
Abstract
Background
Dietary monitoring is critical to maintaining human health. Social media platforms are widely used for daily recording and communication for individuals’ diets and activities. The textual content shared on social media offers valuable resources for dietary monitoring.
Objective
This study aims to describe the development of iFood, an applet providing personal dietary monitoring based on social media content, and validate its usability, which will enable efficient personal dietary monitoring.
Methods
The process of the development and validation of iFood is divided into four steps: Diet datasets construction, diet record and analysis, diet monitoring applet design, and diet monitoring applet usability assessment. The diet datasets were constructed with the data collected from Weibo, Meishijie, and diet guidelines, which will be used as the basic knowledge for further model training in the phase of diet record and analysis. Then, the friendly user interface was designed to link users with backend functions. Finally, the applet was deployed as a WeChat applet and 10 users from the Beijing Union Medical College have been recruited to validate the usability of iFood.
Results
Three dietary datasets, including User Visual-Textual Dataset, Dietary Information Expansion Dataset, and Diet Recipe Dataset have been constructed. The performance of 4 models for recognizing diet and fusing unimodality data was 40.43%(dictionary-based model), 18.45%(rule-based model), 59.95%(Inception-ResNet-v2), and 51.38% (K-nearest neighbor), respectively. Furthermore, we have designed a user-friendly interface for the iFood applet and conducted a usability assessment, which resulted in an above-average usability score.
Conclusions
iFood is effective for managing individual dietary behaviors through its seamless integration with social media data. This study suggests that future products could utilize social media data to promote healthy lifestyles.
Keywords
Introduction
Human nutrition, a critical component of life, growth, and health, is primarily obtained through diet. 1 Poor diets are the leading cause of death worldwide, causing 11 million deaths in 2017 alone, or 1/5 of all fatalities that year. 2 Currently, undernutrition and overnutrition are problems in China. 3 Undernutrition is the cause of child stunting, severe wasting, and maternal short stature, which increase the risk of death of the mother at delivery. 4 Overnutrition is linked to obesity and type 2 diabetes. 5 An important element of a healthy lifestyle that might delay the onset of chronic diseases or lessen their severity is a nutritious diet. However, despite numerous effects by national and international nutrition organizations to promote healthy diet behaviors,67–8 the prevalence of cardiovascular diseases is still rising in most countries due to high total calorie consumption, excessive sugar intake, high sodium intake, and a deficiency in diet fiber.910–11
Thus, many studies have investigated how to encourage behavioral changes, including tailored interventions such as diet self-monitoringt.1213–14 Traditional dietary monitoring methods include dietary records, 24-h dietary recall, food frequency, brief dietary assessment instruments, and diet history. 15 These accurate and valid approaches are frequently used in epidemiological or clinical studies. However, large cohort studies’ traditional dietary monitoring typically requires an expensive and time-consuming manual nutrition coding process. Measurement inaccuracy frequently occurs because of inaccurate portion sizes, short food lists, vague descriptions of meal preparation, and the potential for participants’ diets to be incorrectly classified into worry categories that make nutrient measurement errors. 16
A variety of social networking sites have emerged because of the increased accessibility of internet communication technologies and improvements in software and hardware for social interaction. These sites allow users to share their diet behaviors online, generating a lot of diet data for dietary monitoring. As of January 2020, there were 3.88 billion worldwide social media users, 17 which makes sharing food images on social media became a common practice. Social media data have been found to be a reliable source for monitoring both general and specific dietary behaviors.18,19 In America, there are 65% of adults and 90% of young adults now use social media to share their activities, such as diets. 19 Some studies also used diet data that users posted on social media to describe the state-level food environments and obesity rates. 20
It has proven possible to extract diet-related information from social media sites using a variety of machine learning techniques; for example, Shah et al. 21 evaluated Canadians’ dietary and physical activity habits using tweets about diet. In this study, natural language processing techniques were used to identify dietary and physical activity habits in different provinces, and the results presented that compared to traditional survey methods, diet identification based on social media data can be readily available. Pilař et al. 22 classified the diet hashtags of Twitter based on the Hashtag Research Framework (SMAHR) and found the most communicated individual diet on Twitter, they believe the social media data is useful for food businesses. In the study of Oduru et al., Twitter diet images were used as a reliable source of data for the analysis of dietary patterns of individuals. They used Twitter diet images to assess the performance of the diet image identification model they constructed and analyze broad patterns in food consumption among the general audience. 19 As a complementary source of traditional public health surveillance, Muralidhara et al. 23 used Instagram images and text data to investigate diet health topics. These researchers indicated that social media data can be used to record the users’ diets.
Various diet monitoring applications are designed and developed for dietary monitoring. A total of 400,000 food photographs from social media were gathered by Sahoo et al. 24 to develop a diet identification model. Based on the diet identification model, they also developed a diet record app that could recognize user-uploaded diet photographs and record their daily dietary intake along with an estimation of its nutritional value. Carter et al. 16 constructed a food database containing 45,000 foods and established an online 24-h dietary assessment tool. The good Median system usability scale (SUS) scores in adolescents and adults for the live version have proved the usability of this tool. A smartphone application based on behavior change strategies was created by Kwon et al. 25 Users could enter up to 4 food categories for each diet they eat every day and see the real-time effect on their risk of developing heart disease. Kong et al. 26 developed a dietary monitoring smartphone application, MyDietCam, which could record dietary intake through food image recognition and provide nutrient analyses through visuals. Snap It™, a meal record application developed by FitNow based on a sizable food image library, allows users to take pictures of their food, identify it using image identification technology, and then estimate their diet size to determine the amount of nutrients in it. The diet item's nutrients will also be recorded at the end. 27 There are many applications developed to make the dietary assessment process electronic. However, to the best of our knowledge, there is no application that could link to the social media account and conduct real-time analysis of the social media data related to diet.
To efficiently identify diet information, this study proposed a visual-textual data integration strategy based on social media platform. Considering the text in social media posts is frequently accompanied by images, providing content, supplying context, or expressing feelings, the integration strategy is to identify the dietary items in the text and recognize the dietary item from the images, which is complementary to each other. We chose Sina Weibo as the data source, the widespread social media platform in China, which allows users to follow other users, see their posts in the feed, and engage with them by liking, commenting, or sharing their content. On Weibo, multiple users share their dietary content with text and images. To make the dietary analysis more available and accessible, an applet iFood working on the WeChat platform, a widespread Instant messaging application in China, was also created to collect dietary data actively and authoritatively from social media. The WeChat applet iFood can detect diet items from text and images on Weibo based on the proposed image-text data integration method. iFood then calculates the nutrients in the diet.
Methods
This study constitutes a quantitative research endeavor aimed at evaluating the usability of the iFood applet. The process of the proposed study is shown in Figure 1. Firstly, the dietary datasets were constructed by using data from social media, websites, and national dietary guidelines. Second, we construct models to identify the text and images from social media. Then, to display the results in Step 2, the dietary datasets and models were deployed in an applet, which we called iFood. Finally, we assess the usability of iFood with a questionnaire survey after participants use the diet monitoring applet we developed for 4 weeks.

Process of dietary monitoring based on social media.
Diet datasets construction
In this study, to develop the social media diet monitoring applet, 3 diet datasets were constructed, including User Visual-Textual Dataset, Diet Information Expansion Dataset, and Diet Recipe dataset.
Social media data are multimodal, including both text and visual material. 28 Text in social media posts is frequently accompanied by images to provide content, supply context, or express feelings. Based on this relationship, we built a User Visual-Text Dataset by combining the text and image information from Weibo.
Based on our previous study, 29 we collected Weibo users from 2019.1.1 to 2021.1.9(total 739 days). The inclusion criteria of seed users are as follows: (1) Post their diet every day on Weibo. (2) The content of the tweet contains images and text. (3) The diet images they posted of diet are clear.
After cleaning the Weibo data, seven different categories of attribute information, including user name, user gender, user age, user address, diet time, diet text, and diet-related images, were extracted. The structured data, User Visual-Textual Dataset, were stored in the MySQL database. The content of one post was divided into four parts, including user basic information, diet schedule, diet text, and diet images, as shown in Figure 2. Supplemental Material 1 describes the process of User Visual-Textual Dataset design in detail.
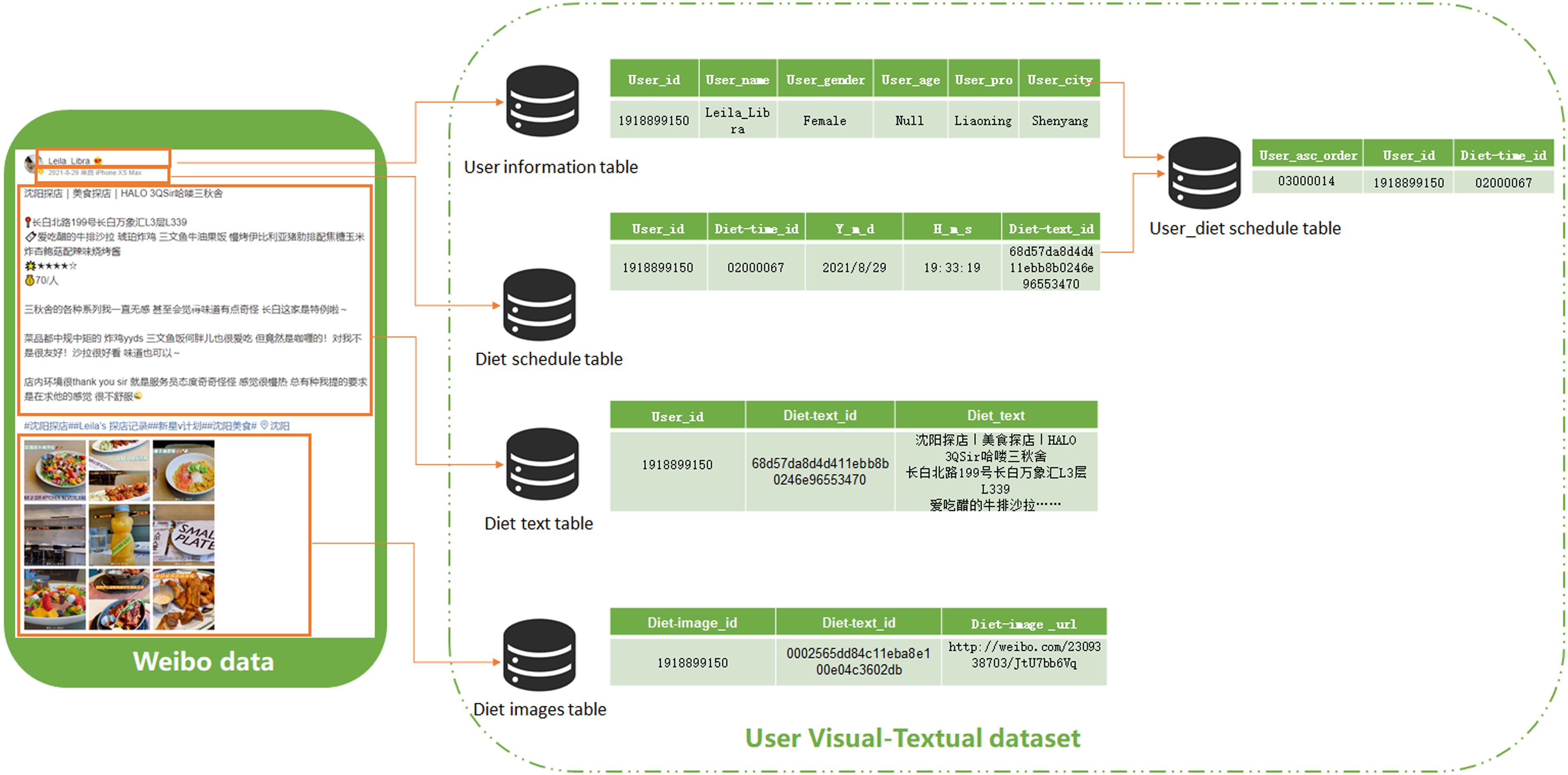
User visual-textual dataset construction process.
To identify the diet-related information from the User Visual-Textual Dataset that we constructed from the Weibo platform, we constructed the Diet Information Expansion dataset. We gathered diet information from websites and diet guidelines. Cooking types, tastes, and synonymous names of the diets were obtained from MeiShijie, a widely used cooking website. 30
Information about the cooking styles and dish styles of diets was obtained from the Baidu search engine. The details of the construction process of the Diet Information Expansion dataset were published in our previous research. 29
Dishes were categorized with reference to the “Balanced Dietary Pagoda for Chinese Residents (2016)”. 31 We removed the top two food groups in the dietary pyramid, which are oil and salt (They are just condiments, not dishes).
The information in the tables was reviewed and amended by one expert from the National Institute of Nutrition and Health, China Centers for Disease Control and Prevention. The Diet Information Expansion dataset was created using diet-related information and diet categorizations.
Besides, to calculate the nutrients that a user ate or drank, we constructed the Diet Recipe Dataset by obtaining diet recipes from Meishijie.
Diet record and analysis
In order to enable iFood to have the functions of diet recording based on social media and nutrient calculation, we constructed 4 models to identify diet categories from Weibo data. Dietary categories in the text from Weibo were identified by dictionary-based model and rule-based model. Dietary items in Weibo images were recognized using the Inception-ResNet-v2 model. The K-nearest neighbor (KNN) algorithm was then used to train the visual-textual data integrator. Nutrients consumed were calculated with the Diet Recipe dataset and China Food Composition. 32
Identification model of diet
To identify diet-related categories from social media text data, dictionary-based and rule-based identification models were constructed and compared. The diet dictionary was constructed by combining diet items of MeiShijie and 251 diet items in the Vireo food-251 dataset. A few irregular names were removed or amended, and 70,213 words were involved in the final dictionary. MATLAB (version R2021a) was used to match the tweet words in the User Visual-Textual Dataset with the diet dictionary. The diet name in each post was identified using the maximum positive matching method.
The rule-based model was constructed by language technology platform (LTP), 33 which was developed by the Harbin Institute of Technology, and can perform word separation, lexical annotation, and dependent syntactic analysis for diet identification services. The diet categories were extracted from Weibo text data with the identification rules (Supplementary Material 2) and then output using the maximum positive matching method.
The performance of 2 classic image recognition models, VGG and Inception-ResNet-v2, 34 was compared in this study. Results showed that the Inception-ResNet-v2 model performed (Accuracy is 84.781%) better than VGG (Accuracy is 84.46%). Thus, the Inception-ResNet-v2 model was used to recognize diet images, which is a convolutional neural network (NN) model.
To combine the results of text and image identification models, we used the visual-text late fusion method. Late fusion is a visual-textual data integration method 34 that has the advantages of better fault tolerance, more substantial anti-interference power, and better analysis of the comprehensive correlation between two modalities.
The visual-text late fusion method is merely a classification method. We experimented with some common algorithms for classification, including the KNN algorithm, 35 decision tree (DT) 36 algorithm, and NN. 37
Different combinations of text and image identification results were input into the aforementioned three late fuse models, and the accuracy rate was calculated.
The late fuse model that performed the best overall was chosen to be deployed in the iFood which could determine the diet name of each tweet's associated diet.
The daily diets will be tracked by social media data based on the integration outcomes. The diet behaviors and preferences of users will be observed and analyzed using a combination of the user information from the User Visual-Textual Dataset and the attribute information of diets from the Diet Information Expansion dataset.
Nutrient calculation
iFood could calculate the nutrients intake of users. The nutrients of each ingredient are obtained using the Chinese Food Composition dataset. 32 Finally, the diet nutrients are calculated by considering weight and preparation methods.
The Chinese Food Composition dataset was constructed with the data source of the “China Food Composition,” 38 including 23 nutrients of 1400 food ingredients. In this study, we calculate the energy and three common nutrients of each diet, including carbohydrates, protein, and fat.
Diet monitoring applet design
To better track and monitor individual diets and nutrition intake, we developed a social media-based WeChat applet called iFood.
We added the models to iFood to recognize diet in tweets and user-posted photographs after training them in the backend. With an emphasis on the individual, iFood will track individual diets, assess food preferences, and calculate nutritional intake. There are two ways for users to record their diets. By linking to users’ social media accounts, their publicly uploaded diet information will be recorded and retrieved. iFood will spare the user the effort of manually recording their dietary information. Besides, the service of manually recording diets is also provided by iFood, the users could upload diets by themselves.
The WeChat applet iFood was developed as the dietary reports generator by using the dietary datasets and the visual-textual data integrator. iFood could automatically obtain users’ dietary information from social media, generate daily, weekly, monthly, and annual dietary reports; and analyze the nutrients consumed in each diet, which makes dietary monitoring more easy, timely, and intelligent.
According to the daily, weekly, monthly, and annual diet reports. Diet behaviors, preferences, and nutrition intake are all covered in the diet report.
Diet monitoring applet usability assessment
To evaluate the usability of iFood, we conducted quantitative research by recruiting participants at the Beijing Union Medical College situated in Beijing, China. We enrolled participants with substantial experience in utilizing social networks. Ten participants were invited to use iFood for 4 weeks, and the SUS questionnaire was used to conduct small-scale user surveys. 39 This questionnaire used a 5-point Likert scale, ranging from “Strongly Agree” to “Strongly Disagree” across 10 items, and a total score of 68 (or higher) was considered ‘above average usability’. 40 We recruited participants in the WeChat group of Peking Union Medical College in February 2023. Advertisements provided a description of the study and eligibility criteria. In Table 1, we have presented explicit details regarding the inclusion and exclusion criteria that were considered when selecting participants for our research.
Inclusion and exclusion criteria.

All assessment processes took place offline, and informed consent was obtained from the participants. The SUS questionnaire is provided in Supplemental Material 3.
Results
Results of diet datasets construction
In this study, we constructed 3 diet datasets in total. User Visual-Textual Dataset contains data from 97 seed Weibo users, including diet-related images and texts.
Diet Information Expansion Dataset 1286 diet categories from the Vireo food-251 dataset27, “Go cooking” and “Meishijie.” The images of 1286 diets were obtained from Baidu and Google image searches. In the Diet Information Expansion Dataset, cooking methods were divided into 33 types, including stir-fry, steam, boil, and stew. Tastes were divided into 29 types, including sweet, sour, and spicy. Synonymous diet names contained 2672 diet names, of which 344 were standard words and the remaining 2328 were synonyms. In addition, cooking styles were divided into 22 regional categories, including Sichuan, Hunan, Guangdong, and Fujian. Dish styles were divided into 7 categories, including primary dishes, drinks, and soups. Then, dishes were categorized into 8 categories, including milk and dairy products; soybeans and nuts; livestock; and poultry and meat.
The Diet Recipe dataset was constructed by obtaining 1286 diet recipes from Meishijie and contains 4 attributes for each recipe: diet names, ingredients, their corresponding weight, and preparation methods.
Performance of diet identification models
In contrast to the rule-based model (precision is 18.45%), the dictionary-based model has the highest precision of 40.43%, recall of 59.99%, and F1 of 48.31% of all the models.
The best performance of the Inception-ResNet-v2 model on identifying the diet images from Weibo users is dish style level, in which top-10's accuracy is 59.945%, and top-1's accuracy is 37.259%. A total of 169,673 images of 251 diets that are currently stored in the food image table of the Diet Information Expansion dataset and the Vireo food-251 26 were used to train the image recognition model.
KNN model achieves the highest accuracy of 51.38%, which is 8.45% higher than the text-only-based identification performance and 33.62% higher than the image-only-based identification performance. Results are shown in Table 2 below. There are a large number of synonyms for Chinese diets and the users’ expressions on social media are diverse, which makes the diet text identification performance poor. Besides, Chinese food is made with a variety of ingredients and cooking methods, and the diet image identification model can identify limited dietary categories. Thus, the visual-text fusion model did not achieve the best performance of other diet identification studies.
Accuracy of the three classification algorithms with different integration of predictor variables.

Note: N i is the ith outcome of the prediction model in order of probability. KNN: K-nearest neighbor algorithm; DT: decision tree algorithm; NN: neural network.
Thus, KNN was deployed in iFood as visual-text fusion model to identify diet categories from Weibo data, and the result of dictionary-based model and the first outcome of image identification model used as input.
Ifood for personal dietary monitoring
Design of iFood functions
We developed iFood based on the visual-textual data integrator and nutrient calculator. A user must log in to their account and grant access to their social media account before using iFood. Then, the user information, which should include demographic information, health condition, and diet preferences, should be completed. Then, iFood will automatically gather the daily diet data that users post on social media, and the users’ diet records will be summarized and reported. The user's diet for the past day, week, month, and year will be recorded by iFood, allowing users to learn their nutritional status and diet preferences.
In this study, we took user “LX182211” as an example to demonstrate how iFood works. As shown in Figure 3, when the user signed into their account, demographic information is input out automatically through their social media account. Additionally, the user should explicitly enter their diet preference, and the demographic information can be revised by himself. Age, weight, and height are typically associated with the risk of diabetes and hypertension, which are important pieces of information for dietary monitoring and recommendation.
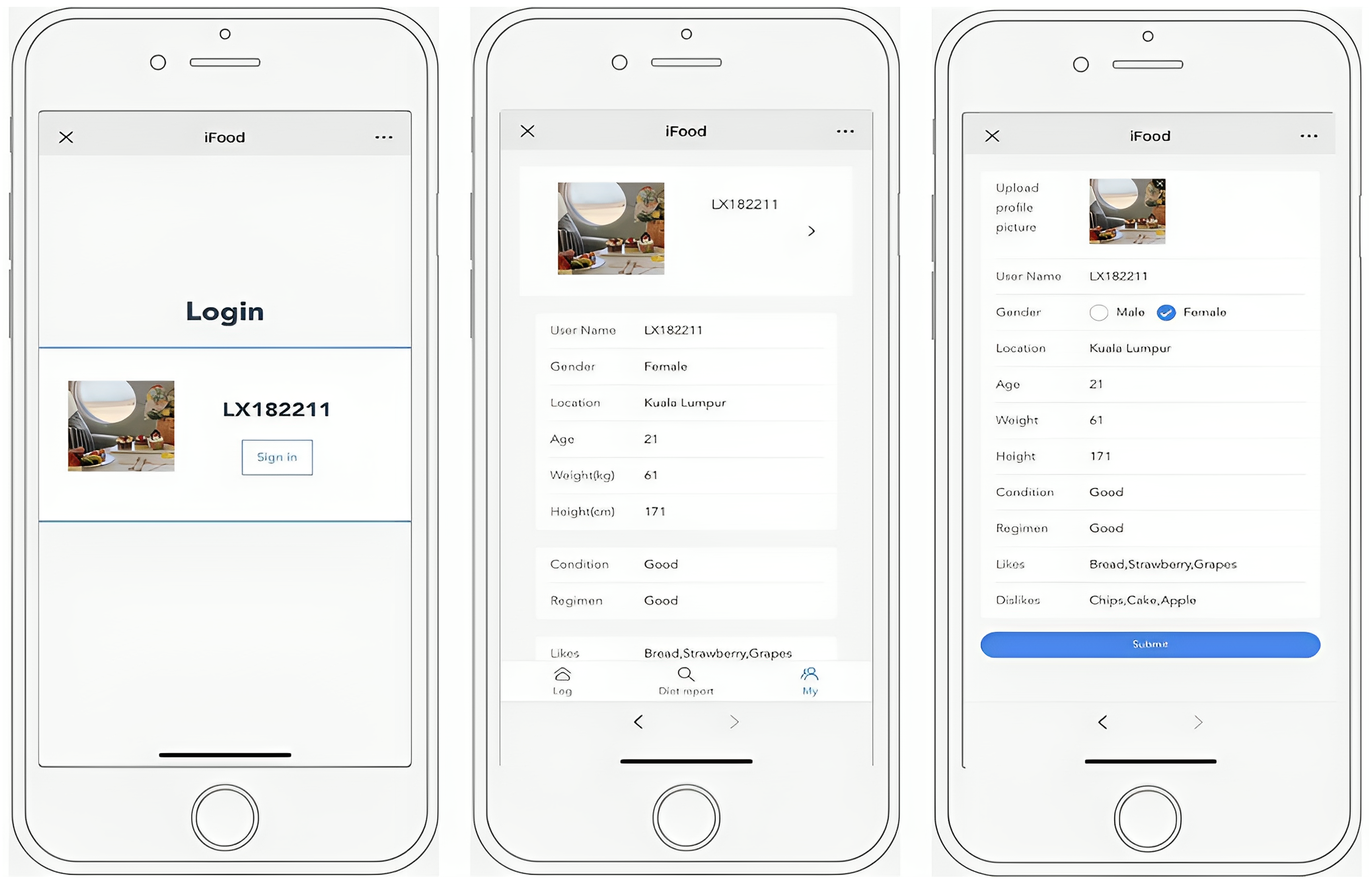
Screenshots of iFood. From left to right: Login interface, user information, and edit personal information.
Diet records were obtained from the user's social media automatically or manually. The diet records of the user for any period can be obtained by combining the visual-textual data integration results, the Diet Information dataset, and the Y_d_d (diet date) field in the diet schedule of the User Visual-Textual Dataset with the Diet_type_name field in the diet type table of Diet Information Expansion Dataset.
In addition, iFood could also use the data from the Diet Information Expansion Dataset to perform multidimensional research on individuals’ preferred cooking styles, tastes, and diet style preferences.
Figure 4 shows how iFood could enable continuous diet monitoring for specific users. iFood could record the user's diet records automatically with the data from social media. The user could select any period they want to know from the calendar and chart that will be prepared for the diet report. Additionally, if the user does not have any diet records on their social media, the diet can be recorded manually. The chart of diet records shows the frequency of each diet intake during a specific period, and the calendar of diet records shows the diet name intake each day.
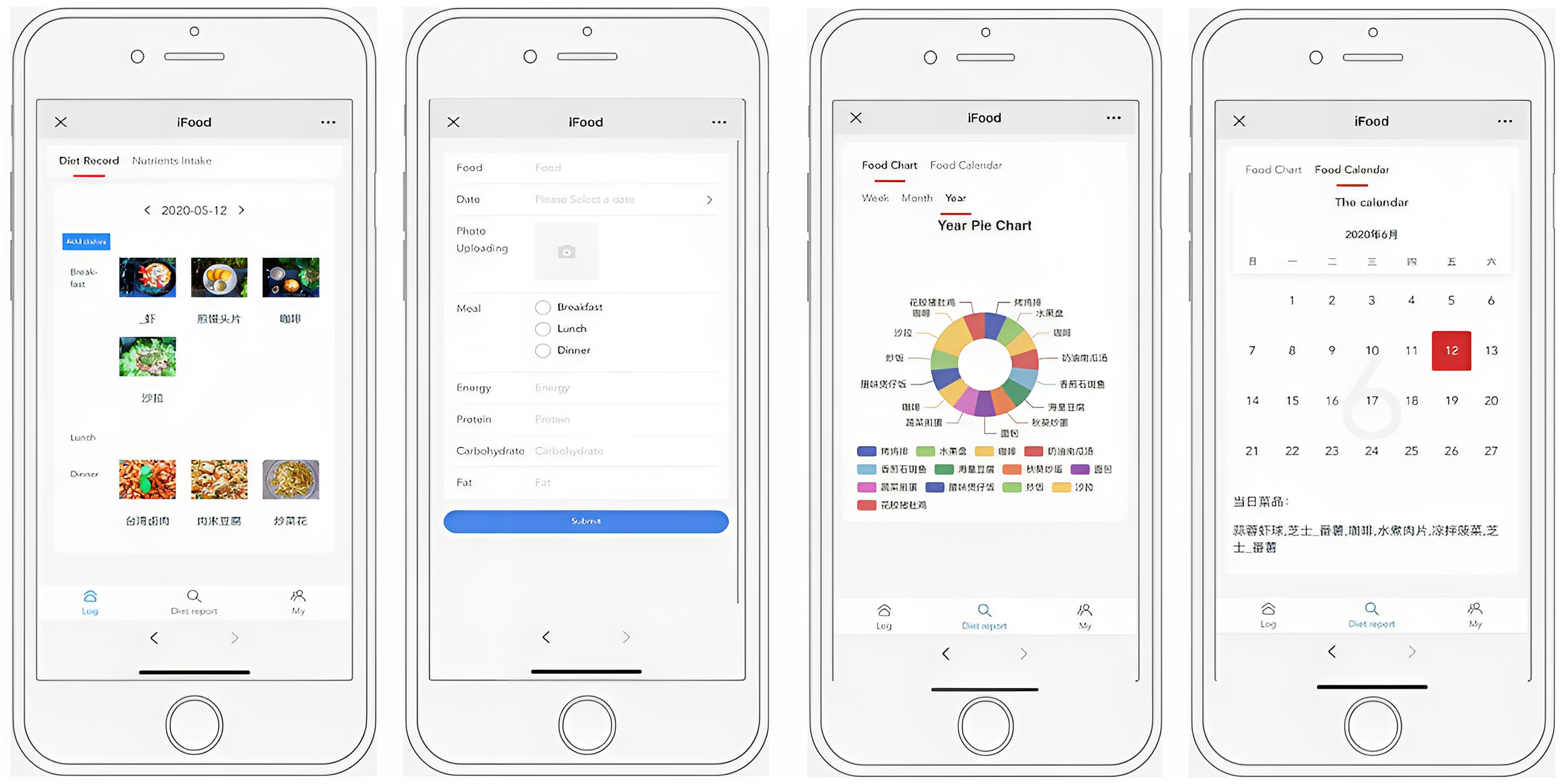
Screenshots of iFood. From left to right: Diet records, record diets manually, and diet reports (chart and calendar).
Following the determination of the diet category, the Diet Recipe dataset and Chinese Food Composition dataset will be used to calculate diet nutrients, as shown in Figure 5. For daily diets, iFood will offer nutrients and energy analysis. The user could use iFood to view the nutritional values of each diet they follow. The nutrients analysis and energy analysis can be presented by iFood, which shows three nutrients (carbohydrate, fat, and protein) that the user ate or drank each day and the energy they ate or drank in each meal. Additionally, the user could check the nutrients and energy of each diet that they ate or drank. When the user chooses a specific diet, iFood will present its images, name, energy, content, and ratio of nutrients.

Screenshots of iFood. From left to right: Daily nutrient analysis, daily energy analysis, and diet nutrient analysis.
Assessment of iFood usability
The demographic characteristics of participants were collected by iFood, including age, gender, weight, and height. The participants’ demographic characteristics are shown in Table 3.
Demographic characteristics of survey participants (N = 10).

After using the applet for 4 weeks, 10 participants were invited to evaluate the usability of iFood by reporting their results on the SUS questionnaire.
The mean SUS index was 74.8 (SD = 11.7, Min = 52.5, Max = 90.0), which indicated an above-average usability score. All participants thought that they would not need assistance with using the applet. Six participants wanted to use the applet more frequently. Table 4 shows the results of the SUS questionnaire.
System usability scale (SUS) questionnaire scores for platform, (dis)agreement in n(%) (n = 10).
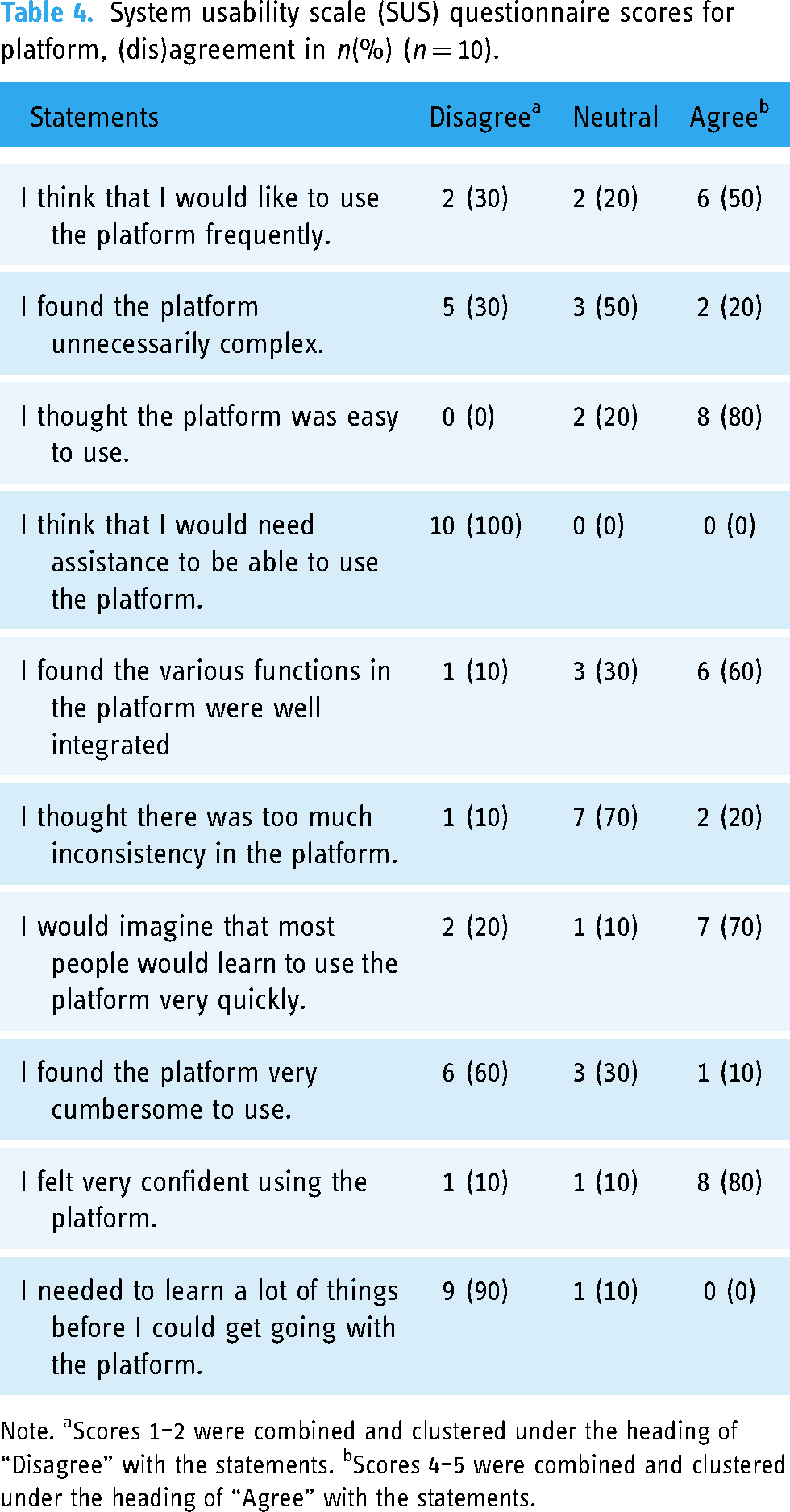
Note. aScores 1–2 were combined and clustered under the heading of “Disagree” with the statements. bScores 4–5 were combined and clustered under the heading of “Agree” with the statements.
Discussion
Principal findings
In this study, we developed a visual-textual data integration method, and based on that method, we created a dietary monitoring WeChat applet called iFood.
We identify the text data using dictionary-based and rule-based methods. In this study, the dictionary-based accuracy rate was 40.43%, and the recall rate was 59.99%. Weibo users follow a wide range of diets, some of which are nondish essentials, such as fruits, snacks, and pastries; however, the diet dictionary developed in this study was based on the MeiShijie website, and the majority of the categories were dishes, leading to a poor match. There are two reasons contributing to the lower performance observed. Firstly, the arbitrary nature of Weibo users’ expressions, makes it challenging to summarize the characteristics of most people's expressions with a limited number of rules. Secondly, many diet names are cut apart when words are cut, and many diet name fragments are produced, making it difficult to fully match real diet names. The rule-based accuracy rate is 18.45%, and the recall rate is 18.59%. However, whether based on a dictionary or rules, there is still room for improvement in the performance of diet identification for diet-related tweets. In recent years, with the development of machine learning and deep learning, we can try to use conditional random field, bidirectional encoder representations from transformers, and other methods for diet name identification.
We use the Inception-ResNet-v2 model to recognize image data. The accuracy of identification increases as the granularity relaxes when comparing the results of the Inception-ResNet-v2 model on the benchmark image set at different granularities. The diet names’ synonymy is one potential explanation for the low accuracy at the diet name level. The Inception-ResNet-v2 model that was trained in this study can only recognize 251 diet images, while the baseline data included 1142 different types of diet, and the frequency of 251 diets used to train the Inception-ResNet-v2 model only accounted for 42.4% of all diets; this issue is the primary cause of the poor overall performance.
We used the KNN model as a visual-textual data integrator to fuse the findings of text and image identifications. Although the accuracy of the visual-textual data integrator was 51.38%, the integrator was still quite accurate compared to text-only-based identification and the performance of image-only-based identification. Due to fewer features being recorded, the single integration strategy and diet identification based on unimodal data both perform poorly. In future studies, we plan to assess the effectiveness of early fusion, mid-term fusion, and late fusion while also obtaining more data characteristics under unimodality. By referring to the Diet Recipe dataset and the Chinese Food Composition dataset, we dissect the diet's constituents and calculate the overall number of nutrients in the diet.
In contrast to conventional 24-h dietary recall method and alternative dietary survey methodologies, the dietary monitoring method introduced in this study demonstrates a notable capacity to significantly diminish the temporal demands associated with the input of dietary records. This method offers an engaging mechanism for dietary recording. Concurrently, engagement with individuals through social media has the potential to amplify user commitment to record maintenance, thereby establishing a robust framework for sustained dietary monitoring.
Limitations
Health promotion through dietary monitoring has already benefited from the support of social media resources. The key advantages of social media platforms are their engagement and potential cost-effectiveness which will save time and money compared to traditional large cohort methods. For example, in a dietary monitoring of Vietnam and Burkina Faso, $820 will be costed when investigating a person's diet with a traditional method. But only $755 was costed when using an online platform to investigate a person's diet. In Burkina Faso, the traditional method costs $539/respondent and the online platform costs $544/respondent. 41 However, because coverage has not reached 100%, Internet access is a limiting constraint for this strategy. The discontinuity and imprecision of the social media data have an impact on the subsequent analysis results. Therefore, the applet developed in this study can only assist users in recording and managing diets, and we have added a manual upload function for diet as a supplement.
Although we have improved the performance of diet identification with the visual-textual data integrator, the demonstrated diet identification performance is still not sufficiently precise for use in the real world. Also, we only consider the text content and image data from the social media platform in this study, and other multimodal data, such as audio and vlog, should also be incorporated.
In this study, we described the development of iFood, and conducted a small-scale survey to assess usability in general healthy adults. More survey and verification experiments are required to demonstrate the effectiveness of the WeChat applet iFood. Besides, the usability assessment conducted in a university, there are no elderly. In the future, we plan to recruit a large cohort that covers a larger age range, to demonstrate the usability, acceptability, and feasibility of iFood. The method proposed in this study holds universal applicability, it could be transferred to other social media platforms, the databases constructed and the deep learning models trained could also be used in other scenarios.
Conclusion
The study introduced a novel approach to monitoring dietary habits by leveraging information from social media platform. We collected and analyzed personal information, text-image data related to diets, and dietary attributes of social media users. Our goal was to identify dietary information through the integration of visual and textual data and to develop a WeChat applet for further dietary monitoring. The proposed approach aimed to enhance and complement traditional dietary monitoring practices.
The findings of our study indicate that the proposed diet identification method and dietary monitoring applet have the potential to assist individuals in monitoring their diets based on social media data. With the growing popularity of shared dietary information on social media platforms, the future of social media-based dietary monitoring is promising.
Supplemental Material
sj-docx-1-dhj-10.1177_20552076231210707 - Supplemental material for Ifood: Development and usability study of a social media-based applet for dietary monitoring
Supplemental material, sj-docx-1-dhj-10.1177_20552076231210707 for Ifood: Development and usability study of a social media-based applet for dietary monitoring by Yushan Lan, Xiaowei Xu, Zhen Guo, Lianglong Sun, Jianqiang Lai and Jiao Li in DIGITAL HEALTH
Supplemental Material
sj-docx-2-dhj-10.1177_20552076231210707 - Supplemental material for Ifood: Development and usability study of a social media-based applet for dietary monitoring
Supplemental material, sj-docx-2-dhj-10.1177_20552076231210707 for Ifood: Development and usability study of a social media-based applet for dietary monitoring by Yushan Lan, Xiaowei Xu, Zhen Guo, Lianglong Sun, Jianqiang Lai and Jiao Li in DIGITAL HEALTH
Supplemental Material
sj-docx-3-dhj-10.1177_20552076231210707 - Supplemental material for Ifood: Development and usability study of a social media-based applet for dietary monitoring
Supplemental material, sj-docx-3-dhj-10.1177_20552076231210707 for Ifood: Development and usability study of a social media-based applet for dietary monitoring by Yushan Lan, Xiaowei Xu, Zhen Guo, Lianglong Sun, Jianqiang Lai and Jiao Li in DIGITAL HEALTH
Footnotes
Acknowledgments
The authors would like to thank all the research assistants and participants for their contributions and participation in this study.
Contributorship
YL and Jiao L conceived of and designed the study. YL performed the statistical analysis and authored the manuscript. LS conducted the workflow design and data analysis. LS, XX, and Zhen G promoted the development of this app, supported the curriculum design. XX and Jiao L assisted with draft editing. XX offered suggestions for study. JQ supervised YL, reviewed and revised the manuscript with valuable suggestions. All authors read and approved the final manuscript.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethical approval
This study was approved by the Ethics Committee of the Institute of Medical Information of the Chinese Academy of Medical Sciences (IMICAMS/01/21/HREC).
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by the CAMS Innovation Fund for Medical Sciences (CIFMS) (Grant No. 2021-I2M-1-056), the Key R&D Program of Hunan Province (Grant No. 2021SK2024), the Key Laboratory of Medical Information Intelligent Technology, and the National Key R&D Program of China (Grant Nos. 2016YFC0901901 and 2017YFC0907503).
Guarantor
YL.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.