
Abstract
Introduction
We have conducted research on building a robot dialogue system to support the independent living of older adults. In order to provide appropriate support for them, it is necessary to obtain as much information, particularly related to their health condition, as possible. As the first step, we have examined a method to allow dialogue to continue for longer periods.
Methods
A scenario-based dialogue system utilizing pause detection for turn-taking was built. The practicality of adjusting the system based on the dialogue rhythm of each individual was studied. The system was evaluated through user studies with a total of 20 users, 10 of whom were older adults.
Results
The system detected pauses in the user’s speech using the sound level of their voice, and predicted the duration and number of pauses based on past dialogue data. Thus, the system initiated the robot’s voice-call after the user’s predicted speech.
Conclusions
Multiple turns of dialogue between robot and older adults are found possible under the system, despite several overlaps of robot’s and users’ speech observed. The users responded to the robot, including the questions related to health conditions. The feasibility of a scenario-based dialogue system was suggested; however, improvements are required.
Keywords
Introduction
In recent years, the advancement of a super-aged society has been accelerating at a rapid pace. Along with this, the shortage of care workers and the shortage of care facilities are becoming social problems, and thus the care support equipment and systems using information and communication technology (ICT), including robotic technology, are being intensively developed.1,2 The number of older adults living at home is increasing remarkably due to the shortage of care facilities, and the proportion of older adults living alone is increasing accordingly. Therefore, ensuring the quality of their daily living and finding ways to manage their physical and mental health are becoming urgent social issues. 3
Various studies aiming to support the “aging well” of older adults are being carried out using ICT and robotic technology under these circumstances. A typical example of the efforts is an approach called “ambient assisted living (AAL),” which supports independent living of older adults as much as possible by applying technology such as internet of things (IoT).4–7 Systems that provide services in cooperation with various sensors and robots connected through networks, robotized smart houses, and remote monitoring services using sensors are typical examples.8–12
In these systems, the required information is obtained using sensors, and the action or output is delivered through robots or presentation devices. Thus, the quality of the output depends on the types and setups of the sensors used. For example, it is necessary to determine the state of the living environment, such as room temperature and humidity, and the behavior of the older adults themselves, to learn their living conditions.
In most cases, however, the detectable information is only related to the external state of the older adults or the state and behavior exhibited on the outer surface and provides only speculation about their internal state. Such input is therefore imperfect and insufficient, considering the purpose of learning about their physical and mental health. The common method humans use to learn the inner state of another person is a voice call and perceiving or hearing responses to the call. Here, our idea is to use this strategy to design a robot that speaks to older adults and senses their responses to obtain more accurate information directly related to their physical and mental health.
This can be said to be an active sensing method in the sense that the person’s inner state is known through output reactions for the voice-call input. It is understood that the content of the voice-call is an important issue when obtaining the necessary information to estimate the physical and mental conditions of older adults. It is desirable and essential to make the interaction a form of dialogue that continues as long as possible to acquire as much information related to the person’s conditions as possible. Furthermore, it is also important to consider the kind of assistance that could be provided based on the information obtained, including voice-calls, to help maintain the physical and mental health of the older adults.
This research can be regarded as an AAL system in which a voice-call is performed as one of the major ways of sensing conditions, as explained above. This paper describes the results obtained at an earlier stage of the research and the method adopted to extend the dialogue for longer periods.
The structure of this paper is as follows. Basic concept of the system and development of the system are described after introduction section. Then, pairs of methods and results for three user studies are explained in a chronological order, since we had refined the experimental system step by step, in such a way that the issues revealed at the time of each experiment were being improved. In the discussion section, user studies 1, 2 and 3 are arranged and discussed in parallel manner, so as the comparison between the methodologies and results can be understood easier. We will summarize the findings and implications for future studies in conclusion section.
Basic concept of the system
Background of the proposed system
Naturally, the greatest concern in assisting older adults is about their health problems. The research and development activities related to AAL systems deal with this issue by utilizing various IoT sensors and robotic devices. Some examples13–15 include monitoring systems 16 that can activate calls to care centers in case of emergency17,18 or that can notify them about wandering dementia patients.
The health condition of a person in daily life can generally be estimated from the irregularity in the continuation of a regular life pattern; thus, it is meaningful to pay attention to the temporal transition of sensor information reflecting the life pattern of older adults living alone. The time to get up or the time to go to the bathroom are some examples that indicate life patterns. Another such example is the number of times the person goes to the bathroom, which correlates with the amount of water intake 19 and is considered to be a guide for the intake of necessary water.
Sensing such externally appearing behavior can be used as an index for the physical and mental health of a person, although it is only indirect information. From this point of view, we propose a novel idea, which is to positively and directly sense the physical and mental health of the person by voice-calls, using a robot, and observing their response to the voice-calls, in addition to the conventionally available sensors’ information. It should be noted that the reason for using a real robot, instead of the voice-calls from a simple speaker, is to promote the feeling of affinity and presence of a partner by the older adults, especially those living alone, by talking to an entity that is substantial and to inspire long-term use through such feelings.
The most important issue when using voice-calls in sensing the state of a person is to prepare appropriate content suited to obtain the necessary information regarding the health status of the person. It is desirable to continue the interaction of voice-calls and responses, that is, the dialogue, as long as possible to acquire as much information as possible. Here, we assumed that the contents or a basic scenario of the voice-call could be determined in a fixed manner, since the purpose of the voice-call in this case is to obtain information regarding the physical and mental health of the older adults. However, certain considerations were given, such as changing some parts of the voice-call contents according to the season, time of the day, weather, etc., to make it possible to continually use the content for a long period of time with less discomfort.
In this research, we have defined the term “scenario-based dialogue” as a set of dialogue consisting of pre-determined statements in such a way that the next statement from the robot is not unnatural, regardless of the utterance made by the user in response to the first statements made by the robot. This method has the features that the dialogue can be established even when the pronunciation of the older adult is not clearly recognizable, or that the contents of the robot’s speech can be carefully prepared in advance. Regarding such scenario-based dialogue, we have already succeeded in making the dialogue to continue up to two user’s turns. 18
Along with the content of the linguistic information spoken by the older adults, the reactions and non-verbal information during the interaction of the older adults with the robot are also considered effective in estimating their health condition. Research on estimating diseases from voice has been conducted. Stress level, 20 arousal level,21,22 and in the case of depressed people, the speed of the voice,23–25 volume, 26 acoustic information, 27 and the number of pauses25,28 have been studied as characteristics that are thought to be key to estimating mental state.
Voice volume and tone of the voice are the examples of non-verbal information. The content of the response to the robot’s voice-call regarding specific topics, such as meal, sleep, confirmation of medication, as well as the length of the response, the reaction speed, etc., are also considered to be useful information for estimating the life pattern and physical condition of the older adults. 29 Caregivers usually talk to older adults to check their physical condition. If caregivers find some abnormality in the older adults, they give specific countermeasures and advice. When engaged in dialogue, if someone asks an inconvenient question, the other person may reply after a short delay, or the volume of the reply may be lower than usual. Moreover, emotional information extracted from the voice of a user includes these acoustic characteristics.30–32 Human emotion is expressed not only toward humans but also to robots; this emotional information is used for the design of robots' behavior.33–37 Therefore, we hypothesized that the emotional information in the user’s response to the robot’s voice-call is key to estimating the user’s life patterns and physical conditions.
Thus, by using dialogue, it is possible to proactively interact with older adults utilizing the robot’s voice-calls, actively sense their daily behavior and status through voice responses, and accurately estimate their health condition. Furthermore, the robot can make recommendations to the older adults that are useful for maintaining and improving their health, by responding to users based on the estimated health condition of the older adults. Additionally, we considered it useful for older adults to think about the response to the robot’s voice-call themselves to maintain their cognitive function.
As mentioned above, it is possible to obtain more information regarding the health condition of older adults if the conversation with the robot is maintained for a long period. It is also desirable to build an intimate relationship between the robot and the human as much as possible when the robot makes recommendations for maintaining the older adult’s health using a voice-call.
Positioning of this study
The development of an AAL system with a dialogue robot that acts as a dialogue partner for older adults consists of various technologies such as sensor hardware, electronics, data processing, robotics controls, etc. Technologies related to dialogue management and control must solve elemental problems by developing a: (1) method to keep conversation between an older adult and a robot for longer period of time, (ii) a method to prolong the older adult’s interests and to maintain engagement with the robot, (iii) the contents of the robot’s voice-call suited to obtain the necessary information regarding the person’s health status, (iv) a method to effectively extract the person’s health status based on the utterance of the person 38 along with the output data from various sensors, (v) the contents of the robot’s voice-call to give appropriate recommendations for promoting health-friendly activities for the older adult. It should also be able to identify character differences among persons and find ways to deal with these differences so as to individualize the system applicable to the practical AAL application. In this paper, the methods outlined above, specifically the method to keep conversation between the older adult and the robot going for a longer period of time, has been studied as the first step for developing the system explained earlier. A method for estimating a person’s rhythm of speech and end-of-turn utterance has been proposed, and its effect has been experimentally evaluated as the preliminary study of this first development step.
When considering the case of dialogue between people, it is known that the timing or rhythm of turn-taking is important for continuing the conversation comfortably, while maintaining a good mutual relationship.39,40 For this reason, we have decided to introduce a method to make the dialogue continue as long as possible, by controlling the robot’s turn-taking and the timing of the start of a voice-call, based on the utterance pattern of older adults. We have also studied whether the method is effective in the dialogue between humans and robots, especially in the cases where multiple turn-takings (more than three turns) are included.
In this study, we investigated the user’s reaction to the voice-call of the robot and the possibility of controlling the turn-taking process by using the blank time after the users response to the voice-call as a variable in the study. The main purpose of this study was to collect fundamental data regarding the user’s reaction to the robot’s voice-call, and therefore the contents of the user’s utterance were not the focus of our the analysis. Therefore, we did not apply voice recognition techniques to the user’s utterance, and a simple scenario-based method with mostly fixed content has been employed. A machine learning technology utilizing neural networks was applied as a strategy for determining the appropriate turn-taking timing.
In this paper, we describe the preliminary experiment regarding the system based on the above-mentioned concept, the results on the user’s reaction, and the analysis of data, such as the duration and number of blanks between the dialogues obtained through the experiment. We also provide an outline of the experimental system, results of the preliminary experiments, the user’s reactions, including the analysis of data obtained through experiments, such as the duration and number of blanks between the dialogues.
Development of a scenario-based dialogue system
Scenario-based dialogue system
Figure 1 shows an example of scenario-based dialogue with a robot and a user. The rectangle bar represents the sound of speech for the robot and the user. The content to be spoken by a robot is decided in advance, since this system is a scenario-based dialogue. As a first step, we constructed a robot system to control the timing to begin speaking. For privacy reasons, it is better not to use facial data for turn-taking. Moreover, in the case that older adults cannot speak clearly, the accuracy of the speech recognition results may not be high enough to allow the robot system to take turns. We started by developing a simple system as a first step. Overview of scenario-based talking between a robot and a user.
To develop a scenario-based dialogue system, we used information from the on/off microphone for turn-taking. When the system detected a soundless segment, the section could be (1) the user’s breathing during his/her reply or (2) the end of his/her reply.
Steps for developing the robot system
We developed the trial production, user study, and improvement in steps. In the development, we used a scenario in which the user and robot dialogue at home. We report the development process of a scenario-based dialogue system with an automated turn-taking function, which involved three steps of development and user studies in this paper. The paper is constructed as follows: a scenario-based dialogue user study to collect data for prototyping (User Study 1), a prototype of a scenario-based dialogue system with a silence-based turn-taking system (Development and User Study 2), and an update of the automated scenario-based dialogue system and an attempt to individualize turn-taking (Development and User Study 3).
First, we conducted a user study to investigate the reactions of users to the robot in scenario-based dialogue. In the user study, the timing at which the robot voice-calls is remotely controlled by an operator. Based on the results of the user study, we then constructed a prototype of a scenario-based dialogue system that can automatically control the timing of the start of a voice-call, followed by the user study, again using the prototype system. All of the dialogue user studies were conducted via video chat communication system Zoom as a video chat software (Zoom is a trademark or a registered trademark of Zoom video communications, Inc.) (see Figure 2) Scene of the user study of scenario-based dialogue and turn-taking with video chat software.
The robot we used this study was BONO-06 (Figure 3,41,42) and the robot was displayed on the screen of the PC/tablet of a user. The voice of the robot is synthesized in advance and played back at the timing of the speaker change. We used ReadSpeaker
43
for speech synthesis. As for the voice parameters, a high, childlike voice was employed to give users a positive impression. Before a dialogue segment begins, the volume of the sound was adjusted for each user. After User Studies 1, 2, and 3 were finished, we brushed up on the parameters of the robot’s voice-call based on the opinions of our study’s participants. Specifically, the speed of the robot’s voice-call was updated. We updated the parameter of the sound of robot’s voice-call depending on the step of the development of this system. To help older users hear the robot’s voice-call more clearly, we updated the parameters of the sound synthesis of the robot’s voice-call depending on the step of this system’s development based on user feedback. We updated the parameters of the sound for the robot’s voice-call with step-by-step approach. To realize the actual situation that the robot is set as if in a house that appears on the screen of video chat software. Also, the sound of the user is output from the PC which runs the video chat software and was recorded by a microphone attached to the robot system. The appearance of the robot BONO-06.
The studies described in this paper were conducted in accordance with the research ethics committee of RIKEN (No. Wako3 2019-31). Written informed consent was obtained from the participants in accordance with the Declaration of Helsinki. All participants provided informed consent and the consent was written.
Scenario-based dialogue user study to collect data for prototyping
User Study 1: Survey of users’ reactions to the robot
We also conducted a questionnaire to qualitatively evaluate the naturalness of the content of the scenario-based dialogue.
1. The robot starts the first voice-call V
i
, (i = 0). 2. The robot waits for the user’s reply 3. After the user’s reply 4. If the robot’s voice-call V
i+1
and the user’s one more reply The flowchart of the system for user study 1.

Scenario script for the robot and the type of the contents of the voice-calls (User Studies 1 and 2).

Type of the voice-call of a robot.

We also conducted another dialogue using a chat system to compare these evaluation items. The chat system has the three following functions: speech recognition, getting a reply, and speech synthesis. The chat system recorded the user’s speech for 3 seconds and the recorded sound data were converted into text data. The system then received a reply generated by a chat dialogue system, Katarai API*, based on the speech data, and synthesized sound data were output as the robot’s voice-call. We assumed a short reply of a user to the chat robot, and the duration of the speech recognition was 3 seconds not to delay the timing of the robot’s voice-call. The chat dialogue system used in User Study 1 outputs a reply regardless of the length of the input. One keyword is thought to be enough to output the robot’s reply. The robot asked some open questions prepared in advance in case the speech recognition is not successful. After the number of the robot’s voice-calls reached the number of the scenario-based dialogue lines, the dialogue finished with the robot saying, “It’s about time to end. Let’s close this dialogue now.”
To evaluate the naturalness of the content of scenario-based dialogue, we conducted two types of methods to determine the content of each dialogue. At first, the user had a dialogue with the scenario-based dialogue system. Then, the user had another dialogue with the chat-based dialogue system. Half of the participants took a reverse order for counterbalance. The user answered the questionnaire after each dialogue experiment of the scenario-based dialogue and the chat-based dialogue. The naturalness of the scenario-based dialogue, the enjoyableness of the dialogue and the level of desire to continue the dialogue were evaluated by 5-point Likert scale 44 questionnaires after each dialogue.
Four healthy older adults (from 60 to 80 years old) of two men and two women participated. The participants were accustomed to digital devices such as smartphones and laptop. The users were instructed to answer to the robot’s voice-call in as much detail as possible before starting the user study.
We focused on silent segments for voice-call interactions from robots to humans. There were two cases of silent segments. First, there was a silent segment in the middle of the user’s talking. Second, a silence segment after a user said one sentence. In this study, we distinguished these silent segments caused by breathing in the middle of the user’s reply from another soundless segment after the end of the user’s reply. We define the silence segment caused by breathing in the middle of talking one sentence as the “pausing segment.” The silence segment after one sentence was not the pausing segment.
During this user study, the robot system was connected to the microphone and recorded the time when the sound of the user’s utterance started and the time when the silence segment starts. After the user study, the recorded time of the silence segments were manually divided into the pausing segments and the end of speech segments based on what the user said in the dialogue. This manual work was done by one researcher according to the protocol of the work below. Using transcribed text data of reply of the user and the sound data of the user’s reply to the robot recorded during User Study 1, we marked the timing of when the sound arose and when it disappeared, calculating the duration of the pauses accordingly.
The level of assessment score: scenario-based dialogue versus chat dialogue in User Study 1.
Figure 6 shows the duration of pause and non-pause pausing segments for each participant. The duration of blank during pausing was about 0.5 s, and the duration of non-pause segment was longer than twice the length of the duration of pause. Comparing the variances of the distribution of the blank data, the variance of the blank in the non-pause segment was larger than that of the blank of pause segment. Duration of the pausing segments and the end of the speech segments.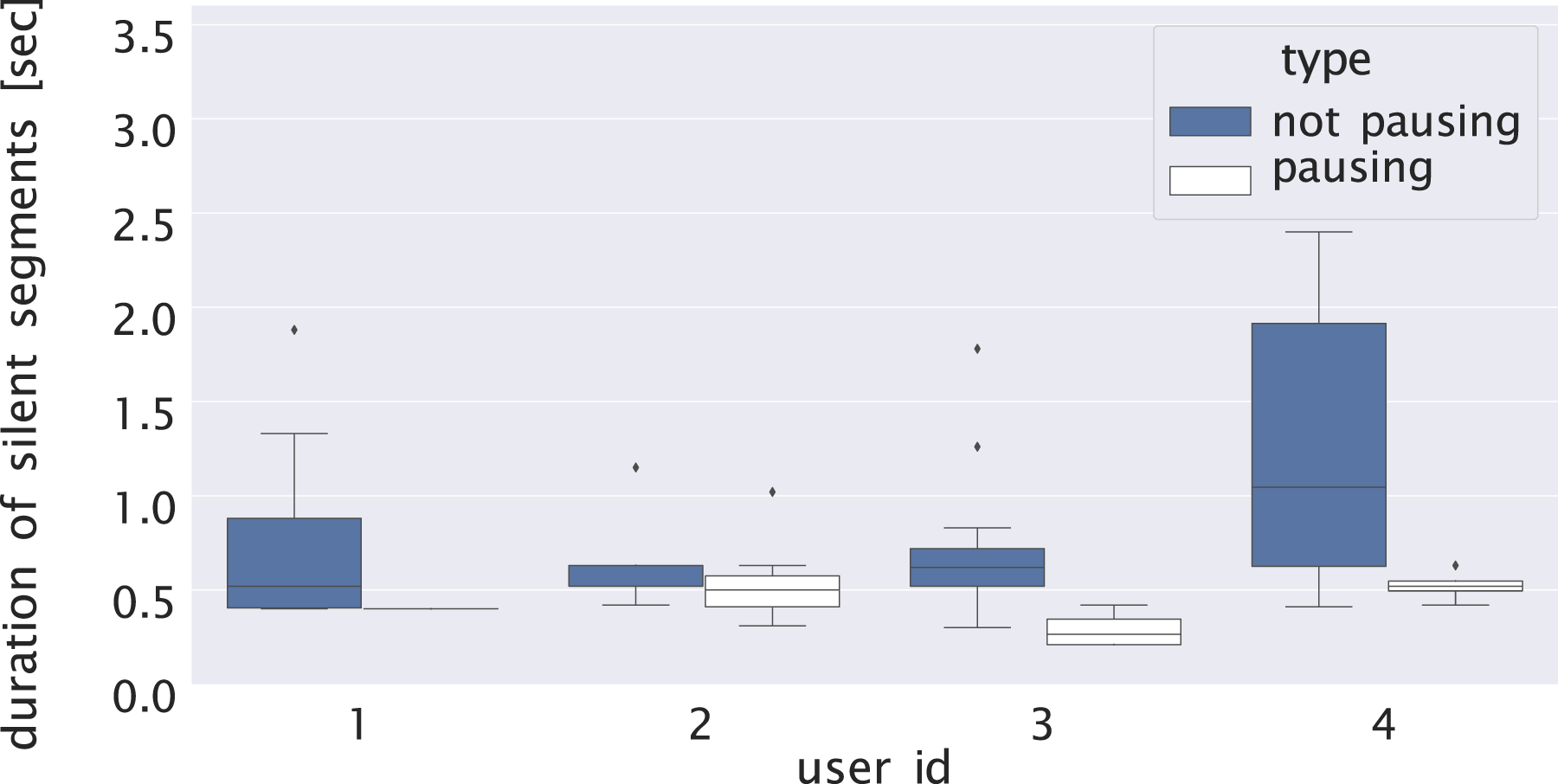
Next, we counted the number of blanks that are included in the users’ reply to one robot’s voice-call (between the robot’s voice-call Vi and the next voice-call Vi+1). For each type of blank (blank of pausing and other blanks), Figure 7 shows the average value of the number of blanks included in one user reply. Overall, for each user, the blanks were about 0–1 time. When the pausing segments and the other blanks were combined, one reply contained about two to four blanks. We considered that it was good to wait for two to four times of blanks during a user’s reply. Since the number of blanks except for pausing was the same as the number of sentences included in the user’s reply to one voice-call of the robot, if this number was large, it suggests that the user has spoken to the robot many times. Average number of blanks during a reply to the robot’s voice-call according to the types of blank in the 1st user study.
Consequently, the number of blanks may change depending on the user’s attitude toward the dialogue with the robot.
Sometimes the robot’s voice-call and the user’s reply overlapped because the user started speaking, trying to break a silence. There were five cases in which the user attempted to break a silence, and the duration of the silence was about 1.3–2.5 s. To deal with such a situation, the robot system would need to have a function that detects overlapping and stops the robot’s voice-call if an overlap is detected.
As a conclusion of this user study, the outline of the results of this user study and key marks are listed as follows. The following results become indicators to encourage a human to speak at a good tempo.
In this study, 1. the blank for pausing was about 0.5 s, 2. the duration of the blank before the user’s speaking was from 1.3 to 2.5 s.
Prototype of a scenario-based dialogue system with a silence-based turn-taking system
Silence-based turn-taking system
We used the same experimental setup of the User Study 1, comprising a robot and remote meeting system. The difference was that the turn-taking was automated based on the detection of silent segments by processing the sound level.
The previously proposed methods for voice interaction systems of turn-taking generally employ voice recognition results45,46 the user’s gesture or gaze, 47 or prosody information48–51 to detect the end of turn.
For turn-taking, the four states of the user’s speech—“silence state, utterance start, utterance in progress, and utterance end”—were detected based on the time-series data of the sound level of the voice of the participant, which is acquired by the microphone. We defined four modes of speaking of users: “pausing,” “start talking,” “talking,” and “start pausing.” • “Pausing” is the state in which the sound level is lower than the threshold value. In this state, the user is assumed to listen to the robot’s voice-call or pause during his/her speech. • “Start” is the moment when the sound level increases. In this state transition, the user is assumed to start speaking. • “Talking” is the state in which the sound level is higher than the threshold value. In this state, the user is assumed to speak to the robot. • “Pause” is the moment when the sound level decreases. In this state transition, the user is assumed to stop his/her speech.
In addition to the automation of turn-taking, we improved the following based on the users’ comments. To help turn-taking, the color of the LEDs on the robot’s cheek was changed according to the user’s speaking state. However, to determine how the user reacted, the user was not informed in advance of the robot’s color change.
The speed of the robot’s voice-call in User Study 2 was set slower than in User Study 1 because some users felt it difficult to hear the robot clearly in User Study 1. Moreover, the sound of the robot was output directly from the video chat software’s speaker to allow users to hear the robot’s voice-call clearly.
User Study 2: Prototype experiments of an automated scenario-based dialogue system
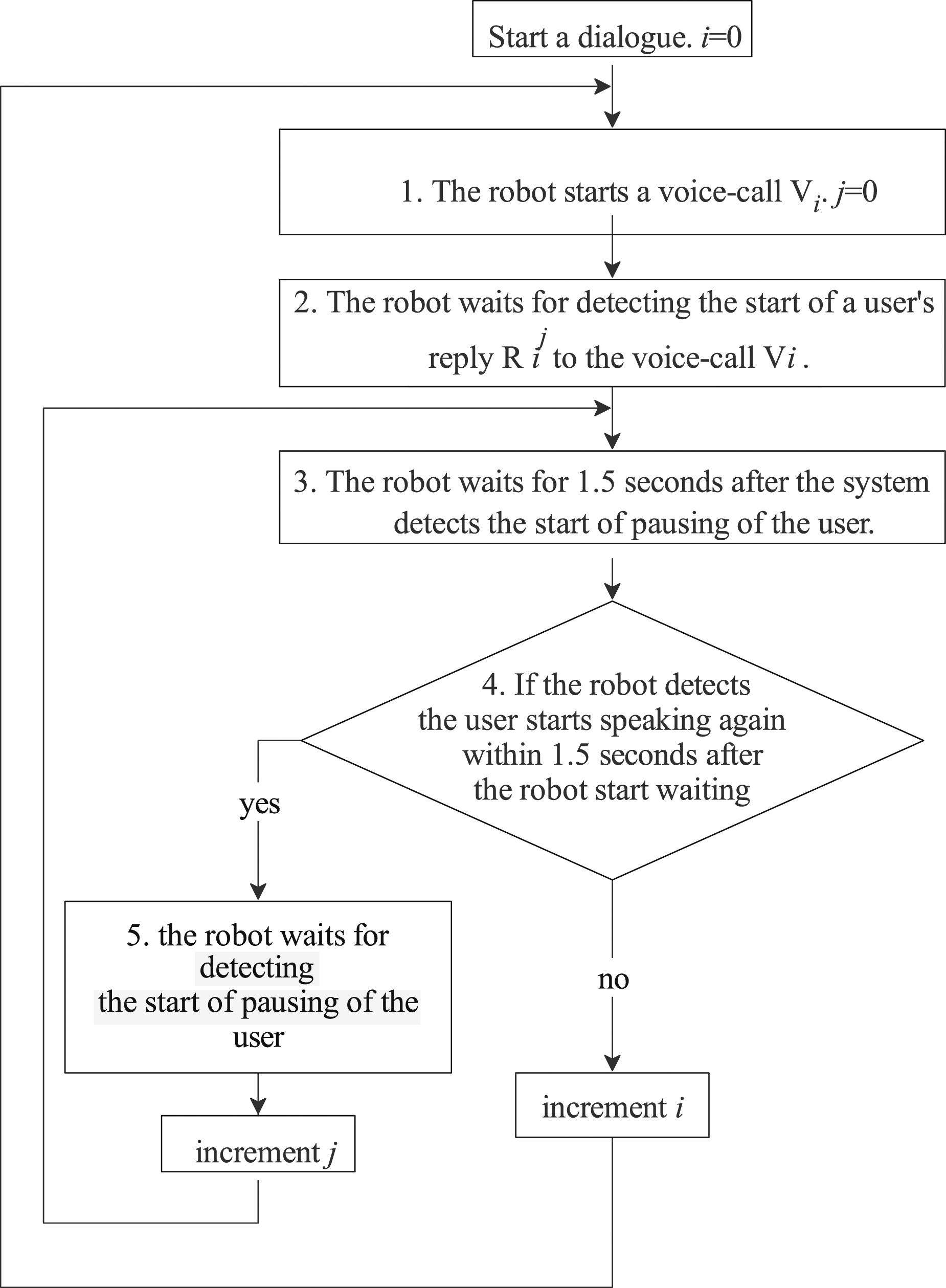
1. The robot starts the first voice-call Vi, (i = 0). 2. The robot waits after detecting the start of a user’s reply Ri to the previous voice-call Vi. 3. The robot waits for 1.5 s after the system detects the user’s starting pausing of the user. 4. After the silence segment continues for 1.5 s, the robot starts the next voice-call Vi+1 (back to 2nd procedure). 5. If the robot detects the user starts speaking again within 1.5 s after the robot starts waiting, the system waits for detecting the starting pausing of the user (back to 3rd procedure). The flowchart of User Study 2.
The users were instructed to answer to the robot’s voice-call in as much detail as possible before starting the user study. The same questionnaire as in User Study 1 was conducted.
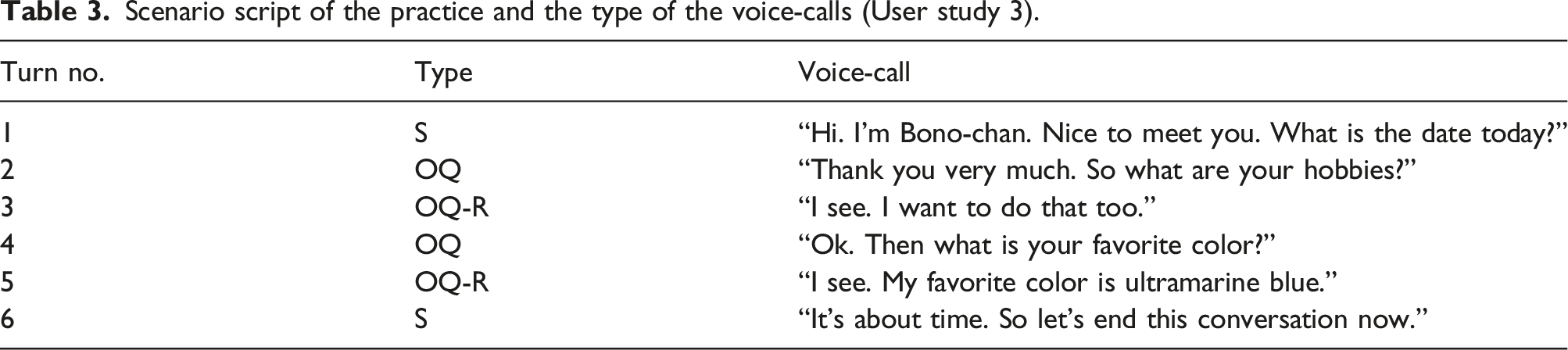
We decided that the condition of waiting time for the robot to start a voice-call was that the silence segment lasts for 1.5 s; the number was based on the result of User Study 1. Table 1 shows the dialogue scenario in this study. The type represents the kind of utterance applied to the voice-calls which are defined in Table 2. OQ represents the abbreviation of the open question. S represents the abbreviation of the statement. OQ-R represents the response to the user’s answer to the previous open question by the robot. S-R represents the response to the user’s comments to the previous statement by the robot. The voice-call row represents the voice-call script from robots to older adults. For example, turn number 1 indicates that the robots starts to talk with a generic greeting with type “S” and says to older adults, “It’s nice weather today.”
The number of overlaps, and the number of times that the robot started a voice-call before the end of the user’s speech according to each user in User Study 2.
The results of the questionnaire were good (Figure 10). The evaluation results for the scenario-based dialogue with the automated turn-taking system were generally higher than the standard score of 3, suggesting that users enjoyed the dialogue and were motivated to continue the dialogue in User Study 2. However, there were some problems when the robot’s voice-call and the user’s speech overlapped. When the robot stopped its voice-call after the robot and a user overlapped, the user also stopped his/her speech and the silence continued for a while. The maximum length of the silence was about 40 s. The other problem was that the robot was not able to distinguish between the user’s interrupts and back-channeling. When the robot scenario was long and the user’s response to it was judged as an interruption, even though the response was back-channeling, the robot stopped its voice-call and a silence continued. The user looked to feel the robot stopped because of some accidents. The level of assessment score in User Study 2.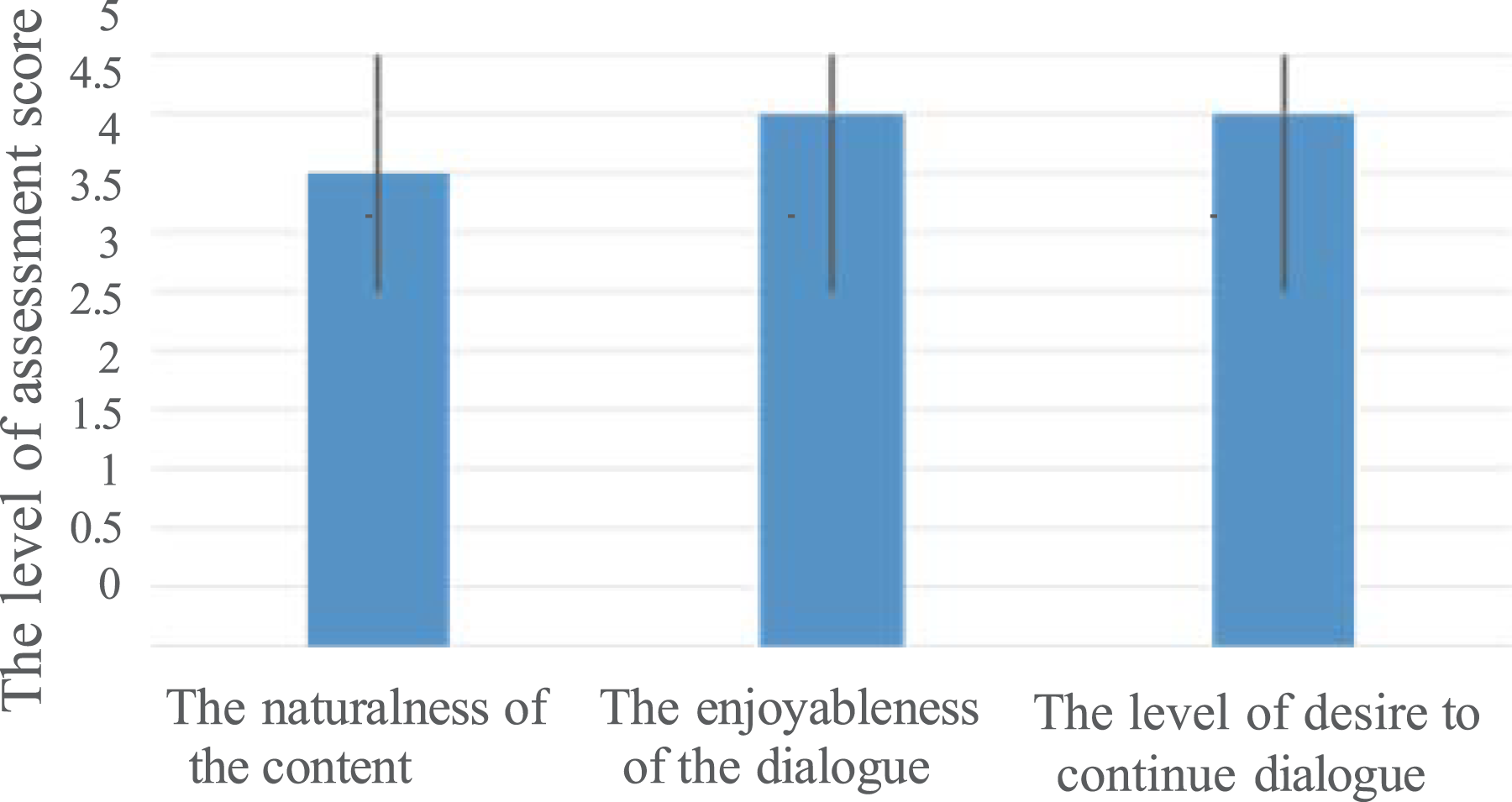
We summarize the results of the users’ reactions, including the blank and speech length data except for the data when the problem described in the previous paragraph occurred (Figures 11, 12, and 13). The reaction of the users was thought to differ according to the type of robot’s voice-call. When the robot’s voice-call was an open-question that prompted the user to think freely, the blanks during the user’s reply was thought to be more than the case when the robot’s voice-call was not open-question. We divided the user’s reactions according to the type of the robot’s voice-call: open-question or non-open-question. Duration of blank according to the type of robot’s voice-call. The number of blanks according to the type of robot’s voice-call. The amount of speech of users according to the type of robot’s voice-call.
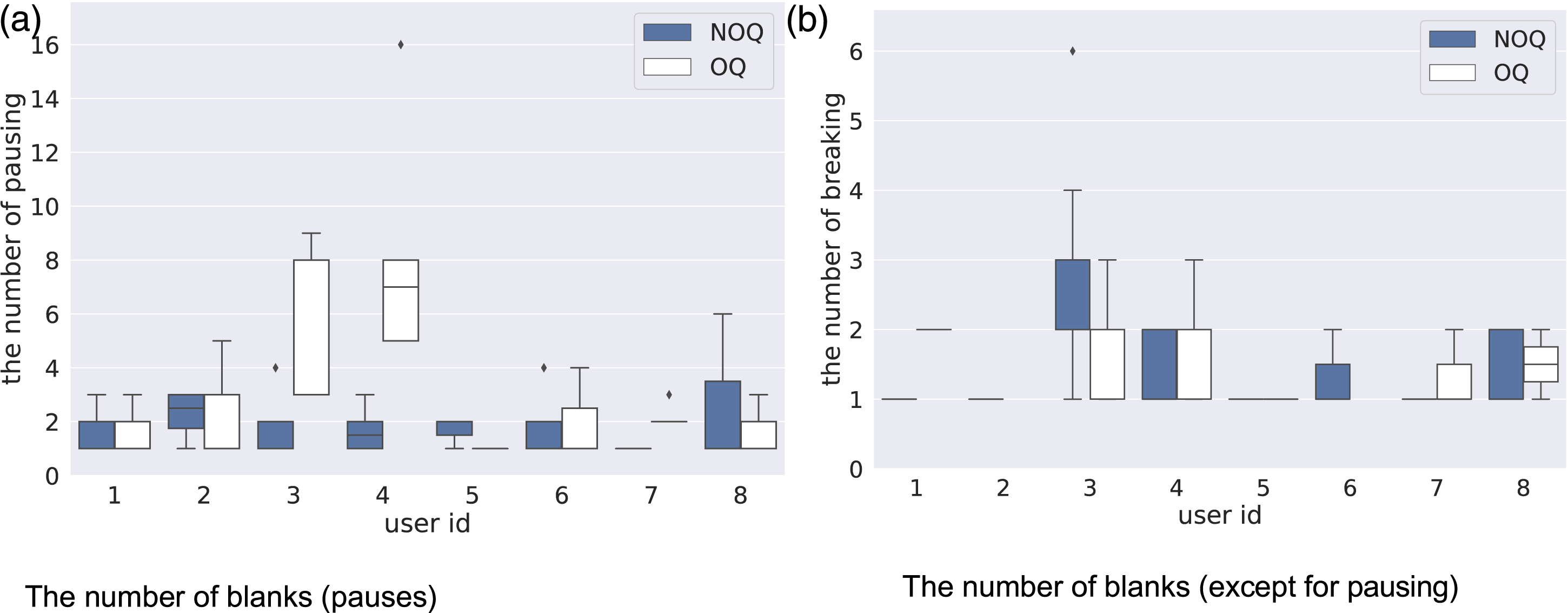

Figure 11 shows the duration of the blank of pausing for each user. The blank of pauses during a reply to the robot’s voice-call which is not open question was about 0.5 s. The duration was close to the result of User Study 1. The blank of pauses during a reply to the robot’s voice-call which is open question was almost the same. However, for some users, the variance value of the blank duration of open questions was longer than the blank of non-open questions. Figure 12 shows the number of pauses for each user. The number of pausing segments during a reply to one voice-call involving “non-open question” was up to six times, about one to five times. By contrast, in the case of open questions, the number of pause blanks differed according to the users.
Based on Figures 11, 12, and 13, the users were thought to require more time to think and speak if asked open questions compared with non-open ones. The word count and number of pauses of the users’ answers to the robot’s open questions (OQ) are thought to be higher than those of the answers to the non-open questions (NOQ) asked by the robot. Also, the pausing duration is thought to be longer because the user has to think about what to say in their reply instead of simply answering yes or no.
The speech duration, the word count of the speech, the pause duration, and the number of pauses were summarized according to the type of the robot’s voice-call (Figures 14 and 15). As for speech duration, word count, pause duration, and the number of pauses, Welch’s test
52
was used because these two distributions were independent samples and these were unequal population variances. In each case, the p-value is smaller than 0.01, and there is a significant difference between the average values of the two groups. The amount of the users’ speech, the number of characters of the users’ speech, the pause duration, and the number of pauses during the responses to the open questions tended to be longer and higher than these features of users’ responses to the non-open questions. The difference in the duration of users’ replies (OQ: open question vs. NOQ: non-open question) ∗: p-value < 0.05, ∗∗: p-value < 0.01, ∗∗*: p-value < 0.001, ns: p-value > 0.5. The difference in the number and duration of pauses (OQ: open question vs. NOQ: non-open question) ∗: p-value < 0.05, ∗∗: p-value < 0.01, ∗∗*: p-value < 0.001, ns: p-value > 0.5.
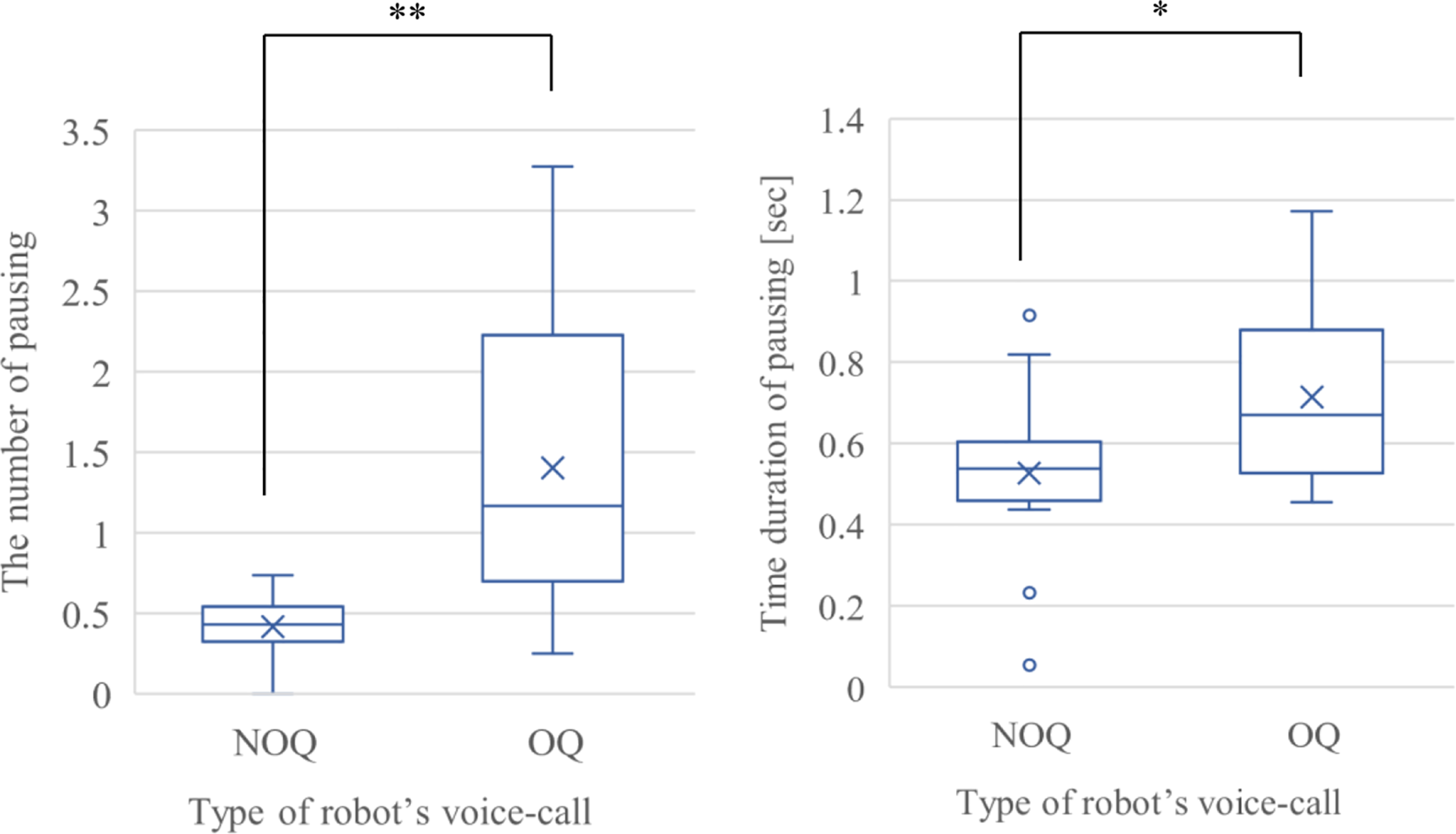
The number of pauses and the pause duration of the responses to the non-open questions had less variation than those to the open questions. From examining these findings, it is revealed that the system does not necessarily have to consider individual differences regarding pause duration during the user’s speech in the case in which the robot’s voice-call is a non-open question.
On the other hand, the number of pauses and the pause duration had greater variance in the case of the open questions. Some users are thought to spend more time thinking about what to answer depending on the content of the question. For example, depending on whether the user thinks about the future or is reminded of the past, the speech duration and the pause duration change, and this may differ depending on the individual’s personality or way of thinking.
Regarding the users’ responses to the open question, it seems to be necessary to further examine the influence of individual differences and the content of the robot’s voice-call on the pause duration and other features of the user’s responses.
Update of the automated scenario-based dialogue system in an attempt to individualize the turn-taking
Based on the results of User Study 2, we updated the scenario-based dialogue system. We also built a method for individualizing the timing of starting the robot’s voice-call. First, we explain the method of individualizing the turn-taking system. Second, we explain User Study 3, which was conducted to confirm the operation of the dialogue system and check the reactions of users and the effects of the dialogue system.
System of individualizing the timing of turn-taking of robot
How to individualize the timing of turn-taking: This section describes a method of individualizing the timing of the turn-taking of a robot. In a dialogue with a user and a robot, we think it is better that the robot individualizes the timing of the start of a voice-call according to the character of the user to regularly continue the dialogue. For example, the robot should wait longer and start the voice-call after the user ends his/her speech if the user usually talks slowly. If a user usually talks with a good tempo, the robot should start the robot’s voice-call at a faster time. We built a system to individualize the timing of turn-taking by controlling the timing to start the robot’s voice-call, based on the prediction of different durations of blank for each individual. Two subsystems comprised the individualized dialogue system: a system of predicting the duration of a blank and the number of blanks for each user and a system of controlling the timing of the start of the robot’s voice-call based on the prediction.
System of predicting the duration of the blank and the number of the blanks: In this section, we describe how we build a predictor framework that predicts the timing to respond to a user based on the number and duration of blanks in a user’s response. We also describe how we developed such a machine learning model. Specifically, the system estimates user reactions (blank duration and the number of pauses) that differ from person to person. The system estimates the maximum number of pauses and the duration of pausing during the user’s reply to each voice-call of the robot. However, in real life, sometimes it is difficult to acquire user-specific speech data in advance for parameter tuning of an individualized dialogue system. Therefore, we employed a method for estimating the reaction of a user using online learning with the state in which the parameters are not tuned for each user as the initial state.
A method for controlling the timing of the robot’s voice-call based on the predicted result will be described. First, in this method, the type of the contents of the voice-call was used to predict the user’s blank space. This is because in User Study 2, the user’s blank duration tended to differ depending on the type of robot’s voice-call (whether the voice-call was OQ (open question) or not). Second, the reaction of a user is thought to be affected by the number of voice-calls about a topic because the more times the robot voice-calls about a topic, the longer the user has to think his/her reply. Further, except for some examples, the variance of the blank duration or the number of blanks for each user was small in User Study 2. For blank prediction, another clue is the average value of blank duration and the number of blanks for each user. We supposed that the content (topic) of the robot’s voice-call affected the user’s reaction; however, it takes a longer time to learn various interests of users in detail by online learning. Collecting more individualized data during a dialogue is an issue to be addressed for the next step.
Based on the data described above, online learning was performed to predict the user’s blank time and number of times. In this method, we employed a neural network (NN) as a framework for learning the reactions of individual users. The aim of using NN’s was to address situations that had not been experienced in the past by the generalization capabilities of NN. We regarded the prediction of the users’ reactions as a problem of predicting the duration and number of pauses, not as a classification problem. Therefore, we employed NN instead of a support-vector machine (SVM 53 ) or decision trees. Generally, overfitting should be avoided, however, we do not address overfitting at this point because the values that are normally considered outliers could be individual characteristics.
The data used for learning are explained next. When the robot makes the i-th scenario voice-call • The type of voice-call: binary value in which the voice-call is OQ or not. • Number of topics: How many times a topic is called. • Number of pauses: The number of blanks confirmed so far for one reply. • Average value for each user: blank time during response to robot’s OQ voice-call, blank time during response to robot’s non-OQ voice-call, and the number of blanks in reply to OQ and NOQ voice-call.
The output vectors—that is, the data to be predicted— were: • Next maximum blank time, • How many more blanks will occur.
Using these data, we constructed a predictor that predicts individual reactions.
From the state that the predictor was trained using the data of multiple users, the parameters of the predictor were tuned using the individual participant’s data. This is to get closer to the parameters that match the individual data faster.
Scenario script of the practice and the type of the voice-calls (User study 3).
1. If the predicted number of blanks is zero, the system starts the next voice-call after the end of the first blank is detected. 2. If the predicted number of blanks is not zero, the system waits for the predicted blank duration after detecting the start of the blanks. 3. When the predicted blank duration has elapsed, the system starts the next voice-call. 4. If the user starts his/her speech again before the predicted blank duration elapses, the next blank duration and blank time of the user are predicted again, and the process returns to 1. The flowchart of User Study 3.

In the actual experiment, the system learned the relationship between the input/output data based on the reaction data of all the participants in the User Study 2, and this was set as the initial state.
User Study 3: Individualizing the timing of robot’s voice-call and surveying user’s reactions
This dialogue system was updated with some points based on feedback from User Study 2.
Example of scenarios in User Study 3.

Each participant had a dialogue a day and the user study for each participant was conducted once a day for a total of 2 days. On the final day, an interview was conducted, and participants answered their impressions of the content of the dialogue with the robot and the timing of start a voice-call of the robot etc. The procedure of the user study was as follows.
• 1st day The practice of a dialogue with the robot. First dialogue with the individualized turn-taking system*. A participant fills in the questionnaire to evaluate the dialogue.
• 2nd day The practice of a dialogue with the robot. Second dialogue with the not individualized turn-taking system*. The participant fills in the questionnaire to evaluate the dialogue Interviews about the dialogues with the robot.
The order of the two dialogues (individualized/not individualized) was randomized in consideration of counterbalance.
In this study, 10 older adults (from 60 to 80 years old) of four men and six women, and 10 non-elderly adults (younger than 60 years old) and five men and five women participated. Eight of the older adults were participants in the second user study. The users were instructed to answer to the robot’s voice-call in as much detail as possible before starting the user study.
The number of overlaps for each methods (individualized method vs. generalized method) in User Study 3.
Next, we describe the prediction results of the blank duration and the number of blanks during the user’s speech. We calculated the difference between the predicted value and the observed value (we defined the difference as the prediction error). To ensure the change of the prediction error as a result of online learning, we compared the prediction error at the beginning and at the end of one dialogue user study consisting of 20 voice-calls. The list of the voice-calls is shown in Table 4. Specifically, the beginning stage is a set of 4 turns (turn no 4–7) of a scene about the weather and a walk, except for the first greeting and confirmation of physical condition. Also, the end stage is the set of 4 turns (turn no 16–19) of a scene about the resolution of this year or next year, except for the greeting at the end of the dialogue. Each set includes three voice-calls of not open-question and one voice-calls with open question.
Figures 18–23 shows a graph comparing the prediction errors of the blank duration and the number of blanks at the beginning and at the end of the user study. The prediction error of the duration of blank in the case of replies to non-open questions (predicted in the early stage vs. predicted in the late stage). The prediction error of the number of blanks in the case of replies to non-open questions (predicted in the early stage vs. predicted in the late stage). The prediction error of the duration of blank in the case of replies to open questions (predicted in the early stage vs. predicted in the late stage). The prediction error of the number of blanks in the case of replies to open questions (predicted in the early stage vs. predicted in the late stage). The observed values of duration of blank according to the type of robot’s voice-call and the values predicted by the robot system at the beginning (before) and at the end of the user study (after) for each user. The observed values of the number of blanks according to the type of robot’s voice-call and the values predicted by the robot system at the beginning (before) and at the end of the user study (after) for each user.





Users 1 to 10 were younger than 60 years old, and users 11 to 20 were older than 60 years old. In the case of the blank duration and the number of blanks included in the user’s reply to the robot’s voice-call of not open-question, the prediction error of the blank duration decreased in the end stage compared to the beginning (Figures 18 and 19). By contrast, regarding the number of blanks, there were some users whose prediction errors were large in the latter half of the voice-call. Second, in the case of the robot’s voice-call with open question, about half of the participants’ prediction error of the blank time did not change from the beginning stage. For some participants, the prediction error of the number of blanks was smaller than at the beginning; however, the maximum value of the prediction error was about six (Figures 20 and 21).
The box plot in Figures 22 and 23 show the results of each user’s reactions: duration and number of blanks for OQ and NOQ. These figures also include the values predicted at the beginning and at the end of the user study. In some user cases, the plots of the value predicted at the end of the user study were closer to the observation results than the plots of the value predicted at the beginning. In the case of the prediction of pause duration, the values predicted at the beginning were larger than those predicted at the end of the user study. The figure suggests that after the system learned each user’s reactions in this user study, the predicted value tended to be shorter than the observed values. This result may indicate that some users feel the robot does not listen to the user. Therefore, we will consider the method to cope with this issue, such as waiting longer than predicted before starting a voice-call in future work.
Figure 24 shows the score of the degree to which the user tried to adjust his/her speaking pace to the robot. There was no difference between the two conditions: the individualized condition and the generalized condition, although a few more participants tried to adjust the timing to the robot in the individualized condition. Figure 25 shows the relationship between the number of overlaps and the score of willingness to continue dialogue. Overall, 6 out of 20 participants overlapped with the robot more than five times, and the evaluations of those six participants were almost the same as the scores of other participants. The score of the degree to which the user tried to adjust his/her speaking pace to the robot in User Study 3. The score of willingness to continue dialogue versus the number of overlaps.

User’s answer to the voice-call about health.

Discussions
Individual differences in responses to a scenario-based dialogue robot in User Study 1 and 2
Example of the scenario to handle the User’s repeating the same question to the robot (User Study 2).

User’s reaction to match the timing of the robot’s voice-call in User Study 3
In the case of using the individualized method, some participants felt it was difficult to adjust the timing of the speech to the robot’s side because the robot also tried to adjust its timing. For example, some answers obtained during the interview were: (A) “I felt that the robot was waiting for me when my speech was short. But I did not know whether it was better to talk longer or shorter, so I could not adjust the timing well,” (B) “It was easier to talk if the timing of voice-call was constant because I can read the timing of the robot.” However, according to the results of the questionnaire, most of the participants answered that they adjusted their pace of speaking to the robot.
This result of Figure 24 and the interview may indicate that many of the participants in this user study were accustomed to interacting with robots. In future studies, we will include users whose attributes are different from the participants of this user study, confirm the user’s attributes in advance, and investigate their reaction while comparing their attributes and their subjective evaluation of the robot.
In the condition of the generalized method, the average number of times the robot’s voice-call and the user’s speech overlapped was about 1.5 times (there were 20 voice-calls in one user study). In the interview about the system with the generalized condition, there were few negative references to the overlap. Thus, it is probable that the turn-taking was successful in the dialogue of this condition. When the robot’s voice-call and a user’s speech overlap, the robot’s voice-call “Please go ahead” allowed users to know the situation in which they overlapped with each other, and the robot gave the turn to the user.
Comparison of the results of User Study 1, 2, and 3
One of the causes of the increased overlap in User Study 3 was a user’s attempt to break a silence. In User Studies 1 and 2, the robot and a user overlapped because the user tried to break a silence. Similarly, some user’s speech overlapped with the robot’s voice-call because the robot waited for 2.0 s after the user’s speech. Such a situation was observed under the conditions of the generalized method. By contrast, under individualized conditions, the robot learned that the blank duration was shorter than predicted and tried to shorten the waiting duration after the end of the user’s speech, which resulted in the overlap between the user and the robot. Some participants felt that the robot limited the time required for the user’s speech. We assume that overlapping with a robot does not necessarily reduce the satisfaction of the dialogue based on Figure 25. Interview responses showed that several participants felt that the robot’s voice-call, “Please go ahead,” was as if the robot was saying “speak more.”
Key contribution of this paper
We built a scenario-based dialogue system in which the robot’s voice-call was preset while the turn-taking was automated. Then, we conducted user studies of dialogues between the robot and older adults using the turn-taking system and found that dialogues including multiple turn-taking (up to 20 turns), can be successfully performed with the system. We observed users' reactions to the robot’s voice-call (i.e. the time before beginning to reply to the robot, the frequency of the back-channeling, and returning the same questions to the robot) differed across individuals. Moreover, other individual differences of users’ behavior in relation to the robot were observed when their speeches overlapped with the robot and when silence occurred during dialogue. In User Study 3, we used the dialogue system, which was updated so that the system learns the pauses of the user during dialogue and controls the start time of voice-calls to the user based on the result of this learning. The system estimates the length and the number of pauses based on the content of voice-calls. We observed that some users had conversations at a good tempo, while for other users, the number of overlaps between the robot and the user increased. We thought these differences were a result of the users’ attitude, that is, whether they tried to adjust to the robot or not. As a contribution, our paper found that some participants tried to adjust their talking pace to the robot, while some others did not. We also found that there was a lack of information regarding the appropriate estimation of the pausing segments of each individual. The individual differences in reactions to the robot are considered to be one of the keys to estimate appropriate pausing segments. It is important that experimental research clarify the information needed for estimating appropriate pausing segments as the next step of the research.
Application and limitation
Of the five technologies described in the Chapter 2, we studied a method to keep conversations between older adults and the robot going for longer period of time as our first step. This chapter describes what we found and limitations. Furthermore, we observed user responses related to the next steps so we discuss future works. (i) (ii) (iii)
Integration of sensor-based AAL and scenario-based dialogue system
The developed system is designed for monitoring health conditions of older adults. It would be integrated to sensor-based AAL system. We have developed sensor-driven scenario-based dialogue system. 18 The mat sensors are located on the bed and based on the state transition of the user on the bed, the robot talks to the user on the bed using scenario-based dialogue system. Also, the scenario-based dialogue system could be implemented where one scenario is selected among multiple candidate scenarios based on the output of the sensors. If the temperature sensor detects that the temperature is hot, the scenario which begins with “Today is hot, isn’t it” may be selected.
Conclusion
In this study, our objective was to realize a robot dialogue system that supports the independent living of older adults. We plan to use the voice-calls of a robot to encourage older adults to speak and estimate the health condition of the person based on the speech. In this way, it is most important to continue the dialogue for longer periods, since more information might be extracted if conversations last longer. We have studied the method to prolong the conversation by managing the rhythm of turn-taking. The proposal and verification results of the turn-taking method for the scenario-based dialogue have been reported in this paper. We built a scenario-based dialogue system in which the robot’s voice-call was preset while the turn-taking system was automated. The robot system monitored the sound level acquired by the microphone during the user’s speech and detected pauses in the user’s speech. The robot’s waiting time after detecting the pause was determined based on the prediction of the pause duration and the number of pauses.
We conducted three user studies in which the user and robot had a scenario-based dialogue. First, we collected the pause data of the users to obtain training data to train the pause predictor in User Study 1. In User Study 2, we built a prototype of the system of scenario-based dialogue, and the responses of the users were observed. In User Study 3, we used a pause predictor to predict the user’s pauses, and the responses of the users were compared with the dialogue system without the individual pause predictor.
The content of the scenario was evaluated as natural in the studies. Regarding turn-taking in the dialogue with the robot, users’ speech and the robot’s voice-call sometimes overlapped in some users. We collected data on pause duration, the number of pauses, the speech duration, and the word count of the users’ speech, and found that there was a difference in these features according to the types of the robot’s voice-call. Individual differences were also found. Based on these results, we added the function of predicting an individual’s pause duration and the number of pauses to the dialogue system as an approach to smoother turn-taking. With the updated scenario-based control method, the number of overlap was 1.5 times on average. In the cases where the individualized method is employed, however, the number of overlaps was higher. Some of the users who overlapped with the robot’s speech tried to adjust the timing of starting their own speech by predicting the robot’s waiting time and failed.
Further consideration is needed to yield any findings regarding individual differences in responses to the robot’s voice-call. Additionally, we are planning to integrate the voice-call system with a system that estimates the health condition of older adults, as well as to build a system with a scenario determination method according to the individual’s condition.
Footnotes
Acknowledgements
We thank Fonobono Research Institute for help with recruiting participants, enabling us to conduct our user study smoothly. We are also grateful for all the participants and staff for this study.
Author contributions
NM and MO-M researched literature and conceived the study. ST, NM, KT, and MO-M developed of the system and the robot. KK, ST, NM, and KT updated the system design and the program. NM and MO-M gained ethical approval. KK, ST, NM, and KT conducted user study, data analysis and data collection. KK and NM wrote the first draft of the manuscript. All authors reviewed and edited the manuscript and approved the final version of the manuscript.
Declaration of conflicting interests
The author(s) declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the JSPS KAKENHI (Grant Numbers JP18KT0035, JP19H01138, JP20H05022, JP20H05574, JP20K19471, JP22H00544, JP22H04872) and the Japan Science and Technology Agency (Grant Numbers JPMJCR20G1, JPMJST2168, JPMJPF2101, JPMJMS2237).
Guarantor
MO-M