
Abstract
Replacing users with models that simulate users’ behaviors has been a long-standing vision in interface design. Cognitive models can simulate users’ cognitive processes and behaviors, but they cannot fully interact with user interfaces and simulate all behaviors. VisiTor (Vision+Motor) is a tool that provides cognitive models with methods to interact with the interface that users interact with. However, currently, cognitive models can only simulate experts and error-free users. Previous attempts at using cognitive models were inadequate due to hard-coded errors, which led to predictions that were not applicable to all users and tasks. Therefore, a general approach is required to include error generations and error corrections in cognitive models. VisiTor has been extended to generate and correct errors, leading to the development of an Automatic Error Cognitive Model that simulates more complete users’ behaviors in an Excel spreadsheet. This model helps to get closer to developing complete cognitive models that can replace users.
Introduction
Spreadsheets are commonly used in business operations and finance (Croll, 2007; Kappelman et al., 1993). The selection of the appropriate spreadsheet application; however, can be a challenging task as there are various options available. It can also be a time-consuming and financially burdensome process as operators must test and compare each application. Many studies have been conducted to compare the effectiveness of various spreadsheet applications in different tasks and to identify ways to improve them (Keeling & Pavur, 2011; Sani et al., 2019).
Spreadsheet errors can have costly, even devastating, consequences (Fisher et al., 2006). A significant amount of research exists on the topic of spreadsheet errors and their causes. Powell et al. (2008) provide a comprehensive review of different types of errors, their frequency, and strategies to avoid errors through proper spreadsheet design. Furthermore, Kankuzi and Sajaniemi (2013, 2014) have shown that experts employ unique mental models when interpreting spreadsheet data, identifying errors, and correcting them. (Cunha et al., 2018) leveraged these findings by incorporating error types proposed by Bishop and McDaid (2008) to create a userfriendly interface aimed at facilitating spreadsheet authors in comprehending and correcting errors in spreadsheets created by other authors.
Additionally, researchers have explored the use of cognitive models as a means of replicating user behavior in interface design. These models are developed using cognitive architectures such as ACT-R (Anderson et al., 1998), for simulating human cognitive processes and users’ behaviors (Kim et al., 2007; Kim & Ritter, 2015; Paik et al., 2015). These studies demonstrate the utility of cognitive architectures in understanding and improving human performance in spreadsheet tasks. Also, different studies used the ACT-R, which makes errors such as missing a step or repeating an already executed step in a process, and found a significant relationship between the task that is mandatory and the task that is taking a user closer to the goal with the tendency of that user making an error (Halbrügge, Quade, & Engelbrecht, 2015; Halbrügge, Quade, Engelbrecht, Möller, & Albayrak, 2016).
Errors play a significant role in the occurrence of accidents and mistakes in many industries. As a result, the field of human factors and ergonomics has emphasized the importance of studying and minimizing such errors. A particular area of interest in this field is the examination of the impact of cognitive processes on user errors. Cognitive architectures are widely used to study human performance and error in various domains. A study by Pan et al. (2017) reviewed different types of cognitive models, including rulebased, knowledge-based, and memory-based models, and compared their strengths and limitations. They also evaluated the application of these models in human reliability analysis in nuclear power plants and aviation. The study concludes that there is a need for more comprehensive and realistic models as well as improved validation and evaluation methods to fully comprehend and predict human behavior in high-risk industries.
Despite the significant impact of spreadsheet errors, limited research has been conducted on using cognitive models to simulate the cognitive processes of users completing spreadsheet tasks, taking into consideration errors. (Tehranchi et al. (2022); Tehranchi (2020)) conducted a study comparing two commonly used spreadsheet applications (Emacs and Microsoft Excel) using a similar spreadsheet task. The results showed that while the simulation results correlated with the users’ results, predictions were not entirely accurate. This discrepancy was attributed to the assumption of expert user behavior by cognitive architectures. To overcome this issue, the researchers introduced hard-coded errors made by one user, which resulted in a better Mean Squared Error (MSE) compared to the expert model (Tehranchi, 2020). To the best of the researchers’ knowledge, this is the first attempt to model user error in a spreadsheet task using a cognitive architecture.
This paper expands on the work of Kim and Ritter (2015) and (Tehranchi et al., 2023) in the field of cognitive modeling of spreadsheet tasks. Kim introduced a spreadsheet task to study users’ learning and forgetting theory in a non-iterative spreadsheet task over different periods of time in Emacs. (Paik, 2011) developed cognitive models in ACT-R and Soar for the task, (Tehranchi & Ritter, 2018) developed interactive cognitive models for the same task. (Tehranchi, 2023) built their error-simulating model based on the same spreadsheet task in Excel. The current study extends VisiTor’s capabilities by using the tool to provide cognitive models with the ability to “see” and “use” a User Interface (UI) like an actual user. The new extension of VisiTor’s capabilities is to generate and detect errors with probabilities that are similar to users. This approach provides a more realistic simulation of user behavior in spreadsheet tasks and improves the process of selecting the right spreadsheet application (Excel, Emacs, etc.) more efficiently.
Cognitive Model Development
Developing a cognitive model involves three key stages: (1) Establishing a baseline for evaluating the model’s performance by either collecting data or using already available datasets, (2) Model development, by hypothesizing about the cognitive processes of the users, and (3) Comparison of model’s predictions with user data and iteration of the model as needed.
We utilized existing data from (Tehranchi et al., 2023) which includes eye tracking data, mouse movements, and keyboard inputs from 23 users. Users were instructed to complete 14 subtasks, where each subtask required a specific set of actions. The developed model used ACT-R v7 and JSegMan (Tehranchi & Ritter, 2018) to interact with the task environment (i.e., Emacs spreadsheet). In this study, we use a similar experimental design to (Tehranchi, 2020). For details about the experiment design, please refer to (Tehranchi, 2020). We utilized an external tool called VisiTor (Bagherzadeh & Tehranchi, 2022). VisiTor is designed to mimic user interaction with UIs and simulate similar procedures to a user. It provides the model with the ability to see virtual environments similar to users and interact with them. One challenge in developing an ACT-R agent is that they typically simulate error-free expert behavior, which is not a realistic representation of user behavior. To address this, we extended VisiTor’s capabilities to simulate typing errors that are similar to those made by users. Our hypothesis is that users do not make mistakes intentionally, and in our case, typing errors stem from inaccuracies in the command execution of hands rather than from a lack of knowledge or illiteracy. To simulate this in our model, we included a probability of incorrect command execution to VisiTor, while ACT-R still requests the correct action.
User Typing Errors Implementation
The methodology for simulating the typing process with the inclusion of errors in the ACT-R is divided into three distinct steps: (a) error generation, (b) error detection, and (c) error correction. We first provide an overview of the process, including the specific modules utilized. In order to simulate user typing errors in VisiTor, we first needed to understand the probability densities of pressing a wrong key while intending to press another specific key. We hypothesize that when a user intends to press a specific key, there is a higher probability of them mistakenly pressing a key that is close to the intended one, rather than those keys that are further away in a standard keyboard layout. We expect that neighbor keys might have a higher probability assigned to them, while those keys that are further away would have a lower probability assigned to them. Moreover, Keno et al. (2007) reported a higher chance of pressing neighbor keys directly next to the intended key than pressing those keys that are neighboring the intended key, either above or below it. However, how this probability is distributed remains unanswered.
To develop the probability of user typing errors, we utilized the Microsoft Research Spelling-Correction Data and TYPO CORPUS datasets, which contain a total of 83277 typing errors of various types. Specifically, we are interested in the errors where an incorrect key was pressed. Dhakal et al. (2018) called this type of error, “Substitution Error Rate”. Out of all errors, 21171 of them fell into this category. We implemented error-making algorithm in VisiTor using the probabilities calculated from these datasets.
A challenge we encountered in this path was that the datasets only included incorrectly written words, and we did not have access to all the words that were written by the users. They only included the words that were incorrectly typed and not those that were correctly written. This limited our ability to calculate the probability of a key being pressed incorrectly, which is the number of times a key is incorrectly pressed over the total number of times that key was pressed. But we were still able to determine the probability distribution for each incorrect key that might be pressed if a key is intended to be pressed incorrectly.
The probability of users pressing the wrong key on the keyboard varies depending on the study and the population. In general, the likelihood of typing errors depends on various factors such as typing speed, familiarity with the keyboard, and typing context (MacNeilage, 1964). Here, we rely on the reported average errors that were reported in different literature.
According to a study by MacKenzie and Soukoreff (2003), the mean error rate for typing was found to be approximately 8%. However, more recent research by Dhakal et al. (2018); (Ross, 2016) suggests that the error rate is closer to 2% when typing natural language text using a physical keyboard.
It is important to note that the probability of users pressing the wrong key on the keyboard can also be affected by other factors, such as the type of keyboard, the design of the keys, and the layout of the keyboard. These factors can also influence the likelihood of specific types of errors, such as adjacent key errors or home-row errors. In this study, we use Dhakal et al. (2018) findings due to the similarity to the performance of the users in our dataset.
In case of a typing error, for each letter, we calculate the frequency of wrong key presses. For example, for the letter “e”, users have mistakenly pressed “a” 243 times, pressed “i” 132 times, etc. Based on these frequencies, we calculate a conditional probability distribution for each key being pressed if we intend to press a specific key. This distribution allows us to simulate user typing errors in VisiTor by using these probability densities.
This process can be formulated with the following:

Where “key” can be any character with a button on keyboard, “int” is the key that one intends to press and “char” indicates the character that a user intends to press. To simulate users typing errors in the ACT-R architecture. Every time the ACT-R agent requests VisiTor to press a key, VisiTor correctly executes the action with a probability of 0.98. This process is implemented as follows:
Random number “U” is generated from a uniform distribution between 0 and 1: u ~ U(0,1)
The following formula determines if a mistake is made (1) or not (0):
If u is less than 0.02, a typing error will be executed. Otherwise, the model will press the correct key.
Otherwise, VisiTor samples from the conditional probability of each key being pressed while a specific key press is requested by ACT-R, and then VisiTor presses an incorrect key based on the sample from the distribution.
All key press requests from the motor module in ACT-R are requests to press the correct key, but the possibility of error is introduced through VisiTor’s conditional probability sampling.
With VisiTor capable of simulating user typing errors, it is now necessary to add the cognitive process of looking for errors and finding them into the ACT-R model. The process begins with ACT-R requesting the motor module to press the correct key, which is then executed using VisiTor. In this paper, we assume that the agent checks if the correct key was pressed after each key press. We added a production rule for “type-check” which requests VisiTor to check if the intended key was pressed correctly. If the correct key is pressed, the production rule, “Correct-press” is fired, which requests the agent to proceed to the next process. If an error is made, the production rule “Wrong-press” sends a request to VisiTor to press the backspace key using its motor module, and then repeats the key press process once more. As illustrated in Figure 1, the flowchart depicts the process of how the ACT-R agent types, with the added step of checking for and correcting errors using the type-check feature implemented in VisiTor and also Figure 2, demonstrates the algorithm for the implementation of error generation and correction.
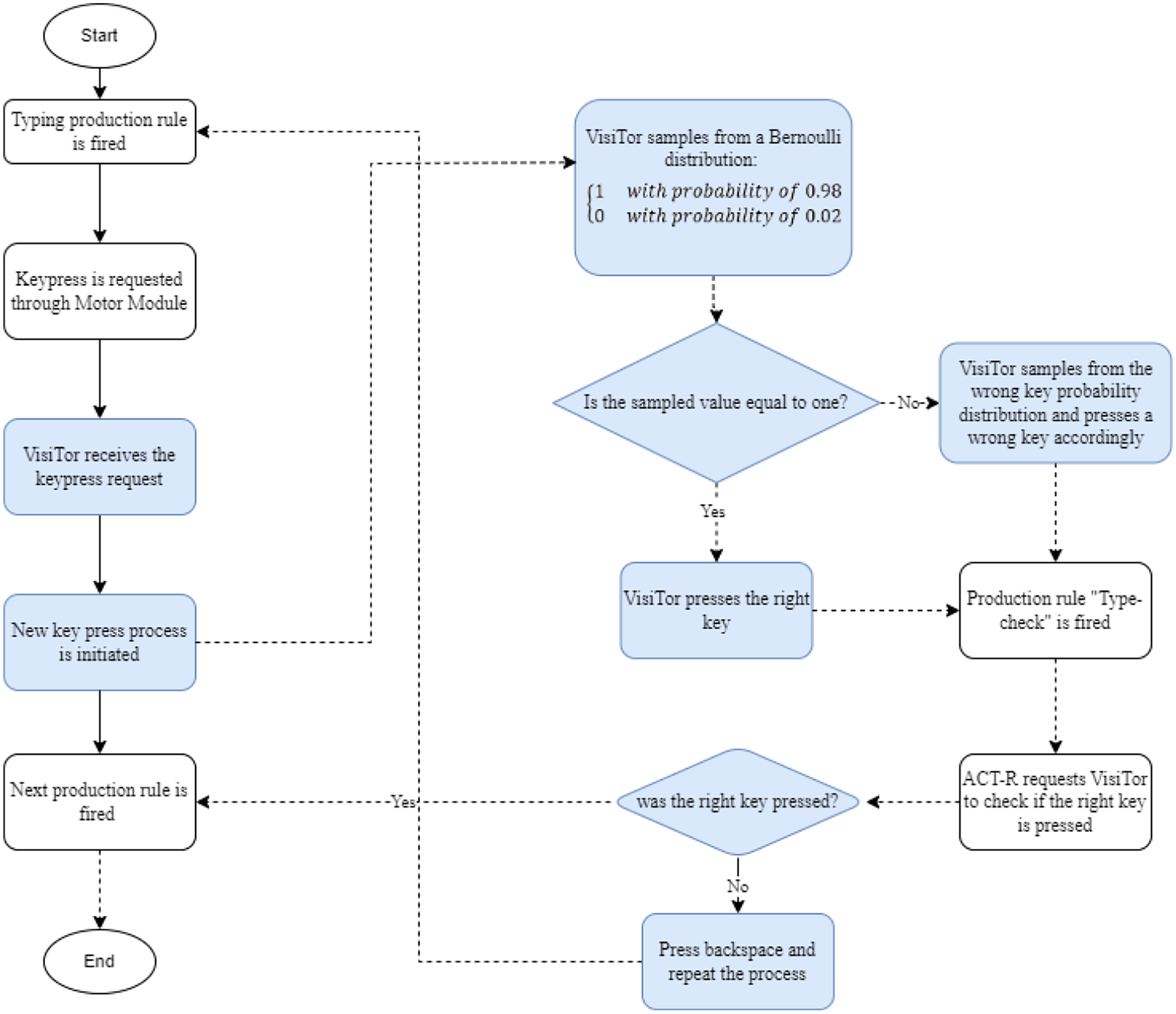
The flowchart of the process of simulating the typing process with the inclusion of errors in the ACT-R. The highlighted parts indicates Visitor’s actions. Dashed lines represent new subprocesses that handle press a key in the updated version of VisiTor (with the inclusion of error making and error detection). Without implementing the error making capability in VisiTor, the process follows the solid line.

The ACT-R typing process algorithm.
ACT-R Models Description
Our proposed model features an additional 5 production rules when compared to the previous Error Model developed by (Tehranchi et al., 2023). AEM also has 732 declarative knowledge chunks, which is a reduction of 45 chunks when compared to the Error Model presented before by (Tehranchi et al., 2023). Because our previous model did not require the additional chunks for implementing backspace(s) for corrections. Instead, error correction is achieved through the new production rules that have been incorporated into the model. Also, our analysis of both the users’ typing speed and the ACT-R model revealed that users type faster than what the model predicts. Upon examining the users’ performance and the model, we reached the conclusion that the activation of chunks representing letters should be lower than that of chunks representing words. This is because while users need to learn the words they are instructed to write, the spelling of these words is already ingrained in their memory, making retrieval faster.
The proposed model is executed within the Emacs environment and the interaction between ACT-R and VisiTor is facilitated through the use of the Inferior-shell lisp library. Inferior-shell is a Lisp library that facilitates communication between processes through a command-line interface.
Results
We narrow our analysis focus to subtasks 3, 4, 5, 6, 7, 8, 9, and 10, which require typing after automating the errormaking and correction in the model. A paired-sample t-test was employed as each row in the dataset represents a single subtask. The results of the t-test indicates that there is insufficient evidence to claim that the means of the Automatic Error Model and the user data are significantly different (t(13) = -0.06, p-value =.47 >>.05). A comprehensive summary of the model’s performance and its comparison to previous models can be found in Table 1. We compare our results to the models developed by (Tehranchi, 2023). In the Error Model, they hardcoded the typing errors made by one of the users, and they named the expert error-free model, “Excel model”.
The performance comparison of models.

The results from our study, as demonstrated in Table 1, indicate that the performance of the Automatic Error Model aligns well with the users’ data. Furthermore, we observed a significant reduction in the Mean Squared Error (MSE) and Root Mean Squared Error (RMSE) values, with a 50% decrease in RMSE. Our analysis revealed that certain tasks deviated from the predictions made by the ACT-R model. As depicted in Figure 3, tasks 3 and 5 were underestimated, while tasks 7 and 9 were overestimated. This discrepancy could be due to the difficulty level of the formulas associated with tasks 3 and 5, which users found challenging to understand. Conversely, tasks 7 and 9 comprised formulas that users could comprehend, leading to an easier time typing the formulas after practicing on a few cells.
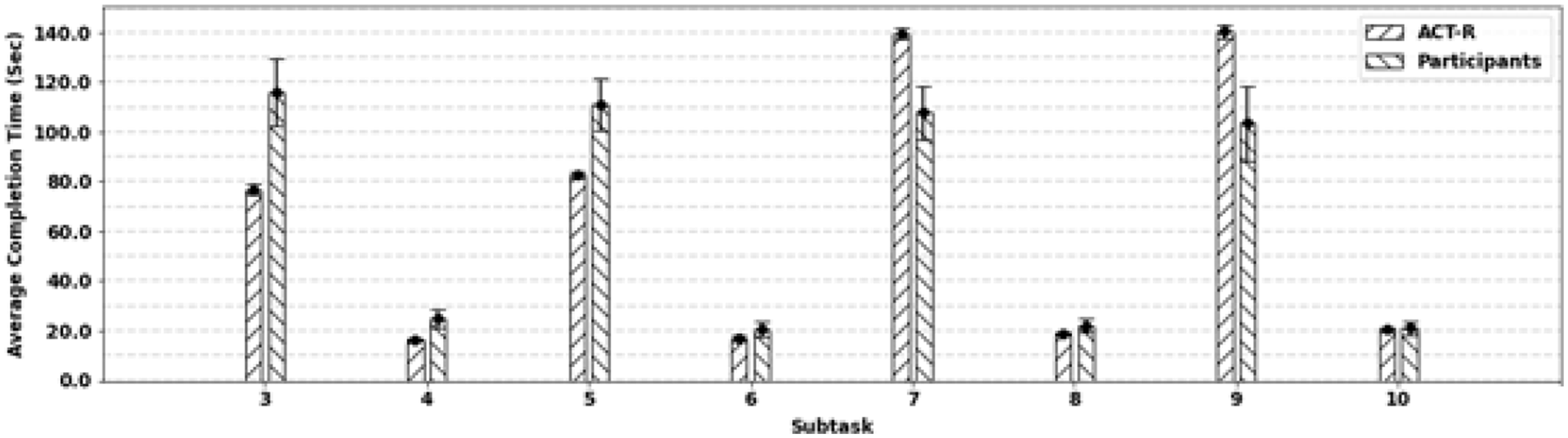
The average completion time for each subtask with 95% confidence intervals for ACT-R model (left) and Users N =23 (right).
Conclusion and Future Works
We enhanced the capabilities of VisiTor by introducing the ability to generate and detect typing errors, similar to those made by users. Using these advancements, we developed an Automatic Error Model (AEM) within ACT-R that can mimic user behavior by making and detecting mistakes in typing and correcting them. The new model surpasses previous cognitive models for spreadsheet tasks. However, there is still room for improvement. Currently, we only modeled typing slips and we need to consider a broader range of error types, as indicated in (Kano et al., 2007). Furthermore, the formula’s complexity impacts the time it takes for users to retrieve and type the formula. The modeling of other tasks, such as searching for visual modules, must also be improved to enhance tasks 1, 2, 11, 12, 13, and 14, as they all require the user to search and find visual modules on the screen. If the visual modules are predetermined, the model will move the attention without searching. If visual modules are defined correctly, meaning instead of the location, we define their characteristics, ACT-R performs a visual search to find these visual objects. Creating a comprehensive spreadsheet model that accurately simulates user behavior is a challenging task, but this paper represents progress toward that goal by including typing errors.