
Abstract
The rise of synthetic data has begun to inspire novel data-driven projects in highly sensitive development contexts. For example, a collaboration between the UN's International Organization for Migration and Microsoft Research has resulted in the release of four “Global Synthetic Datasets” (GSDs) on human trafficking—the 2025 iteration of which contains information on over 222,000 trafficking survivors. These datasets are expected to support the combat against human trafficking by leveraging the privacy promised by synthetic data. While existing scholarship has explored political-economic, ethical, and legal implications of synthetic data, this article presents a situated case study of the GSDs, exploring data justice issues that arise when synthetic data are used in global development projects. Drawing on Linnet Taylor's 2017 data justice framework, this paper asks: how do synthetic data both extend and reconfigure questions of political economy, (in)visibility, disengagement, and non-discrimination in development contexts? Methodologically, the article employs a technography of publicly available materials related to the GSDs, additionally drawing from three key informant interviews. The analysis highlights that while synthetic data-driven development projects enable new knowledge, they continue long-standing critical concerns around the political economy of “data for development,” the visibilization of marginalized communities, and the datafied abstraction from lived experience. Thus, development scholars and practitioners ought to recognize the risk of “synthetic-washing,” where faith in the presumed safety and privacy of synthetic data obscures their entanglement with power asymmetries. This underlines the need for further research on frameworks for synthetic data justice, in development contexts and beyond.
Keywords
This article is a part of special theme on Datafied Development. To see a full list of all articles in this special theme, please click here: https://journals.sagepub.com/page/bds/datafied_development?pbEditor=true
Introduction
“The resulting dataset is the largest of its kind globally, with information on over 206,000 individual cases of human trafficking visualized throughout the site, including through interactive dashboards and global maps. Thanks to an algorithm developed together with Microsoft Research, a synthetic [emphasis added] version of this dataset is publicly available to download.” (Migration Data Portal, 2024).
The public availability of a dataset containing information about hundreds of thousands of human trafficking survivors should raise serious questions for scholars of data politics and development. The above quote, however, reflects a different view: namely, that sharing this kind of data has become tenable. In fact, the quote refers only to one iteration of thus far four “Global Synthetic Datasets” (henceforth GSDs) on human trafficking that have been published since 2021. These datasets are synthesized on the basis of underlying data contributed by the UN's International Organization for Migration and multiple anti-trafficking NGOs. Crucially, the synthetic data approach means that individual data points on cases of human trafficking do not directly correspond to individually identifiable persons. Being based instead on “statistical individuals,” the GSDs provide insights about the overarching structure and statistics of the underlying datasets. The GSDs are employed to produce more fine-grained knowledge about the socio-demographic dynamics of human trafficking and are thereby expected to support more effective policy interventions globally.
Releasing these data in a way that is safe, however, is said to have become viable only due to the specific affordances of “synthetic data”—artificially generated data that are used for various data science tasks (Offenhuber, 2024). While synthetic data proponents claim several potential benefits, their use in the above example is motivated by the particular promise that synthetic data—due to being untethered from individually identifiable humans—resolve privacy concerns (Helm et al., 2024). Data privacy is a particularly thorny problem in the context of migration and trafficking, where data often refer to highly vulnerable people whose identity must be protected at all costs (Beduschi, 2018). Thus, the case of the GSDs illustrates how the privacy promised by synthetic data inspires their use in highly sensitive domains, such as anti-trafficking practice.
Nevertheless, synthetic data do not come without problems. Emerging critical scholarship has interrogated the relationship between synthetic data and data capitalism (Steinhoff, 2022), AI ethics discourses (Helm et al., 2024; Jacobsen, 2023), data protection frameworks (Beduschi, 2024), and the hype underpinning their rise (Ravn, 2025). Moreover, machine learning researchers have challenged the notion that synthetic data imply inherent privacy guarantees (Stadler et al., 2022). Collectively, these studies show that synthetic data engender urgent political, ethical, and legal concerns. In this paper, I build on these studies but shift the analytical focus by developing a situated case study that unpacks the particular configuration of the GSDs. Concretely, this implies a contextually specific investigation of the GSDs’ history, their uses, and how they reshape development practices. This analytical shift is crucial if we are to better understand how synthetic data reconfigure practices in particular domains.
The objective of this article, then, is to attend to both the specificities of the GSDs and their embeddedness within wider sociopolitical contexts. To that end, the paper mobilizes a data justice framework, an approach that has been utilized in both critical data studies (Dencik, 2025; Taylor, 2017) and scholarship on “data for development” (D4D) (Heeks and Renken, 2018; Qureshi, 2020). Taylor's (2017) formulation, based on the four dimensions of political economy, (in)visibility, digital (dis)engagement, and non-discrimination, constitutes a uniquely suitable analytical scaffolding for this paper. This is because these dimensions directly resonate with critical scholarship on both synthetic data (Helm et al., 2024; Jacobsen, 2023; Steinhoff, 2022) and D4D (Mann, 2017; Taylor and Meissner, 2020). Mobilizing this framework allows me to ask: How do synthetic data both extend and reconfigure questions of political economy, (in)visibility, disengagement, and non-discrimination in the context of data-driven development projects? Asking this question is meaningful because synthetic data risk foreclosing critical discussions (Helm et al., 2024), while increasingly seeping into such highly sensitive domains as anti-trafficking.
The central contributions of this article are three-fold. First, it advances the critical literature on synthetic data (Beduschi, 2024; Helm et al., 2024; Jacobsen, 2023, 2025; Offenhuber, 2024; Ravn et al., 2025; Steinhoff, 2022) with a case study that examines how synthetic datasets function in particular empirical contexts, such as development practice. The data justice framework, moreover, provides a new critical angle that underscores how specific synthetic data projects remain steeped in relations of power, including the political economy of data, the (in)visibilization of vulnerable groups, and the datafied abstraction from lived experience. Second, the article shows that synthetic data do not constitute a fundamental break from long-standing insights produced by critical scholarship on D4D (Cinnamon, 2019; Mann, 2017; Taylor and Broeders, 2015) and anti-trafficking (Mendel and Sharapov, 2022; Musto et al., 2020; Uhl, 2017). While synthetic data potentially offer new evidence, they remain grounded in power asymmetries—and risk perpetuating them. Furthermore, the fabricated inaccuracies of synthetic data (Lee et al., 2025) introduce a unique new risk and challenge for development projects. Finally, by articulating data justice questions for synthetic data, this article brings the political and epistemological concerns raised by synthetic data into the purview of data justice scholarship (Dencik, 2025; Heeks and Renken, 2018; Taylor, 2017). This undertaking is worthwhile because data justice scholarship offers unique sensibilities to foreground how synthetic data projects may affect communities that have been historically marginalized, underlining the continued relevance of data justice frameworks in the age of synthetic data.
The article proceeds in five steps. First, I situate the case study of this paper within the context of the rise of synthetic data, the political economy of “data for development,” and data-driven anti-trafficking approaches. Then, I unfold the conceptual approach of this paper, formulating data justice questions for synthetic data. Third, I explain my methodology that combines technography of publicly available materials with a small set of key informant interviews. In the analysis, I investigate how the GSDs relate to questions of political economy, (in)visibility, digital (dis)engagement, and non-discrimination. Finally, the concluding discussion articulates how this study contributes insights to critical scholarship on synthetic data, data justice, and datafication in development contexts.
Context
The rise and politics of synthetic data
In recent years, the emergence of synthetic data has inspired a growing body of scholarship that interrogates their ethical, political, and legal implications. As Offenhuber (2024) demonstrates, there are many shapes of synthetic data, including but not limited to algorithmically generated data, statistically imputed data, augmented data, and mimicry data. Moreover, he suggests that synthetic data cement the need to depart from a representational towards a relational data model, one that foregrounds the socio-political and institutional relations within which synthetic data are embedded. Taking a political economy perspective, Steinhoff (2022) analyses how synthetic data signal a move away from surveillance capitalism towards a capitalism of bespoke data production. Crucially, he suggests that synthetic data may contribute to the automation of AI systems’ production. Jacobsen (2023), on the other hand, subtly demonstrates how various companies position synthetic data as a fix to the ethical problems of machine learning algorithms, allegedly rendering them risk-free. He argues against this, proposing that scholars remain attentive to how synthetic data shape ideas of the social good, (ab)normality, and notions of difference. Similarly, synthetic data often serve to silence critical debates about the socio-political implications of AI (Helm et al., 2024), usually underpinned by a misleading dichotomy between raw and synthetic data. In addition, it has been shown that the expectations surrounding synthetic data have evolved to the point that they are now imbued with a range of generalized promises (Ravn, 2025).
While all these are important insights, most relevant for the purposes of this article are: first, the relational model of synthetic data, which underlines the socio-political relations within which the datasets are embedded; second, the insistence that synthetic data do not foreclose debates about the ethics and politics of data; and third, the insight that synthetic data are qualitatively different from other kinds of data, underlining the need to study the implications of this distinctiveness. Moreover, this literature crucially attests to the multiplying ways in which synthetic data are already being used, including in healthcare research, policymaking, and the prevention of human trafficking (e.g. the GSDs) (Beduschi, 2024). Synthetic data, thus, are already reshaping the development sector, a domain with a long history of datafication (Mann, 2017).
The political economy of (big) “data for development”
Emerging in the early 2010s, “data for development” (D4D) discourses extend longer-standing “information and communications technologies for development” (ICT4D) ideas by positing that digital (big) data can help improve human welfare (Cinnamon, 2019; Hilbert, 2016; Mann, 2017). Specifically, the notion is that big data enable knowledge about vulnerable populations’ well-being with higher levels of frequency and precision (Qureshi, 2020), thereby facilitating better development solutions. Moreover, D4D discourses rest on the premise that technology is a force for good and that data solutions produce win-win outcomes, often portraying marginalized communities as the primary beneficiaries (Mann, 2017; Taylor and Broeders, 2015).
Many scholars have noted the problems of the assumptions underlying D4D discourses. For one, powerful international technology companies often assume a central role in D4D initiatives (Taylor and Broeders, 2015). Specifically, the power relations underpinning D4D frameworks enable these firms “to gain access to the data, networks, support and expertise of non-profit entities,” which then “allows them to expand their businesses and position themselves as indispensable partners” (Mann, 2017: 5). This has crucial political economy consequences because such data infrastructures often facilitate the transfer of data from Global South countries to the Global North (Mann, 2017), thereby reinforcing historical power asymmetries. Therefore, it matters who governs data infrastructures in development contexts and to what consequences. Importantly, the strategic positioning of technology firms as contributors to philanthropic causes is not a new phenomenon; it is also reflected in humanitarian efforts (e.g. Madianou, 2021) and AI/tech “for good” discourses (e.g. Magalhães and Couldry, 2021). Concretely, Henriksen and Richey (2022) note that capitalism and humanitarianism have historically gone hand in hand. They argue that modern corporate philanthropic operations and models of firms like Google are not necessarily innovative. Instead, they suggest that the distinction between tech for good and tech for profit—as well as between philanthropy and capitalism—has become increasingly blurred. Hence, development projects that depend on data must be scrutinized, particularly regarding the power asymmetries of involved actors.
These insights into the political economy of (big) D4D and tech-for-good discourses in development and humanitarian projects enable us to understand the GSDs as a continuation of precisely such D4D endeavors. Importantly, they also sensitize us to the politics of Microsoft's involvement in the GSDs. Notably, while Microsoft has promoted human rights through technology for over a decade (e.g. Microsoft, 2013), their involvement in seemingly benign tech projects has also been described as a tactic to deflect attention from problematic practices (Kwet, 2020). The politics of using data technologies to combat trafficking is the subject of the next section.
Data-driven anti-trafficking: Between evidence and techno-solutionism
Various scholars have remarked upon the potential for digital data to provide valuable evidence for anti-trafficking efforts (e.g. Beduschi, 2018). For example, Milivojevic et al. (2020) suggest that technology may under certain circumstances support information sharing, safety mechanisms, and strategy-building against exploitation. Their central argument is that technology can productively help contextualize problems. Moreover, Chen and Tortosa (2020) recall a case in which digital evidence proved vital to constructing a case against perpetrators. Based on this, the authors stress the need to establish how technologies may aid the exercise of trafficked persons’ rights, emphasizing the need to center on humans rather than technology. The use of digital data in anti-trafficking efforts, hence, can facilitate the production of important insights.
At the same time, the production of and access to human trafficking data has historically often involved and relied on problematic public-private collaborations (Uhl, 2017). For example, a 2013 collaboration between several non-profit anti-trafficking organizations (including Polaris and La Strada International) and Google, Palantir, and Salesforce was devoted to building a global database on trafficking routes (Ungerleider, 2013). This endeavor has been critiqued for enabling global data industries to assume a central role (Uhl, 2017). Musto et al. (2020) provide a similarly critical account of the use of technology in anti-trafficking, lamenting a deep-seated techno-solutionism that persists despite a lack of evidence regarding how technology enables or unsettles human trafficking. Significantly, the authors suggest, such technological solutions often benefit technology corporations by perpetuating the underlying capitalist structures that condition vulnerability to trafficking in the first place. In a further study, Musto (2020) points to critical questions that must be asked of such data-driven projects, importantly entailing whether people who may be vulnerable to trafficking have a say in how their data are utilized. Centrally, the author highlights the need to interrogate who benefits and who is harmed when complex experiences of vulnerability are translated into decontextualized data. Often, technology corporations benefit from data-driven initiatives while already vulnerable communities risk being subjected to intensified profiling and surveillance (Musto, 2020).
These critical insights on synthetic data, the political economy of D4D, and data-driven anti-trafficking bring to the fore the relevance of data justice questions for investigating the GSDs. Building on this, the following section unfolds this paper's conceptual approach, formulating data justice questions for synthetic data projects.
Towards data justice questions for synthetic data
Data justice has been conceptualized and operationalized from multiple angles, including in the context of open data (Johnson, 2014), international development (Heeks and Renken, 2018), and social justice (Dencik, 2025). These different approaches are united by a commitment to asking how social justice is affected by the growing ubiquity of data-driven practices. Taylor (2017) offers an overarching framework for data justice, highlighting three foundational pillars: (in)visibility, digital (dis)engagement, and non-discrimination. Beyond these pillars, Taylor (2017: 8) emphasizes the need to engage with the political economy of data, specifically related to the actors holding the power to shape and govern data infrastructures. Her approach to data justice directly draws from Sen's (1999) capability approach to justice, which foregrounds people's agency and the extent to which they can exercise freedoms. Significantly, a capabilities approach to data justice starts from the question of “what functionings people value with regard to data technologies” (Akbari, 2025: 8; see also Heeks and Renken, 2018: 98), for instance related to privacy, representation, and non-discrimination. Accordingly, by drawing from Taylor's (2017) data justice framework, my approach most closely approximates a capabilities approach to synthetic data justice. This is uniquely pertinent to the purposes of this article because the dimensions of political economy, invisibility, digital (dis)engagement, and non-discrimination critically intersect with long-standing critical data studies insights as well as with emerging political and epistemological concerns raised by synthetic data. However, anchoring perspectives of synthetic data justice in other justice frameworks—such as Marxist or feminist traditions (Dencik, 2025)—would doubtless constitute an equally worthwhile undertaking.
First, the political economy dimension of Taylor's (2017) data justice framework highlights the need to engage with the underlying capitalist forces shaping data-driven projects, centrally related to their who and how. As noted above, it is often big tech firms who have a strategic interest in positioning themselves as indispensable players in humanitarian and development projects (Henriksen and Richey, 2022). This insight is crucial for data justice scholarship because technology companies, in this way, effectively establish infrastructural dependencies (Mann, 2017). More recently, the political economy of data and AI has highlighted the increasing centralization of data infrastructures operated by large technology companies (Luitse, 2024; van der Vlist et al., 2024). The emergence of synthetic data, however, poses new political economy questions. Concretely, early research speculated about the emergence of a data capitalism without surveillance due to the tailored producibility of synthetic data (Steinhoff, 2022). More recently, however, Steinhoff and Hind (2025) suggest that synthetic data add new layers to pre-existing technological stacks. Against this backdrop, a relevant data justice question presents itself: whose technology is strategically positioned as indispensable to data synthesis and to what consequences?
Second, with the (in)visibility pillar, Taylor (2017) refers to privacy and access to representation. Particularly relevant here are insights regarding the tensions between individual and group privacy (Helm, 2016). Synthetic data reinvigorate these (in)visibility concerns insofar as privacy is posited as one of their central promises (Beduschi, 2024). While this privacy promise should not be taken for granted in the first place (Stadler et al., 2022), the crucial point about synthetic data privacy is that it tends to rely on an individualistic conception of privacy (Ravn et al., 2025). Concretely, even if individual synthetic data points may be private, synthetic datasets are not detached from people's group memberships. For example, synthetic datasets about people living in a particular district may still shape these people's lives as inhabitants of that district (Helm et al., 2024: 3). This insight also speaks to more recent data justice scholarship that places emphasis on collectivities emerging through datafication (Dencik, 2025). Accordingly, an important corresponding data justice question demands attention: who or what becomes visibilized in and through synthetic datasets?
Third, digital (dis)engagement refers to autonomy in technology choices as well as the ability to share in data's benefits (Taylor, 2017). While critical data studies research has long pointed to the absence of data subjects’ autonomy in datafication processes (Benjamin, 2019; Taylor and Meissner, 2020), recent data justice scholarship has also problematized frameworks relying on notions of autonomy (Dencik, 2025). Nonetheless, here I mobilize the concept of autonomy in technology choices because synthetic data amplify existing problems with respect to it: synthetic data constitute further abstractions away from lived experience (Kapania et al., 2025; Ravn et al., 2025). For instance, tabular synthetic data usually don’t correspond to individual people in a one-to-one way, instead modelling the underlying dataset's relationships (Beduschi, 2024). This relates to data subjects’ possibility for autonomy in technology choices in the sense that “synthetic data undermines stakeholders’ ability to exert meaningful agency over AI systems” (Kapania et al., 2025: 11). Agency, however, is a crucial concern for trafficked individuals because they are often elided and harmed by the use of data-driven technology (Musto, 2020). Consequently, there emerges a crucial question: How do synthetic data perform new abstractions away from the lived experience of vulnerable communities and how do these reconfigure degrees of autonomy and the capacity to reap data's benefits?
Finally, the non-discrimination dimension relates to the ability to challenge biases and the prevention of discrimination (Taylor, 2017). These concerns have been integral to critical data studies scholarship, which has long pointed to the structures and mechanisms that fuel data biases and discrimination (boyd and Crawford, 2012)—often harming already marginalized communities most. For example, large datasets often encode racist and sexist stereotypes (Crawford, 2021); the use of data-driven technologies tends to amplify the surveillance of societies’ most vulnerable groups (Benjamin, 2019). In this context, synthetic data pose new issues: first, since they allow the tailored generation of differences devoid of sociopolitical frictions (Jacobsen, 2025), synthetic data seem to render moot critiques of data bias. While this argument pertains to synthetic training data for machine learning, the GSDs primarily serve the purpose of demographic research. Therefore, the GSDs still invite the long-standing investigation of the biases they perpetuate. Second, tabular synthetic data constitutively rely on what Lee et al. (2025) call “intersectional hallucinations”: the fabrication of attribute combinations that do not exist in the original data modelled by synthetic data. In light of this, an old and a new question arise: What biases persist in synthetic datasets? And: how are the intersectional fabrications of tabular synthetic datasets governed?
In this paper, thus, I understand synthetic data justice as a framework that facilitates critical questions about political economy, (in)visibility, digital (dis)engagement, and non-discrimination in the context of specific synthetic data projects. This provides a new angle to synthetic data studies that decidedly foregrounds how core data justice concerns remain of utmost relevance in the age of synthetic data. This is crucial because the use of synthetic data in highly sensitive development contexts demands an analytical framework capable of confronting justice issues. The following section provides an overview of the methodology I mobilize to investigate the GSDs.
Methodology: A technography of synthetic datasets
Aligned with the objective to provide a situated analysis of the GSDs, I analyze my empirical material by drawing from technography. Technography is a methodology that aims to carve out the broader social implications of technology by closely investigating its technical aspects, to that end drawing from a wide range of empirical material. What importantly distinguishes technography from other approaches is that it facilitates analyses that stay close to the technical workings of technology while also cultivating a critical sensitivity to how these are always thoroughly social.
Here, I draw inspiration from the growing variety of ways in which technography is operationalized in social studies of digital technology (Bucher, 2018; Luitse, 2024; Rieder and Skop, 2021; Steinhoff and Hind, 2025; van der Vlist et al., 2024). In her formative development of the approach, Bucher (2018: 60) characterizes technography as “a way of describing and observing the workings of technology in order to examine the interplay between a diverse set of actors (both human and nonhuman).” Importantly, technographic inquiry does not attempt to reveal the hidden truth of technologies, but instead to “develop a critical understanding of the mechanisms and operational logic” (Bucher, 2018: 61) inherent to them. For instance, in their study of cloud infrastructure, van der Vlist et al. (2024) realize such a detailed examination of technology's material aspects by drawing from a wide range of empirical materials, including technical documentations, product websites, press articles, and blog postings. By upholding “a critical stance towards promotional language or industry jargon found in these materials” (van der Vlist et al., 2024: 4), they demonstrate that the technical aspects of cloud infrastructures are deeply social in how they condition the wider industrialization of AI. Importantly, they also highlight that technography is both descriptive and interpretative (van der Vlist et al., 2024: 4): descriptive because of the emphasis placed on technological functionality; interpretative due to the focus on explaining the implications of these material aspects. Moreover, Luitse (2024: 4) develops an “evolutionary platform technography” that critically traces the development of digital platforms’ technical systems over time. Similarly, her technographic approach facilitates important insights into how cloud platforms configure technical aspects of their products in ways conducive to consolidating their infrastructural power. In the context of synthetic data, Steinhoff and Hind (2025) have productively forged a historical approach to technography. By drawing from archival materials, they shed light on the materialities of different historical regimes of simulation. What unites these different mobilizations of technography is that they investigate the social implications of digital technologies by staying close to their respective technical characteristics.
In this study, I draw from these technographic sensibilities to foreground how the GSD's technical aspects—its data sources, mechanism of synthesis, and uses—relate to the data justice concerns articulated in the conceptual framework. As the analysis will show, seemingly minute aspects of the “Global Synthetic Datasets” invite critical data justice considerations.
Empirically, this article enacts the technographic approach by mobilizing a wide range of publicly available sources about the GSDs, including press releases, YouTube videos, codebooks, digital interfaces, and PowerPoint explainers. These were located by means of a systematic online search for publicly available materials produced by the involved project partners, including the IOM, Microsoft Research, and The Counter Trafficking Data Collaborative (CTDC). Accordingly, the resulting body of empirical material approximates an exhaustive overview of all publicly available sources regarding the GSDs. The benefit of mobilizing this diverse range of materials is that it allows a comprehensive picture of the GSDs’ technical specificities as well as the narratives surrounding them. Additionally, in October 2024, I conducted three key informant interviews with practitioners, selected and recruited on the basis of being directly and centrally involved in the GSDs’ production. The number of people directly engaged in the GSD's production was relatively limited due to the project's small scale, hence the rather small number of interviews. My informants worked for two different organizations: an innovation research lab and a multinational service provider. They spanned three different professional roles: a technology analyst, a global migration expert, and a quantitative data analyst. They were engaged in multiple stages of the GSDs’ lifecycle, including their production, successive updates, and support of downstream uses. Thus, the interviews were highly conducive to gaining a deeper understanding of the sociotechnical processes surrounding the GSD's production and uses. This body of empirical material was iteratively analyzed by means of thematic analysis (Bryman, 2012) geared towards the outlined data justice dimensions of political economy, (in)visibility, digital (dis)engagement, and non-discrimination. The Appendix contains a comprehensive overview of these materials.
This study has a few limitations. First, the breadth of the empirical material is constrained to the particular case of the GSDs. As of 2025, these are the only publicly available synthetic datasets on human trafficking. Nonetheless, they are outstanding in terms of size and institutional collaboration, therefore meriting scholarly analysis. Second, the GSDs constitute a specific form of tabular synthetic data, exemplifying but one form of the different shapes of synthetic data (Offenhuber, 2024). Still, analysing the GSDs is meaningful because they constitute an example of how synthetic data, as a distinctive data technology, reshape anti-trafficking practice. Finally, this case study focuses on organizational and professional perspectives of synthetic data in anti-trafficking practice. While community perspectives are not explicitly documented in the materials gathered, the NGOs involved are advocates for communities affected by trafficking.
Analysis
Evolution, political economy, and uses of the Global Synthetic Datasets
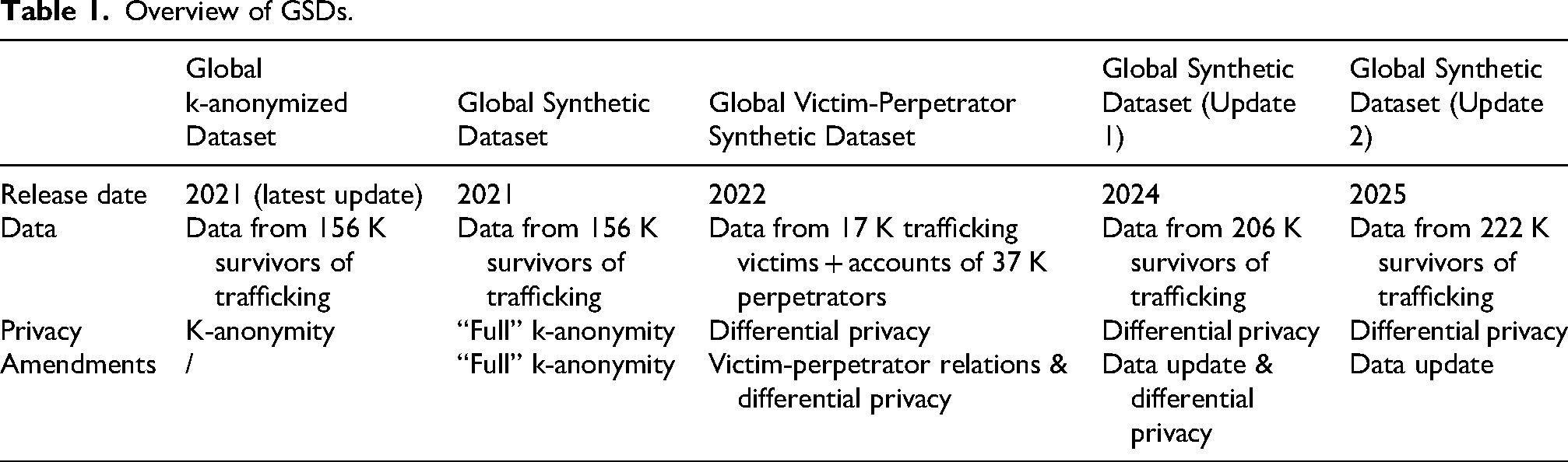
The “Global Synthetic Datasets” (GSDs) have grown out of a collaboration between the UN's International Organization for Migration (IOM), the Counter Trafficking Data Collaborative (CTDC), and Microsoft Research. While the CTDC—itself an initiative of the IOM—was launched in 2017, it was the 2019 Tech Against Trafficking (TAT) accelerator program that laid the foundation for the GSDs’ production. The TAT is a “coalition of technology companies collaborating with global experts to help eradicate human trafficking using technology” (TAT, n.d.a), including Amazon, Salesforce, BT, and Microsoft. The 2019 accelerator program's core participant was the CTDC, the aim of whose participation was to reduce “barriers to information-sharing” so as to “get data to public and policy audiences” (TAT, n.d.b). Importantly, the CTDC pools the data on survivors and perpetrators of human trafficking from the IOM and several anti-trafficking organizations, including Polaris, Recollectiv, A21, and OTSH. These data consist of case file data and hotline data (CTDC, 2025, february 2025), constituting the basis for the GSDs. The reason why the CTDC got involved with the accelerator program was that its previous data de-identification method, k-anonymization, engendered a range of problems (CTDC, 2024, february 2024). Simply speaking, k-anonymization entails the removal of data that belongs to sets of less than k members, where “each set is defined by a unique combination of values of the different variables in a dataset” (CTDC, n.d.a). Accordingly, the precursor to the GSDs, the “Global K-anonymized Dataset,” was characterized by two central issues: first, k-anonymization led to 40% of the cases being removed from the dataset, meaning “the loss of much potentially useful and crucial data” (IOM, 2024); and second, 40% were unique and hence potentially “linkable to individuals in the world” (Microsoft Research, 2022b). This problematization of the k-anonymization technique is a recurring motif in the discursive necessitation of synthetic data.
The ecosystem of actors involved in the 2019 TAT accelerator, for our purposes most centrally involving Microsoft Research, developed a synthetic data solution to the problems posed by k-anonymization. The resulting release of the first “Global Synthetic Dataset” occurred in 2021. For this, IOM used a new algorithm developed by Microsoft Research (CTDC, 2022) to achieve “full” k-anonymity through synthetic data—ensuring k-anonymity for all combinations of attributes, not merely those designed as “quasi-identifiers” (CTDC, 2022: 10). Crucially, this first synthetic dataset resolved the issue of data loss and managed to preserve “the statistical properties and relationships in the original data” (IOM, 2021). In December 2022, the CTDC published the second synthetic dataset—the so-called “Victim-Perpetrator Synthetic Data” with two new features: first, it contained data on the relations between victims and perpetrators; second, it came with “differential privacy”—a method that offers mathematical privacy guarantees. The third and fourth synthetic datasets were released in February of 2024 and 2025, featuring extensions in size and the guarantee of differential privacy (Migrant Protection Platform, 2024, 2025).
Significantly, Microsoft Research assumed a central role in the production of the GSDs. One informant stated: “I feel that we should give all the credits to Microsoft Research because they are the people to be developing this tool so that we can basically make this application available to any organisation.” (Quantitative Data Analyst, 10/10/2024)
Concretely, Microsoft Research was responsible for developing the project's synthesis approach by embedding the differential privacy approach in the GSDs. Differential privacy (DP) is a method that ensures mathematical privacy guarantees that go beyond k-anonymity; this approach is particularly relevant for datasets where successive data releases with data overlaps are planned. The DP framework was itself developed by scholars working at Microsoft Research (Dwork, 2006), and while it is widespread in the context of synthetic data (Beduschi, 2024), it relies on a narrow framing of privacy and has also been subject to critique (Orwat et al., 2024: 9). Notably, in a self-published case study, Microsoft explains its participation in the GSDs as a way “to combat forced labor in its supply chain, and tackle the issues of human trafficking, exploitation, and child trafficking more broadly” (Microsoft Research, 2021; see also Microsoft, 2013). While Microsoft Research never accessed the highly sensitive data pooled by the CTDC themselves (Microsoft Research, 2021), there still emerges a data justice concern. Specifically, a technology company with a strategic interest in data technological solutions here actively shapes the synthesis approach by which the phenomenon of human trafficking is tackled.
Finally, the GSDs are put to a variety of uses. Most centrally, they serve the production of new knowledge regarding the socio-demographic dynamics of trafficking survivors. For instance, this includes the CTDC's publicly available “data stories” (CTDC, n.d.c) and maps (e.g. CTDC, n.d.b). While the former provide demographic insights into particular aspects of human trafficking (e.g. abducted victims and perpetrators of trafficking), the latter facilitates exploration of the geography of human trafficking via a world map interface. The quantitative data analyst I spoke to remarked that the entire micro dataset is useful primarily to researchers. Importantly, the knowledge produced on the basis of the GSDs is imagined as capable of influencing policy interventions that address human trafficking: “What they're very useful for is pointing to the existence of a problem, right? There's a problem and it's at least this big, and it affects these kinds of people in these kinds of ways. And often that's enough to kind of like trigger the policy actions downstream.” (Technology Analyst, 01/10/2024)
While one informant stated that they are not authorized to speak about specific examples of how the GSDs figure in policy interventions, they did provide an idealized outline of how this occurs in practice: “But we know that what colleagues tend to use it [the GSD] for, for instance, is informing project proposals and also sort of engaging with their government counterparts because […] a lot of the time, the question is: How do we measure this [the extent of human trafficking]? […] And that's one of the things that they can really use our data for.” (Global Migration Expert, 07/10/2024)
Here, my informant describes how the GSDs’ unique granularity substantially improves knowledge of the scale, dynamics, and demographics of human trafficking in particular geographic areas. According to them, these features are conducive to supporting governmental actors in their design of policy responses to human trafficking. Thus, the GSDs are used to produce more fine-grained evidence about human trafficking, which in turn is leveraged to support policy interventions. While this section provided an overview of the evolution, political economy, and uses of the GSDs, the next turns to an analysis of (in)visibility (Table 1).
Overview of GSDs.
(In)visibility: The data sharing imperative and “statistical individuals”
The two central aspects of (in)visibility in Taylor's data justice framework are privacy and data subjects’ access to representation. In the case of the GSDs, these two are connected: because of the belief in synthetic data's provision of higher levels of privacy, it becomes tenable for “IOM and CTDC to share data that couldn’t otherwise be shared, helping address problems that couldn’t otherwise be solved” (Edge and Larson, 2021). This is argued to be in the service of victims and survivors of trafficking as there is an “urgent need to ensure that vulnerable populations are both represented to those making evidence-based policy decisions while also being protected from those who would cause them harm” (Edge et al., 2020: 1). In this rendition, the data sharing itself is believed to be beneficial, also echoed by one informant: “[…] there is also a belief within the community and from our side as well that better data and more data will also lead to better interventions.” (Global Migration Expert, 07/10/2024)
Importantly, the belief in synthetic data's privacy facilitates the publication of data “with a precision and scale that couldn’t otherwise be imagined” (Microsoft Research, 2022a). On a first level, then, synthetic data fits into a basic premise of well-entrenched big data imaginaries in development contexts (Taylor and Meissner, 2020): the more data the better, here making more visible the underlying phenomenon of human trafficking.
At the same time, the synthetic data also enact a reconfiguration with regard to representation and visibility. Particularly, the individual data points in the GSDs “no longer correspond to actual individuals” (IOM, 2021), since they are synthetically generated. Here emerges the crucial difference between “real” records and synthetic data: “whereas […] real records whose details on demand may lead to insights about an individual record, this is not the case for synthetic microdata in which each record represents a “statistical individual” rather than an actual person (or an “identifiable natural person” as described in the GDPR).” (Edge et al., 2020: 11). Instead, the visibility generated by the GSDs is on the level of “the structure and statistics of the original data” (Edge et al., 2020: 5). What the datasets visibilize, then, are primarily the overarching statistics about the population assembled within the GSDs. This dynamic is moreover reflected in the interfaces for which the GSDs form the basis. Concretely, the publicly available dashboards based on the GSDs facilitate exploration exclusively of the assembled population's overall features (see Figure 1).
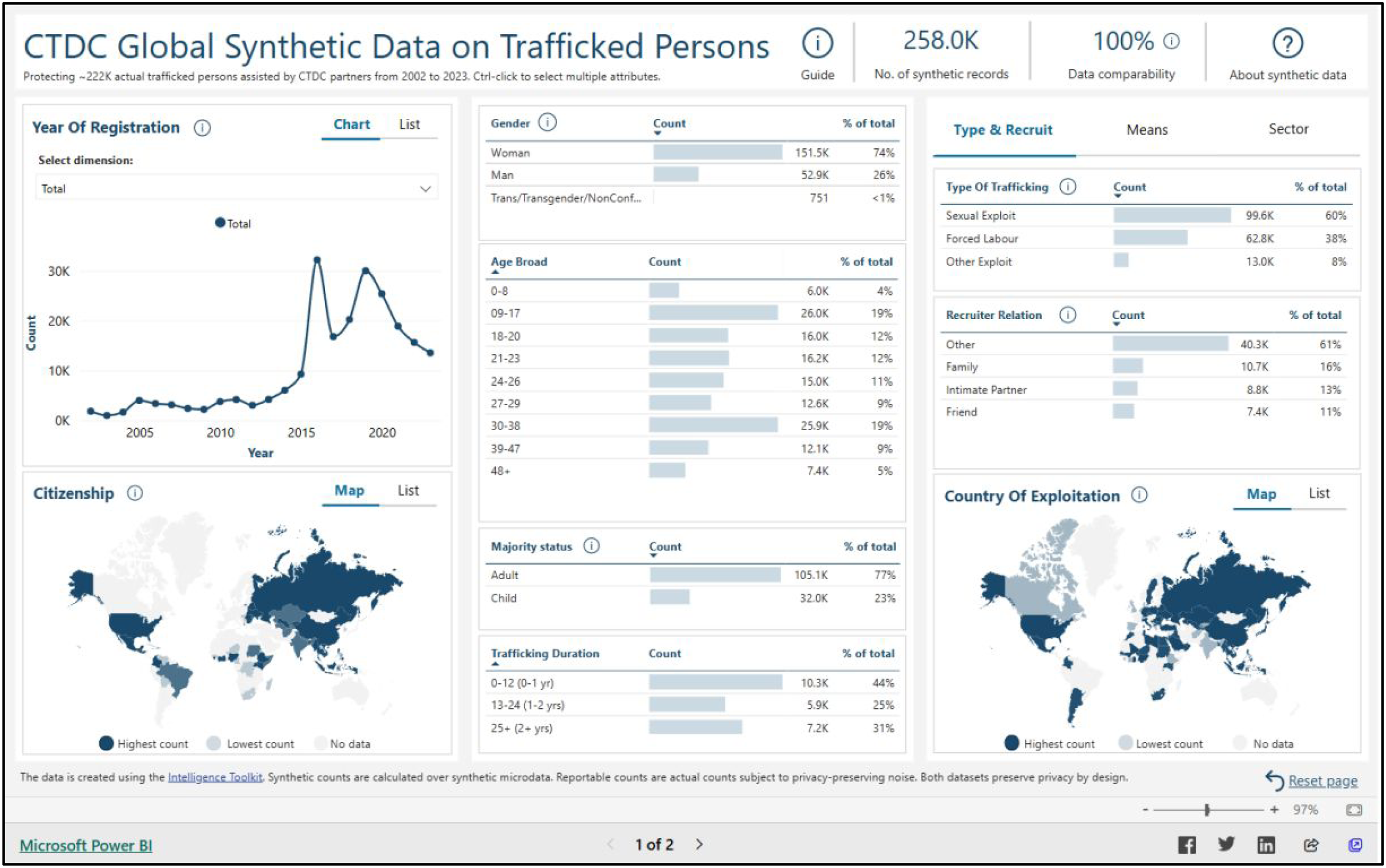
Interface based on 2025 GSD.
This surfaces a crucial insight with regard to the (in)visibility dimension of data justice: even if the dataset's “statistical individuals” are indeed private, this overlooks that the GSDs visibilize parts of the population of trafficked persons. Put differently, the characterization of the GSDs as private relies on a conceptualization of privacy as an individual affair, when in fact group membership is entangled with a given person's privacy. Specifically, synthetic data may render trafficked humans visible as members of the population of trafficked individuals, thereby still potentially shaping individual's lives (see also Helm et al., 2024). Therefore, the use of synthetic data to address development issues does not obviate long-standing questions of the privacy and protection of vulnerable communities in development practice (Musto, 2020).
Digital (dis)engagement: Synthetic abstraction and data removal
The digital (dis)engagement dimension of Taylor's (2017) data justice framework concerns both autonomy in technology choices and the ability to share in data's benefits. First, autonomy in technology choices gives rise to a complex issue in the context of the GSDs, relating centrally to the mechanism of data synthesis being employed. Importantly, autonomy here entails also the possibility of opting out of data processing. On the one hand, some contributing organizations explicitly state that the trafficking survivors whose data they contribute to the GSDs have the right to withdraw their data as they please: “Survivors reserve the right to remove their data from A21 records at any time” (CTDC, n.d.d) “Upon request, Polaris will remove information about contacts who do not wish to be included in the dataset” (CTDC, n.d.e)
While this should of course be the case, it is complicated by two factors. On a first level, the four GSDs have been made publicly available, meaning that disengagement from previously released datasets is difficult to perform (an issue that is not new, see Thylstrup et al., 2022; Taylor et al., 2025). More importantly, disengagement from the dataset is complicated in light of the data enacting “statistical individuals” rather than corresponding to actual individual persons. Here, the statistical individuals perform an additional layer of abstraction in the sense of being more untethered from lived experience than simply de-identified data. While this is precisely the unique feature of synthetic data in the case of the GSDs, it also means that one person's removal of consent does not simply correspond to one data point less in the dataset. Instead, what is implied by opting out of the GSDs is that one's data would not form part of the data to which the synthetic data algorithm is applied in the first place, thereby reshaping the very fabrication of these statistical individuals. Thus, the further abstraction from lived experience that synthetic data enact complicates the justice concern of disengagement. Specifically, synthetic data further complicate the well-established problem of how decontextualized data circumscribe vulnerable populations’ autonomy (Taylor and Meissner, 2020).
These datafied abstractions, however, cannot be disentangled from the ability to share in data's benefits. This is because they are deeply related to the suggested advantages emanating from the synthesis mechanism underlying the GSDs: on one hand, multiple data releases are enabled through differential privacy; on the other, sensitive micro-scale analysis becomes possible through “statistical individuals.” The abstractions performed by the GSDs’ synthesis approach are precisely what equips them with the supposed benefits of privacy, implying a complication of autonomy in technology choices.
Non-discrimination: (Un)known biases and fabricated inaccuracies of synthetic data
Finally, the third dimension of Taylor's (2017: 9) framework concerns non-discrimination, entailing both the ability to “identify and challenge bias in data use” as well as the prevention of discrimination through data. These are especially relevant since critical scholarship has interrogated the claim that synthetic data eliminate biases (Helm et al., 2024).
Notably, the parties involved in the production of the GSDs are candid about the dataset's biases, as exemplified in the 2025 version's codebook: “This sample may be biased if certain types of trafficking or socio-demographic groups are more likely to be identified or referred to than others. Since the unidentified population is by definition unknown, the extent of bias is not known and cannot be corrected for.” (CTDC, 2025, february 2025: 4). Similarly, these data are geographically limited in the sense that “Data are only available where the contributing organizations are operational and can share such data” (CTDC, 2025, february 2025: 4). While acknowledging the unknowability of the biases, one informant gave an example of underreporting in the GSDs: “[…] most likely people in the absolute worst forms of trafficking or in the most severe conditions are often the ones who are least able to seek assistance or be assisted. So, I would say that that's probably another potential bias in the data.” (Global Migration Expert, 07/10/2024)
These quotes bring to the fore that the institutional inability to reach those survivors in the most severe conditions crucially shapes the GSDs. As another interviewee pointed out, these biases stem from the correspondence between GSDs and underlying data: “[…] the synthetic data basically retains the properties of the original data. So, I think it's important when you’re talking about biases, it's basically related to the original data.” (Quantitative Data Analyst, 10/10/2024) “We don’t want to be making things up, but differential privacy has to allow for some fabrication. So again, we went to great lengths to minimize the amount of fabrication that we get in theses synthetic datasets that we generate. We can’t eliminate it and keep differential privacy, but we can do our best to keep it down.” (Technology Analyst, 01/10/2024)
The data synthesis also explains why the 2025 iteration of the GSDs contains 257,969 rows of data while being based on the data of 222,852 survivors of trafficking—fabrication is an inescapable aspect of synthesis (Lee et al., 2025). Crucially, the amount of fabrication may pose risks in that it may precipitate misleading knowledge, which may then induce misplaced policy interventions. The synthetic data are not always the best representation of evidence: “There's a kind of quirk with the synthetic datasets that the synthetic data is not the best representation of the kind of cases with a combination of attributes. The aggregate dataset is the better kind of representation of that.” (Technology Analyst, 01/10/2024)
It therefore becomes crucial to communicate the extent to which the synthetic data represent the aggregate count that is sometimes more accurate. The publicly available interface that allows exploration of the GSDs, for example, features a “data comparability” metric that quantifies the extent to which synthetic and protected aggregate count are comparable when multiple attributes are selected (see Figure 2).

2025 GSD interface's data comparability metric.
Concretely, in this example, when querying the dashboard for survivors in the age category of 39–47 who have been subject to trafficking for a duration of 13–24 months, we see that the actual protected count is 795 whereas the synthetic count is only 524. This example provides us with a crucial insight regarding the data justice dimension of non-discrimination: the GSDs, like all synthetic tabular data, are always subject to fabrications (Lee et al., 2025). These must be understood and navigated carefully to avoid deceptive knowledge production. This is especially important in development contexts, such as anti-trafficking, where misleading knowledge risks harming highly vulnerable populations (Musto, 2020). In this way, the need to understand and govern the constitutive fabrications of synthetic data introduces a new challenge for development projects.
Concluding discussion: The need for synthetic data justice
The case study of the “Global Synthetic Datasets” (GSDs) demonstrates the continued relevance of data justice frameworks in the context of synthetic data, underlining the need for synthetic data justice. Regarding political economy, we saw how Microsoft Research assumes a central role in the GSD's production by developing the data synthesis algorithm, concretely shaping the project's trajectory by embedding the individualistic differential privacy approach. Data synthesis techniques, thus, become part of the toolkit by which powerful technology companies assume strategic involvement in data-driven development projects, such as anti-trafficking endeavours. Furthermore, the analysis of (in)visibility highlighted that the GSDs consist of “statistical individuals” that seemingly offer a high level of privacy due to not being linkable to identifiable individuals. However, this relies on the narrow understanding of privacy ingrained in differential privacy (Ravn et al., 2025); the GSDs still visibilize parts of the broader population of trafficking survivors. This is a crucial insight because people's privacy is also shaped by their group memberships (Helm et al., 2024): the lives of trafficked humans might still be impacted qua membership in the group of trafficked humans, underscoring the practical import of the individualistic conception of privacy that often attends synthetic datasets. Relatedly, the interrogation of digital (dis)engagement highlighted the issues that result from synthetic data enacting further abstractions away from embodied experience. Not only does this merit the practical question of how to facilitate data disengagement, but it also opens onto a deeper ethicopolitical question of how to encounter highly abstract synthetic datasets that are nonetheless grounded in violent realities (Ferrari and McKelvey, 2022). Finally, the analysis of non-discrimination revealed how “geographies of missing data” (D’Ignazio et al., 2024: 4) shape the GSDs’ biases and the need to carefully govern the fabricated inaccuracies that are constitutive of all synthetic tabular data (Lee et al., 2025). These fabricated inaccuracies constitute a new challenge and risk for data-driven development projects: if misunderstood, they may induce misplaced policy interventions that could further harm vulnerable communities. Taken together, these insights advance the literature on synthetic data by showing that data justice frameworks can support critical investigations into particular synthetic datasets and their role in data-driven development projects.
The paper's analysis also has important implications for critical scholarship on “data for development” (D4D) and anti-trafficking. On one hand, the release of the GSDs facilitates the production of new knowledge regarding the phenomenon of human trafficking, for instance allowing more fine-grained insights into the demographics and social circumstances of human trafficking survivors. However, the GSDs—via their promise of privacy—project long-standing problematic narratives of big data as critical to furthering human welfare (Mann, 2017). For anti-trafficking efforts by international organizations and state actors, the GSDs constitute an extension of techno-solutionist approaches that have a long history in the wider D4D scholarship (Musto et al., 2020; Uhl, 2017). Thus, development scholars and practitioners ought to beware of the ways in which synthetic data risk being used for what we may call “synthetic-washing,” where faith in the presumed safety and privacy of synthetic data obscures their entanglement with power asymmetries. Particularly, the rise of synthetic data in development contexts risks doing little to confront the structural conditions of human trafficking, such as profound global inequalities.
Finally, I hope by means of this article to initiate a dialogue between scholarship on synthetic data and data justice. On one hand, the framework drawing from Taylor's (2017) data justice sensibilities was suitable to ask critical questions of synthetic data in development contexts. At the same time, the analysis indicates that a particularly productive angle for investigations of synthetic data may be found in more recent data justice theorizing, which foregrounds how collectivities are shaped by datafication (Dencik et al., 2025). Bearing in mind this paper's central finding that the GSDs invisibilize individual lives while visibilizing parts of the population of trafficking survivors, Dencik (2025: 13) strikes a chord by advocating for data justice scholarship to focus on collectivity; this would productively shift “attention towards population-level effects of datafication,” facilitating “system-level critique in which the parameters of the debate do not begin and end with the technology itself.” Significantly, this proposal may constitute an angle by which to pursue synthetic data critique beyond representationalist frameworks—as proposed by Jacobsen (2025). Thus, while in this paper I have showcased how synthetic datasets remain steeped in questions of political economy, (in)visibility, digital (dis)engagement, and non-discrimination, a more powerful critique might lie beyond these dimensions’ scope. For example, the response to the issues of particular synthetic datasets—while important to point out—cannot “be confined to fairness-informed design or debiasing algorithms” (Dencik, 2025: 12). Instead, a focus on collectivity might begin from the question of how marginalized communities can be empowered when they are implicated by emerging synthetic data practices. Such a reframing is urgent because synthetic data-driven projects, such as the GSDs, already reconfigure the parameters by which deep-rooted phenomena like human trafficking are understood and governed.
Accordingly, critical scholarship on synthetic data stands to gain numerous productive methodological and conceptual entry points from data justice frameworks. Exploring their potentials is an urgent task for future research on synthetic data justice, in development contexts and beyond.
Footnotes
Acknowledgments
This article is greatly indebted to the editorial guidance and encouragement of Mohammad Amir Anwar and Nanna Bonde Thylstrup, thank you very much. Moreover, this research has hugely benefited from early feedback provided by the DALOSS team: thank you Esmeé Colbourne, Katie Mackinnon, and Frederik Schade. I also thank the participants of the “Synthetic data: provocations and frictions of emerging data regimes” workshop at the University of Copenhagen in October 2024 for comments on an earlier version of this paper. Particular thanks go to Tanja Wiehn and Ekaterina Pashevich for the organization and moderation of the workshop.
In addition, this paper has hugely benefitted from the three anonymous reviewers’ brilliant comments as well as the journal editors’ remarks—thank you very much. Finally, I express my sincere gratitude to the three interviewees who were willing to share their insights.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was partly funded by the European Research Council project “Deep Culture—Living with Difference in the Age of Deep Learning” (Grant no. 101141330) as well as by the Independent Research Fund Denmark research project “AI Reuse” (Grant no. 9131-00115B).
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Appendix
Overview of key informant interviews.

| # | Informant occupation | Location | Date |
|---|---|---|---|
| 1 | Technology analyst | Virtual | 01/10/2024 |
| 2 | Global migration expert | Virtual | 07/10/2024 |
| 3 | Quantitative data analyst | Virtual | 10/10/2024 |