
Abstract
From 1990 to 1999 MTV promoted a series of 288 music videos called “Buzz Clips”, designed to highlight emerging artists and genres. Such promotion had a measurable impact on an artists’ earnings and record sales. To date, the kinds of musical and visual practices MTV promoted have not been quantitatively analyzed. Just what made some videos Buzzworthy, and others not? We applied two phases of content analysis to this corpus to determine the most common sonic and visual signifiers in Buzz Clips, then processed the results of that content analysis using polychoric correlations. Our findings show high degrees of shared variance between certain pairs of musical and visual elements observed in the sample music videos. We interpret a number of these relationships in terms of their relevance to a performer’s perceived ethnicity and gender, showing how certain audiovisual features regularly accompany white men (e.g., electric guitar) while others regularly accompany women and performers of color (e.g. drum machines).
Introduction
Recent research in music videos has applied a number of distinct approaches from different academic disciplines, especially popular music, 1 film and media studies (Caston, 2017; Korsgaard, 2013; Vernallis, 2013), gender and sexuality (Benson-Alcott, 2013), and critical race theory (Balaji, 2010; Reid-Brinkley, 2008). Several authors have attempted to combine approaches derived from each of these fields into an interdisciplinary study (Lafrance & Burns, 2017). The current study aims to augment this significant body of research by detailing a decade of musical and visual elements observable in a set of music videos and applying correlational analysis to draw conclusions about relationships between those variables.
Our corpus for this study is a series of 288 music videos MTV promoted in the 1990s as “Buzzworthy,” from the “Buzz Bin,” or simply as “Buzz Clips.” 2 Such videos were instantly recognizable as such, bearing an iconic “BUZZ BIN” logo alongside the video’s ID tags. Additionally, Billboard’s Video Monitor publication indicated which videos were being promoted as Buzz Clips with an asterisk. MTV itself recorded the complete list of such videos on a now-defunct website. 3 Table 1 shows the metadata for all videos analyzed in our corpus, including artist, video title, month of premiere, and peak position on the Billboard Hot 100 chart (if applicable).
Metadata for all videos analyzed in the corpus.

A number of hypotheses might be made about why these particular 288 videos were deemed “Buzzworthy.” There is, of course, a commercial incentive. According to Entertainment Weekly (1995), by 1994, an artist’s Buzz Clip was ∼75% likely to earn its corresponding album gold or platinum sales. In addition, the “payola” schemes between the network and record companies have been well documented (Banks, 1997). Andy Schuon, then Executive Vice President at MTV, once said “The Buzz Bin is our way of saying ‘Of all the things on MTV, here’s what you should pay attention to’” (Entertainment Weekly, 1995).
Most Buzz Clips were from new, breakthrough artists, and most artists only got one video in the corpus. MTV tended to prioritize and promote new, emerging genres. The series focused on alternative rock, grunge, and hip-hop from 1990 to 1993, and, as the decade progressed, helped introduce the world to pop-punk, music associated with the Lilith Fair Festival, electronica, and nü-metal. As such, Buzz Clips constitute a subgenre of MTV’s video output in the 90s, and are themselves linked to particular emerging genres.
Our approach differs from methods described above in that it relies on quantitative methods to analyze this corpus of data. The most applicable antecedent for such an approach comes from music video researcher Kip Pegley’s 2008 book. Pegley watched one continuous week (November 4–11, 1995) of programing on the Canadian music video network MuchMusic. Through a process known as content analysis, she recorded the frequency with which a number of pre-determined variables appeared. Her aim was to establish what kinds of people and content were being promoted through these music videos. Highlighting the concept of identity formation in the pre-internet era—especially for women and sexual/ethnic minorities—Pegley claims “Before North American teenagers began downloading on-demand videos from countries at home and abroad, MTV and MuchMusic were the two sources that shaped their lifestyle and their sense of themselves as a gendered and racially defined citizen of the United States or Canada” (Pegley, 2008, p. 15). Pegley was especially interested in how often viewers saw women playing instruments (other than the voice). 4 Koskoff (1987, p. 7) has highlighted the importance of analyzing women’s musical performance particularly because it reflects a particular society’s gender structure and views regarding women’s sexual identity.
Like Pegley, our analysis sets out to assess the kinds of people and cultural practices MTV promoted as buzzworthy in the 1990s. However, our analytical methods differ from those applied in Pegley’s book. For example, while Pegley’s statistical tools are designed to answer questions like how often black musicians were seen relative to white musicians, 5 we introduce two further steps in order to answer ethnomusicologist Bruno Nettl’s (2015, p. 468) challenge to bring to bear more sophisticated tools to the analysis of music and identity. First, we split the content analysis into separate quantitative and qualitative phases. Second, we apply correlational analyses to that content to more accurately describe how certain people and practices are portrayed alongside one another.
Our research activity took place across three phases. The following research questions are provided to guide the reader during the explanation of these three phases, as well as the results and discussion. Phase 1: What themes emerge from content analysis of the Buzz Clips corpus? Phase 2: To what extent are the emergent Buzz Clips themes present in the corpus? Phase 3: What types of relationships exist between both musical and visual qualities in Buzz Clips?
Methods
Phase One, completed in May 2017, was an exploratory, bottom-up content analysis of the marked audio-visual themes in these videos. Content analysis procedures were chosen for their suitability in analyzing frequency and trend. 6 Phase Two, completed in August 2017, was a corpus study in which the primary investigator, along with two PhD candidates from musicology and film studies, re-analyzed the 288 videos from a quantitative perspective in order to determine the frequency of the 88 most common themes generated in Phase One. Phase Three, completed in December 2018, was a correlational study conducted by the secondary investigators that estimated the strength of the relationships between any two signifiers coded in Phase Two.
In Phase One, we watched all 288 videos and created codes for recurring themes in a spreadsheet. For example, the first flannel shirt appears in Alice in Chains’s 1991 video “Man in the Box.” After noticing this in several other videos, we created the code (Flan) to signify the emergent theme of flannel clothing. 7 We inserted this code as a vertical column in a spreadsheet, creating a matrix with the 288 music videos in the horizontal rows. Any corresponding cells of music videos containing flannel shirts received a code of “1”. Absence of flannel resulted in a code of “0”. This procedure was repeated for all music videos and all emergent themes.
In order to maximize the possibility of spotting all trends, two additional research assistants acted as independent coders, watching all 288 videos separately and keeping their own independent spreadsheets. In addition to each of our individual spreadsheets, we also maintained a separate shared log of collective emergent themes and codes as they were created. As soon as new codes appeared on our shared spreadsheet, each of us began to look for instances of that theme in subsequent videos. These themes emerged as data-sensitive, authentic representations of music video analysis. The complete list of the 88 emergent themes resulting from Phase One can be found in Table 2.
Total variables by observation frequency.

The 88 emergent themes from Phase One constituted the variable set utilized in Phase Two. In Phase 2, two raters analyzed all videos for code frequencies within the thematic categories of fashion, setting, imagery, gender/sexuality/race, and narrative. Supplemental Material 1 displays the presence (marked with a “1”) or absence (marked with a “0”) of each of these 88 themes in each of the 288 videos. Per the standards of Landis and Koch (1977), we calculated Cohen’s Kappa, a measure of observer agreement. Values were quite high in all categories, ranging from “substantial” (.61–.80) to “almost perfect” (.81–.99) in all categories: fashion (.73), setting, (.77), imagery (.69), gender/sexuality/race (.89), and narrative (.73). Music and video codes were only observed by one rater, so rater reliability was not calculated for either of these categories. Phase Two normalized the dataset by showing us exactly when trends began, regardless of when they were observed in Phase One. For example, Phase One coders only noticed pixie haircuts (Pixie) alongside the rise of women singer-songwriters in 1994, but Phase Two revealed that there were several instances of pixie cuts in both 1990 and 1992.
Phases One and Two tackled the same problem from different angles. The strength of Phase One was its bottom-up assessment. It presumed nothing—viewers recorded what happened in the videos without imposing a preconceived idea of what they expected might happen. Phase Two was, instead, a top-down assessment that determined the frequencies of codes, implying the emergence, rise, and fall of these trends. Following research standards in social sciences and communication studies (Stevens, 2012), the blend of bottom-up and top-down methods is helpful for avoiding both selection and exposure biases.
In Phase Three we computed polychoric correlations between each of the variables to look at relationships between the various musical and non-musical aspects of each video. The commonly used Pearson correlation was not appropriate for this analysis, because it underestimates the relationship between variables in dichotomous data. We also considered analyzing purely descriptive data, but worried that this type of information lacked inferential power necessary to prompt future research on this topic. It seemed best to reference a statistical standard for guidance in our analysis, though not through the utilization of alpha to determine statistical significance. As a result, we elected to calculate tetrachoric correlation coefficients. These correlations are a special case of polychoric correlations and are appropriate for binary data (Chesire et al., 1933; Muthén & Hofacker, 1988). The full correlation matrix of all variables coded can be found in Supplemental Material 2 and Supplemental Material 3.
Using these resulting correlations, we elected to use a measure of shared variability between variables to identify relationships warranting future analysis. The variance inflation factors (VIF) references the extent of shared variability between variables through a numerical score. Truly independent variables have a VIF of zero. As the VIF increases, the degree of dependence increases. We elected to use a VIF of 5 (representing no less than 80% shared variability between fit lines) as our threshold for analysis. 8 Selected relationships reflecting VIF values above 5 can be viewed in Table 5.
Results and discussion
Results of Phases 1 and 2 define the presence and magnitude of 88 emergent themes in the corpus. Table 2 shows the frequency with which the themes appear. Table 3 shows these same 88 variables ranked by observation frequency, but grouped by category.
Observation frequency ordered by category.

Interpreting Table 2 is difficult because of the sheer number and variety of variables coded. It also reveals that some codes generated as a result of emergent themes in Phase One may have been too broad. For example, nice clothing (Nice) was found in 259 (89.9%) of all videos. That a more specific signifier, leather (Leath), appears in 121 videos (42%) gets closer to establishing a prominent fashion aesthetic for these videos. Other signifiers that drew our attention in Phase One, such as music videos that contain scenes from a motion picture (Movie), nevertheless appear as outliers in the corpus (5 videos, 1.7%). In this article we focus on statistical signifiers, though it is worth considering the possibility that viewers might just as well take special notice of novel yet rare signifiers such as the appearance of movies in music video.
Table 3 separates the Table 2 data into different coding categories (e.g. Music, Fashion, Narrative), making it easier to draw conclusions about the people and practices represented in this corpus. We can see that women are only shown playing instruments in roughly one of every nine videos (NFinst = 33, 11.4%). Black men are shown as lead vocalists (NBmal = 28) more often than black women (NBfeml = 19), with white women faring better than either (NWfem = 41). But those three together (N = 88) represent less than half of the remaining 200 videos, in which white men are depicted as lead singers. Savage et al. (2015, p. 8991) has explained the widespread disparities between men’s and women’s musical participation across cultures as evidence of “patriarchal restrictions on female performance.”
While Pegley’s discussion relates this data to a wide swath of social practices (contractual, socio-economic), her data is limited to counting the frequency of these variables. We wanted to determine not only the frequency of these variables, but also which variables were regularly seen (or not seen) together. Supplemental Material 2 shows the number of times that any pair of variables appears together in the 288 videos analyzed during the third and final phase of this project. Supplemental Material 3 displays that same information as a complete correlation matrix showing the strength and direction of the relationships between each of the 88 variables. Table 4 presents this information as a visually accessible heat map—negative correlations are red, positive correlations are blue, and the opacity of the color in each cell reflects the strength of the correlation. We are including Tables 2–4 and Supplemental Material 1, 2 and 3 as downloadable, editable .xlsx files with a CC BY-NC license in the hopes that future researchers will analyze the data to reach yet unforeseen conclusions.
Heat map.

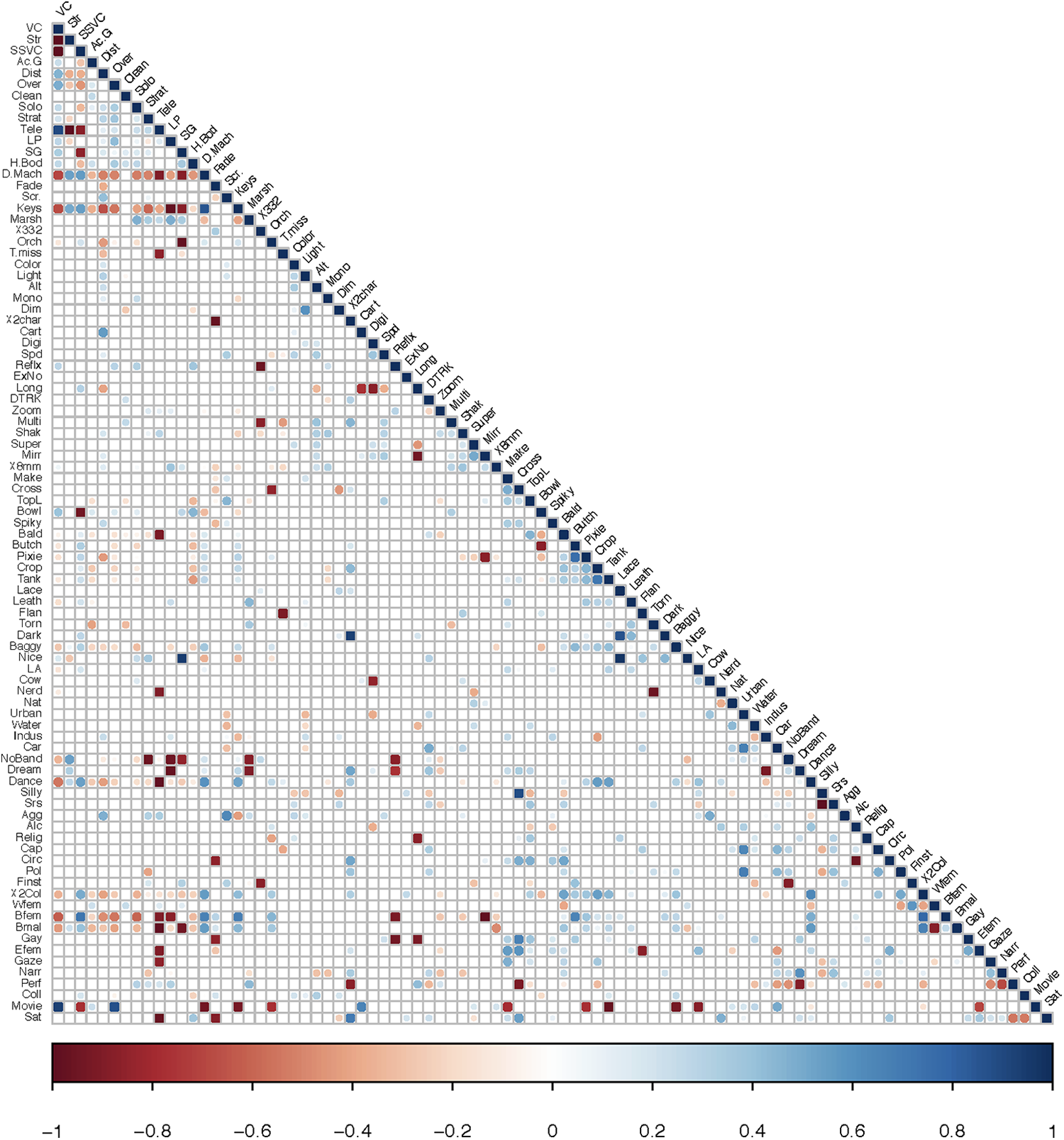
Table 5 shows selected moderate-to-strong positive and negative correlations that emerged from Supplemental Material 3 and Supplemental Material 2, separated into the same categories presented in Table 3. Correlation coefficients are an index of a linear relationship between any two variables. 9 Correlation coefficients imply direction: they can be either positive (X and Y tend to appear together) or negative (X and Y tend to appear separately). In addition, correlation coefficients communicate strength on a scale between -1 and +1 with the central point of 0 indicating no linear relationship. In other words, correlation coefficients indicated by values of ±1 communicate a perfect linear relationship between two variables (for every single increase/decrease of X, a respective increase/decrease of Y can be expected). Values between ±1 imply varying relationship magnitudes, with values ±.30 or smaller generally implying weak relationships, ±.50 implying moderate relationships, and values of ±.70 implying strong relationships. For the purpose of this study, though, we elected to use variance inflation factor results above our designated cutoff value (higher than 5) as standard for potential discussion. In the following paragraphs, we will address and interpret the relationships from several categories demonstrating high amounts of shared variability.
Selected (moderate to strong) positive and negative correlations.

Musical elements
All three of the most common electric guitar types seen in the corpus—the Fender Stratocaster (Strat), the Gibson Les Paul (LP), and the Gibson SG (SG)—correlate negatively with women (Finst) and musicians of color (2col), suggesting that the electric guitar, the most identifiable signifier of rock music, is associated with white men. By contrast, the drum machine (D.mach), an instrument that is virtually anathema to rock “authenticity” in the 90s, correlates strongly with musicians of color, keyboards (Keys), and choreographed dancing (Dance) regularly seen in hip-hop and R&B videos. Timbral mismatch (T.miss), in which the seen instrument does not match the heard timbre, correlates negatively with flannel shirts (Flan), the dominant fashion aesthetic of (white) grunge music.
In addition to the visual appearance of these instruments, it is hard to overstate the sonic importance of the electric guitar and drum machines in determining rock and hip-hop genres (respectively). While the latter has remained a dominant sound in the Billboard Hot 100 hits of today, the electric guitar has largely been replaced by synthesizers as a primary chording instrument. As such, it is possible that the sound of a (distorted) electric guitar playing (power) chords might signify a “throwback” 90s sound.
Video elements
In certain videos, one actor plays two separate fictional characters (2char). This correlates strongly with videos that contain dream sequences (Dream), in which the dreamt character is usually portrayed by the same actor as the dreaming character. Conversely, the presence of an actor playing two fictional characters correlates negatively with performance videos (Perf), in which the dominant narrative (or lack thereof) is the band playing on a simulated soundstage. It would be both visually confusing (and technologically demanding in the 90s) to see one musician playing alongside another played by the same actor.
Fashion
Men dressing in fashion attire or makeup generally associated with women, aka cross-dressing (Cross), appears in only sixteen videos (5.5%), but it correlates negatively with musicians of color (2col). It was more culturally acceptable in this corpus to depict white musicians transgressing masculine gender norms than it was for musicians of color. Baldness (usually intentional, i.e. shaved head; Bald) was much more common among musicians of color than white musicians.
Setting
Music videos with dream sequences (Dream) correlate negatively with videos that contain police or military imagery (Pol), suggesting that these topics were too “serious” to be depicted through dreams. They correlate positively with videos than contain well-formed narrative stories (Narr), and negatively with videos that do not (e.g., performance videos; Perf), in which the narratives are replaced by extensive footage of the band performing. Urban settings (Urban), which constitute just under half of all videos in the corpus (41.6%), correlate strongly with themes of police, military, and capitalism (Cap), suggesting the city as the site of such cultural practices.
Imagery
Circus performers (Circ) are relatively rare in the corpus (N = 11), but they correlate negatively with women instrumentalists (FInst) and people of color (2col). It could be the case that white men have the cultural capital to risk being depicted alongside such “freaks,” while others do not. Extended dance sequences (Dance), a hallmark of hip-hop and R&B videos, correlate positively with other elements heard and seen in those videos, including musicians of color and use of keyboards (Keys).
Gender/sexuality/race
When black women (Bfem) appear as lead singers in these videos, they are depicted in more “butch” fashions (Butch) than white women (Wfem). They also almost never wear cowboy/western-influenced clothing (Cow). Men perceived as dressing effeminately (Efem) also disavow cowboy clothing, as well as flannel (Flan), and are regularly seen wearing makeup (Make) and/or crossdressing (Cross).
Narrative
When movie footage (Movie) does appear in Buzz Clips, it is always from a movie in which the heard song appears on the soundtrack. Though there are only 5 such videos, it is interesting that movie footage correlates strongly with a number of elements linked to rock music, including verse/chorus forms (VC) and overdriven guitars (Over). These videos correlate negatively with elements linked to hip-hop or R&B, including drum machines (D.mach), keyboards (Keys), and musicians of color (2col). Buzz Clips, then, promoted movies associated with white rock culture (e.g. Urge Overkill’s video “Girl You’ll be a Woman Soon,” promoting Pulp Fiction) but not hip-hop videos promoting black culture (e.g. Dr. Dre’s video for “Keep Their Heads Ringin’,” promoting the movie Friday).
Conclusion
This article has introduced quantitative methods for the analysis of a corpus of music videos, has discussed some of the most common elements observed in those videos, and has attempted to interpret some of the correlations between those elements. We are making the data available to music video researchers in the hopes that it will promote future research along these lines by other scholars.
Supplemental material
Supplement_Material_1 - Content and Correlational Analysis of a Corpus of MTV-Promoted Music Videos Aired Between 1990 and 1999
Supplement_Material_1 for Content and Correlational Analysis of a Corpus of MTV-Promoted Music Videos Aired Between 1990 and 1999 by Brad Osborn, Emily Rossin and Kevin Weingarten in Music & Science
Supplemental material
Supplement_Material_2 - Content and Correlational Analysis of a Corpus of MTV-Promoted Music Videos Aired Between 1990 and 1999
Supplement_Material_2 for Content and Correlational Analysis of a Corpus of MTV-Promoted Music Videos Aired Between 1990 and 1999 by Brad Osborn, Emily Rossin and Kevin Weingarten in Music & Science
Supplemental material
Supplement_Material_3 - Content and Correlational Analysis of a Corpus of MTV-Promoted Music Videos Aired Between 1990 and 1999
Supplement_Material_3 for Content and Correlational Analysis of a Corpus of MTV-Promoted Music Videos Aired Between 1990 and 1999 by Brad Osborn, Emily Rossin and Kevin Weingarten in Music & Science
Footnotes
Action editor
Tecumseh Fitch, University of Vienna, Department of Cognitive Biology.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Contributorship
BO researched literature and conceived the study. ER and KW were involved in empirical design and data analysis. All authors drafted, reviewed, and edited the manuscript and approved the final version of the manuscript.
Peer review
Patrick Savage, Keio University Shonan Fujisawa Campus, Faculty of Environment and Information Studies.
Carol Vernallis, Stanford University, Department of Music.
Supplemental material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.