
Abstract

Keywords
Introduction
Dementia is prevalent among older adults (age ≥65 years) globally, 1 with Alzheimer's disease (AD) being the most common etiology; AD cases are estimated to reach nearly 14 million by 2050 in the United States. 2 AD can be detected 10–25 years before clinical onset using gold-standard biomarkers; however, these are costly, invasive, and hard to scale at the population level.3–5 Conventional biomarkers create high individual-test costs, patient burden, and limited access outside major metropolitan areas.6–8 Plasma biomarkers obtained via blood draws offer a more accessible and efficient alternative 5 ; however, many assays are still undergoing validation in large, diverse cohorts. 9
Passive body-worn sensors, smartphones, or in-vehicle devices offer a complementary, continuous, and low-burden signal of everyday function.10,11 These data streams can quantify subtle changes in basic activities of daily living, like sleep efficiency, gait speed, and heart rate, but can also assess instrumental activities of daily living, like managing finances, 12 cognitive fluctuations, 13 and driving behavior. 14 Over the past decade, our team deployed in-vehicle telematics sensors to study driving, linking behavior to biofluid, imaging, and clinical symptoms as markers of AD.15,16 Across multiple cohorts, we showed that preclinical AD pathology, depression, and day-to-day cognitive variability are associated with—and can forecast—changes in route, complexity, and adverse behaviors years before clinical impairment or driving cessation.17–23 We complemented these discoveries with methodological work (e.g., disease-specific modeling, feature development, machine learning), attention to disparities, geriatrics, and translational science.24–29
We aver that digital markers will only serve patients if infrastructure, governance, and ethics are treated as intentional outcomes. Passive sensing can complement molecular markers, but it is not a simplified plug-and-play solution. The field advances when we privilege (1) interpretability over volume, (2) consent that evolves with declining cognitive capacity, and (3) vendor-agnostic, versioned pipelines. We posit that these commitments are the gatekeepers between research and equitable clinical utility. Operational choices matter clinically because interpretability, fairness, and longitudinal stability are prerequisites for robust, equitable, and generalizable results and precision medicine. Dual timestamping prevents day-night misclassification, which would bias sleep and circadian metrics. Schema versioning and contracting tests ensure reproducibility, a crucial aspect for regulatory review. Transparent handling of missing data guards against subgroup drift, which could undermine equity. These choices determine whether a digital marker can forecast meaningful outcomes (e.g., independence, safety, disease progression, change-point detection), be understood by clinicians and families, and ultimately justify its use alongside—or in advance of—molecular biomarkers.
We distill five lessons from large, longitudinal deployments, including signal gaps, missing GPS, time-handling, data volume, and vendor dependencies, and we couple each with pragmatic, standard-operating-procedures researchers can adopt. We use driving as a contextual exemplar, but the lessons generalize to passive sensing broadly. This perspective targets clinical and digital health researchers and decision-makers to provide technical details that affect study validity, equity, and translation.
Lessons from deployment
The challenges and remedies apply broadly to passive sensing, including wearables (e.g., PPG/actigraphy), smartphones (e.g., GPS/IMU), home/ambient sensors (e.g., Wi-Fi localization, PIR), and environmental monitors (e.g., air quality). This section summarizes five common challenges inherent to sensor data, regardless of the commercial-off-the-shelf (COTS) platform used for passive measurement (Figure 1). The remainder of this perspective will use COTS dataloggers as a benchmark for passively collecting driving data from vehicles for behavioral analysis. These dataloggers record per-trip driving metrics in separate data streams (30- and 1-s intervals), convert those metrics into comma-separated value (CSV) files using a vendor's pipeline, and upload those CSV files to a cloud repository for researchers to access.

Prospective data ecosystem of datalogger from a third-party vendor spanning participant use to research output, with five key challenges overlaid onto the pipeline.
Lesson 1: Incomplete data stream (applies to any passive stream)
Sensor-based longitudinal studies are vulnerable to interruptions in data transfer from devices to the cloud or local storage due to device malfunctions, connectivity issues, weather, and electromagnetic or solar conditions. In-vehicle telematics are particularly sensitive because signal capture depends on external infrastructure (e.g., cellular networks, internet service providers [ISP], Global Navigation Satellite System [GNSS]), while balancing dead zones, poor satellite connectivity, and tampering that can result in incomplete trips or missing key fields (e.g., speed, GPS). Digital health researchers should deploy automated quality-control pipelines that validate file schemas, monitor completeness in near-real time, flag gaps in data transmission against expected volume (file size), and trigger re-ingestion when feasible. If recoverable variables are absent, derive them from raw data (e.g., compute total trip time by summing recorded 1–30 s epochs). For irrecoverable gaps, avoid single-value methods such as mean imputation; instead, use time-series approaches (e.g., Kalman/state-space smoothing, multiple imputation, model-based estimation) with prespecified sensitivity analyses. Sensor datasets also contain identifiers (e.g., device/participant, vehicle, latitude/longitude). Missing or incomplete identifiers typically indicate improper installation/pairing or vendor-side redaction. These fields should not be imputed but instead resolved at the source via documented communication with participants (to confirm use) and vendors (to reconcile data versions/backend processing). Researchers should specify governance upfront, including which identifiers are collected, how they are anonymized, and how linkage keys are protected to preserve data integrity, privacy, and reproducibility, consistent with FAIR principles and digital health reporting standards (Table 1).
Challenges and insights for processing sensor data.

Lesson 2: Missing GPS data (location-aware sensors)
Telematics sensor data often involves missing GPS coordinates at trip start or end, which prevents accurate origin–destination assignment. This typically reflects cellular degradation/ISP/GNSS acquisition (e.g., weak signal at ignition, shielding), rather than participant nonadherence, and is beyond the control of researchers or vendors. For digital-health workflows, we recommend a prespecified hierarchical imputation: (1) when the temporal gap between consecutive data are short and the terminal speed is ∼0 km/h, carry forward the prior trip's end point to impute the next start (and vice-versa), enforcing distance thresholds (e.g., ≤ 100–200 meters) and time limits (e.g., ≤ 3 h); (2) if intermediate coordinates exist, apply map-matching or state-space/Kalman smoothing to infer the most probable origin/destination on the road network; (3) when criteria are not met, label the endpoints as missing rather than forcing values. All imputations should be flagged with uncertainty metadata, and sensitivity analyses should confirm that endpoint reconstruction does not change primary inferences. Consecutive trips with missing start/end coordinates are a device-level signal at a specific location. Building automated quality checks to detect such runs and trigger participant/vendor follow-up (e.g., installation check, firmware update, device replacement). Finally, do not impute or manufacture core identifiers (vehicle/participant IDs, latitude/longitude) but resolve these at the source to preserve linkage integrity, privacy, and reproducibility.
Lesson 3: Transforming time values for use (all time-stamped sensors)
Timestamping is foundational in sensor-based research; however, the choice of time standard determines what questions can be answered. Storing observations in Coordinated Universal Time (UTC) creates a single, consistent reference that simplifies aggregation across regions. However, UTC obscures individual behavior that depends on local clock time, such as the ratio of day-to-night driving, rush-hour exposure, or alignment with circadian/sleep–wake cycles. A trip that occurs at night for a driver on the East Coast can appear as a daytime event when viewed only through UTC, leading to misclassification of circadian patterns and biased subgroup comparisons. Recording both a canonical UTC timestamp and a location-aware local time obviates this obstacle. The local time should be computed based on the geographic location of the event and must incorporate the correct historical rules for standard time and daylight-saving time. For trips that cross time-zone boundaries, events should be assigned to the local time of the destination where the trip occurred, not the origin or destination. Alongside these fields, store the human-readable name of the time zone and the numeric offset from UTC in minutes at the moment of the observation. This dual representation preserves global consistency while enabling analyses meaningful to an individual's behavior. Over the course of 10 years, our participants drove across the contiguous US, including parts of Canada and Mexico (Figure 2). Analytically, researchers should derive day–night indicators, day-of-week indicators, and holiday or school-calendar flags from local time and, when relevant, classify light conditions using sunrise and sunset for the event's GPS and date rather than a fixed temporal threshold. Quality control should include checks for temporal anomalies (e.g., skipped or repeated hours around daylight saving transitions), negative or implausible trip durations, and discrepancies between reported location and time-zone metadata. All transformations must be reproducible, documenting the time-zone database and software versions used, retaining the original device timestamps, and logging each conversion in the data-processing provenance. Adopting these practices enables investigators to compare participants across regions equitably and to draw valid inferences about diurnal patterns, mobility, and health behaviors throughout a longitudinal study.
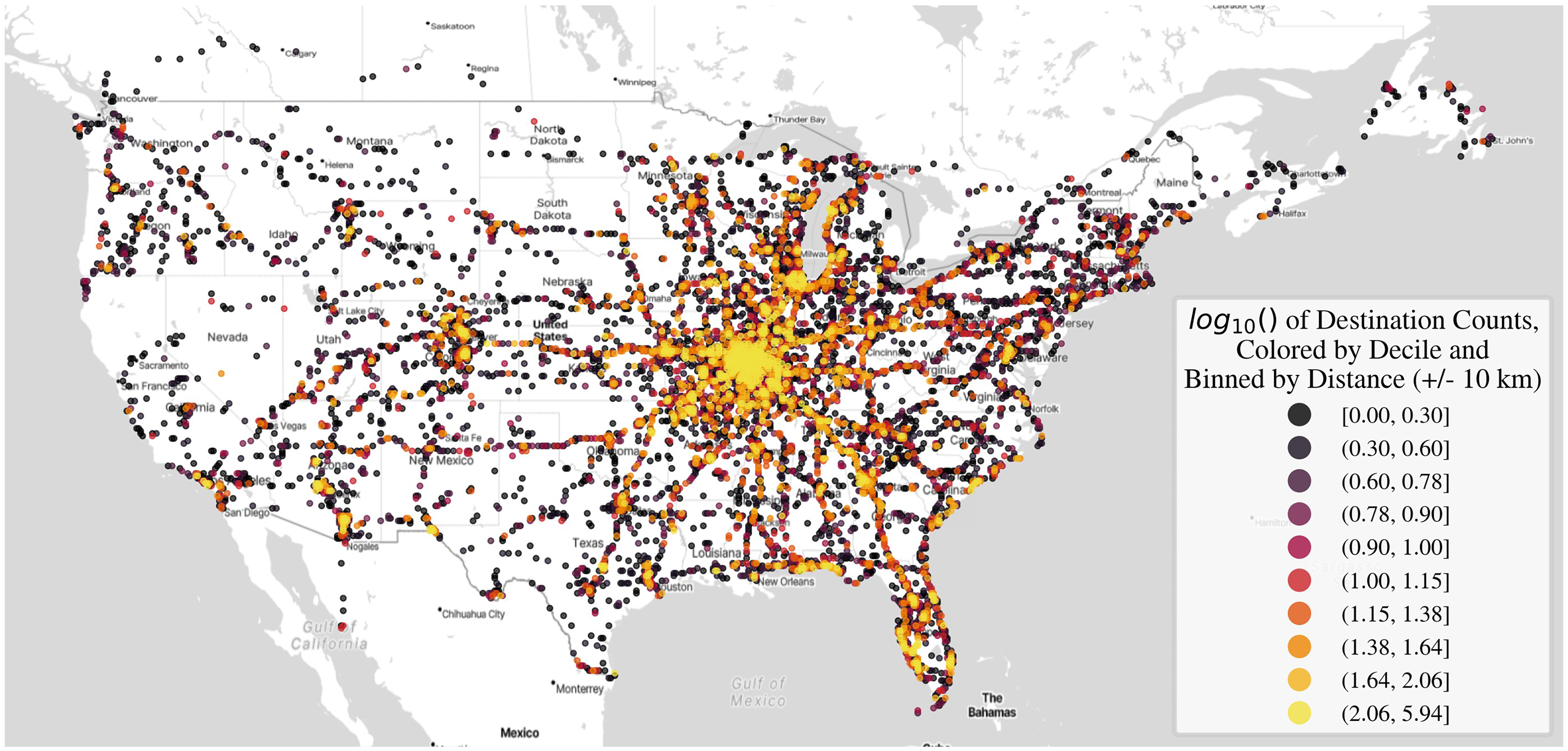
Starting and ending destinations of trips made by participants enrolled from July 1, 2015, to July.
Lesson 4: Processing large volumes of data (high-frequency data streams)
High-fidelity sensors can generate event-level data at one-second intervals, producing a separate file for each vehicular trip and, over longitudinal follow-up, hundreds of thousands of raw objects. This “small-files problem” quickly exceeds the capacity of local machines and processing scripts. A digital health—ready architecture should leverage cloud storage (e.g., AWS S3, Azure Blob, or Google Cloud Storage) as a centralized data lake for raw objects, with scheduled compression into open, analytics-optimized formats (e.g., tarball, Parquet) that incorporate compression and partitioning by participant and date. Store derived features and metadata in a relational warehouse, maintain schema versioning and a metadata catalog, and capture full ETL provenance. For processing, deploy parallel and distributed computing (e.g., Dask, Spark, or Ray) to ingest, validate, and feature files at scale, and containerize workflows with orchestration (e.g., Airflow/Prefect) for reproducibility. This stack enables near-real-time completeness checks, rapid architecture development, and scalable modeling. Implementing role-based access control, encryption at rest/in transit, audit logging, and cost monitoring can meet privacy and governance requirements while keeping budgets predictable. Together, these practices turn high-volume sensor streams into an efficient, secure, and analyzable pipeline suitable for multi-year, multi-site, digital health studies.
Lesson 5: Managing expectations and communication (any vendor-mediated data)
When partnering with vendors to store or process high-volume sensor data, treat the relationship as part of the informatics pipeline. Establish a Data Transfer Agreement and change-control plan that specifies versioned schemas, machine-readable data dictionaries, units/time zones, file formats (e.g., CSV/Parquet plus JSON metadata), upload cadence, and provenance fields. Since vendors often modify internal pipelines without notice, requesting advance release notes, backward-compatible exports, and a staging area where researchers can run automated contract tests (e.g., schema validation, type checks) before data ingestion is imperative. Request explicit pipeline documentation describing storage structure, feature definitions, and update frequency, and mandate prompt notification of any changes with dated version tags. Maintain regular, bidirectional communication and keep governance explicit, especially regarding how identifiers are handled/pseudonymized, what logs and audit trails are retained. The goal is to ensure that longitudinal datasets remain interoperable, reproducible, and analysis-ready throughout a study.
Ethics, trust, and lived realities
Digital health in dementia raises questions beyond data pipelines. Consent evolves as decisional capacity declines. Protocols should anticipate re-consent, caregiver assent, and clear opt-out paths that do not compromise care. Participant burden persists even in “passive” sensing—installation, charging, and perceived surveillance can cause distress. Minimizing burden and offering plain-language dashboards that return value (e.g., mobility summaries) builds trust. Privacy should be contextual and flexible, not absolute. Location and routine patterns are re-identifiable; adopt data minimization, on-device pre-processing where feasible, privacy budgets for sharing, and strict role-based access controls. Caregiver mediation complicates attribution and responsibility. As a result, document who installs, who monitors, and who acts on alerts. Finally, equity requires calibration across devices and geographies, participatory design with diverse older adults and caregivers, and transparent communication about what the data cannot say. Ethical guardrails are not optional, but they determine scalability and legitimacy.
Conclusion
Passive sensing has clear value for longitudinal phenotyping and forecasting outcomes relevant for our aging population. Yet clinical readiness hinges on three unresolved areas: 1) interpretable features that clinicians and families can understand, 2) equitable performance across diverse hardware/operating systems and populations, and 3) governance that supports evolving consent and regulatory review. The short-term goal is not an AD diagnosis but rather support for aging in place by flagging changes, informing safety planning, and enriching trials. With transparent methods, shared dictionaries, and ethically grounded deployment, passive sensing can transition from promising pilots to tools that assist clinicians and patients at the population level.
Footnotes
Acknowledgment
We acknowledge the altruism of our participants and their families for their often decade-long follow-up in our research studies.
Ethical approval
N/A
Contributorship
GMB designed the study. All co-authors contributed to interpreting the results and critically reviewed the manuscript.
Funding
This work was funded by the National Institute of Health (NIH)/National Institute on Aging (NIH/NIA) grants R01AG089700 (GMB), R01AG068183 (GMB), R01AG067428 (GMB), R13AG096982 (GMB).
Conflicting interests
All authors report no conflict of interest
Guarantor
N/A