
Abstract
Ontology matching approaches commonly leverage similarity metrics to establish mappings between entities in the ontologies participating in the process. However, the lack of standardized entity names across these ontologies can cause such metrics to overlook correct mappings. Generally, existing approaches that focus on standardizing entity names neglect the ongoing matching process, leading to inaccurate results, and fail to address the syntactic standardization of entity names. To address these issues, we introduce a novel process that standardizes entity names both lexically and syntactically through a customized lexical analyzer tailored to the ontologies participating in the process. We evaluate this process efficacy using
Introduction
An ontology is a formal and explicit artifact that represents a shared conceptualization of a particular domain, structurally consisting of a collection of interconnected entities, including concepts (also referred to as classes), attributes of concepts, and relationships between concepts. One advantage of using ontologies is that they enhance communication not only among humans but also among application systems, thereby fostering interoperability. However, with the recent and rapid advancements in semantic technologies and the web, multiple ontologies for the same domain have emerged, each using different entities to refer to the same real-world objects. This proliferation of ontologies can lead to communication issues among individuals or application systems that utilize these different ontologies.
Ontology matching involves finding the optimal set of correspondences (mappings) between entities in different ontologies (Euzenat & Shvaiko, 2013). A mapping asserts a semantic relationship between ontology entities, such as disjunction, subsumption, or equivalence. An ontology matching system is responsible for identifying the mappings to be included in the alignment from among all possible options.
One approach to ontology matching is the interactive method, which involves domain experts and can yield better results compared to fully automatic approaches (Paulheim et al., 2013). In some interactive approaches, domain experts provide feedback on selected mappings, determining which should be accepted or rejected. This feedback leverages their expertise to refine the alignment, with a crucial step being the selection of mappings that will receive expert input.
Many ontology matching tools use similarity metrics to select mappings, which are either directly included in the final alignment or presented to experts in interactive systems. Many of these tools incorporate a preprocessing step to standardize entity names before calculating similarity, as the lack of standardization can result in lower similarity values and cause the tool to miss some correct mappings. This preprocessing involves adjustments such as converting characters to lowercase, splitting compound words, removing underscores, etc. (see Section 2).
However, these tools generally do not consider the ongoing matching process during standardization, which can lead to incorrect similarity metric values. For instance, a tool might use a preprocessing technique that removes all symbols except letters and numbers from entity names. As a result, the entity name “head/neck’’ would be transformed into “head neck.’’ When compared to “Head and Neck’’ in another ontology, this would yield a similarity value lower than the maximum if the metric assigns the highest value only to identical strings. If prior studies had revealed that the slash denotes “and,” the preprocessing could be adjusted to convert “head/neck’’ to “head and neck.’’ With all letters converted to lowercase, the comparison would then be between “head and neck’’ and “head and neck,’’ achieving the maximum similarity value and increasing the likelihood that the tool would select this mapping. Conversely, without this adjustment, the tool’s probability of discarding the mapping increases.
An aspect often neglected by these tools is the syntactic standardization of entity names, which enables the application of techniques that would otherwise be hindered. A syntactic analyzer relies on a specific grammar, a formalism developed to describe syntactically well-formed structures in a given language. We propose a grammar to describe well-formed entity names. This grammar incorporates characteristics that improve the use of similarity metrics.
Thus, we aim for two types of entity name standardization. The first focuses on standardizing the spelling of words and symbols in the entity names, which we will refer to as lexical standardization. The second focuses on ensuring that the entity names in both ontologies follow the same grammar, which we will refer to as syntactic standardization. Typically, development teams that produce these tools incorporate lexical standardization directly into the code. Our proposal aims to incorporate both lexical and syntactic standardization into lexical analyzers. We propose creating a lexical analyzer for each ontology considering the ongoing matching process. Since we do not include these lexical analyzers in the code, it is possible for other ontology matching tools to reuse them to match the same ontologies. To evaluate the benefits of our proposal, we use the ontology matching systems
The hypothesis we aim to verify in this paper is that standardizing entity names both lexically and syntactically according to the proposed grammar, while considering the involved ontologies, improves the effectiveness of similarity metrics in the ontology matching process.
The contribution of this work is the proposal of a process for developing lexical analyzers to standardize entity names. This standardization will be performed lexically and syntactically, according to the proposed grammar, while considering the ongoing matching process.
The remainder of this paper is organized as follows. Section 2 presents related work. Section 3 explains the process of creating lexical analyzers and discusses related concepts. Section 4 details the ontologies used to test our hypothesis and the tools employed,
Related Work
In this section, we review works related to our study, specifically ontology matching approaches that address the issue of entity name standardization within ontologies. Many approaches tackle this problem through a preprocessing step that modifies entity names to achieve standardization, thereby facilitating better comparison between entities.
Several approaches employ techniques for standardizing entity names, including:
In Table 1, we present the standardization techniques used by various approaches, providing the tool name if the approach is associated with one, or the title of the paper in quotes if it is not. It is important to note that only documented techniques are listed, meaning that additional techniques are missing if not explicitly documented. We implemented all the standardization techniques discussed in this section in
Standardization Technique by Tool/Approach.

Standardization Technique by Tool/Approach.
Preliminaries
In this subsection, we will explain several concepts related to the lexical analyzer creation process.
Standardization Technique
It is a technique employed by ontology matching approaches to standardize entity names.
Examples of such techniques include those discussed in Section 2 such as Normalization by uppercase or lowercase, Stemming, and others.
To understand the lexical analyzer creation process, it is crucial to note that it will generate multiple versions of the lexical analyzer. Each new version will incorporate all the standardization techniques (Definition 3.1) from the previous version, along with possibly additional techniques.
Regular Expression and Lexical Analyzer
Lexeme, token and word
A lexeme is a sequence of characters in the source string that match a token pattern. A token is a category into which the lexical analyzer classifies lexemes. We will refer to lexemes that are English words as “words.’’
Regular expression
A regular expression (abbreviated as regex) is a sequence of characters used to specify a matching pattern in text.
A regex can be associated with a token and any set of characters matching its pattern can be categorized under that token. For example, the regular expression
Lexical analyzer
A lexical analyzer is a group of regular expressions, each associated with an action.
An action can be associated with a matched regex to return a variation of the name that triggered it. If a non-standard entity name appears, we can modify the lexical analyzer to recognize the name and return a standardized version based on a standardization technique. We used this feature to generate standardized names in the two ontologies involved in the matching process.
Lexical analyzer generator and lexer
A lexical analyzer generator takes a lexical analyzer as input and produces a source code (lexer) to read a string, match it against the regexes and execute the associated actions.
Lexers typically serve as the initial front-end phase in compilers, matching keywords, comments, operators, and other elements, generating a stream of tokens for the syntactic analyzer. Another feature of lexers is their ability to list all strings that do not match a regex included in them. We will utilize this list to develop subsequent versions of the lexical analyzers.
To utilize lexical analyzers in the ontology matching systems, we generated lexers as Java classes using a lexical analyzer generator provided by JFlex and compiled them with the systems. Whenever we refer to executing the lexical analyzers in the remainder of this text, we refer to the execution of the compiled lexers.
Existing tokens in the lexical analyzer
Our lexical analyzers will categorize the lexemes into three tokens:
Noun or modifier—Lexemes composed solely of letters, with the first letter possibly being uppercase; Numeral—Lexemes composed only by numbers; Preposition—Lexemes that are an English preposition, such as “of,’’ “for,’’ “at,’’ etc.
It is important to note that some entity names may contain substrings that do not conform to any of the three tokens mentioned above. For example, hyphenated words may not fit into any of these categories. We defined these tokens for the first version of the lexical analyzers and may insert new lexemes as instances of a token in future versions. For example, in the future, the “noun or modifier’’ token might accept hyphenated lexemes. When an entity name contains a lexeme that does not match any token, it appears in a listing generated by the lexical analyzer.
Take the following entity name as an example: 3rd ventricle choroid plexus. Although it contains four words, when the lexical analyzer, implementing the three tokens (Definition 3.6), processes this string, it does not output exactly these four words. Instead, it generates five strings: 3, rd, ventricle, choroid, and plexus.
According to our definition, a noun or modifier consists only of letters. Therefore, the lexical analyzer outputs the last four strings, while the first is returned based on the numeral definition.
The tokens passed to the syntactic analyzer will be (numeral, noun or modifier, noun or modifier, noun or modifier, noun or modifier). The five generated strings—3, rd, ventricle, choroid, and plexus—are lexemes. It is important to note that a lexeme may not always correspond directly to a single word, as in the case of “3rd,’’ which resulted in two distinct lexemes. Thus, the lexical analyzer categorizes lexemes, not necessarily words, into the three defined tokens.
One of the goals of the final version of the implemented lexical analyzers is to ensure that each lexeme corresponds to a single word.
Noun Phrase
A noun phrase (Spasić et al., 2018) is a phrase made up of a head noun that can be modified with words before it (pre-modifiers), such as adjectives and nouns, or after it (post-modifiers).
Examples of noun phrases with pre-modifiers:
academic language (adjective + noun) email address (noun + noun)
Examples of noun phrases with post-modifiers:
articles by leading academics (noun + prepositional phrase)
Considering only the noun phrases without a preposition, the head noun is the last word. However, in cases where a preposition is present, the head noun is the word immediately before the preposition.
A concept is a mental category that helps us organize objects, and within a domain a term is typically associated with a concept.
For example, in a classroom, the category of objects used for sitting is associated with the term “chair.’’ Terms refer to the same concept in a domain if they refer to the same objects. We can say that entity names are terms.
Term Variation
Two terms are variations of the same term in a domain when both refer to the same concept.
One way to obtain a variation of a term is by replacing an adjective with a modifier noun, a process known as derivation. For instance, “enzymatic activity’’ can be varied to “enzyme activity.’’ We find some of these variations in human and mouse ontologies. Another method of obtaining term variations is permutation, which occurs when a term contains prepositions. For example, “activity of enzyme’’ can be varied to “enzyme activity.’’
Syntax
Syntax addresses how words are arranged to form phrases, clauses, and sentences.
For example, consider that terms used as entity names in an ontology are composed of noun phrases, and their words can be classified into three tokens as outlined in Definition 3.6: noun or modifier, preposition, or numeral. Furthermore, the entity name has to begin with a noun or modifier. However, only a noun or modifier can follow a preposition, and only a preposition or a noun or modifier can follow a numeral. Consequently, a term with two consecutive numeral words would not conform to this syntax. Similarly, a term that begins with a numeral or a preposition or includes symbols not classified as one of the three tokens, such as a comma, would also be non-compliant with this syntax.
In Definition 3.11, we provide a context-free grammar for the syntax described above.
Target Grammar
Where “S’’ is the initial symbol, “q’’ represents a noun or modifier, “n’’ represents a numeral, “p’’ represents a preposition , we refer to the following context-free grammar:



Syntactic analyzer is a program that processes the sequence of tokens generated by the lexical analyzer. Its main job is to verify that the token sequence adheres to the syntax defined by a given grammar.
We have developed a syntactic analyzer specifically for the Target Grammar. Our syntactic analyzer receives a sequence of tokens from the lexical analyzer and checks whether it conforms to the syntax defined in the Target Grammar. For example, if the lexical analyzer passes the sequence “n p q q’’ to the syntactic analyzer, this sequence does not conform to the syntax. According to the Target Grammar, the first token should be “q,’’ representing a noun or modifier.
We can associate an action with a grammar rule. We used this feature to identify the head noun and create variations of the entity name.
We will use the final version of each lexical analyzer to ensure that all entity names in the ontologies comply with the syntax defined by the Target Grammar. An entity name that conforms to this syntax offers the following advantages:
We can identify the head noun of an entity name, which will always be a “noun or modifier’’—typically the last word of the entity name unless the last word is a “numeral.’’ If there are prepositions in the entity name, the head noun may not be the last word, but we can determine it using the “preposition’’ classification. Knowing the head noun facilitates the implementation of useful strategies for finding mappings (Spasić et al., 2018), and we leverage this knowledge in the We can generate variations of the entity name in two types, as defined in Definition 3.9:
One type of variation involves replacing adjectives in the entity name with nouns. To do this, we search for words classified as “noun or modifier’’ that are not the head noun and then query these words in WordNet. If WordNet classifies a word as an adjective, we retrieve all associated nouns and generate the variations. Another type of variation is permutation, which requires identifying the words in the entity name that are prepositions.
We utilize variations to improve string-based metrics and the head noun in the
The syntactic analyzer generates a list of all entities with syntactically incorrect names (Definition 3.14). We use this information to improve subsequent versions of the lexical analyzers by modifying syntactically incorrect names to ensure that they conform to the Target Grammar.
An entity has a standardized name when the lexical analyzer recognizes all characters in its name as part of lexemes, all of which can be classified into one of the three tokens defined in Definition 3.6.
An entity with a non-standard name includes at least one character, such as punctuation or special characters, that cannot be included in a lexeme. These and other characters may be incorporated into lexemes in subsequent versions of the lexical analyzer.
Entity with syntactically correct name
It is an entity with a standard name (Definition 3.13) whose name adheres to the Target Grammar (Definition 3.11).
An entity with a non-syntactically correct name is one that either has a non-standard name or whose name does not adhere to the Target Grammar. For example, this occurs when the lexical analyzer classifies the first lexeme of an entity name as a numeral.
Rejected entity
It is an entity flagged as invalid for comparison by the lexical analyzer. When this occurs, the entity is no longer considered part of those eligible for inclusion in a mapping in the alignment.
An entity can be rejected by the lexical analyzer when it is an entity with a non-standard or a non-syntactically correct name. It must also meet one of the following conditions:
The entity name has a synonym defined within the ontology, one that is syntactically correct. We can use it to search for a mapping instead of the original name; We cannot standardize its name, or we can, and it still shows no similarity to any name in the other ontology.
Another approach for handling entities with non-standard or non-syntactically correct names is to standardize their names.
An entity whose name is standardized using a standardization technique to unify its spelling.
When the lexical analyzer standardizes an entity name, it must unify the spelling of the modified words, considering both ontologies.
Suppose we want to implement a technique to remove non-alphanumeric characters. One of the non-alphanumeric characters in the entity names contained in the list of non-standardized entity names from the last version of the lexical analyzers is the hyphen. After analyzing the entity names with hyphens in both ontologies, we determined that standardizing entity names with hyphens is preferable to removing the hyphens. For example, if one ontology includes the names “hindlimb bone’’ and “hind limb connective tissue,’’ while the other has “hind-limb joint,’’ it would be beneficial to retain the hyphen consistently. Therefore, we could modify the entity names to “hind-limb bone,’’ “hind-limb connective tissue,’ and “hind-limb joint,’’ thereby unifying the spelling across both ontologies.
The lexical analyzer writer should incorporate “hind-limb’’ as a valid word for the “noun or modifier’’ token into the lexical analyzers so that, in subsequent executions, the analyzers recognize entities whose names contain this word as having a standard name (Definition 3.13). These entities should no longer appear on the list of entities with non-standard names of the lexical analyzers.
The process of creating a lexical analyzer is as follows:
Choose a standardization technique. In the first iteration of the lexical analyzer, the "Separation of the words" technique will be implemented. Select the entity names to be standardized by the selected technique. This step is only necessary after the first iteration. The selection of entity names can be based on the list of entities with non-standard names generated by the lexical analyzer. If the chosen technique is expected to affect entities with standard names, run also a dedicated program to identify such names. For example, we developed a program to list stop words.
Create a new version of the lexical analyzer
Run the lexical and syntactic analyzers on the ontologies and list the entities with non-standard names. This list may assist in selecting the next standardization technique and in identifying which entity names should be standardized. If any standardization technique remains unimplemented, return to step 1.
An example of this process can be found in Appendix A, where we detail the construction of the lexical analyzers for the mouse and human ontologies.
With the proposal to develop lexical analyzers for ontologies in ontology matching, a new role emerges: the lexical analyzer writer.
Among the tasks of the lexical analyzer writer are:
Developing various versions of the lexical analyzer; Running each version of the lexical analyzer and generating a list of non-standard entity names for that version; Occasionally, creating programs to assist in identifying and handling entity names from the ontologies to standardize them; Evaluating how to implement a standardization technique in the next version of the lexical analyzer based on the list of non-standard entity names from the current versions of both ontologies and the outputs of the programs he developed.
As lexical analyzer writers, we developed several programs to help in constructing the lexical analyzer. These programs can:
Generate a list of words from the ontologies, illustrating how each ontology handles specific constructions in entity names, such as possessive case, the use of “and’’ and “or,’’ and others; Automatically generate lines for the lexical analyzer, as we did in the sub-activity “standardize hyphenation’’ in subsection A.1.4.
Although the consideration of another professional to the process may increase complexity, this inclusion is justified given the following reasons:
The work of the lexical analyzer writer will save effort for another professional, the system developer, as systems include entity name standardization in their code. Lexical analyzers can handle entity name standardization rather than system developers. He can do this initially without considering an ontology matching. Subsequently, for each pair of ontologies in an ontology matching, the original lexical analyzers can be adjusted to account for the specific ontologies involved; Using the techniques described in this article, the lexical analyzer writer does not need to be familiar with the specific domain of the ontologies. That makes them a person who can be employed across multiple matching tasks; Once we identify the ontologies, there is a time required to find domain experts, train them on the tool, and have them available to perform the alignment. During this period, the lexical analyzer writer can focus on developing the lexical analyzers. From our experience, the lexical analyzer complexity increases with the size of the ontology and the number of non-standard entity names it contains. For the human ontology (For further information regarding the ontologies, refer to subsections 4.1.1 and 4.1.2), it took us four days to develop the lexical analyzer and supporting programs. In contrast, for the mouse ontology, smaller and with fewer non-standard entity names, we completed the work in one day, leveraging the programs previously developed for the human ontology. There are seven ontologies in the Conference track, each matched with all the others, resulting in 21 possible alignments. Although we initially planned to create one lexical analyzer for each ontology in each match, we developed one for each ontology that could handle all its matches. As a result, we developed seven lexical analyzers, which are significantly smaller than those required for the human and mouse ontologies. We complete the lexical analyzers in about one day; We can reuse the lexical analyzers in any other matching system that performs the matching for which the lexical analyzer writer created them; Most importantly, we improve the matching results by using lexical standardization—considering the ongoing matching process—and syntactic standardization, performed by the lexical analyzer writer, as discussed in Subsection 4.7.1.
Acting as lexical analyzer writers, we utilized ChatGPT to standardize entity names containing abbreviations and acronyms. During the development of the lexical analyzer, we encountered situations where neither the ontologies nor external sources (WordNet and FMA) provided information on entity names with acronyms that could relate one entity to another from a different ontology. For example, with the name “hippocampus CA1’’ from the mouse ontology, we were unable to find the expansion of CA1 in either the ontologies or external sources. However, searching for this acronym in human ontology, we found the term “CA1_Field_of_the_Cornu_Ammonis.’’ Since we did not have clues from the available resources to determine whether these referred to the same entity, we consulted ChatGPT, which confirmed that they were synonyms. This allowed us to unify the names of the two entities, resulting in a successful mapping in the final alignment.
ChatGPT 2 is a software that generates human-like text based on the input it receives. It can utilize various large language models (LLMs), including GPT-3.5, GPT-4, and others. To standardize entity names containing abbreviations and acronyms, the GPT-4 model was used.
One of its key features is the ability to identify and suggest synonyms for terms, improving clarity and variety in writing. To determine synonyms, ChatGPT analyzes context and can recognize variations of a term, such as different grammatical forms, word inflections, abbreviations, domain-specific jargon, or regional preferences. With this feature, a reasonable question is the following: Does ChatGPT make the standardization of entity names unnecessary? We will attempt to answer this question in Subsection 4.6.
Experimental Evaluation
At the beginning of this section, we will discuss preliminary concepts, such as the OAEI tracks and the
Next, we will present several experiments:
In the first experiment, we will demonstrate the impact of incorporating standardization techniques into each version of the lexical analyzer; Then, using ALIN, we will show how lexical and syntactic standardization affect the quality of the generated alignment; In the next study, we will explore the influence of lexical standardization on ChatGPT’s responses regarding the search for mappings; Finally, we will investigate whether it is possible to use lexical analyzers created for ALIN in another tool, AML. We will examine the impact of this usage on the quality of the generated alignment.
The Ontology Alignment Evaluation Initiative (OAEI) is a coordinated international effort to assess the strengths and weaknesses of ontology matching systems. As part of this initiative, the OAEI Interactive Matching Track (Pour et al., 2024) provides two data sets—Conference and Anatomy—used in our evaluations.
Conference Track
The Conference track (also known as the Conference dataset) includes 16 ontologies from the conference organization domain, created by real companies to model their systems. This dataset consists of moderate-sized, real-world ontologies, making it well-suited for ontology matching tasks because of its diverse origins. Since different individuals developed these ontologies, the same concepts are often labeled differently, contributing to their heterogeneous nature.
Among the 16 ontologies, 21 reference alignments are present for pairs of 7 of these ontologies, listed in Table 2. We used these seven ontologies for our tests, focusing on mappings between entities of the same type (e.g., class-to-class). The total number of possible mappings across the 21 alignments is approximately 125,000, while the reference alignments contain 305 mappings. Over time, this track has become one of the most widely used for matching evaluation.
Number of Classes, Attributes, and Relationships in the Conference Ontologies.
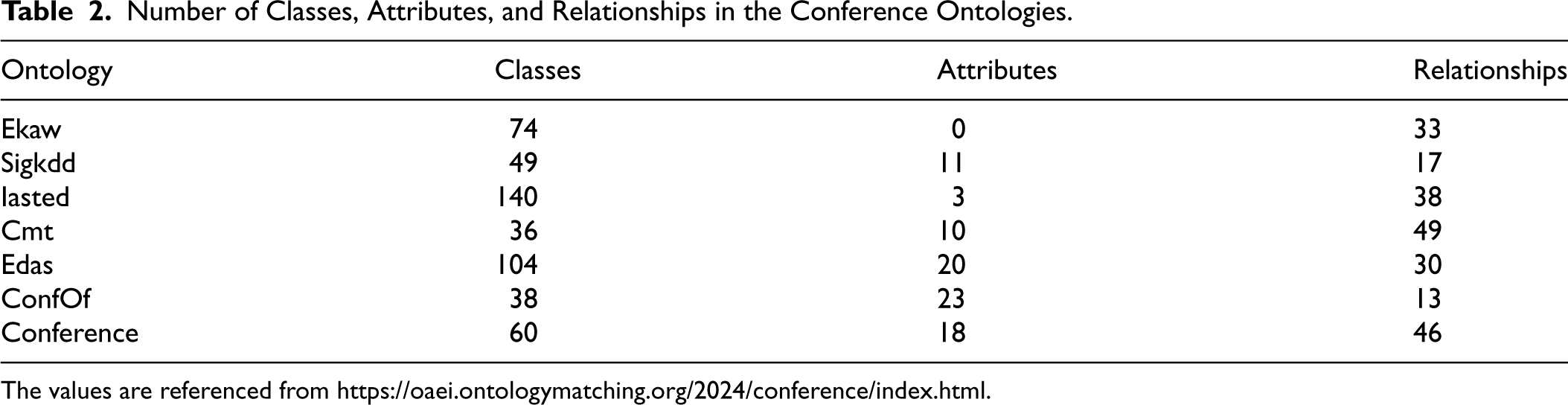
Number of Classes, Attributes, and Relationships in the Conference Ontologies.
The values are referenced from https://oaei.ontologymatching.org/2024/conference/index.html.
A characteristic of the ontologies in this track is the use of short names for classes and attributes, typically consisting of one or two words. Examples of these names include “Person,’’ “Reviewer,’’ “ProgramCommittee,’’ “Committee_member,’’ and “Passive_conference_participant.’’ To calculate the similarity metrics, we consider only the names of the classes and attributes without taking their descriptions into account.
The Anatomy track involves matching an ontology that describes adult mouse anatomy with an ontology from the NCI Thesaurus that details human anatomy. Although there are only two ontologies in the Anatomy track, their combined number of entities is significantly higher than the total number of entities in the seven ontologies with reference alignments in the Conference track. Specifically, the mouse ontology contains 2,738 classes, while the human ontology contains 3,298 classes. Neither ontology includes attributes. The mouse ontology has 3 relationships and the human ontology has 2. The total number of possible mappings between these ontologies is 9,066,176, with 1,516 mappings present in the reference alignment.
A characteristic of this track is the greater complexity of names compared to the Conference track. It is common for class names to consist of more than two words. Examples include: “Inferior Oblique Muscle,’’ “Epithelium of Human Prostate Gland,’’ “Antero-Lateral Ascending Tract,’’ “Distal Phalanx of Foot,’’ “visceral organ system,’’ “glomerular capillary basement membrane,’’ and “glomerular capsule.’’ In this track, we also calculate similarity metrics based solely on the entity names, without considering their descriptions.
Another characteristic of this track is the association of synonyms with entity names in the ontologies, which is more pronounced in the human ontology (6,104 synonyms) compared to the mouse ontology (345 synonyms).
Alin Overview
AML Overview
AgreementMakerLight 3 (AML) is an automated and efficient ontology matching system. It has a flexible and extensible framework and is primarily based on the use of element-level matching techniques supported by background knowledge. AgreementMakerLight has been very successful in the OAEI competition, ranking first in F-measure in several tracks throughout the years including: Anatomy, Conference, Multifarm, Library, Interactive Matching Evaluation, and Large Biomedical Ontologies. AgreementMakerLight has been used by several institutions, including NASA, the Janssen Pharmaceutical Companies of Johnson & Johnson, and in the Global Agricultural Concept Scheme (GACS) from the Food and Agriculture Organization of the United Nations.
Analysis of the Evolution of the Lexical Analyzers in the Anatomy Track from Version to Version
We developed several versions of the lexical analyzer during its construction process, each potentially introducing new standardization techniques. In this subsection, we will examine the impact of incorporating these standardization techniques into the lexical analyzer on the quality of the generated alignment and the number of non-standard entity names.
To illustrate the evolution across versions, we analyzed the lexical analyzers of the Anatomy track ontologies by running
We created Tables (3 and 4) that show the number of entities with non-standard names, syntactically incorrect names, and rejected items. We represented each version of the lexical analyzer by a Roman numeral on the graph. Since the first version, the lexical analyzer for the human ontology has not included any entities with standard but syntactically incorrect names; thus, we omitted these data from Table 3. Additionally, we created Table 5 to show the improvement in alignment quality and the number of expert interactions. Only versions with modifications in the lexical analyzer compared to the previous version are displayed.
Entities With Non-Standard Name and Rejected Entities in Each Version of the Lexical Analyzer of the Human Ontology.
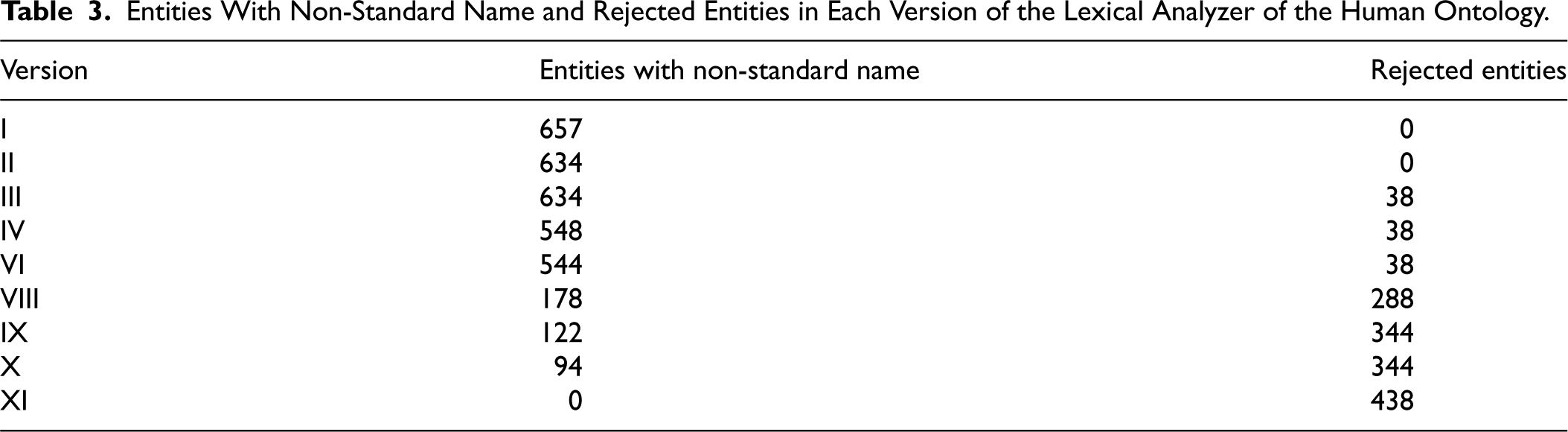
Entities With Non-Standard Name and Rejected Entities in Each Version of the Lexical Analyzer of the Human Ontology.
Entities With Non-Standard or Non-Syntactically Correct Name and Rejected Entities in Each Version of the Lexical Analyzer of the Mouse Ontology.
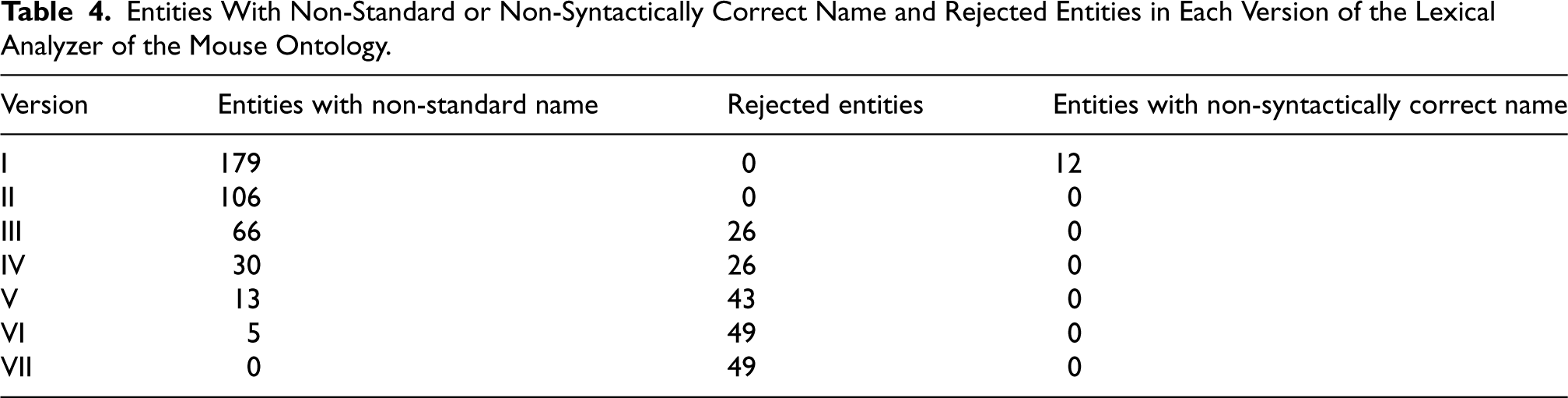
We processed all terms related to classes, attributes, and their synonyms through the lexical analyzers, totaling 9,402 terms from the human ontology (3,298 classes, 0 attributes, and 6,104 synonyms) and 3,083 terms from the mouse ontology (2,738 classes, 0 attributes, and 345 synonyms).
In Table 4 the column “entities with non-syntactically correct names’’ represents the number of entities with standard but non-syntactically correct names, noting that every entity with a non-standard name is also an entity with a non-syntactically correct name.
The tables indicate that in most new versions, the number of entities with non-standard or syntactically incorrect names decreased compared to the previous version, ultimately reaching zero. In Version VII of the mouse ontology, we achieved this reduction to zero by implementing the last standardization technique. In the final version, the lexical analyzer rejected 49 entities in the mouse ontology, representing 1.58% of the total of entity names, while for the human ontology, 438 entities were rejected, accounting for 4.66% of the total of entity names.
The results presented (Table 5) demonstrate that the inclusion of new standardization techniques in lexical analyzers improves the quality of the generated alignment.
Performance of
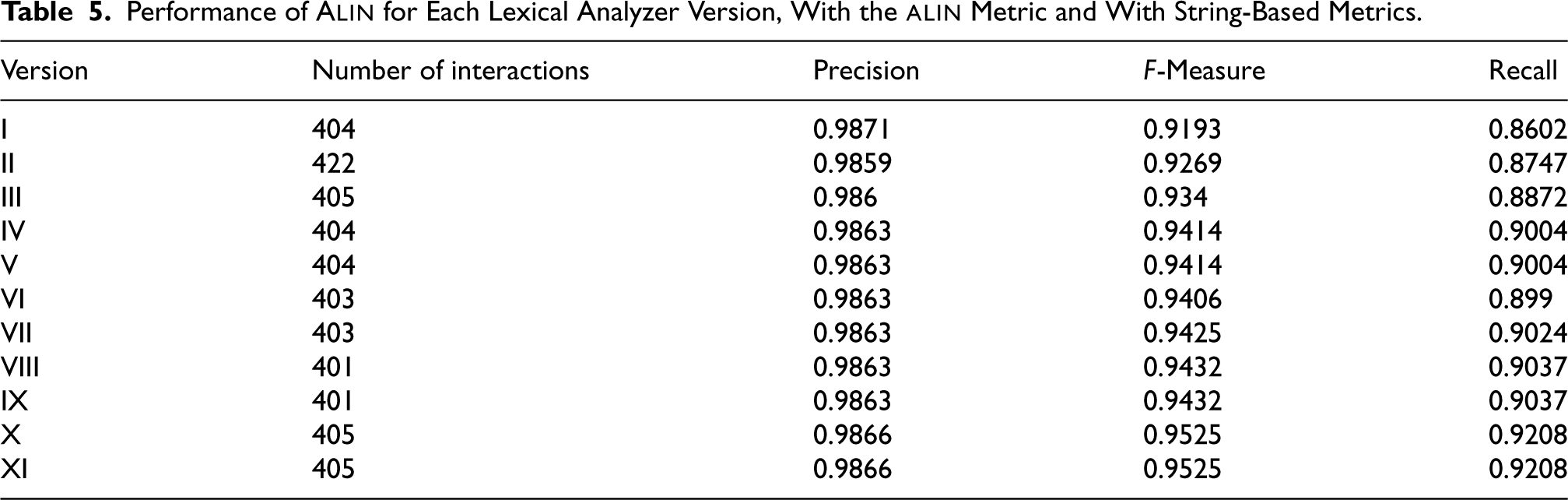
All versions of the lexical analyzers were uploaded to OSF 5 .
To evaluate the lexical analyzers, we followed the same protocol as the OAEI interactive matching track (Pour et al., 2024) in which
In each interaction, up to three selected mappings can be submitted to the expert, as long as each selected mapping has one entity in common with another selected mapping in the interaction (Faria, 2016).
The quality of an alignment generated by a matching approach is typically measured using the F-Measure, the harmonic mean of Recall and Precision. In interactive ontology matching processes, an additional quality metric is the number of interactions with the expert (total requests).
To assess whether lexical standardization considering the other ontology and syntactic standardization considering the Target Grammar improve the use of similarity metrics, we will run
In the first execution, we ran In the second execution, we employed lexical analyzers to implement standardization techniques without considering the other ontology. The techniques included “Separation of the words,” “Conversion of Roman numerals to Arabic numerals,” “Removal of stop words,” “Removal of non-alphanumeric characters or their replacement with white spaces,” and “Removal of punctuation characters.” From this point onward, entity name conversion to uppercase and stemming were applied, but rather than including them in the lexical analyzer, we implemented these processes directly in the code; In the third and subsequent executions, we used the latest version of the lexical analyzers, which took the other ontology into account. In the fourth execution, we ran In the fifth execution, we included the three string-based metrics along with the In the sixth execution, we used the same metrics as in the fifth execution but modified the application of the string-based metrics. Instead of applying the string metric solely to the entity name returned by the lexical analyzer, we incorporated variations and synonyms. For example, consider two entities: the first has two variations and two synonyms, resulting in five associated names, including the original. If we aim to calculate the string metric relative to a second entity with three associated names, this will result in fifteen comparisons.
In the second and third executions, we opted to include in the alignment, without requiring expert approval, all names that became identical after preprocessing, i.e., after applying the lexical analyzers. In the last three executions, we no longer included mappings with identical entity names in the alignment. Instead, we included mappings where entities shared the same concept (Appendix C.3) or where the value of the
We can see the results of these executions in Tables 6 and 7.
Comparison of Various Uses of Lexical Analyzers—Conference.
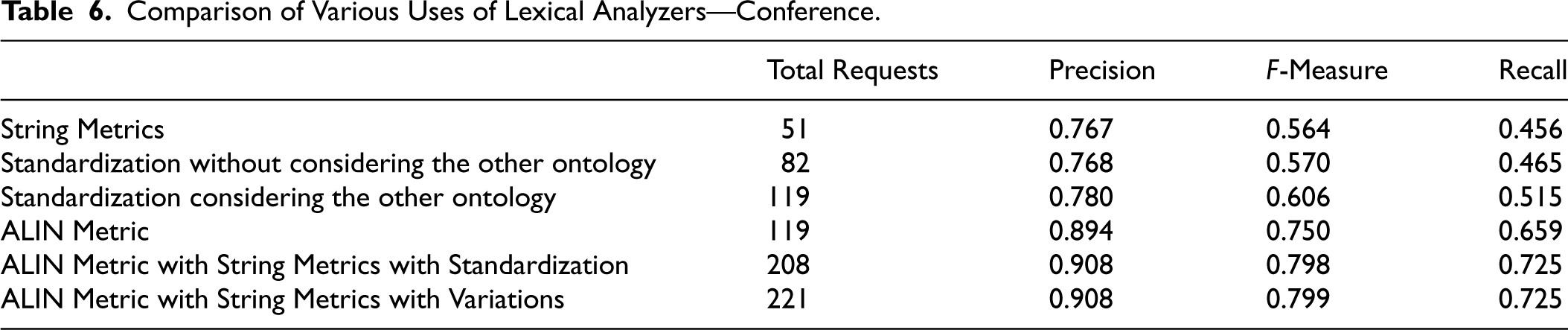
Comparison of Various Uses of Lexical Analyzers—Conference.
Comparison of Various Uses of Lexical Analyzers—Anatomy.
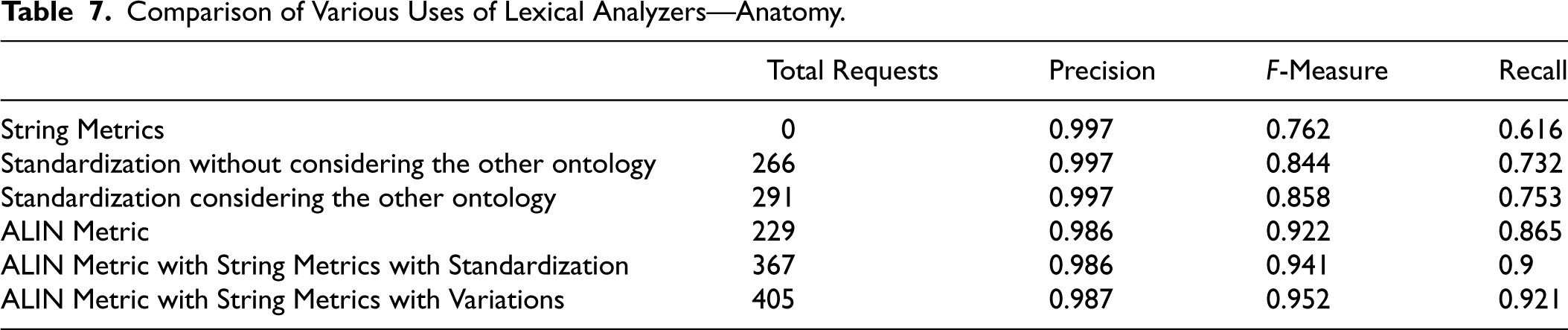
One of the features of ChatGPT is its ability to recognize synonyms, including variations of a term, such as different grammatical forms, word inflections, or abbreviations. Therefore, a reasonable question is: Does ChatGPT make the standardization of entity names unnecessary?
To address this question, we will conduct the following experiment: we will perform ontology matching twice with
Initially, we considered comparing all entity names, but the number of possible combinations is too large—approximately 125,000 on the Conference track and around 9,000,000 on the Anatomy track. That would result in both matchings taking many days to complete and, in the case of the Anatomy track, even several weeks, as accessing ChatGPT through a program is slow. Additionally, ChatGPT, when invoked from within a program, limits the number of similar questions it can process. Once we exceed this threshold, it intermittently does not respond to the questions. Based on our experience, we reached this limit after fewer than 2,000 queries.
We experimented as follows: ChatGPT will evaluate only the mappings selected by
We can see the results in Table 8, which shows that the standardization of entity names improves the quality of the ChatGPT responses.
Ontology Matching Using ChatGPT.

Ontology Matching Using ChatGPT.
To evaluate whether we can utilize the lexical analyzers generated for the Anatomy track in another tool and whether they improve its results, we modified
We integrated the classes related to the two lexical analyzers into the One option in which it does not utilize the standardization techniques already employed by the program; Another option in which it employs its standardization techniques as usual; A third option where, instead of using its standardization techniques, it utilizes the lexical analyzers.
The
We conducted five executions of the AML, characterized by the following features:
One employs only string matching without using the standardization techniques already implemented by the program; Another uses only string matching while employing the standardization techniques it typically utilizes; A third uses only string matching but employs the lexical analyzers; A fourth utilizes all matching techniques of the AML while employing its standardization techniques; A fifth utilizes all matching techniques of the AML but employs the lexical analyzers.
We can see the results in Table 9.
Use of Lexical Analyzers in AML .

Use of Lexical Analyzers in
Our results demonstrate that considering the other ontology during lexical standardization yields better outcomes than disregarding it, as evidenced by the comparison between the results of the third and second executions in Tables 6 and 7, where we can observe that the F-Measure for the Conference track increased from 0.570 to 0.606, while the growth in the Anatomy track was from 0.844 to 0.858.
Syntactic standardization has also proved beneficial. The use of the
Using synonyms and variations in the sixth run resulted in ambiguous outcomes. Although the Conference track showed almost no variation between the sixth and fifth runs, the Anatomy track exhibited a more significant change, with the F-Measure increasing from 0.941 to 0.952. We can attribute this difference to the fact that the Anatomy track ontologies include many synonyms (6,104 in the human ontology and 345 in the mouse ontology), whereas the Conference ontologies contain no synonyms. The Conference track contains entity names with few words, resulting in fewer variations, which also impacts the results.
Table 8 shows us that the standardization of entity names leads to higher quality responses from ChatGPT, which results in improved alignment when using it. We achieved that on both the Conference track (an increase in F-measure from 0.577 to 0.631) and the Anatomy track (an increase in F-measure from 0.772 to 0.824).
The experiment carried out with
Conclusion and Future Work
Many tools lexically standardize entity names before calculating the values of similarity metrics, often overlooking both the ongoing matching process and the syntactic standardization of entity names.
Lexical standardization focuses on standardizing the spelling of words and symbols in entity names. Syntactic standardization focuses on ensuring that the entity names in both ontologies follow the same grammar.
The contribution of this work is the proposal of a process for developing lexical analyzers to standardize entity names. This standardization will be performed lexically and syntactically, according to the proposed grammar, while considering the ongoing matching process.
We evaluated the effectiveness of this standardization by evaluating how the inclusion of ongoing matching and the proposed grammar improves the quality of the generated alignment. For this evaluation, we used the ontology matching systems
The hypothesis we will verify in this paper is that standardizing entity names both lexically and syntactically according to the proposed grammar, while considering the involved ontologies, improves the effectiveness of similarity metrics in the ontology matching process.
To measure the improvement in alignment quality due to lexical standardization, while considering the other ontology, we compared the performance of
To leverage the syntactic standardization of entity names, we developed a new metric, the
The Conference track did not show gain using synonyms and variations in the sixth run, but the Anatomy track exhibited improvement, with the F-Measure increasing from 0.941 to 0.952. Variations of an entity name occur when, for example, we substitute a noun with its corresponding adjective or when we permute its modifiers.
We also compared the response quality of ChatGPT with and without the standardization of entity names, finding that standardization improves ChatGPT’s response quality, with the F-Measure increasing from 0.596 to 0.642 in the Conference track and from 0.772 to 0.824 in the Anatomy track, as illustrated in Table 8.
The experiment carried out with
An area for future exploration is the standardization of entity names not only within ontologies but also across external resources such as WordNet and FMA. Standardizing terms from WordNet and FMA could prove valuable for identifying new mappings, especially in cases where a synonym exists in these external resources but not within the involved ontologies.
Another area of interest is the automation of lexical analyzer construction. We have developed programs that provide information to the lexical analyzer writer. In some cases, these programs directly generate the lines to be included in the lexical analyzer, suggesting that we can further automate this process.
Footnotes
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Kate Revoredo is funded by the Berliner Chancengleichheitsprogramm (BCP) as part of the DiGiTal Graduate Program. Fernanda Baiao is partially funded by FAPERJ (grants 200.514/2023 and 211.308/2019) and CNPq (grants 312059/2022-1 and 422810/2021-5). The article processing charge was funded by the Open Access Publication Fund of Humboldt-Universität zu Berlin.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.