
Abstract
Background
With the rapid development of artificial intelligence (AI) technologies, AI chatbots have been widely applied in the healthcare to provide patients with immediate information. Many people feel embarrassed to discuss gynecomastia in person and turn to online resources for support.
Objective
This study aims to fill this gap by evaluating the performance of five popular AI chatbots (ChatGPT, DeepSeek, Gemini, Perplexity, and Copilot) in answering questions about gynecomastia, focusing on their reliability, quality, readability, and guideline consistency.
Methods
In this study, the top 25 gynecomastia-related queries searched globally from 2004 to 2025 were retrieved from Google Trends and input into five AI chatbots for responses. The reliability and quality of responses were assessed using the DISCERN questionnaire and the Ensuring Quality Information for Patients (EQIP) tool. Readability was analyzed via the Flesch-Kincaid Grade Level (FKGL) and Flesch-Kincaid Reading Ease Score (FKRE). Accuracy, supplementary, and incompleteness were compared with the European Association of Andrology guidelines.
Results
Copilot had the lowest DISCERN score (median [interquartile range (IQR)]: 41.5[36.0-45.0]), while DeepSeek performed best in EQIP scoring (median [IQR]: 60.4[59.0-64.1]). For readability, ChatGPT exhibited the highest FKGL score (mean ± standard deviation (SD): 15.1 ± 2.0) but the lowest FKRE score (mean ± SD: 15.1 ± 2.0), indicating the poorest readability. In contrast, DeepSeek achieved the lowest FKGL (mean ± SD: 11.0 ± 1.2), suggesting superior readability. Guideline consistency analysis revealed an overall accuracy of 85.71% for AI responses, but key details were often omitted.
Conclusion
AI chatbots provide immediate informational support for gynecomastia patients, but there is significant variability in readability and reliability, alongside risks of omitting guideline content.
Introduction
Gynecomastia, characterized by benign proliferation of glandular breast tissue in males, is a common disorder primarily linked to imbalances between testosterone and estrogen levels. Reported prevalence ranges from 32% to 65%. 1 While typically not life-threatening, gynecomastia may profoundly affect psychological health and social functioning in affected individuals, potentially resulting in depressive symptoms, anxiety disorders, and diminished self-confidence. 2 Surgical intervention is indicated for gynecomastia that persists despite conservative management, causes significant physical discomfort, or leads to debilitating psychological distress. 3 Given the sensitive nature of this condition involving privacy and body image concerns, studies have demonstrated that 20% of patients perceive clinic visits as embarrassing, while 28% report feeling ashamed during interactions with other patients in clinical settings, 4 prompting many to avoid direct consultations with healthcare professionals. 5 Consequently, online platforms and chatbots have become critical sources of medical information for these individuals.
Advances in artificial intelligence (AI), particularly large language model-based chatbots, offer new avenues for disseminating and accessing medical information. These systems leverage extensive internet text corpora to provide immediate, personalized health advice.6,7 This anonymous inquiry approach is particularly appealing to individuals who are reluctant to consult healthcare providers directly. 8
Despite their potential, concerns persist about the quality and reliability of AI-generated health information, particularly for individuals with limited medical literacy. 9 It is essential to evaluate the readability of chatbot responses to ensure that patients receive both accurate and easily understandable information. 10 Additionally, assessing the alignment of chatbot outputs with clinical guidelines, including completeness and over-supplementation, remains vital.11,12
While existing studies have evaluated AI chatbots in fields such as head and neck cancer, premature ejaculation, and low back pain,11,13,14 research on gynecomastia-specific AI applications is lacking. Given its high prevalence and impact on quality of life, this study aims to evaluate five mainstream AI chatbots (ChatGPT, DeepSeek, Copilot, Gemini, Perplexity) in generating gynecomastia-related information, focusing on quality, readability, reliability, and guideline consistency.
Methods
This study was conducted on 12 March 2025, at the Department of Breast Surgery, People's Hospital of China Medical University. Ethical approval was waived as the study involved no human or biological data. To minimize bias, personal browser data were cleared before searches.
Google Trends (https://trends.google.com/) was used to search for high-frequency search phrases related to gynecomastia under the “Health” category. 15 Search queries from a global range between 2004 and 12 March 2025 were collected. A list of related questions, sorted by popularity, was generated in the “related questions” section of the results. The top 25 most popular gynecomastia-related questions were selected, and important geographical regions were categorized and recorded using subregions of the search page. To avoid bias, all personal browser data were deleted prior to the search.
The chatbots used in this study were as follows: ChatGPT (Model name: GPT-4o), DeepSeek (Model name: DeepSeek-V3), Gemini (Model name: Gemini 2.0), Perplexity (Model name: Sonar), and Copilot (Microsoft Copilot in Bing; Model name: GPT-4). Independent accounts were created for each chatbot, and all browser-related records were deleted. The queries obtained were queried sequentially in each chatbot in their original order, with each query conducted on a separate chat page. The responses to each query were recorded (Supplement 1-5), and the search history was retained (Figure 1).

Study design flowchart.
Quality and reliability
This study utilized the DISCERN questionnaire to evaluate the reliability of each AI-generated response. The DISCERN questionnaire is a validated tool designed to assist information providers and patients in assessing the quality and reliability of written medical content, particularly regarding treatment options. The questionnaire comprises 16 items scored on a 1–5 scale, divided into three sections: reliability of information, treatment options, and overall quality. 16 Cumulative scores were used to classify the reliability of the AI-generated texts. Since the original DISCERN development paper did not specify grading criteria, this study adopted classification standards from prior literature, as detailed in Table 1. 17
Classification of DISCERN, EQIP, FKGL and FKRE.

EQIP: Ensuring Quality Information for Patients; FKGL: Flesch-Kincaid Grade Level; FKRE: Flesch-Kincaid Reading Ease Score.
The Ensuring Quality Information for Patients (EQIP) tool was employed to assess the quality of AI-generated responses. This tool evaluates content across multiple dimensions, including coherence and overall writing quality. The EQIP questionnaire contains 20 items with response options of “yes,” “partly,” “no,” or “does not apply.” Scoring involved assigning 1 point for “yes,” 0.5 for “partly,” and 0 for “no.” The total score was calculated by summing these values, dividing by the total number of items (excluding “does not apply”), and converting the result to a percentage. 18 Queries were categorized into five groups based on the EQIP framework: Condition or Illness; Test, Operation, Investigation, or Procedure; Miscellaneous; Discharge or Aftercare; and Drug, Medication, or Product. The quality of AI-generated responses was graded strictly according to the criteria outlined in the original EQIP development paper (Table 1). 18
Readability
The readability of AI-generated responses was assessed using the Flesch-Kincaid Grade Level (FKGL) and Flesch-Kincaid Reading Ease Score (FKRE). The FKGL estimates the minimum educational grade level required to comprehend a text, with scores ranging from 0 to 18, where lower values indicate simpler readability and higher values reflect greater complexity. 19 The FKRE evaluates text readability on a scale of 0 to 100, where higher scores denote easier comprehension. 20 All readability calculations were performed using the online tool. 21 Grading criteria for FKGL and FKRE scores are summarized in Table 1.
Consistency with clinical guidelines
Consistency between the responses of the five chatbots and the European Association of Andrology guidelines was evaluated using four metrics: Applicability, Accuracy, Supplementary, and Incompleteness. This methodology was adapted from a prior study by the Mejia group. 12 Some questions retrieved in this study were deemed inapplicable to the guidelines (e.g. surgical costs, gynecomastia surgeon) and were excluded from Accuracy, Supplementary, and Incompleteness assessments. The evaluation criteria are described as Table 2. Following the exclusion of responses deemed applicability (NO), we conducted a quantitative analysis of affirmative responses (YES) across metrics Accuracy, Supplementary, and Incompleteness, enumerating their frequency distributions.
Evaluation of chatbot performance in medical question answering based on EAA guidelines.

EAA: European Association of Andrology.
To minimize bias, the assessments of DISCERN, EQIP scales, and guideline consistency were independently conducted and recorded by two breast surgeons (S.X.R. and R.T.) with over 5 years of clinical experience. Prior to evaluation, the assessors underwent training to ensure a unified understanding of the scoring criteria. Any discrepancies between the two evaluators were resolved by a third researcher (C.J.C.) with over 20 years of clinical experience, who made the final decision.
Statistical analysis
Statistical analyses were conducted using Python (version 3.10). The distribution of variables was determined to be consistent with normality with the help of Shapiro–Wilk test. The Levene test was used to perform the test of chi-square. One-way analysis of variance (ANOVA) and Tukey Honestly Significant Difference (HSD) post-hoc tests were used for comparisons of data that satisfied normal distribution with chi-square. Welch's ANOVA and Games-Howell tests are used to compare data that are normally distributed but do not meet the assumption of homogeneity of variance. Kruskal–Wallis test and Mann–Whitney U test were used for comparison. Chi-Square Test and standardized residuals analysis were used to analyze the categorical data. Inter-rater reliability was assessed using the intraclass correlation coefficient (ICC) for quantitative data and Cohen's kappa coefficient for categorical data. The false discovery rate (FDR) correction method was adopted for multiple comparisons. A p-value of less than 0.05 was considered statistically significant, with 95% confidence intervals (CI).
Results
The top three most frequently searched queries were “gynecomastia surgery,” “gynecomastia male,” and “gynecomastia cost.” Two keywords (“testosterone” and “estrogen”) were excluded from analysis due to irrelevance to the study objectives (Table 3). The remaining 23 queries were input into five AI chatbots, generating a total of 115 responses for evaluation.
Global google trends data for top 25 gynecomastia-related queries (2004–2025) with EQIP classification.

EQIP: Ensuring Quality Information for Patients.
United States with a Search Interest Score (SIS) of 100, Pakistan (SIS: 100) and Nepal (SIS: 94) are the three countries with the highest search interest in gynecomastia. Figure 2 shows the search popularity of gynecomastia in different countries.

Regional distribution of global search interest in gynecomastia (2004-2025) based on google trends data.
Google Trends reports that searches for gynecomastia have shown a fluctuating upward trend in recent years (Figure 3).

Temporal trends in global search interest for gynecomastia (2004-2025) based on google trends data.
Quality and reliability
The Shapiro–Wilk test for the DISCERN scores indicated that not all chatbots followed a normal distribution (Supplement 6). However, Levene's test showed that they met the assumption of homogeneity of variance (p = 0.334), thus Kruskal–Wallis and Mann–Whitney U tests were employed. DISCERN scores differed significantly across chatbots (Kruskal–Wallis test: H = 30.23, p < 0.001), with excellent physician agreement (ICC = 0.905, 95% CI: 0.865–0.933). After pairwise analysis of the DISCERN scores, FDR correction of the p-values revealed that Copilot results (median [interquartile range IQR]: 41.5[36.0–45.0]) were significantly lower than other chatbots (median [IQR]: ChatGPT 52.0[47.5–55.0], DeepSeek 50.0[44.0–53.0], Gemini 52.0 [46.0–57.5], and Perplexity 52.0[44.0–54.5]; p < 0.001). No significant difference was observed in other chatbots.
Similarly, not all chatbots’ EQIP scores followed a normal distribution (Supplement 6), but Levene's test indicated that they met the assumption of homogeneity of variance (p = 0.066). A significant difference in EQIP scores was observed among the chatbots (Kruskal–Wallis test: H = 29.78; p < 0.001). Inter-rater reliability between the two physicians was excellent (ICC = 0.848; 95% CI: 0.791–0.907). After applying FDR correction for pairwise analysis of EQIP scores, DeepSeek (median [interquartile range, IQR]: 60.4[59.0–64.1]) was found to have the highest EQIP scores among the other chatbots (median [IQR]: ChatGPT 52.0[47.5–55.0], Copilot 51.32[43.5–54.0], Gemini 52.5 [47.4–62.7], and Perplexity 57.9[52.5–60.4]; p < 0.05). There were also significant differences between ChatGPT and Copilot (p = 0.045), Copilot and Perplexity (p = 0.005).
Readability
The Shapiro–Wilk test for the FKGL scores of the five chatbots showed that they all followed a normal distribution (Supplement 6). However, Levene's test revealed unequal variances (p = 0.024), so Welch's ANOVA and Games-Howell tests were employed. Significant differences in FKGL scores among the chatbots (Kruskal–Wallis test: H = 36.58; p < 0.001). A pairwise analysis of the FKGL scores, after applying the FDR correction, revealed that ChatGPT (mean ± standard deviation (SD): 15.1 ± 2.0) had significantly higher FKGL scores than other chatbots(mean ± SD: DeepSeek 11.0 ± 1.2, Copilot 12.3 ± 2.0, Gemini 12.9 ± 3.0, Perplexity 12.1 ± 2.0; p < 0.05). Whereas FKGL scores of DeepSeek were significantly lower than other chatbots (p < 0.05).
The FKRE scores of the five chatbots all followed a normal distribution (Supplement 6), and the homogeneity of variance was confirmed (p = 0.263), so ANOVA and Tukey HSD tests were used. There was a significant difference in the FKRE scores among the five chatbots (ANOVA: F = 15.44; p < 0.001). p-values were corrected for FDR, and pairwise analysis showed that there was a significant difference in the FKRE scores between ChatGPT (mean ± SD: 15.1 ± 11.5) and the other chatbots (mean ± SD: DeepSeek 35.7 ± 7.3, Copilot 39.3 ± 11.2, Gemini 29.9 ± 13.6, Perplexity 30.4 ± 11.8; p < 0.05), with much lower values for ChatGPT.
The scores of AI chatbots are presented in Figure 4, with post-hoc pairwise comparisons of their scores detailed in Table 4.
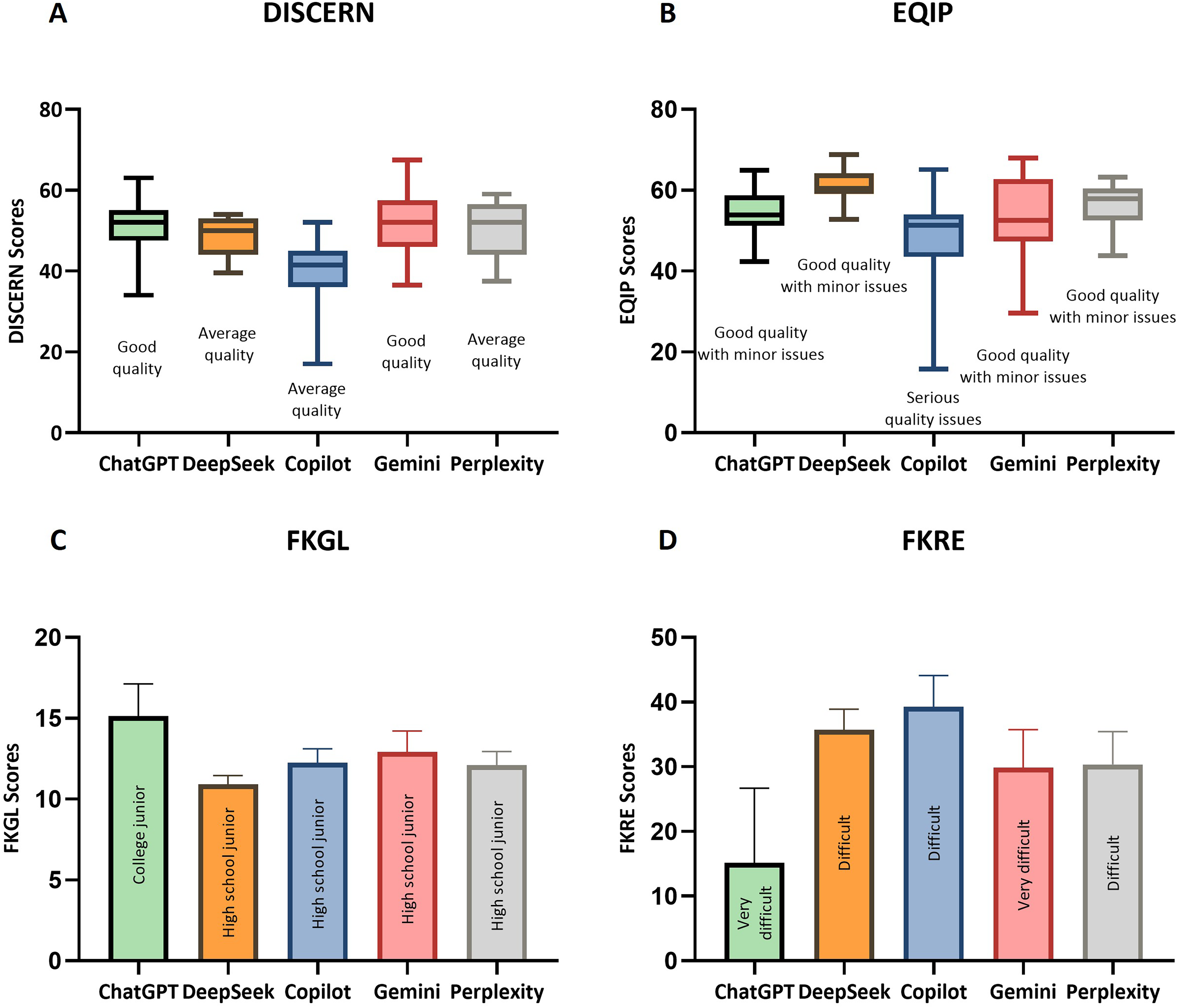
Comparation of 5 AI chatbots: DISCERN, EQIP, FKGL and FKRE. (The box plots A and B represent the DISCERN and EQIP scores of the five chatbots, with the grades marked below each box. The bar charts C and D show the FKGL and FKRE scores of the five chatbots, with the grades marked on each bar.). AI: artificial intelligence; EQIP: Ensuring Quality Information for Patients; FKGL: Flesch-Kincaid Grade Level; FKRE: Flesch-Kincaid Reading Ease Score.
Post-hoc pairwise comparisons of AI chatbots scores.

p-values were derived from Mann–Whitney U tests with FDR correction.
p-values were derived from Games-Howell tests with FDR correction.
p-values were derived from Tukey HSD tests with FDR correction.
p-value <0.05.
AI: artificial intelligence; EQIP: Ensuring Quality Information for Patients; FKGL: Flesch-Kincaid Grade Level; FKRE: Flesch-Kincaid Reading Ease Score; HSD: Honestly Significant Difference; FDR: false discovery rate.
Consistency with clinical guidelines
In the analysis of guideline consistency, both surgeons agreed that nine questions did not require guideline interpretation. For the remaining 14 questions, inter-rater reliability was assessed using the kappa statistic, yielding near-perfect agreement (κ = 0.936; 95% CI: 0.899–0.973). Descriptive statistics were performed and it was found that Accuracy was the highest of the three metrics at 95.71% and compared to other chatbots, Copilot had the lowest Accuracy and Supplementary (85.71% and 42.86%). And Incompleteness is the highest among the five chatbots, as high as 92.86% (Figure 5). In addition, we analyzed the between-group differences by performing chi-square tests for Accuracy, Supplementary, and Incompleteness, respectively, and found that there were significant differences in Supplementary among the five chatbots (Accuracy: χ2 = 5.6, p = 0.234; Supplementary: χ2 = 28.0, p < 0.001; Incompleteness: χ2 = 4.6, p = 0.328). Further analysis of the standardized residuals revealed that the supplementation rate of Copilot responses was smaller than that of the other four chatbots, with a large deviation (−5.12–5.12).

Guideline consistency assessment for AI chatbots across 14 gynecomastia-related questions. AI: artificial intelligence.
Discussion
This study represents the first comparative evaluation of information quality, reliability, readability, and guideline consistency in responses generated by chatbots to questions regarding gynecomastia. Previous studies on online medical information about gynecomastia mainly focused on information presented on web pages, and only evaluated the readability of the information without assessing the reliability of the content and its practical value for patients. 22 This study included five chatbots. Besides the commonly used ones in such studies, like ChatGPT, Perplexity, Copilot, and Gemini, it also included DeepSeek, a new AI chatbot developed by DeepSeek AI. Currently, there are few studies on DeepSeek in the provision of medical information, which makes this study innovative.
Data from Google Trends show that the three countries with the highest SIS for “gynecomastia” are the United States, along with Pakistan and Nepal in South Asia. Sinno et al. conducted an analysis of 453 plastic surgery-related websites and found that gynecomastia reduction surgery was the most frequently marketed procedure targeted specifically at male patients (58%). Notably, dedicated male service sections were identified in 99 websites (22%), with gynecomastia treatment emerging as the predominant service offered (90%) within these gender-specific portals. 23 The Aesthetic Society, the leading authority in esthetic plastic surgery, released its 2023 Aesthetic Plastic Surgery National Databank Report, which revealed gynecomastia treatment as the second most frequently performed surgical procedure among male patients in 2023 (21,043 cases). This represents a 45.6% increase in surgical volume compared to 2019 (14,454 cases). 24 Currently, research on the prevalence of gynecomastia in the South Asian population is scarce. Qadri SK et al. from India analyzed 148 pathological specimens of breast lesions. The results indicated that gynecomastia is the most common type of breast lesion among men, accounting for 90.9% of cases. 25 The study conducted by Saleem et al. revealed that among 79 patients with idiopathic hypogonadotropic hypogonadism from Pakistan, 24 cases (30.3%) had gynecomastia. 26 When we look at the regional distribution, it appears that almost the entire world shows an interest in gynecomastia, indicating that it is a widespread problem. It has been reported that the incidence of asymptomatic gynecomastia is 50%–60% among adolescents and as high as 70% among men aged 50–69. 27 They may lack sufficient medical knowledge, which results in the majority of search categories being “Condition or illness” for gynecomastia (12/23). 1 Shame sometimes prevents patients from openly discussing this delicate issue with doctors. 5 This leads men with gynecomastia to seek solutions via the Internet. As a result, many searches are related to “Test, operation, investigation, or procedure” for gynecomastia (8/23). Google Trends indicates that the search volume has shown a fluctuating upward trend in recent years, which might be attributed to the increasing incidence of gynecomastia. 28
None of the five chatbots achieved an “excellent quality” DISCERN score. The lowest value (17) was found in Copilot, which had a significantly lower score compared to other chatbots. Erkan et al. assessed keratoconus-related responses from large language models using DISCERN scores: ChatGPT (41) and Gemini (42) demonstrated medium quality, while Copilot (35) showed lower quality. 29 Demir et al. studied the responses of chatbots to endophthalmitis-related questions. The results showed that Copilot had the lowest DISCERN score among ChatGPT, Gemini, and A-eye consult, with scores of 33, 63, 55, and 75 respectively. 30 Although in this study, the DISCERN value of ChatGPT did not show a significant difference from other chatbots except Copilot, many existing studies have compared ChatGPT with other chatbots. Statistical analyses from these studies demonstrate that ChatGPT achieves significantly higher DISCERN scores compared to other chatbots31,32
EQIP results indicate superior text quality in responses generated by DeepSeek compared to other chatbots. As the first EQIP evaluation of medical answers produced by DeepSeek, the limited technical transparency makes causal attribution difficult. Copilot has lower text quality than three other chatbots (except Gemini). Kacer et al. reported that Copilot-generated responses achieved superior EQIP scores (48.9 ± 14.2) relative to ChatGPT-generated (42.5 ± 7.6) and Gemini-generated (47.0 ± 9.2) responses in breastfeeding question evaluations (p < 0.001). 10 Malak et al. evaluated the responses of 10 chatbots, including Copilot, Gemini, ChatGPT, and Perplexity, to four questions related to female urinary incontinence. No significant differences were found in the EQIP values between Copilot and other chatbots. 33 These differences may be due to variations in the sample data or contextual information across different diseases, and the sensitive confidence filtering mechanism based on the Bing browser may also have an impact.
As highlighted in the literature, improved text readability plays a significant role in enhancing health literacy, boosting treatment adherence among patients, reducing emergency department utilization, and shortening hospitalization durations. 34 In terms of readability, although the text generated by DeepSeek has the lowest FKGL scores, understanding these texts still requires an educational level equivalent to the high school junior level. This is higher than the reading level of general health-related text materials, which is at the 8th-grade level or below. 35 In this study, the text generated by ChatGPT was considered to have the worst readability among the five chatbots. The FKGL value indicates that understanding its content requires a reading level equivalent to around the college junior level, and the FKRE value shows that it is “very difficult.”
This is consistent with the conclusions drawn by many existing studies. For example, Zhou et al. evaluated the readability of the responses provided by ChatGPT and DeepSeek models to questions about spinal surgeries. DeepSeek-R1 generated the most readable health materials, with FKGL scores ranging from 7.2 to 9.0 and FKRE scores ranging from 48.4 to 55.6. 19 This indicates that the texts generated by DeepSeek demonstrate good readability. In a parallel assessment of language complexity, Deng et al. evaluated responses generated by ChatGPT to questions regarding patellar tendinopathy using the FKGL scale, reporting a median reading level of 15.4 (IQR:2.2), indicating college-level comprehension requirements. 36 Akyol et al. evaluated ChatGPT-4o's performance on pediatric vesicoureteral reflux topics, finding the generated texts exhibited elevated reading difficulty levels, with FKRE scores averaging 26.0 ± 12.0 and FKGL scores of 15.0 ± 2.5. 37 Fahy et al. compared the responses to questions related to tibial osteotomy from guidelines and ChatGPT. They found that the average FKGL of guideline was 8.2 ± 1.4, while that of ChatGPT4 was 14.0 ± 1.4. None of the answers given by ChatGPT reached or were below the recommended 8th-grade reading level. In addition, compared with ChatGPT, the FKRE of the responses given by guideline was significantly higher (p < 0 .001). The average FKRE of guideline was 60.0 ± 7.8, indicating good readability and consistency with the 8th-grade reading level, while the average FKRE of ChatGPT was 32.0 ± 8.3, suggesting a reading level consistent with that of college graduates. 38
These findings suggest limitations in the capacity of ChatGPT to effectively communicate complex medical information to end users, potentially affecting patient education outcomes and clinical decision-making processes. Akkan et al. investigated how prompt statement types affect responses generated by ChatGPT. Analysis of FKRE scores demonstrated significantly higher readability for plain language prompts (median: 34.4, IQR: 14.8) compared to keyword-only prompts (median: 23.6, IQR: 19.5; p = 0 .01). Similarly, the FKGL showed that the grade level of prompts in plain language (median: 12.1, IQR: 2.1) was lower compared to keyword-only prompts (median: 14.5, IQR: 4.2; p < 0.001). From this, it can be concluded that some prompt statements can be used to facilitate understanding when using AI for medical knowledge. 39
An analysis of the answers given by five chatbots to 14 medical questions about gynecomastia shows that chatbots can accurately answer most questions (85.71%). This might be due to the progress of modern deep learning algorithms, especially the improvement of Natural Language Processing technology, enabling AI to better analyze and generate medical text, thus increasing answer accuracy and relevance. However, AI responses often add content beyond the guidelines. For example, when answering “Gynecomastia surgery,” DeepSeek provided extra information like postoperative recovery time and Keyhole Surgery, which was confirmed correct by experienced clinicians. Still, AI sometimes misses information clearly stated in the guidelines. For instance, when answering “gynecomastia cause,” ChatGPT ignored factors like cannabis and the refeeding syndrome. This could be because the training data did not include the latest clinical guidelines. Mejia et al. evaluated ChatGPT responses to lumbar disc herniation with radiculopathy questions against established clinical guidelines. He found that ChatGPT-4 gave accurate answers to 17 out of 29 questions (59%). 12 Walker et al. evaluated guideline adherence in ChatGPT-generated responses to biliary and pancreatic disease queries, finding 60% consistency (15/25) with established recommendations. 40 However, in this study, even Copilot with the lowest accuracy rate reached 85.71%. This discrepancy might be due to the different questions posed to the chatbot. The questions in the aforementioned two studies were adapted from guideline recommendations, covering a broad scope, diverse types, and were highly professional. In contrast, the questions used in this study were summarized from Google Trends, focusing on the topics that users care about most and were highly practical. According to the EQIP classification, the 14 questions consisted of Test, operation, investigation, or procedure (5), Condition or illness (8), and Discharge or aftercare (1). This may suggest that chatbots exhibit high accuracy when answering questions of public concern.
This study has several important methodological constraints that should be acknowledged. First, we opted to directly input queries rather than converting them into full questions. While this approach ensured comparability with similar studies and minimized human error, it may not fully capture how users typically phrase their inquiries. We intend to explore the use of natural language queries to evaluate chatbot replies in future studies. Second, the focus on English-language keywords limits our ability to assess linguistic competency in non-English medical queries, which presents a significant cross-cultural limitation. Third, the assessment was limited to just five AI chatbot platforms. Given the rapid advancements in large language models, future studies should include a wider variety of emerging AI systems.
Based on the findings of this study, we propose several future directions. First, to address the readability challenges observed in AI chatbots, future research should systematically explore the effectiveness of various prompt strategies in enhancing the clarity of generated texts. This will help reduce comprehension barriers for patients seeking medical information. Additionally, we suggest that public health authorities work towards establishing a quality certification and regulatory framework for AI-generated medical content. Integrating clinically validated and reliable tools—such as DeepSeek, which demonstrated strong performance on EQIP in this study—into official health portals could make it easier for privacy-conscious or resource-limited individuals to access trustworthy medical information.
Conclusion
This study was the first to systematically assess the quality, reliability, readability, and guideline consistency of medical information on gynecomastia from five leading AI chatbots. The results demonstrated that responses generated by DeepSeek achieved the highest EQIP score, reflecting superior text quality, whereas responses produced by Copilot yielded the lowest DISCERN score, which raises concerns about information reliability. All AI-generated content required at least an high school junior level and ChatGPT had the poorest readability. AI responses were mostly accurate but often missed key guideline details. AI chatbots are valuable for patients with privacy concerns. However, current limitations include poor readability and missing guideline details. Future research should optimize training data, involve medical experts in review, and use prompt engineering to improve response quality.
Supplemental Material
sj-docx-1-dhj-10.1177_20552076251367645 - Supplemental material for Evaluating artificial intelligence chatbots’ responses to gynecomastia inquiries: Comparative study of information quality, readability, and guideline consistency
Supplemental material, sj-docx-1-dhj-10.1177_20552076251367645 for Evaluating artificial intelligence chatbots’ responses to gynecomastia inquiries: Comparative study of information quality, readability, and guideline consistency by Xinran Shao, Ting Ruan, Xingai Ju, Yihan Sun and Jianchun Cui in DIGITAL HEALTH
Supplemental Material
sj-docx-2-dhj-10.1177_20552076251367645 - Supplemental material for Evaluating artificial intelligence chatbots’ responses to gynecomastia inquiries: Comparative study of information quality, readability, and guideline consistency
Supplemental material, sj-docx-2-dhj-10.1177_20552076251367645 for Evaluating artificial intelligence chatbots’ responses to gynecomastia inquiries: Comparative study of information quality, readability, and guideline consistency by Xinran Shao, Ting Ruan, Xingai Ju, Yihan Sun and Jianchun Cui in DIGITAL HEALTH
Supplemental Material
sj-docx-3-dhj-10.1177_20552076251367645 - Supplemental material for Evaluating artificial intelligence chatbots’ responses to gynecomastia inquiries: Comparative study of information quality, readability, and guideline consistency
Supplemental material, sj-docx-3-dhj-10.1177_20552076251367645 for Evaluating artificial intelligence chatbots’ responses to gynecomastia inquiries: Comparative study of information quality, readability, and guideline consistency by Xinran Shao, Ting Ruan, Xingai Ju, Yihan Sun and Jianchun Cui in DIGITAL HEALTH
Supplemental Material
sj-docx-4-dhj-10.1177_20552076251367645 - Supplemental material for Evaluating artificial intelligence chatbots’ responses to gynecomastia inquiries: Comparative study of information quality, readability, and guideline consistency
Supplemental material, sj-docx-4-dhj-10.1177_20552076251367645 for Evaluating artificial intelligence chatbots’ responses to gynecomastia inquiries: Comparative study of information quality, readability, and guideline consistency by Xinran Shao, Ting Ruan, Xingai Ju, Yihan Sun and Jianchun Cui in DIGITAL HEALTH
Supplemental Material
sj-docx-5-dhj-10.1177_20552076251367645 - Supplemental material for Evaluating artificial intelligence chatbots’ responses to gynecomastia inquiries: Comparative study of information quality, readability, and guideline consistency
Supplemental material, sj-docx-5-dhj-10.1177_20552076251367645 for Evaluating artificial intelligence chatbots’ responses to gynecomastia inquiries: Comparative study of information quality, readability, and guideline consistency by Xinran Shao, Ting Ruan, Xingai Ju, Yihan Sun and Jianchun Cui in DIGITAL HEALTH
Supplemental Material
sj-xlsx-6-dhj-10.1177_20552076251367645 - Supplemental material for Evaluating artificial intelligence chatbots’ responses to gynecomastia inquiries: Comparative study of information quality, readability, and guideline consistency
Supplemental material, sj-xlsx-6-dhj-10.1177_20552076251367645 for Evaluating artificial intelligence chatbots’ responses to gynecomastia inquiries: Comparative study of information quality, readability, and guideline consistency by Xinran Shao, Ting Ruan, Xingai Ju, Yihan Sun and Jianchun Cui in DIGITAL HEALTH
Footnotes
Acknowledgements
SXR and YT contributed to conceptualization, data curation, formal analysis, investigation, methodology, software, visualization, writing—original draft. JXA contributed to project administration, supervision. CJC and SYH contributed to project administration, validation, supervision, and resources. All authors reviewed the manuscript.
Ethical considerations
This article does not contain any studies with human or animal participants.
Author contributions
SXR and YT contributed to conceptualization, data curation, formal analysis, investigation, methodology, software, visualization, writing—original draft. JXA contributed to project administration, supervision. CJC and SYH contributed to project administration, validation, supervision, and resources. All authors reviewed the manuscript.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability
The data supporting the findings of this study are available in the public domain. Search trend data were obtained from Google Trends (https://trends.google.com/), and chatbot responses were collected via publicly accessible interfaces of ChatGPT (https://chat.openai.com/), DeepSeek (https://www.deepseek.com/), Gemini (https://gemini.google.com/), Perplexity (https://www.perplexity.ai/), and Copilot (![]() ).
).
Statements and declarations
This research did not receive any specific grant from funding agencies in the public, commercial, or not-for-profit sectors.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.