
Abstract
While social media platforms are often assumed to be sites of speaking, they are also important sites of knowing, where businesses use content produced by individuals in order to understand markets and make predictions and where individuals understand their own position and importance. This article considers social knowledge production in the context of influencer marketing, a growing industry in which social media users are ranked according to measures of influence and compensated for promoting products online. Working from industry press, technical documentation and interviews with tool developers, marketing professionals, and social media users, it traces the sociotechnical shaping of influence, moving from computer scientists’ optimal solutions through technical constraints and business needs to the practices of marketing professionals and individual users. In doing so, it identifies two conceptions of influence. The first is connected to celebrities and practices of branding, while the second, more novel conception is associated with less prominent social media users who make themselves and their willingness to work visible to marketers through practices I describe as hustling. While social influence is conventionally conceptualized in relation to extensive, naturally occurring networks of individuals, in this context it is evaluated in relation to much simpler networks that bring together users who may never interact directly. In this context, users understand and manipulate their influence by positioning their followers (branding) and by explicitly affiliating themselves with non-human entities such as brands and topical hashtags (hustling).
Keywords
Introduction
Dorsey opened today’s event with a paean to Twitter’s idealistic side. “Twitter stands for freedom of expression and we will not rest until that’s recognized as a universal human right,” he said. He cited the Black Lives Matter movement as an example of how “Twitter stands for speaking truth to power”—and then handed over to executives who introduced new products with a commercial focus. (Simonite, 2015)
As Twitter CEO Jack Dorsey’s comments to attendees of a developers’ conference make clear, social media platforms are sites of speaking where individuals express themselves and social justice groups operate—but they are also sites of knowing, where businesses use individuals’ speech in order to understand markets and make predictions. Indeed, the products announced at the conference point to the value of these data for Twitter: (1) an update to Gnip, the Twitter-owned data reseller, that helps businesses understand activity related to their brand and (2) a service that helps app makers better understand their audience demographics. These developments indicate the central role played by knowledge production in the business strategies of social media platforms. Much of this knowledge pertains to the status of users; metrics such as follower counts are valuable to marketing companies and brands but also to individual users of social media for whom these same metrics shape self-understanding and behavior. The relations between platform developers, marketing agencies, and individual users are part of a complex sociotechnical system that also includes application programming interfaces (APIs), algorithms for ranking users and third-party tools that make these rankings available to marketers and users. These systems are not only designed to accord with the values and assumptions of their designers but are also modified and negotiated through time and in relation to unexpected business needs, technical constraints, and user behaviors. The development and use of these systems shape the meanings of social concepts such as status and, of central concern here, influence.
This article describes social media platforms’ shaping of influence by focusing on influencer marketing, an opportune context for this research because it involves, first, the explicit sorting and ranking of individuals and, second, actors in various positions with respect to social media platforms, from developers and computer scientists to marketing professionals and individual social media users. As I discuss in more detail below, influencer marketing is a rapidly growing industry that attempts to promote products or increase brand awareness through content spread by social media users who are considered to be influential. These “influencers” are identified through a number of practices and also work to understand their own influence and to manage how they are known and valued in this context. These practices, which respond to technical constraints and business decisions, shape how influence is conceived. Specifically, while influence has often been viewed in relation to extensive, naturally occurring networks of people through which ideas spread (see e.g. Latané, 1996), I argue here that social media platforms encourage networks to be viewed as simple structures of users gathered around a central hub that sometimes represents a prominent individual but at other times represents a brand or topic. In the case of celebrity and micro-celebrity (Senft, 2008), these networks are evaluated primarily in relation to audience demographics. However, I also describe an alternative conception of influence that instead looks to users’ explicit affiliation with non-human entities such as brands and hashtags. I describe the practices that result from these two conceptions of influence below as branding and hustling.
As this article crosses several borders to consider business decisions, technical features of platforms, and social practices, I draw on industry press and technical documentation, as well as on interviews with a range of individuals involved in influencer marketing, including tool developers, marketing professionals, and social media users who work as influencers. In this way, I follow platform studies’ call to investigate “the connection between technical specificities and culture” (Bogost & Montfort, 2009). While previous work on social media platforms has focused on technical features, medium specificity, or interface choices (e.g., Bucher, 2013; Helmond, 2013, 2015; Puschmann & Burgess, 2013), this article attempts to connect these facets of platforms with the individual practices through which they are enacted. For example, while Gerlitz and Lury (2014) have argued that social media metrics encourage conceptions of inclusion “in terms that are highly compatible with the market as represented by third parties,” I build from such observations to include the perspectives and practices of those working directly with such metrics (p. 185).
The contributions of this article are both theoretical and methodological. First, I present a novel conception of influence, the origins of which can be traced from technical constraints and business needs to individual practices. Second, I argue for the importance of connecting sources of data conventional to platform studies (e.g., documentation and industry press) with empirical data collected from practicing users. This approach allows for the tracing of meaning through sociotechnical systems in a way that is attentive to the diverse practices of individual users who may behave in ways unexplained by attending only to platforms’ technical features.
Influencer Marketing
The general narrative of influencer marketing is that consumers no longer pay attention to traditional advertising, so companies now look to experts and other influential individuals to promote products. These influencers generally have large social media followings and are assumed to be trusted voices that can reach large audiences. The promotions involved often take the form of posts to social media platforms, for which the influencers are compensated. Examples of these posts range from a blog post reviewing a hotel to a photo of a jacket posted to Instagram to a YouTube video that surreptitiously promotes a department store. Compensation for these posts varies widely, from a free magazine subscription in exchange for a promotional tweet to tens of thousands of dollars for a sponsored YouTube video. As one marketer described to me, influencers act as both production and distribution channels; brands look to these individuals to produce compelling text, images, and videos and also to distribute that content to a network of followers.
Industry reports suggest that influencer marketing is growing rapidly. Augure (2015), a company producing software for influencer marketing, reports that 84% of brands intended to run influencers campaigns in 2015, and this is consistent with reports of strong growth that have appeared in a variety of publications (Newman, 2015; Talavera, 2015; Tomoson, 2015). Additionally, industry surveys and business press, as well as interviews conducted for this project, indicate that identifying influencers is the most important problem faced by businesses in this area.
Addressing this problem, software tools and platforms have developed around influencer marketing, ranging from analytics products such as SimplyMeasured and FollowerWonk to recently emerging influencer platforms that focus on the relationships between influencers and their followers. As these examples indicate, understanding social influence is a relevant task for a range of actors. Additionally, the problem of identifying influential users is also relevant to those developing social media platforms (see e.g. Goel et al., 2015; Gupta et al., 2013) and has been taken up, as well, by academic computer scientists. The following sections work through the practices and assumptions of individuals in each of these positions, beginning with computer scientists.
Conceptions of Influence in Computer Science
As a way to begin to understand how influence comes to be defined in relation to social media platforms, this section looks to how computer scientists have approached similar tasks. I focus on literature from computer science because, first, it often reviews, formalizes, and builds off work in sociology in a way that makes it relevant to a sociotechnical investigation of social media platforms and, second, because there are indications that developers working on social media platforms draw from and contribute to this literature (e.g., Goel et al., 2015; Gupta et al., 2013). Additionally, computer scientists often have privileged access to data and view tasks rather abstractly, without many of the layers of human behavior that become pertinent in subsequent sections of this article that turn to the practices of marketers and social media users. For these reasons, definitions of influence and measures developed in these contexts serve as a useful starting point to which the complexities of data access and business goals can be added. Indeed, as I note below, this literature ultimately poses an interesting question: if computer scientists appear to have reached a rough consensus on the question of evaluating influence, why do the vast majority of marketers, influencer platforms, and third-party tools not follow this lead?
AlFalahi, Atif, and Abraham (2014) define a “real-life” influencer as “a person who is followed by many people and has the power to make changes in a community,” stressing the importance not just of having many friends but also of being able to encourage action within a group defined by interest in a topic or brand (p. 162). Bakshy, Hofman, Mason, and Watts (2011) point out that this definition of influence does little to sort out the differences between, for example, endorsements from celebrities and recommendations from friends (p. 66), but in the technical literature this conception of influence is highly consistent, with researchers interested in how behaviors or content are spread among users. Indeed, many of these studies are motivated by the marketing problem of identifying influential users to promote products or increase brand awareness (e.g., Chen, Wang, & Wang, 2010; He, Ji, Beyah, & Cai, 2014; Zhou, Zhang, & Cheng, 2014).
A common assumption in this work is that influence cascades through a naturally occurring and extensive network; a message is spread to a user’s followers or friends, who have some chance of then spreading it to their followers or friends and so on. As Domingos (2005) notes,
A customer’s network value does not end with her immediate acquaintances. Those acquaintances in turn influence other people, and so on recursively until potentially the entire network is reached. . . . A customer who is not widely connected may in fact have high network value if one of her acquaintances is highly connected (for example, an advisor to an opinion leader). (p. 2)
As a result of observations such as these, influence on social networks is overwhelmingly modeled using graph structures, with users represented as nodes connected by edges that represent various relationships such as follows or mentions. Assumptions of this work that become relevant in the following sections are, first, that these networks exist naturally in the world as individuals communicate across them and, second, that these networks can be known to the extent that talking about a message reaching “the entire network” is plausible.
A number of algorithms have been developed to measure influence based on such graphs, with all but the most basic sharing the assumption that network structure matters; influence is not just a matter of who a user is but also of their position in the larger network. Users are described, for example, as functioning as crucial ties between two otherwise unconnected cliques (AlFalahi et al., 2014, p. 167). In terms of diffusion, such users may have relatively few followers, but their position within a network’s structure means they are ultimately capable of reaching a large number of total users.
While the computer science literature focuses on comparing the performance of specific algorithms, I focus briefly here on a broad distinction between approaches that measure influence only in relation to measures related to a single node and those that also utilize network structures:
Single-node measures. At their most basic, algorithms consider information related to a single node in a network. For example, in-degree measures the number of in-bound edges, most often the number of followers a user has. Other measures related only to a single node include the number of times that user’s content is shared or the number of times they are mentioned by others. Importantly, such measures do not take into account network structure, ignoring, for example, if a user has 10 followers who are all peripheral or whether those 10 followers are important nodes that link disparate parts of the network. Due to their simplicity, single-node measures are often used as a baseline against which to compare more advanced algorithms, discussed below, which are generally found to be more effective (Cha, Haddadi, Benevenuto, & Gummadi, 2010; Embar, Bhattacharya, Pandit, & Vaculin, 2015).
Structural measures. The majority of algorithms evaluated in the computer science literature rely on measures related to single nodes but also on information about how those nodes are positioned in relation to the larger network’s structure (Figure 1). While single-node measures consider, for example, how many followers a user has, structural measures might take into account how important those followers are. One of the most basic structural measures is betweenness centrality, which measures a node’s importance by calculating the likelihood that it exists on the shortest path between any two other nodes. Other algorithms such as PageRank and HITS similarly measure a node’s importance, or influence, in relation to the importance of the nodes it is connected to. More advanced algorithms assume that individuals tend to be influential in relation to specific topics (Cano Basave, Mazumdar, & Ciravegna, 2014; Embar et al., 2015; Katsimpras, Vogiatzis, & Paliouras, 2015). For example, a user who is an expert on technology is unlikely to be useful in marketing a fashion product. Algorithms such as TwitterRank (Weng, Lim, Jiang, & He, 2010) and Topic-Sensitive Page Rank (Haveliwala, 2002) incorporate information about users’ interests with network structure and have been shown, in some studies, to outperform methods that do not include such topical information.

Overview of structural measures of influence.
As noted above, while there is a good deal of consensus within this literature as to the effectiveness of structural measures, there is very little use of these algorithms in actual marketing contexts. As Gerlitz and Lury (2014) note, the vast majority of third-party tools focus on what I describe above as single-node measures. Services like Klout and Kred, for example, largely draw on a user’s number of followers and various engagement metrics such as average number of likes in order to calculate a measure of influence that does not rely on network structure. This is also overwhelmingly the case for the marketers and social media users with whom I spoke, with proprietary software and in-house practices following this trend of focusing on single-node measures. While it should not be surprising to find that everyday practices differ from what are perceived as optimal technical solutions, these descriptions do provide a useful ground against which to consider the ways social media platforms shape how marketers and social media users understand influence and position themselves accordingly. To this end, the following section looks to the historical development of Twitter’s APIs and business strategies in order to better understand some of the ways this shaping happens.
Technical Constraints and Business Decisions
In order to understand the divergence between what are perceived as optimal solutions and the practices of marketers and social media users, this section focuses on how Twitter positions its data, arguing that the design of the platform’s various APIs privileges the understanding of individual nodes over their place in the larger network. While critics such as Bucher (2013) have pointed to the consequences of these restrictions for academic researchers who have seen their access to data consistently shrink in recent years (Weller & Kinder-Kurlanda, 2015), they are equally important in understanding users who do not directly interact with APIs but, as Bodle (2011) notes, equally experience restrictions to their autonomy and freedom. Through the use of third-party tools that draw on these APIs, social media users and marketing professionals come to understand influence in relation to certain measures. While influencer marketing crosses platforms, I focus in this section on Twitter in part because its technical features have received considerable attention by academic researchers and in part because it makes its data more available than, for example, Instagram. As such, Twitter can give some indication of the limits of knowing in relation to social media platforms.
Twitter’s version 1.1 update to its APIs, which took effect in 2012, sets the tone for its approach to data access. While the update increased the number of tweets from the recent past that could be gathered from 1,500 to 18,000, it also greatly reduced the number of follower relationships that could be obtained. Previously, API users were allowed to request a user’s followers up to 350 times per hour, with up to 5,000 user IDs returned per request. Additionally, users with whitelisted accounts were allowed up to 20,000 requests per hour (Gaffney & Puschmann, 2013, p. 60). However, whitelisted accounts were suspended in 2011, and version 1.1 of the API reduced the number of requests for a user’s followers to 60 per hour. As Smith (2013) notes, follower networks can easily consist of several thousand accounts (and up to millions in the case of users such as Barack Obama or Justin Bieber), making it impractical to create a social graph using the restricted REST API. So, while it is relatively simple to request information about a single user such as how many people follow them and even to download a large number of tweets by that user, understanding the relationships around a user is made difficult.
These API restrictions have generally been explained as managing infrastructure load (Gaffney & Puschmann, 2013). John Kalucki (2011), an engineer at Twitter at the time, suggests that requests to the REST API were relatively expensive for Twitter to process and that the company decided to encourage use of the less computationally intensive Streaming API. This is an important decision because, while the REST API is primarily differentiated from the Streaming API by the former’s limited access to recent historical tweets and the latter’s access to ongoing tweets, the REST API also provides access to information about users (such as who they follow and who follows them) in a way that the Streaming API does not. So, while the Streaming API is a robust tool for creating large, representative collections of tweets for research, it does not replicate the original REST API’s ability to gather follower relationships and create social graphs.
With Twitter’s acquisition of data reseller Gnip in 2014 and the revocation of complete, historical access to tweets from other data resellers, the platform’s positioning of data becomes clearer. As Kepes (2015) argues, this restriction of access will narrow the applications of these data to those of interest to large corporations, ignoring niche cases. Indeed, the examples used to market Gnip focus on the value of large datasets that are not connected to relational data, offering, for example, demographic data such as the interests of users that interact with a brand but not the social relationships around those users.
These developments have two consequences. First, third-party analytics products overwhelmingly focus on measures derived from information about a single user. Scores like Kred, for example, draw on data related to a single node in order to produce a measure of influence, generally determined by a user’s number of followers as well as the level of interaction with the content they post (“Kred Scoring Guide,” n.d.). Using Twitter’s REST API or similar options offered by most platforms (with notable exceptions of tightly guarded platforms such as LinkedIn and Snapchat), this information is relatively easy to obtain. Other tools used by marketers to understand the conversation around a brand or topic take a similar approach, with most providing lists of, for example, the users who post the most, are mentioned the most, or have the most followers.
Second, while using structural measures of influence is not common in marketing contexts, the scattered cases of their use rely on graphs constructed using reply, retweet, mention, or similar relationships rather than follower relationships, as these can be obtained by processing the data returned by either the Streaming or REST APIs. As Smith (2013) notes, these relationships are less common than follow relationships, and the resulting networks tend to be sparse. Still, Smith’s NodeXL project continues to use these edges as the only available option, as does a marketer I spoke with who described his desire to incorporate structural measures into his company’s analytics product.
As I discuss in the following sections, these aspects of data availability lead away from computer scientists’ focus on information diffusion through a network and toward two alternative approaches to measuring influence. The first, which I connect to the identification and evaluation of celebrities and micro-celebrities, focuses on who a potential influencer is and, more importantly, who their followers are. The second approach identifies users of lower profile by looking to declared brand and topic affinities. Following these sections, I describe the practices that emerge, among social media users, in relation to these approaches.
Identifying Celebrities: Audience Demographics
One way to think about influencer marketing is in relation to celebrity endorsements. Indeed, at times it is difficult to separate the two, as marketers I interviewed described working with traditional celebrities such as movie stars and musicians but also with social media users who are treated in similar ways. As one marketer told me,
When you get to things like vloggers [video bloggers], Youtube stars, I mean they all have representation now . . . they’re all like legitimate, they’ve been legitimized as celebrities, you know? There are teenage girls that do fashion vlogs and beauty vlogs, and they make $25,000 a video from brands or $50,000 a video depending upon how well followed they are and if they’re really a celebrity in their own right.
Identifying influencers at this scale is described as happening largely through instinct and manual search. In part this is because these individuals are already known; their self-branding efforts, if successful, make them visible to marketers as much as to fans. While some of the marketing practices I discuss in the following section identify individuals who may have never worked as an influencer, celebrities receive enough attention that they are likely already known to marketers and have representation or at least a document that lists their rates and the kinds of metrics that marketers might otherwise generate themselves. While marketers do consider celebrities’ follower and engagement measures, they downplay these elements, instead suggesting that once a level of popularity has been achieved, a celebrity’s identity and relationships to fans become more important. One marketer describes her decision-making process when evaluating celebrities:
I’ve had multiple celebrities in consideration for a campaign and ruled some of them out based upon the fact that Celebrity A was kind of like boring and dry and I didn’t think was going to inspire any kind of like fervent sales behavior. I qualified another one out because we felt like she was, for the brand, this is really shitty, but like a little too progressive.
Similar dynamics are also seen with influencers who behave as micro-celebrities, individuals who see themselves as public personas, see their audiences as fans and who use online social networking tools to increase their popularity (Senft, 2008). While micro-celebrities are not traditional celebrities, they treat themselves as brands and are identified in many of the same ways as celebrities. The manager of a prominent Instagram fitness model told me that he thought his client is identified for promotions just because she is one of the most popular users in that space. Another marketer described to me a plan to use strippers as influencers for a liquor campaign and the role of intuition in, first, planning the campaign and, second, in identifying the individuals who would take part:
Strippers are really big on Instagram right now . . . A lot of those girls have half a million Instagram followers or a million Instagram followers . . . We call it like influencer casting, so it’s kind of like people that have been casting movies for a really long time, they start to know who’s going to be good in the role and who’s not.
Apart from celebrities’ appeals to target demographics and their by definition large following, marketers do not consider the role these individuals play in a network. While they may look at an influencer’s follower count or engagement rates, this is the kind of “single-node” data that I pointed to above as being relatively easy to access either through APIs or even just by visiting an individual’s profile. Indeed, this is the same information that services like Klout and Kred use to attempt to rank all social media users. Klout, for example, assigns both the basketball player Kobe Bryant and the soccer player Cristiano Ronaldo influence scores of 90. At this point, the demographics of their followers become crucial, and tools deliver various kinds of information in this regard, from simple gender information to attributes like location, income, and interests that are determined using machine learning algorithms to make predictions based on users’ social media content. While this level of analysis is uncommon and is generally used as a competitive advantage to attract the business of very large brands, it is also noteworthy that it bears considerable resemblance to the use cases that data resellers such as Gnip advertise, with sophisticated analytics and large quantities of data used to reveal demographic trends.
Instead of seeing these individuals as enmeshed in existing communication networks, these approaches conceive of social networks as forming around celebrities and micro-celebrities in a way that makes social structure less important. Everyone is simply a fan or follower, and the influencer sits at the center of this simple network (Figure 2). In the following section, while the perceived networks remain simple, it is centered on brands and topics rather than celebrities.
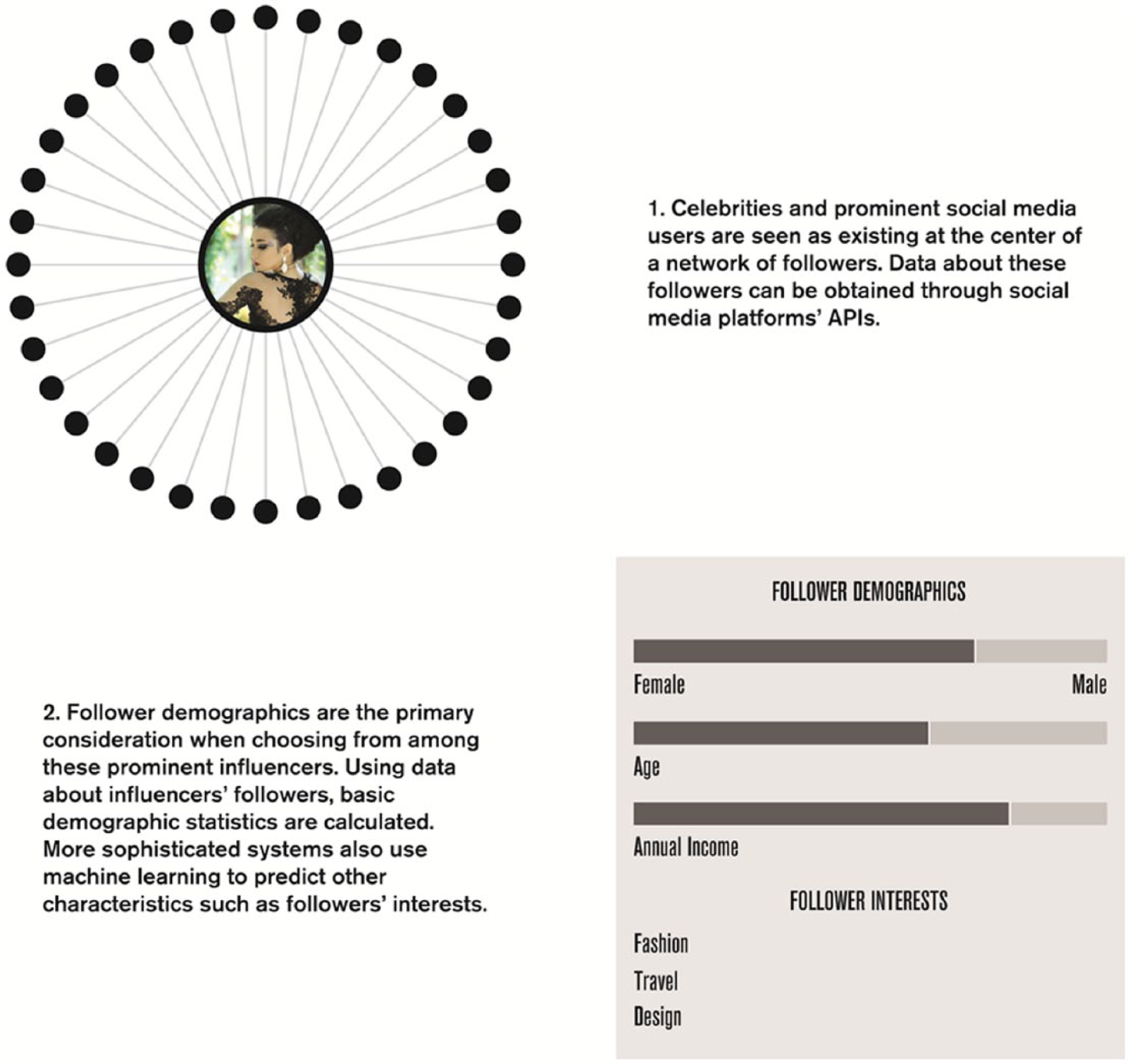
Overview of how celebrity influencers are identified.
Identifying Non-Celebrities: Brand and Topic Affinity
While traditional celebrities and high-profile social media users can be identified and evaluated as if they exist at the center of a network of followers, this approach does not apply to all influencer marketing, as many campaigns attempt to avoid the obvious endorsements of celebrities and social media users who are known to promote products. While the compensation in these contexts is much smaller (at times free products or gift cards are offered in exchange for a social media post), the numbers of influencers involved can be much higher, with some campaigns utilizing as many as 50 influencers.
While intuition and informal indicators of attention still play a role in identifying these influencers, the scale of the problem and marketers’ lack of previous awareness of the individuals make tools for ordering and sorting more important. These processes usually begin with the generation of lists of users ranked by followers or engagement that are then manually filtered for content quality and brand fit. One marketer described the process of finding a large number of influencers for a product promotion campaign:
I first ran reports on [the brand’s] Instagram account to see who really likes [the brand], and I found their top followers and then I looked at them with a human eye after the reports were run to see, OK, which of these accounts . . . do I think fit that brand.
Other times these searches start with a topical hashtag or with a list of accounts that are relevant to the campaign:
I ran a report for [a fitness brand] but I also ran reports on [a similar brand], on big Instagram users that are based on fitness. So, for example, sometimes there’s an influencer who has 50,000 followers and it’s all based on health and fitness. I might run a report on that account to find other fitness people that would be interested in [the original brand]. So it’s always just about finding the right people in that category. It’s just the easiest to start with the company itself. And then you just branch out from there to kind of find people in the same vertical.
While the identification of celebrities often relies on intuition or implicit indicators of attention, the identification of smaller influencers relies heavily on data made available through APIs. The nature of the data utilized is relevant, especially in relation to the above discussion of API restrictions and the positioning of data. While it is not feasible to collect an extensive network of follower relationships, it is much easier to collect information about the followers of a handful of accounts representing brands, as the marketer above describes. Furthermore, this process can easily be automated, with the marketers I spoke with in this space largely using proprietary tools. From this data, measures such as number of posts or mentions can be used to generate lists of users who may be influential in relation to the search terms.
In these contexts, it is possible to see ways that API restrictions and business decisions impact work practices and conceptualizations around influencer identification. Primarily, influence comes to be understood in close proximity to non-human entities like hashtags and brands’ social media accounts. Whether working from a brand’s followers or a topical hashtag, for an individual to be identified as influential she must have direct contact with the entity around which the collection occurred. Furthermore, influence is almost always, in these contexts, considered in relation to first-degree relationships, as data beyond this level are difficult to obtain.
This is a markedly different conception of influence than that described in the previous section, where celebrities and prominent social media users were seen as accreting followers around themselves in ways that centered decisions largely on identity and audience demographics. Instead, less recognizable influencers are seen not so much in relation to their own followers but instead in relation to non-human entities like brands and hashtags (Figure 3). In both of these contexts, networks lack the complexity and social dimensions of those assumed by computer scientists. Rather than making important friends or positioning oneself as a bridge between two communities (as the structural measures promoted by computer scientists might suggest), individuals adopt a different set of practices to increase their influence in relation to the identification and evaluation practices discussed above. The following section describes these practices as branding and hustling.

Overview of how non-celebrity influencers are identified.
Branding and Hustling: How Users Understand and Manipulate Their Own Influence
As sites of knowledge production, social media platforms are not only used by marketers to identify and rank potential influencers, they are also used by social media users to understand and manipulate their own influence and value. For the most part, the measures used by marketers to rank users are available to the users themselves through the platforms’ interfaces; indeed, on platforms such as Snapchat users have greater access, through built-in analytics and dashboards, to these numbers than do marketers (Shields, 2015). In addition, individuals use third-party tools such as Social Blade and epoxy.tv to monitor their number of followers and engagement rates. Indeed, while both marketers and influencers repeat that follower counts are less important than engagement, all of the influencers with whom I spoke kept an eye on these numbers and could tell me how many followers they had recently gained or lost.
However, more interesting than influencers’ understanding of their own measures are the actions they take to be successful in relation to marketers’ varying conceptions of influence. These individuals not only understand their own value and metrics, they also understand how marketers conceptualize influence—as described above, either in relation to audience demographics or to brand affinity. In this section, I look to some of the consequences of this shaping of influence, as seen through individuals’ practices. These connections are especially relevant, as the majority of influencers describe their work as expressions of authentic selves. Content posted to social media is described as “creative,” “genuine,” and “authentic,” and influencers repeatedly stress that they would not promote products that they do not use themselves or regard highly. Still, individuals’ social media practices and understandings of their own work reflect technical and business decisions that can seem very distant from individual behavior.
A first way to understand individual behavior in this way is by noting how influencers who act as celebrities and micro-celebrities manage and interact with their followers, conceptualizing them as fans and manipulating their own content in ways that strategically shift these demographics. In line with marketers’ conceptions of these influencers as drawing around themselves a network of fans, these individuals implicitly, and often explicitly, discuss themselves as brands. This was the case with one of my interview participants, a former reality television star who promotes products on Instagram, and it is especially true of influencers on YouTube. While this is likely related to the higher compensation rates attached to promotions on that platform, it also reflects the structure of the network, as it exhibits a greater distinction between content creators and content viewers, in contrast to platforms such as Instagram and Twitter that foster reciprocal relationships. YouTube personalities see their content as separate from their personal identities and discuss attempts to manage their current brand as well as aspirations to recreate it in the future. “You are a brand whether you realize it or not on Youtube,” an influencer who focuses on video games said,
And if you don’t know how to market yourself, if you don’t know what you are and who you are, there’s no way . . . You cultivate the kind of audience you want based on the games you play. If you want a really young audience, you play games that cater to, really, those young people.
These demographic strategies are directly linked to the analytics that YouTube makes available—as the influencer describes, viewers under the age of 18 are desirable because “those are the people that engage and comment and take time to like, and those are the people that keep coming back everyday.”
Furthermore, like brands, prominent influencers also think strategically about how to engage with their followers. This problem is actually quite similar to the problem of identifying influencers: who should time be spent engaging with in order to most effectively grow a following and increase value? Indeed, one of the functions of third-party tools is to let influencers know when other prominent users follow them or engage with their content so that they can attempt to strengthen those relationships. These tools enable prominent influencers to strategically build a following that meets certain demographic goals. By manipulating their content and building relationships, these influencers work to position their entire network of followers in relation to the perceived needs of brands.
In contrast, less prominent influencers position themselves, and not their network of followers, directly in relation to brands. Reflecting the ways marketers conceptualize influence and use data to sort and rank individuals, these users strategically form relationships and manage their content in order to create a visible and cohesive appearance that speaks to brand affinity. While this practice can encourage a rhetoric of authenticity—I like this brand and engage with it whether I’m being compensated or not—it also leads to a phenomenon that one marketer described to me as “hustling,” or following brands and creating content that has the appearance of that created by paid influencers as a way of signaling a willingness to do such work.
On the content creation side of this practice, influencers produce a stream of content that must be both consistent in its aesthetics but also diverse, as influencers described the negative effects of having every post appear to be sponsored. Especially in the context of new Federal Trade Commission (FTC, n.d.) rules that require sponsored posts to use hashtags such as #ad, influencers are eager to avoid the impression that they are only doing paid work. One marketer, worried about influencer marketing losing its feeling of authenticity, described her concerns with these legal changes: “It looks like you’re Kim Kardashian holding up that bottle of medicine that you may or may not love.” As a result, some influencers hide these required signals among large numbers of other hashtags, further disguising their sponsored content, and one influencer even described wanting to keep his best, most creative content “pure” of sponsorships, saving endorsements for content that he felt was of lower quality.
However, because brands look to users’ content as a way to gauge fit, influencers are also careful to create topically and aesthetically consistent streams. For an influencer who promotes fitness products, this means only posting about fitness and not pictures of parties or sports events. For influencers who are known for focusing more on lifestyle photography, for example, this consistency means giving everyday posts the same care and aesthetic manipulation as they give posts that resemble and function similarly to magazine ads. Indeed, especially on Instagram, it is often difficult to determine which posts are sponsored and which are not—vacation photos could be promoting a hotel, but they could also just be documentation of a vacation. This is especially important as some contracts allow influencers to remove sponsored content from their feed after a certain amount of time, meaning that marketers who arrive at a user’s profile may make judgments of fit based primarily on non-sponsored content.
In addition to making their content appear, aesthetically, as if it was sponsored, hustling also involves making oneself visible to brands by using certain hashtags or following and mentioning brands’ social media accounts. By posting content that shares an aesthetic affinity with a brand and that also has the formal features that allow marketers to capture it in the kind of searches described above, individuals indicate their availability and willingness to do the work of influencer marketing. One marketer describes these actions of influencers she has worked with:
Hustling is kind of what I meant about the . . . guy who loves all these brands . . . So he’s constantly tagging brands in his posts and being like, “Hey, I want to work with you” or, “Hey, look at me in your outfit. Like, I can rock it for you in all these campaigns if you just call me.”
This willingness, demonstrated through the cultivation of ties with non-human entities, replaces the concerns over identity and follower demographics that are important when evaluating celebrities. The conception of influence that leads to hustling is social in that potential influencers still need to have relatively large followings, but it is less about who the individual is or to whom they can distribute content; instead, influence comes to be seen in part through individuals’ relationships to brands and consumption.
It is important to note that these two conceptions of influence are not mutually exclusive. Particularly with influencers engaged in hustling, their practices are often strategically oriented to one conception of influence while their aspirations are more in line with the branding activities of celebrities and micro-celebrities. Indeed, the transition between hustling and branding can be seen in the compensation and reward structures of influencer marketing. As influencers hustle to receive free products and, at times, invitations to conferences and special brand events, they also gain social prominence in their communities. In this way, positioning oneself in relation to brands can lead to opportunities to position oneself in relation to a group of followers and, finally, positioning those followers in relation to the demographics valued by brands.
Conclusion
This article has traced the sociotechnical shaping of influence, as it is enacted in the practice of influencer marketing. It takes conceptions of influence and techniques for its measurement from the computer science literature as a starting point and, working away from the optimal solutions found there, reviews the development of Twitter’s APIs in order to consider how technical constraints and business decisions shift the enactment of influence. Drawing on interviews with marketing professionals, tool developers, and social media users, the article follows the impact of these technical constraints and business decisions on the practices, first, of marketers who must identify and evaluate influential social media users and, second, to the practices of the users themselves. In doing so, it identifies two conceptions of influence. The first is related to celebrities and practices of branding, while the second, more novel conception is associated with less prominent social media users who make themselves and their willingness to work visible to marketers through practices I describe as hustling.
These conceptions of influence do not conform to the computer science literature’s assumptions of complex, naturally occurring networks of individuals through which information is diffused. As this article has described, due to API restrictions and other technical limitations, the networks marketers construct to evaluate influence are relatively simple and bring together users who may never interact directly. Furthermore, in the case of less prominent users, these networks center on brands or topical hashtags, and individuals engaged in hustling manipulate their own influence by signaling their affiliation with these non-human entities. While influence remains social in that measures such as number of followers continue to matter, it can be seen to be less so in that the identities and structural positions of these followers are less important than a user’s ties to brands or topics of discussion.
One of the implications of these observations is that multiple conceptions of influence can coexist within the same system. While marketers’ needs and users’ positions privilege certain practices and understandings, these can be at odds with expressed views. Influencers can engage in hustling by forming strategic connections with brands while at the same time talking about themselves as future celebrities. As I note above, being identified as influential in relation to one conception of influence can lead to the realization of other conceptions, as those who hustle are rewarded with the material needed to grow followings that can become the basis of celebrity branding. In relation to Healy’s (2015) argument that networks may exhibit strong forms of performativity—in that, for example, the identification of influential users would bring reality in line with that measurement—this article provides evidence that encourages further investigation while also suggesting the need to better understand performativity in relation to the various positions of individuals and their attendant practices and conceptions.
Implicit in this article is a methodological argument for connecting the analysis of technical platforms with the practices of individuals. While platform studies and related work has often moved from technical features or interface choices to social implications, making this link through practice allows for more nuanced and unpredictable observations to emerge. As the social world is increasingly seen through formal measures that are generated by algorithms and negotiated by various communities, the assumptions and practices of those in analytic roles (including users who work to understand their own value) become an important resource for understanding sociotechnical systems.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: I gratefully acknowledge the Institute of Museum and Library Services for supporting this work under grant RE-02-12-0009-12, awarded to researchers at the University of Texas at Austin School of Information.