
Abstract
Initially proposed by Marcoulides and further expanded by Raykov and Marcoulides, a structural equation modeling approach can be used in generalizability theory estimation. This article examines the utility of incorporating auxiliary variables into the structural equation modeling approach when missing data is present. In particular, the authors assert that by adapting a saturated correlates model strategy to structural equation modeling generalizability theory models, one can reduce any biased effects caused by missingness. Traditional approaches such as an analysis of variance do not possess such a feature. This article provides detailed instructions for adding auxiliary variables into a structural equation modeling generalizability theory model, demonstrates the corresponding benefits of bias reduction in generalizability coefficient estimate via simulations, and discusses issues relevant to the proposed approach.
Keywords
Generalizability theory
When it comes to educational and psychological measurements, the estimate of reliability—an index reflecting the precision of an assessment—provides the researcher with a critical understanding of measurement quality. For example, when attempting to determine an individual’s mathematical proficiency, it is common to use a set of relevant test items (items) to gauge proficiency. However, according to measurement theory, the measurement process itself can be rife with multiple, simultaneously occurring measurement errors. Indeed, the raw test scores within such a scenario are implicitly distinct from the phenomenon being measured and, therefore, cannot accurately reflect the true skill level of an examinee. By controlling for various measurement errors, statistical frameworks, such as the well-known classical test theory (CTT), yield more accurate estimations of proficiency or skill level. Within this context, measurement reliability is expressed as the correlation between the true skill levels of an examinee and those observed levels of skill represented by a testing score.
Within the framework of CTT, which assumes (1) each observed score has errors and (2) the errors follow a normal distribution, an observed score is equal to a true score plus the measurement error (i.e. X = T + e). Here coefficient α provides the mathematical equivalent of parallel tests, allowing for a derivation of test reliability that indicates what proportion of observed test score variance is attributable to true score variance (Cronbach, 1951). However, as this approach only assumes two components for a test score (i.e. true score and measurement error), this technique promotes an overly simplistic solution within the context of most research designs. To overcome this shortcoming, CTT and Cronbach’s alpha have been further extended to generalizability theory (G theory) (Cronbach et al., 1972).
While CTT calls for the decomposition of observed variances into true score variance and a single, all-compassing error term, G theory allows the researcher to account for several sources of variation, also known as facets. This provides for the disentanglement of any number of sources of measurement error originating from test items and/or graders. Such robust control of measurement error is simply not possible with CTT, and is what allows G theory to attain greater accuracy when generalizing observed scores to a broader universe.
G theory can provide the variance estimates for a wider variety of errors than CTT—errors that should not be ignored in a research design. These variance estimates allow one to calculate the level of generalizability or dependability of behavioral measurements. While research designs focused on generalizability are used to examine relative interpretations of measurement outcomes, those which aim at dependability are applied toward absolute interpretations. G theory decomposition also enables researchers to make decisions about how to increase generalizability/dependability coefficient to any specified level. For example, if one uses G theory and finds that there is large variance in grader effect (i.e. a lack of consistency among graders, which is undesirable), a follow-up G theory study (namely, a decision study, or D-study) can be used to identify the number of graders required for the measurement to reach a sufficient level of precision.
G theory provides answers to questions such as the following: What is the largest source of error? Is the study generalizable enough to provide important insights regarding latent variables of interest? Based on the current analysis, what test alterations can be made to reach a certain level of generalizability/dependability? These features provide G theory with wide applicability within the realm of psychological and educational assessments. For instance, Dunbar et al. (1991) studied the generalizability of findings across a substantial number of direct writing assessments, Gebril (2009) applied G theory in language testing, Jiang and Raymond (2018) used G theory to investigate subscore validity in score reporting, and Raymond, Clauser, and van Zanten (2009) studied spoken English proficiency scores within a G theory framework. Essentially, selecting an appropriate modeling strategy for a G theory study depends on the research designs. Nested design is a research design where levels of one facet are hierarchically subsumed under or nested within levels of another facet. Crossed design is a research design that has at least two facets that are crossed, that is, every category of one facet co-occurs in the design with every category of the other facet. Here a facet is defined by a certain set of conditions.
In a testing context, for example, test items and test administrations could be regarded as two separate facets. However, a test-taker’s ability is the object of measurement (Nuβbaum, 1984). Here, an educational testing scenario, which incorporates test-takers, items, and test-raters (raters), is used for illustration. Setting rater effect aside for the moment, the mathematical expressions for a typical one-facet, fully crossed design are as follows


Equation (1) shows that an observed score, X, for person p on item i is defined by the sum of the grand mean µ, person effect µp, item effect µi, and error effect µpi. Note that the fully crossed design in the current scenario means that all persons have responded to all items. Correspondingly, the relevant variance components are outlined in equation (2). A typical two-facet, fully-crossed design can be expressed as follows
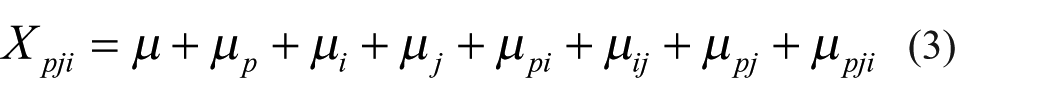
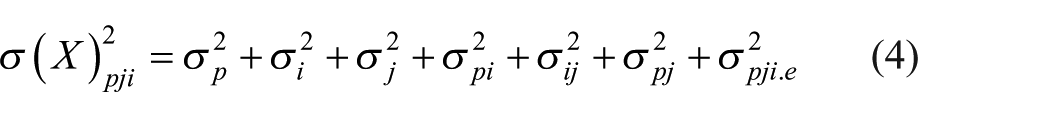
In addition to person effect µ
p
and item effect µ
i
, equation (3) also contains rater effect µ
j
as well as interaction terms for any two random components. Equation (4) provides variance components in accordance with equation (3). In both one- and two-facet designs, all
After estimating variance components, the G coefficient, a reliability-type index, can be calculated. As the aforementioned delineation between generalizability and dependability implies, the G coefficient can be either relative (norm-referenced) or absolute (criterion- or domain-referenced) (see Brennan, 1997, for details). However, here, only the norm-referenced G coefficient is addressed. The G coefficient, based on relative errors, is defined as follows
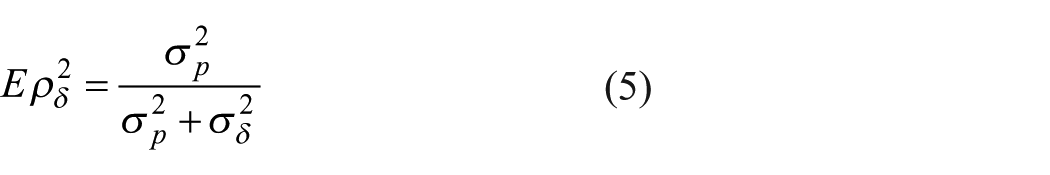

for a design that is defined by equations (3) and (4), where
Structural equation modeling (SEM) approach in G theory
SEM is widely used in the psychological, educational, and behavioral sciences. It is a powerful technique combining multivariate observed variables with complex structures. For instance, Figure 1 shows a simplified SEM example for modeling life satisfaction, turnover intent, and organizational citizenship behavior that are linked with 12 manifest or observed variables. Here, all three latent variables are measured with statement-based, self-report instruments and a Likert-type scale (see Schreiber, 2008). Note that a manifest analysis model differs from the latent models in the variables included: unlike latent models such as SEM, the manifest analysis model only contains observed variables and does not have any latent variable.
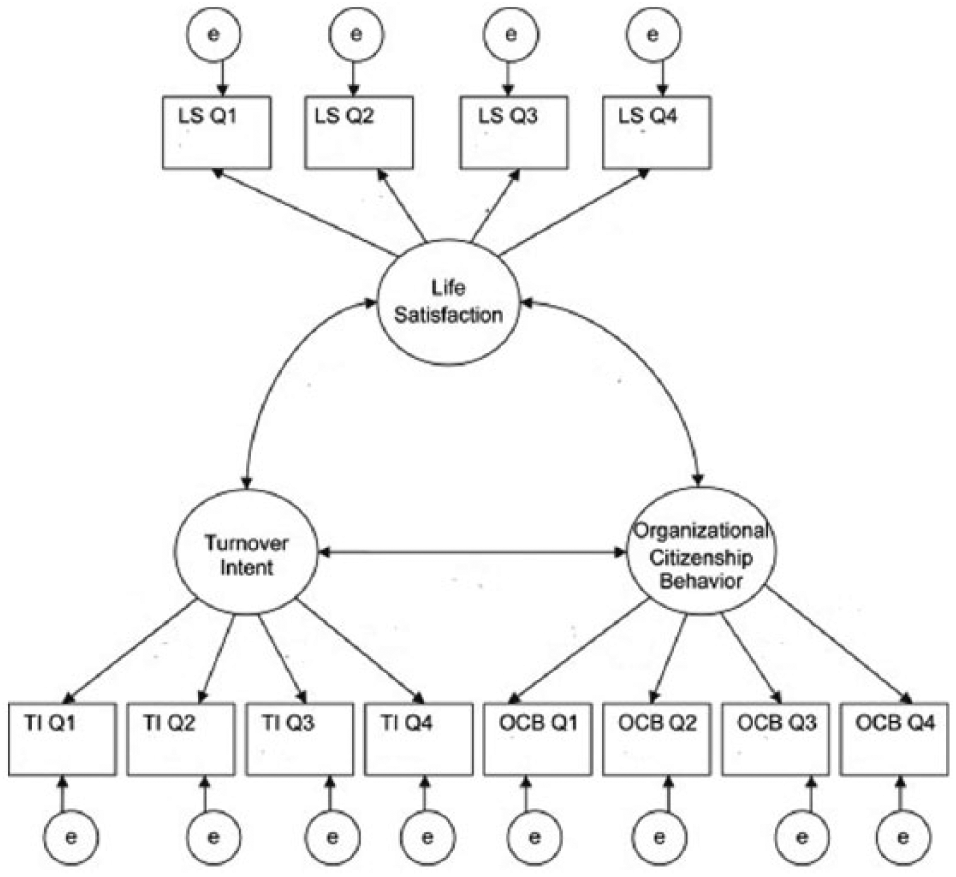
A structural equation model example for life satisfaction, turnover intent, and organizational citizenship behavior.
Within a SEM framework, one can verify the relations between (1) observed variables and latent/unobservable variables and (2) any pair of latent/unobservable variables. In the case of Figure 1, SEM allows the researcher to investigate the ways in which latent variables correlate with one another. In addition to providing insights linked to causal inferences and path analyses, SEM can also be used to study those longitudinal/repeated measurements typical to growth modeling and path analysis.
Within the context outlined here, G theory estimations are based primarily upon a special case of SEM known as confirmatory factor analysis (Jöreskog, 1969), which provides several benefits not present with other methods. For instance, the SEM approach can derive model fit indices, calculate standard errors of the estimates, and handle missing data. It is likely that such benefits have led to an increased use of SEM over the past decade by researchers like Gessaroli and Folske (2002), Hagtvet (1997, 1998) Marcoulides (1996, 2000) and Raykov and Marcoulides (2006).
Marcoulides (1996) described how to derive estimations using G theory within the context of a covariance structure analysis, while Raykov and Marcoulides (2006) fit this methodology within the SEM framework. Here a brief introduction to these methods is provided. Consider a two-facet, fully crossed design where the number of test-takers, items, and raters are 100, 5, and 2. Following the structure and notations of Raykov and Marcoulides, a corresponding diagram is presented in Figure 2. Rectangular boxes containing the letter Y represent observed variables, whose subscripts indicate their respective groupings. For example, Y32 contains the responses for the 100 test-takers to Item 3 scored by Rater 2. Latent variables—the variance components of G theory—are represented by circles. µ p represents person effect. µ pi 1 to µ pi 5, constrained to be equal, represent the interactions between item and person effects. The same applies to µ pr 1 and µ pr 2 so that the interaction between rater and person effects can be derived. Each arrow is a factor loading that regresses a certain variance component on a corresponding observed variable Y. These loadings are equal to one (1). Note, not all residuals for observed variables are shown in Figure 2. Nevertheless, they are constrained to be equal when a computation is performed. Mathematical proofs of converting a G theory model to SEM can be found in Raykov and Marcoulides (2006). With the rapid development of various statistical software packages, standard errors of estimates in SEM are now computed more easily than many other solutions, such as a traditional analysis of variance (ANOVA) (Searle, 1971) or restricted maximum likelihood (REML) estimator (Shavelson and Webb, 1991).
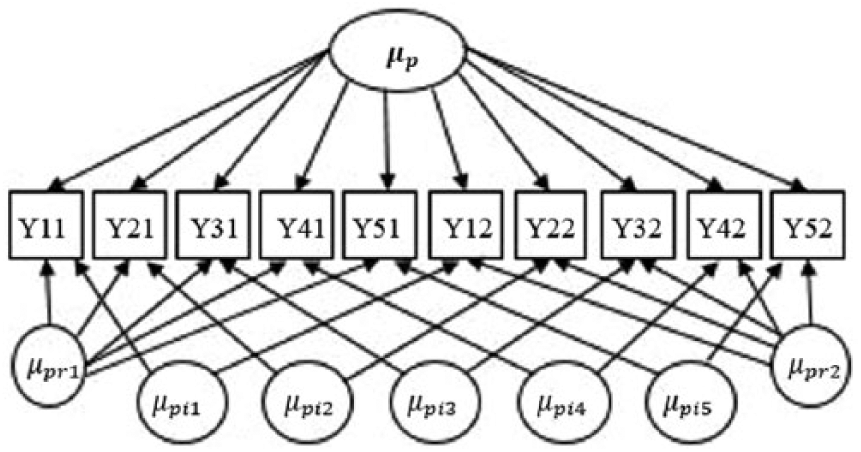
A structural equation model for estimating the variance components in a two-facet fully crossed design.
Missing data in SEM framework
A majority of scholars outside of the field applied statistics remain blissfully unaware of the dangers of missing data. They are unaware of techniques that could help nullify the negative effects of missing data within their research studies. Indeed, previous research has shown how cases of pairwise and case-wise deletion hurt validity—and yet the use of data flawed in this manner persists. What’s more, in the face of missing data, the use of inappropriate methods continues to inform biased estimates that lead to invalid conclusions (Enders, 2008). For these reasons, it is of the utmost importance that researchers become familiar with those statistical techniques that provide a robust solution to the problem of missing data.
There are three types of missing data. Data can be missing completely at random (MCAR), missing at random (MAR), or not missing at random (MNAR) (Little and Rubin, 2002). With data that are MCAR, missingness is defined independently of other observable and missing data. For example, a questionnaire/survey might be lost in the post, or a web browser malfunction might lead to the loss of question response records. In the case of data that are MAR, missingness is defined independently of missing data themselves, given other observed data. Furthermore, once those observed data are controlled for, missingness is explainable independently of any missing data. For example, if test data are missing due to test-taker illness (i.e. the test-taker was not present to provide data), the missingness is sufficiently explainable by the test-taker’s circumstance and has no relation to those data that would have been provided had the test-taker not fallen ill. Finally, missingness of data said to be MNAR is attributable to unobserved data (Allison, 2001; Enders, 2010). For example, a person does not complete a drug screening because they have used drugs and do not want to fail the test (Kang, 2013). Importantly, while solutions are available to account for missing data in the cases of MCAR and MAR, there are no appropriate solutions to MNAR.
To reiterate, the MAR assumption holds when the probability of missing data for a particular variable relates to other variables (informative variables) present in the model. If the informative variables are not included in the model, the analysis is performed with an MNAR mechanism, which tends to produce biased estimates. Therefore, MAR and MNAR differ in their inclusion of informative variables within a given model. In the current article, only MAR is considered because (1) true MCAR is rare in practice and (2) the solutions that work for MAR mechanism also works for MCAR situations. Particular in G theory literature, missing issues are discussed intensively within a MCAR pattern, which is essentially treated as unbalanced data situation. For example, Brennan (2001) used analogous-ANOVA estimators, also known as Henderson’s (1953) Methods 1 and 3, to adjust unequal sample sizes in different groups. In yet another example, Chiu and Wolfe (2002) proposed subdividing method by “creating data sets that exhibit structural designs that are common in generalizability analyses.”
Recent missing data studies have demonstrated advantages of an “inclusive analytic strategy” that incorporates auxiliary variables into the analysis model or into the imputation process (Enders, 2008). An auxiliary variable is defined as a variable that one would include in an analysis because it provides the information about the part of data that are missing (Collins et al., 2001; Rubin, 1976; Schafer, 1997; Schafer and Graham, 2002). As described previously, to meet the MAR assumption, the “cause” information must be considered when data are modeled. Indeed, this “cause” information defines those auxiliary variables, the primary function of which is to reduce potential bias within any explanatory model—as opposed to providing direct explanatory insights of those phenomena being studied.
Many studies have illustrated how auxiliary variables can be used to bolster explanatory power and mitigate bias by recapturing certain lost information (Collins et al., 2001; Enders, 2008). Nevertheless, such methods are not fool proof, in that they cannot guarantee unbiased estimates (Enders, 2010). Instead, success depends upon how well auxiliary variables correlate with missingness or any incomplete variables within the model under study—as signaled by the degree of bias reduction in model estimations. To illustrate, if income is an important variable within a survey analysis, a question that asks respondents to report their occupation will likely provide a good auxiliary variable, due to the correlation between the resulting data and income.
Although auxiliary variables have fewer downside effects on a model’s parameter estimates, fitting a maximum likelihood estimation with a large number of auxiliary variables can be problematic, due to complex specification (Enders, 2010: 133). That said, to successfully perform a likelihood-based estimation, one should only incorporate auxiliary variables that have more informative utility. An ideal auxiliary variable can reflect, or at least highly correlate with, the true cause of missingness within a model. Selecting useful auxiliary variables, however, is not always a straightforward process. In many cases an extensive review of the pertinent literature may be called for, coupled with good, old-fashioned guesswork. For example, knowing that family mobility can lead to school attrition, a researcher conducting survey researcher might ask households to report the likelihood of an upcoming move (Enders et al., 2006; Graham et al., 1997). In addition to utilizing theory to guide one’s selection of appropriate auxiliary variables, statistical evidence may also be used. Collins et al. (2001) any variable that correlating at a level of 0.4 or higher with any incomplete variable, would make for a good auxiliary variable.
Graham (2003) described two SEM-based strategies for incorporating auxiliary variables into a maximum likelihood analysis: the extra dependent variable model and the saturated correlates model. Here, the inclusion of auxiliary variables is possible without fear of altering the interpretation of substantive theoretical constructs of interest. The saturated correlates model, in particular, provides for an easier path than the extra dependent variable model, while producing similar results. Alternatively, researchers have proposed the various versions of a two-stage approach, while cautioning that inappropriate specification of auxiliary variables could lead to some bias (see Savalei and Bentler, 2007 and Yuan and Bentler, 2000 for details).
Given the reasons just cited, the authors propose the saturated correlates model as the preferred choice. The term “saturated” does not imply a full model (i.e. a model with a perfect fit). Instead, the name follows from the fact that the model includes all possible associations among the auxiliary variables as well as all possible associations between the auxiliary variables and the manifest analysis model variables (i.e. the auxiliary variable portion of the model is saturated). To be concrete about the saturated correlates model concept, the degrees of freedom of the model tested in Figure 3 is 51; that is to say, df = 78–27 because there are 12 × 13/2 = 78 unique elements in the observation variance/covariance matrix, and df consumptions are (1) four aforementioned random effects:
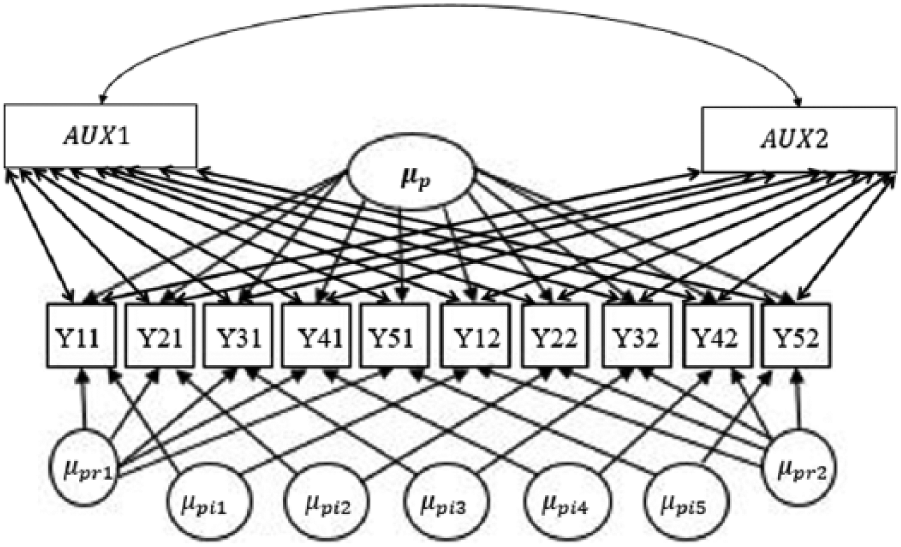
A saturated correlates model for estimating the variance components in a two-facet fully crossed design with missing data.
Yoo (2009) utilizes a Monte Carlo analysis to examine variable performance of auxiliary variables. Specifically, Yoo simulates responses from an eight-variable, two-factor measurement model and uses a six-variable, two-factor measurement model for evaluation, after excluding two auxiliary variables. By altering (1) the levels of factor loadings, (2) the correlations between auxiliary and latent variables, (3) the probability of missing, and (4) the missing mechanism, Yoo finds that including auxiliary variables in the confirmatory factor analysis (CFA) model can improve parameter estimation in most cases, particularly in cases of MAR data associated with the absence of auxiliary variables in the imputation model.
In this article, auxiliary variables are incorporated into the saturated correlates model, a SEM-based approach, to handle missing data problems in a G theory study. The research hypotheses are (1) MAR missing data can lead to biased G coefficient estimates to a degree in accordance with the variance size and the association with the missing cause(s), (2) using the proposed approach would yield more accurate estimates when missing data exist, and (3) it is a safe strategy to incorporate auxiliary variables into the model because it has no harmful impacts on the actual estimates even with no missingness. Figure 3 illustrates the application of G theory within a SEM framework. Aside from the inclusion of two auxiliary variables (AV1 and AV2), which correlate (1) with each other and (2) with the indicators’ error variance, this model is identical to that seen in Figure 2. In addition, bi-directional arrows represent correlations between auxiliary variables and observed variables. In the coming simulation section, synthetic data are all modeled following the same strategy.
Within this study, lavaan is used to conduct SEM analysis. As described by Rosseel (2012), lavaan is a software package for use within the R software environment. It is an open source software that provides a straightforward approach to constructing complex SEM frameworks. In the hope that it will provide a more approachable example of the concepts shared herein, Figure 4 illustrates the lavaan coding syntax used for constructing the theoretical model shown in Figure 3 (see link for downloading the script file). Within Figure 4, the first line of code displays HS.model, an object that contains a G theory SEM model that meets those parameters outlined in coding lines 2 through 30. Furthermore, facets such as person effect, item effect, and rater effect are represented by the coding variable labels p_factor, i_factor, and r_factor, respectively. Here also, ys represent indicators, while auxs represent auxiliary variables. Finally, pvar, ivar, and rvar represent functions used to constrain the equivalency of estimates within the model. The right-most portion of those formulas contained in coding lines 2 through 9 are predicted by corresponding facets shown to the left of the =~ symbol—where all loadings are set to 1. Coding lines 10 through 30 use ~~ to represent correlation (if linking different variables) and variance/residuals (if linking the same variable). For example, aux1 ~~ aux2 specifies the correlation between the two auxiliary variables, while coding lines 11 and 12 prompt correlation comparisons between each auxiliary variable and all other observed variables. At Lines 19 and 20, the variance of r_factor1 and the variance of r_factor2 are set to equal by rvar. The similar idea applies to other constraint labels such as pvar and res. Line 31 feeds the specified HS.model object to the lavaan function sem such that the model can be actually executed. Here also, the data set which contains missing data is named lav_dat. Furthermore, the method of deriving those missing data within this SEM model is set to full information maximum likelihood (FIML), and, finally, the exoxenous latent variables are assumed to be uncorrelated by setting the orthogonal model feature to TRUE. Additional details regarding SEM model specification within the lavaan R package can be found in Rosseel (2012).

Lavaan specification for the model illustrated in Figure 3.
Simulation design
The process of testing the utility of a SEM framework began with a pilot study conducted using a data set that contained no missing values. The results of this pilot show that when data are complete, both SEM and REML yield extremely similar estimates. To investigate the utility of incorporating auxiliary variables into SEM G theory, a comprehensive simulation study was conducted. Instead of arbitrarily choosing variance component values, the results of the California Assessment Program (CAP) dependability analyzed by Shavelson et al. (1993) were used to serve as a baseline for data generation. For the purpose of notation consistency, the facet of measurement occasion is treated as an item facet. Here it should be noted that this type of two-item design is not uncommon within the realm of educational assessment, especially when such assessments are aimed at writing tasks.
Within the context of equations (3) and (4), outlined in an earlier section of this article, the baseline true parameters are
In order to inject variance within the G coefficient during testing, three additional levels of person effect,
After generating responses from a given true variance set, incomplete data conforming to a MAR pattern were injected into the data. Following the approach prescribed by Park and Shin (1998), a MAR pattern was injected into the data set via two auxiliary variables (AV1 and AV2) derived by simulating two columns of data correlating with µp. Here it should be noted that the method for deriving AV1 and AV2 falls in line with that approach taken by Wu et al. (2015). In addition, three levels of average correlation were used to generate AV1 and AV2:
Consistent with the modeling practice outlined in Figure 3, there were
Given that REML and the FIML produce nearly identical results within the context of large samples, a FIML estimator approach to SEM, as seen in the work of Raykov and Marcoulides (2006), is used here. In total, this FIML simulation study incorporates 72 conditions, each of which are replicated 500 times. Feinberg and Rubright (2016) suggest that performing simulation studies of this kind requires at least 250 times. Based on the results provided, the accuracy of G coefficient and its variance component estimates are examined. The bias and mean square error (MSE) of each estimate in all conditions were recorded. The formula to calculate absolute bias is
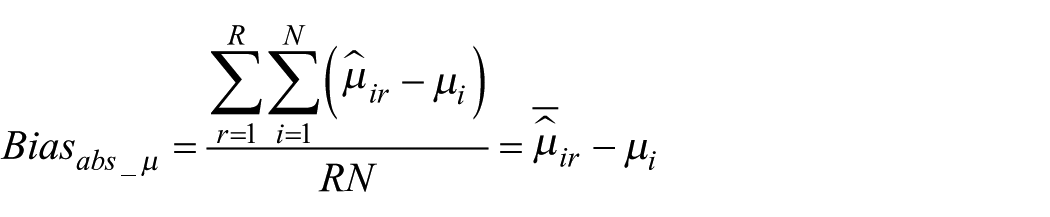
In order to make simulations comparable across different settings, relative bias, obtained by
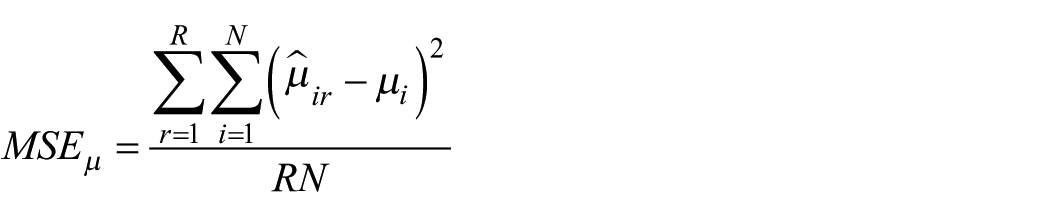
Where N is the number of elements in the set of
Simulation results
Comprehensive results for FIML simulations can be found in Appendix 1. In addition, Figure 5 shows the G coefficient bias and MSE results when the missing percentage is set to 15%. When
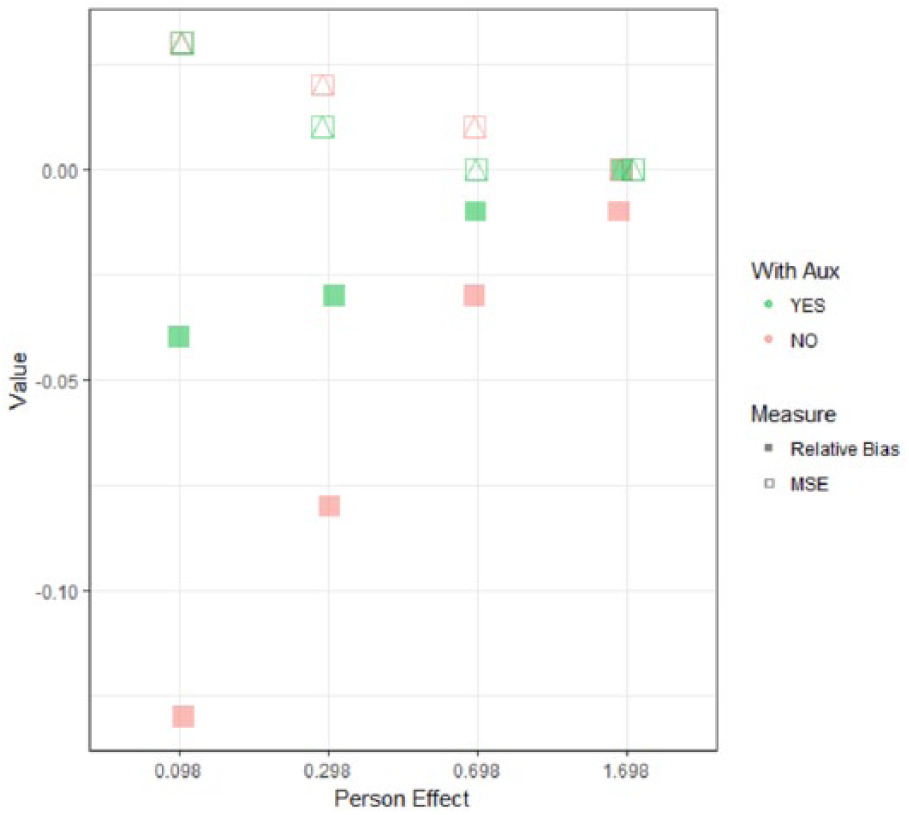
Average relative biases and mean square errors across six correlation levels.
For a given absolute value of
To analyze how the components of G coefficients function within this simulation study, the biases and MSEs of
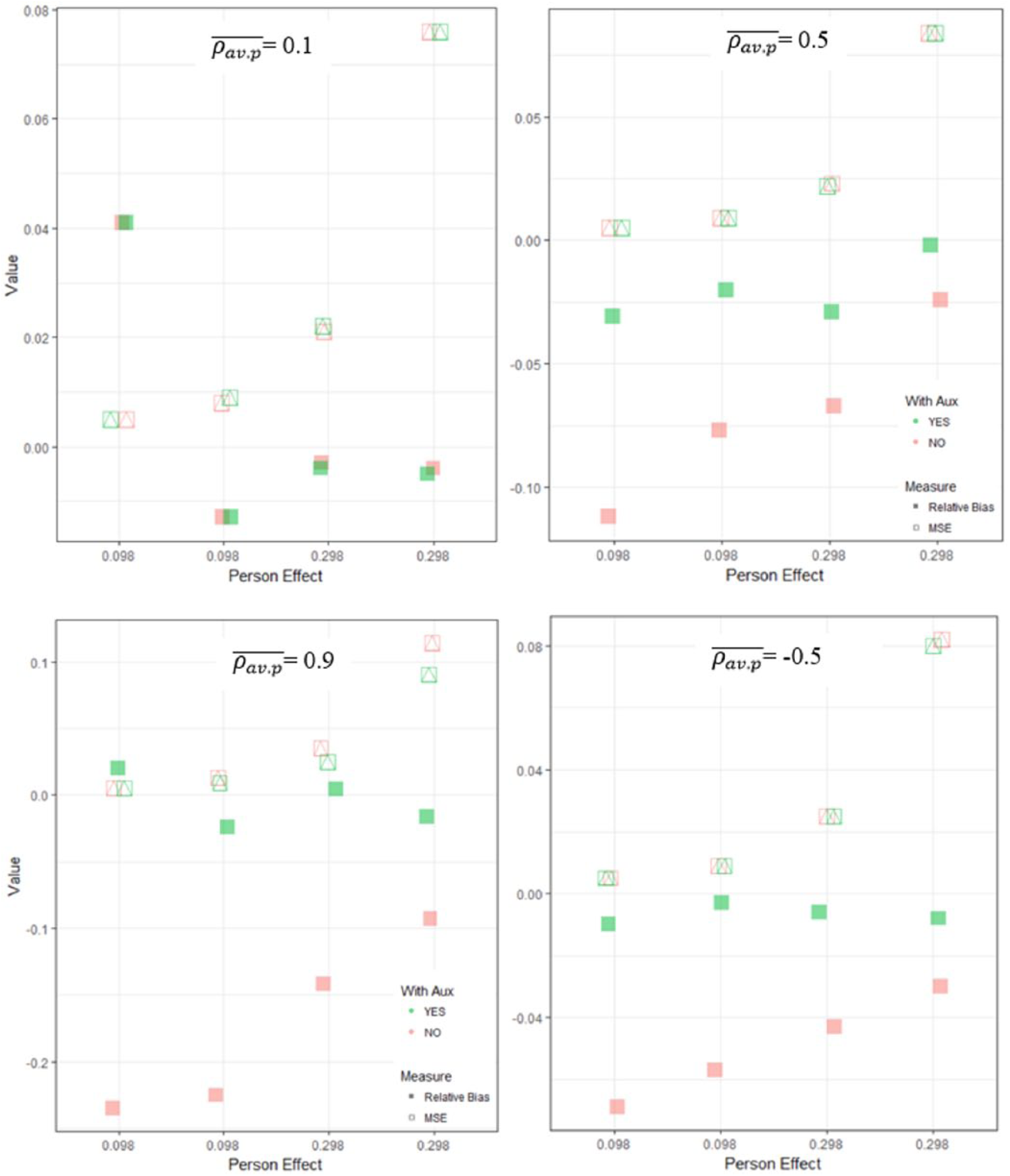
Sample average relative biases and mean square errors for
Here it should be noted that the MSE of
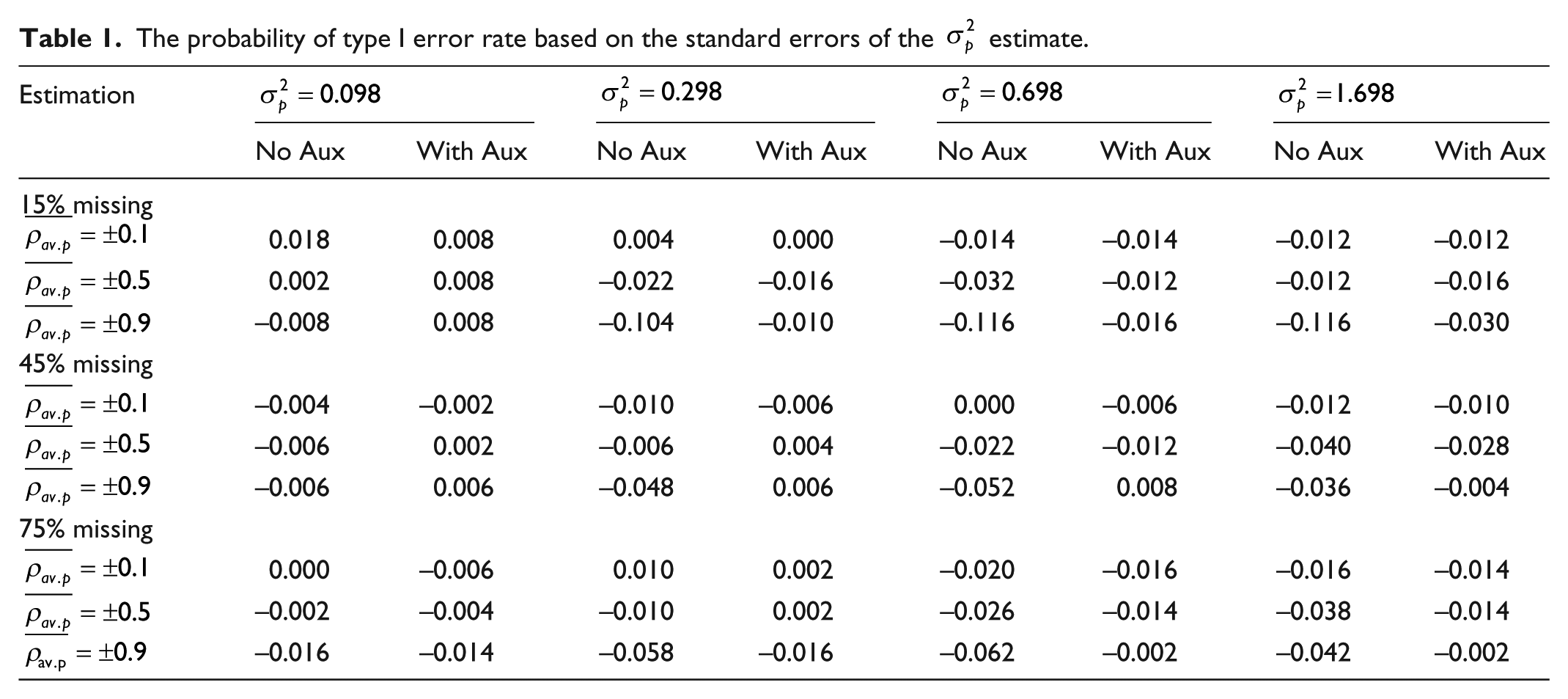
While the primary focus of this article is determining the accuracy of G coefficient estimates, standard errors of the estimates are also studied—since they speak to the quality of statistical inferences. As shown in Table 1, results of the true
The probability of type I error rate based on the standard errors of the
Discussion
Missing data can lead to biased estimates, and thus eliminating or reducing the influence of missing data is important when G theory analysis is used for decision making, especially those that are high stakes. It can be calculated from Table 1, in the condition where
To keep simulation design manageable, the missing data mechanism was based upon person effect only. Although theoretically, it could relate to item effect and/or rater effect, in practice it is more viable to assume participants themselves are the missingness reason. Besides, in some situations, it would be redundant to assume that the causes of missing data stem from various effects simultaneously. To illustrate, participants from a high-income family are likely to miss a survey question about free and reduced lunch. Assuming that the missingness takes place due to the item being too difficult for persons from a high-income family, is in fact, commensurate with the assumption on persons’ socioeconomic statuses. This practice, correlating auxiliary variables with person effect only, would be attenuated when missing cells are removed from the full data set. That said, the actual correlation between missingness in an observed data set and an auxiliary variable is lower than what it would be at the person effect level.
Providing model fit is another important feature of SEM. In particular, if a G theory framework fits data poorly, further analyses based on the estimation will be untrustworthy. Essentially, G theory is a modeling framework like any other statistical models. Traditional estimations do not provide fit information about a certain G theory framework used in research; if a data set that was planned in a two-facet design but is inappropriately/wrongfully fitted into a one-facet design, the model fit in SEM is expected to capture the misfit. In addition, SEM has assembled with a FIML estimator, which makes the modeling easier for handling missing data problems without complicated corrective procedures (Allison, 2000). Recent model fit interpretation can be found in Kline (2015), Shi et al. (2017) and Shi et al. (2018).
Theoretically, SEM approach can estimate other main effects such as item effect and rater effect; it needs to handle the data format differently. For example, if one is interested in estimating the item effect, each row of the input data should be responses of an item (instead of a person). Practically, however, this practice often is not permissible as the levels of other main effects are not sufficiently large, while the person effect can result in many indicators. To solve the problem, Marcoulides (2000) derived an approach of estimating other main effects by analyzing the matrix of correlations. In this article, if a measurement is domain-referenced, SEM approach used here is not appropriate as it provides insufficient information. If absolute errors are needed and current existing software packages are considered, the saturated correlates model can be used to cross-validate the feasibility of the traditional approaches such as REML. If the common variance components from both estimations are close to a certain acceptable level, the effects that the saturated correlates model does not estimate can be obtained from REML. Alternatively, one can use a Bayesian framework to analyze a G theory study (Little and Rubin, 2014). During the Bayesian estimation process, missing data imputation can be accommodated simultaneously (Jiang and Skorupski, 2017; Qin, 2018).
Footnotes
Appendix 1
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.