
Abstract
This article presents findings from a rigorous, three-wave series of qualitative research into public expectations of data-driven media technologies, conducted in England, United Kingdom. Through a range of carefully chosen scenarios and deliberations around the risks and benefits afforded by data-driven media personalisation technologies and algorithms, we paid close attention to citizens’ voices as our multidisciplinary team sought to engage the public on what ‘good’ might look like in the context of media personalisation. We paid particular attention to risks and opportunities, examining practical use-cases and scenarios, and our three-wave councils culminated in citizens producing recommendations for practice and policy. In this article, we focus particularly on citizens’ ethical assessment, critique and improvements proposed on media personalisation methods in relation to benefits, fairness, safety, transparency and accountability. Our findings demonstrate that public expectations and trust in data-driven technologies are, fundamentally, conditional, with significant emphasis placed on transparency, inclusiveness and accessibility. Our findings also point to the context dependency of public expectations, which appears more pertinent to citizens, in hard political as opposed to entertainment spaces. Our conclusions are significant for global data-driven media personalisation environments – in terms of embedding citizens’ focus on transparency and accountability, but equally, also, we argue that strengthening research methodology, innovatively and rigorously to build in citizen voices at the very inception and core of design – must become a priority in technology development.
This article presents findings from a three-wave series of qualitative research into public expectations of data-driven media technologies, conducted across locations in England, by a team bringing together sociology, engineering and media practice. We begin by outlining previous research on user experiences of algorithms in media personalisation, particularly, people's understandings of algorithms (c.f. Siles, 2023) in the light of longstanding theorising on citizen and consumer interests in media and communication (c.f. Livingstone and Lunt, 2011), integrating concerns for both the everyday micro-processes of digital media navigation and the macro-processes of regulatory interventions and technological platform design. We then elaborate on our citizens' council methodology to articulate the concerns, needs and expectations of users in relation to media personalisation, before moving on to analysis and discussion where we explore public expectations for a safe and inclusive media environment. We demonstrate the significant overarching finding, that public expectations and trust in data-driven technologies is, fundamentally, conditional, with significant emphasis placed on transparency, inclusiveness and accessibility.
User experiences of media personalisation
Personalisation is an umbrella term referring to the process of deploying algorithms to automate decisions, defined by Thurman (2011: 2) as a form of ‘user-to-system interactivity that uses a set of technological features to adapt the content, delivery, and arrangement of a communication to individual users’ explicitly registered and/or implicitly determined preferences’. Content recommender systems are one example of this, and user-centric algorithm studies have made numerous strides in critically assessing user experiences of them. Hallinan and Striphas (2016), note how recommendations and user data function in a constant loop, which generates a variety of user stances and feelings, including uncertainty (Alvarado et al., 2020), not knowing fully what underlies these recommendation systems (Bishop, 2019), and users’ own admissions of not having sufficient technical knowledge (Dogruel, 2021). Studies note divergent degrees of awareness about personalised recommendations across user communities (Espinoza-Rojas et al., 2023) and the close intertwining of recommendations and/as culture (Seaver, 2019), bringing users and algorithmic systems into relationships of mutual domestication (Siles et al., 2019). More broadly, critical commentary on the social impact of data (Gillespie, 2012; Lomborg et al., 2023; Neff et al., 2017) underlines the necessity of listening to the publics’ voices at the earliest, design stages of technologies (see recommendations from the Ada Lovelace Institute, on building public trust in contact tracing apps, 2020, 2022; Hintz et al., 2022).
In this article, we pay attention to ‘object-based media’ which enables the recombination of component parts of audio, video and text at playback (e.g. by changing the length, presentation, or content order) to adapt media to users in the context of their interaction with it. Ofcom, the United Kingdom's media regulator, highlighted this as likely to have significant implications for the future of broadcasting and for its own regulatory duties (Howells and Jackson, 2021). In the United Kingdom, the AI4ME project, which these citizens’ councils are related to, represents a consortium of academic and industry partners tasked to develop applications to support the delivery of personalised media, and in our citizens’ councils, we paid attention to the public's expectations of trust, transparency and accountability around this. This original, in-depth, qualitative and deliberative study sought to probe into citizens’ ethical assessments around key socio-technical choices for AI systems in media personalisation, recognising, foremost, the serious dangers associated with poorly managed AI. Our series aimed to critically review the ethics of proposed technologies against internationally agreed AI principles, identify ethical challenges and embed mitigations in engineering research, evaluate approaches for the ethical development of new technologies and demonstrate the value of public engagement in research.
An expanding body of critical data studies scholarship has emerged to examine the role that data plays in social life, integrating the science and technology concerns of data scientists and the social processes and practices focus of social science scholars. Lupton's (2020) work on more-than-human data selves, draws upon work on users’ data-generating practices of self-knowledge in a range of contexts, to inquire into people’s motivations to generate data, and their feelings and ambivalences around these, to argue that people-generated data challenges boundaries between self and others, nature and culture, human and non-human or indeed living and dead. Iliadis and Russo (2016: 2) draw attention to the importance of interrogating data so as to unveil ‘how they permeate and exert power on all manner of forms of life’ (see also Kitchin and Lauriault, 2014). Taking media personalisation as a prime case, we analyse how users feel about media personalisation, how they believe their data is being used, what coping strategies they mobilised to protect their privacy, and what expectations they have of public and private institutions in relation to data ethics and user experience. We acknowledge the ‘nuances of people's agency beyond its metrification into computable data’ (Mollen and Dhaenens, 2018: 44) and seek to mobilise this agency (see here Ytre-Arne and Das, 2021 on communicative agency) to give voice to what citizens think a diversity of stakeholders – including users, regulatory and advisory public bodies, technology giants, SMEs, public and private service providers – should do to minimise social harms and ensure social good. Ytre-Arne and Das (2019) point to the long history of audience research in popular culture, technological and new media contexts, arguing for the need to expand audience research into emerging technologies such as the Internet of Things and algorithmic media to bring new understanding to the phenomenon. Similarly, Mathieu et al. (2018) consult with stakeholders about emerging media technologies and conclude that stakeholders fail to acknowledge audience dilemmas over whether to engage with or protect oneself from the pressures and intrusions of media technologies. Kennedy and Moss (2015) advocate for alternative approaches to the study of algorithms that take into account the lived experience of media users. Ytre-Arne and Moe (2021) draw upon folk theories of algorithms to identify a range of active, agentic modes in which people respond to algorithms. Bucher (2017: 42) argues that social media users experience a multitude of emotions in their Facebook participation, since ‘the lived reality of the Facebook algorithm generates a plethora of ordinary affects which may be distancing as well as enticing, generating resistance as well as appeal’. Andrejevic's (2014) study reports users’ frustration and powerlessness over data mining strategies – similar to Draper and Turow's (2019) notion of ‘digital resignation’, which, as Dencik and Cable (2017) argue, is a consequence of the normalisation of everyday surveillance (see also Markham, 2021, on inevitability as discursive closure in people's imaginations of technological futures).
Work by Kennedy and Hill (2017: 830) reports that audiences’ affective engagement with data is essential and that ‘the feeling of numbers is important’. Lomborg and Kapsch (2019), draw on Hall's (1980) Encoding-Decoding model to examine how media users learn about algorithms, what they think algorithms do and how they responded to their awareness of algorithms. In the Royal Society's (2017) dialogue with the public, findings suggest that attitudes towards AI vary with the circumstances within which machine learning technologies are implemented, with more positive stances attributed to the use of AI to improve services, increase efficiency and manage information overload. In the throes of the pandemic, work done by the Ada Lovelace Institute (2020) on contact-tracing apps reiterates the importance of building public trust through deliberation and transparency in line with their past work on public attitudes to uses of NHS data, where good governance, public accountability and transparency were found to be central and key. Ada Lovelace Institute's focus on public trust and accountability is carried into their recent 2022 report on recommendation systems, with an emphasis on achieving diversity of voices and engagement with audience in the design of personalisation tools.
This attention to people's lived experiences of data-driven technologies sits within a broader context of research on audiences as citizens and the publics. In discussing findings from our citizens’ council, throughout, we too use the language of citizens, as opposed to consumers, users, audience or markets. This is a deliberate choice, and reflects normative priorities in researching participants as publics, rather than consumers alone, where the focus is on the public footprints of media and digital institutions and the question of what good should look like in relation to the best interests of publics and citizens. Livingstone and Lunt, in their 2011 discussion of the United Kingdom's communications regulator Ofcom, draw out this distinction clearly, arguing that the citizen interest is distinct from the consumer interest, noting the critical importance of this normative focus on good and fair, ethical practice for audiences and users, and the wider interests of publics and citizens. Das and Graefer (2017), likewise, in listening to focus group conversations about audiences’ expectations around television content they find ‘offensive’, draw attention to the citizen interest, which positions audiences ‘as publics … where media institutions function with key social and democratic responsibilities, rather than the consumer interest where audiences are conceptualized as self-regulating consumers’ (Das and Graefer, 2017: 2). The language of citizens, then, is a conscious choice, which guides our methodological decisions around the citizens’ council (as we discuss later in this article), and the conversational priorities around public expectations, ethics and good practice that we carried through all waves of the council. Livingstone's (2018: 179, 170) work posits media audiences within the broader virtual and public world, advocating for an ‘engage[ment] with audiences meaningfully in and across the contexts of their lives’ from their everyday sociorelations to the public sphere of ‘citizen action, regulatory intervention, and the wider society’. In designing our citizens’ council, we engaged with this citizen/consumer distinction in the media and communications (Das and Graefer, 2017; Livingstone and Lunt, 2007) as our starting point, to position participants as citizens, highlighting public good, expectations, benefits and interests, citizen rights and expectations, rather than market-driven focus on individuals’ needs.
Existing scholarship on AI-driven personalisation point to risks to the public such as vulnerabilities of collaborative recommender systems to malicious security attacks (Mobasher et al., 2007) and search engine manipulation targeting the voting and consuming public (Epstein and Robertson, 2015; Nadler et al., 2018; Stewart et al., 2019). In spite of knowledge about the risks of AI-driven media personalisation in subjecting citizens to the algorithmic manipulations of corporate entities and politicians, more is needed, urgently, to ensure citizen engagement in algorithmic decision-making or understanding public expectations of media services. Our research responds to Livingstone's (2018: 175) call to ‘amplify audiences’ voices in the interests of social justice, and to imagine with them alternative futures’. Adopting a citizens council approach which empowers citizens to reimagine possibilities for regulatory interventions and organisational/institutional accountability, we contribute to the critical scholarship on user experience of algorithms through moving beyond the micro level of everyday encounters with data-driven technologies to explore citizen influence and aspirations for change at the macro level of organisations, institutions and legislations.
In an Ofcom review by Lee and Giles (2020), an online citizens assembly investigating public expectations of public service media, indicated two top priorities identified by citizens: (1) a well-regulated and independent public media service and (2) a diversity of perspectives and programme commissioners. This work sits against the backdrop of investigation on whether, and to what extent, true empowerment of digital media users occurs with digitisation-led transformations to content and offerings to media audiences and users (c.f. Boulianne, 2015; Daniels, 2016; Loader and Mercea, 2011; Napoli, 2010; Rishel, 2011). This history of work over the past decades has demonstrated succinctly that all new technology must be treated as an essentially non-neutral space, and as Richardson (2014: 106) argues, attention must be paid to the possibilities that it might ‘perpetuate social divides and generate and actively promote hierarchy and inequalities’. We have learnt, from the history of digitisation research, for instance, that it unevenly benefits those with digital literacies and the financial abilities to navigate the virtual space with knowledge of algorithms and content creation, stable internet connections and powerful computing infrastructure (see Yates et al., 2015, 2020). Audiences are now newly visible, through organisational data mining and normalised surveillance practices which stand to strengthen ‘the already-powerful’ companies with control over how networked publics come to be represented and understood (Kennedy and Moss, 2015: 3). Cautions arise, for instance, around regulatory guidelines being potentially exploited by advertisers, posing a threat to data privacy and protection (Howells and Jackson, 2021). Livingstone (2018) places responsibility on the democratic state and international civil society and governance bodies to ensure big data contributes to social good, so that transparency and accountability of platforms are achieved and that infrastructural institutions are regulated and held accountable for the decisions they make in their use of algorithms. Kennedy et al. (2022) reiterate the need for alternative forms of data delivery systems which instil confidence among users in the collection and use of their personal data. Indeed, regulation by itself is unlikely to be sufficient, as we need public discourse and action of civil society, education and independent experts to highlight and elucidate the ever-changing technological landscape. It is in this context that we designed our citizens’ council project on public understandings and expectations of data-driven media personalisation.
Method
Deliberative research has become a critical method for exploring public attitudes to sociotechnical policy problems, with ‘mini-publics’ being the more commonly adopted method (Hintz et al., 2022). In our citizens council approach (see also Mooney and Blackwell, 2004; Rogers et al., 2009; and the Data Justice Lab engaging citizens in decision-making on the deployment of AI and data systems, Hintz et al., 2022), we brought together a deliberative, focus group methodology (c.f. Livingstone and Lunt, 1994) with a repeated multi-round approach, enabling us to listen to a cross section of participants and to develop their capacity to engage thoughtfully with these complex socio-technical topics. We used ‘citizens' council’ workshops as a participatory method of involving user voices at the heart of technology design, connecting individual user experiences to collective recommendations. We completed the University of Surrey's research ethics questionnaire satisfactorily before embarking on recruitment or data collection. The council was a participatory process for ethical discovery in relation to an area of technology, so that its findings could guide and inform ethics-related processes throughout technology design and development lifecycle. Our participatory methodology took the form of a three-stage series of workshops in Guildford, Woking and Manchester in the United Kingdom, culminating in a final council that brought all the groups together to determine their priorities and recommendations.
First, our longitudinal, three-round approach to the citizens’ council was located intellectually within a long tradition of citizens’ juries and focus groups (c.f. Livingstone and Lunt, 1994; Mooney, 2004; Rogers et al., 2009). We argue that the method prioritised representation, voice, capacity, and investment into the relationships with and amongst our participants. Second, two key instruments involved in ensuring the participatory approach both built capacity and drew out normative considerations as well as individual experiences in citizens discussing technological workings which can otherwise be fairly abstract or obscure. We constructed and used a ‘booklet’ in the second-round workshops to explain specific use cases (provocatypes 1 ) of data-driven media personalisation, and included short, jargon-free vignettes – fictitious scenarios involving lay users, as part of our research design. Third, the participatory element aligned with broader priorities within user-centric AI and algorithm studies, where, giving voice to the citizen interest (c.f. Livingstone and Lunt, 2007), and its potentials for developing user literacies and awareness, building vocabulary, exposing risks and opportunities, deepening knowledge and shared understanding and developing complexity and consensus around themes mattered greatly for research design.
We recruited in two stages. We used a questionnaire distributed in locations across the North West and South East of England, namely Manchester (large metropolitan area), Woking (commuter town) and Guildford (university city). Stratified sampling was then used to ensure that selected participants covered the desired diversity characteristics and were representative of the national population and the audience interests (Abelson et al., 2007). In total, we recruited 20 participants, with each workshop in the first round consisting of between four and 10 participants, and the final workshop conducted online with participants across the three locations. Selected citizens were contacted and given the details of the sessions to attend. We ensured that participants were informed about the purpose of our study through a participant information sheet, and that they had adequate opportunities to ask questions and clarify doubts before making a decision to participate. Informed consent was obtained before data collection. Our topic guide focused on (1) benefits citizens felt media personalisation could offer, (2) identifying risks of such technologies and (3) proposing guidelines for practice and policy to address risks in ways that can change the communicative power of individuals and communities. Workshops were transcribed, and coded at each stage to identify key themes, emerging issues and priorities to play back to participants at subsequent stages to foster reflection and deliberation.
One of the key benefits of our approach was its longitudinal nature, which helped build capacity in participants. The first round, conducted in person, consisted of a baselining on AI, data sharing and personalisation, to establish the boundaries of the study, understand citizens’ level of digital media engagement, and examine their attitudes towards personalisation and knowledge on the topic. We introduced some common examples to encourage participants to discuss in greater detail how they used personalisation and their attitudes towards data sharing for personalisation. Key concepts such as automation, automated decision-making and AI were introduced and discussed. Lastly, we introduced participants to the OECD's principles for ethics of AI 2 to kick start dialogues and deliberations around key ethical issues relating to AI and the use of AI in media personalisation. The same participants were invited back to the second round for more focused discussion on media personalisation in relation to recent developments in the use of AI – grounded in an analysis of tools and techniques underpinning recent trials with object-based media within the BBC and the wider broadcast media industry (Howells and Jackson, 2021; Nixon et al., 2022). Using a combination of speculative design and user/ethical scenarios we developed three ‘provocatypes’ which encapsulated these technical priorities in the form of relatable examples and scenarios situated in everyday life, presented in a short booklet which we used to guide the session. The booklet included: (1) the fundamental concept used to adapt media content in each case (2) an illustration of how this might translate into a familiar media context and (3) a scenario for a notional user and how this might affect their experience. We based the illustrations of how this might work on familiar media events such as the Glastonbury Festival, Strictly Come Dancing TV show and news and carefully crafted the user stories to balance the benefits and risks and draw out a range of ethical issues such as digital access, inclusion, algorithmic profiling, and data-sharing. The first two rounds of workshops culminated in a third round in the format of a citizens council, where we used the online platform, Microsoft Teams, to bring together participants from all three locations to develop and prioritise recommendations for media personalisation. In this final session, we posed the overarching question: what are the most important criteria for ensuring good media personalisation? The session focused on facilitating group-level (1) deliberation of key statements about the risks and benefits of personalisation generated from sessions 1 and 2 of face-to-face workshops, (2) collective decision on a set of high-level principles/requirements for personalisation, and (3) proposals for the inclusive and safe implementation of media personalisation technologies. Members of the council first considered and ranked risk/benefit statements individually according to their importance using Mentimeter, before discussing and ranking these as a group.
We drew upon decades of research using focus groups as a methodology particularly within media and communications (Lunt and Livingstone, 1996), to note that ‘researchers using focus group methods are often more interested in socially expressed, and contested, opinions and discourses than in eliciting individual attitudes’ (p. 93). In our role as facilitators, we spent time listening, nodding, providing prompts or reassurances that people have been heard, and sometimes taking a back seat as participants debated with each other. We created a respectful and inclusive environment, firstly, through stratified sampling (see above) to achieve representativeness and equality in voices, minimising the negative implications of unequal symbolic power within the citizen panel (Gooberman-Hill et al., 2008). As expected in any similar group situation, we had a mix of more vocal participants and quieter participants, and various others in between. We took care to intervene if a couple of participants were dominating the conversation too much, gently inviting others to speak. This does not mean there was no disagreement because there were plenty of ways in which participants disagreed with each other, but this took the form of a respectful exchange of views, often with good humour. We were particularly careful to avoid elevating our viewpoints as ‘experts’ over those of the community at large and actively engaged residents in decision-making about priority-setting and resource allocation. We planned prompts for engagement, provided ample time for citizens to consider things, and supported their debates and conversations without imposing our opinions or past knowledge on them (Abelson et al., 2003; Ireland et al., 2006).
Discussion of findings
We present a summary of the council's criteria for good personalisation followed by a more in-depth discussion of the overarching themes emerging from the council's iterative elaboration and reflection on priorities over the course of the workshops (n7). The three themes that speak to normative ideas about the good in relation to personalisation are: (1) good faith (2) fair access and (3) shaping personalisation. Our thematic elaboration on these three themes includes context dependency that gives them nuance. We then discuss the council's broad recommendations for good personalisation, first through a summary of brief statements made by the council before examining them in relation to the existing literature.
Citizens’ six criteria for good personalisation
The council reviewed and discussed a list of 18 statements about personalisation which had been generated from previous discussions and workshops. Each of these statements represented a benefit, ethical issue, or risk they had identified. The council deliberated each in turn and agreed collectively on six priorities to reflect socially desirable/undesirable aspects of media personalisation. The council agreed that personalisation could bring a range of individual and socially desirable benefits (Kerr et al., 2020), from ‘helping people with different interests and tastes discover content, equipping people with added options and controls to configure media and making media more accessible to those with different needs’. Despite acknowledging the benefits of personalisation as a group, citizens expressed diverse feelings about the use of such technology. Some had ambiguous feelings around personalisation, with the key question being – ‘is it safe?’. Others described ongoing ambiguities about their everyday use of technology, voicing concerns over whether they might encounter similar issues with personalisation technologies. Citizens’ confusion was captured in reflective statements about their daily technological encounters, such as: ‘How on earth did you get onto the internet? And that makes me very very confused’, and ‘I slightly failed to understand why everything I say to Alexa, for the last 30 days or something is going to be recorded. (…) Why does she need to know that? She needs to respond to what I have just asked her for. (…) I think the storage of some of this information is dubious’. Whilst some were worried about the loss of personal information and described the need to practice more vigilance with personalisation technologies, others appeared less concerned, posing a question back to citizens expressing worries as such: ‘Why would you want to prevent it? Is there something that is worth protecting?’ Through our deliberative process (see method), differences were acknowledged and actively discussed with the intention of arriving at a consensus among citizens, enabling the council to come to agreements. The diverse opinions among citizens informed a consensus that benefits alone did not equate to personalisation being good, which became a key emphasis of the group. ‘Good personalisation’ was felt to be more than delivering tangible benefits to individuals at the moment, it was conditional on the social and ethical issues and risks being resolved or sufficiently mitigated, including lack of transparency, privacy, concealed profiling and lack of control. There was broad agreement among the council that the benefits delivered by personalisation cannot be deemed solely good, if they do not also adequately address or omit the risks. As one citizen summarised I think my general principle would be to have all the benefits provided once the risks are taken care of first. And if they can’t be dealt with, then I do without the benefits.
This conditionality was a theme throughout the workshops as citizens deliberated on the risks and benefits and agreed that in order to deliver personal and socially desirable outcomes, their priorities for personalisation need to be met.
The council's final six priorities (Table 1) placed significant emphasis on the equality and fairness of personalised media, particularly in terms of the distribution of benefits among different social groups and in terms of access to information and content. Additionally, they placed emphasis on reducing information and power asymmetries between tech companies and users through greater transparency and re-distribution of control between algorithmic systems and the people using them, echoing the concerns raised by critical studies data scholars (Iliadis and Russo, 2016; Kennedy and Moss, 2015; Kitchin and Lauriault, 2014). A thematic analysis revealed three themes emerging from these priorities: (1) good faith, (2) fair access and (3) shaping personalisation. ‘Good faith’ encompasses citizens’ calls for transparency, including the expressed desire for platforms and companies to disclose information about what they are doing and why so this can be scrutinised, and users can become better informed to manage their exposure to risks. This represents a foundational condition, predicated on which were consequent demands for agency, assurances, and accountability to address a perceived imbalance of power. ‘Fair access’ encompasses citizens’ critical questioning of whether data-driven developments in personalisation would end up privileging those users who had the technology, knowledge, and skills to exploit the benefits of new features. ‘Shaping personalisation’ brings together citizens’ uncertainties on the competition between risks and benefits of having more control over one's media feed or programme configuration, and ambivalences about whether adaptations should be more implicitly or explicitly driven.
Priorities for personalisation.
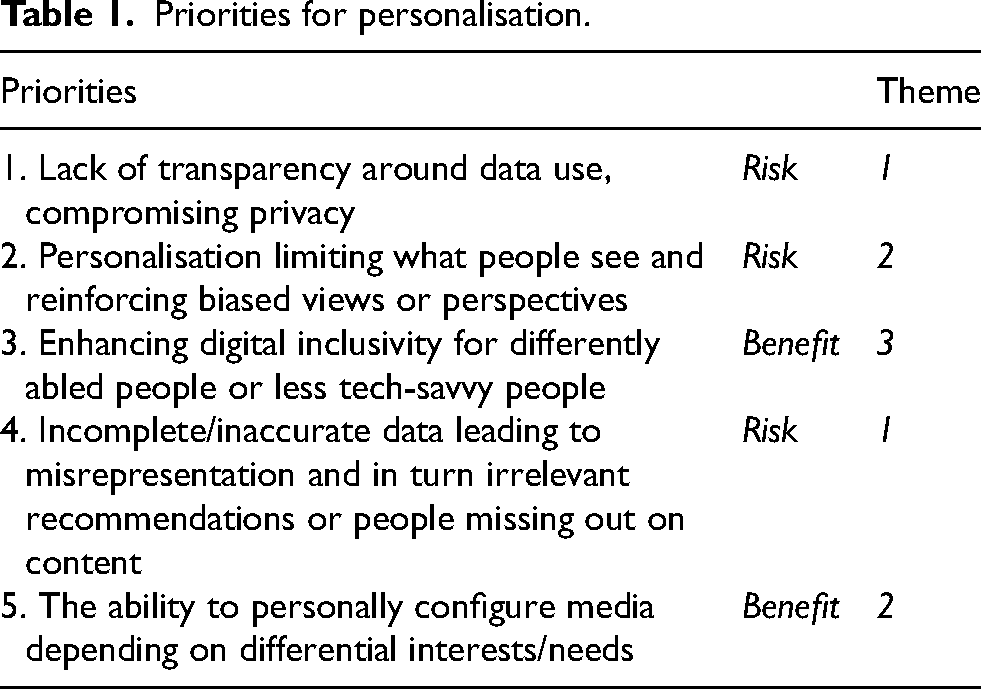
Good faith: Conditions for establishing a basis for trust
In everyday interactions with media organisations that provide personalised products and services, citizens expect such exchanges to be conducted in good faith, that is in a manner that respects their human dignity and rights, and without deceit, deception, exploitation, abuse of power or danger. The persistent presentation of good faith behaviour can be seen as a basis for trust; trust that is in deficit in many instances in people's current interactions with technology platforms and media organisations (see Doteveryone, 2018; Steedman et al., 2020), which damages their trust in media personalisation. For instance, a council member said ‘I cannot now trust any of the (big companies) and therefore, the whole of the internet as far as I am concerned!’ This was elaborated by another council member, who said: ‘They are the ones who are telling you what they will do with your information and what they do will protect you. While it may not be true, you have to trust them to be telling you the truth.’ In our workshops, members of the council discussed what is known (or assumed) about the declared purposes and ulterior motives of media organisations and technology providers, to attain an understanding of more acceptable behaviours that could facilitate fair dealing in this space. As one participant noted: ‘If you are talking about the algorithms and the AI behind it, (…) we do not know what those algorithms are. And the corporations concerned generally are very reluctant to give any information away’. Members of the council reflected on the need for greater transparency around data-driven practices (Diakopoulos, 2015; Kennedy and Moss, 2015), ‘so you can see the real behaviours’, as a condition on which to establish good faith and a basis for trust. While there was agreement on the importance of transparency in personalised media, their calls for transparency went beyond the limited scope of the OECD Principle on responsible disclosure and the ability for users to challenge outcomes. Rather, they called for transparency on their terms – for an understanding that was meaningful to them in the context of use; a relational understanding in the context of their situated engagement, echoing Steedman et al.'s (2020: 817) notion of ‘complex ecologies of trust’. Similarly, Ballantyne et al. (2022) found citizen's trust to be dependent on context (purpose) as a willingness to share health data was only limited to public and private industries practicing accountability and transparency in medical research, and not with insurance companies. This need for situated understanding was allied with the availability of options to allow or prevent behaviours according to their own judgements around trust and legitimacy. While there was recognition that controls and settings may not necessarily be used with regularity, having the choice to opt out or make personal judgements about data sharing and use is needed for interactions with personalised media to be conducted in good faith. Unlike Hartman et al.'s (2020) finding that users prioritise self-control and regulatory oversight over the control of data by commercial organisations, citizens in our study emphasised the importance of balancing organisational responsibilities with self-regulation through opt-out options. Such a balanced perspective was however only arrived at through friendly debate among citizens. Some citizens prioritised self-regulation, making statements which encompassed some degree of self-blame such as: You are the one that is mainly responsible? You are the one that is on there typing away
You just, you know, you don’t open your door and tell to everyone.
So you think it is all responsibility of institutions? I think it is my responsibility.
Best way to protect the people is to teach them how to do things, but not to tell anyone off to blow off steam.
You know, they don’t force you to use that technology. If you don’t want it, you don’t use it.
Citizens upholding self-regulation as the means to self-protection appear to be pointing at technology use is a personal choice, arguing that the onus should be on the individual to take responsibility for their decisions relating to technological engagement. The comparison of risk exposure through online engagement to that of opening a door suggests citizens in this group have a very individual-centric view of the technology landscape. On the other side of the spectrum are citizens who expect commercial organisations to take responsibility for creating a safer online space, although this expectation appears to revolve around large tech organisations. Normative expectations of organisations were expressed by several citizens as such: Dare I say that Twitter, I think is largely responsible for all of this.
I am sure Facebook would sue me for this. But I am saying that I believe that they do not make it clear exactly how widely some of that (information) goes. I think again some of these companies need to take a lot more responsibility for what they are doing.
Well, I think it is more the responsibility of the tech companies, (…) we cannot all be experts at everything (…) Ultimately it's with the provider, the tech company, to make sure all of the things that affect the user are explained clearly.
Constant deliberation and debate between citizens advocating for either self or organisational responsibility contributed to a common consensus that both are necessary for the maintenance of trust and transparency in personalised media. This common understanding led to the imagination of possibilities for combined regulatory efforts between the self and commercial organisations. Examples of such imaginations include opt-in options and the provision of information booklets for users: I cannot really imagine that, but yeah, having the option of being completely transparent, this is what is gonna happen if you use the service, opt in or out only about certain things. Yeah, that would be amazing.
It would kind of come with kind of all the terms and conditions about that, it is up to providers of the service to form one, and then stick to those terms and conditions, they need to honour the commitment from their side to protect and keep the data with themselves and not share with anyone else.
These imagined futures were however discussed in a rather hypothetical manner, pointing to citizens’ lack of faith that their suggestions will be implemented. Several members expressed pessimism at what they saw to be a lack of progress with regard to these issues and what they perceived to be important responsibilities of technology and media companies. Such was a citizen's response to the proposal for shared responsibility between citizens and commercial organisations: ‘It is nice, I fully agree with what you are saying, That is never going to happen in a million years’.
Fair access: Recognise inequalities with reasonable accommodations and support
The members of our council took a broad view of digital inclusion encompassing everything from more traditional notions of accessibility (e.g. physiological needs) through to access and the possession of skills and literacies needed to reap the benefits of personalised media (Gran et al., 2021; Kennedy et al., 2022). They recognised the advantages of personalisation for supporting inclusion, such as ‘the ability to choose how to configure devices and programmes’, such as ‘enlarging the text or subtitles’, or ‘being able to modify content to be available in multiple languages’ to cater for people with differing needs, or very different socio-cultural and economic situations. They also recognised related barriers to access and participation. The need to address inequalities cut across all aspects of workshop discussions. Key issues and concerns included complex interfaces, complicated controls, technical jargon, convoluted instructions, and explanations, (in)compatibility of devices, access to suitable internet connection, access to data, connectivity between devices. Members of the council wanted to see support in the form of simple user experience (UX) design to address Gran et al.'s (2021) three levels of digital divide in access, skills and usage. For example, a citizen said: ‘I think this needs to be something that developers are aware that there are people out there that struggle, and it needs to be a simplified version for them that is very, very simple to use’. They also highlighted that the nature of support itself must be accessible (e.g. not another technical solution) and foregrounded the role that wider systems of social and community support can play. ‘The kind of support that is available, how accessible is that support? All of these things need taking into account’. Drawing on the experiences of friends and family, participants realised that absent voices had valuable information to add to discussions, including elderly relatives and children, and they relayed these perspectives to the group. One citizen recalled an instance with his friend who was struggling with digital technology: He has learning difficulties (…) I think one of his daughters disconnected the account, he couldn’t come inside, and it was so complicated to set it up again. He said to me ‘no, no, I cannot do it. I cannot do it’ So I had to do it all. It took me two hours.
It was clear that participants could not divorce the discussion of personalisation from that of inequalities and digital divides, and they recognised the intersectionality of inequalities and associated barriers some people faced, including inter-generational differences in skills, needs or abilities (Kennedy et al., 2022). During discussions of new ‘object-based’ approaches to personalisation, members of our council questioned whether these developments would end up privileging those users who had the technology, knowledge, and skills to exploit the benefits of new features. They worried that some people – often those who they felt could stand to benefit the most – are in fact the ones that will inevitably face the most barriers – ‘Not everybody will have the capacity, so that is where people are left behind’. Whilst there was strong consensus that increasing accessibility was priority, several citizens had different understandings of what constituted disability. Some suggested that ‘being not tech savvy (was) a disability in a sense’, while others highlight that ‘there are two distinct categories, one pertaining to data, the other talking about physicality’. Definitions apart, citizens as a whole considered it integral to increase accessibility for both groups in order for these new developments to qualify as ‘good’, enabling everyone to fairly access and benefit from personalised media, which requires making reasonable accommodations, and reinforcing wider systems of social support.
Shaping personalisation: Balancing human-machine decision-making
One result of the group learning about how personalisation could work, e.g. adapting implicitly based on behavioural data or as a result of explicit choices made by the user, was that the focus shifted onto the process by which personalisation systems learned about people, and how decisions were made. While there could be some benefits to having more control over one’s media feed or programme configuration, there was an interplay between the complexity of an individual’s own tastes and the desire for being in control – and ambivalence as to whether adaptations should be more implicitly or explicitly driven. Some of the group commented on instances where implicit ‘learning’ about their tastes was helpful (Bol et al., 2018; Marwick and Hargittai, 2019), such as on music platforms like Spotify (see here Siles, 2023) or BBC Sounds as a council member explains – ‘the more you do it, the more they know how to do it, and more in line with the suggestions you get, I find it quite positive actually’. Whilst for others, this implicit approach to ‘learning’ – based on a system inferring things about tastes to personalise – raised some red flags, as it delegated a lot of influence to non-human actors. There was unease that implicit learning algorithms conceal what is being learnt and what changes as a result (Bucher, 2018). In the case of implicit adaptation of content to one’s preferences, as with a recommender system, scrolling feeds, or personalised programme, questions arose about which ‘information about them’ was being used, how and with what effect, discussing the influence of both people and systems. This unease extended to explicit personalisation, with anxieties raised about the potential effects of giving individuals ‘too much’ control to filter and fine tune their preferences, which could result in media experiences becoming overly individualised, destabilising the communal social aspects and benefits of shared experiences. Questions around how personalisation should work also varied according to media type or genre. Here, the perceived benefits and risks could not be divorced from context – owing to established social norms and expectations around different media. For example, when discussing the use of object-based media to personalise programmes, examples in entertainment evoked very different responses from the group when compared to use of the same technology in news and factual content. Talking about an example of a personalised playout of the BBC entertainment programme Strictly Come Dancing, which would allow a viewer to choose which aspects of the programme to include or exclude and the order of playout, one group member noted: ‘that seems like a really good move to me, you know, if you do really like the dancing, you can just like select dance, and skip the stories’. However, when the same technology was applied to a news scenario, reactions shifted, and the group focused on the potential social implications of personalisation within factual or news programming. There is a news app I use, and you choose the topics you want to hear about. You can do that on the BBC News app, (…) there is a section where it shows the topics you are interested in. You could say, I really want to hear about World News or Covid, or particular things. But what you shouldn’t be able to do is say, I only want to see things that are fairly favourable to my beliefs (…) it is not impartial.
On balance, the group felt that the role of news and news values were potentially at odds with some aspects, and types of, personalisation such as the more implicit behaviour-driven personalisation or the provision of controls that might encourage people to filter in/out specific segments or commentary from within news programmes. Unease about the use of algorithms to automate decisions about the prioritisation and presentation of news content reflected a general concern about algorithms disrupting perceived news functions such as balance, diversity, or impartiality (see also Bodó et al., 2019; Dylko et al., 2017). They also expressed concerns that such systems might unduly privilege content that is engaged with by lots of people (Harper, 2017) which could reduce the visibility of niche content, as one council member asked – ‘what would this mean for the people who make content that is a bit more on the edge?’. Once again, the context dependency that citizens expressed highlights how the purpose, i.e. to entertain or to inform, alters their determination of good practice.
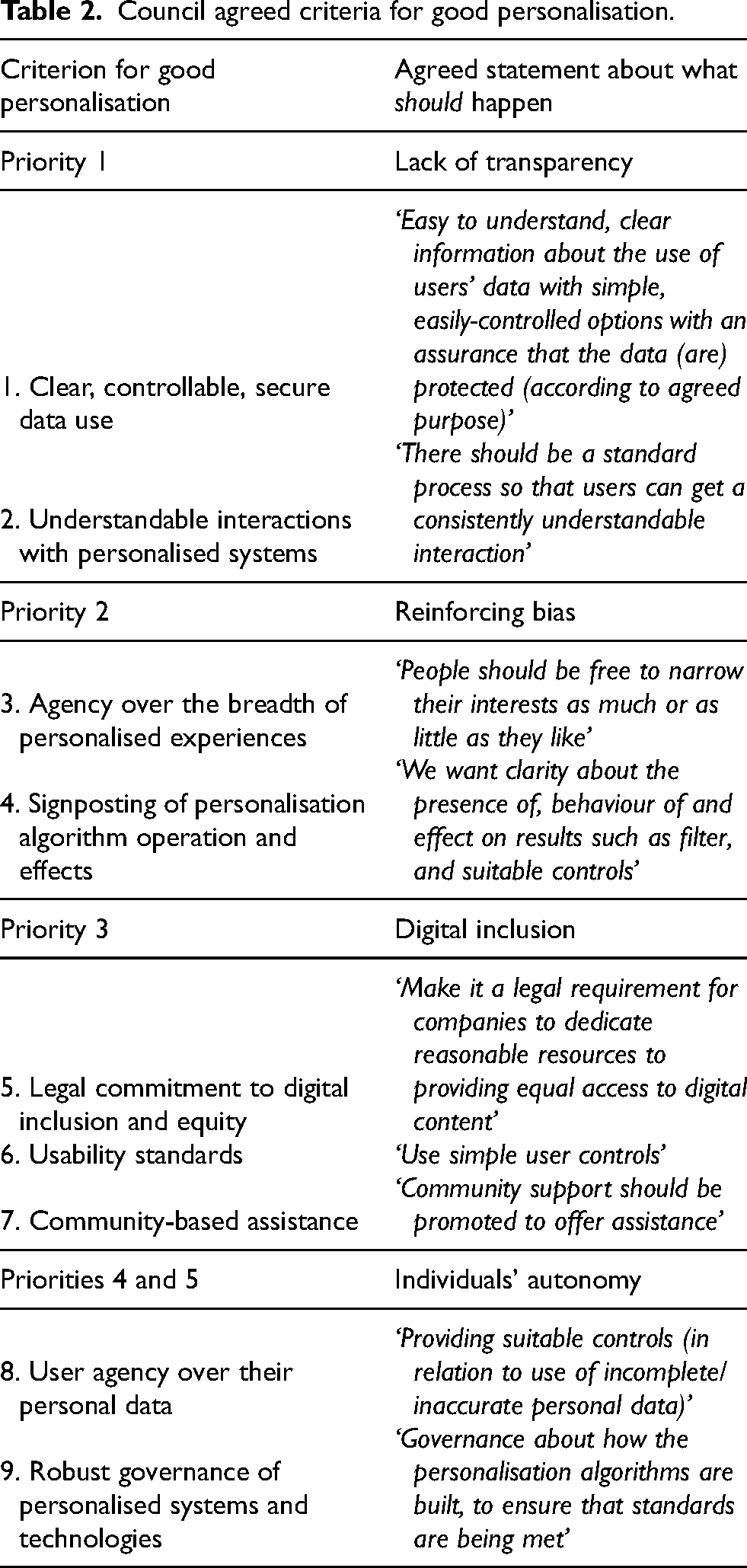
Recommendations of the council
The council then deliberated on what should happen to advance their priorities and worked together to arrive at a set of collective ‘should’ statements, which can be read as recommendations for courses of action (Table 2). At this stage, council members appeared task-oriented and focused on working together to propose recommendations, possibly an outcome of the debates engaged in earlier in the ranking of priorities, leading to the arrival at a strengthened, common position for the imagination of what good constitutes. The council agreed on the need ‘for greater understanding and clarity’ over when, why and how personalised algorithms are deployed and shape their experiences; they agreed on the need for simpler and more effective controls, underpinned by strong assurances around data use and robust governance of personalised systems. Finally, there was strong consensus on the relatedness and importance of digital inclusion and ensuring equality in access when it comes to personalised media – underpinned by wider systems of social and community support to assist those with low levels of access, skill and understanding. These statements highlight areas of broad consensus regarding an emerging collective view on what is needed to advance notions of good personalisation.
Council agreed criteria for good personalisation.
Throughout, we noticed participants departing from narratives of what individuals ought to do to protect their personal data from misuse that were expressed in our first workshop, to embrace more collective expectations of what institutions should do, for example to protect the privacy of individuals and ensure the provision of an inclusive digital environment. In the first workshop, many participants discussed at length using self-coping strategies to prevent data loss, at the same time expressing a sense of helplessness at being able to cope with the immense and expanding scale of digitisation as such. However, by the final workshop, this narrative transformed into attributing responsibilities to private and public institutions to enforce data protection procedures and regulations. Citizens felt strongly that regulation was an important part of ensuring good personalisation, stemming in part from low trust in technology and media organisations effectively self-regulating. They wanted to see private institutions, adopt more transparent data use practices, and greater oversight from regulatory bodies. As one council member argued – ‘If there was a trusted watchdog, and you could check with them and say, are these (tech and media institutions) doing everything they promise?’ Several participants agreed institutions that collect data and use AI without abiding by internationally agreed principles, such as the OECD principles, ought to be penalised. For example, one participant expressing dissatisfaction at the uneven power dynamics that have emerged between corporations and users, called for public organisations to redress the situation through the criminal justice system: ‘They often have enough legal people defending them, they have got the best lawyers and best people in the world. (…) How do you make the CEOs of these companies or the board of directors responsible? It is only one way you know, put them in jail’. It appears that citizens place some degree of trust in state actors to address the uneven power structure and ensure their data privacy in the digital realm. Such a shift in perspective emerged from citizens acquiring new knowledge of different actors in the field of media personalisation and perceiving the limitations of individual coping strategies within our increasingly digital lives.
Conclusions
Reading across the conversations in all these workshops, we highlight how citizens’ impetus to improve outcomes for themselves and society at large sits across a spectrum, from individual action sometimes fuelled by uncertainty or mistrust, and sometimes inspired by confident and curious stances around algorithms on the one hand, to well-articulated expectations of diverse sets of institutions – an individual to institutional spectrum – in citizens’ stances towards healthier outcomes in datafied societies. We note, also, that while we invited people to reflect in a setting that was neither policy nor industry led, the citizens’ council method itself created a middle-ground between the individual and the institutional. Our findings indicate a range of expectations from individual to institutional levels, with no citizens fully situated at either extreme. Instead, citizens integrated institutional (private and public) expectations with self-regulatory practices to varying degrees in their daily interactions with technology. Moving conversations from individual responses towards collective recommendations was a journey that the participatory methodology enabled. Our method itself prioritised the representation, voice, capacity, and investment into the relationships with our participants. The consequence of this was that they were able to articulate individual accounts, anecdotes, views and feelings, and yet, also, listen to others’ accounts, discuss, debate and finally to deliberate on their multiple rounds of discussions and move towards collective recommendations. The workflow of the method included both inputs and outputs designed at each round, each building on the last, offering not solely an efficient procedure for exploring, scoping and prioritising the ethical issues most prominent for a given technology and its deployment in a given domain of application, but also opening up time and space for individual reflections to grow towards collective recommendations, inviting thinking from both individual and institutional perspectives.
We also draw attention to the benefits of including citizens in these discussions about technology design, including the critical role of this process for design and speaking about media futures. First, we made numerous attempts – through the longitudinal process, and through the specific attempts in the final round – to ensure that the council yields distinct recommendations. We aimed to ensure that we arrive at clear recommendations using moderator-led recaps and reminders of previous debates in past rounds, re-seeding the conversation with citizen-identified ethical issues, and opening up ways for citizens to recognise, debate, rank and reflect on risks and benefits attendant to the technical use cases. Citizens were encouraged to translate each ranked priority into a clearly articulated recommendation, in a safe space for discussion with as flat a hierarchy as possible and priority given to the moderators’ listening over speaking, in a process paced by participants, with progressive engagement – each stage building on the previous one. This important process of deliberation through discussion and debate also generated, we suggest, a sense of agency, above and beyond the substance of citizens’ recommendations. We suggest that on both these counts, the methodology is particularly useful for integration into industry and policy conversations on technology design, reform and regulation.
Methodologically our approach argues for a shift from an individual lens to a collective view on media personalisation, drawing out people's views on responsibility shifting from an individual level to a societal one. In terms of current research into personalisation, this bridges a disconnect between individual experiences versus societal implications and effects. Overarchingly, we demonstrate the value for a space to give expression to and arrive at more collective notions of good with regard to personalised media. This moves us beyond binaries in the framing and discourse around personalisation – for instance risks versus benefits, or utility versus privacy – towards a more holistic and multifaceted view. The effectiveness of our citizen-oriented capacity-building approach was in highlighting citizens’ priorities and showing the potential for delivering useful recommendations for informing policy and technical design decisions. In this sense, the research supports efforts in value-sensitive design (Friedman and Hendry, 2019) by helping to identify what values groups of people consider important. The observable shift from discussing individual strategies to articulating a collective ‘should’ among citizens is evidence of how people can play a more active role in discussions and decisions about technology futures. Deliberative methods are an established approach in policy contexts to give the general public a voice and say in relation to policy debates and questions. We think these methods have an important role to play in technology innovation and should be better utilised along the more traditional forms of technical, design and ‘UX’ research – and our rigorous, multiwave, qualitative approach to these scenario-based citizens’ councils takes this conversation forward.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported through HEIF (UK) funding at the University of Surrey for Public Engagement in Research in Science, Technology, Engineering and Mathematics (PER-STEM). Thanks to Maxine Glancy, Miranda Marcus and Craig Cieciura via the ‘AI4ME’ BBC-EPSRC Prosperity Partnership (EP/V038087) on media personalisation for inputs to the experimental design on the use case, multi-wave structure and audio recording, and to our citizen participants and venue hosts.