
Abstract
While linearly directed imageboards like 4chan have been extensively studied, user participation on nonlinearly directed imageboards, or “boorus,” has been overlooked despite high activity, expansive multimedia repositories with user-defined classifications and evaluations, and unique affordances prioritizing mutual content curation, evaluation, and refinement over overt discourse. To address the gap in the literature related to participatory engagement on nonlinearly directed imageboards, user activity around the full database of
As the Internet grew from a subcultural phenomenon to a ubiquitous global presence, so too did imageboards evolve from their roots as short-lived, localized “textboards” into sprawling multimedia sharing and discussion spaces with global participation and influence (Okeh, 2017). Today, imageboards are among the most active and controversial Web sites, with glowing descriptions as havens of rich subcultures and sources for societal transformation alongside blistering critiques casting them as the dark, disgusting underbelly of humanity (e.g., Phillips, 2013; Prichard, Watters, & Spiranovic, 2011).
Regardless of one’s opinions about imageboards, there is little denying their significance online and their potential to impact society at large. In particular, the term “imageboard” may evoke thoughts of 4chan (2018), easily the most widely recognized English imageboard. Just one of 4chan’s subboards, “/b/,” receives 35,000 new threads daily (Bernstein et al., 2011), and its users are responsible for everything from generating long-standing memes like Rickrolling, lolcats, and Pedobear to tricking talk show host Oprah Winfrey into saying “over 9,000 penises,” unknowingly referencing a notorious meme, on daytime television (Adams, 2008).
Yet countless other imageboards exist, and some of the most popular ones depart from 4chan’s bulletin board system (BBS)-like structure. These newer “booru” imageboards focus more on uploaded content rather than the textual interactions that ultimately serve as the crux of “chan”-style sites like 4chan. The most prominent “boorus” feature several million media artifacts, each of which has been individually uploaded, tagged, classified, reviewed, scored, and in some cases, discussed at length. On the most widely used and recognized boorus, the user community itself is responsible for curating content to ensure that only the best submissions are retained; evaluating submissions by voting for quality content and marking their favorites to increase their visibility; and refining submissions by adding metadata, translating textual content, and denoting related posts such as variants of the same image.
The degree to which the community of users holds shared responsibility and ownership over the collection of submissions is unique to boorus, and the affordances of these communities privilege consumption of the media products rather than text-based discourse with other users. This ultimately results in a greater emphasis on the creative media and thus the user–media relationship than that seen on other, BBS-based imageboards. Moreover, imageboards like Gelbooru (2018b) and The Big ImageBoard (TBIB; 2018) rank within the top few thousand Web sites in the world (Alexa, 2018b, 2018c), while Danbooru (2018a), the first “booru,” stands among the top 2,000 Web sites (Alexa, 2018a) and receives well over 200,000 unique visitors per day (SEMrush, 2018). Thus, “boorus” host considerable activity and user effort to develop content.
This study builds a foundation for research into user engagement with media content and with one another within these “booru” domains. The processes of content curation, evaluation, and refinement were examined as they occurred in the unique interaction spaces defined by each of the nearly 3,000,000 submissions, or posts, to one imageboard, Danbooru. This illustrates how imageboard participants contribute to content production and, through this crowdsourced effort, build an expansive yet organized resource enjoyed by millions of peers around the globe.
Literature Review
Prevalence of Imageboards
Imageboards, especially 4chan, have received substantial media attention. In 2008, for instance, Fox News commentator Bill O’Reilly famously referred to 4chan as a “despicable, slimy, scummy Web site” after one of its members hacked US presidential candidate Sarah Palin’s e-mail account. From 2010 to 2012, multiple 4chan users were arrested for posting and downloading child pornography on 4chan (Prichard et al., 2011). 4chan users have also leaked nude celebrity photographs (Marwick, 2017), threatened to bomb National Football League (NFL) stadiums (Mark, 2006), and spawned Anonymous, the infamous hacker group (Phillips, 2013).
While 4chan and other imageboards have received substantial press coverage, scholarship has been less consistent. Among researchers studying imageboards, many focus only on image recognition and processing tools (e.g., Vie et al., 2017). Those studies addressing users tend to examine textual conversations rather than engagement with the media (e.g., Nissenbaum & Shifman, 2017); discuss interactions between users and outside actors (e.g., Phillips, 2013); only refer to imageboards within the larger online culture (e.g., Douglas, 2014); or view imageboards as mere stores of adult-oriented media; misogynistic and racist behavior and discourse; or anarchic destabilization (Goode, 2015). Furthermore, the literature on imageboards has maintained a narrow focus on 4chan as a near-exclusive representation, with only passing references to other imageboards among larger collections of Web sites in other publications (e.g., Attwood et al., 2018; van Zoggel, 2011).
Just as concerningly, once we set aside assessments of user–user and organization–public dialogues, such as those presented by Phillips (2013) and Nissenbaum and Shifman (2017), it becomes clear that few studies have explored user engagement with the creative media themselves, which are ostensibly the hallmark of imageboards. Rather, most prior studies have all but ignored the “image” in “imageboard,” prioritizing the processes and consequences of discourse on imageboards instead (e.g., Nagle, 2017). This is, in part, a consequence of the narrow focus on 4chan, as there are obvious societal implications of users’ disclosures about hacking, child pornography, terrorist attacks, and so forth. Dialogues between users are also clearly visible, while records of engagement with media products may be hidden in server logs or require data mining to access. In short, it is easier for researchers to examine public conversations, and to report on the controversies surrounding the extreme, isolated case of 4chan, than to engage with the nuanced, personal interactions between users and creative media.
Yet the images, videos, audio, and other media that imageboards showcase constitute the key affordance that distinguishes them from text-heavy BBSes, which are themselves a dying breed (Driscoll, 2016). As Evans, Pearce, Vitak, and Treem (2016) discuss, the design or material characteristics of a given technology or interface impacts how individuals are able to use that resource, as well as what actions are most straightforward to perform. In other words, “the materiality of technology influences, but does not determine, the possibilities for users” (p. 37). Thus, the affordances or “action possibilities” of BBSes privilege textual discourse. Even if, strictly speaking, it is possible to integrate images into the dialogue, it is nonetheless easier to rely on textual communication using keyboard entry, so users generally tend to do so (see Faraj & Azad, 2012). In other words, BBSes themselves frame textual communication as the normal, expected method of interaction, a norm that is reinforced by other users’ textual bulletin board posts (see Hutchby, 2001). In contrast, the relative importance granted to images and other media products in the design and implementation of imageboards, down to their inclusion in the name “imageboard” itself, suggests and facilitates the use of media products as the central focus of communication within these contexts.
The Internet as a whole is gradually shifting away from purely textual communication toward multimedia engagement (Kreps & Kimppa, 2015), so it is no surprise that imageboards that privilege engagement with media products are steadily gaining prominence online. Given that media-rich imageboards are gaining prestige as traditional text-based BBSes fall by the wayside, it is important to examine how users engage with the media at the heart of these thriving imageboard communities, especially given the potential implications for user–media interactions across the online realm.
In short, the processes through which users directly engage with uploaded media need to be examined as communicative phenomena of interest in their own right. While studies on 4chan are a useful start, we risk overgeneralizing findings about this single example if it remains the only imageboard seriously considered in the literature. The media posted to many other imageboard communities constitute their core; in their absence, all user interaction would inevitably dissolve. Thus, the manner in which different media gain prestige or fall from favor is of great importance, as this contributes to communication phenomena ranging from user agency in participative communities to the manifestation of media effects online.
Types of Imageboards
As noted above, the term “imageboard” comprises two primary types of sites: linearly directed imageboards and nonlinearly directed imageboards. These two distinct classes of imageboards offer different affordances (Gibson, 1966) that facilitate different types of user engagement, so the distinctions between them must be addressed.
Linearly directed imageboards, including “chan” sites like 4chan, are structured around BBS-style discussion threads (Figure 1). Users may start a thread by posting an image, video clip, or other file with complementary text to prompt replies. Active threads that continue receiving responses are listed at the top of the site, while those that stagnate fall down the page. On some sites, defunct threads are eventually deleted, whether to reduce server costs or to simply suggest a sense of ephemerality. Such linearly directed imageboards are inspired by traditional BBSes and textboards (e.g., 2chan, 2019), with the ability to add media content essentially built onto otherwise plain textboards. Consequently, just like BBSes and textboards, the affordances of linearly directed imageboards tend to privilege textual communication, with media products serving to support ongoing dialogue rather than standing as its focal element.

Sample 4chan discussion thread.
In contrast, nonlinearly directed imageboards (or nonhierarchical semantic structured imageboards; see van Zoggel, 2011), sometimes called “booru” sites, are organized around individual submissions rather than threads (Figure 2). On such sites, users upload images, video clips, and other media, with each post treated as a self-contained unit. Users then apply “tags” to facilitate future searches—a user interested in the show Sailor Moon, for example, can search for all relevant posts simply by clicking the “sailor_moon_(series)” tag. Posts may include attributes like a content rating applied by the uploader—usually “safe,” “questionable,” or “explicit,” based on how sexually explicit the submission is deemed—as well as a numeric “score” that affects its visibility. Registered users may develop a list of their favorite posts, or “favs,” to which they can easily return. Finally, on some boorus, users can make comments on posts. These occasionally evolve into fully fledged conversations, although in practice, comment systems are rarely the focus, as the uploaded media take precedence.

Sample Danbooru post.
Unlike linearly directed imageboards, nonlinearly directed imageboards bring user engagement with media to the forefront, as the focus is on curating, evaluating, and refining submissions over time. The affordances of these boorus, which emphasize uploaded content and user–media engagement, further contribute to the tone of these interactions. Figure 2 demonstrates the affordances that privilege user–media engagement over user–user discourse. As is immediately evident, the media content is inescapably placed at the forefront of the interaction space, with supporting information about the image placed alongside (tags), above (parent/child relationships), and below (pools). Only by scrolling past, all of these pieces of content can users reach a space for discussion with other users. Since that space is clearly assigned to this specific post—with other posts featuring their own distinct discussion spaces—it is little surprise that any discourse among users centers around the content itself.
In short, the imageboard user–media relationship, which has been largely neglected in the literature, may be directly assessed on “booru”-style systems. Thus, in the interest of examining this dynamic, the remainder of this article is framed around nonlinearly directed imageboards on which user–media interactions are more visible.
Content Curation
Not all submissions may be considered suitable on a given imageboard. For instance, many imageboards permit sexually explicit images, so it is easy to envision users posting illegal content that could put the imageboard in legal jeopardy. Even if the terms of service prohibited such content, an unwitting or rogue user could nonetheless contribute unwanted material at will.
On most imageboards, common users cannot delete offending posts themselves, but they can flag existing posts for moderators to review. Moderators may also remove offending content without user intervention. On Danbooru, for instance, all new posts are placed in a moderation queue, and users can flag existing posts, which moves them back to the queue. Any moderator may approve a queued post, but if no one does so within three days, it is automatically deleted.
Thus, the process of content curation, and more specifically of removing an undesirable submission, has two components: flagging and deletion. These may not occur in order, and one may occur without the other, but each is important in its own right.
As an initial step toward understanding the types of content that are flagged for review and ultimately deleted, let us consider whether submissions denoted as being more explicit (accurately or otherwise) are more likely to be flagged or deleted. Two hypotheses are proposed:
H1. Submissions labeled as more sexually explicit are more likely to be flagged.
H2. Submissions labeled as more sexually explicit are more likely to be deleted.
Content Evaluation
Voting
Assuming that a given submission is worthy of remaining, the next question is what content is more or less attractive to users.
As previously noted, imageboard users have multiple means to evaluate posts, the most obvious of which is voting to increase (upvote) or lower (downvote) their scores. However, not all users may be permitted to do so. In Derpibooru (2018), for instance, only logged-in users may upvote or downvote; on Danbooru (2018b), only “upgraded” members who, in most cases, paid a fee for special access privileges may cast upvotes and downvotes.
These evaluation processes, and the scores that they yield, are not merely idle diversions. Rather, they play a critical role in shaping and reinforcing the standards of imageboards and other participatory online environments. Singer (2014) discussed the role of “secondary gatekeepers” on news Web sites, noting that while professional journalists and editors make initial decisions on what stories are produced, when users who rate those stories are integral “in assessing the individual value—and, in doing so, determining the visibility—of what is published on a newspaper website” (p. 66). This role is just as critical on nonlinearly directed imageboards, where the relative prominence of each submission is collectively determined. Yet imageboards do not necessarily follow the same news cycle as a journalism outlet, so any given submission may persist atop the rankings indefinitely, making users’ roles as secondary gatekeepers even more important.
Broadly speaking, on many imageboards, the upvotes and downvotes that a submission receives serve to represent how those especially dedicated users, such as those who have paid for the privilege to vote, feel about it. Such users may have different standards for casting a vote than the average user may apply, which makes it important to assess upvotes and downvotes separately from other evaluation mechanisms.
One might expect “safe,” “questionable,” and “explicit” posts to perform differently. For instance, since imageboards are sometimes perceived as pornography havens (Attwood et al., 2018), some users may visit them solely to view sexually explicit content. In that case, users might gravitate toward more explicit posts, which would in turn make them more likely to cast votes for (or against) them, as one cannot vote on a post without visiting its page.
However, imageboards are not necessarily mere pornography receptacles. Consider the first “booru,” Danbooru (Know Your Meme, 2018). As others (e.g., Branwen, 2018) have noted, most Danbooru posts are deemed “safe,” while only a small minority are “explicit.” The same can be said by Gelbooru (2018b) despite general perceptions that it is a more adult-oriented version of Danbooru (e.g., Gelbooru, 2018a). The majority of Gelbooru posts made as of 27 March 2018 are safe (
In short, some users may actively pursue sexually explicit content, while others are deeply concerned with avoiding it. Thus, it is difficult to anticipate whether “safe,” “questionable,” or “explicit” submissions perform better or worse. Nonetheless, we may expect ratings to have an effect on voting, even if we do not know its direction.
The relationships between submissions are also of interest. While each post functions as an independent unit, users can link posts in two ways. First, if an artist creates an image and alternate versions, variants may be uploaded as “children,” with the original version as the “parent.” A parent–child relationship may also signify multiple copies of the same media product, such as a low-resolution “child” subordinated to a high-resolution “parent.”
While parent–child relationships provide a hierarchical structure, pools create horizontal connections between posts. Most imageboards feature two types of pools: series pools connect sequential submissions in an existing set, such as pages of a manga volume, while collection pools group unordered posts whose unifying theme is not represented by a tag. Parent–child relationships and pools are both visible to users: on the page of any post that has a parent, has a child, or is part of a pool, hyperlinks to related submissions are prominently displayed (see Figure 2).
As with explicitness rating, connections between posts likely affect voting behaviors. Since parent–child relationships and pools help users navigate between related submissions, we can surmise that connected posts are more discoverable. A user who enjoys one submission in a pool can quickly browse the rest of the pool rather than trying to guess unifying tags; much the same is true of parent–child relationships. Since connected posts are likely to be viewed by more users, they have more opportunities to receive upvotes.
The impact on downvoting practices is less clear. If connected posts are viewed by more users, they have more opportunities to be downvoted. On the other hand, those connections might lend perceived legitimacy to the linked submissions. If, for instance, a user would be inclined to downvote one submission in a pool, does that mean that the entire pool deserves to be downvoted? Psychologically, it might be harder to condemn a set of submissions than to downvote just one. This “strength in numbers” phenomenon could protect such posts from downvotes. The same may be true of parents and children, although parents may benefit more—a user viewing a parent might conclude, “This is at least better than the children, so I should downvote those instead”—but children may also be protected by their parents, particularly if one parent has many children that a user hesitates to downvote en masse. Thus, we have the following hypotheses:
H3. Visible attributes affect how many upvotes a submission receives.
H3a. Explicitness rating affects how many upvotes a submission receives.
H3b. Submissions with a parent receive more upvotes than those that do not.
H3c. Submissions with children receive more upvotes than those that do not.
H3d. Submissions in a pool receive more upvotes than those that are not.
H4. Visible attributes affect how many downvotes a submission receives.
H4a. Explicitness rating affects how many downvotes a submission receives.
H4b. Having a parent affects how many downvotes a submission receives.
H4c. Having children affects how many downvotes a submission receives.
H4d. Pool membership affects how many downvotes a submission receives.
Favs
While voting rights may be restricted to high-status members, on most imageboards, anyone can create a personal list of favorite posts (“favs”). We may conceptualize the difference between upvotes and favs like that between passively appreciating museum artwork (“I should like this; it’s obviously good”) versus being actively fascinated by a particular piece (“I really like this”). Thus, the number of favs received is important to distinguish between excellent and mediocre content despite the lack of a negative analogue.
It stands to reason that users would select favorite posts based on factors they see, just as we expect visible attributes to drive voting behaviors. Consequently, a submission’s explicitness rating might impact how many users “fav” it.
The role of connections between posts is harder to predict. A post’s inclusion in a pool could result in more viewers, yielding more chances to be selected as a fav. However, pooled posts might compete and preclude otherwise fav-worthy content from recognition, as faving an entire pool would clutter the user’s collection of favs. Unlike upvotes, favs may lose their meaning if every post in a pool is selected—the pool already aggregates them—so users may avoid doing so even if each individual post would otherwise merit the designation.
In short, pools may enhance discoverability, and they may also cause competition between related posts. Much the same is true of parent–child relationships, especially for children that are derivatives or lower quality versions of their parents. Finally, as before, explicitness rating likely affects how many favs a post receives, but it is difficult to predict the direction of this effect.
Based on these factors, we have the following hypothesis:
H5. Visible attributes affect how many favs a submission receives.
H5a. Explicitness rating affects how many favs a submission receives.
H5b. Having a parent affects how many favs a submission receives.
H5c. Having children affects how many favs a submission receives.
H5d. Pool membership affects how many favs a submission receives.
Content Refinement
As we have seen, users play a central role in curating imageboard content and evaluating submission quality. However, the feature that distinguishes nonlinearly directed imageboards from almost every other Web site is user-defined tags.
Tags are applied to each post to describe its content, including facts like the artist (e.g., “haruyama_kazunori”), characters (e.g., “kurosaki_ichigo”), and source material (e.g., “touhou”) along with visible objects (e.g., “sword”) or actions (e.g., “running”). They may also feature subjective assessments like the size of body parts (e.g., “long_hair”), emojis representing facial expressions (e.g., “:<>”), and abstract terms like “wtf.” Users can click any tag to view a list of all posts sharing that feature. Some imageboards also allow combinations of tags to be searched, in addition to other post attributes (e.g., “rating:safe”), making it easy to find relevant content.
However, as tags are applied, they proliferate. The most prominent imageboards feature hundreds of thousands of tags; some, like TBIB (2018), have well over a million. With so many tags, many of which are as narrow as “horseshoe_crab” or “taishuu_high_school_uniform,” it would be unrealistic for anyone to maintain encyclopedic knowledge of all of them, let alone accurately and consistently apply them to the numerous submissions made daily. Thus, as Branwen (2018) noted, each post on any sizable imageboard is likely missing many tags that, strictly speaking, should be applied. The specific tags applied may largely result by chance based on the particular users who happen to see that post and the specific tags those individuals happen to remember.
While the tagging process is imperfect, it is nonetheless a core element of imageboard engagement. Aside from uploading new content, tagging may be the most critical activity in which users can participate.
If we conclude that each submission should have far more tags applied than it actually does, we must ask what factors affect how many tags a post actually receives. First, the same elements that affect voting and faving may also impact the number of tags applied. Explicitness may play a role—again, rating may affect post visibility, influencing how many opportunities exist for further tagging. The same goes for parent–child relationships and pools. This prompts the following hypothesis:
H6. Visible attributes affect how many tags a submission receives.
H6a. Explicitness rating affects how many tags a submission receives.
H6b. Submissions with a parent receive more tags than those that do not.
H6c. Submissions with children receive more tags than those that do not.
H6d. Submissions that are part of a pool receive more tags than those that are not.
Furthermore, users who like a post enough to upvote or fav it may also contribute by adding missing tags during the same browsing session. Alternatively, a post that gains many upvotes or favs may thus be more visible to other users who, upon seeing it, add additional tags; likewise, a highly tagged post will likely appear in more searches, yielding more chances to receive upvotes and favs. In short, posts may receive tags before, after, or concurrently with upvotes and favs. Regardless of timing and causality, posts with more tags are expected to also have more upvotes and favs.
The relationship between downvotes and tagging is more complicated. A post with 100 downvotes must have been seen by at least 100 users, which may not be the case for another post with only 10 downvotes. Presumably, more views also mean more opportunities to receive tags, but only if those users are motivated to refine the post. A user who deems a submission poor enough to downvote is unlikely to add tags since downvoting is, in effect, an acknowledgment that the post is not worth viewing—in other words, downvoting a submission and lowering its score is a way to warn other users. Why, then, would a user who downvotes a post bother adding missing tags to improve its discoverability? Likewise, since downvotes reduce post visibility, a submission receiving many downvotes will garner fewer subsequent views, reducing its chances for further engagement. Thus, posts with fewer downvotes likely also have more tags, so our final hypothesis is as follows:
H7. Submissions with more favorable user engagement receive more tags.
H7a. Submissions with more upvotes receive more tags.
H7b. Submissions with fewer downvotes receive more tags.
H7c. Submissions with more favs receive more tags.
Methods
Research Context
This analysis uses Danbooru (2018a), which was the first “booru” site (Know Your Meme, 2018) and remains one of the most prominent imageboards (e.g., Attwood et al., 2018). As previously noted, Danbooru ranks among the 2,000 most active Web sites in the United States and worldwide (Alexa, 2018a), representing a collective spanning national and linguistic boundaries. Danbooru has received nearly 3,000,000 submissions since its creation in 2005 (Danbooru, 2018c). Like most major imageboards, almost all of its submissions are based around anime, manga, video games, and other Japanese media. All other nonlinearly directed imageboards are based in some fashion on Danbooru, with some directly importing its source code (Yi, 2018) and others mirroring its content (e.g., TBIB, 2018), making it the most appropriate site for an initial investigation of content curation, evaluation, and refinement processes on imageboards.
Sample
Data Collection and Cleaning
Since 2016, Danbooru administrators have maintained a database on Google BigQuery (Google, 2018). This dump, which is updated nightly, features information on every Danbooru post from its inception in 2005 through the present day, including the submission date, the tags applied to it, and how many upvotes and downvotes it has received, among other details.
The full data set was downloaded as a set of 17 JSON files on 27 February 2018. A Java program was written to import these data into R 3.3.2. Variables not included in any hypotheses were removed.
For each post, a nominal variable was created to indicate whether or not it had a parent; a complementary “has_children” variable already existed in the original data. Similarly, variables were created representing the number of tags and favs received, as well as the number of pools in which the post was included.
Finally, the “rating” variable was dummy coded before analysis. On Danbooru, the default rating for new uploads is “questionable,” so action is required to change it to either “safe” or “explicit” (Branwen, 2018). Therefore, in the dummy coding, “questionable” status was used as the default rating against which “safe” and “explicit” posts were compared. This yielded a data set comprising 14 variables and 2,987,525 observations.
Descriptive Statistics
Most Danbooru posts (
A total of 165,391 posts had been deleted; metadata on these posts were still available for analysis. On the other hand, only 30 flagged posts appeared in the data set that also featured 236,550 parents of 323,355 children, as well as 390,756 posts belonging to at least one pool.
Analysis
H1–H2 were assessed using logistic regression. Since the date, a post was created may have affected its likelihood of being flagged or deleted, creation date was used as a control variable, with the “safe” and “explicit” dummy coded variables predicting a post’s likelihood of being flagged or deleted.
The numbers of upvotes, downvotes, and favs received were “count” variables following a Poisson distribution, so H3–H5 were assessed via Poisson regression, with post creation date again used as a control variable. Predictors included the number of pools with which a post was affiliated, along with its rating and parent/child statuses. These were used in regression models to predict the numbers of upvotes, downvotes, and favs received, respectively.
Since tags, like votes and favs, were Poisson distributed, H6–H7 were assessed with one additional Poisson regression model. Creation date, pools, rating, and parent/child status were again incorporated into the model, along with the numbers of upvotes, downvotes, and favs received, comprising one control variable and eight predictors for the number of tags received.
Ninety-three posts without creation dates were removed, leaving
Results
H1. Submissions labeled as more sexually explicit are more likely to be flagged.
As evident from Table 1, none of the variables used to explain flagged posts—creation date
Logistic Regression of Variables Predicting Flagged Status.
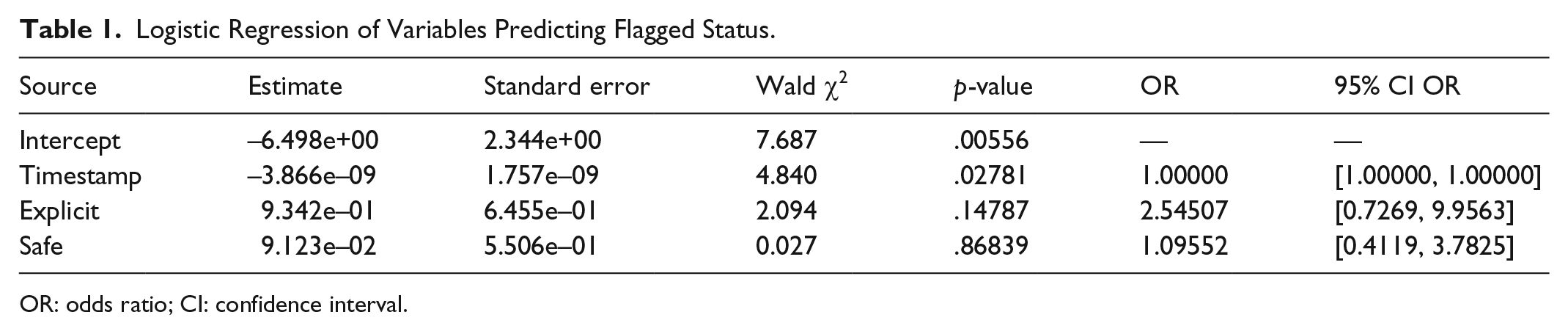
OR: odds ratio; CI: confidence interval.
H2. Submissions labeled as more sexually explicit are more likely to be deleted.
Table 2 lists the results for H2. Posts designated as explicit were more likely to be deleted than questionable posts (
Logistic Regression of Variables Predicting Deleted Status.
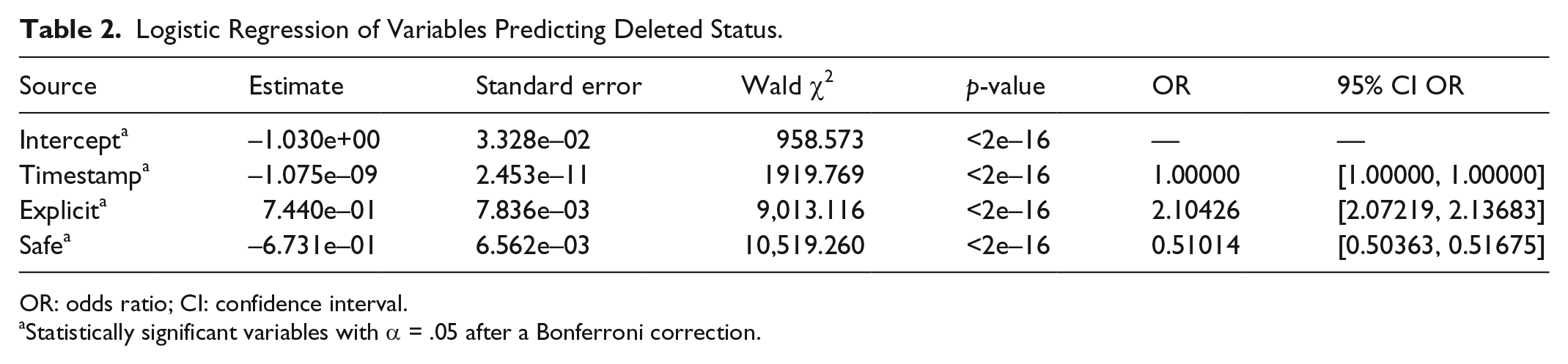
OR: odds ratio; CI: confidence interval.
Statistically significant variables with α = .05 after a Bonferroni correction.
H3. Visible attributes affect how many upvotes a submission receives.
As shown in Table 3, after controlling for submission date, explicit posts generally received more upvotes than questionable posts (
Poisson Regression of Variables Predicting Upvotes.

CI: confidence interval; IRR: incidence rate ratio.
Statistically significant variables with α = .05 after a Bonferroni correction.
H4. Visible attributes affect how many downvotes a submission receives.
Table 4 gives the results for H4. Posts labeled as explicit tended to be downvoted more than questionable posts (
H5. Visible attributes affect how many favs a submission receives.
As shown in Table 5, explicit posts received more favs than questionable ones (
H6. Visible attributes affect how many tags a submission receives.
H7. Submissions with more favorable user engagement receive more tags.
Table 6 displays the results for H6–H7. Increasing explicitness was associated with more tags, as explicit posts received more tags than questionable ones (
Poisson Regression of Variables Predicting Downvotes.

CI: confidence interval; IRR: incidence rate ratio.
Statistically significant variables with α = .05 after a Bonferroni correction.
Poisson Regression of Variables Predicting Favs.

CI: confidence interval.
Statistically significant variables with α = .05 after a Bonferroni correction.
Poisson Regression of Variables Predicting Tags.

CI: confidence interval.
Statistically significant variables with α = .05 after a Bonferroni correction.
Finally, posts with more favs (
Conclusion
In this article, several common types of participation on boorus were described and classified into three major groups: content curation, evaluation, and refinement. As the above analyses demonstrated, these operate in relatively stable ways across millions of observations. Importantly, these processes are not necessarily exclusive to nonlinearly directed imageboards. Other sites featuring user-generated media allow users some control over content curation—on Wikipedia (2019), for instance, users can nominate articles for deletion (Geiger & Ford, 2011)—and plenty of others have evaluation mechanisms (Sumner, Ruge-Jones, & Alcorn, 2018) and refinement systems (Yu, Zhou, Den, & Hu, 2018) in which users can engage. Yet Danbooru and other nonlinearly directed imageboards are relatively unique in allowing users to participate in all three activities, which allow us to readily examine factors that independently affect each activity as well as interrelationships between them. In any case, if these sociocognitive processes are also prevalent in other online environments, even if they manifest in different ways or to different degrees, then these findings may be generalizable across those contexts as well.
First, more explicit posts were much more likely to be deleted and to receive more upvotes, downvotes, favs, and tags (H2–H6, sub-hypothesis a in all cases). We might broadly say that more explicit Danbooru submissions gain more attention, both positive and negative, across the processes of content curation, evaluation, and refinement.
Of course, while explicit media received more attention on Danbooru, this may not be the case for every booru. For instance, this effect may have resulted from Danbooru’s low proportion of explicit (8.7%) and questionable (15.0%) content. If safe posts represent the majority (76.4%), minority content may be eye-catching. On other imageboards where explicit posts are not especially rare, they may not get special attention. Likewise, on imageboards that expressly prohibit sexual content, “explicit” submissions might simply be removed. This is just one possible confounding factor; the unique characteristics drawing different users to different imageboards and the affordances of different sites may also affect explicitness’ role. Nonetheless, while the direction of this effect may vary depending on site affordances, user proclivities, and content tendencies, the effect of explicitness may itself persist.
On the other hand, the impact of connections between posts (H3–H6, sub-hypotheses b–d) likely persists as observed across contexts. Most booru-style imageboards have mechanisms to connect posts, particularly since many competing imageboards use Danbooru’s open-source software architecture (Yi, 2018). There is little reason to believe that parent/child relationships or their role in guiding user activity would significantly differ across boorus.
While connections between submissions were associated with positive content evaluation and refinement outcomes (more upvotes, favs, and tags), the impact on downvotes was more complicated. Pooled posts tended to receive more downvotes, perhaps because they received more views due to the ease of navigating through a pool. On the other hand, being a child did not significantly affect the number of downvotes received, while being a parent shielded posts from downvotes, possibly due to appearing superior. It is noteworthy that parents benefited from their status but children did not experience a detriment of similar magnitude.
Users who dislike or feel tepid about a parent may expect to dislike subordinate versions and thus not navigate to child posts, preventing them from experiencing negative repercussions from connections to their parent. In contrast, pooled posts may not be directly related, and low-quality posts may follow excellent ones. Consequently, a user navigating through an otherwise high-quality pool may stumble onto lackluster submissions worth downvoting.
Finally, submissions receive more tags when they are also beneficiaries of other positive outcomes like more upvotes and favs or fewer downvotes (H7). The causal relationships between these factors are unclear, as higher scores, more favs, and more tags can all result in greater visibility, further increasing all forms of engagement. Thus, these four variables may generate a feedback loop where improvements in one affect the others, keeping a given post visible for a prolonged period and gradually but significantly increasing all factors together. Thus, content evaluation and refinement go hand in hand: better evaluations likely prompt more refinements, which may then boost evaluations, and so forth.
The focal points of interactions on nonlinearly directed imageboards, and therefore the shape those interactions take, are different from those of more heavily studied sites like 4chan. For instance, anonymous 4chan users on the /pol/ board take advantage of their anonymity—compromised only by a national flag that vaguely represents the user’s location—to engage in arguments that, in other discursive spaces, might be deemed toxic (Ludemann, 2018). The purposes of users vary from asserting one’s own worldview and socially constructed identity to idly trolling for its own sake. Regardless, the positioning in which users engage is directed toward the argumentative context, with the platform’s design elements (e.g., national flags) and the affordances that they facilitate (e.g., the ability to anonymously speak on behalf of a specific nation) offering a narrative tool that can be employed to win an argument, even if definitions of “winning” vary from demonstrating the subjective superiority of one’s own political stance to frustrating other users via trolling.
In contrast, many Danbooru posts feature no comments at all, so the entire engagement process revolves around curating, evaluating, and refining the media product itself. When users do make comments within a post’s interactive space, those comments tend to feature minimal competitiveness between users, as the underlying objective is generally not to achieve victory over an opponent, but to appreciate artistic products and their respective source materials for their own sake. Users offer nostalgic or comedic references to the media product’s original source material (e.g., a joke on a Kantai Collection—inspired comic that “Gotland’s powers has [sic] extended beyond hypnosis into retrocausality,” Danbooru, 2019a), engage in mutual sensemaking about the media product’s content (e.g., regarding a representation of hand-me-down clothing, “Wouldn’t his old clothes just get passed down to the siblings? How much money do these people make?”, Danbooru, 2019c), share similar and divergent opinions about the artistic works (e.g., “The breasts looked pretty bad in this one,” Danbooru, 2019b), and address the curation, refinement, and evaluation processes themselves (e.g., “Why does the pixiv tag say one of them is Misaya Reiroukan if neither of them are,” Danbooru, 2019d).
In short, the most prevalent discourse on 4chan often centers around no-holds-barred argumentation, with relative incivility facilitated by users’ anonymity and further shaped by the emphasis on user–user interactions, with media content generally playing a supporting role. As Hine et al. (2017) noted, 4chan’s limited affordances motivate aggressiveness: “the only way for a user to receive validation from (or really any sort of direct interaction with) other users is to entice them to reply, which might encourage users to craft as inflammatory or controversial posts as possible” (p. 96). In contrast, boorus privilege the creative media, which are inescapably placed at the forefront of each interaction space, implicitly suggesting user–media interactions as the primary form of engagement supported by user–user interactions on a secondary level at most. Thus, as previously suggested, earlier findings about 4chan user engagement do not adequately represent all imageboards, especially not nonlinearly directed imageboards like Danbooru.
Yet the communicative processes highlighted in this study—content curation, evaluation, and refinement—and the related findings extend far beyond imageboards alone. Consider, for instance, the conclusion that sexually explicit content gains more positive attention. As an example, such a finding could be applied to Facebook (2019), where explicit posts might get more attention. Facebook does not feature a “downvote” button, but its option to “like” posts is analogous to Danbooru upvotes. Without any risk of downvotes, a variety of tactics may be used to gain attention and earn more likes. This is one explanation for the prevalence of polarizing content on Facebook, for instance (see Bessi et al., 2016): with no risk of “downvotes” that would lower a given post’s visibility, organizations are free to make polarizing contributions that support one among multiple competing narratives, and trust that they will continue to benefit from their supporters’ likes without being subject to negative consequences from the opposing camp. To put it in different terms, Facebook’s affordances privilege users’ appetitive systems of content evaluation over their aversive systems, as it is easier to identify content that may be appealing than to detect material that one would wish to avoid (Wise, Alhabash, & Park, 2010). Furthermore, the diversity of Facebook users who have wildly different beliefs and sensibilities (Omnicore, 2019)—as opposed to imageboards like Danbooru, which cater to narrower niche audiences that at least share one common interest—may create even greater opportunities for diverse perspectives and competing ideas to emerge, making Facebook’s lack of negative evaluations all the more important.
Of course, when posting controversial content, one would have to avoid going too far and getting banned from Facebook—an analogue to post removal on Danbooru—particularly given the recent punitive actions that the platform has taken to curb the spread of fake news (Newcomb, 2019). Still, even mildly controversial, risqué, or otherwise “questionable” content would likely gain more traction than the “safe” content that is the norm on Facebook, particularly given Facebook’s well-established use as a means for companies to evaluate job candidates (Karl, Peluchette, & Schlaegel, 2010). In fact, this strategy is hardly new—advertisers have been using risqué content to get audiences’ attention for many years (Belch, Holgerson, Belch, & Koppman, 1982)—but this study highlights its application for individual social media users within the online realm.
However, this strategy may not be so effective on sites where downvotes are more common, or where each negative evaluation has a greater detrimental effect. For instance, consider established product sellers on eBay (2019) who already have thousands of positive reviews and few negative ones. Such sellers would see minimal benefit from yet another positive review atop the thousands they already have, but a few extra negative reviews could damage their overall seller rating and have a substantial impact on their future sales. Because seller ratings are dependent on the ratio of positive and negative reviews, rather than the subtractive difference between upvotes and downvotes, a negative review cannot simply be “negated” by a positive review in the way that an upvote and a downvote cancel out one another. Consequently, negative reviews on eBay are more damaging to eBay sellers than downvotes are on Danbooru: as Cabral and Hortaçsu (2010) found, individual eBay sellers saw their sales precipitously drop in the week following their first negative review. In more general terms, the negative consequences incurred by highly visible submissions or users may be substantially greater—particularly if they are also controversial enough to make them likely targets for negative evaluations—so strategies that insulate posts and contributors from negative feedback may be more important than attempts to attract a large viewership.
While Facebook, eBay, and countless other Web sites feature mechanisms to perform content curation, evaluation, and refinement, the exact manner in which they are implemented differs, such as Facebook’s lack of an analogue to Danbooru’s downvotes or the manner in which eBay distinguishes between positive and negative feedback. Yet while these implementations differ from those of Danbooru, the curation, evaluation, and refinement processes themselves still play a critical role in user engagement with these sites. Therefore, as shown here, we may use Danbooru’s system as a baseline to understand these processes, and adjust our expectations about how these processes manifest on other sites based on differences in their respective affordances. In short, Danbooru is unique insofar as it facilitates content curation, evaluation, and refinement within a single interactive environment, thereby offering a foundation to understand all three of these core processes across a wide range of implementations and online contexts.
Future Directions
This study dealt with millions of user submissions and actions, but it was nonetheless isolated to one site. Future research should explore similar processes in other online and off-line contexts where content curation, evaluation, and refinement play a central role.
Furthermore, this study focused on broad attributes like explicitness and parental status. However, tags constitute one of the most vital affordances of nonlinearly directed imageboards. Certain tags might be associated with specific outcomes, and some may often be applied in tandem due to conceptual similarities or other common characteristics. Further research on the relationships between specific tags and outcomes like votes, favs, and deletions would help users engage in intelligent content refinement. This would also help administrators to anticipate post evaluations and detect potentially problematic posts (e.g., terms of service violations) upon their creation.
Finally, while uploaded media stand as the core of nonlinearly directed imageboards, these environments still offer a place for traditional discourse between fellow users. The comment systems on many imageboards, as well as supplementary spaces like forums, would be useful to address phenomena including users’ sensemaking practices about their own engagement and their conceptualizations of the group and their peers.
All told, this study lays a clear foundation for further studies into nonlinearly directed imageboards, which hold growing significance within the online realm, as well as the broadly applicable processes of content curation, evaluation, and refinement. Researchers should take note of these domains and the communicative phenomena therein, both because of the unique interactions that they feature and the potential of these growing groups to cross cultural boundaries and significantly influence society as a whole.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.