which is calculated as a combination of a distance score (number of subjects relating source and target), and a semantic similarity depending on the most specific class subsuming the classes of the pair of nodes (Lin & Sandkuhl, 2008), calculated over WordNet (Fellbaum & George, 1998). The ranking is a combination of compactness-based and semantics-based factors.
Evaluation. Only an efficiency evaluation was performed using 10 manually created keywords over three subsets of DBpedia (Lehmann et al., 2015). The approach was compared with the RDF management system Jena (McBride, 2001) by retrieving the first two results (using SPARQL queries for Jena). Results show that the proposed system is faster.
Zhang et al. (2022) do not focus on finding top-
Method. To achieve the previous purpose, a specific answer type is defined. The authors represent a so-called key-core, which is a subgraph containing highly related answers. Answer ranking was not addressed.
Evaluation. The evaluation is performed using two datasets, DBpedia and DBLP, using 500 randomly selected queries from the datasets’ vocabularies. The effectiveness is manually evaluated on five example queries. For testing efficiency, their approach based on graph traversal is compared against a defined naive baseline (retrieve all key-components and then compute the key-core by union of all key-components) while also varying the graph size, the number of keywords, and other used thresholds such as the distance maximal to the keywords.
Schema-based Methods
In contrast to graph-based methods, schema-based ones require the existence of a data schema and thus work on a very small graph. We notice that the answer type produced by this method is always a structured query.
Sitthisarn (2014) propose a bidirectional approach for keyword search with defined answer types over RDF graphs with an available data schema (ontology).
Method. The proposed system constructs two indexes: the keyword-element index, and an extended version of the single-level index by BLINKS that stores for each node the distance to the other node and the direction. The algorithm takes as input a set of nodes corresponding to keywords and a desired answer type (root of interest). The first step is the node merging, where it is checked whether each pair of keyword nodes can be directly connected, have the same class, or one is a subclass of the other. In the latter cases, the nodes are marked as nonactive. The remaining active nodes are bidirectionally expanded to connecting nodes in a round-robin manner until finding a connection with a root. The results are ranked and the best rooted tree is transformed to a SPARQL query.
Ranking. The results are ranked by combining compactness-based, textual-based, and importance-based factors based on a previous version of the same authors (Sitthisarn et al., 2011). The overall tree score is given by the multiplication of three scores, each is a function of: the shortest path between the root and keywords, keyword frequency, and the predicate frequency.
Evaluation. The effectiveness is evaluated with 20 manually created queries and five ontologies. The result of the current approach and its previous version (not bidirectional) are compared with a manually created SPARQL query using the MRR as metric. Results show that the new approach outperforms the old one.
García et al. (2017) propose a tool to simplify access to specific data from an industry use case. Similar to Sitthisarn (2014), it first retrieves a tree-shaped intermediate result before generating the top-1 structured query. However, it does not require a data schema (ontology).
Method. The overall aim is to construct one SPARQL query to answer a keyword query. The algorithm operated on the data schema where keywords are matched to literals after removing stop words. The matched structure is called nucleus and consists of a class, a list of properties, and property values. Each nucleus is assigned a matching score that is used to construct a minimal tree that covers all keywords. While a prototypical user interface was proposed, answer ranking was not addressed.
Evaluation. The evaluation was conducted over an industrial database (hydrocarbon exploration) and using Coffman’s benchmark (Mondial and IMDb (IMDb-MO) 29 ). The relational databases were first converted to triples, and the retrieved results using the proposed approach were compared with the ground truth. Results were only analyzed without using any evaluation metric, where 64% (Mondial), 75% (IMDb) of the 50 queries were correctly answered. Using six queries for the industrial database, it is shown that the execution time is reasonable.
Menendez et al. (2019) focus on improving the ranking of results by proposing a new definition of node importance in RDF graphs.
Method. The method aims at generating one structured query (SPARQL) as in García et al. (2017); Sitthisarn (2014) to produce a list of ranked entities. First, the system finds nodes (instances and classes) whose labels match the keywords. Next, for each query keyword, the node with a higher accum score is selected (number of keywords that appear in the label). In the case of equal accum scores, the disambiguation is performed using another specific node scoring function (info_score). The next step is the linking of the classes corresponding to the selected nodes over the graph schema. This consists of finding the minimal Steiner tree, but no details are given about how this tree can be found. The authors only claim that this step will give the information that, for example, two selected nodes are connected through one specific property. This connected tree is transformed to a SPARQL query and the results are ranked based on the sum of the info_score of the tree nodes.
Ranking. An importance-based ranking of entities is used by proposing a new metric InfoRank for scoring instances, classes, and object properties that is based on the informativeness of an instance, which is defined as the number of its data properties (literals). Each object property is assigned a score that is the maximum of the sum of the InfoRank of the subject and object (over all triples involving the property), divided by the sum of the InfoRank of all other existing properties. Next, the PageRank of each instance is calculated using the object property score as edge weight. The final score assigned to an instance (info_score) is the PageRank after
Evaluation. The proposed ranking score was evaluated by comparing it with the PageRank of some classes, instances, and properties over two datasets 30 : IMDb (IMDb-MO) and MusicBrainz 31 (enriched with DBpedia). This has shown that the info_score gives higher scores to the most important classes in both considered domains compared to PageRank. Other experiments were conducted using Coffman’s IMDb (50 queries adapted to RDF) and QALD-2 32 MusicBrainz (25 queries) with different ranking measures (e.g., PageRank or HITS; Kleinberg, 1999). InfoRank-based ranking achieved the highest MAP.
Navarro et al. (2021) aim at generating the set of structured queries (SPARQL) that answer a keyword query. As in Sitthisarn (2014), the data schema is also required.
Method. Their approach starts with an entity identification module based on the Stanford Regexner Annotator (Manning et al., 2014), which annotates keywords with candidate classes/individuals from the underlying ontology/RDF repositories. Filter expressions are also detected using a gazetteer. Afterwards, entity combinations are generated, since a keyword can be associated with multiple entities. Less specific annotations (ontology hierarchy) are considered as redundant and thus removed. The answer search algorithm operates on the ontology of the target KG, extended with the detected individuals and filters. For each different candidate entity of a specific keyword, such an ontology-based graph model will be built. The graph exploration is done by starting Breadth-First Search from a specific keyword node, and the neighbors exploration continues until all candidate keyword elements are included. No cost function is used during the graph exploration. The result is a rooted tree that is further cleaned by removing unwanted edges and leaves. Each keyword interpretation results in a corresponding tree. Finally, each tree is translated to a SPARQL query. Only one representative is selected in case of redundant SPARQL queries. Answer scoring is not addressed.
Evaluation. The evaluation was conducted using the QALD-7 dataset for question answering over DBpedia, where each question is associated with a set of keywords. Some types of questions were discarded (e.g., boolean) and the keywords were manually reviewed and adapted. The final test set contained 136 queries. Precision, recall, and F1-score are used as metrics to evaluate the generated SPARQL queries against the provided ones. In this case, different cases (e.g., correct/imprecise/partial answer) are defined. The evaluation reveals a precision of 0.52 and a recall of 0.60, considering the best answer for each query. The runtime was also reported with an average time of
Summary-based Methods
Summary-based methods also aim at searching over a reduced-size graph but without relying on the existence of a data schema. The works under this category aim at retrieving trees (Dalvi et al., 2008; Zhong & Liu, 2009), subgraphs (Sinha et al., 2018), or structured queries (Tran et al., 2009).
Dalvi et al. (2008) propose an approach to deal with large graphs that may not fit into memory.
Method. This work represents the graph in a hybrid manner (multi-granular) and aims at retrieving minimal rooted directed trees: (1) an in-memory summary graph, where nodes are clustered to create supernodes, and (2) a disk-resident part that contains the nodes appertaining to each cluster, together with their adjacency information.
Furthermore, two alternative algorithms that adapt existing exploration algorithms are suggested to work over multigranular graphs, with the goal of reducing input output calls.
Ranking. The same importance-based ranking as in Kacholia et al. (2005) was used.
Evaluation. The authors implemented their approaches by extending BANKS. DBLP (8 queries) and IMDb (4 queries) were used as evaluation datasets and compared different configurations of the proposed algorithm with a schema-based approach (the Sparse algorithm; (Hristidis et al., 2003)) with respect to the execution time, recall, and cache misses per query.
Zhong and Liu (2009) concentrate on improving the efficiency for complex queries where the keywords have a lot of matching nodes in the graph (frontier).
Method. This paper proposes a solution to reduce the frontier that aims at performing search only on parts where actually the candidate answers are more likely to reside. The rationale behind their approach is the fact that if we have multiple matching nodes for each keyword, only a few of the different keyword nodes will be tightly related to each other. A graph index that maps keywords to a set of subgraphs from the whole graph is used, together with additional indexes such as keyword-vertex and vertex-subgraph indexes. While creating the subgraph index, a bound for the size of the extracted subgraphs is set. In this way, answering a query would mean searching only subgraphs that actually contain all keywords. The data graph is considered as undirected and defines possible answers as distinct rooted trees. A so-called composed subgraph search that it performed over a combination of matched subgraphs is used. The graph exploration algorithm is similar to the backward search (Bhalotia et al., 2002).
Ranking. A compactness-based ranking is used with the distance as a ranking factor, and the total score of an answer is defined as the sum of the shortest distances between the root and each keyword node (root-keyword scoring) without scoring the nodes.
Evaluation. This work evaluated effectiveness and efficiency and compared with BLINKS using the DBLP XML datasets with 12 queries. As a metric for calculating effectiveness, the minimum scores and average scores of the top 10, 25, and 50 answers found by the baseline and their approach are compared, which shows comparable results. The analysis of the execution time shows that their method is overall faster compared to the baseline.
Tran et al. (2009) propose another paradigm for keyword search over graphs (RDF).
Method. Instead of presenting the user with the top-
Ranking. The score of an answer subgraph is calculated as the sum of its path scores following the root-keyword scoring while aggregating both edge and node weights. The cost of a path is computed as the aggregation of its element costs. Three different ranking functions are introduced: (1) a compactness-based ranking using the path length that is defined as the number of elements in a path, (2) an importance-based ranking using the popularity of path elements (nodes and edges), where node/edge popularity is given as a function of the number of original instances/edges that were clustered into the corresponding class/edge divided by the number of nodes/edges in the summary graph. The latter is defined in a way that elements with higher popularity should have lower cost and thus contribute to answers with higher scores, and (3) textual-based ranking using the keyword matching score which is incorporated by dividing one of the previously defined cost functions by a matching score that is either ranging between 0 and 1 if the element is corresponding to a keyword or is set to one otherwise.
This should reflect the fact that higher matching scores reduce the path cost. The authors use a matching score (between keywords and labels in the graph) that combines both syntactic and semantic similarity (e.g., WordNet) and recommend TF–IDF in case of labels with a sufficient number of terms.
Evaluation. The approach was evaluated using 30 queries together with information needs for DBLP and nine queries for TAP (KG describing sports, geography, music, and other domains). Twelve participants rated the returned structured queries (query is correct if it matches the information need), and the MRR was used as a metric for the assessment of effectiveness. Results reveal that the textual-based ranking function using keyword matching performed best compared to the other two previously proposed functions. The authors also perform an evaluation of the query processing time, comparing it with other approaches (e.g., Kacholia et al., 2005 and other indexing-based methods) together with an investigation of the impact (on the time) of the number of queries to retrieve, and index performance (also using LUBM). Results show that overall, the proposed approach is faster than the other baselines.
Sinha et al. (2018) propose a method that takes advantage of the user profile information. This is so far the only work that exploits profiles to rank answers.
Method. The proposed approach starts by extracting a structural summary graph from the data that consists of classes, relations between them derived from the relations of corresponding entities, and the union of entity labels. First, keywords are matched to corresponding labels in the graph, and for each possible matching, a minimal subgraph that connects corresponding classes is constructed. For each possible matching, only the smallest connecting subgraph is considered. Subgraphs producing empty results are discarded.
Ranking. The returned subgraphs are ranked based on their similarity with available profile graphs. The latter are either added explicitly or implicitly after a search activity. The similarity is a combination of four metrics: concept similarity, relation similarity, entity property similarity, and entity connection similarity.
Evaluation. The evaluation was conducted using 10 queries for each of the Jamendo 33 (music) and DBpedia 34 datasets. The ground truth was constructed by two users who rated every pattern graph based on its relevance to the result subgraph. The metrics used for evaluation are Kendall-Tau (Agresti, 2010), P@k and Rank-DCG (cf. Section 6). Results reveal a Kendall-Tau above 0.5 and a Rank-DCG above 0.6 for most queries. The average P@5 is at least 0.5 for both datasets. In addition, efficiency experiments show that the system responds in a reasonable time that allows user interaction.
Jiang et al. (2021) propose an index (BiG-Index) to speed up finding answers for keywords over KGs and test the efficiency of some existing works (He et al., 2007; Kargar & An, 2011) using it.
Method. The rationale behind the approach is first to replace the labels of instances with their corresponding generalized ontology labels. Afterwards, this generalized graph version is summarized by merging similar subgraphs into one representative. The last two steps are recursively repeated to build a hierarchy of graphs (indexes). Furthermore, details on how to answer a query using the proposed index are provided. Answer ranking was not addressed.
Evaluation. The performance of some algorithms (BLINKS and r-clique; Kargar & An, 2011) for keyword search over graphs is compared both with and without using the index. The evaluation is performed using both real and synthetic datasets (YAGO3 35 , DBpedia, and IMDb with a total of 18 synthetic queries). Since the methodology requires the usage of an ontology, both DBpedia and IMDb were used with an ontology generated from YAGO3. Results reveal a decrease of the runtime by 50.5% and 29.5% for BLINKS and r-clique, respectively.
Virtual Document-based Methods
Virtual-based methods transform the graph content into text documents and apply techniques for full-text search. In the following existing works, the retrieved answers are either trees (Dosso & Silvello, 2020; Mass & Sagiv, 2016; Zhang et al., 2021) or triples and entities (Kadilierakis et al., 2020).
Mass and Sagiv (2016) propose a virtual document-based method that tries to deal with efficiency by reducing the search space and enhancing effectiveness by using a scoring function that combines both query-dependent and -independent scores.
Method. The method starts by preparing a virtual document representation for the whole graph. For each node, a virtual document is created by concatenating the textual information (title and attributes) of the node itself and its neighbors within a specific distance. First, a two-level node filtering is performed to reduce the search space. Nodes whose virtual document contains every query keyword are ranked based on a specific score, and the top-
Ranking. The ranking used by the selection of nodes and ranking final answers is calculated using a Markov random field model (Metzler & Croft, 2005) by combining query-dependent and -independent features. Those features are functions of the frequency of a query term in a virtual document, the node importance, which is proportional to its degree, and the edge weights that are set to one to favor smaller answers.
Evaluation. The evaluation was performed using Coffman’s benchmark, where the MAP (top-1000) was compared with four other systems (e.g., BANKS). Their approach outperforms all the baselines and shows a good trade-off between effectiveness and efficiency.
Dosso and Silvello (2020) propose an approach based on virtual documents, since the authors claim that this is a promising method in terms of efficiency. As in Mass and Sagiv (2016), the retrieved answer type is minimal tree.
Method. This work introduces Topological Syntactical Aggregator+BM25 (TSA+BM25; Robertson & Zaragoza, 2009) and Topological Syntactical Aggregator+Virtual Documents Pruning (TSA+VDP). TSA is a very first offline phase where the virtual documents are created by clustering triples with related concepts. In practice, it first builds subgraphs having a specific distance around single topics (classes) together with their corresponding text documents (literals, IRIs, and predicate strings). Only predicates with a frequency higher than a threshold are taken into account. In the online phase, an initial list of ranked documents relevant to the user query is retrieved. The next step aims at merging overlapping subgraphs corresponding to the top-
Ranking. The initial and second rankings are both textual-based using BM25. The final ranking combines compactness-based and textual-based factors using the Markov random field model that considers unigrams and bigrams within the virtual document and the distance of the words from the root in the graph.
Evaluation. The evaluation was conducted using real (LinkedMDB and IMDb with 100 queries, and DBpedia-Entity v1 (Balog & Neumayer, 2013) with 50 queries) and synthetic databases (LUBM with 14 queries and BSBM (Bizer & Schultz, 2009) with 13 queries). Only one best answer is considered as ground-truth answer. The latter is the result of a manually created SPARQL query corresponding to the keywords. The authors propose a new definition of precision, recall, and the DCG based on a new metric signal-to-noise ratio that gives a score to a returned graph based on the intersection of its triples and the ones from the ground truth. Their approach is compared with other three (Elbassuoni & Blanco, 2011; Le et al., 2014; Mass & Sagiv, 2016) virtual-document based baselines, using average tp-DCG (cf. Section 6), recall, P@1, P@5, and runtime over all queries. Overall, TSA-based systems outperform the baselines, but all in general have low precision. Considering the online runtime, the proposed approach was among the fastest systems.
Kadilierakis et al. (2020) aim at adapting an existing information retrieval system (Elasticsearch 36 ) and thereby use traditional document indexing and retrieval instead of traversing the underlying graph (Dosso & Silvello, 2020) or generating structured queries.
Method. The textual content of a triple is considered as a virtual document that is indexed and retrieved. Two index versions are evaluated depending on the extent of the stored textual content: (1) a baseline index stores only textual content of the considered triple, for example, text of the URI, and (2) an extended index considering also information on other properties of the triple’s resources, for example, rdfs:label.
Ranking. The authors use the textual-based ranking functions provided by Elasticsearch to rank triples and derive a ranking for the entities involved in a triple using the DCG formula.
Evaluation. The DBpedia-Entity v2 was used as a test collection using the nDCG@100 and nDCG@10 as metrics. Its goal is to test the influence of different configurations of Elasticsearch (e.g., query type) together with the index content on the effectiveness of the search. Their system (Elas4RDF) was compared to the unsupervised methods tested in the context of DBpedia-Entity v2 and reached comparable results when used with the extended index and the BM25 ranking. The average query time was also reported:
Zhang et al. (2021) propose a pipeline consisting of an offline and online stage. The key contribution is the usage of community detection techniques to create a group of entities (subgraphs) belonging to the same topic (e.g., computer security in DBpedia). This is used as an index to accelerate answer retrieval.
Method. During the offline phase, the two indexes are created: (1) the entity index is built by transforming each entity together with its data properties into a virtual document whose terms are indexed, and (2) the community index, which maps each entity to its community of entities.
The online phase starts with mapping query keywords to candidate entities using the entity index. For each entity, the common community containing all entities is constructed, which is, in the end, a subgraph of the whole RDF entity graph. Finally, a ranked list of trees connecting all keywords (Steiner tree) is computed. No further details are given on the tree’s construction algorithm or the specific structural compactness-based ranking.
Evaluation. Three aspects were compared with an index-based system (EASE) using five queries for each dataset (DBLP and KMap 37 ): index building (time and storage), runtime, and effectiveness. The latter is based on answer completeness with respect to the relations connecting keywords using the answer of a method that directly works over the whole graph (not index-based) as a baseline. Both systems have comparable results.
Conclusion and Future Directions
In this survey, we have systematically selected, classified, and provided an overview of 35 research papers. We have derived four overall aspects for classifying related works: (1) search space, (2) answer type, (3) answer ranking, and (4) answer scoring. Each of those aspects is further specified by defining different possible aspect types (e.g., compactness-based answer ranking). In the following, we highlight some potential directions for future research using a structure that is based on the typical components of a system for keyword search over graph-shaped data.
Keyword Mapping
Answer Retrieval
Answer Ranking
Answer Presentation
Existing works usually focus on proposing functioning systems aiming at increasing efficiency and effectiveness. However, one aspect is not sufficiently studied, namely, finding new and suitable ways to present the results to the end user and improve the browsing experience.
Evaluating Search Performance
As already mentioned in Section 6, only a few systems were evaluated using existing test collections. On the other hand, we also notice a lack of standardized benchmarks dedicated to keyword search over KGs (Feddoul et al., 2023; only three 38 ). Two of them should be adapted before usage since they were originally created to serve other tasks (question answering) or to work with other data formats (relational databases). Future research can focus on developing established evaluation datasets for keyword search over KGs.
Other Specific Cases
The literature review also revealed the existence of some additional niche areas with very few contributions 39 , namely probabilistic/uncertain graphs, distributed graphs, incomplete graphs, or temporal graph. Future research can further investigate the application of keyword search over the previously mentioned special graphs.
Footnotes
Acknowledgements
We thank all members and partners of the involved projects: simpLEX, Canarėno, and KollOM-Fit. We would further like to thank Birgitta König-Ries for the guidance and feedback.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work has been funded by the German Federal Ministry of the Interior and Community and the Thuringian Ministry of Finance.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.