
Abstract
Objective
This paper aims to understand vaccine hesitancy in the post-epidemic era by analyzing texts related to vaccine reviews and public attitudes toward three prominent vaccine brands: Sinovac, AstraZeneca, and Pfizer, and exploring the relationship of vaccine hesitancy with the prevalence of epidemics in different regions.
Methods
We collected 165629 Twitter user comments associated with the vaccine brands. The comments were labeled based on willingness and attitude toward vaccination. We utilize a causality deep learning model, the Bert multi-channel convolutional neural network (BertMCNN), to predict users’ willingness and attitude mutually.
Results
When applied to the provided dataset, the proposed BertMCNN model demonstrated superior performance to traditional machine learning algorithms and other deep learning models. It is worth noting that after March 2022, the public was more hesitant about the Sinovac vaccines.
Conclusions
This study reveals a connection between vaccine hesitancy and the prevalence of the epidemic in different regions. The analytical results obtained from this method can assist governmental health departments in making informed decisions regarding vaccination strategies.
Introduction
COVID-19, a highly devastating epidemic discovered in 2019, has led to significant disruptions in various sectors worldwide. 1 Several countries have been profoundly affected by the outbreak. Despite the development of COVID-19 vaccines in November 2020 by pharmaceutical companies like Pfizer, 2 research on the virus and its vaccination continues. 3 Unfortunately, some individuals skeptical of vaccines have raised concerns about potential side effects, contributing to vaccine hesitancy and the spread of conspiracy theories in the post-epidemic era. 4 Furthermore, researchers and public health experts have been working diligently to understand vaccine hesitancy and public attitudes or willingness in the post- epidemic era. 5
Vaccine hesitancy refers to hesitancy about getting vaccinated, 6 which has been identified as a major threat to global health. To address this issue, various interventions have been implemented around the world to disseminate scientific knowledge to promote vaccination. 7 However, such attempts are often ineffective and may even have the opposite effect than expected. 8 In particular, people's reactions to vaccination campaigns in different places are negatively influenced by their attitudes and willingness. 9 Particularly in social media, negative public discussion can manifest as comments of anti-vaccination propaganda messages. 2 Indeed, anti-vaccine words have proliferated on social media. For example, after the introduction of COVID-19, 85% of Facebook comments on vaccines have been in anti-vaccine status, describing the severe side effects of vaccines and spreading conspiracy theories. 10
The Internet has become the main source of almost all information, especially information on vaccination for most people. 11 This kind of information spreads quickly and many people express their opinions through social media platforms. 12 Thus, there is a need to use the vast wealth of data generated by social media, which detect concerns about the issue of vaccination in the population and control for changes in the users' behavior. 13 To do this effectively requires artificial intelligence technology to monitor epidemic situations. 14 Given the launch of the COVID-19 vaccine, the real-time use of artificial intelligence to support vaccination campaigns is more important than ever. 15 Health organizations are implementing social listening to identify and understand posts about vaccines on social media, which understand what topics are being discussed, whether information is being shared, and whether it is accurate. 16 Machine learning is already widely used with the COVID-19 vaccine. However, due to the limitations of machine learning in processing large amounts of textual data for feature extraction, deep learning can effectively improve feature extraction. 17 Moreover, this paper contributes to this growing literature, including using deep learning techniques to improve vaccination and protect society.
The main interest of this paper lies in developing a classification method for the users’ willingness and attitudes that can detect indecision on social media in different regions. Unlike the traditional sentiment classification, this paper develops two categories of willingness and attitude. Therefore, we specifically address the problem of vaccine hesitancy following the classification of willingness and attitude. In addition to detecting the two labels, we also found that the attitude detection task can benefit from the willingness label as an additional input and vice versa. This finding supports the theory of causal inference, 18 which emphasizes causal. This paper utilizes a dependency tree-based graph convolutional network to construct the model, which can better capture the syntactic dependencies and improve the model performance. The experimental results showed a higher hesitation towards the Sinovac vaccine after March 2022. This result truly reflects the attitudes and willingness of different regions towards vaccines after the epidemic, fully allowing the government to understand the people's needs. Our discoveries aid policymakers and medical institutions in formulating more efficient approaches to tackle issues pertaining to the vaccination process.
To this end, we analyzed people's opinions on COVID-19 on Twitter, investigating public willingness and attitudes toward vaccines using deep learning. In summary, the main contributions of this paper are as follows: First, it employs deep learning to categorize vaccine hesitancy and utilizes a causal inference model to enhance the interpretability of the results. Second, the multi-channel model we propose analyzes tweets with multiple emotions to identify the reasons for public vaccine refusal, and the experimental results surpass those of the baseline model. Finally, the new insights gained from this research are crucial, aiding governments and vaccine companies understand the reasons for vaccine hesitancy and thereby gaining public trust. This contributes to the effective control of the post-pandemic era of the COVID-19 pandemic.
The remainder of the paper is structured as follows: In Section 2, we review pertinent related work. Section 3 furnishes a comprehensive description of our proposed approach. In Section 4, we showcase our experiment and discuss the results obtained. Section 5 delves into a discussion concerning the presented work. Lastly, Section 6 summarizes the work presented, outlines potential internal threats to validity, and discusses possible research extensions.
Literature review
Vaccine hesitancy in social media
Since the onset of the COVID-19 pandemic, numerous studies have employed sentiment analysis to investigate COVID-19 vaccination hesitancy. Researchers employ diverse techniques to scrutinize public sentiments surrounding COVID-19. 17 The general public utilizes Twitter datasets to express their opinions on the matter. Historically, prior literature studies have predominantly applied sentiment analysis in machine learning. In contemporary contexts, the primary objective of sentiment analysis is to comprehend individuals’ attitudes toward the ongoing epidemic, particularly on social media. 2 A study conducted by Li et al. delved into the behaviors of Americans and Chinese on various social media platforms amid the COVID-19 pandemic. 19 The findings of their sentiment analysis revealed notable disparities in the attitudes between the two countries, with prevailing confidence among most individuals in controlling the virus’s spread. Another investigation by Zhou et al. focused on extracting tweets from the pandemic period, 20 examining the emotional dynamics of Australians, and observing temporal shifts in their emotions. In a separate study, Yin et al. analyzed the sentiment of tweets related to COVID-19, 21 discovering a slight predominance of positive tweets over negative ones. The analysis provided tweets emphasizing themes such as securing one's home and commemorating those who succumbed to COVID-19 in the post-epidemic era.
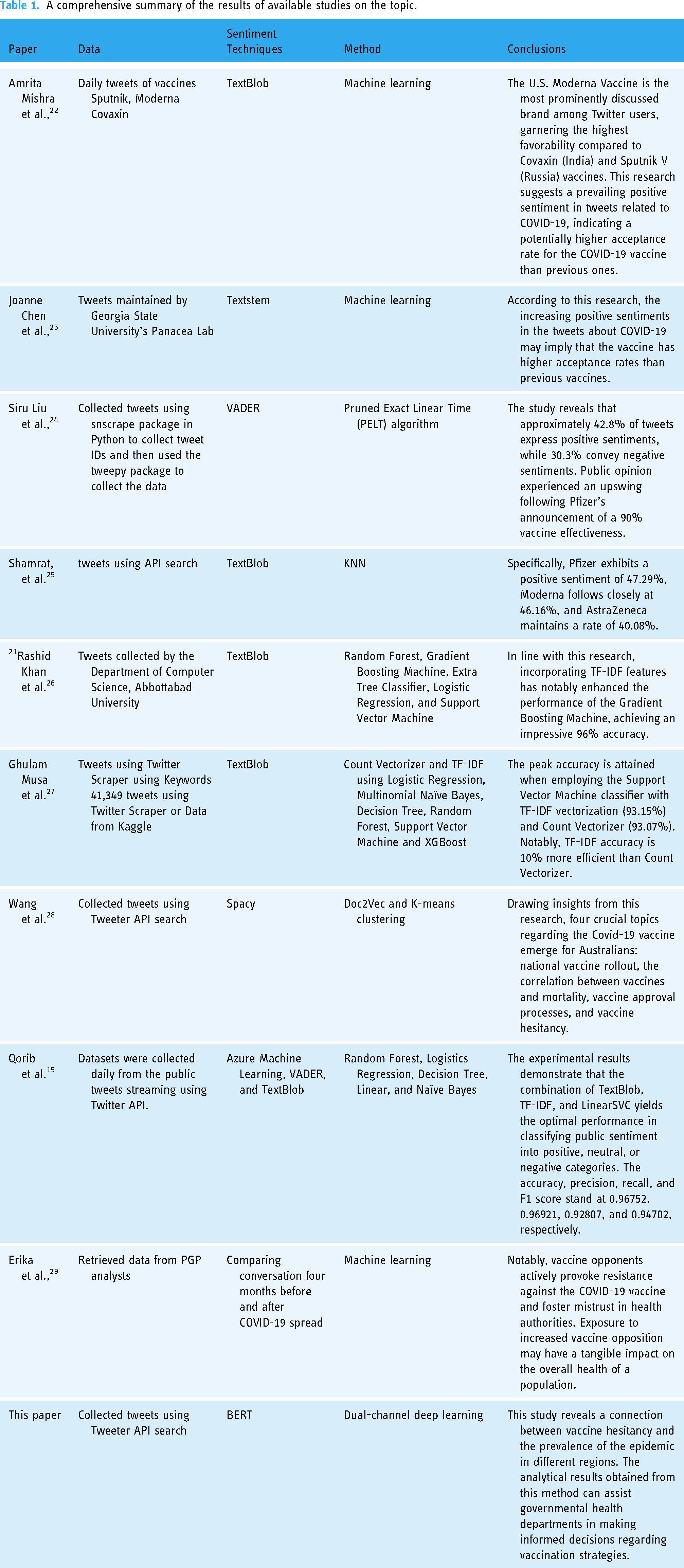
Table 1 presents a comprehensive comparative study on sentiment analysis related to COVID-19 vaccines. The juxtaposition of previous studies will facilitate the current research in exploring uncharted territories that were not addressed in earlier investigations. Additionally, it will serve as a valuable guide for forthcoming studies, providing insights into making unique contributions to the subject matter. This summary table encapsulates diverse studies employing distinct approaches, all conducted using Twitter datasets specifically focused on the study of COVID-19 vaccination hesitancy.
A comprehensive summary of the results of available studies on the topic.
Machine learning in vaccine hesitancy
The COVID-19 pandemic underscores the imperative for advanced technology to respond to emergencies effectively. In tackling such scenarios, machine learning techniques emerge as valuable tools, offering robust support to public health authorities and complementing traditional approaches. For instance, Tavoschi et al., employed support vector machines to monitor public sentiment regarding vaccine uptake in Italy. 30 Moreover, social media traffic enhanced the performance of various models. Despite the utilization of machine learning in the studies, challenges such as poor classification effectiveness and limited generalization ability have prompted a shift toward deep learning as a viable solution. Hussain et al. applied a deep learning BERT model to analyze public sentiment toward COVID-19 in the UK and the USA. 31 Similarly, Devaraj et al. utilized a multivariate LSTM model for predicting cumulative confirmed cases and deaths in COVID-19 cases, achieving superior accuracy. 32 In another vein, Shastri et al. 33 conducted a comparative analysis of deep learning methods for predicting COVID-19 cases in the USA and India one month in advance.
The work above is confined to sentiment computation technology, where researchers have employed a singular computational approach. 4 We believe that comparing deep learning techniques will enhance the study of COVID-19 vaccine hesitancy in the post-pandemic era. We are convinced that employing multi-channel and multi-task modeling techniques can strengthen research on Covid-19 vaccine hesitancy. Therefore, another critical consideration is determining which methodological approaches are most effective for classifying COVID-19 vaccine hesitancy using post-pandemic datasets. Given the gaps in previous research on COVID-19 vaccine hesitancy, as indicated in Table 1, this study utilizes text mining, sentiment analysis of COVID-19 Twitter datasets, and machine learning techniques to understand public perceptions of COVID-19 vaccine hesitancy in the post-epidemic era. To achieve this goal, we designed, developed, and evaluated three different brands of Twitter COVID-19 classifiers, using causally informed deep learning models to construct optimal models for identifying public hesitancy.
Methods
Data collection
Data preprocessing
We gathered datasets daily from the public tweets stream using the Twitter API. We employed the API's search function with parameters such as ‘q’ for search words, ‘lang’ for language set to English (‘en’), ‘since’, and ‘until’. The search words included #vaccine or #covid19. #CovidVaccine, #AstraZeneca, #Sinovac, and #Pfizer. A notable challenge was the limitation imposed by Twitter, allowing researchers to access API search for only about 7–9 days. Consequently, we gathered COVID-19 vaccine-related tweets that included various predefined hashtags from January 1, 2022 to December 30, 2022. A total of 201960 tweets were collected during this period. Each day's live public tweets were saved as CSV (comma-separated value) files. Upon concluding the data collection, the day-to-day public tweets were aggregated into a comprehensive dataset.
Data preprocessing
The raw crawled tweets encompass diverse non-textual elements, including images, emojis, and symbols like #, $, etc. Moreover, retweets and bot-generated content significantly influence analysis outcomes as well. This poses a considerable challenge to our research, necessitating preprocessing of raw data to derive usable final text data.
Retweets and duplication
Retweets occur when users share others’ tweets on their accounts, leading to potential data duplication. To address this, we utilized Python's ‘re’ library to match the format of retweeted tweets, thereby removing duplicates from our collection.
Bot-generated contents
Given the advancements in artificial intelligence, Twitter has seen a surge in bot-generated tweets. These automated posts often fail to represent genuine user opinions, impacting our analysis. Identifying and excluding this text segment from our research was imperative. Many researchers have conducted extensive studies on bot detection, yielding various recognition algorithms. Leveraging the methods outlined, we identified and subsequently removed bot-generated tweets.
Emojis and punctuations
Non-textual symbols present in the data impact our analysis. Following duplicate removal, we employed Python's ‘re’ library to match and eliminate symbols within tweets. Additionally, we utilized the emoji library to strip emojis from the tweet content.
Tokenization and stop words
Tokenization involves breaking down sentences into individual words, facilitating a more streamlined analysis. However, this process often generates common words like ‘the,’ ‘is, ‘'are,’ etc., known as stop words, which need more contextual meaning. Removing these stop words aids in deciphering user intent and sentiment. To accomplish this, we leveraged this study's NLTK library for tokenization and stop word removal.
Annotation
We eliminated retweets and duplicate tweets to ensure data accuracy, focusing solely on English tweets. Figure 1 illustrates the complete process of data collection and annotation.

The process of data collection and annotation.
After removing retweets and duplicate tweets, there were 185751 tweets remaining. Following the annotation process and removal of controversial annotations, the final count came down to 165629 tweets. Controversial refers to the inability to label accurately or the labelers’ opinions are inconsistent when labeling. Although the date of the user's account comments is valuable for analyzing topic timeliness, we currently do not require this information during the topic modeling stage. Therefore, we have excluded this data and retained only the annotation text. Nevertheless, it is worth noting that pictures and emojis can be valuable for sentiment analysis purposes. 34 We have focused solely on text data and left the multimodal data analysis for future research. Consequently, all pictures and emojis have been removed from the dataset. The primary objective of this paper is to analyze English comments; therefore, we have filtered out non-English characters, retaining only English comments for analysis.
As for the annotation process, it involved the participation of two medical experts and six graduate students of social science who formed the annotation team. The team of six students took on the role of annotators, responsible for labeling each Twitter comment, while the two experts served as team leaders, overseeing the entire process. To establish consistent and reliable annotations, a back-to-back labeling method was adopted. The six students were divided into three groups, and each tweet was annotated by two students simultaneously. Subsequently, the annotation team discussed any discrepancies, and the two experts made final decisions in cases of inconsistent labels. Comments with contentious annotations were discarded to ensure data integrity. Table 2 shows a sample of the data after the processing was completed.
Examples of the processed data.

Among these tweets, each data point was labeled with the user's attitude towards the brand of the vaccine and their willingness to get vaccinated. In detail, attitude labels are divided into three categories: Positive, Neutral, and Negative, and willingness labels are divided into three categories: Yes, Not Sure, and No. After excluding the controversial comments, 165629 comments remained for further analysis. As a result, the annotator's agreement score was deemed 100%, indicating a high level of consistency and accuracy in the annotation process. Then we categorize the three brands. The quantities of the three brands are shown in Table 3. For example, the Pfizer vaccine is produced in the United States, so most people in the United States received this brand of vaccine. The distribution of each label for the three brands is shown in Figure 2, with the

Distribution of each label; the left is before oversampling while the right is after oversampling.
Statistics on the number of datasets.

It is evident that the distribution of labels in the data related to
Model
Taking inspiration from various text classification models like BertCNN, LSTM, and TextGCN, we hypothesize that GCN and LSTM have distinct abilities idn extracting information at different levels, while CNN excels in synthesizing diverse localized features. Consequently, based on these insights, we introduced a graph convolutional networks multi-channel model (GCNMC). Our hypothesis is further substantiated in the subsequent experimental section.
Figure 3 offers an overview of the whole model. Mathematically, we defined the standing detection classification task. Given a short text
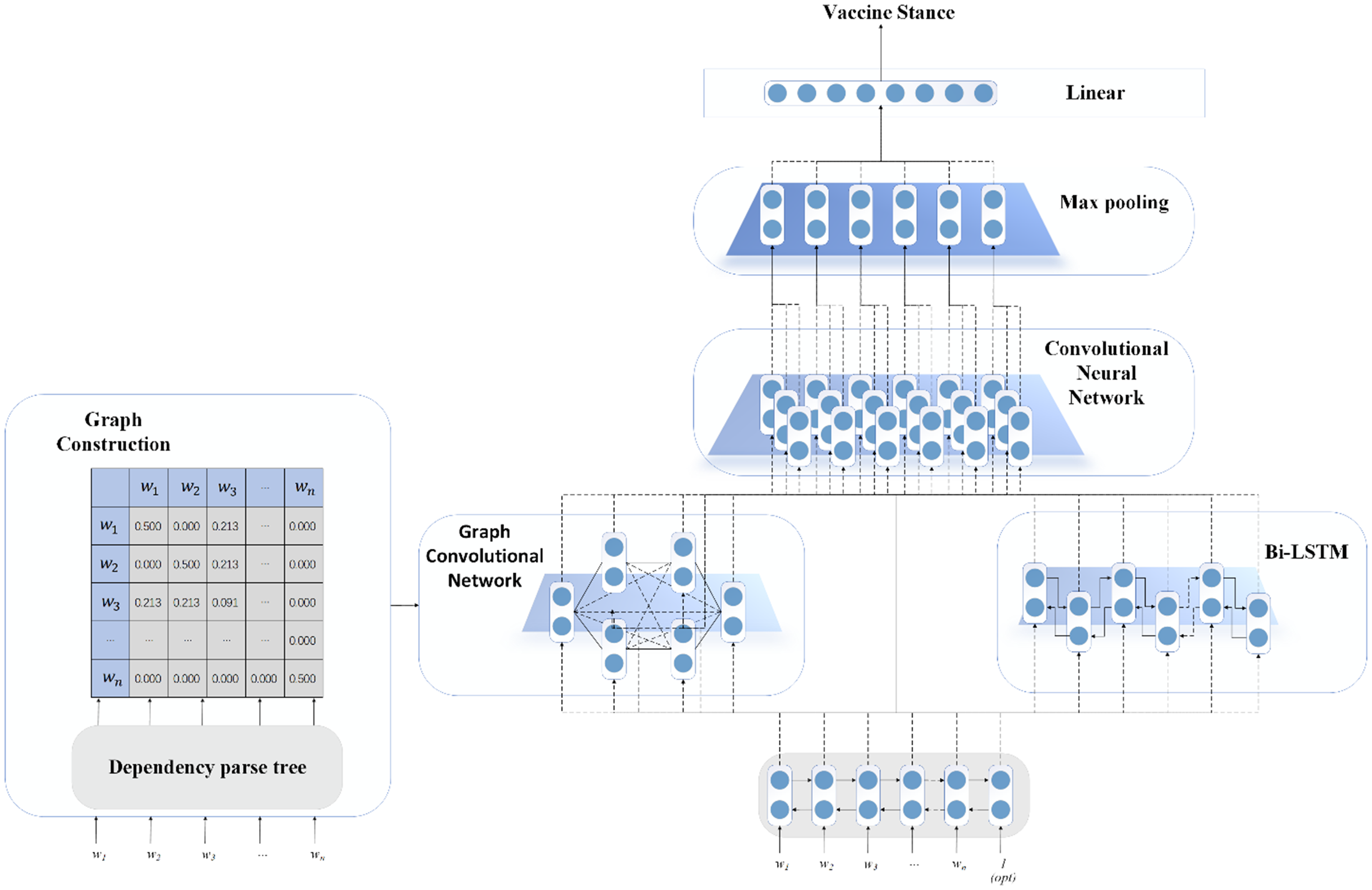
The structure diagram of our proposed model.
Embedding layer
We feed our context into bidirectional encoder representations from transformers (BERT)
35
embedding, whose output is a sequence of high dimensional vectors. These vectors reflect information from the whole context. Specifically, BERT has two types of scale, which has different numbers of parameters,
Graph neural network layer
In our work, we built a graph based on dependency trees. Offered by Stanford CoreNLP
36
tools, we leveraged the dependency parser in the package to gain relationships between different words in a short text. Mathematically, based on the dependency tree, we constructed the graph 


Multi-channel layer
To extract all kinds of features and information in the sequence of the text, 38 we designed this layer, which contains different types of components like the Graph Neural Network and Bidirectional Long Short-Term Memory (Bi-LSTM). There are two LSTMs that compute the given vectors from different directions. After that, we fed the graph and the node features into graph convolutional network. The node features updates with the convolution of the GNN and finally output the features with the same dimension of the input node features.
Mathematically, the graph 
We concatenated different feature matrices derived from the abovementioned channels to enrich the feature. In detail, we extracted dependency relationships feature and contextualized features through GNN and the Bi-LSTM, respectively. We merged these two channels, which means we concatenated O and O. Additionally, to combine low level features, we also directly concatenated the Bert embedding with them as well. It can be described as follows: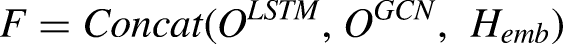
Convolutional neural network layer
Convolutional neural network (CNN) utilizes several kernels or filters to extract local features of the given matrix. In a single convolution operation, a filter, or a kernel is computed as follows:
Classification layer
In this section, we show how to classify the sentiment based on the vector obtained by the convolution operation. We apply a linear layer followed by a SoftMax layer to classify the vector. It can be described as follows:
Experiment and results
Experiment settings
In our experiments, we used some baseline to compare the generated performances. Three classic machine learning models were used, 39 logistic regression (LR), support vector machines (SVMs) and random forests (RFs). In addition, there are three ensemble learning, 40 namely adaboost (AB), bagging (BG) and XGBoost (XGB). Meanwhile, we used seven deep learning models; the specific models are as follows:
TextCNN 41 : Uses a trainable embedding to gain word vectors and classify the vaccine stance by 1 dimensional filter.
BERT: Performs fine-tuning based on the pre-trained model and then models it into a classifier.
BERT-CNN 42 : Initializes word embeddings by Bert and classifies the given sentences by dimensional filters.
BERT-GCN-CNN (BertGCTM)41,43: Initializes the word embeddings through the Bert model and then inputs the matrix to the Graph Neural Network followed by CNN. Finally, it classifies the feature matrix to the three vaccine stances.
BERT-GCN-LSTM (BertGCTM)43,44: Initializes the word embeddings through the Bert model. After that, it feeds the feature matrix into the Graph Neural Network and then models the derived output of GNN to LSTM. Finally, it classifies the hidden states generated by LSTM.
BERT-LSTM-attention (BertATTM) 45 : Initializes the word embeddings through the Bert model. Next, it models the obtained embeddings directly to LSTM. After that, it leverages multi-head attention layer and linear layer to gain the classification consequences.
BERT-multi-channel-CNN (BertMCNN)42,46: Initializes the word embeddings through the Bert model. Then, it leverages the proposed multi-channel feature extraction method to obtain different kinds of features based on the Graph Neural Network and the Bi-LSTM. Next, it concatenates the embeddings, the features derived from GNN and the features from the Bi-LSTM and feeds the concatenation to the CNN followed by a classifier.
Note that, for the machine learning algorithm, we used the default parameters from the scikit-learn package in Python. For the deep learning algorithm, we utilized the Bert tokenizer to tokenize the word for all models mentioned above and we adopted the base type of the Bert model, which means the dimension of hidden states and word embeddings is 768. For the CNN component, 10 different sizes of kernels 

Results
Classification results
To compare the performance of all models, we aggregated the results in Tables 4 and 5. It is evident that deep learning algorithms significantly outperformed traditional machine learning methods. Among them, our proposed model achieved the best or notably good results across all four datasets. Specifically, in the context of the twelve classification tasks for the three vaccines, our BertMCNN model delivered the top results in five tasks while securing second or third place in the remaining seven tasks. Obviously, the Bert-based model yields higher result scores, indicating a substantial performance gap between the Bert-based model and other models. Specifically, when comparing TextCNN and BertCNN, it becomes apparent that BertCNN outperforms the TextCNN model significantly. This highlights the efficiency of Bert in converting words into vectors, which proves crucial in text classification tasks.
The results of using different algorithms by four labels for different brands.

The F1-score of using different algorithms by four labels for different brands.

Table 5 presents the F1-scores of all models, where, like the accuracy shown above, the deep learning model demonstrates its outstanding performance compared to the machine learning algorithm. What is worth noting is our proposed model's consistent superiority. Across the three datasets, encompassing a collective tally of 12 distinct classification tasks, our proposed model manifests its efficiency by securing the highest scores while attaining second or third position in the remaining six tasks. These outcomes serve as robust evidence affirming the encouraging performance of our devised model.
Moreover, the results produced by BertCNN are only marginally inferior to those of Bert on three datasets. This discrepancy might arise because CNN can only capture local features within a limited range, whereas textual features often exhibit a global nature. CNNs might need help with handling sequence vectors effectively. When comparing the proposed model with the BertGCNN model, it becomes evident that the BertGCNN model performs admirably, achieving results only marginally lower than the proposed model on individual tasks and even slightly surpassing the proposed BertMCNN model on some tasks. This result indicates that GCN and CNN layers are used together to model the text sequence's contextualized information. Overall, the GCN models exhibited in the table outperform the other models. This result underscores the significance of GCN's ability to construct the graph from the dependency tree, enabling it to fully capture semantic information and enhance performance in subsequent components. In the overall context, our proposed deep learning model incorporating causality plays a vital role. When considering the prediction accuracy for the three vaccine brands, the overall accuracy achieved through reasoning inputs is notably higher than the mere 3% achieved with single-label inputs. This improvement underscores the significant contribution of incorporating causality to enhance the results.
Further analysis
In addition to analyzing the model's performance, as mentioned earlier, we can also glean valuable insights from the prediction results of different vaccines. Overall, while there is some variation in outcome predictions among other algorithms, they consistently show lower accuracy for Sinovac and higher accuracy for AstraZeneca and Pfizer vaccines, as shown in Figure 4. This result reflects the public's views and attitudes towards each brand in different regions to a certain extent.
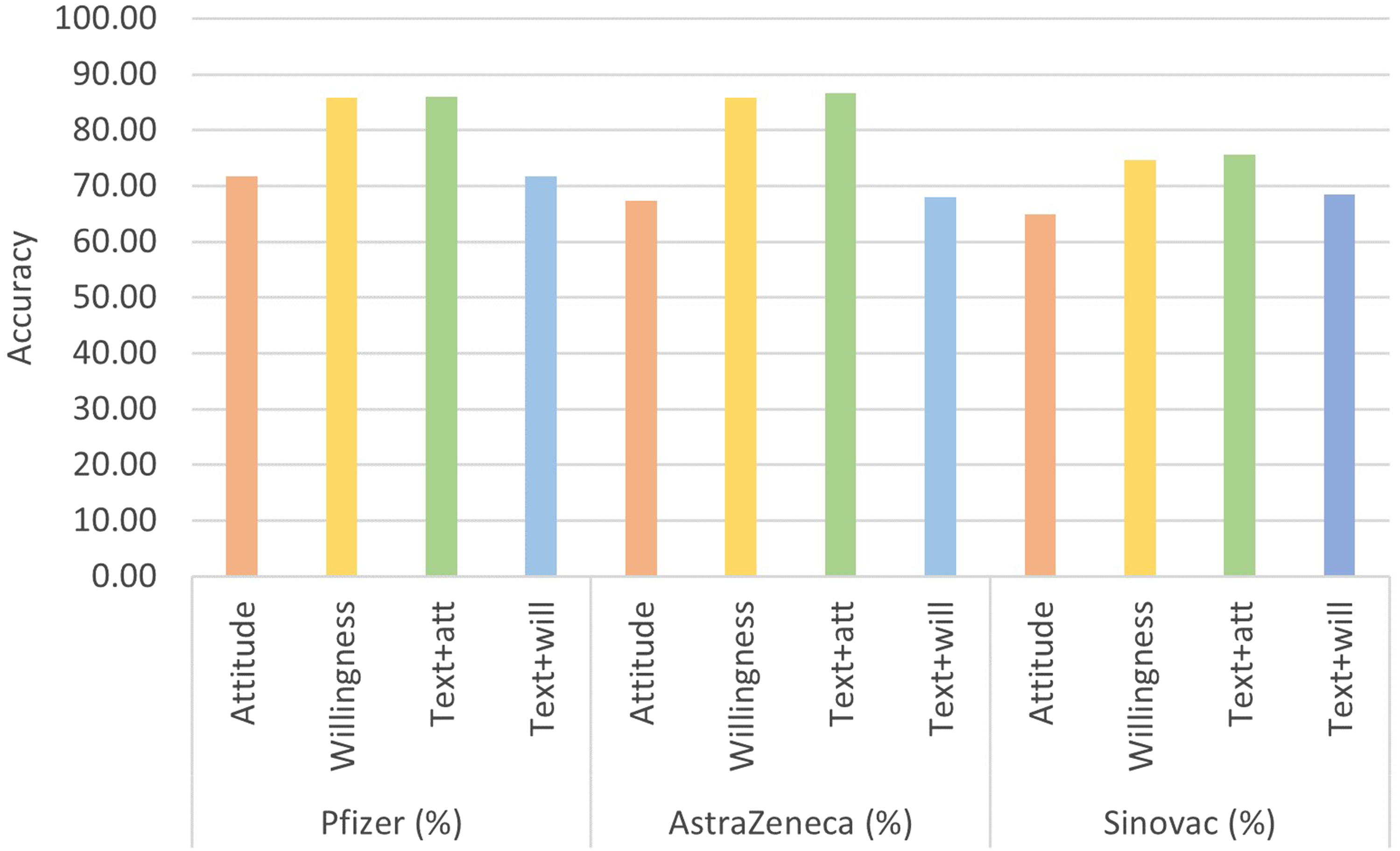
The average accuracy performance of each brand.
Our data are for the whole year of 2022. This period can be referred to as the post-epidemic era, during which people's attitudes towards virus control have transformed compared to the early stages of the outbreak. People now strive to balance between epidemic preparedness and returning to everyday life. This year, China continued to implement strict measures to prevent and control epidemics, and despite a significant portion of the population being vaccinated following expert recommendations, there were still instances of large-scale epidemic spread. These occurrences have led to public skepticism regarding the effectiveness of the Sinovac vaccine, consequently fostering a relatively negative perception of it. On the other hand, in the United Kingdom and the United States, where Pfizer and AstraZeneca vaccines are more widely administered, the spread of epidemics occurred in recurring waves. As a result, the public has become more accustomed to this situation and does not have excessive expectations of vaccines. Consequently, their attitude towards vaccines remains relatively stable, and they do not experience significant fluctuations in response to specific rounds of epidemics.
To further explore the predictive ability of our proposed model, we analyzed its performance concerning two distinct tasks: the prediction of Attitude and Willingness from textual inputs without the other label. Figure 5 shows the confusion matrix of the predictive outcomes for these two tasks. For the Attitude prediction task, it is evident that there is no discernible bias within the proposed model, while for the Willingness prediction task, the model tends to predict the user's willingness toward ‘Not Sure’. This tendency comes from the notable prevalence of ‘Not Sure’ instances within the dataset. Furthermore, although we have oversampled the text under the ‘No’ label, there is still an upside in the model's prediction for this text category.

The confusion matrix of the prediction of attitude and willingness from text input without the other label.
We selected a snippet of text data, “More rare side effects from AstraZeneca vaccine.” from our dataset and fed it into the BERT model discussed in Figure 6. Within the BERT model lies an attention mechanism, the weighted results we have visualized. The visualization illustrates the degree of correlation between pairs of tokens; the more robust their correlation, the higher the weight value. For instance, consider the words “side” and “effects” depicted in the figure. Their conjunction forms the term “side effects,” a pivotal phrase in vaccine evaluation, warranting a correspondingly high weight, as emphasized in the visualization.

Text weight heatmap.
Conversely, when traditional statistical machine learning approaches are employed, methods like TF-IDF, which rely on statistical feature extraction, are typically utilized. Such techniques can account for the frequency of specific word elements but must catch up in capturing the nuanced positional and semantic relationships between them. This nuanced understanding of context and meaning is where deep learning models excel, showcasing their advantage over traditional methodologies.
Discussions
Implications for research
Understanding vaccine hesitancy is crucial for effective public health interventions and disease surveillance. 47 Most existing studies analyzing vaccine hesitancy on social media focus on global perspectives (positive, negative, neutral) or anti-vaccine issues. In this study, people's underlying attitudes towards vaccines in post epidemic era are considered rather than categorized as solely anti- or pro-vaccine. 48 This approach acknowledges the heterogeneous nature of vaccine-hesitant individuals along a continuum, making it challenging to identify and label such content accurately. Our study distinguishes itself from previous research by offering a complementary approach that enhances recognition accuracy and develops strategies to mitigate vaccination hesitancy. 49 By considering the spectrum of vaccine hesitancy, our causality deep learning techniques can capture a more nuanced understanding of people's attitudes towards vaccination. This enables the creation of a robust and adaptable framework for identifying vaccine hesitancy in social media content, which is particularly relevant in the dynamic landscape of the post-epidemic era.
The implications of our research extend beyond academia and can be valuable in government administration for disease surveillance and outbreak communication. 2 By effectively identifying vaccine hesitancy, health authorities can tailor communication strategies to address the concerns of hesitant individuals and encourage vaccination. Moreover, our approach allows for the integration of digital technologies in outbreak management and production systems, 50 to minimize the impact of outbreaks on society and economy. By harnessing the power of deep learning, we can respond swiftly to emerging health challenges and mitigate their consequences.
Limitations and future work
This study has identified several limitations that must be addressed in future research. Firstly, the tweets used in this paper constitute only a tiny fraction of daily tweets due to Twitter's data access restrictions. Consequently, the messages collected may only partially represent a global perspective. 51 To overcome this limitation, future work should incorporate tweets from relevant regions to ensure a more comprehensive and diverse dataset. Another limitation pertains to the fine-tuning process of the models, which were restricted to specific hyperparameters such as learning rate, batch size, and number of periods. This limitation led to the neglect of other important parameters that could have enhanced the models’ performance. Thus, further research should focus on extensive tuning of the models to optimize their effectiveness in identifying vaccine-hesitant tweets for future studies.
As for future directions, additional investigations should be conducted to explore the role of social media in exacerbating hesitancy about the COVID-19 vaccine. To delve deeper into this aspect, employing content analysis and network analysis techniques such as topic modeling, trend analysis, and social network analysis. 52 These methods can provide valuable insights into the dynamics of hesitancy-related discussions on social media. Furthermore, understanding the extent to which the rhetoric of vaccine hesitancy influences vaccination attitudes and behaviors within the population is crucial. 53 This can be achieved by studying how vaccine hesitancy information spreads among communities of social media users.
Conclusion
Vaccine hesitancy has always existed in the post-epidemic era, but not global anti-vaccine sentiment, its causes, and consequences. This study aims to identify hesitant behaviors in public vaccination through deep learning models. This paper presents an innovative methodology focusing on social media monitoring and deep learning models to address vaccine hesitancy effectively. By employing these advanced algorithms, public health authorities and organizations can proactively combat the adverse impact of vaccine hesitancy on vaccine acceptance rates. This approach offers valuable insights and lessons in assessing public opinion, thereby enhancing decision-making processes related to vaccine deployment. As we navigate the complexities of the post-epidemic era, where attitudes towards virus control and vaccination have shifted, our research paves the way for more informed and data-driven initiatives to promote vaccine acceptance in the post-epidemic era.
Footnotes
Contributorship
YL: Conceptualization, Methodology, Investigation, Writing - Original Draft; CXZ: Data Curation, Software, Formal Analysis, Writing - Original Draft; CZZ: Visualization, Writing - Review & Editing.
Data availability
Requests to access the datasets should be directed to the corresponding author.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethical statement
The study was reviewed and approved by the Human Research Ethics Committee of Wuhan University (WHU241127). This article does not contain any studies with human participants or animals performed by any of the authors.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (No. 72204190), the Youth Fund for Humanities and Social Science Foundation of the Ministry of Education of China (No. 22YJZH114), China Postdoctoral Science Foundation (No. 2022M722476), Scientific research project of the National Language Commission of China (No. YB145-74). Thanks for the support by iSchools ResearchGrants and the Fundamental Research Funds for the Central Universities.