
Abstract
Over the past decade, China has gradually begun to take a more proactive approach to digital development, passing a range of policies that aim to restructure how data is treated within its national economic system. These policies reflect the construction of a new data ecology in which data is gradually reconceptualized as a quasi-public good, rather than a private good. Strategic interventions aim to increase data circulation and supply, with the goal of promoting high-quality economic growth. Central to these reforms is the designation of data as a factor of production, which accelerates the authority of the communist party to shape the allocation of data within the national economic system. Viewed holistically, these policies reflect an intentional effort to construct a more communal data ecosystem that facilitates increased data circulation in support of a state-led centralized approach to social and economic development. What emerges is a variety of data communism, in which data resources are increasingly conceptualized to serve collective interests rather than the interests of capital.
Keywords
Data is increasingly acknowledged by states as a resource that advances development and economic growth. Questions of ownership, access, and control are central to how this resource is used in economic systems. Around the world, societies are gradually making determinations that shape how data circulates. The first generation of data policies has come primarily in the form of privacy regulations, which restrict the flow of certain types of data. More recently, states have also begun to consider how data practices intersect with social issues, cultural values, and economic development. Tech giants in particular have increasingly become the targets of antitrust inquiry, as regulators consider how exclusive control of data can entrench market dominance. In most places, regulatory responses have been reactive, responding to patterns and problems identified by stakeholders, civil society, political forces, and regulatory agencies. China however has increasingly taken a more proactive approach in recent years to shape the role of data in its development trajectories.
This article explores how the CCP has begun to envision data's role in social and economic development, proposing that efforts to actualize these visions should be interpreted as the construction of a unique data ecology. The concept of a “data ecology” is drawn from Chinese policy documents, which employ the term to describe a more relational and holistic understanding of data governance at the national level. As data governance becomes increasingly entwined in social and economic development, and as new policies continue to emerge and evolve, an ecological approach becomes increasingly appropriate given the complex relational dynamics that are embedded in the management of data flows. Indeed, China is not alone in the construction of a data ecosystem. In the EU, data policies under the umbrella of the Digital Single Market seek to construct a unifying data ecosystem that shapes social and economic development trajectories while also codifying data ethics (Krarup and Horst, 2023). The United States meanwhile has developed a data ecosystem that primarily reflects the interests of big tech, which wields substantial influence at the policy interface (Guay and Birch, 2022).
China has adopted a different approach, developing a policy strategy focused on unlocking the potential economic benefits of data by maximizing data supply and circulation. This article will demonstrate how CCP policies are gradually shifting data away from being treated primarily as a private good—excludable and rivalrous. Instead, the state is advancing a broad economic conceptualization of data as a semi-public good—increasingly nonexcludable and nonrivalrous, which serves the broader interests of the economy as a whole, rather than the more singular interests of individual corporations. As a first step, the CCP has officially classified data as a factor of production, asserting state authority over allocation while also establishing the foundational legitimacy necessary to proactively shape its data ecosystem. Viewed together, these policies reflect a more communist-oriented approach to data governance, advancing a national system of data governance that may eventually be understood as a variety of “data communism.” Under data communism, private ownership of data resources is gradually challenged by systems of collective management which prioritize collective benefit over private interests. A more detailed discussion of data communism is provided further on.
The next section will introduce many of the concepts used throughout the article and will attempt to situate the article's contribution to the existing literature. Here, the article will propose the concept of data ecologies as a useful approach for the comparative study of national systems of data governance. Next, the article will dive into the China case, highlighting the CCP efforts to reconceptualize data in both a theoretical and practical sense within the context of economic governance. This includes a more empirical analysis of the policies and initiatives that have begun to shape China's new data ecosystem. Finally, the article will discuss data communism from a global perspective, illustrating how the comparative analysis of data ecosystems represents a field that is ripe for future development.
Conceptualizing national systems of data circulation
Whilst avoiding the tired oil cliche, there is truth in the idea that data has become a new resource that drives economic development. There are parallels to consider between the ways that energy flows through an economy and the ways that data flows through an economy. Electrification and datafication both provide efficiency benefits, accelerating technological and economic development; the systems that govern allocation also impact development trajectories. In a similar way as energy development has profoundly shaped the development of political systems (Mitchell, 2013), the development of data technologies also carries the potential to restructure relationships between states and societies. As argued by Mayer-Schönberger and Ramge (2018), societies are undergoing a shift from finance capitalism to data capitalism, in which data is quickly replacing capital as the dominant structuring resource of economies. According to Sadowski (2019), datafication has essentially created a political economic regime under which data is increasingly collected and circulated like capital, creating an imperative to circulate more data by producing commodities and infrastructure to facilitate the creation of more data. As a result, societies are now beginning to create various management regimes to facilitate or control the circulation of data.
Unlike other economic resources, a unique property of data is that it is fundamentally nonrival—that is, it can be copied and used by multiple organizations simultaneously without depletion (Jones and Tonnetti, 2020). For example, a hypothetical data-set containing the locations of all electronic vehicle charging stations in a geographic area has value for a wide range of firms and organizations; various auto retailers may simultaneously use the data to target those living close to (or far from) a charging station; urban planners may use the data to plan long-term infrastructure investments; retail businesses may interpret charger density as a sign of elevated eco-consciousness in a particular neighborhood; and real estate companies may incorporate charger proximity in their sales strategies. In each case, the data may undergo multiple manipulations and combinations with other datasets, as each organization explores how to best achieve its own unique aims. While exclusive access to a hypothetical dataset may provide economic benefits to a single organization, broader access may have greater benefits to the economy as a whole. These characteristics mean that data is not necessarily bound to the same constraints as capital or commodities, leaving space for the theorization, development and implementation of new modes, models and systems of circulation. As this article will demonstrate, the current ubiquity of data capitalism does not preclude the emergence of more communist-oriented data ecologies.
Data governance has become the focus of a number of high-profile publications in recent years. Perhaps most notable is Shoshanna Zuboff's (2019) elaboration of surveillance capitalism, which documents how US tech companies successfully staved off regulatory intervention while expanding dataveillance and business practices premised on the processing of behavioral data. The work of Julie Cohen (2019) adds to this, demonstrating how corporations act as the chief architects of the US data ecology by harnessing legal institutions that have been shaped through decades of neoliberal politics. In the European space, Gry Hasselbalch's (2021) work is noteworthy, providing context to sociotechnical infrastructures that have shaped the integration of ethics within the EU's data policies. Krarup and Horst's (2023) recent article in this journal complements this, highlighting how market integration drives ecosystem construction. The field of international political economy (IPE) has also begun to examine data governance, typically focusing on the frictions that result from variation, as well as ideological and political disagreements between the clashing data ecologies of the US, the EU and China (Drezner et al., Farrell and Newman, 2021; Farrell and Newman, 2019; Inkster, 2021; Ma, 2021).
Macro studies of the China case however are few and far between and typically focus on more narrow sets of issues. Kai-Fu Lee's (2018) characterization of China's tech landscape, for example, highlights the rapid corporate expansion of algorithmic data practices but mostly avoids discussing CCP policy. Other work tends to focus more narrowly on state surveillance, cybersecurity, or espionage (i.e. Chin and Lin, 2022; Lindsay et al., 2015) or else on the so-called digital silk road (i.e. Chan, 2022; Hillman, 2021; Keane et al., 2020). Recent policy developments have also necessitated substantial rethinking of much existing work. This article aims to help provide important contextual framing to the Chinese case by theorizing data governance in a macro-perspective, highlighting the uniqueness of the rules, regulations, and practices that govern data flows in China compared to other jurisdictions. In addition, the article seeks to avoid the pitfalls of monocentrism as well as rote normative critiques of authoritarianism that often plague scholarship about China.
Variation between different data ecologies is the result of “data sovereignty,” a concept that has also taken on various interpretations (Hummel et al., 2021). In broad and simple terms, data sovereignty refers to the fact that data tends to be subject to jurisdictional rules. The concept is often employed in reference to the rights of nation states to create their own systems of governance. Kukutai and Taylor's (2016) volume on indigenous data sovereignty is noteworthy here, highlighting the importance of first nations to be able to control their own data futures. A similar concept is that of “digital sovereignty,” which primarily refers to nation states asserting jurisdictional authority over the digital sphere (Pohle and Thiel, 2020). In the context of regulatory vacuum, Floridi (2020) also highlights the possibility of corporate digital sovereignty, in which corporations assert jurisdictional authority; this is of particular relevance to the US case where Apple has played the role of de-facto regulator, implementing app-store policies which constrain the data practices of Facebook and other tech companies (Swisher, 2022).
Another important concept that has steadily grown in relevance is that of platformization, referring to the rise and expansion of digital platforms as the ordering architectures of digital societies (Srnicek, 2017). Around the world, most digital economic activity now occurs within platforms owned and operated by large technology companies. As stressed by Jose Van Dijck (2020), platforms have started to become the infrastructure providers of societies, taking over many vital functions from the state and acting as gatekeepers to the circulation of educational, informational, and health data. This may become problematic when big tech platforms organize data practices around data-extractive models that advance shareholder interests rather than the interests of consumers or broader society (Viljoen, 2021; Zuboff, 2019); particularly so when architectures developed within the private sector bleed over into the public sector, resulting in corporate-flavored data practices within public administration (Dencik et al., 2019).
Data ecologies
Within this context, stakeholders, governments, and firms around the world are increasingly negotiating norms and systems of governance that shape how data flows through economic systems. These constellations of norms and rules are often labeled as governance “regimes,” placing focus on intersecting legal structures that establish rules and rights. The concept of “data ecologies” however encompasses a more dynamic way to describe the intersecting practices, policies, relationships, norms, and behaviors that shape data flows (Ruppert, 2016). An ecological approach considers the ways that data flow and are channeled through individuals, devices, firms, infrastructures, and organizations. It also suggests a complex dynamism, which reflects the shifting relational dimensions of data and the multi-dimensionality and -directionality of data flows. In this sense, an ecological approach considers how data flows alter the behaviors of both individuals and institutions, examining interrelationships to understand knowledge flows, hierarchies, and structure. In the context of a national economic system, an ecological approach suggests a mapping of flows, a complex dynamic pattern of relations involving the management of data flows between individuals, firms, and government bodies.
Evelyn Ruppert (2016) highlights the difference between big data economies (systems of valuation) and big data ecologies (systems of ordering and dependencies). Her interpretation of the term considers the relationship between data and platforms, observing that data cannot be separated from context and environment, and are “attached to the assumptions, definitions, constraints, choices, values, and normativities of their platforms including the actions and interactions of subjects in relation to them” (p. 19). A broader interpretation of the concept elaborated in this article goes a step further and considers the relationship between data and the society in which it exists. Government regulation represents only one underlying facet of any particular data ecology. Data ecologies also include nonlegal mechanisms of data governance, including norms and ethics. As a result, history, culture, and institutions all play important roles in the shaping of data ecologies (Cohen, 2019; Viljoen, 2021). At this point in history though, state regulation is quickly becoming a highly influential factor—one that has the potential to create underlying rules that fundamentally alter how data is treated within national economic systems, creating boundaries between distinct data ecologies.
There are already substantial differences that have emerged between the data flows of the US, the EU, and China which point to the existence of at least three distinct national data ecologies, reflecting a trifurcation in digital development trajectories. With a lack of regulation at the federal level, the United States has advanced a neoliberal approach to data governance, resulting in the expansion of consumer surveillance, personalized advertising, data behaviorism, and monopolistic behavior (Cohen, 2019; McNamee, 2020; Rouvroy, 2012; Zuboff, 2019). In Europe, data flows have become regulated and modulated by EU policies such as the Digital Single Market, GDPR, DSA, DMA, AI Act, and Data Act, resulting in a data ecology shaped by an evolving discussion about data ethics centered around the concept of dignity (Aho and Duffield, 2020; Rouvroy, 2016; Whitman, 2004). China has taken a different path—the state-led construction of its data ecology is the subject of this article.
Constructing a data ecology
The CCP has long exercised authority over China's information economy, controlling flows of content deemed to be sensitive. Throughout the nation's digital history, oversight, surveillance, and censorship have accompanied the steady expansion of online networks, digital services, and data infrastructures. These policies have proven fairly successful at managing public opinion while advancing certain political and ideological goals of the CCP (Roberts, 2018). However, over the past decade, economic development has risen in importance, joining social governance as a primary dimension of data policy. This section will demonstrate how China has begun to expand regulatory oversight over data circulation beyond purposes of social governance, positioning data as a key component of its economic development strategy.
Data, the fifth factor of production
In April 2020, the State Council and the CCP officially recognized data as the fifth “factor of production,” establishing a theoretical foundation for constructing a new data ecology (State Council, 2020). In basic terms, factors of production refer to the resources (inputs) that are used to produce goods and services (outputs). In Chinese economic theory, these inputs have been officially recognized as land, labor, capital, and technology. Since the founding of the PRC, control and influence over factors of production have been at the core of evolving communist policy. Following the market reforms of Deng Xiaoping and the formal establishment of the “Socialist Market Economy” under Jiang Zemin, factors of production have been allocated based on market principles, though the state still exercises a substantial degree of direction and regulation. For example, the 2020 guidelines which formally recognize data as a factor of production, consist of a set of supply-side reforms that are broadly aimed at increasing flows of economic inputs, including a relaxation of the hukou system which controls labor movement, more flexibility in land-use policies, a relaxation of access conditions for foreign capital, and improvements to technology transfer and intellectual property rights frameworks. When it comes to the fifth factor of production, the guidelines lay out three aims under the heading “accelerating the cultivation of data markets.” First by developing new institutional norms while facilitating data flows from public agencies; second, by promoting economic development based on data collection and utilization in such areas as “agriculture, transportation, education, security, urban management, public resource trading, artificial intelligence, wearable devices, internet of vehicles and internet of things”; and third by establishing a unified and standardized data management system, along with improved systems for data classification, integration, and security.
In a similar way as the Chinese state cautiously exerts its authority over the supply of labor, land, capital, and technology, the state has now begun to assert its role in the supply of data. The move highlights that data is seen as one of the integral dimensions of China's social and economic development. With the publication of the guidelines, the National Development and Reform Commission (NDRC) noted that new production factors such as data have a multiplier effect on the efficiency of other factors, forming advanced productive forces. Particularly, defining data as a new type of production factor in the new document will help energize such a modern production factor, injecting new impetus to promote high-quality development and foster innovation-driven development (China Daily, 2020).
Cementing the importance of data as a factor of production, in March 2023 a proposal was submitted to the National People's Congress, calling for the establishment of a National Data Administration, a new government body managed by the NDRC. The document, signed by Premier Li Keqiang, notes that the new administrative body would be responsible for “the coordination and advancement of building the data factor system” and “for overall planning of the integrated sharing and development and use of data resources” (Webster, 2023).
After the rapid development of its tech sector, these reforms are part and parcel of China's efforts to transition the country from high-speed to high-quality development, which has become a focus of CCP planning over the past decade. In brief, these efforts are associated with reigning in many of the perceived destructive features that have accompanied rapid economic development. This includes environmental degradation, labor exploitation, rising inequality, high-risk investments, and corruption. Digital development is expected to accelerate green development, transform domestic consumption patterns, improve the quality of human capital, shift industrial production from being labor-intensive to technology-intensive, and reform unbalanced and uncoordinated infrastructure development (Zhang et al., 2021).
Data as a quasi-public good
The CCP's current approach to data can trace its roots to a 2014 white paper on big data (subsequently updated in 2016, 2018, 2019, and 2022), published by the China Academy of Information and Communications Technology (CAICT). The article focuses on a lack of data-openness in China, lamenting that institutions must rely on internal data because the “opening and trading of data is not yet mainstream” (CAICT, 2014, p. 37). The white paper also calls on the government to formulate strategies to open up its own data resources, encourage data trading activities, and create favorable conditions for the circulation of data resources (p. 68). In response, the State Council turned these recommendations into policy through the 2015 Outline of Operations to Stimulate the Development of Big Data; the two main tasks within being to: “(1) forcefully promote the sharing of government departments' data… and (2) steadily promote the openness of public data resources,” by “guiding enterprises, sectoral associations, scientific research bodies, social organizations, etc., to actively gather and publish data” (State Council, 2015).
Since then, a series of policies have steadily sought to increase the availability and circulation of data resources. The “14th Five-Year Plan for National Informatization,” is particularly noteworthy, laying out a wide range of policy goals for the 5-year period between 2021 and 2025. As the “guiding ideology” of the CCAC plan states—“with deepening supply-side structural reform as the main line, we will further liberate and develop digital productive forces, accelerate the construction of a new economic structure with great domestic circulation as the principal aspect” (CCAC, 2021, p. 10). For the inaugural 5 years of data as a production factor, the plan lays out substantial groundwork that will better position the CCP to oversee and manage China's data resources. This includes the development of both physical and intellectual infrastructures, including centralized databases, data classification systems, and data resource surveys, as well as the formulation of standards for data collection, storage, processing, circulation, trading, etc. Specifically, the plan outlines three steps to further cultivate data as a factor of production: first, to advance theoretical research on data and to develop new property rights frameworks that are “oriented toward stimulating industry development”; second to establish effective data circulation and management structures, including “mechanisms for data registration, assessment, pricing, transaction tracing, and security inspection”; and third, to develop standardized data trading platforms, including systems for “data asset assessment, registration and settlement, transaction matching, dispute mediation, and other such market operations” (CCAC, 2021).
Leading by example, the CCP has taken substantial steps to open up public data resources through the construction of public data platforms, openly sharing government datasets that may be of use to firms. While the question of de-siloing private data for the sake of broader sectoral development remains a difficult one, the document notes that it will “encourage enterprises to open up data on search, e-commerce, social interactions, etc.” (CCAC, 2021, p. 22). The dilemma faced by the CCP is to identify in which cases it is preferable for datasets to remain privately controlled, and in which cases data should be made available to other firms or state organizations. Further, the state must develop market mechanisms for when it mandates the sale or release of privately-held data. In many cases, it may be in the interest of the state to pressure firms to open up their private data stores to allow these datasets to be circulated and used to their full potential to stimulate economic development. To this end, the State Council's 2023 Plan for the Overall Layout of Building a Digital China, promises to “unleash the value potential of commercial data, accelerate the establishment of a data property rights system, carry out data asset valuation research, and establish a distribution mechanism for data elements based on value contribution” (State Council, 2023).
In essence, China is attempting to develop an economic system in which data is increasingly understood as a quasi-public good (Liu, 2021). Again, a public good is a good that is both nonrivalrous (using the good does not deplete it for others) and nonexcludable (others are not excluded from using the good). Data is clearly nonrivalrous, however, most data in China, as in the rest of the world, are privately held in a manner that currently makes them excludable. Challenging these entrenched practices of data-siloing, the CCP aims to develop policies that allow data to flow more freely and circulate through the Chinese economy. An early example of this can be found in the case of a 2017 law that mandates that companies in the new energy vehicles (NEV) sector share data (electromechanical, statistical, structural, navigational, etc.) via a government database. These datasets are then made available to interested parties (such as other NEV stakeholders) in the spirit of accelerating innovation and sectoral growth. As noted by Martens and Zhao (2021), In an unregulated private data market, information about the performance of innovative electric car technologies remains locked in manufacturers' private data silos…This causes information frictions in markets and has negative effects on private consumer welfare and social welfare from emission reductions. The government's mandatory data pooling overcomes these obstacles and can potentially reveal the best performing technologies to all stakeholders (p. 2).
The relative impact of these specific data-sharing policies is hard to weigh given the complexity of government subsidy programs for NEVs—however, from 2018 to 2021, the market share of NEVs in China rose from 4.2% to 13.3%, putting the state on track to achieve its EV penetration goals of 20% by 2025 and 30% by 2030 (Miotech, 2021).
In part, because it is unburdened by fixed-year electoral cycles like in the United States or Europe, China tends to initiate substantial policy reforms through gradual implementation and long-term planning. Pilot projects and special economic zones are often used to understand policy effects on a smaller scale before implementing larger reforms, and often concrete policies may only materialize years after plans are initially proposed, studied, and discussed. Substantial economic reforms in particular continue to follow Deng Xioping's philosophy of “crossing the river by touching the stones.” The construction of a new data ecology is no exception. Many pilot projects have involved Guizhou Province, which was designated as the country's first “National Big Data Comprehensive Experimental Zones” (NBDCEZs) in 2015. Guizhou, along with nine additional pilot areas, have served as experimental data policy zones, hosting a range of initiatives and experiments involving data management, data infrastructure, and data circulation (Qin et al., 2023; Zhang and Ran, 2023). The outcomes of these experiments continue to help shape new data policies enacted on the national level.
Civilizing gladiators
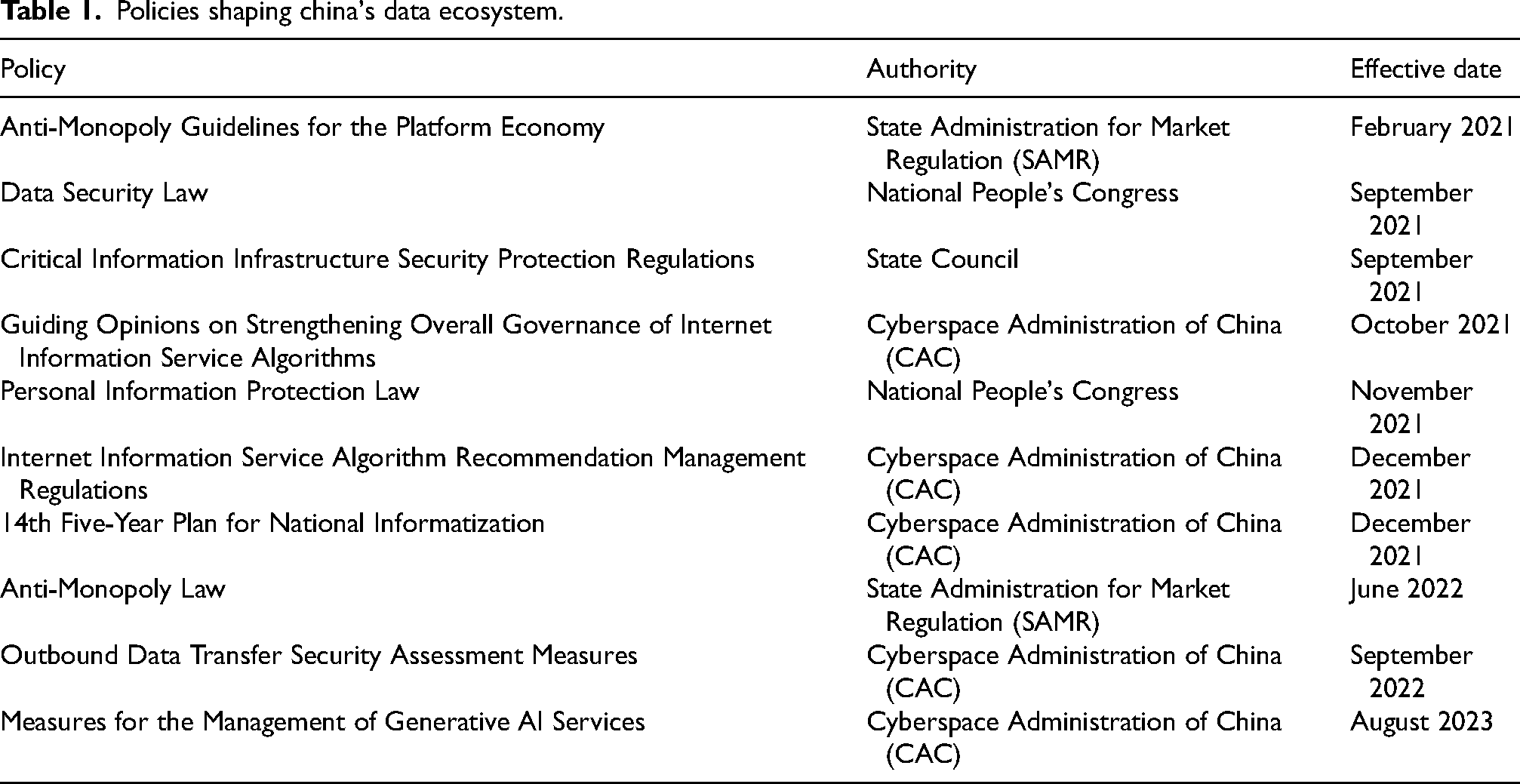
Over much of its digital development, China took a relatively laissez-faire approach to its tech sector, allowing a certain flavor of techno-capitalist anarchy to reign. In his characterization of tech competition in China, Kai-Fu Lee (2018) refers to the tech sector as a “gladiatorial arena,” describing a sector with few rules, where cut-throat behavior has tended to serve firms well. In this arena, intellectual property rights were more or less irrelevant, and the act of copying and improving became a way of doing business (pp. 24–26). In many ways, this lack of rules helped to spark a culture of innovation and facilitated rapid growth of the sector as a whole. However as China begins to navigate its transition from high-speed growth to high-quality growth, the rules of the game have begun to change. With a salvo of new policies and tech regulations, as well as a relatively harsh crackdown on the tech sector, the CCP has initiated a more proactive approach towards digital development, revealing the outlines of a new data ecosystem. Table 1 provides an overview of many of the policies that, when interpreted together, shine a light on the CCP's new approach. Excellent English language translations of many of these policies can be accessed via Stanford University's DigiChina Project.
Policies shaping china's data ecosystem.
Efforts to regulate the digital space have also necessitated the creation of new systems of data classification and categorization which differentiate between type of data, type of platforms, and form of data processing. Article 21 of China's Data Security Law for example mandates that: “The state shall establish a categorization and classification system and carry out data protection based on the importance of the data in economic and social development” (DSL, 2021). In the context of data as a factor of production, classification systems facilitate effective management and optimization of data flows. In the Chinese data ecosystem, rules and responsibilities can vary depending on data type, firm function, or size of platform. This is designed to create regulatory burdens that are appropriate for the particular risks inherent to the type of data, and commensurate with the size of the platforms processing that data. A common critique of Europe's GDPR has been the administrative burdens that it places on small firms and nonprofits; by forgoing the construction of a classification system with different rules for different sizes and types of organizations, the law can act as an impediment to data circulation, and complicates the operations of small businesses, as well as academic and civil society organizations (Franz et al., 2019). On the other hand, while categorization may preempt the pitfalls of a one-size-fits-all approach, rigidity can also lead to perverse incentives and unintentional power asymmetries (Bowker and Star, 2000). The granularity of China's current categorization efforts is perhaps best exemplified by the SAMR's “Guidelines for Internet Platform Categorization and Grading,” an outline of which is provided in Table 2.
Regulatory categorization of platforms (SAMR, 2021).

In addition, the SAMR also classifies each platform according to size, creating different designations for super platforms, large platforms, and small- and mid-size platforms. These classifications are based on a number of variables, including market capitalization, number of active annual users, and ability to restrict merchants' connections with consumers. On the one hand, extensive subcategorization allows for the development of state interventions that may only target one or more specific subsets of China's digital economy, providing the CCP with a regulatory scalpel for targeting smaller subsets of the digital economy; however, at the same time, it also increases the risk of collusion or administrative malfeasance associated with preferential categorization.
Cracking down, or cracking open big tech?
Over the course of 2021, the CCP initiated a broad crackdown on big tech, requiring many big tech firms to restructure their data operations and to open up their data operations to state authorities. Many companies, including ride-hailing giant DiDi, were targeted based on the size and depth of their data stores (CCAC, 2022). DiDi, which in 2018 initially resisted sharing its real-time trip data with authorities, was eventually banned from App stores in July 2021 as a result of “serious violations of laws and regulations to collect and use personal information” (State Internet Information Office, 2021; Zhong and Yuan, 2021). An editorial in the state-owned Global Times explaining the DiDi ban noted “the state will never allow tech giants to collect more detailed personal information in their mega-databases than the state has of the Chinese people” (Global Times, 2021). In the wake of the DiDi ban, the Ministry of Transportation issued a new set of regulations, which require all ride-hailing apps to transmit real-time data to a newly created industry-wide data-sharing platform which further disseminates data to provincial and municipal platforms (Ministry of Transportation, 2022). In addition, in January 2023 the state launched its own ride-hailing app “Strong Nation,” citing the need for greater data security in the ride-hailing industry. According to state media, the app acts as a layer that aggregates third-party providers, and will eventually also aggregate bookings for freight, road, railway, water transport, and air-shipping, potentially providing the state with a bird's eye view over the transportation and logistics sector (McMorrow, 2023).
Another example can be read in the case of Ant Group, an affiliate company of the Alibaba Group. Ant is the country's largest holder of consumer financial data and is also the world's second-largest financial services group after Visa. Over the course of 2021, Chinese authorities fought against Ant to try and gain access to company data, a move that was resisted by Ant. After a series of progressively harmful sanctions on the company, including a $2.8 antitrust fine and a mandated restructuring, Ant eventually agreed to integrate its consumer credit data into a government credit reporting system (Yu, 2021; Yu and Mitchell, 2021). In the case of Ant, much of the pressure to share consumer financial data came from the People's Bank of China (PBoC), which has been pushing companies to find ways to share data by requiring consumers to agree to data-sharing as a condition of using digital services. The PBoC has called data collected by platforms as a public good that should be regulated to balance privacy protection and fair use (Yu, 2021). Indeed, data sharing is listed as one of the primary goals of the PBoC's Fintech Development Plan, which aims to “promote the orderly sharing and comprehensive application of data under the premise of ensuring security and privacy, and fully activate the potential of data elements” (PBoC, 2022).
Another dimension of the efforts to crack open big tech has come in the promotion of interoperability. Excludability has allowed companies to fortify their data silos by ensuring that users and their data stay within a single platform environment. For example, Alibaba's properties previously did not accept the use of Tencent's payment systems, nor could Douyin videos be shared on WeChat. A goal of most tech firms has been to shepherd users between their own platforms as bridges to competitor platforms threaten data continuity. However, after a September 2021 meeting hosted by the Ministry of Industry and Information Technology, many of China's largest tech companies, including Tencent and Alibaba announced that they would allow access to their “walled gardens” (Nuttal, 2021). In the eyes of the State Council, interoperability not only better serves consumers, but it also encourages competition and innovation. In a data ecosystem, interoperability allows data to flow more freely across the digital economy and incentivizes data trading between companies seeking to maximize data network effects. Network effects are part and parcel of the economic potential that China seeks to unlock by challenging the entrenched notion of data as a private, exclusive resource. In brief, the value of a dataset is increased when it is combined with associated datasets; with more data points, the more valuable data becomes. Under the dominant private data ownership regime, platforms have been incentivized to expand vertically to widen their data trawls and maximize data network effects (Prüfer and Schottmüller, 2021). However, when data flows more freely, network effects become available to a wider swath of the economy; they do not exclusively benefit big tech firms that operate the biggest data collection networks. An economy in which data is treated as a semi-public good is one in which firms are less incentivized to behave monopolistically nor exploit data to behave in an anticompetitive manner.
One of the mechanisms by which the state exerts pressure on companies to comply with the nation's fledgling data governance ecosystem is through the deployment of golden shares (Wei, 2023). In brief, a golden share is a minority stake in a company (typically 1%) which affords the state some degree of supervisory control over that company. In China, these so-called “special management shares” typically involve a seat on the board along with some form of veto power. University of Hong Kong Law Professor Angela Huyue Zhang (2022) estimates that between April 2020 and May 2022, the CAC obtained stakes in over 40 tech firms, covering a substantial swath of the Chinese tech sector—this includes Alibaba, Tencent, Weibo, Bytedance, Qutoutiao, 36kr, Kuaishou, Full Truck Alliance, Ximalaya, and SenseTime. While it is difficult to measure the actual extent of control exercised through these mechanisms, the arrangements have been critiqued by US authorities, including US Secretary of State Anthony Blinken, for essentially blurring the distinction between private companies and the state. One consultant describes the arrangement as a Sword of Damocles hanging over the companies that have them (Yang et al., 2021). Research by Sayari (2024) demonstrates that these arrangements often involve the direct appointment of CAC officials to influential positions within company hierarchies.
Long-term planning
The state-led development of China's data ecology is not without precedent. For better or for worse, data has long played a central role in the management of social and economic development. In many ways, the development of an integrated public data ecosystem can be interpreted as a lineage of the Danwei system—a public database that previously served as an organizational locus of Chinese society, linking local communities with national political projects. As a database and administrative tool, the Danwei previously allowed the state to oversee substantial swathes of social life, from healthcare, housing, and travel, to marriage and childrearing. Today, data-informed social governance is becoming the purview of the Social Credit System (SCS), which is gradually becoming the CCP's next-generation tool for managing individuals and firms in accordance with national political projects. SCS can be regarded as a successor to the Danwei—an upgrade that incorporates new data technologies to develop more efficient approaches and solutions for the management of society. The marriage of surveillance and social governance is not unique to China but rather reflects the broader emergence of “cybernetic citizenship,” a global trend by which states have increasingly sought to manage populations via reflections of their data (Calzada, 2022; Reijers et al., 2022). The SCS is emblematic of China's embrace of cybernetic citizenship and is being developed to serve as the backbone of China's digital regulatory state (Aho and Duffield, 2020). It ranks among the largest big data projects ever attempted and is premised on the collection and algorithmic processing of diverse data streams from all economic actors (both firms and individuals), consolidating a wide range of data from both public and private institutions (Zhang, 2020).
The origins of the SCS can be found in the CCP's adherence to systems engineering as a field of study (Hoffman, 2018; Hvistendahl, 2018). Systems engineering as a field, focuses on the design, integration, and management of complex systems. In the Anglophone world, the interdisciplinary field had its heyday in the 1960s (reaching peak interest in 1965), before quickly falling into relative obscurity by the 1980s (Google Ngram—“systems engineering”). However interest in China continued to grow, such that it is a required curriculum for students at the Central Party School in Beijing (Hvistendahl, 2018). The development of the SCS involves the integration of many of the diverse policies, data systems, and governance approaches explored within this article. Indeed, the SCS is perhaps best understood as a system of systems—a massive policy framework that seeks to consolidate a broad range of disparate initiatives (Drinhausen and Brussee, 2021). As a system of systems, the SCS sits atop the country's diverse data infrastructures, bringing them together in a manner that allows the party not only to better understand and predict economic processes but also to strategically control economic processes using flexible regulatory instruments (carrots and sticks) built into the system (Aho and Duffield, 2020). As the 14th Five-Year Plan for National Informatization states, a foundational goal is to “uphold the entire country as one chessboard” (CCAC, 2021, p. 11). Cheung and Chen (2022) argue that the eventual integration of systems under the SCS may represent the emergence of a governance model they refer to as a “data state,” referring to the comprehensive monitoring, evaluation, and control of subjects through datafication and data-driven techniques (p. 1157). In economic terms, these efforts represent a gradual return to a more planned economic system, albeit based on a fundamental adherence to the socialist market economy, with “Chinese characteristics” in this regard upgraded to reflect the algorithmic turn (Aho, 2023).
Towards data communism
Perhaps the most accurate way to frame China's new data ecology is through the concept of data communism. While varieties of data capitalism have become entrenched in most of the world, China is attempting to advance a more communal approach to data that serves the interests of the collective rather than the interests of capital. To achieve this, the state has asserted its authority over data supplies and has begun experimenting with new approaches to data governance that challenge exclusive ownership of data. The result is that China has begun moving towards a new model of data governance—a new data ecosystem—a new variety of data communism.
Under a system of data communism, data resources (as a factor of production) are commonly owned by a society and are managed by state actors in a manner that seeks to benefit the communal good. To achieve this, state institutions must exert some degree of control over the allocation of data resources in a manner that prioritizes societal needs over private market interests. This may include the redistribution of privately held data resources in ways that align with societal goals (i.e. to improve public services, healthcare, education, or economic planning). It is also likely to involve wider access of public data to private actors in support of societal goals (i.e. to spur economic development, innovation). As this article has highlighted, a policy strategy under a system of data communism might involve mandatory data-sharing regimes within particular economic sectors (such as new electric vehicles) as a way to stimulate sectoral development. Though policy regimes and governance strategies may vary substantially, a defining characteristic of data communism is that data resources are treated as communal assets to be managed according to communal needs and interests.
Since the founding of the PRC, the words of Marx, Lenin, and Mao have continued to echo throughout China's halls of power. Communist theory is firmly embedded within China's state institutions, even as globalized market economics has necessitated ideological and practical flexibility. In light of this, it is interesting to note that China's conceptual transformation of data towards a quasi-public good is progressing in a similar manner as the process prescribed by Marx and Engels in 1848 for the abolition of private property. In their theorization, the abolition of private property does not refer to personal possessions, but rather targets private ownership of the means of production, referring specifically to the resources (factors of production) and infrastructures used to produce goods and services. In their prescription, Marx and Engels highlight that these changes cannot be achieved with one stroke, but rather must undergo a more gradual transformation spanning an unspecified historical timeline. Applying the same proposition to the fifth factor of production, the hegemonic notion of data as private property is something that is perhaps more effectively undermined incrementally, informed by policy experimentation and regulatory learning.
So far, this appears to be the approach that the CCP has begun to take. In the wake of historical collectivization initiatives and their failures, data collectivization is something with which the CCP has begun proceeding both gradually and cautiously, with the “Scientific Outlook on Development” as a guiding principle. Given the CCP's embrace of dialectical materialism and regulatory learning (both historical and transnational), the incremental transition toward data communism currently appears to be proceeding on a low-risk trajectory. In light of the broad economic benefits that are expected to stem from new data technologies and AI, it is possible that data governance may represent a frontier where communism in theory and practice prove to be more closely aligned, at least in the quantifiable terms of economic efficiency and development.
Even outside of a communist framing, it is increasingly recognized that the current hegemonic model of data siloing by large corporations acts as an impediment to social, economic and technological development; Mayer-Schönberger and Ramge's (2022) book Access Rules: Freeing Data from Big Tech for a Better Future eloquently lays out this argument, calling for a similar liberation of the data held by Big Tech oligopolies, noting that “the principle of open access to information is not extraordinary or radical but a fundamental component of the legal and societal fabric of many nations” (p. 131). In this sense, the core principle of data communism may not necessarily need to maintain an association with communist theory, nor do data communist practices need to be contained to countries ideologically receptive to communist ideas. Rather, similar outcomes may be achieved by strategically framing the data-liberation process in terms of open access, competition, anti-data-colonialism, or even simply “industrial policy.” Management of communal data resources in the public interest can also be achieved through democratic institutions.
Implementation challenges
By many accounts, the development of a data ecology that seeks to increasingly channel data flows through state institutions raises concerns about the entrenchment of a surveillance state and the potential for authoritarian abuses of power. Centralized securitization and censorship practices have already become characteristics of China's data ecology. In its repurposing of data as a factor of production, China is essentially reviving practices of high modernism, which were historically fraught with unforeseen complications (Scott, 2020). The CCP may be conducting a risky experiment—no state has yet attempted to exert such a high degree of governance over its own data flows. Various shades of failure and injustice can be found in historical attempts at the centralized management of factors of production, especially among Communist governments in the 20th century. However, data is a fundamentally different input and may prove to be inherently more manageable than land, labor, or capital. If successful, these efforts may be the first steps toward an AI-planned economy (Aho, 2023). As Jack Ma describes, Over the past 100 years, we have come to believe that the market economy is the best system, but in my opinion, there will be a significant change in the next three decades, and the planned economy will become increasingly big. Why? Because with access to all kinds of data, we may be able to find the invisible hand of the market (Global Times, 2017).
However, in China there is often a gap between ambitious planning and policy implementation. Many of the aforementioned initiatives may only achieve partial implementation, burdened by technical or economic complexities. The delayed, gradual implementation of the massively ambitious SCS is an example of this, particularly in light of the lofty goals set by the State Council in 2014 (Cheung and Chen, 2022; State Council, 2014). In addition, there still remain a substantial number of kinks to be ironed out both within and between China's flurry of new data policies, along with many unresolved questions about monitoring and enforcement. Many firms have already demonstrated their willingness to resist the implementation of certain data policies (Cao and Yang, 2023; Yu, 2022). In light of all this, it is important to acknowledge the impossibility of meaningful temporal predictions about success or failure. The path ahead is uncharted territory—the river will be crossed by feeling the stones.
Rival ecosystems
China's digital ambitions can be broadly defined by the slogan 网络强国 (wǎngluò qiángguó), which can be roughly translated as “cyber superpower” (Creemers et al., 2018). The term occurs often in speeches and policy documents and reflects a state that sees digital development as a means for achieving a dominant global position. China explicitly acknowledges that data governance represents a focal point of international rivalry: International competition in the digital space is entering a new phase, and national innovation and competitiveness focused on information technology ecosystem advantages, digitization transformation capabilities, and data governance abilities at the core, is currently becoming the focal point of a new round of competition between countries worldwide; the competition over normative systems in the digital area and core technology ecosystems is growing more fierce by the day (CCAC, 2021, p. 8).
As China constructs a new data ecology, it is overtly doing so with international competition in mind. This competition also contains ideological dimensions, pitting a control-oriented state-led market approach towards data against the US's corporatocratic pro-capitalist approach, as well as the EU's social democratic regulatory approach.
A useful framework for understanding processes that shape different constructions of data ecologies can be found within varieties of market economies and comparative capitalism literature (Ebenau et al., 2015; Hall and Soskice, 2009; Nederveen Pieterse, 2021). In the liberal market economy of the United States, large corporations act as the chief architects of the American data ecosystem, resulting in the nonexistence of meaningful data regulation at the national level (Cohen, 2019; Zuboff, 2019). With few rules to govern the ecosystem, big tech has thrived, using monopolistic data power to entrench market dominance (Birch et al., 2021; Eliot and Murakami Wood, 2022). In the coordinated market economy of Europe, the construction of the digital single market and the various policies that govern its data (GDPR, DMA, DSA, etc.) reflect a balance of commercial and ethical interests that have been negotiated through stakeholder participation in democratic processes (Hasselbalch, 2019; Krarup and Horst, 2023). When it comes to the state-led market economy of China, data policies are predominantly constructed by the state and therefore tend to reflect the evolving interests of the communist party. To this end, China's new data ecosystem aims to advance quality economic growth while solidifying state control over social and economic development. In each case, the data ecology can be seen as a lens, revealing how power is distributed in each variety of market economy.
Data ecosystems also tend to radiate outward. With the publication of every new EU data policy, lawmakers declare they are intended not only for Europeans but to serve as a model for the world. The spread of the GDPR via the “Brussels effect” demonstrates that this is more than just rhetoric (Bradford, 2020). Erie and Streinz (2021) document a comparable “Beijing effect,” demonstrating how China's data policies also travel through the digital silk road, shaping data governance in many developing countries via political partnerships and infrastructure investments. One risk is that competition between data ecologies may result in an increasingly divided world—a data ecological balkanization of the World Wide Web. In the globalized world, competition and conflict between data ecologies can create friction, which becomes hotter in the presence of ideological division. Already, there are signs that the competition for technological supremacy is causing a digital and economic decoupling between China and the United States (Inkster, 2021). Much of the 20th century was characterized by an ideologically motivated competition between the economic systems of communism and capitalism, two rival ecosystems governing the production, distribution, and flow of goods and resources. There are already signs that the 21st century may witness a similar rivalry emerge between rival data ecosystems governing the production, distribution, and flow of data.
As national data ecosystems continue to develop, evolve, and conflict with each other, the centrality of data governance within the political economy will continue to grow. Comparative data ecologies reflect one approach for understanding variation and friction at the macro level. Data has already begun to rival capital as a dominant structural resource, necessitating new approaches and methodologies for the development of a new field of economics, in which focus is placed on identifying patterns and tensions in the circulation of data. Future studies might seek to understand how variation between data ecosystems can create comparative advantage or disadvantage; how regulating data flows may disrupt or stabilize institutions and markets; or how variations in data governance can alter social outcomes in health, education, or service provision. The rules that shape and govern the flows of data throughout societies already have substantial socioeconomic and development implications and are likely to only continue growing in importance. As this article has hopefully demonstrated, the field is ripe for fresh theorization.