
Abstract
Algorithmically defined aspects of reinforcement learning correlate with psychopathology symptoms and change with symptom improvement following cognitive-behavioral therapy (CBT). Separate work in nonclinical samples has shown that varying the structure and statistics of task environments can change learning. Here, we combine these literatures, drawing on CBT-based guided restructuring of thought processes and computationally defined mechanistic targets identified by reinforcement-learning models in depression, to test whether and how verbal queries affect learning processes. Using a parallel-arm design, we tested 1,299 online participants completing a probabilistic reward-learning task while receiving repeated queries about the task environment (11 learning-query arms and one active control arm). Querying participants about reinforcement-learning-related task components altered computational-model-defined learning parameters in directions specific to the target of the query. These effects on learning parameters were consistent across depression-symptom severity, suggesting new learning-based strategies and therapeutic targets for evoking symptom change in mood psychopathology.
Disruptions in learning and valuation are features that cross psychopathologies (e.g., Bouton et al., 2001; Brown et al., 2021; Eshel & Roiser, 2010; Pike & Robinson, 2022). Computational-model-based analyses can delineate which aspects of learning and valuation are disrupted across levels of analysis (Montague et al., 1996; Niv & Langdon, 2016; Schultz et al., 1997; Sutton & Barto, 1998). Equally important, individual-level parameters derived from these models have shown encouraging psychometric properties: They have good split-half and test–retest reliability and the ability to track learning and valuation across levels of psychopathology (Brown et al., 2020, 2021; Chung et al., 2017; Waltmann et al., 2022). These data have been particularly promising for mood- and anxiety-related disorders. Specifically, studies that examined reinforcement learning in depression have shown that alterations in algorithmically defined learning components both correlate with distinct symptoms of depression and are sensitive to symptom improvement following treatment, including cognitive-behavioral therapies (CBTs; Brown et al., 2021; Huys et al., 2016; Vrieze et al., 2013). For both depression- and anxiety-related disorders, verbal targeting of learning mechanisms may increase efficacy in behavioral therapies (Craske et al., 2014, 2016). Together, this work suggests that understanding how reinforcement-learning processes can be changed may identify new therapeutic targets and strategies for behavioral and symptom change in psychopathologies.
Reinforcement-learning models formalize learning as a process of updating values associated with stimuli based on the discrepancy between experienced and expected outcomes (prediction error). Free parameters in these models can be estimated based on participants’ behavioral choices or used in simulations to understand varied influences on learning. These parameters then index various aspects of reinforcement learning, including how much prediction error is used to update values on each trial (learning rate) and how much the values or probabilities of different outcomes are dissociated (reward sensitivity or inverse temperature), among other processes (Daw, 2011). A few previous studies have suggested that certain conditions can effect changes in these components of reinforcement learning. Specifically, instructed knowledge about the statistics of a task environment, such as giving explicit information about the probabilities of outcomes during learning or the possibility of changes in reinforcement contingencies, changes participants’ behavior such that they incorporate this knowledge instead of relying solely on experienced prediction errors for learning (Atlas et al., 2016; Li et al., 2011; Payzan-LeNestour & Bossaerts, 2011). In addition, covertly altering aspects of the task environment, such as modulating the volatility of outcomes (Behrens et al., 2007; Pulcu & Browning, 2017), or re-presenting past choices (Bornstein et al., 2017), changes behavior and learning parameters in accordance with these environmental manipulations. Note that these approaches have largely been tested in community samples, and initial studies that have examined psychopathology indicate that individuals with anxiety and depression symptoms may not adapt to covert changes in task environments (Browning et al., 2015; Gagne et al., 2020; but see Patzelt et al., 2019). Thus, although prior work has provided support that learning processes can be systematically changed, it also indicates that to examine factors that enact such changes in psychopathology, more refinement is needed.
Here, we took an intermediate approach combining the evidence-based structure of CBT, in which a guided approach is used to restructure thought processes, with the computationally defined mechanistic targets suggested by reinforcement-learning models for depression. Existing efficacious approaches to behavior change in psychopathology, including CBT, effect change through raising awareness of relevant aspects of behavior through targeted questions while allowing patients to generate and practice new behaviors to use in a variety of situations (Beck, 2011). In these approaches, interventions that are explicit to the learner and can be used in other situations are an important component of generalization and eventual treatment success (Swan et al., 2016). In previous work (Brown et al., 2021), we found distinct depression symptoms associated with distinct learning-parameter disruptions, and following a standard 12-week course of CBT, reduced learning disruption paralleled symptom improvement. Specifically, higher anhedonia symptoms were related to a lower learning rate at baseline, and improvements in symptoms were related to increased learning rate after treatment, whereas higher negative affect symptoms were related to a more negative valuation at baseline, and symptom improvement was related to increased (more positive) valuation after treatment.
Given the above literatures, we thus aimed to establish whether queries addressing distinct features of the task environment might evoke changes in the learning processes that rely on these features. Toward this goal, we tested verbal queries whose content targeted various statistical and structural aspects of the task environment and assessed the extent to which queries changed learning parameters in a single session. Given the possibility that such work may identify novel learning-related therapeutic targets, we additionally examined effects of self-reported depression, anxiety, and stress symptoms to assess the acceptability of the task and feasibility of changing learning in individuals with psychopathology symptoms.
Transparency and Openness
De-identified data and analysis code are available at osf.io/zb4d7. We report how we determined our sample size, all data exclusions, all manipulations, and all measures in the study. All procedures were approved by the Institutional Review Board at Virginia Tech and were carried out in accordance with the Declaration of Helsinki except for preregistration. This study comprised exploratory analyses carried out in preparation for a larger preregistered trial (ClinicalTrials.gov ID NCT05384158).
Method
Study overview
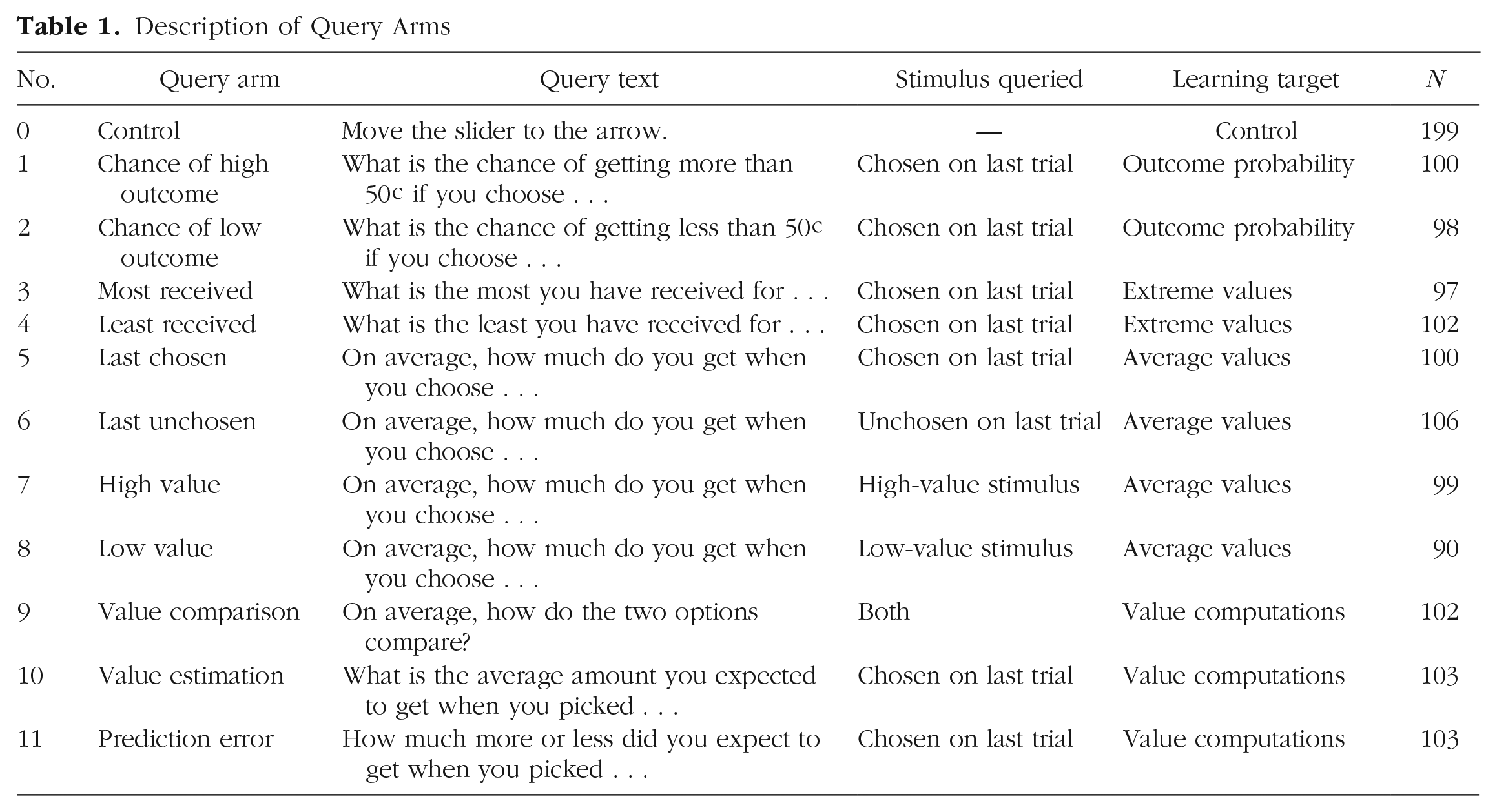
The study was implemented in a parallel-arm design in which each of 12 arms consisted of participants performing a probabilistic reward-learning task while receiving repeated queries about the experimental task environment (11 learning-query treatment arms) or a control query (one active control query arm). Upon enrollment, participants were randomly assigned to one of the 12 study arms; each arm’s intended query target and associated query were unique, and participants in each arm received repeat administrations of one distinct query (for a full list of treatments and their associated queries, see Table 1). This method of assignment meant that participants viewed the same query throughout their study enrollment.
Description of Query Arms
Participants
Participants were recruited via Amazon’s Mechanical Turk platform. Participants were required to have a history of at least 95% of previous Mechanical Turk jobs approved and to have an IP address based in the United States. To be eligible, participants affirmed that they had fluent English and were at least 18 years old. Participants provided informed consent by clicking “I Agree” to the question, “Do you understand and consent to these terms?” after reading study information and consent information. All procedures were approved by the Institutional Review Board at Virginia Tech. For demographic information, see Table 2.
Participant Demographics and Self-Report Variables
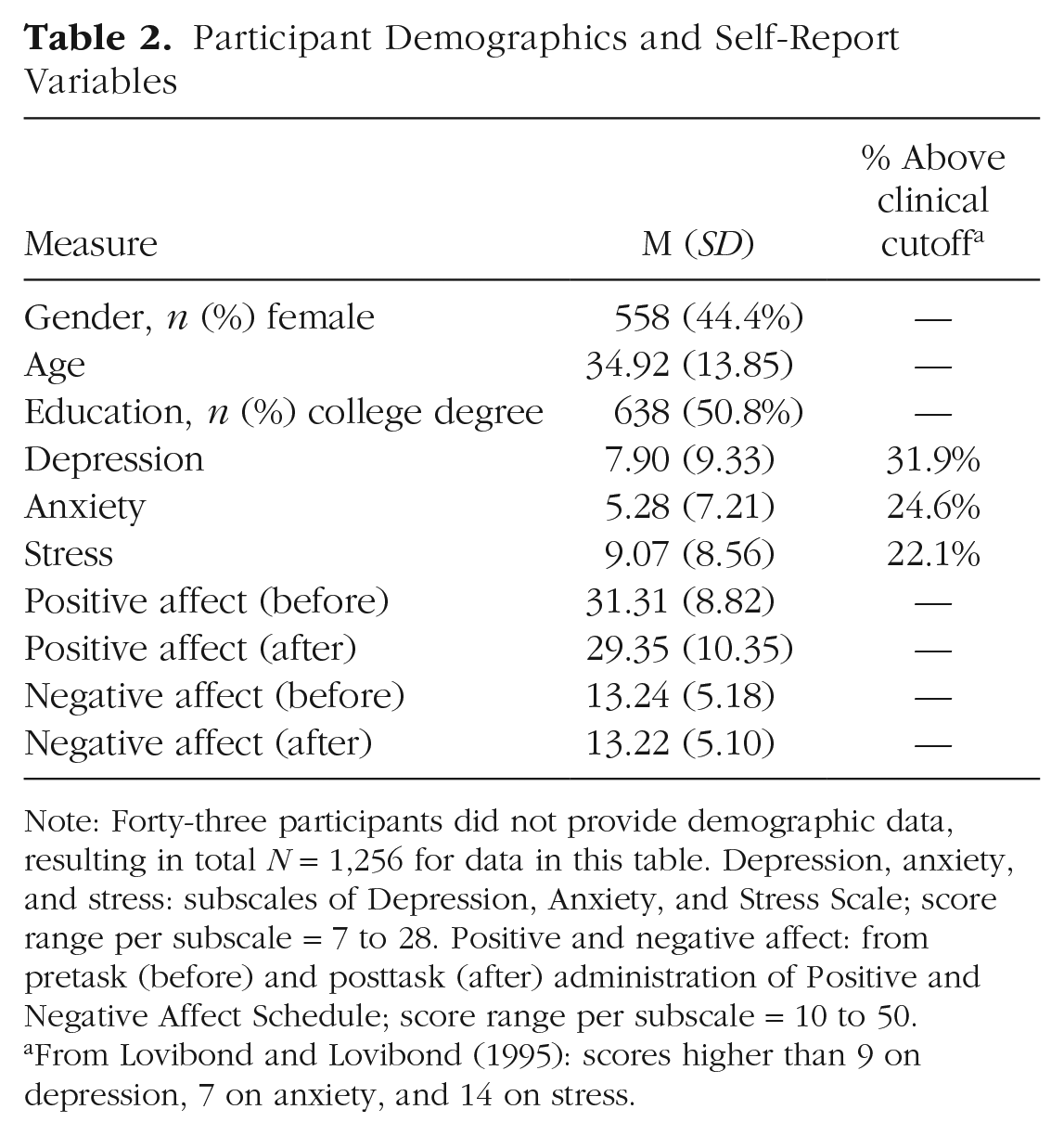
Note: Forty-three participants did not provide demographic data, resulting in total N = 1,256 for data in this table. Depression, anxiety, and stress: subscales of Depression, Anxiety, and Stress Scale; score range per subscale = 7 to 28. Positive and negative affect: from pretask (before) and posttask (after) administration of Positive and Negative Affect Schedule; score range per subscale = 10 to 50.
From Lovibond and Lovibond (1995): scores higher than 9 on depression, 7 on anxiety, and 14 on stress.
A priori power analyses were conducted by simulating parameter changes of varying effect sizes (0.2–0.8) and with varying numbers of participants; parameter values for the control group were based on a previous study with a similar learning task (Brown et al., 2021) and were set at learning rate = 0.289 and reward sensitivity = 1.162 (for further information, see Analyses of Reinforcement Learning Parameters below). Based on this simulation, 100 participants per treatment arm was sufficient to detect effect sizes 0.4 (small/medium) and above. Therefore, participants were recruited until at least 100 participants had completed each of the 12 study arms. After exclusions, 1,299 participants’ data were analyzed (N = 200 for the active control arm; N range = 90–106 for the remaining 11 arms; for data-retention criteria, see below).
Experimental session
Following informed consent, the study visit included three parts: (a) 50 trials of a probabilistic two-choice learning task commonly used to assess reinforcement learning (Brown et al., 2018, 2021; Pessiglione et al., 2006) in which (b) a query about an aspect of the task environment was interspersed every three trials and (c) self-report measures assessed state positive and negative affect, depression and anxiety symptoms, and task engagement. Participants took a mean of 13.9 min to complete the study visit. A schematic depiction of the learning task and associated queries is provided in Figure 1. The three primary visit components are described below.
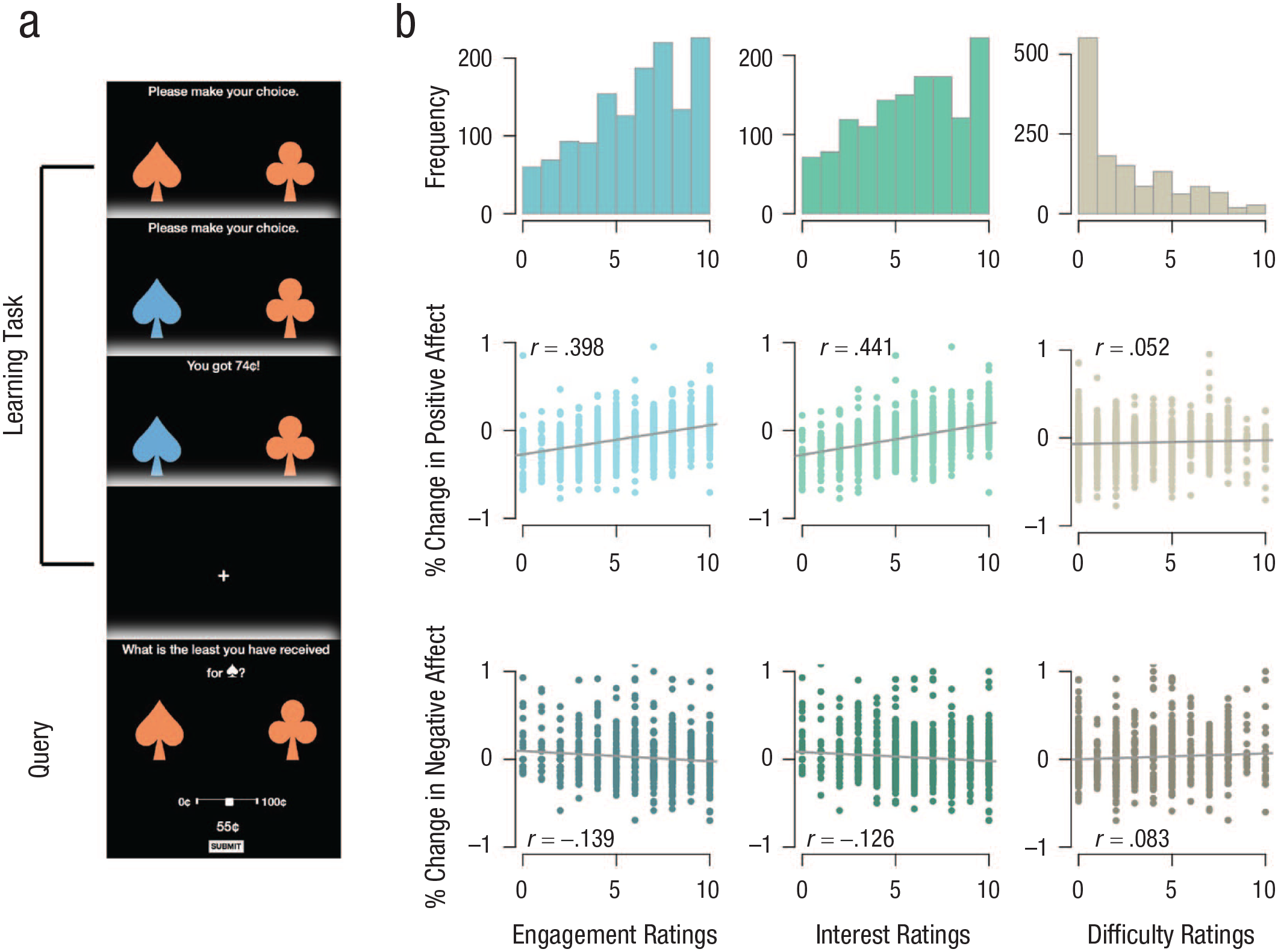
Task design and ratings. (a) A single trial with query in the guided learning task. Participants were presented two stimuli, made a choice, received the outcome for that choice, and on every third trial were then queried about a specific aspect of a stimulus—here, the least ever received for the last chosen option. (b) Participants’ ratings of engagement (first column), interest (second column), and difficulty (third column); ratings were obtained from a Likert-type scale where 0 = not at all and 10 = very much. The first row displays histograms of ratings for all participants, the second row displays relationships between ratings and changes in positive affect during the task, and the third row displays relationships between ratings and changes in negative affect. Each plot in the second and third rows displays a dot per participant, a line of best fit, and Pearson correlation coefficient.
Probabilistic learning task
The learning task was a standard two-option probabilistic reward-learning task, adapted from our and others’ previous work (Brown et al., 2018, 2021; Pessiglione et al., 2006). Participants were presented with a series of two stimuli (a club and a spade) and instructed to choose one stimulus with their computer mouse or keyboard to maximize earnings on the task. Upon selection, the chosen stimulus was highlighted, and the outcome associated with that stimulus was shown. Higher outcomes ranged from $0.65 to $0.85 (chosen each trial from a uniform distribution of whole cents in this range), and lower outcomes ranged from $0.15 to $0.35 (similarly chosen from a uniform distribution). One stimulus (the “better option”) was associated with a higher probability (70%) of the higher outcome and a lower probability (30%) of the lower outcome, whereas the other stimulus (the “worse option”) had reversed probabilities. In previous lab-based studies, this task used an adaptive algorithm that ended a block of trials once participants’ learning had plateaued (defined as choosing the better outcome at least seven of the last 10 trials; Brown et al., 2018, 2021). The present online implementation used one nonadaptive block of 50 trials to ensure capture of the full range of learning trials. To best match previous analyses of trials before learning plateaus, only the first 25 trials were used for parameter estimates (for sensitivity analyses using all trials and yielding comparable primary results, see the Supplementary Material and Fig. S2 in the Supplemental Material available online). A change-point analysis (Killick & Eckley, 2014) found one change point after Trial 22, confirming differences in learning trajectories in the two halves of the task. This number of trials is similar to the adaptive version of the task used previously, in which participants’ behavior usually plateaued after 15 to 25 trials. Participants were compensated with a base payment plus a performance bonus of the sum of three randomly selected outcomes from the learning task.
Queries
Every third trial of the learning task, participants were shown a query after the outcome of their choice was displayed. Queries were implemented in a parallel-arm design: Participants were randomly assigned to one of 12 arms; each arm contained a unique repeated query about some part of the experimental task environment (11 learning-query treatment arms) or a control query (one active control arm). The 11 learning-query targets captured structural or statistical features of the task (stimulus values, outcome probabilities, and stimulus-value comparisons including prediction error) that are known to affect different components of reinforcement learning for different stimulus options (chosen stimulus, unchosen stimulus, high-value stimulus, low-value stimulus). The text for each query is shown in Table 1 and represents these reinforcement-learning concepts in lay language.
As illustrated in Figure 1a, for each query, the query text was displayed at the top of the screen, two stimuli were displayed in the middle of the screen, and a slider bar and a “submit” button were at the bottom of screen, allowing the participant to respond to the query. The slider-bar response was randomly initialized at a different location for each query presentation. Anchor values for the slider bar were based on the specific query target (e.g., when queried about value, the range was specified as between 0 and 100 cents, and when queried about differences in value between the two options, the range was −100 to +100 cents). To minimize confounds related to remembering specific choices, the stimulus option being queried was always displayed as the relevant symbol (i.e., club or spade). For the active control arm, participants also viewed queries every three trials and were simply asked to move the slider bar to a certain point as indicated by an arrow.
Self-report measures
Participants completed the Positive and Negative Affect Schedule (PANAS; Watson et al., 1988) before and after the learning task to measure acceptability of the task. Changes in PANAS scores were defined as posttask minus pretask, all divided by pretask scores. Participants also completed the short (21 question) version of the Depression Anxiety and Stress Scale (DASS; Antony et al., 1998; Lovibond & Lovibond, 1995), which includes subscales for depression, anxiety, and stress. Scores on each subscale were doubled to be consistent with the long (42 question) version of the DASS, and clinical cutoffs were applied per the DASS manual. Participants also reported their level of engagement, interest, and difficulty with the task and basic demographic information. Exploratory analyses of variance (ANOVAs) assessed task acceptability and feasibility and examined effects of DASS symptom subscales on learning-task performance and query accuracy.
Data cleaning and preprocessing
To ensure data collected online were of sufficient quality (Chmielewski & Kucker, 2020), systematic data-cleaning steps were followed to remove problematic data and to verify that participants were sufficiently engaged with the task. Specifically, prespecified data-retention criteria, taken from previous work on a similar task (Brown et al., 2018, 2021) and applied sequentially, included completing a sufficient number of learning trials (at least 30 out of 50; excluded 38 of 1,467), choice accuracy of chance level or above on the learning task (minimum choice accuracy of 35%; excluded 71 of 1,429), and selection of each choice to ensure exploration of each option during learning (switching between options on at least 5% of trials; excluded 59 of 1,358). These data-cleaning steps resulted in 1,299 participants’ data retained for analyses and 168 participants’ data (11%) removed. Results of sensitivity analyses including these participants did not meaningfully differ from analyses excluding these participants (see Supplementary Materials, Supplementary Results, and Fig. S1 in the Supplemental Material). An additional 43 participants completed the task but did not complete posttask questionnaires or demographic information. These participants were included in analyses except for those requiring demographic or questionnaire information. Retention of 87% to 89% of the original sample is in the range of or somewhat higher than similar studies in Mechanical Turk populations (Gillan et al., 2016; Rouault et al., 2018).
Model-agnostic behavioral variables
Two primary model-agnostic behavioral-performance variables were used: (a) learning-task choice accuracy and (b) query accuracy.
Learning-task choice accuracy was calculated as the total proportion of accurate choices over all learning trials in the two-option probabilistic learning task, in which an accurate choice was defined as choosing the better option regardless of whether the resulting outcome was high or low.
To quantify query accuracy, the correct answer to each query was defined according to outcomes the participant had experienced up until that trial. Therefore, if the query asked to rate the chance that the better option stimulus would lead to the high-value outcome, the correct answer was defined as the proportion of times this had occurred during the learning task to that point, rather than the predefined probability of 75%. If the correct answer could not be calculated for a specific query instance (e.g., that particular stimulus had not been selected yet), that query instance was excluded for that participant. One participant could not have query accuracy calculated for this reason and was excluded from analyses of query accuracy. The deviation from this correct answer was calculated per query (plotted in Fig. 2); therefore, a query accuracy of 0 indicates perfect accuracy, and values further from 0, whether positive or negative, indicate worse accuracy. The absolute value of the distance from the correct answer was summed over all 16 instances of the query and used as the quantitative measure of query accuracy for analyses. Because a larger value for this measure indicates worse query accuracy, correlations and t tests are reported with signs reversed to aid in interpretation.
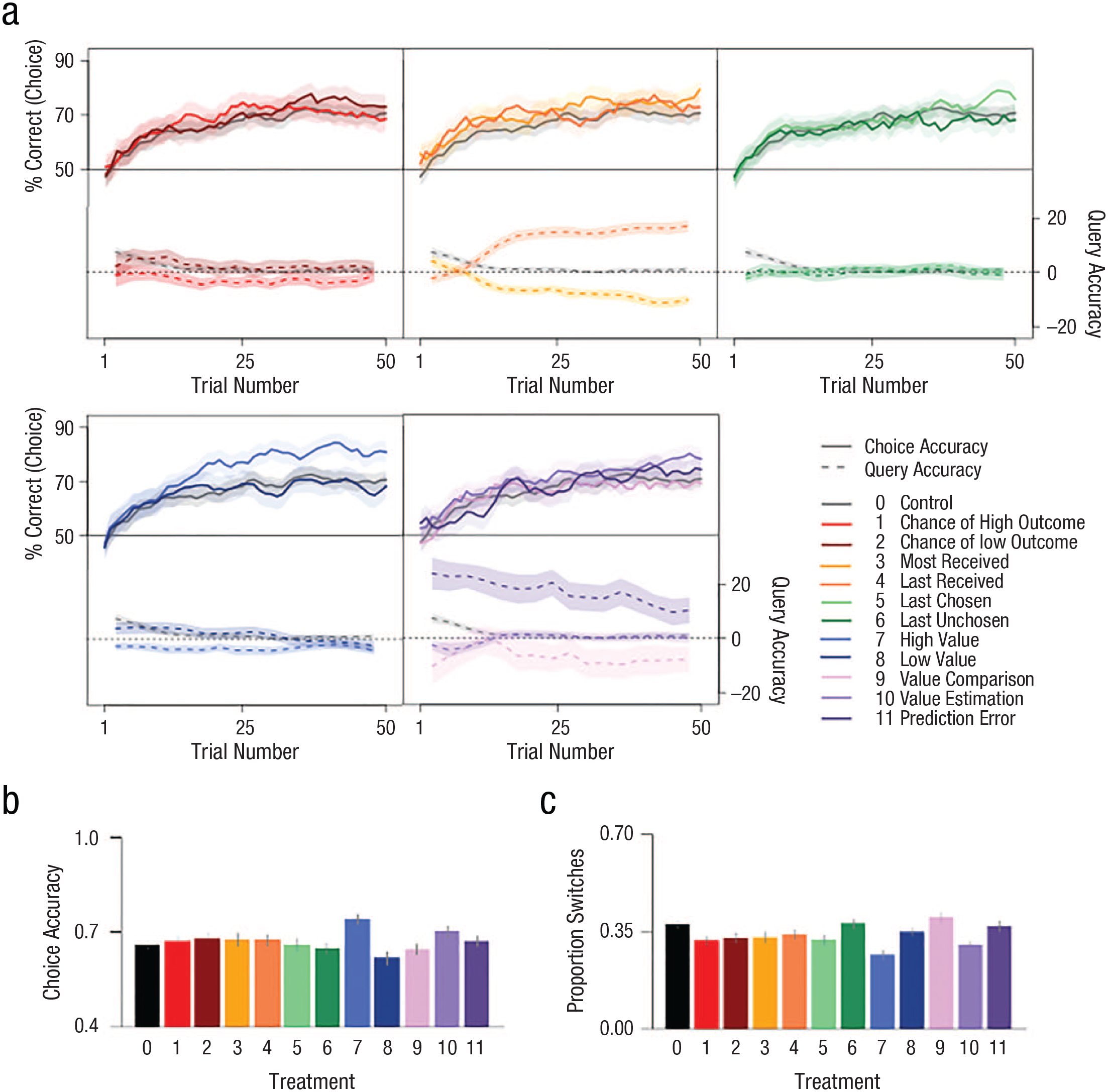
Learning curves by query arm. Query arms are indicated by color/and or number. (a) Each panel shows learning curves and query accuracy over time for the indicated query arms. The active control arm is plotted in gray on each panel. The top half of each panel shows a running average (last five trials) of choice accuracy (y-axis), defined as the percentage of time the stimulus more likely to lead to a higher monetary outcome is chosen. Each bottom panel shows a running average (last three queries) of query accuracy (y-axis), defined as the signed difference between the actual and correct responses to queries. Here, 0 on the y-axis indicates perfect accuracy, and distance above or below 0 indicates greater query inaccuracy. The x-axis shows the trial number. (b) Overall choice accuracy by query arm. Bars indicate SEM. (c) Overall proportion of switches between options by query arm. Bars indicate SEM. For display purposes, query arm data are grouped by query target or stimulus chosen.
Analyses of model-agnostic variables
Model-agnostic analyses used Pearson correlations to assess relationships between continuous variables (choice accuracy, query accuracy, DASS subscales, change in PANAS subscales, and subjective ratings of task engagement). Effects of learning queries on these variables were assessed with ANOVAs; these ANOVAs were run with query arm as a factor and the active control participants’ data as the reference group. If an ANOVA showed significant effects, follow-up regressions were run with each treatment as a separate factor to investigate effects of each treatment arm. Significant results were defined as α < .05.
Analyses of reinforcement-learning parameters
The primary reinforcement-learning model used specifications previously shown to capture symptom-relevant learning processes in depression (Huys et al., 2013) and included parameters for learning rate (α), reflecting how quickly participants updated their expectations of value, and reward sensitivity (ρ), reflecting differential valuation:
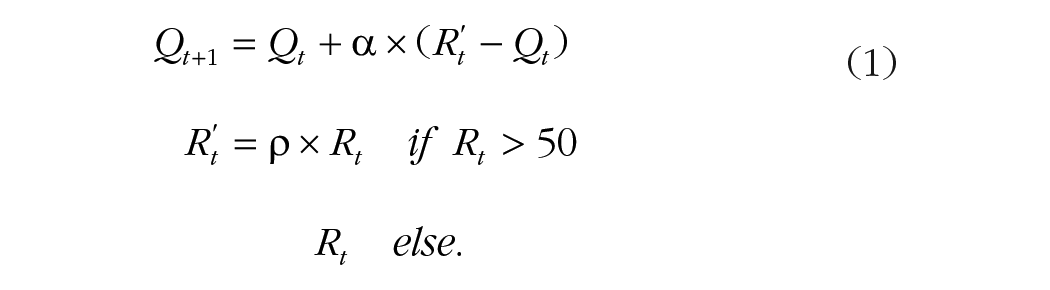
In this model, t represents trial number, Rt is the reward received on that trial (R′t is the reward value modified by reward sensitivity), and Qt is the expected value of the chosen option at that trial. Choices were modeled with a softmax function with an inverse temperature parameter (β) fixed, because of its collinearity with the reward-sensitivity parameter, at 6 (its value in a model without reward sensitivity; Brown et al., 2021):
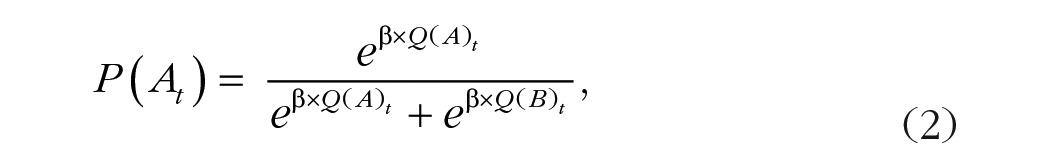
where A and B indicate the two choices in the trial. A model with an additional outcome sensitivity parameter (τ), which shifted values additively to reflect overall biases in valuation (Brown et al., 2021), was tested to see if it improved model fit:
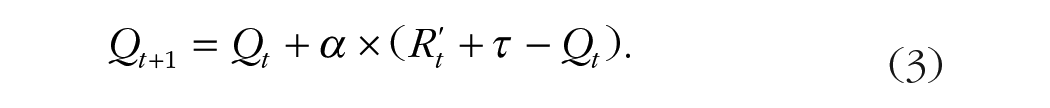
Model fit was compared using integrated Bayesian information criterion (iBIC; Huys et al., 2013), which calculates the average log likelihood over all samples from a posterior distribution and applies a complexity correction based on the number of group-level parameters. Model checks indicated minimal correlation between learning rate and reward-sensitivity parameters (r = .167).
Individual-level parameters were estimated using hierarchical Bayesian estimation as implemented in Stan (Carpenter et al., 2017). Learning rate and reward sensitivity were specified as normally distributed at the group level with a noncentered parameterization to aid in estimation. Learning rate was transformed with a logistic transformation after specification to constrain values between 0 and 1. The prior distribution for the mean of the group-level parameter was set at N(0, 2.5) for learning rate and N(0, 10) for reward sensitivity, and the prior for the variance was set at Cauchy(0, 2) and Cauchy(0, 2.5), respectively. For the model with an outcome-sensitivity parameter, the priors for the mean and variance of the group-level parameter were set at N(0, 1) and Cauchy(0, 2.5). The individual variance, effect of each treatment, effect of covariates (e.g., DASS subscale score), and interaction of covariates and treatment effects were all specified with a prior of N(0, 1). This model specification means that model estimation and effects of covariates and treatment effects are estimated simultaneously in the Bayesian hierarchical model, an approach that maximizes estimation accuracy and reliability of effects (Brown et al., 2020). We note that priors in this type of Bayesian analyses are not intended to strongly affect the posterior estimates but, rather, to regularize estimates to be in an interpretable range for the variables being estimated (Gelman et al., 2014). Four Markov chain Monte Carlo chains were run for 4,000 samples each for each analysis. The first 2,000 samples of each chain were discarded as warm-up, resulting in 8,000 samples for analysis. All chains were inspected for convergence and showed good mixing; all values of the potential scale-reduction factor were below 1.1 (Gelman & Rubin, 1992). The primary analysis included variables for each query arm (coded 1 for participants in that arm and 0 otherwise; the active control participants was the reference group) and the interaction of treatment with DASS depression scores; additional analyses substituted anxiety and stress subscales and query accuracy for depression to test interactions with these symptoms and with query accuracy. Subscale scores were z-scored before entering in the model.
This estimation procedure resulted in estimates of changes in learning parameters for each query arm relative to the control arm, relationships between a covariate (e.g., DASS subscale severity) and learning parameters, and the interaction of a covariate with changes in learning parameters for each query arm relative to the control arm. For all estimates, statistical significance was defined as the 95% credible interval (CI) of the posterior probability distribution of an effect falling completely outside 0 (e.g., entirely above or below 0).
Results
Model-agnostic behavioral performance
Participants displayed intact learning across all query arms (Fig. 2), showing initial performance near chance, improvement over time, and a plateau in performance for most arms. Accuracy on responses to queries was also high in all query arms (performance vs. chance for all query arms: all ts > 9, all ps < .001; Fig. 2a). As expected, given the range of difficulty in correctly answering the different queries, an ANOVA examining query accuracy by query arm was significant, F(11, 1286) = 27.69, η2 = .19, p < .001. A follow-up regression showed that queries asking about the chance of a high outcome (Arm 1: t[1,286] = −2.60, p = .009), the most ever received (Arm 3: t[1,286] = −5.14, p < .001), the least ever received (Arm 4: t[1,286] = 7.04, p < .001), the value of the better option (Arm 7: t[1,286] = −3.19, p = .001), value comparison (Arm 9: t[1,286] = −4.876, p < .001), and prediction error (Arm 11: t[1,286] = 9.13, p < .001) had accuracies significantly different from the control condition. An ANOVA examining choice accuracy by query arm was also significant, F(11, 1287) = 3.07, η2 = 0.03, p < .001. A follow-up regression indicated that queries asking about the most ever received (Arm 3: t[1,287] = 2.27, p = .024), the value of the better option (Arm 7: t[1,287] = 4.33, p < .001), and the overall value of the chosen option (Arm 10: t[1,287] = 2.28, p = .023) led to higher choice accuracy relative to the control condition. There were no queries that worsened performance relative to the control condition (Fig. 2b). Finally, for switching behavior, the ANOVA of proportion switches by query arm was significant, F(11, 1287) = 5.66, η2 = 0.05, p < .001. A follow-up regression indicated that queries asking about the chance of a high or low outcome (Arm 1: t[1,287] = −2.96, p = .003; Arm 2: t[1,287] = −2.36, p = .018), most or least ever received (Arm 3: t[1,287] = −2.14, p = .03; Arm 4: t[1,287] = −2.00, p = .045), the option most recently chosen (Arm 5: t[1,287] = −2.30, p = .02), the value of the better option (Arm 7: t[1,287] = −5.29, p < .001), and the overall value of the chosen option (Arm 10: t[1,287] = −3.74, p = .001) all decreased switching relative to the control condition (Fig. 2c).
Effects of queries on model-derived learning parameters
To quantify query effects on specific learning components, we estimated learning parameters of learning rate (measuring the degree of value updating based on prediction error) and reward sensitivity (measuring the relative valuation of high vs. low outcomes) based on a reinforcement learning model previously validated in this learning task and sensitive to depression-related alterations in reward learning (Brown et al., 2021). A model with an additional outcome shift parameter, as was used in Brown et al. (2021), had worse fit, likely because of the inclusion of rewarding outcomes only in this version of the task (iBIC of 44.88 vs. 35.65 for the model with learning rate and reward sensitivity only, where a smaller iBIC indicates a better fit), and so was not used.
Posterior probability distributions of the effects of each of the 11 active queries on learning parameters are plotted in Figure 3 (significant effects are plotted with opaque colors). Queries assessing value estimation of the most recently chosen option resulted in a higher learning rate (Arm 10: logit-transformed mean effect on learning rate = 1.05, β = 2.35, 95% CI = [.182, 1.95]), whereas queries assessing the value of the unchosen option resulted in a lower learning rate (Arm 6: logit-transformed mean effect = −1.01, β = −2.00, 95% CI = [–2.00, –0.021]). For reward sensitivity, queries asking about the probability of both high (Arm 1: mean effect = 0.225, β = 2.53, 95% CI = [0.071, 0.419]) and low outcomes (Arm 2: mean effect = 0.174, β = 1.71, 95% CI = [0.015, 0.415]), the least ever received for an option (Arm 4: mean effect = 0.214, β = 2.43, 95% CI = [0.066, 0.412]), and the value of the high value option (Arm 7: mean effect = 0.165, β = 2.83, 95% CI, [0.054, 0.283]) all increased reward sensitivity.
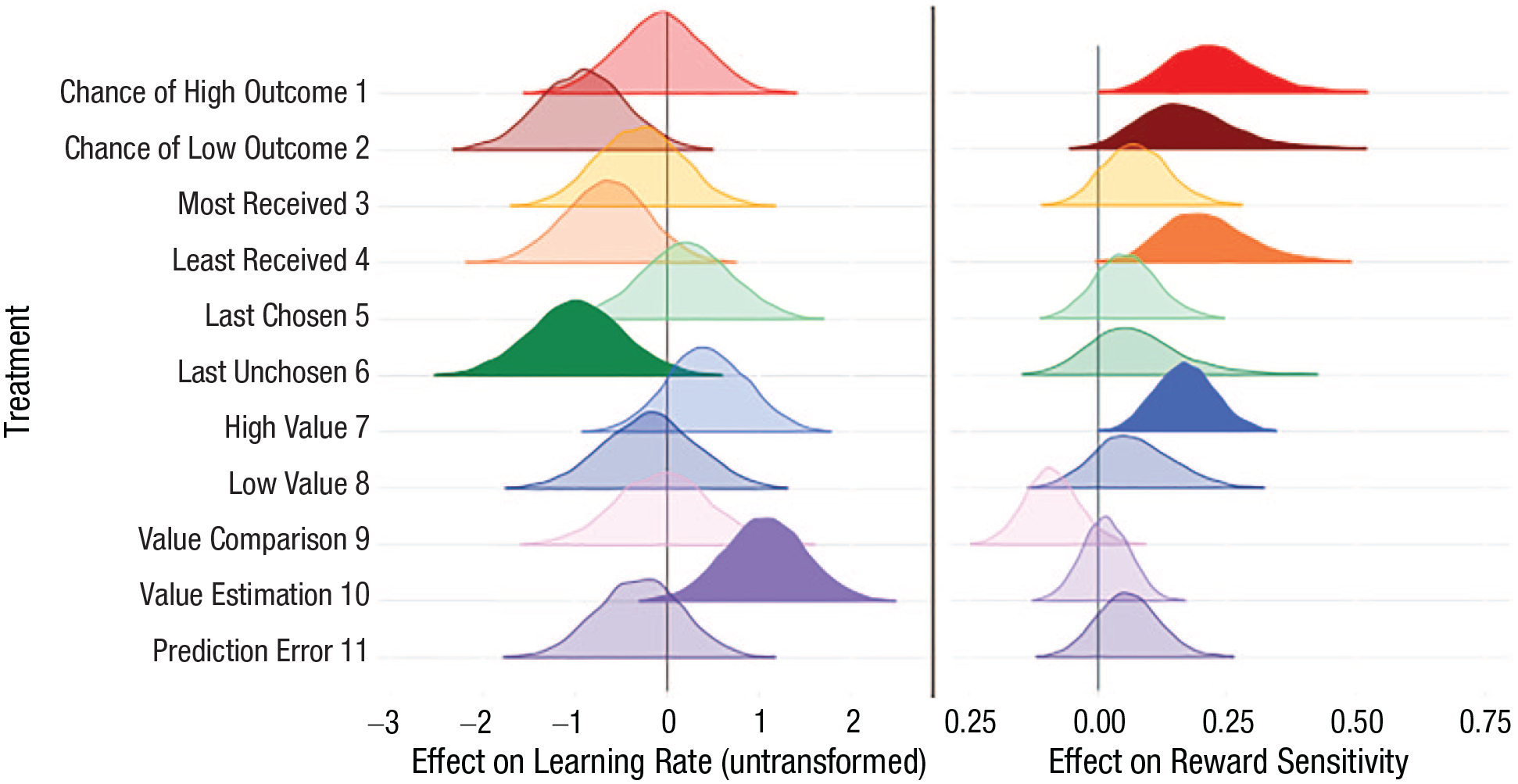
Changes in learning parameters by query arm relative to active control. Shaded areas represent the posterior distribution of the difference from active control for each query arm. Opaque colors represent distributions significantly different from 0 (95% of posterior above or below 0).
Relationships of depression/anxiety symptoms with model-agnostic and model-derived behavioral performance
As summarized in Table 2, participants reported a range of depression, anxiety, and stress symptoms, including a substantial proportion of participants reporting clinically elevated symptoms (22%–32% of sample, consistent with previous reports in online crowdsourced populations, Arditte et al., 2016; Chandler & Shapiro, 2016; clinically elevated defined as at least “mild” severity based on published cutoffs).
For choice accuracy on the learning task, there was a main effect of symptom severity for each DASS subscale (depression: F[1, 1232] = 7.41, η2 = .005, p = .007; anxiety: F[1, 1232] = 21.72, η2 = .02, p < .001; stress: F[1, 1232] = 14.54, η2 = .01, p < .001; Fig. 4b) and no interactions with query arm (depression: F[11, 1232] = 0.41, η2 = .004, p = .95; anxiety: F[11, 1232] = 0.91, η2 = .008, p = .53; stress: F[11, 1232] = 0.82, η2 = .007, p = .62), indicating that participants with higher symptom severity were less accurate on the learning task regardless of the queries asked. Likewise, a main effect of symptom severity was observed for query accuracy for each DASS subscale such that depression was related to slightly worse query accuracy overall (F[1, 1232] = 5.50, η2 = .004, p = .02; Fig. 4c) and anxiety and stress were more strongly related to worse query accuracy (anxiety: F[1, 1232] = 53.07, p < .001, η2 = .04; stress: F[1, 1232] = 16.58, η2 = .01, p < .001).
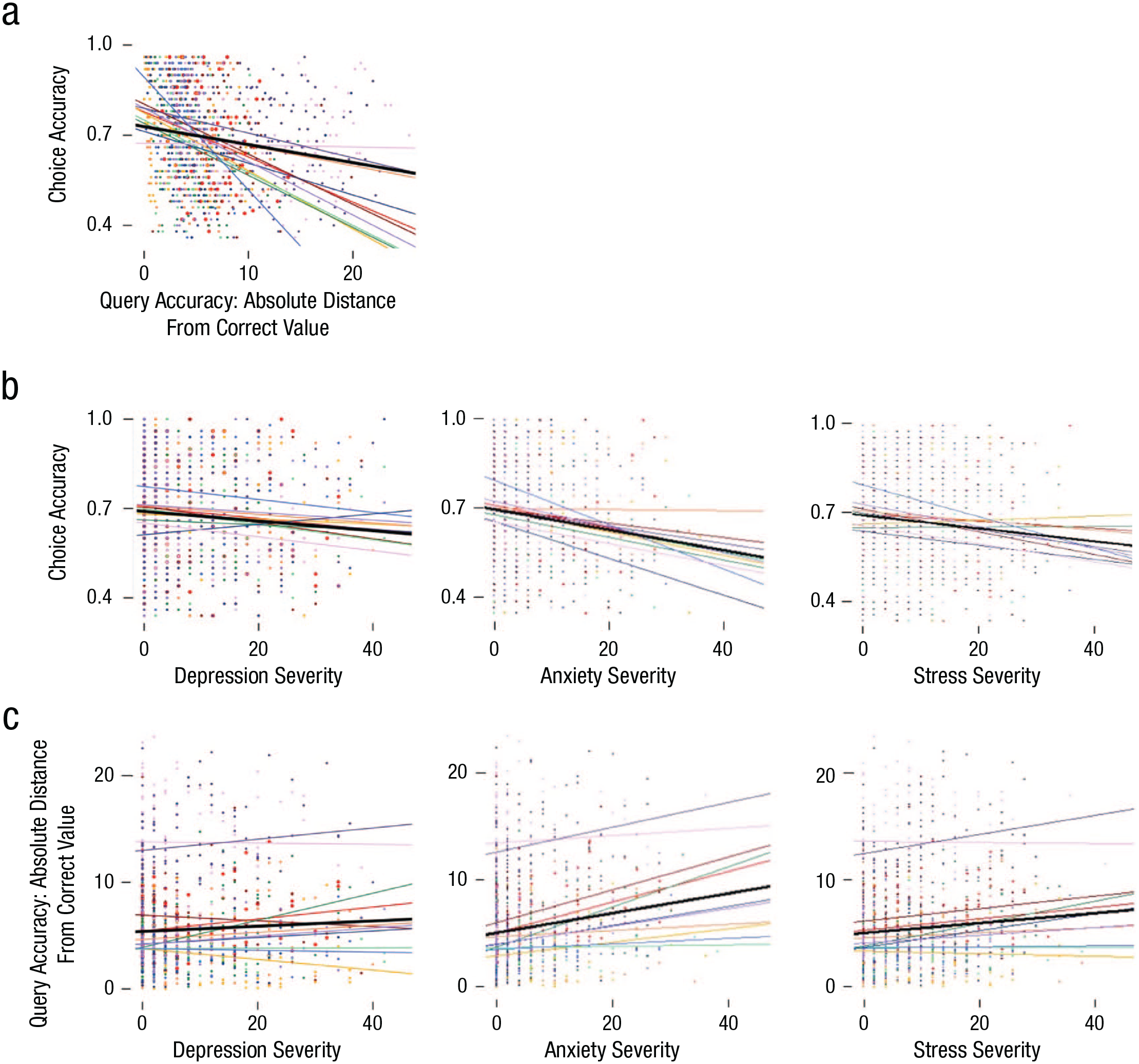
Relationships among choice accuracy, query accuracy, and symptom severity. On each plot, colored lines and dots indicate query arm (see Table 1). Each dot represents one participant, and colored lines represent the line of best fit per arm. Thick black lines indicate the line of best fit for all participants across all arms. “Depression,” “anxiety,” and “stress severity” refer to Depression Anxiety and Stress Scale depression, anxiety, and stress subscale scores, respectively. (a) Relationship between query and choice accuracy. Across all conditions, more accurate responses on queries (lower distance from correct value) were related to better choice accuracy. (b) Relationship between symptom severity and choice accuracy. Overall, higher symptom severity was related to worse choice accuracy. (c) Relationship between symptom severity and query accuracy. Overall, higher symptom severity was related to worse query accuracy.
To explore whether mood, anxiety, or stress symptoms affected the effects of the queries on model-derived learning components, we then examined the effects of DASS subscales as covariates. Depression was not related to query effects on learning parameters for any query (all 95% CIs encompassing 0), suggesting that any query effects were consistent across levels of depression. The consistency of query effects by depression was similar when the depression covariate was binarized to categorize reported severity as above the clinical cutoff versus below (Lovibond & Lovibond, 1995). For anxiety, higher symptom severity was related to a lower learning rate when queried about the chance of a high outcome (Arm 1: logit-transformed mean effect = −1.08, β = −2.00, 95% CI = [–2.15, –0.01]) but showed no learning differences when binarized into scores above the clinical cutoff versus below. Stress was related to a lower learning rate when queried about the chance of a low outcome (Arm 2: logit-transformed mean effect = −0.91, β = −2.01, 95% CI = [–1.79, –0.004]) or the value of the last unchosen option (Arm 6: logit-transformed mean effect = −1.31, β = −2.39, 95% CI = [–2.37, –0.20]); when binarizing stress severity in above the clinical cutoff versus below, high-stress participants had lower reward sensitivity when queried about the chance of a high outcome (Arm 1: mean effect = −0.40, β = −2.27, 95% CI = [–0.71, –0.01]).
For completeness, we used the active control arm and examined whether our previous findings of reinforcement-learning parameter differences in clinical-interview-diagnosed depression (Brown et al., 2021) generalized to the current study sample and task. In the present study, DASS depression scores were not related to learning parameters (learning rate: logit-transformed mean effect = −0.074, β = 0.190, 95% CI = [–0.841, 0.146]; reward sensitivity: mean effect = −0.010, β = −0.319, 95% CI = [–0.067, 0.050]). We note that several differences (e.g., online sample, self-report depression assessment, learning-task structure; likely subclinical sample even in high DASS scorers per Flint, 2023) between our prior and current work precluded direct replication, which remains of interest and to be carried out.
Relationship of query accuracy with model-derived behavioral performance
To assess whether difficulty of queries, as assessed with participant-level query accuracy, was related to effects, an additional analysis was run examining effects of query accuracy as a covariate. All parameter changes in the primary analyses remained significant; in addition, when query accuracy was controlled for, querying about the probability of low outcomes decreased learning rate (Arm 2: logit-transformed mean effect = −0.91, β = −2.03, 95% CI = [–1.79, –0.027]), and querying about prediction error increased reward sensitivity (Arm 11: mean effect = 0.14, β = 1.87, 95% CI = [0.001, 0.30]). For differences in parameter changes with and without covarying for query accuracy, see Figure S3 in the Supplemental Material.
Participant perceptions of task
Because related approaches may be used to evoke behavioral change in individuals with psychopathology, we assessed the acceptability and feasibility of our query-guided reinforcement-learning paradigm (Fig. 1b). Overall, participants rated the task as engaging (M = 6.5 [out of 10], mode = 10), interesting (M = 6.3, mode = 10), and not difficult (M = 3.0, mode = 0). Participants also rated their positive and negative affect before and after completing the queried learning task, and participants who rated the task as more engaging and interesting also reported increases in positive affect (rs = .40 and .44, ps < .001) and decreases in negative affect (rs = −.15 and –.13, ps < .001), whereas participants who rated the task as not difficult reported a decrease in negative affect (r = .08, p = .006; Fig. 1b). Ratings of engagement, interest, and difficulty did not differ by query (ANOVA of effect of treatment on ratings: all Fs < 1.7, ps > .05).
To assess the possibility that participants answered queries accurately at the expense of performing the learning task well, we examined the relationship between choice accuracy on the learning task and query accuracy. Overall, participants who performed better at the learning task had more accurate responses to queries (r = .138, p < .001; range of correlations by query arm: rs = .03–.44; Fig. 4a). These data indicate that accurate performance on the learning task and attending to queries were not at odds. Together, these data demonstrate that participants found the task acceptable and displayed both good performance on the learning task and accurate responses to queries.
Discussion
Understanding how and under what circumstances reinforcement learning can be changed is vital to better comprehend and effect learning-related changes. In the present study, we found that querying participants about reinforcement-learning-related task components, in the absence of feedback on these queries, significantly altered learning in directions specific to the type of query for several query types. These effects on learning parameters were independent of depression severity, suggesting generalizability to samples with psychopathology, and participants’ behavior and reports showed the query-guided learning task to be feasible and acceptable.
Distinct queries had distinct effects on reinforcement-learning parameters. Learning rate increased, relative to the control group, in participants queried about the expected value of their most recent choice (Arm 10); learning rate was lowered when participants were queried about the value of the option they had not chosen (Arm 6). Of interest, queries assessing prediction error (i.e., differences in actual and expected outcomes, Arm 11) or the outcome of the last choice (Arm 5) did not affect learning rate. This pattern of results suggests that some components of prediction error, such as past expected value, may be incorporated more into learning, whereas others, such as received outcomes, may be less affected by reminding via queries. In addition, simpler queries, rather than those that closely follow learning processes, may be more effective for changing learning. That is, although we expected that querying about prediction error would change learning rate, this was the case only for queries about the expected value of options (value estimation) and not prediction error itself. Supporting this, querying participants about the actual outcome of the last choice did not increase learning rate, suggesting a ceiling effect whereby learners may already be incorporating this information as much as possible. In comparison, querying about the average value of the unchosen option did decrease learning rate, suggesting that focus on counterfactual outcomes slows learning about chosen options.
For reward sensitivity, querying about the probability of outcomes increased this parameter (Arms 1 and 2); in addition, asking about the value of the high-value option (Arm 7) and the least ever received when choosing an option (Arm 4) also increased reward sensitivity; there were no queries that decreased reward sensitivity. Although queries focused on probability or extremes of value increased reward sensitivity more than other queries, we also note that a majority of the learning-related queries increased reward sensitivity to some degree relative to the control arm. That is, drawing attention to different features of value led participants to be more sensitive to value differences during learning, as evidenced by increases in the reward-sensitivity parameter. By comparison, the effect of querying about comparing values, which we hypothesized would decrease reward sensitivity, did not reach statistical significance but was the only query to qualitatively decrease this parameter. These data indicate that focusing on single options, regardless of the specific query, increases reward sensitivity, whereas focusing on comparing options may have an opposite effect.
More generally, we found that querying about learning can significantly alter learning processes. These findings build on our previous work showing distinct learning disruptions related to symptoms of depression and remediation of these learning disruptions with symptom improvement in depression (Brown et al., 2021). Together, this work suggests the potential to reduce depressive symptoms directly through changing learning parameters. If successful, such learning-retraining interventions could be delivered remotely and at scale, addressing a critical need for increased access to evidence-based depression treatment (Kazdin, 2017). This work builds on past research that examined experimental task-derived cognitive interventions for psychopathology (e.g., attention-bias modification; McNally, 2019; Price et al., 2019; Rodebaugh et al., 2016) and further brings in a strong theoretical and empirical body of work in learning theory and neuroscience (Niv, 2009; Sutton & Barto, 1998) and task-based measures with both good psychometric properties and connection to symptom change (Brown et al., 2020, 2021).
Our sample included individuals with a wide range of depression, anxiety, and stress severity, allowing us to examine whether self-reported symptoms influenced whether queries altered learning processes. In the present single-session study, we did not find an overall effect of depression or an interaction of depression with the effect of any treatment, suggesting that the present approach to changing learning processes is effective for changing learning in individuals with depression-related symptoms, including participants meeting clinical thresholds. For increasing anxiety and stress symptoms, some queries were associated with reduced learning rate; however, the presence of these relationships was inconsistent across continuous and binarized measures of anxiety/stress, suggesting the effects may not be systematic. Future studies may need to address potential symptom-specific effects of learning training paradigms and tolerability for individuals with anxiety or stress symptoms. The single session of guided learning was at an intensity and duration intended to create acute learning changes but less than an anticipated therapeutic dose for changes in psychopathology symptoms. Longer-term studies with longer or repeated sessions could be implemented at an intensity anticipated to change depression symptoms through targeting learning processes. In line with some previous findings (Blanco et al., 2013; Pizzagalli et al., 2008), we did find significant relationships between symptom severity and both performance on the learning task and query accuracy. However, the effect sizes for these relationships were small, suggesting that even participants reporting high symptom severity could complete all aspects of the session effectively. Indeed, the present task structure was both well tolerated by participants and effective in changing learning. Participants rated the task as engaging, interesting, and not difficult, and most participants passed our quality checks, performed accurately on the learning task, and answered queries accurately. These results are encouraging for future applications of learning retraining-related tasks in treatment settings (Paulus et al., 2016). Future studies should also test whether learning effects persist beyond the training session and generalize to learning outside a specific task.
In addition to providing support for using learning queries to alter behavior, these findings also shed light on basic mechanisms of reinforcement learning. Participants’ choices, driven by the expected value of these choices, changed in response to targeted queries without any feedback-driven learning from the queries themselves. These shifts in valuation and learning suggest that retrieved value during decisions incorporates past experiences in a malleable way and adds to the growing literature on the interaction between reinforcement learning and memory representations (Gershman & Daw, 2017; Shohamy & Daw, 2015). Queries may have also changed learning through directing attention to different stimuli or aspects of the task, consistent with the role of attention in shaping reinforcement learning (Leong et al., 2017). However, these shifts did not always occur in predictable ways. For example, querying about prediction error, which most directly relates to the learning-rate parameter, did not change learning rate. This facet of our results highlights the potential complexity of altering learning and that therapeutic approaches to targeting learning (e.g., Craske et al., 2014, 2016) require thoroughly investigating how to bring about intended changes in learning. The relative difficulty of the queries may play a role in their effectiveness at targeting learning. In particular, participants were not very accurate when estimating prediction error, and the effect of this query on reward sensitivity became significant when covarying for query accuracy. Therefore, simpler queries may be more effective at targeting learning, or strategies that increase accuracy of query responses may boost effects for more difficult queries. Recent work in fear conditioning and computational modeling of consumer choice has also found that queries and nudges alter processes involved in these behaviors (Atlas et al., 2022; Zhao et al., 2022), suggesting that querying participants during learning has wide-ranging and likely understudied effects on many types of learning and decision-making.
The experimental manipulation of learning reported here also has implications for previous correlational findings of learning disruptions in depression. Our previous study in clinically depressed participants (Brown et al., 2021) found reduced reward-learning rates, accompanied by intact striatal signal to reward prediction errors, but altered relationships between striatal prediction error and expected value reward signals in depressed participants with high anhedonia. Here, our experimental manipulation found reduced learning rates when participants were asked to focus on unchosen options or low values. Participants with higher depressive symptoms were also less accurate at reporting the value of unchosen options. Future work could examine if the reduced learning rates previously observed with anhedonia result from a learning process that focuses on alternate, unchosen options with uncertain values.
This work represents an initial step toward using an experimental-therapeutics (Insel & Gogtay, 2014) mechanism-guided approach to target aspects of learning associated with depression. Thus, we focused on reward learning only. Because learning from negative outcomes is also disrupted in depression (Brown et al., 2021; Chen et al., 2015), future work should examine effects of queries targeting loss learning. Other psychopathology-relevant aspects of learning (e.g., Brown et al., 2018; Price et al., 2019; Shohamy & Daw, 2015; Wang et al., 2019), such as attention, memory, or learning from positive versus negative prediction errors, ought to also be explored. We did not expect the single session of learning retraining tested here to change symptoms directly; future work should also use queries identified here in longitudinal settings to assess changes in symptoms. Future studies should also test whether learning effects persist beyond the training session and generalize to learning outside a specific task. Another limitation of the present work was the reliance on self-reported, rather than clinically assessed, psychopathology in online participants.
In summary, we found that explicit learning-related queries are effective in changing learning parameters in specific ways. These effects were present across individuals with a range of depression, anxiety, and stress symptoms, and the paradigm was acceptable to participants. These findings lay the groundwork for future studies exploring the effects of repeated applications of learning retraining paradigms on real-world behavior and psychopathology.
Supplemental Material
sj-docx-1-cpx-10.1177_21677026231213368 – Supplemental material for Reinforcement-Learning-Informed Queries Guide Behavioral Change
Supplemental material, sj-docx-1-cpx-10.1177_21677026231213368 for Reinforcement-Learning-Informed Queries Guide Behavioral Change by Vanessa M. Brown, Jacob Lee, John Wang, Brooks Casas and Pearl H. Chiu in Clinical Psychological Science
Footnotes
Acknowledgements
We gratefully acknowledge the research assistance of Brennan Delattre and Cari Rosoff.
Transparency
Action Editor: DeMond M. Grant
Editor: Jennifer L. Tackett
Author Contributions
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.