
Abstract
Objective
To examine user perceptions of human advisors versus chatbots in mental health apps and assess the impact of algorithm literacy interventions.
Methods
In an online experiment, participants engaged in simulated chats about digital stress. A within-subjects condition compared effects of human advisors and chatbots on perceived likeability, credibility, and social competence. A between-subjects condition tested information interventions (positive vs. negative vs. no evaluation of algorithms) aimed at increasing algorithm literacy.
Results
Participants rated human advisors more favorably than chatbots on all measured dimensions (p < .001). Information interventions designed to increase algorithm literacy did not change participants’ attitudes toward chatbots.
Conclusion
Users consistently preferred human advisors over chatbots for mental health advice. Brief algorithm literacy interventions had no significant effect on these preferences. This suggests that simply increasing users’ understanding of chatbots is insufficient to enhance their acceptance in mental health settings, underscoring the need for more effective approaches to improve their adoption.
Keywords
Introduction
Mental health issues, especially among younger people, are becoming increasingly prevalent, yet access to treatment remains difficult due to high cost and limited availability. 1 Online mental health apps offer a solution by providing anonymous, time-efficient, cost-effective, and accessible services, even in remote areas. 2 The number of mental health apps available increases, with options that connect users with human- or AI-based advisors, such as chatbots. 3 AI refers to systems designed to simulate human intelligence, enabling them to perform tasks autonomously, such as decision-making and problem-solving, through methods like natural language processing (NLP) and machine learning (ML). 4
It is unclear if advisor type—human or chatbot—affects user acceptance in mental health advice. Most research compares human and algorithmic advisors in customer service or recommendations, 5 rather than in the field of mental health. Chatbots could expand access to care, but users may prioritize empathy, credibility, and social competence—traits often associated with human strengths. 6 Another factor that may shape perceptions is algorithm literacy. Prior studies indicate that understanding how AI systems function can reduce uncertainty and perceived risks, leading to more favorable attitudes toward AI.7,8 Yet it remains unclear whether brief literacy interventions can have a causal effect on attitudes toward chatbots in sensitive contexts, such as mental health.
Taken together, these considerations underscore the need for experimental research directly comparing user perceptions of human and chatbot advisors in mental health, while also testing whether algorithm literacy influences these perceptions. This study focuses on digital stress to examine user perceptions of chatbots, as it is a common phenomenon in our permanently online and connected world.9,10 Unlike more subjective or personally sensitive issues (e.g. dating or parenting), which can bias attitudes toward AI,11,12 digital stress affects many people, is not stigmatized, and thus allows for examination with a broad user sample. At the same time, digital stress directly links technology to mental well-being. This provides a strong context for evaluating empathy, trust, and credibility in AI-based mental health support.
Hence, the central research question of this study is: How do users’ attitudes, perceptions of credibility, and perceptions of social competence differ when receiving mental health advice about digital stress from a human versus a chatbot?
First, the article references social identity theory and social presence theory, both of which suggest that users tend to trust human advisors more. 13 Second, it introduces algorithm literacy, which has been shown to improve attitudes toward AI by reducing uncertainty and perceived risks.7,8
This research tests these theories in a sensitive care setting and suggests ways to improve human–machine interaction models in which empathy is key. Results show users prefer human advisors. A one-time literacy intervention does not close the gap between humans and chatbots. Still, the gap is small, showing chatbots can develop social abilities for mental health care.
Attitudes toward humans versus chatbots
Resistance to AI applications, such as chatbots, particularly in the healthcare sector, remains significant. Recent research specifically addressing mental health chatbots has revealed mixed user attitudes: while some users appreciate the accessibility and anonymity, many still express concerns about empathy, trust, and effectiveness.14,15 These concerns align with earlier findings that many users feel anxious or uncomfortable with the use of AI in sensitive contexts, such as mental health advice, because AI-systems are perceived to lack empathy and emotional understanding—traits essential for human interaction in this field. 6
Social identity theory further explains this preference for humans over chatbots, as people may perceive the AI-based bot as an out-group, resulting in lower identification and trust.12,16 Prahl and Van Swol 17 also found that participants based their own decisions more on advice given by humans than AI, even in neutral contexts.
Advice Response Theory 17 complements this perspective by emphasizing that advice-taking depends not only on advisor-related factors (human vs. chatbot), but also on receiver characteristics (e.g., prior experiences, stress levels) and message qualities (e.g., content relevance). In the present study, we focus primarily on advisor-related characteristics, while acknowledging that receiver- and message-related factors may also shape perceptions.
Taken together, the existing literature suggests that, despite the growing interest and potential of mental health chatbots, users continue to favor human advisors. However, the evidence base remains fragmented and largely descriptive. Meta-analyses on chatbots in the (mental) health sector reveal that research either analyzes the effects of chatbot usage on health but not the perceptions of the chatbots
18
or reduces perceptions to patient satisfaction and usability.
19
The examination of detailed facets of the perception of chatbots falls short. This underlines the need for experimental research directly comparing user perceptions of human and chatbot advisors in mental health contexts. Therefore, we hypothesize that humans tend to favor socially identifiable operators, which are perceived as human (“in-group”) rather than artificial (“out-group”), especially in sensitive areas such as mental health.
Social presence theory posits that an interaction partner evokes a sense of closeness and connection through social cues, such as body language, tone of voice, or immediate feedback.
20
Human interactions naturally provide these cues, enhancing credibility, whereas interactions with chatbots often lack them, making it harder for users to assess credibility.
21
Attributed cognitive competence—the ability to process information and solve problems—also influences perceived credibility.
17
However, AI systems, such as chatbots, often lack transparency and the ability to explain their decisions, which undermines their credibility, particularly in emotionally sensitive contexts like mental health.
22
In line with this, research indicates that individuals tend to rate other humans as more credible due to their higher social presence and emotional cues, particularly in fields where trust is crucial.
12
Social presence theory furthermore considers perceived social competencies of interaction partners, that is, them being perceived as “sociable, warm, sensitive and personal when it is used to interact with others.”
21
(p1216) Higher social presence in an advisor fosters a stronger social connection, leading users to attribute greater social competence to the advisor.
21
Social competence encompasses the ability to engage effectively in communication and respond appropriately in emotionally charged situations. This competence is composed of traits such as capability, empathy, and trustworthiness,
23
all of which are essential for user trust and acceptance, particularly in the context of AI-based applications.
24
While chatbots can simulate elements of social competence, findings indicate that users typically assign higher social competence to human interaction partners or those they believe to be human, as AI applications lack the intrinsic empathy and intentionality found in human interactions
25
:
Influence of algorithm literacy on attitudes toward humans versus AI
Algorithm literacy (AL) refers to an individual's awareness of algorithms and their ability to comprehend algorithmic processes, their underlying logics, as well as the impact of algorithms on society, culture, economy, and politics. 26 AL enables people to successfully evaluate algorithmic systems, adapt to an algorithmically governed environment, and utilize these skills in one's own decision-making. 27 Based on previous studies, AL is divided into three dimensions: cognitive, affective, and behavioral. 28 Studies indicate that the cognitive dimension influences attitudes toward AI and ultimately behavior, as increased knowledge leads to a clearer evaluation of risks and benefits, thereby shaping how users interact with a system. 29 Research on explainable AI (XAI) supports this by highlighting that cognitive literacy improves user trust, especially when users understand the technology's functions and implications. For instance, objective information has led users to view AI as less deceptive, increasing both trust and satisfaction. 30 These results can be explained by uncertainty reduction theory (URT): When interacting with AI, individuals face uncertainty due to the unpredictability of algorithmic responses, which can evoke cognitive dissonance and discomfort.31,32 URT postulates that obtaining more information leads to less uncertainty. 33 Therefore, negative attitudes can be reduced through algorithm literacy. 7
In the context of mental health advice, this mechanism becomes particularly relevant. Users seek empathy, competence, and trustworthiness in such interactions, yet chatbots often appear non-transparent and unpredictable. This uncertainty can intensify skepticism, and users may doubt whether a chatbot can understand or respond appropriately to sensitive issues. Algorithm literacy can mitigate this by providing users with factual knowledge about how chatbots function and their respective capabilities. By reducing uncertainty about what to expect from a chatbot, literacy interventions may ease discomfort, foster more realistic expectations, and thereby lower resistance to chatbot-delivered mental health advice.
Individuals acquire algorithm literacy through various means, most notably through experiential learning when engaging with algorithmic media, reflecting on these experiences, their thoughts and emotions, and drawing conclusions to adapt their media use behaviors. However, the individual learning processes can be self-referential and lead to wrongful folk theories about algorithmic processes.
26
This suggests factual information (cognitive literacy) about algorithms as an important complement. An information intervention on chatbots that provides both technical explanations of their functionalities (e.g. the use of NLP) and addresses their personal and societal implications (e.g. application areas, quality of output) could help clarify these processes, fostering learning and alleviating uncertainty. Thus, we postulate:
Information interventions designed to improve cognitive literacy can significantly enhance users’ understanding of chatbots by providing them with the necessary knowledge to critically assess their performance.4,34 As users’ understanding of AI increases, they are able to adapt their expectations and evaluate a chatbot's credibility more critically. This heightened awareness, in turn, affects their perception of AI-generated content, leading to more informed and accurate credibility judgments.
32
The perceived credibility of information is influenced by multiple factors, including the characteristics of the information itself, the perceived expertise of the source, and the context in which the information is encountered.
35
In the case of chatbots, users’ prior knowledge—enhanced through information interventions—can mitigate the uncertainty around what constitutes credible AI-generated content. As users become more literate in understanding a system, they are better equipped to critically assess the relevance and trustworthiness of the outputs. This improvement in knowledge reduces ambiguity in credibility judgments and aligns users’ assessments more closely with objective measures of AI performance, especially when comparing chatbots to human advisors.
According to URT, social cues further reduce uncertainty.
33
As suggested by social identity theory and social presence theory, chatbots show fewer social attributes than humans.12,21 However, after receiving information about an algorithmic system, people can reflect on the benefits and calculate the risks of AI.
36
This can reduce perceived distance and mimic closeness to the system.
28
It is assumed that receiving an information intervention to increase algorithm literacy leads to an increase in perceived social presence of AI operators.
Influence of positively or negatively framed information interventions on attitudes toward humans versus AI
Framing shapes how information is perceived. Entman
37
defines framing as the process of emphasizing certain aspects of reality to promote specific interpretations, evaluations, or recommendations. Frames highlight what is deemed relevant, which individuals then use to classify and interpret information.
38
Drawing from prospect theory, gain and loss framing influences decision-making based on how information is presented.
39
Gain frames emphasize benefits that promote risk aversion and enhance perceived advice quality (e.g., “using AI tools improves health conditions”). Loss frames focus on potential harm from inaction, often evoking fear and encouraging risk-seeking behavior (e.g., “without AI, certain health risks may go unmanaged”).
40
In health contexts, gain frames are effective for promoting preventive behaviors (e.g., using sunscreen), while loss frames are more persuasive for risk-related actions, such as cancer screening.
41
For mental health apps that employ chatbots, gain frames could highlight benefits like increased accessibility and personalized support, potentially boosting user acceptance. On the other hand, loss frames, which focus on the risks of not using such technology, may raise awareness but also increase aversion, especially if users are unfamiliar with the technology. For example, Hou and Jung found that positive framing of an AI-based agent led to more favorable user attitudes compared to negative framing.
8
Digital stress, algorithm aversion, subjective algorithm literacy, and sociodemographic attributes as covariates
This empirical study analyzes individuals’ general perception, perceived credibility, and perceived social competence of human advisors or chatbots in a mental health setting, specifically advice on situations where users might encounter digital stress. Digital stress is a contemporary issue arising from the demands and constant connectivity of today's digital environment, leading to negative psychological and physical effects. 42 Given the high prevalence of digital stress, particularly among younger users, this study examines its interaction with attitudes toward AI-generated mental health advice.
Humans are often reluctant to accept decisions made by algorithmic systems, a phenomenon known as algorithmic aversion. 17 This is primarily due to AI's perceived lack of human attributes, such as empathy. 2 This aversion contrasts with algorithm appreciation, representing a spectrum where positive attitudes toward AI can exist. The technology acceptance model (TAM) offers a useful lens for understanding these reactions. 34 TAM proposes that attitudes toward a technology are shaped by its perceived usefulness and perceived ease of use, with later extensions adding perceived risk. 43 Applied to AI systems, TAM suggests that if users perceive chatbots as low in usefulness or difficult to use, or if they view them as risky, they are more likely to exhibit algorithm aversion. Consequently, high perceived usefulness and ease of use can foster acceptance. Integrating TAM helps explain why chatbots in mental health contexts, where errors could lead to high-risk outcomes (e.g., health deterioration), may encounter particularly strong aversion compared to other situations. 44
According to self-affirmation theory, humans strive to maintain a positive self-image and tend to overestimate their own competencies. 45 Research has explored a potential overconfidence in one's AL, which leads to an overreliance on algorithmic systems. 46 As cognitive algorithm literacy, in the form of an information intervention, is assumed to be a predictor of perception of chatbots in this study, subjective algorithm literacy is included as a control variable to ensure that perceptions aren’t solely based on subjective perceptions of one's own literacy.
The way that members of society engage with and benefit from AI systems is often shaped by demographic factors such as age, education, and gender. 47 Research shows that younger generations, particularly Millennials and Gen Z, tend to be more accepting of AI compared to older generations. 48 Additionally, findings suggest that men view AI more favorably than women, and higher levels of education correlate with greater algorithm literacy and acceptance. 47
Method
Study design
A cross-sectional online experimental survey was conducted from December 2023 to January 2024 and again in December 2024 using the open access tool SoSci-Survey (To meet the requirements of the power analysis, a second wave of data collection was conducted. No significant differences emerged between the results from the two waves. A comparison of the pre-resampling and full sample is provided in the online appendix (https://osf.io/puxgf/?view_only=697ae546b9ba4f8c8a7412d9cc314734)). The study followed a 1 × 2 within- and 1 × 3 between-subjects design. In the within-condition, participants were shown four simulated chat excerpts from a mental health app addressing digital stress issues according to Hall et al.'s key dimensions of digital stress: (a) availability stress—pressure to be always reachable; (b) approval anxiety—concern over online social approval; (c) fear of missing out (FoMO) —anxiety over missing experiences; (d) connection overload—overwhelm from excessive notifications; and (e) online vigilance—continually monitoring digital interactions even when offline. 49 Each participant received two chats from human advisors (introduced as “health coaches” with unique profile icons) and two from chatbots (labeled as “virtual assistants” with a robot icon). Human advisors’ responses included a delay message to simulate real-world availability, while chatbot responses were immediate and marked by an “powered by AI” symbol.
For the between-condition, participants were randomly assigned to one of three information interventions with general information about chatbots based on current literature that covered both technical and ethical dimensions of chatbots: a positively framed intervention (n = 116) highlighting, for example, workplace efficiency and handling of large amounts of data, a negatively framed intervention (n = 101) which emphasized drawbacks like lack of empathy or privacy concerns, and a control group with no intervention (n = 121).
All stimuli were created using Canva Pro in full compliance with the platform's licensing terms, ensuring that no copyright infringement occurred.
Procedure
Participants provided informed consent after being briefed on study objectives, their rights, and data security. Those eligible (at least 18 years old) completed questions on sociodemographic characteristics, digital stress, subjective AL, and algorithm aversion. Following this, participants were randomly assigned to one of three groups: a positively framed, a negatively framed, or a control AL intervention group, each receiving relevant information on chatbots. The following manipulation checks assessed perceived text sentiment and comprehension. Participants viewed a fictitious mental health app with either a human advisor or a chatbot, and were presented with four scenarios on digital stress (two from each, in random order). The dependent variables—likeability, perceived credibility, and perceived social competence—were measured immediately following each chat interaction. A final manipulation check asked participants to recall how many chats involved human advisors or chatbots. The survey concluded with a debriefing, during which the study's aim and manipulation details were disclosed, and participants were offered an expanded information sheet as a token of appreciation.
Measures
This study was pre-registered, and materials (including measurements and stimuli) are available on OSF (https://osf.io/ym8ur/?view_only=f9dd7cbd45fe4470abf63ed3c683f885). The measures were sourced from peer-reviewed publications and are freely available for use without explicit copyright permission. The majority of scales used were validated in prior research and marked as such. Scales that could not be retrieved were derived from extensive literature research and tested for internal consistency.
Digital stress was assessed using a shortened 10-item version of the validated Digital Stress Scale 49 (α = .85), which covered the two best-loading items of each factor. The items were presented in random order, using a 5-point Likert scale anchored at 1 (“strongly disagree”) and 5 (“strongly agree”). Items were averaged to create an index for overall digital stress (α = .85, M = 2.39, SD = 0.73).
Subjective algorithm literacy included 12 items assessing cognitive, affective, behavioral, and experiential dimensions of AL derived from the literature,26–28,36 rated on a 5-point Likert scale ranging from 1 (“strongly disagree”) to 5 (“strongly agree”). The scale, though not previously validated, demonstrated acceptable internal consistency (α = .73, M = 3.9, S = 0.59) after index construction, with one item removed to enhance reliability.
AI aversion was measured with the validated General Attitudes toward Artificial Intelligence Scale 50 (GAAIS; α = .84), capturing positive and negative attitudes toward AI on a 5-point Likert scale from 1 (“strongly disagree”) to 5 (“strongly agree”), with higher scores indicating greater aversion after reverse-coding positive items (α = .87, M = 2.75, SD = 0.59).
General perception of the human advisor or chatbot. To assess the general perception, participants were asked to indicate on a slider how they rated the interaction with the human advisor or chatbot after each chat interaction (1 = “very negative” to 5 = “very positive”). All ratings were aggregated to represent one value for the attitude toward the human advisor and one for attitude toward the chatbot (Mhuman = 3.88, SDhuman = .71; MChatbot = 3.53; SDChatbot = .80). This assessment was adapted from Sundar and Marathe's questionnaire on attitudes toward customized news content and modified to a 5-point Likert scale to enhance response consistency and minimize misinterpretation of scale points. 51
Perceived credibility was adapted from a validated scale on credibility 52 (α = .87), with four items (fair, accurate, believable, comprehensive) combined into an index (αhuman = .89; αChatbot = .88). Participants were asked how they rated the chat responses of the chatbot or human advisor on a 5-point Likert scale (1 = “strongly disagree” to 5 = “strongly agree”) (Mhuman = 4.13, SDhuman = 0.61; MChatbot = 3.9, SDChatbot = 0.69).
The perceived social competence measure was adapted from a validated scale on social cognition of voice-based AI-assistants 53 (α = .80). The scale measured, for example, warmth and competence, on a 5-point Likert scale (1 = “strongly disagree” to 5 = “strongly agree”) (Mhuman = 3.78, SDhuman = 0.67; MChatbot = 3.45, SDChatbot = 0.73), yielding indices for chatbot and human advisor (αhuman = .90; αChatbot = .88).
Sociodemographic data. Sociodemographic data included gender, age, and education levels. Education was dichotomized into high and low education status (before and after obtaining a high school diploma).
Manipulation checks. After receiving an intervention (positive/ negative), participants were asked to indicate whether the information they had just seen elaborated on the benefits or advantages of chatbots (1 = “more disadvantages” to 5 = “more advantages”). They were furthermore asked to answer three single-choice questions about the content of the text to control for attention. For each question, they could choose between three potential answers as well as an “I don’t know” option. The questions were the same for both the negative and positive conditions; solely the answering option in one question was changed to reflect the negative and positive information (e.g., “What types of Machine Learning can be differentiated?” with option A: Rule-based and AI-based, option B: Supervised and unsupervised, option C: Input and output).
To test whether the manipulation of different conversational agents was successful, participants were asked how many of the just-seen conversations were with a human advisor and how many with a chatbot after they had seen all four conversations.
Pretest
A pretest was conducted to evaluate the chat stimuli and information sheets for the main study. Six initial chat designs addressed digital stress factors, with distinct icons and cues to differentiate human advisors and chatbots. Participants rated whether they perceived the conversational agent as human or a chatbot and further assessed the relevance of the digital stress factors. Results confirmed accurate differentiation between human advisors and chatbots, and most scenarios effectively communicated digital stress. Two ambiguous scenarios were removed, and the “online vigilance” scenario was revised. The positive and negative information sheets were confirmed to have distinct framing effects, leading to a final version optimized for readability on mobile devices based on participant feedback.
Participants
Participants were recruited via university and corporate newsletters, social media, and public postings. Recruitment included a raffle for online shopping vouchers as an incentive. Following the guidelines of the University of Mannheim, ethical approval from the IRB was not required as the study was fully anonymous and did not include health or mental risks for the participants, nor did it actively induce strong negative emotions. Written informed consent was obtained from all participants prior to the initiation of the study, in line with GDPR guidelines (see OSF: https://osf.io/puxgf/?view_only=697ae546b9ba4f8c8a7412d9cc314734 for details).
An a priori power analysis (pwrss statistical power and sample size calculation tool, R version 0.3.1) (for 80% power (α = .05) with an expected moderate effect size (r2 = .05)) was conducted and revealed a target sample size of 306 participants. Initially, 443 individuals participated in the survey. Participants were excluded if they failed to consent to the procedure according to GDPR (n = 21), completed the survey in an unreasonable time (Reasonable processing time was determined according to the range and average processing time (in minutes) of consenting participants (n = 422, m = 14.06, SD = 5.82, min = 1.52, max = 40.83)) (<5 minutes or > 40 minutes; n = 15), or failed the attention (n = 64) and manipulation checks (n = 5). The final sample consisted of 338 participants; hence, the target of the power analysis was fully met.
The final sample (34.6% men, 64.8% women, 0.6% other) ranged in age from 18 to 87 (M = 34.44, SD = 14.38) and had diverse educational backgrounds. A full overview of the distribution of age, gender, and educational background can be found in the online appendix (https://osf.io/puxgf/?view_only=697ae546b9ba4f8c8a7412d9cc314734).
Results
Randomization and manipulation check
Participants were randomized into three conditions of information intervention: positive (n = 116), negative (n = 101), or control (n = 121). Chi-squared and bootstrapped ANOVA tests showed no significant differences across groups in age (t = 2.08, p = 0.13), gender (X2 = 0.12, p = .94), education levels (X2 = 1.12, p = .35), digital stress (F(2, 332) = 0.29, p = .75), algorithm aversion (F(2, 237) = 0.62, p = .54), or subjective general algorithm literacy (t = 1.01, p = .37), confirming successful randomization.
Two manipulation checks assessed the effectiveness of the chat coach and algorithm literacy interventions. After viewing the chat interactions, most participants accurately identified their interactions with human advisors (M = 1.81, SD = 0.57) and chatbots (M = 2.24, SD = 0.57), verifying the manipulation. Regarding the information intervention, participants correctly perceived the tone of the intervention as more positive (M = 3.96, SD = 0.72) or negative (M = 2.85, SD = 0.88) and answered questions about the previously seen information accurately (M = 0.71, SD = 0.32), confirming the manipulation's success.
Hypotheses testing
To test H1a, a mean index for the aggregated general attitude toward the human advisor (M = 3.88, SD = 0.71) and a mean index for the aggregated general attitude toward the chatbot (M = 3.53, SD = 0.8) was created. A paired t-test revealed that participants generally perceived human advisors as more positive than chatbots (t(334) = 7.75, p < .001, d = 0.42). H1a was confirmed (Table 1).
Results of linked t-tests for general likeability, perceived credibility, perceived social competence.
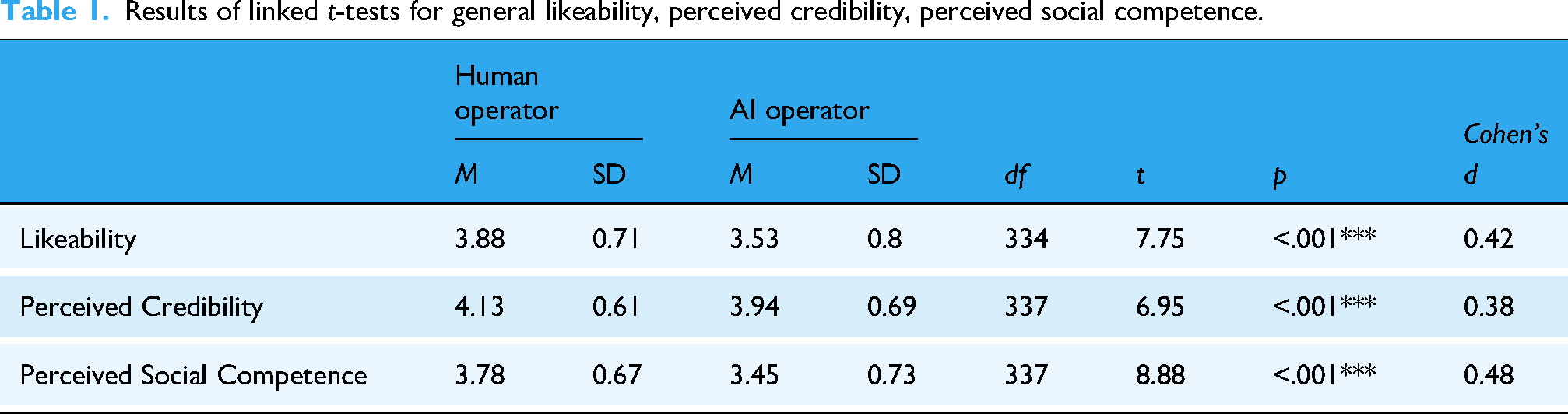
For H1b, indices for credibility of human advisors (M = 4.13, SD = 0.61) and credibility of chatbots (M = 3.9, SD = 0.69) was created. A paired t-test revealed that participants perceived human advisors as more credible than chatbots (t(337) = 6.95, p < .001, d = 0.38). H1b was confirmed (Table 1).
Furthermore, indices for social competence of human advisors (M = 3.78, SD = 0.67) and chatbots (M = 3.45, SD = 0.73) were created. A paired t-test revealed that participants perceived human advisors as more socially competent than chatbots (t(337) = 8.88, p < .001, d = 0.48). H1c was confirmed (Table 1).
To test hypotheses H2a–H2c, and H3a–H3c, three discrepancy variables for general perception (M = 0.35, SD = 0.82), perceived credibility (M = 0.22, SD = 0.59), and perceived social competence (M = 0.33, SD = 0.69) were created by subtracting the chatbot values from the human values. Higher values indicate a more positive, credible, and socially competent evaluation of the human advisor compared to the chatbot.
To test the influence of a positively framed versus negatively framed information intervention and information intervention versus no intervention on general perception toward human advisors compared to chatbots, two multiple linear regression models were calculated. To include the variables for information intervention, two dummy-variables were coded to compare the groups receiving any intervention (positive and negative) and the control group without intervention (included in model 1) and to compare positive versus a negative intervention (included in model 2). As both variables were logically correlated, two independent regressions with model 1 including positive and negative intervention versus no intervention (model 1: R2 = –0.02, F(7, 205) = 0.51, p = .83) and model 2 including positive versus negative intervention (model 2: R2 = –0.01, F(7, 125) = 0.72, p = .65) were calculated. The influence of information intervention compared to the control group of no intervention (H2a) (β = –.02, p = .89) or the influence of positive compared to negative information intervention (H3a) (β = .05, p = .56) was not significant. Age, gender (male vs. female), and education group (low vs. high), digital stress, algorithm aversion, and subjective general AL were added to the models but showed no significant influence (see Table 2).
Regression models for general likeability toward humans versus chatbots.

To test the influence of positive versus negative information intervention and information intervention versus no intervention on perceived credibility of human advisors compared to chatbots, two multiple linear regression models were calculated (model 1: R2 = –0.01, F(7, 207) = 0.38, p = .91; model 2: R2 = –0.01, F(7, 127) = 0.80, p = .59). The influence of information intervention compared to the control group of no intervention (H2b) (β = –0.06, p = .48) and the influence of positive compared to negative information intervention (H3b) (β = .09, p = .23) was not significant. Age, gender (male vs. female), education group (low vs. high), digital stress, algorithm aversion, and subjective general AL were added to the models but showed no significant influence (see Table 3).
Regression models for perceived credibility toward humans versus chatbots.

To test the influence of a positive versus negative information intervention and information intervention versus no intervention on perceived social competence of human advisors compared to chatbots, two multiple linear regression models were calculated (model 1: R2 = –0.01, F(7, 206) = 0.67, p = .698; model 2: R2 = 0.003, F(7, 127) = 0.78, p = .60). The influence of information intervention compared to the control group of no intervention (H2c) (β = .008, p = .90) and the influence of positive compared to negative information intervention (H3c) (β = .05, p = .56) was not significant. Age, gender (male vs. female), education group (low vs. high), digital stress, algorithm aversion, and subjective general AL were added to the models (see Table 4).
Regression models for perceived social competence toward human versus AI operator.

Hypotheses H2a–H2c and H3a–H3c must be rejected.
Discussion
The goal of this study was to assess whether the perception of health advisors (general likeability, perceived credibility, and perceived social competence) differs when interacting with either a human advisor or a chatbot, and whether algorithm literacy, provided through a one-time information intervention, impacts these perceptions. The findings suggest that humans generally perceive human advisors as more likable than chatbots and, furthermore, perceive humans as more credible and socially competent. The assumed effect that a literacy intervention to foster algorithm literacy would decrease the discrepancy in perceptions could not be supported in this study. Neither a person's algorithm aversion, subjective algorithm literacy, level of digital stress, nor sociodemographics influences the discrepancy.
As social identity theory suggests, individuals are more likely to relate to others who share similar characteristics, while social presence theory further explains that humans interpret human-like qualities as indicative of competence and trustworthiness. The difference in perception was most noticeable regarding social competence, with chatbots struggling to meet the emotional competencies expected of human advisors. 23 This finding supports the notion that chatbots frequently fail to exhibit the behavioral and emotional cues that would enhance their perceived human competence. Although human advisors were generally rated more favorably, effect sizes were modest, reflecting low to moderate practical relevance. This nuance suggests that while humans remain the preferred source of advice, chatbots are not categorically rejected and already demonstrate some potential to be accepted as social actors in sensitive domains. A low level of chatbot anthropomorphism may have prevented participants from connecting with the chatbot as effectively. In future research, this context could be expanded by including different anthropomorphic features and personalization cues. For instance, Nowak and Fox found that avatars with characteristics similar to those of their users (e.g., ethnicity) were rated more positively. 54 Similarly, Edwards et al. identified a correlation between voice-based AI assistants and age perception, particularly regarding the credibility of advice. 55
Algorithm literacy, which was manipulated with an information intervention about chatbots, is useful for assessing AI technologies, as “pre-existing attitudes, knowledge, and expectations are also unconscious mechanisms that form a user's disposition to trust a particular technology.” 4 (p689) However, in this study, the information intervention had no significant effect on participants’ perceptions of the advisor. This aligns with earlier findings showing persistent skepticism toward chatbots in sensitive contexts: while chatbots can be valued for accessibility and anonymity, concerns about empathy and competence often remain.6,14,15 Our results reinforce this broader trend, suggesting that literacy interventions alone may not be sufficient to alter deeply ingrained preferences for human advisors.
It is questionable whether the information intervention actually evoked literacy. One possible explanation for this lack of effect lies in the Inoculation Theory, which posits that exposure to weak counterarguments helps individuals build resilience against future stronger challenges. 56 In the context of literacy interventions, this theory suggests that pre-existing knowledge and experience can facilitate individuals’ critical assessment of new information. 57 However, in this study, it must be assumed that participants only experienced short-term learning, as they only received the information once, and it is impossible to assess whether an actual learning process occurred. The difficulty of accurately measuring and assessing actual literacy is well-documented in political knowledge research. 58 While the manipulation check in this study indicates that participants were reading the information intervention and gave sufficiently correct answers, it does not allow us to assess the underlying processing of the information. It is likely that, rather than gaining actual literacy, participants gained heightened familiarity with the system. It is also possible that more knowledgeable individuals about chatbots were able to pass the manipulation check without actively reading the text provided in the information intervention. This suggests that familiarity with the system might reduce the need for deep processing. Given that a one-time intervention is often extremely focused and short in duration, it may not be sufficient to create lasting change or genuine literacy. Future studies should therefore consider more intensive designs, such as interactive or multimedia-based formats, repeated exposures, or scenario-based approaches, which may be more effective in fostering meaningful cognitive change. It is also worth considering whether participants trusted the information provided. If participants did not accept the validity of the information intervention, then it is less likely that it had an impact on the perception of the human advisor and the chatbot. It is also plausible that cognitive algorithm literacy does not directly influence perceptions, and that other factors, such as prior experience 59 or the context of use, 6 may have a greater impact on perceptions. Future research could also examine potential moderating or mediating roles of individual differences such as algorithm aversion, subjective literacy, or digital stress, using study designs and sample sizes specifically powered to test these mechanisms. This may provide deeper insights into when and for whom chatbots are more or less accepted in sensitive mental health contexts.
Furthermore, the distinction between heuristic and systematic processing can provide further insight into why the intervention had limited effects. According to Petty & Cacioppo
It is further important to consider message-related characteristics, which could potentially explain why perceptions were not significantly impacted by the intervention. Advice response theory posits that attitudes toward advice are influenced by advisor-related characteristics (human vs. chatbot), receiver-related characteristics (e.g. digital stress level, algorithm aversion), and message-related characteristics (e.g. content). 17 While this study concentrated on advisor-related characteristics (human vs. chatbot) and certain receiver characteristics, message-related characteristics might have played a more significant role in shaping participants’ attitudes, as acceptance of advice is often linked to the perceived quality of the message itself. 64 Participants in this study may have evaluated the advice they received based on its content rather than the agent delivering it. This suggests that message quality might be a more significant factor in determining perceptions, especially in contexts where the emotional or psychological needs of the user are at stake. Given that the level of digital stress in the sample was relatively low, indicating a low issue involvement, participants may have had little need for advice related to digital stress, leading to less critical engagement with the chatbot and a diminished impact of the literacy intervention. Hoff & Bashir suggest that humans rely more on algorithmic advice when their issue involvement is high, which could have influenced participants’ willingness to accept the chatbot's advice more positively in a different context. 34
The missing effects of a positive or negative framing of the information intervention on perception of chatbots raise important questions about the effectiveness of how information is displayed. Gain and Loss Framing posits that the way information is presented influences how it is perceived, and, subsequently, how decisions are made. 39 Gain frames typically emphasize benefits and encourage risk avoidance, whereas loss frames highlight the costs or potential harms associated with inaction. 40 In the context of this study, rather than highlighting inaction, the focus was to emphasize the negative consequences of using chatbots (e.g. harmful output, unregulated data). A possible explanation for the missing effects could be a mismatch between framing and the user expectations: negative framing works best for individuals who perceive the subject as risky or harmful, but participants in this study may not have viewed chatbots as inherently problematic. If the perceived risks were not strong enough to evoke concern, the negative consequences presented in the intervention may not have had the desired effect on perceptions. While the positive framing emphasized the benefits of using chatbots, participants may not have seen these benefits as sufficiently relevant or compelling to shift their perception. According to the TAM, users are more likely to engage with technologies they find useful and reliable. 65 If participants did not perceive chatbots as particularly useful, then neither the positive framing nor the negative framing would have had a significant influence on their perceptions. Furthermore, participants with prior experience or familiarity with chatbots may have been less impacted by both types of framing, as they may have already formed their own opinions about the technology.
Emphasizing negative consequences or risks is often intended to evoke a sense of urgency or fear, which can motivate a change in attitude. However, for negative framing to be effective, it must highlight risks that feel relevant and immediate to the participants. If the perceived risks of using a chatbot were not seen as significant (e.g., concerns about privacy or data security may not have felt as urgent), the negative framing may not have triggered the expected emotional response, such as fear or anxiety. Conversely, positive framing is most effective when participants are already inclined to view the technology as useful or helpful. If this connection between positive framing and perceived usefulness was weak, the intended benefits might not have been compelling enough to change participants’ views.
We must also consider that the information intervention provided general knowledge about chatbots rather than context-specific knowledge regarding the application of chatbots in mental health. For example, the benefits of chatbots might not have felt meaningful in the following chat interactions if participants were thinking about chatbots in a general rather than the mental health context. This could also have led to dissonance in expectations, as participants were first presented with general information about chatbots and then faced a mental health scenario. Thus, their expectations about the potential benefits and risks of chatbots may not have aligned with the context of mental health. Future research should adapt the information intervention to specific contexts to make the message more compelling. General literacy interventions may not be sufficient to change perceptions, and the focus should be on context-dependent interventions.
Limitations
This study had several limitations: The complex design, especially the AL information intervention, may have reduced participant attention, as suggested by a high dropout rate and attention check failures (21%). Furthermore, the content of the intervention was general, providing technical and ethical information about chatbots and AI-based systems, but was not specifically tailored to their application in therapeutic or psychological care contexts. While we delibaretly chose this approach as the technical and ethical aspects of AI-systems and chatbots are irrespective of context, future research could examine whether domain-specific interventions have an effect or whether such general intervention has an effect in contexts other than mental health. The use of multiple human avatars versus a single chatbot icon aimed to improve external validity but may have introduced unexpected issues regarding the likability of human advisors, for example, gender stereotypes. 54 Another limitation is the use of a scale for subjective algorithm literacy that had not been validated beforehand; however, it was theoretically grounded, informed by extensive literature, and demonstrated good internal consistency in this study (α = .73), suggesting its potential for future use and validation. Additionally, the sample consisted mainly of highly educated, young, female participants, which limited generalizability and potentially reduced variance in attitudes toward AI. We further did not include measures of participants’ prior experience with chatbots or their current mental health status. This choice reflects protection of the participants’ privacy concerns and well-being.
Conclusion
This study examined user perceptions of chatbots versus human advisors in a mental setting, offering valuable insights into human–machine communication in a mental health context. Results showed a preference for human advisors, who were rated both higher in credibility and social competence, underscoring the importance of social presence and empathy in shaping user attitudes within sensitive contexts, such as mental health. Although participants were somewhat receptive to chatbots, a perceived lack of empathy tempered these attitudes. Interestingly, interventions designed to enhance algorithm literacy did not significantly impact preferences, suggesting that entrenched expectations for human empathy in mental health support persist.
The findings underscore the importance of algorithm literacy in fostering a critical assessment of chatbots and mitigating the risks of over-reliance. Although the results suggest that short-term interventions may be insufficient, they point to the importance of sustained literacy efforts. The lack of a significant impact from the literacy intervention may be attributed to multiple factors, including low personal relevance, insufficient perceived usefulness, and insufficient engagement with the content. Furthermore, message-related characteristics—such as the perceived quality of the advice provided—likely influenced participants’ attitudes more than the advisor-related characteristics alone. This underscores the need for context-specific, engaging information interventions to promote algorithm literacy. The lack of impact from a general information intervention highlights that a “one-size-fits-all” approach to literacy is insufficient, especially when it fails to connect with individuals’ personal concerns and needs.
Additionally, how the information was presented (positively/negatively) did not affect perceptions. This raises an important point for framing theory: context matters. When an intervention is too broad, it may lack the personal relevance needed to trigger the emotional responses to change an individual's attitudes. General interventions fail to account for the fact that people interpret and react to information differently based on their prior personal experiences and knowledge of a specific context. This suggests that, for framing to be effective, the message must be tailored to address particular concerns and motivations of individuals. To improve the effectiveness of literacy interventions, future research should focus on creating interactive, repeated exposure to interventions, emphasizing the usefulness of the technology, and ensuring that the content is relevant to the specific context it refers to.
Supplemental Material
sj-pdf-1-dhj-10.1177_20552076251413307 - Supplemental material for Perceived credibility and social competence of chatbots in mental health apps and the influence of algorithm literacy
Supplemental material, sj-pdf-1-dhj-10.1177_20552076251413307 for Perceived credibility and social competence of chatbots in mental health apps and the influence of algorithm literacy by Maria F. Grub and Teresa K. Naab in DIGITAL HEALTH
Supplemental Material
sj-pdf-2-dhj-10.1177_20552076251413307 - Supplemental material for Perceived credibility and social competence of chatbots in mental health apps and the influence of algorithm literacy
Supplemental material, sj-pdf-2-dhj-10.1177_20552076251413307 for Perceived credibility and social competence of chatbots in mental health apps and the influence of algorithm literacy by Maria F. Grub and Teresa K. Naab in DIGITAL HEALTH
Footnotes
Acknowledgments
The authors would like to thank all individuals who helped with participant recruitment, including those who shared the survey in company newsletters, social media, and other outreach channels, for their essential support in data collection.
Ethical approval
Written informed consent was obtained from all participants prior to the initiation of the study. Ethical approval from the authors’ institutional IRB (University of Mannheim) was not required as the study was fully anonymous and did not include health or mental risks for the participants, nor did it actively induce strong negative emotions.
Contributorship
All authors made substantial contributions to the conception, design, analysis, and interpretation of data, and have approved the final version of the manuscript.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Guarantor
The corresponding author takes full responsibility for the integrity and accuracy of the data presented in this article.
Use of AI tools
The authors declare that no AI tools were used for text generation or for conceptualizing, conducting, or analyzing the research presented in this article. Stimuli were created using Canva Pro, which offers AI-generated images in its licensing. Language proofreading was performed with Grammarly.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.