
Abstract
The Drug Facts Label is designed to guide consumers in comparing nonprescription drugs. Undergraduates studied and recalled drug facts for three analgesic or non-analgesic labels using Drug Facts Label headings as retrieval cues. They then studied and recalled drug facts from an aspirin label. Aspirin recall was greater when the prior labels were analgesics, but prior-label intrusion errors were also greater. These two effects were associated with the number of prior drug labels on which facilitating and interfering drug facts appeared. Using the Drug Facts Label schema to read drug labels can both enhance and degrade the recall of nonprescription drug facts.
Introduction
Nonprescription analgesics may seem to be relatively harmless because they can be purchased without consulting a physician or pharmacist (Eaves, 2015; Shehnaz et al., 2014). However, intentional or accidental overuse of nonprescription drugs can be dangerous (Shehnaz et al., 2014). Excessive amounts of acetaminophen, for example, are known to compromise liver functioning (Hawton et al., 2004), and efforts continue to be made to alert consumers to that hazard (Goyal et al., 2012). Despite increasing concern about the general risks posed by consumers failing to understand the information provided on nonprescription drug labels (Cooper, 2013; Pawaskar and Sansgiry, 2006; Schwartz et al., 2007), we know relatively little about the cognitive processes that contribute to effective label comprehension (Bennin and Rother, 2014; Catlin et al., 2013; Pineles and Parente, 2013). In particular, we do not know how successful consumers are in distinguishing among the properties of different drugs in the same class. Common over-the-counter analgesics, for example, vary significantly in their dosing instructions. In this study, we seek to determine whether young adults can distinguish among the drug facts they read about one nonprescription analgesic from those they have just read about other nonprescription analgesics.
The Drug Facts Label (DFL) is mandated by the Food and Drug Administration (FDA) for all nonprescription drugs. Essentially, the DFL is a text schema that provides a standardized organization of the drug facts consumers need to self-medicate safely and effectively. In introducing the prototype version of the DFL, the FDA (1999) argued that a standard order of label headings and subheadings (e.g. Active Ingredient, Purpose, Uses, Warnings, Directions) “… would help consumers locate and read important health and safety information and allow quick and effective product comparisons” (p. 13254). As such, the ordered set of headings incorporated into the DFL encourages consumers to make use of a sanctioned “medication schema” rather the naive medication schemas they might otherwise employ (Catlin et al., 2015; Morrow et al., 1996).
Schema-based comprehension of nonprescription drug labels
Morris and Aikin (2001) have suggested that a patient who has an existing schema for a given class of drugs may quickly develop a detailed schema for a new drug in that class by concentrating only on information about those distinctive features of that new drug that are incongruent with the existing schema for similar drugs (p. 151). Jungermann et al. (1988) had earlier offered a similar account. However, they assumed that the schema copy created for a new drug may contain as well drug facts from the original schema that are not specified on the label for the new drug. The original schema thereby provides a source of “default values” for drug facts not specified in the label for a new drug. As illustrated in Table 1, a consumer may develop a nonprescription analgesic schema by incorporating drug facts found on ibuprofen, acetaminophen, or naproxen product labels. As can be seen for the label property Active Ingredient, the emergent schema for nonprescription drugs would preserve the distinctive ingredient values for each drug. However, the property values for Uses in that schema include both <toothache pain> and <backache pain> as typical values for nonprescription analgesic drugs. For someone using that analgesic schema to process label information about a “novel” analgesic (as aspirin is for most college students), <aspirin> will represent an atypical value for Active Ingredient and will have to be distinguished in the copy of the analgesic schema developed for aspirin-label information. The Uses value <toothache pain> is included in the aspirin label and would appear in the aspirin schema, presumably adding to the strength of that Uses value in the existing analgesic schema. In contrast, the Uses value <backache pain> is not present in the aspirin label. In this instance, Jungermann et al.’s (1988) account makes the interesting prediction that the existing analgesic schema will endow the emerging aspirin schema with that default value. Therefore, it is likely that those using the analgesic schema to process the drug facts on the supposedly novel aspirin label will develop a schema copy for aspirin that includes <backache pain> as a default value.
Examples of schema-based beneficial/detrimental intrusions and label-based recall when reporting aspirin drug facts.
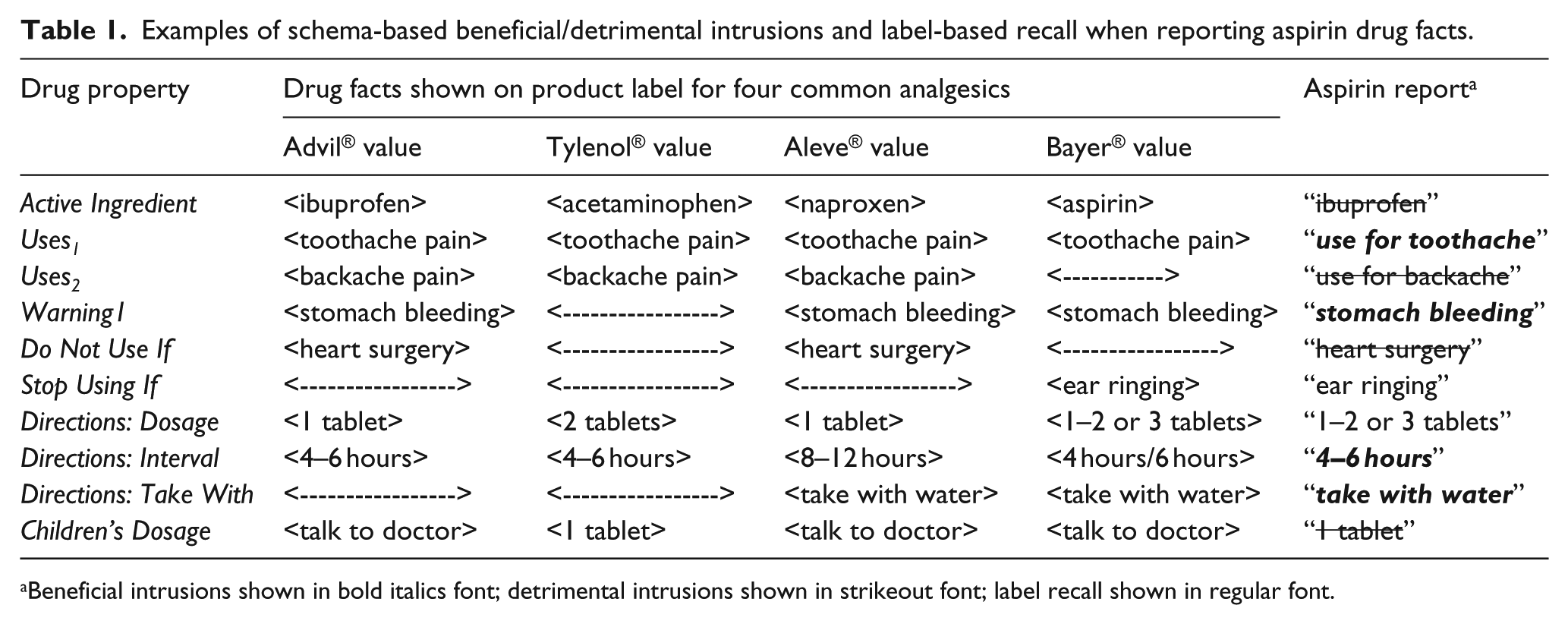
Beneficial intrusions shown in bold italics font; detrimental intrusions shown in strikeout font; label recall shown in regular font.
As described above, both the Morris and Aiken (2001) and the Jungermann et al. (1988) accounts make easily tested predictions about the use of medication schemas to process the drug facts on nonprescription labels. Neither account offers empirical support for the predictions described above and others discussed in the following paragraph. Subsequent label-comprehension research has failed to address the question of how well consumers distinguish between the drug facts associated with one drug and those associated with another drug serving the same purpose. In order to permit effective product comparisons, the DFL schema should help aid consumers in the task of distinguishing among sets of drug facts when they select an over-the-counter medication and when they later use that medication. What has gone unexamined is the degree to which the use of the DFL schema produces schema-based intrusion errors that have both beneficial and detrimental effects on the recall of information from an unfamiliar nonprescription drug label.
As shown in Table 1, some analgesic-schema property values are congruent with those on the aspirin label. If these property values are incorporated into a tailored schema developed for aspirin, then the recall of those values as aspirin drug facts should benefit from their appearance in both the existing analgesic schema and the schema copy developed for the aspirin label. There may also be label frequency effects. An aspirin drug fact that is congruent with a drug property value that appears on each of the three drug labels that contributed to the development of the pre-aspirin analgesic schema (e.g. <toothache pain>) may be better recalled than one that is congruent with just two contributing labels (e.g. <stomach bleeding risk>). As shown in Table 1, some analgesic-schema property values are incongruent with those on the aspirin label. Although both Morris and Aiken (2001) and Jungermann et al. (1988) agree that such aspirin property values should receive more attention because they are atypical, they may still be confused with other atypical property values in the existing analgesic schema. The drug property values for Dosage Amount and Dosage Interval for ibuprofen, acetaminophen, and naproxen, for example, all differ from those values for aspirin. The availability in the analgesic schema of other atypical values of a given drug property may then prove detrimental to the recall of the atypical value for aspirin. Here too, there can be label frequency effects. As can be seen in Table 1, an aspirin drug fact may be incongruent with the values of that drug property for each of the three drug labels that contributed to the development of the pre-aspirin analgesic schema (e.g. <ibuprofen>, <acetaminophen>, and <naproxen>). As a consequence, that drug fact may be less well recalled than one that is incongruent with just two contributing labels (e.g. <do not use right before or right after heart surgery>). These implications of the Morris and Aikin (2001) and Jungermann et al. (1988) accounts suggest that the schema-based processing of a novel analgesic may result in both beneficial and detrimental intrusion errors that vary as a function of the frequency with which they have contributed to the development of the analgesic schema.
Design and hypotheses
Design
In order to help our participants develop a DFL-based medication schema, we asked them to read and recall drug facts from four facsimiles of the back-panel label for branded nonprescription drugs. We used the FDA-mandated label headings and subheadings as retrieval cues, allowing participants recall time proportionate to the amount of information associated with a heading or subheading. In addition, we displayed the complete set of label headings and subheadings on a wall chart throughout the experimental session. The first three labels were Advil®, Tylenol®, and Aleve® for those in the analgesic-schema condition or Claritin®, Imodium®, and Prilosec® for those in the non-analgesic-schema condition. The fourth label was always a Bayer® aspirin label. Cued recall of aspirin drug facts was assessed again after a 48-hour delay, but with no intervening exposure to the aspirin label. Our experimental task is neither an analogue of the cognitive process a consumer uses to select an analgesic from pharmacy shelves nor an analogue of the cognitive process a consumer uses to determine how to use an analgesic from his or her medicine cabinet for symptomatic relief. Instead, we designed a task that would allow us to test specific implications of the use of medication schemas to process label information about a new drug.
We used brand-name facsimiles rather than generic facsimiles in order to enhance the realism of the facsimile. We used aspirin as our “new” drug because very few young adult college students use it or are familiar with it (Shone et al., 2011). The analgesic-only condition provides participants with the opportunity to build (or activate) a medication schema during the first three label trials which is tailored to nonprescription analgesic drugs. This condition allows us to determine whether the use of that schema for processing the aspirin drug-label contaminates the construction of an accurate mental representation of aspirin drug facts with previously processed ibuprofen, acetaminophen, and naproxen drug facts. The non-analgesic training condition serves as a baseline condition with which we can assess the degree to which making product comparisons is a reactive process—changing what a consumer later recalls about the product labels examined in his or her deliberations.
Hypotheses
If young adults learn a DFL text schema based on their reading of three analgesic labels (ibuprofen, acetaminophen, and naproxen), their processing of the drug facts on a hitherto-unread aspirin label will differ predictably from that of young adults who learn a DFL text schema based on their reading of three non-analgesic labels (the antihistamine loratadine, the anti-diarrheal loperamide, and the acid-reducer omeprazole). First, overall correct recall of aspirin drug facts should be higher for those using the analgesic text schema because many of those drug facts will be common to those for other analgesics. Second, the overall number of schema-based intrusion errors in aspirin recall should also be higher for those using the analgesic text schema because aspirin drug facts will be harder to distinguish from the analgesic drug facts already incorporated into that schema. In contrast, correct recall for aspirin drug facts and schema-based intrusion errors will be lower when the more general non-analgesic text schema is used to process the drug facts on an aspirin label. Fewer aspirin drug facts will be common to the non-analgesic schema, and aspirin drug facts ought to be easier to distinguish from the loratadine, loperamide, and omeprazole drug facts incorporated into the non-analgesic schema.
Two additional sets of predictions follow from our assumptions. If the analgesic schema has incorporated the same drug fact for ibuprofen, acetaminophen, and naproxen (e.g. “can be used to treat arthritis pain” or “can be used to treat back pain”), then that drug fact may be especially available as a default value for the drug property Uses. In some cases, a consumer may not find a corresponding value for the Uses drug property on the aspirin label during the schema-based processing of that label. If no value is assigned to the Uses property as the aspirin label is processed to create a mental representation for the aspirin drug facts, either <can be used to treat arthritis pain> or <can be used to treat back pain> may be assigned instead as a default value. In the former case, a consumer may recall the default intrusion as having been on the aspirin label when later asked to respond to the cue Uses with aspirin drug facts. The schema-based intrusion of <relieves arthritis pain> would count as a correctly recalled aspirin drug fact—we label this fortunate schema-based intrusion a beneficial intrusion error. In the latter case, a consumer may also recall the default intrusion as having been on the aspirin label when cued with Uses. The schema-based intrusion of <can be used to treat back pain> would not count as a correctly recalled aspirin fact—we label this unfortunate schema-based intrusion a detrimental intrusion error.
As can be seen in Table 1, any particular report of an aspirin drug fact may arise from beneficial intrusions of analgesic property values found in one, two, or three of the previously studied analgesic labels. Likewise, an incorrect aspirin drug facts report may arise from detrimental intrusions of analgesic property values found in one, two, or three of the prior-analgesic labels. On this basis, we predict that the correct recall of an aspirin drug fact will increase as a function of the number of prior labels on which that drug fact has appeared. We also predict that mistaking a non-aspirin drug fact for an aspirin drug fact will increase in likelihood as a function of the number of prior labels on which that non-aspirin drug fact has appeared.
Method
Participants
We recruited 32 female and 26 male undergraduates between the ages of 18 and 25 years for an hour-long group session 1 day and a half-hour group session 48 hours later. All were native English speakers in an introductory psychology course who were satisfying a research requirement. In the initial group session, the experimenter randomly assigned participants to the two label conditions by alternating the two kinds of material folders handed out to participants after they had signed the consent form approved by our Institutional Review Board. As expected, our young adult college students rarely made use of aspirin as an analgesic. Among the 29 participants assigned to the analgesic-only training condition, only two reported aspirin to be an analgesic they had used. Among the 29 participants in the non-analgesic training condition, only one reported the use of aspirin.
Materials
We created our facsimiles of the DFL panels for Bayer® aspirin, Aleve® naproxen, Advil® ibuprofen, and Tylenol® acetaminophen on letter-sized paper. We also developed facsimiles of the DFL panels for three non-analgesic drugs: the antihistamine loratadine (Claritin®), the anti-diarrheal loperamide (Imodium®), and the acid-reducer omeprazole (Prilosec®). In each case, we used the exact wording from then-current labels. The order of information and headings in these simulated labels mirrored the standard DFL (i.e. Active Ingredient, Uses, Warnings, etc.). Barlines, hairlines, indenting, bulleting, boldface, italics, and the use of white space closely matched those of the actual labels. We increased font sizes proportionately to make our facsimiles highly legible, using 16-point, 14-point, and 12-point Arial font. Appendix 1 depicts the DFL label facsimile for aspirin. We provided no front-panel information as cover sheets for these label facsimiles because we did not want to call attention to any drug facts that we expected participants to discover as they read the back-panel label information. We included only the heading “<Brand Name®> Drug Facts” on our facsimiles in order to remind participants of the advertised drug name while minimizing the confounding impact of brand-name identities on the processing of the actual drug facts information.
Measures
DFL knowledge
We assessed participants’ prior knowledge of the FDA’s DFL headings and subheadings with a set of 30 true–false statements. Statements focused on three kinds of information. Some concerned the meaning of a label heading (e.g. “Stop use and ask a doctor if” gives information about the possible side effects of the drug). Some concerned the order in which information occurs on the DFL (e.g. “Warnings” information immediately follows “Uses” information on the label). Some concerned information included on all DFLs (e.g. “If pregnant or breast-feeding, ask a health professional before use”). We used the total number of correct answers on the DFL test as a covariate to control for differences in familiarity with nonprescription drug labels. The mean score was 18.24 (standard error of mean (SEM) = 0.33), with values ranging from 10 to 26. Scores on this measure did not vary across the two label conditions, t(56) < 1.00.
Verbal ability
We used the Extended Range Vocabulary Test (ERVT; Ekstrom et al., 1976) as an index of verbal comprehension skills. This 6-minute, 24-item test is suitable for Grades 7–16, covering the wide range of ability levels that appear among freshmen at a large state university. The mean ERVT score was 10.20 (SEM = 0.34), with values ranging from 2 to 17. ERVT scores did not vary significantly as a function of label condition, t(56) < 1.00. We used the total number of correct answers as a covariate to control for differences in comprehension ability. Although the Rapid Estimate of Adult Literacy in Medicine (REALM; Davis et al., 1993) is often used as a measure of domain-specific literacy, the range of reading levels is restricted. In pilot testing, we found that those in our participant population rarely missed more than one or two REALM items. For our purposes, the DFL Expertise score described above is the more relevant domain-specific literacy measure.
Procedure
At the first experimental session, all participants had three study-test trials with three analgesic or three non-analgesic drug labels to enhance the salience of the DFL schema. The fourth study trial provided an opportunity for the effects of schema instantiation on the first three trials to influence the processing of aspirin drug facts that all participants read as their fourth label. Prior to reading the first label, participants examined a poster display of the standard DFL headings (Active Ingredients, Purpose, Uses, Warnings, etc.). The experimenter directed them to use the headings to organize the information on each label they studied so that they could later make use of the headings as retrieval cues for the drug facts on each label. The poster remained on display throughout the session.
On each training trial, participants had 4 minutes to read carefully the drug facts on the simulated label. After reading a label, participants worked on a mental-multiplication task for 1 minute. Participants then wrote the brand name of the drug as the title for the recall form, and the experimenter paced them through a 7-minute cued recall test. Pointing to each displayed heading in turn, the experimenter asked participants to copy that heading down on their recall form. Participants then “free-associated” to each heading by writing down any facts they could recall from the current label, entering each fact on a separate line of the form. The pacing allowed participants response times that were proportional to the amount of label text associated with each heading. Guessing was strongly encouraged in order to ensure the reporting of all heading-associated drug facts recalled. Participants were told to write down any drug fact they recalled whenever it came to mind, even if it was not related to the current heading cue.
On the fourth test trial, participants in both experimental conditions had 4 minutes to study the aspirin label and 10 minutes to report the aspirin facts that came to mind in response to each of the posted DFL headings. They were free to spend as much time responding to each heading as they wished on this recall trial. They returned 48 hours later for an unexpected delayed recall test. The set of DFL headings was again on display throughout the task. Participants first wrote “Bayer® Aspirin” as the heading on their recall form and then spent 10 minutes writing down as many drug facts as they could recall from “the aspirin label—the last label you read in the first session.” As on the immediate recall test, they to the DFL headings in label order, first writing down the heading and then responding to each cue in turn with any aspirin drug fact that came to mind.
Results
Coding procedures
Coding of aspirin-label recall
In both training conditions, we counted an aspirin drug fact as correctly recalled if it appeared anywhere in a participant’s recall protocol, whether in response to its proper DFL heading or not. We coded responses as multiple drug facts wherever possible. For example, “used for toothaches, menstrual pain, and headaches” counted as three aspirin drug facts. Similarly, “1 or 2 tablets every 4 hours” counted as two aspirin drug facts. We omitted any reported drug fact not identifiably linked to a particular drug fact on the aspirin label.
Coding of analgesic intrusion errors
We counted as an analgesic intrusion in aspirin recall any drug fact identifiably related to the Tylenol, Advil, or Aleve labels, but not found on a Bayer label. As we had done in coding the recall of aspirin drug facts, we counted the number of distinguishable drug facts in each analgesic intrusion. For example, “you should take one tablet every 8 hours” counted as two intruding drug facts—“one tablet” is the dose and “every 8 hours” is the dosage interval for naproxen. We did not distinguish among the three non-aspirin analgesics in counting aspirin-recall intrusions; any acetaminophen, ibuprofen, and naproxen label drug fact not shown on the aspirin label counted as an analgesic intrusion error.
Coding of non-analgesic intrusion errors
We coded intrusion errors in the recall of aspirin drug facts in two ways in the non-analgesic label condition. First, we coded any intruding drug facts that appear on the Claritin, Imodium, and Prilosec labels, but not on the Bayer label. In addition, we coded separately any intruding drug facts that could be found on the Tylenol, Advil, or Aleve labels. Although participants in the non-analgesic condition read no analgesic labels prior to reading the aspirin label, they might mistakenly report drug facts from nonprescription analgesic labels they had read prior to the study.
Inter-judge reliabilities for recall coding
The second and third authors independently coded all aspirin-recall protocols. We used Spearman’s rho value ρ to compare the total recall and intrusion counts assigned by each judge to each participant. Overall inter-judge reliability was acceptable for recall scoring, with ρ(56) = .89 (p < .001) for the total count of correct aspirin propositions on the immediate aspirin test and ρ(56) = .79 (p < .001) for the total count of aspirin propositions on the delayed test. Overall reliability was also acceptable for the coding of analgesic intrusions, with ρ(56) = .81 (p < .001) for the total count of analgesic intrusions on the immediate aspirin test and ρ(56) = .79 (p < .001) on the delayed test. Overall reliability was acceptable too for the coding of non-analgesic intrusions, with ρ(56) = .83 (p < .001) for the total count of analgesic intrusions on the immediate aspirin test and ρ(56) = .81 (p < .001) on the delayed test. The first author resolved disagreements between these two judges by imposing additional coding rules as necessary.
Measuring schema mastery
The three analgesic or non-analgesic training trials in each condition served to focus our participants on the use of DFL headings and subheading as retrieval cues for the drug facts on each label. Their skill in doing so provided a surrogate measure of the degree to which they learned to use the DFL text schema to organize drug facts information in the two training conditions. The use of Advil, Aleve, and Tylenol labels as training labels should have fostered the development of an analgesic-specific DFL schema, while the use of Claritin, Imodium, and Prilosec labels should have fostered the development of a more general DFL schema. Because we expected the relative mastery of each schema to influence the subsequent recall of drug facts from the Bayer label, we used aggregate recall performance on the training-trial labels as our measure of schema mastery. In order to control for differences in the ease with which analgesic and non-analgesic drug facts were learned, we coded correct recall of training-trial drug facts as described above. We then converted the number of drug facts recalled from each label into z-scores and used the sum of the three training-label z-scores for each participant as our measure of mastery of the analgesic or non-analgesic schema prior to studying the drug facts for aspirin. We used this z-score sum as our Schema Mastery covariate in all of our analyses of the correct and incorrect recall of aspirin drug facts.
Is the recall of aspirin-label information influenced by having read other labels?
Data transformation
The correct-recall and intrusion-error measures are both counts, with relatively low counts for intrusion errors. We examined the data distributions and found that the intrusion-error counts for both immediate and delayed recall were strongly positively skewed, with skewness values significantly different from 0 (3.16 and 2.33 standard errors, respectively). Correct-recall counts at both recall intervals were also positively skewed, but less strongly so, with skewness values not significantly different from 0 (0.44 and 1.43 standard errors, respectively). We used a simple square-root transformation—x′ = √x—to normalize both correct-recall counts and intrusion-error counts (Howell, 2007: 318–324; Tabachnick and Fidell, 2007: 86–89).
Correct recall of aspirin drug facts
We entered Prior Labels (analgesic or non-analgesic) as a between-subjects factor and Retention Interval (5 minutes or 48 hours) as a within-subjects factor in a repeated-measures analysis of variance of the square-root-transformed correct-recall counts. In addition, we entered Verbal Ability, DFL Knowledge, and Schema Mastery as covariates. The effect of Prior Labels was highly significant, F(1, 53) = 24.57, mean squared error (MSE) = 0.42, p < .001, eta-squared = 0.32. However, neither Retention Interval nor its interaction with Prior Labels was significant, F(1, 53) = 1.94 and F(1, 53) < 1.00, respectively. Back-transformed values of the covariate-adjusted correct-recall means and their 95 percent confidence intervals are shown in the top portion of Table 2. Correct recall of aspirin drug facts was significantly greater when more similar and potentially interfering analgesic labels had been studied beforehand than when less similar non-analgesic labels had been studied beforehand. Overall, the number of aspirin facts correctly recalled was 36 percent greater when the prior labels were three other analgesic drugs than when they were non-analgesic drugs.
Adjusted means and 95 percent confidence intervals for number of recalled aspirin drug facts and intruding non-aspirin drug facts as a function of training condition and retention interval.
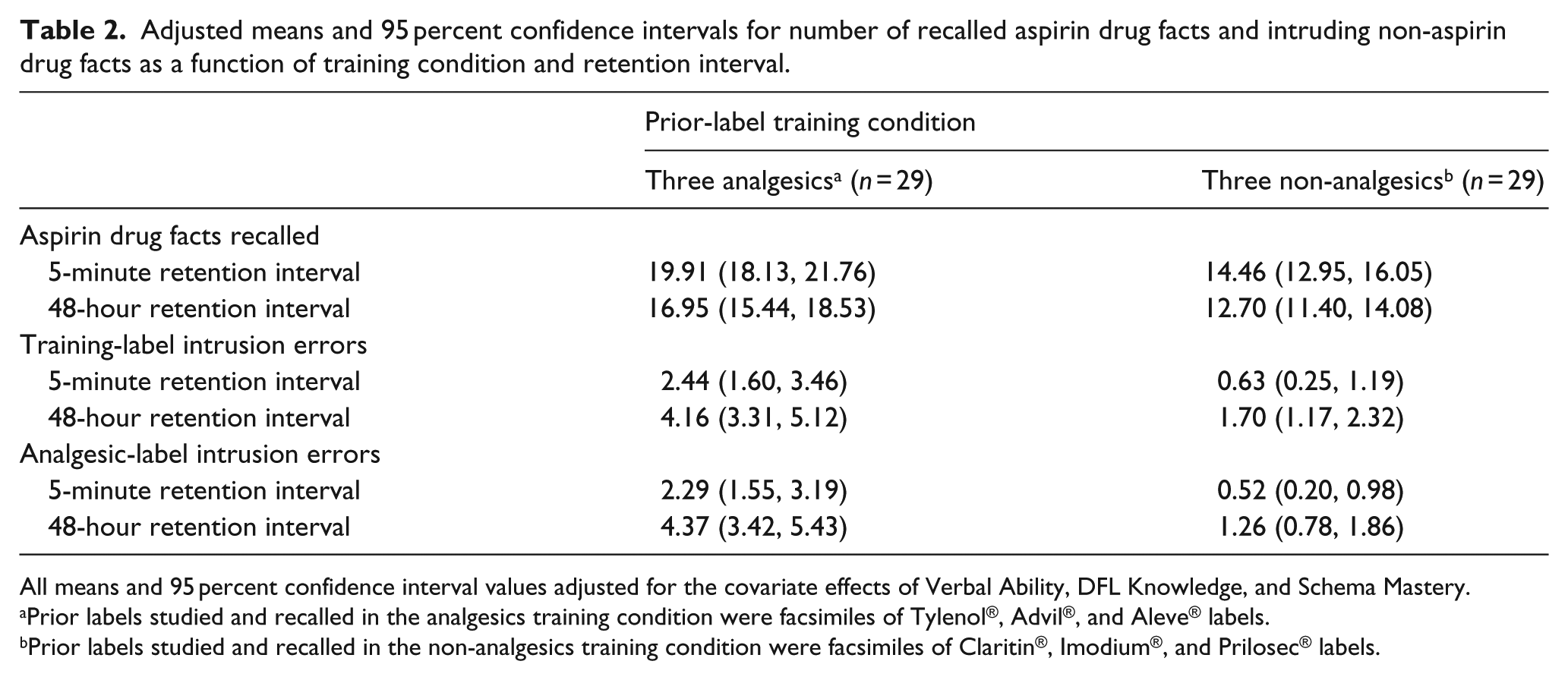
All means and 95 percent confidence interval values adjusted for the covariate effects of Verbal Ability, DFL Knowledge, and Schema Mastery.
Prior labels studied and recalled in the analgesics training condition were facsimiles of Tylenol®, Advil®, and Aleve® labels.
Prior labels studied and recalled in the non-analgesics training condition were facsimiles of Claritin®, Imodium®, and Prilosec® labels.
Prior-label intrusion errors
The most relevant intrusion-error analysis involves the mistaken recall of acetaminophen, ibuprofen, and naproxen drug facts as aspirin drug facts in the analgesic-label condition as compared to the mistaken recall of loperamide, loratadine, and omeprazole drug facts as aspirin drug facts in the non-analgesic label condition. As above, we entered Prior Labels (analgesic or non-analgesic) as a between-subjects factor and Retention Interval (5 minutes or 48 hours) as a within-subjects factor in a repeated-measures analysis of variance of square-root-transformed intrusion-error counts. In addition, we entered Verbal Ability, DFL Knowledge, and Schema Mastery as covariates. The effect of Prior Labels was again highly significant, F(1, 53) = 25.90, MSE = 0.59, p < .001, eta-squared = 0.33. Once again, neither Retention Interval nor its interaction with Prior Labels was significant, Fs < 1.00. Back-transformed values of the covariate-adjusted intrusion-error means and their 95 percent confidence intervals are shown in the middle portion of Table 2. For both immediate and delayed testing, prior-label intrusion errors were significantly greater when more similar and potentially interfering analgesic labels had been studied beforehand than when less similar non-analgesic labels had been studied beforehand. Overall, the number of prior-label intrusion errors was nearly three times greater when the prior labels were three other analgesic drugs than when they were non-analgesic drugs.
We conducted an additional analysis to examine the possibility that the decreased level of prior-label intrusions in the non-analgesic condition is an artifact of comparing analgesic with non-analgesic intrusion errors. Although participants in the non-analgesic condition had seen no analgesic labels prior to reading and recalling aspirin-label information, extra-experimental intrusions might result from having used one or more of the three analgesics prior to the study. For this reason, we repeated the foregoing analysis, substituting counts of acetaminophen, ibuprofen, or naproxen intrusions in the non-analgesic prior-label condition for counts of loperamide, loratadine, and omeprazole drug prior-label intrusions. We then analyzed analgesic intrusions in the two conditions just as we had analyzed prior-label intrusions in the previous analysis.
The effect of label conditions was again highly significant, F(1, 53) = 40.25, MSE = 0.54, p < .001, eta-squared = 0.43. As in prior analyses, neither Retention Interval nor its interaction with Prior Labels was significant, Fs < 1.00. Back-transformed values of adjusted means and confidence intervals are shown in the bottom portion of Table 2. As can be seen in the middle and bottom portions of that table, prior-label intrusions were no more frequent in the non-analgesic condition than intrusions of drug facts that had never been presented to participants in that condition. In other words, prior-label intrusions in the non-analgesic condition occurred at a near-chance level. This result suggests that prior-label intrusion errors in aspirin-label recall are minimal if labels from very different classes of nonprescription drugs are presented beforehand.
Finally, we examined the degree to which recall performance on the three training trials in each condition was predictive of the number of intrusion errors in drug facts recall for aspirin. If some participants are better at learning prior-label drug facts than other participants, then those prior-label drug facts should be more likely to be misrecalled as aspirin drug facts. The number of drug facts recalled on each of the three training trials varied as a function of the prior-label condition. For that reason, we transformed recall scores on each training trial in each condition into z-scores and used the sum of the three z-scores for each participant as a measure of his or her success in recalling prior-label drug facts. As would be expected, the correlation is high and positive for immediate-test correct recall in both the analgesic-only and the non-analgesic conditions, Spearman’s ρ(27) = +.60, p < .001 and +.67, p < .001, respectively. However, the correlation is not significant for immediate-test intrusion errors in either condition, Spearman’s ρ(27) = +.21, p > .20 and +.19, p > .20, respectively. The same Spearman values are obtained if square-root-transformed correct-recall and intrusion-error counts are used in the analysis.
Are there beneficial effects of DFL-guided label processing?
The foregoing analyses demonstrate that having read three analgesic labels prior to reading an aspirin label significantly increases the recall of aspirin facts over that obtained having read three non-analgesic labels. That increase may reflect the intrusion into aspirin recall of shared drug facts from one of the other three analgesic labels. “Can be used to treat a toothache,” for example, occurs on all four labels. An individual might then mistakenly recall that drug fact as having been on the aspirin label when he or she has recalled it instead from the acetaminophen, ibuprofen, or naproxen label. The number of such “beneficial” intrusions should increase as a function of the number of other analgesic labels on which a given aspirin drug fact has appeared. That number can be three, two, one, or zero. We tested this hypothesis by computing the number of times each participant in the analgesic-only condition recalled aspirin drug facts that varied in the number of analgesic labels on which they had appeared. We found 18 aspirin drug facts that also appeared on acetaminophen, ibuprofen, and naproxen labels; 34 that appeared on only two of the other three labels; four that appeared on just one other label; and 15 that appeared only on the aspirin label. Recall data for the last two categories were combined into a single “one or none” category because there were so few aspirin drug facts in the “one-other-label” category.
Because there were different numbers of drug facts in each other-label category, we computed simple proportions for each category and each recall interval for each participant in the analgesic-only prior-label condition. Skewness values were all positive, but only the value for the delayed recall in the one-or-none condition was significantly greater than 0. Because a log-transformation of the proportions—log10(p + 1)—produced a comparably extreme skewness value, we elected to conduct the analysis with untransformed proportions. The six proportions for each participant were analyzed with a within-subjects analysis of covariance in which Label Frequency (three, two, or one/none) and Retention Interval (immediate or delayed) served as within-subjects factors. As in previous analyses, we included Verbal Ability, DFL Knowledge, and Schema Mastery as covariates.
As can be seen in the top half of Table 3, the more prior-analgesic labels on which an aspirin drug fact had appeared, the more likely was its recall. Only the Label Frequency × Retention Interval × Verbal Ability interaction was statistically significant, F(2, 50) = 7.86, MSE = 0.003, p < .001, eta-squared = 0.24. Within-subjects linear contrasts showed the proportion of aspirin drug facts recalled in the three-label condition to be significantly greater than that in the two-label condition, F(1, 25) = 17.72, MSE = 0.004, p < .001, eta-squared = 0.42, while the difference between the two-label and the one/none-label conditions was not, F(1, 25) <1.00.
Mean adjusted proportions and 95 percent confidence intervals for aspirin drug facts reports and analgesic drug facts intrusion as a function of prior-label frequency and retention interval.

Only the 29 participants in the Analgesic Prior-Label Condition are included in this analysis. Values of i in parentheses indicate the number of aspirin or non-aspirin analgesic drug facts in that label category.
Correct report of an aspirin drug fact found on Tylenol®, Advil®, or Aleve® Drug Facts Label as well as the Bayer® Drug Facts Label.
Incorrect report of an aspirin drug fact found on Tylenol, Advil, or Aleve Drug Facts Label, but not found on a Bayer Drug Facts Label.
Are there detrimental effects of DFL-guided label processing?
As shown previously in Table 2, we demonstrated in our main analyses that reading three analgesic labels prior to reading an aspirin label selectively increases the number of non-aspirin drug facts recalled. That increase may reflect the intrusion into aspirin recall of shared drug facts from one of the other three analgesic labels. “Temporarily relieves … pain of backache,” for example, appears on Tylenol, Advil, and Aleve labels, but does not appear on the Bayer label. An individual might then mistakenly recall that drug fact as having been on the aspirin label when he or she has recalled it instead from the acetaminophen, ibuprofen, or naproxen label. The number of such “detrimental” intrusions should increase as a function of the number of other analgesic labels on which a given aspirin drug fact has appeared. That number can be three, two, or one. We computed the number of times each participant in the analgesic-only condition recalled non-aspirin drug facts that varied in the number of labels on which they appeared. We found 11 non-aspirin drug facts that appeared on acetaminophen, ibuprofen, and naproxen labels; 18 that appeared on only two of those three labels; and 37 that appeared on just one of those labels.
Because there were different numbers of drug facts in each of the three label categories above, we computed simple proportions for each category and each recall interval for each participant in the analgesic-only prior-label condition. Skewness values in three of the six conditions were not significantly different from 0, but three were significantly positive (1.732, 1.831, 1.260). Because a log-transformation—log10(p + 1)—produced a comparably extreme skewness value in each case (1.596, 1.831, 1.217), we again elected to conduct the analysis with untransformed proportions. The six proportions for each participant were analyzed with a within-subjects analysis of covariance in which Label Frequency (three, two, or one) and Retention Interval (immediate or delayed) served as within-subjects factors. We again included Verbal Ability, DFL Knowledge, and Schema Mastery as covariates.
As can be seen in the bottom half of Table 3, the more prior-analgesic labels on which a non-aspirin drug fact had appeared, the more likely was its erroneous recall as an aspirin drug fact. However, the effect is not a significant one, with F values less than 1.00 for Label Frequency, Retention Interval, and the Label Frequency × Retention Interval interaction.
Discussion
Summary of findings
Using DFL headings as retrieval cues, we asked participants to study and recall the drug facts from three different nonprescription drug labels before studying and attempting to recall the drug facts on an aspirin label. Those who first studied three analgesic drug labels recalled more aspirin drug facts on the cued-recall test than those who first studied three non-analgesic drug labels (see Table 2). The increase in aspirin-label recall was 38 percent greater after a 5-minute delay and 33 percent after a 48-hour delay. However, those who had first studied analgesic drug labels were also more likely to recall by mistake drug facts from previously studied labels. The increase in intrusion errors was nearly four times greater after a 5-minute delay and more than two-and-a-half times greater after a 48-hour delay. We conducted additional analyses to determine whether the number of prior labels on which an aspirin or non-aspirin drug fact had appeared influenced its subsequent recall as an aspirin drug fact (see Table 3). Participants recalled significantly more of those aspirin drug facts that had appeared on all three of the other analgesic labels than those aspirin facts that did not. Participants also recalled more non-aspirin drug facts as having been on the aspirin label if those drug facts had appeared on all three of the other analgesic labels than those non-aspirin facts that did not—but this effect was not statistically significant.
Theoretical interpretation
The schema-copy-plus-tag (SCT) model (Graesser and Nakamura, 1982; Nakamura et al., 1985) provides a helpful theoretical context for interpreting our findings. According to that model, the DFL text schema organizes and guides the processing of information in a novel drug label by creating a mental representation into which typical elements of the schema are copied. If a particular label element differs from any in the guiding schema, it is assigned a distinctive “tag” in the emerging mental representation of the new label. These atypical-element tags then serve to distinguish schema-typical elements from schema-atypical elements in the final mental representation of the novel drug label. In the SCT model, there is no information in the new mental representation that would serve to distinguish between schema-typical elements imparted by the schema and schema-typical elements obtained from the label itself. For that reason, individuals using an analgesic DFL schema to guide their processing of aspirin information would find it difficult to distinguish between a schema-typical drug fact not actually appearing on the aspirin label and a schema-typical drug fact that does appear on the aspirin label. Therefore, drug facts in that schema would sometimes be mistakenly remembered as having been seen on the aspirin label even if they had not. As a result, the analgesic schema would enhance the recall of aspirin drug facts more than the non-analgesic schema would. However, the analgesic schema would also more often enhance the false recall of drug facts incorporated into that schema by the processing of acetaminophen, ibuprofen, and naproxen labels.
Limitations of the study
Our use of actual product labels and our efforts to encourage participants to use the DLF schema for processing label information limit our findings in important ways.
Stimulus materials
Rather than constructing artificial medication labels for fictional drugs (cf. Morrow et al., 1996), our drug labels displayed the actual drug facts specified by the FDA for each drug and organized them as dictated by the format of the DFL (FDA, 1999). For that reason, we could not manipulate the typicality, the importance, or the label location of specific drug facts. Future studies might well make use of synthetic labels with such simulated drug facts as are necessary to manipulate these variables. We also limited the generality of our findings by choosing the aspirin drug label as our target label. We made that choice because aspirin is the only single-ingredient nonprescription analgesic that young adult college students rarely use. In contrast to acetaminophen, ibuprofen, naproxen, and multi-ingredient analgesics, aspirin is a nonprescription analgesic whose drug facts will be unfamiliar to our participant population. Future studies might well focus on the very interesting question of what drug facts participants can recall from re-reading the drug label for a nonprescription drug they use regularly. We might expect that what young adult college students can recall from an Advil or Tylenol label, for example, might reveal a variety of misconceptions that have developed with the continual use of the product. A further limitation of our stimulus materials is our use of branded rather than unbranded drug labels. Continual exposure to commercial advertisements might well lead to brand-specific misconceptions about a given drug. The potential confounding is mitigated to some extent by the fact that only 3 of our 58 subjects reported having used aspirin previously. Additional research is necessary to determine the nature and extent of intrusion errors for branded as compared to generic drug labels.
Schema formation task
The FDA (1999) argues that the DFL organization of drug facts information “is modeled after the decision-making process consumers would be expected to follow, and should follow, when selecting and using OTC drug products” (p. 13258). In order to examine the potential consequences of DFL-based label processing, we sought to enforce the use of that schema in our participants’ processing of label information. We displayed the mandated headings and subheadings for a nonprescription drug label on a wall chart throughout the study, and we made use of those headings and subheadings in our cued-recall test of drug facts knowledge after participants had read each drug label. We examined the effects of using an analgesic-specific DFL schema as compared to the effects of a non-specific DFL schema as a way of manipulating the strength of DFL schema effects on the recall of analgesic drug facts. As such, this study does not provide any information about the degree to which our participants had possessed or made use of that schema in any prior examination of nonprescription drug labels. It does, however, indicate that efforts to encourage the adoption and use of that schema by consumers may increase the recall of drug facts within a given drug class while also increasing the degree to which sets of drug facts within that class are confused with each other.
Practical implications
Our findings have important practical implications for the cost of using the DFL schema to “allow quick and effective product comparisons” (FDA, 1999: 13254). Comparing different drug products to self-medicate a given ailment involves successive and perhaps cursory readings of the product labels for suitable nonprescription drugs. In the process, typical drug facts encoded into the DFL schema a consumer uses may intrude in beneficial or detrimental ways into the mental representation he or she constructs of some new set of drug facts. The following examples from our recall protocols illustrate the phenomenon. In all, 19 of the 29 participants in our analgesic-only prior-label condition mistakenly recalled that aspirin alleviates backache pain (not stated on the aspirin-label but an approved off-label use). Nine participants recalled that aspirin could cause severe liver damage (only stated on the acetaminophen label). Five participants recalled skin reddening, rash, or blisters as symptoms of an allergic response to aspirin (not listed on the aspirin label, but useful indicators of an allergic reaction as noted on the ibuprofen and naproxen labels). And four participants recalled that 6- to 11-year olds could safely take a reduced dose of aspirin (only stated on the acetaminophen label). An aggregate cost–benefit analysis of intrusion errors is beyond the scope of this study. However, schema-based intrusion errors arising from product comparisons may well influence a consumer’s appropriate choice and use of nonprescription analgesics (see Hanoch et al., 2007). Future research is necessary to determine the degree to which the more common intrusion errors compromise the ability of consumers to use nonprescription drugs safely and effectively.
Significance of the findings
This study highlights the need for a greater emphasis on the role that prior knowledge plays in drug-label comprehension. Some researchers have explored the impact of naive medication schemas (Morrow et al., 1996). Others have focused on ways in which individuals can misinterpret label instructions (Wolf et al., 2007). Still others have examined the degree to which naive beliefs about a nonprescription drug can be corrected by reading the drug label (Ryan, 2011). However, much of the research in this area has focused on improving the quality of the label format or text (Bennin and Rother, 2014; Catlin et al., 2012; Cho, 2015; Pawaskar and Sansgiry, 2006; Schwartz et al., 2007; Shrank et al., 2007; Wasowicz et al., 2015). More than a decade ago, Morris and Aikin (2001: 510–519) provided a very thorough review of the nature of the cognitive processes that might contribute to the effective comprehension of drug labels and the many patient influences that might influence those processes. Unfortunately, in our search for the better drug label, we remain relatively uninformed about the nature and importance of the cognitive processes involved in understanding the information on an over-the-counter drug label.
Footnotes
Appendix 1
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.