
Abstract
There is a significant degree of heterogeneity in scales that purport to measure depression and generalized anxiety in adolescent samples, which makes it difficult to directly compare scores across studies. The aim of the current study is to develop a common metric that facilitates the comparison of scores from different but related scales of depression and generalized anxiety using a large adolescent sample. A nonequivalent-anchor-test design in conjunction with simultaneous calibration was used to equate and develop a common metric for six different scales. The common metric provided scores with acceptable levels of precision across the −1 to 3 range on θ, which represents the more severe and often clinical end of the spectrum. Thus, in the current study, we identified a coherent common metric that is closely aligned with the “distress” subfactor of the Hierarchical Taxonomy of Psychopathology model. Additional validation testing in independent samples is now required.
In psychiatric-epidemiological research, there are no standardized biological or laboratory tests that can objectively detect the severity of disorders, identify risk and protective factors associated with disorders, and demonstrate whether population trends have changed across time or cohorts. Instead, observational, cross-sectional, and cohort studies depend on the use of item-based severity or diagnostic scales that are predominantly self-report and generate total scores to represent a construct of interest. Thus, there has been a significant proliferation of scales to measure mental-health constructs that can differ in terms of content, context, and psychometric rigor (Fried, 2017). Indeed, it is rare that different studies use a common set of scales despite purportedly measuring the same or similar constructs. This heterogeneity has made it difficult to standardize mental-health assessment and prevented the comparability of data across studies (Gatz et al., 2015). For example, any differences that emerge between studies may reflect a mix of true differences in the underlying construct and unrelated differences in how the samples respond to the different measures. This may potentially bias results and obfuscate findings from studies that seek to identify long-term trends in mental health to better inform policy and treatment-service planning, complicate studies that draw comparisons across different forms of treatment, and limit studies that seek to increase sample sizes to detect small associations or interactions between mental disorders and other clinically relevant factors (i.e., those examined using individual participant meta-analysis; e.g., Buckman, Saunders, Cohen, et al., 2021; Buckman, Saunders, Stott, et al., 2021; Karyotaki et al., 2021). Indeed, inconsistent measurement limits the potential knowledge gains that could be made from using large and powerful data sets to answer key questions about the nature of and risk for psychopathology (Curran et al., 2018).
The prospect of making significant gains from analyzing large-scale combined data sets has led to calls for international standards that identify a common set of self-report measures for mental health that can be used in studies on adolescent and adult populations moving forward (Farber et al., 2020; Wolpert, 2020). Although this approach is strong in principle, the practical application of a single set of common measures used across different studies may face several barriers that necessitate the use of different measures across studies (Patalay & Fried, 2021). For example, some studies may attempt to reduce respondent burden by giving preference to brief measures, whereas other studies might be more interested in obtaining scores from longer scales with greater precision to detect minor changes in outcomes. Moreover, scale selection depends on how the assessment information will be used; different measures are more ideal for tasks associated with screening compared with diagnosis or assessing individual differences over time. Mental disorders also manifest in numerous forms; some studies may wish to focus on a smaller subset of symptoms while other studies may prefer to focus on broad disorder severity, and different measures will be needed to reflect these different aims. For longitudinal studies, multiple scales measuring the same disorder are required with slight alterations depending on the population under investigation or alterations required to the time frame referred to by each item (e.g., different scales are needed to suit adolescent vs. adult participants). In short, researchers and clinicians often face competing interests. Different measures that purportedly measure the same construct are required across studies or across longitudinal-measurement points for practical reasons, yet to generate accurate comparisons over time or across studies, there is a need to establish a truly comparable score.
To address some of these limitations, researchers have advocated for an alternative approach based on methods that statistically recalibrate and equate different scales, reducing biases associated with differences in scale content and severity, by determining a “common metric” (Kolen & Brennan, 2014). The common-metric approach to standardized measurement has been exemplified in the adult population by the Patient Reported Outcomes Measurement and Information System (PROMIS) to equate existing self- and proxy-reported scales for physical and emotional health (Choi et al., 2014; Cook et al., 2015; Schalet et al., 2014; Schalet, Revicki, et al., 2015; Schalet, Rothrock, et al., 2015). In adolescent/pediatric samples, there have been previous attempts to estimate common metrics that measure depression to facilitate harmonization (Kaat et al., 2020; Olino et al., 2013). Indeed, Kaat and colleagues (2020) found high agreement between PROMIS-pediatric depression scores and those derived from three equated depression scales (Patient Health Questionnaire 9 Adolescent adaptation (PHQ-A); Center for Epidemiological Studies - Depression Child version (CES-DC); Short Mood and Feelings Questionnaire (SMFQ)). According to Bland-Altman plots, the agreement between scores was best for individuals with a higher degree of severity associated with their depressive symptoms.
The method employed by PROMIS involves reestimating scores on existing measures by finding the equivalent scores on the PROMIS item banks for a given construct using a “calibration” sample of participants who complete the PROMIS item bank and additional measures to be equated. However, other studies have developed common metrics using slightly different methods to equate 11 scales that measure depression in the adult general population (Wahl et al., 2014), seven scales that measure psychological distress in an adult community sample (Batterham et al., 2018), and 11 scales that measure social anxiety in an adult community sample (Sunderland et al., 2018) onto a new shared common metric. These studies demonstrated that existing scales can be used to derive scores on an associated common metric with acceptable precision/accuracy and possess a high level of agreement, particularly compared with previously validated cut points on the equated scales that index clinical significance (Wahl et al., 2014). Moreover, Olino and colleagues (2013) found a high degree of convergence (intraclass correlation coefficients [ICCs] ≥ .85) across the two equating approaches (i.e., linking scales to the PROMIS metric compared with equating all items to a single-item pool). Thus, different studies or longitudinal cohorts that use different yet equated scales can use the scoring algorithms to convert scores to the common metric for more accurate comparisons and data harmonization (Gibbons et al., 2014).
In addition to robust methods to equate mental-health scales, a standardized and preferably empirically grounded framework in which to guide and inform the development of common metrics is needed. Previously, mental-health assessments have been established on the basis of the categorical/medical model promoted by the Diagnostic and Statistical Manual (DSM) and the International Classification of Diseases. Indeed, many common metrics discussed above primarily reflect these categorical constructs (e.g., depression, generalized anxiety, social anxiety). However, epidemiological evidence has consistently identified high rates of comorbidity that call into question the categorical-medical model (Andrews et al., 2008, 2009; Krueger, 1999; Slade & Watson, 2006). The presentation of homogeneous symptom clusters across putatively distinct diagnostic constructs, particularly in children and adolescents, indicate that broad or general dimensional traits might better reflect the emergence of psychopathology rather than highly specific diagnostic categories (McElroy et al., 2018). Measurements and metrics that seek to capture psychopathology accurately and validly should aim to strongly reflect how they emerge in nature.
The Hierarchical Taxonomy of Psychopathology (HiTOP) is an empirically driven framework that offers substantial promise as a framework for organizing a set of dimensional constructs that represent broad and specific facets of psychopathology that are linked hierarchically (as observed by higher-order statistical models; Conway et al., 2019; Hyland et al., 2021; Kotov et al., 2017; Ringwald et al., 2021). The HiTOP framework uses dimensional, transdiagnostic latent constructs that attempt to overcome limitations with categorical diagnoses and better capture and reflect comorbidity. One construct that has seen extensive empirical evidence is a midtiered construct in the HiTOP framework, commonly referred to as the “distress” subfactor, that accounts for the extensive co-occurrence between symptoms of depression and chronic worry/generalized anxiety and can be differentiated from other anxiety symptoms that represent the “fear” subfactor (e.g., panic, specific phobias, social anxiety; Forbes et al., 2021). Both distress and fear subfactors have been shown to represent a broader spectrum of “internalizing” that captures the shared variance across all mood and anxiety disorders. Recent evidence has indicated that rates of broad distress and internalizing may emerge in early childhood and become increasingly more specific in later adolescence, manifesting into clinical levels of depression and anxiety in early adulthood (Cervin et al., 2021; McElroy et al., 2018). Thus, it might be possible to use the HiTOP framework to equate measures that purportedly target various signs, symptoms, and features that make up the broader distress subfactor in adolescent samples.
On the basis of this theoretical and empirical background, in the current study, we sought to develop a common metric for broad distress in adolescent samples that can be used to equate multiple measures that target symptoms of depression and chronic worry/generalized anxiety that commonly co-occur. Prior studies have focused on developing either common metrics for more specific constructs, such as depression or social anxiety (Kaat et al., 2020; Olino et al., 2013; Sunderland et al., 2018; Wahl et al., 2014), or broader constructs that target psychological distress/internalizing but have done so in adult populations (Batterham et al., 2018). To our knowledge, no study has examined the possibility of a common metric focusing on comorbid internalizing symptoms (in particular, symptoms indexing the distress subfactor) in an adolescent population. Given adolescence is a time when internalizing symptoms often develop and manifest, it could be argued that a more nonspecific common metric would be suitable for detecting earlier onset cases rather than any disorder-specific metric (McElroy et al., 2018). The aim of the common metric is to provide a single interpretation when combining existing data sets that contain at least one of the equated measures or use the equated scales for research in the future. In the current study, we used data from two large-scale, school-based cohorts to equate six measures designed to measure distress on a common interpretable metric.
Transparency and Openness
The analysis plan for the current study was not preregistered. Code and output files associated with the analysis are available at https://github.com/mmsunderland/disstresscommonmetric. Additional example code required to generate item-response-theory (IRT)-based scoring is provided in the Supplemental Material available online. In the current study, we used secondary data analysis of previously collected samples; the sample-size determination and data exclusions are reported elsewhere (Teesson et al., 2017, 2020). We report all manipulations and measures used in the current study below. The current study received ethical approval from the University of Sydney Human Research Ethics Committee (No. 2020/443).
Method
Sample
Data for the current study were from the baseline collection of two longitudinal, school-based, randomized controlled trials for mental health and substance use. The first study, known as the Climate and Preventure (CAP) study, recruited 26 Australian secondary schools (17 independent and nine government) between September 2011 and February 2012 (Teesson et al., 2017). A total of 2,190 students who received parental consent and consented themselves were eligible to participate. The second sample, known as the Climate Schools Combined (CSC) study, recruited 71 Australian secondary schools from New South Wales, Queensland, and Western Australia between September 2013 and February 2014 (Teesson et al., 2020). A total of 6,386 students who received parental consent and consented themselves were eligible to participate and provided data during at least one collection point. Data from both samples were combined into a harmonized data set (e.g., common items were matched in terms of labeling and response options) that totaled 8,576 students. However, there were some students who had missing data on all variables of interest and were therefore removed from the analysis, resulting in a final analyzed sample size of 8,238 (96%). All data for the current study were deidentified. A random split cross-validation sampling strategy was used to calibrate the common metric and crosswalks in 80% of the data, followed by validating the crosswalks in an independent 20% holdout sample.
The baseline characteristics for the CAP and CSC studies have been presented in previous studies (Teesson et al., 2017, 2020). In brief, the CAP study comprised adolescents with a mean age of 13.4 years (range = 11.9–15.2), 86% of participants were born in Australia, approximately 58% were male, and 82% reported their usual grades on subjects at school were above 70 (out of 100). The CSC study comprised adolescents with a mean age of 13.6 years (range = 11.6–15.5), 82% of participants were born in Australia, approximately 45% were male, and 76% reported their usual grades on subjects at school were above 70 (out of 100). Both studies did not collect information on the racial/ethnic identification of the participating students. The sample broadly reflects Australian school-attending adolescents, albeit the studies had an overrepresentation of adolescents from higher socioeconomic status given recruitment of independent schools. In terms of clinical characteristics, approximately 9.2% scored 13 or above on the Kessler 6, indicating high psychological distress and potential serious mental illness. In contrast, prevalence of psychological distress in a general Australian population sample of adolescents, measured using the Kessler 10, was estimated at 13.3% for high psychological distress and 6.6% for very high psychological distress (Lawrence et al., 2015).
Given that both samples were not administered all scales to be equated, the average number of items with nonmissing responses across the two samples was 29 (SD = 10, range = 5–35). The most common items completed by the sample were from the Kessler 6 Psychological Distress Scale (K6) and Strengths and Difficulties Questionnaire– emotionality (SDQ), which formed the anchor set, followed by the Patient Health Questionnaire-8 (PHQ-8), Generalized Anxiety Disorder seven-item scale (GAD-7), and Child Health Utility instrument (CHU-9D; for details, see Table S1 in the Supplemental Material). The scale with the least number of participants providing data for each item was the Brief Symptom Inventory-depression (BSI-D) subscale (n = 1,538).
Measures
Items that form the common metric were extracted from established mental-health scales that have been widely used and validated. A descriptive summary of all the items and the specific sample they were obtained from are provided in Table S1 in the Supplemental Material.
CHU-9D
The CHU-9D was developed by health economists as a utility function to measure preference-based health-related quality of life among children 7 to 11 years old and has demonstrated validity in adolescents up to the age of 17 (Ratcliffe et al., 2016). The CHU-9D comprises nine questions with five response categories targeting current functioning across domains of worry, sadness, pain, tiredness, annoyance, school, sleep, daily routine, and activities. Previous studies have identified the CHU-9D as a useful proxy measure for mental-health outcomes in routine clinical practice with moderate associations and good discriminate power to detect nonclinical and clinical ranges as determined by the SDQ (Furber & Segal, 2015). Moreover, the CHU-9D has good representation of items that traditionally target internalizing symptoms such as sadness, worry, and irritability.
GAD-7
The GAD-7 was developed as a brief self-report screening tool for generalized anxiety and other anxiety disorders to be administered in public-health and primary-care settings (Spitzer et al., 2006). The scale comprises seven items with a 4-point response scale that targets the frequency of symptoms experienced in the past 2 weeks. The items directly map onto the diagnostic criteria for generalized anxiety disorder of the fifth edition of the DSM (DSM-5), and the scale has been shown to have good predictive properties and validity. More recently, the GAD-7 demonstrated strong associations with a diagnosis of GAD, panic disorder, and social anxiety and other widely used anxiety scales in adolescent populations (Mossman et al., 2017).
PHQ-8
The PHQ-8 is an eight-item measure developed as a valid diagnostic and severity scale for depression symptoms experienced in the past 2 weeks. It has been shown to be a useful depression measure in population-based studies (Kroenke et al., 2009). The PHQ-8 consists of eight items that are included in the PHQ-9; the item targeting suicidal ideation/thoughts of death has been removed. The remaining items each target the frequency of DSM-5 symptoms of depression on a 4-point scale. The PHQ-8 has been shown to be just as useful and valid as the PHQ-9 as a screening tool for depression and more suitable for use in adolescent and school-based samples given the removal of potentially sensitive content (Shin et al., 2019; Wu et al., 2020).
BSI-D
The BSI is a 53-item self-report scale developed to measure nine dimensions (somatization, obsession-compulsion, interpersonal sensitivity, depression, anxiety, hostility, phobic anxiety, paranoid ideation, and psychoticism; Derogatis & Melisaratos, 1983). The current study included the depression subscale, which has previously demonstrated strong validity with a clinical diagnosis of depression, psychological distress, quality of life, and the full mental-health-symptom checklist (Symptom Checklist-90). The depression subscale comprises six items on a 5-point scale that target the current frequency of depressive symptoms.
K6
The K6 was developed as a short form of the Kessler 10 Psychological Distress Scale to rapidly assess psychological distress associated with depression and anxiety in the general-population and primary-care settings (Kessler et al., 2002). The K6 comprises six items measured on a 5-point response scale and has previously demonstrated high levels of internal consistency and fair-to-good predictive ability associated with abnormal scores on the SDQ in adolescents (Mewton et al., 2016).
SDQ
The SDQ is a 25-item scale designed to measure psychological adjustment in children and adolescents. It has been widely used and applied to measure five domains of mental health and distress, including emotional symptoms, conduct problems, hyperactivity-inattention, peer problems, and prosocial behavior. The SDQ has demonstrated excellent convergent validity with other instruments such as the Child Behavior Checklist and the Youth self-report as well as DSM-IV diagnoses (Goodman, 2001). In the current study, we used a self-report version of the SDQ suitable for participants ages 11 to 16, and only the five items from the emotional-symptom subscale were extracted to index internalizing psychopathology.
Statistical analysis
The common metric was developed under the assumption of a nonequivalent-anchor-test design (Dorans, 2007) using IRT. This design allows items from the identified scales across the two samples to be equated using a smaller set of common anchor items that are shared by both samples. In the current study, the two samples were primarily equated using responses obtained from the items on the K6 and the SDQ emotional subscale. The scale-equating algorithms require some degree of commensurability between total scores, suggesting that each of the scales measure a single construct. To evaluate this, we first estimated McDonald’s omega and Cronbach’s alpha coefficients for each scale separately (Dunn et al., 2014). Each scale was also assessed using confirmatory factor analysis (CFA) to evaluate unidimensionality. The CFAs were conducted with the items entered as categorical indicators with a polychoric correlation matrix and a weighted least squares estimator in Mplus version 8.8 (Muthen & Muthen, 2017). Good model fit was determined using a combination of fit statistics, including the confirmatory fit index (CFI; > .95), the Tucker-Lewis fit index (TLI; .95), the root mean square error of approximation (RMSEA; < .08), and the standardized root mean square residual (SRMR; < .08; Hu & Bentler, 1998; Maydeu-Olivares & Joe, 2014).
Items from each scale across both samples were then pooled into a single, large-item pool and simultaneously calibrated using all available information; missing items were treated as missing by design and handled via maximum likelihood estimation. The simultaneous (or concurrent) calibration approach was chosen compared with linking separate calibrations given prior research that suggested better performance of simultaneous calibration (Kim & Cohen, 2016). The graded-response model, as implemented in the mirt package for R, was used to calibrate the items and generate item parameters that were used to convert sum scores to the common metric (Samejima, 1997). Substantively, the graded-response model is used to estimate the ability (or severity) level of each respondent from both samples and identify the location on the severity spectrum and the discrimination associated with each item. The use of simultaneous calibration places items from multiple test forms on the same common metric (estimated with M = 0 and SD = 1), and item parameters generated from the model can be used to generate scores on the common metric from multiple subsets of items (i.e., different test forms). The graded-response model requires additional assumptions to be met of the total-item pool (i.e., essential unidimensionality, local independence, and an absence of differential item functioning for the common items). Testing of the essential unidimensionality assumption was again conducted using CFA of the total-item pool and inspection of standardized factor loadings. The potential impact of unmeasured multidimensionality on a single general factor and the possibility of estimating multidimensional IRT equating were assessed using exploratory-bifactor analysis. The exploratory-bifactor model was estimated using a robust maximum likelihood estimate and an orthogonal bi-geomin rotation provided in Mplus. Additional indices to examine the importance of the single general factor and whether the assumption of essential unidimensional could be made, including the explained common variance, h-index, OmegaH coefficient, and the average relative parameter bias, were estimated from the rotated loadings of the bifactor exploratory-factor-analysis model (Rodriguez et al., 2016).
Local independence was examined by estimating the residual correlation matrix across pairs of items after fitting the single latent dimension. Given that residual correlations require data from complete cases, two subsamples were generated that contained complete case data from the largest number of items across both samples. The first subsample contained the CHU-9D, GAD-7, PHQ-8, K6, and SDQ, and the second subsample contained the BSI-D, K6, and SDQ. Items with pairwise residual correlations that were deemed as high (i.e., >0.3) were flagged as locally dependent as applied in previous IRT-equating studies (Wahl et al., 2014). Finally, differential item functioning of the common items (K6 and SDQ) across sex, sample groups (CAP vs. CSC), and age (above or below 13 years) were examined using the hybrid ordinal logistic regression/IRT method (LORDIF; Choi et al., 2011). This method compares the fit of a series of nested regression models to determine whether the item parameters display greater than trivial levels of differential item functioning. For the current study, the difference between pseudo-R2 values for the nested models were used as effect-size measures such that values of 0.02 or higher indexed nontrivial differential item functioning (i.e., greater than a small effect size; Kim et al., 2007).
Items that met all the assumptions were included in the final item calibration. The standard-error curve outlining the degree of precision as a function of the common metric for the total-item pool was generated using the final calibration. In addition, the standard-error curves associated with the individual scales as a function of the common metric were also generated. Crosswalk tables that convert sum scores from each scale to the corresponding value on the common metric were generated using the expected a priori to sum score method proposed by Thissen and colleagues (1995) as well as example syntax to score the common metric using available data in R package mirt (see Appendices A and C in the Supplemental Material). Values on the common metric can be interpreted in two ways. The first involves setting the mean value to 0 and standard deviation to 1 (often labeled “theta scores”), and the second involves setting a mean value of 50 and standard deviation of 10 (often labeled “t scores”). To aid the interpretation of the common metric, previously derived clinical cut points associated with the PHQ-8, GAD-7, K6, and the SDQ were mapped onto the common metric to determine the range of clinical significance. Finally, item-characteristic curves for each item on the common metric were generated as a mechanism to map the highest probabilities of responding to each category of each item from the different scales on the common-metric score (Rothrock et al., 2020).
The crosswalks were then validated in the holdout 20% sample by estimating the theta scores from items administered in the validation sample but using item parameters estimated in the calibration sample. Theta scores were estimated several times using all available items from the full calibration and items from each of the individual scales (e.g., theta scores estimated using only PHQ items, etc.). The estimated theta scores using items from each scale were then compared with the theta scores generated from all available items using the ICC and Bland-Altman plots. A high degree of agreement demonstrates that the scores from the common metric could be reliably estimated using items from just one of the scales that was equated in the current study.
Results
Item-equating assumptions
Scale-level alpha and omega values and CFA fit statistics for the unidimensional model in the calibration sample are provided in Table S2 in the Supplemental Material. Most fit statistics provided evidence for excellent model fit of the unidimensional model for each of the scales according to published cut points. The standardized factor loadings for the single calibration of the total-item pool are provided in Table 1; all factor loadings were greater than 0.4. The strongest factor loadings were associated with items indexing feelings of worthlessness, hopelessness, sadness, loneliness, depression, and uncontrollable worry. The factor loadings for the bifactor model and additional fit indices are provided in Table S3 in the Supplemental Material and provide evidence for a strong general factor accounting for 82% of the common variance and a well-defined latent variable (H = 0.98). The average relative parameter bias indicating the absolute difference between the loadings based on a unidimensional solution and bifactor solution was 0.05 and suggests that the bias due to treating the items as unidimensional is minimal and is not of serious concern (Rodriguez et al., 2016). Inspection of the residual correlation matrices of the two subsamples provided no evidence of substantial local dependence between pairs of items; all pairwise residual correlations less than 0.3 (the average residual correlation for Subsample 1 was 0.01, and Subsample 2 was −0.03). Finally, the results of the LORDIF analysis across sample group (CAP vs. CSC), sex, and age for the K6 and the SDQ items provided no evidence of nontrivial differential item functioning given that differences in pseudo-R2 values were less than .02 (see Tables S4 and S5 in the Supplemental Material). Given these findings, the final item pool comprised all 41 items originally included in the analysis.
Item-Level Properties and Item-Bank Parameters
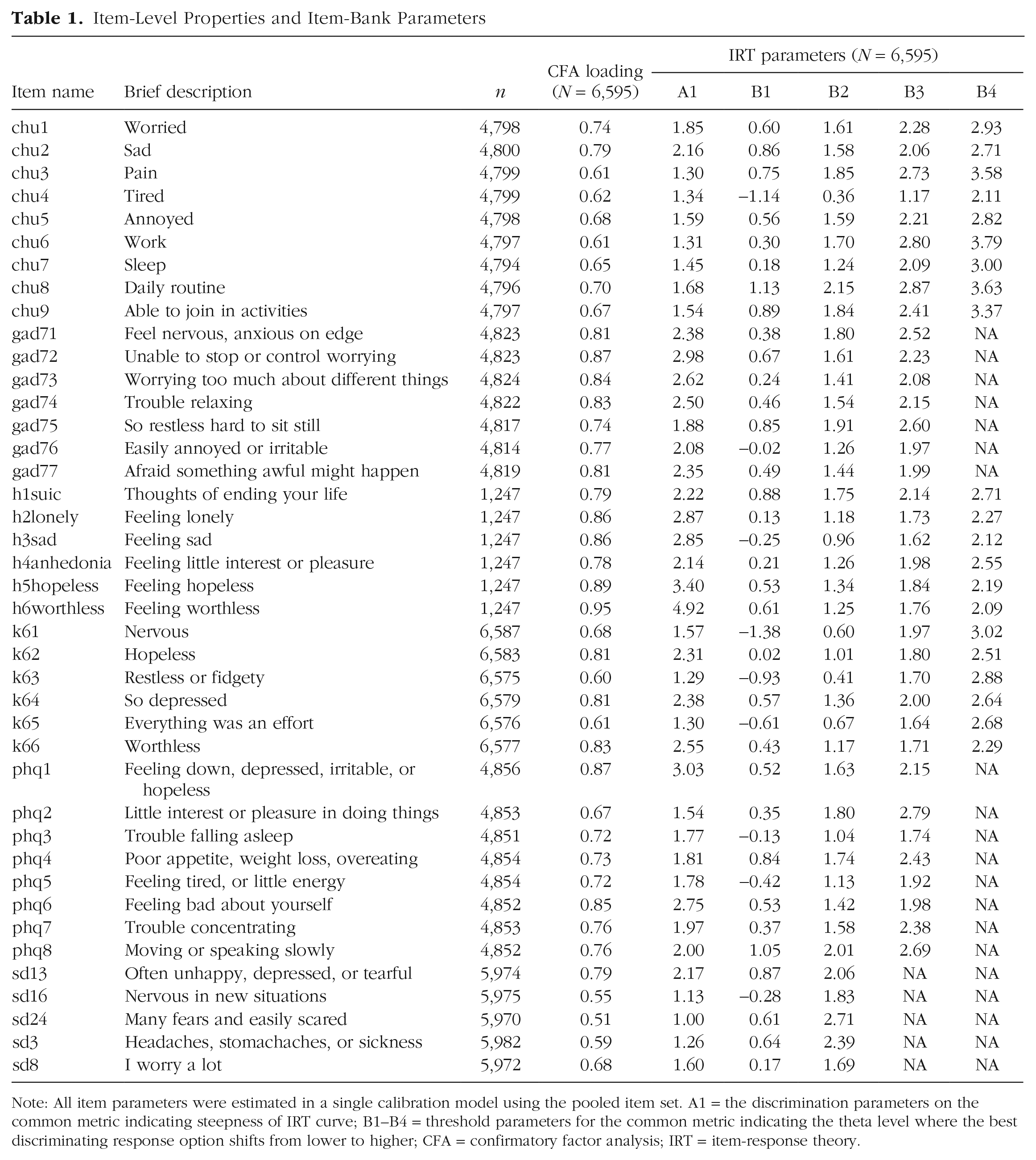
Note: All item parameters were estimated in a single calibration model using the pooled item set. A1 = the discrimination parameters on the common metric indicating steepness of IRT curve; B1–B4 = threshold parameters for the common metric indicating the theta level where the best discriminating response option shifts from lower to higher; CFA = confirmatory factor analysis; IRT = item-response theory.
Item-bank properties
The final item parameters for the total-item pool generated from a single concurrent calibration are provided in Table 1. These parameters can be used to generate common-metric scores using any combination of items included in the total pool. Scores derived from the total-item pool will differ in precision depending on where the individual sits on the underlying dimension. As shown in Figure 1, the total-item pool provides the most precision and therefore the least error for people who exhibit scores in the mid to upper severity levels (greater than −1 to 3 on theta) and relatively little precision for less severe ranges (less than –1 on theta). Note that a value of 0.44 in terms of standard error is equivalent to a reliability of 0.8. Inspection of the standard-error curves using the items that form each of the scales, provided in Figure S1 in the Supplemental Material, indicate differing degrees of precision depending on whether the scores on the common metric were derived using different scales. Common-metric scores derived using the K6, PHQ-8, GAD-7, CHU-9D, and BSI-D provide acceptable level of precision for scores that fall between the −1 and 3 range. Scores on the common metric derived using the SDQ provide relatively less precision at the theta range between −1 and 3 compared with the remaining scales, given a higher standard error.
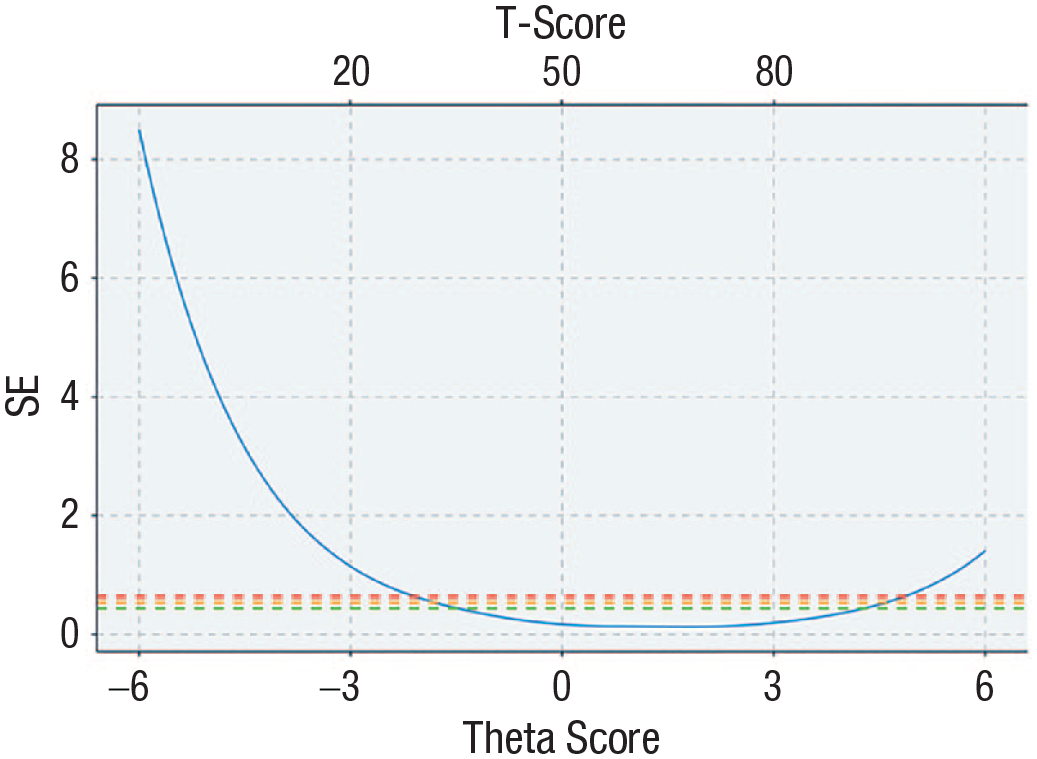
Standard-error curve of full-item bank. Green dashed line represents an equivalent reliability of 0.8, orange dashed line represents an equivalent reliability of 0.7, and red dashed line represents an equivalent reliability of 0.6.
Common-metric crosswalks and interpretation of scores
Easy-to-use crosswalk tables that take sum scores from each of the scales and map them to the equivalent theta and t score on the common metric are displayed graphically in Figure 2 and available in Appendix A in the Supplemental Material. These tables provide a quick indication of the potential common-metric score and associated error. However, this method is somewhat limited in that the same sum score can be generated from different items with different item parameters. Given access to full-response data on the individual items, it is possible to take the item parameters into account and generate individual common-metric scores using the mirt package in R (Chalmers, 2012). An example program is provided in Appendix C in the Supplemental Material. To assist with interpretation of scores on the common metric, curves relating the total sum scores to theta and t scores for each scale are provided in Figure S2 in the Supplemental Material. In addition, published clinical cut points for the PHQ-8, GAD-7, K-6, and SDQ were assessed with respect to the equivalent scores on common metric to identify a “clinical range.” The cut points converged on an area of the common metric ranging between theta scores of 1.17 and 2.02 (or 61.7 and 70.2 in t scores).
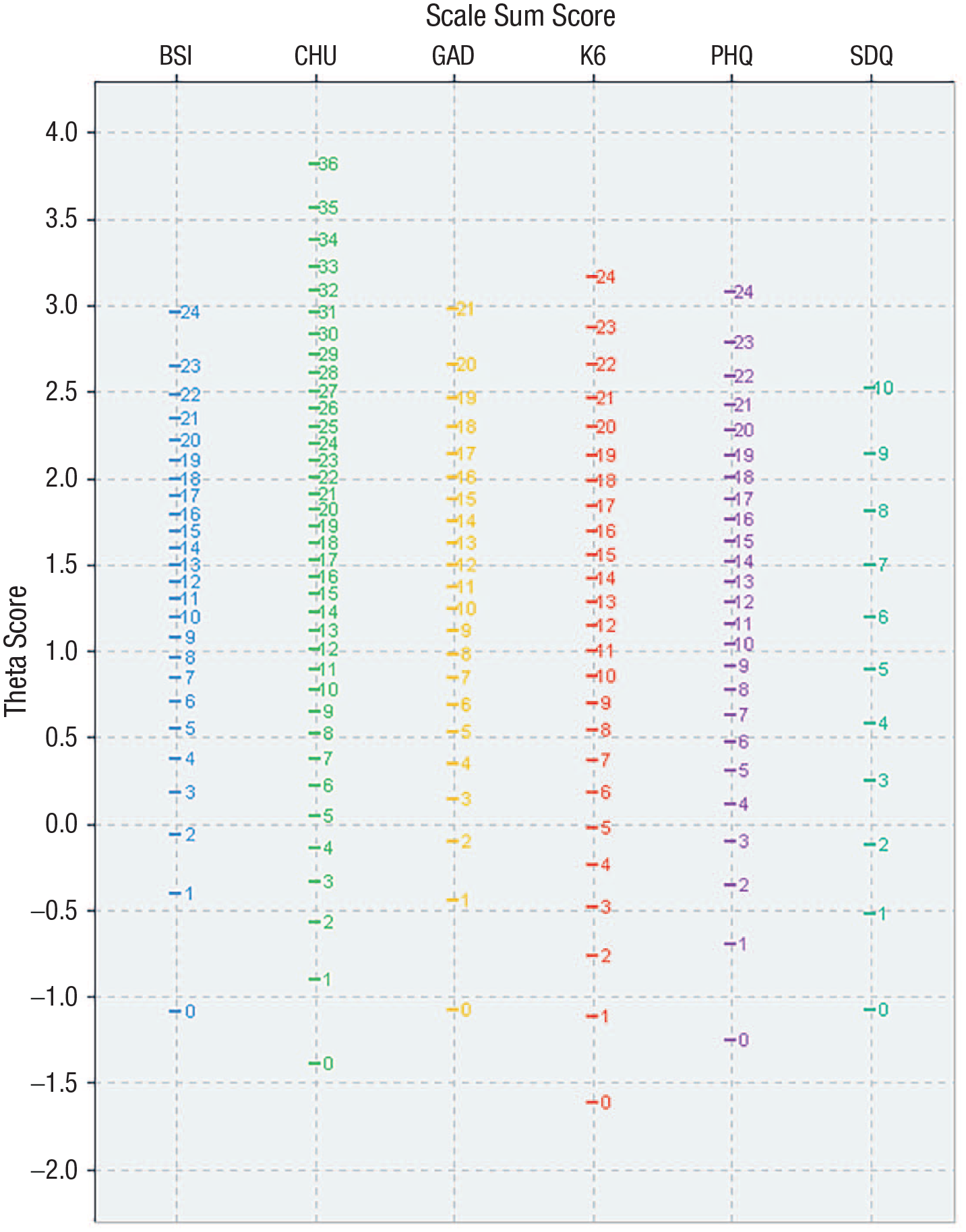
Crosswalk table for sum scores to theta scores for each of the equated scales.
To further assist with interpretation, additional graphs were generated that map the theta and t scores onto the response category with the highest probability of endorsement for each item from all the scales (graphs are provided in Appendix B in the Supplementary Material). These graphs provide a concrete interpretation of the common-metric scores by back translating the scores to what might be expected in terms of responses on the individual items. For example, individuals who score an average score on the common metric (e.g., 0) or lower have the highest probability of endorsing the “not at all” option for each item on the GAD-7 scale. However, we note that back translating theta scores in this manner can contribute increased levels of measurement error, and therefore, we recommend using these maps to aid interpretation of the theta scores rather than for conversion.
The level of agreement between common-metric scores derived from responses from each individual scale compared with common-metric scores derived from all available items is shown in Figure 3 (and Table S6 in the Supplemental Material). ICCs in the validation sample ranged from 0.76 for the SDQ to 0.92 for the BSI-D. The Bland-Altman plots provide some indication that agreement between scores was better at the more severe/clinical range of the common-metric spectrum (i.e., theta scores ranging between 0 and 3), particularly scores derived from the PHQ-8, GAD-7, and BSI-D, and there was evidence of a floor effect across all measures, as is common in measures of psychopathology in general samples.
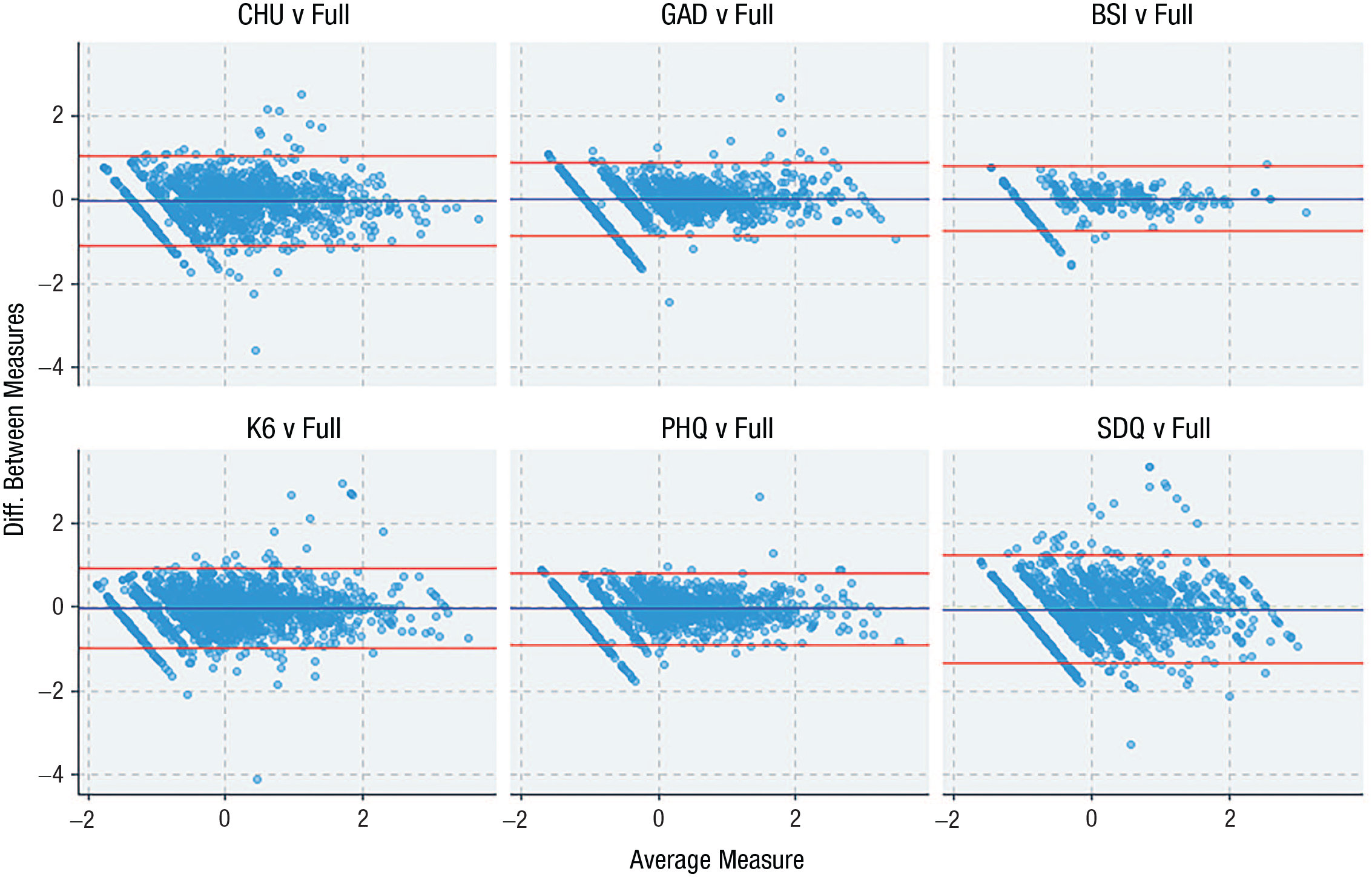
Bland-Altman plots comparing common-metric scores derived from the full-item pool in comparison with common-metric scores derived from individual scales using all available data in the validation sample (n = 1,716).
Discussion
The aim of the current study was to develop a common metric based on existing and widely applied scales to measure symptoms of distress in adolescent samples. In the current study, we equated six scales using an IRT-based equating approach and developed crosswalks to map scores from each scale onto a common metric that offers a standardized interpretation of data across different data sets (and R programs to generate individual scores). The common metric provides scores with acceptable levels of precision across the −1 to 3 range on theta, which equates to the more severe and often clinical end of the spectrum. Indeed, many symptom-based measures in mental health capture the upper severity end of the respective dimensional spectra given the relatively lower prevalence of the symptoms in the general population and the greater interest among clinicians and researchers in targeting clinical or at-risk levels. Thus, the precision level of the common metric at lower, “nonclinical” levels may be insufficient for detailed assessment and monitoring and might be suitable only for broad screening of the population. A clinical threshold was determined by mapping preexisting clinical cut points for the individual scales on the common metric, which converged on similar values ranging between 1.17 and 2.02. These values could be used to inform clinicians that individuals who score at or above this range may require additional follow-up or treatment for depression or anxiety disorders. However, the use of these cut points should be to aid interpretation rather than a formal diagnosis given that the metric is best represented as a continuous dimension to capture more nuanced information rather than categorizing people above or below an artificial threshold.
Further inspection of the standardized factor loadings and the discrimination parameters for the total-item pool indicate that the common metric is best represented by indicators that target hopelessness, depression, and worry. This corresponds to prior evidence indicating that the distress subfactor of the HiTOP model can be best described as representing symptoms of depression, dysthymia, and generalized anxiety (Kotov et al., 2017). The interpretation of the common metric as a distress subfactor may also explain why the precision rates based on items from the CHU-9D and SDQ were relatively worse than those from the GAD-7, PHQ-8, K6, and BSI-D. The CHU-9D was developed as a broad, preference-based, quality-of-life measure for adolescents and includes only three items that target distress with the other items that index physical health and daily functioning (that are moderately related to mental health). Likewise, the SDQ emotionality subscale contains only two items that target depression and worry, whereas the other items index fear-type symptoms such as panic and social anxiety as well as somatization, which have previously been demonstrated as loading on separate but related subfactors in the HiTOP structure. Thus, it could be questioned whether the CHU-9D and SDQ should be incorporated into the current common metric. However, recent studies have demonstrated the utility of using the CHU-9D as a potential mental-health measure in addition to economic evaluations (Furber & Segal, 2015). Given the widespread use of the CHU-9D and SDQ in many routine data collections, the inclusion of these scales potentially enhances the utility of the common metric and may enable greater data comparisons. The choice of additional scales to include on the common metric for the current study was also largely restricted to the availability of data. Future studies could possibly expand on the common metric derived in the current study by using fixed-item calibration methods in new samples that contain at least one of the previously equated scales and the new scale to be included on the common metric. Previous evidence has demonstrated the feasibility of this approach by equating additional scales that measure depression on the PROMIS-depression metric (Kaat et al., 2017).
The results of the current study demonstrate the initial utility of the HiTOP structure as a potential empirical framework to generate a hierarchy of common metrics that can be used to link related scales and data sets. For example, the different levels of the hierarchy could be used to equate broader or more specific sets of scales depending on whether there is interest in scoring broad internalizing, broad distress, or specific disorders/symptoms clusters, such as depression. Other published common metrics in the literature, specifically those targeting depression and social anxiety, have provided more information about the specific syndromes/disorders at the lower levels of the hierarchy (Sunderland et al., 2018; Wahl et al., 2014). Therefore, it might be feasible to use a single scale such as the PHQ-8 to provide two different scores depending on whether the interest is in evaluating the distress subfactor (using item parameters published in this study) or major depressive disorder (using item parameters published in previous work focusing on depression scales).
The current study has many strengths, including the use of two large samples of Australian school-age adolescents to generate the item parameters for a comprehensive set of widely used scales that measure depression and anxiety. However, the study is somewhat limited given the reliance on self-reported data and that the sample was not obtained to be representative of Australian adolescents and does not represent a clinical sample. Likewise, the racial and ethnic identification of the students participating in the study was unknown. Additional validation work is required to ensure the item parameters generated in this population are invariant in clinical populations and can be used to accurately compare clinical cohorts. Likewise, additional work could be conducted by recruiting a representative sample of adolescents and then normalizing the common metric according to the representative population mean, thus providing a more generalizable interpretation of common-metric scores. Finally, the validation and interpretation of the common metric developed in the current study should be examined further in independent samples by inspecting associations with other clinically relevant and theoretically related constructs, such as emotional regulation, neuroticism, and negative cognitive bias.
In summary, in the current study, we identified a coherent common metric that is closely aligned with the distress subfactor of the HiTOP model and captures common variance between symptoms of depression and chronic worry/generalized anxiety in adolescent samples. This metric offers researchers and clinicians a greater level of flexibility to score, combine, and compare different data sets without the requirement of having used consistent measures, moving the field forward in terms of data harmonization to answer important questions that may not be sufficiently answered in any single data set.
Supplemental Material
sj-docx-1-cpx-10.1177_21677026231168564 – Supplemental material for “One Metric to Rule Them All”: A Common Metric for Symptoms of Depression and Generalized Anxiety in Adolescent Samples
Supplemental material, sj-docx-1-cpx-10.1177_21677026231168564 for “One Metric to Rule Them All”: A Common Metric for Symptoms of Depression and Generalized Anxiety in Adolescent Samples by Matthew Sunderland, Nicholas Olsen, Rachel Visontay, Cath Chapman, Louise Mewton, Lexine Stapinski, Nicola Newton, Maree Teesson and Tim Slade in Clinical Psychological Science
Footnotes
Transparency
Action Editor: Jennifer L. Tackett
Editor: Jennifer L. Tackett
Author Contributions
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.