
Abstract
Study Design
Retrospective cohort study.
Objectives
Leveraging electronic health records (EHRs) for spine surgery research is impeded by concerns regarding patient privacy and data ownership. Synthetic data derivatives may help overcome these limitations. This study’s objective was to validate the use of synthetic data for spine surgery research.
Methods
Data came from the EHR from 15 hospitals. Patients that underwent anterior cervical or posterior lumbar fusion (2010-2020) were included. Real data were obtained from the EHR. Synthetic data was generated to simulate the properties of the real data, without maintaining a one-to-one correspondence with real patients. Within each cohort, ability to predict 30-day readmissions and 30-day complications was evaluated using logistic regression and extreme gradient boosting machines (XGBoost).
Results
We identified 9,072 real and 9,088 synthetic cervical fusion patients. Descriptive characteristics were nearly identical between the 2 datasets. When predicting readmission, models built using real and synthetic data both had c-statistics of .69-.71 using logistic regression and XGBoost. Among 12,111 real and 12,126 synthetic lumbar fusion patients, descriptive characteristics were nearly the same for most variables. Using logistic regression and XGBoost to predict readmission, discrimination was similar with models built using real and synthetic data (c-statistics .66-.69). When predicting complications, models derived using real and synthetic data showed similar discrimination in both cohorts. Despite some differences, the most influential predictors were similar in the real and synthetic datasets.
Conclusion
Synthetic data replicate most descriptive and predictive properties of real data, and therefore may expand EHR research in spine surgery.
Keywords
Introduction
Spine surgeons treat a wide variety of complex conditions, creating difficulty identifying the most effective treatments for particular patients. Historically, randomized controlled trials have been considered the gold standard for generating evidence regarding the efficacy of treatment interventions. 1 However, randomized trials are time-consuming, include a small number of all eligible patients, use narrow eligibility criteria, and are typically extremely costly.2-4 In spine surgery populations in particular, trials are also hindered by high rates of nonadherence, where patients do not pursue the treatment assigned, substantially limiting study conclusions.5,6 Collectively, these problems have made randomized trials impractical for studying many pressing spine surgery questions.
Responding in part to the challenges of conducting randomized trials, there has been tremendous growth in spine surgery registries.7-11 These registries have undoubtedly facilitated the development of evidence-based practices and new quality improvement initiatives. Nonetheless, maintaining these registries is costly, and data elements must be manually abstracted, limiting both hospital participation and the breadth of data collection. With at least 98% of hospitals now using an electronic health record (EHR), 12 automated queries of multidimensional clinical, laboratory, imaging, and diagnostic data are increasingly viable alternatives to traditional registries. Yet obtaining EHR data within a healthcare system is often cumbersome, and sharing of EHR data across health systems remains extremely uncommon, particularly because of questions relating to patient privacy and data ownership.13,14
One option for obtaining and sharing detailed health information across health systems is the use of synthetic data derivatives. Moving beyond simple deidentification (e.g., the removal of names and dates of birth), synthetic datasets are novel cohorts derived from the actual EHR but no longer corresponding to real individual patient data. 15 While synthetic data no longer maintain one-to-one correspondence with real patient records, when generated properly, they have the same statistical properties as the original EHR data (e.g., the same distribution of comorbidities and laboratory values). 15 Consequently, in principle, synthetic data platforms have the potential to facilitate acquisition of EHR data and also sharing of multicenter datasets, while avoiding challenges related to patient privacy.
Our institution recently implemented a synthetic data platform developed by MDClone (Be’er Sheva, Israel), which is effective when studying select populations identified based on clinical diagnoses (e.g., sepsis and heart failure).15,16 However, it is unknown whether this synthetic data platform produces valid results for studying spine surgeries, such as spinal fusion surgery. Consequently, the objective of this study was to validate the use of synthetic data in 2 spine fusion populations to evaluate its potential for accurately characterizing spine surgery outcomes.
Methods
Patient Population and Variable Selection
This study used both real data and synthetic data derivates created from the Research Data Core (RDC) at the authors’ institution from the years 2010 to 2021. The RDC is a centralized data repository that includes information from the EHR of 15 hospitals that are part of a single health system. EHR data are periodically downloaded from the EHR to the RDC, ensuring an updated source of research data.
Descriptive statistics of the cervical fusion cohort.
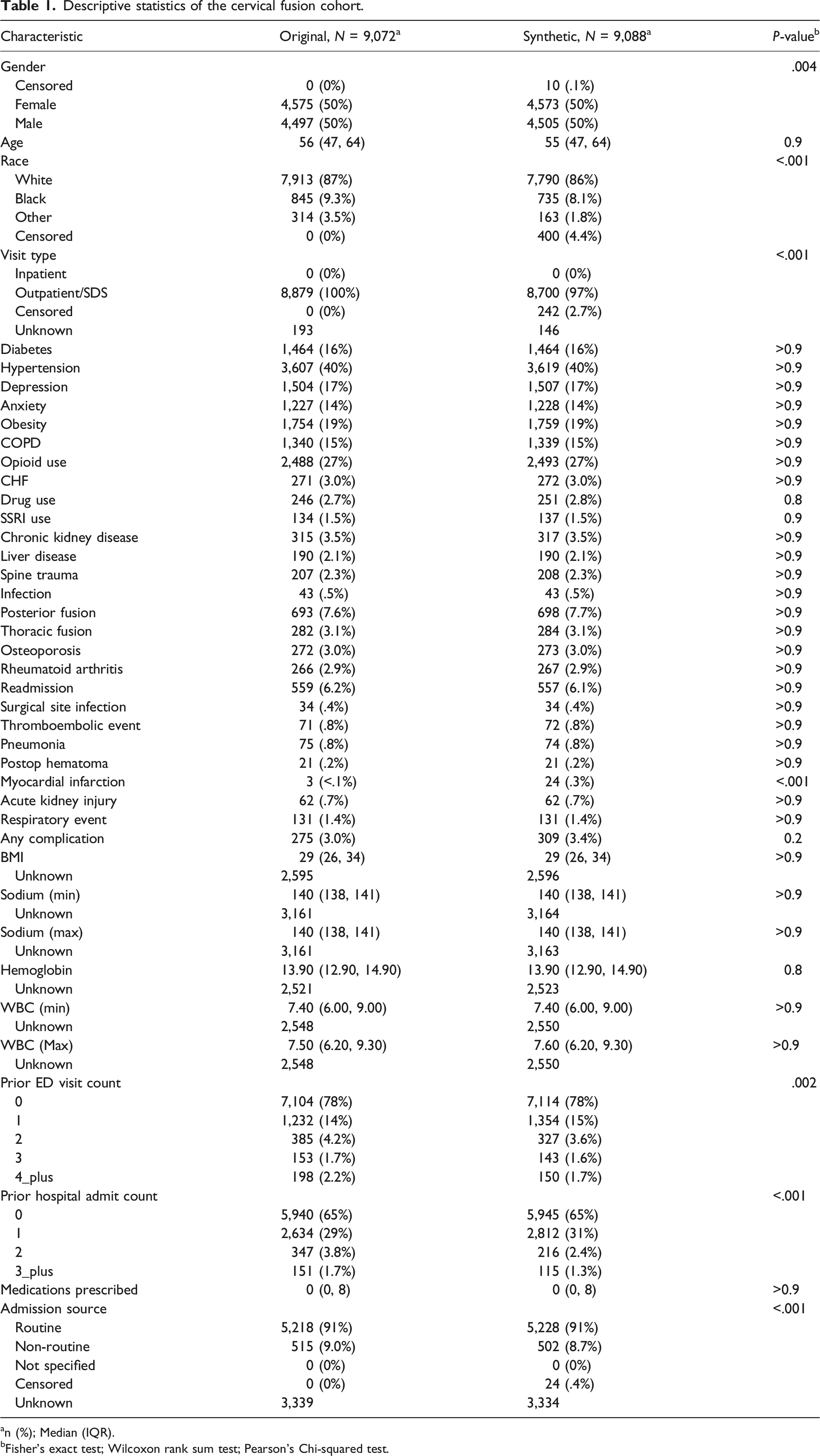
an (%); Median (IQR).
bFisher’s exact test; Wilcoxon rank sum test; Pearson’s Chi-squared test.
For both descriptive and predictive analyses, we evaluated variables related to comorbid diagnoses (e.g., diabetes), relevant laboratory values (e.g., sodium level), body mass index (BMI), medication prescriptions, and demographic characteristics. We also noted the presence of a concomitant posterior/thoracic (cervical cohort) or anterior/thoracic (lumbar cohort) fusion. We chose these variables to be representative of data elements that can typically be captured via structured EHR queries. Comorbid medical diagnoses were evaluated from 1year before until the time of the index procedure. Laboratory values were evaluated from 30 days before until 1day after index surgery. Surgical indications (e.g., myelopathy and spine trauma) were evaluated within 30 days of surgery.
To examine predictive performance, our primary outcome was 30-day readmission to our health system, an increasingly important quality metric. 17 As a secondary outcome, we evaluated postoperative complications within 30days of surgery, including both surgical (e.g., postoperative hematoma) and medical (e.g., pneumonia) events.
Synthetic Data Generation
In essence, synthetic data are new populations of patients created based on real datasets that do not maintain any one-to-one correspondence with the real patients they are intended to mimic. Methods for generating synthetic clinical data can be generally classified as statistical simulation or computational derivation. 15 Statistical simulation methods use real-world, often publicly available, datasets as the basis for generating artificial datasets. Such synthetic data should mimic disease distribution at the population level and maintain the appearance of patient-level data. This approach may be appropriate for broad descriptive analyses (e.g., evaluating trends in surgery rates over time). However, these methods do not account for covariate relationships at the individual patient level (eg, the relationship between individual patient comorbidities and clinically relevant endpoints). 18 Addressing these deficiencies, the MDClone platform is based on the “derivation” approach of synthetic data generation. This method uses computer algorithms to create new synthetic datasets on demand (i.e., in real-time) that are based on real, individual patient EHR data. The new synthetic dataset includes a similar number of patients as the real source dataset and also maintains the distribution and covariance structure of variables in the original data.15,19 In other words, both descriptive characteristics (e.g., demographics and surgical details) and the relationships among the dataset variables (e.g., the relationship between surgical approach and complications) should be maintained. At the same time, patients in the synthetic dataset have no one-to-one correspondence with real patients, thereby preserving anonymity. While the exact algorithm used by MDClone is proprietary, it involves using statistical and artificial intelligence techniques to learn complex relationships among variables in the real dataset and preserve those relationships in the newly created synthetic dataset.
The details of the MDClone platform and workflow have been published previously. 15 Briefly, the real data used by the platform comes from our RDC. The RDC contains multimodal data that includes diagnoses and medical problems, medication prescriptions, surgical procedures, laboratory values, and demographic information across both inpatient and outpatient settings. MDClone includes a “query tool” that searches the data lake to define a reference event for a population of interest (e.g., lumbar fusion in 2019). Other time-related covariates (e.g., comorbid diagnoses prior to surgery) are also defined using the query tool. During this process, MDClone provides an approximation of the size of the target population and the frequency of relevant variables requested in the query (e.g., medication prescriptions). During the last step, MDClone’s “synthetic data generator” transforms real data from the RDC into a synthetic dataset that users can download. An image of the query tool is shown in the appendix (Supplement Appendix E-Figure 1).
MDClone will only create datasets with at least 200 patients, reflecting its definition of a moderately sized population. Additionally, as more detailed information is requested based on rare combinations of categorical variables (e.g., demographic subgroups), the system will “censor” some values to avoid the possibility of identifying individual patients. Because real patient data are not reported, the authors’ institution permits users to generate synthetic datasets based on real EHR data without obtaining institutional review board (IRB) approval.
For this study, we used a single query applied to the MDClone platform to generate a synthetic dataset and then, separately, retrieve the original dataset containing the records of the population from which it was derived.
Statistical Analysis
Descriptive statistics compared variables of interest between the synthetic and real datasets. To evaluate whether proportions and mean values were significantly different between datasets, Chi-Square tests, t-tests, and Mann–Whitney U tests were performed, depending on the distribution of the data. We did not correct for multiple comparison testing to avoid potentially missing meaningful differences between the real and synthetic datasets. Variables with less than 20% missing data were imputed using the missForest package in R. 20 Variables that had 30% or more missing data missing were excluded from the study. Less than 5% of data were censored, and these were excluded from predictive analyses.
To determine the performance of the real and synthetic datasets in a predictive modeling context, we compared 2 multivariable models to predict both 30-day readmission and 30-day complications for each cohort. First, we used multivariable logistic regression. Second, we trained an extreme gradient boosting machine (XGBoost) model, which is a machine learning technique. XGBoost is based on predictions from classification trees, which involve sequential splits in the data based on variables that distinguish patients with vs those without the outcome. To improve model accuracy over a single classification tree, XGBoost combines input from many individual trees. 21 For the logistic regression model, we compared statistically significant variables and variable odds ratios between real and synthetic datasets. For the XGBoost model, we compared the most influential variables. 22 To test predictive performance, we split each dataset into training (70%) and testing (30%) datasets. We developed each predictive model in both the real and synthetic datasets using the “training” (70%) data. Our goal was to evaluate how a predictive model built based on synthetic data would perform when applied to a real dataset. Therefore, we compared the discrimination of each model in the real testing dataset (30%), which had not been used for model development. Discrimination—that is, the ability to distinguish patients that do versus those that do not experience the outcome—was measured using the c-statistic, which represents the area under the receive operating characteristic curve. 23 This study was reviewed by the authors’ IRB and granted exempt status and a waiver of HIPAA authorization. Consequently, patient consent was not required. Statistical analyses were conducted in R version 4.0.1 using base functions along with the xgboost, caret, and iml packages. P < .05 was considered statistically significant.
Results
Cervical Fusion
From 2010-2020, we identified a total of 9,072 real and 9,088 synthetic patients who underwent anterior cervical fusion in our healthcare system. Only the variables for gender (.1%), visit type (2.7%), admission source (.4%), and race (4.4%) included censored data. Comparing the real and synthetic datasets, no continuous variables showed significant differences between datasets. Furthermore, as shown in Figure 1A, the distribution of the data also appeared nearly identical between datasets. Most categorical variables were nearly identical between the real and synthetic datasets. However, there were small but statistically significant differences in race in the real versus synthetic data (9.3% vs 8.1% Black). Likewise, when the number of recent hospital and emergency department (ED) visits was categorized, there were very small but significant differences between the datasets (e.g., 2.2% vs 1.7% with ≥4 recent hospital admissions). Finally, we did note a difference in the rate of myocardial infarction, which was the rarest single variable we evaluated (real <.1% vs synthetic .3%). The descriptive results with P-values are summarized in Table 1. Comparison of cervical (A) and lumbar (B) cohort characteristics in the real and synthetic datasets. Violin plots shows the distribution of the data for select continuous variables.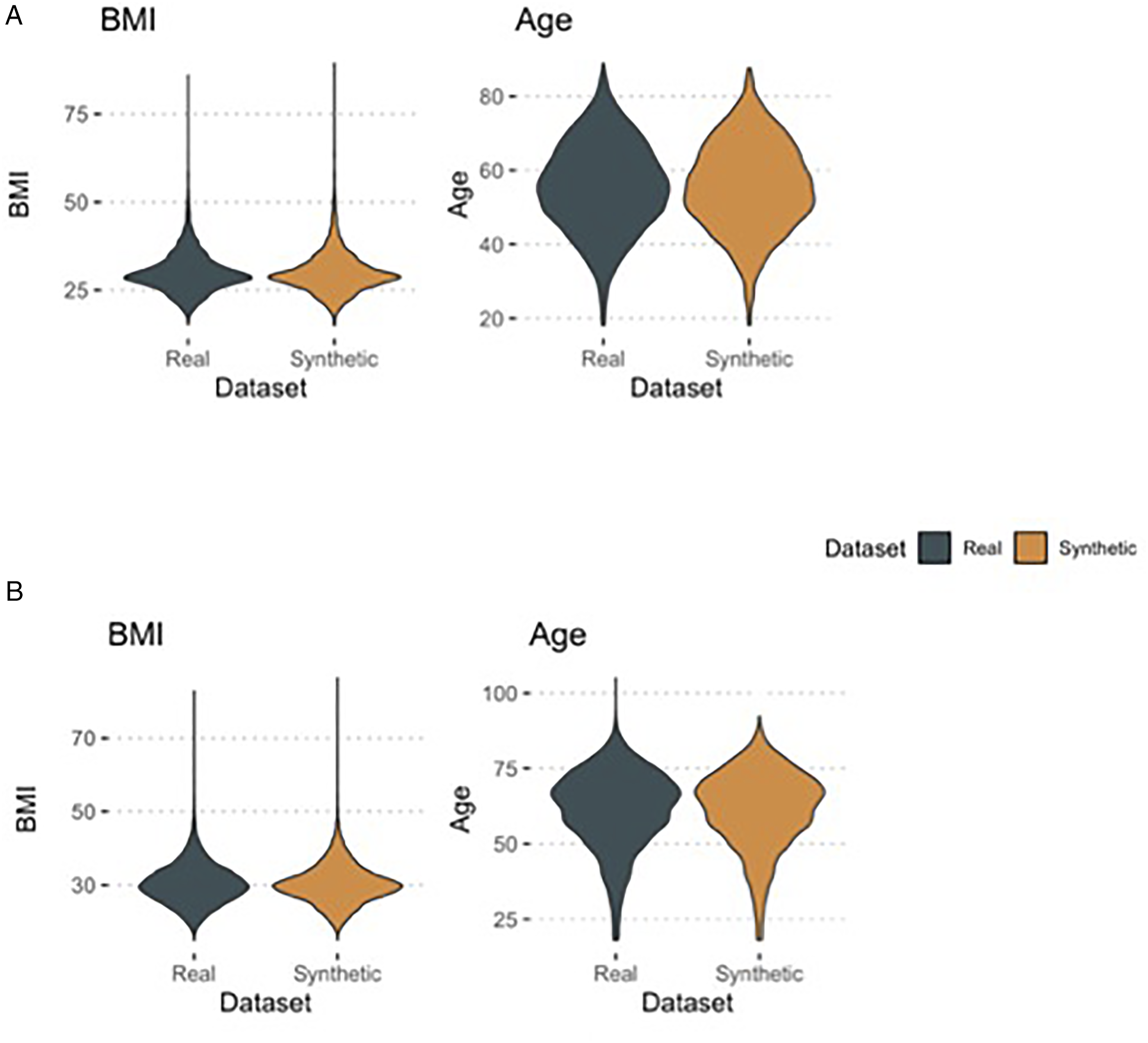
Outcome Prediction
Influential logistic regression parameters predicting 30-day readmission for the cervical fusion cohort by dataset. Variables with P < .10 in either dataset are shown.
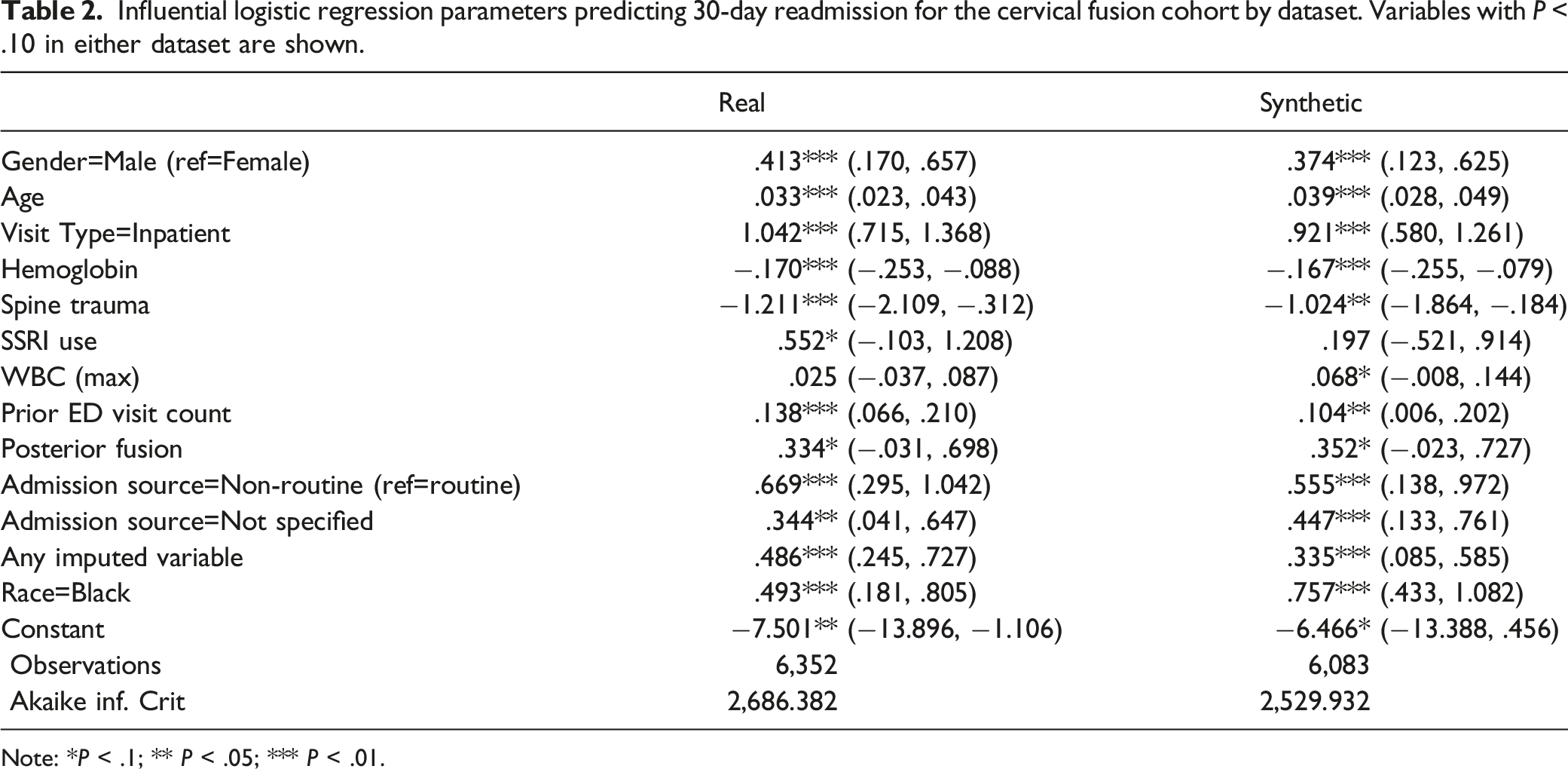
Note: *P < .1; ** P < .05; *** P < .01.
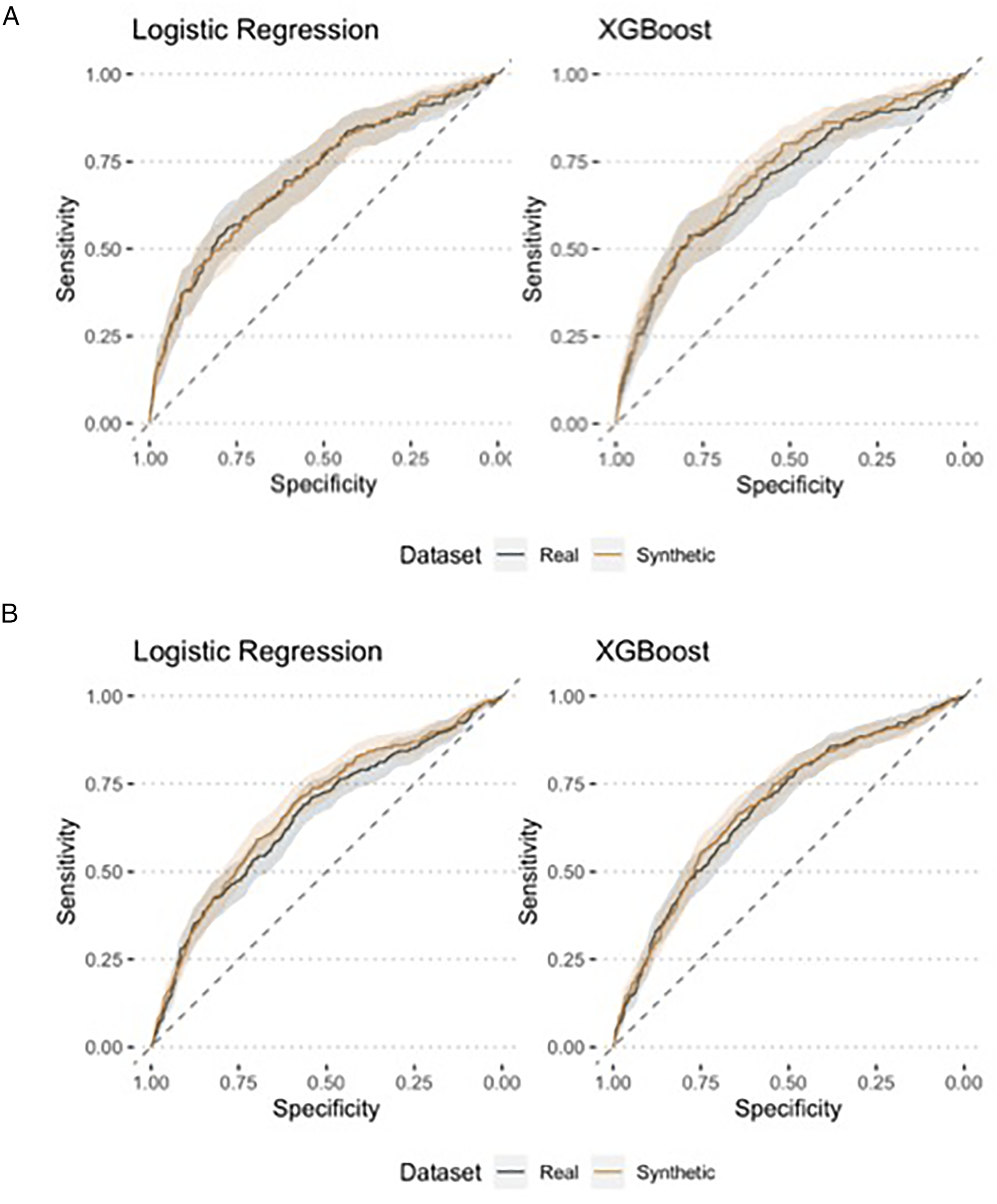
Receive operating characteristic (ROC) curves showing model discrimination predicting readmission for the cervical (A) and lumbar (B) cohorts.
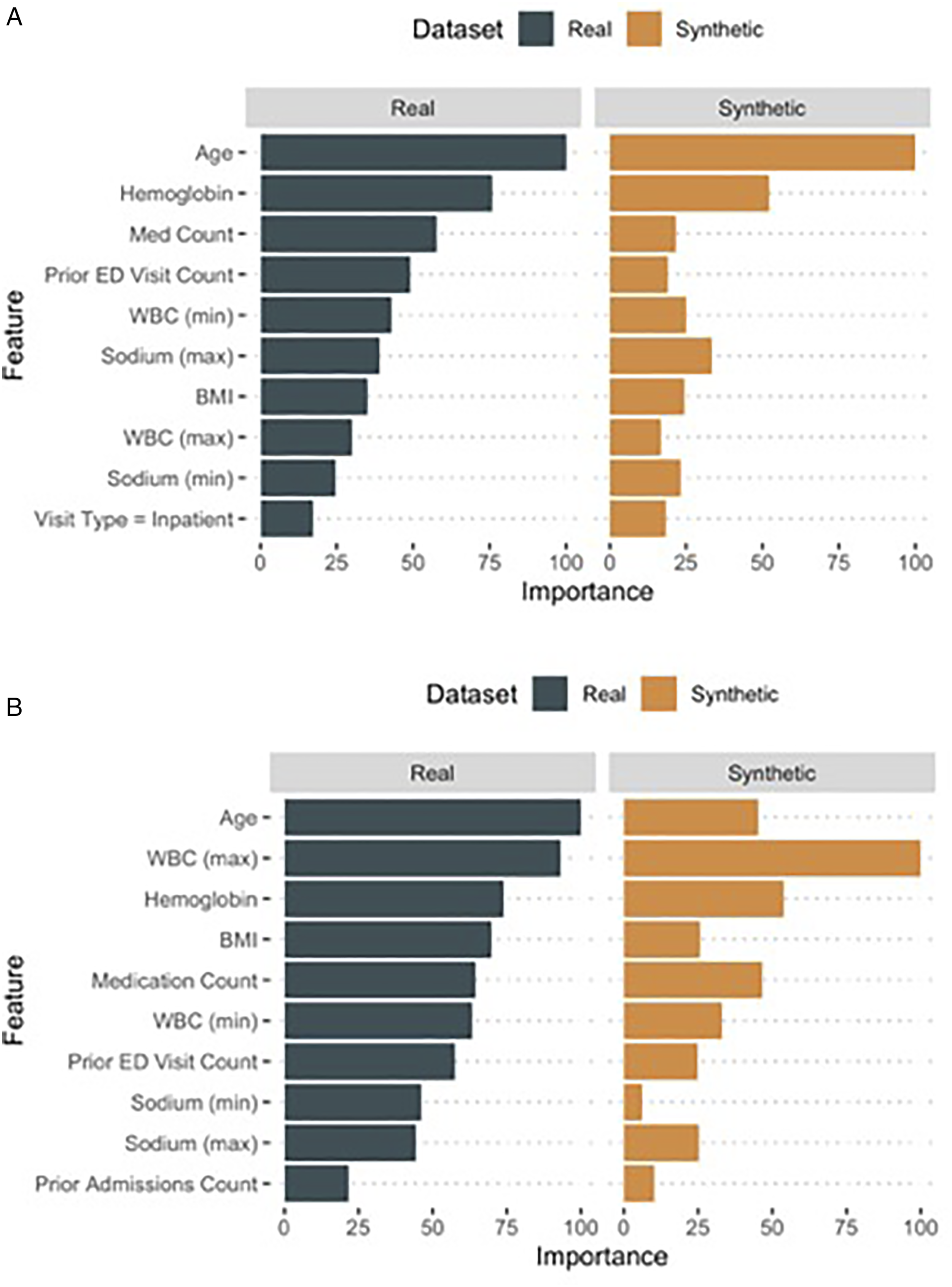
A comparison of the most influential variables between the models built using real versus synthetic data to predict readmission for the cervical (A) and lumbar (B) cohorts.
In the real dataset, 3.0% of patients experienced a 30-day complication compared to 3.4% in the synthetic dataset (P = .2), with respiratory failure (1.4% in both datasets) being the most common event (Table 1). The c-statistics for predicting a 30-day complication were similar in models developed using real (c = .83 for logistic regression; c=.82 for XGBoost) and synthetic datasets (c = .86 for logistic regression; c = .84 for XGBoost). Like with readmission prediction, there was substantial overlap among the most influential predictors in both the logistic regression and XGBoost models (Supplemental Appendix E-Figure 3; Supplemental Appendix E-Figure 2). However, there were also notable differences (e.g., hemoglobin was more influential in the real vs synthetic model).
Lumbar Fusion Cohort
In the lumbar fusion cohort, we identified 12,111 real and 12,126 synthetic patients. There was a small amount of censoring in this population, which was restricted to race (2.0%), visit type (<.1%), and admission source (1.3%). Similar to the cervical cohort, the only variables with significant differences between the real and synthetic groups were race and number of recent hospital and ED admissions. However, the magnitude of the differences was small. Other categorical variables and all continuous variables were nearly identical between the 2 cohorts. These descriptive characteristics are summarized in Table 3 and Figure 1B.
Descriptive statistics of the lumbar fusion cohort.
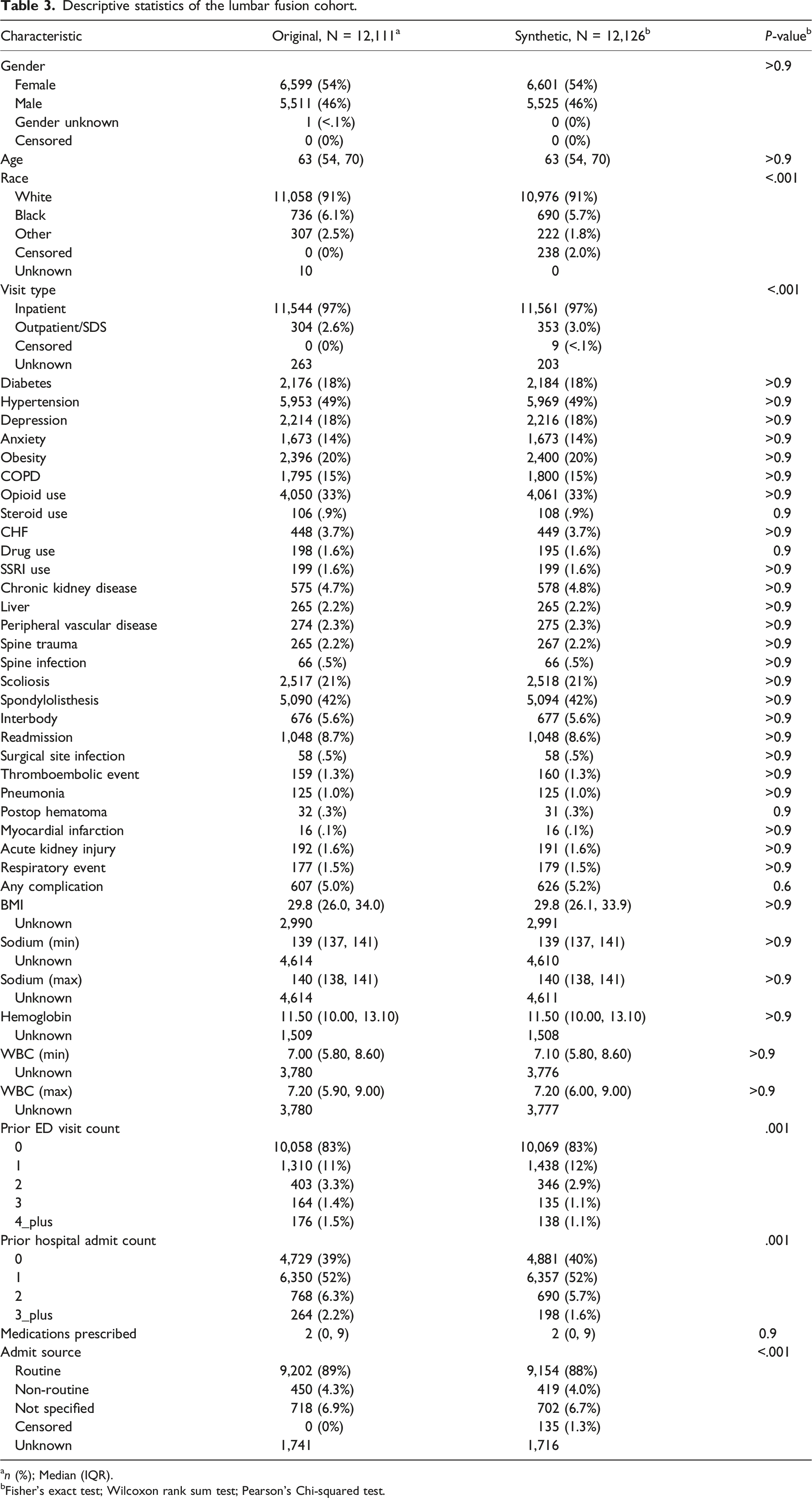
an (%); Median (IQR).
bFisher’s exact test; Wilcoxon rank sum test; Pearson’s Chi-squared test.
Outcome Prediction
Influential logistic regression parameters predicting 30-day readmission for the lumbar fusion cohort by dataset. Variables with P < .10 in either dataset are shown.

Note: *P < .1; ** P < .05; *** P < .01.
A total of 5.0% patients in the real and 5.2% in the synthetic datasets experienced a complication within 30days of surgery (P = .6), with acute kidney injury (1.6%) being the most common event. Again, discrimination was similar in models developed using real (c=.74 logistic regression; c = .76 XGBoost) and synthetic (c = .75 logistic regression; c = .80 XGBoost) datasets. The most influential predictors were similar in both sets of models using XGBoost, though 12 variables were only significant in 1 dataset in the logistic regression model. The most influential variables from each model are shown in E-Table 5 and E-Figure 3.
Discussion
In this study of a large, multi-hospital system, we found that synthetic data derivatives were effectively able to simulate the descriptive and predictive characteristics of real data from anterior cervical and posterior lumbar fusion patients. In descriptive analyses, real and synthetic data showed nearly identical characteristics, with the exception of slight differences in some categorical variables. Using both regression and machine learning prediction analyses, models built using synthetic data showed similar predictive performance as models built using real data when tested in real testing datasets. While there were some differences noted among the most influential predictors, these overall results suggest that synthetic data derivatives may be appropriate for many spine surgery predictive analyses.
Corresponding to unabated grow in healthcare data, there is rapidly growing interest in using “big data” in spine surgery.7,24,25 Although administrative billing are a highly accessible source for multicenter analyses, there is growing recognition that such datasets are limited both in the accuracy and breadth of the variables available.24,26 Clinical registries offer a high quality alternative,27-29 but their high cost and potentially restrictive data sharing policies limit their growth.30,31 Additionally, clinical registries typically rely on manual data abstraction and do not incorporate comprehensive laboratory and prescription records, limiting potential uses. While the widespread availability of hospital EHRs has created opportunities to expand use of these data assets,12,32 progress advancing EHR-based research has been tepid.
Circumventing many problems related to patient privacy and data ownership, synthetic data derivatives offer a promising opportunity to leverage artificial intelligence analytics to streamline spine surgery research using EHR data. Indeed, such methods are becoming increasingly common in non-surgical populations,15,33 including a recent effort by the National Institutes of Health to use synthetic data for COVID-19 research. 34 Our results in 2 spine surgery populations suggest that synthetic data derivatives almost entirely replicate population descriptive characteristics, while also closely simulating predictive performance. These findings suggest a wide array of potential applications, including epidemiological analyses, studies of surgical trends, and profiling quality outcome metrics. As patient-reported outcome measures are integrated as structured data elements in the EHR, opportunities for comparative effectiveness analyses will also expand substantially.
Beyond the availability of structured data elements, the ultimate impact of synthetic data derivatives will depend on the extent of stakeholder buy-in. At the authors’ institution, the use of synthetic data markedly expedites EHR research by removing the need for either IRB approval or the assistance of paid data brokers to facilitate access. Therefore, physicians and clinical investigators are given immediate access to conduct EHR queries across the health system, which has implications for both quality improvement investigations and exploratory research efforts.
However, likely the greatest potential benefit of synthetic datasets in spine surgery relates to the creation and sharing of multicenter datasets supported by multi-institution partnerships. For example, in Israel, a major medical center linked records of COVID-19 patients with a large insurance provider to obtain comprehensive health histories and medical records. Lacking privacy concerns, synthetic datasets based on these linked data were then made available to external data scientists to expedite research efforts. 35 Such examples illustrate the power of synthetic data to facilitate scientific advances when healthcare organizations work together to create and share such datasets.
Despite these opportunities, our findings also highlight important limitations to using synthetic data derivatives. First, there were slight but statistically significant descriptive differences between real and synthetic data related to rare categorical variables (e.g., some racial minorities; number of recent ED visits). While the size of these differences was generally small, the impact may be magnified in rare subgroups. Consequently, real data should likely be used to verify precise treatment effects related to very rare outcomes or small subgroups (e.g., rare demographic subgroups). Second, although discrimination was comparable in models built using real and synthetic data, there were differences noted among the most influential predictors identified. Therefore, while synthetic data appear capable of predicting clinically relevant endpoints in real populations, they may not be best-suited for analyses focused on identifying the impact of individual predictors in complex multivariable analyses. Third, since the MDClone platform is proprietary, users can validate its performance but cannot investigate the detailed methods of its underlying algorithm. Finally, synthetic data derivatives are dependent on the structured data encoded within the RDC. At our institution, the RDC does not currently include some clinically relevant outcomes, like patient-reported outcomes and pain scores. As such additional data elements are added to the RDC, opportunities for synthetic data research will expand.
Conclusions
Synthetic data derivatives offer a novel approach for leveraging EHR analytics to support multicenter spine surgery research. In this initial validation in 2 spine surgery populations, the descriptive characteristics and predictive performance from synthetic data closely mirrored those obtained using real data. As both the use of structured EHR data and buy-in from large organizations expand, synthetic data derivatives are likely to assume a growing role in spine surgery research.
Supplemental Material
sj-pdf-1-gsj-10.1177_21925682221085535 - Leveraging Artificial Intelligence and Synthetic Data Derivatives for Spine Surgery Research
Supplemental Material, sj-pdf-1-gsj-10.1177_21925682221085535 for Leveraging Artificial Intelligence and Synthetic Data Derivatives for Spine Surgery Research by Jacob K. Greenberg, Joshua M. Landman, Michael P. Kelly, Brenton H. Pennicooke, Camilo A. Molina, Randi E. Foraker, and Wilson Z. Ray in Global Spine Journal
Footnotes
Acknowledgment
We thank Dr Noa Zamstein for her valuable input on our search strategy and her feedback on the manuscript content.
Declaration of Conflicting Interests
No Authors report any financial conflicts of interest. Drs. Greenberg and Foraker have delivered one or more webinars on the use of MDClone and received a nominal gift card in appreciation. Dr. Ray received research support from the Defense Advanced Research Projects Agency, Department of Defense, Missouri Spinal Cord Injury Foundation, National Institute of Health/NINDs, Hope Center, and Johnson & Johnson. Dr. Ray reports: stock/equity in Acera surgical; consulting support from Depuy/Synthes, Globus, and Nuvasive; royalties from Depuy/Synthes, Nuvasive, Acera surgical. Dr. Foraker received no funding specifically related to this study. Dr. Foraker reports research support from the Washington University Institute for Public Health, National Institutes of Health, Global Autoimmune Institute, Agency for Healthcare Research and Quality, Siteman Investment Program, Alzheimer’s Drug Discovery Foundation, and Children’s Discovery Institute. Dr. Kelly reported no funding related to this submission. Dr. Kelly received research support from the Setting Scoliosis Straight Foundation and the International Spine Study Group Foundation. Dr. Kelly received personal fees from The Journal of Bone and Joint Surgery. Dr. Molina reported equity in Augmedics and consulting fees from Depuy/Synthes and Kuros.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Dr Greenberg was supported by grants from the Agency for Healthcare Research and Quality (1F32HS027075-01A1), the Thrasher Research Fund (#15024), and a Young Investigator research grant from AO Spine North America. This study received no dedicated funding.
Ethics Approval
This study was reviewed by the Washington University in St Louis institutional review board (IRB) and granted exempt status (IRB #202012138) and a waiver of HIPAA authorization. Because of the waiver of HIPAA authorization, patient consent was not required or obtained.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.