
Abstract
This study examines what types of messages users posted and spread about #Black/Blue/AllLivesMatter during the Black History Month of 2022. Using both qualitative and quantitative methods, about one million tweets were analyzed to test if different levels of opinion leaders tend to spread different kinds of messages related to the context. Using the curation logic of Thorson and Well and Lakoff’s semantic theory as theoretical lenses, we offer some observations about the differences in logics (incentives and norms) that opinion leaders in our dataset might face. We find that different levels of opinion leaders shared different types of messages. The implications of this study call for strategies that foster meaningful discussions on social movements amid polarized views. The study also advocates for refining platform design to encourage the dissemination of factual information over contentious arguments and reaching a societal consensus on critical social issues, such as racial inequality and police brutality. This research contributes to updating the theory of curation logics, virality, and opinion leaders, as well as provides empirical data for the discussions of the #BlackLivesMatter social movement and its related discussions of #AllLivesMatter and #BlueLivesMatter.
Introduction
Researchers have been studying the diffusion of information on the internet at least since Jurvetson (2000) coined the term viral marketing. More recently, Nahon and Hemsley (2013) suggest that a viral information spread is when many people simultaneously share a piece of information, which results in a sharp acceleration in the number of people being exposed to the information. Nahon and Hemsley (2013) used the concept of network gatekeepers to explain how some actors have more influence over the flow of information than others. However, the gatekeeping concept is limited as it implies editorial message selection by high-level actors in the network (Shoemaker & Vos, 2009; Thorson & Wells, 2015, 2016). In our socially networked world, it seems worthwhile to understand how actors with different levels of followers may influence the flow of information in different ways (Hemsley, 2019). For example, actors on social media with many followers such as politicians or journalists may influence the kinds of news we receive, but our real-life friends that we follow on social media who do not have many followers may influence how we interpret the news. Therefore, knowing the impacts of different types of actors for a given topic on social media helps us to better understand how and why users spread certain information.
Since our research focuses on how different levels of actors might influence the spread of information differently, we leverage the concept of opinion leaders, people who are followed by and have some influence over other social media users (Dalrymple et al., 2013; Katz & Lazarsfeld, 1955; Walter & Brüggemann, 2020; Walter & Hanke, 2020). In addition, we leverage the theory of curation logics (Thorson & Wells, 2016), which posits that actors’ decision to share or curate content is driven by the incentives they face and the social norms within which they are embedded. Our opinion leaders are the actors who spread Twitter messages related to #BlackLivesMatter (BLM), #BlueLivesMatter, or #AllLivesMatter (ALM) during February 2022, the Black History Month of 2022. While this study examines the technical aspects of the messages associated with the three hashtags, we acknowledge that the BLM movement is a politically charged topic in the United States, reflecting the unfair treatment such as police brutality that Black Americans have encountered for centuries (Hawkins, 2023). To provide meaning to the curation choices we see of the opinion leaders in our dataset, we also leverage George Lakoff’s (2016) semantic theory. Lakoff uses the metaphor of “strict/nurturant parent” to suggest political/moral meanings of messages.
Using content analysis, machine learning algorithms, inferential statistics, and data visualizations, this study reveals that despite there being about the same percentages of supportive and critique-related messages available for users to spread, users retweeted more critique tweets regardless of their opinion leader levels (OLLs) across the #Black/Blue/AllLivesMatter discussion spaces. We also find that different levels of opinion leaders shared different kinds of messages. Using Thorson and Wells’s (2016) curation logic and Lakoff’s (2016) semantic theory as theoretical lenses, we offer some observations about the differences in logic (incentives and norms) that opinion leaders might face.
The contribution of this study is twofold. Theoretically, it expands the understanding of opinion leaders, Lakoff’s (2016) semantic theory, virality, network gatekeepers, and curation logics. Empirically, it supplements data to the #Black/Blue/AllLivesMatter discussion space on Twitter, which has been renamed to X since this research was completed. The implications of this study underscore the necessity for strategies fostering meaningful discussions about social movements amid polarized views. The implications also advocate for refining platform design to encourage the dissemination of factual information over contentious arguments and reaching a societal consensus on critical social issues, such as racial inequality and police brutality.
Background
#BlackLivesMatter
The context for our examination is #BlackLivesMatter, a hashtag movement started in 2013 as a collective of Black radical organizers and self-identified Black/Queer feminists, Patrisse Cullors, Alicia Garza, and Opal Tometi (Edrington & Lee, 2018; Tillery, 2019). They organized the movement in response to the death of Trayvon Martin and George Zimmerman’s acquittal (Edrington & Lee, 2018; Tillery, 2019). The organizational interests are in ending police brutality and racist bias in law enforcement (Francis & Wright-Rigueur, 2021; Freelon et al., 2016; Hawkins, 2023). Although BLM started in 2013, the issues reflected by the movement are not new; the historical roots of the excessive violence perpetrated by law enforcement against Black Americans can be traced back for centuries. The BLM movement shares the historical genealogy of antilynching protests and the civil rights movement in the 1960s (Francis & Wright-Rigueur, 2021).
While the initial uptake of the hashtag #BlackLivesMatter was small, it has grown into a large movement in the last 10 years, far beyond the original organization. The hashtag gained both online (the spread of the hashtag on social media) and offline attention (mainstream media attention and nationwide protests) with unarmed Black Americans being killed by police officers, such as Michael Brown’s death in 2014, Freddie Gray’s death in 2015, or Stephon Clark’s death in 2018 (Francis & Wright-Rigueur, 2021). Numerous protests happened following the killing of Ahmaud Arbery, a Black American man, while jogging in a Georgia neighborhood by three White residents in February 2020. Two of the residents were a retired police officer and his son. Two weeks later, Breonna Taylor was shot by police in her home in Louisville on March 13, 2020, sparking nationwide protests calling for the public to “say her name.” The use of #BlackLivesMatter reached a peak after Derek Chauvin, a former police officer, killed Black American George Floyd on May 25, 2020, which resulted in global protests for police brutality and unfair treatment of Black Americans (H. H. Wu et al., 2023).
Not long after #BlackLivesMatter was formed, social media users started using #BlueLivesMatter and #AllLivesMatter to support law enforcement officers and question the BLM movement (Shanahan & Wall, 2021). #BlueLivesMatter started as a counter-movement of BLM in 2014, as a result of two New York City police officers being shot and killed by a Black American (Keyes & Keyes, 2022). Supporters of #BlueLivesMatter advocate for treating attacks on police officers as hate crimes and the attacked police officers as victims (Shanahan & Wall, 2021). Four U.S. states (Louisiana, Kentucky, Mississippi, and Texas) updated their hate crime laws to incorporate this petition, which resulted in hate crime laws in some states covering authoritarian figures as victims (Mason, 2022). Drawing on an analysis of legislative debates around the enactment of the updated hate crime laws, Gail Mason (2022) concludes that these laws escalated the tension between law enforcement officers and Black Americans. He contends that treating the police as victims reframes and minimizes the history of police brutality that Black Americans have faced.
On a similar note, ALM also started as a counter slogan toward BLM. ALM appears to be a response to the idea that BLM suggests that only Black lives matter (Atkins, 2019). ALM, then, tries to serve as a color-blind racism example that dismisses racial inequalities and police brutality (Carney, 2016). Compared to BLM and #BlueLivesMatter, ALM does not have a formal organization that organizes protests.
Supporting or opposing one of the above hashtags also reflects political ideologies. A 2018 survey shows that older conservative males in the United States are more likely to oppose BLM (Updegrove et al., 2020), and a 2023 Pew survey shows that 84% of the participants who identified as Democrats support BLM, while 82% of the participants who identified as Republicans oppose it (Pew Research Center, 2023).
BLM Studies on Twitter
Numerous studies have examined social movements on Twitter, particularly BLM, and the related Blue and All Lives hashtags. For example, Carney (2016) looked at how the debates on Twitter around “#AllLivesMatter” and “#BlackLivesMatter” reflect a power struggle over the discourse on race and racism in the United States. Carney (2016)’s study highlights strategies used by youth of color to influence the national discussion around race after the death of Michael Brown and Eric Garner in 2014. Blevins et al. (2019) seek to contribute to the literature by showing how the public and social justice groups use Twitter to involve more diverse voices in the national discussion. The authors show that members of the public frame high-profile tragedies as relatable events that have personal meaning for them.
Other research that looks at how BLM frames were constructed and contested by actors on the political left and right shows that in this context, hashtags may act as mechanisms that shape how information flows on Twitter (Stewart et al., 2017). Examining the role of content in retweeting, Keib et al. (2018) found that social movements may increase effectiveness in getting their messages spread by producing content about policy or action, or about a group, along with emotion. From the aforementioned literature, we know that Twitter is an important platform to study because it can act as a platform connecting other platforms (Agarwal et al., 2021; Bennett & Segerberg, 2013) and that viral information flows on Twitter have been shown historically to help the growth of social movements (Hemsley, 2016).
Virality and Spread of Information
The virality of social movements, as exemplified by BLM’s widespread reach on social media platforms like Twitter, is not a random or linear process. Rather, it represents a complex interplay of forces that needs careful analysis and understanding. This article adopts the theoretical framework of “negotiated diffusion” (Hemsley et al., 2017) to move beyond simplistic explanations that attribute viral occurrences to a single dominant factor or a linear combination of a few factors. Instead, it views virality as “a consequence of dialogue and tension among many forces” (Nahon & Hemsley, 2013, p. 139).
Specifically, the negotiated diffusion perspective implies that the process of information diffusion occurs through the dynamics of two processes: top-down and bottom-up (Nahon & Hemsley, 2013). On the one hand, the bottom-up force is driven by individuals’ sharing activities, where the content’s remarkability and the closeness of the relationship between the users play a role in explaining its virality. On the other hand, the top-down force is mainly explained by the role of gatekeepers who let information into their network and facilitate its flow. According to Nahon and Hemsley (2013), gatekeepers’ position in networks gives them disproportionately more influence over the flow of information. Flows from the top and bottom can harmonize (dialogue) or conflict (tension), but in most cases, they manifest as a combination of both (Hemsley et al., 2017). When they do harmonize, the likelihood of something going viral grows.
In a hypothetical example, we might find that someone posts a tweet with a video showing police brutality. If that person’s friends and family retweet it, assuming those people do not have massive followings, the post really will not go far. It is possible, but unlikely, that enough of these regular users would retweet the message such that it spreads far and wide. If it did happen, we would call this a bottom-up event. But it would be much easier for the tweet with the video to go viral if someone with a massive following retweeted the message. This is because users with, for example, a million followers, have a much wider reach in the overall network. When they retweet something, they are more likely to reach users for whom the content is novel, who are sympathetic to the content, and feel that the content should spread (Nahon & Hemsley, 2013).
The information we receive every day constitutes our social reality, and gatekeepers play a crucial role in determining what types of information we receive (Shoemaker & Vos, 2009). The concept of gatekeeping was first coined by Kurt Lewin in 1947, referring to the roles that housewives play when deciding food selections from different channels, such as gardens and markets (Lewin, 1947). While scholars have traditionally studied gatekeepers from a communication perspective (Shoemaker & Vos, 2009), Karine Barzilai-Nahon (2008) examined the concept of gatekeepers from a network perspective. Nahon and Hemsley (2013) define network gatekeepers in their conception of virality: “network gatekeepers (people, collectives, or institutions) are those with the discretion to control information as it flows in and among networks” (p. 43). From an analytic perspective, such gatekeepers have high betweenness centrality, meaning that they are the ones bridging other nodes in a network, and ultimately, bridging disparate networks (Fujita et al., 2018). Overall, gatekeepers are key to information diffusion because they can facilitate or constrain the flow of information as they select which messages pass the gates (Shoemaker & Vos, 2009). A problem with the gatekeeper view of virality is that we live in distributed networks where information may flow along many pathways. The gatekeeping view also implies control. If gatekeepers opt to spread information, people see it; otherwise it does not pass through the gate and become seen.
Other conceptual actors can be important in the flow of information. One is the concept of opinion leaders, which stems from the two-step flow of communication theory by Elihu Katz and Paul Lazarsfeld (1955). For Katz and Lazarsfeld (1955), information flows in two steps: first, from mass media (newspaper, TV, radio, and so on) to opinion leaders, and then, second, from opinion leaders to the public. They define opinion leaders as “the individuals who were likely to influence other persons in their immediate environment” (Katz & Lazarsfeld, 1955, p. 3). Just like network gatekeepers, the network position of opinion leaders also plays a role in the flow of information. Their closeness in the network to the people they influence helps them contextualize the information and make it salient. As Katz and Lazarsfeld put it, “opinion leadership is . . . an integral part of the give-and-take of everyday personal relationships . . . an opinion leader can best be thought of as a group member playing a key communications role” (p. 33).
Curation Logics and Lakoff’s Metaphors
Aside from a two-step flow framework, another way opinion leaders can be understood is within the structure of the curation logics framework. It says, “curation logics—that is, the norms and incentives that guide curation processes—will be more similar within sets of curating actors than across sets” (Thorson & Wells, 2016, p. 12). Following this line of logic, we propose that each actor in an individual’s social network is a curator, curating a selection (“flow”) of content for the individual’s consideration. The curation logics framework enables us to investigate how the norms and incentives faced by different opinion leaders within the BLM and its related online discussion spaces are reflected in the types of messages they share.
However, opinion leaders are partly restricted by the power inherent in the Twitter environment and the social networks in which they are embedded. By power we mean the design of Twitter; by tweeting, retweeting, quoting, or using the @ (at) function that Twitter provides to post or interact with other users, a connection is built. When multiple connections are linked together, a network emerges. This networking mechanism allows researchers to trace how information travels through different networks as well as enables users to discover new content that they may otherwise not have access to (Hemsley, 2016). Due to the political nature of our data, we also link the curation logics framework with George Lakoff’s (2016) cognitive semantic theory. Lakoff’s cognitive semantic theory states that what people say, or perhaps even what they curate, reflects their political ideologies.
Lakoff (2016) coined two family structure-related metaphors, “strict father” and “nurturant parent,” to explain political ideologies and describe “conservative” and “liberal” stances, respectively (pp. 65–140). Lakoff’s “strict father” metaphor means that what is curated is partly based on an opinion leader’s perceptions of absolute right and wrong; one who follows this model will appeal to the perceived patriarchal head of the conversation. The moral goal of such curation is the maintenance of authority and factuality over the well-being of their social networks. The “strict father” morality generates hierarchical semantics but also hierarchical power dynamics in the curation structure. Meanwhile, the “nurturant parent” metaphor opts for the protection and well-being of the “family” instead of focusing on absolute rights and wrongs (Lakoff, 2016). There is no appeal to a patriarchal head of the conversation, and as such, curation is less hierarchical and provides more discussion spaces.
Note that we do not assume that all messages tagged #BlackLivesMatter are “liberal” or that tweets tagged #BlueLivesMatter are “conservative.” However, we suspect that different kinds of discussion spaces may have different content makeup. For example, tweets including #BlackLivesMatter may contain almost equal amounts of support and opposition messages, while ALM may have more opposing messages than support. As such, our first research question is:
Within a given discussion space (e.g., #BlackLivesMatter) on Twitter/X, we think that opinion leaders are sensitive to their audience and the norms and incentives they face. For example, we suspect that those with more followers will tend to have different curation habits than those with fewer followers. Thus, our second research question is:
Finally, we are interested in knowing the possible difference between what is available to curate and what actually got curated. If curating was simply random, then we would expect that the distribution of message types would tend to be similar to what was curated. However, as noted earlier, we expect that opinion leaders are sensitive to their audience and spread different types of messages. Therefore, our third research question is:
Data and Methods
The curation logic framework (Thorson & Wells, 2016) indicates that different groups of people face different norms and incentives to curate, which suggests that people would spread different types of messages. Our three research questions attempt to shed light on what kinds of messages exist, what kinds of messages are being curated by different levels of opinion leaders, and finally, how is the posted content (tweets) different from what opinion leaders choose to curate (the original tweets that were retweeted). To answer the three research questions, we first need to annotate the tweets, so we can see what kinds of messages are available to share (original tweets) and what were curated (the original tweets that were retweeted). We used qualitative content analysis and supervised machine learning models to achieve this step. The Qualitative Content Analysis and Supervised Machine Learning Models sections below describe these two methods in detail. The follower numbers of users help us classify the level of opinion leaders who are curating, or sharing, the messages. Fisher’s exact test helps to determine if certain levels of opinion leaders tend to share certain messages, and data visualizations provide a more straight-forward view of our data.

The data pipeline from the collection, through coding, modeling, and analysis.
Data
We collected 993,320 tweets in real time that contained #Black/Blue/AllLivesMatter (case insensitive) and their variations such as BLM and ALM, from February 1, 2022, to February 28, 2022, using Twitter’s streaming application programming interface. Of all, 258,776 are original tweets, and 734,544 are retweets (73.9%). Tweets show the original content posted about the aforementioned hashtags, while retweets reflect what users chose to spread or curate.
Qualitative Content Analysis
Since we are interested in knowing the types of messages posted and curated about #Black/Blue/AllLivesMatter, we randomly selected 3,000 tweets to do qualitative content analysis with (Saldana, 2015) so that we could identify themes in the original tweets. We also applied inductive coding instead of deductive coding for our qualitative content analysis because inductive coding helps to grasp the meaning that emerged from the data while deductive coding involves a top-down coding process to fit new data into predefined codes (McKibben et al., 2020). The sample size was decided based on previous studies that explored Twitter hashtags for conducting content analysis (see Cavazos-Rehg et al., 2019; Jussila et al., 2021; Oh et al., 2021). Previous studies show that random sampling is an efficient strategy to gather a representative sample of data for tweets (Kim et al., 2018; Le et al., 2019). We chose qualitative content analysis instead of quantitative analysis because qualitative content analysis focuses on understanding the meanings of the given text, while quantitative content analysis emphasizes how information from the text is presented in frequencies, typically as percentages or actual counts within specific categories (Kleinheksel et al., 2020; White & Marsh, 2006).
To get an initial understanding of the themes that emerged from our dataset, three of the authors worked together to code a random sample of 200 tweets (retweets were not coded). We then discussed the codes and adjudicated the tweets. In the process, we merged some codes and created new ones. We repeated these steps two more times with increasingly larger sets until we reached saturation. The team then independently coded batches of 100 tweets, checked intercoder reliability (O’Connor & Joffe, 2020) using percentage agreement and Krippendorff’s alpha (Stromer-Galley & Rossini, 2023), and adjudicated tweets until two of the coding researchers reached 75% intercoder reliability using Krippendorff’s alpha, indicating good agreement.
Using Twitter’s academic API, we were able to collect tweets as soon as they are posted, so even if a user deletes their tweet right after posting it, we have a copy of the metadata (including text, userID, TweetID, posted time, and so on) in our dataset. Using TweetID from the metadata we collected, we generated the URLs (links) of the selected tweets to view the original content online and proceed with annotation. Even though some of the selected tweets for annotation became unavailable (seen with the error message “sorry this account has been suspended or this tweet has been deleted” once we clicked the URL) when we attempted to annotate them, we retained a copy of the metadata. To eliminate the unavailable tweets in our annotating sets, two coders then independently coded more random selected tweets until we had a final set of 3,000 coded tweets that were all available.
This qualitative content analysis step enabled us to develop a codebook that includes the following categories, or message types: Support, Critique, Definition, Information, and Other. We also annotated tweets as to whether they were related to BLM, #BlueLivesMatter, or ALM. We refer to this level of coding as the context.
After developing the codebook, we noticed that Support, Critique, and Information perform much like the moral agreement or disagreement that marked Lakoff’s “strict father” metaphor of communication. That is, in practice, these statements were about the simple agreement or disagreement or offer a factual moral frame without suggesting space for additional nuance. Comparatively, we noticed that Definition functions much like Lakoff’s “nurturant parent” metaphor. That is, these tweets offer spaces for disagreement, but they provide reasons or space to agree or disagree with the perceived facts. Table 1 shows the definition of each message type and provides an example of them.
Message Types of Our Codebook, Tweet Examples, and How They Reflect Lakoff’s Metaphors.

Supervised Machine Learning Models
In an ideal world, we could manually annotate all the tweets and their retweets; however, this is impractical given the time needed to annotate our entire dataset. Also, one issue that arises with relying on human annotators over a long period of time is the accuracy of the annotations; annotators’ understanding of the original annotations may drift over time and therefore reduce the accuracy of annotations (Hillard et al., 2008). Using machine learning models helps resolve this issue, as the accuracy of machine learning models remains the same over time (Stromer-Galley & Rossini, 2023). It also takes less time for machine learning models to process large-scale data than human annotators. Given the aforementioned reasons, we use the 3,000 annotated tweets from the qualitative content analysis step as the gold label dataset that we train machine learning models with, so that the machine learning models can annotate the retweeted tweets, as previous studies have demonstrated (Indra et al., 2016; Stromer-Galley & Rossini, 2023).
In our study, we tried several machine learning models to find the best-performing one for annotating the data. For the traditional machine learning models, we chose Naïve-Bayes, logistic regression, random forest, gradient boosting, and support vector machine (SVM). These five models were selected because of their popularity in identifying patterns in tweets (Abdurrahman et al., 2020; Hitesh et al., 2019; Indra et al., 2016; Ragini & Anand, 2016; Saif et al., 2014). We also tried two deep learning models: Bidirectional Encoder Representations from Transformers (BERT) (Devlin et al., 2019) and Robustly Optimized BERT Pre-Training Approach (RoBERTa) (Liu et al., 2019) The former is known for its high performance in various natural language-processing tasks, while the latter is an enhanced version of BERT further trained on datasets like OpenWebText.
For the traditional machine learning models, we used regular expressions and the natural language toolkit (NLTK) python package to process the text first (e.g., removed special characters and usernames). We then made a note of the tweets that were quoted or replies, or contained a link, and used these features for the machine learning models. We also included a text string that indicated if we coded the tweet context as #Black/Blue/AllLivesMatter. We then converted the text to a Term Frequency-Inverse Document Frequency (TF-IDF) matrix for the machine learning models.
For the transformer-based deep learning models, BERT and RoBERTa, we employed specific preprocessing methods. We utilized BertTokenizer for BERT and RobertaTokenizerFast for RoBERTa to tokenize the tweets, ensuring that the text was processed in a way that aligned with the pretrained models’ requirements.
We compared the performances of these aforementioned models for both contexts (Black/Blue/All) and message types (Critique/Definition/Information/Support/Other). Table 2 shows the performance of each model. We bold-formatted the F1 scores of the two machine learning models we chose to use in Table 2.
The Performance of Each Machine Learning Model.
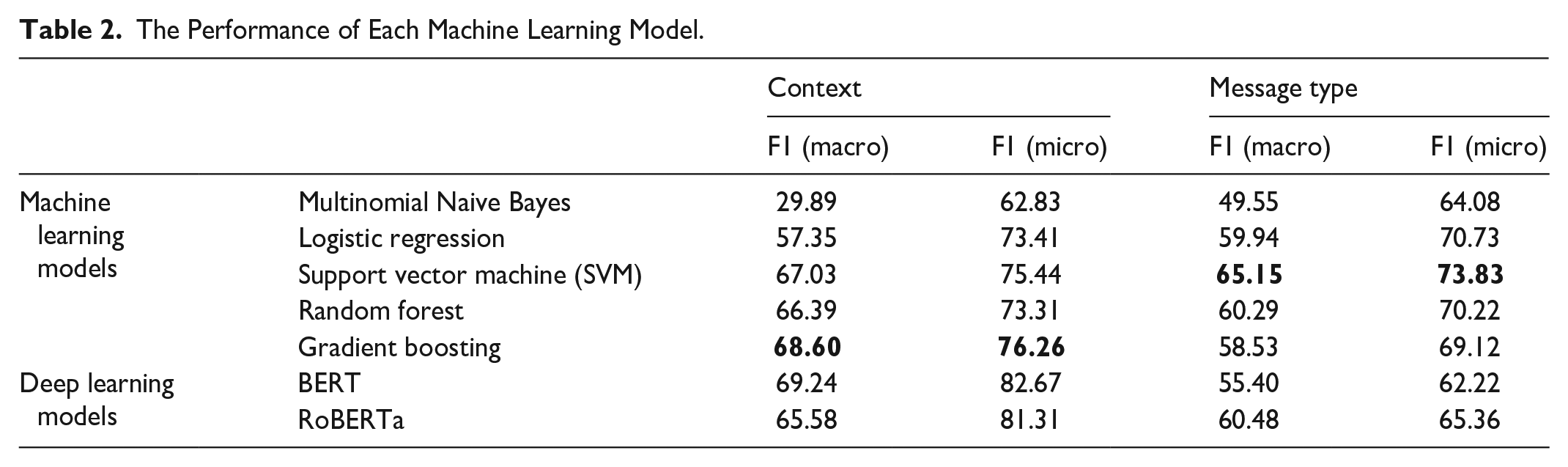
There were a few criteria we took into consideration in terms of selecting the models from Table 2 to run on the retweets. First, we looked at the F1 score, a measurement of the machine learning models’ performance, which combines the recall and precision scores of a model (Varoquaux & Colliot, 2023). Due to the class imbalances in both context and message type classification tasks, we considered two types of F1 scores: micro F1, which calculates precision and recall globally, giving more weight to the majority class in imbalanced situations, and macro F1, which calculates the F1 score for each class independently, ensuring that each class contributes equally to the final score, regardless of its size (Li et al., 2021).
Second, we ruled out the models that performed well for only one class. We did not include the numbers of each nuanced class in Table 2 given the limited space. The models that had the highest micro and macro F1 scores were BERT, followed by RoBERTa. However, their high performance was primarily attributed to the high F1 scores of the largest class for context, Black. In the case of BERT, the F1 score for the Black class was .9021, but for Blue, it was .6667. For RoBERTa, Black had an F1 score of .9038, but for Blue, it was .5833. On the contrary, the gradient-boosting model, which showed the third-highest Macro F1, had an F1 score of .8622 for the Black and .7500 for the Blue. Given the aforementioned explanations, we selected gradient boosting as the final model for classifying context. Again, the model’s ability to distinguish whether a tweet belongs to the Blue class or other classes, rather than the Black class, is critical for our study. This is especially important since the majority of tweets are categorized in the Black class.
For the message type classification, SVM was the model with the highest performance. This performance was not due to a particular class, which is the case when we tested with BERT and RoBERTa for context. The second and third highest-performing models, random forest and logistic regression, had lower F1 scores in the smallest two classes, Definition and Information, than SVM. Therefore, SVM was chosen as the final model for classifying message types. In our study, the performance of the more complex deep learning models was found to be lower than that of some of the traditional machine learning models. While the exact cause of this is challenging to pinpoint due to the black-box nature of deep learning models, we suggest that the short length and simple structure of the text data may have caused overly complex models to overfit.
To further contextualize our selection process based on the F1 scores, it is important to recognize that there is no universally accepted threshold for their performance in the context of supervised machine learning for social science applications (Stromer-Galley & Rossini, 2023). A previous study suggests that an F1 score below .70 or significant disparities between the F1 score and either precision or recall require cautious interpretation (Stromer-Galley & Rossini, 2023). For our study, the chosen models’ F1 micro scores surpass .7, although their F1 macro scores are slightly below .7. However, given the significant disproportion in the sizes of different classes, it is more appropriate to use the macro F1, which represents the global performance across all classes, for the final acceptance of our model. We anticipate achieving better classification performance by adopting language-specialized deep learning models in our future work.
After selecting the best-performing models (gradient boosting for context and SVM for message type), we ran the models on tweets that were retweeted at least once. We could have just run the models on all the retweets, but since a tweet can be retweeted many times, we would have been redundantly classifying the same text over and over for those cases. We found it computationally less expensive to only classify those tweets that had been retweeted and then merge the classifications back into the retweet data. Again, we are interested in the message types that get curated, or retweeted, and by comparing them to what was available to curate, we could better understand users’ curation logics (Thorson & Wells, 2016). We looked into the retweets to get the IDs of the tweets they are retweets of (retweets contain the ID of the tweet that they are a retweet of). With these IDs, we pulled those original tweets and sent them through the classifier. The retweet data are also used to identify different levels of opinion leaders (OLL). That is, the retweet metadata also contain information about the user who posted the retweet including how many followers they have. We inserted the OLL into the retweet metadata as an additional field.
Opinion Leader Levels
In this study, we view all users as being some level of opinion leader since even a user with one follower could influence someone else. We thought about using the term influencers, but according to the influencer literature (Freberg et al., 2011; Khamis et al., 2017), the concept of influencer is about users who make profits such as endorsing brands on social media, which is not generally the case in the #Black/Blue/AllLivesMatter discussion spaces. The unfit meaning of influencers leads us to choose the term opinion leaders, as mentioned in the Background section, this concept describes people who are able to shape others’ thoughts without implying the meaning of making profits through brand marketing.
Previous studies have broken users into various groups based on the number of followers they have (Djafarova & Trofimenko, 2019; Kay et al., 2020; Ouvrein et al., 2021; Starbird et al., 2023). Oftentimes, these groupings are arbitrary and follow convenient numbers. For example, Starbird et al. (2023) start with less than 1,000 followers, then go from 1 K to 5 K, 5 K to 25 K, and so on into seven different groups. Hemsley’s (2019) breakdown was more interesting to us because there were fewer categories (three), and the cut points were derived empirically. His system’s lowest level includes all users with between 0 and 1,799 followers, the middle-level users were from 1,800 to 26,000 followers, and the highest level being users with more than 26,000 followers. We use his system except that we add a fourth higher level of users with more than a million followers, which other studies also had (Alassani & Göretz, 2019; Brewster & Lyu, 2020). Our names for the different levels of opinion leaders are similar to the other researchers we cited earlier. Thus, we have the nano level as the lowest (0–1,799 followers), mini level (1,800–26,000), meso level (26,001–999,999), and mega level (1 million and above followers). Finally, Like the tweet context and message type, we add the OLL name to the retweet metadata for later analysis.
Inferential Statistics and Data Visualization
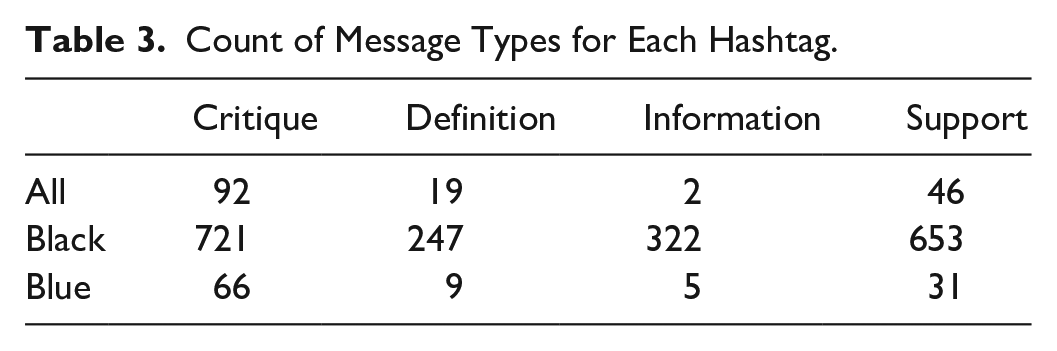
Answering RQ1 involves building a table (Table 3) for the 3,000 annotated gold-label tweets based on their message types and context, visualizing the result (Figure 2), and running Fisher’s exact test on the table. Both Chi-square test and Fisher’s test can tell if the associations or differences we see are random or not (Ragini & Anand, 2016; Upton, 1992), but we use Fisher’s test because our data are uneven, with some cells in the tables having smaller numbers than are acceptable in a Chi-square test (Ott & Longnecker, 2015). Using Fisher’s test tells us how the different discussion spaces tend to include some message types more (less) than others. Again, the 3,000 annotated tweets represent a sample of available tweets to be curated, or shared, by our opinion leaders. We expect that by understanding the different mixtures of message types, we might gain some understanding of the similarities and differences of the discussion spaces.
Count of Message Types for Each Hashtag.

Percentage of message types by hashtags.
RQ2 and RQ3 focused only on the data from the BLM movement. For RQ2, we again built a table (Table 4), this time with the number of each message type retweeted by each of the different levels of opinion leaders. This gives us a sense of how different levels of opinion leaders post different content, providing us insights into how their norms and incentives may be different at these different levels. For RQ3, we compared, again in a table (Table 5) using Fisher’s test, the number of tweets available in the stream, with what is getting retweeted.
Opinion Leader Level Statistics.

Message Types Curated by Different OLLs.

Results
For our dataset, we found that 152,602 users posted 258,776 original tweets. Of those tweets, 61,964 (24%) were retweeted 734,544 times by 411,224 users. To answer RQ1, we first look at the counts of message types within the gold-label data, broken down by discussion space. As mentioned in the Data and Methods section, some categories for the gold-label data are less than 5 as Table 3 shows, so we ran Fisher’s exact test instead of a Chi-square test. The result gives us a p-value < .0001, indicating that the differences we see in Figure 2 reflect nonrandom effects.
Since Figure 2 shows the data as percentages, we can interpret the ratio of messages about the hashtags. Figure 2 shows that Critique messages are significantly higher for Blue and All than for Black, while within the discussion around BLM, the message types are more balanced. We also see that BLM has the highest percentage of Information messages. All three groups post a similar ratio of Definition messages. This brief interpretation answers RQ1.
RQ2 looks at how different levels of opinion leaders tend to share different kinds of messages within the BLM discussion space. To answer RQ2, we first offer a breakdown of some descriptive statistics about our opinion leaders in Table 4. There are only 30 opinion leaders at the mega level, and they posted 42 retweets, or 1.4 retweets per user at this level. The most active retweeters in this discussion space were at the meso level, where the average opinion leader posted 2.58 retweets. By far, and as we would expect, the nano-level opinion leaders make up the largest group.
Figure 3 shows the data as percentages of message types posted by different OLLs, so we can interpret it as the ratio of messages those OLLs tend to curate. We ran Fisher’s exact test for the data shown in Table 5 for the same reason as we did for Table 3. Figure 3 shows that as a percentage, Critique messages are curated significantly more often for all the OLLs, but for mega OLLs, it appears that Critique messages are by far the most common kind of message got curated. Also, the further down we go (from mega toward nano), the more likely OLLs are to curate messages that define the movement or send informational messages. This finding suggests a negotiation of meanings rather than a resounding moral agreement or disagreement. This interpretation shows us how OLLs practice different curation behaviors, which answers RQ2.

Percentages of message types posted by different OLLs.
To answer RQ3, we zoom into the BLM section of Figure 2, which is illustrated as Figure 4. Figure 4 shows the percentage of messages available for curation across various OLLs, derived from the gold-label data, which can be compared with the information presented in Figure 3. Figure 4 shows that 39% of the messages are labeled as Critique in the gold-label data. Support is next with 35%, followed by Information with 17% and Definition with 13%.
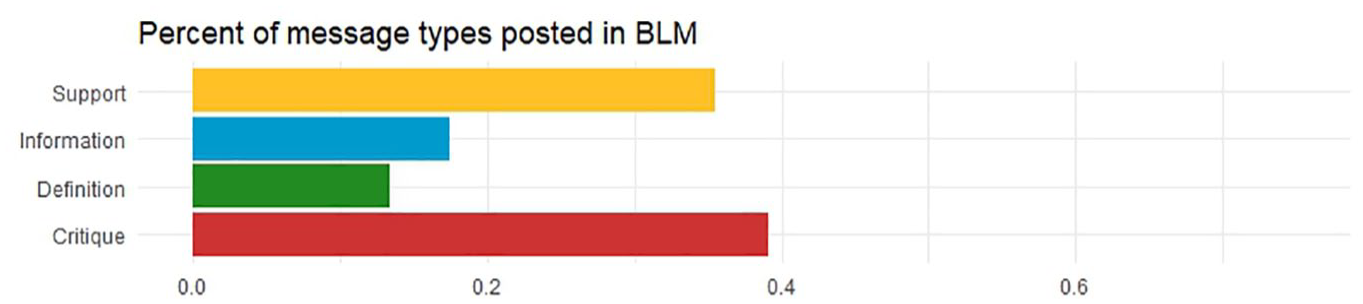
Percentage of message types posted related to #BlackLivesMatter for comparison with Figure 3.
While both Figures 3 and 4 show that the ratio of most to least used is Critique, Support, Information, and Definition in the BLM discussion space, it is clear that OLLs are selecting a disproportionately large number of Critique messages to curate. In other words, opinion leaders, especially the ones of the mega level, chose to spread more Critique information (Figure 3) about BLM even though there are about the same amount of messages from the Support and Critique categories (Figure 4). Also, while there are similar amount (17% and 13%) of Information and Definition messages available to curate, OLLs appear to select significantly fewer of these at an average across all OLLs of 8% and 2%, respectively. As both Figures 3 and 4 illustrate, we can see that while 13% of messages attempt to define the movement, this kind of message is rarely curated, and at the top, not at all.
Discussion
Contextualizing the “Nurturant Parent” vs. the “Strict Father” Metaphors
Our findings about the #Black/Blue/AllLivesMatter discussion spaces support Lakoff’s “strict father” and “nurturant parent” metaphors. While the order of message types seem to remain consistent across different discussion spaces, the conversations stand out due to the regularity of specific message types when compared to others. For example, as Figure 2 shows, the message types of BLM-related tweets tend to be more evenly distributed than #BlueLivesMatter and ALM. This echoes Lakoff’s (2016) “nurturant parent” metaphor of political discourse semantics, suggesting that opinion leaders may encounter more negotiation regarding the ideological understandings of BLM.
While we see a lot of Critique and Support tweets curated in each discussion space, ALM and #BlueLivesMatter are particularly critiquing or supportive spaces (way more Critique and Support messages than other message types) compared to BLM, as Figure 2 shows. These critiquing and supporting positions can be understood as reflective of Lakoff’s (2016) “strict father” metaphor, showing a tendency to share messages that are “right” or “wrong” for users who retweeted them. For example, the “blues lives matter” tweet example for Support in Table 1 signals that in the #BlueLivesMatter space, respecting Blue life is the right thing and is not to be contested.
However, within ALM, there is a noticeable amount of Definition happening, suggesting that there is some negotiation around what ALM implies ideologically. Much of the ALM discussion is negotiating how much focus should be on “Black lives” relative to everyone else. Instead of a Definition category in #BlueLivesMatter, we see a slightly higher amount of the Information category than in ALM, as Figure 2 presents. When we were annotating the tweets, we noticed this information consisted of semantically factual reports that imply the police are “victims” of public disputes or “heroes” standing up to wrongs. That is, like with the “strict father” metaphor, information is expressed as explaining an indisputable moral high ground, often supported by news-like or infographic-like genres of content.
Curation Behaviors of Opinion Leaders
Now, we turn to the curation behavior of our different levels of opinion leaders and try to infer the different norms and incentives they face, all in the context of the #Black/Blue/AllLivesMatter discussion spaces. First, we see that our mega-level opinion leaders overwhelmingly curated Critique messages at about 86%. In terms of Lakoff’s metaphors, we might interpret this as those with the highest number of followers are incentivized to share more critical messages and operate in a space where being critical is the norm. That is, if one perceives themselves as being at the top of the social hierarchy, they may have an incentive and operate within certain norms, to follow the “strict father” metaphor of semantics regardless of their actual political ideology. Since mega-level opinion leaders tend to have disproportionately greater influence over the flow of information (Hemsley, 2019), when they share their “strict father” messages, they reinforce doing so as a norm in the space they are in.
As we move down OLLs, we see a steady relative decline of Critique messages at the same time as we see an increase in the diversity of message types, as Figure 3 presents. We note that the most-used message type for each OLL was Critique, followed by Support. It could be that the more clearly a message is morally “for” (support) or “against” (critique), the more likely users are to share/curate it, which is possibly associated with getting more followers. While the causational direction of message content and number of followers is unclear, the incentives are overt: being critical garners more attention. That is, Twitter’s structure of conversation may tend to incentivize curating messages in the “strict father” metaphor for BLM regardless of OLL. Typically BLM is seen as a leftist conversation (Pew Research Center, 2023). Yet, the hierarchical incentives of the platform lead to more “conservative” semantic norms in this space.
Furthermore, as opinion leaders in the BLM space tend to have fewer followers, we see more of Lakoff’ “nurturant parent” metaphor. That is, despite Critique and Support being the largest two message types (in respective order), the fewer followers an opinion leader has, the more likely they are to share other message types, as shown in Figure 3. The opinion leaders may be incentivized to appeal to fact-like news and infographics (Information). Or they are likely to negotiate what these ideological spaces are about (Definition). Another way of interpreting this findng is that these users are incentivized to engage in equitable conversations with their network or appeal to ready-made narratives such as news-like or infographic-based content.
Implications
When we take our findings and look them through Lakoff’s metaphors, coupled with the curation logic framework, there are a few takeaways we would like to point out. First, zooming into the BLM discussion space alone, we can see that it has roughly the same percentage of Support and Critique messages, as Figures 2 and 4 present. This implies users have a more polarized view about BLM than about #Blue/AllLivesMatter. Such a polarized view is likely to impede users from reaching a consensus or finding compromise when discussing the BLM social movement, which raises concerns for a society as a whole, especially given what this social movement represents: advocating for racial equality and against police brutality that Black Americans have faced for centuries (Carney, 2016).
Second, Figure 2 shows that #BlueLivesMatter has the least amount of Definition messages compared to the other hashtags, suggesting that users who interacted with this hashtag had a clear view on what #BlueLivesMatter represents, while there are more disagreements for what BLM and ALM stand for. We suspect that not having the same understanding for a topic, especially a social movement, could limit the ability of users to engage in meaningful discussions, which would fill the online discussion spaces with arguments rather than factual information.
Third, our findings show that Critique has the highest percentage as a message type across #Black/Blue/AllLivesMatter, indicating that users engaged in more of a negative way regardless of the discussion spaces on Twitter. It could be that negative content gains more attention, as the study by B. Wu and Shen (2015) reports that news with negative tones exhibits certain correlations with retweet popularity, whereas news with positive tones do not. However, having Critique as the leading message type across #Black/Blue/AllLivesMatter discussion spaces also raises the concern about how to have meaningful discussions regarding these hashtags; especially coupled with the fact that mega-level opinion leaders, who have great influence given the large amount of followers they have, chose to curate Critique excessively. This finding also questions Twitter’s platform design and power; users may deliberately spread negative information about #Black/Blue/AllLivesMatter just to gain retweet popularity and followers on Twitter, ignoring what these hashtags and the social movements behind them actually stand for.
Limitations
There are a few limitations of this study that could be addressed in future research. First, we acknowledge that we are comparing message types for the different hashtags, #Black/Blue/AllLivesMatter, and that the data were collected during Black History Month. We think the ratios of message types could be different during a different month or depending on current events. We see this as an opportunity for future work comparing the effects of context on curation logics (Thorson & Wells, 2016). Second, the F-1 score of the machine learning models in this study could be further improved with more annotated tweets. Third, this study shows what users chose to curate in the #Black/Blue/AllLivesMatter discussion spaces on Twitter/X and infer the reasons behind users’ actions based on the curation logics framework (Thorson & Wells, 2016) and Lakoff’s (2016) semantic theory. However, we do not know exactly why users curated certain tweets. Future work could interview users who posted information about #Black/Blue/AllLivesMatter to probe the reasons behind their actions.
Conclusion
This study examines what types of messages users posted and spread about #Black/Blue/AllLivesMatter during the Black History Month of 2022. Using both qualitative and quantitative methods, we find that despite there being about the same percentages of supportive and critical messages in the original tweets, users retweeted more critical tweets than other message types regardless of their OLLs. We also find that different levels of opinion leaders shared different message types. Using the curation logics of Thorson and Wells (2016) and Lakoff’s (2016) semantic theory as theoretical lenses, we offer some observations about the differences in the logic (incentives and norms) that opinion leaders might face.
This study makes both theoretical and empirical contributions. Theoretically, it offers an update to the concept of virality proposed by Nahon and Hemsley (2013) by considering the concept of opinion leaders. It also suggests some developments for reconsidering how Lakoff’s (2016) semantic theory signals liberal and conservative statements. Empirically, our work supplements data to contextualize the framework of curation logics (Thorson & Wells, 2016), as well as adds to the existing data collections for #Black/Blue/AllLivesMatter discussion spaces. The work also makes a contribution to the BLM literature by contrasting the ways opinion leaders in the #Black/Blue/AllLivesMatter discussion spaces on Twitter frame messages, often for the purposes of retaining or negotiating power. We conclude by highlighting the implications of this study for social movements.
Footnotes
Acknowledgements
Although this study takes a technical approach that examines the types of messages that users posted and spread regarding #BlackLivesMatter and its related hashtags, we would like to show our gratitudes toward protesters who fight against racism and police brutality online and offline. We also want to thank the reviewers who provided constructive feedback to us in shaping this article, as well as the editoral team for their work in faciliating the publication.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Author Biographies
![]() may impact the design industry and education by conducting interviews with designers using this platform, while her quantitative work looks at the types of messages spread regarding #BlackLivesMatter using machine learning models.
may impact the design industry and education by conducting interviews with designers using this platform, while her quantitative work looks at the types of messages spread regarding #BlackLivesMatter using machine learning models.