
Abstract
Objective
Adolescence is a critical developmental stage during which mental health vulnerabilities often emerge. Traditional self-report methods are insufficient to capture the complexity of emotional and physiological responses, underscoring the need for data-driven, personalized mental health strategies. This study aimed to develop and validate a structured multimodal data collection system for adolescents to support the future advancement of precision mental health care.
Methods
This study was conducted as the baseline phase of a longitudinal panel study designed to construct and validate a structured multimodal dataset for adolescent mental health research. A total of 74 adolescents aged 11–15 years from schools and community facilities in Korea was selected through convenience sampling. Multimodal data were collected by integrating six data types: self-reported surveys, electroencephalography (EEG), heart rate variability (HRV), genotyping, microbiome data, and video-based psychological counseling. Data collection was standardized through a three-phase protocol (pre-, on-site, and post-assessment), and participant privacy was protected via pseudonymization based on international standards. Variables were systematically labeled and structured to enable cross-modality analysis. Statistical analyses, including correlation and descriptive statistics, were performed to examine preliminary relationships across modalities.
Results
The study successfully constructed a comprehensive dataset encompassing biological and psychosocial indicators from 74 adolescents. Preliminary analysis revealed statistically significant associations between survey-based BMI and both genomic data (ρ = 0.30, p < 0.01) and microbiome-based obesity indicators (ρ = 0.27, p < 0.05), whereas other psychological constructs (e.g., stress, resilience) showed non-significant cross-modal correlations.
Conclusions
This study presents a replicable framework for collecting rich, multimodal data from adolescents in real-world settings. By enabling integrative analysis of biological and psychosocial variables, the dataset lays the groundwork for personalized mental health prediction and intervention strategies. Future research should expand longitudinally and optimize context alignment to improve predictive precision and clinical utility.
Introduction
Adolescence is characterized by emotional instability, heightened social sensitivity, and pronounced emotional vulnerability. 1 Many psychiatric disorders and behavioral problems diagnosed in adulthood are closely associated with psychological changes that occur during adolescence, emphasizing the need for early intervention.2,3 Recent approaches to mental health management have increasingly highlighted the need for personalized strategies that consider individual biological, psychological, and environmental characteristics. A one-size-fits-all model is inappropriate.4,5 This perspective aligns well with the emerging paradigm of precision medicine that is gaining traction across various domains of healthcare.
Precision medicine integrates heterogeneous data including genomic information, biosignals, and behavioral patterns when defining disease subtypes and designing personalized prediction and intervention strategies. This paradigm is increasingly accepted when treating chronic diseases such as cancer, cardiovascular conditions, and diabetes.6,7 However, although mental health conditions may exhibit chronic progression, associated with significant public health implications, mental health has seldom been discussed by those who promote precision medicine, largely because the supposed biological markers thereof are not reproducible and the diagnostic criteria therefore subjective. 8 Mental health issues in adolescents are triggered by complex interactions between biological vulnerabilities and psychosocial factors. A precision-based approach is essential. Feasible, data-driven integrative strategies are lacking. 9
Most mental health services for adolescents focus on groups at high risk of suicide or addiction. The services do not consider all developmental changes at this stage of life, or the effects of digital environments.10,11 Existing assessment methods rely on self-reported answers to questionnaires or interviews, which are associated with subjective bias and one-time evaluation. Neither dynamic emotional states that require attention, nor emerging risk signals, are captured in a timely manner. 12 The validity and reliability of the data modalities used for mental health assessment have not been adequately evaluated. 13 Systematic comparisons are lacking. It remains unclear how heterogeneous variables that are supposed to reflect the same contextual phenomena in fact capture the relevant psychological constructs.
In response, multimodal data-driven approaches that integrate the collection and analysis of various data types (text, speech, images, and biosignals) have been developed. 14 Multimodal data fusion aids an understanding of adolescent emotional states, psychological characteristics, and behavioral patterns. In particular, studies combining unstructured data such as smartphone sensor inputs, voice and text information, and biosignals from wearable devices with self-reported survey data have demonstrated practical potential in predicting adolescents’ depression and anxiety, tracking symptoms, and recognizing emotions, showing notable technological progress in the field.15,16 Accordingly, multimodal data have been recognized as a promising methodological framework that captures emotional and behavior changes often overlooked by single measures, thereby enhancing the early detection and predictive precision of mental health problems. 17
Nevertheless, research on multimodal data construction for adolescents remains in its early stages, and there is a notable lack of systematically developed and practically applicable data collection processes. Existing studies have primarily employed two or three modalities that were combined in a parallel manner, with limited temporal alignment and contextual integration across data sources. These approaches have been criticized for their insufficient capacity to capture the developmental characteristics and environmental interactions unique to adolescence.18,19 Studies utilizing modalities such as speech, video, text, and physiological signals for depression risk detection have consistently reported that unimodal features often lack robustness and that cross-modal interactions are insufficiently captured. 20 Furthermore, the absence of standardized protocols for data labeling, quality control, and the definition of modalities and tasks limits the reproducibility and reliability of multimodal datasets. 21 These methodological and ethical challenges are further complicated in adolescence research, given their developmental characteristics and the sensitivity of personal data. Addressing these complexities requires the establishment of a systematic and collaborative data collection process that can be feasibly implemented in real-world research setting, with active engagement from schools and local communities to ensure both technical rigor and ethical integrity. 22
This study designs and implements an adolescent data collection process applicable to real-world settings. This approach may serve as a foundation for future, multimodal data utilization, and aid the development of personalized mental health care for adolescents in need.
Methods
The preparatory phase
Prior to construction of a multimodal dataset, a systematic preparatory phase explored the research design, the development of data collection protocols, the need for appropriate Institutional Review Board (IRB) approval, the recruitment of participants, and the required equipment. The key variables in terms of physiological, psychological, and genetic factors were established. To ensure data reliability and standardization, all measurements were defined in detail, as were the instruments required by each data item.
This study was designed as the baseline phase of a longitudinal panel study, aiming to construct and validate a structured multimodal dataset for adolescent mental health research. As the same cohort will be used for subsequent follow-up and effectiveness studies, the sample size was determined by referring to previous studies and by considering an expected dropout rate of approximately 30% to maintain statistical power and ensure sample normality.23,24 Therefore, efforts were made to recruit at least 50 adolescents to secure a sufficient number of valid cases for analysis. The Kongju National University IRB approved the study (approval no. KNU_IRB_2024_071).
We targeted adolescents aged 11–15 years either enrolled in elementary and middle schools of the Chungcheongnam-do region or affiliated with welfare centers/facilities in the Bucheon area. Prior to participation, informational sessions were offered to both the guardians and adolescents. Detailed explanations of the study purpose, procedures, the types of data to be collected, the intended uses thereof, and the measures employed to protect personal information were visually presented. Written informed consent was obtained from both the adolescents and their parents or legal guardians in compliance with ethical requirements. Eligible participants were those who understood the purpose of the study and voluntarily agreed to participate, providing informed consent for the use of personal information together with their parents or legal guardians. Individuals who did not agree to provide personal information during the preliminary screening, who withdrew participation due to personal reasons during the study period, or who had difficulty completing the electroencephalography (EEG) or heart rate variability (HRV) measurements were excluded.
For data collection, bio-signal devices were prepared to measure EEG and HRV, along with testing kits for genotype and microbiome analyses. Additionally, an online survey tool based on Google Forms was developed to assess psychological and emotional characteristics, thus establishing all necessary data collection tools in advance.
Data collection
In coordination with associated institutions, data were collected on single visits between October 2024 and January 2025. Data collection was rigorously standardized. The protocol was continuously refined to address issues encountered during data collection. A multimodal approach was employed, as detailed below.
Here, a “modality” was operationally defined based on the nature of the data and the method of measurement. The six types of data collected were divided into three modalities by the sources of measurement and the biological characteristics, as follows:
- Psychosocial modality: Self-reported and expert-evaluated data, including survey responses and counseling records, - Bio-signal modality: Signal data (physiological responses); EEG and HRV measurements, - Biological modality: Genotypic and microbiome data.

Genotypic data collection and processing.

Microbiome data collection and analysis.
Data protection, structuring, and context-level fusion validation
We used a consistent pseudonymization/de-identification procedure to protect personal information, which, nonetheless enabled the analysis and integration of multimodal data. The procedure was developed in accordance with the 2024 Guidelines on Pseudonymized Information Processing issued by the Personal Information Protection Commission and the ISO/IEC 27559:2022 standard (Information security, cybersecurity and privacy protection—Privacy enhancing data de-identification framework).
As data were collected, each participant was assigned a pseudo-identifier (PID) mapped to his/her personal information in a table stored in a physically isolated/encrypted location that only the designated data protection officer could access. The PID served as the file name and internal identifier across all modalities, and was used to link/integrate data from the same individual. The following pseudonymization methods were applied. These depended on the data type.
Names, dates of birth, and phone numbers were removed from all datasets. Quasi-identifiers such as addresses, affiliated institutions, and age were either categorized or generalized. For example, dates of birth were in years only, and regional information was reduced to the city/province level. For EEG and HRV data, metadata in file headers (names and collection timestamps) were deleted. Only the PID served as the filename and the internal identifier. Genotypic and microbiome data were received from external agencies in a preprocessed/quality-controlled format; no raw data were delivered. Identifiable elements within these datasets (sample IDs and collection dates) were replaced by the PIDs. When viewing video data during counseling, participant faces were blurred, and any personal data (such as real names) either muted or edited out. All voice data were voice-morphed, and personal information in the text and counseling records (names, family information, school descriptors) either removed or replaced with symbols such as “[Name].” To allow future analysis of facial expressions, the original (unblurred) videos were stored in encrypted form.
In addition, to ensure efficient utilization and reliability of the collected multimodal data, a consistent naming convention was established. Each variable was assigned a standardized prefix and format, and a variable guide developed. This detailed the definition, measurement unit, and data format for each variable.
We performed an exploratory, context-level correlation analysis to examine whether variables representing the same context exhibited similar patterns across different types of data. The analysis was limited to cases where two or more such variables were present across distinct modalities. Spearman rank correlation analysis was employed because certain variables were ordinal in nature, or grouped, and the distribution was therefore not normal. All analyses employed Python 3.12.0 of the PyCharm environment. The target valuables included attention, resilience, stress, and the body mass index (BMI). The corresponding indicators were:
- Attention: The survey attention score and the concentration index derived from EEG data, - Resilience: The survey resilience score, the fatigue recovery index of the HRV data, and the fatigue-related index obtained from the microbiome data, - BMI: The self-reported weight and height, the obesity risk score derived from the genotyping data, and the obesity index obtained from the microbiome data, - Stress: The survey PSS score, the EEG stress index, the HRV stress resistance index, and the frequency of the Korean word “스트레스” (stress) from the counseling reports.
Results
The multimodal data collection protocol
A standardized data collection protocol was employed during construction of multimodal data. The protocol featured three phases: pre-assessment, on-site assessment, and post-assessment (Figure 3).

Multimodal data collection protocol.
The results of multimodal data collection
Ninety-three adolescents aged 11–15 years from Chungcheongnam-do and Bucheon were recruited. Nineteen later withdrew; data were finally collected for 74 of mean age 14.45 years. Of all participants, 63.5% were male, and 10.8% were out-of-school (Table 1).
Sociodemographic characteristics of the study participants.

SD: standard deviation.
Seventy-four multimodal datasets were constructed. As certain individuals did not respond in terms of particular modalities, the final numbers of microbiome and psychological counseling datasets were 73 and 70, respectively. The multimodal data established in this study featured six modalities: survey, EEG, HRV, genotyping, microbiome, and psychological counseling data. The key data types and their characteristics in terms of each modality are summarized below.
Key variables of the survey data.

Key variables of the counseling data.

The videos were segmented into 5-s units to generate individual samples for subsequent analysis. Each analytical batch featured 16 samples. Each sample contained multimodal data (images, audio, and text). Images were extracted as individual frames and resized and filtered before storage. Audio data were extracted in .wav format. Preprocessing featured format unification and noise reduction. This improved the audio quality and will aid future analysis. Text data were generated by distinguishing the speakers on the audio followed by alignment of segments with the audio timeline, and transcription (Figure 4).

Multimodal data collection using the counseling videos.

Key variables of the genotyping data.

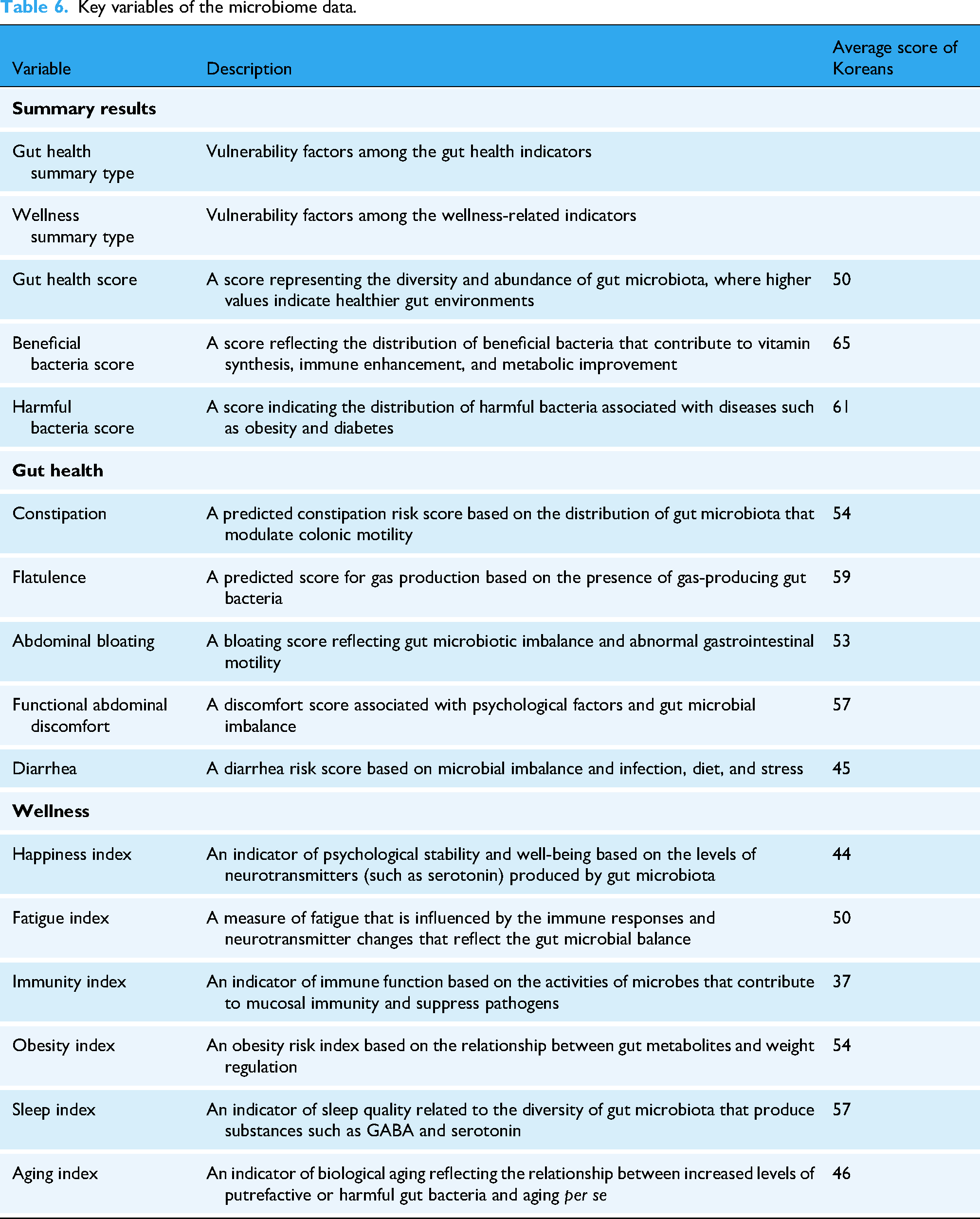
Key variables of the microbiome data.
Data integration and context-level correlations
The derived multimodal data were integrated in a format that established links across the modalities—survey, EEG, HRV, genotyping, and microbiome data; and psychological counseling—based on the participant-specific PIDs. This enabled seamless integration of diverse data types, both structured and unstructured. Structured data were tabled and unstructured data managed using PID-based metadata and linkage keys. The architecture supports cross-modal connectivity and enables integrated analysis at the participant level. The data can be input to multimodal machine learning models.
Spearman rank correlation analysis was conducted to explore whether indicators that measured the same context exhibited similar trends across different datasets (Figure 5). Relatively consistent correlations among the BMI-related indicators were observed. Significant positive correlations were apparent between the survey-based BMI and genomic data (ρ = 0.30, p < 0.01) and between the survey-based BMI and microbiome-based obesity indicators (ρ = 0.27, p < 0.05). In contrast, indicators of stress, attention, and resilience were generally minimally correlated, with no statistical significance.

Multimodal data collection and the context-level correlations. Note. The color of each circle corresponds to the specific data source from which the associated variable was extracted. The data sources used for each context-level fusion were as follows: ·Attention: The survey-based attention score and the EEG-based concentration index.·Resilience: The survey-based resilience score, the HRV-based fatigue recovery index, and the microbiome-derived fatigue index.·BMI: The survey-calculated BMI, the genotypic obesity risk score, and the microbiome obesity index.·Stress: The survey PSS score, the EEG-based stress index, the HRV-based stress resistance, and the frequency of the Korean word “스트레스” (stress) from the counseling reports.
To enable systematic data analysis and management, variable names with modality-specific prefixes were assigned to all data types except survey data, and a corresponding variable guide developed. Variables were labeled by their data source as follows: E_ (EEG), H_ (HRV), G_ (genotype), M_ (microbiome), and C_ (counseling). The variable guide included the variable names, the data types, and the value ranges. It was sought to ensure consistency and reproducibility throughout the entire analysis (Supplementary 2).
Discussion
This study constructed a multimodal dataset containing six heterogeneous types of data from individual adolescents: survey responses, EEG, HRV, genotype, microbiome, and psychological counseling records. Mental health issues tend to emerge in various complex ways during adolescence; early intervention is critical. The collection and linking of diverse physiological and psychological data are essential when it is sought to understand individual characteristics and risk factors in a multi-layered manner. 40 Most previous multimodal studies evaluated the modalities either in parallel or independently, rendering it difficult to interpret biological factors within their psychosocial contexts. In contrast, this study used structured multimodal data for integrated analysis of adolescent mental health.
Adolescents often do not well-articulate their emotional states. Their statements are easily influenced (and indeed altered) by the social context. Standardized questionnaires do not fully capture internal experiences. 41 To address this limitation, the present study constructed a dataset that included not only self-reported survey information but also text, audio, and image data collected during psychological counseling. It was thus possible to analyze verbal and nonverbal characteristics in an integrated manner. This approach enabled identification of discrepancies between self-reported and externally observable responses, aiding in the detection of high-risk emotional suppression, avoidance, and defensive reporting. 42 The higher-order psychological indicators employed, including metacognition and resilience measured by the survey instruments, can be used to assess the capacity for self-regulation and psychological flexibility.43,44 When such structured psychological data are integrated with biosignals and qualitative data derived during counseling sessions, a psychosocial context emerges in which the connections between subjective experiences and physiological responses can be interpreted. 45 This aids the quantification and interpretation of individual differences in terms of emotional expression strategies.
EEG and HRV biosignals reflect the reactivities of the central and autonomic nervous systems, respectively. Both neurophysiological tools have been widely used to define and detect adolescent mental health conditions early. EEG data reflect brain activities associated with attention, cognitive loads, and emotional responses, and changes in specific frequency bands have been reported to be related to emotional states such as depression, anxiety, happiness, and anger.46–49 HRV indices including the RMSSD, SDNN, and LF/HF ratio vary with stress reactivity. The levels are significantly correlated with various emotional states including anxiety, depression, and post-traumatic stress disorder.17,50 However, in previous studies, EEG and HRV data were often collected in different environments or at various times, rendering it difficult to interpret the relationship between the two physiological signal groups in any contextualized manner. 51 Such disjointed research yields only a fragmented understanding of emotional responses. The signal data are interpreted in isolation, rendering it difficult to capture interplays among physiological responses across the various modalities. 52 In this study, EEG and HRV were measured sequentially in the identical setting, yielding the empirical foundation required when interpreting the interactions between the two signal types under relatively consistent emotional conditions. This rendered it possible to analyze precisely any discrepancies or individual variations in how physiological signals responded to emotional states.53,54 This enhances the utility of biosignal-based, nonverbal indicators in terms of adolescent mental health research.
Genotypic and microbiome data afford essential insights when seeking to understand the underlying multi-layered mechanisms of adolescent mental health. Genotyping yields information on emotional reactivity and temperamental vulnerability by identifying genetic variations associated with depression, anxiety, and impulsivity.55,56 Genotyping data obtained during adolescence thus serve as important biological indicators that enable early prediction and personalized intervention. 5 The microbiome, through the gut–brain axis, reflects environmental factors associated with emotional regulation, and certain gut microbial communities have been reported to show significant associations with conditions such as ADHD and depression.57,58 It reflects lifestyle factors such as diet, sleep, and stress and can be modified through behavioral regulation, making it a biological indicator with high potential for intervention. 59 In this study, both biological modalities were examined in the same individuals at the same times. This enabled integrative analysis of the interactions between fixed genetic traits and modifiable environmental factors. The empirical evidence showed that the biological pathways of mental health are neither linear nor unique being, rather, components of an interactive system. When both biological and psychosocial variables are subjected to multimodal integrative analysis, the interpretability and applicability of genotypic data improve, in turn advancing precision psychiatry. 60
The correlations among variables reflecting the same context across the different data modalities revealed that most associations were not significant. This does not necessarily indicate inconsistencies among the variables but, rather, that each modality uniquely captures the same context at a different level of observation. 61 For example, stress may be a subjective perception in self-reported questionnaires, a physiological response in EEG data, and an expert interpretation in counseling records.62,63 Such results suggest that theoretical and methodological considerations of how best to interpret and operationalize specific data are more important than the extent of agreement among the indicators per se. 64 Furthermore, the low correlations should not be attributed to a single cause but, rather, to multiple factors, including differences in sensitivity and specificity across the tools, the multidimensional nature of psychological constructs, and the mismatch between physiological responses and self-awareness. 65 Accordingly, the growing need for integrative interpretation of heterogeneous data has brought increased attention to digital phenotyping, with empirical evidence demonstrating its effectiveness in enhancing predictive accuracy and early detection of mental health conditions.66,67 Digital phenotyping features continuous, ecologically valid assessments of psychological states using everyday data sources such as smartphones, biosignals, and language. Such an approach aligns closely with the goals of precision medicine, which emphasizes data-driven prediction and personalized intervention. 68 In this context, the structured collection of diverse data from the same individual and the empirical analysis of interrelationships among such data constitute a foundational step toward future, precise mental health care. 69 Future research should employ longitudinal designs that align multimodal data both temporally and contextually and also consider developmental changes and environmental influences. Also, it is essential to quantify the contribution of each modality and to develop systematic interpretive frameworks. This would improve clinical applicability and predictive precision.
This study empirically demonstrated that precise mental health assessment was possible using a structured multimodal design that integrated biological with unstructured data. However, several practical challenges emerged. First, some participants found saliva and stool collections psychologically uncomfortable. Second, the quality of an EEG or HRV measurement may be compromised by noise, unfamiliar equipment, or participant tension. Multimodal data collection requires not only technically accurate devices but also participant-sensitive environments and carefully designed protocols. 70 Third, as counseling was online, all of platform resolution, camera positioning, and network stability may have limited the clarity of speech and compromised the capture of subtle facial expressions. Some participants, especially those unfamiliar with virtual communication or constrained in terms of physical movement, seemed to be “stiff”; expression was inhibited. All of pre-session adaptation, standardization of the measurement environment, and improvements in equipment are required to enhance the reliability and sensitivity of multimodal data collected via online counseling. In addition, a limitation of this study is that participants were recruited from specific regional populations, which may limit the generalizability of the findings to broader adolescent groups. Nevertheless, this study provides an important empirical foundation for developing standardized and ethically grounded multimodal data collection processes in real-world adolescent populations. Future research should build upon these findings by broadening participant diversity, enhancing environmental control, and refining data collection procedures to ensure the reproducibility and scalability of multimodal research frameworks.
Conclusions
This study developed and implemented a standardized multimodal data collection protocol integrating surveys, EEG, HRV, genotypic, microbiome, and counseling records to enhance comprehensive assessment of adolescent mental health. The protocol addresses the limitations of traditional self-report-based methods and provides a structured, data-driven framework incorporating biological, psychological, and social indicators. Technical and ethical considerations identified during implementation, including standardized environmental conditions and participant-oriented procedures, offer practical guidance for the reliable acquisition of high-quality multimodal datasets. The resulting dataset and collection system provide foundational infrastructure for early identification of mental health concerns and for the development of personalized intervention strategies, with increasing utility anticipated as the system is applied in larger and longitudinal studies.
Supplemental Material
sj-pdf-1-dhj-10.1177_20552076261415916 - Supplemental material for Development and validation of a multimodal data collection system for adolescent mental health management
Supplemental material, sj-pdf-1-dhj-10.1177_20552076261415916 for Development and validation of a multimodal data collection system for adolescent mental health management by Siyeon Ko, Kyoungsu Oh, Uhyeong Won, Jung-A Oh, Nak-Jung Kwon, Hyun-sook Park, Young-A Ji, Sungjin Kim, Yonghwan Moon, Nayoung Park, Dohyoung Kim, Euijun Yang, Kyungmin Na, Yeonju Kim, Youngho Lee and Hyekyung Woo in DIGITAL HEALTH
Supplemental Material
sj-xlsx-2-dhj-10.1177_20552076261415916 - Supplemental material for Development and validation of a multimodal data collection system for adolescent mental health management
Supplemental material, sj-xlsx-2-dhj-10.1177_20552076261415916 for Development and validation of a multimodal data collection system for adolescent mental health management by Siyeon Ko, Kyoungsu Oh, Uhyeong Won, Jung-A Oh, Nak-Jung Kwon, Hyun-sook Park, Young-A Ji, Sungjin Kim, Yonghwan Moon, Nayoung Park, Dohyoung Kim, Euijun Yang, Kyungmin Na, Yeonju Kim, Youngho Lee and Hyekyung Woo in DIGITAL HEALTH
Footnotes
Acknowledgments
The authors would like to thank everyone who agreed and offered to take part in this study.
Author’s Note
Sungjin Kim is currently affiliated with 6 Letters Inc., Seongnam-si, Republic of Korea. Nayoung Park is currently affiliated with Office of eHealth Research and Business, Seoul National University Bundang Hospital, Seongnam-si, Republic of Korea. Dohyoung Kim is currently affiliated with SK shieldus, Seongnam-si, Republic of Korea. The original affiliations reflect the institutions at the time of submission.
ORCID iDs
Ethical approval
This study was approved by the Institutional Review Board of Kongju National University (approval no. KNU_IRB_2024-071).
Contributorship
Study conception and design: HW, YL, SK. Data collection: all authors. Analysis and interpretation of results: SK, KO, UW, HW, YL. Draft manuscript preparation: SK, KO, UW, YM, EY, YK, HP, YJ, JO, HW, YL. All authors reviewed the results and approved the final version of the manuscript.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT) (RS-2024-00350688).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Guarantor
Not applicable.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.