
Abstract
Smartphone applications routinely collect precise location data from users by offering free services and this information is often monetized for advertising and marketing purposes. While many companies limit sales to aggregate behaviors, data aggregators and data brokers (DA&DB) provide access to individual-level location data. Some DA&DB have implemented privacy-preserving rules and the Federal Trade Commission (FTC) has also intensified its regulations on location-data practices. This paper presents an in-depth exploration of U.S. privacy perceptions regarding specific location features that can be derived from data made available by DA&DB. These findings can provide policy-relevant insights that could assist organizations such as the FTC in defining clearer access rules. Using a factorial vignette survey, we collected responses from 1,405 participants to assess comfort levels with sharing various types of location features, including individual trajectories and visits to points of interest, which are currently available for purchase from DA&DB worldwide. Our results show that trajectory-related features elicit higher privacy concerns, that certain data broker based obfuscation practices increase comfort, and that race, ethnicity and education have an effect on data sharing privacy perceptions.
Introduction
Location (GPS) data collection has become widespread, with smartphones routinely collecting precise location data from users in exchange for free services. App developers use this data to understand app usage, improve functionalities and most importantly, to deliver personalized advertisements that drives monetization.
Monetization is primarily driven by two distinct models. Large technology companies like Google, 1 Apple, and Meta collect precise location data for internal purposes such as improving app functionality and sell only aggregate behaviors insights (e.g. geographical areas visited) for advertising, without sharing individual-level location data. In contrast, data aggregators and data brokers (DA&DB) collect, repackage, and sell individual level location data to third parties, including private organizations and academic researchers (Chen and Poorthuis, 2021; Hunter et al., 2021; Sila-Nowicka et al., 2016; Wang and Hu, 2024). DA&DB either develop their own applications, or distribute software development kits (SDKs) to app developers to collect location data from specific apps. Major technology companies have faced lawsuits for tracking user’ location without consent.2, 3 The Federal Trade Commission (FTC) has also penalized two DA&DB in 2024 for selling location data to advertisers without adequately informing consumers or obtaining consent (Record, 2024a). Unlike tech companies which do not share individual level location data with third parties, DA&DB do and this has enabled several instances of inappropriate uses, including: the US Defense Department’s access to a prayer app’s location data to monitor Muslim communities (Center, 2024), local law enforcement agencies tracking racial-justice protesters using location apps (Center, 2024), identifying gay priests (Morrison, 2021) and individuals who visit abortion clinics (Cox, 2022).
In response to these concerns, some DA&DB have introduced internal policies to limit disclosure of sensitive information about individuals. For example, DA&DBs such as Cuebiq prohibit the identification of visits to healthcare facilities on their platforms, or only limit identification of home locations at the census tract level. 4 However, these internal guidelines are solely based on DA&DB’s decisions rather than on the perceptions of users whose location data is being monetized. We put forward that true consumer privacy rules need to come directly from consumer privacy perceptions.
In this paper, we evaluate user comfort with the use of individual level location data—acquired from DA&DB—to identify and characterize personal trips and visits to places. Previous studies have used survey approaches to explore people’s perceptions of the collection and use of individual level location data, primarily focused on points of interest (POI) visited (Gamarra et al., 2019; Gilbert et al., 2023; Martin and Nissenbaum, 2019). For example, previous research has shown that users are more comfortable in sharing their work or home location than their location when they attend a rally or visit a medical facility (Gilbert et al., 2023).
However, points of interest are only one of the category of features available from DA&DB. In fact, travel history of millions of individual devices are available from data aggregators. 5 These data enables derivation of trajectory-based features such as origin-destination trips (e.g. trips from home to work) or modes of transport inference (e.g. identifying driving vs. use of public transit vs. walks). We extend the state of the art in individual level location data sharing perceptions by evaluating user perceptions of both trajectory-based features and points of interest (POIs) visits, using a U.S.-representative survey.
Understanding these nuanced privacy perceptions can inform the creation of policies governing the types of location features that can be extracted from location data and the features that should be restricted due to low comfort levels, and which obfuscation practices effectively increase users’ level of comfort.
The FTC has started to regulate consumer privacy providing “bright-line rules” for companies to clarify what can and cannot be done with location data (Record, 2024b). This paper contributes to the effort by offering empirical guidance for potential future FTC rulemaking. The main contributions and findings of this paper are:
An evaluation of user comfort with respect to the use of trajectory data and visits to points of interest taking into account actors and purposes. Participants low comfort with movement (trajectory-based) features such as frequent travel paths. Comfort increased when the data was used for social-benefit purposes but decreased when data was accessed by actors such as government agencies or employers. An analysis on how obfuscation approaches affect levels of comfort. Obfuscation significantly increased levels of comfort, especially for detailed trajectory data but also for points of interests, such as home or work locations. An analysis of how levels of comfort vary with educational background, race and ethnicity. Our analysis show that there are significant differences in comfort between racial and ethnic groups, with Hispanics having the highest levels of comfort (even after controlling for education levels). Highly educated individuals report significantly higher comfort with obfuscated features, while those with lower education levels show no significant effect. To the best of our knowledge, this is the first study to evaluate user privacy perceptions across racial and educational groups with respect to trajectory data, taking into account current data aggregator obfuscation practices.
Literature review
Location data tracking
Location data has been widely used for pandemic modeling (Akinbi et al., 2021; Organizers et al., 2019), inferring socio-economic indicators (Hong et al., 2016; Yang et al., 2023a), assessing health outcomes (Garcia-Bulle et al., 2022), supporting urban development and disaster risk (Fraser et al., 2024; Frias-Martinez et al., 2012; Wang and Hu, 2024; Wu et al., 2022), enabling targeted marketing and advertising (Bauer and Strauss, 2016), understanding migration patterns (Hong et al., 2019), or improving public transit systems (Ma and Wang, 2014).
Obfuscation techniques
The archetypes for location privacy-preserving mechanisms fall under Anonymization, Dummy data, or a combination of both. Anonymization-based methods report coarser information to reduce geo-distinguishability (Andrés et al., 2013; Gao et al., 2022; Gramaglia et al., 2021; Shen et al., 2023), whereas dummy methods attempt to simulate realistic location data (Du et al., 2019; Shankar et al., 2009).
In this paper, we focus on anonymization techniques commonly used by DA&DB. For example, instead of computing an exact home location, some providers report home area as a census tract (SafeGraph SafeGraph, 2025); or rather than sharing exact route trajectories, data points are changed to obfuscate movement patterns towards sensitive locations and home/work location (Spectus, 2025).
Privacy perceptions of location data
Our research builds on previous work examining privacy perceptions related to Gamarra et al. (2019); Martin and Nissenbaum (2019); Vitak et al. (2022): (1) Actors, defined as entities accessing the location data, for example, commercial entities or federal agencies (Gilbert et al., 2023; Martin and Nissenbaum, 2019; Vitak et al., 2022; Vitak and Zimmer, 2023) (2) Purposes, referring to how the location data will be used, such as advertising or public health applications (Gilbert et al., 2023; Gorra, 2007; Martin and Nissenbaum, 2019) (3) Time, or duration of the access to location data (Gorra, 2007; Martin and Nissenbaum, 2019) (4) Age (Chakraborty et al., 2013; Gamarra et al., 2019; Haffner et al., 2018) (5) Privacy attitudes, including general disposition towards data sharing (Bansal et al., 2016; Junglas and Spitzmuller, 2006), and (6) Socio-cultural aspects, such as norms and contextual expectations (Gorra, 2007; Ioannou and Tussyadiah, 2021; Wang and Lin, 2017; Zhang et al., 2020).
Survey design
We used a factorial vignette survey approach following Nissembaum’s contextual integrity framework. Each vignette in the survey follows the format: Actor X wants to do Purpose Y and for that, they need to use Feature Z. We systematically varied actors, features and purposes across participants to test their influence on levels of comfort. For example, a vignette might read ”A doctor wants to monitor your personal wellness. For that purpose they want to access your detailed walking activity. How comfortable would you feel with this use of your personal location data?”. Levels of comfort were measured using a 5-point Likert scale, ranging from Very Uncomfortable to Very Comfortable. Participants were also asked to fill out a free-form text box explaining their answer (see Figure 1 and Appendix Figure 5 for two survey question examples). Next, we describe location features, actors, and purposes in detail.

Example of vignette question (Actor: Commercial entity, Purpose: Personal wellness and physical activity, Feature: Walking activity). The feature is obfuscating and only shows general statistics.
Second, we evaluate trajectory-based and POI visit features in two forms: detailed and obfuscated. Detailed features use all available GPS points whereas obfuscated features characterize location data using current state-of-the-art data aggregator practices. For example, an obfuscated driving trip only specifies the origin and destination census tract of the trip rather than the full GPS trajectory. Similarly, an obfuscated home location would only report home location at the county level instead of the exact location.
Table 1 lists all features used to construct the survey vignettes. These features can be categorized into six groups: Home+Work, Places Visited, Transportation, Movement, Walking Activity, and International Trips. For each feature in each category, we define both its Detailed (D) and its Obfuscated (Ob) version. Both the features and obfuscation approaches are inspired by real-world uses of location data by academia, data aggregators, and location-intelligence companies. Further information is provided in the Appendix, section Features Definitions and Obfuscation. Next to each feature in the Table, we provide links to papers that compute these features using location data acquired from DA&DB, showing that these are in fact state-of-the-art features when working with datasets from DA&DB.
Location features and abbreviations.

We cite examples of recent studies where such features are used in the ‘‘feature cluster’’ column. HTML visualizations for detailed features and image format charts available on OSF Awasthi et al., 2025. Additional details provided to survey participants on each feature are in the appendix section feature background information.
While features such as home, work and places visited have already been explored in previous works, comfort perceptions for obfuscating approaches and for other trajectory-based features have not been explored.
Given the complexity of these features, each vignette includes background information explaining the feature and its typical uses, along with an interactive visualization. See Figure 3 in the Appendix for an example vignette with background information, visualizations and the corresponding question. See Description column in Table 1 for links to sample visualizations shown to survey participants. All individual visualizations are also available in our anonymized Open Science Foundation link visualization folder. More details about survey design choices, including visualizations, are explained at the end of this section.
Actors and the abbreviations.

Actors taken from previous studies like (Gorra, 2007; Martin and Nissenbaum, 2019; Vitak et al., 2022).
These actors have been examined in previous studies related to location-data privacy (Martin and Nissenbaum, 2019; Vitak et al., 2022) and represent the major entities that may access an individual’s location information. Our work’s novel contribution lies in examining how these actors influence privacy perceptions in conjunction with novel trajectory-based features, while controlling for demographic and educational factors.
Purposes and abbreviations.
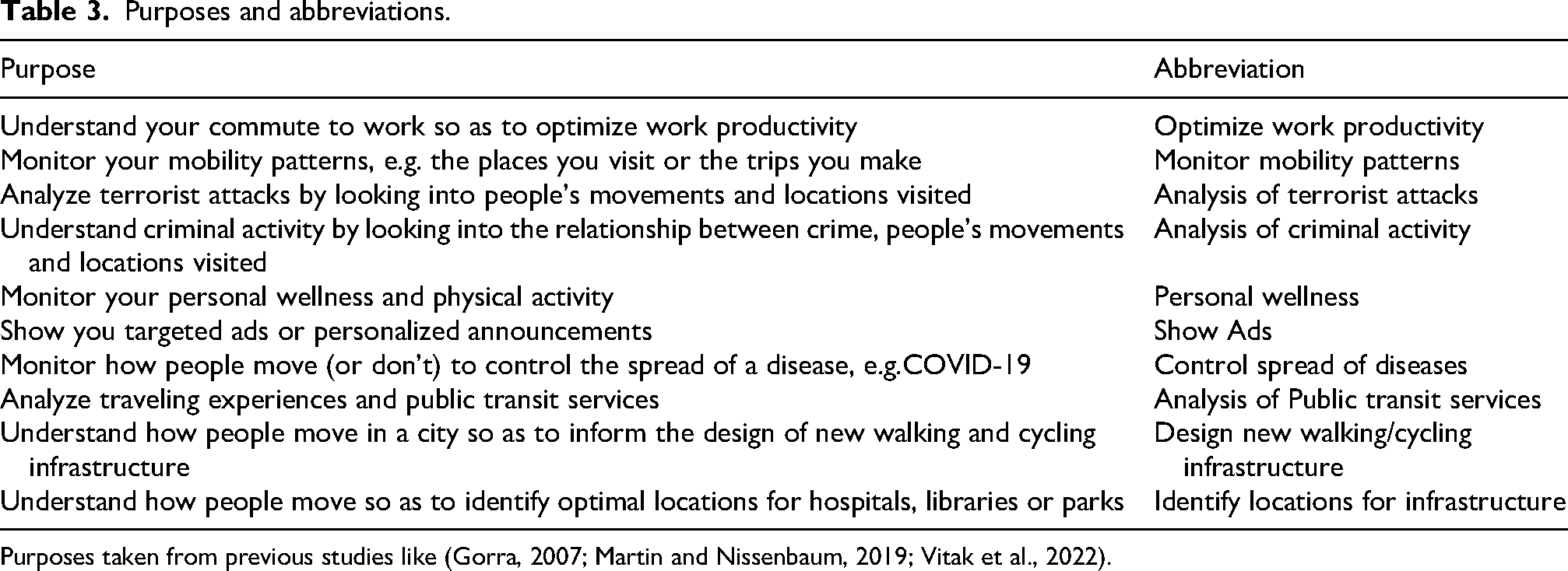
Purposes taken from previous studies like (Gorra, 2007; Martin and Nissenbaum, 2019; Vitak et al., 2022).
Some combinations of actor, feature and purpose are implausible. For example, a doctor will not be interested in getting access to mobility patterns at city scale. Therefore, we manually eliminated such implausible combinations from the pool of possible vignette questions. After this process, a total of 445 valid combinations of actor, purpose and feature remain and were randomly shown to participants. Additional details are provided in Appendix section Approach to Selecting Plausible Survey Questions for details. All vignette questions are available in OSF (Awasthi et al., 2025) file allQuestionsForViewing.csv column humanreadableQuestions.
Design choices
Prior work in privacy-risk perception studies has shown three important insights that we build on when creating the survey. First, Gerber et al. (2019) showed that abstract scenarios are often perceived as less risky than personal scenarios. Hence, before starting the survey questions, we ask participants to situate themselves in the vignettes as if this was their own personal data. The questions are also phrased to put the participant at the center of the vignette using the ”you” pronoun (see Appendix section ‘‘Consent and briefing’’ for more details on this design).
Second, previous work has shown that visualizations can improve understanding of privacy risks, and that when privacy-related questions are asked with visualizations, privacy risk concerns with data sharing tend to decrease (Farke et al., 2021). Hence, each of the vignette includes an interactive visualization of the location feature and a brief explanation of the visualization to make sure that the user understand the feature extracted from the location data. Figure 2 illustrates the Detailed Frequent Trips features, where actual trips and destinations are identified. Additional examples of feature visualizations can be found in the Appendix, including transportation-mode visualization(Appendix Figure 3), visits to points of interest (Appendix Figure 11), and obfuscated frequent trips using synthetic trajectories generated with Google Maps (Appendix Figure 20).
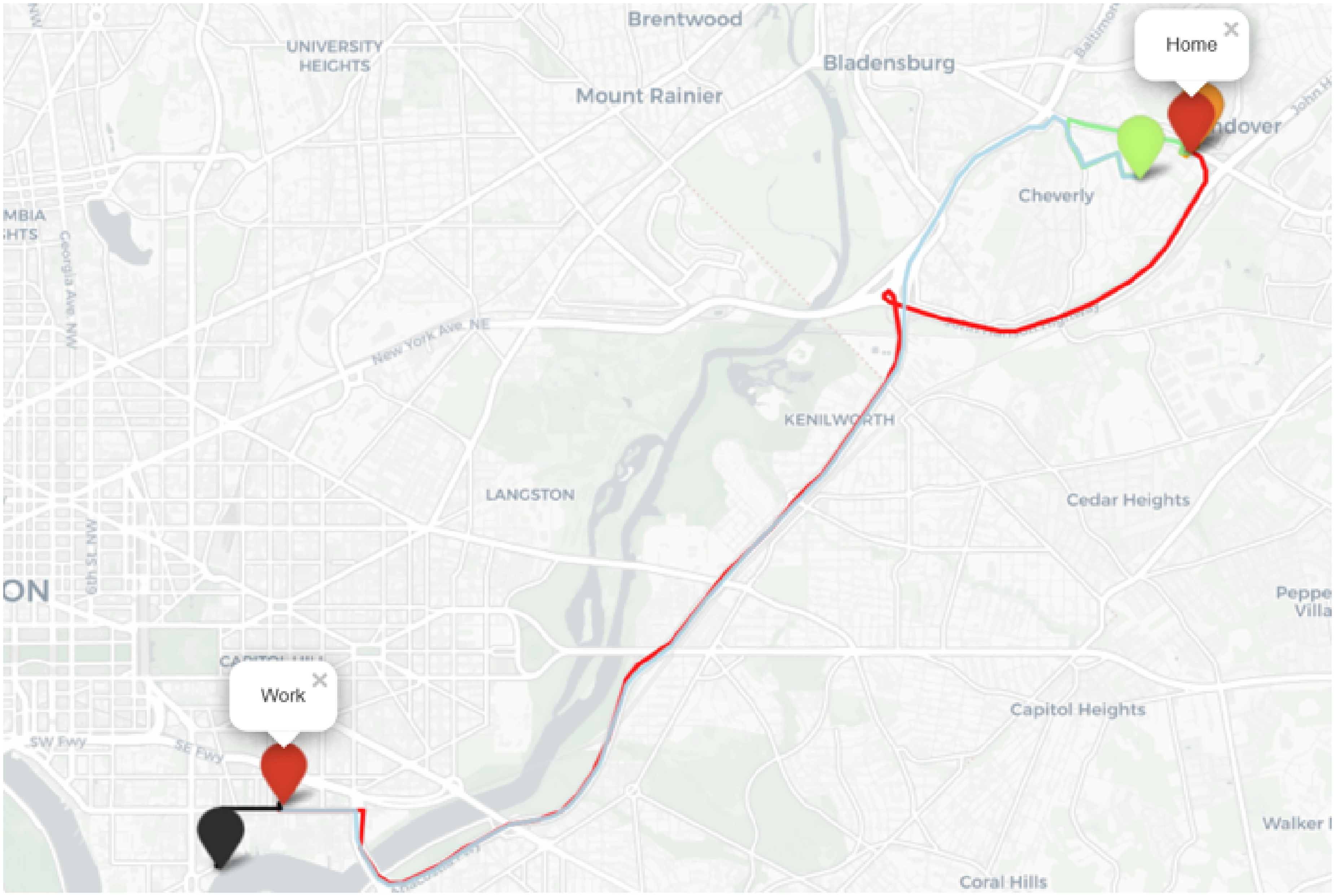
Snapshot of interactive map with most frequent trips feature (FreqT (D)) as visible to participants. For our hypothetical data contributor, the pins denote the start and end points and the line joining the pins denote one of the most frequent routes. For example red pins and line segment denote the most frequent trip between home and work.
Third, previous work has shown that having technical knowledge or specific demographic or personality traits might affect privacy perceptions (Martin and Nissenbaum, 2019). Hence, we also ask participants to fill out questions covering both privacy attitudes, technical knowledge, and demographic data. These questions were divided into two blocks, Demographic and general technology knowledge questions appeared before the vignettes and the Privacy-attitudes questionnaire appeared afterwards.
Following Martin and Nissenbaum (2019), the privacy-attitudes questionnaire asked participants to rate their agreement with different privacy attitude statements on a 5-point Likert scale (from “strongly disagree” to “strongly agree”). These statements captured attitudes such as trust in business or government agencies. Figures 5 and 6 in the Appendix list all the questionnaire items, and Appendix section Privacy Attitudes provides further details on the rationale behind the privacy questionnaire design.
We conducted a qualitative study with five respondents recruited from Craigslist to evaluate vignette comprehension and survey usability. Details of the study procedures and findings are provided in the Appendix section Qualitative Survey Evaluation. Using feedback from participants of the qualitative survey and methodological considerations of effective sample sizes, we set the number of vignette questions to five. Additional details of effective sample size are provided in the Appendix section Ordinal Regression, Design Effect.
Platform
We advertised our online survey on Cint 6 from March 2023 to March 2024. Interested participants clicked on a link on Cint that redirected them to an external webpage where the survey was hosted. We did not use Cint built-in survey tools because of the elaborate nature of the factorial vignettes that were randomly sampled and the custom map visualizations needed to explain the survey questions. Each participant was paid $7 for completing the survey, which consisted of five vignette questions, seven demographic and computer knowledge questions, and ten privacy-attitude questions. All participants were protected under IRB protocol 1768475-4 (see Appendix section Ethical considerations for further details).
Analytical approach
We analyze users’ levels of comfort with the use of individual-level trajectory and POI visits, accounting for the actors and purposes involved in the data analysis, as well as the presence or absence of obfuscation approaches. We also examine how these perceptions vary with respect the participants’ educational background and racial or ethnic identities.
To conduct this analysis, we use a mixed-effects ordinal logistic regression model (the clmm function in R Christensen, 2023) appropriate for ordinal 5-point Likert scale responses (ranging from very uncomfortable to very comfortable). We follow best practices for the vignette data analysis using ordinal regressions (Baguley et al., 2022). Participant ID (randomly assigned) and vignette ID (vignette number) are included as two random effects in the analysis. The dependent variable is the level of comfort (five ordered categories). The independent variables are the variables whose effect we want to evaluate: actors, purposes, features, education, and race or ethnicity. We also include responses to the privacy attitudes, demographic and technical knowledge questionnaires as control variables in the regression, given their documented associated with privacy comfort levels in prior work (Martin and Nissenbaum, 2019).
Analyzing regression coefficients allows us to identify which variables are statistically significant and thus influence the level of comfort that users have with different types of location data being shared.
A detailed description of the ordinal-regression model and the model analysis using AIC (see Appendix Table 4) is provided in the Appendix section Ordinal Regression. We also verify that the assumptions for the ordinal-regression model are satisfied.
In addition, we are also interested in pairwise comparisons between independent variables. For example, while the ordinal regression may show that a trajectory-based feature has a significant negative effect on the level of comfort, we are also interested in quantifying significant changes in levels of comfort for that feature across different actors or purposes. For these analyses, we first transform the 5-point Likert scale responses into a numerical scale from -2 to +2, (-2
In the next section, we provide general statistics about the survey participants and the distribution of levels of comfort across features, actors, and purposes. We then address our three main research questions: (1) RQ1: What are the effect of individual trajectory features and POI visits on user levels of comfort?, (2) RQ2: What are the effect of obfuscation approaches on user levels of comfort?, and (3) RQ3: What are the effect of educational background or race and ethnicity on privacy perceptions?
Survey response analysis
We analyze answers from 1,405 participants. On average, each participant spent 18 minutes completing the survey, which included five factorial vignettes as well as the demographic, technical-knowledge and privacy-attitudes questionnaires.
Overall, 7,930 participants viewed the survey, and, 5,577 agreeing to participate in the survey. From the completed surveys, we removed responses whose required free-form text-box explanations did not align with the user comfort level selected on the Likert scale, including both lack of quality explanations or low quality text. Two researchers independently reviewed all responses and agreed upon its quality. Additional details are in the Appendix section Survey Response Quality Control.
We aimed for a U.S. representative sample, with demographic proportions similar to those reported by the U.S. Census American Community Survey (ACS) (U.S. Census Bureau, 2022). Table 4 summarizes the participants’ education levels and racial or ethnic identities, which are the focus of our analysis. Additionally, statistics for age and gender can be found in the Appendix Table 1 and Appendix Table 2, respectively.
U.S. census and survey population distribution across four major races/ethnicities and education levels.

The bold values indicate total for each row and column.
The sample is approximately representative of the U.S. population for White and Black groups. The percentages for Asian, Black and White groups closely match ACS estimates, while the values for Hispanic are lower. To account for this imbalance, we apply weights in our ordinal-regression analysis, giving more importance to groups that are less represented (further details are provided in the Appendix section Ordinal Regression).
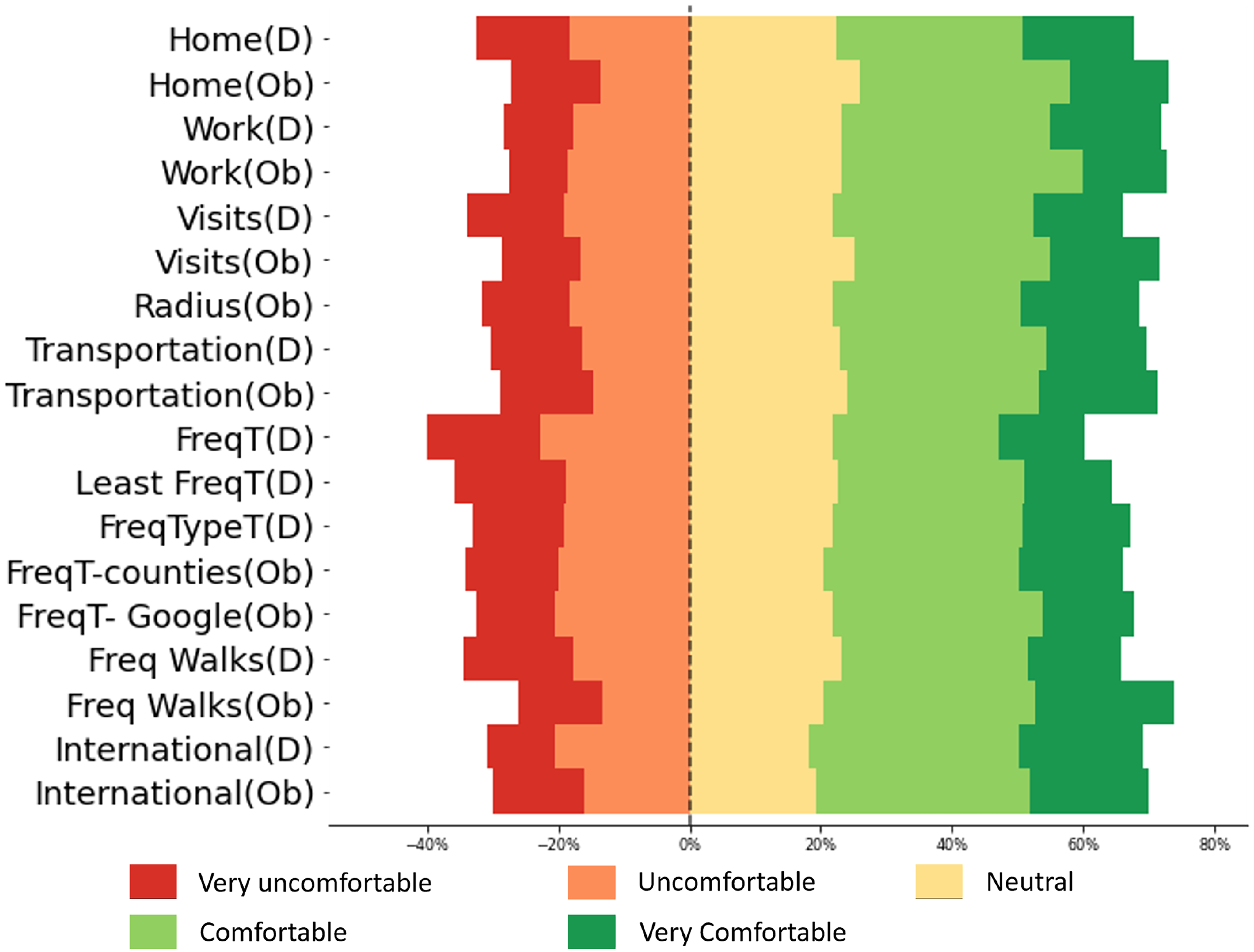
Percentage of responses per feature type and level of comfort (ordered left to right: Very uncomfortable, Uncomfortable, Neutral, Comfortable, Very comfortable).
Feature and comfortableness (means).

The privacy-attitudes questionnaire at the end of the survey asked participants to rate their agreement with statements related to trust in businesses or in government agencies, as well as attitude towards authority. Interestingly, trust in institutions and a general predisposition towards compliance associates with increase comfort levels with sharing location data (detailed or obfuscated), while skepticism towards authority is associated with reduced willingness to share location information. Detailed results can be explored in the Appendix Table 3. These results confirm the importance of adding participant responses to privacy attitude questionnaires in the regression model as control variables, since they appear to play a role in the perception of comfort.
The distribution of comfort levels across purposes and actors aligns with prior work like (Akinbi et al., 2021; Apthorpe et al., 2018; Martin and Nissenbaum, 2019; Vitak et al., 2022) (see Figures 4 and 5 and Tables 6 and 7 for detailed results). Participants were more likely to respond with ”Very Uncomfortable” or ”Uncomfortable” for purposes related to optimizing work productivity and monitoring mobility patterns. In contrast, Purposes with perceived societal benefits, such as identifying locations for infrastructure development, designing walking/cycling infrastructure, and analyzing public transit services were more frequently rated as comfortable or very comfortable. Consistent with prior work, participants expressed greater discomfort sharing data with Employers and Federal Government Agencies whereas actors such as Academic Researchers, Family, Emergency Services, and Doctors were rated higher on the comfort scale (see Figure 5 and Table 7 for further details).

Percentage of responses per actor and level of comfort (ordered left to right: Very uncomfortable, Uncomfortable, Neutral, Comfortable, Very comfortable).

Percentage of responses per purpose and level (ordered left to right: Very uncomfortable, Uncomfortable, Neutral, Comfortable, Very comfortable). Infra stands for Infrastructure.
Actor and comfortableness (mean).

Purpose and comfortableness (means).

RQ1: Effect of location features, actors and purposes on privacy perceptions
Table 8 reports the ordinal-regression coefficients and odds ratios for actors, purposes and location features. Statistically significant coefficients indicate variables that have a significant effect on participants’ levels of comfort. The odds ratio quantify how much more or less likely the participants are to report higher comfort with respect to the baseline, holding all other variables constant. First, we analyze the effect of location features (individual trajectory and POI visit data) on privacy perceptions, including pairwise comparisons between location features and actors or purposes. Next, we report our main findings for actors and purposes, confirming significant insights found in prior work.
Regression coefficients for actors, purposes, features, ethnicity and education.

Odds ratio column is the likelihood of being more comfortable compared to the baseline class. Coefficients for the control variables are shown in the appendix, in Table 5. Significance **
Location features
Table 8 shows that participants reported statistically significant lower levels of comfort when sharing detailed trajectory data compared to detailed visits to POIs (the regression baseline). For example, the odds of being comfortable sharing Most Frequent Trips (Detailed) were 0.74 times that of sharing detailed visits to POIs. In other words, participants were significantly less comfortable with the use of detailed trajectory data than with the use of visits to specific types of POIs (e.g. restaurants, libraries, schools, etc.). As one participant stated: ”There is no good reason for them to monitor my trips on the regular at all.”(Participant-8a6a).
In contrast, participants expressed higher comfort levels sharing obfuscated trajectory data compared to detailed visits to POIs. For example, walking (Frequent Walking Activity) was 1.5 times more likely to be rated as comfortable and international trips (International Visits) were 1.44 times more likely to be rated as comfortable relative to the baseline.
Participants were also significantly more comfortable sharing their home and work locations (obfuscated to the census tract) than sharing detailed visits to specific POIs, although no significant difference was observed when home and work locations were not obfuscated (we discuss this further in RQ2).
These results reflect that if appropriately obfuscated, users are willing to share some forms of trajectory data. As Participant-D303 noted, ”This is general information and I would be interested in this as well”.
Subset of significant differences in (feature,actor) and (feature,purpose) pairs after applying Kruskal–Wallis analysis with post hoc Dunn test.

Complete results can be found in Table 6 in the appendix. M”i” represents median level of comfort value for distribution ”i.” Significance at p-value <0.05).
Actors and purposes
Our ordinal-regression results align with prior findings on the effect of actors and purposes on privacy perceptions (Martin and Nissenbaum, 2019; Vitak et al., 2022). Federal Government Agencies and Employers were significantly negatively related to comfort when accessing location data (Table 8). In fact, participants had 0.78 and 0.53 times the odds (p<0.01), respectively, of rating their level of comfort higher for these actors than for the baseline actor (Commercial Entities).
On the other hand, Academic Researchers, Emergency Services, Family members, and Doctors were positively related to levels of comfort, with participants having 1.7, 3.2, 4 and 2.9 times the odds (p<0.01) of rating their level of comfort higher for these actors than for the baseline actor (Commercial Entities).
For purposes, we observe that socially beneficial purposes such as Designing public infrastructure were perceived more favorably than marketing purposes (regression baseline), with the odds ratio being 1.79 times higher.
In contrast, generic purposes (e.g. Monitor mobility patterns) were associated with significantly lower comfort levels compared to the baseline, that is, people were approximately half as likely to be comfortable with sharing data (p-value<0.05).
Appendix Table 7 summarizes the KW and Dunn test results for the pairwise analysis between (actor, feature) and (purpose, feature) pairs. Here, we would like to highlight two significant findings. First, sharing walking activity (obfuscated) was associated with higher median levels of comfort (median
Finally, no significant differences were identified between purposes and location features, indicating similar levels of comfort independently of the trajectory feature or POI visit feature.
RQ2: Effect of obfuscating approaches on privacy perceptions
The Features column in Table 8 shows that several obfuscated trajectory and POI visit features are associated with statistically significant higher levels of comfort than their detailed counterparts (Places you visit (detailed) as baseline). Specifically, obfuscated frequent walking activity, obfuscated international trips, obfuscated home and work locations had 1.58, 1.4, 1.55 and 1.45 times the odds (p<0.05) of being rated higher in level of comfort than detailed places visited, indicating that individuals were more prone to sharing certain types of trajectory and visits data if protected by obfuscation approaches. Beyond statistical significance, it is important to highlight that all means (see Table 5) were higher for obfuscation features than for their detailed counterpart, for example, Home (Detailed
RQ3: Effect of race/ethnicity and education on privacy perceptions
Race and ethnicity
The results in Table 8 show that Hispanic participants reported significantly higher levels of comfort that White participants (regression baseline), having 1.6 times the odds (OR
”(In) this particular scenario I feel very comfortable with my data being accessed & used for this purpose. Hospital locations are important and their location within a community can severely impact the quality of life for that community too.” (Participant-2ae1). No significant difference in level of comfort was observed between any other racial or ethnic groups.
In contrast, Black participants perceived marketing purposes more positively (median
In contrast, for Asian and White respondents showed significant change in level of comfort between detailed and obfuscated features. For example, ”Most frequent trips (Detailed)” had lower median comfort (median
Education
We do not observe any statistically significant difference in comfort levels for different education groups when compared to participants with education high school to bachelors (baseline).
No statistical difference between detailed and obfuscated location data were observed for the other two educational groups (”High School to Bachelors” and ”Under High School”). Participants with a ”Bachelors and above” degree also showed significantly lower levels of comfort with purposes related to monitoring mobility (median
Participants in the “High School to Bachelors” group were significantly less comfortable sharing their location data with the Federal Government, Law Enforcement agencies (median
Implications for policy and practice
These findings suggest the need for implementation of more granular control mechanisms that allow users to specify which types of location features can be derived from the data collected. As DA&DB collect data from apps via SDKs, they could allow users to select their preferences of sharing feature clusters (defined in Table 1) during the app installation or permissions page. Users should also have a mechanism to control which actors may access their location features and for which purposes.
These findings could be used to pre-populate app settings for location data sharing. Settings could be detailed with actors or purposes, and include, the educational background of the person installing the app, thus reducing the burden of having to select among many different options from scratch.
However, offering granular controls can limit access to detailed variables valuable in specific circumstances, for example, monitoring evacuation during a disaster. Hence, companies using location data for societal benefit, could consider explaining well the benefits of sharing location data, encouraging users to support data for good initiatives; or could use economic incentives that would encourage participants to share more of their data.
Second, the FTC could promote meaningful data minimization by adopting an obfuscation-by-default rule, requiring companies to use privacy-preserving transformations unless users explicitly opt-in to granular data sharing. Importantly, the FTC could also incorporate equity-aware protections informed by our findings. Because comfort with specific data uses varies substantially across racial and ethnic identities, the agency could permit companies to offer empirically grounded, pre-populated privacy profiles that reduce user burden while preserving full control for individuals to modify defaults. Alternatively, the policies could default to the most cautious user. Further, to prevent disparate privacy risks, the FTC could require periodic assessments of racial and socioeconomic disparities in data exposure and mandate disclosures to users when certain groups face higher risks due to a company’s data practices. Together, these measures would ensure that location data governance is not only transparent and user-centered but also attentive to equity considerations evident in public preferences.
Limitations and future work
Our list of actors, purposes and features is not exhaustive, mostly due to a need to narrow down the number of potential actor-purpose-feature combinations to collect statistically significant information in the survey. Our research focuses on only 18 features derived from location data and examines how six actors may use these features for ten purposes. However, most actors do not publicly disclose the full range of purposes for which they use collected location data, except in limited cases such as academic publications or investigative reporting that uncovers significant privacy breaches by government or commercial entities. Important actors such as foreign entities purchasing U.S. data or large language model (LLM) developers using personal data to generate behavioral profiles are not captured in our framework. Similarly, additional purposes, such as selecting billboard locations or identifying optimal sites for new retail stores, could be considered in future work.
Future vignette designs could incorporate additional factors that influence comfort with data sharing, such as the time span of data collection, the presence of monetary incentives and the granularity of obfuscation (e.g. census tract vs counties, different radii of obfuscation). The manual assessment of free-form text responses could be replaced in future work by an LLM-based few-shot learning system, especially now that we have identified several examples of both high-quality and low-quality responses.
Conclusion
This study advances our understanding of the nuanced factors shaping privacy perceptions in location data sharing. By highlighting the importance of the type of location feature (trajectory or visits to POIs), the presence of an obfuscation approach, contextual factors such as actors and purpose, and privacy attitudes and demographic variations our findings provide a foundation for user-centric, feature focused approach to location privacy. Our results show that trajectory-related features are associated with higher privacy concerns, current obfuscation approaches by DA&DBs are sometimes successful, and that race, ethnicity and education have an effect on privacy perceptions with Hispanic participants and those with High School to Bachelor’s education reporting higher levels of comfort in location data sharing. As technology continues to evolve, ongoing research in this area will be crucial for developing privacy practices and policies that effectively balance the benefits of location-based services with individual privacy rights.
Supplemental Material
sj-pdf-1-bds-10.1177_20539517261429203 - Supplemental material for From “I have nothing to hide” to “Its stalking”: Americans’ comfort sharing individual mobility features
Supplemental material, sj-pdf-1-bds-10.1177_20539517261429203 for From “I have nothing to hide” to “Its stalking”: Americans’ comfort sharing individual mobility features by Naman Awasthi, Saad Mohammad Abrar, Daniel Smolyak and Vanessa Frias-Martinez in Big Data & Society
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.