
Abstract
People experiencing homelessness seek support from homeless services systems that increasingly rely on prioritization algorithms to determine who is the most deserving of scarce resources. In this paper, we argue that algorithmic harms in homeless services require a reparative approach that takes the data work of care workers seriously. Building on Davis, Williams, and Yang's concept of algorithmic reparation, we present a qualitative study that examines the intertwining of data work and care labor of 15 care workers. We show how they wrestle with the ethics of algorithmic prioritization and develop workarounds that allow them to advocate for their clients. We contribute an empirical understanding of how care workers provide care under homeless services systems that equate data work with care labor to justify work intensification. Our findings have implications for understanding the future of care labor in datafied conditions and the social and political ramifications of algorithmically mediated care.
This article is a part of special theme on Algorithmic Reparation. To see a full list of all articles in this special theme, please click here: https://journals.sagepub.com/page/bds/collections/Algorithmic%20Reparation?pbEditor=true
Introduction
People experiencing homelessness face hardships that force many to seek support from homeless services systems which rely on prioritization algorithms for allocating scarce resources. These systems provide emergency shelter, subsidized housing, and a plethora of other resources to people experiencing homelessness, a persistent social inequality tied to larger social and economic factors such as poverty and racism. On paper, these systems move unhoused people from emergency shelters to long-term housing quickly and efficiently. In practice, demand for subsidized housing far outstrips supply and people experiencing homelessness languish in shelters for months or years. As a result, care workers such as social service workers are tasked with deploying homelessness prioritization algorithms to decide who will receive housing 1 and who will go without.
The increasing use of algorithmic processes for resource allocation has also produced a growing need for data that has changed how workers participate in decision-making and provide care. Care workers are encouraged to view interactions with unhoused clients as opportunities for data collection. They are required to log information repetitively across multiple redundant systems, including collecting the information fed into homelessness prioritization algorithms. The stakes of this data work are high. If an interaction is mislogged, an unhoused person could be deprioritized for services months or even years later. Thus, the promise of these systems—a fairer and more efficient resource allocation process—is counterbalanced by their potential harms.
In this paper, we argue that addressing the harmful impacts of algorithmic processes in homeless services requires a reparative approach that takes the data work of care workers seriously. As Davis, Williams and Yang (2021) contend, reparation through algorithmic praxis is vital because decisions about automation are never neutral, and algorithms are inextricable from larger sociotechnical assemblages. Building on Davis et al.'s (2021) argument, we examine the intertwining of data work and care labor through the experiences of 15 social service workers in a single homeless services jurisdiction on the US east coast. While not formally considered curation professionals, these workers are nevertheless responsible for “managing, collecting, arranging, and auditing [the] data” that underpin algorithmic decisions (Davis et al., 2021: 7). Care workers perform this data work in a context that is shaped both by macro institutions, such as Housing and Urban Development (HUD) policies, and by the nuances of microinteractions with unhoused people seeking assistance.
We interviewed care workers to address the following research questions: How do care workers interact with homelessness prioritization algorithms in their daily work practices? How do those interactions shape how they conceptualize and provide care for their unhoused clients? Our findings show how data generated, collected, and processed by care workers have large downstream impacts on algorithmic prioritization and the datafication of homelessness. We uncover how care workers wrestle with the ethics of algorithmic prioritization, sometimes intentionally influencing outcomes to advocate for their clients and retain agency. We contribute an empirical understanding of how care workers’ professional judgment, views of data, and client relationships affect how they implement homelessness prioritization algorithms and navigate a prioritization system that impacts the lives of vulnerable constituents.
Background
Centralization of homeless services
Homelessness represents a significant and growing social crisis in the U.S., with the total number of unhoused people rising for the sixth consecutive year in 2022 (Joint Center for Housing Studies of Harvard University 2023). A myriad of actors and institutions have long been dedicated to addressing this crisis, providing services and aid such as subsidized housing, emergency shelter, and healthcare. In 1987, the US government sought to formalize these services into a national system with the passage of the McKinney-Vento Homelessness Assistance Act (PL100-77). With the passage of the act, existing institutions (such as nonprofits, state and municipal governments, and hospitals) and spatial configurations (shelter buildings, churches, and existing housing) were drawn together into a more coherent system.
Since McKinney-Vento, the homeless services system has become increasingly centralized and data-driven. The US government has united disparate organizations who provide housing resources into cohesive, geographically bounded Communities of Care by mandating a single set of data-gathering and reporting elements (Balagot et al. 2019). By uniting disparate organizations, the US government congealed homeless services into a formal “system-level bureaucracy” (Bovens and Zouridis 2002).
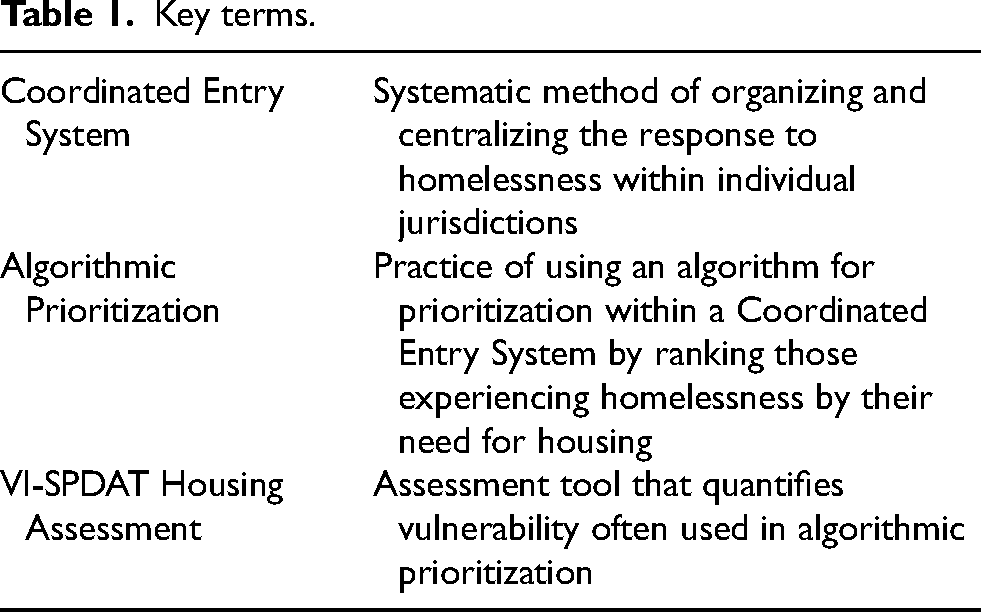
This formalization paved the way for a systematic assessment and resource allocation process known as Coordinated Entry, in which housing resources are distributed in order of vulnerability rather than on a “first come, first serve” basis (Ecker et al. 2022). Coordinated Entry Systems (see Table 1 for review of key terms) were established through the implementation of the 2009 Homeless Emergency Assistance and Rapid Transition to Housing Act and are used in nearly every jurisdiction in the U.S.. Simply put, Coordinated Entry refers to the entire sociotechnical infrastructure which “inputs” people experiencing homelessness, sorts them, and provides housing to some but not to others. This combination of federal legislation, jurisdictional implementation, and unified practices created the homeless services system as it exists today—a loosely centralized assemblage of actors connected by funding stipulations, reporting mandates, and shared technologies.
Key terms.
Algorithmic prioritization in homeless services
A central dilemma for homeless services systems is one of scarcity: there are many more people in need of help than there are available resources. Because of this scarcity, jurisdictions must triage the slim resources at their disposal. As part of their larger effort toward centralization, HUD mandated that jurisdictions choose a standardized tool for determining which unhoused people should be prioritized for housing assistance. Many jurisdictions chose to adopt algorithmic systems for this purpose, to “steer the allocation of scarce, beneficial resources to those deemed most deserving” (Johnson and Zhang 2022:1671).
Algorithmic prioritization varies across jurisdictions in two main ways: the data sources used to quantify vulnerability, and the level of human input in the prioritization process. Some systems use predictive models based on government records like emergency room visits or interaction with the criminal legal system (Kuo et al. 2023), while others use assessments which “are meant to quantify a [unhoused] client's vulnerability” (Karusala et al. 2019:7). Some use a combination of approaches. Systems also vary in the extent to which prioritization is automated, with some jurisdictions favoring fully automated approaches whereas others use tools as recommenders for decision-support. In all cases, algorithmic prioritization is a sociotechnical process which extends beyond software and data to include analog technologies such as forms and documentation, as well as a host of human actors.
For example, in the jurisdiction we studied, algorithmic prioritization included little-to-no input from a human assessor. The jurisdiction used an assessment-based approach in which vulnerability scores were generated by one of the most commonly used tools, the Vulnerability Index and Service Prioritization Decision Assistance Tool 2.0 (VI-SPDAT). When using the VI-SPDAT, a care worker reads the assessment questionnaire to an unhoused person and then records their answers, either directly into the local Coordinated Entry database or on a paper form which is then entered into the system later. The VI-SPDAT takes the life experience of an unhoused person as an input and produces a vulnerability score—a quantification of the person's experience with violence, trauma, substance use, institutionalization, employment, debt, and homelessness—as an output.
The use of algorithms in homeless services has generated a substantial amount of debate. Those in favor argue that these systems improve efficiency and fairness, factors that Pääkkönen et al. describe as the “express motivations for using algorithms” in homeless services (2020:6). Those against argue that these tools are invalid and unreliable (Brown et al. 2018), racially biased (Cronley 2022; Wilkey et al. 2019), expand police surveillance (Eubanks 2018), or are fundamentally flawed (Slota et al. 2021; Tracey, Garcia and Punzalan 2023). In one framing, algorithmic governance is the objective, evidence-based alternative to slow, and potentially biased, humans. In the other, it is opaque, technocratic, and unjust.
One method for bridging this divide has been to attempt to develop more equitable algorithms, the domain of growing subfields such as algorithmic fairness or fair machine learning. However, these proposed remedies have also drawn criticism, both in terms of their proposed solutions (Green 2020) and of their narrow focus on algorithmic tools at the expense of broader sociotechnical context (Selbst et al. 2019). These issues are at the heart of Davis et al.'s (2021) theory of algorithmic reparation, which calls for attention to the institutions, policies, and practices which surround algorithmic tools, in order to avoid the surface-level diagnoses and band-aid solutions that are typical of what they term “algorithmic idealism.” Instead, they argue for a reparative approach with greater care given to data work—highlighting that “unjust algorithmic outputs” result from flawed “representation in datasets and/or social factors that crystalize in data form” (2021:7). While Davis et al. focus on one specific form of careful data work, archival data curation, the promise and perils of careful data work are also extant in other contexts, such as the homeless services system.
Building on Davis et al.'s work, we contribute to work studying algorithmic prioritization in homeless services (Kube et al. 2022; Shinn and Richard 2022; Slota et al. 2021). To focus our work, we studied the data work required to implement algorithmic prioritization and analyzed how the increasing demand for data impacted how care workers conceptualize and provide care for their unhoused clients. We chose to focus on data work because the process that allows data to become “useful” to an algorithm requires “encounters between people, technologies, and data” (Bossen et al. 2019:466). As Bossen et al. (2019) argue, “data do not sit in ready repository, fully formed, and easily harvestable. Data must be created through various forms of situated work…[work that is] rooted in particular places and particular times and require (often considerable) effort on the part of the people involved” (465). In other words, someone has to put in the work to generate, collect, and process data. In our analysis, we considered this work through the rubric of care labor.
Conceptual framework
Data work and care
To better understand how algorithmic prioritization impacts homeless service workers, we specifically investigated the realities and complexities of performing data work as a form of care labor in technologically mediated work settings. Care labor lies under the umbrella of what Boris and Parreñas call “intimate labor”—work which seeks to “promote the physical, intellectual, affective, and other emotional needs of strangers, friends, family, sex partners, children, and elderly, ill, or disabled people” (2010:2). We adopt their conceptualization because it encapsulates the gamut of caring activities that appear in homeless services, which range from professionalized social workers providing talk therapy to frontline shelter staff helping unhoused people launder their clothes or fight bedbug infestations.
The increasing presence of data work within care settings is linked to the neoliberal transformation of the welfare state and the transition to a managed care system—an organized approach to delivering care services in the United States that aims to reduce costs by using strategies such as selective contracting, economic incentives, and utilization review. While a data-driven approach to providing care services seems effective and efficient, prioritizing efficiency comes at the expense of other values (Berman 2022). The data work required to sustain a managed care system has introduced new forms of bureaucracy and increased labor demands, which can result in a diminishment of care because care and bureaucracy are often incompatible. The underpinnings of bureaucratic control, such as systematic processes, centralized decision-making, hierarchical relationships, and efficiency maximization, are at odds with notions of care that involve personalized treatment, relationship-building, and collaborative patient–care provider decision-making.
A data-driven approach to care has also required the expansion of technological infrastructures to support large-scale data collection and analysis (Ducey 2010). For example, Selberg's (2013) study of nurses found that technologically mediated management practices contributed to work intensification with disastrous consequences for the nurses’ well-being. Similarly for therapists, the introduction of on-demand therapy platforms resulted in pressures to be constantly available to their clients, which exacerbated burnout and diminished the value that therapists saw in their work (Huber, Pierce and Lindtner 2022; see also, Anjali Anwar, Pal and Hui 2021; Ticona and Mateescu 2018). Using literature on care labor and technology as a conceptual springboard helped point our analysis toward the competing values and interests that are negotiated in the daily work of making algorithmic prioritization possible. Juxtaposing our participants’ differing orientations toward care brought out the lively, situated interplay of their work, and revealed algorithmic prioritization as much more than an optimization problem.
Selberg concludes that nurses’ “‘caring too much’ provides a buffer between what the organization proffers in terms of resources and what patients receive in terms of service” (2013:28). In light of Suchman's argument that representations of work are always “interpretations in the service of particular interests and purposes” (1995:58), we can understand the work intensification of care labor as enabled by the representation of data work as an extension of other care work. As our findings will show, homeless services organizations depend on care workers “caring too much” and overextending themselves to meet the increasing demands for data work required to implement prioritization algorithms in ways that produce favorable outcomes for their clients. Thus, through our study, we demonstrate how an ethos of care can be exploited in ways detrimental to both caregivers and recipients.
Methods
Study context
In the jurisdiction we studied, people experiencing homelessness are sorted based on five, ranked criteria: VI-SPDAT score, then chronic homelessness status, 2 then length of homelessness, then living situation (unsheltered vs. sheltered homelessness), and then date of VI-SPDAT completion. 3 Each criteria acts as a “tie-breaker” for the one before—so if two single adults both scored a maximum “17” on the VI-SPDAT, but only one met the “chronic homelessness” designation, then that person would be placed higher on the prioritization list. If both were chronically homeless, then the person who had been homeless longest would be prioritized higher, and so on. For a person to be prioritized for housing, a care worker must ensure they have a completed VI-SPDAT, chronic homelessness status documentation, and multiple forms of identification, along with other optional documentation such as paperwork verifying the number and ages of children in an unhoused family, proof of military service, or verification of HIV-positive status. For care workers, completing this additional documentation is vital for their clients to be prioritized, and for a high prioritization score to actually become a move-in.
Participant recruitment
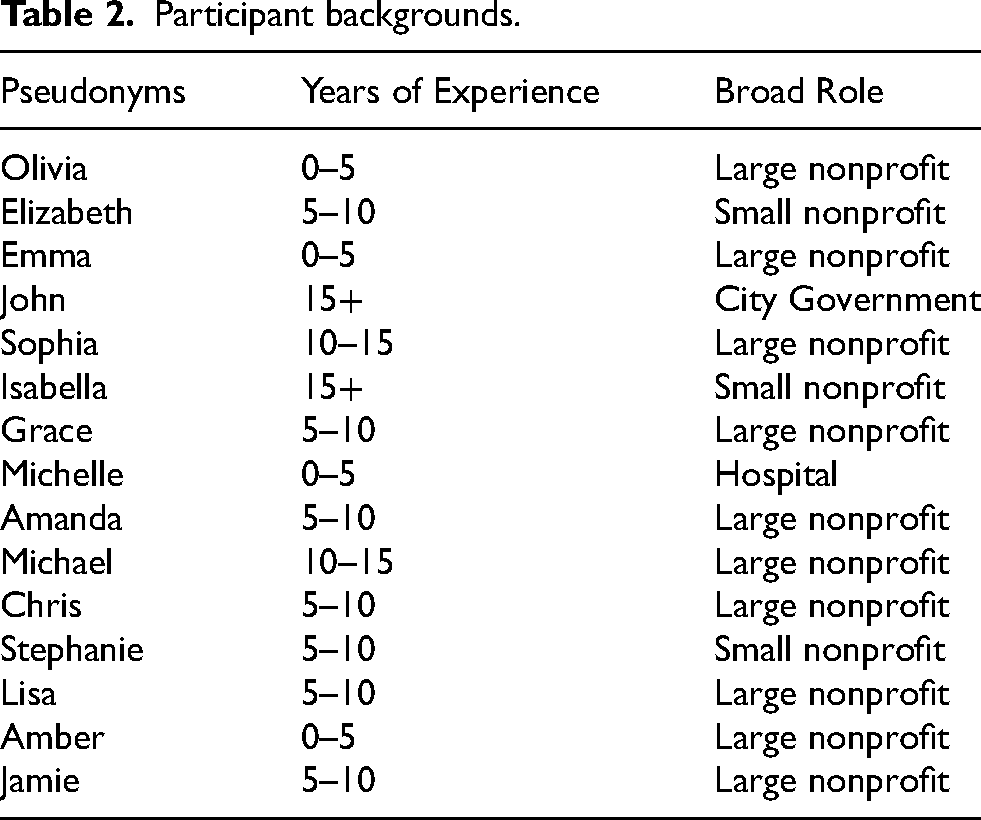
We recruited interview participants by email and phone through professional networks in the homeless services field. We identified additional participants through snowball sampling, following recommendations from earlier participants to include perspectives that appeared to be missing “as concepts emerge[d],” based on theoretical sampling (Bernard 2011:435). All study participants had direct experience working in the homeless services field. They had a variety of years of experience in the field, worked at nonprofit and state institutions, and held a wide range of job roles. The following table lists our participants, identified by pseudonyms, along with their years of experience and broad role within the system (Table 2).
Participant backgrounds.
Data collection and analysis
We generated insights from 15 semistructured, 1-hour remote interviews. We anonymized identifying information using pseudonyms for participants, organizations, and employers. Participants gave consent to record the interviews. We utilized a semistructured interview protocol (Appendix I) to direct the conversations and approached participants as knowledgeable collaborators.
We analyzed transcripts utilizing inductive thematic coding, borrowing from Clarke's approach to situational analysis. We iteratively memoed and reworked our themes until they fit the data well and additional refinement did not facilitate further insight (Braun and Clarke 2006:92). We then analyzed the coded data alongside the forms and tools identified through interviews to bolster our understanding and to remain committed to “taking the nonhuman—including discourses—in the situation of inquiry seriously” (Clarke 2005:xxxvi). This was important for achieving a deep comprehension of data work, given that conceptualizing their work as related to data or technology was counterintuitive for some participants.
Positionality
Settings of care labor are sensitive sites for research. We aimed to be self-reflexive about our positions as researchers and thoughtful about the ethics of this work. The research was informed by the first author's prior experience working in homeless services which extended them some of the benefits and challenges of an insider–researcher position. For instance, prior experience facilitated building trust with participants and provided some familiarity with work processes. Prior experience also potentially introduced blindspots, which the first author sought to mitigate through frequent consultation with the second author who did not have prior insider experience. Since the second author did not have experience working in homeless services, they tried to be cognizant about their lack of firsthand experience with the types of precarities experienced by care workers and the clients they serve. Additionally, we were thoughtful about the process of representing participants’ experiences, who faced potential harms, such as reputational harms, from speaking honestly about their professional lives. To mitigate these risks, we developed an informed consent process in which the first author discussed potential harms with participants, highlighted the option to speak off the record, and solicited feedback in determining what might be potentially identifying for purposes of anonymization.
Limitations
The voices of people with direct, lived experience of homelessness are largely missing from this paper (a few of our participants had previously experienced homelessness). Data collection for this study was completed between July 2021 and September 2021 during the Covid-19 pandemic (coinciding with the Delta-variant wave in the USA). Despite wanting to also interview people currently experiencing homelessness, we determined that it was unreasonably risky to do so in-person and logistically impractical to do via video or phone calls. The absence of these voices is a significant study limitation, which we hope to rectify through future work.
Findings
Data work is everywhere in homeless services and goes by many names. Referred to as documentation, paperwork, or “notes,” these work practices convert the lived experience of unhoused people into data. Data work is not limited to digitally mediated tasks. Analog practices, such as completing paper forms and worksheets, also helped preserve traces of our participants’ working lives. We found that these data work tasks occupy an enormous portion of care workers’ time and provide the foundations for algorithmic prioritization.
Our findings detail a dynamic sociotechnical interplay between algorithmic prioritization and care workers’ professional lives. Care workers’ data work, highly mundane tasks like filling out forms, enable algorithmic prioritization by making the “raw” data that undergirds a data-driven approach to resource allocation. Algorithmic prioritization, so enabled, raises the stakes of data work and makes care work more challenging. These pressures prompt workers to grapple with how to retain an ethical and caring approach to their work in the context of algorithmic prioritization.
Our findings section proceeds as follows. First, we outline the forms of data work that our participants undertook as part of their roles and explicate how these tasks underpin algorithmic prioritization. Second, we identify three impacts of this data work on our participants and their ability to provide care. Third, we explore how our participants responded to these impacts. We show that for many of our participants, the pressures associated with data work caused them to rethink what care meant in the context of their work, leading some to develop workarounds—forms of caring with data.
Finding 1: Data work in homeless services
Counting, census-making, and documentation have been part of the work of homeless services in the U.S. for as long as such work has existed (Hopper, 2003). Much of this data work has been focused on the production of proof, due in part to the political and practical difficulties of delineating “homelessness” as a social problem, and the paucity of resources dedicated to fighting it. Using data work to produce proof—both of the scale of homelessness as a social issue, and of the eligibility status of individual unhoused clients—is an entrenched part of work in the homeless services system. As Michelle, who worked with unhoused and formerly unhoused clients as a case manager stated, “everything is about documentation in this job, so if I wasn't to write a note, then it's almost like it didn't happen.”
The deployment of algorithmic prioritization introduced novel forms of such data work while breathing new significance into old practices. Few of these tasks are straightforward exercises in data entry. Rather, data work in homeless services often necessitates a great deal of skillful situated work and expert knowledge, as well as immense patience. In our participants’ narratives, two tasks stood out in particular: documenting chronic homelessness status, and administering the VI-SPDAT assessment. We highlight these specific forms of data work for several reasons. First, these tasks had the largest impact on algorithmic prioritization because VI-SPDAT score, “chronic status,” and length of homelessness are major factors in whether a given client would be prioritized for housing. Second, the outcome of either workflow is not tightly circumscribed and is instead a process of negotiation or co-creation between the client and worker. As a result, both workflows often require significant and relatively lengthy interactions and are rich sites for analysis. Lastly, chronic homelessness documentation is an entrenched part of the homeless services system, dating to the early 2000's (Willse 2015:153–55), whereas the VI-SPDAT is relatively new, with adoption in the mid 2010's (Ecker et al. 2022). Therefore, these tasks represent a wide time span and level of familiarity to those who undertake them.
Tracking contacts with care: Documenting chronic homelessness status
Documenting chronic homelessness is vital for algorithmic prioritization. However, establishing a detailed history of where an unhoused client has been living for each month in the last three years can be extremely challenging. Unhoused people are allowed to self-certify a portion of this history, but the majority needs to be certified by a third party. In some cases, this is straightforward. If a client has been staying in an emergency shelter for long enough to qualify, that stay will typically have been tracked in the city's HMIS database, and proving chronic homelessness status is relatively painless. However, other cases can be more difficult. Amber, a case manager at a large nonprofit who worked with unhoused women, found that documenting chronic status for her clients could be challenging. She explained, I find a lot of [my clients] have not spent as much time in shelter. They've typically spent more time either couch surfing, living in cars, or just living on the street. So, it becomes more difficult. I will try to trace back as much as I can on the computer for what's in the system for them. And then they can also self-verify up to three months. They can also get any sort of peer that would have come across them in their time to write a letter. Sometimes, we can use doctor's notes if they have a primary care physician. I try my best to figure out if there is anyone in this community, like a pastor, a doctor that you might have had any interaction with, who can say to the best of their knowledge you've been homeless.
For the most part, this process of creative outreach was limited only by the extent of a care worker's persistence. One participant described being so stymied in trying to document a clients’ chronic status that they eventually asked the client's mother to write a letter on his behalf. For clients for whom all other options are exhausted, the only other choice is to wait in a shelter until documentable status is reached.
This creative and persistent approach to capturing chronic homelessness exemplifies the nuanced nature of data work in homeless services. Through tracking down references to a client's time on the streets via their doctor or a Seven-Eleven night clerk, care workers transform the messy, highly situated realities of homelessness into the raw data for algorithmic prioritization. While this data work was still necessary for proving eligibility prior to the implementation of algorithmic prioritization and Coordinated Entry, in this new paradigm it becomes even more important because length of homelessness is a prioritization criteria. A care worker chasing down a friendly pastor with a sharp memory could be the difference between a short wait for housing or a long one.
Quantifying the care required: Administering the VI-SPDAT
The most central data work for algorithmic prioritization is the housing assessment, the VI-SPDAT. The assessment for single adults consists of 27 “yes/no” and “how many times” questions (the family and youth assessments have 41 and 28 questions, respectively.) The care worker reads the questions verbatim and records the answers. They are prohibited from deviating from the assessment script and forbidden from disclosing details of algorithmic prioritization, although they can answer clarifying questions. The process was familiar to Emma who had worked at a men's shelter for several years and done the VI-SPDAT dozens of times.
Emma explained that the data work of the assessment is an “extremely confusing and also kind of miserable process because you're asking people to talk through all of their traumas and vulnerabilities.” She described how it could be very difficult to convince clients to be forthcoming when answering deeply personal questions. As a result, clients might not maximize their score, hurting their chances at receiving housing. Two factors contributing to this reticence were the emotional intensity of the interviews and contradictory messaging around the disclosure of sensitive information.
Emma's description underscores how the emotional intensity of the interview can make accurate assessment difficult. “The two questions that I've talked about with my coworkers as being the most painful questions to ask are ‘Have you been attacked or beaten up since becoming homeless? (Q5)’ and the ‘Do you have planned activities, other than just surviving, that make you feel happy and fulfilled? (Q12)’ And getting a ‘no’ answer to that is just like… I just met you and you have to tell me that you don't do anything other than just survive, that makes you feel happy and fulfilled. That's fucked up.
Additional data work was also required to help clients understand that accurate disclosure would help, not hinder, their housing search. Emma relayed how, in response to a question about substance use, she “had someone stop me like in the middle of the VI-SPDAT to be like, ‘Why are you asking me these questions again? I've explained this to everyone. You're just looking for reasons to disqualify me for housing.’” In a context in which substance use can lead to disqualification from some housing programs, it made little sense to her client that openly discussing drug or alcohol use could actually help his search for stable housing. This confusion was compounded by the restriction on care workers discussing the mechanics of algorithmic prioritization with their clients. As Emma remarked, “So why wouldn't he assume that, if we're not allowed to tell him how the thing works?”
Emma's practice of asking additional probing questions was part of a series of workarounds that some participants developed—ways of interjecting their professional expertise and drive for advocacy into their interactions with algorithmic prioritization or to correct what they saw as the systems’ failings. These strategies worked by influencing how individual unhoused people were represented as data subjects. These practices included care workers changing the wording of the assessment questionnaires they read to their clients; asking additional, probing questions either during or after the interview; making liberal use of the “flag” system for appealing incorrect scores; and/or hinting at or revealing aspects of the process that clients were not supposed to know. Emma's account of her own workarounds, shows how the data work of administering the VI-SPDAT is not confined to reading questions and recording answers, but extends to crucial additional work done to ensure that VI-SPDAT scores were aligned with clients’ lived experience and that clients were not leaving points “on the table.”
Finding 2: Impacts of data work
As algorithmic prioritization raised the quantity and stakes of data work, it became a larger part of our participants’ jobs. This emphasis on data work or datafication of homeless services had three primary impacts on the care workers we interviewed: it limited their face time with unhoused clients, increased pressure to provide unpaid labor off-the-clock, and exacerbated mental strain and secondary trauma.
Limiting facetime
Several of our participants reported that data work sometimes detracted from their ability to provide direct care to their clients. Olivia, who had worked as a therapist at a temporary housing site, described this phenomenon, When you spend most of your time in your office typing notes, the clients notice that. And some of the clients would make fun of me, like ‘oh [Olivia], just loves to type all day.’ It's like ‘no, this is what I have to do to make sure this program gets funded, so you have somewhere to be and then we can connect you to housing. That's how this program exists.’
The reason I do this work is for the people. The people you're there to help want to spend time with you, whether that's processing difficult emotions, or they're bored and they want to connect to their therapist and just hang out. You just don't have the time for that. And that is what I'm in the work to do, so that's very frustrating.
Olivia's frustration illustrates how datafication is changing the nature of work in homeless services as care workers are required to do increasing amounts of data entry. The face-to-face interactions which do still occur are also increasingly mediated by data processes, like the VI-SPDAT.
Increasing time pressures
Other participants instead saw their time with clients remain constant, which pushed data work tasks into uncompensated evening and weekend work. As Michelle, the case manager, explained, I think in some ways it's supposed to be 50% of your job, like you're supposed to do four hours of client care and four hours of administration and record keeping, but that's just not reasonable. I would say that if I consider 24 h of my day, it takes up like 40% or 30%, but if it's the actual eight hour workday, it's incredibly hard to keep up.
In order to actually do what is expected in the time frame that is expected, you would be doing paperwork 50% to 65% of the time. What ends up happening is people are either scrambling to put notes in as it goes, or they do what I do which is wait and then do all of the paperwork at the end of the week while watching movies at home, which is a terrible practice. You're not paid for that. You're not recognized for that. It creates a hard standard for people in the future.
While working off the clock gave workers a chance to catch up, doing so made a demanding job more difficult. Additionally, the fact that this work could be completed away from the job site reinforced that this work was tangential to the primary work of interacting with clients more directly.
Exacerbating stress and secondary trauma
The quantity of data work was not the only factor which added stress to our participants’ working lives. Time frames for data entry also added pressure to an intense work environment. Stephanie, a former manager of social services at a family shelter, described how “unfortunately, at times we have to ask someone to leave shelter. You got in a physical fight, you brought people here to beat someone up, you made a threat, you had drugs out on the floor, things that are extreme.” This process exemplifies how the pressure to continuously transform interpersonal interactions into data complicates already fraught situations.
Expelling a person or family from a shelter to the street was, understandably, an emotional and potentially explosive situation. And yet in the midst of these moments of chaos, Stephanie and her coworkers were required to do data work. “The city instructs us to fill out this form, sit down with the person, have them fill out their appeal, give them all this paperwork and send them on their way.” However in practice, this was rarely feasible. “Things get hot. People absolutely flip out. The idea that anyone would sign anything, in a blind rage, not knowing where they're going to go… It's so inconceivable. And so then we don't ever have this appeal paperwork filled out.” The intensity of the atmosphere—a highly charged situation in which parents and children who have no place to live are being made to vacate emergency housing—is fundamentally misaligned with the expectations for data entry.
Such intensity was not limited to discharges. Olivia, the therapist, described how data work also impacted other intense situations, like when a client overdosed or passed away. She told me, So much of the job was crisis management that it was very hard to meet the 48 h deadlines. And some of the reasons that we didn’t meet that deadline were like clients passing away. Or attempted arson on the site. Like really difficult and traumatic things. It is very dehumanizing to have to do that level of paperwork at that pace. While you're grieving or someone used [injection drugs] in the building and so it took all day to manage that. The amount of paperwork wasn’t flexible to the reality of the job.
The shitty part is then things cool down and people realize ‘I need shelter, I have nowhere else to stay, I have to go in.’ They go down to the intake center and they get asked, ‘Well, where's your appeal paperwork?’ And the person's like, ‘I have no idea, what on earth?’
This had impacts beyond further infuriating a person being discharged. If the discharge and appeal forms were not completed, the city's intake center had difficulty linking the person or family in front of them with their digital presence in the city's database. In addition to making access to another shelter more difficult, this could also potentially jeopardize their chance of securing permanent housing through algorithmic prioritization.
Finding 3: Responses to data work: Rethinking care and developing workarounds
While our participants reported specific negative experiences stemming from algorithmic prioritization and increased data work, they interpreted the efficacy and ethics of the new system in different ways. A few, like John, an administrator with the city's office of homeless services, felt the positives outweighed the negatives. He argued that algorithmic prioritization was more efficient and was, better than the prior process because that was basically allowing people to stay stuck in shelter indefinitely, waiting for a housing resource when oftentimes there were households that could have moved forward more quickly if they weren't holding out for something that might take years to be matched to. Now, you know earlier on whether or not you're going to be matched.
For John and Amanda, the data work associated with algorithmic prioritization felt like an extension of their other care work, as they were strongly supportive of the algorithmic prioritization process as a whole and believed it was the best way for the unhoused people they worked with to achieve housing quickly. However, other participants saw algorithmic prioritization differently. For instance, Sophia felt strongly that reducing her clients’ choice in their own housing was both unethical and inefficient in the long run. She remembered how under earlier iterations of the system, you would say, ‘Okay, what kind of place are you looking for?’ and then you would go to visit a place. An [unhoused] person would make a determination if that worked for them and then you would do an application for that place.
I think that often my even rapid assessments of ‘what do you need in this moment’ just even interpersonally can be pretty acute. And they're based on personal, professional, et cetera, experience. But how many times I learned that I was wrong about what a person needed or someone said what they thought they wanted and we got there and it was not right for them.
As Sophia saw it, if an experienced care worker could not always correctly identify the best housing solution for an individual, how could an algorithm possibly do so? And while she acknowledged that some thought speed of matching trumped individual preferences, she pointed out that prioritization might actually reduce efficiency if “bad matches” resulted in people returning to homelessness rather than staying stably housed. In her words, I mean, it should go without saying that motherfuckers should be able to choose where they live, right? Could you imagine if you were like, ‘I think I want an apartment,’ and someone told you, ‘Here's one, take it.’
Bad matches were not only the product of reducing client input but they also stemmed from the design of the VI-SPDAT tool itself. Chris, who works in homeless outreach and had substantial experience with housing assessment and outcomes, put it bluntly: “I do not think this version of the VI-SPDAT is good. It doesn't really allow for the assessor to put in an observation.” He described previous experiences using a different tool, which “was more expansive and it did allow more for the assessor to enter in data. I think we often got more accurate results with the product of that tool.” He was consistently frustrated by the quality of the matches that the system produced, We see folks who are typically not that vulnerable scored very high and folks who are often the most vulnerable, especially those with serious mental illness and a lot of serious health conditions, getting scored very low and therefore getting referred to [short-term subsidies] or services that they are not appropriate for. I feel like our current housing assessment is a bit cursed in that it finds the worst possible housing opportunity for someone every time… I don't think it's an accurate gauge of someone's vulnerability.
Stephanie also found the VI-SPDAT frustrating, calling it, a very formal process lacking a true clinical impression because you could only speak to what the questions are, without accounting for whether the person answered the question honestly or not.
She saw the true cost of this process being not the professional frustration but the harm it caused her clients through inaccurate assessments and matches. She shared, I could tell you who had worked before and who could get a job if you just tell them… you can have that conversation. But a different client might be matched to a housing option [with time-limited support] and I'm like, ‘Oh, this is never going to happen because their income will never increase. They have social security’.
For Sophia, Chris, and Stephanie, algorithmic prioritization was, as Sophia put it, a system in which “people are matched without choice, autonomy, self-determination, and are often inappropriately matched.” These workers were less willing to integrate the data work associated with algorithmic prioritization into their conceptions of care, as they saw this work as part of a process which violated their clients’ autonomy and treated their own expertise as bias to be excised from the decision-making process.
If workers like John and Amanda saw the negative aspects of algorithmic prioritization as a necessary evil in support of a fairer, more efficient system, many of our other participants were less convinced. These other participants, such as Sophia, Chris, and Stephanie, were unsure about how fair and efficient algorithmic prioritization actually was, and contested how efficiency and fairness were even constructed—who was the system more efficient for? Who was it more fair to? They also questioned whether these were the best values to organize a system around at all. While these responses could be construed as nostalgia for a bygone era, participants were also critical of prior iterations of the system, and in particular described the long waiting times that characterized the earlier system as cruel. Nevertheless, several were quick to note that lengthy waiting times of months or years remained stubbornly ingrained in the system, even for those who scored high on the VI-SPDAT.
The qualms many of our participants had with algorithmic prioritization were somewhat at odds with the effort they expended on the data work which sustained it, and our interlocutors responded to these dilemmas in different ways. Many expressed ethical commitments to housing and racial justice or described expansive dreams for how homelessness might be combated differently. Some described advocacy or activist work they did outside of their formal job titles. However, for a sizable group of our interlocutors, one response was to bend the rules or use workarounds. Many of these practices violated workers’ training. However, for our participants, these workarounds were not only ethically permissible but also essential to coordinated entry functioning at all. As Amber put it, “some of [the questions] are just phrased so oddly that they're going to score a lower score when they deserve to be higher.” Contrary to the logic of impartiality underpinning algorithmic prioritization, in Ambers’ account, the subjective input of individual care workers not only continued to influence decision-making but was also vital to unhoused people being represented accurately as data.
Conclusions
Is the creative and situated work of making, collecting, and cleaning data always already a practice of care? Or does datafication rob care labor of its intimacy, its moments of gentleness amidst the sharp edges of bureaucracy?
Certainly both care labor and data work are systematically devalued. The provision of care is, as Boris and Parreñas argue, “work assumed to be the unpaid responsibility of women, and, consequently, is usually considered to be a nonmarket activity or an activity of low economic value that should be done by lower classes or racial outsiders” (2010:2). Similarly, as Møller et al. show, “practices of data work are often invisible to managers, and data-work tasks get neither the necessary resources nor the proper compensation” (2020:52). Indeed, it is often the lowest-paid “frontline” workers who are responsible for data collection practices and for providing care and emotional labor, because of their immediate proximity to the people about whom the data are made.
In our research, we found that practices of care, like listening sympathetically to a long story about a cruel landlord or soothing a client frustrated with the glacial movement of the housing process, often coexisted or were intertwined with data work. A VI-SPDAT interview might recall a traumatic memory which a client needs help processing. Listening to a client recount an eviction might prompt a care worker to consider new possibilities for documenting chronic homelessness. A joint trip to the Social Security Administration office for a new Social Security Card might enmesh both care worker and client in another frontline clerk's own overlapping labors of data and care.
Yet care work and data work did not intertwine seamlessly. The realities of algorithmic prioritization were challenging and sent care workers scrambling to develop workarounds. These improvisational practices, such as finding unlikely sources of proof for a chronic homelessness form or bending the rules of the VI-SPDAT, were both evidence of care for clients and major sources of frustration. Nevertheless, we resist reading these tensions as evidence that technology is inherently in opposition to practices of care. In this, we follow Ducey's caution that, By depicting caring labor as unique because of its nontechnological or immaterial character and acknowledging only its corporeal elements, [some scholars] not only create a partial image of the process of caring labor—one that offers little resistance to the gendered notion of caring labor as primarily emotional and innate—but also disguise material shifts in the nature of contemporary sociality and strategies for governing bodies, subjects, and populations (2010: 19).
The feelings of frustration and unease that some care workers had, however, should not be ignored. Rather than lead us to conclude that “care” is somehow separate from the activities of data work, these feelings instead emphasize that the presence of care does not necessarily mean that a system or technology is normatively good or harm-free. It is essential to recognize the importance of data work as a form of labor, without which algorithmic prioritization could not take place. But it is equally vital to consider the structural role that such work plays. If, at a micro scale, these practices represent acts of care—instances when a care worker went “above and beyond” for a client—at a macro scale, they reveal and reinscribe what we might call the atomization of vulnerability. While workarounds and makeshifts may be care workers’ best recourse for helping their clients, these practices reinforce the overarching impact of algorithmic prioritization: it fragments a collective social and political crisis into a series of disaggregated cases, in which each unhoused person is solely responsible for their own housing deprivation.
These tensions—data work as a form of care and an impediment to it; a means of resisting some structural forces while exacerbating others—have two important implications for a reparative approach to algorithmic injustice. First, careful data work, like that which we discuss above, should be seen as a form of algorithmic praxis because, despite a lack of formal data curation training, many of our participants recognized the stakes of their data work—that “unjust algorithmic outputs are inextricable from problems with source data” (Davis et al. 2021:7).
They saw that algorithmic tools such as the VI-SPDAT could not fully account for the nuances of their clients’ life circumstances and developed workarounds to counter inaccurate assessments and matches, clearly demonstrating “the capacity to account for complex identity configurations… and the insight to determine which pieces of data are relevant to collect and, more importantly, what data ought not be collected” (Davis et al. 2021:7). As such, we argue for the importance of studying routine data work. Overlooking routine data work buried in seemingly banal bureaucratic processes risks missing extant forms of algorithmic praxis, and their contradictory impacts.
Second, these tensions emphasize that careful data work cannot be a panacea for algorithmic injustice. Indeed, as our findings show, even expert, situated data work which attempts to account for individuals’ differential exposure to intersecting systems of violence and oppression, may exacerbate structural problems, even while ameliorating individual ones. The atomization of vulnerability occurs when the structure of algorithmic prioritization encourages care workers and their clients to maximize their own chances at an individual level. Despite the widespread consensus that homelessness is a structural, socioeconomic problem, when faced with a VI-SPDAT interview it becomes the responsibility of an unhoused person to prove that they are individually “vulnerable enough” to warrant assistance. A care worker may help them do so, through creative data work, but this too is subject to the particular beliefs or work processes of an individual. This atomization obscures the larger structural factors including poverty, racism, and the financialization of housing that produce homelessness and conceals the state's abdication of responsibility for providing a safety net. While care may characterize the interactions between individual care workers, unhoused people, and technologies, the process of algorithmic prioritization is not a careful one.
Our study complicates the idea that care is intrinsically opposed to technological or automated systems, showing instead how care is flexible and can adapt to include technological practices. We argue that while we should hope to make sociotechnical systems “more caring,” we should be cautious in how we do so. This is particularly important in the context of Davis, Williams and Yang's (2021) call to implement algorithmic reparation, in part, through more careful data work. We wholeheartedly support the call to scrutinize source data when seeking redress for algorithmic harms, and our findings underscore the impact of data work on algorithmic outputs. However, we argue that incorporating more caring data work will not lead to reparation without also addressing context-specific structural factors.
Supplemental Material
sj-docx-1-bds-10.1177_20539517241239043 - Supplemental material for After automation: Homelessness prioritization algorithms and the future of care labor
Supplemental material, sj-docx-1-bds-10.1177_20539517241239043 for After automation: Homelessness prioritization algorithms and the future of care labor by Pelle Tracey and Patricia Garcia in Big Data & Society
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by a Google Award for Inclusion Research (AIR), awarded by Google Research.
Supplemental material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.